Experimental Observations of the Topology of
Convolutional Neural Network Activations††thanks: Version including technical appendix can be found on ArXiv.
Abstract
Topological data analysis (TDA) is a branch of computational mathematics, bridging algebraic topology and data science, that provides compact, noise-robust representations of complex structures. Deep neural networks (DNNs) learn millions of parameters associated with a series of transformations defined by the model architecture, resulting in high-dimensional, difficult-to-interpret internal representations of input data. As DNNs become more ubiquitous across multiple sectors of our society, there is increasing recognition that mathematical methods are needed to aid analysts, researchers, and practitioners in understanding and interpreting how these models’ internal representations relate to the final classification. In this paper, we apply cutting edge techniques from TDA with the goal of gaining insight into the interpretability of convolutional neural networks used for image classification. We use two common TDA approaches to explore several methods for modeling hidden-layer activations as high-dimensional point clouds, and provide experimental evidence that these point clouds capture valuable structural information about the model’s process. First, we demonstrate that a distance metric based on persistent homology can be used to quantify meaningful differences between layers, and we discuss these distances in the broader context of existing representational similarity metrics for neural network interpretability. Second, we show that a mapper graph can provide semantic insight into how these models organize hierarchical class knowledge at each layer. These observations demonstrate that TDA is a useful tool to help deep learning practitioners unlock the hidden structures of their models.
Introduction
Convolutional neural networks (CNNs) are a class of deep learning (DL) models that have been widely used for image classification tasks with great success, but the reasoning behind their decisions is often difficult to determine. Recent work has established an active field of explainable DL to tackle this problem. There are tools that highlight areas of the images most influential to the classification (Selvaraju et al. 2017), or reconstruct idealized input images for each output class (Mahendran and Vedaldi 2015; Wei et al. 2015). There are even tools that try to impose human concepts on the DL model (Kim et al. 2018). The complexity and dependencies present within these trained models demand methods in explainable DL that can summarize complex data without losing critical structures, producing features of internal representations that are both stable and persistent with respect to changing inputs and noise, and significant with respect to representing meaningful features of the input data.
Topological data analysis (TDA) is an emerging field that bridges algebraic topology and computational data science. One of the hallmarks of TDA is its ability to provide compact, noise-robust representations of complex structures within data. These are exactly the kind of representations that are needed in the DL space where different training runs or noisy input data may result in slightly different hidden activations but in no change in the ultimate classification. In other well-documented cases, slight changes in input, perhaps unseen to the human eye, result in misclassifications. We believe TDA can help us understand these cases as well by recognizing changes in the compact representations of the complex structures of hidden activation layers.
In this paper, we build upon others’ recent work in using TDA to understand various aspects of machine learning (ML) and DL models. We provide experimental results that show how a topological viewpoint of hidden-layer activations can summarize and compare the complex structures within them and how the conclusions align with our human understanding of the image classification task. We begin by providing some preliminaries on CNNs and TDA and summarize related work. We then show our experiments, which use two tools from TDA: persistent homology and mapper. Finally, we conclude with a discussion and our directions for future work.
Preliminaries
Convolutional Neural Networks
CNNs are a type of deep neural network that respects the spatial information existing in the input data. They use shared weights to provide translation invariant measures of correlation across an input, which makes them ideal for image classification tasks, where objects requiring identification might be found anywhere in an image.
Mathematically, a trained neural network used for classification is best described as the composition of linear and non-linear tensor maps called layers, where a tensor is a multi-dimensional real-valued array. The input to a neural network is a tensor, and the output of the network is a probability vector indicating the likelihood the input belongs to each class. The intermediate outputs from each layer of the composition are called feature maps or activation tensors. Linear layers use tensor maps that respect element-wise addition and scalar multiplication, and can be either fully connected or convolutional.
Convolutional layers use cross correlation, also known as a sliding dot product, to map 3D tensors to 3D tensors. If the activation tensor from a convolutional layer has dimensions , we say the tensor has channels and spatial dimensions. Activation tensors may be sliced into spatial and channel activations, as shown in Figure 1, and then reshaped to obtain vector representations of their values.

Persistent Homology
One of the two topological tools that we use in our work is persistent homology (PH). At a high level, PH is a method for understanding the topological structure of a space that data are sampled from. We typically have access only to the sample, in the form of a point cloud, and use PH to infer large-scale structures of the unknown underlying space. Here, we provide a brief overview of PH and point readers to Edelsbrunner and Harer (2008); Ghrist (2008) for more details.
The theoretical basis for persistent homology lies in the concept of homology from algebraic topology. Given a topological object, e.g., a surface or the geometric realization of a simplicial complex (a collection of finite sets, , such that if and then ), its homology is an algebraic representation of its cycles in all dimensions. In dimensions 0, 1, and 2, the cycles have simple interpretations as connected components, loops, and bubbles, respectively. Higher dimensional interpretations exist but are less intuitive.
Given a single point cloud, , we can construct a family of associated simplicial complexes on which to compute homology. In this paper, we use the Vietoris-Rips (VR) complex given a scale parameter , . In short, is a simplicial complex where each collection of points in whose pairwise distances are all at most is a set in . We show examples of two VR complexes (just the 1-skeleton, the pairwise edges) of the same point cloud at two scale parameters in Figure 2.
