Exploring Adversarial Learning for Deep Semi-Supervised Facial Action Unit Recognition
Abstract.
Current works formulate facial action unit (AU) recognition as a supervised learning problem, requiring fully AU-labeled facial images during training. It is challenging if not impossible to provide AU annotations for large numbers of facial images. Fortunately, AUs appear on all facial images, whether manually labeled or not, satisfy the underlying anatomic mechanisms and human behavioral habits. In this paper, we propose a deep semi-supervised framework for facial action unit recognition from partially AU-labeled facial images. Specifically, the proposed deep semi-supervised AU recognition approach consists of a deep recognition network and a discriminator . The deep recognition network learns facial representations from large-scale facial images and AU classifiers from limited ground truth AU labels. The discriminator is introduced to enforce statistical similarity between the AU distribution inherent in ground truth AU labels and the distribution of the predicted AU labels from labeled and unlabeled facial images. The deep recognition network aims to minimize recognition loss from the labeled facial images, to faithfully represent inherent AU distribution for both labeled and unlabeled facial images, and to confuse the discriminator. During training, the deep recognition network and the discriminator are optimized alternately. Thus, the inherent AU distributions caused by underlying anatomic mechanisms are leveraged to construct better feature representations and AU classifiers from partially AU-labeled data during training. Experiments on two benchmark databases demonstrate that the proposed approach successfully captures AU distributions through adversarial learning and outperforms state-of-the-art AU recognition work.
1. Introduction
Automatic facial action unit (AU) recognition has attracted increasing attention in recent years due to its wide applications in human-computer interaction. The variety of imaging conditions and differences between subjects make it challenging to correctly detect multiple facial action units from facial images. A large-scale facial image database collected from several subjects under various imaging conditions can facilitate AU classifier learning. However, current facial action unit recognition work requires fully AU-labeled facial images. AU labels must be provided by experts, and it can take hours to label a minute of video footage. It would be difficult and time-consuming, even impractical, to manually label a vast number of facial images.
Facial action units describe the contraction or relaxation of one or more facial muscles. The underlying anatomic mechanisms governing facial muscle interactions lead to dependencies among AUs. For example, as shown in Figure 1, AU1 (Inner Brow Raiser) and AU2 (Outer Brow Raiser) are highly likely to appear simultaneously because AU1 and AU2 are governed by the same facial muscles, i.e., frontalis and pars medialis. Conversely, AU12 (Lip Corner Puller) and AU15 (Lip Corner Depressor) usually do not appear together, since it is anatomically impossible to represent mouth shapes of “” and “” at the same time. Such AU dependencies indicate that the AUs present on the face must follow certain underlying distributions. The distributions are controlled by anatomic mechanisms and thus hold true for all facial images, whether they are labeled or not.


Therefore, in this paper we propose a novel system for facial action unit recognition which learns AU classifiers from large-scale partially AU-labeled facial images, and inherent AU distributions through adversarial learning. The power of deep networks is leveraged to learn facial representations from many facial images. Then, the AU classifier is trained to minimize the recognition loss from the labeled facial images and faithfully represent inherent AU distribution for both labeled and unlabeled facial images simultaneously. We further introduce a discriminator to estimate the probability that a label is the ground truth AU rather than the AU label predicted by . The training procedure for maximizes the probability of making mistakes. Through adversarial learning, we successfully exploit partial ground truth AU labels and the inherent AU distributions caused by underlying anatomic mechanisms to construct better AU classifiers from large-scale partially AU-labeled images. Experimental results on two benchmark databases demonstrate the superiority of the proposed method over state-of-the-art approaches.
2. Related Work
A comprehensive survey on facial action unit analysis can be found in (Fasel and Luettin, 2003). This section provides a brief review of recent advances in deep AU recognition, AU recognition enhanced by label dependencies, and AU recognition from partially labeled data.
2.1. Deep AU recognition
Due to the rapid development of deep learning in recent years, several works have utilized deep AU analysis.
Some works adopt deep networks such as convolutional neural networks (CNNs) to learn spatial representations. They then construct an end-to-end network, treating AU recognition as a multi-output binary classification problem. For example, Ghosh et al. (Ghosh et al., 2015) and Gudi et al. (Gudi et al., 2015) propose a multiple output CNN that learns feature representation among AUs from facial images. Khorrami et al. (Khorrami et al., 2015) experimentally validate the hypothesis that CNNs trained for expression category recognition may be beneficial for AU analysis, since learned facial representations are highly related to AUs. Li et al. (Li et al., 2018) introduce enhancing and cropping layers to a pre-trained CNN model. The enhancing layers are designed attention maps based on facial landmark features, and the cropping layers are used to crop facial regions around the detected landmarks and learn deeper features for each facial region. Han et al. (Han et al., 2018) propose an advanced optimized filter size CNN (OFS-CNN) for AU recognition, which is capable of estimating optimal kernel size for varying image resolutions, and outperforms traditional CNNs. Shao et al. (Shao et al., 2018) propose a joint AU detection and face alignment framework called JAA-Net. Adaptive attention learning module is proposed to localize ROIs of AUs adaptively for better local feature extraction. Shao et al. (Shao et al., 2019) also propose an attention and pixel-level relation learning framework for AU recognition. Sankaran et al. (Sankaran et al., 2020) propose a novel feature fusion approach to combine different kinds of representations. Niu et al. (Niu et al., 2019) utilize local information and the correlations of individual local facial regions to improve AU recognition. A person-specific shape regularization method is also involved to reduce the influence of person-specific shape information. Those works totally ignore AU dependencies while training AU classifiers.
Other works try to incorporate AU dependencies and discriminative facial regions into deep networks. For example, Zhao et al. (Zhao et al., 2016) propose Deep Region and Multi-Label Learning (DRML) to address region learning and multi-label learning simultaneously. They adopt multi-label cross-entropy loss to model AU dependencies. As with Zhao et al. (Zhao et al., 2016), multi-label cross-entropy loss is adopted to model AU dependencies. Multi-label cross-entropy loss is the sum of the binary cross entropy of each label. Therefore, it does not capture label dependencies effectively.
In addition to using CNN to capture spatial representations, several works integrate long short-term memory neural networks (LSTM) to jointly capture spatial and temporal representations for AU recognition. For example, Jaiswal and Valstar (Jaiswal and Valstar, 2016) directly combine CNNs with bidirectional long short-term memory neural networks (CNN-BiLSTM) by using the spatial representations learned from the CNN as the input of BiLSTM. Their work does not consider AU dependencies. Li et al. (Li et al., 2017) propose a deep learning framework for AU recognition that integrates region of interest (ROI) adaptation, multi-label learning, and optimal LSTM-based temporal fusing. Their multi-label learning method combines the outputs of the individual ROI cropping nets, leveraging the inter-relationships of various AUs from facial representations without considering AU dependencies among target labels. Chu et al. (Chu et al., 2017) propose a hybrid network architecture to jointly capture spatial representations, temporal dependencies, and AU dependencies through CNN, LSTM, and multi-label cross-entropy loss respectively. As mentioned above, multi-label cross-entropy loss summarizes cross entropy of each label and does not effectively exploit label dependencies.
