Exploring Stronger Transformer Representation Learning for Occluded Person Re-Identification
Abstract
Due to some complex factors (e.g., occlusion, pose variation and diverse camera perspectives), extracting stronger feature representation in person re-identification remains a challenging task. In this paper, we proposed a novel self-supervision and supervision combining transformer-based person re-identification framework, namely SSSC-TransReID. Different from the general transformer-based person re-identification models, we designed a self-supervised contrastive learning branch, which can enhance the feature representation for person re-identification without negative samples or additional pre-training. In order to train the contrastive learning branch, we also proposed a novel random rectangle mask strategy to simulate the occlusion in real scenes, so as to enhance the feature representation for occlusion. Finally, we utilized the joint-training loss function to integrate the advantages of supervised learning with ID tags and self-supervised contrastive learning without negative samples, which can reinforce the ability of our model to excavate stronger discriminative features, especially for occlusion. Extensive experimental results on several benchmark datasets show our proposed model obtains superior Re-ID performance consistently and outperforms the state-of-the-art ReID methods by large margins on the mean average accuracy (mAP) and Rank-1 accuracy.
Index Terms:
Person re-identification, Visual Transformer, Self-supervised learning, Multi-task learning, Random rectangle mask, Data augmentationI Introduction
Person re-identification (ReID) has been being a fundamental yet challenging computer vision task, which aims at associating the person of the same identity across multiple non-overlapping cameras [1]. In past decade, with the fast development of deep learning technology, person ReID has made great progress and been dominated by the deep learning-based methods for a long time [2, 3, 4]. However, person ReID task confronts some complex challenges, such as occlusion, pose changes, view variation and background clutter, so it is the fucus of current research to how to extract robust and discriminate features to combat them.
At present, most existing person ReID methods [5] assume that the entire human body is visible in camera views which hence can’t generalize well to camera scenes with a lot of occlusion, because the occluded camera scenes may be contain plenty of incomplete body information. Since humans are occluded often occurs in natural scenes, occluded person ReID [6, 7, 8] has attracted much attention from many researchers recently. By reviewing the occluded person ReID methods [9], we find that occluded person ReID mainly solve the following problems: 1) the occlusion will introduce the noisy information, which leads to mismatch; 2) the occlusion may have the similar features to human body parts, resulting in failing to learn more discriminative features; 3) the human pose changes, camera view variation and inter-frame human movement may cause feature misalignment. However, lots of ReID methods [10, 11] adopted the common data augmentation strategies (e.g., color distortion, random horizontal flipping and random erasing) to enhance the feature representation, which is only suited to the normal scenes not existing the occlusion and fails to deal with the occluded person images because these models lack the occlusion data for their training.
Recently, Vision Transformer (ViT) [12] adopts the information of all image patches to extract the global features by self-attention mechanism, which has been proven to have good performance and outperform the CNN-based approaches [13, 14] in image classification task. However, the ability of ViT to extract local features is weak because the difference between image patch embeddings will decrease gradually and the spatial information contained in them will became blurred with the processing of self-attention blocks. This weakness of ViT has little impact on general visual tasks such as image classification [12] and face recognition [15] but is susceptible to interference for the occlusion scenes [6]. Thus, in order to solve this problem, different from the strategy of occlusion suppression in [6], inspirited by the paper [16], we proposed a novel data augmentation strategy with random rectangle mask, which can improve the performance of ViT model under occlusion conditions.
In addition, as an efficient representation learning method, contrastive learning shows great potential in person ReID, especially for self-supervised and unsupervised learning, which makes the model learn more distinguishable feature representations so as to enhance the recognition performance by contrasting the feature differences between different samples. For unsupervised contrastive learning, how to generate the pseudo labels and update them is the key step, which usually relies on some clustering algorithms to gradually approximate the true label distribution. Unlike it, self-supervised contrastive learning realizes the representation learning without manual annotation by some specially designed tasks such as image transformation prediction and image context prediction [17], which opens up a new way for person ReID. Furthermore, there are also some methods [6, 18] based on self-supervised contrastive learning for the occlusion problem, and they usually solve the occlusion problem by a per-trained encoder or predictor. Although these methods have made significant progress, it has come at a high training cost. Thus, in this paper, we proposed a novel joint-training framework combining self-supervised and supervised learning, which aims at combating the occlusion challenge in a more cost-effective way. The main contributions of this work are summarized as follows:
-
•
We designed a novel random rectangle mask strategy to simulate the occlusion in real scenes so as to learn more robust feature representation for occlusion. In order to enhance the ability of feature representation further, we still cleverly fused other image enhancing methods such as Gaussian blur [19], Random color jittering and Solarization [20].
-
•
We builded a self-supervised contrastive learning branch based on the sharing ViT construction, which doesn’t rely on the negative samples sampling in traditional contrastive learning and directly adopts the inherent structure information of the image to enhance the feature learning ability of the ViT encoder by self-supervision.
-
•
We utilized the joint-training loss function to integrate the advantages of supervised learning with ID tags and self-supervised contrastive learning without negative samples, which can promote the performance of our model.
-
•
Quantitative evaluation and ablation study on several authoritative benchmark datasets show that the proposed model and its each components are reasonable and effective.
The remaining of this work is organized as follows: Section II introduces the related works. In section III, we elaborate the proposed transformer-based person re-identification framework and data augmentation method designed for its contrastive learning branch. Section IV shows the ablation study and evaluation results on several benchmark person Re-ID datasets. Finally, conclusions are explained in Section V.
II Related works
II-A Occluded person re-identification
The occluded person re-identification mainly confronts the challenges of incomplete body information and spatial misalignment. The existing occluded person ReID solutions can be classified into two categories, methods based on the feature alignment of visible region cues [21, 22, 23] and methods based on information completion [24, 25, 26].
