Expansion-Squeeze-Excitation Fusion Network for Elderly Activity Recognition
Abstract
This work focuses on the task of elderly activity recognition, which is a challenging task due to the existence of individual actions and human-object interactions in elderly activities. Thus, we attempt to effectively aggregate the discriminative information of actions and interactions from both RGB videos and skeleton sequences by attentively fusing multi-modal features. Recently, some nonlinear multi-modal fusion approaches are proposed by utilizing nonlinear attention mechanism that is extended from Squeeze-and-Excitation Networks (SENet). Inspired by this, we propose a novel Expansion-Squeeze-Excitation Fusion Network (ESE-FN) to effectively address the problem of elderly activity recognition, which learns modal and channel-wise Expansion-Squeeze-Excitation (ESE) attentions for attentively fusing the multi-modal features in the modal and channel-wise ways. Specifically, ESE-FN firstly implements the modal-wise fusion with the Modal-wise ESE Attention (M-ESEA) to aggregate discriminative information in modal-wise way, and then implements the channel-wise fusion with the Channel-wise ESE Attention (C-ESEA) to aggregate the multi-channel discriminative information in channel-wise way (referring to Figure 1). Furthermore, we design a new Multi-modal Loss (ML) to keep the consistency between the single-modal features and the fused multi-modal features by adding the penalty of difference between the minimum prediction losses on single modalities and the prediction loss on the fused modality. Finally, we conduct experiments on a largest-scale elderly activity dataset, i.e., ETRI-Activity3D (including 110,000+ videos, and 50+ categories), to demonstrate that the proposed ESE-FN achieves the best accuracy compared with the state-of-the-art methods. In addition, more extensive experimental results show that the proposed ESE-FN is also comparable to the other methods in terms of normal action recognition task.
Index Terms:
Elderly activity recognition, Activity recognition, Fusion network, Multi-modal fusion.I Introduction
With the increasing population of the society, the aging of the population is becoming more and more serious. Coupled with the absence of young people from home all year round, the proportion of empty-nesters in many countries is increasing sharply. Since the physical quality and movement ability of the elderly begin to decline, some kinds of dangers are inclined to occur in life. In such circumstances, some institutions are trying to provide intelligent monitoring for the daily activities of the elderly by employing some advanced technologies in the fields of artificial intelligence and computer vision in recent years. As the key to intelligent monitoring, elderly activity recognition is attracting increased attentions.
By reviewing the normal action recognition methods, we can divide these methods into two categories based on the types of input data, i.e., RGB-based action recognition approach [1, 2, 3, 4, 5, 6, 7, 8], and skeleton-based action recognition approach [9, 10, 11, 12, 13]. For these two types of action recognition methods, various deep neural networks, as the currently main models, have shown remarkable ability to model human actions, such as Convolution Neural Network (CNN) [14], Recurrent Neural Network (RNN) [15], Convolutional 3D (C3D) [16], Long short-term memory (LSTM) [17], Graph Convolutional Networks (GCN) [18], and so on. Generally, the RGB-based action recognition approach mainly gets motion information of actions from RGB videos, which is disturbed by the background information to some extent. The skeleton-based action recognition approach faces a challenge for recognizing the actions with similar postures. Thus, a natural way is to jointly model motion information from both RGB videos and skeleton sequences [19, 20]. One impressive solution of these methods is to build two-branch deep neural networks, that firstly learn multi-modal features from RGB and skeleton modalities, and then fuse them.


Compared with normal action recognition, elderly activity recognition is a more challenging task due to the existence of individual actions and human-object interactions in elderly activities, where many human-object interactions are local; the amplitudes of many elderly activities are unapparent; and the movements of some elderly activities are particularly similar. For example, Figure 2 shows two groups of the typical elderly activities, i.e., “Blowing hair” vs “Combing hair”, and “Making call” vs “playing mobile”. For the comparison between “Blowing hair” and “Combing hair”, the motion trajectory and amplitude are very similar in spatiotemporal space, except for the subtle clues of different objects in hand, i.e., comb and blower. For the comparison between “Making call” and “Playing mobile”, most motions and the interacting object (e.g., mobile) are the same as each other, except for local hand movement in some frames. Therefore, how to capture and fuse the discriminative information in RGB and skeleton modalities is crucial for modeling elderly activities.

Multi-modal data or features fusion across different modalities has always been a hot topic for years [21, 22, 23, 24, 25, 26, 27, 28, 29, 30]. Since multi-modal features often contain irrelevant (modal-specific) information, the straightforward feature-level or score-level fusion will degrade the discriminative ability of the fused features. The key to successful fusion is how to reinforce the discriminative information while suppressing the irrelevant information among multi-modal features. To this end, some works [31, 32, 33] propose to utilize the linear attention to selectively fuse multi-modal features. Witnessing the impressive classification performance of Squeeze-and-Excitation Networks (SENet) [34] on ImageNet, some researchers [35, 36, 37, 38] extend linear fusion to the nonlinear fusion via Squeeze-and-Excitation (SE).
In this work, we consider designing a couple of Squeeze-and-Excitation based networks as nonlinear attention mechanisms for effectively aggregating the motion information in video and skeleton modalities by additionally bringing in expansion, called Expansion-Squeeze-Excitation (ESE). Based on this, we propose a novel Expansion-Squeeze-Excitation Fusion Network (ESE-FN) to fuse multi-modal features with modal and channel-wise ESE attentions. The overview framework of ESE-FN is shown in Figure 3, which mainly consists of four parts, i.e., feature extractor module, modal-fusion module, channel-fusion module, and multi-modal loss. First, ESE-FN randomly samples RGB frames in different video clips, which are fed into the backbone to extract the RGB features. Likewise, the skeleton features can be also extracted from sampled skeleton sequences. Second, the concatenated RGB and skeleton features are fed into the modal-fusion module for attentively fusing features in modal-wise way, where M-Net aims to learn the Modal-wise Expansion-Squeeze-Excitation Attention (M-ESEA) via modal-wise ESE, as shown in Figure 1. Third, the output from the modal-fusion module is further fed into the channel-fusion module for attentively fusing features in channel-wise way, where C-Net aims to learn the Channel-wise Expansion-Squeeze-Excitation Attention (C-ESEA) via channel-wise ESE. Finally, we utilize three types of features, i.e., RGB features, skeleton features, fused multi-modal features, to construct three sub-losses, which are integrated into a new Multi-modal Loss (ML). Here, ML additionally brings in the penalty of difference between the minimum prediction losses on single modalities and the prediction loss on the fused modality, which can keep the consistency between the single-modal features and the fused multi-modal features.
Overall, the main contributions of this work can be summarized as follows.
-
•
We deeply explore the characteristics of elderly activities, and propose a novel Expansion-Squeeze-Excitation Fusion Network (ESE-FN) to attentively fuse multi-modal features in the modal and channel-wise ways for effectively addressing the problem of elderly activity recognition.
-
•
To well capture the discriminative information of multi-modal features, we design a flexible Modal-fusion Net (M-Net) and Channel-fusion Net (C-Net) to learn Modal-wise Expansion-Squeeze-Excitation Attention (M-ESEA) and Channel-wise Expansion-Squeeze-Excitation Attention (C-ESEA) for capturing the modal and channel-wise dependencies among features, respectively.
