1
Example-based Synthesis of Static Analysis Rules
Abstract.
Static Analysis tools have rules for several code quality issues and these rules are created by experts manually. In this paper, we address the problem of automatic synthesis of code quality rules from examples. We formulate the rule synthesis problem as synthesizing first order logic formulas over graph representations of code. We present a new synthesis algorithm RhoSynth that is based on Integer Linear Programming-based graph alignment for identifying code elements of interest to the rule. We bootstrap RhoSynth by leveraging code changes made by developers as the source of positive and negative examples. We also address rule refinement in which the rules are incrementally improved with additional user-provided examples. We validate RhoSynth by synthesizing more than 30 Java code quality rules. These rules have been deployed as part of a code review system in a company and their precision exceeds 75% based on developer feedback collected during live code-reviews. Through comparisons with recent baselines, we show that current state-of-the-art program synthesis approaches are unable to synthesize most of these rules.
1. Introduction
Software is an integral part of today’s life and low code quality has large costs associated with it. For example, the Consortium for Information & Software Quality notes that “For the year 2020, the total Cost of Poor Software Quality (CPSQ) in the US is $2.08 trillion.”111https://www.it-cisq.org/pdf/CPSQ-2020-report.pdf Hence automated tools to detect code quality issues are an important part of software development. Developers use a variety of tools to improve their software quality, ranging from linters (e.g., SonarLint) to general-purpose code analysis tools (e.g., FindBugs, ErrorProne and Facebook Infer) to specialized tools (e.g., FindSecBugs for code security). There are many facets to code quality and often developers want to develop custom analyzers which detect code quality issues that are of specific interest to them.
A common approach for developing custom analyzers or checkers is expressing them in a domain specific language (DSL), such as Semmle’s CodeQL222https://codeql.github.com/ or Semgrep333https://semgrep.dev/. Code analysis tools such as SonarQube and Semgrep have thousands of rules that have been manually developed by the community of users or the product owners. Development of these rules is a continuous process: new rules are added to guide usage of new APIs or frameworks, and existing rules evolve as the APIs evolve. Further, expressing code checks in a DSL requires specialized knowledge and extensive testing. On the whole, the development of rules is tedious and expensive, and the amount of required human intervention limits the scalability of this manual approach.
In this paper, we address the problem of developing code quality rules from labeled code examples. These examples can be provided by rule authors in the form of conforming and violating examples. In most cases, providing these examples is easier than writing the rule itself. In fact, often, these rules are developed following test-driven development (TDD) (Beck, 2002), where the conforming and violating code examples are used to guide the development of these rules (Ryzhkov, 2011). Rules from various tools such as SonarQube and Semgrep, actually, come with such labeled test code examples. Additionally, we can leverage code changes as the source of labeled examples. In a corpus of code changes, common code quality issues will have multiple code changes that fix those issues. Similar code changes that are performed by multiple developers across projects can be used to obtain examples to synthesize code quality rules. For a code change (code-before, code-after) that fixes a code quality issue, code-before is a violating example and code-after is a conforming example.
We propose RhoSynth, an algorithm for automatically synthesizing high-precision rules from labeled code examples. RhoSynth reduces the rule synthesis problem to synthesizing first order logic formulas over Program Dependence Graphs (PDGs). Using a PDG based program representation not only allows our approach to be more robust to syntactic variations in code, but it also enables a succinct expression of semantic information such as data-flow relation and control-dependence. Compared to existing approaches that synthesize bug-fixes on Abstract Syntax Trees (ASTs) (Bader et al., 2019; Rolim et al., 2018, 2017; Meng et al., 2013), synthesizing rules over a graph representation comes with its own challenge. Unlike trees, where a node can be uniquely identified with the path from the root of the tree to itself, there is no such unique id for nodes in a graph. This ambiguity in identifying a node, consequently identifying a subgraph, makes the synthesis problem hard (Haussler, 1989). We use Integer Linear Programming (ILP) (Schrijver, 1986; Lerouge et al., 2017) to solve this problem that lies at the core of rule synthesis.
We express rules as first order logic formulas comprising an existentially quantified precondition and an existentially quantified postcondition. Specifically, rules have the following format: , where and denotes a set of nodes in the PDG. The precondition captures the applicability of the rule in violating code examples and the postcondition captures the pattern that must be present in conforming code, if the code example satisfies the precondition. This is a rich format that can express a wide range of code quality issues. We synthesize such rules by first synthesizing a precondition over violating examples, and then synthesizing the postcondition that accepts conforming examples satisfying for a given valuation . Through this decomposition, we simplify the rule synthesis problem to synthesizing existentially quantified precondition and postcondition formulas, which are themselves synthesized using ILP. Further, the postcondition formula may contain disjunctions. We propose a top-down entropy-based algorithm to partition conforming examples into groups and synthesize a conjunctive postcondition disjunct for each group.