The core idea of methods based on the feature alignment of visible region cues is to accurately locate the visible regions of person in the image, which only relies on the semantic information of visible region to align the feature representations of different body parts and match the pedestrians with the same identity in other camera view. Miao et al. [21] proposed a feature alignment method based on the human key-points information, taking advantage of human key-points information to guide the model to focus on the non-occluded regions and only these are utilized for the retrieval. He et al. [22] designed a deep spatial feature reconstruction method for partial person ReID, which realized the implicit feature alignment when calculating the reconstruction error of the spatial feature maps. However, solving the reconstruction error needs the time-consuming computation and is not suitable for the large scale re-identification task. Chen et al. [23] proposed an occlusion-aware mask network, which utilizes the attention-guided mask module to precisely capture body parts regardless of the occlusion. Wang et al. [27] proposed a novel feature erasing and diffusion network to simultaneously handle the interference from non-pedestrian occlusions and non-target pedestrians, improving the model’s perception ability towards target pedestrians and robustness towards non-target pedestrians.
The person ReID methods based on information completion usually adopt the spatiotemporal context to recover the pedestrian information of the occluded parts so as to improve the features’ discrimination [24, 26]. Xu et al. [25] proposed a feature recovery transformer to exploit the pedestrian information in its -nearest neighbors features for occluded feature recovery. In [26], a spatiotemporal feature completion module was proposed to recover the occluded body parts via a region-encoder and a region-decoder for video person ReID.
Different from these methods above, we presented a joint-training model combining the supervised and self-supervised learning, which only introduces our specially designed data augmentation method in the training stage to learn more robust feature representation for the occlusion, not increasing the inference cost.
II-B Transformer-based person re-identification
When capturing the long range dependencies of features, the CNN-based methods confront some challenges due to the limitation of receptive fields. In contrast, the ViT can overcome it by the self-attention mechanism, demonstrating excellent performance in some areas such as image understanding, image segmentation and visual question and answer. TransReID [4], as the first person ReID model to use the pure transformer architecture for extracting features, has further promoted the development of this field. The PFT [28] utilized the proposed three modules (patch full dimension enhancement module, fusion and reconstruction module and spatial slicing module) to enhance the efficiency of vision transformer. The PFD [29] utilized pose information to clearly disentangle semantic components (e.g. human body or joint parts) and selectively match non-occluded parts correspondingly, improving the performance of person ReID effectively. Li et al. [30] proposed a novel end-to-end part-aware transformer for occluded person ReID via a transformer encoder-decoder architecture, including a pixel context based transformer encoder and a part prototype based transformer decoder. In [6], the authors proposed the occlusion suppression and repairing transformer, including a self-supervised occlusion predictor, occlusion suppression encoder and feature repairing head, which can enhance the model’s ability of extracting discriminative local features for the occlusion scenes. There are other some methods to try to use the transformer to aggregate the features extracted from the CNN backbone, e.g., GiT [31], HaT [32] and so on.
II-C Self-supervised learning
Recently, self-supervised learning is widely applied to person re-identification task because it can mine the useful information from unlabelled data and has become an important direction of person ReID research, which can be classified into contrastive learning and masked image modeling.
Contrastive learning is aimed at learning similar/dissimilar representations from sample pairs with same semantic and ones with different semantic. The traditional contrastive learning usually relies on the annotated datasets where each image has a clear identity label. The core idea of this model is to attract the positive sample pairs and repulse the negative sample pairs by a reasonable designed loss function (e.g., Triplet loss [33], InfoNCE [34], contrastive loss [35] and so on) so as to learn the more discriminative features. Different from it, the self-supervised contrastive learning constructs positive and negative sample pairs from the strong and normal enhancing results of the same image, which can learn the meaningful features representation from lots of unlabelled data by the pre-designed tasks in the absence of labelled data. The existing self-supervised contrastive learning methods mainly include MoCo [36], SimCLR [19], BYOL [37], SimSiam [38] and so on.
Masked image modeling was first proposed in [39], which can enhance the ability of representation learning by performing pretext tasks such as image/feature reconstruction. Its basic idea is to randomly mask some image patches and reconstruct them from visible image patches by ViT in a self-supervised manner. This technology not only can be transferred to downstream computer vision tasks such as image classification and instance segmentation, but also provided a new way to solve the occluded person re-identification. In this paper, inspirited by the masked image modeling, we designed a novel data augmentation method for contrastive learning branch, that is random rectangle mask strategy.
III Methodology
In this section, we first describes the data augmentation method designed for our contrastive learning branch in subsection III-A. Next, in subsection III-B, we introduce our proposed transformer-based person re-identification framework in details. Finally, we give the joint-training loss combining supervised and self-supervised learning in the proposed model in subsection III-C.
III-A Data augmentation
Empirically, the occlusion often occurs for the person re-identification tasks. The normal data augmentation methods, e.g., random cropping, flipping and random color distortion, are not very effective in the face of occlusion. Thus, in order to improve the model’s performance under the situation of partial occlusion and incomplete information, inspirited by the paper [16], we designed a novel data augmentation method to imitate the occlusion in real scenes, that is random rectangle mask strategy, whose implementing method is given in detail in Algorithm 1 and the visualized results see the figure 1. This data augmentation method can help the model learn more discriminative features so as to facilitate effective recognition and classification in the case of incomplete information. In addition, in order to further enhance the model’s generalization, we also use other data augmentation methods, such as Gaussian blur, random color jittering and Solarization.
Input: The image: ; the masked ratio: ; the maximum mask size: .
