[table]capposition=top
Exponential GARCH-Itô Volatility Models
Abstract
This paper introduces a novel Itô diffusion process to model high-frequency financial data, which can accommodate low-frequency volatility dynamics by embedding the discrete-time non-linear exponential GARCH structure with log-integrated volatility in a continuous instantaneous volatility process. The key feature of the proposed model is that, unlike existing GARCH-Itô models, the instantaneous volatility process has a non-linear structure, which ensures that the log-integrated volatilities have the realized GARCH structure. We call this the exponential realized GARCH-Itô (ERGI) model. Given the auto-regressive structure of the log-integrated volatility, we propose a quasi-likelihood estimation procedure for parameter estimation and establish its asymptotic properties. We conduct a simulation study to check the finite sample performance of the proposed model and an empirical study with 50 assets among the S&P 500 compositions. The numerical studies show the advantages of the new proposed model.
Keywords: High-frequency financial data, non-linear GARCH, stochastic differential equation, volatility estimation and prediction
1 Introduction
In finance practice, volatility plays a pivotal role. Low-frequency and high-frequency financial data are widely used to analyze volatility dynamics. For example, generalized auto-regressive conditional heteroskedasticity (GARCH) models are introduced to catch the low-frequency volatility dynamics, such as volatility clustering, by employing the squared low-frequency log-return as the innovation (Bollerslev,, 1986; Engle,, 1982). However, when the volatility changes rapidly, it is often difficult to catch the change using only the low-frequency log-returns as the innovations (Andersen et al.,, 2003). On the other hand, high-frequency financial data are available to construct the so-called realized volatility for estimating daily integrated volatility. Examples include two-time scale realized volatility (TSRV) (Zhang et al.,, 2005), multi-scale realized volatility (MSRV) (Zhang,, 2006), kernel realized volatility (KRV) (Barndorff-Nielsen et al.,, 2008), quasi-maximum likelihood estimator (QMLE) (Aït-Sahalia et al.,, 2010; Xiu,, 2010), pre-averaging realized volatility (PRV) (Jacod et al.,, 2009), and robust pre-averaging realized volatility (Fan and Kim,, 2018; Shin et al.,, 2021). These realized volatility estimators contain high-frequency information about the market volatility, and many studies show that incorporating high-frequency information helps account for low-frequency market dynamics (Corsi,, 2009; Hansen et al.,, 2012; Kim and Wang,, 2016; Shephard and Sheppard,, 2010). Several conditional volatility models have been developed to combine high-frequency and low-frequency data and enhance volatility estimation and predication by employing realized volatility as the volatility proxy. Examples include the realized volatility based modeling approaches (Andersen and Bollerslev, 1997a, ; Andersen and Bollerslev, 1997b, ; Andersen and Bollerslev, 1998a, ; Andersen and Bollerslev, 1998b, ; Andersen et al.,, 2003), the heterogeneous auto-regressive (HAR) models (Corsi,, 2009), the realized GARCH models (Hansen et al.,, 2012), the high-frequency based volatility (HEAVY) models (Shephard and Sheppard,, 2010), and the unified GARCH/SV-Itô models (Kim and Fan,, 2019; Kim and Wang,, 2016; Song et al.,, 2021). These models have been developed based on the linear auto-regressive structure of realized volatilities. However, we often observe that non-linear auto-regressive structures, such as exponential functions, better capture the volatility dynamics (Nelson,, 1991; Hansen and Huang,, 2016; Kawakatsu,, 2006). This may be because log-volatilities often have a stronger linear auto-regressive relationship. In fact, when variables are close to normal distributions, linear models work well. To check the normality of realized volatilities, we draw normal QQ-plots of realized volatilities and log realized volatilities for AAPL stock. Figure 1 shows that the log-transformation makes the realized volatilities closer to a normal distribution. Most of assets have the similar phenomena. Thus, we can conjecture that log-volatilities better explain volatility dynamics. To harness this feature, Hansen and Huang, (2016) employed the exponential GARCH structure with the log-realized volatility as the innovation, and their empirical study indicates that the non-linear GARCH structure helps account for market dynamics. Although, as discussed above, empirical studies support that incorporating high-frequency data with a non-linear auto-regressive structure better captures the market dynamics, the mathematical gap between the empirical low-frequency discrete-time non-linear volatility models, such as the exponential realized GARCH, and high-frequency-based continuous-time diffusion process is not well-studied. In fact, several studies have been conducted to fill the gap between the discrete-time volatility models and continuous-time diffusion process (Kim and Fan,, 2019; Kim and Wang,, 2016; Song et al.,, 2021). However, these studies are based on the linear auto-regressive structure, and the extension from linear to non-linear structures is not straightforward. This fact increases the demand for developing continuous-time diffusion process-based models that provide a rigorous mathematical formulation for the non-linear auto-regressive structure of realized volatilities.
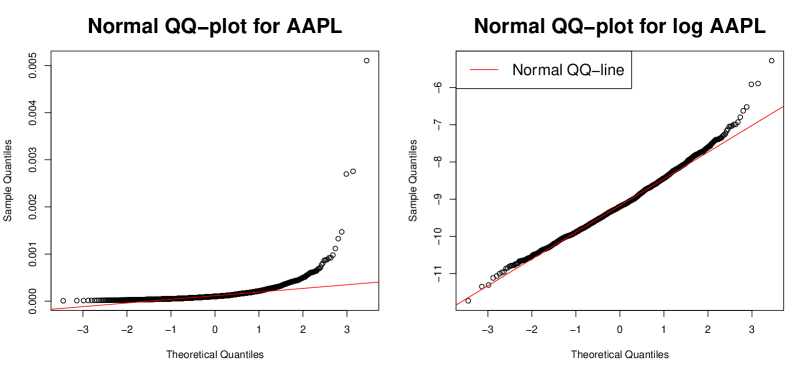
In this paper, we develop a novel diffusion process to model high-frequency financial data, which can accommodate a non-linear GARCH structure of the realized volatilities. From the empirical study, we often observe that the log-realized volatility has a stronger auto-regressive structure than the original realized volatility. To reflect this, we employ the exponential GARCH structure as the non-linear function. Specifically, the log-realized volatility follows the realized GARCH structure. To connect this low-frequency volatility structure with the continuous-time diffusion process, we develop a novel continuous instantaneous volatility process. Since the volatility process has a non-linear structure, the linear structure of the unified GARCH-Itô (Kim and Wang,, 2016) is not applicable. Furthermore, usual log-diffusion processes for instantaneous volatility processes can not provide the solution. To tackle this issue, we propose a novel instantaneous volatility process, based on the average integrated volatility process. Then, the proposed instantaneous volatility process is continuous with respect to time, and its daily integrated volatility is decomposed into the exponential realized GARCH with the daily log-integrated volatility as the innovation and exponential martingale difference. We call it the exponential realized GARCH-Itô (ERGI) model. Unlike the linear realized GARCH model, the log-realized volatility can have negative values. Thus, we allow model parameters to be negative. To estimate the model parameter, we propose a quasi-maximum likelihood estimation procedure. Specifically, we adopt the Gaussian quasi-likelihood function and use the realized volatility as the proxy of the conditional expected value. Furthermore, we establish its asymptotic properties. To illustrate the benefit of the proposed model, we apply the ERGI model to real trading high-frequency data and find that the exponential structure helps account for the volatility dynamics.