Finally, we can describe the motivation and concept of PH. A single point cloud technically is a simplicial complex, but it is not interesting homologically. Whereas constructing a VR complex at a single scale parameter does provide an interesting topological object, it does not capture the multiscale phenomena of the data. PH is a method that considers all VR scale parameters together to identify at which a cycle is first seen (is “born”) and at which the cycle is fully triangulated (“dies”). This set of birth and death values for a sequence of simplicial complexes of a given point cloud provides a topological fingerprint for a point cloud often summarized in a persistence diagram (PD) as a set of coordinates. Figure 2 also shows the point cloud’s PD from the full sequence of thresholds.

PDs form a metric space under a variety of distance metrics. In this paper, we will use sliced Wasserstein (SW) distance introduced by Carrière, Cuturi, and Oudot (2017). Given two PDs, the SW distance is computed by integrating the Wasserstein distances for all projections of the PD onto lines through the origin at different angles.
Mapper
The mapper algorithm was first introduced by Singh, Memoli, and Carlsson (2007). It is rooted in the idea of “partial clustering of the data guided by a set of functions defined on the data” (2007). On a high level, the mapper graph captures the global structure of the data.
Let be a high-dimensional point cloud. A cover of is a set of open sets in , such that . In the classic mapper construction, obtaining a cover of is guided by a set of scalar functions defined on , referred to as filter functions. For simplicity, we describe the mapper construction using a single filter function . Given a cover of where , we can obtain a cover of by considering as cover elements the clusters (for a choice of clustering algorithm) induced by for each .
Then, the 1D nerve of any cover is a graph and is denoted as . Each node in represents a cover element , and there is an edge between nodes and if is non-empty. If is constructed as above, from a clustering of preimages of a filter function , then its 1D nerve, denoted as , is the mapper graph of .
Consider the point cloud in Figure 3 as an example containing two nested circles. It is equipped with a height function . A cover of is formed by five intervals (see Figure 3 middle). For each (), induces a number of clusters that are subsets of . Such clusters form the elements of a cover of . As shown in Figure 3 (left), the cover elements of are contained within the 12 rectangles on the plane. The mapper graph of is shown in Figure 3c. For instance, cover induces a single cover element of , and it becomes node 1 in the mapper graph of . induces 3 cover elements , and , which become nodes 2, 3 and 4. Since , an edge exists between node 1 and node 2. The two circular structures in Figure 3 (left) are captured by the mapper graph in Figure 3 (right).

Related Work
The value of TDA to organize, understand, and interpret various aspects of ML and DL models has been recognized in several current research directions. Much of this research has focused on model parameters, structure, and weights. Guss and Salakhutdinov (2018) examine model architecture selection by defining the “topological capacity” of networks, or the ability for the network to capture the true topological complexity of the data. They explore the learnability of model architectures in the face of increasing topological complexity of data. Gabrielsson and Carlsson (2019) build the mapper graph of a point cloud of learned weights from convolutional layers within a simple CNN and find that the weights of different CNN model architectures trained on the same data set have topological similarities. “Neural persistence”, developed by Rieck et al. (2019), is a topological measure of complexity of a fully connected deep neural network that depends on learned weights and network connectivity. They find networks that use best practices such as dropout and batch normalization have statistically higher neural persistence, and define a stopping criterion to speedup the training of such a network.
Other studies, like that of Wheeler, Bouza, and Bubenik (2021) use TDA to study activation tensors of simple multi-layer perceptron networks to discover how the topological complexity, as measured by a property of persistence landscapes, changes through the layers. Gebhart, Schrater, and Hylton (2019); Lacombe, Ike, and Umeda (2021) investigate the topology of neural networks via “activation graphs,” which model the natural graphical structure of the network. Finally, most closely related to our work is that of Rathore et al. (2021), which describes TopoAct, a visual platform to explore the organizational principle behind neuron activations. TopoAct displays the mapper graph of activation vectors for a single layer at a time in a CNN to show how the model organizes its knowledge via the branching structures. The authors consider a point cloud formed by randomly sampling a single spatial activation in a given layer for each image in a corpus. We extend this work by using a larger and more data-driven sample of spatial activations to build our mapper graphs, quantifying the intuition of “pure” and “mixed” mapper nodes, considering the effect of noisy input on the resulting graph, and showing how our results generalize to multiple common model architectures.
Point Cloud Summaries of Activations
Following the approach of Rathore et al. (2021), we model each convolutional layer of a CNN as an point cloud by sampling spatial activation vectors from the activation tensors produced by images in a dataset. This gives us a collection of point clouds that can be used to study the evolution of the activation space (i.e., the space of spatial activations), as the complexity of features learned by each layer increases as we move deeper into the model (Zhou et al. 2015; Olah et al. 2020). We introduce several data-driven sampling methods with the goal of improving upon the quality of the sampled point cloud representation.
Random and full activations.
In our mapper experiments, for a fixed layer, we construct a high-dimensional point cloud by randomly sampling a single () spatial activation from each input image, as in Rathore et al. (2021). We additionally experiment with full activation sampling () by including all spatial activations of a given layer for each image in the point cloud construction.
Top -norm activations.
In our PH experiments, for a fixed layer we construct a point cloud with top -norm sampling () by selecting the spatial activation with the strongest -norm from each image.
Foreground and background activations.