Output: the masked image:

III-B Dual branch architecture
In [4], the TransReID has been proven to a well-performing person re-identification model based on the transformer. Based on it, we build our self-supervised and supervised combining transformer-based person re-identification framework, shown in Figure 2. Our model consists of the normal augmentation and strong augmentation branches, and they utilize the TransReID as the feature extractor and share the same weight of transformer layers. Specifically, each image is first processed by inputting the normal augmentation and strong augmentation branches respectively, where the normal augmentation includes some common methods, such as random horizontal flipping, random cropping, random erasing and so on, and the strong augmentation adopts the data augmentation methods mentioned in subsection III-A. Next, each augmented image is split into fixed-sized patches, and each patch is mapped to a dimensions vector by a linear projection. Subsequently, their patch embedding, position embedding and side information embedding are fed into layers transformer encoder together. Finally, the output features of the normal augmentation branch are fed into the global predicted head and jigsaw predicted head to further extract the features and calculate the ID loss and triplet loss, and the output features of the strong augmentation branch are input the projector and predictor in sequence to further process, obtaining features and the output ones of the normal branch calculate the similarity by the contrastive learning together. Our proposed model not only retains the Side Information Embedding (SIE) and jigsaw patch modules of the TransReID, but also assists features learning in the training phase by the contrastive learning branch, which greatly improves the model’s performance in complex scenes without affecting the efficiency of inference, especially for the occlusion.

III-C Joint-training loss combining self-supervised and supervised learning
Similar to the TransReID, we optimize the normal augmentation branch network by building ID loss and triplet loss for global features and fine-grained local features that obtained by the jigsaw patch module. The ID loss is the cross-entropy loss without label smoothing. For a triplet set , the triplet loss with soft-margin is defined as following
| (1) |
Thus, for the normal augmentation branch, the total loss of supervised learning can be represented as
| (2) |
where is served as the global feature obtained by the standard transformer encoder, and denotes the output token of the -th group obtained by re-grouping them after shuffling the patches through the -th transformer encoder.
In order to enhance the representation ability of the transformer encoder, we assist the training of ReID task by self-supervised contrastive learning. In the contrastive learning branch, we adopt the same loss function as the paper [38], which can be defined as following:
| (3) |
where respectively denote the output vectors by the predictor of two stream branches, denote the output features of the -th transformer encoder of two stream architectures, is the stop-gradient operation which means that are treated as the constant, that is, only receiving gradients from and no gradient from when encoding the corresponding input image, and is the negative cosine similarity.
Thus, the final total loss is defined as following:
| (4) |
where is the hyper-parameter for balancing two losses. by adjusting it reasonably, we can let the contrastive loss assist the training of ReID task efficiently so as to utilize the advantage of self-supervised learning to enhance the performance and robustness of our proposed model against complex and variable scenes.
IV Experiments
In this section, we first introduce the benchmark datasets and evaluation metrics used in our experiments. Next, we describe the implementation details. Then, we compare our proposed method with the state-of-the-art person Re-ID methods on several benchmark person Re-ID datasets. Finally, we conduct ablation study to analyze the effect of weights setting of patch linear projection layer, data augmentation methods and hyper-parameter in our proposed person Re-ID model.
IV-A Datasets and evaluation metric
Datasets. To verify the performance of our proposed model, we compare it with other some the state-of-the-art person ReID methods on five person ReID benchmark datasets, including Market-1501 [40], MSMT17 [41], DukeMTMC-reID [42], Occluded-Duke [21] and Occluded-Market [43]. The details of these datasets are summarized in Table I, where Occluded-Duke is formed by applying a special division on DukeMTMC-reID and Occluded-Market is formed by integrating and re-partitioning MARS [44] and Market-1501 [40], but the occlusion ratio in the training set of Occluded-Market reaches 63%, which is much higher than that in Occluded-Duke.
| Dataset | #cam | Training dataset | Query | Gallery | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ID | Image | ID | Image | ID | Image | |||||
| Market-1501 | 6 | 751 | 12936 | - | 750 | 19732 | - | 750 | 3368 | - |
| MSMT17 | 15 | 1041 | 32621 | - | 3060 | 11659 | - | 3060 | 82161 | - |
| DukeMTMC-reID | 8 | 702 | 16522 | - | 702 | 2228 | - | 702 | 17661 | - |
| Occluded-Duke | 8 | 702 | 15618 | 9 | 702 | 2210 | 100 | 702 | 17661 | 10 |
| Occluded-Market | - | 780 | 9287 | 63 | 533 | 2343 | 100 | 751 | 15913 | 8 |
Evaluation metric. For the fairness of comparison, we follow conventions in the ReID community and adopt the cumulative matching characteristic (CMC) curve and the mean average precision (mAP) as evaluation metrics. Specifically, we adopt the first element of the CMC curve, i.e., Rank-1, which indicates the hit rate of the first match.
IV-B Implementation details
In this paper, all the experiments of our proposed method are run on a single NVIDIA A100 GPU with 40G RAM. All input person images are resize to . For the normal augmentation branch, the training images are augmented with random horizontal flipping, random cropping and random erasing, and for another branch, they are augmented by the methods mentioned in subsection III-A. The maximum mask size is set to in Algorithm 1. The batch size is set to 100 with 4 images per ID. Stochastic Gradient Descent (SGD) optimizer is employed with a momentum of 0.9 and the weight decay of . The base learning rate is set to with cosine learning rate decay. The projection head and prediction head are respectively a 3-layer MLP and 2-layer MLP, the hidden layers of which are 768-d and 4096-d and are with ReLU; the output layers are both 256-d, without ReLU. The hyper-parameter is set to 0.95. The parameters of patch projecting layer in our model are randomly initialized and frozen rather than the learnable ones in the traditional methods. The initial weights of ViT adopt the officially released per-trained model, the model of which is first trained on Image-21K and then fine-tuned on ImageNet-1K.
