[table]capposition=top \newfloatcommandcapbtabboxtable[][\FBwidth]
Exploiting VLM Localizability and Semantics for
Open Vocabulary Action Detection
Abstract
Action detection aims to detect (recognize and localize) human actions spatially and temporally in videos. Existing approaches focus on the closed-set setting where an action detector is trained and tested on videos from a fixed set of action categories. However, this constrained setting is not viable in an open world where test videos inevitably come beyond the trained action categories. In this paper, we address the practical yet challenging Open-Vocabulary Action Detection (OVAD) problem. It aims to detect any action in test videos while training a model on a fixed set of action categories. To achieve such an open-vocabulary capability, we propose a novel method OpenMixer that exploits the inherent semantics and localizability of large vision-language models (VLM) within the family of query-based detection transformers (DETR). Specifically, the OpenMixer is developed by spatial and temporal OpenMixer blocks (S-OMB and T-OMB), and a dynamically fused alignment (DFA) module. The three components collectively enjoy the merits of strong generalization from pre-trained VLMs and end-to-end learning from DETR design. Moreover, we established OVAD benchmarks under various settings, and the experimental results show that the OpenMixer performs the best over baselines for detecting seen and unseen actions. We release the codes, models, and dataset splits at https://github.com/Cogito2012/OpenMixer.
1 Introduction
Action Detection (AD) aims to recognize actions and spatially and temporally localize the actors in videos. It plays a vital roles in various applications like video surveillance [83, 85, 8], autonomous driving [61], and sport event analysis [28], and it thus draws increasing attentions in recent literature [24, 63, 26, 49, 7, 74, 91, 76, 6].
Existing AD methods are mostly developed in a closed-set setting where the models are trained and tested on videos from the same fixed set of action categories. While significant progress has been made over the past few years [7, 91, 76, 6], the assumption that the training and test videos are from the same action categories limits their application to the real world, where test videos could contain actions beyond the pre-defined training categories. For example, a video surveillance system may be able to detect fighting, but other dangerous or suspicious actions like shooting and chasing will not be detected if the system has not been trained with annotated videos from these action categories. In addition, being able to detect actions in an open world facilitates a comprehensive understanding of videos and opens doors to high-level video understanding tasks, like reasoning [89], forecasting [64], etc., that usually require detecting various actions in videos.
This motivates us to investigate Open-Vocabulary Action Detection (OVAD), a task aiming to detect any actions in videos, including both seen categories contained in the training set and unseen categories absent in the training set. However, OVAD is challenging as it requires understanding the human motion dynamics across frames. While motion dynamics modeling has been well studied by the conventional closed-set action detection [13, 7, 91, 76] that takes advantages of full supervision in training, it is challenging in the open-vocabulary setting since there is no supervision for the unseen action categories.
Recently, harvesting the strong generalization capability of pre-trained large visual-language foundation models (VLMs) [51], various open-vocabulary approaches have been proposed for image recognition [90], object detection [1, 25, 79, 35, 27], and image segmentation [97, 34]. However, these methods are designed for images and do not consider temporal dynamics among video frames. In addition, image VLMs such as the CLIP [51] are struggling to capture the action verbs in text and human motion in videos [42]. This inevitably requires learning the temporal dynamics [22] or fully fine-tuning [53] for recognizing the actions on downstream tasks, which take the risk of poor generalizability to the unseen.
There are a few seminal works that leverage VLMs for open-vocabulary video understanding, including action recognition [45, 72, 37, 53] and temporal action localization [54, 43, 82]. However, for the region-level action detection by VLM, there exists a representation gap between video-level pre-training and the region-level adaptation, which is analogous to the representation gap issue discussed in image-based open-vocabulary object detection literature [1, 25, 79]. Specific to the OVAD task, the representation gap stems from the holistic video-action alignment in pre-training and the downstream region-level sub-tasks, i.e., region-action alignment and action-relevant person localization. The cause of the representation gap can be attributed to their intrinsically different adaptation goals from pre-trained video VLMs, i.e., transferring the semantics and localizability of VLMs from video to regions for the two sub-tasks, respectively.
Re-thinking the Transformer-like design of VLMs, we found that the way of using VLM semantic features and the undervalued localizability of VLMs are both critical to the OVAD task. First, to transfer the video-level semantics to each region, we propose to learn a set of region-wise queries to decode the temporal dynamics from videos, by using the pre-trained video-level features as adaptive semantics conditions. The updated queries and video-level features are further dynamically fused and aligned with the textual semantics for recognition. Second, to exploit the video VLM localizability for region-wise localization, we learn a set of queries to decode the person boxes starting from the prior locations revealed by the VLM visual attention.
Specifically, we develop a query-based open-vocabulary action detector, OpenMixer, to detect any video actions in an open vocabulary. It fits in the family of the detection transformers (DETR) [2, 58, 15, 91, 76]. The basic idea is to decouple the action recognition and localization by learning two sets of queries and corresponding decoding modules. Our OpenMixer consists of a spatial OpenMixer Block (S-OMB) for person localization, a temporal OpenMixer Block (T-OMB) for capturing the region-level temporal motion, and a dynamically fused alignment (DFA) for open-vocabulary action recognition. The S-OMB inherits the localizability of VLMs by the text-patch cross-attention, the T-OMB exploits the visual semantic features of VLMs to capture the temporal dynamics, and the DFA dynamically fuses the pre-trained semantics into learnable region-level queries for generalizable recognition. Eventually, our model enjoys the merits of semantics and localizability from VLMs and the end-to-end detection capability from the DETR pipeline.
In experiments, we set up OVAD benchmarks based on popular action detection datasets and evaluate technically viable baselines, showing the superior performance of OpenMixer. In summary, the contributions are three-fold:
-
•
We formulate the task of open-vocabulary action detection (OVAD), which is valuable while challenging even by foundation models.
-
•
We develop the OpenMixer model that exploits the semantics and localizability of pre-trained video-language models toward the OVAD task.
-
•
We empirically reveal the effectiveness of the proposed modules that show strong generalizability on multiple video action detection datasets.
2 Related Work
Spatio-temporal Action Detection. This task aims to localize human actions spatially and temporally in videos and recognize their actions, which has been a fundamental video understanding topic [73, 13, 12, 59]. A line of recent works [63, 26, 66, 49, 5, 92] adopts the two-backbone design to separately extract features of the keyframes and the entire video for actor localization and actor-context relation modeling, respectively. Though they are flexible by taking advantage of both image and video backbones for achieving promising performance, the model parameters are redundant in design and heavy to optimize [6]. With the recent advances in detection transformer (DETR) [2], end-to-end action detection by a single backbone shows impressive performance and thus becomes a more popular design choice [16, 7, 91, 76, 6]. The basic idea is to use a single video transformer to get features of all video frames, and then introduce learnable queries to mix with video features for actor localization and action recognition. Specifically, WOO [7] follows the Sparse RCNN [65] for localization, TubeR [91] learns the action tubes following the classical DETR [2], and STMixer [76] follows the AdaMixer [15] design that achieves the sate-of-the-art performance. The query-based design is advantageous in modeling the interaction between actors and actor context while simplifying the architecture as a single-stage design. However, none of these works could handle unseen actions in an open world. Therefore, we introduce an open-vocabulary action detection method in a query-based design to detect any actions.