-
•
To keep the consistency between the single-modal features and the fused multi-modal features, we design a new Multi-modal Loss (ML) to additionally measure the difference between the minimum prediction loss on single modalities and the prediction loss on the fused modality.
-
•
By conducting extensive experiments on both elderly activity recognition and normal action recognition tasks, we illustrate that the proposed ESE-FN method achieves the SOTA performance compared with the other competitive methods.
The rest of this paper is organized in the following. Section II surveys some works related to RGB-based action recognition, skeleton-based action recognition, and multi-modal fusion. Section III introduces the proposed method for elderly activity recognition in details. Section IV presents results and analysis of experiments, followed by the conclusions in Section V.
II Related Work
We survey some works related to RGB-based action recognition, skeleton-based action recognition, and multi-modal fusion.
II-A RGB-based Action Recognition
Most existing RGB-based Action Recognition methods [39, 40, 41, 42, 43, 44, 1, 45, 46, 47, 48, 49] can be categorized into two classes. The first class is based on a two-stream network that usually uses RGB and optical flow to model spatial and temporal information, respectively. Karen et al. [50] proposed a two-stream network to model spatial and temporal information in RGB and optical flow frames for the first time. Subsequently, Wang et al. [51] proposed a Temporal Segment Network (TSN) to model long-range temporal action. Crasto et al. [52] proposed a distillation network that uses optical flow to distill RGB data, which can make the RGB-based model learn the temporal information. It is well known that optical flow is computed by using the RGB frames, which is time-consuming and would bring in a bottleneck. The second class is based on a series of 3D convolutional networks, such as, C3D [16], I3D [7], T3D [53], Res3D [54], and so on, which are extended from 2D networks in spatiotemporal dimension. Due to the computation consumption of general 3D convolutional networks, Qiu et al. [55] proposed a Pseudo-3D residual network (P3D) that decomposes the convolutions into separate 2D spatial and 1D temporal filters. Moreover, Feichtenhofer et al. [3] proposed to use two different frame rates to accelerate train 3D networks.
The above-mentioned methods are proposed to address the problem of normal action recognition. Compared with the normal action recognition task, the elderly activity recognition task requires more discriminative information to identify some subtle individual actions and human-object interactions in elderly activities. Due to the lack of temporal information on RGB data, the network implementing on RGB data cannot accurately describe the actions with obvious temporal information. Although some temporal information can be captured from optical flow data, the calculation of optical flow is too time-consuming.
II-B Skeleton-based Action Recognition
So far, there are many action recognition works based on skeleton [13, 9, 10, 11, 10, 56, 57], called skeleton-based action recognition methods. The main target of skeleton-based action recognition is to learn temporal and spatial information from skeleton sequences. In the early stages, researchers utilized various deep neural networks. e.g., Recurrent Neural Network (RNN), Convolution Neural Network (CNN), and Long Short-Term Memory (LSTM), to model skeleton motions for capturing temporal and spatial information. For example, Zhang et al. [9] proposed an adaptive model designed by CNN and RNN to solve the problem of view difference during the skeleton data collection and action shooting. Banerjee et al. [10] used CNN to extract different complementary motion information from skeleton sequences, e.g., distance and angle between joint points, to better model the temporal information of skeleton data. Recently, researchers used Graph Convolution Network (GCN) to model temporal and spatial information from skeleton sequences by treating skeletons, joints, and bonds as graphs, nodes, and edges, respectively [11, 58, 12]. For example, Yan et al. [11] proposed a Spatial-Temporal Graph Convolutional Network (ST-GAN) that employs graph convolution to aggregate the joint features in the spatial dimension. Liu et al. [58] proposed a multi-stream graph convolutional network to avoid the missing of structural information in the training phase. Cheng et al. [12] proposed a Shift Graph Convolutional Network (Shift-GCN) for solving the problem of inflexible acceptance domain of graph convolution network on both spatial and temporal dimensions.
It can be found that skeleton-based action recognition methods mainly design an effective model to capture temporal and spatial information from skeleton sequences, which is difficult to recognize human-object actions, e.g., blowing hair, combing hair, etc.
II-C Multi-modal Fusion
Many works [59, 60, 19, 20, 61, 26, 23, 24, 30, 29, 62, 47, 63, 46, 64, 65, 66] consider aggregating information from multi-modal data for various image and video content analysis tasks, such as video action recognition, video anomaly detection and localization, and so on. For example, Wang et al. [23] and Tang et al. [24] proposed the score-level and feature-level multi-modal fusions, respectively. Those straightforward fusion methods did not consider the interaction among different multi-modal information. Zhang et al. [30] proposed to employ several convolutions to fuse the RGB and depth features, which only considered the interaction among multi-modal information from the local view. Zhou et al. [29] proposed to fuse the RGB and thermal image features by channel and spatial-wise attentions, respectively. Overall, on the one hand, different modality data have different distributions. On the other hand, multi-modal data often contain irrelevant (modal-specific) information. Thus, how to aggregate information from multi-modal features is the main problem. Multi-modal data or features fusion across different modalities is always a hot topic, some classical methods [31, 32, 33] were proposed to utilize the linear embedding or attention mechanism to fuse multi-modal features. For example, Hori et al. [32] propose a multi-modal attention model that selectively fuses multi-modal features based on learned attention. With the advancement of Convolutional Neural Networks (CNN), some nonlinear fusion approaches of multi-modal features are proposed by designing various convolutional networks as the attention mechanism [35, 36, 37, 38, 67]. For example, Kuang et al. [36] proposed a multi-modal fusion network based on CNN for face anti-spoofing detection. Fooladgar et al. [37] used an efficient attention method based on CNN architecture to fuse RGB data and depth maps in channel-wise way. Su et al. [68] used the soft attention method to interact multi-modal data in channel-wise way. To fully fuse the multi-modal features, we consider interacting information of multi-modal features not only in channel-wise way but also in modal-wise way. In this work, we design a flexible Expansion-Squeeze-Excitation (ESE) in Modal-fusion Net (M-Net) and Channel-fusion Net (C-Net) to learn modal and channel-wise nonlinear attention for capturing the modal and channel-wise dependencies among features, respectively.
III Methodology
In this section, we mainly introduce Expansion-Squeeze-Excitation Fusion Network (ESE-FN). Specifically, we first revisit the SENet as a warm-up, and then introduce the framework of ESE-FN in details, including Modal-fusion Net (M-Net), Channel-fusion Net (C-Net), and Multi-modal Loss (ML).
III-A Revisiting SENet
Squeeze-and-Excitation Networks (SENet) [34] has shown remarkable performance in the ImageNet database by explicitly capturing the channel-wise dependencies between feature maps. Here, the channel-wise dependencies are quantified via the nonlinear attention corresponding to each channel. The nonlinear attention is obtained by Squeeze-and-Excitation (SE). SENet has been proven that learning channel-wise nonlinear attention can improve the discriminative ability of features.