IV-C Comparison with state-of-the-art methods
Comparison on Occluded Person ReID Datasets. On Occluded-Duke and Occluded Market, we compare our proposed model with other state-of-the-art methods which is classified into two categories: CNN-based ReID methods and Transformer-based ReID method, the results of which are shown in Table II. We find that our proposed method obtains the competitive performance on the Occluded-Duke dataset. Specifically, comparing with the most related method, e.g., TransReID, our proposed model obtains the 1.8% and 2.8% performance gains in terms of the mAP and Rank-1 scores. It’s noting that our proposed model does not surpass some ReID methods that used the feature recovery (e.g., FRT [25] and OSRTrans [6]) or extra clues (PFD [29]), but these methods either utilize the pre-trained occlusion predictor to predict the occluded regions and recover them by some designed reconstructing model (e.g., GAN or ViT) or use the extra clues (e.g, pose information [29], which is only usually obtained by the trained pose estimation model) to selectively match non-occluded parts, which needs other extra models and increases the inference time. Compared to them, our proposed model does not require any pre-trained module or negative samples but achieves comparable performance. With the increase of occluded samples in the training set, our proposed model obtains the highest mAP and Rank-1 scores (e.g., Occluded Market, the occlusion ratio of its training set rises to 63%, seeing the Table I), which is superior to the state-of-the-art OSRTrans [6] by 4.2% and 1.3% in terms of mAP and Rank-1. In addition, we also notice that our proposed model exceeds the second place TransReID [4] by 2.0% in mAP score. These experimental results show that our proposed model is more adaptive to different datasets, unlike the feature recover is susceptible to domain gap.
| Method | Extra-clue | Occluded-Duke | Occluded-Market | ||
| mAP | Rank-1 | mAP | Rank-1 | ||
| Transformer-Based | |||||
| TransReID∗[4] | ✗ | 59.2 | 66.4 | 69.7 | 80.2 |
| FED[27] | ✗ | 56.4 | 68.1 | 53.3 | 66.7 |
| PFD[29] | ✓ | 61.8 | 69.5 | - | - |
| PFT[28] | ✗ | 60.8 | 69.8 | - | - |
| FRT[25] | ✓ | 61.3 | 70.7 | - | - |
| PAT[30] | ✗ | 53.6 | 64.5 | - | - |
| DRL-Net[45] | ✗ | 53.9 | 65.8 | - | - |
| OSRTrans[6] | ✗ | 61.5 | 72.9 | 67.5 | 82.0 |
| CNN-Based | |||||
| HOReID[46] | ✓ | 43.8 | 55.1 | 49.3 | 64.9 |
| MSOSNet[47] | ✗ | 56.3 | 68.6 | - | - |
| QPM[48] | ✗ | 49.7 | 64.4 | - | - |
| PVPM[49] | ✓ | 42.9 | 54.2 | 49.4 | 66.8 |
| MVI2P[50] | ✗ | 57.3 | 68.6 | - | - |
| SCSRL[43] | ✗ | 51.4 | 62.6 | 54.5 | 73.8 |
| AET-Net[51] | ✗ | 54.5 | 64.5 | - | - |
| Ours∗ | ✗ | 61.0 | 69.2 | 71.7 | 83.3 |
Comparison on General Person ReID Datasets. We also compare our proposed model with some state-of-the-art methods on three general person ReID datasets, including Market1501, MSMT17 and DukeMTMC-ReID, the results of which are shown in Table III. Seeing from it, we find that our SSSC-TransReID ranks No.1 among these person ReID methods on Market1501 and MSMT17 datasets, especially obtaining the improvement of 1.5% and 0.4% than the second place TransReID [4] in terms of mAP and Rank-1 scores on MSMT17. In addition, it is worth noting that our proposed method outperforms the state-of-the-art OSRTrans that used the occlusion suppression and repairing, respectively rising 1.1%/0.5% and 3.3%/1.7%in terms of mAP/Rank-1 on Market1501 and DukeMTMC-ReID datasets, which illustrates that our proposed method have better performance than the ReID method that specifically designed for the occluded ReID dataset on the general ReID dataset. The main reason is that the occluded ReID models are designed to fit the occluded scenarios and focus on dealing with occlusion interference, so they can not extract features from each detail region of the image, which affects their ability to generalize across domains. But our method has good adaptability to different domains and is not sensitive to domain gap. Although the performance of our method is slightly inferior to that of PFD [29], different from the PFD, our method does not need pre-training human pose estimation model to extract pose information to guide the local features aggregation so as to selectively match non-occluded parts. Therefore, our proposed model is simpler and more efficient in inference. In a word, our SSSC-TransReID not only performs well and has strong robustness on Occluded ReID datasets, but also achieve excellent performance on the general ReID datasets.