Open-vocabulary Visual Understanding. Thanks to the strong alignment capability of pre-trained visual language models (VLM), visual data from unseen classes in an open world can be recognized by the alignment between the visual feature and the text feature of the class names [75, 51]. This motivates a series of open-vocabulary works in object detection [87, 39, 86, 93, 25, 35, 27, 79], action recognition [69, 46, 36, 22, 53, 71], and temporal action localization (OVTAL) [22, 54, 43, 37]. For localizing unseen, the recent image-based open-vocabulary object detectors OV-DETR [86] and CORA [79] share a common spirit with ours by injecting VLM semantics into the learnable queries. However, the query conditions in OV-DETR are class-specific such that they are not adaptive to test-time samples, and the two-stage training in CORA limits its flexibility in video domains. For the video understanding, the recent work [22], [54], and STAN [37] are built on existing image-based CLIP model. However, compared to the OVTAL task, the proposed OVAD task in this paper is even more challenging as it needs to distinguish between any actions in both spatial regions and temporal segments. In literature, the iCLIP [20] aims for a zero-shot action detection, which does not consider seen actions in testing. Moreover, it skipped learning to localize actions by off-the-shelf person detectors [56] and only learns to recognize the unseen actions, which lacks the adaptability to localize action-relevant persons. We noticed a concurrent work [78] for the OVAD problem, but it is two-stage designed and relies on extra large-scale region-text pre-training data, without fully exploiting the inherent detection knowledge of video-based VLMs (see Appendix F for more comparative discussions). To the best of our knowledge, the OpenMixer is the first query-based OVAD model that can be combined with any video VLMs without region-level pre-training.
3 Method
In contrast to the closed-set video action detection [63, 24], open-vocabulary action detection (OVAD) aims to recognize and spatiotemporally localize any human actions in videos, including action categories seen and unseen in training. Concretely, an OVAD model is learned from a training set of samples where denotes the training video and denotes the bounding box annotations on the keyframe that consists of box coordinates and action category . In training, an action is drawn from a fixed set of base action categories . In testing, the learned action detector could detect “any” actions in a given video from the open vocabulary , where contains any novel action categories.
3.1 OpenMixer



In this paper, we propose the OpenMixer to solve the OVAD task. The OpenMixer model is developed within the family of query-based action DEtection TRansformers (DETR) [76, 7, 91]. Basically, DETR-style models treat the action detection task as a set-to-set prediction problem, i.e., learning a sparse set of query features from videos to match with the ground truth boxes and action classes. Specific to the OVAD task, the action classes are predicted from an open vocabulary that contains both the base and novel actions.
The OpenMixer is shown in Fig. 1 (left), given a video and a list of text prompted action class as input, we leverage the visual and text encoders and of a pre-trained video VLM to obtain all features of the video and action text, i.e., and . Here, , and are the 4D patch-level video feature, video-level feature, and video attention, respectively, and is the text feature of class . Then, we build cascaded OpenMixer Blocks (OMB) to learn a set of spatial queries and temporal queries from for person detection and action classification, respectively. The OMB takes as input all the features from VLM and the and to predict person boxes, person scores, and action scores.
For the -th OMB, as shown in Fig. 1 (right), it consists of a Temporal OpenMixer Block (T-OMB) , a Spatial OpenMixer Block (S-OMB) , and a dynamically fused alignment (DFA). The S-OMB consists of prior location sampling, query-query (Q-Q) mixing by self-attention [68] and query-video (Q-V) mixing by AdaMixer [15], while the T-OMB sequentially consists of Q-Q mixing, query conditioning, and Q-V mixing (see Fig. 2(a) and 2(b) for reference). The DFA module recursively updates the , , and person boxes from the -th OMB, and predict person scores and action scores. These three modules are developed for the OVAD task with the consideration of VLM semantics and localizability, which will be introduced in the following sections.
3.2 Localizability Prior for Spatial OMB
A major challenge for one-stage query-based detectors is the low convergence of localization. One of the causes is the lack of prior knowledge of object locations. Specific to the action detection, recent two-stage action detectors [84, 20, 11, 6] address location prior by an off-the-shelf person detector and RoIAlign [18] cropping, but the feature cropping lacks the spatiotemporal context and suffer from representation gap when a pre-trained VLM is introduced. For recent query-based action detectors [7, 91, 76], the prior knowledge of the person locations is missing in their design. Therefore, when it comes to the OVAD task by VLMs, a natural question is that, Can we obtain the prior locations of actors from pre-trained VLMs in a cheap way? Motivated by these considerations, we resort to the visual attention from a pre-trained VLM.
Prior Locations from VLM Attention. Visual attention maps are traditionally represented by the class activation map (CAM) to visually explain recognition models [95, 60]. In the era of ViT [9] and VLM [51], recent works [3, 4, 30] propose to use the multi-head self-attention (MHSA) of the last ViT layer, or the gradient-weighted accumulative product over multi-layer self-attention. However, MHSA is not visually faithful due to the high redundancy of video tokens, and the gradient-based methods suffer from a huge computational cost on video VLMs and ad-hoc implementation for different VLMs. Moreover, due to the lack the token-level video-text correlation, their attention map does not closely relevant to the action specified by the vocabulary. Therefore, an efficient and structure-agnostic CAM is preferable to large video VLMs, which motivates us to use patch-text correlation as VLM attention to encode the location priors.
Specifically, with the -dimensional 4D video feature where is the number of frames and is the number of visual tokens in each frame, the holistic video feature , and the text features of classes as . The features are normalized. We first get the pre-matched text feature by maximum similarity: , since we do not have access to the class label in testing. Thus, the inner-product between and determines the patch-text correlation: . Furthermore, as discussed in [32, 30], the q-v attention in self-attention layers shows an opposite heatmap where the foreground regions are associated with low attention value. In practice, we also observed this issue so that similar to [32], our CAM is determined by the reversed patch-text similarity: (see detailed explanation in Appendix B). By reshaping and spatial interpolation over , the attention map is obtained for prior location sampling. We treat the as the prior distribution of person locations indicated by the VLM, thus the top- positions are sampled as the initial boxes centers: where are 2D coordinates on the keyframe and is the number of queries.
Spatial OMB. With the sampled prior locations, the S-OMB (see Fig. 2(a)) that consists of Q-Q and Q-V mixing modules takes as input the video patch features and the box prediction of the previous -th stage, to update the spatial queries by . The updated spatial queries are used to predict the person scores and person box offsets by MLP. Then, the predicted boxes at stage are updated by , where initial box queries consist of the sampled prior locations and the video spatial range.
The technical intuition behind the design is to encourage the proposed Spatial OMB to learn the box offset starting from the prior locations inherited from the pre-trained VLM. Besides, compared to [76] that uses the fixed non-informative frame centers as prior locations, our VLM attention-based prior locations are adaptive to the test-time video content and vocabulary, which improves not only the seen action localization but also the generalization to the unseen (see Tab. 1 ZSR+TL section).
3.3 Adaptive Semantics for Temporal OMB
For the query-based OVAD models, temporal queries are expected to be discriminative for both base and novel actions. This requires a strong capability of content decoding for the query-video (Q-V) mixing module. The pioneering work DETR [2] uses cross-attention while [15, 76] adopt the MLP-Mixer [67]. However, without VLM semantics, these approaches inevitably overfit the seen class data and are unable to detect the unseen. Recent works [86, 79] rightly address the importance of VLM semantics for the query features, but they lack the adaptability to the test-time visual content due to the class-wise semantic condition in [86] and the region prompting in [79]. These motivate us to propose the Temporal OMB that exploits adaptive semantics from pre-trained VLMs.
Temporal OMB. As dipicted in Fig. 2(b), with the temporal queries and the predicted boxes at the current stage , the queries are updated by interacting with the video features and by the function . To achieve our motivation of using adaptive semantics, we propose a query update:
| (1) |
where and are Q-Q mixing and Q-V mixing modules by self-attention [68] and AdaMixer [15], respectively. Here, is the adaptive semantic condition by the pre-trained VLM video feature, which is broadcastly added (denoted as ) to the output of Q-Q mixing.
