Explicit-Implicit Subgoal Planning for Long-Horizon Tasks with Sparse Reward
Abstract
The challenges inherent in long-horizon tasks in robotics persist due to the typical inefficient exploration and sparse rewards in traditional reinforcement learning approaches. To address these challenges, we have developed a novel algorithm, termed Explicit-Implicit Subgoal Planning (EISP), designed to tackle long-horizon tasks through a divide-and-conquer approach. We utilize two primary criteria, feasibility and optimality, to ensure the quality of the generated subgoals. EISP consists of three components: a hybrid subgoal generator, a hindsight sampler, and a value selector. The hybrid subgoal generator uses an explicit model to infer subgoals and an implicit model to predict the final goal, inspired by way of human thinking that infers subgoals by using the current state and final goal as well as reason about the final goal conditioned on the current state and given subgoals. Additionally, the hindsight sampler selects valid subgoals from an offline dataset to enhance the feasibility of the generated subgoals. While the value selector utilizes the value function in reinforcement learning to filter the optimal subgoals from subgoal candidates. To validate our method, we conduct four long-horizon tasks in both simulation and the real world. The obtained quantitative and qualitative data indicate that our approach achieves promising performance compared to other baseline methods. These experimental results can be seen on the website https://sites.google.com/view/vaesi.
Note to Practitioners
This paper addresses the persistent challenges in executing long-horizon tasks in robotics, which are hindered by inefficient exploration and sparse rewards in traditional reinforcement learning methods. Existing methods typically struggle with the complexity of long-horizon tasks due to their inability to effectively break down these tasks into manageable subgoals. EISP overcomes this limitation by employing a hybrid subgoal generator, a hindsight sampler, and a value selector. The hybrid subgoal generator utilizes an explicit model to infer subgoals and an implicit model to approximate the subgoals by maximizing the similarity between the final goal and the reconstructed goal. EISP has been validated through rigorous testing on four long-horizon tasks in both simulation and real-world environments. The results demonstrate that EISP offers superior performance compared to existing baseline methods. While preliminary results are promising, future research will delve into integrating with advanced exploration methods and explore its application across a broder range of tasks.
Index Terms:
Motion control; Learning control systems; Manipulator motion-planning; Motion-planning.I Introduction
Human daily activities often involve performing long-horizon tasks, which are characterized by hierarchical structures and multiple distinct types of actions [1, 2]. These tasks typically comprise numerous simpler yet sequential subtasks, the successful execution of which necessitates long-horizon planning and reasoning capabilities [3, 4]. Humans generally excel at performing long-horizon tasks, largely due to our understanding of the subgoal dependency structure inherent to the task of interest. Although recent advances in the field of intelligent control have demonstrated the effectiveness of robots in performing complex tasks through imitation and reinforcement learning [5, 4, 6], state-of-the-art methods are typically limited to completing either short-term tasks with intensive rewards or long-horizon tasks guided by a series of instructions provided by humans [7]. Empowering robots with the ability to reason and plan long-horizon tasks could increase the areas in which robots can assist or even replace humans, further expanding the frontiers of robotic automation.
Current efforts in robotics to tackle long-horizon tasks involve, e.g., imitation of expert trajectories [8, 9, 5], enhancement of goal-oriented exploration [10, 11, 12, 13, 14] and divide-and-conquer tactics [15, 2, 16]. For instance, imitation learning learns effective strategies to generate subgoals by extracting key points from expert demonstrations. Yet, it usually suffers from time-consuming demonstration collection and sub-optimal expert strategies. While enhancing the exploration efficiency of robots is essential for the discovery of effective and feasible subgoals, the exploration of goals remains limited to neighboring states of the explored region. Given the conspicuous lack of experience with rarely explored state spaces, a significant gap remains in the efficiency requisite for more generalized reinforcement learning applications [17]. Recently, some research has focused on decomposing complex tasks into simpler ones for solving long-horizon problems. However, most existing methods [15, 2, 16] cannot simultaneously guarantee the feasibility and optimality of the generated subgoal sequence and often operate under the strong assumption that the state space and the goal space are the same. Thus, developing a robot capable of solving an extensive range of combinatorial decision problems continues to pose a long-standing challenge.
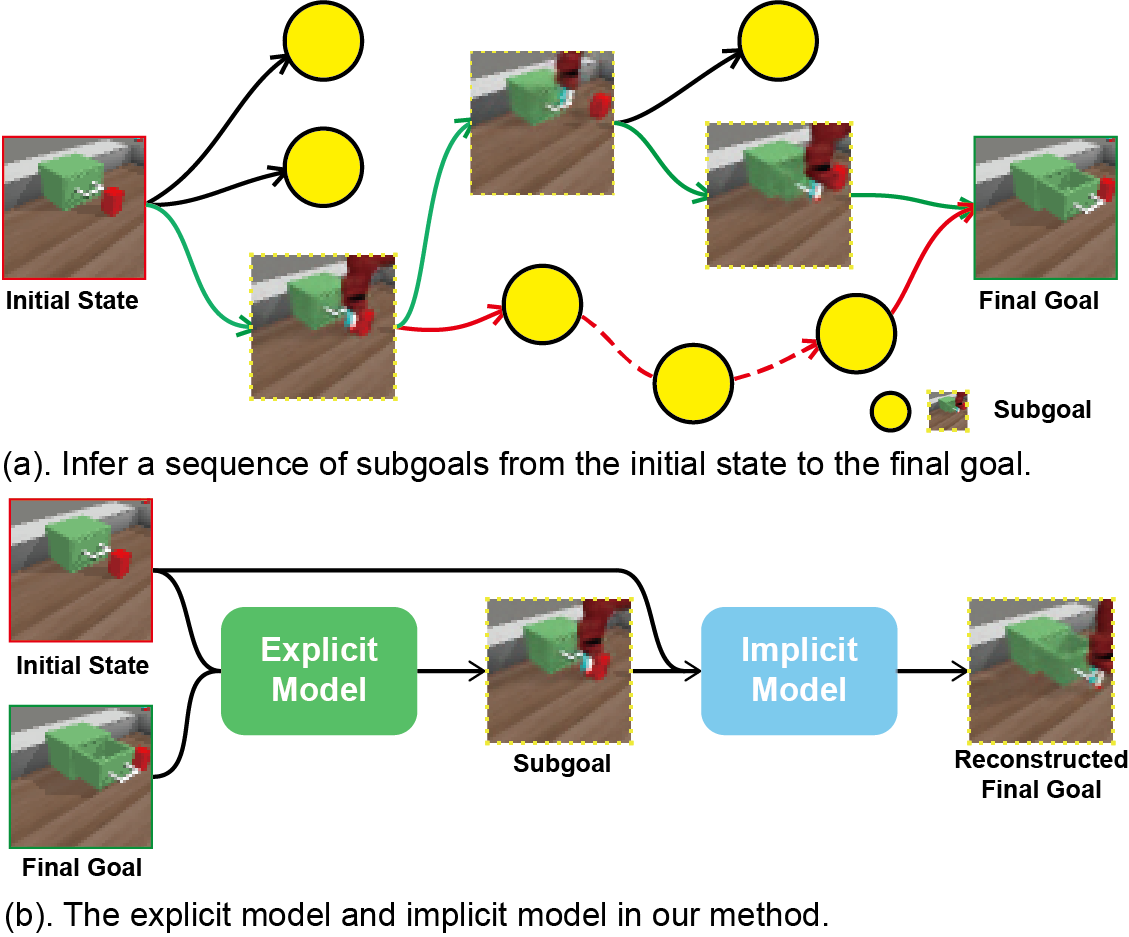
To alleviate these challenges, we propose Explicit-Implicit Subgoal Planning (EISP) that solves the long horizon problem by inferring easy-to-achieve subgoals and then accomplishing each subgoal sequentially. Fig.1 (a) illustrates the potential subgoals that can be generated at different stages from the initial state to the final goal. The subgoal sequences connected by the green line and the red line represent possible approaches to accomplishing the long-horizon task. Because the subgoal sequence linked by the red line may require more time to complete the task, we consider the subgoal sequence connected by the green line is more optimal. Our study mainly focuses on the subgoal generation process (without delving into the underlying subgoal approach process). Inspired by the human approach to solving long-horizon tasks by breaking them down into smaller and manageable components, it is intuitive to employ an explicit model that takes as input the current state and final goal and outputs the subgoals, as demonstrated in previous studies [2, 15]. However, a critical aspect often overlooked is humans’ ability to predict long-term outcomes by identifying short-term subgoals based on the current state. As depicted in Fig.1 (b), we formulate two models: one for inferring subgoals based on the current state and the final goal, and the other for reconstructing the final goal using the current state and the given subgoals. The former model explicitly generates the subgoal, whereas the latter provides a guarantee on the worst-case for the log-likelihood of the subgoal distribution. As suggested in [18], we anticipate that adding the implicit model may outperform using only an explicit model when accomplishing subgoal generation for long-horizon tasks.
The contributions of this study are outlined as follows:
-
1.
We introduce a Hybrid Subgoal Generator, which employs both explicit and implicit models to generate accurate subgoals by maximizing the evidence lower bound of the final goal.
-
2.
We quantify the quality of inferred subgoals by establishing two criteria: feasibility and optimality. We employ a Hindsight Sampler to facilitate the feasibility of the generated subgoals and a Value Selector to facilitate the selection of optimal subgoals.
-
3.
We conduct a series of simulations and real-world experiments to evaluate the performance of our algorithm. The results demonstrate that our method outperforms other approaches under comparable environmental conditions.
II Related Work
Deep reinforcement learning (DRL) can seek an optimal solution for a given task through well-designed reward functions. Researchers have built on the recent success of DRL by extending this technique to long-horizon tasks with varying goals, known as goal-conditioned reinforcement learning (GCRL). Current approaches to solving the long-horizon GCRL problem are mainly imitating expert trajectories, increasing the goal-orientated exploration space, and decomposing complex tasks into small ones.