The rest of paper is organized as follows. In Section 2, we propose the ERGI model and investigate its properties. In Section 3, we suggest the quasi-maximum likelihood estimation procedure and study its asymptotic behaviors. In Section 4, we conduct a simulation study to check the finite sample performance of the ERGI model. In Section 5, we apply the ERGI model to the top 50 high trading volume assets among the S&P 500 compositions. Section 6 contains the conclusions. All the technical proofs are collected in Section 7.
2 Exponential realized GARCH-Itô models
In this section, we develop an exponential realized GARCH-Itô (ERGI) model as follows.
Definition 1.
We call the log-price to follow the ERGI process if it satisfies
where , denotes the integer part of , except that when is an integer, , and is the model parameter. For the jump part, is the jump size and is the Poisson process with the intensity .
We note that is an adjust term to handle some remaining terms. Specifically, we set , where ’s are functions of , which are defined in Theorem 1. The log-average integrated volatility, , provides the innovation term, and is the random fluctuation. Since the process is continuous with respect to time , the instantaneous volatility process is also continuous. At the integer time points, we have
That is, can be explicitly expressed by the past log-integrated volatilities, and has a form of the interpolation between these values. Thus, when considering , the ERGI model has a similar structure of realized GARCH-Itô model (Song et al.,, 2021) with the log-integrated volatility as the innovations. However, unlike the realized GARCH-Itô model, to obtain the non-linear exponential realized GARCH form, the instantaneous volatility process has a non-linear structure, such as . The solution for this structure is
Details can be found in Lemma 1. Using the above solution, we can measure the integrated volatility with and , which has the realized GARCH form with the log-integrated volatilities. Specific properties of the integrated volatility are shown in the following theorem.
Theorem 1.
Under the ERGI model, for and , the integrated volatilities have the following properties.
-
(a)
We have
where
and
is a martingale difference.
-
(b)
We have
(2.1) (2.2) where
and
is an exponential martingale difference.
Theorem 1(a) shows that the log-integrated volatility is decomposed into the realized GARCH with the log-integrated volatility innovations, , and the martingale difference . Thus, the log-realized GARCH, , is the conditional expected value of the log-integrated volatility, but it is not the conditional expected value of the original integrated volatility. In Theorem 1(b), we show that the integrated volatility is decomposed into the exponential function of the realized GARCH with the log-integrated volatility innovations, , which has the additional interceptor term from the martingale difference term , and the exponential martingale difference . Since the expectation is a linear function, the additional interceptor term does not appear in the linear realized GARCH. However, the ERGI is non-linear, and, thus, we have the additional interceptor term. The main purpose of this paper is to develop a model for analyzing the original integrated volatility, so we develop a statistical inference based on (2.2). Theorem 1 indicates that the proposed model has a non-linear exponential GARCH structure. From the empirical study, we find that this non-linear structure helps explain the volatility dynamics as compared to the usual linear realized GARCH. Details can be found in Section 5.
2.1 Relationship with the daily log-returns
The traditional discrete GARCH models are models of close-to-close volatilities for log-returns. In this section, we discuss the relationship between the proposed ERGI and close-to-close volatilities for log-returns.
We first consider the continuous part. That is, we assume that the log-price process does not have the jump part. Then, by Itô’s lemma and Theorem 1(b), we have
Thus, the exponential GARCH volatility, , is the conditional volatility of the daily log-return. Unfortunately, in practice, we do not have the observations during the close-to-open period. Thus, in order to investigate the close-to-close volatility, we need to impose a structure on the overnight period. For example, we can simply use squared close-to-open log-returns as as the proxy of the integrated volatility for the close-to-open period. Then, we can apply the proposed ERGI model to the realized volatility plus squared close-to-open log-return. On the other hand, we can assume that the close-to-open volatility dynamics is same as the open-to-close period. Then, we only need to match the scale. To do this, we can calculate the averages for the open-to-close realized volatilities and the squared close-to-open log-returns, and we multiply the inverse of the proportion of the average of the realized volatility. The above methods are practical solutions without theoretical justifications. Thus, it is interesting and important to develop a diffusion process which can accommodate the close-to-close period. We leave this for future study.
To investigate the jump diffusion process. We assume that the jump sizes ’s are i.i.d. with mean and variance , and the intensity is constant over time; that is, . Furthermore, we assume the continuous part and jump part are not correlated. Then, the conditional volatility of the daily log-return is
The squared log-return has the exponential GARCH, , and additional expected jump variation. The jump variation part depends on the assumption of the jump structure. Thus, it is interesting and important to investigate the jump variation dynamics and to model the jump part. We leave this for future study.
3 Estimation procedure
3.1 A model setup
We assume that the log-prices follow the ERGI process defined in Definition 1. The intra-day log-prices for the th day are observed at , where . We denote as the average number of the high-frequency observations; that is, . Unfortunately, true high-frequency observations, ’s, are not observed due to market micro-structure noises. To accommodate the market micro-structure noises, we assume that the observed log-prices has the following structure:
where is the true log-price and ’s are micro-structure noises with mean zero.
Without the presence of price jumps, several nonparametric realized volatility estimators have been constructed that take advantage of sub-sampling and local-averaging techniques to remove the effect of market micro-structure noises so that the integrated volatility can be estimated consistently and efficiently (Barndorff-Nielsen et al.,, 2008; Fan and Kim,, 2018; Jacod et al.,, 2009; Shin et al.,, 2021; Zhang,, 2006; Xiu,, 2010). To identify the jump locations given noisy high-frequency data, Fan and Wang, (2007) and Zhang et al., (2016) proposed wavelet methods to detect jumps and applied the MSRV method to jump-adjusted data. They showed that the estimator of jump variation has the convergence rate of , and the estimator of integrated volatility achieves the optimal convergence rate of . On the other hand, Aït-Sahalia and Xiu, (2016) proposed jump robust pre-averaging methods by employing a truncation method. They also demonstrated that the estimators of jump variation and integrated volatility achieve the optimal convergence rate of . In this paper, for the th day, we let to be the corresponding estimator of daily integrated volatility that is robust to micro-structure noises and price jumps. In the numerical study, we employ the jump robust pre-averaging method.
3.2 GARCH parameters estimation
We first fix notations. For a given vector , we define . Let ’s be generic constants whose values does not depend on , and and may change from occurrence to occurrence. In this section, we develop an estimation procedure for the true GARCH model parameters .