For a fixed convolutional layer, each spatial position in the activation tensor can be traced back to its effective receptive field, which is the region of the input image that the network has “seen” via contributions from previous layers. Naturally, each spatial activation corresponds to the subset of the foreground and background pixels in its effective receptive field. To investigate how foreground and background information of an input image manifests in the activation space, we first use cv2.grabCut from the OpenCV library (Bradski 2000) to perform image segmentation and identify the foreground and background pixels in the images. We then assign a weight to each spatial activation according to the number of foreground or background pixels in its effective receptive field, as illustrated in Figure 4. The spatial activations with the greatest weight are selected to represent each image in the point cloud construction, referred to as foreground or background sampling. In our mapper experiments, we study the “top ” foreground and background activations for and .
Reproducibility Details
The following two sections outline our experiments using PH and mapper graphs to study the standard benchmark dataset CIFAR-10 (Krizhevsky and Hinton 2009) on a ResNet-18 architecture (He et al. 2016). We perform standard preprocessing to normalize the images by the mean and variance from the full training set. Code for the models and additional details regarding the dataset, as well as the parameters and computing infrastructure specific to each set of experiments, are provided in the arXiv technical appendix.

Experiments with PH
Using the top -norm sampling method, we construct point cloud summaries of activations from the CIFAR-10 dataset on a ResNet-18 model to study the PH of the activation space. The SW distance between PDs of these point cloud summaries — which we will refer to from now on as the SW distance between layers — proves to be an interesting topological metric for capturing similarity between layers; it exhibits some of the fundamental qualities of strong representation similarity metrics for neural networks but fails to be sensitive to others (Ding, Denain, and Steinhardt 2021).
Relationships Between Layers
In Figure 5, we observe a grid-like pattern in the SW distances between layers of ResNet-18 similar to the results found in Kornblith et al. (2019), which the authors attribute to the residual architecture. This observation supports our belief that meaningful qualities of the model and its architecture can be uncovered by studying the topology of the activation space with PH.

Representation Similarity Metrics & Intuitive Tests
Metrics such as canonical correlation analysis (CCA) (Morcos, Raghu, and Bengio 2018; Raghu et al. 2017), centered kernel alignment (CKA) (Kornblith et al. 2019), and orthogonal Procrustes distance (Ding, Denain, and Steinhardt 2021) provide dissimilarity measures that can be used to compare layers of neural networks. Recent work has demonstrated the value of topological approaches to representation similarity such as Representation Topology Divergence (Barannikov et al. 2022). These methods operate on an matrix representation of a convolutional layer, where the activation tensors produced by each of the inputs from the dataset are normalized and unfolded into vectors in . Here we note this as a key difference from our point cloud representation obtained through top -norm sampling but leave a more thorough comparison to future work.
We apply the intuitive specificity and sensitivity tests outlined by Ding, Denain, and Steinhardt (2021) to probe the utility of the SW distance between layers as a representation similarity metric for neural networks. In comparison to the intuitive test results shown for CCA, CKA, and orthogonal Procrustes distance from Ding, Denain, and Steinhardt (2021), this metric exhibits some non-standard behavior, for which we provide some speculative explanations but further work is needed to fully understand such a metric.
Specificity.
To measure the impact of model initialization seed on the SW distance between layers, we trained 100 ResNet-18 models with different initialization seeds on CIFAR-10, and constructed top -norm point cloud representations of the layers of each model from test set images. Figure 6 shows SW distances for two of the models “A” and “B”, comparing pairs of layers in Model A (left) as well as pairs of layers between Model A and Model B (right). We find that variation in model seed has almost no impact on the SW distances, as shown by the near-identical heatmaps and highlighted for layer 9 (bottom row). The internal and cross-model SW distances relative to Model A layer 9 are highly correlated, with computed by averaging correlation with fixed Model A over the 99 remaining randomly initialized models as Model B. Averaging internal and cross-model correlation relative to each layer of Model A, we find . We conclude that SW distance between layers is highly specific and robust to variation in initialization seed.

Sensitivity.
A representation similarity metric should be robust to noise without losing sensitivity to significant alterations. We apply the intuitive sensitivity test of Ding, Denain, and Steinhardt (2021) by taking the SW distance between each layer and its low-rank approximations as we delete principal components from the point cloud. The SW distance to the corresponding layer in another model is averaged over the remaining 99 randomly initialized models to compute a baseline SW distance for each layer. This baseline defines a threshold of detectable SW distance, above which distance cannot be solely attributed to different initialization. In Figure 7, we see the sensitivity of this metric is heavily dependent on layer depth.
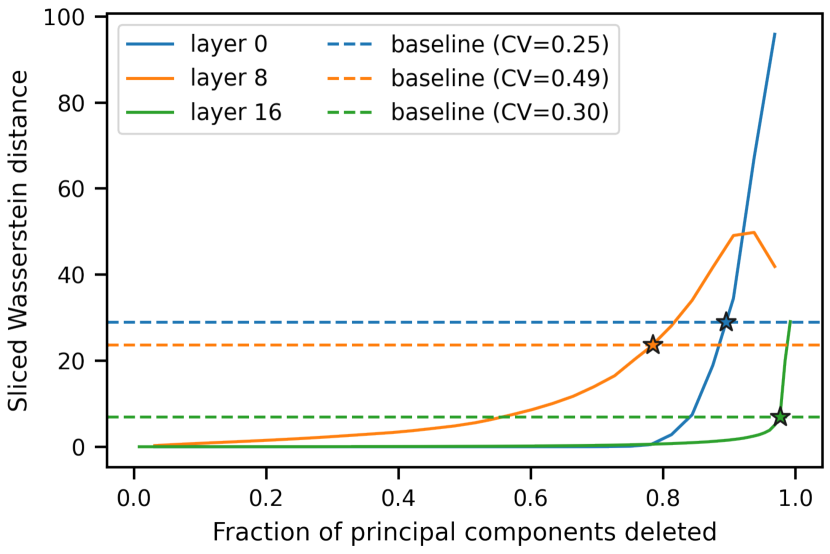
Experiments with Mapper Graphs

In this section, we explore how the topology of the activation space changes across layers by constructing mapper graphs from spatial activations from CIFAR-10 training images on a ResNet-18 model. The mapper graph filter function is the -norm of each spatial activation. We employ and extend MapperInteractive (Zhou et al. 2021), an open-source web-based toolbox for analyzing and visualizing high-dimensional point cloud data via its mapper graph. Because of the visual nature of mapper graphs, our experiments will largely be evaluated by exploring and comparing the qualitative properties of the visualizations rather than quantitative comparisons of structures. The exception will be our purity measures, introduced in a later subsection.