Remark. Note that the adaptiveness of the semantic condition stems from the test-time video feature . Alternatively, when the semantic condition is changed to over classes, it is equivalent to the way in [86]. However, we empirically show this leads to inferior performance (see Tab. 4) especially for the seen action detection. The inferiority can be attributed to the lack of adaptability to test-time video content. Besides, as another alternative, the post-condition that places the condition after the Q-V mixing, i.e., , the module is thus to learn the residual of . We empirically found that our pre-condition by Eq. 1 is superior to the post-condition, potentially because of the better query features used to learn the important Q-V mixing module.
3.4 Dynamically Fused Alignment
To recognize both seen and unseen actions, the model needs to learn discriminative region-wise visual features to align with seen actions, while keeping the generalizable knowledge of the pre-trained VLMs to align with the unseen actions. Dealing with the two goals is challenging. A line of recent approaches uses model adaptation by prompt tuning [22, 10, 43, 71, 79, 20], adapters [50, 14], and gradient preserving [72, 98]. However, these methods either struggle in generalization to novel categories or need to back-propagate through the large VLM that incurs huge computational costs, especially for long videos. Therefore, we resort to a dynamically fused alignment (DFA) for open-vocabulary action recognition, which is lightweight in design and works well for both seen and unseen actions.
Specifically, as shown in Figs. 1 and 2(c), the DFA is formulated to learn the action classification at each stage , i.e., , where are the predicted actions for all queries and the are the learnable parameters. This module includes dynamic feature fusion and query-text alignment.
Dynamic Feature Fusion. This step aims to fuse the video-level feature into each of the queries dynamically. Specifically, we first repeat times of the to be . Then, the fusion between and is achieved by , where are learnable in training. The intuition behind the query-specific learnable is that, it allows the dynamic contributions of the video-level knowledge from to the different learnable queries in the set-matching training.
| Settings | Models | J-HMDB | UCF101-24 | ||||
|---|---|---|---|---|---|---|---|
| Mean | Base | Novel | Mean | Base | Novel | ||
| ZSR+ZSL | Region + GPT | 31.86 | 30.06 | 33.51 | 19.92 | 21.54 | 18.29 |
| Video + HC | 54.40 | 49.89 | 58.51 | 31.04 | 31.43 | 30.64 | |
| Video + GPT | 66.73 | 64.61 | 68.66 | 35.01 | 34.59 | 35.43 | |
| ZSR+TL | STMixer [76] | 63.53 | 58.27 | 68.31 | 36.66 | 45.26 | 28.07 |
| Spatial OpenMixer | 74.06 | 68.04 | 79.53 | 40.32 | 48.80 | 31.85 | |
| E2E | STMixer [76] | 49.16 | 73.06 | 27.44 | 33.72 | 60.91 | 6.54 |
| STMixer [76] (w. CoOp [96]) | 42.27 | 75.66 | 11.91 | 36.12 | 60.42 | 11.81 | |
| OpenMixer (w. CoOp [96]) | 86.86 | 94.18 | 80.20 | 45.11 | 62.48 | 27.75 | |
| OpenMixer | 86.34 | 90.75 | 82.33 | 47.71 | 61.18 | 34.23 | |
Query-Text Alignment. To make the classification decision by and open vocabulary of actions, for the action category, we leverage GPT-4 [47] to generate multiple visually descriptive action prompts for each category (see the prompts in Appendix A). With VLM text encoder, the aggregated text features of classes are represented as , where is the number of classes. Eventually, we use the softmax of visual-text cosine similarity to represent the multi-class classification probability: where is the VLM temperature. In testing, the open-vocabulary action recognition for all queries is achieved by finding the maximum visual-text cosine similarity: .
3.5 Training and Inference
In training, for action localization, we adopt the regular set matching loss following the DETR literature [2, 58, 15]: , where is a binary cross-entropy loss for person score prediction, and are the coordinate distance and GIoU distance [57] between predicted and ground truth boxes, respectively. Then, we use the Hungarian matching [2] to find the optimal bipartite matching between the predicted and ground truth boxes for each video. For action recognition, we use a multi-class cross-entropy loss so that the total loss for training is where the hyperparameters and are used to balance between the two subtasks.
During inference, the thresholded person scores determine the kept person boxes, while the action scores assign the action categories to boxes from input class categories.
4 Experiments
Datasets. Our method is implemented on two commonly-used action detection datasets, i.e., J-HMDB [21] and UCF101-24 [62]. J-HMDB dataset contains per-frame annotated bounding boxes of persons along with 21 action classes. Similar to [22, 20], with 50% of actions as the novel classes, we randomly split it into 10 base classes for training and 11 novel classes for testing, which results in 10,570 training samples and 9,139 testing samples. UCF101-24 dataset is a subset of UCF101 [62]. It is also per-frame annotated for action detection and contains 24 action classes. With the same 50% splitting strategy, we split it into 12 base classes for training and 12 novel classes for testing. Similar to [22, 43], we also report results on other random splits with ratios of both 50%-50% and 75%-25% in Appendix D. We will release all data splits.
Evaluation criteria. Following the standard paradigm in action detection literature [26, 11, 7, 91, 76], the model performance is evaluated by video mAP. It evaluates the spatiotemporal action tubes of the detected bounding boxes over the classification and 3D intersection-over-union (IoU). Following [11], the 3DIoU threshold is set to 0.5 for J-HMDB and 0.2 for UCF101-24, respectively.
Implementation details. We experiment with two VLMs including the image pre-trained OpenAI CLIP [51] and video pre-trained CLIP-ViP [80]. We use the same ViT-B/16 architecture for the two VLMs. The VLMs are kept frozen in training. For the image CLIP, we get video-level semantic features by temporal mean pooling. We obtain the patch token features of the last ViT layer and use them to construct the 4D pyramid feature by multi-scale residual convolutions. By default, we set the number of queries and OMB stages to 100 and 3, respectively. In training, we set the mini-batch size to 16 and frame sampling by . The weight of the set loss and action loss are set to 2.0 and 48.0, respectively. Following [2, 7, 76], each intermediate stage is individually supervised by the loss and . We set the base learning rate to 1e-5 and use the AdamW [41] optimizer to train models for 12 epochs on 4 RTX 6000Ada or 2 A100 (80G) GPUs. In testing, the person detection threshold is set to 0.6. We individually test the base and novel classes and report their video-mAP results and the mean on all categories. In Appendix D, we also report generalized zero-shot testing by giving a complete list of base and novel classes. Our model inference speed is 0.23 s/video per A6000 GPU, with 587M parameters based on CLIP-ViP/B16 VLM. Other details are in Appendix C.
OVAD task settings. To benchmark methods on OVAD task, three settings are presented considering if the localization and classification are trained or not.
- •
-
•
ZSR+TL (zero-shot action recognition and trainable actor localization): we use pre-trained CLIP-ViP [80] to perform video-level action recognition while training the localization modules to detect persons.
- •
4.1 Comparative Results
The main results are reported in Tab. 1. To analyze the baseline performance, we summarize the discussion below.
Zero-shot recognition and localization. In the ZSR+ZSL setting, the findings are as follows. First, region-level features (the 1st row) by RoIAlign [18] perform significantly worse than the video-level features (the 3rd row). This indicates that the RoI-cropped features from VLM suffers from a large representation gap between the video-level pre-training and downstream region-level recognition. Second, the descriptive GPT-generated prompts (the 3rd row) achieve a better performance than the handcrafted (HC) prompt such as the “a video of person [CLS]” (the 2nd row). This can be explained by the more transferable knowledge in the GPT prompts than the handcraft ones.