In summary, current deep AU recognition requires fully AU-labeled facial images. Although some methods employ multi-label cross-entropy loss to handle recognition of multiple AUs, they cannot model AU dependencies effectively since the summarization of cross entropy from each label does not represent label dependencies.
2.2. AU recognition with learning AU relations
Unlike the more recent interest in deep AU recognition techniques, AU recognition using shallow models has been studied for years. These shallow models explore AU dependencies through both generative and discriminative approaches.
For generative approaches, both directed graphic models (such as dynamic Bayesian networks (DBNs) (Tong et al., 2007) and latent regression Bayesian networks (LRBNs) (Hao et al., 2018)) and undirected graphic models (such as restricted Boltzmann machine (RBM) (Wang et al., 2013)) are utilized to learn AU dependencies from ground truth AU labels. Corneanu et al. (Corneanu et al., 2018) combine CNN and recurrent graphical model and propose Deep Structure Inference Network (DSIN) to deal with patch and multi-label learning for AU recognition. Through parameter and structure learning, graphic models can successfully capture AU distributions using their joint probabilities. Li et al. (Li et al., 2019) propose an AU semantic correlation embedded representation learning framework (SRERL). AU knowledge-graph is utilized to guide the enhancement of facial region representation. However, these joint probabilities have certain analytical forms and assume the inherent AU distributions follow these forms. Such an assumption may be false, since we do not have complete knowledge about AU distributions caused by muscle interactions. Furthermore, approximation algorithms are often used for the learning and inference of graphic models. This further impedes the ability of graphic models to faithfully represent AU distributions.
Discriminative approaches use additional constraints of the loss function to represent AU relations. For example, Zhu et al. (Zhu et al., 2014) and Zhang et al. (Zhang and Mahoor, 2014) use the constraints of multi-task learning to explore AU co-occurrences among certain AU groups. Zhao et al. (Zhao et al., 2015) investigate the constraints of group sparsity as well as local positive and negative AU relations to select a sparse subset of facial patches and learn multiple AU classifiers simultaneously. Eleftheriadis et al. (Eleftheriadis et al., 2015) propose constraints to encode local and global co-occurrence dependencies among AU labels to project image features onto a shared manifold.
Each of the proposed constraints can model certain AU dependencies, but none represent the hundreds of AU relations embedded in AU distributions. Furthermore, all of these works require fully AU-labeled facial images.
2.3. AU recognition from partially labeled data
Most current work on AU recognition formulates it as a supervised learning problem and requires fully AU-labeled facial images. Researchers have only recently begun to address AU recognition when data is partially labeled. Some of these works require expression annotations, leveraging the dependencies between AU and expressions to complement missing AU annotations. For example, Wang et al. (Wang et al., 2017) propose a Bayesian network (BN) to capture the dependencies among AUs and expressions. For missing AU labels, the structure and parameters of the BN are learned through structured expected maximization (EM). Ruiz et al. (Ruiz et al., 2015) learn the AU classifier with a massive data set of expression-labeled facial images. They generate pseudo AU labels by exploiting the prior knowledge of the relations between expressions and AUs. Wang et al. (Wang et al., 2018) and Peng et al. (Peng and Wang, 2018) leverage an RBM and adversarial learning, respectively, to model AU relations in the task of AU recognition assisted by facial expression. Zhang et al. (Zhang et al., 2018) propose a knowledge-driven method to jointly learn multiple AU classifiers from images without AU annotations by leveraging prior probabilities of AUs and expressions. These works require expression labels to complement the missing AU labels.
Other methods do not require expression annotations. For example, Wu et al. (Wu et al., 2015) and Li et al. (Li et al., 2016) leverage the consistency between the predicted labels, the ground truth labels, and the local smoothness among the label assignments to handle the missing labels for multi-label learning with missing labels (MLML). However, the smoothness assumption is likely to be incorrect because adjacent samples in the feature space may belong to the same subject rather than the same expression. Song et al. (Song et al., 2015) tackle missing labels by marginalizing over the latent values during the inference procedure for their proposed Bayesian Group-Sparse Compressed Sensing (BGCS) method. Their work handles missing labels by leveraging the characteristics of generative models, but may not outperform discriminative models in classification tasks.
Although the above works consider AU recognition under incomplete AU annotations, they all use hand-crafted features. As such, none can fully explore the advantages of deep learning when studying many facial images.
Wu et al. (Wu et al., 2017) recently proposed a deep semi-supervised AU recognition method (DAU-R) from partially AU-labeled data and AU distributions captured by RBM. Specifically, a deep neural network is learned for feature extraction. Then, an RBM is learned to capture the inherent AU distribution using the available ground truth labels. Finally, the AU classifier is trained by maximizing the log likelihood of the AU classifiers with regard to the learned label distribution while minimizing the error between predictions and ground truth labels from partially labeled data. Their approach makes full use of both facial images with available ground truth AU labels and the massive quantity of facial images lacking annotations. However, as mentioned before, RBM is a graphic model with certain forms of joint probability. Since we do not have complete knowledge about the inherent AU distributions, the assumed analytical forms of probability may be invalid.
Therefore, in this paper we introduce an adversarial learning mechanism to learn the AU distribution directly from available ground truth labels without any assumptions of distribution form. Specifically, we introduce a discriminator to distinguish the ground truth AU labels from the AU labels predicted by classifier . A deep network is used to learn facial representations and classifiers from both AU-labeled and unlabeled facial images by minimizing the recognition errors for the AU-labeled data and maximizing the probability of making mistakes. Through an adversarial mechanism, the learned AU classifiers can minimize the predicted errors on labeled images and output AUs from any images following inherent AU distributions.
Our contribution can be summarized as follows. (1) We are among the first to introduce adversarial learning for AU distributions, and to leverage such distributions to construct AU classifiers from partially labeled data. (2) We conduct AU recognition experiments with completely labeled data and partially labeled data. Experimental results demonstrate the potential of adversarial learning in capturing AU distributions, and the superiority of the proposed method over state-of-the-art methods.
3. Semi-Supervised Deep AU Recognition
3.1. Problem Statement
The goal of this paper is to learn AU classifiers from a large quantity of facial images with limited AU annotations. Since certain AU distributions are controlled by anatomic mechanisms, they must be generic to all facial images regardless of annotation status. We leverage these inherent AU distributions to construct AU classifiers from partially labeled facial images. In addition to minimizing the loss between the predicted AU labels and the ground truth labels for the labeled facial images, we use adversarial learning to enforce statistical similarity between the AU distribution inherent in ground truth AU labels and the distribution of the predicted AU labels from both labeled and unlabeled facial images.