Random and Full Activations
In Figure 8, we compare the mapper graphs generated from a point cloud of random activations () against those generated from the full activations () across different convolutional layers, where is the number of dimensions of each activation, and is the total number of spatial activation vectors per image. The glyph for each node of the mapper graph is a pie chart showing the composition of class labels in that node. It can be seen that at layer 16, the mapper graphs of the random and full activations clearly capture the separation among class labels; there is a central region in the graph where nodes with mixed labels (with lower -norm) separate out into branches with single labels (with higher -norm). As we move toward earlier layers, the ability of the mapper graphs to show class separation gradually deteriorates. In addition, both random and full activations show similar bifurcation patterns, indicating robustness with respect to the sampled activations.
Foreground and Background Activations
Next, we study whether branching structures emerge at earlier layers if we use top foreground or background activations. Figure 9 shows the evolution of mapper graphs using the foreground and background activations across layers. We observe that the mapper graph of foreground activations at layer 15 already shows notable class bifurcations. Such early separations are less obvious for random and full activations. The mapper graphs of background activations also show clear class separations at layer 15 and 16, indicating that background pixels likely play an important role in class separation as well. Mapper graphs for the top 5 foreground and background activations are provided, along with similar observations in the technical appendix.

Activations with Gaussian Noise

To explore the stability of mapper graphs to noise in the input data, we injected pixel-wise Gaussian noise to all 50k images with different standard deviations (). Examples of how the images change as the standard deviation increases are shown in Figure 10, and the corresponding mapper graphs at layer 16 are shown in Figure 11. It can be seen that the mapper graphs are stable for small perturbations (). As increases, mapper graphs illustrate that the model’s ability to differentiate different classes decreases. This observation aligns with the intuition that increasing the noise level will decrease prediction accuracy.

Mapper Graph Purity Measures
For an image classification task, each point (i.e., a spatial activation) is assigned a class label (inherited from the class label of its corresponding input image). We introduce three quantitative measures to quantify how well a mapper graph of the activation space separates the points from different classes.
Node-wise purity.
Given a mapper graph , the node-wise purity of a node is defined as where is the number of class labels in node : the more classes in node , the less pure node is. Figure 12 (bottom) shows the node-wise purity of mapper graphs for foreground (top 1 and 5), random, and full activations at a variety of layers (aligning with the layers seen in Figures 8 and 9). We observe that node-wise purity is larger in deeper layers, indicating that the underlying model gets better at separating the classes the deeper we go. However, the type of sampling seems not to influence the purity as much. Top 5 foreground sampling tends to have slightly higher purity, whereas random sampling has lower purity.
Point-wise purity.
For a point , the point-wise purity is defined as
where is the number of nodes containing point . It is the average node-wise purity of all nodes containing .
Class-wise purity.
For a class , the class-wise purity is defined as
where is the number of points in class . It is the average value of point-wise purity for all points in class . Figure 12 (top) shows the class-wise purity of the deer class for foreground (top 1 and 5), random, and full activations at the same set of layers as node-wise purity. As was the case for the node-wise purity, we observe a general trend of increased class-wise purity of mapper graphs in deeper layers of the neural network.

Generalization of Mapper Experiments to Additional Models

In order to show that our mapper graph observations are not dependent on the ResNet-18 architecture or CIFAR-10 data set we also perform these experiments using a different model-data pair. To compare with the prior experiments which use the lower resolution CIFAR-10 data set, the experiments in this section use a subset of 10 classes from the ImageNet dataset (Deng et al. 2009), as shown in the legend of Figure 13. There are 1300 images per class, resulting in a set of images. The images have varying resolutions with an average resolution of . The data is pre-processed by first resizing each image to 256 pixels and center cropping to a patch of size 2, followed by a normalization with mean and variance of the original ImageNet training set images. For foreground extraction, we apply a different strategy than previously used since cv2.grabCut does not work as well with the ImageNet dataset due to the large amount of high frequency details in the image backgrounds. Instead we use a pre-trained DeepLabV3 semantic segmentation model (Chen et al. 2017) to obtain the foreground mask which is then applied to the images to get the foreground pixels.
The models that we use for the generalization experiments include ResNet-18, Inception_v1 (Szegedy et al. 2015), Inception_v3 (Szegedy et al. 2016) and AlexNet (Krizhevsky, Sutskever, and Hinton 2012). The number of parameters of each model is 11.6M, 6.6M, 27.2M and 61.1M respectively.