Theorem 1 indicates that the integrated volatility is decomposed into the exponential GARCH term and the exponential martingale difference term , which implies
Since is the exponential martingale difference, is a martingale difference. This inspires us to use integrated volatility as a proxy for exponential GARCH volatility, and we define a quasi-likelihood function as follows:
We can estimate the parameter by maximizing the above quasi-likelihood function. However, in practice, the integrated volatility is not observable, so we need to estimate it first. We employ the jump robust realized volatility estimator (Aït-Sahalia and Xiu,, 2016; Fan and Wang,, 2007; Zhang et al.,, 2016). Then, we estimate the log-conditional expectation of the integrated volatilities as follows:
| (3.1) |
where the initial value is set to be . The effect of the initial value is negligible with the rate of (see Lemma 1 in Kim and Wang, (2016)), so its choice does not have a significant effect on the parameter estimation. With the estimated conditional expected volatility function, we define the following quasi-likelihood function:
Then, we obtain the estimator for the GARCH parameters by maximizing the above quasi-likelihood function,
where is the parameter space of . To establish its asymptotic properties, we need the following technical conditions.
Remark 1.
Even if the effect of the initial value is negligible, for the finite sample, the random variable happens to be far from the true initial value. To handle this practical issue, we can assume that the initial value is a long-term average. Under this condition, we can use the theoretical average value as the initial value. That is, we additionally assume that the initial value is . With this condition, we can obtain the same asymptotic result derived in Theorem 2.
Assumption 1.
-
(a)
, where are some known constants.
-
(b)
and
-
(c)
, , , and for all .
Remark 2.
Under Assumption 1(a), unlike the linear GARCH-Itô models (Kim and Wang,, 2016; Song et al.,, 2021), we allow the parameters to be negative. The condition provides stationary properties of conditional volatilities. There exist realized volatility estimators satisfying Assumption 1(b) under some finite moment condition (see Kim et al., (2016); Tao et al., (2011)). The sufficient condition for Assumption 1(c) is that and for .
In the following theorem, we establish the asymptotic properties of the proposed quasi-maximum likelihood estimator (QMLE).
Theorem 2.
Remark 3.
Theorem 2 shows that the QMLE has the convergence rate . The term is the usual convergence rate due to the low-frequency errors, . The term is the cost to estimate the integrated volatility, which is known as the optimal rate with the presence of the micro-structure noises. Specifically, by Theorem 1, we have the following relationship:
and additionally, due to the estimation error of the latent integrated volatility, we have
where is the estimation error of the latent integrated volatility. The error rate of is , and its asymptotic variance is specified in the literature of estimating integrated volatility (Aït-Sahalia et al.,, 2010; Barndorff-Nielsen et al.,, 2008; Jacod et al.,, 2009; Xiu,, 2010; Zhang,, 2006). Then, the asymptotic variance of in Theorem 2 has an additional term that is a function of variance of . For example, we have
where is the asymptotic variance of , and and are functions of .
Remark 4.
The condition is required to remove the effect from the estimation error of the realized volatility when establishing the asymptotic normality. However, as in the realized GARCH model (Hansen et al.,, 2012), if we assume that the conditional volatility is a function of the realized volatility estimator , this assumption is not required.
3.3 Hypothesis tests
In financial practices, we are interested in statistical inferences about the GARCH parameters , such as hypothesis tests. In this section, we discuss how to conduct hypothesis tests for the GARCH parameters.
Theorem 2 implies that
where and . To evaluate the asymptotic variances of the GARCH parameter estimators, we first need to estimate and . We use the following estimators,
where is defined in (3.1). Under some stationary condition, we can establish their consistency. Then, by the Slutsky’s theorem, we can obtain
where and are the th elements of and , respectively, and is the th diagonal element of . Thus, using the proposed Z-statistics , we can conduct the hypothesis tests based on the standard normal distribution.
4 A simulation study
We conducted Monte-Carlo simulations to check the finite sample performance of the ERGI model. The log-prices were generated from the ERGI model given in Definition 1 for days with high-frequency observations. The model parameters were set to be and . Then, the GARCH parameters . For the jump part, we set the intensity and the jump size . The signs of the jump size were randomly generated. Let for and . We generated the noisy observations as follows:
where ’s are i.i.d. normal random variables with mean zero and standard deviation . To generate the true process, we chose . We varied from 100 to 500 and from 390 to 11700, which corresponds to the number of minutes and 2-seconds during the open-to-close period, respectively. We used as the high-frequency observations. To estimate the integrated volatilities, we used the jump robust pre-averaging method (Aït-Sahalia and Xiu,, 2016; Jacod et al.,, 2009) as follows:
where we take the weight function , the bandwidth size ,
is an indicator function, and is a truncation level for the constant . We chose as four times the sample standard deviation of the pre-averaged prices . We estimated the parameters using the procedure in Section 3. We repeated the whole procedure 500 times.
To check the performance of the realized volatility estimator, we calculated squared relative errors as follows:
Then, we calculated the sample average of squared relative errors over 500 simulations. We have the average errors 0.0117, 0.0463, and 0.10751 for and , respectively. As increases, the average errors decreases. This result supports the theoretical findings in the realized volatility estimator literature (Aït-Sahalia and Xiu,, 2016; Jacod et al.,, 2009).
| 100 | 390 | 0.0854 | 0.1312 | 0.0468 |
|---|---|---|---|---|
| 1170 | 0.0852 | 0.1217 | 0.0415 | |
| 11700 | 0.0865 | 0.1204 | 0.0408 | |
| 200 | 390 | 0.0435 | 0.0714 | 0.0309 |
| 1170 | 0.0428 | 0.0690 | 0.0280 | |
| 11700 | 0.0453 | 0.0720 | 0.0274 | |
| 500 | 390 | 0.0296 | 0.0484 | 0.0213 |
| 1170 | 0.0249 | 0.0395 | 0.0177 | |
| 11700 | 0.0244 | 0.0367 | 0.0171 |
Table 1 reports the mean squared errors (MSE) of the parameter estimates with and . In Table 1, MSEs usually decrease as the number of high-frequency observations or daily observations increases. This result supports the theoretical findings in Section 3.

To check the asymptotic normality of the GARCH parameters , we calculated the Z-statistics defined in Section 3.3. In Figure 2, we draw the standard normal quantile-quantile plots (QQ-plots) of the Z-statistics estimates of , , and for and . In Figure 2, we find that the Z-statistics become close to the standard normal distribution as the sample period increases. This result supports the theoretical findings in Section 3. Thus, based on the proposed Z-statistics, we can conduct hypothesis tests using the standard normal distribution.