II-A Imitation Learning
Recent advancements [9, 5] in imitation learning reveal the capacity of humans to identify and learn critical points from expert demonstrations or trajectories to accomplish the final goal. For instance, Paul et al. [8] derive a mapping from current states to subgoals using labels directly acquired from expert trajectories. Jin et al. [19] propose a method enabling the robot to learn an objective function from a few sparsely demonstrated keyframes to solve long-horizon tasks. [20] learns dual-arm manipulation tasks from demonstrations generated by a teleoperation system. Joey et al. [21] first utilize representation learning with an instruction prediction loss that operates at a high level of abstraction to accelerate imitation learning results. However, since the trajectories generated by human experts cannot cover the entire region of the state space, the trained policies generalize poorly to unseen tasks. In addition, the strategies trained through imitation learning may not be optimal since the demonstration data probably is not optimal and the trained strategies are unlikely to surpass the demonstration policy. Our approach does not require expert demonstrations and instead employs Reinforcement Learning (RL) to explore the optimal policy through trial and error.
II-B Exploration efficiency
Increasing the exploration efficiency of robots is crucial for solving long-horizon tasks. Numerous studies have endeavored to enhance exploration efficiency by enriching the experience replay buffer to incorporate more unknown states. Works such as Skew-Fit [10], RIG [11], and MEGA [12] prioritize exploring low-density or sparse regions, with the intent of maximizing the likelihood of visiting fewer states, which is equivalent to maximizing the entropy of the desired goal distribution. Warde-Farly et al. [22], on the other hand, aim to learn goal-conditional policies and reward functions by maximizing the mutual information between the achieved and final goals. Conversely, Hartikainen et al. [23] chose subgoals that maximize the distance from the initial state, thereby maximizing the entropy of the desired goal distribution. In general, these methods expand the exploration space but continue to depend on uniformly distributed actions and random action noise. Thus, goal exploration remains limited to neighboring states near the explored region. Our work tackles the exploration challenge by automatically generating subgoals that can be predicted on the way to the long-horizon final goal.
II-C Subgoal orientated goal-conditioned RL
Drawing inspiration from the human tendency to decompose long-horizon tasks into smaller ones, some researchers are exploring the generation of subgoals by selecting them from historical experiences [24, 15, 25] or by training subgoal models [2, 16]. The experience replay buffer, rich in valuable historical data, facilitates the extraction of valid states as subgoals in a simple and efficient manner, while also ensuring their reachability. However, some methods necessitate the explicit specification of the number of subgoals or decision layers and rely solely on the initial state to predict future subgoals [2]. And distance-based methods, like [2, 16] strive to maximize the distance between the subgoals and the initial state to obtain better subgoals. They typically assume the co-existence of states and goals within the same space. This assumption does not hold true in numerous environments. For example, in the Stack environment, the state comprises the information of blocks and gripper, whereas the goal pertains solely to the goal position of blocks.
Recently, new image editing diffusion models like SuSIE [26] and SkillDiffuser [27] have been introduced for subgoal generation. Despite their powerful capabilities, these models depend on pretrained large diffusion models and robot demonstration video data, and are confined to image-based environments. Moreover, the substantial computational resources required for these large models pose a challenge for deployment in real-world robotic tasks.
Contrary to previous work that infers subgoals exclusively using an explicit model, we restrict our policy search by employing an implicit model and the prior distribution implicitly represented in the offline dataset. Our work also adopts a divide-and-conquer manner to solve long-horizon tasks by utilizing the hierarchical architecture [28, 29, 30], where the top-level focuses on reasoning and decision-making to generate subgoals, and the low-level interacts with the environment to achieve the subgoals sequentially.
III Preliminaries
III-A Semi-MDP
We formulate the long-horizon task as a Semi-Markov Decision Process (Semi-MDP) [31]. More precisely, we extend the general MDP by adding option policy and options . The Semi-MDP is denoted by , where is state space containing all possible state, is action space and is the reward function. We use and to denote the distribution of initial state and final goal, respectively. is the transition function and is the discount factor. is the goal space from which final goals and subgoals can be sampled. is the option consisting of three components, where is the initial state space, is the terminal state space, is the specific policy for current option, respectively.
We denote the achieved goal at time step as . Typically, , where represents a known and traceable mapping that defines goal representation [32]. The subgoal is often identified as the achieved goal at the terminal state of an option. is the option policy mapping from state and final goal to subgoal for inferring a sequential option where each . And for each option , the policy is utilized when the agent encounters the initial state and terminates in .
In sparse reward goal-conditioned RL, the reward function is a binary signal indicating whether the current goal is achieved, as expressed by,
| (1) |
where is a small threshold indicating whether the goal is considered to be reached, and , are the state and action at time step and is the final goal. Denote that the initial state of the whole trajectory is the initial state of option , and the final state is the terminal state of option . And the terminal state of option is the initial state of next option . All options are connected in a head-to-tail manner to form the entire trajectory.
III-B Soft Actor-Critic
Soft Actor-Critic (SAC) [33] is an off-policy reinforcement learning algorithm that attempts to maximize the expected return and increase the policy’s entropy. The underlying idea is that increasing entropy leads to more exploration and effectively prevents the policy from reaching a local optimum.
Let be the trajectory starting from initial state . We use to denote the distribution of the induced by the policy .
In contrast to the standard maximum expected reward used in traditional reinforcement learning, the objective of action policy aims to maximize its entropy at each visited state by augmenting with an entropy term,
| (2) |
where is the entropy of the policy , and is the temperature parameter that determines the importance of the entropy term with respect to the reward and is used to control the stochasticity of the optimal policy.
Thus, we can obtain the optimal action policy by:
| (3) |
III-C Hindsight Experience Replay
Hindsight Experience Replay (HER) [34] is an algorithm that improves data efficiency by relabeling data in the replay buffer. It builds on the basis that failed trajectories may still achieve other unexpected states, which could be helpful for learning a policy.
It mitigates the challenge of sparse reward settings by constructing imagined goals in a simple heuristic way to leverage previous replays. During the training process, the HER relabeled the desired goal of this trajectory by specific sampling strategies, such as future and final, which take the future achieved goal and the final achieved goal as the desired goal, respectively.
IV Problem Formulation
Given an initial state and desired final goal , our objective is to infer a sequence of feasible and optimal options by using option policy , where . As the terminating state becomes the initial state for the subsequent option, the option inference problem can be simplified to a terminal state inference problem. In other words, we aim to infer a sequence of feasible and optimal subgoals , where for .
Definition IV.1 (Feasibility).
The sequence of subgoals is feasible if the robot can approach the subgoal from the previous one .
Within the subgoal space , the majority of subgoals generated by the option policy are unfeasible, either due to spatial distance or the strict dependency order of subtasks inherent in long-horizon tasks [35]. An option policy is anticipated to generate a subgoal sequence , such that the transition probability from previous subgoal to current subgoal exceeds 0. Here, the transition probability is denoted as and is the probability of state . More details can be found in Appendix -A.
Definition IV.2 (Optimality).
We call a sequence of subgoals optimal only if the robot can achieve the maximum accumulated reward of all options to finish the task.
Resolving long-horizon tasks can be distilled down to the challenge of optimization over a sequence of subgoals for the goal-conditioned policy. This optimization over subgoals can be viewed as high-level planning, wherein the optimizer identifies waypoints to accomplish each subgoal [2]. We aim to find an optimal option policy to maximize the total accumulated reward of all options,
| (4) |
where is the objective of option , denoted as
| (5) |
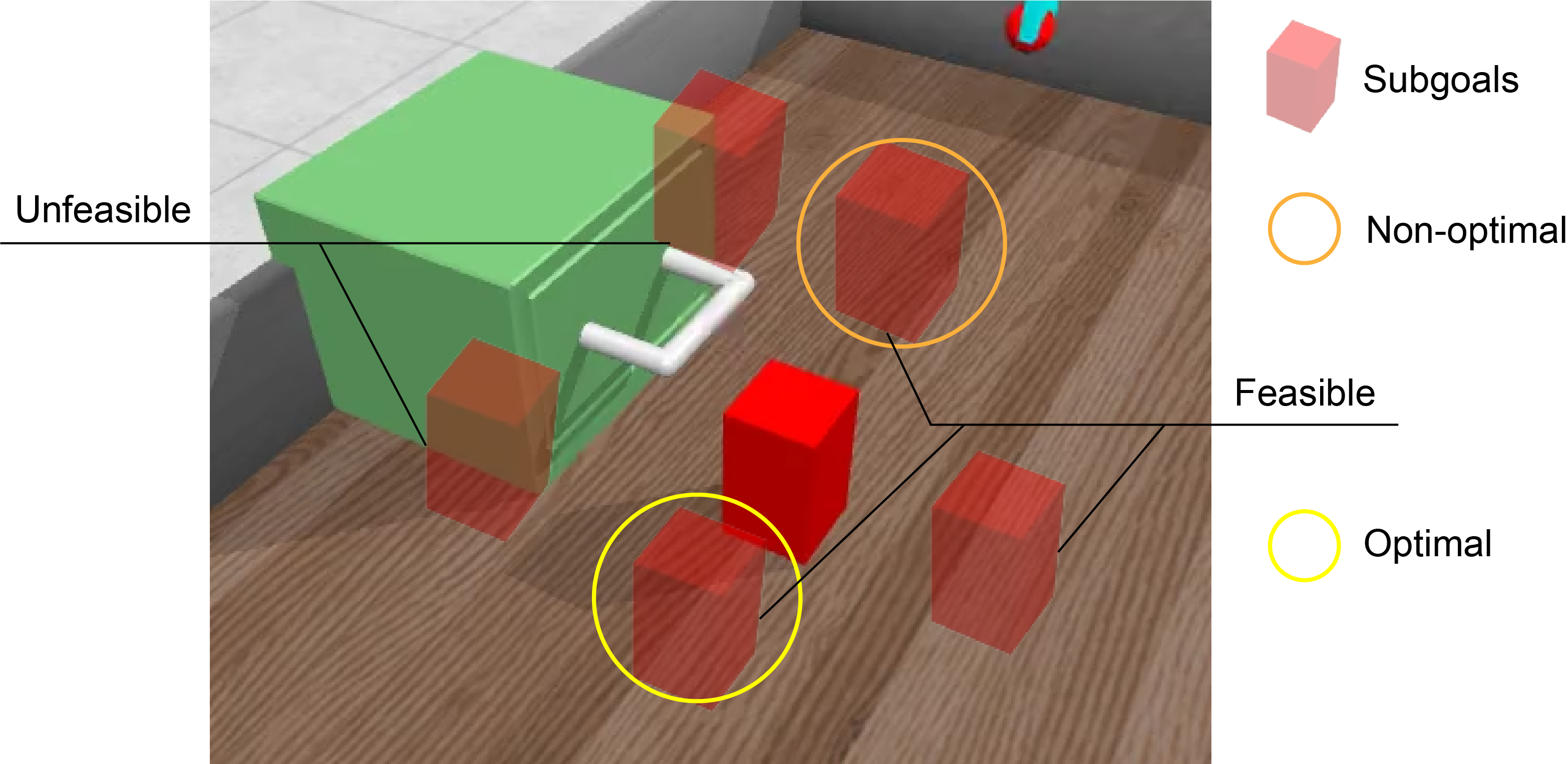
We employ the OpenDrawer environment as a case study to elucidate the concept of feasible and optimal subgoals. As illustrated in Fig. 2, the ultimate objective is to open the drawer by manipulating the handle. However, a red obstacle block is positioned in front of the drawer, necessitating that the robotic arm first push the block away. This task encompasses two distinct skills: pushing the block and opening the drawer. The option policy infers subgoals within the subgoal space, which can sometimes interfere with the drawer, rendering them unfeasible for the robot. Considering the spatial relationship between the block and the drawer, the subgoal encircled by the yellow line is deemed optimal as it enables the robot to move the block away more efficiently.