Zero-shot recognition with learnable localization. Under the ZSR+TL setting, we observe a significant superiority of Spatial OpenMixer to the STMixer baseline, with more than 10% performance gain on J-HMDB dataset. Since the training is only encouraged to localize actors in videos, the outperformance suggests a good exploitation of the localizability in pre-trained VLMs.
| Models | f-mAP | v-mAP |
|---|---|---|
| iCLIP [20] | 65.41 | – |
| OpenMixer | 77.06 | 81.20 |
| S-OMB | DFA | T-OMB | Mean | Base | Novel |
|---|---|---|---|---|---|
| ✗ | ✓ | ✓ | 81.77 | 86.32 | 77.64 |
| ✓ | ✗ | ✓ | 74.06 | 68.04 | 79.53 |
| ✓ | ✓ | ✗ | 83.47 | 86.01 | 81.18 |
| ✓ | ✓ | ✓ | 86.34 | 90.75 | 82.33 |
End-to-end learnable OVAD. For the E2E setting, the OpenMixer (the last row) outperforms the simple STMixer baseline (STMixer+VLM) by large margins, with and of video mAP gains on base and novel categories of the J-HMDB dataset, respectively. Besides, we explored the widely-used VLM adaptation method CoOp [96] that optimizes the context of class names, i.e., prompt tuning. From Tab. 1, we observe that CoOp improves the base class performance with sacrifice on the novel classes, while the GPT-prompted OpenMixer achieves much better performance on novel classes. Lastly, we notice the relatively smaller numbers on UCF101-24 than those on J-HMDB. This reflects the challenging aspects of the UCF101-24 dataset such as the long duration ( longer), heavy background bias, and multi-person scenarios.
Zero-shot action detection. We note the iCLIP [20] defines the zero-shot action detection (ZSAD) task which is different from our OVAD task. The ZSAD only cares about the samples from novel classes while OVAD values both the base and novel classes. Therefore, ZSAD uses all samples from base classes in training and only tests on novel classes. Following the same settings as iCLIP, the results in Tab. 2 show that our method could achieve much better performance than iCLIP, even though iCLIP relies on pre-detected person boxes from YOWO [26].
| Methods | Queries | Modalities | Mean | Base | Novel |
| w/o condition | 83.99 | 85.86 | 82.28 | ||
| post | TQ | video | 85.48 | 88.74 | 82.52 |
| pre | TQ, SQ | video | 85.66 | 90.29 | 81.45 |
| TQ | text | 76.36 | 70.25 | 81.92 | |
| video | 86.34 | 90.75 | 82.33 | ||
| Methods | Mean | Base | Novel |
|---|---|---|---|
| w/o. () | 68.84 | 88.94 | 50.58 |
| w/o. () | 74.06 | 68.04 | 79.53 |
| w/o. dynamics () | 51.48 | 63.08 | 40.93 |
| concat & mlp | 85.51 | 89.19 | 82.17 |
| Ours | 86.34 | 90.75 | 82.33 |
4.2 Ablation Study


| kick ball |  |
 |
 |
 |
 |
 |
|---|---|---|---|---|---|---|
| pullup | |
 |
 |
 |
 |
 |
In this section, we analyze the properties of the OpenMixer model on the J-HMDB dataset. Results of the component-wise ablation are reported in Tab. 3. It shows that all three components could work well. Specifically, without S-OMB which means the attentional location prior is removed, the performance drops significantly especially for the novel classes. If the DFA is removed, we only use the pre-trained VLM feature for zero-shot recognition, it shows that the base class performance is the worst. Without T-OMB which means the semantic condition is removed and both spatial and temporal queries are used for recognition, it shows a decrease of % and % on base and novel actions, respectively.
Query condition strategies. Specific to the T-OMB, we further investigate different alternatives of query condition strategies in Tab. 4, which shows the following observations: (1) Without any condition, it performs worse on the base class with % mAP drop. (2) Pre-condition performs much better than post-condition on base classes (%), with negligible performance drop on the novel classes (%). This can be explained that the pre-condition alleviates the difficulty of content decoding by the following Q-V mixing module. (3) The additional condition on spatial queries (SQ) hurts the performance on both the base and novel classes, because this essentially makes the recognition and localization entangled in training. (4) When using text feature as a condition, base class performance significantly decreased (%) and novel class performance also decreased a bit. This is due to the large semantic gap between text feature and patch-wise video token features , suggesting that the test-time adaptive is preferable even though and are semantically aligned.
Feature fusion strategies. To validate the design choice of our DFA module, we explored different feature fusion strategies, as shown in Tab. 5. The results show that only using the learned query feature (the 1st row) performs much worse performance on the novel classes, indicating the loss of generalization. If only using the pre-trained feature (the 2nd row), the model cannot work well on the base classes which indicates an under-fitting to the task. If fusing the features by simple averaging, the performance still lags behind ours as it is not adaptive to the variety in queries. Moreover, we notice that [76] uses both spatial and temporal queries for recognition by MLP layers. Thus, we additionally include the spatial queries by concatenation with temporal queries and use MLP layers for dimension reduction. We observe the performance drop, which can be explained as the MLP layers eliminate the benefits of the semantic conditions and makes localization and recognition entangled in training.
Number of queries and OMB stages. In Fig. 3(a) and 3(b), we show that using 100 queries and 3 OMB stages achieves the best average mAP. The figures also indicate that the number of OMB stages is more important than the number of queries, as the bipartite matching could handle the redundant queries in training. The decreasing trend with more than three OMB stages can be attributed to the risk of overfitting to training data. More interesting results and discussions can be found in Appendix D.
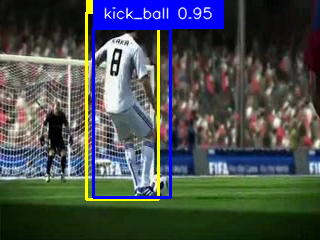
Qualitative results. We visualize results on the J-HMDB novel categories in Fig. 4. They show that OpenMixer could precisely localize and confidently recognize those unseen actions, even though there are multiple persons. More visualizations are in Appendix E.
Limitations and Future Work. The recent large-scale action detection dataset AVA [17] is not included in this paper, as we emphasize on the adaptation of existing pre-trained VLMs for downstream small datasets. In the future, similar to the concurrent work [78], we will explore how to effective pre-train on AVA to benefit for a more general audience.
5 Conclusion
We present an open-vocabulary action detection method OpenMixer to detect any human actions in videos. It is a query-based detection transformer that fully exploits the semantics and localizability of pre-trained VLMs. Furthermore, we build OVAD benchmarks that extensively evaluate baselines and our model under various settings, showing the superiority of the OpenMixer.
Acknowledgement. Wentao Bao and Yu Kong are partially supported by the Army Research Office (ARO) grant W911NF-24-1-0385 and Office of Naval Research (ONR) grant N00014-23-1-2046. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of ARO nor ONR.
References
- [1] Hanoona Bangalath, Muhammad Maaz, Muhammad Uzair Khattak, Salman H Khan, and Fahad Shahbaz Khan. Bridging the gap between object and image-level representations for open-vocabulary detection. In NeurIPS, pages 33781–33794, 2022.
- [2] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In ECCV, pages 213–229, 2020.
- [3] Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. In ICCV, pages 9650–9660, 2021.
- [4] Hila Chefer, Shir Gur, and Lior Wolf. Generic attention-model explainability for interpreting bi-modal and encoder-decoder transformers. In ICCV, pages 397–406, 2021.
- [5] Lei Chen, Zhan Tong, Yibing Song, Gangshan Wu, and Limin Wang. Cycleacr: Cycle modeling of actor-context relations for video action detection. arXiv preprint arXiv:2303.16118, 2023.
- [6] Lei Chen, Zhan Tong, Yibing Song, Gangshan Wu, and Limin Wang. Efficient video action detection with token dropout and context refinement. In ICCV, 2023.