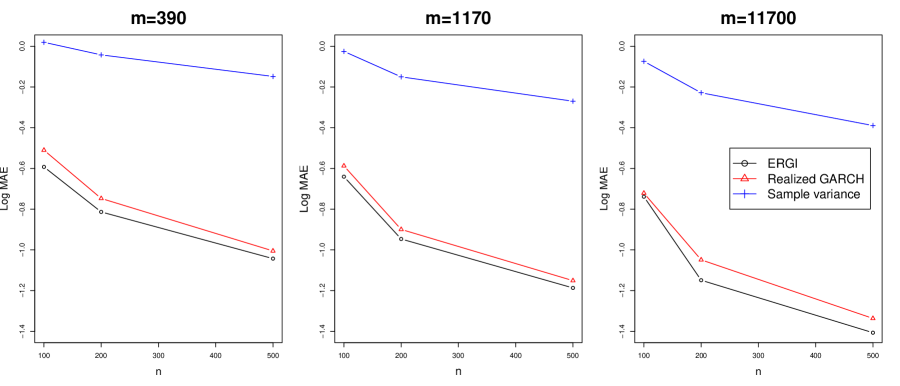
We examined the out-of-sample performance of estimating the one-day-ahead GARCH volatility . To estimate future GARCH volatility, we employed the proposed conditional ERGI estimator , realized GARCH volatility estimator (Hansen et al.,, 2012; Song et al.,, 2021), and PRV of the previous day. For example, the realized GARCH volatility estimator is estimated based on the following conditional volatility,
That is, the realized GARCH volatility estimator has the usual linear GARCH structure with the realized volatilities. We measured the mean squared errors with the one-day-ahead sample period over 500 samples as follows:
where is one of the above future volatility estimators at the th sample path given the available information at time . Figure 3 depicts the mean squared errors for the ERGI, realized GARCH, and PRV against varying the numbers of low- and high-frequency observations, and . In Figure 3, we find that the ERGI models show the best performance. The interesting finding is that the realized GARCH model can also capture some volatility dynamics. This may be because even if the volatility dynamic structure is non-linear, it could have some linear dynamics. Especially, when the log-volatility quantities are small, by Taylor’s expansion, the linear model can capture some non-linear dynamics. However, using the only linear structure, it cannot fully explain the non-linear dynamic structure. From these results, we can conjecture that modeling appropriate dynamic structure helps account for market dynamics.
5 Empirical study
We applied the proposed ERGI model to real trading high-frequency data. We obtained the top 50 trading volume assets intra-day data from January 2010 to December 2016 from the TAQ database in the Wharton Research Data Services (WRDS) system. We used the log-prices and employed the jump robust PRV estimation procedure defined in Section 4 to estimate open-to-close integrated volatility. In the empirical study, we chose the tuning parameter as 10 times the sample standard deviation of pre-averaged prices . To check the accuracy of the PRV estimator, we calculated standard errors (SE) as follows. We first calculated the asymptotic variance, proposed by Aït-Sahalia and Xiu, (2016), and divided the square root of the asymptotic variance estimator by the square root of the number of high-frequency observations. We report data summary in Table 2. The number of high-frequency data is from 16,000 to 90,000 on average, and we find that the proportion of the jump variation is about 8% to 40% of the total variation on average. The standard error is less than 10% of realized volatility.
| Stock | of obs | RV | SE | JV | Stock | of obs | RV | SE | JV | |
|---|---|---|---|---|---|---|---|---|---|---|
| PG | 16912.4 | 0.5637 | 0.0414 | 0.4000 | MO | 23667.5 | 0.6886 | 0.0075 | 0.2074 | |
| HBAN | 15941.4 | 2.7678 | 0.0183 | 0.3550 | QCOM | 40986.1 | 1.3487 | 0.0059 | 0.2306 | |
| FCX | 37196.1 | 5.4242 | 0.0222 | 0.8249 | MRK | 36710.1 | 0.9756 | 0.0198 | 0.2643 | |
| MRO | 31241.5 | 3.8938 | 0.0203 | 0.6569 | GILD | 43938.5 | 1.8619 | 0.0132 | 0.4030 | |
| ORCL | 44489.4 | 1.3062 | 0.0062 | 0.1915 | DAL | 35653.1 | 4.2791 | 0.0219 | 0.6506 | |
| AMD | 22373.9 | 5.9256 | 0.0345 | 0.9735 | LUV | 23756.9 | 2.3442 | 0.0120 | 0.6057 | |
| AMAT | 33556.6 | 2.0554 | 0.0079 | 0.3043 | T | 38606.7 | 0.7138 | 0.0037 | 0.1288 | |
| XRX | 18877.3 | 2.3137 | 0.0172 | 1.4115 | CSCO | 40328.4 | 1.2632 | 0.0079 | 0.2128 | |
| WFC | 44023.8 | 1.4846 | 0.0073 | 0.3143 | DIS | 16682.3 | 1.0435 | 0.0108 | 0.1842 | |
| NFLX | 30613.5 | 5.4658 | 0.0293 | 0.5557 | NVDA | 27743.1 | 3.2549 | 0.0151 | 0.4210 | |
| F | 34610.1 | 2.2033 | 0.0177 | 0.4130 | SLB | 31761.7 | 2.0279 | 0.0094 | 0.4409 | |
| GE | 46327.4 | 1.2444 | 0.0153 | 0.2523 | BMY | 27565.6 | 1.1346 | 0.0157 | 0.2655 | |
| INTC | 45515.7 | 1.4031 | 0.0076 | 0.2464 | ATVI | 25432.0 | 2.0102 | 0.0100 | 0.3804 | |
| XOM | 45802.3 | 0.9642 | 0.0072 | 0.1490 | MU | 38907.5 | 5.1948 | 0.0301 | 0.9009 | |
| RF | 19662.3 | 3.7024 | 0.0236 | 0.4208 | JPM | 40898.6 | 1.6448 | 0.0729 | 0.4199 | |
| DOW | 28093.0 | 1.9877 | 0.0190 | 0.3006 | CVX | 32592.7 | 1.1472 | 0.0067 | 0.2205 | |
| NEM | 29263.8 | 3.3862 | 0.0118 | 0.4225 | MSFT | 61219.5 | 1.2213 | 0.0035 | 0.1855 | |
| CSX | 16106.8 | 1.6852 | 0.0153 | 0.4427 | BAC | 63492.7 | 2.4282 | 0.0098 | 0.3718 | |
| TXN | 25727.4 | 1.3822 | 0.0072 | 0.3163 | WMT | 30549.0 | 0.6412 | 0.0033 | 0.1288 | |
| JNJ | 31877.1 | 0.5137 | 0.0062 | 0.1689 | WMB | 26970.9 | 3.8400 | 0.0394 | 0.8323 | |
| VZ | 32309.9 | 0.7749 | 0.0185 | 0.2155 | AAPL | 90386.9 | 1.4419 | 0.0118 | 0.3017 | |
| HST | 21239.2 | 2.2687 | 0.0135 | 0.2591 | BSX | 24163.9 | 2.3119 | 0.0145 | 0.4101 | |
| MGM | 16642.6 | 4.5845 | 0.0309 | 0.6648 | PFE | 43600.5 | 1.0821 | 0.0160 | 0.2296 | |
| KO | 37024.6 | 0.6041 | 0.0034 | 0.1091 | HAL | 39739.1 | 3.2834 | 0.0136 | 0.4913 | |
| SCHW | 27159.3 | 2.0437 | 0.1963 | 0.3522 | GLW | 25151.0 | 1.8426 | 0.0155 | 0.3186 |
We first estimated the model parameters using the recent 1000 days data. From the estimated model parameters, we obtained the following conditional expected volatility for each asset
Table 3 reports the estimation results. From Table 3, we show that dynamic structures can be explained by the past log-PRV, and the coefficients of realized volatilities are statistically significant. Thus, the proposed exponential model is valid.
