Explaining Off-Policy Actor-Critic From A Bias-Variance Perspective
Abstract
Off-policy Actor-Critic algorithms have demonstrated phenomenal experimental performance but still require better explanations. To this end, we show its policy evaluation error on the distribution of transitions decomposes into: a Bellman error, a bias from policy mismatch, and a variance term from sampling. By comparing the magnitude of bias and variance, we explain the success of the Emphasizing Recent Experience sampling and 1/age weighted sampling. Both sampling strategies yield smaller bias and variance and are hence preferable to uniform sampling.
1 Introduction
A practical reinforcement learning (RL) algorithm is often in an actor-critic setting (Lin, 1992; Precup et al., 2000) where the policy (actor) generates actions and the Q/value function (critic) evaluates the policy’s performance. Under this setting, off-policy RL uses transitions sampled from a replay buffer to perform Q function updates, yielding a new policy . Then, a finite-length trajectory under is added to the buffer, and the process repeats. Notice that sampling from a replay buffer is an offline operation and that the growth of replay buffer is an online operation. This implies off-policy actor-critic RL lies between offline RL (Yu et al., 2020; Levine et al., 2020) and on-policy RL (Schulman et al., 2015, 2017). From a bias-variance perspective, offline RL experiences large policy mismatch bias but low sampling variance, while on-policy RL has a low bias but high variance. Hence, with a careful choice of the sampling from its replay buffer, off-policy actor-critic RL may achieve a better bias-variance trade-off. This is the direction we explore this work.
To reduce policy mismatch bias, off-policy RL employs importance sampling with the weight given by the probability ratio of the current to behavior policy (the policy that samples the trajectories) (Precup et al., 2000; Xie et al., 2019; Schmitt et al., 2020). However, because the behavior policy is usually not given in practice, one can either estimate the probability ratio from the data (Lazic et al., 2020; Yang et al., 2020; Sinha et al., 2020) or use other reasonable quantities, such as the Bellman error (Schaul et al., 2016), as the sampling weight. Even using a naive uniform sampling from the replay buffer, some off-policy actor-critic algorithms can achieve a nontrivial performance (Haarnoja et al., 2018; Fujimoto et al., 2018). These observations suggest we need to better understand the success of off-policy actor-critic algorithms, especially in practical situations where a fixed behavior policy is unavailable.
Our contributions are as follows. To understand the actor-critic setting without a fixed behavior policy, we construct a non-stationary policy that generates the averaged occupancy measure. We use this policy as a reference and show the policy evaluation error in an off-policy actor-critic setting decomposes into the Bellman error, the policy mismatch bias, and the variance from sampling. Since supervised learning during the Q function update only controls the Bellman error, we need careful sampling strategies to mitigate bias and variance. We show that the 1/age weighting or its variants like the Emphasizing Recent Experience (ERE) strategy (Wang and Ross, 2019) are preferable because both their biases and variances are smaller than that of uniform weighting.
To ensure the applicability of our explanation to practical off-policy actor-critic algorithms, we adopt weak but verifiable assumptions such as Lipschitz Q functions, bounded rewards, and a bounded action space. We avoid strong assumptions such as a fixed well-explored behavior policy, concentration coefficients, bounded probability ratios (e.g., ratios of current to behavior policy), and tabular or linear function approximation. Hence our analysis is more applicable to practical settings. In addition, we explain the success of the ERE strategy (Wang and Ross, 2019) from a bias-variance perspective and show that ERE is essentially equivalent to 1/age weighting. Our simulations also support this conclusion. Our results thus provide theoretical foundations for practical off-policy actor-critic RL algorithms and allow us to reduce the algorithm to a simpler form.
2 Preliminaries
2.1 Reinforcement learning
Consider an infinite-horizon Markov Decision Process (MDP) where are finite-dimensional continuous state and action spaces, is a deterministic reward function, is the discount factor, and is the state transition density; i.e., the density of the next state given the current state and action Given an initial state distribution the objective of RL is to find a policy that maximizes the -discounted cumulative reward when the actions along the trajectory follow :
| (1) |
Let be the state distribution under at trajectory step . Define the normalized state occupancy measure by
| (2) |
Ideally, the maximization in (1) is achieved using a parameterized policy and policy gradient updates with (Sutton et al., 1999; Silver et al., 2014):
| (3) |
Here is given in (2), and is the Q function under policy :
| (4) |
Off-policy RL estimates by approximating the solution of the Bellman fixed-point equation:
It is well-known that is the unique fixed point of the Bellman operator . Hence if then may be a “good” estimate of . In the next subsection, we will see that an off-policy actor-critic algorithm encourages this to hold for the replay buffer.
2.2 Off-policy actor-critic algorithm
We study an off-policy actor-critic algorithm of the form shown in Alg. 1.
In line 2, for episode index , samples one trajectory of length The transitions in this trajectory are then added to the replay buffer. Since the policies for different episodes are distinct, the collection of transitions in the replay buffer are generally inconsistent with the current policy.
Line 3 is a supervised learning that minimizes the Bellman error of , making for in the replay buffer. When this holds, we will prove that the “distance” between and become smaller over the replay buffer. This is a crucial step for line 4 to be truly useful. In line 4, is replaced by , and the policy is updated accordingly.
In practice, line 3 is replaced by gradient-descent-based mini-batch updates (Fujimoto et al., 2018; Haarnoja et al., 2018). For example, with and being the parameter and the Bellman error of respectively. In section 5.2, we show that a uniform-weighted mini-batch sampling biases learning towards older samples; this motivates the need for a countermeasure.