- [7] Shoufa Chen, Peize Sun, Enze Xie, Chongjian Ge, Jiannan Wu, Lan Ma, Jiajun Shen, and Ping Luo. Watch only once: An end-to-end video action detection framework. In ICCV, pages 8178–8187, 2021.
- [8] Ishan Dave, Zacchaeus Scheffer, Akash Kumar, Sarah Shiraz, Yogesh Singh Rawat, and Mubarak Shah. Gabriellav2: Towards better generalization in surveillance videos for action detection. In WACV, pages 122–132, 2022.
- [9] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2021.
- [10] Yu Du, Fangyun Wei, Zihe Zhang, Miaojing Shi, Yue Gao, and Guoqi Li. Learning to prompt for open-vocabulary object detection with vision-language model. In CVPR, pages 14084–14093, 2022.
- [11] Gueter Josmy Faure, Min-Hung Chen, and Shang-Hong Lai. Holistic interaction transformer network for action detection. In WACV, pages 3340–3350, 2023.
- [12] Christoph Feichtenhofer. X3d: Expanding architectures for efficient video recognition. In CVPR, pages 203–213, 2020.
- [13] Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition. In ICCV, pages 6202–6211, 2019.
- [14] Peng Gao, Shijie Geng, Renrui Zhang, Teli Ma, Rongyao Fang, Yongfeng Zhang, Hongsheng Li, and Yu Qiao. Clip-adapter: Better vision-language models with feature adapters. International Journal of Computer Vision, pages 1–15, 2023.
- [15] Ziteng Gao, Limin Wang, Bing Han, and Sheng Guo. Adamixer: A fast-converging query-based object detector. In CVPR, pages 5364–5373, 2022.
- [16] Rohit Girdhar, Joao Carreira, Carl Doersch, and Andrew Zisserman. Video action transformer network. In CVPR, June 2019.
- [17] Chunhui Gu, Chen Sun, David A Ross, Carl Vondrick, Caroline Pantofaru, Yeqing Li, Sudheendra Vijayanarasimhan, George Toderici, Susanna Ricco, Rahul Sukthankar, et al. Ava: A video dataset of spatio-temporally localized atomic visual actions. In CVPR, 2018.
- [18] Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask r-cnn. In ICCV, pages 2961–2969, 2017.
- [19] Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask r-cnn. In ICCV, pages 2961–2969, 2017.
- [20] Wei-Jhe Huang, Jheng-Hsien Yeh, Min-Hung Chen, Gueter Josmy Faure, and Shang-Hong Lai. Interaction-aware prompting for zero-shot spatio-temporal action detection. In ICCV Workshop, pages 284–293, 2023.
- [21] Hueihan Jhuang, Juergen Gall, Silvia Zuffi, Cordelia Schmid, and Michael J Black. Towards understanding action recognition. In ICCV, pages 3192–3199, 2013.
- [22] Chen Ju, Tengda Han, Kunhao Zheng, Ya Zhang, and Weidi Xie. Prompting visual-language models for efficient video understanding. In ECCV, pages 105–124, 2022.
- [23] Chen Ju, Tengda Han, Kunhao Zheng, Ya Zhang, and Weidi Xie. Prompting visual-language models for efficient video understanding. In ECCV, pages 105–124, 2022.
- [24] Vicky Kalogeiton, Philippe Weinzaepfel, Vittorio Ferrari, and Cordelia Schmid. Action tubelet detector for spatio-temporal action localization. In ICCV, 2017.
- [25] Dahun Kim, Anelia Angelova, and Weicheng Kuo. Region-aware pretraining for open-vocabulary object detection with vision transformers. In CVPR, pages 11144–11154, 2023.
- [26] Okan Köpüklü, Xiangyu Wei, and Gerhard Rigoll. You only watch once: A unified cnn architecture for real-time spatiotemporal action localization. arXiv preprint arXiv:1911.06644, 2019.
- [27] Weicheng Kuo, Yin Cui, Xiuye Gu, AJ Piergiovanni, and Anelia Angelova. F-vlm: Open-vocabulary object detection upon frozen vision and language models. In ICLR, 2022.
- [28] Yixuan Li, Lei Chen, Runyu He, Zhenzhi Wang, Gangshan Wu, and Limin Wang. Multisports: A multi-person video dataset of spatio-temporally localized sports actions. In ICCV, pages 13536–13545, 2021.
- [29] Yanghao Li, Hanzi Mao, Ross Girshick, and Kaiming He. Exploring plain vision transformer backbones for object detection. In ECCV, pages 280–296, 2022.
- [30] Yi Li, Hualiang Wang, Yiqun Duan, and Xiaomeng Li. Clip surgery for better explainability with enhancement in open-vocabulary tasks. arXiv preprint arXiv:2304.05653, 2023.
- [31] Yi Li, Hualiang Wang, Yiqun Duan, and Xiaomeng Li. Clip surgery for better explainability with enhancement in open-vocabulary tasks. arXiv preprint arXiv:2304.05653, 2023.
- [32] Yi Li, Hualiang Wang, Yiqun Duan, Hang Xu, and Xiaomeng Li. Exploring visual interpretability for contrastive language-image pre-training. arXiv preprint arXiv:2209.07046, 2022.
- [33] Yi Li, Hualiang Wang, Yiqun Duan, Hang Xu, and Xiaomeng Li. Exploring visual interpretability for contrastive language-image pre-training. arXiv preprint arXiv:2209.07046, 2022.
- [34] Feng Liang, Bichen Wu, Xiaoliang Dai, Kunpeng Li, Yinan Zhao, Hang Zhang, Peizhao Zhang, Peter Vajda, and Diana Marculescu. Open-vocabulary semantic segmentation with mask-adapted clip. In CVPR, pages 7061–7070, 2023.
- [35] Chuang Lin, Peize Sun, Yi Jiang, Ping Luo, Lizhen Qu, Gholamreza Haffari, Zehuan Yuan, and Jianfei Cai. Learning object-language alignments for open-vocabulary object detection. In ICLR, 2022.
- [36] Ziyi Lin, Shijie Geng, Renrui Zhang, Peng Gao, Gerard de Melo, Xiaogang Wang, Jifeng Dai, Yu Qiao, and Hongsheng Li. Frozen clip models are efficient video learners. In ECCV, pages 388–404, 2022.
- [37] Ruyang Liu, Jingjia Huang, Ge Li, Jiashi Feng, Xinglong Wu, and Thomas H Li. Revisiting temporal modeling for clip-based image-to-video knowledge transferring. In CVPR, pages 6555–6564, 2023.
- [38] Ruyang Liu, Jingjia Huang, Ge Li, Jiashi Feng, Xinglong Wu, and Thomas H Li. Revisiting temporal modeling for clip-based image-to-video knowledge transferring. In CVPR, pages 6555–6564, 2023.
- [39] Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv preprint arXiv:2303.05499, 2023.
- [40] Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv preprint arXiv:2303.05499, 2023.
- [41] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In ICLR, 2018.
- [42] Liliane Momeni, Mathilde Caron, Arsha Nagrani, Andrew Zisserman, and Cordelia Schmid. Verbs in action: Improving verb understanding in video-language models. In ICCV, pages 15579–15591, 2023.
- [43] Sauradip Nag, Xiatian Zhu, Yi-Zhe Song, and Tao Xiang. Zero-shot temporal action detection via vision-language prompting. In ECCV, pages 681–697, 2022.
- [44] Sauradip Nag, Xiatian Zhu, Yi-Zhe Song, and Tao Xiang. Zero-shot temporal action detection via vision-language prompting. In ECCV, pages 681–697, 2022.