In SENet, Squeeze-and-Excitation (SE) can be divided into two steps: squeeze and excitation in turn, which are used for obtaining channel-wise representation and channel-wise nonlinear attention. Specifically, assuming feature maps, denoted by , for one feature map in the -th channel, the squeeze operation is performed as follows,
| (1) |
where and denote the height and width of the feature map, respectively, is the result of global average pooling for the -th channel. In the squeeze step, all feature maps are transformed to a channel-wise representation , which is a one-dimensional vector. In the excitation step, the channel-wise representation is fed into multi fully-connected layers to obtain the channel-wise attention , as follows,
| (2) |
where denotes a Fully Connected (FC) layer in this work, and is a sigmoid function. Finally, the original feature maps can be updated to by the following equation
| (3) |
where denotes channel-wise multiplication between and . Compared with the original feature maps , the updated feature map has enhanced the discriminative information, while suppressing the useless or irrelevant modal-specific information to some extent.
Through the above analysis, we can find that SENet uses the global average pooling to interact spatial information. Since the global average pooling is implemented from the global view, the learned nonlinear attention is significantly affected by noise (e.g., a large area of background). In this work, to well capture the local and global spatial information of features, we consider interacting spatial information from the local and global views.
III-B Overview of ESE-FN
For the task of elderly activity recognition, we attempt to aggregate the discriminative information from both RGB videos and skeleton sequences by attentively fusing multi-modal features. Thus, multi-modal features fusion across multiple modalities is key to modeling the motion among RGB videos and skeleton sequences. Based on Squeeze-and-Excitation in SENet, we design a new Modal-fusion Net (M-Net) and a new Channel-fusion Net (C-Net) to learn the Modal-wise Expansion-Squeeze-Excitation Attention (M-ESEA) and Channel-wise Expansion-Squeeze-Excitation Attention (C-ESEA) for capturing the modal and channel-wise dependencies among features, respectively. By integrating M-Net and C-Net as the main components, a novel Expansion-Squeeze-Excitation Fusion Network (ESE-FN) is proposed to attentively fuse the multi-modal features with M-ESEA and C-ESEA. The framework of ESE-FN is shown in Figure 3, which mainly consists of four parts, i.e., feature extractor module, modal-fusion module, channel-fusion module, and multi-modal loss.
Denoted as an video set with size , we first split each video into clips and random sample a frame from each clip. Then, we get the frame set as one input video , which are fed into the RGB backbone (e.g., ResNeXt101 [69]) to extract the RGB feature ( denotes the feature dimension in this paper), as follows,
| (4) |
Likewise, for video , the corresponding skeleton sequence is obtained and fed into the skeleton backbone (e.g., Shif-GCN [12]) to extract the skeleton feature ,
| (5) |
Generally, the multi-modal features, i.e., and , have different sizes and cannot be directly concatenated. Thus, we use two MLPS to unify the size of and , and then concatenate them, as follows,
| (6) |
where , is the number of modality, and are MLP, and is a modal-wise concatenation operator.
Subsequently, we transpose the feature and feed it into M-Net for modal-wise fusion, as follows,
| (7) |
where is a transpose operator. Likewise, is transposed and fed into C-Net for channel-wise fusion, as follows,
| (8) |
We sum up feature in modal-wise way and get the fused multi-modal feature .

Finally, RGB feature , skeleton feature and fused multi-modal feature are fed into a new Multi-modal Loss (ML) for optimizing all parameters of ESE-FN, as follows,
| (9) |
where denotes the parameter set of the proposed ESE-FN. The following sections introduce M-Net, C-Net, Multi-modal Loss in details.
III-C Modal-fusion Net (M-Net)
The detailed configuration of Modal-fusion Net (M-Net) is shown in Figure 4. M-Net can attentively aggregate the local and global spatial discriminative information of multi-modal features via M-ESEA in modal-wise way. Specifically, we firstly extend the transposed feature to as the input of M-Net. Similar to Squeeze-and-Excitation in SENet, we divide the implementation of M-Net into three steps, i.e., modal-wise expansion, modal-wise squeeze, and modal-wise excitation in turn, which are detailed in the following.
Modal-wise expansion step. It uses several stacked convolutional layers with different kernels to interact modal-wise information by expanding the modal information from the local view. Then the expanded feature can be described as follows,
| (10) |
where , is the spatial dimension after convolution transformation (). Here, can be also regarded as the single-modal feature set .
Modal-wise squeeze step. It utilizes to calculate the modal-wise representation () from global view via the average pooling, as follows,
| (11) |
Modal-wise excitation step. It utilizes the modal-wise representation to learn the Modal-wise Expansion-Squeeze-Excitation Attention (M-ESEA) for capturing the modal-wise dependence of features. Finally, the original input feature can be updated to the modal-wise fused feature based on the following equations,
| (12) |
| (13) |
Compared with SENet, it is noted that we additionally bring in the expanding of features as the partner of the squeezing. Expanding and squeezing provide the interactions of features in up-size and down-size ways, which can capture both of local and global dependencies of features. Different from SENet dealing with the single-modal feature map, we deal with the multi-modal features which can been seen as a feature map by concatenating two modal feature vectors. In the modal-wise expansion step, the convolutions with different kernels can be used to capture the local spatial correlation of multi-modal features in different regions, which can capture the local dependencies of features. In the modal-wise squeeze step, the global average pooling can be used to capture the global spatial correlation of multi-modal features, which can capture the global dependencies of features.

III-D Channel-fusion Net (C-Net)
In this section, we focus on our Channel-fusion Net (C-Net), as shown in figure 5. C-Net aims to learn C-ESEA for fusing multi-modal features in channel-wise way. Similar to M-Net, the implementation of C-Net can be also divided into the channel-wise expansion, channel-wise squeeze, and channel-wise excitation in turn, described in the following.
Channel-wise expansion step. It uses the convolutional layer to interact channel-wise information by expanding the channel information from the local view. Then the expanded features can be calculated as follows,
| (14) |
where , . It is noted that the multi-modal features are processed by M-Net and C-Net in turn. First, in M-Net, the difference of cross-modal features is relatively large, thus the expansion is large by setting multi-layers. Subsequently, in C-Net (after processed by M-Net), the difference of cross-modal features is relatively small, which only requires a relatively smaller expansion. Thus we set only one convolution layer in C-Net for lightweight designing.
Channel-wise squeeze step. It utilizes to calculate the channel-wise representation from the global view via the average pooling, as follows,
| (15) |
where, can be also regarded as the single-channel feature set .
Channel-wise excitation step. It utilizes the channel-wise representation to learn the Channel-wise Expansion-Squeeze-Excitation Attention (C-ESEA) for capturing the channel-wise dependence of features, as follows,
| (16) |
Finally, we get the feature updated in channel-wise way, described as follows,
| (17) |
By comparing with the formulations of M-Net and C-Net, modal-wise fusion can be seen as a rough fusion of multi-modal features in modal-wise way, while channel-wise fusion can be seen as a fine-grained fusion of multi-modal features in channel-wise way. Both of them attentively aggregate the discriminative information of multi-modal features based on modal and channel-wise dependencies of features.