Figure 13 shows the resulting mapper graphs generated from the last layer of each model. Through these experiments, we demonstrate that the structures and insights we observe on ResNet-18 applied to CIFAR-10 are applicable to a wide range of other image recognition models as well.
Discussion and Future Work
Our experiments using PH and mapper to study activation tensors of CNNs add to the growing body of literature to suggest that TDA provides useful summaries of DL models and hidden representations. The ability of mapper graphs to summarize point clouds from activation tensors and identify branching structures was previously shown in (Rathore et al. 2021). In our paper, we go beyond the random activations of that prior work to build mapper graphs of foreground, background, and full activation point clouds. These mapper graphs exhibit branching structures at earlier layers and show robustness with respect to image noise. Our new purity measures further quantify the observation that mapper graphs’ branching structures align with class separations, and improve as we go deeper into the layers. Moreover, we also show that the mapper graph branching structures are present not just in ResNet-18 applied to CIFAR-10 but also to ImageNet studied using ResNet-18, InceptionV1 and V3, and AlexNet.
Although the mapper graphs we study come from a single trained model, our PH experiments show that the topological structures of the point clouds from which the mapper graphs are built are independent of the training run. Work has yet to be done to characterize those topological structures for CNNs beyond mapper graphs, but the fact that the distances are training-invariant indicates that such structures are indeed present and thus likely relevant to model interpretation. Although SW distance does pass the specificity test, we observed that, like the widely-cited CKA, it does not pass the sensitivity test of Ding, Denain, and Steinhardt (2021). We expect this is in part due to the previously noted differences between the standard representation and our sampled point cloud; however, our sampling approach is needed to mitigate the computational costs of PH, which scale with dimensionality of the underlying space.
In future work, we plan to further characterize the types of topological structures present in hidden layers of CNNs, explore theoretical justifications for the success of our experiments, and complete a more thorough analysis of the sensitivity of the SW distance via principal component removal. Finally, in order to aid DL practitioners in unlocking the hidden structures of their models, we plan to implement our methods into user-friendly tools.
Appendix A Technical Appendix
Additional Figures for Mapper Experiments
Here we include some additional figures that further strengthen our observations on foreground and background activation point clouds and their robustness to image noise.

In the main body of the paper we showed mapper graphs generated from the top 1 foreground and background activations. In Figure 14 we show additional mapper graphs from the top 5 foreground and background activations. The branching properties and conclusions are similar to those for the top 1 foreground and background mapper graphs.
For our image perturbation experiment we showed mapper graphs generated from the full and foreground activations in the last layer for different levels of injected noise in the input images. In Figure 15 we show additional mapper graphs for the top 5 full activations, again for only the last convolutional layer. We observe that even at noise level there is good branching structure in the last layer while the mapper graphs for the same noise level as in Figure 11 have less clear branching. This may indicate that top 5 activations are more robust to input noise than full and foreground top 1 activations.











Finally, we provide figures for the class-wise purity measures across all classes. In the main body of the paper we showed class-wise purity for the deer class across a variety of layers and for random, full, and foreground (top 1 and top 5) spatial activation sampling. Figures 16 - 25 show the same class-wise purity plot for all 10 classes across all sampling methods with the same scale. The value range for the class-wise purity is . However, to avoid too much white space in the visualizations we make the scale in the plots to be , a bit more than the maximum purity observed.
Reproducibility Checklist
Many of the items in the full reproducibility checklist are addressed in the main body of the paper. Here we provide more details on model parameters, preprocessing and randomization code, and mapper graph parameters for the purposes of reproducibility of our results.
6.1:
Code for preprocessing the data is contained in the following supplementary code files:
-
•
ResNet-18 models implemented and trained from scratch
-
–
PH experiments:
-
*
cifar_resnet.py
-
*
ffcv_cifar10_train.py
-
*
-
–
Mapper experiments:
-
*
cifar_train.py
-
*
-
–
-
•
Injecting Gaussian noise to input data:
-
–
cifar_extract_full_activations_noises.py
-
–
-
•
All types of point cloud creation for both PH and mapper experiments:
-
–
Pulling top -norm activation vectors from each layer for the Experiments with PH section:
-
*
topL2_pointclouds.py
-
*
-
–
Pulling activation vectors for the Experiments with Mapper section
-
*
Functions shared with all following scripts:
cifar_extract.py -
*
Full activations:
cifar_extract_full_activations.py -
*
Random activations:
cifar_extract_sampled_activations.py -
*
Foreground (top 1, top 5) activations:
cifar_extract_full_activations_foreground.py -
*
Background (top 1, top 5) activations:
cifar_extract_full_activations_background.py -
*
Full, foreground activations with Gaussian noises:
cifar_extract_full_activations_noises.py
cifar_extract_full_activations_foreground_noises.py -
*
Activations of ImageNet from additional models: model-forward-pass.ipynb
-
*
-
–
6.2:
Code for conducting and analyzing experiments uses the following custom scripts, openly available packages, and open source tools:
-
•
To compute PD given a point cloud we use the ripser Python package (function ripser.ripser) using default parameter choices (Tralie, Saul, and Bar-On 2018)
-
•
To compute the SW distance we use the persim Python package (function persim.sliced_wasserstein) using default parameter choices
-
•
Code for Experiments with PH:
-
–
SW distances between layers, for a single model or across differently initialized models for specificity test:
-
*
SW_distances.py
-
*
-
–
Removing principal components of point clouds for sensitivity test:
-
*
sensitivity_testing.py
-
*
-
–
-
•
Computing mapper graphs
-
–
Mapper Interactive command line API:
-
*
cover.py
-
*
kmapper.py
-
*
mapper_CLI.py
-
*
nerve.py
-
*
visuals.py
-
*
-
–
The “elbow” approach to get the eps parameter value:
-
*
get_knn.py
-
*
-
–
Full activations:
-
*
get_mapper_full_batches.py
-
*
-
–
Random activations:
-
*
get_mapper_random_batches.py
-
*
-
–
Foreground activations:
-
*
top 1: get_mapper_full_fg_1.py
-
*
top 5: get_mapper_full_fg_5.py
-
*
-
–
Background activations:
-
*
top 1: get_mapper_full_bg_1.py
-
*
top 5: get_mapper_full_bg_5.py
-
*
-
–
Full activations with Gaussian noises:
-
*
get_mapper_full_batches_with_noises.py
-
*
-
–
Foreground activations with Gaussian noises:
-
*
top 1: get_mapper_full_fg_1_noises.py
-
*
top 5: get_mapper_full_fg_5_noises.py
-
*
-
–
Activations from additional models of ImageNet:
-
*
get_mapper_additional_models.py
-
*
-
–
-
•
To compute the mapper graphs using MapperInteractive there are four important parameters to be tuned in the interactive interface: the number of intervals and the overlap rate to create the cover; the DBSCAN clustering parameters eps which sets the maximum distance between two points for one to be considered as in the neighborhood of the other; and min_samples, the number of points in a neighborhood for a point to be considered as a core point.