- [45] Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, and Haibin Ling. Expanding language-image pretrained models for general video recognition. In ECCV, pages 1–18, 2022.
- [46] Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, and Haibin Ling. Expanding language-image pretrained models for general video recognition. In ECCV, pages 1–18, 2022.
- [47] OpenAI. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- [48] OpenAI. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- [49] Junting Pan, Siyu Chen, Mike Zheng Shou, Yu Liu, Jing Shao, and Hongsheng Li. Actor-context-actor relation network for spatio-temporal action localization. In CVPR, pages 464–474, 2021.
- [50] Junting Pan, Ziyi Lin, Xiatian Zhu, Jing Shao, and Hongsheng Li. St-adapter: Parameter-efficient image-to-video transfer learning. In NeurIPS, pages 26462–26477, 2022.
- [51] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In ICML, pages 8748–8763, 2021.
- [52] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In ICML, pages 8748–8763, 2021.
- [53] Hanoona Rasheed, Muhammad Uzair Khattak, Muhammad Maaz, Salman Khan, and Fahad Shahbaz Khan. Fine-tuned clip models are efficient video learners. In CVPR, pages 6545–6554, 2023.
- [54] Vivek Rathod, Bryan Seybold, Sudheendra Vijayanarasimhan, Austin Myers, Xiuye Gu, Vighnesh Birodkar, and David A Ross. Open-vocabulary temporal action detection with off-the-shelf image-text features. In BMVC, 2022.
- [55] Vivek Rathod, Bryan Seybold, Sudheendra Vijayanarasimhan, Austin Myers, Xiuye Gu, Vighnesh Birodkar, and David A Ross. Open-vocabulary temporal action detection with off-the-shelf image-text features. In BMVC, 2022.
- [56] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In NeurIPS, 2015.
- [57] Hamid Rezatofighi, Nathan Tsoi, JunYoung Gwak, Amir Sadeghian, Ian Reid, and Silvio Savarese. Generalized intersection over union: A metric and a loss for bounding box regression. In CVPR, pages 658–666, 2019.
- [58] Byungseok Roh, JaeWoong Shin, Wuhyun Shin, and Saehoon Kim. Sparse DETR: Efficient end-to-end object detection with learnable sparsity. In ICLR, 2022.
- [59] Chaitanya Ryali, Yuan-Ting Hu, Daniel Bolya, Chen Wei, Haoqi Fan, Po-Yao Huang, Vaibhav Aggarwal, Arkabandhu Chowdhury, Omid Poursaeed, Judy Hoffman, et al. Hiera: A hierarchical vision transformer without the bells-and-whistles. In ICML, 2023.
- [60] Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. In ICCV, pages 618–626, 2017.
- [61] Gurkirt Singh, Stephen Akrigg, Manuele Di Maio, Valentina Fontana, Reza Javanmard Alitappeh, Salman Khan, Suman Saha, Kossar Jeddisaravi, Farzad Yousefi, Jacob Culley, Tom Nicholson, Jordan Omokeowa, Stanislao Grazioso, Andrew Bradley, Giuseppe Di Gironimo, and Fabio Cuzzolin. Road: The road event awareness dataset for autonomous driving. IEEE TPAMI, 45(1):1036–1054, 2023.
- [62] Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild. In CRCV-TR-12-01, 2012.
- [63] Chen Sun, Abhinav Shrivastava, Carl Vondrick, Kevin Murphy, Rahul Sukthankar, and Cordelia Schmid. Actor-centric relation network. In ECCV, pages 318–334, 2018.
- [64] Chen Sun, Abhinav Shrivastava, Carl Vondrick, Rahul Sukthankar, Kevin Murphy, and Cordelia Schmid. Relational action forecasting. In CVPR, 2019.
- [65] Peize Sun, Rufeng Zhang, Yi Jiang, Tao Kong, Chenfeng Xu, Wei Zhan, Masayoshi Tomizuka, Lei Li, Zehuan Yuan, Changhu Wang, et al. Sparse r-cnn: End-to-end object detection with learnable proposals. In CVPR, pages 14454–14463, 2021.
- [66] Jiajun Tang, Jin Xia, Xinzhi Mu, Bo Pang, and Cewu Lu. Asynchronous interaction aggregation for action detection. In ECCV, pages 71–87, 2020.
- [67] Ilya O Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, et al. Mlp-mixer: An all-mlp architecture for vision. In NeurIPS, pages 24261–24272, 2021.
- [68] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NeurIPS, 2017.
- [69] Mengmeng Wang, Jiazheng Xing, and Yong Liu. Actionclip: A new paradigm for video action recognition. arXiv preprint arXiv:2109.08472, 2021.
- [70] Mengmeng Wang, Jiazheng Xing, and Yong Liu. Actionclip: A new paradigm for video action recognition. arXiv preprint arXiv:2109.08472, 2021.
- [71] Syed Talal Wasim, Muzammal Naseer, Salman Khan, Fahad Shahbaz Khan, and Mubarak Shah. Vita-clip: Video and text adaptive clip via multimodal prompting. In CVPR, pages 23034–23044, 2023.
- [72] Zejia Weng, Xitong Yang, Ang Li, Zuxuan Wu, and Yu-Gang Jiang. Open-vclip: Transforming clip to an open-vocabulary video model via interpolated weight optimization. In ICML, 2023.
- [73] Chao-Yuan Wu, Christoph Feichtenhofer, Haoqi Fan, Kaiming He, Philipp Krahenbuhl, and Ross Girshick. Long-term feature banks for detailed video understanding. In CVPR, 2019.
- [74] Jianchao Wu, Zhanghui Kuang, Limin Wang, Wayne Zhang, and Gangshan Wu. Context-aware rcnn: A baseline for action detection in videos. In ECCV, pages 440–456, 2020.
- [75] Jianzong Wu, Xiangtai Li, Shilin Xu Haobo Yuan, Henghui Ding, Yibo Yang, Xia Li, Jiangning Zhang, Yunhai Tong, Xudong Jiang, Bernard Ghanem, et al. Towards open vocabulary learning: A survey. arXiv preprint arXiv:2306.15880, 2023.
- [76] Tao Wu, Mengqi Cao, Ziteng Gao, Gangshan Wu, and Limin Wang. Stmixer: A one-stage sparse action detector. In CVPR, pages 14720–14729, 2023.
- [77] Tao Wu, Mengqi Cao, Ziteng Gao, Gangshan Wu, and Limin Wang. Stmixer: A one-stage sparse action detector. In CVPR, pages 14720–14729, 2023.
- [78] Tao Wu, Shuqiu Ge, Jie Qin, Gangshan Wu, and Limin Wang. Open-vocabulary spatio-temporal action detection. arXiv preprint arXiv:2405.10832, 2024.
- [79] Xiaoshi Wu, Feng Zhu, Rui Zhao, and Hongsheng Li. Cora: Adapting clip for open-vocabulary detection with region prompting and anchor pre-matching. In CVPR, pages 7031–7040, 2023.
- [80] Hongwei Xue, Yuchong Sun, Bei Liu, Jianlong Fu, Ruihua Song, Houqiang Li, and Jiebo Luo. Clip-vip: Adapting pre-trained image-text model to video-language representation alignment. In ICLR, 2022.
- [81] Hongwei Xue, Yuchong Sun, Bei Liu, Jianlong Fu, Ruihua Song, Houqiang Li, and Jiebo Luo. Clip-vip: Adapting pre-trained image-text model to video-language representation alignment. In ICLR, 2022.
- [82] Shen Yan, Xuehan Xiong, Arsha Nagrani, Anurag Arnab, Zhonghao Wang, Weina Ge, David Ross, and Cordelia Schmid. Unloc: A unified framework for video localization tasks. In ICCV, pages 13623–13633, 2023.