III-E Multi-modal Loss (ML)
To keep the consistency between the single-modal features and the fused multi-modal features, we design a new Multi-modal Loss (ML) to additionally measure the difference between the prediction loss on single modalities and the prediction loss on the fused modality. The key idea of multi-modal loss is that we take the minimum prediction loss on single modalities to be consistent with the prediction loss on the fused modality. Formally, we define three types of recognition losses , , and corresponding to the RGB modality, skeleton modality, and fused modality, respectively. Then the multi-modal loss can be described as follows,
| (18) |
where and are hyper-parameters (will be discussed in Section IV-C). In this work, the forms of , , and are cross entropy loss.
IV Experiments
In this section, we conduct experiments to evaluate the performance of the proposed ESE-FN in terms of the elderly activity recognition task. Besides, we further conduct comparative experiments between the proposed ESE-FN and the other advanced methods in terms of the normal action recognition task.
IV-A Datasets
We evaluate the performance of ESE-FN in terms of the elderly activity recognition task on the ETRI-Activity3D dataset [70]. It is the currently largest elderly activity recognition dataset collected in real-world surveillance environments, which contains 112,620 samples performed by 100 persons including RGB videos, depth maps, and skeleton sequences. All videos are grouped into 55 classes of actions, including individual activities, human-object interactions, and multiperson interactions. The splitting of training and testing sets is based on person ID, namely the samples with person ID for testing, and the samples with person ID for training.
IV-B Implementation details
In the data pre-processing phase, we split each video into clips, and randomly select one frame for each clip. Finally, we obtain a new video set, wherein each video contains frames. Likewise, we also obtain a new skeleton set, wherein each skeleton sequence contains frames.
In the feature extraction phase, we use ResNeXt18 or ResNeXt101 [69] as the RGB backbone, and Shift-GCN [12] as the skeleton backbone. For the pre-trained ResNeXt18 and ResNeXt101, we fine tune them with the standard SGD optimizer by setting the momentum, initial learning rate, weight decay, and total epochs as 0.9, 0.1, , and 120, respectively. Especially, the batch size is set to 128 and 32 for ResNeXt18 and ResNeXt101, respectively. For the pre-trained Shift-GCN, we fine tune it with the standard SGD optimizer by setting the momentum, initial learning rate, batch size, and total epochs as 0.9, 0.1, , 32, and 140, respectively. Subsequently, we use the fine-tuned RGB and skeleton backbone to extract RGB and skeleton features, respectively. Here, to test the representation performance of ResNeXt18, ResNeXt101, and Shift-GCN, we use these three models to extract single-modal features for training a softmax independently. For example, we use ResNeXt18 to extract RGB features and feed them into the softmax. The obtained performance for three models is listed in Table I. We can see that ResNeXt101 performs better than ResNeXt18. In this paper, we choose ResNeXt101 as the RGB backbone in default.
| Modality | Backbone | Params | Accuracy (%) |
|---|---|---|---|
| RGB | ResNeXt18 | 15.60M | 87.1 |
| ResNeXt101 | 48.16M | 93.5 | |
| Skeleton | Shift-GCN | 0.42M | 88.6 |
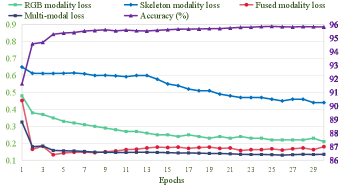
In the training phase of ESE-FN, we use the standard SGD optimizer to train it by setting the momentum, basic learning rate, weight decay, batch size, and total epochs as 0.9, 0.1, , 32 and 30, respectively. All above experiments are performed via the PyTorch deep learning framework on the Linux server equipped with Titan RTX GPU. The training loss and accuracy of ESE-FN as the number of epochs are shown in Figure 6. We can see that the training loss and accuracy of ESE-FN reach a steady state after about epochs. And then, the overall loss is consistent with the other sub-losses (i.e., RGB modality, skeleton modality, and fused modality losses) in terms of convergence.
IV-C Diagnostic Study
We conduct the diagnostic study to discuss the sensitiveness of the hyper-parameters and in Eq. (18). Here, to enhance the efficiency of the diagnostic study, we use ResNeXt18 instead of ResNeXt101 as the RGB backbone and set without loss of generality. Specifically, we empirically tune them by and , respectively. The corresponding results are shown in Figure 7. It can be found that the best performance of ESE-FN is achieved when , and . Thus, we set , and in experiments. Moreover, when =0, the multi-modal loss is degraded to a basic action recognition loss , where the performance is degraded significantly. This illustrates that the designed Multi-modal Loss is more effective than the basic loss.

IV-D Ablation Study
As mentioned before, Modal-fusion Net (M-Net), Channel-fusion Net (C-Net), and Multi-modal Loss (ML) are new components in the framework of the proposed ESE-FN. Thus we conduct ablation study to evaluate the superiority of M-Net, C-Net, and ML. We firstly set seven baselines, as follows,
-
•
B1: Single modal for RGB employs RGB backbone to extract the RGB features, which are directly used to train the softmax classifier. This aims to test the basic recognition performance by using the single-modal features in RGB videos.
-
•
B2: Single modal for skeleton employs skeleton backbone to extract the skeleton features, which are directly used to train the softmax classifier. This aims to test the basic recognition performance by using the single-modal features in skeleton sequences.
-
•
B3: Multi modal for RGB and skeleton employs RGB backbone and skeleton backbone to extract the RGB features and skeleton features, which are concatenated and fed into the softmax classifier. This aims to test the basic recognition performance by simply combining multi-modal features.
-
•
B4: ESE-FN w/o C-Net is a degraded version of ESE-FN by dropping out the channel-fusion module. This aims to show the superiority of M-Net.
-
•
B5: ESE-FN w/o M-Net is a degraded version of ESE-FN by dropping out the modal-fusion module. This aims to show the superiority of C-Net.
-
•
B6: ESE-FN w/o ML is a degraded version of ESE-FN by using the basic loss instead of ML , namely setting , and . This aims to show the superiority of ML.
-
•
B7: the proposed ESE-FN.
| Baseline | RGB | Skeleton | M-Net | C-Net | ML | Accuracy (%) |
|---|---|---|---|---|---|---|
| B1 | ✓ | 93.5 | ||||
| B2 | ✓ | 88.6 | ||||
| B3 | ✓ | ✓ | 94.0 | |||
| B4 | ✓ | ✓ | ✓ | ✓ | 95.3 | |
| B5 | ✓ | ✓ | ✓ | ✓ | 94.5 | |
| B6 | ✓ | ✓ | ✓ | ✓ | 95.7 | |
| B7 | ✓ | ✓ | ✓ | ✓ | ✓ | 95.9 |
| Baseline | Expansion | Modal fusion | Channel fusion | Accuracy (%) |
| A1 | ✓ | 94.3 | ||
| A2 | ✓ | 94.9 | ||
| A3 | ✓ | ✓ | 95.3 | |
| A4 | ✓ | ✓ | 94.5 | |
| A5 | ✓ | ✓ | 95.3 | |
| A6 | ✓ | ✓ | ✓ | 95.9 |
The comparison results among all baselines are shown in Table II. Compared with single-modal and multi-modal baselines, B3-B7 (using multi-modal features) outperform B1-B2 (using single-modal features), which validates that the multi-modal features contain more complementary information than the single-modal features. In particular, B4-B7 are equipped with the newly designed components, and perform better than B3 (simply combining multi-modal features). This validates that each component, i.e., M-Net, C-Net, or ML, is superior to help improving the representation ability of multi-modal feature fusion. Here, B6 integrated with M-Net and C-Net further improves by 0.4%(1.2%) over B4(B5) only with M-Net(C-Net). Obviously, ESE-FN (i.e., B7) integrated with all new components achieves the best performance. It is further validated that M-Net, C-Net, and ML can jointly improve the representation ability of multi-modal feature fusion.