| Stock | Stock | |||||||
|---|---|---|---|---|---|---|---|---|
| PG | -1.18 (0.00) | 0.33 (0.00) | 0.54 (0.00) | MO | -1.37 (0.00) | 0.33 (0.00) | 0.51 (0.00) | |
| HBAN | -1.06 (0.00) | 0.35 (0.00) | 0.52 (0.00) | QCOM | -1.67 (0.00) | 0.21 (0.00) | 0.59 (0.00) | |
| FCX | -0.07 (0.00) | 0.48 (0.00) | 0.50 (0.00) | MRK | -0.98 (0.00) | 0.33 (0.00) | 0.55 (0.00) | |
| MRO | -0.12 (0.00) | 0.39 (0.00) | 0.58 (0.00) | GILD | -0.86 (0.00) | 0.33 (0.00) | 0.56 (0.00) | |
| ORCL | -1.60 (0.00) | 0.18 (0.00) | 0.64 (0.00) | DAL | -1.91 (0.00) | 0.18 (0.02) | 0.57 (0.00) | |
| AMD | -0.50 (0.00) | 0.50 (0.00) | 0.42 (0.00) | LUV | -1.45 (0.00) | 0.33 (0.00) | 0.49 (0.00) | |
| AMAT | -1.83 (0.26) | 0.19 (0.00) | 0.59 (0.00) | T | -1.98 (0.01) | 0.28 (0.00) | 0.50 (0.00) | |
| XRX | -0.57 (0.00) | 0.47 (0.00) | 0.45 (0.00) | CSCO | -1.83 (0.00) | 0.18 (0.00) | 0.61 (0.00) | |
| WFC | -1.17 (0.00) | 0.24 (0.00) | 0.62 (0.00) | DIS | -1.41 (0.00) | 0.23 (0.00) | 0.61 (0.00) | |
| NFLX | -0.69 (0.05) | 0.29 (0.00) | 0.60 (0.02) | NVDA | -1.31 (0.02) | 0.29 (0.00) | 0.54 (0.00) | |
| F | -1.56 (0.00) | 0.26 (0.03) | 0.56 (0.00) | SLB | -0.62 (0.00) | 0.36 (0.00) | 0.55 (0.00) | |
| GE | -1.40 (0.00) | 0.19 (0.10) | 0.66 (0.00) | BMY | -1.71 (0.00) | 0.23 (0.00) | 0.57 (0.00) | |
| INTC | -1.14 (0.00) | 0.27 (0.00) | 0.60 (0.00) | ATVI | -0.82 (0.00) | 0.42 (0.00) | 0.47 (0.00) | |
| XOM | -0.62 (0.00) | 0.34 (0.00) | 0.59 (0.00) | MU | -1.10 (0.00) | 0.34 (0.07) | 0.51 (0.00) | |
| RF | -0.98 (0.00) | 0.42 (0.00) | 0.46 (0.00) | JPM | -1.42 (0.00) | 0.15 (0.00) | 0.68 (0.00) | |
| DOW | -1.06 (0.00) | 0.32 (0.00) | 0.55 (0.00) | CVX | -0.39 (0.00) | 0.38 (0.00) | 0.57 (0.00) | |
| NEM | -0.74 (0.00) | 0.35 (0.00) | 0.55 (0.00) | MSFT | -1.29 (0.00) | 0.29 (0.00) | 0.55 (0.00) | |
| CSX | -0.83 (0.00) | 0.32 (0.00) | 0.58 (0.00) | BAC | -1.26 (0.00) | 0.27 (0.00) | 0.58 (0.00) | |
| TXN | -1.31 (0.00) | 0.23 (0.00) | 0.61 (0.04) | WMT | -0.71 (0.00) | 0.52 (0.00) | 0.40 (0.00) | |
| JNJ | -1.02 (0.01) | 0.38 (0.00) | 0.51 (0.00) | WMB | -0.09 (0.00) | 0.41 (0.00) | 0.56 (0.00) | |
| VZ | -1.91 (0.00) | 0.21 (0.00) | 0.58 (0.00) | AAPL | -2.01 (0.00) | 0.08 (0.00) | 0.68 (0.00) | |
| HST | -0.62 (0.10) | 0.46 (0.00) | 0.46 (0.00) | BSX | -1.40 (0.00) | 0.29 (0.00) | 0.54 (0.00) | |
| MGM | -1.04 (0.00) | 0.31 (0.00) | 0.55 (0.00) | PFE | -0.89 (0.00) | 0.33 (0.00) | 0.56 (0.00) | |
| KO | -1.46 (0.00) | 0.26 (0.00) | 0.58 (0.00) | HAL | -0.70 (0.00) | 0.30 (0.00) | 0.60 (0.03) | |
| SCHW | -1.14 (0.00) | 0.33 (0.00) | 0.53 (0.00) | GLW | -1.92 (0.00) | 0.18 (0.00) | 0.59 (0.00) |
For comparison, we employed the realized GARCH (Hansen et al.,, 2012; Song et al.,, 2021), unified GARCH-Itô (UGARCH) (Kim and Wang,, 2016), and HAR (Corsi,, 2009) models. To measure the performance of the volatility, we used the mean squared prediction errors (MSPE) and relative mean squared prediction errors (RMSPE) as follows:
where is one of the ERGI, realized GARCH, HAR, and UGARCH. We used as the nonparametric daily volatility estimator. Furthermore, we calculated the out-of-sample R-square (OSR) (Campbell and Thompson,, 2008) as follows:
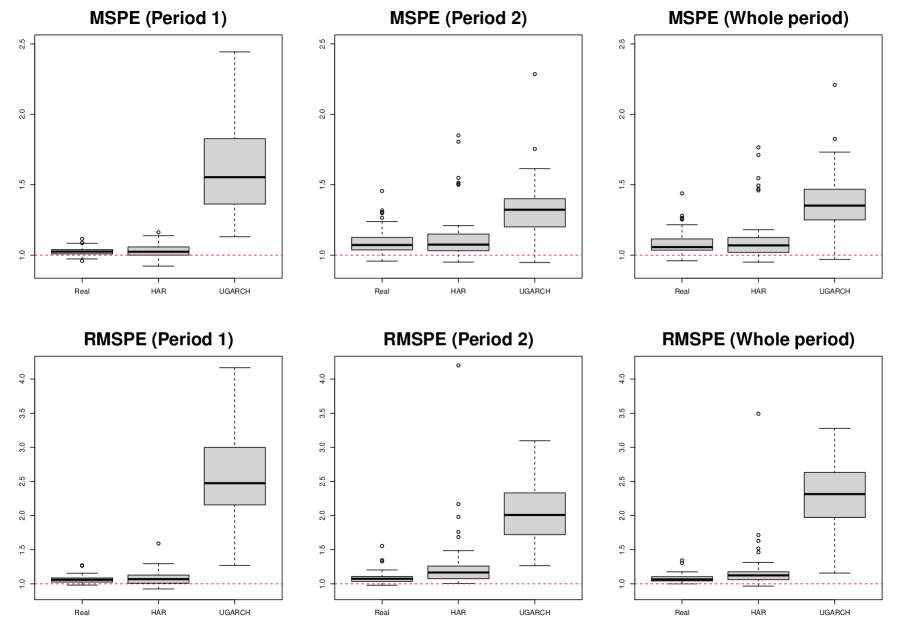
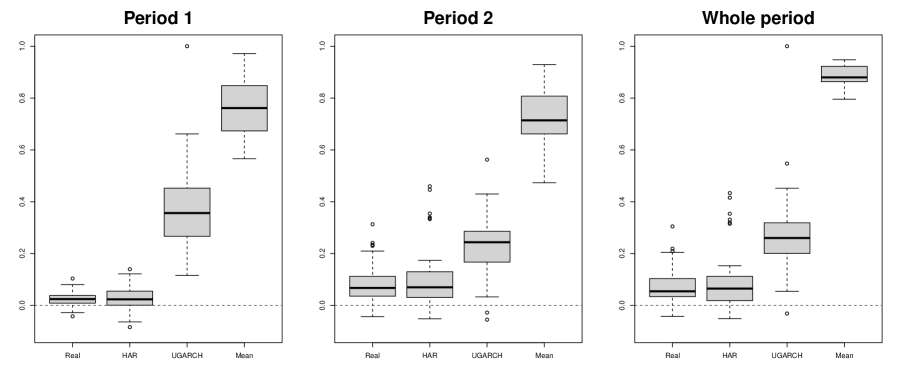
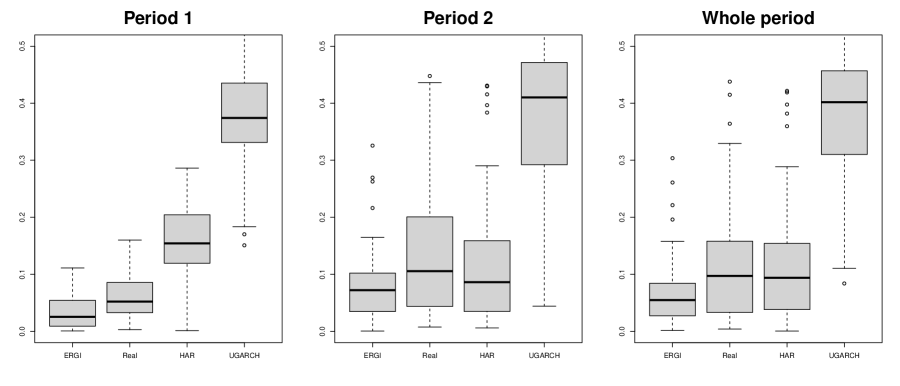