Let denote the training set, where denotes the subset of dimensional training instances with AU annotations and the corresponding ground truth label , where is the number of instances and is the number of AU labels. and store the labeled facial images and corresponding AU labels respectively. denotes the subset of training instances without AU annotations, where is the number of instances. stores all facial images. Given the training set with partial AU annotations, our goal is to learn an AU classifier by optimizing the following formula:
| (1) |
where is the loss between the predicted label and the ground truth label. is the AU classifier and are parameters of . and are predicted label corresponding to the labeled sample and the unlabeled sample respectively. is the distribution of the predicted AU labels, and is the distribution of the ground truth AU labels. represents the distance between two distributions. is the trade-off rate between the two terms in Equation 1.
In practice, it is difficult to model the distribution of the predicted AU labels (), and errors may occur during the modeling procedure. To alleviate these problems, we close the two distributions through an adversarial learning mechanism.

3.2. Proposed Approach
We propose a novel AU recognition method leveraging adversarial learning mechanisms, inspired by Goodfellow’s generative adversarial network (Goodfellow et al., 2014). In addition to the AU classifier , we introduce an AU discriminator to leverage the distribution constraint from limited ground truth labels. Figure 2 displays the framework of the proposed method.
A training batch consisting of labeled facial images and unlabeled facial images sampled from training set is inputted to AU classifier . The training batch is used to obtain the predicted AU labels and , which correspond to and . The predicted AU labels from are regarded as “fake”, and the ground truth labels corresponding to are regarded as “real”. Both “real” ground truth AU labels and “fake” predicted AU labels are inputted to AU discriminator . tries to distinguish the “real” AU labels from the predicted AU labels, while tries to fool into making mistakes. By leveraging the competition between and , the distribution of the predicted AU labels nears the distribution of the ground truth AU labels until convergence. Ground truth AU labels could provide supervisory information for learning the AU classifier, minimizing the error between the predicted AU labels and the ground truth AU labels for AU-labeled samples. Therefore, we get the following objective:
| (2) | ||||
Observing the above equation, when , the AU classifier is learned without the constraints of the label distribution.
The proposed method can be trained in a fully supervised manner if all facial images in are labeled with action units. Otherwise, the proposed method is learned in a semi-supervised manner.
Similar to (Goodfellow et al., 2014), we do not optimize Equation 2 directly, but use an iterative and alternative learning strategy as Equations 3 and 4.
| (3) | ||||
| (4) | ||||
is for AU discriminator and is for AU classifier . In practice, it is better for to minimize instead of minimizing , to avoid gradient vanishing of the AU classifier (Goodfellow, 2016). The detailed training procedure is described in Algorithm 1.
In our work on AU recognition, we use cross-entropy loss, so can be written as Equation 5:
| (5) | ||||
We use a three-layer feedforward neural network for the structure of the AU discriminator. For the AU classifier, we enable end-to-end learning directly from the input facial image via a deep CNN. Specifically, ResNet-50 (He et al., 2016) is used as the backbone network and one fully connected layer is built upon the 2048D feature vectors.
4. Experiments
4.1. Experimental Conditions
To validate the proposed adversarial AU recognition method, we conducted experiments on two benchmark databases: the BP4D database (Zhang et al., 2013) and the Denver Intensity of Spontaneous Facial Action (DISFA) database (Mavadati et al., 2013).
The BP4D database provides both 2D and 3D spontaneous facial videos of eight facial expressions recorded from 41 subjects. Among them, 328 two-dimensional videos in which each frame is a 2D image are coded with 12 AUs: 1, 2, 4, 6, 7, 10, 12, 14, 15, 17, 23, and 24. In total, there are around 140,000 valid image samples. Like most related works, we use all available AUs and all valid samples.
The DISFA database contains spontaneous facial videos from 27 subjects watching YouTube videos. Each image frame is coded with 12 AUs: 1, 2, 4, 5, 6, 9, 12, 15, 17, 20, 25, 26. The annotations of AUs are represented as intensities ranging from zero to five. The number of valid image samples is around 130,000. Like most related works, we treated each AU with an intensity equal or greater than 2 as active, and considered 8 AUs (i.e., 1, 2, 4, 6, 9, 12, 25, and 26). For both databases, the number of occurrences per AU are shown in Figure 3.
Facial alignment was taken into account to extract the face region for each image. Specifically, the face region is aligned based on three fiducial points: the centers of each eye and the mouth. After cropping and warping the face region, all images in both databases were normalized to pixels.
We conduct semi-supervised AU recognition experiments on images with incomplete AU annotations and fully supervised AU recognition experiments on completely AU-annotated images on both databases. For semi-supervised scenarios, we randomly miss AU labels according to certain proportions: 10%, 20%, 30%, 40%, and 50%. On the BP4D database, we adopt three-fold subject-independent cross validation, a commonly used experimental strategy for AU recognition. For a fair comparison to (Wu et al., 2017) and (Han et al., 2018), we apply their AU selection and data split strategy on the BP4D database. On the DISFA database, similar to most related works, we adopt 3-fold subject-independent cross validation. Because of the different experimental conditions with (Wu et al., 2017) and (Han et al., 2018), we don’t conduct 9-Folds and 10-Folds experiments on the DISFA database. We adopt F1 score, AUC and accuracy to evaluate the performance of the proposed method. Moreover, the best values of alpha in the above-mentioned experiments are the same of the optimal values in Section 4.3.2.
To demonstrate the effectiveness of the adversarial mechanism in the semi-supervised scenario, we compare our method to the method without label constraint (“O-wlc” for short). For this method, we set the tradeoff rate in Equation 2 to remove the AU label distribution constraint. For the semi-supervised scenario, we also compare the proposed method to DAU-R (Wu et al., 2017) and BGCS (Song et al., 2015). We re-conduct the semi-supervised experiments of BGCS using their provided codes, since Song et al. (Song et al., 2015) didn’t conduct semi-supervised experiments on the BP4D or DISFA databases. Totally, for experiments on the DISFA database, we compare our method to BGCS and O-wlc. DAU-R is not involved due to the difference of experimental conditions. And O-wlc, DAU-R and BGCS are employed to compare with our method on the BP4D database. In addition, we don’t compare our results with MLML(Wu et al., 2015) on both databases because of the memory problems. We do not compare our method to the methods found in (Ruiz et al., 2015; Wang et al., 2017; Wang et al., 2018; Peng and Wang, 2018) and (Zhang et al., 2018) either, since these works require expression annotations.
For the fully supervised scenario, we compare the proposed method to state-of-the-art works, including ARL (Shao et al., 2019), LP-Net (Niu et al., 2019), SRERL (Li et al., 2019), U-Net (Sankaran et al., 2020), DSIN (Corneanu et al., 2018), JAA-Net (Shao et al., 2018), EAC-Net (Li et al., 2018), OFS-CNN (Han et al., 2018), DAU-R (Wu et al., 2017), CPM (Zeng et al., 2015), DRML (Zhao et al., 2016), JPML(Zhao et al., 2015), and APL(Zhong et al., 2014). The results of CPM are taken from (Chu et al., 2017), since Zeng et al. (Zeng et al., 2015) did not provide the results on three-fold protocol. The experiments conducted in Hao et al.’s work (Hao et al., 2018) are based on the apex facial images with expression labels, and (Li et al., 2017) and (Chu et al., 2017) use temporal models, so these methods are ignored in the comparison. In (Li et al., 2017), the best results from non-temporal model (ROI) are used for comparison.