| Methods | Modalities | Backbones | Accuracy(%) |
|---|---|---|---|
| Deep Bilinear Learning [72] | RGB+Depth+Skeleton | VGG16+RNN | 88.4 |
| Evolution Pose Map [71] | RGB+Skeleton | - | 93.6 |
| c-ConvNet [73] | RGB+Depth | VGG16 | 91.3 |
| FSA-CNN [70] | RGB+Skeleton | - | 93.7 |
| ESE-FN (Ours) | RGB+Skeleton | VGG16+Shift-GCN | 93.4 |
| ResNeXt101+Shift-GCN | 95.9 |
SENet is the most related work, where we have added the Expansion step based on SENet and pushed it into the multi-modal fusion task. Thus, we also conduct the ablation experiment to compare with the proposed ESE-FN and SENet by setting six baselines, as follows:
-
•
A1: SENet only for channel-wise fusion uses SENet instead of C-Net for multi-modal feature fusion only in the channel-wise way. This can be seen as simply using Squeeze-Excitation for channel-wise fusion.
-
•
A2: SENet only for modal-wise fusion uses SENet instead of M-Net for multi-modal feature fusion only in the modal-wise way. This can be seen as simply using Squeeze-Excitation for modal-wise fusion.
-
•
A3: SENet for modal and channel-wise fusion uses SENet instead of M-Net and C-Net for multi-modal feature fusion in both the modal-wise and channel-wise ways. This can be seen as simply using Squeeze-Excitation for both modal-wise and channel-wise fusions.
-
•
A4: ESE-FN only for channel-wise fusion only uses C-Net for multi-modal feature fusion in channel-wise way.
-
•
A5: ESE-FN only for modal-wise fusion only uses M-Net for multi-modal feature fusion in modal-wise way.
-
•
A6: ESE-FN (Ours) uses M-Net and C-Net for multi-modal feature fusion in both the modal-wise and channel-wise ways.
The comparison result of the ablation study is listed in Table III. We can find that 1) ESE-FN improves by 0.6% over A3 (SENet for modal and channel-wise fusion), which illustrate that the Expansion step is effective; and 2) A3 outperforms both A1 and A2, as well as A6 outperforms both A4 and A5, which illustrate that our modal and channel-wise fusion strategy is effective and flexible for the SENet family.
IV-E Results and Analysis
We evaluate the performance of the proposed ESE-FN on the elderly activity recognition task by comparing it with the currently representative multi-modal methods, including Deep Bilinear Learning [72], Evolution Pose Map [71], c-ConvNet [73], and FSA-CNN [70]. Specifically, Deep Bilinear Learning uses RGB frames, depth maps, and skeleton sequences; Evolution Pose Map uses 3D and 2D poses extracted from RGB frames and HeatMaps, respectively; c-ConvNet uses RGB frames and depth maps; FSA-CNN uses 2D and 3D skeletons extracted from RGB frames and depth maps. The comparison results of all methods are shown in Table IV, where some results have been reported in [70]. The proposed ESE-FN with the accuracy of 95.9% achieves the state-of-the-art performance, which improves by 2.2% (a relative 2.3% improvement) over the previous SOTA method, namely FSA-CNN with the accuracy of 93.7%. For a fair comparison, ESE-FN adopts the same backbone as the RGB feature extractor, and also performs better than the Deep Bilinear Learning method and c-ConvNet method, which illustrates the robustness of ESE-FN.


In addition, the confusion matrices obtained by ESE-FN, Shift-GCN and ResNeXt101 are shown in Figure 8. First, the confusion matrix of ESE-FN shows that the color of the main diagonal is lighter than other spaces, which illustrates all classes of elderly activities can be well recognized by ESE-FN. Second, compared with the confusion matrices of ESE-FN, Shift-GCN, and ResNeXt101, we can find that the color of the main diagonal in Figure 8(c) is lighter than the color of the main diagonal in Figure 8(a) and (b). This shows that ESE-FN is more effective for recognizing the confusing elderly activities by capturing more discriminative multi-modal information.
| Method | CS (%) | CV (%) |
|---|---|---|
| IndRNN [74] | 81.8 | 88.0 |
| Beyond Joint [75] | 79.5 | 87.6 |
| SK-CNN [76] | 83.2 | 89.3 |
| ST-GCN [11] | 81.5 | 88.3 |
| Motif ST-GCN [77] | 84.2 | 90.2 |
| Ensem-NN [78] | 85.1 | 91.3 |
| MANs [79] | 83.0 | 90.7 |
| HCN [80] | 86.5 | 91.1 |
| Deep Bilinear Learning [72] | 85.4 | - |
| Evolution Pose Map [71] | 91.7 | - |
| c-ConvNet [73] | 82.6 | - |
| FSA-CNN [70] | 91.5 | - |
| STGR-GCN [81] | 86.9 | 92.3 |
| 2s-AGCN [82] | 88.5 | 95.1 |
| DGNN [83] | 89.9 | 96.1 |
| Shift-GCN [12] | 90.7 | 96.5 |
| MS-G3D Net [84] | 91.5 | 96.2 |
| ESE-FN (Ours) | 92.4 | 96.7 |
IV-F Extended Experiment on Normal Action Recognition
To test the generalization of the proposed ESE-FN, we also conduct comparative experiments between the proposed ESE-FN and the other advanced methods in terms of the normal action recognition task. We use the NTU RGB+D dataset [85] as the benchmark. The NTU RGB+D dataset is a large-scale dataset collected by three Kinect cameras from different views concurrently, and has been widely used for evaluating RGB-based or skeleton-based action recognition methods. It includes 56,880 skeleton sequences and 60 different classes from 40 distinct subjects. NTU RGB+D dataset provides two standard evaluation protocols, i.e., Cross-Subject (CS) setting, and Cross-View (CV) setting. In the CS setting, the training set includes 40,320 samples performed by 20 subjects, and the testing set includes 16,560 samples performed by the other 20 subjects. In the CV setting, the training set includes 37,920 samples obtained from camera views 2 and 3, and the testing set includes 18,960 samples obtained from camera view 1.