| Method | Extra-clue | Market1501 | MSMT17 | DukeMTMC-reID | |||
| mAP | Rank-1 | mAP | Rank-1 | mAP | Rank-1 | ||
| Transformer-Based | |||||||
| TransReID∗[4] | ✗ | 88.9 | 95.2 | 67.4 | 85.3 | 82.0 | 90.7 |
| FED[27] | ✗ | 86.3 | 95.0 | - | - | 78.0 | 89.4 |
| PFD[29] | ✓ | 89.7 | 95.5 | - | - | 83.2 | 91.2 |
| PFT[28] | ✗ | 88.8 | 95.3 | - | - | 82.1 | 90.7 |
| FRT[25] | ✓ | 88.1 | 95.5 | - | - | 81.7 | 90.5 |
| PAT[30] | ✗ | 88.0 | 95.4 | - | - | 78.2 | 88.8 |
| DRL-Net[45] | ✗ | 86.9 | 94.7 | - | - | 76.6 | 88.1 |
| OSRTrans[6] | ✗ | 88.7 | 95.3 | - | - | 79.6 | 89.9 |
| CNN-Based | |||||||
| OSNet[52] | ✗ | 84.9 | 94.8 | 52.9 | 78.7 | 73.5 | 88.6 |
| MSOSNet[47] | ✗ | 88.8 | 95.7 | 60.1 | 82.3 | - | - |
| MVI2P[50] | ✗ | 87.9 | 95.3 | 61.4 | 83.9 | - | - |
| SCSRL[43] | ✗ | 86.2 | 95.0 | 53.2 | 78.9 | - | - |
| AET-Net[51] | ✗ | 87.5 | 94.8 | - | - | 80.1 | 89.5 |
| Ours∗ | ✗ | 89.8 | 95.8 | 68.9 | 85.7 | 82.9 | 91.6 |
IV-D Visualize and analysis

In order to clearly clarify why our proposed method perform well on the occluded and general ReID datasets, we use Grad-CAM [53] to visualize the attention maps of the encoders from TransReID and our method by the heatmap, shown in Figure 3, which selects two occluded and one unoccluded images. Seeing from the Figure 3, comparing with the TransReID, our proposed method not only keeps paying attention to the overall features of target but also is not sensitive to the occlusion. For the occluded person, our proposed method makes the encoding features more focus on the unoccluded parts of person, which efficiently reduces the effect of the occlusion. This property of our proposed method ensures that it can extract more robust and discriminative features for person ReID task on the occluded and unoccluded images, which further verifies the superiority of our proposed method in person ReID task.
IV-E Ablation study
On Occluded-Duke dataset, we perform a number of ablation experiments to validate the effectiveness of our proposed method from different aspects.
| Method | mAP | Rank-1 |
|---|---|---|
| Learned | 60.3 | 68.5 |
| Frozen | 61.0 | 69.2 |
Weights setting of patch linear projection layer. Previous studies [54] have found that the use of ViT as backbone will affect the performance and stability of the model. In order to explore the effect of different setting methods of patch linear projection layer weights for the model performance, we compare two different patch linear projection layer weights, one is the learned weights, that is linear projection layer weights are updated with the training processing after they are randomly initialized; another is the frozen weights, namely linear projection layer weights are not updated when our model is trained. Table IV shows the mAP and Rank-1 scores of our proposed method under two different setting of patch linear projection layer weights. Seeing from it, the frozen weights method is superior to the learned one by 0.7% and 0.7% in terms of mAP and Rank-1 scores, which illustrates that freezing patch linear project layer weights after random initialization can make our proposed model’s training more stable and perform better.
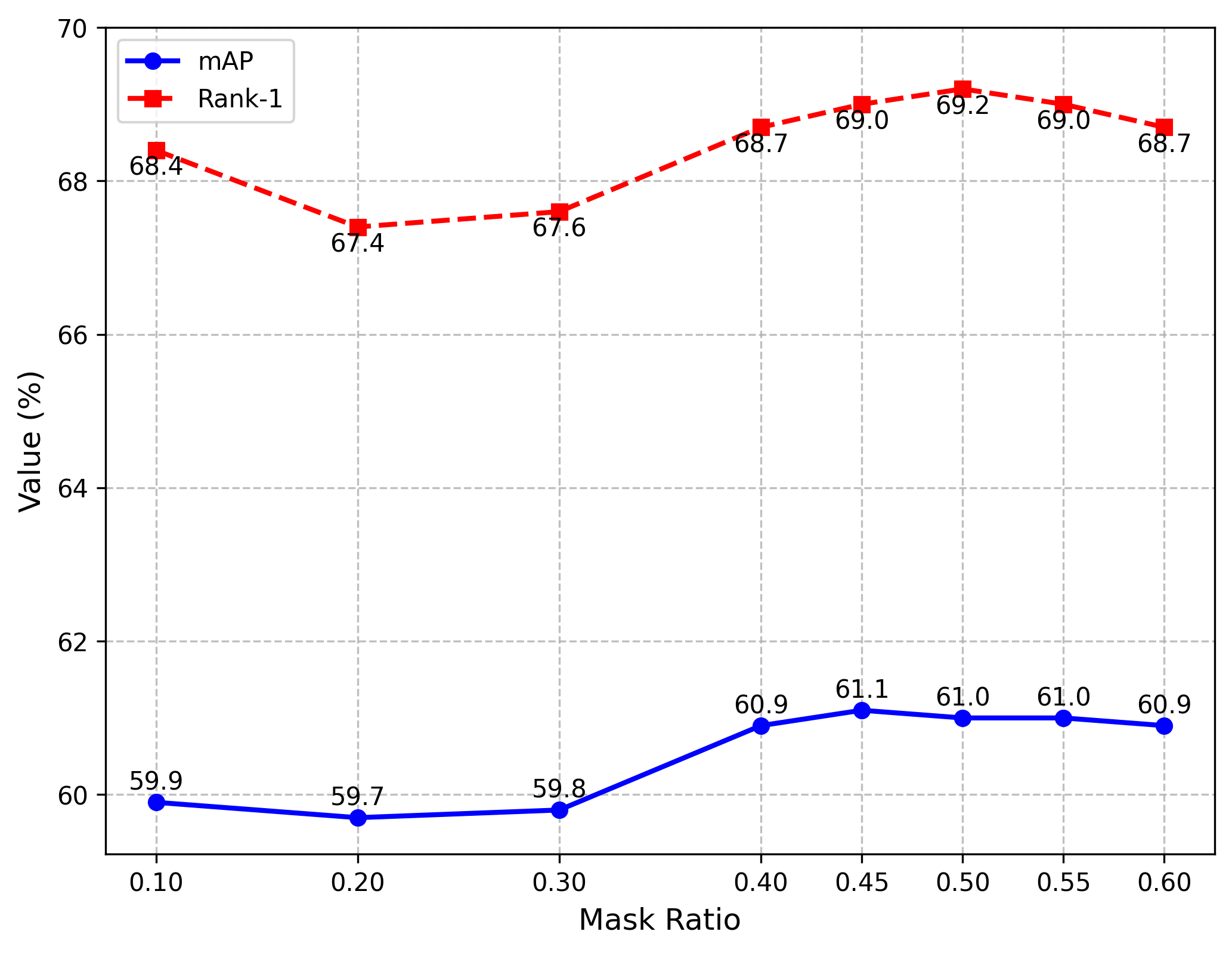
Data augmentation. We analysed the impacts of different mask ratios and data augmentation combining methods for our model performance. In Figure 4, we plot the curves of mAP and Rank-1 scores when selected different mask ratios in our proposed data augmentation method. Seeing from it, the mAP and Rank-1 scores of our proposed method fluctuate with respect to mask ratio when it varies from 0.1 to 0.6 with a step of 0.1. In order to obtain the best mask ratio, the step size is further reduced to 0.05 when approaching the estimated peak. When the mask ratios are set to 0.45 and 0.5, the mAP and Rank-1 scores of our method respectively reach the highest points. As the mask ratio continues to increase, the performance of our method becomes worse. For the person ReID task, the Rank-1 metric is more important than the mAP one, and when the mask ratio is set to 0.45 or 0.5, there is only a slight gap of 0.1 for the mAP scores of our method. Consequently, in our experiments, the mask ratio of our proposed data augmentation method is set to 0.5, namely the mask ratio that the Rank-1 score reaches the peak.