2.3 The construction of our behavior policy
Although Alg. 1 doesn’t have a fixed behavior policy, in Lemma 1, we construct a non-stationary policy that generates the averaged occupancy measure at every step. This describes the averaged-over-episode behavior at every trajectory step of the historical trajectory . We hence define it to be our behavior policy and use it as a reference when analyzing Alg. 1.
The construction is as follows. Denote the state distribution at trajectory step in episode as . By Eq. (2), is the state occupancy measure generated by . Intuitively, describes the discounted state distribution starting at trajectory step 0 in episode .
More generally, define as the state occupancy measure generated by . Then, describes the discounted state distribution starting at trajectory step in episode .
| (5) |
Since Alg. 1 considers trajectories from all episodes, the average-over-episodes distribution is of interest. It describes the averaged-discounted state distribution at trajectory step over all episodes.
Behavior policy through averaging.
Let be the average-over-episodes of ; i.e., is the averaged occupancy measure if initialized at step . To describe the average-over-episodes behavior at step , we want a policy that generates , and Eq. (5) helps construct such a policy. Concretely, let , be the averaged state distribution and the averaged policy at step , respectively.
| (6) |
Lemma 1 shows in Eq. (6) is a notion of behavior policy in the sense that generates ; i.e., generates the averaged occupancy measures when the initial state follows . Since describes the averaged discounted behavior starting at step , we define it to be our behavior policy. This is a key to analyzing the policy evaluation error in Alg. 1.
Lemma 1.
Let be the normalized state occupancy measure generated by . Then and hence from Eq. (6),
3 Related work
There are two main approaches to off-policy RL: importance sampling (IS) (Tokdar and Kass, 2010) and regression-based approach. IS has a low bias but high variance, while the opposite holds for the regression-based approach. Prior work also suggests that combining IS and the regression-based yields robust results (Dudík et al., 2011; Jiang and Li, 2016; Thomas and Brunskill, 2016; Kallus and Uehara, 2020). Below, we briefly review these techniques.
Importance Sampling. Standard IS uses behavior policy to form an importance weight from the probability ratio of the current to the behavior policy. For a fully accessible behavior policy, examples of this approach include: the naive IS weight (Precup et al., 2000), importance weight clipping (Schmitt et al., 2020) and the marginalized importance weight (Xie et al., 2019; Yin and Wang, 2020; Yin et al., 2021). Alternatively, one can use the density ratio of the occupancy measures of the current to the behavior policies (Liu et al., 2018). This is estimated using a maximum entropy approach (Lazic et al., 2020), a Lagrangian approach (Yang et al., 2020), or a variational approach (Sinha et al., 2020). A distinct approach emphasizes experience without considering probability ratios. Examples include emphasizing samples with a higher TD error (Schaul et al., 2016; Horgan et al., 2018), emphasizing recent experience (Wang and Ross, 2019) or updating the policy towards the past and discarding distant experience (Novati and Koumoutsakos, 2019).
Regression-based. A regression-based approach can achieve strong experimental results using proper policy exploration and good function approximation (Fujimoto et al., 2018; Haarnoja et al., 2018). It also admits strong theoretical results such as generalization error using a concentration coefficient (Le et al., 2019), policy evaluation error using bounded probability ratios (Agarwal et al., 2019)[Chap 5.1], minimax optimal bound under linear function approximation Duan et al. (2020), confidence bounds constructed by kernel Bellman loss Feng et al. (2020), and sharp sample complexity in asynchronous setting (Li et al., 2020). However, these settings require a fixed behavior policy and bounded probability ratios (i.e., the behavior policy should be sufficiently exploratory). Both requirements rarely hold in practice. To avoid this issue, we construct a non-stationary behavior policy that generates the occupancy measure and use it to analyze the policy evaluation error. This allows us to avoid assumptions and to work with continuous state and action spaces.
4 Policy evaluation error of off-policy actor-critic algorithms
Let , be the Q function of the optimal policy and , respectively. Let be the estimated Q function. The performance error decomposes into . The first term is the policy evaluation error and is the focus in the off-policy evaluation literature (Duan et al., 2020). The second term is the policy’s optimality gap and to bound this term currently requires strong assumptions such as tabular or linear MDPs (Jin et al., 2018, 2020). In an off-policy actor-critic setting, the policy evaluation error has not been analyzed adequately since most analysis requires a fixed behavior policy. This is the focus of our analysis.
Suppose we are given the trajectories sampled in the past episodes (the replay buffer). We analyze the policy evaluation error over the expected distribution of transitions. We express this error in terms of the Bellman error of , the bias term in 1-Wasserstein distance between the policies and the variance term in the number of trajectories . Note is the behavior policy at trajectory step defined in Eq. (6). The use of 1-Wasserstein distance (Villani, 2008) makes the results applicable to both stochastic and deterministic policies. Since supervised learning only makes the Bellman error small, we need good sampling strategies to mitigate the bias and variance terms. We hence investigate sampling techniques from a bias-variance perspective in the next section.
4.1 Problem setup
Notation.
In episode a length- trajectory following policy is sampled (Alg. 1, line 2). Then, is fitted over the replay buffer (line 3). Because the error of at step depends on the states sampled at steps , the importance of these samples depends on the trajectory step . Also, due to the discount factor, the importance of step is discounted by relative to step . Hence, we will use a Bellman error and a policy mismatch error that reflects the dependency on the trajectory step and the discount factor. For and , define an averaging-discounted operator over the replay buffer in episodes:
Using , the Bellman error of and the distance between the policies on the replay buffer are written as
| (7) |
is the 1-Wasserstein distance between two policies at state , which can be viewed as a function of . Both the Bellman error and the policy mismatch error depend on trajectory step and are both discounted by .
Assumptions.