To create the mapper graphs we use MapperIneractive with the following parameter choices:
-
–
num_intervals=40
-
–
overlap_rate=25%
-
–
min_samples=5
-
–
For the mapper graphs generated from the random, full, foreground and background activations of the CIFAR-10 images at layers 16, 15, 13, 12, 8, and 4, the choices of eps are listed in Table 1
-
–
For the mapper graphs generated from the perturbed images, the eps values are the same as those generated from the original images for comparison purpose.
-
–
For the mapper graphs generated from the random and foreground activations of the ImageNet dataset at the last layers of models ResNet-18, Inception V1, Inception V3 and AlexNet, the choices of eps are listed in Table 2
-
–
-
•
Computing purity measures from a mapper graph and a labeling of points
-
–
Node-wise purity: get_nodewise_purity.py
-
–
Class-wise purity: get_classwise_purity.py
-
–
| Layer | 16 | 15 | 13 | 12 | 8 | 4 |
|---|---|---|---|---|---|---|
| random | 8.71 | 4.22 | 5.04 | 7.69 | 6.80 | 4.50 |
| full | 8.52 | 2.50 | 3.50 | 5.41 | 4.50 | 3.50 |
| fg (top 1) | 10.65 | 8.50 | 9.29 | 11.87 | 8.51 | 4.99 |
| fg (top 5) | 11.00 | 7.50 | 9.52 | 10.05 | 7.00 | 4.00 |
| bg (top 1) | 12.09 | 8.19 | 9.20 | 12.41 | 8.20 | 4.85 |
| bg (top 5) | 10.07 | 8.50 | 9.55 | 11.02 | 7.57 | 4.52 |
| Model | random | foreground |
|---|---|---|
| ResNet-18 | 51.5 | 55.0 |
| Inception V1 | 25.0 | 38.5 |
| Inception V3 | 45.0 | 56.0 |
| AlexNet | 37.0 | 35.0 |
6.3:
All scripts and code outlined in this reproducibility checklist will be publicly released with a permissive license upon publication of this paper.
6.4:
The only code implementing new methods is for the purity measures which was already noted in reproducibility checklist item 6.2.
6.5:
Where randomness is employed in applying Gaussian noise we use numpy.random.randint() to generate random seeds. When selecting random batches of test images in the PH section we use a PyTorch DataLoader with shuffle=True and a random seed of 0. All seeds are applied using torch.manual_seed().
6.6:
For our experiments we used the following computing infrastructures:
-
•
PH experiments:
-
–
GPU models (training): NVIDIA DGX-A100 with 8 A100 GPUs
-
–
GPU models (experiments): Dual NVIDIA P100 12GB PCI-e based GPU
-
–
CPU models: 16 Dual Intel Broadwell E5-2620 v4 @ 2.10GHz CPUs
-
–
Amount of memory: 64 GB 2133Mhz DDR4
-
–
Operating system: Centos 7.8 based operating system (ROCKS 7)
- –
-
–
-
•
Mapper experiments using ResNet-18 on CIFAR-10:
-
–
GPU models: NVIDIA 4x TITAN V with CUDA 11.2
-
–
CPU models: 32 Intel Xeon Silver 4108 CPU @ 1.80GHz cores (HT)
-
–
Amount of memory: 132GB of RAM
-
–
Operating system: OpenSUSE Leap 15.3 (x86_64)
-
–
Relevant software libraries and frameworks:
-
*
Python (v3.6.15)
-
*
MapperInteractive
-
*
PyTorch (v1.9.0)
-
*
sklearn (v0.24.2)
-
*
-
–
-
•
Mapper experiments using ResNet-18, Inception V1, Inception V3 and AlexNet on ImageNet:
-
–
GPU models: NVIDIA GTX 1060
-
–
CPU models: Intel Xeon CPU E5-2630 v3 @ 2.40GHz
-
–
Amount of memory: 32GB of RAM
-
–
Operating system: OpenSUSE Leap 15.1
-
–
Relevant software libraries and frameworks:
-
*
Python (v3.7.5)
-
*
MapperInteractive
-
*
Pytorch (v1.4.0)
-
*
sklearn (v0.23.2)
-
*
-
–
6.10:
Our comparison against other methods (e.g., SW distance vs. CCA and CKA) is not a head-to-head performance comparison and so comparison metrics are not applicable. Instead we discuss the similarities and differences between our observations on SW distance and trends observed by Ding, Denain, and Steinhardt (2021) on CCA and CKA.