For strong augmentation branch, we compare our random mask with four most similar data augmentation methods, the results of which are shown in Table V. Although these data augmentation methods are designed to simulate occlusion so as to improve the generalization ability of the model, we observe that our random mask and Hide-and-seek perform better than other three methods. The main reason is that our random mask and Hide-and-seek simulate more severe occlusion, compared with other three methods (the occlusion ratio of each sample is set to 0.5 for our random mask and Hide-and-seek, and the occlusion ratio of each sample is randomly selected from 0 to 0.5 for other three methods), which is beneficial for the contrastive learning. Seeing from the Table V, our random mask is superior to Hide-and-seek. Even though they have the same mAP score, the Rank-1 score of our random mask is 0.6% higher than the Rank-1 one of Hide-and-seek. The possible reason is that the occlusion simulated by our method is more diverse and complex, and the one generated by Hide-and-seek is uniformly and randomly distributed, because more complex and diverse samples are helpful for contrastive learning. In Table VI, we compare the results of our random mask in combination with other several data augmentation methods (Color Jitter, Gaussian Blur and Solarize), and we find that our Rank-1 score rises by 0.5% when combining simultaneously with those three augmentation methods.
| Augmention | mAP | Rank-1 | Rank-5 | Rank-10 |
|---|---|---|---|---|
| Random Erasing[55] | 59.7 | 67.3 | 81.8 | 86.2 |
| CutOut[56] | 60.7 | 67.6 | 82.4 | 87.6 |
| CutMix[57] | 60.8 | 68.1 | 82.7 | 87.3 |
| Hide-and-seek[58] | 61.0 | 68.1 | 82.5 | 87.2 |
| Random mask (ours) | 61.0 | 68.7 | 83.0 | 87.6 |
| Random Mask (ours) | Color Jitter | Gaussian Blur | Solarize | mAP | Rank-1 |
| ✓ | 61.0 | 68.7 | |||
| ✓ | ✓ | 60.5 | 68.1 | ||
| ✓ | ✓ | 60.1 | 68.0 | ||
| ✓ | ✓ | 60.9 | 68.3 | ||
| ✓ | ✓ | ✓ | 60.9 | 68.8 | |
| ✓ | ✓ | ✓ | 60.7 | 68.0 | |
| ✓ | ✓ | ✓ | 61.0 | 68.3 | |
| ✓ | ✓ | ✓ | ✓ | 61.0 | 69.2 |
Effect of hyper-parameter . The hyper-parameter is used to balance the supervised learning loss and self-supervised contrastive learning loss of our model. In Figure 5, we plot the curves of mAP and Rank-1 scores when the hyper-parameter is set to 0.5 and increases in some certain steps until 0.97 in our final loss function. We observe that our proposed method obtains the best mAP and Rank-1 scores when the hyper-parameter , which illustrates that the labeled data dominates in our model training. If is too small or too large, the performance of our proposed method degrades significantly. When is decreased to 0.9, the mAP and Rank-1 scores of our method respectively reduce by 0.1% and 0.5%. If continues to decrease slowly, the performance of our method become worse. However, when increases to 0.97, the performance of our method degrades severely, the mAP and Rank-1 scores of which respectively drop by 1.4% and 1.6%. The main reason is that the larger makes the self-supervised contrastive learning no longer work. Thus, selecting an appropriate hyper-parameter is extremely important for robust person ReID. In our experiments, the hyper-parameter in the equation 4 is set to 0.95.

V Conclusion
In this paper, we propose a novel self-supervision and supervision combining transformer-based Re-ID framework, which can excavate stronger discriminative features by integrating advantages of supervised learning with ID tags and self-supervised contrastive learning without negative samples. In order to train our model, we design a novel data augmentation method based on random rectangle mask for the contrastive learning branch. The experimental results on several benchmark datasets demonstrate that our proposed model is superior to the state-of-the-art person ReID methods on the mean average accuracy (mAP) and Rank-1 accuracy. Based on it, we believe that integrating self-supervised and supervised learning has great potential to be further explored for ReID tasks.
Acknowledgment
This work is supported by the National Natural Science Foundation of China (No.61602288) and Fundamental Research Program of Shanxi Province (No.20210302123443). The authors also would like to thank the anonymous reviewers for their valuable suggestions.
References
- [1] L. Zheng, Y. Yang, and A. G. Hauptmann, “Person re-identification: Past, present and future,” arXiv preprint arXiv:1610.02984, 2016.