where is the proposed ERGI, and is one of the realized GARCH, HAR, unified GARCH-Itô, and sample mean of the in-sample ’s. We predicted the one-day-ahead conditional expected volatility by the ERGI, realized GARCH, HAR, and UGARCH models using the in-sample period data. We fixed the in-sample period as 500 days and used the rolling window scheme to estimate the parameters. The number of out-of-sample was 1,262. To check the period dependency, we split the period into two equal parts. We denote the two periods as Period 1 and Period 2. Table 4 reports the average rank and the number of the first rank of MSPEs and RMSPEs for the ERGI, realized GARCH, HAR and UGARCH for Period 1, Period 2, and the whole period over the 50 assets. Figure 4 depicts the relative MSPE and RMSPE for the realized GARCH, HAR, and UGARCH with respect to the ERGI for Period 1, Period 2, and the whole period. Figure 5 draws the OSR for the ERGI with respect to realized GARCH, HAR, UGARCH, and sample mean for Period 1, Period 2, and the whole period. From Table 4 and Figures 4–5, we find that the realized volatility-based model, such as the ERGI, realized GARCH, and HAR models, perform better than the UGARCH model, which incorporates the squared open-to-close returns as the innovation. That is, incorporating the realized volatility helps account for the volatility dynamics. When comparing the realized volatility-based models, the proposed ERGI model shows the best performance. From this result, we can conjecture that the non-linear exponential form with realized volatilities helps explain the market dynamics.
| Period 1 | Period 2 | Whole period | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ERGI | Real | HAR | UGARCH | ERGI | Real | HAR | UGARCH | ERGI | Real | HAR | UGARCH | |||
| MSPE | 1.4 (33) | 2.3 (5) | 2.2 (12) | 4.0 (0) | 1.1 (42) | 2.5 (2) | 2.6 (4) | 3.6 (2) | 1.2 (41) | 2.5 (2) | 2.4 (6) | 3.7 (1) | ||
| RMSPE | 1.2 (38) | 2.4 (3) | 2.3 (9) | 4.0 (0) | 1.0 (48) | 2.2 (1) | 2.8 (0) | 3.8 (1) | 1.0 (47) | 2.3 (0) | 2.6 (3) | 3.9 (0) | ||
To further compare the predictive accuracy among the ERGI, realized GARCH, HAR, and UGARCH models, we conducted Diebold-Mariano tests (Diebold and Mariano,, 2002) as follows. We first calculated the residuals for the four models:
where is one of the ERGI, realized GARCH, HAR, and UGARCH, and is the non-parametric realized volatility. We define
where is the residuals from the ERGI and is the residuals from one of realized GARCH, HAR, and UGARCH. Then, we conducted hypothesis tests for
The first alternative statement () is to test whether the ERGI is better, while the second alternative statement () is to test whether other model is better than the ERGI. We call them “less” and “greater” tests, respectively. Figure 6 depicts box plots of p-values of the less and greater DM tests for the ERGI versus one of the realized GARCH, HAR, and UGARCH for Period 1, Period 2, and the whole period. From Figure 6, the less tests show that p-values of 22, 16, and 46 assets for realized GARCH, HAR, and UGARCH models, respectively, were less than 10% over the whole period. In contrast, the greater tests indicate that a couple of assets for the HAR model have significant p-values over the whole period. From these results, although the ERGI does not give significant better predictive accuracy for all assets, we can conclude that for most assets, the ERGI is at least not worse than other models, and, for some assets, the ERGI shows significantly better performance than the other models.