6.11:
All architectures and hyper-parameters for the models are standard choices. For all models in the PH section we use the standard ResNet-18 architecture outlined by He et al. (2016) in their analysis of CIFAR-10. For the mapper experiments on the CIFAR-10 dataset, we trained a ResNet-18 model that we implement from scratch. For the mapper experiments on the ImageNet dataset, all the models (ResNet-18, Inception V1, Inception V3 and AlexNet) used are the pre-trained models from the PyTorch built-in model library without any modifications.
Parameters for creating mapper graphs were explained under item 6.2 above.
To create our mapper graphs the final parameter choices were a result of the following process. The num_intervals, overlap_rate and min_samples were determined by manually tuning, and eps values were determined by sorting the distances of the -th nearest neighbor for all points and finding the elbow point, where .
Acknowledgements
MS, BW, and YZ are key contributors to this work. BW was partially funded by NSF DMS 2134223 and IIS 2205418.
References
- Barannikov et al. (2022) Barannikov, S.; Trofimov, I.; Balabin, N.; and Burnaev, E. 2022. Representation Topology Divergence: A Method for Comparing Neural Network Representations. In Chaudhuri, K.; Jegelka, S.; Song, L.; Szepesvari, C.; Niu, G.; and Sabato, S., eds., Proceedings of the 39th International Conference on Machine Learning, volume 162 of Proceedings of Machine Learning Research, 1607–1626. PMLR.
- Bradski (2000) Bradski, G. 2000. The OpenCV Library. Dr. Dobb’s Journal of Software Tools.
- Carrière, Cuturi, and Oudot (2017) Carrière, M.; Cuturi, M.; and Oudot, S. 2017. Sliced Wasserstein Kernel for Persistence Diagrams. In Precup, D.; and Teh, Y. W., eds., Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, 664–673. PMLR.
- Chen et al. (2017) Chen, L.-C.; Papandreou, G.; Schroff, F.; and Adam, H. 2017. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv preprint arXiv:1706.05587.
- Deng et al. (2009) Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; and Fei-Fei, L. 2009. ImageNet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, 248–255.
- Ding, Denain, and Steinhardt (2021) Ding, F.; Denain, J.-S.; and Steinhardt, J. 2021. Grounding Representation Similarity Through Statistical Testing. In Ranzato, M.; Beygelzimer, A.; Dauphin, Y.; Liang, P.; and Vaughan, J. W., eds., Advances in Neural Information Processing Systems, volume 34, 1556–1568.
- Edelsbrunner and Harer (2008) Edelsbrunner, H.; and Harer, J. 2008. Persistent homology—a survey. In Surveys on Discrete and Computational Geometry, volume 453, 257–282. American Mathematical Society.
- Gabrielsson and Carlsson (2019) Gabrielsson, R. B.; and Carlsson, G. 2019. Exposition and Interpretation of the Topology of Neural Networks. In 2019 18th IEEE International Conference on Machine Learning and Applications (ICMLA), 1069–1076.
- Gebhart, Schrater, and Hylton (2019) Gebhart, T.; Schrater, P.; and Hylton, A. 2019. Characterizing the Shape of Activation Space in Deep Neural Networks. 2019 18th IEEE International Conference On Machine Learning And Applications (ICMLA), 1537–1542.
- Ghrist (2008) Ghrist, R. 2008. Barcodes: the persistent topology of data. Bulletin of the American Mathematical Society (New Series), 45(1): 61–75.
- Guss and Salakhutdinov (2018) Guss, W. H.; and Salakhutdinov, R. 2018. On Characterizing the Capacity of Neural Networks using Algebraic Topology. arXiv preprint arXiv:1802.04443.
- He et al. (2016) He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- Kim et al. (2018) Kim, B.; Wattenberg, M.; Gilmer, J.; Cai, C.; Wexler, J.; Viegas, F.; and sayres, R. 2018. Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV). In Dy, J.; and Krause, A., eds., Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, 2668–2677. PMLR.
- Kornblith et al. (2019) Kornblith, S.; Norouzi, M.; Lee, H.; and Hinton, G. 2019. Similarity of Neural Network Representations Revisited. In Chaudhuri, K.; and Salakhutdinov, R., eds., Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, 3519–3529. PMLR.
- Krizhevsky and Hinton (2009) Krizhevsky, A.; and Hinton, G. 2009. Learning multiple layers of features from tiny images. Technical Report TR-2009, University of Toronto, Toronto, Ontario.
- Krizhevsky, Sutskever, and Hinton (2012) Krizhevsky, A.; Sutskever, I.; and Hinton, G. E. 2012. ImageNet Classification with Deep Convolutional Neural Networks. In Pereira, F.; Burges, C.; Bottou, L.; and Weinberger, K., eds., Advances in Neural Information Processing Systems, volume 25.