- [2] L. He, J. Liang, H. Li, and Z. Sun, “Deep spatial feature reconstruction for partial person re-identification: Alignment-free approach,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7073–7082.
- [3] L. He and W. Liu, “Guided saliency feature learning for person re-identification in crowded scenes,” in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXVIII 16. Springer, 2020, pp. 357–373.
- [4] S. He, H. Luo, P. Wang, F. Wang, H. Li, and W. Jiang, “Transreid: Transformer-based object re-identification,” in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 15 013–15 022.
- [5] L. Wei, S. Zhang, H. Yao, W. Gao, and Q. Tian, “Glad: Global–local-alignment descriptor for scalable person re-identification,” IEEE Transactions on Multimedia, vol. 21, no. 4, pp. 986–999, 2019.
- [6] Z. Zhang, S. Han, D. Liu, and D. Ming, “Focus and imagine: Occlusion suppression and repairing transformer for occluded person re-identification,” Neurocomputing, vol. 578, p. 127442, 2024.
- [7] L. Tan, P. Dai, R. Ji, and Y. Wu, “Dynamic prototype mask for occluded person re-identification,” in Proceedings of the 30th ACM international conference on multimedia, 2022, pp. 531–540.
- [8] J. Zhuo, Z. Chen, J. Lai, and G. Wang, “Occluded person re-identification,” in 2018 IEEE international conference on multimedia and expo (ICME). IEEE, 2018, pp. 1–6.
- [9] Y. Peng, J. Wu, B. Xu, C. Cao, X. Liu, Z. Sun, and Z. He, “Deep learning based occluded person re-identification: A survey,” ACM Transactions on Multimedia Computing, Communications and Applications, vol. 20, no. 3, pp. 1–27, 2023.
- [10] Y. Chen, S. Xia, J. Zhao, Y. Zhou, Q. Niu, R. Yao, D. Zhu, and D. Liu, “Rest-reid: Transformer block-based residual learning for person re-identification,” Pattern Recognition Letters, vol. 157, pp. 90–96, 2022.
- [11] A. Mohanty, B. Banerjee, and R. Velmurugan, “Ssmtreid-net: Multi-target unsupervised domain adaptation for person re-identification,” Pattern Recognition Letters, vol. 163, pp. 40–46, 2022.
- [12] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020.
- [13] A. Kolesnikov, L. Beyer, X. Zhai, J. Puigcerver, J. Yung, S. Gelly, and N. Houlsby, “Big transfer (bit): General visual representation learning,” in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part V 16. Springer, 2020, pp. 491–507.
- [14] Q. Xie, M.-T. Luong, E. Hovy, and Q. V. Le, “Self-training with noisy student improves imagenet classification,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 10 687–10 698.
- [15] J. Dan, Y. Liu, H. Xie, J. Deng, H. Xie, X. Xie, and B. Sun, “Transface: Calibrating transformer training for face recognition from a data-centric perspective,” in Proceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 20 642–20 653.
- [16] K. He, X. Chen, S. Xie, Y. Li, P. Dollár, and R. Girshick, “Masked autoencoders are scalable vision learners,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 16 000–16 009.
- [17] C. Doersch, A. Gupta, and A. A. Efros, “Unsupervised visual representation learning by context prediction,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 1422–1430.
- [18] B. Hu, X. Wang, and W. Liu, “Personvit: Large-scale self-supervised vision transformer for person re-identificat,” arXiv preprint arXiv:2408.05398, 2024.
- [19] T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” in International conference on machine learning. PMLR, 2020, pp. 1597–1607.
- [20] C. Lei, B. Hu, D. Wang, S. Zhang, and Z. Chen, “A preliminary study on data augmentation of deep learning for image classification,” in Proceedings of the 11th Asia-pacific symposium on internetware, 2019, pp. 1–6.
- [21] J. Miao, Y. Wu, P. Liu, Y. Ding, and Y. Yang, “Pose-guided feature alignment for occluded person re-identification,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 542–551.
- [22] L. He, J. Liang, H. Li, and Z. Sun, “Deep spatial feature reconstruction for partial person re-identification: Alignment-free approach,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7073–7082.
- [23] P. Chen, W. Liu, P. Dai, J. Liu, Q. Ye, M. Xu, Q. Chen, and R. Ji, “Occlude them all: Occlusion-aware attention network for occluded person re-id,” in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 11 833–11 842.
- [24] T. Wang, M. Liu, H. Liu, W. Li, M. Ban, T. Guo, and Y. Li, “Feature completion transformer for occluded person re-identification,” IEEE Transactions on Multimedia, 2024.
- [25] B. Xu, L. He, J. Liang, and Z. Sun, “Learning feature recovery transformer for occluded person re-identification,” IEEE Transactions on Image Processing, vol. 31, pp. 4651–4662, 2022.
- [26] R. Hou, B. Ma, H. Chang, X. Gu, S. Shan, and X. Chen, “Feature completion for occluded person re-identification,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 9, pp. 4894–4912, 2021.
- [27] Z. Wang, F. Zhu, S. Tang, R. Zhao, L. He, and J. Song, “Feature erasing and diffusion network for occluded person re-identification,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 4754–4763.
- [28] Y. Zhao, S. Zhu, D. Wang, and Z. Liang, “Short range correlation transformer for occluded person re-identification,” Neural computing and applications, vol. 34, no. 20, pp. 17 633–17 645, 2022.
- [29] T. Wang, H. Liu, P. Song, T. Guo, and W. Shi, “Pose-guided feature disentangling for occluded person re-identification based on transformer,” in Proceedings of the AAAI conference on artificial intelligence, vol. 36, no. 3, 2022, pp. 2540–2549.