V Methodology
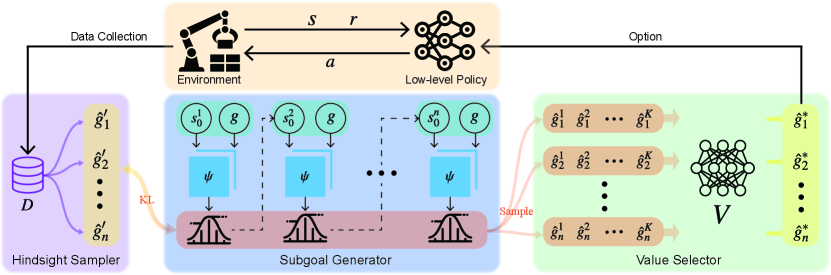
As illustrated in Fig. 3, our EISP algorithm comprises three components: the Hybrid Subgoal Generator, the Hindsight Sampler, and the Value Selector.
V-A Hybrid Subgoal Generator
Given an initial state and a final goal , we expect the robot to infer a series of subgoals to guide it to the final goal . These subgoals are subsequently utilized to bootstrap the low-level action policy , thereby generating the actions to accomplish each subgoal.
Generally, most current subgoal generators [2, 24, 15] employ an explicit feed-forward model that maps subgoals directly from the state and the final goal. These methods are inspired by the human approach to solving long-horizon tasks, wherein humans generate subgoals to decompose long-horizon tasks into smaller, more manageable ones based on the final goal and the current state. However, one critical aspect often overlooked is that humans can also predict long-term outcomes using short-term subgoals conditioned on the current state. Current research [18] in behavior cloning has demonstrated that implicit models possess a superior capacity to learn long-horizon tasks more effectively than their explicit counterparts. This evidence incites us to employ the implicit model in subgoal generators, which is anticipated to enhance the ability to solve long-horizon tasks significantly.
Based on these insights, we propose a hybrid subgoal generator, fundamentally structured as a Conditional Variational Autoencoder (CVAE) [36]. Within this framework, the encoder serves as an explicit model that can infer a sequence of subgoals based on the current state and the final goal, while the decoder functions as an implicit model, designed to reconstruct the final goal using the current state and the given subgoals, as depicted in Fig. 4. After preprocessing the state and the final goal through several fully connected layers, the encoder computes the mean and the standard deviation via two fully connected networks. The subgoal is then sampled from the normal distribution modeled using these calculated values of and . The decoder takes the subgoal as input and conditioned on the current state to generate the reconstructed final goal . Notably, we also employ the reparameterization trick to make the encoder and decoder differentiable.
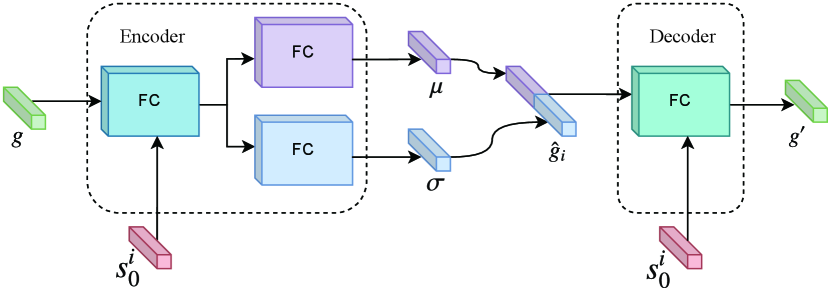
Unlike the original CVAE, where the latent space serves as a low-dimensional mapping from the inputs, we employ the CVAE structure but interpret the latent space as the subgoal space. This approach distinguishes our work from previous studies [2], which also use the CVAE structure to generate subgoals but focus on reconstructing the subgoal using a learned latent representation of the transitions. By modeling the conditional option policy , which takes as inputs the initial state of option and the final goal , we transition the subgoal generation approach from the initial planner (which infers subgoals only at the initial state) to an incremental Planner (which infers subgoals based on current state). That is, the subgoals can be inferred incrementally by:
| (6) |
where . To ensure the robustness of the inferred subgoals and prevent the agent from lingering at one subgoal, we impose a time limit of . The option policy deduces a new subgoal either when the agent reaches the current subgoal or when the allocated time step for the current subgoal expires. This can be expressed as follows:
| (7) |
where is the terminal state when the robot reaches the subgoal of option . We denote the implicit model as , which is designed to accurately reconstruct the final goal from the subgoal. The objective is to maximize the log probability of the final goal, , by maximizing its evidence lower bound (ELBO) [37], formulated as:
| (8) |
Thus, the objective of the hybrid subgoal generator can be defined as follows:
| (9) |
where is the prior distribution over the subgoals, typically a standard normal distribution . denotes the Kullback-Leibler (KL) Divergence [37] between the prior distribution and the distribution of the generated subgoals by . A detailed derivation can be found in Appendix -B. We will introduce an improved prior distribution for the subgoals in the following section.
V-B Hindsight Sampler for Feasible Subgoals
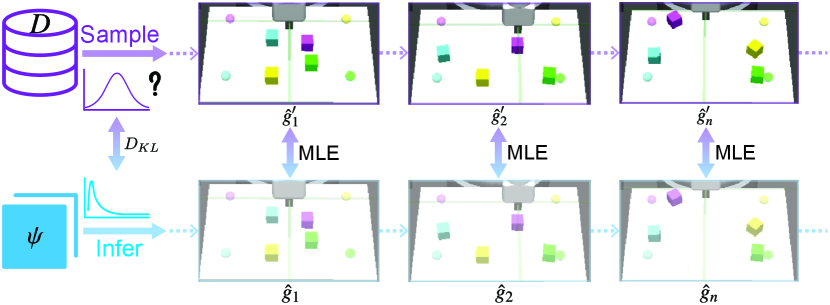
The subgoals sampled from the ground truth subgoal distribution ensure that the transition probability from the current subgoal to the next subgoal is greater than zero. Thus, the distribution of the generated subgoals should closely approximate the true subgoal distribution, which can be achieved by minimizing the KL divergence between the distribution of the generated subgoals by and the true valid subgoal distribution . However, the primary challenge arises from the unknown ground truth subgoal distribution , which complicates the estimation of the KL divergence.
Empirically, the subgoal distribution within the offline dataset can be approximately regarded as the ground truth subgoal distribution. Therefore, we adopt the subgoal distribution of the offline dataset as our prior distribution and aim to minimize the KL divergence between them. To this end, we present a Hindsight Sampler, an approach based on the Hindsight Experience Replay buffer [34], designed to sample valid subgoals from an offline dataset. The core idea is to regard the achieved goal reached at the end of the trajectory as the final goal and recalculate the rewards for all states in the current trajectory. This revised trajectory is then employed to train the option policy. As shown in Fig. 5, during the training period, we first sample the trajectory with total time step from the offline dataset , and take the final achieved goal of this trajectory as the desired goal of the current trajectory. We then select waypoints from the trajectory as subgoals at intervals of , denoted as .
We utilize the maximum likelihood estimation (MLE) [38], which is a method estimating the parameters of an assumed probability distribution given some observed data, to maximize the log-likelihood of the valid subgoals sampled from the offline dataset under the unknown option policy . The objective of the Hindsight Sampler is as follows:
| (10) |
where is the probability of sampled subgoals under the distribution of subgoals generated by the hybrid subgoal generator.