4.2. Semi-Supervised AU recognition
4.2.1. Experimental Results of Semi-Supervised AU Recognition


Experimental results of semi-supervised AU recognition are shown in Figure 4. We can observe the following:
First, the performances of most methods illustrated in Figure 4 maintain a downward trend as the missing rate increases. For example, on the BP4D database, the average F1 scores of our method drop from 62.6% in 0.1 missing rate to 60.6% in 0.5 missing rate. On the DISFA database, the average F1 scores of our method drop from 58.5% to 56.0% as the missing rate increases. This is expected, since additional ground truth AU labels provide more supervisory information to better train AU classifiers.
Secondly, when using different missing rates, the proposed method substantially outperforms the “O-wlc” method, with higher average F1 scores on both databases. The adversarial learning mechanism introduced in our method leverages dependencies among AUs so that unlabeled facial images also improve the classifier. This leads to better results in the semi-supervised learning scenario.
Thirdly, compared to DAU-R, which is also a deep AU recognition approach using partially labeled images, the proposed method achieves a higher F1 score for all missing rates on the BP4D database. Instead of using an RBM, the proposed method successfully leverages an adversarial mechanism to capture the statistical distribution of AU labels. This ensures that AUs appearing on all images follow statistical distributions based on facial anatomy and humans’ behavioral habits. Therefore, the proposed method thoroughly takes advantage of limited ground truth AU labels and readily available large-scale facial images to achieve better performance than DAU-R in the semi-supervised learning scenario.
Fourthly, the proposed method outperforms the shallow weakly supervised method(BGCS), with higher F1 scores for all missing rates on both databases respectively. This is an additional evidence of the strength of deep learning and the competence of adversarial mechanisms in semi-supervised learning scenarios.
4.2.2. Evaluation of Adversarial Learning




To validate the effectiveness of adversarial learning for capturing statistical distributions of multiple AUs from ground truth AU labels, we calculate the marginal and conditional distributions of each AU in the predicted AU labels of the testing set, and compare them to the distribution of each AU in the ground truth labels. For example, Figure 5a illuminates the marginal distributions of the predicted AUs from the proposed method and O-wlc, as well as the distributions of each AU in the ground truth labels for the BP4D database. It should be noted that we discuss the results of ours and O-wlc in 0.5 missing rate here. Figure 5b shows the absolute differences between the marginal distribution of each AU in the predicted AU labels and the marginal distribution of each AU in the ground truth AU labels for these two methods. Figure 6 shows the absolute differences between the conditional distribution of one AU under another AU in the predicted AU labels, and the conditional distributions in ground truth AU labels.
From Figure 5b and Figure 6, we find that the marginal and conditional AU distributions predicted by ours are closest to the AU distribution of the ground truth AU labels. As seen in Figure 5b, the absolute differences between ours and ground truth are lower for eight AUs than “O-wlc”. Figure 6 shows that the average absolute differences of conditional distributions between ground truth and predicted AU are 0.054 and 0.056 for ours and “O-wlc”, respectively. The proposed method outperforms “O-wlc” with lower absolute differences of conditional and marginal distributions. “O-wlc” minimizes the recognition errors of each AU but ignores AU dependencies, while the proposed method leverages adversarial learning to capture AU distributions. Therefore, the proposed method can successfully make the distribution of predicted AU labels closer to the distribution of ground truth AU labels. It demonstrates the effectiveness of the adversarial learning for leveraging statistical distributions of multiple AUs from ground truth AU labels.
4.3. Fully Supervised AU Recognition
4.3.1. Experimental Results of Fully Supervised AU Recognition
The fully supervised experimental results of AU recognition on the BP4D and DISFA database are listed in Tables 1, 2 and 3.
The proposed method performs better than the baseline method “O-wlc” on both databases. Specifically, on the BP4D database, the proposed method achieves 1.3% and 0.9% higher average F1 score than “O-wlc” on 60%-20%-20% and three-fold protocol, and a 0.7% higher average AUC score than “O-wlc” on three-fold protocol. On the DISFA database, our method achieves a 1.7% higher average F1 score than “O-wlc”. Unlike “O-wlc”, which only minimizes the error of the predicted AUs and ground truth AUs, the proposed method imposes adversarial loss to enforce statistical similarity between the predicted and ground truth AUs. Thus, the proposed method can leverage AU distributions existing in ground truth AU labels to construct better AU classifiers, obtaining better performance on AU recognition.