- [83] Ming Yang, Shuiwang Ji, Wei Xu, Jinjun Wang, Fengjun Lv, Kai Yu, Yihong Gong, Mert Dikmen, Dennis J Lin, and Thomas S Huang. Detecting human actions in surveillance videos. In TRECVID, 2009.
- [84] Liangzhe Yuan, Rui Qian, Yin Cui, Boqing Gong, Florian Schroff, Ming-Hsuan Yang, Hartwig Adam, and Ting Liu. Contextualized spatio-temporal contrastive learning with self-supervision. In CVPR, pages 13977–13986, 2022.
- [85] Kimin Yun, Yongjin Kwon, Sungchan Oh, Jinyoung Moon, and Jongyoul Park. Vision-based garbage dumping action detection for real-world surveillance platform. ETRI Journal, 41(4):494–505, 2019.
- [86] Yuhang Zang, Wei Li, Kaiyang Zhou, Chen Huang, and Chen Change Loy. Open-vocabulary detr with conditional matching. In ECCV, pages 106–122, 2022.
- [87] Alireza Zareian, Kevin Dela Rosa, Derek Hao Hu, and Shih-Fu Chang. Open-vocabulary object detection using captions. In CVPR, pages 14393–14402, 2021.
- [88] Alireza Zareian, Kevin Dela Rosa, Derek Hao Hu, and Shih-Fu Chang. Open-vocabulary object detection using captions. In CVPR, pages 14393–14402, 2021.
- [89] Rowan Zellers, Yonatan Bisk, Ali Farhadi, and Yejin Choi. From recognition to cognition: Visual commonsense reasoning. In CVPR, 2019.
- [90] Pengchuan Zhang, Xiujun Li, Xiaowei Hu, Jianwei Yang, Lei Zhang, Lijuan Wang, Yejin Choi, and Jianfeng Gao. Vinvl: Revisiting visual representations in vision-language models. In CVPR, pages 5579–5588, 2021.
- [91] Jiaojiao Zhao, Yanyi Zhang, Xinyu Li, Hao Chen, Bing Shuai, Mingze Xu, Chunhui Liu, Kaustav Kundu, Yuanjun Xiong, Davide Modolo, et al. Tuber: Tubelet transformer for video action detection. In CVPR, pages 13598–13607, 2022.
- [92] Yin-Dong Zheng, Guo Chen, Minglei Yuan, and Tong Lu. Mrsn: Multi-relation support network for video action detection. arXiv preprint arXiv:2304.11975, 2023.
- [93] Yiwu Zhong, Jianwei Yang, Pengchuan Zhang, Chunyuan Li, Noel Codella, Liunian Harold Li, Luowei Zhou, Xiyang Dai, Lu Yuan, Yin Li, et al. Regionclip: Region-based language-image pretraining. In CVPR, pages 16793–16803, 2022.
- [94] Yiwu Zhong, Jianwei Yang, Pengchuan Zhang, Chunyuan Li, Noel Codella, Liunian Harold Li, Luowei Zhou, Xiyang Dai, Lu Yuan, Yin Li, et al. Regionclip: Region-based language-image pretraining. In CVPR, pages 16793–16803, 2022.
- [95] Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. Learning deep features for discriminative localization. In CVPR, pages 2921–2929, 2016.
- [96] Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models. International Journal of Computer Vision, 130(9):2337–2348, 2022.
- [97] Ziqin Zhou, Yinjie Lei, Bowen Zhang, Lingqiao Liu, and Yifan Liu. Zegclip: Towards adapting clip for zero-shot semantic segmentation. In CVPR, pages 11175–11185, 2023.
- [98] Beier Zhu, Yulei Niu, Yucheng Han, Yue Wu, and Hanwang Zhang. Prompt-aligned gradient for prompt tuning. In ICCV, pages 15659–15669, 2023.
Appendix
Appendix A Prompts for Query-Text Alignment
To generate text prompts for each action category, we send a request to GPT [48] by using the template: “For the action type {CLS}, what are the visual descriptions? Please respond with a list of 16 short sentences.” where the placeholder “{CLS}” is replaced by the action class name from the vocabulary. Thus, we obtained multiple caption-like sentence descriptions of the action. Eventually, the text feature for each class is computed by mean pooling of features from the VLM text encoder given the text prompts. In Fig. 5 and Fig. 6, we show a few pieces of the prompt examples on the J-HMDB and UCF101-24 datasets, respectively. We will release all the prompts we used in this work.
Appendix B Explanation of the Reversed Attention
As discussed in the main paper, the seemly counterintuitive phenomenon of the reversed visual-text attention has been studied in [33, 31] and we also observed this in our video-based experiments. For CLIP-based models, [CLS] token in ViT is aligned to the text semantics so that its attention weight corresponds to the foreground, while the rest visual token weights are complementary after softmax over tokens before attention pooling. Therefore, due to the attention pooling, high similarity between text feature (or visual [CLS] token feature) and visual tokens could indicate the background.
Appendix C Implementation Details
Positional Embedding Interpolation. When using the pre-trained VLM without fine-tuning, an immediate challenge is that the input videos have different spatiotemporal resolutions from the data in VLM pre-training. For example, the CLIP-ViP is pre-trained on input videos with size while videos from J-HMDB can be in any resolution after random augmentations in training. A simple solution is to resize the input video size to match with the pre-trained ones. But for the action detection subtask, person localization is sensitive to the input resolution. To handle this challenge, we instead keep the raw resolution as input, but interpolate the pre-trained spatial and temporal positional embeddings. For example, given the CLIP-ViP B16 VLM and an input video with size , we interpolate the temporal positional embeddings to , and interpolate the spatial positional embeddings to where . This technique is found useful for the action detection problem.
4D Feature Pyramid. Following the line of detection literature [29, 77], the pre-trained patch token features are transformed into a 4D feature pyramid before the detection head. Let the be the pre-trained patch token features from the VLM video encoder, where is the number of patches for each frame, is the number of video frames, and is the Transformer dimension. We use deconvolution or convolution to produce hierarchical feature maps by spatial strides where the fractional strides are deconvolutional stides and indexes the pyramid level. Different from [29, 77] that fully fine-tunes the visual encoder, our VLM visual encoder has to be frozen. Therefore, to allow pre-trained features better utilized by OpenMixer head, we propose to add residual connection at each level of the 4D feature pyramid by spatial interpolation: . The function is to spatially interpolate the feature map from the size to the same resolution of .
Appendix D Additional Results
| VLMs | Modality | Mean | Base | Novel |
|---|---|---|---|---|
| CLIP [52] | image | 71.60 | 79.46 | 64.44 |
| CLIP-ViP [81] | video | 86.34 | 90.75 | 82.33 |
| Mean(t) | Base(t) | Novel(t) | |
|---|---|---|---|
| w/o. GPT | 83.57 | 90.74 | 77.06 |
| w. GPT | 91.62 | 93.63 | 89.79 |
| models | person boxes | J-HMDB | UCF101-24 | ||||
|---|---|---|---|---|---|---|---|
| Mean | Base | Novel | Mean | Base | Novel | ||
| ZSR+ZSL | MaskRCNN [19] | 66.73 | 64.61 | 68.66 | 35.01 | 34.59 | 35.43 |
| G-DINO [40] | 69.72 | 67.09 | 72.12 | 45.43 | 44.82 | 46.04 | |
| E2E | Mask RCNN [19] | 83.51 | 87.45 | 79.92 | 42.31 | 48.48 | 36.13 |
| G-DINO [40] | 85.06 | 87.76 | 82.60 | 46.56 | 47.00 | 46.11 | |
Impact of VLMs. We note there is a line of literature [70, 55, 23, 44, 38] built on image CLIP for open-vocabulary video understanding. Therefore, it is interesting to see whether image CLIP also works for the OVAD task. In Tab. 6, we compare OpenMixer with its variants using video-based CLIP-ViP [81] and image-based CLIP [52] under the same ViT-B/16 architecture. The results show that the OpenMixer with CLIP performs way worse than the model with CLIP-ViP, because of the limited capacity of image CLIP in capturing video actions.