Table V shows the recognition accuracies obtained by different methods on the NTU RGB+D dataset, where the performance of the other methods have been reported in [70]. We can see that ESE-FN is comparable to the alternatives, including RNN-based methods (e.g., IndRNN [74], Beyond Joint [75]), CNN-based methods (e.g., SK-CNN [76], MANs [79], Deep Bilinear Learning [72]), and GCN-based methods (e.g., ST-GCN [11], Shift-GCN [12]). Specifically, ESE-FN improves by 0.7% and 0.2% over the SOTA methods, namely Evolution Pose Map with the accuracy of 91.7% and Shift-GCN with the accuracy of 96.5% on CS and CV settings, respectively. In addition, we also show the confusion matrices obtained by ESE-FN on NTU RGB+D (CS and CV) in Figure 9(a) and (b). These confusion matrices show that the color of the main diagonal is lighter than other spaces, which illustrates all classes of normal actions can be well recognized by ESE-FN. It can be concluded that the proposed ESE-FN is generalized to recognize normal actions.
V Conclusion
In this work, we propose a novel Expansion-Squeeze-Excitation Fusion Network (ESE-FN) to well address the problem of elderly activity recognition by learning modal and channel-wise Expansion-Squeeze-Excitation (ESE) attentions for attentively fusing the multi-modal features in the modal and channel-wise ways, respectively. Overall, the framework of ESE-FN consisting of the feature extractor module, modal-fusion module, channel-wise module, and multi-modal loss can be summarised as two main insights. First, Modal-fusion Net (M-Net) and Channel-fusion Net (C-Net) can capture the modal and channel-wise dependencies among features for enhancing the discriminative ability of features via Modal and channel-wise ESEs. Second, Multi-modal Loss (ML) can enforce the consistency between the single-modal features and the fused multi-modal features by additionally bringing in the penalty of difference between the minimum prediction losses on the single modalities and the prediction loss on the fused modality. Experimental results on both elderly activity recognition and normal action recognition tasks demonstrate that the proposed ESE-FN achieves the SOTA performance compared with the other competitive methods. To the best of our knowledge, ESE-FN is the first work that adopts the combination of expanding and squeezing to fully interacting features from the local and global views for learning nonlinear attention.
Discussions. We refer to SENet’s idea that enhances the feature quality of different channels via nonlinear attention. SENet only uses a single global pooling operation to get a representation of channel information, which can be seen as a down-sampling interaction of features. In this work, we consider both the up-sampling and down-sampling interaction of features and present a new Expansion step, which can be further used to expand the modal information and channel information. The idea of up-sampling and down-sampling via Expansion and Squeeze is the first attempt in the SENet family, which will be insightful for the other researchers. Moreover, as one member of the SENet family, ESE-FN is not limited only to the task of conventional feature learning and has been successfully extended for multi-modal feature fusion learning. This can be seen as an exemplary case that shows SENet for multi-modal feature fusion learning.
VI Acknowledgements
The work is supported by the National Key RI&D Program of China (No. 2018AAA0102001), the Natural Science Foundation of Jiangsu Province (Grant No. BK20211520), and the National Natural Science Foundation of China (Grant No. 62072245, and 61932020).
References
- [1] X. Shu, L. Zhang, Y. Sun, and J. Tang, “Host–parasite: graph lstm-in-lstm for group activity recognition,” IEEE transactions on neural networks and learning systems, vol. 32, no. 2, pp. 663–674, 2020.
- [2] C. Li, Q. Zhong, D. Xie, and S. Pu, “Collaborative spatiotemporal feature learning for video action recognition,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 7872–7881.
- [3] C. Feichtenhofer, H. Fan, J. Malik, and K. He, “Slowfast networks for video recognition,” in IEEE International Conference on Computer Vision (ICCV), 2019, pp. 6202–6211.
- [4] X. Wang and A. Gupta, “Videos as space-time region graphs,” in European conference on computer vision (ECCV), 2018, pp. 399–417.
- [5] J. Tang, X. Shu, R. Yan, and L. Zhang, “Coherence constrained graph lstm for group activity recognition,” IEEE transactions on pattern analysis and machine intelligence, 2019.
- [6] J. Lin, C. Gan, and S. Han, “Temporal shift module for efficient video understanding. 2019 ieee,” in IEEE International Conference on Computer Vision (ICCV), 2019, pp. 7082–7092.
- [7] J. Carreira and A. Zisserman, “Quo vadis, action recognition? a new model and the kinetics dataset,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 6299–6308.
- [8] X. Shu, J. Tang, G. Qi, W. Liu, and J. Yang, “Hierarchical long short-term concurrent memory for human interaction recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 3, pp. 1110–1118, 2021.
- [9] P. Zhang, C. Lan, J. Xing, W. Zeng, J. Xue, and N. Zheng, “View adaptive neural networks for high performance skeleton-based human action recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 41, no. 8, pp. 1963–1978, 2019.
- [10] A. Banerjee, P. K. Singh, and R. Sarkar, “Fuzzy integral based cnn classifier fusion for 3d skeleton action recognition,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 6, pp. 2206 – 2216, 2020.
- [11] S. Yan, Y. Xiong, and D. Lin, “Spatial temporal graph convolutional networks for skeleton-based action recognition,” in AAAI Conference on Artificial Intelligence (AAAI), 2018, pp. 7444–7452.
- [12] K. Cheng, Y. Zhang, X. He, W. Chen, J. Cheng, and H. Lu, “Skeleton-based action recognition with shift graph convolutional network,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 183–192.
- [13] X. Shu, L. Zhang, G.-J. Qi, W. Liu, and J. Tang, “Spatiotemporal co-attention recurrent neural networks for human-skeleton motion prediction,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021 (publish online DOI: 10.1109/TPAMI.2021.3050918).
- [14] S. Albawi, T. A. Mohammed, and S. Al-Zawi, “Understanding of a convolutional neural network,” in International Conference on Engineering and Technology (ICET), 2017, pp. 1–6.
- [15] W. Zaremba, I. Sutskever, and O. Vinyals, “Recurrent neural network regularization,” arXiv preprint arXiv:1409.2329, 2014.
- [16] D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri, “Learning spatiotemporal features with 3d convolutional networks,” in IEEE International Conference on Computer Vision (ICCV), 2015, pp. 4489–4497.
- [17] S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural computation, vol. 9, no. 8, pp. 1735–1780, 1997.
- [18] T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” arXiv preprint arXiv:1609.02907, 2016.
- [19] G. Liu, J. Qian, F. Wen, X. Zhu, R. Ying, and P. Liu, “Action recognition based on 3d skeleton and rgb frame fusion,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2019, pp. 258–264.
- [20] S. Das, M. Koperski, F. Bremond, and G. Francesca, “Action recognition based on a mixture of rgb and depth based skeleton,” in IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), 2017, pp. 1–6.
- [21] B. Nojavanasghari, D. Gopinath, J. Koushik, T. Baltrušaitis, and L.-P. Morency, “Deep multimodal fusion for persuasiveness prediction,” in ACM International Conference on Multimodal Interaction (ICMI), 2016, pp. 284–288.
- [22] Y. Wang, W. Huang, F. Sun, T. Xu, Y. Rong, and J. Huang, “Deep multimodal fusion by channel exchanging,” Advances in Neural Information Processing Systems (NeurIPS), vol. 33, 2020.