To further demonstrate the superiority of the proposed method, we compare our method to several state-of-the-art works. From Table 1-3, we observe the following:
| training/development F1 | 60%-20%-20% F1 | 3-fold F1 | |||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AU | Ours | “O-wlc” |
|
Ours | “O-wlc” |
|
Ours | “O-wlc” |
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||
| 1 | 41.9 | 32.4 | 41.6 | 48.7 | 51.6 | 38.1 | 50.8 | 48.6 | 46.9 | 45.8 | 43.4 | 49.1 | 51.7 | 47.2 | 36.2 | 39.0 | 43.4 | 36.4 | 32.6 | ||||||||||||||||||||||||||
| 2 | 37.9 | 32.1 | 30.5 | 28.0 | 23.0 | 16.6 | 44.7 | 42.0 | 45.3 | 39.8 | 38.0 | 44.1 | 41.6 | 44.0 | 31.6 | 35.2 | 40.7 | 41.8 | 25.6 | ||||||||||||||||||||||||||
| 4 | 50.9 | 46.2 | 39.1 | 56.0 | 55.5 | 41.8 | 56.8 | 59.4 | 55.6 | 55.1 | 54.2 | 50.3 | 58.1 | 54.9 | 43.4 | 48.6 | 43.3 | 43.0 | 37.4 | ||||||||||||||||||||||||||
| 6 | 78.6 | 78.5 | 74.5 | 76.6 | 76.3 | 74.1 | 79.6 | 78.4 | 77.1 | 75.7 | 77.1 | 79.2 | 76.6 | 77.5 | 77.1 | 76.1 | 59.2 | 55.0 | 42.3 | ||||||||||||||||||||||||||
| 7 | 77.6 | 79.4 | 62.8 | 76.4 | 76.0 | 62.0 | 80.6 | 80.8 | 78.4 | 77.2 | 76.7 | 74.7 | 74.1 | 74.6 | 73.7 | 72.9 | 61.3 | 67.0 | 50.5 | ||||||||||||||||||||||||||
| 10 | 84.3 | 83.8 | 74.3 | 88.0 | 88.6 | 73.9 | 84.1 | 84.5 | 83.5 | 82.3 | 83.8 | 80.9 | 85.5 | 84.0 | 85.0 | 81.9 | 62.1 | 66.3 | 72.2 | ||||||||||||||||||||||||||
| 12 | 86.6 | 85.4 | 81.2 | 83.0 | 82.6 | 79.2 | 88.4 | 88.3 | 87.6 | 86.6 | 87.2 | 88.3 | 87.4 | 86.9 | 87.0 | 86.2 | 68.5 | 65.8 | 74.1 | ||||||||||||||||||||||||||
| 14 | 65.5 | 62.7 | 55.5 | 56.1 | 58.2 | 58.8 | 66.8 | 63.1 | 63.9 | 58.8 | 63.3 | 63.9 | 72.6 | 61.9 | 62.6 | 58.8 | 52.5 | 54.1 | 65.7 | ||||||||||||||||||||||||||
| 15 | 43.5 | 44.4 | 32.6 | 41.4 | 34.8 | 24.6 | 52.0 | 51.1 | 52.2 | 47.6 | 45.3 | 44.4 | 40.4 | 43.6 | 45.7 | 37.5 | 36.7 | 33.2 | 38.1 | ||||||||||||||||||||||||||
| 17 | 60.3 | 60.7 | 56.8 | 61.4 | 64.2 | 56.4 | 60.4 | 59.7 | 63.9 | 62.1 | 60.5 | 60.3 | 66.5 | 60.3 | 58.0 | 59.1 | 54.3 | 48.0 | 40.0 | ||||||||||||||||||||||||||
| 23 | 44.0 | 34.0 | 41.3 | 49.7 | 38.4 | 26.1 | 47.7 | 46.4 | 47.1 | 47.4 | 48.1 | 41.4 | 38.6 | 42.7 | 38.3 | 35.9 | 39.5 | 31.7 | 30.4 | ||||||||||||||||||||||||||
| 24 | - | - | - | 38.7 | 39.0 | 37.6 | 47.6 | 46.4 | 53.3 | 55.4 | 54.2 | 51.2 | 46.9 | 41.9 | 37.4 | 35.8 | 37.8 | 30.0 | 42.3 | ||||||||||||||||||||||||||
| Avg. | 61.0 | 58.1 | 53.7 | 58.7 | 57.4 | 49.1 | 63.3 | 62.4 | 62.9 | 61.1 | 61.0 | 60.6 | 61.7 | 60.0 | 56.4 | 55.9 | 50.0 | 48.3 | 45.9 | ||||||||||||||||||||||||||
| training/development AUC | 3-fold AUC | 3-fold Accuracy | |||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AU | Ours | “O-wlc” |
|
Ours | “O-wlc” |
|
|
|
Ours | “O-wlc” |
|
|
|
||||||||||||||
| 1 | 64.9 | 57.3 | - | 70.4 | 68.4 | 67.6 | 55.7 | 40.7 | 74.1 | 73.9 | 73.9 | 74.7 | 68.9 | ||||||||||||||
| 2 | 63.9 | 59.5 | - | 67.8 | 65.7 | 70.0 | 54.5 | 42.1 | 78.3 | 78.0 | 76.7 | 80.8 | 73.9 | ||||||||||||||
| 4 | 72.0 | 67.8 | - | 74.4 | 75.3 | 73.4 | 58.8 | 46.2 | 80.1 | 82.6 | 80.9 | 80.4 | 78.1 | ||||||||||||||
| 6 | 80.4 | 79.1 | - | 80.2 | 78.5 | 78.4 | 56.6 | 40.0 | 79.8 | 77.9 | 78.2 | 78.9 | 78.5 | ||||||||||||||
| 7 | 75.2 | 71.9 | - | 75.0 | 74.7 | 76.1 | 61.0 | 50.0 | 76.4 | 76.3 | 74.4 | 71.0 | 69.0 | ||||||||||||||
| 10 | 81.1 | 77.6 | - | 76.8 | 78.6 | 80.0 | 53.6 | 75.2 | 79.5 | 80.6 | 79.1 | 80.2 | 77.6 | ||||||||||||||
| 12 | 84.9 | 82.8 | - | 86.3 | 86.0 | 85.9 | 60.8 | 60.5 | 86.7 | 86.5 | 85.5 | 85.4 | 84.6 | ||||||||||||||
| 14 | 69.4 | 64.7 | - | 66.7 | 64.9 | 64.4 | 57.0 | 53.6 | 66.4 | 65.0 | 62.8 | 64.8 | 60.6 | ||||||||||||||
| 15 | 67.9 | 67.6 | - | 70.8 | 70.2 | 75.1 | 56.2 | 50.1 | 84.1 | 84.0 | 84.7 | 83.1 | 78.1 | ||||||||||||||
| 17 | 67.7 | 68.2 | - | 69.3 | 68.6 | 71.7 | 50.0 | 42.5 | 70.3 | 69.6 | 74.1 | 73.5 | 70.6 | ||||||||||||||
| 23 | 65.4 | 60.4 | - | 69.0 | 68.4 | 71.6 | 53.9 | 51.9 | 82.1 | 81.2 | 82.9 | 82.3 | 81.0 | ||||||||||||||
| 24 | - | - | - | 68.2 | 67.3 | 74.6 | 53.9 | 53.2 | 85.6 | 85.7 | 85.7 | 85.4 | 82.4 | ||||||||||||||
| Avg. | 72.1 | 68.8 | 72.2 | 72.9 | 72.2 | 74.1 | 56.0 | 50.5 | 78.6 | 78.4 | 78.2 | 78.4 | 75.2 | ||||||||||||||
| 3-fold F1 | 3-fold AUC | 3-fold Accuracy | ||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AU | Ours | “O-wlc” |
|
|
|
|
|
|
|
|
|
|
Ours | “O-wlc” |
|
|
|
Ours | “O-wlc” |
|
|
|
||||||||||||||||||||||||||||||||
| 1 | 51.7 | 46.4 | 45.7 | 43.9 | 29.9 | 44.8 | 46.9 | 43.7 | 41.5 | 41.5 | 17.3 | 11.4 | 76.6 | 77.7 | 76.2 | 53.3 | 32.7 | 94.8 | 93.0 | 92.1 | 93.4 | 85.6 | ||||||||||||||||||||||||||||||||
| 2 | 35.1 | 33.6 | 47.8 | 42.1 | 24.7 | 41.7 | 42.5 | 46.2 | 26.4 | 26.4 | 17.7 | 12.0 | 70.1 | 70.8 | 80.9 | 53.2 | 27.8 | 92.8 | 91.8 | 92.7 | 96.1 | 84.9 | ||||||||||||||||||||||||||||||||
| 4 | 67.9 | 66.2 | 59.6 | 63.6 | 72.7 | 52.9 | 68.8 | 56.0 | 66.4 | 66.4 | 37.4 | 30.1 | 81.7 | 81.2 | 79.1 | 60.0 | 37.9 | 89.9 | 89.2 | 88.5 | 86.9 | 79.1 | ||||||||||||||||||||||||||||||||