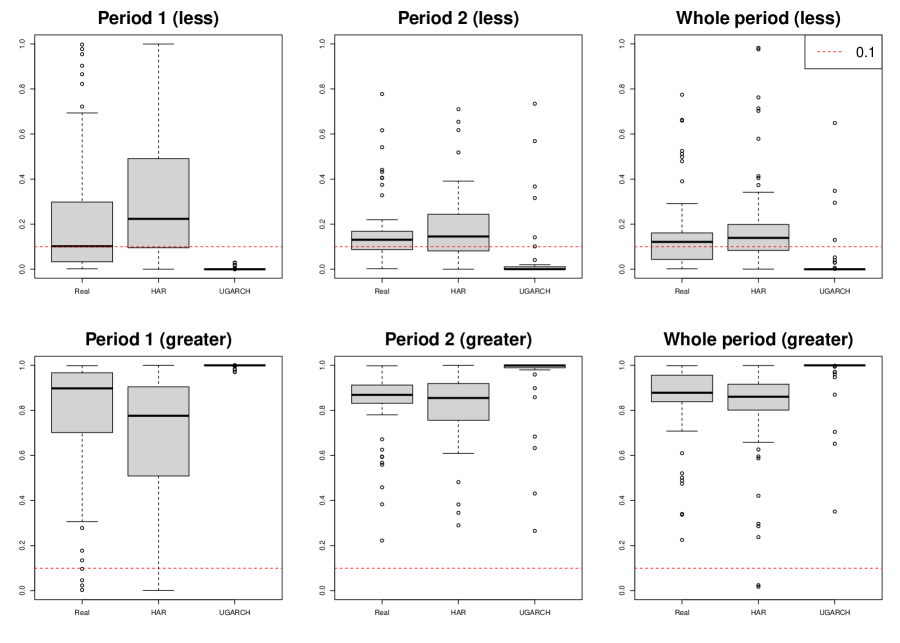
To check the volatility persistence of the nonparametric volatility, we studied the residuals between the nonparametric volatility and estimated conditional volatilities, , where is the predicted one-day-ahead conditional expected volatility by ERGI, realized GARCH, HAR, and UGARCH using the in-sample period data. Then, we checked their autocorrelations. Table 5 reports the average rank and number of the first rank of the first order autocorrelation for the ERGI, realized GARCH, HAR, and UGARCH for Period 1, Period 2, and the whole period over the 50 assets. Figure 7 provides the box plots of the first order autocorrelation for the ERGI, realized GARCH, HAR, and UGARCH for Period 1, Period 2, and the whole period over the 50 assets. From Table 5 and Figure 7, we find that the ERGI has relatively small autocorrelations. That is, the ERGI model can reduce the volatility persistence. These numerical results provide evidence to conclude that the non-linear exponential auto-regressive structure helps explain the market dynamics in the volatility time series.
| Period 1 | Period 2 | Whole period | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ERGI | Real | HAR | UGARCH | ERGI | Real | HAR | UGARCH | ERGI | Real | HAR | UGARCH | ||
| 1.2 (40) | 1.9 (9) | 2.9 (1) | 3.9 (0) | 1.8 (18) | 2.3 (14) | 2.3 (13) | 3.6 (5) | 1.6 (28) | 2.2 (12) | 2.5 (8) | 3.6 (2) | ||
6 Conclusions
In this paper, we propose a novel jump diffusion process to model the non-linear auto-regressive structure of the realized volatility. We employ the exponential GARCH structure. By introducing a continuous instantaneous volatility process whose integrated volatility follows the exponential realized GARCH structure, we fill the gap between the empirical discrete-time non-linear volatility model with the realized volatility and high-frequency based continuous-time diffusion process. That is, this paper provides rigorous mathematical background to understand the exponential realized GARCH structure. To estimate the model parameter, we propose the quasi-maximum likelihood estimation procedure and establish its asymptotic properties. From the empirical study, we find the benefits of incorporating the non-linear exponential realized GARCH.
In this paper, we focus on the continuous part of log-return processes for the open-to-close period. However, it is important and interesting to study dynamic structures of the jump variation and close-to-open returns. We leave this for future study.
7 Proofs
7.1 Proof of Theorem 1
Lemma 1.
Under the ERGI model in Definition 1, we have for ,
| (7.1) |
Proof of Theorem 1. First, we consider . By the Itô’s lemma, we have
and, by Lemma 1, we have
Thus, we have
Then, by (7.1), we have
For , since is a constant, we have
and we obtain .
7.2 Proof of Theorem 2
To simplify the notation, we use for the GARCH model parameters . For derivatives of any given function at , we denote . Define
Since the dependence of on the initial value decays exponentially (Kim and Wang,, 2016), we use the true initial value for the rest of the proofs without of loss of generality.
Lemma 2.
Under the assumptions of Theorem 2, we have .
Proof of Lemma 2. We first show the uniform convergence of . That is, we need to show
For , we have
For (I), we have
| (7.2) | |||||
| (7.3) | |||||
| (7.4) |
where , and the last inequality is due to Assumption 1(b). Consider (II). By Assumption 1(b) and (c), we have
For (III), we have
where the first and second inequalities are due to Holder’s inequality and Taylor’s expansion, respectively, and the last inequality can be showed similar to the proof of (7.2) with Assumption 1(c). Thus, we have
| (7.5) |
We consider . We have
which is a martingale process for any given . Thus, by martingale convergence theorem, we can show its pointwise convergence. To show its uniform convergence, we need to show the stochastic continuity for . By the Taylor’s expansion and the mean value theorem, there exits between and such that
By Assumption 1(c), we have . Then, similar to the proofs of Lemma 3 in Kim and Wang, (2016), we can show
Thus, satisfies the weak Lipschitz condition, so, by Theorem 4 in Andrews, (1992), we can show the uniform convergence. Therefore, we have
| (7.6) |
When for all , is maximized. Obviously, is one of the solutions. Suppose that there exists such that a.s. for all . Since the exponential function is a strictly increasing function, we have a.s. for all . Thus, and satisfy
Since ’s are non-degenerating, is of full rank. Then, is invertible, which implies a.s. Therefore, has the unique maximizer . Then, by Theorem 1 in Xiu, (2010), with the uniform convergence of , we can show .
Proof of Theorem 2. The mean value theorem and Taylor’s expansion, there exists between and such that
where . We first consider . We have
| (7.7) | |||||
| (7.8) | |||||
| (7.9) | |||||
| (7.10) |
where the second equality can be showed similar to the proofs of Lemma 2, and the last equality is due to the martingale convergence theorem.
We consider . Similar to the proofs of (7.7) with the consistency of , we can show
Since ’s and ’s are non-degenerating, is positive definite. Thus, by (7.7), we have
Now, we show the asymptotic normality. By Theorem 1(b), we have
Since ’s are i.i.d., is strictly stationary. By Theorem 2.1 (Francq et al.,, 2013) and Theorem 2.5 (Bougerol and Picard,, 1992), is ergodic. Then, applying the martingale central limit theorem, we obtain
By the ergodic theorem, we can show
Thus, by the Slutsky theorem, we have
Acknowledgments
The authors appreciate the Editor, Professor D. Kristensen, and anonymous two referees for their careful reading of this paper and valuable comments. The research of Donggyu Kim was supported in part by the National Research Foundation of Korea (NRF) (2021R1C1C1003216).