- [23] H. Wang, B. Yu, J. Li, L. Zhang, and D. Chen, “Multi-stream interaction networks for human action recognition,” IEEE Transactions on Circuits and Systems for Video Technology, 2021 (publish online DOI: 10.1109/TCSVT.2021.3098839).
- [24] Y. Tang, Z. Wang, J. Lu, J. Feng, and J. Zhou, “Multi-stream deep neural networks for rgb-d egocentric action recognition,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 29, no. 10, pp. 3001–3015, 2018.
- [25] H. R. V. Joze, A. Shaban, M. L. Iuzzolino, and K. Koishida, “Mmtm: Multimodal transfer module for cnn fusion,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 13 289–13 299.
- [26] W. Zhu, X. Wang, and H. Li, “Multi-modal deep analysis for multimedia,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 30, no. 10, pp. 3740–3764, 2019.
- [27] W. Gao, G. Liao, S. Ma, G. Li, Y. Liang, and W. Lin, “Unified information fusion network for multi-modal rgb-d and rgb-t salient object detection,” IEEE Transactions on Circuits and Systems for Video Technology, 2021 (publish online DOI: 10.1109/TCSVT.2021.3082939).
- [28] X. Zhang, T. Wang, W. Luo, and P. Huang, “Multi-level fusion and attention-guided cnn for image dehazing,” IEEE Transactions on Circuits and Systems for Video Technology, 2020 (publish online DOI: 10.1109/TCSVT.2020.3046625).
- [29] W. Zhou, Q. Guo, J. Lei, L. Yu, and J.-N. Hwang, “Ecffnet: effective and consistent feature fusion network for rgb-t salient object detection,” IEEE Transactions on Circuits and Systems for Video Technology, 2021 (pubish online DOI: 10.1109/TCSVT.2021.3077058).
- [30] Q. Zhang, T. Xiao, N. Huang, D. Zhang, and J. Han, “Revisiting feature fusion for rgb-t salient object detection,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 5, pp. 1804–1818, 2020.
- [31] D. Francis, P. Anh Nguyen, B. Huet, and C.-W. Ngo, “Fusion of multimodal embeddings for ad-hoc video search,” in IEEE/CVF International Conference on Computer Vision Workshops (CVPR), 2019, pp. 0–0.
- [32] C. Hori, T. Hori, T.-Y. Lee, Z. Zhang, B. Harsham, J. R. Hershey, T. K. Marks, and K. Sumi, “Attention-based multimodal fusion for video description,” in IEEE International Conference on Computer Vision (CVPR), 2017, pp. 4193–4202.
- [33] Z. Liu, Y. Shen, V. B. Lakshminarasimhan, P. P. Liang, A. Zadeh, and L.-P. Morency, “Efficient low-rank multimodal fusion with modality-specific factors,” arXiv preprint arXiv:1806.00064, 2018.
- [34] J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 7132–7141.
- [35] D. He, F. Li, Q. Zhao, X. Long, Y. Fu, and S. Wen, “Exploiting spatial-temporal modelling and multi-modal fusion for human action recognition,” arXiv preprint arXiv:1806.10319, 2018.
- [36] H. Kuang, R. Ji, H. Liu, S. Zhang, X. Sun, F. Huang, and B. Zhang, “Multi-modal multi-layer fusion network with average binary center loss for face anti-spoofing,” in ACM International Conference on Multimedia (ACM MM), 2019, pp. 48–56.
- [37] F. Fooladgar and S. Kasaei, “Multi-modal attention-based fusion model for semantic segmentation of rgb-depth images,” arXiv preprint arXiv:1912.11691, 2019.
- [38] D. Liu, K. Zhang, and Z. Chen, “Attentive cross-modal fusion network for rgb-d saliency detection,” IEEE Transactions on Multimedia, vol. 23, pp. 967–981, 2020.
- [39] X. Shu, J. Tang, G.-J. Qi, Z. Li, Y.-G. Jiang, and S. Yan, “Image classification with tailored fine-grained dictionaries,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 28, no. 2, pp. 454–467, 2016.
- [40] Q. Ji, L. Zhang, X. Shu, and J. Tang, “Image annotation refinement via 2p-knn based group sparse reconstruction,” Multimedia Tools and Applications, vol. 78, no. 10, pp. 13 213–13 225, 2019.
- [41] X. Shu, J. Tang, G.-J. Qi, Y. Song, Z. Li, and L. Zhang, “Concurrence-aware long short-term sub-memories for person-person action recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2017, pp. 1–8.
- [42] C. Zhang, Y. Yao, X. Shu, Z. Li, Z. Tang, and Q. Wu, “Data-driven meta-set based fine-grained visual recognition,” in Proceedings of the 28th ACM International Conference on Multimedia, 2020, pp. 2372–2381.
- [43] J. Tang, X. Shu, Z. Li, Y.-G. Jiang, and Q. Tian, “Social anchor-unit graph regularized tensor completion for large-scale image retagging,” IEEE transactions on pattern analysis and machine intelligence, vol. 41, no. 8, pp. 2027–2034, 2019.
- [44] R. Yan, J. Tang, X. Shu, Z. Li, and Q. Tian, “Participation-contributed temporal dynamic model for group activity recognition,” in Proceedings of the 26th ACM international conference on Multimedia, 2018, pp. 1292–1300.
- [45] R. Yan, L. Xie, J. Tang, X. Shu, and Q. Tian, “Higcin: Hierarchical graph-based cross inference network for group activity recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
- [46] K. Song, X.-S. Wei, X. Shu, R.-J. Song, and J. Lu, “Bi-modal progressive mask attention for fine-grained recognition,” IEEE Transactions on Image Processing, vol. 29, pp. 7006–7018, 2020.
- [47] H. Jiang, Y. Song, J. He, and X. Shu, “Cross fusion for egocentric interactive action recognition,” in International Conference on Multimedia Modeling, 2020, pp. 714–726.
- [48] L. Jin, Z. Li, X. Shu, S. Gao, and J. Tang, “Partially common-semantic pursuit for rgb-d object recognition,” in Proceedings of the 23rd ACM international conference on Multimedia, 2015, pp. 959–962.
- [49] Z. Qi, X. Shu, and J. Tang, “Dotanet: Two-stream match-recurrent neural networks for predicting social game result,” in 2018 IEEE fourth international conference on multimedia big data (BigMM). IEEE, 2018, pp. 1–5.
- [50] K. Simonyan and A. Zisserman, “Two-stream convolutional networks for action recognition in videos,” arXiv preprint arXiv:1406.2199, 2014.
- [51] L. Wang, Y. Xiong, Z. Wang, Y. Qiao, D. Lin, X. Tang, and L. Van Gool, “Temporal segment networks: Towards good practices for deep action recognition,” in European Conference on Computer Vision (ECCV), 2016, pp. 20–36.
- [52] N. Crasto, P. Weinzaepfel, K. Alahari, and C. Schmid, “Mars: Motion-augmented rgb stream for action recognition,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 7882–7891.
- [53] A. Diba, M. Fayyaz, V. Sharma, A. H. Karami, M. M. Arzani, R. Yousefzadeh, and L. Van Gool, “Temporal 3d convnets: New architecture and transfer learning for video classification,” arXiv preprint arXiv:1711.08200, 2017.