| 6 | 46.1 | 45.9 | 47.1 | 41.8 | 46.8 | 57.9 | 32.0 | 41.4 | 50.7 | 50.7 | 29.0 | 12.4 | 69.9 | 68.7 | 80.4 | 54.9 | 13.6 | 92.0 | 92.5 | 91.6 | 91.4 | 69.1 | ||||||||||||||||||||||||||||||||
| 9 | 56.2 | 49.0 | 45.6 | 40.0 | 49.6 | 50.7 | 51.8 | 44.7 | 8.5 | 80.5 | 10.7 | 10.1 | 74.5 | 69.7 | 76.5 | 51.5 | 64.4 | 96.7 | 96.5 | 95.9 | 95.8 | 88.1 | ||||||||||||||||||||||||||||||||
| 12 | 77.0 | 77.2 | 73.5 | 76.2 | 72.9 | 72.4 | 73.1 | 69.6 | 89.3 | 89.3 | 37.7 | 65.9 | 88.9 | 88.3 | 87.9 | 54.6 | 94.2 | 93.6 | 93.8 | 93.9 | 91.2 | 90.0 | ||||||||||||||||||||||||||||||||
| 25 | 92.5 | 91.9 | 84.3 | 95.2 | 93.8 | 82.2 | 91.9 | 88.3 | 88.9 | 88.9 | 38.5 | 21.4 | 94.5 | 93.8 | 90.9 | 45.6 | 50.4 | 95.9 | 95.6 | 97.3 | 93.4 | 80.5 | ||||||||||||||||||||||||||||||||
| 26 | 45.1 | 47.5 | 43.6 | 66.8 | 65.0 | 60.9 | 46.6 | 58.4 | 15.6 | 15.6 | 20.1 | 26.9 | 68.7 | 70.6 | 73.4 | 45.3 | 47.1 | 91.1 | 91.1 | 94.3 | 93.2 | 64.8 | ||||||||||||||||||||||||||||||||
| Avg. | 58.9 | 57.2 | 55.9 | 58.7 | 56.9 | 57.9 | 56.7 | 56.0 | 48.5 | 48.5 | 26.7 | 23.8 | 78.1 | 77.6 | 80.7 | 52.3 | 46.0 | 93.3 | 92.9 | 93.3 | 92.7 | 80.6 | ||||||||||||||||||||||||||||||||
First, we compare our method to DAU-R, DSIN and SRERL, which also take AU relations into account. We can observe that the proposed method outperforms the three methods on both databases. Specifically, on the BP4D database, our method achieves 9.6%, 1.6% and 0.4% improvement over DAU-R, DSIN and SRERL on F1 score. On the DISFA database, the proposed method achieves 2.2% and 3.0% higher F1 score than DSIN and SRERL. All these methods attempt to make the distribution of the recognized AUs converge with the distribution of the ground truth AUs while minimizing the recognized error between the recognized AUs and the ground truth AUs. DAU-R uses a RBM to model the existing distribution of ground truth AU labels, and forces the network to output predictions that are subject to the learned label distribution. SRERL utilizes AU relationship graph to represent the global relationships between AUs. The AU distributions take a certain form, which may not be identical to the true distribution forms inherent in AU labels due to facial muscle interactions. The proposed method uses adversarial learning to directly force statistical similarity of the distribution of the predicted AU labels and the distribution inherent in ground-truth AU labels, without any assumption of distribution form. Therefore, the proposed method can more completely and faithfully capture inherent AU distributions, resulting in better performance on AU recognition. Moreover, DSIN used local features and global features to train graphic models for learning AU relations. In fact, our method only involves global features, and has achieved better results. It also demonstrates the effectiveness of the proposed method.
Secondly, the proposed method outperforms other deep models,i.e. ARL, LP-Net, U-Net, JAA-Net, ROI, EAC-Net, OFS-CNN, DRML. On the BP4D database, our method achieves an average F1 score of 0.610 when examining AUs it shares with OFS-CNN, which is 7.3% higher than the average F1 score achieved by that model. The proposed method achieves a 15.0% improvement in average F1 score and 16.9% improvement in average AUC over DRML. The value of average F1 score of the proposed method is 6.9%, 7.4%, 2.7%, 2.3% and 2.2% higher than ROI, EAC-Net, U-Net, LP-Net and ARL, respectively. Our method is also 3.3% better than JAA-Net on the BP4D database. On the DISFA database, our method still performs better than these methods. In fact, the majority of these methods used multi-label cross entropy to handle multiple AU recognition. Since multi-label cross entropy is the sum of binary cross entropy of each label, it cannot effectively explore label dependencies. The proposed method uses adversarial learning to successfully explore AU distribution from the data.
Thirdly, as expected, the proposed method achieves better performances than the shallow models, JPML. Specifically, the proposed method achieves a 17.4% improvement in average F1 score and a 22.4% improvement in average AUC over JPML on the BP4D database. JPML considers positive correlations and negative competitions by introducing constraints in the loss function. The superior performance of the proposed method demonstrates the superiority of deep learning and the potential of the proposed adversarial learning method in capturing high-dimensional distributions from AU data.
4.3.2. Evaluation of the Parameter

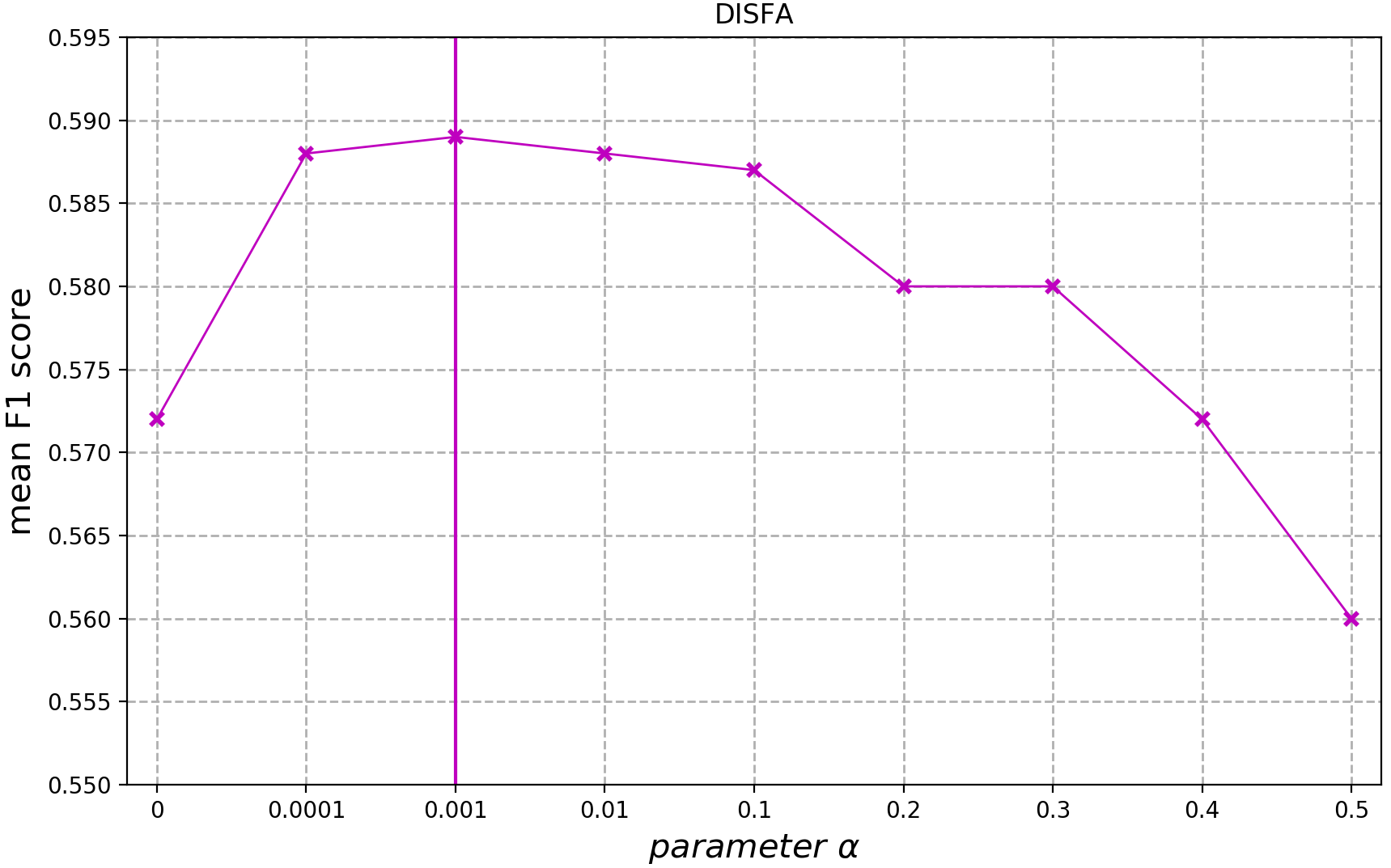
The parameter controls the tradeoff between the supervised loss and the adversarial loss. We conduct experiments with different values of as shown in Figure 7. We find an optimal value of which corresponds to the best tradeoff between supervised and adversarial loss. Specifically, the optimal value of is 0.01 on the BP4D database and 0.001 on the DISFA database. The ratio of the adversarial loss and supervised loss is roughly 1:15 on the BP4D database and 1:3 on the DISFA database. This indicates that supervised loss is more important than adversarial loss.