References
- Aït-Sahalia et al., (2010) Aït-Sahalia, Y., Fan, J., and Xiu, D. (2010). High-frequency covariance estimates with noisy and asynchronous financial data. Journal of the American Statistical Association, 105(492):1504–1517.
- Aït-Sahalia and Xiu, (2016) Aït-Sahalia, Y. and Xiu, D. (2016). Increased correlation among asset classes: Are volatility or jumps to blame, or both? Journal of Econometrics, 194(2):205–219.
- (3) Andersen, T. G. and Bollerslev, T. (1997a). Heterogeneous information arrivals and return volatility dynamics: Uncovering the long-run in high frequency returns. The journal of Finance, 52(3):975–1005.
- (4) Andersen, T. G. and Bollerslev, T. (1997b). Intraday periodicity and volatility persistence in financial markets. Journal of empirical finance, 4(2-3):115–158.
- (5) Andersen, T. G. and Bollerslev, T. (1998a). Answering the skeptics: Yes, standard volatility models do provide accurate forecasts. International Economic Review, 39(4):885–905.
- (6) Andersen, T. G. and Bollerslev, T. (1998b). Deutsche mark-dollar volatility: Intraday activity patterns, macroeconomic announcements, and longer run dependencies. The journal of Finance, 53(1):219–265.
- Andersen et al., (2003) Andersen, T. G., Bollerslev, T., Diebold, F. X., and Labys, P. (2003). Modeling and forecasting realized volatility. Econometrica, 71(2):579–625.
- Andrews, (1992) Andrews, D. W. (1992). Generic uniform convergence. Econometric theory, 8(2):241–257.
- Barndorff-Nielsen et al., (2008) Barndorff-Nielsen, O. E., Hansen, P. R., Lunde, A., and Shephard, N. (2008). Designing realized kernels to measure the ex post variation of equity prices in the presence of noise. Econometrica, 76(6):1481–1536.
- Bollerslev, (1986) Bollerslev, T. (1986). Generalized autoregressive conditional heteroskedasticity. Journal of econometrics, 31(3):307–327.
- Bougerol and Picard, (1992) Bougerol, P. and Picard, N. (1992). Strict stationarity of generalized autoregressive processes. The Annals of Probability, 20(4):1714–1730.
- Campbell and Thompson, (2008) Campbell, J. Y. and Thompson, S. B. (2008). Predicting excess stock returns out of sample: Can anything beat the historical average? The Review of Financial Studies, 21(4):1509–1531.
- Corsi, (2009) Corsi, F. (2009). A simple approximate long-memory model of realized volatility. Journal of Financial Econometrics, 7(2):174–196.
- Diebold and Mariano, (2002) Diebold, F. X. and Mariano, R. S. (2002). Comparing predictive accuracy. Journal of Business & economic statistics, 20(1):134–144.
- Engle, (1982) Engle, R. F. (1982). Autoregressive conditional heteroscedasticity with estimates of the variance of united kingdom inflation. Econometrica: Journal of the Econometric Society, pages 987–1007.
- Fan and Kim, (2018) Fan, J. and Kim, D. (2018). Robust high-dimensional volatility matrix estimation for high-frequency factor model. Journal of the American Statistical Association, 113(523):1268–1283.
- Fan and Wang, (2007) Fan, J. and Wang, Y. (2007). Multi-scale jump and volatility analysis for high-frequency financial data. Journal of the American Statistical Association, 102(480):1349–1362.
- Francq et al., (2013) Francq, C., Wintenberger, O., and Zakoian, J.-M. (2013). Garch models without positivity constraints: Exponential or log garch? Journal of Econometrics, 177(1):34–46.
- Hansen and Huang, (2016) Hansen, P. R. and Huang, Z. (2016). Exponential garch modeling with realized measures of volatility. Journal of Business & Economic Statistics, 34(2):269–287.
- Hansen et al., (2012) Hansen, P. R., Huang, Z., and Shek, H. H. (2012). Realized garch: a joint model for returns and realized measures of volatility. Journal of Applied Econometrics, 27(6):877–906.
- Jacod et al., (2009) Jacod, J., Li, Y., Mykland, P. A., Podolskij, M., and Vetter, M. (2009). Microstructure noise in the continuous case: the pre-averaging approach. Stochastic processes and their applications, 119(7):2249–2276.
- Kawakatsu, (2006) Kawakatsu, H. (2006). Matrix exponential garch. Journal of Econometrics, 134(1):95–128.
- Kim and Fan, (2019) Kim, D. and Fan, J. (2019). Factor garch-itô models for high-frequency data with application to large volatility matrix prediction. Journal of Econometrics, 208(2):395–417.
- Kim and Wang, (2016) Kim, D. and Wang, Y. (2016). Unified discrete-time and continuous-time models and statistical inferences for merged low-frequency and high-frequency financial data. Journal of Econometrics, 194:220–230.
- Kim et al., (2016) Kim, D., Wang, Y., and Zou, J. (2016). Asymptotic theory for large volatility matrix estimation based on high-frequency financial data. Stochastic Processes and their Applications, 126:3527––3577.
- Nelson, (1991) Nelson, D. B. (1991). Conditional heteroskedasticity in asset returns: A new approach. Econometrica: Journal of the Econometric Society, pages 347–370.
- Shephard and Sheppard, (2010) Shephard, N. and Sheppard, K. (2010). Realising the future: forecasting with high-frequency-based volatility (heavy) models. Journal of Applied Econometrics, 25(2):197–231.
- Shin et al., (2021) Shin, M., Kim, D., and Fan, J. (2021). Adaptive robust large volatility matrix estimation based on high-frequency financial data. Available at SSRN 3793394.
- Song et al., (2021) Song, X., Kim, D., Yuan, H., Cui, X., Lu, Z., Zhou, Y., and Wang, Y. (2021). Volatility analysis with realized garch-itô models. Journal of Econometrics, 222(1):393–410.
- Tao et al., (2011) Tao, M., Wang, Y., Yao, Q., and Zou, J. (2011). Large volatility matrix inference via combining low-frequency and high-frequency approaches. Journal of the American Statistical Association, 106(495):1025–1040.
- Xiu, (2010) Xiu, D. (2010). Quasi-maximum likelihood estimation of volatility with high frequency data. Journal of Econometrics, 159(1):235–250.
- Zhang, (2006) Zhang, L. (2006). Efficient estimation of stochastic volatility using noisy observations: A multi-scale approach. Bernoulli, 12(6):1019–1043.
- Zhang et al., (2005) Zhang, L., Mykland, P. A., and Aït-Sahalia, Y. (2005). A tale of two time scales: Determining integrated volatility with noisy high-frequency data. Journal of the American Statistical Association, 100(472):1394–1411.
- Zhang et al., (2016) Zhang, X., Kim, D., and Wang, Y. (2016). Jump variation estimation with noisy high frequency financial data via wavelets. Econometrics, 4(3):34.