Can GPT help temporal action localization? This question is interesting as how textual prompts from language models like GPT could help temporal localization has not been explored in literature. In Tab. 7, we show that by evaluating the temporal action localization performance, GPT prompts could significantly help.
Impact of person detectors. In Tab. 8, we compare the impact of using external person boxes from off-the-shelf person detectors, i.e., G-DINO [40] and Mask RCNN [19], in test time on the two best-performed models under the ZSR+ZSL and E2E settings, respectively. It shows that the high-quality boxes from G-DINO could consistently outperform those from Mask RCNN. With the same external test-time boxes, the results of OpenMixer model are consistently better than those of the strongest ZSR+ZSL baseline (Video+GPT). The relatively smaller gains on UCF101-24 than the gains on J-HMDB can be explained by the background bias in UCF videos that restricts VLMs in action recognition.
| priors from | noise level | Mean | Base | Novel | |
|---|---|---|---|---|---|
| (a) | G.T. (UB) | clean | 91.19 | 93.23 | 89.34 |
| (b) | detection | moderate | 83.92 | 88.19 | 80.03 |
| (c) | random (LB) | serious | 54.15 | 56.50 | 52.02 |
| ours | attention map | slight | 86.34 | 90.75 | 82.33 |
| Models | J-HMDB | UCF101-24 | ||||
|---|---|---|---|---|---|---|
| Mean | Base | Novel | Mean | Base | Novel | |
| STMixer [77] | 36.26 | 55.71 | 18.57 | 28.72 | 53.42 | 4.02 |
| OpenMixer | 74.28 | 77.72 | 71.16 | 40.07 | 54.00 | 26.14 |
Impact of location prior noise. In Table 9, we compare ours with 3 variants that use location priors from (a) ground truth (G.T.) boxes which can be regarded as clean without noise and upper-bound (UB) the performance, (b) detected person boxes that may be moderately noisy, and (c) uniform random boxes that are completely noisy and lower-bounds (LB) the performance. The results show our location priors, which are sampled from the text-patch attention map, perform much better than the baselines (b)(c), and are close to the upper-bound performance in (a).
Generalized zero shot testing. In our main paper, the base and novel categories are individually given in testing. Thus, in Table 10, we additionally present the results of the generalized zero-shot testing, in which a complete vocabulary of base and novel categories is given for each testing video. This is more challenging but our OpenMixer still keeps outperformance than the STMixer baseline [77]. Moreover, according to [88, 94], the rankings of models are stable by the two testing protocols, and only the scales of numbers are different. Therefore, the efficacy of models can still be validated by individual testing in our main paper.
Results on Different Splits. We experiment with five random 50%-50% seen-unseen class splits on both the J-HMDB and UCF101-24 datasets. Full results of video mAP are summarized in Tab. 11 and 12. The split (0) is used in all experiments of the main paper. We also experiment with five random 75%-25% seen-unseen class splits on the two datasets, and report results in Tab. 13 and 14. As some of human actions are much harder to detect than others and they could be included into either base or novel categories, it is normal that the overall performances on different splits vary significantly. Following the existing literature, we will release all splits.
| Metrics | (0) | (1) | (2) | (3) | (4) | avg |
|---|---|---|---|---|---|---|
| Mean | 86.34 | 86.29 | 85.50 | 86.73 | 83.40 | 85.65 |
| Base | 90.75 | 89.89 | 89.20 | 87.70 | 85.36 | 88.58 |
| Novel | 82.33 | 83.02 | 82.13 | 85.85 | 81.61 | 82.99 |
| Metrics | (0) | (1) | (2) | (3) | (4) | avg |
|---|---|---|---|---|---|---|
| Mean | 46.42 | 46.28 | 45.45 | 47.32 | 48.30 | 46.75 |
| Base | 59.10 | 61.11 | 55.85 | 62.33 | 61.25 | 59.93 |
| Novel | 33.73 | 31.45 | 35.05 | 32.31 | 35.34 | 33.58 |
| Metrics | (0) | (1) | (2) | (3) | (4) | avg |
|---|---|---|---|---|---|---|
| Mean | 75.96 | 79.43 | 79.77 | 81.88 | 86.56 | 80.72 |
| Base | 74.73 | 75.21 | 78.34 | 82.14 | 85.46 | 79.17 |
| Novel | 79.03 | 89.98 | 83.34 | 81.23 | 89.30 | 84.57 |
| Metrics | (0) | (1) | (2) | (3) | (4) | avg |
|---|---|---|---|---|---|---|
| Mean | 55.78 | 55.83 | 57.04 | 57.19 | 61.85 | 57.54 |
| Base | 64.85 | 61.83 | 60.16 | 58.74 | 61.82 | 61.48 |
| Novel | 28.55 | 37.80 | 47.69 | 52.55 | 61.96 | 45.71 |
Appendix E Visualizations
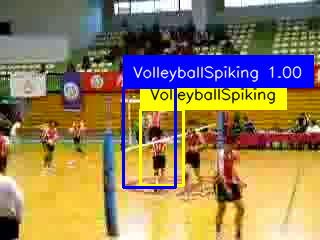
We present more visualizations on the J-HMDB dataset and UCF101-24 in Fig. 7 and 8, respectively. They show that our method could detect human actions with precise bounding boxes for both seen and unseen actions. Specifically, in scenarios where multiple persons exist, for the examples of the seen action Volleyball Spiking and the unseen action Ice Dancing on the UCF101-24 dataset, our method could still localize the action-relevant persons on most frames. Referring to single-person action detection, there is still room to improve the performance of multi-person action detection in the future.
Appendix F Comparison with Concurrent Work [78]
The prior work [78] defines the same task setting and identifies similar challenges as ours. However, there are several important differences in terms of technical motivations and design. First, for the roadmap, [78] focuses on large-scale video region-text pre-training followed by downstream fine-tuning, while we emphasize the model adaptation to small downstream datasets in one-time training. Second, for model design, [78] is a two-stage method with region proposal generation and action detection refinement, while we adopt DETR-like end-to-end design. As for empirical comparison, currently, this is not feasible because (1) the [78] is a concurrent work as ours without releasing any code, data, and models (during the submission period), and (2) it is not an apple-to-apple comparison since the data splits and evaluation metrics of the benchmarks in [78] are different from ours as indicated in the paper [78].
| brush hair | |
|
|
|
|
|
|---|---|---|---|---|---|---|
| catch | |
 |
 |
 |
 |
 |
| pick | |
|
|
|
|
|
| pour | |
 |
|
 |
 |
 |
| push | |
|
|
|
|
|
| golf | |
|
|
|
|
|
| shoot bow | |
|
|
|
|
|
| shoot gun | |
|
|
|
|
|
| sit | |
|
|
|
|
|
| baseball | |
|
|
|
|
|
| Biking | |
 |
 |
 |
 |
 |
|---|---|---|---|---|---|---|
| Floor Gym. | |
|
 |
 |
 |
 |
| Horse Riding | |
 |
 |
|
 |
 |
| Surfing | |
|
|
|
|
|
| Volleyball |  |
 |
 |
 |
 |
|
| Basketball |  |
|
 |
 |
 |
 |
| Ice Dance | |
|
|
|
|
|
| Long Jump | |
|
|
|
|
 |
| Skijet | |
|
|
|
 |
 |
| Walking Dog | |
|
|
|
|
 |