We now relate the Bellman error and the policy mismatch error defined in Eq. (7) to the policy evaluation error To do so requires some assumptions. First, to control the error of by policy mismatch error in distance, we assume that for every state, and are -Lipschitz over actions. We provide reasoning for this assumption in the later discussion. Next, observe that both quantities in Eq. (7) are random with sources of randomness from initial states, policies at different episodes, and the state transitions. To control this randomness, we need assumptions on the Q functions and apply a concentration inequality. Because Alg. 1 only samples one trajectory in each episode, higher-order quantities (e.g., variance) is unavailable. This motivates us to use first-order quantities (e.g., a uniform bound on the Q functions) and apply Hoeffding’s inequality. Hence, we assume that and are bounded in the interval and that the action space is bounded with the diameter . A justification of these assumptions is provided in Appendix A.2.
4.2 Policy evaluation error
Observe that the Q function, Eq. (4), is defined on infinite-length trajectories while the errors, Eq. (7), are evaluated on length- trajectories. Discounting makes it possible to approximate the Q functions using finite-length . To approximate the Q function at trajectory step up to a constant error, we need samples at least to step . Hence, we first prove the main theorem with and . Then, we generalize the result to and finite in Corollary 1.
Theorem 1.
Let be the number of episodes. For define the operator . Denote the policy mismatch error and the Bellman error as and , respectively. Assume
-
(1)
For each and are -Lipschitz in
-
(2)
and are bounded and take values in .
-
(3)
The action space is bounded with diameter .
Then, with probability at least ,
Theorem 1 expresses the error of as the sum of Bellman error, bias, and variance terms. To be more specific, the first two terms are understood as the “variance from sampling” because these decrease in the number of episodes . On the other hand, is the “policy mismatch bias” w.r.t. . Because the behavior policy is a mixture of the historical policies Eq. (6), we expect it to increase in until begins to converge.
Theorem 1 only indicates the difference between and at and infinite-length trajectories. We can generalize it to and finite-length trajectories as follows. Recall from Eq. (6) and Lemma 1, the average state distribution at the -th step, and the behavior policy at the -th step, generate the average state occupancy measure, i.e., Therefore, by restricting attention to the states sampled at time steps the “initial state distribution” and the behavior policy become and , which generalizes Theorem 1 from to . In addition, due to -discounting, we may use length- trajectories to approximate infinite-length ones, provided that . These observations lead to the following corollary.
Corollary 1.
Fix assumptions (1) (2) (3) of Theorem 1. Rewrite the policy mismatch error and the Bellman error as and , respectively. Note is defined in Eq. (7). Then, with probability at least ,
Moreover, if with and the constants are normalized as , , then, with probability at least ,
where is a variant of that ignores logarithmic factors.
Note that if and Corollary 1 is identical to Theorem 1. Because the Bellman error of and the bias of the policy are both evaluated using the averaging-discounted operator , Corollary 1 implies the difference of and at trajectory step mainly depends on states at trajectory steps . Since the Q function is a discounted sum of rewards from the current step to the future, the error at step should mainly depend on the steps .
Normalization.
Although the first conclusion in Corollary 1 gives a bound on the error of , the constants may implicitly depend on the expected horizon Hence its interpretation requires care. For instance, , the Lipschitz constant of the Q functions w.r.t. actions, is probably the most tricky constant. While it is used extensively in the prior work (Luo et al., 2019; Xiao et al., 2019; Ni et al., 2019; Yu et al., 2020), its magnitude is never properly addressed in the literature. Intuitively, if a policy is good enough, it should quickly correct some disturbance on actions. In this case, the rewards after the disturbance only differ in a few trajectory steps, so the Lipschitzness of in actions is sublinear in . On the other hand, if the policy fails to correct a disturbance , due to error propagation, the error propagates to every future step, leading to a linear error dependency to the horizon . Therefore, the Lipschitzness of in actions can be as large as . In addition to , the Bellman error should scale linearly in because the Q function represents the discounted cumulative reward, Eq. (4), which scales linearly in . These observations suggest that and in Corollary 1 are either linear in the horizon or lie between sublinear and linear. To better capture the dependency on the horizon, we normalize the constants and get the second conclusion.
Interpretation.
The second conclusion shows the approximation error from infinite to finite-length trajectories is bounded by a constant for , and will become harder to control for the higher due to the lack of samples. Besides, the variance from sampling and the bias from policy mismatch correspond to the same order of the expected horizon . This means that the relative magnitude between them is irrelevant to the expected horizon and may largely depend on . The variance term dominates when is small, while the bias term dominates when is large. Therefore, one may imagine that the training of Alg. 1 has two phases. At phase 1, the variance term dominates and decreases in , so the learning improves quickly as more trajectories are collected. At phase 2, the bias term dominates, so becomes harder to improve and tends to converge. The tendency of convergence makes the bias smaller, meaning that the error of becomes smaller, too. Therefore, the policy can still slowly improve in at phase 2. This explains why experiments (Figure 2) usually show a quick performance improvement at the beginning followed by a drastic slowdown.
5 Practical sampling strategies
As previously mentioned, the supervised learning during the Q function update fails to control the bias and variance. We need careful sampling techniques during the sampling from the replay buffer to mitigate the policy evaluation error. In particular, Wang and Ross (2019) proposes to emphasize recent experience (ERE) because the recent policies are closer to the latest policy. We show below that the ERE strategy is a refinement of 1/age weighting and that both methods help balance the expected selection number of each training transition . Balanced selection numbers reduce both the policy mismatch bias and sampling variance. Hence, this suggests the potential usefulness of ERE and 1/age, which we verify through experiments in the last subsection.