V-C Value Selector for Optimal Subgoals
The Universal Value Function Approximator (UVFA) plays a critical role in goal-conditioned RL. It functions as a mapping from the goal-conditioned state space to a nonlinear value function approximator [39]. We denote the state value function as . In the context of goal-conditioned RL, it is typically utilized to assess the current state under the condition of the goal. The value function of SAC in goal-conditioned RL involves the extra entropy bonuses from every time step utilized to assess the state, denoted as follows:
| (11) |
where . In our algorithm, serves a dual purpose: guides the updates of low-level policy and selects optimal subgoals for the high-level planner. To generate subgoal at current state , conditioned on the final goal , we initially sample candidates using the Hybrid Subgoal Generator, where . As shown in Fig. 3, the candidates are then ranked using the state value function , where higher state values represent better subgoals. Hence, the subgoal state corresponding to the highest value will be selected as the optimal subgoal for the action policy, that is,
| (12) |
The optimal subgoal is subsequently utilized to guide the low-level action policy. The value function may not be optimal during the initial stages of training as the low-level policy may not be sufficiently trained. However, as the training of the value function progresses and improves, the selected subgoals also tend towards optimality.
V-D Integrate with RL
Alg. 1 offers a detailed description of the process of collecting rollout experience for the experience replay buffer. The function is employed to estimate the distance between goals and . We will initially infer a set of potential subgoal candidates via the Hybrid Subgoal Generator when the current subgoal is achieved or the time limit is expirated. Then, the optimal subgoal is selected using the Value Selector. By replacing the final goal with the selected subgoal continuously, we can obtain trajectories of transitions and store it to the replay buffer .
The entire training process of EISP is shown in Alg. 2. At first, a mini-batch is sampled from , consisting of transitions of , where . For each transition, the final goal is relabeled by the future achieved goal, and valid subgoals will be sampled by using the Hindsight Sampler. Then, the objective of the EISP is formulated as:
| (13) |
where is the hyper parameter. The explicit policy and implicit policy can be updated by using stochastic gradient descent with . By alternating between the collection of rollout experience using Alg. 1 and optimization of parameters via Alg. 2, an optimal subgoal generator can be obtained.
Since the off-policy RL algorithms are used to train the low-level action policy, we collect trajectories by using scripted policies to pre-train the subgoal generator and then fine-tune it during the low-level training process. The proposed subgoal inference algorithm is entirely compatible with other off-policy algorithms, owing to its exclusive focus on high-level planning. We employ the SAC method to train the low-level policy.
VI Experiments and Analysis

VI-A Tasks
We evaluate EISP in four tasks: 1) Stack, 2) Push, 3) OpenDrawer, and 4) Store, as depicted in Fig. 6. The left and right columns present the simulation tasks and real-world tasks. All simulation environments are created using the Gymnasium Robotics [40] Framework. The dimensional information of the state space , action space , goal space , and the episode length are provided in Table I.
Stack The block stacking task consists of picking up three blocks and placing them in sequence at the target location. The dimension of the observation space is 55, containing information about the fixture blocks. The action space contains the position of the fixture end-effector and the grasping signal. Multi-step planning makes it more difficult because we have to complete the whole task without disturbing all the completed subtasks [9].
Push4 This task combines the four block-pushing tasks of D4RL [41]. The observation space is 70-dimensional and consists of information about fixtures and blocks. The action space is the position of its end-effector and the gripper status. The robot must sequentially push four objects to the four target positions on the table. The situations can become more complex when some blocks are blocked by others, necessitating the robot to push the blocks in a specific order.
OpenDrawer The robot needs to open the drawer by first removing the block and then pulling the handle. We evaluate EISP in both the state-based and image-based environment. In the state-based environment, the observation space is 42-dimensional, containing information about the drawer, the handle, the block and the gripper. In the image-based environment, the observation space is a image. The action space is the position of the end-effector and the gripper status. The task is challenging due to it contains multiple skills (Pushing the block and pulling the handle) and task dependencies.
Store This task requires the robot to first open the drawer, then pick and place the block into the drawer, and finally close the drawer. Multiple skills like pushing, picking, placing and grasping are involved in this task. Like the OpenDrawer task, we also conduct experiments in both the state-based and image-based environment. The settings of the observation and action space are the same as the OpenDrawer task.
| Env | Stack | Push4 |
|
|
||||
| 55 | 70 | 42 | 42 | |||||
| 9 | 12 | 6 | 6 | |||||
| 4 | 4 | 4 | 4 | |||||
| 300 | 400 | 300 | 1000 | |||||
| SAC | ||||||||
| 0.01 | 0.01 | 0.01 | 0.01 | |||||
| EISP | ||||||||
| 30 | 30 | 50 | 50 | |||||
| 4 | 4 | 6 | 6 | |||||
VI-B Implementation Details
The Hybrid Subgoal Generator is based on the CVAE structure and consists of an encoder and a decoder . The encoder takes the current state and the desired goal as inputs and uses two probabilistic neural networks to output the mean and deviation . We then parameterize the Laplace distribution with the above outputs. We implement two probabilistic neural networks using one layer of fully connected network mapping from the encoder output to the subgoal space. The decoder has the opposite structure to the encoder. It takes as inputs the encoder-generated subgoals and the current state and outputs the reconstructed desired goal. The SAC is used as the underlying RL algorithm for action policy training and then fine-tuned online. We use a fixed temperature parameter for all tasks. Table I presents the specifications of various parameters including the size of the replay buffer and the mini-batch , the network structure, and the learning rates of SAC and EISP. We set the number of subgoals used in Hindsight Sampler as Table I. The weight used in (13) refer to Table I. Both the option and action strategies use the Adam optimizer to update the network parameters. During the training process, we set a time limit of to update the subgoal when the current subgoal is not reached. For image-based observations, we employ a vector quantized variational autoencoder (VQ-VAE) [42] to extract features, which are subsequently used as input for subgoal generation. Detailed training procedures and results of the VQ-VAE can be found in Appendix -C and -D.
VI-C Qualitative Analysis
This section demonstrates the feasibility and optimality of inferred subgoals through the qualitative results.


Feasibility Fig. 7 shows the subgoals generated by EISP in four state-based tasks mentioned above. We mark the inferred subgoals as transparent cubes in the Stack and Push task and solid small cubes in the OpenDrawer and Store task. For each task, we show the sequence of subgoals in different stages, starting from the initial state to the final goal. Each task involves different skills; for example, the Stack task uses Pick and Place skills iteratively to reach the final goal, whereas the Store task requires four skills to finish the entire task. Besides, we also infer subgoals for image-based environments, specifically OpenDrawer and Store, with the results shown in Fig. 8. For these tasks, low-dimensional features extracted from image observations serve as input, and the inferred subgoals are reconstructed using a pretrained VQ-VAE decoder. These reconstructed subgoals are depicted in Figure 8 with yellow dashed rectangles.
It should be noted that many inferred subgoals are still noisy, indicating that certain subgoals may be unreachable within a given time step. This phenomenon is expected, as these subgoals typically provide the direction to aim for rather than the precise position the robot should achieve. The robot can ultimately achieve the final goal as this direction is progressively updated. Furthermore, EISP demonstrates robustness against non-optimal or unfeasible subgoals that may emerge during strategy execution, as it infers subgoals based on the current observation. For instance, the third subgoal generated in the Stack task seems not optimal since it is not directly on the path to the final goal. However, it still provides directional guidance for the robot. As time progresses and the time budget for the current option expires, the next subgoal will offer more accurate information for the robot to achieve its objective.