4.3.3. Evaluation of Learned Feature Representations


We demonstrate the effectiveness of feature representations by investigating and visualizing the representations in 2D plots with t-SNE (Maaten and Hinton, 2008). Two feature spaces are visualized. The first is the feature space of facial images. The other is the space of the ResNet50 encoding vectors. Figure 8 shows the visualization of AU24 on the BP4D database. Samples from the same subject are in the same color and are tagged with the subject ID at the centroid position. From Figure 8, we can see that centroids of different subjects are dispersive in the space of facial images, indicating a high variance between individuals. Compared to the facial image space, samples from different subjects tend to blend together in the learned feature space. This demonstrates that feature representations learned by deep neural networks are not impacted by subject, and are beneficial for the task of AU recognition.
5. Conclusion
Current approaches to facial action unit recognition are primarily based on deep neural networks trained in a supervised manner, and require several labeled facial images for training. Dependencies among AUs are either ignored or captured in a limited fashion. In this paper, we explore adversarial learning for deep semi-supervised facial action unit recognition. We first utilize a deep neural network to learn feature representations and make predictions. Then, a discriminator is introduced to distinguish predicted AUs from ground truth labels. By optimizing the deep AU classifier and the discriminator in an adversarial manner, the deep neural network is able to make predictions which are increasingly close to the actual AU distribution. Experiments on the DISFA and BP4D databases demonstrate that the proposed approach can learn the AU distributions more precisely than state-of-the-art AU recognition methods, outperforming them in both supervised and semi-supervised learning scenarios.
Acknowledgements.
This work has been supported by the National Natural Science Foundation of China (Grant No. 917418129, 61727809), and the major project from Anhui Science and Technology Agency (1804a09020038).References
- (1)
- Chu et al. (2017) Wen-Sheng Chu, Fernando De la Torre, and Jeffrey F Cohn. 2017. Learning Spatial and Temporal Cues for Multi-label Facial Action Unit Detection. In Automatic Face and Gesture Conference, Vol. 4.
- Corneanu et al. (2018) Ciprian Corneanu, Meysam Madadi, and Sergio Escalera. 2018. Deep structure inference network for facial action unit recognition. In Proceedings of the European Conference on Computer Vision (ECCV). 298–313.
- Eleftheriadis et al. (2015) Stefanos Eleftheriadis, Ognjen Rudovic, and Maja Pantic. 2015. Multi-conditional latent variable model for joint facial action unit detection. In Proceedings of the IEEE International Conference on Computer Vision. 3792–3800.
- Fasel and Luettin (2003) Beat Fasel and Juergen Luettin. 2003. Automatic facial expression analysis: a survey. Pattern recognition 36, 1 (2003), 259–275.
- Ghosh et al. (2015) Sayan Ghosh, Eugene Laksana, Stefan Scherer, and Louis-Philippe Morency. 2015. A multi-label convolutional neural network approach to cross-domain action unit detection. In Affective Computing and Intelligent Interaction (ACII), 2015 International Conference on. IEEE, 609–615.
- Goodfellow (2016) Ian Goodfellow. 2016. NIPS 2016 tutorial: Generative adversarial networks. arXiv preprint arXiv:1701.00160 (2016).
- Goodfellow et al. (2014) Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative adversarial nets. In Advances in neural information processing systems. 2672–2680.
- Gudi et al. (2015) Amogh Gudi, H Emrah Tasli, Tim M den Uyl, and Andreas Maroulis. 2015. Deep learning based facs action unit occurrence and intensity estimation. In Automatic Face and Gesture Recognition (FG), 2015 11th IEEE International Conference and Workshops on, Vol. 6. IEEE, 1–5.
- Han et al. (2018) Shizhong Han, Zibo Meng, James O’Reilly, Jie Cai, Xiaofeng Wang, and Yan Tong. 2018. Optimizing filter size in convolutional neural networks for facial action unit recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 5070–5078.
- Hao et al. (2018) Longfei Hao, Shangfei Wang, Guozhu Peng, and Qiang Ji. 2018. Facial Action Unit Recognition Augmented by Their Dependencies. In Automatic Face & Gesture Recognition (FG 2018), 2018 13th IEEE International Conference on. IEEE, 187–194.
- He et al. (2016) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition. 770–778.
- Jaiswal and Valstar (2016) Shashank Jaiswal and Michel Valstar. 2016. Deep learning the dynamic appearance and shape of facial action units. In 2016 IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, 1–8.
- Khorrami et al. (2015) Pooya Khorrami, Thomas Paine, and Thomas Huang. 2015. Do deep neural networks learn facial action units when doing expression recognition?. In Proceedings of the IEEE International Conference on Computer Vision Workshops. 19–27.