5.1 Emphasizing recent experience
In Wang and Ross (2019), the authors use a length- trajectory ( may differ across episodes) and perform updates. In the -th () update, a mini-batch is sampled uniformly from the most recent samples, where is the current size of the replay buffer, is the maximum horizon of the environment, is the decay parameter, and is the minimum coverage of the sampling. For MuJoCo (Todorov et al., 2012) environments, the paper suggests the values: . One can see that does a uniform weighting over the replay buffer, and the emphasis on the recent data becomes larger as becomes smaller. To see how the ERE strategy affects the mini-batch sampling, we prove the following result.
Proposition 1.
ERE is approximately equivalent (Taylor Approx.) to the non-uniform weighting:
| (8) |
where is the age of a data point relative to the newest time step; i.e., is the newest sample.
Note that Prop. 1 holds for because it is derived from the geometric series formula: , which is valid when . Despite this discontinuity, we may still claim that the ERE strategy performs a uniform weighting when is close to 1. This is because when , Eq. (8) suggests is proportional to for all , which is a uniform weighting. The emphasis on the recent experience (indicated by ) is also evident from Eq. (8). Precisely, the second term increases logarithmically when becomes smaller, so the smaller indeed gives more weight on the recent experience.
Discussion.
A key distinction between the original ERE and Prop. 1 is that the original ERE considers the trajectory length while Prop. 1 doesn’t. Intuitively, the disappearance of ’s dependency results from the aggregation of all effects in updates. We verify that Eq. (8) tracks the original ERE well in the next subsection.
Another feature of Prop. 1 is an implicit 1/age weighting in Eq. (8). Although the original ERE samples uniformly from the recent points, the aggregate effect of all updates appears to be well approximated by a 1/age weighting. To understand the effect of 1/age, recall from section 2.2 that in practice, is updated using mini-batch samples. Define a point ’s time step as . Then the expected number of times in all batch samples that a point at a certain time step is selected (the expected selection number) gives the aggregate weight over the time steps. As shown in Figure. 1, 1/age weighting and ERE_apx, Eq. (8), give almost uniform expected selection numbers across time steps while uniform weighting is significantly biased toward the old samples. Therefore, 1/age weighting and its variants help balance the expected selection number.

5.2 Merit of balanced selection number
Recall the expected selection numbers are the aggregate weights over time. To understand the merit of balanced selection numbers, we develop an error analysis under non-uniform aggregate weights in the Appendix (Theorem 2 & Corollary 2). Similar to the uniform-weight error in section 4, the non-uniform-weight error is controlled by bias from policy mismatch and variance from sampling. In the following, we discuss these biases and variances in ERE, 1/age weighting, and uniform weighting. We conclude that the ERE and 1/age weighting are better because both of their biases and variances are smaller than that of uniform weighting.
For the bias from policy mismatch, Figure 1 shows the uniform weighting (for each sampling from the replay buffer) makes the aggregate weights (expected selection number) bias toward old samples. Because the old policies tend to be distant from the current policy, the uniform weighting has a larger policy mismatch bias than ERE and 1/age weighting.
As for the variance from sampling, we generalize Corollary 1’s uniform case: to Corollary 2’s weighted case: in the Appendix. To see this, let be a martingale difference sequence with . Consider a weighted sequence with weights . The Azuma-Hoeffding inequality suggests that with probability ,
which means that a general non-uniform weight admits a Hoeffding error and is reduced to when the weights are equal. Furthermore, one can prove that the Hoeffding error is minimized under uniform weights:
Proposition 2.
Let be the weights of the data indexed by . Then the Hoeffding error is minimized when the weights are equal: .
Therefore, the variance from sampling is large under non-uniform aggregate weights and is minimized by uniform aggregate weights. Since the uniform weighting leads to more non-uniform aggregate weights than ERE and 1/age weighting, its variance is also larger.
Because the ERE and 1/age weighting have balanced selection numbers (i.e., balanced aggregate weights), their biases and variance are smaller. They should perform better than uniform weighting for off-policy actor-critic RL. We will verify this in the next subsection.
5.3 Experimental verification
Since we’ve established a theoretical foundation of ERE and 1/age from a bias-variance perspective, we will explore two main propositions from the preceding subsections: (1) Are ERE and 1/age weighting better than uniform weighting? (2) Does the approximated ERE proposed in Eq. (8) track the original ERE well? In addition, since prioritized experience replay (Schaul et al., 2016) (PER) is a popular sampling method, a natural question to ask is (3) Do ERE and 1/age outperform PER?
We evaluate five sampling methods (ERE, ERE_apx, 1/age weighting, uniform, PER) on five MuJoCo continuous-control environments (Todorov et al., 2012): Humanoid, Ant, Walker2d, HalfCheetah, and Hopper. All tasks have a maximum horizon of 1000 and are trained using a Pytorch Soft-Actor-Critic (Haarnoja et al., 2018) implementation on Github (Tandon, 2018). Most hyper-parameters of the SAC algorithm are the same as that in Tandon (2018) except for the batch size, where we find a batch size of 512 tends to give more stable results. Our code is available at https://github.com/sunfex/weighted-sac. The SAC implementation and the MuJoCo environment are licensed under the MIT license and the personal student license, respectively. The experiment is run on a server with an Intel i7-6850K CPU and Nvidia GTX 1080 Ti GPUs.


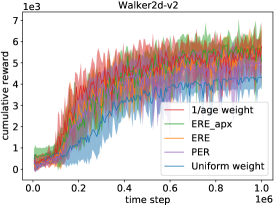
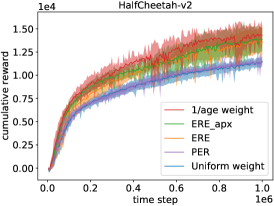

In Figure 2, the ERE and 1/age weighting strategies perform better than the uniform weighting does in all tasks. This verifies our preceding assertion that the ERE and 1/age weighting are superior because their biases and variances of the estimated Q function are smaller. Moreover, ERE and ERE_apx mostly coincide with each other, so Eq. (8) is indeed a good approximation of the ERE strategy. This also explains the implicit connection between ERE and 1/age weighting strategies: ERE is almost equivalent to ERE_apx and 1/age is the main factor in ERE_apx, so ERE and 1/age weighting should produce similar results. Finally, ERE and 1/age generally outperform PER, so the 1/age-based samplings that we study achieve nontrivial performance improvements.