- [30] Y. Li, J. He, T. Zhang, X. Liu, Y. Zhang, and F. Wu, “Diverse part discovery: Occluded person re-identification with part-aware transformer,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 2898–2907.
- [31] F. Shen, Y. Xie, J. Zhu, X. Zhu, and H. Zeng, “Git: Graph interactive transformer for vehicle re-identification,” IEEE Transactions on Image Processing, vol. 32, pp. 1039–1051, 2023.
- [32] G. Zhang, P. Zhang, J. Qi, and H. Lu, “Hat: Hierarchical aggregation transformers for person re-identification,” in Proceedings of the 29th ACM international conference on multimedia, 2021, pp. 516–525.
- [33] A. Hermans, L. Beyer, and B. Leibe, “In defense of the triplet loss for person re-identification,” arXiv preprint arXiv:1703.07737, 2017.
- [34] A. v. d. Oord, Y. Li, and O. Vinyals, “Representation learning with contrastive predictive coding,” arXiv preprint arXiv:1807.03748, 2018.
- [35] R. Hadsell, S. Chopra, and Y. LeCun, “Dimensionality reduction by learning an invariant mapping,” in 2006 IEEE computer society conference on computer vision and pattern recognition (CVPR’06), vol. 2. IEEE, 2006, pp. 1735–1742.
- [36] K. He, H. Fan, Y. Wu, S. Xie, and R. Girshick, “Momentum contrast for unsupervised visual representation learning,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 9729–9738.
- [37] J.-B. Grill, F. Strub, F. Altché, C. Tallec, P. Richemond, E. Buchatskaya, C. Doersch, B. Avila Pires, Z. Guo, M. Gheshlaghi Azar et al., “Bootstrap your own latent-a new approach to self-supervised learning,” Advances in neural information processing systems, vol. 33, pp. 21 271–21 284, 2020.
- [38] X. Chen and K. He, “Exploring simple siamese representation learning,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 15 750–15 758.
- [39] H. Bao, L. Dong, S. Piao, and F. Wei, “Beit: Bert pre-training of image transformers,” arXiv preprint arXiv:2106.08254, 2021.
- [40] L. Zheng, L. Shen, L. Tian, S. Wang, J. Wang, and Q. Tian, “Scalable person re-identification: A benchmark,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 1116–1124.
- [41] L. Wei, S. Zhang, W. Gao, and Q. Tian, “Person transfer gan to bridge domain gap for person re-identification,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 79–88.
- [42] E. Ristani, F. Solera, R. Zou, R. Cucchiara, and C. Tomasi, “Performance measures and a data set for multi-target, multi-camera tracking,” in European conference on computer vision. Springer, 2016, pp. 17–35.
- [43] S. Han, D. Liu, Z. Zhang, and D. Ming, “Spatial complementary and self-repair learning for occluded person re-identification,” Neurocomputing, vol. 546, p. 126360, 2023.
- [44] L. Zheng, Z. Bie, Y. Sun, J. Wang, C. Su, S. Wang, and Q. Tian, “Mars: A video benchmark for large-scale person re-identification,” in Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part VI 14. Springer, 2016, pp. 868–884.
- [45] M. Jia, X. Cheng, S. Lu, and J. Zhang, “Learning disentangled representation implicitly via transformer for occluded person re-identification,” IEEE Transactions on Multimedia, vol. 25, pp. 1294–1305, 2022.
- [46] G. Wang, S. Yang, H. Liu, Z. Wang, Y. Yang, S. Wang, G. Yu, E. Zhou, and J. Sun, “High-order information matters: Learning relation and topology for occluded person re-identification,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 6449–6458.
- [47] Y. Zhang, Y. Yang, W. Kang, and J. Zhen, “Multi-scale occlusion suppression network for occluded person re-identification,” Pattern Recognition Letters, vol. 185, pp. 66–72, 2024.
- [48] P. Wang, C. Ding, Z. Shao, Z. Hong, S. Zhang, and D. Tao, “Quality-aware part models for occluded person re-identification,” IEEE Transactions on Multimedia, vol. 25, pp. 3154–3165, 2022.
- [49] S. Gao, J. Wang, H. Lu, and Z. Liu, “Pose-guided visible part matching for occluded person reid,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 744–11 752.
- [50] N. Dong, S. Yan, H. Tang, J. Tang, and L. Zhang, “Multi-view information integration and propagation for occluded person re-identification,” Information Fusion, vol. 104, p. 102201, 2024.
- [51] J. Wang, P. Li, R. Zhao, R. Zhou, and Y. Han, “Cnn attention enhanced vit network for occluded person re-identification,” Applied Sciences, vol. 13, no. 6, p. 3707, 2023.
- [52] K. Zhou, Y. Yang, A. Cavallaro, and T. Xiang, “Omni-scale feature learning for person re-identification,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 3702–3712.
- [53] R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-cam: Visual explanations from deep networks via gradient-based localization,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 618–626.
- [54] X. Chen, S. Xie, and K. He, “An empirical study of training self-supervised vision transformers,” in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 9640–9649.
- [55] Z. Zhong, L. Zheng, G. Kang, S. Li, and Y. Yang, “Random erasing data augmentation,” in Proceedings of the AAAI conference on artificial intelligence, vol. 34, no. 07, 2020, pp. 13 001–13 008.
- [56] T. DeVries, “Improved regularization of convolutional neural networks with cutout,” arXiv preprint arXiv:1708.04552, 2017.
- [57] S. Yun, D. Han, S. J. Oh, S. Chun, J. Choe, and Y. Yoo, “Cutmix: Regularization strategy to train strong classifiers with localizable features,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 6023–6032.
- [58] K. K. Singh, H. Yu, A. Sarmasi, G. Pradeep, and Y. J. Lee, “Hide-and-seek: A data augmentation technique for weakly-supervised localization and beyond,” arXiv preprint arXiv:1811.02545, 2018.