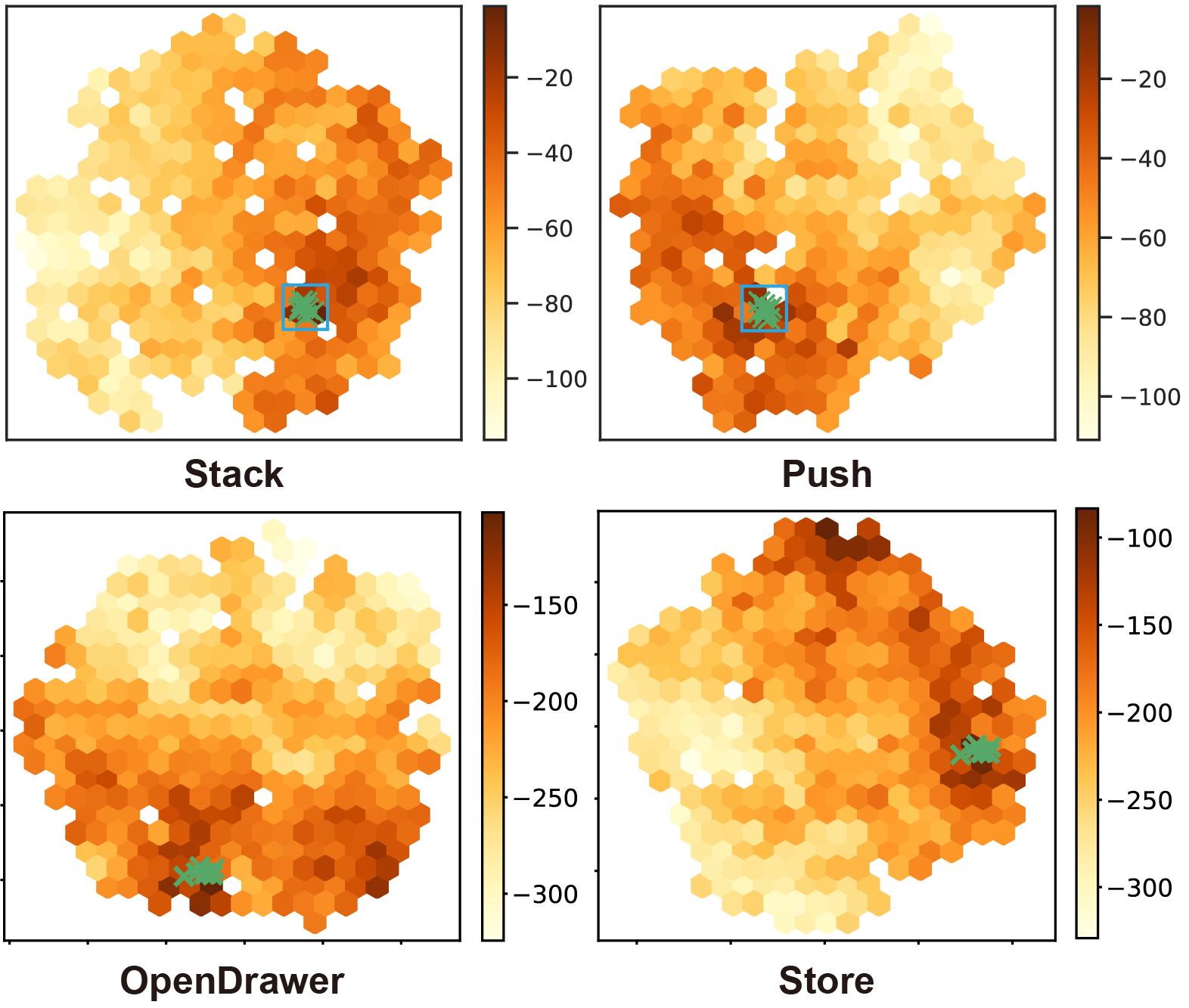
Optimality To assess the optimality of generated subgoals, we visualize the distribution of subgoals in the high-dimensional subgoal space. For simplicity, the results of later experiments with OpenDrawer and Store were conducted in image-based environments. We compute the values of 1000 randomly sampled subgoals from the subgoal space of each task. The t-SNE [43] algorithm is then employed to reduce the high-dimensional data into a two-dimensional format. The results are visualized in Fig. 9. Subgoals with lower values are marked with lighter hues, indicating they may not be the optimal choice for the current state. In contrast, subgoals with higher values are shown with darker hues, suggesting they would be more beneficial for the long-horizon task. Subgoal candidates obtained from the trained subgoal strategy are also plotted as green crosses in the figure. The plot reveals that the subgoals inferred by the VAE generator are mainly distributed within the space of higher values. Initially, these subgoals are not located in regions with high values, but as the training goes on and the dataset is updated with high-quality data, they are gradually shifted to regions with high values.

VI-D Quantitative Analysis
Additionally, we perform qualitative experiments to demonstrate the superiority of our proposed methods. We conduct two ablation experiments, with the Hindsight Sampler and the Value Selector components being excluded respectively, to isolate their individual contributions to the overall performance. We also conduct comparative experiments against current state-of-the-art subgoal-generator algorithms, namely RIS (Reinforcement learning with Imaged subgoals) [24], HP (Hindsight Planner) [15], and LEAP (Latent Embeddings for Abstracted Planning) [16].
-
•
RIS aims to identify subgoals that are maximally distant from the initial state and final goal.
-
•
HP employs the LSTM [44] architecture to sequentially generate subgoals by continuously integrating previously generated subgoals.
-
•
LEAP learns the goal-conditioned policy predicated on the latent embedding of original complex observations.
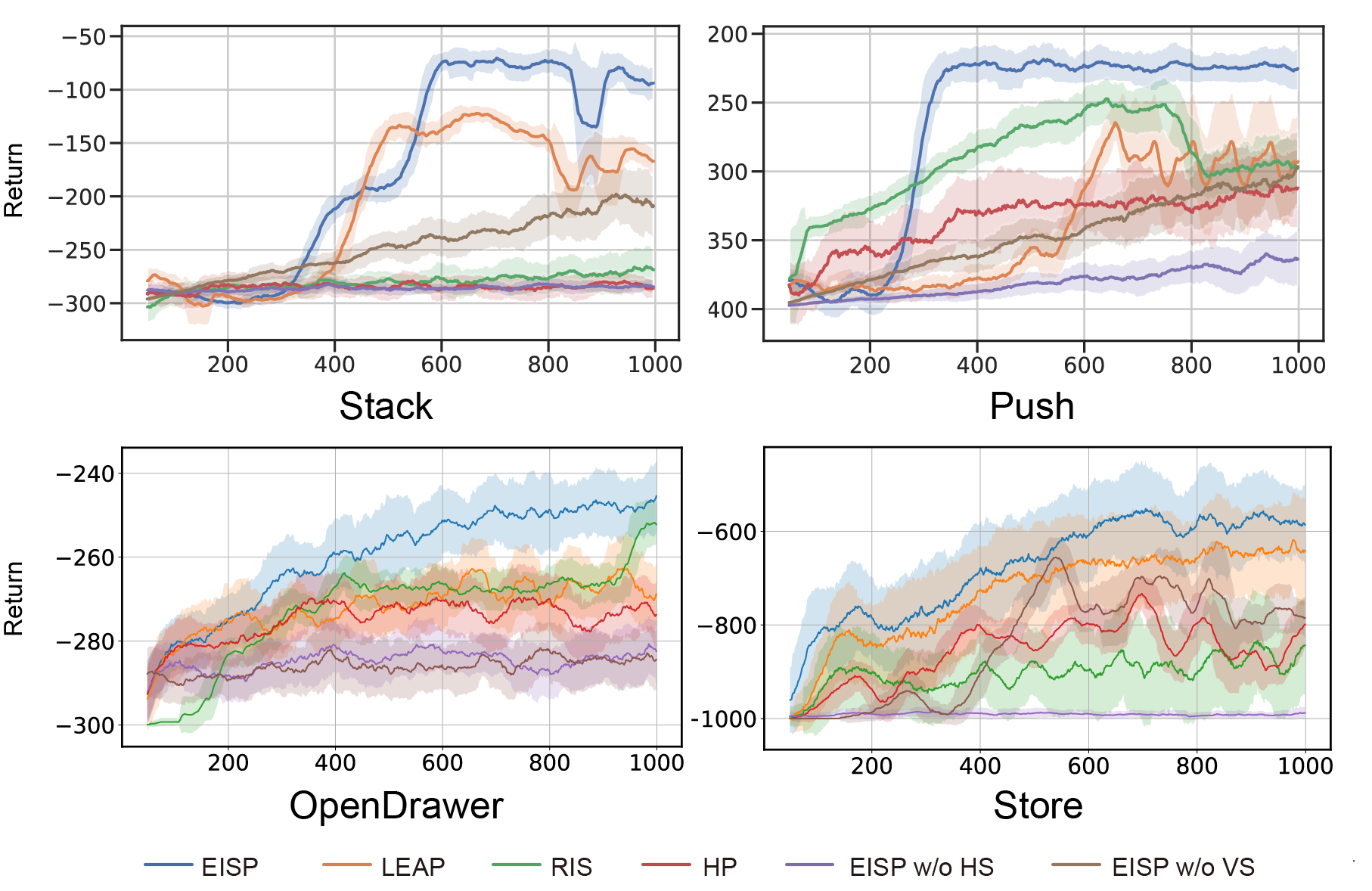
To ensure a fair comparison, all methods employ SAC as the underlying RL algorithm with identical network architecture. The trained policies are tested on four long-horizon tasks, inclusive of our method and the aforementioned baselines, with success rates depicted in Fig. 10. The results demonstrate that the EISP algorithm, which utilizes both the Hindsight Sampler and the Value Selector module, yields the highest success rates. The strategy without the Hindsight Sampler, labeled EISP w/o HS, encounters difficulties in rendering the subgoals generated by the RL agent feasible, resulting in low success rates across all four environments. Conversely, the strategy lacking the Value Selector module, denoted as EISP w/o VS, still manages to achieve a measure of success (for instance, approximately a 60% success rate on the Stack task). This suggests that the optimization module primarily functions as a facilitator to expedite the training of the subgoal generator, enabling the strategy to converge more rapidly and attain a higher success rate. When compared to other state-of-the-art subgoal-oriented reinforcement learning methods, EISP consistently demonstrates a superior success rate. On the Push task, EISP achieves a success rate exceeding 70%, while LEAP achieves a success rate of approximately 38%, and other methods yield success rates of less than 20%.
| Policy | Stack | Push | OpenDrawer | Store |
| RIS | -256.374 | |||
| HP | -844.58 | |||
| LEAP | ||||
| EISP w/o HS | ||||
| EISP w/o VS | ||||
| EISP (Ours) | -89.29 | -228.89 | -246.91 | -581.96 |
After conducting five tests on four tasks using distinct seeds, the expected returns recorded for all the training policies are presented in Table II, with the highest return for each task emphasized in bold and the second highest return emphasized in underlining. A higher expected return indicates a superior policy. While all policies can potentially lead to higher expected returns, our approach produces the most substantial improvements in expected returns. The LEAP and HP methods rely solely on the initial state to infer subgoals, which proves insufficient for tasks with varying desired goals. These methods lack robustness for complex long-horizon tasks in most scenarios, and a change in the desired goal results in the generated subgoals becoming less accurate, leading to task failure. Furthermore, sampling subgoals randomly from the experience buffer can result in inaccurate subgoals, impeding the generation of optimal lower-level action policies. For detailed information on episodic returns throughout the entire training procedure, you can refer to Appendix -E.