6 Conclusion
To understand an off-policy actor-critic algorithm, we show the policy evaluation error on the expected distribution of transitions decomposes into the Bellman error, the bias from policy mismatch, and the variance from sampling. We use this to explain that a successful off-policy actor-critic algorithm should have a careful sampling strategy that controls its bias and variance. Motivated by the empirical success of Emphasizing Recent Experience (ERE), we prove that ERE is a variant of the 1/age weighting. We then explain from a bias-variance perspective that ERE and 1/age weighting are preferable over uniform weighting because the resulting biases and variances are smaller.
References
-
Agarwal et al. (2019)
Agarwal, A., N. Jiang, S. M. Kakade, and W. Sun
2019. Reinforcement learning: Theory and algorithms. CS Dept., UW Seattle, Seattle, WA, USA, Tech. Rep. -
Duan et al. (2020)
Duan, Y., Z. Jia, and M. Wang
2020. Minimax-optimal off-policy evaluation with linear function approximation. In Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, Pp. 2701–2709, Virtual. PMLR. -
Dudík et al. (2011)
Dudík, M., J. Langford, and L. Li
2011. Doubly robust policy evaluation and learning. In Proceedings of the 28th International Conference on International Conference on Machine Learning, ICML’11, P. 1097–1104, Madison, WI, USA. Omnipress. -
Fan and Ramadge (2021)
Fan, T.-H. and P. Ramadge
2021. A contraction approach to model-based reinforcement learning. In Proceedings of The 24th International Conference on Artificial Intelligence and Statistics, A. Banerjee and K. Fukumizu, eds., volume 130 of Proceedings of Machine Learning Research, Pp. 325–333. PMLR. -
Feng et al. (2020)
Feng, Y., T. Ren, Z. Tang, and Q. Liu
2020. Accountable off-policy evaluation with kernel Bellman statistics. In Proceedings of the 37th International Conference on Machine Learning, H. D. III and A. Singh, eds., volume 119 of Proceedings of Machine Learning Research, Pp. 3102–3111. PMLR. -
Fujimoto et al. (2018)
Fujimoto, S., H. van Hoof, and D. Meger
2018. Addressing function approximation error in actor-critic methods. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018, J. G. Dy and A. Krause, eds., volume 80 of Proceedings of Machine Learning Research, Pp. 1582–1591. PMLR. -
Fujita and Maeda (2018)
Fujita, Y. and S.-i. Maeda
2018. Clipped action policy gradient. In Proceedings of the 35th International Conference on Machine Learning, J. Dy and A. Krause, eds., volume 80 of Proceedings of Machine Learning Research, Pp. 1597–1606. PMLR. -
Gulrajani et al. (2017)
Gulrajani, I., F. Ahmed, M. Arjovsky, V. Dumoulin, and A. C.
Courville
2017. Improved training of wasserstein gans. In Advances in Neural Information Processing Systems, I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, eds., volume 30. Curran Associates, Inc. -
Haarnoja et al. (2018)
Haarnoja, T., A. Zhou, P. Abbeel, and S. Levine
2018. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018, J. G. Dy and A. Krause, eds., volume 80 of Proceedings of Machine Learning Research, Pp. 1856–1865. PMLR. -
Horgan et al. (2018)
Horgan, D., J. Quan, D. Budden, G. Barth-Maron, M. Hessel, H. van Hasselt, and
D. Silver
2018. Distributed prioritized experience replay. In International Conference on Learning Representations. -
Jiang and Li (2016)
Jiang, N. and L. Li
2016. Doubly robust off-policy value evaluation for reinforcement learning. In Proceedings of The 33rd International Conference on Machine Learning, M. F. Balcan and K. Q. Weinberger, eds., volume 48 of Proceedings of Machine Learning Research, Pp. 652–661, New York, New York, USA. PMLR. -
Jin et al. (2018)
Jin, C., Z. Allen-Zhu, S. Bubeck, and M. I.
Jordan
2018. Is q-learning provably efficient? In Advances in Neural Information Processing Systems, S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, eds., volume 31. Curran Associates, Inc. -
Jin et al. (2020)
Jin, C., Z. Yang, Z. Wang, and M. I. Jordan
2020. Provably efficient reinforcement learning with linear function approximation. In Conference on Learning Theory, Pp. 2137–2143. PMLR. -
Kallus and Uehara (2020)
Kallus, N. and M. Uehara
2020. Doubly robust off-policy value and gradient estimation for deterministic policies. In Advances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, eds., volume 33, Pp. 10420–10430. Curran Associates, Inc. -
Lazic et al. (2020)
Lazic, N., D. Yin, M. Farajtabar, N. Levine, D. Gorur, C. Harris, and
D. Schuurmans
2020. A maximum-entropy approach to off-policy evaluation in average-reward mdps. Advances in Neural Information Processing Systems, 33. -
Le et al. (2019)
Le, H., C. Voloshin, and Y. Yue
2019. Batch policy learning under constraints. In International Conference on Machine Learning, Pp. 3703–3712. PMLR. -
Levine et al. (2020)
Levine, S., A. Kumar, G. Tucker, and J. Fu
2020. Offline reinforcement learning: Tutorial, review, and perspectives on open problems. arXiv preprint arXiv:2005.01643. -
Li et al. (2020)
Li, G., Y. Wei, Y. Chi, Y. Gu, and Y. Chen
2020. Sample complexity of asynchronous q-learning: Sharper analysis and variance reduction. In Advances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, eds., volume 33, Pp. 7031–7043. Curran Associates, Inc. -
Lin (1992)
Lin, L. J.