- Lacombe, Ike, and Umeda (2021) Lacombe, T.; Ike, Y.; and Umeda, Y. 2021. Topological Uncertainty: Monitoring trained neural networks through persistence of activation graphs. In Proceedings of the 30th International Joint Conference on Artificial Intelligence, 2666–2672.
- Leclerc et al. (2022) Leclerc, G.; Ilyas, A.; Engstrom, L.; Park, S. M.; Salman, H.; and Madry, A. 2022. FFCV: Accelerating Training by Removing Data Bottlenecks. https://github.com/libffcv/ffcv/. Commit f253865.
- Mahendran and Vedaldi (2015) Mahendran, A.; and Vedaldi, A. 2015. Understanding Deep Image Representations by Inverting Them. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- Marcel and Rodriguez (2010) Marcel, S.; and Rodriguez, Y. 2010. Torchvision the Machine-Vision Package of Torch. In Proceedings of the 18th ACM International Conference on Multimedia, MM ’10, 1485–1488. New York, NY, USA: Association for Computing Machinery.
- Morcos, Raghu, and Bengio (2018) Morcos, A.; Raghu, M.; and Bengio, S. 2018. Insights on representational similarity in neural networks with canonical correlation. In Bengio, S.; Wallach, H.; Larochelle, H.; Grauman, K.; Cesa-Bianchi, N.; and Garnett, R., eds., Advances in Neural Information Processing Systems, volume 31.
- Olah et al. (2020) Olah, C.; Cammarata, N.; Schubert, L.; Goh, G.; Petrov, M.; and Carter, S. 2020. Zoom In: An Introduction to Circuits. Distill. Https://distill.pub/2020/circuits/zoom-in.
- Paszke et al. (2019) Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; Desmaison, A.; Kopf, A.; Yang, E.; DeVito, Z.; Raison, M.; Tejani, A.; Chilamkurthy, S.; Steiner, B.; Fang, L.; Bai, J.; and Chintala, S. 2019. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Wallach, H.; Larochelle, H.; Beygelzimer, A.; dAlché Buc, F.; Fox, E.; and Garnett, R., eds., Advances in Neural Information Processing Systems 32, 8024–8035. Curran Associates, Inc.
- Raghu et al. (2017) Raghu, M.; Gilmer, J.; Yosinski, J.; and Sohl-Dickstein, J. 2017. SVCCA: Singular Vector Canonical Correlation Analysis for Deep Learning Dynamics and Interpretability. In Guyon, I.; Luxburg, U. V.; Bengio, S.; Wallach, H.; Fergus, R.; Vishwanathan, S.; and Garnett, R., eds., Advances in Neural Information Processing Systems, volume 30.
- Rathore et al. (2021) Rathore, A.; Chalapathi, N.; Palande, S.; and Wang, B. 2021. TopoAct: Visually Exploring the Shape of Activations in Deep Learning. Computer Graphics Forum, 40(1): 382–397.
- Rieck et al. (2019) Rieck, B.; Togninalli, M.; Bock, C.; Moor, M.; Horn, M.; Gumbsch, T.; and Borgwardt, K. 2019. Neural Persistence: A Complexity Measure for Deep Neural Networks Using Algebraic Topology. In International Conference on Learning Representations (ICLR).
- Saul and Tralie (2019) Saul, N.; and Tralie, C. 2019. Scikit-TDA: Topological Data Analysis for Python.
- Selvaraju et al. (2017) Selvaraju, R. R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; and Batra, D. 2017. Grad-CAM: Visual Explanations From Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV).
- Singh, Memoli, and Carlsson (2007) Singh, G.; Memoli, F.; and Carlsson, G. 2007. Topological Methods for the Analysis of High Dimensional Data Sets and 3D Object Recognition. In Botsch, M.; Pajarola, R.; Chen, B.; and Zwicker, M., eds., Eurographics Symposium on Point-Based Graphics.
- Szegedy et al. (2015) Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; and Rabinovich, A. 2015. Going deeper with convolutions. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 1–9.
- Szegedy et al. (2016) Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; and Wojna, Z. 2016. Rethinking the Inception Architecture for Computer Vision. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2818–2826.
- Tralie, Saul, and Bar-On (2018) Tralie, C.; Saul, N.; and Bar-On, R. 2018. Ripser.py: A Lean Persistent Homology Library for Python. The Journal of Open Source Software, 3(29): 925.
- Wei et al. (2015) Wei, D.; Zhou, B.; Torrabla, A.; and Freeman, W. 2015. Understanding intra-class knowledge inside CNN. arXiv preprint arXiv:1507.02379.
- Wheeler, Bouza, and Bubenik (2021) Wheeler, M.; Bouza, J.; and Bubenik, P. 2021. Activation Landscapes as a Topological Summary of Neural Network Performance. In 2021 IEEE International Conference on Big Data (Big Data), 3865–3870. IEEE.
- Zhou et al. (2015) Zhou, B.; Khosla, A.; Lapedriza, À.; Oliva, A.; and Torralba, A. 2015. Object Detectors Emerge in Deep Scene CNNs. In Bengio, Y.; and LeCun, Y., eds., 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings.
- Zhou et al. (2021) Zhou, Y.; Chalapathi, N.; Rathore, A.; Zhao, Y.; and Wang, B. 2021. Mapper Interactive: A Scalable, Extendable, and Interactive Toolbox for the Visual Exploration of High-Dimensional Data. In 2021 IEEE 14th Pacific Visualization Symposium (PacificVis), 101–110.