VI-E Real World Demonstrations

To demonstrate the adaptability of our algorithms in the real world, we employ the Tiago++ robotic arm [45] to execute Stack and Push tasks, and the UR3 robotic arm for OpenDrawer and Store tasks. The setups of these four environments are the same as in the simulation. Our experiments utilize Pinocchio [46] for both motion planning and inverse kinematics. As depicted in Fig. 11, red cubes are manipulated by the robotic arm to complete the assigned task, with the number of red blocks used in Stack and Push being 3 and 4, respectively. We mount a calibrated Intel RealSense D435i RGB-D camera on the top of the table to facilitate top-view observation. We also fix a soft beam to the end of the gripper to mitigate potential collisions between the gripper, the table, and the blocks during the execution of the Push task.
The strategy employed to guide the robot is identical to that used in the simulation. To gather environmental observations, we utilize Aruco markers for the detection of each object’s and gripper’s position. Fig. 12 illustrates the subgoals inferred from the initial state to the desired goals for four manipulation tasks. The desired goals are denoted as green spherical shades and the subgoals as transparent squares. During execution, the Aruco markers may be occluded by the robotic arm, causing the top-view camera unable to detect the markers at certain time steps, primarily in the Stack and Push task. To address this problem, we maintain the last known position of the markers and update it when markers become detectable again. Additionally, the robot arm is reset to a specific pose to observe the current state after achieving each subgoal. We also conducted robustness tests and failed case studies, with the results presented in Appendix -F and -G.
VII Conclusion
In conclusion, we propose Explicit-Implicit Subgoal Planning (EISP), a novel algorithm that leverages an explicit encoder model to produce feasible subgoals and an implicit decoder model that provides a guarantee on the worst-case log-likelihood of the subgoal distribution. The efficiency of the proposed algorithm is substantiated by both qualitative and quantitative results derived from simulations and real-world experiments, demonstrating its superiority over prevailing baselines in terms of subgoal efficacy and overall performance.
As we learned from the failure analysis, the generated subgoals are not conducive to long-horizon task accomplishment under extreme distributions, i.e., too far or too close to the current state. Future research will delve deeper into integrating with the exploration method to ensure that the subgoals are within a reasonable range from the current achieved goals, which can make the generated subgoals more accurate. Despite these limitations, the approach presented in this paper offers a promising avenue for designing effective divide-and-conquer strategies through abstract subgoal reasoning in complex robotics tasks.
References
- [1] V. N. Hartmann, A. Orthey, D. Driess, O. S. Oguz, and M. Toussaint, “Long-horizon multi-robot rearrangement planning for construction assembly,” IEEE Transactions on Robotics, vol. 39, no. 1, pp. 239–252, 2022.
- [2] K. Fang, P. Yin, A. Nair, and S. Levine, “Planning to practice: Efficient online fine-tuning by composing goals in latent space,” in 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2022, pp. 4076–4083.
- [3] D. Xu, S. Nair, Y. Zhu, J. Gao, A. Garg, L. Fei-Fei, and S. Savarese, “Neural task programming: Learning to generalize across hierarchical tasks,” in 2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2018, pp. 3795–3802.
- [4] S. Sohn, H. Woo, J. Choi, and H. Lee, “Meta reinforcement learning with autonomous inference of subtask dependencies,” arXiv preprint arXiv:2001.00248, 2020.
- [5] M. H. Lim, A. Zeng, B. Ichter, M. Bandari, E. Coumans, C. Tomlin, S. Schaal, and A. Faust, “Multi-task learning with sequence-conditioned transporter networks,” in 2022 International Conference on Robotics and Automation (ICRA), 2022, pp. 2489–2496.
- [6] F. Stulp, E. A. Theodorou, and S. Schaal, “Reinforcement learning with sequences of motion primitives for robust manipulation,” IEEE Transactions on robotics, vol. 28, no. 6, pp. 1360–1370, 2012.
- [7] J. Borras, G. Alenya, and C. Torras, “A grasping-centered analysis for cloth manipulation,” IEEE Transactions on Robotics, vol. 36, no. 3, pp. 924–936, 2020.
- [8] S. Paul, J. Vanbaar, and A. Roy-Chowdhury, “Learning from trajectories via subgoal discovery,” Advances in Neural Information Processing Systems, vol. 32, 2019.
- [9] A. Nair, B. McGrew, M. Andrychowicz, W. Zaremba, and P. Abbeel, “Overcoming exploration in reinforcement learning with demonstrations,” in 2018 IEEE international conference on robotics and automation (ICRA). IEEE, 2018, pp. 6292–6299.
- [10] V. H. Pong, M. Dalal, S. Lin, A. Nair, S. Bahl, and S. Levine, “Skew-fit: State-covering self-supervised reinforcement learning,” arXiv preprint arXiv:1903.03698, 2019.
- [11] A. V. Nair, V. Pong, M. Dalal, S. Bahl, S. Lin, and S. Levine, “Visual reinforcement learning with imagined goals,” Advances in neural information processing systems, vol. 31, 2018.
- [12] S. Pitis, H. Chan, S. Zhao, B. Stadie, and J. Ba, “Maximum entropy gain exploration for long horizon multi-goal reinforcement learning,” in International Conference on Machine Learning. PMLR, 2020, pp. 7750–7761.
- [13] C. Florensa, D. Held, X. Geng, and P. Abbeel, “Automatic goal generation for reinforcement learning agents,” in International conference on machine learning. PMLR, 2018, pp. 1515–1528.
- [14] M. Liu, M. Zhu, and W. Zhang, “Goal-conditioned reinforcement learning: Problems and solutions,” arXiv preprint arXiv:2201.08299, 2022.
- [15] Y. Lai, W. Wang, Y. Yang, J. Zhu, and M. Kuang, “Hindsight planner,” in Proceedings of the 19th International Conference on Autonomous Agents and MultiAgent Systems, 2020, pp. 690–698.
- [16] S. Nasiriany, V. Pong, S. Lin, and S. Levine, “Planning with goal-conditioned policies,” Advances in Neural Information Processing Systems, vol. 32, 2019.
- [17] L. Wu and K. Chen, “Goal exploration augmentation via pre-trained skills for sparse-reward long-horizon goal-conditioned reinforcement learning,” Machine Learning, pp. 1–31, 2024.
- [18] P. Florence, C. Lynch, A. Zeng, O. A. Ramirez, A. Wahid, L. Downs, A. Wong, J. Lee, I. Mordatch, and J. Tompson, “Implicit behavioral cloning,” in Conference on Robot Learning. PMLR, 2022, pp. 158–168.
- [19] W. Jin, T. D. Murphey, D. Kulić, N. Ezer, and S. Mou, “Learning from sparse demonstrations,” IEEE Transactions on Robotics, vol. 39, no. 1, pp. 645–664, 2022.
- [20] H. Huang, C. Zeng, L. Cheng, and C. Yang, “Toward generalizable robotic dual-arm flipping manipulation,” IEEE Transactions on Industrial Electronics, 2023.
- [21] J. Hejna, P. Abbeel, and L. Pinto, “Improving long-horizon imitation through instruction prediction,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 7, 2023, pp. 7857–7865.
- [22] D. Warde-Farley, T. Van de Wiele, T. Kulkarni, C. Ionescu, S. Hansen, and V. Mnih, “Unsupervised control through non-parametric discriminative rewards,” arXiv preprint arXiv:1811.11359, 2018.
- [23] K. Hartikainen, X. Geng, T. Haarnoja, and S. Levine, “Dynamical distance learning for semi-supervised and unsupervised skill discovery,” arXiv preprint arXiv:1907.08225, 2019.
- [24] E. Chane-Sane, C. Schmid, and I. Laptev, “Goal-conditioned reinforcement learning with imagined subgoals,” in International Conference on Machine Learning. PMLR, 2021, pp. 1430–1440.
- [25] B. Eysenbach, R. R. Salakhutdinov, and S. Levine, “Search on the replay buffer: Bridging planning and reinforcement learning,” Advances in Neural Information Processing Systems, vol. 32, 2019.
- [26] K. Black, M. Nakamoto, P. Atreya, H. Walke, C. Finn, A. Kumar, and S. Levine, “Zero-shot robotic manipulation with pretrained image-editing diffusion models,” arXiv preprint arXiv:2310.10639, 2023.
- [27] Z. Liang, Y. Mu, H. Ma, M. Tomizuka, M. Ding, and P. Luo, “Skilldiffuser: Interpretable hierarchical planning via skill abstractions in diffusion-based task execution,” arXiv preprint arXiv:2312.11598, 2023.
- [28] P. Dayan and G. E. Hinton, “Feudal reinforcement learning,” Advances in neural information processing systems, vol. 5, 1992.
- [29] T. G. Dietterich, “Hierarchical reinforcement learning with the maxq value function decomposition,” Journal of artificial intelligence research, vol. 13, pp. 227–303, 2000.
- [30] A. Levy, G. Konidaris, R. Platt, and K. Saenko, “Learning multi-level hierarchies with hindsight,” arXiv preprint arXiv:1712.00948, 2017.
- [31] R. S. Sutton, D. Precup, and S. Singh, “Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning,” Artificial Intelligence, vol. 112, no. 1, pp. 181–211, 1999.
- [32] Z. Ren, K. Dong, Y. Zhou, Q. Liu, and J. Peng, “Exploration via hindsight goal generation,” Advances in Neural Information Processing Systems, vol. 32, 2019.
- [33] T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor,” in International conference on machine learning. PMLR, 2018, pp. 1861–1870.
- [34] M. Andrychowicz, F. Wolski, A. Ray, J. Schneider, R. Fong, P. Welinder, B. McGrew, J. Tobin, O. Pieter Abbeel, and W. Zaremba, “Hindsight experience replay,” Advances in neural information processing systems, vol. 30, 2017.
- [35] S. Sohn, J. Oh, and H. Lee, “Hierarchical reinforcement learning for zero-shot generalization with subtask dependencies,” Advances in neural information processing systems, vol. 31, 2018.
- [36] K. Sohn, H. Lee, and X. Yan, “Learning structured output representation using deep conditional generative models,” Advances in neural information processing systems, vol. 28, 2015.