1992. Self-improving reactive agents based on reinforcement learning, planning and teaching. Machine Learning, 8:293–321. -
Liu et al. (2018)
Liu, Q., L. Li, Z. Tang, and D. Zhou
2018. Breaking the curse of horizon: Infinite-horizon off-policy estimation. In Advances in Neural Information Processing Systems, volume 31, Pp. 5356–5366. Curran Associates, Inc. -
Luo et al. (2019)
Luo, Y., H. Xu, Y. Li, Y. Tian, T. Darrell, and
T. Ma
2019. Algorithmic framework for model-based deep reinforcement learning with theoretical guarantees. In International Conference on Learning Representations. -
Miyato et al. (2018)
Miyato, T., T. Kataoka, M. Koyama, and
Y. Yoshida
2018. Spectral normalization for generative adversarial networks. In International Conference on Learning Representations. -
Ni et al. (2019)
Ni, C., L. F. Yang, and M. Wang
2019. Learning to control in metric space with optimal regret. In 2019 57th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Pp. 726–733. -
Novati and Koumoutsakos (2019)
Novati, G. and P. Koumoutsakos
2019. Remember and forget for experience replay. In Proceedings of the 36th International Conference on Machine Learning, K. Chaudhuri and R. Salakhutdinov, eds., volume 97 of Proceedings of Machine Learning Research, Pp. 4851–4860, Long Beach, California, USA. PMLR. -
Precup et al. (2000)
Precup, D., R. S. Sutton, and S. P. Singh
2000. Eligibility traces for off-policy policy evaluation. In Proceedings of the Seventeenth International Conference on Machine Learning, ICML ’00, P. 759–766, San Francisco, CA, USA. Morgan Kaufmann Publishers Inc. -
Schaul et al. (2016)
Schaul, T., J. Quan, I. Antonoglou, and
D. Silver
2016. Prioritized experience replay. In ICLR. -
Schmitt et al. (2020)
Schmitt, S., M. Hessel, and K. Simonyan
2020. Off-policy actor-critic with shared experience replay. In Proceedings of the 37th International Conference on Machine Learning, H. D. III and A. Singh, eds., volume 119 of Proceedings of Machine Learning Research, Pp. 8545–8554, Virtual. PMLR. -
Schulman et al. (2015)
Schulman, J., S. Levine, P. Abbeel, M. Jordan, and
P. Moritz
2015. Trust region policy optimization. In Proceedings of the 32nd International Conference on Machine Learning, F. Bach and D. Blei, eds., volume 37 of Proceedings of Machine Learning Research, Pp. 1889–1897, Lille, France. PMLR. -
Schulman et al. (2017)
Schulman, J., F. Wolski, P. Dhariwal, A. Radford, and
O. Klimov
2017. Proximal policy optimization algorithms. arXiv:1707.06347. -
Silver et al. (2014)
Silver, D., G. Lever, N. Heess, T. Degris, D. Wierstra, and
M. Riedmiller
2014. Deterministic policy gradient algorithms. In Proceedings of the 31st International Conference on Machine Learning, E. P. Xing and T. Jebara, eds., volume 32 of Proceedings of Machine Learning Research, Pp. 387–395, Bejing, China. PMLR. -
Sinha et al. (2020)
Sinha, S., J. Song, A. Garg, and S. Ermon
2020. Experience replay with likelihood-free importance weights. arXiv:2006.13169. -
Sutton et al. (1999)
Sutton, R. S., D. McAllester, S. Singh, and
Y. Mansour
1999. Policy gradient methods for reinforcement learning with function approximation. In Proceedings of the 12th International Conference on Neural Information Processing Systems, NIPS’99, P. 1057–1063, Cambridge, MA, USA. MIT Press. -
Tandon (2018)
Tandon, P.
2018. Pytorch soft actor critic. Github Repository, https://github.com/pranz24/pytorch-soft-actor-critic. -
Thomas and Brunskill (2016)
Thomas, P. and E. Brunskill
2016. Data-efficient off-policy policy evaluation for reinforcement learning. In Proceedings of The 33rd International Conference on Machine Learning, M. F. Balcan and K. Q. Weinberger, eds., volume 48 of Proceedings of Machine Learning Research, Pp. 2139–2148, New York, New York, USA. PMLR. -
Todorov et al. (2012)
Todorov, E., T. Erez, and Y. Tassa
2012. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Pp. 5026–5033. -
Tokdar and Kass (2010)
Tokdar, S. T. and R. E. Kass
2010. Importance sampling: a review. Wiley Interdisciplinary Reviews: Computational Statistics, 2(1):54–60. -
Villani (2008)
Villani, C.