- [54] D. Tran, J. Ray, Z. Shou, S.-F. Chang, and M. Paluri, “Convnet architecture search for spatiotemporal feature learning,” arXiv preprint arXiv:1708.05038, 2017.
- [55] Z. Qiu, T. Yao, and T. Mei, “Learning spatio-temporal representation with pseudo-3d residual networks,” in IEEE International Conference on Computer Vision (ICCV), 2017, pp. 5533–5541.
- [56] Z. Shao, Y. Li, and H. Zhang, “Learning representations from skeletal self-similarities for cross-view action recognition,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 1, pp. 160–174, 2020.
- [57] Y. Song, C. Ning, L. Fa, X. Liu, X. Shu, Z. Li, and J. Tang, “Multi-part boosting lstms for skeleton based human activity analysis,” in 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), 2017, pp. 605–608.
- [58] K. Liu, L. Gao, N. M. Khan, L. Qi, and L. Guan, “A multi-stream graph convolutional networks-hidden conditional random field model for skeleton-based action recognition,” IEEE Transactions on Multimedia, vol. 23, no. 4, pp. 64–76, 2020.
- [59] J. Liu, X. Fan, J. Jiang, R. Liu, and Z. Luo, “Learning a deep multi-scale feature ensemble and an edge-attention guidance for image fusion,” IEEE Transactions on Circuits and Systems for Video Technology, 2021 (publish online DOI: 10.1109/TCSVT.2021.3056725).
- [60] J. Chen, L. Yang, Y. Xu, J. Huo, Y. Shi, and Y. Gao, “A novel deep multi-modal feature fusion method for celebrity video identification,” in Proceedings of the 27th ACM International Conference on Multimedia (ACM MM), 2019, pp. 2535–2538.
- [61] C. Chen, R. Jafari, and N. Kehtarnavaz, “Fusion of depth, skeleton, and inertial data for human action recognition,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2016, pp. 2712–2716.
- [62] X. Gu, X. Shu, S. Ren, and H. Xu, “Two dimensional slow feature discriminant analysis via l 2, 1 norm minimization for feature extraction,” KSII Transactions on Internet and Information Systems (TIIS), vol. 12, no. 7, pp. 3194–3216, 2018.
- [63] X. Chen, Y. Sun, X. Shu, and Q. Li, “Attention-aware conditional generative adversarial networks for facial age synthesis,” Neurocomputing, vol. 451, pp. 167–180, 2021.
- [64] L. Jin, X. Shu, K. Li, Z. Li, G.-J. Qi, and J. Tang, “Deep ordinal hashing with spatial attention,” IEEE Transactions on Image Processing, vol. 28, no. 5, pp. 2173–2186, 2018.
- [65] C. Shi, J. Zhang, Y. Yao, Y. Sun, H. Rao, and X. Shu, “Can-gan: Conditioned-attention normalized gan for face age synthesis,” Pattern Recognition Letters, vol. 138, pp. 520–526, 2020.
- [66] X. Zhao, P. Huang, and X. Shu, “Wavelet-attention cnn for image classification,” Multimedia Systems, pp. 1–10, 2022.
- [67] A. Raza, H. Huo, and T. Fang, “Pfaf-net: Pyramid feature network for multimodal fusion,” IEEE Sensors Letters, vol. 4, no. 12, pp. 1–4, 2020.
- [68] L. Su, C. Hu, G. Li, and D. Cao, “Msaf: Multimodal split attention fusion,” arXiv preprint arXiv:2012.07175, 2020.
- [69] S. Xie, R. Girshick, P. Dollár, Z. Tu, and K. He, “Aggregated residual transformations for deep neural networks,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 1492–1500.
- [70] J. Jang, D. Kim, C. Park, M. Jang, J. Lee, and J. Kim, “Etri-activity3d: A large-scale rgb-d dataset for robots to recognize daily activities of the elderly,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020, pp. 10 990–10 997.
- [71] M. Liu and J. Yuan, “Recognizing human actions as the evolution of pose estimation maps,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
- [72] J.-F. Hu, W.-S. Zheng, J. Pan, J. Lai, and J. Zhang, “Deep bilinear learning for rgb-d action recognition,” in European Conference on Computer Vision (ECCV), 2018.
- [73] P. Wang, W. Li, J. Wan, P. Ogunbona, and X. Liu, “Cooperative training of deep aggregation networks for rgb-d action recognition,” in AAAI Conference on Artificial Intelligence (AAAI), 2018.
- [74] S. Li, W. Li, C. Cook, C. Zhu, and Y. Gao, “Independently recurrent neural network (indrnn): Building a longer and deeper rnn,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 5457–5466.
- [75] H. Wang and L. Wang, “Beyond joints: Learning representations from primitive geometries for skeleton-based action recognition and detection,” IEEE Transactions on Image Processing, vol. 27, no. 9, pp. 4382–4394, 2018.
- [76] C. Li, Q. Zhong, D. Xie, and S. Pu, “Skeleton-based action recognition with convolutional neural networks,” in IEEE International Conference on Multimedia & Expo Workshops (ICMEW), 2017, pp. 597–600.
- [77] Y.-H. Wen, L. Gao, H. Fu, F.-L. Zhang, and S. Xia, “Graph cnns with motif and variable temporal block for skeleton-based action recognition,” in AAAI Conference on Artificial Intelligence (AAAI), 2019, pp. 8989–8996.
- [78] Y. Xu, J. Cheng, L. Wang, H. Xia, F. Liu, and D. Tao, “Ensemble one-dimensional convolution neural networks for skeleton-based action recognition,” IEEE Signal Processing Letters, vol. 25, no. 7, pp. 1044–1048, 2018.
- [79] C. Li, C. Xie, B. Zhang, J. Han, X. Zhen, and J. Chen, “Memory attention networks for skeleton-based action recognition,” IEEE Transactions on Neural Networks and Learning Systems, 2021 (Publish online DOI: 10.1109/TNNLS.2021.3061115).
- [80] C. Li, Q. Zhong, D. Xie, and S. Pu, “Co-occurrence feature learning from skeleton data for action recognition and detection with hierarchical aggregation,” arXiv preprint arXiv:1804.06055, 2018.
- [81] B. Li, X. Li, Z. Zhang, and F. Wu, “Spatio-temporal graph routing for skeleton-based action recognition,” in AAAI Conference on Artificial Intelligence (AAAI), 2019, pp. 8561–8568.
- [82] L. Shi, Y. Zhang, J. Cheng, and H. Lu, “Two-stream adaptive graph convolutional networks for skeleton-based action recognition,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 12 026–12 035.
- [83] ——, “Skeleton-based action recognition with directed graph neural networks,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 7912–7921.
- [84] Z. Liu, H. Zhang, Z. Chen, Z. Wang, and W. Ouyang, “Disentangling and unifying graph convolutions for skeleton-based action recognition,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 143–152.
- [85] A. Shahroudy, J. Liu, T.-T. Ng, and G. Wang, “Ntu rgb+ d: A large scale dataset for 3d human activity analysis,” in IEEE conference on computer vision and pattern recognition (CVPR), 2016, pp. 1010–1019.