- [37] D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” arXiv preprint arXiv:1312.6114, 2013.
- [38] R. J. Rossi, Mathematical statistics: an introduction to likelihood based inference. John Wiley & Sons, 2018.
- [39] T. Schaul, D. Horgan, K. Gregor, and D. Silver, “Universal value function approximators,” in International conference on machine learning. PMLR, 2015, pp. 1312–1320.
- [40] R. de Lazcano, K. Andreas, J. J. Tai, S. R. Lee, and J. Terry, “Gymnasium robotics,” 2023. [Online]. Available: http://github.com/Farama-Foundation/Gymnasium-Robotics
- [41] J. Fu, A. Kumar, O. Nachum, G. Tucker, and S. Levine, “D4rl: Datasets for deep data-driven reinforcement learning,” arXiv preprint arXiv:2004.07219, 2020.
- [42] A. Van Den Oord, O. Vinyals et al., “Neural discrete representation learning,” Advances in neural information processing systems, vol. 30, 2017.
- [43] L. Van der Maaten and G. Hinton, “Visualizing data using t-sne.” Journal of machine learning research, vol. 9, no. 11, 2008.
- [44] S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural computation, vol. 9, no. 8, pp. 1735–1780, 1997.
- [45] J. Pages, L. Marchionni, and F. Ferro, “Tiago: the modular robot that adapts to different research needs,” in International workshop on robot modularity, IROS, vol. 290, 2016.
- [46] J. Carpentier, G. Saurel, G. Buondonno, J. Mirabel, F. Lamiraux, O. Stasse, and N. Mansard, “The pinocchio c++ library – a fast and flexible implementation of rigid body dynamics algorithms and their analytical derivatives,” in IEEE International Symposium on System Integrations (SII), 2019.
- [47] A. Khazatsky, A. Nair, D. Jing, and S. Levine, “What can i do here? learning new skills by imagining visual affordances,” in 2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 14 291–14 297.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/0da2467f-71fc-4b0d-9532-64043e6fbc5b/fy.jpeg) |
Fangyuan Wang received the M.Sc. degree in software engineering from Zhejiang Sci-Tech University, China, in 2022. He is currently pursuing the Ph.D. in mechanical engineering at The Hong Kong Polytechnic University, Hong Kong. His research interests focus on reinforcement learning, multi-agent systems, and robotic manipulation. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/0da2467f-71fc-4b0d-9532-64043e6fbc5b/x4.png) |
Anqing Duan received his bachelor’s degree in mechanical engineering from Harbin Institute of Technology, Harbin, China, in 2015, his master’s degree in mechatronics from KTH, Sweden, in 2017, and his Ph.D. degree in robotics from the Italian Institute of Technology and the University of Genoa, Italy, in 2021. Since 2021, he has been a Research Associate with The Hong Kong Polytechnic University. His research interest includes robot learning and control. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/0da2467f-71fc-4b0d-9532-64043e6fbc5b/pengzhou.jpg) |
Peng Zhou received his Ph.D. degree in robotics from PolyU, Hong Kong, in 2022. In 2021, he was a visiting Ph.D. student at KTH Royal Institute of Technology, Stockholm, Sweden. He is currently a Research Officer at the Centre for Transformative Garment Production and a Postdoctoral Research Fellow at The University of Hong Kong. His research interests include deformable object manipulation, robot reasoning and learning, and task and motion planning. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/0da2467f-71fc-4b0d-9532-64043e6fbc5b/kyle.jpeg) |
Shengzeng Huo received the B.Eng. degree in vehicle engineering from the South China University of Technology, China, in 2019, and the M.Sc. degree in mechanical engineering from The Hong Kong Polytechnic University, Hong Kong, in 2020, and he is currently pursuing the Ph.D. degree in the same discipline since 2021. His current research interests include bimanual manipulation, deformable object manipulation, and robot learning. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/0da2467f-71fc-4b0d-9532-64043e6fbc5b/guo.jpg) |
Guodong Guo (M’07-SM’07) received the B.E. degree in Automation from Tsinghua University, Beijing, China, the Ph.D. degree in Computer Science from the University of Wisconsin, Madison, WI, USA. He is now a Professor at Eastern Institute of Technology, and the Vice President of Ningbo Institute of Digital Twin, China. He is also affiliated with the Dept. of Computer Science and Electrical Engineering, West Virginia University, USA. His research interests include computer vision, biometrics, machine learning, and multimedia. He is an AE of several journals, including IEEE Trans. on Affective Computing. He received the North Carolina State Award for Excellence in Innovation in 2008, New Researcher of the Year (2010-2011), and Outstanding Researcher (2017-2018, 2013-2014) at CEMR, WVU. He was selected the “People’s Hero of the Week” by BSJB under Minority Media and Telecommunications Council (MMTC) in 2013. His papers were selected as “The Best of FG’13” and “The Best of FG’15”, respectively, and the “Best Paper Award” by the IEEE Biometrics Council in 2022. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/0da2467f-71fc-4b0d-9532-64043e6fbc5b/charlie.jpg) |
Chenguang Yang (Fellow, IEEE) received the B.Eng. degree in measurement and control from Northwestern Polytechnical University, Xian, China, in 2005, and the Ph.D. degree in control engineering from the National University of Singapore, Singapore, in 2010. He performed postdoctoral studies in human robotics at the Imperial College London, London, U.K from 2009 to 2010. He is Chair in Robotics with Department of Computer Science, University of Liverpool, UK. He was awarded UK EPSRC UKRI Innovation Fellowship and individual EU Marie Curie International Incoming Fellowship. As the lead author, he won the IEEE Transactions on Robotics Best Paper Award (2012) and IEEE Transactions on Neural Networks and Learning Systems Outstanding Paper Award (2022). He is the Corresponding Co-Chair of IEEE Technical Committee on Collaborative Automation for Flexible Manufacturing. His research interest lies in human robot interaction and intelligent system design. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/0da2467f-71fc-4b0d-9532-64043e6fbc5b/david.jpg) |
David Navarro-Alarcon (Senior Member, IEEE) received his Ph.D. degree in mechanical and automation engineering from The Chinese University of Hong Kong in 2014. He is currently an Associate Professor at the Department of Mechanical Engineering at The Hong Kong Polytechnic University (PolyU). His current research interests include perceptual robotics and control theory. He currently serves as an Associate Editor of the IEEE Transactions on Robotics. |
-A Probability of the feasibility
To ensure a given subgoal sequence is feasible, we must guarantee that the transition probability from current subgoal to next subgoal exceeds 0.
Assuming the initial state of the current subgoal is feasible to reach, i.e., the probability of . The transition probability can be obtained as follows:
-B Derivation of the objective of the Hybrid Subgoal Generator
Proof.
Given the initial state of option , we want to maximize the log probability of the final goal .
| () | ||||
| (Chain rule) | ||||
| () | ||||
where is the evidence lower bound (ELBO) and is the KL divergence greater than 0. Thus, the objective now is:
| (Chain rule) | ||||
| () |
∎
-C Bootstrapped data collection
Deep reinforcement learning not only allows us to extract the best strategies from bootstrapped data but also allows robots to continually improve as they increasingly interact with spoiled data. To accelerate training, we collect demo trajectories for offline policy training using a scripted policy that utilizes privileged information from the environment (e.g., object pose and fixture state). We collect trajectories for offline policy training using scripted policies that utilize privileged information from the environment (e.g., object pose and fixture state). Within each demo trajectory, we initialize the environment randomly and set an arbitrary level of the desired goal. Trajectory lengths range from to for different tasks. The success rate of the scripted policies is no greater than .
-D Image-based observation processing
For the OpenDrawer and StoreBlock tasks, we also use image-based observation to train the subgoal generator. The observation is a image, which is processed by a vector quantized variational autoencoder (VQ-VAE) [42] first to extract the features [47]. To elaborate, we pretrain an encoder, denoted as , which takes the original image as input and outputs the latent embedding of the image. The resulting low-dimensional latent representation is then input to the subgoal generator. The VQ-VAE comprises a convolutional encoder and a deconvolutional decoder. The encoder consists of three convolutional layers with kernel size and stride . The decoder consists of three deconvolutional layers with kernel size and stride . The latent space size is . The VQ-VAE is trained using the Adam optimizer with a learning rate of and a batch size of for steps. Then, the subgoal generator for the image-based environment is trained using the Adam optimizer with a learning rate of and a batch size of .