2008. Optimal transport – Old and new, volume 338, Pp. xxii+973. -
Wang and Ross (2019)
Wang, C. and K. Ross
2019. Boosting soft actor-critic: Emphasizing recent experience without forgetting the past. arXiv:1906.04009. -
Xiao et al. (2019)
Xiao, C., Y. Wu, C. Ma, D. Schuurmans, and
M. Müller
2019. Learning to combat compounding-error in model-based reinforcement learning. arXiv:1912.11206. -
Xie et al. (2019)
Xie, T., Y. Ma, and Y.-X. Wang
2019. Towards optimal off-policy evaluation for reinforcement learning with marginalized importance sampling. In Advances in Neural Information Processing Systems, volume 32, Pp. 9668–9678. Curran Associates, Inc. -
Yang et al. (2020)
Yang, M., O. Nachum, B. Dai, L. Li, and
D. Schuurmans
2020. Off-policy evaluation via the regularized lagrangian. Advances in Neural Information Processing Systems, 33. -
Yin et al. (2021)
Yin, M., Y. Bai, and Y.-X. Wang
2021. Near-optimal provable uniform convergence in offline policy evaluation for reinforcement learning. In Proceedings of The 24th International Conference on Artificial Intelligence and Statistics, A. Banerjee and K. Fukumizu, eds., volume 130 of Proceedings of Machine Learning Research, Pp. 1567–1575. PMLR. -
Yin and Wang (2020)
Yin, M. and Y.-X. Wang
2020. Asymptotically efficient off-policy evaluation for tabular reinforcement learning. In Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, S. Chiappa and R. Calandra, eds., volume 108 of Proceedings of Machine Learning Research, Pp. 3948–3958, Online. PMLR. -
Yu et al. (2020)
Yu, T., G. Thomas, L. Yu, S. Ermon, J. Y. Zou, S. Levine, C. Finn, and
T. Ma
2020. Mopo: Model-based offline policy optimization. In Advances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, eds., volume 33, Pp. 14129–14142. Curran Associates, Inc.
Appendix A Appendix
A.1 Hyper-parameters
To train the SAC agents, we use deep neural networks to parameterize the policy and Q functions. Both networks consist of dense layers with the same widths. Table 1 presents the suggested hyper-parameters. As mentioned in the experiment section, the hyper-parameters are similar as the implementation in Tandon (2018).
| Variable | Value |
|---|---|
| Optimizer | Adam |
| Learning rate | 3E-4 |
| Discount factor | 0.99 |
| Batch size | 512 |
| Model width | 256 |
| Model depth | 3 |
| Environment | Hopper | HalfCheetah | Walker2D | Ant | Humanoid |
| Temperature | 0.2 | 0.2 | 0.2 | 0.2 | 0.05 |
A.2 Justification of assumptions
In section 4.1, we introduce three main assumptions in this work. Below is a validation for each.
-
1.
For each and are -Lipschitz in As mentioned in the paragraph ”Normalization” of section 4.2, the Lipschitzness of is sublinear or linear in the horizon, which quantifies the magnitude of ’s Lipschitz constant. Since approximates , should have a similar property as long as the training error is well controlled. The practitioner can also enforce the Lipschitzness of using gradient penalty (Gulrajani et al., 2017) or spectral normalization (Miyato et al., 2018).
-
2.
and are bounded and take values in . This is a standard assumption in the RL literature. If the bound is violated, one can either clip, translate, or rescale to obtain new Q functions that satisfy the constraint. Note a bounded reward has implied .
-
3.
The action space is bounded with diameter . This is a standard assumption in continuous-control environments and is usually satisfied in practice. It is also common to use clipping to ensure the bounds of the actions generated by the policy (Fujita and Maeda, 2018).
A.3 The construction of our behavior policy
We first discuss some important relations between state occupancy measures and Bellman flow operator. Similar results about Fact 1 and 2 be found in Liu et al. (2018)[Lemma 3] and Fan and Ramadge (2021)[Appendix A.1].
Definition 1 (Bellman flow operator).
The Bellman flow operator generated by with discount factor is defined as
Fact 1.
is a -contraction w.r.t. total variational distance.
Proof.
Let be the density functions of some state distributions.
∎
Fact 2.
The normalized state occupancy measure generated by with discount factor is a fixed point of ; i.e., .
Proof.
∎
Thus, the Bellman flow operator is useful to analyze the state occupancy measures, and we have the following lemma to construct the behavior policy .
Lemma 1.
Let the state distribution at trajectory step in episode . Let be the normalized occupancy measure starting at trajectory step in episode . Then , where is the normalized state occupancy measure is generated by . Moreover, we have
Proof.
Precisely, is the state distribution at trajectory step following the laws of . Since is the normalized occupancy measure generated by , each is the fixed-point of the Bellman flow equation:
This implies the average normalized occupancy measure is the fixed point of the Bellman flow equation characterized by :
where is the average behavior policy at step . Since the Bellman flow operator is a -contraction in TV distance and hence has a unique fixed point in TV distance, denoted as , we arrive at almost everywhere. Also, by construction, we have
∎
A.4 Policy Evaluation Error
Lemma 2.
If is -Lipschitz in for any , then, for any state distribution ,
Proof.
For any fixed , we have
where the second line follows from Kantorovich-Rubinstein duality (Villani, 2008). Since the 1-Wasserstein distance is symmetric, we can interchange the roles of and , yielding
Taking the expectation on both sides completes the proof. ∎
Lemma 3.
If is -Lipschitz in for any , then
Proof.
For any , we have
where the last line follows from Lemma 2. Let be the state distribution at step following the laws of . Take expectation over and expand the recursive relation. We arrive at
where the second line follows from . ∎
Lemma 4.
If is -Lipschitz in for any , then
Proof.
For any , we have a recursive relation:
Expand the recursive relation. We have
| (9) |
The last line uses a fact for the normalized occupancy measure :
We are almost done once the in Eq. (9) is replaced by . Note that
| (10) |
The second-last line follows from that the distribution of is , which satisfies the identity
Lemma 5.
Let be a bounded function for . Let be the averaging-discounted operator with infinite-length trajectories in episodes; i.e., . Then, with probability greather than ,
Proof.