- Kingma and Ba (2014) Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
- Li et al. (2019) Guanbin Li, Xin Zhu, Yirui Zeng, Qing Wang, and Liang Lin. 2019. Semantic relationships guided representation learning for facial action unit recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 33. 8594–8601.
- Li et al. (2017) Wei Li, Farnaz Abtahi, and Zhigang Zhu. 2017. Action unit detection with region adaptation, multi-labeling learning and optimal temporal fusing. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 6766–6775.
- Li et al. (2018) Wei Li, Farnaz Abtahi, Zhigang Zhu, and Lijun Yin. 2018. EAC-Net: Deep Nets with Enhancing and Cropping for Facial Action Unit Detection. IEEE Transactions on Pattern Analysis and Machine Intelligence (2018).
- Li et al. (2016) Yongqiang Li, Baoyuan Wu, Bernard Ghanem, Yongping Zhao, Hongxun Yao, and Qiang Ji. 2016. Facial action unit recognition under incomplete data based on multi-label learning with missing labels. Pattern Recognition 60 (2016), 890–900.
- Maaten and Hinton (2008) Laurens van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-SNE. Journal of machine learning research 9, Nov (2008), 2579–2605.
- Mavadati et al. (2013) S Mohammad Mavadati, Mohammad H Mahoor, Kevin Bartlett, Philip Trinh, and Jeffrey F Cohn. 2013. Disfa: A spontaneous facial action intensity database. IEEE Transactions on Affective Computing 4, 2 (2013), 151–160.
- Niu et al. (2019) Xuesong Niu, Hu Han, Songfan Yang, Yan Huang, and Shiguang Shan. 2019. Local Relationship Learning with Person-specific Shape Regularization for Facial Action Unit Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 11917–11926.
- Peng and Wang (2018) Guozhu Peng and Shangfei Wang. 2018. Weakly Supervised Facial Action Unit Recognition Through Adversarial Training. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2188–2196.
- Ruiz et al. (2015) Adria Ruiz, Joost Van de Weijer, and Xavier Binefa. 2015. From emotions to action units with hidden and semi-hidden-task learning. In Computer Vision (ICCV), 2015 IEEE International Conference on. IEEE, 3703–3711.
- Sankaran et al. (2020) Nishant Sankaran, Deen Dayal Mohan, Nagashri N Lakshminarayana, Srirangaraj Setlur, and Venu Govindaraju. 2020. Domain adaptive representation learning for facial action unit recognition. Pattern Recognition 102 (2020), 107127.
- Shao et al. (2018) Zhiwen Shao, Zhilei Liu, Jianfei Cai, and Lizhuang Ma. 2018. Deep adaptive attention for joint facial action unit detection and face alignment. In Proceedings of the European Conference on Computer Vision (ECCV). 705–720.
- Shao et al. (2019) Zhiwen Shao, Zhilei Liu, Jianfei Cai, Yunsheng Wu, and Lizhuang Ma. 2019. Facial action unit detection using attention and relation learning. IEEE Transactions on Affective Computing (2019).
- Song et al. (2015) Yale Song, Daniel McDuff, Deepak Vasisht, and Ashish Kapoor. 2015. Exploiting sparsity and co-occurrence structure for action unit recognition. In Automatic Face and Gesture Recognition (FG), 2015 11th IEEE International Conference and Workshops on, Vol. 1. IEEE, 1–8.
- Tong et al. (2007) Yan Tong, Wenhui Liao, and Qiang Ji. 2007. Facial action unit recognition by exploiting their dynamic and semantic relationships. IEEE transactions on pattern analysis and machine intelligence 29, 10 (2007).
- Wang et al. (2017) Shangfei Wang, Quan Gan, and Qiang Ji. 2017. Expression-assisted facial action unit recognition under incomplete AU annotation. Pattern Recognition 61 (2017), 78–91.
- Wang et al. (2018) Shangfei Wang, Guozhu Peng, and Qiang Ji. 2018. Exploring Domain Knowledge for Facial Expression-Assisted Action Unit Activation Recognition. IEEE Transactions on Affective Computing (2018).
- Wang et al. (2013) Ziheng Wang, Yongqiang Li, Shangfei Wang, and Qiang Ji. 2013. Capturing global semantic relationships for facial action unit recognition. In Computer Vision (ICCV), 2013 IEEE International Conference on. IEEE, 3304–3311.
- Wu et al. (2015) Baoyuan Wu, Siwei Lyu, Bao-Gang Hu, and Qiang Ji. 2015. Multi-label learning with missing labels for image annotation and facial action unit recognition. Pattern Recognition 48, 7 (2015), 2279–2289.
- Wu et al. (2017) Shan Wu, Shangfei Wang, Bowen Pan, and Qiang Ji. 2017. Deep facial action unit recognition from partially labeled data. In Proceedings of the IEEE International Conference on Computer Vision. 3951–3959.
- Zeng et al. (2015) Jiabei Zeng, Wen-Sheng Chu, Fernando De la Torre, Jeffrey F Cohn, and Zhang Xiong. 2015. Confidence preserving machine for facial action unit detection. In Proceedings of the IEEE International Conference on Computer Vision. 3622–3630.
- Zhang and Mahoor (2014) Xiao Zhang and Mohammad H Mahoor. 2014. Simultaneous detection of multiple facial action units via hierarchical task structure learning. In Pattern Recognition (ICPR), 2014 22nd International Conference on. IEEE, 1863–1868.
- Zhang et al. (2013) Xing Zhang, Lijun Yin, Jeffrey F Cohn, Shaun Canavan, Michael Reale, Andy Horowitz, and Peng Liu. 2013. A high-resolution spontaneous 3d dynamic facial expression database. In Automatic Face and Gesture Recognition (FG), 2013 10th IEEE International Conference and Workshops on. IEEE, 1–6.
- Zhang et al. (2018) Yong Zhang, Weiming Dong, Bao-Gang Hu, and Qiang Ji. 2018. Classifier Learning With Prior Probabilities for Facial Action Unit Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 5108–5116.
- Zhao et al. (2015) Kaili Zhao, Wen-Sheng Chu, Fernando De la Torre, Jeffrey F Cohn, and Honggang Zhang. 2015. Joint patch and multi-label learning for facial action unit detection. In Computer Vision and Pattern Recognition (CVPR), 2015 IEEE Conference on. IEEE, 2207–2216.
- Zhao et al. (2016) Kaili Zhao, Wen-Sheng Chu, and Honggang Zhang. 2016. Deep region and multi-label learning for facial action unit detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 3391–3399.
- Zhong et al. (2014) Lin Zhong, Qingshan Liu, Peng Yang, Junzhou Huang, and Dimitris N Metaxas. 2014. Learning multiscale active facial patches for expression analysis. IEEE transactions on cybernetics 45, 8 (2014), 1499–1510.
- Zhu et al. (2014) Yachen Zhu, Shangfei Wang, Lihua Yue, and Qiang Ji. 2014. Multiple-facial action unit recognition by shared feature learning and semantic relation modeling. In Pattern Recognition (ICPR), 2014 22nd International Conference on. IEEE, 1663–1668.