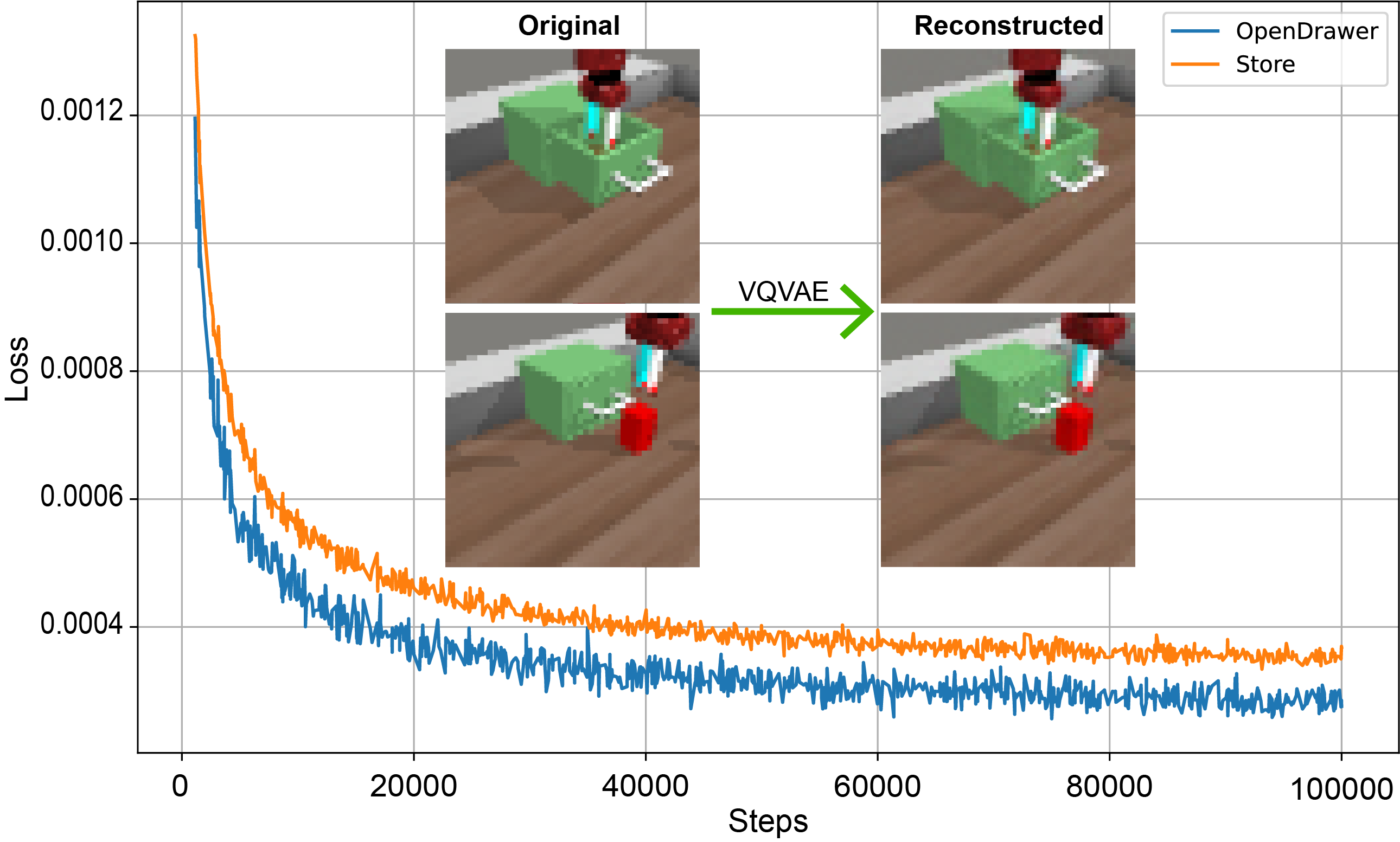
Fig.13 shows the training process of the VQ-VAE on the OpenDrawer and Store tasks. The VQ-VAE loss progressively decreases as the training progresses. Additionally, we present two examples comparing the original and reconstructed images. The upper images depict the original images, while the lower images show the reconstructed counterparts. The reconstructed images closely resemble the original ones, indicating that the VQVAE effectively extracts features from the image observations and reconstructs them using embeddings. We utilize the features extracted by the VQ-VAE, which are low-dimensional data (around 8 times smaller than the original), which are then fed into the subgoal generator to generate the subgoals.
-E Episodic return
The evolution of the expected reward during training, i.e., the cumulative reward over the entire trajectory, is depicted in Fig. 14.
-F Real world tasks analysis
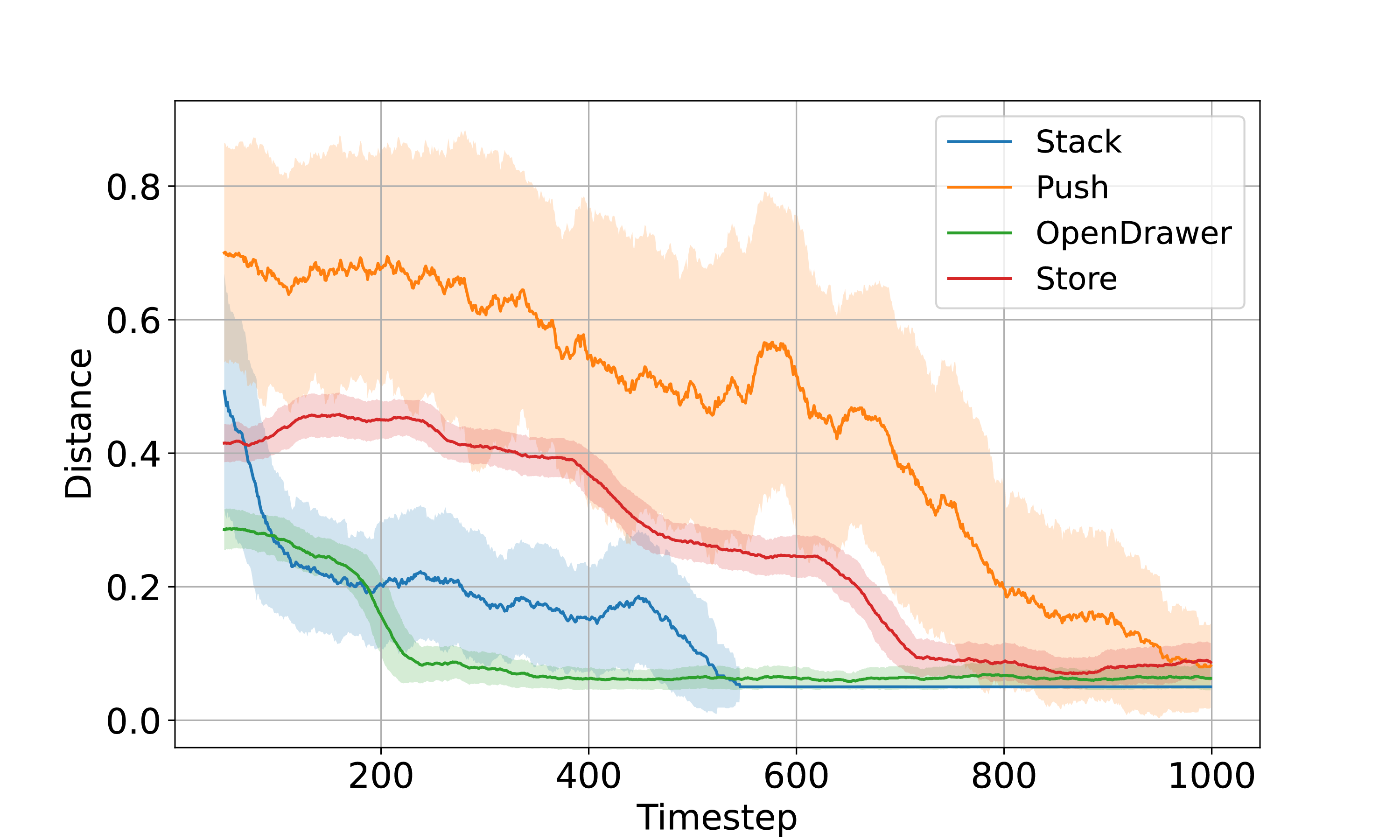
Fig. 15 illustrates the evolution of the distance between the current achieved goal and the final goal over the task execution. The distance is calculated as the average of the Euclidean distances between the positions of the manipulating objects and their corresponding target positions. A task is deemed successful if this distance falls within a threshold of . As the experiment goes on, the distance for all tasks steadily declines to 0.05m.
| Task | Stack | Push4 |
|---|---|---|
| No interference | 8/10 | 8/10 |
| Interference after completion | 8/10 | 10/10 |

We also conducted ten tests for the Stack and Push task, incorporating human disturbances to interfere with the completed task. The success rate of each task is detailed in Table III. The results indicate that EISP achieves higher success rates of 80% and 100% for the Stack and Push tasks, respectively, despite human interaction. As depicted in Fig. 16, when a block is moved away from its designated goal intentionally, the subgoal is promptly updated upon detection of the block, thereby guiding the gripper to complete the subtask. EISP possesses the capacity to infer subgoals from arbitrary states due to its sequential planning characteristics. In contrast, other subgoal generators, such as LEAP and HP, lack robustness because they infer subgoals only at the initial stage.
-G Failed cases analysis
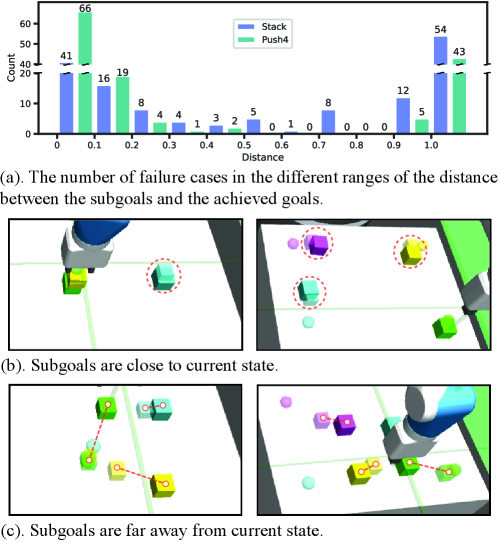
Although our algorithm generally performs well, occasional failures are observed, particularly in the Stack and Push4 tasks. We conduct 1000 tests on each of these tasks on different initial states and final goals, and quantify the failures across varying ranges of distance between the generated subgoal and the goal achieved at the end of the episodes. As shown in Fig. 17 (a), a notably high number of failures in the distance range of to and above , far surpassing the failure count in intermediate distance ranges. We analyze that the following two reasons may cause it. First, the subgoal is extremely close to the current state, as shown in Fig. 17 (b), indicating that the action policy prematurely deems the subgoal as achieved due to its minimal difference from the current state. Secondly, the subgoal is significantly far from the current state, as depicted in Fig. 17 (c), implying that the generated subgoal is still considered a long-horizon task, challenging the action policy to accomplish.