Let be the delta measure at the initial state in episode . Because the empirical distribution is composed of the realization of the trajectories’s initial states, we know . Then, Lemma 1 implies is an average of the normalized occupancy measures in episodes.
| (11) |
where is the state density at trajectory step in episode . Since , we have
| (12) |
We claim that defined as is a martingale difference sequence. To see this, let be the filtration of all randomness from episode to , with being a null set. Clearly, we have , and since by assumption, which proves is a martingale difference sequence.
Finally, since is bounded in , by Azuma-Hoeffding inequality, we conclude that with probability greater than ,
∎
Theorem 1.
Let be the number of episodes. For define the operator . Denote the policy mismatch error and the Bellman error as and , respectively. Assume
-
(1)
For each and are -Lipschitz in
-
(2)
and are bounded and take values in .
-
(3)
The action space is bounded with diameter .
Note means , which is a function of . Then, with probability greater than , we have
Proof.
The proof basically combines Lemma 3, 4 and 5. To start with, the objective is decomposed as:
| (13) |
Because , we know , too. Suppose have independent samples. By Hoeffding’s inequality, with probability ,
| (14) |
Also, let . Then is bounded in . Thereby, Lemma 5 implies that with probability greater than ,
| (15) |
Combining Eq. (13), (14) and (15), a union bound implies with probability greater than ,
Finally, rescaling to finishes the proof. ∎
Corollary 1.
Let be the operator defined as . Fix assumptions (1) (2) (3) of Theorem 1. Rewrite the policy mismatch error and the Bellman error as and , respectively, where . Let be the average state density at trajectory step over all episodes. Then, with probability greater than , we have
Moreover, if and the constants are normalized as , , then, with probability greater than , we have
Proof.
Notice that Theorem 1 is the situation when and . To push this to and , recall that Lemma 1 defines the behavior policy , the average state distribution and the state occupancy measure at step . Also, since the trajectories in each episode are initialized using the same initial state distribution, we have . Therefore, the objective of Theorem 1 is actually . This is generalized to using substitutions: , yielding
Finally, observe that for any bounded :
We arrive at
As for the second conclusion, with the substitutions in the statement, we know . Hence,
∎
A.5 Policy Evaluation Error under Non-uniform Weights
Lemma 6.
Following from Lemma 1, let be the (unnormalized) weights for the episodes. We have for the weighted case, , where is the normalized state occupancy measure is generated by . Also,
Proof.
The proof is basically a generalization of Lemma 1. Since is the normalized occupancy measure generated by , we know each is the fixed-point of the Bellman flow equation:
Taking a weighted average, we get
where is the weighted behavior policy at step . Since the Bellman flow operator is a -contraction in TV distance and hence has a unique (up to difference in some measure zero set) fixed point, denoted as , we arrive at Finally, by definition of , we conclude that ∎
Theorem 2.
Let be the (unnormalized) weights for the episodes. Let be the operator defined as . Fix assumptions (1) (2) (3) of Theorem 1. Rewrite the policy mismatch error and the Bellman error as and , respectively, where . With probability greater than , we have
Proof.
The proof basically follows from Theorem 1. Decompose the objective using Lemma 3, 4 as:
| (16) |
where is the weighted empirical initial state distribution. Because , we know , too. By Hoeffding’s inequality, with probability greater than ,
| (17) |
Also, let . Then is bounded in . Using a weighted version of Azuma-Hoeffding in Lemma 5, we have that with probability greater than ,
| (18) |
Combining Eq. (16), (17) and (18), a union bound implies with probability greater than ,
Finally, rescaling to finishes the proof. ∎
Corollary 2.
Let be the operator defined as . Fix assumptions (1) (2) (3) of Theorem 1. Rewrite the policy mismatch error and the Bellman error as and , respectively, where . Let be the average weighted state density at trajectory step . Then, with probability greater than , we have
Moreover, if and the constants are normalized as , , then, with probability greater than , we have
A.6 Proof of Emphazing Recent Experience
Proposition 1.
The ERE strategy in Wang and Ross (2019) is equivalent to a non-uniform sampling with weight :
where is the age of a data point relative to the newest time step; i.e., is the newest sample. is the size of the experience replay. is the maximum horizon of the environment. is the length of the recent trajectory. is the decay parameter. is the minimum coverage of the sampling. Moreover, the ERE strategy can be approximated (by Taylor Approximation) as
Proof.
Recall that Wang and Ross (2019) assume a situation of doing updates in each episode. In the th update, the data is sampled uniformly from the most recent points.
To compute the aggregrated weight over these updates, observe that a data point of age is in the most recent points if and that the weight in each uniform sample is . Therefore, should be proportional to
| (19) |
Because is designed to be lower bounded by , we shall discuss Eq. (19) by cases.
-
(1)
When , we know because is a constraint in the sum. This means and hence is equivalent to . Eq. (19) becomes
where (*) is a substitution: .
-
(2)
When , we know for all because by definition. Eq. (19) becomes
where (*) does a substitution: and split the sum. (**) reuses the analysis in case (1).
Combining cases (1) and (2), we arrive at the first conclusion. As for the approximation, since , let . We have
Thus the first term in the conclusion of Prop. 1 is proportional to . The second term is also proportional to . Since is only made to be proportional to the RHS and both terms on the RHS become proportional to , we can remove on the RHS:
Finally, because , is a positive number, the above expression can be further simplified by timing on the RHS, yielding the result. ∎
Proposition 2.
Let be the weights of the data indexed by . Then the Hoeffding error is minimized when the weights are equal: .
Proof.
Let be the weight vector and be the Hoeffding error. Observe that is of the form:
where is the 2-norm of . Thereby, let be the normalized vector. That is minimized is equivalent to that is minimized for . By the lagrange multiplier, this happens when
This can be achieved by for some . Therefore, we know is minimized when
Since does not depend on , we conclude that the minimizer happens at ∎