Recently, there has been lots of work on automated program repair from code changes (Bader et al., 2019; Rolim et al., 2018, 2017; Bavishi et al., 2019; Meng et al., 2013). While code changes themselves are a good source of examples for synthesizing code quality rules, there may be variations in correct code that are not captured in code changes. We propose rule refinement to incrementally improve the rule by providing additional examples corresponding to such code variations. It turns out, both ILP-based graph alignment and disjunctive postcondition synthesis are instrumental in leveraging "unpaired" code examples for refining the rules.
The main contributions of the paper are as follows.
-
(1)
We formulate the problem of synthesizing rules from labeled code examples as synthesis of logical formulas over graph representations of code. We present a novel algorithm RhoSynth that is based on ILP based graph alignment, for identifying nodes in the graph that are relevant to the rule being synthesized.
-
(2)
We propose rule refinement which improves the precision of rules based on a small number of labeled false positive examples.
-
(3)
We validate our algorithm by synthesizing more than 30 Java code-quality rules from labeled code examples obtained from code changes in GitHub packages. These rules have been deployed as part of a code review system in a company. We validate these synthesized rules based on offline evaluation as well as live code review feedback collected over a period of several months. The precision of synthesized rules exceeds 75% in production. Rule refinement improves the precision of rules by as much as 68% in some cases.
-
(4)
We show that recent baselines can synthesize only 22% to 61% of the rules. In addition, we show that, compared to ILP-based graph alignment, commonly used tree-differencing approaches do not perform well when aligning unpaired code examples for rule refinement and this results in rules not being synthesized in a majority of cases.
The paper is organized as follows. Section 2 formally defines the rule synthesis problem and provides an outline of the approach. Section 3 describes the representation for programs and rules. Section 4 describes the rule synthesis algorithm. Section 5 describes the implementation details. Section 6 describes the experimental results. Section 7 presents related work and Section 8 concludes the paper.
2. RhoSynth Overview
This section precisely defines the problem and provides an overview of the approach with a running example.
2.1. Problem Statement
We are given a set of violating or buggy code examples and a set of conforming or non-buggy code examples , for a single code quality issue. The problem is to synthesize a rule from a subset of examples such that = True and = False, for all and in the held-out test set. We consider code examples at the granularity of a method. This offers sufficient code context to precisely capture a wide range of code quality issues (Tufano et al., 2018; Sobreira et al., 2018), while at the same time being simple enough to facilitate efficient rule synthesis.
The corpus of code changes made by developers is a natural source of positive and negative examples. In such a corpus, common code quality issues will have multiple code changes that fix those issues. It is possible to obtain examples for single code quality issues in an automated manner by clustering code changes (Kreutzer et al., 2016; Paletov et al., 2018; Bader et al., 2019). Code changes in the input consist of pairs where is the code-before and is the code-after. To synthesize a rule , we consider code-befores as violating examples and code-afters as conforming examples.
A user can also provide additional conforming examples corresponding to variations in correct code that may not be captured by the code changes.
2.2. RhoSynth Steps
Consider the two code changes shown in Figure 1(a)-(b). The code before the change does not handle the case when the cursor accessing the result set of a database query is empty. Without this check, the app might crash when subsequent operations are called on the cursor (e.g., getString call on line in Figure 1(a). In these code changes, the developer adds this check by handling the case when Cursor.moveToFirst() returns False.
(a) ⬇ 1 ... 2 Cursor cursor = cr.query(...); 3 - cursor.moveToFirst(); 4 + if (cursor.moveToFirst()) { 5 + cursor.close(); 6 + return null; 7 + } 8 final String id = cursor.getString(0); (b) ⬇ 1 ... 2 - mProviderCursor.moveToFirst(); 3 + if (mProviderCursor.moveToFirst()) { 4 + return; 5 + } 6 do { 7 if(mProviderCursor.getLong(...) == id) { 8 ...
As mentioned earlier, RhoSynth first synthesizes the precondition from buggy code examples and then synthesizes the postcondition from non-buggy code examples.
Rule Precondition Synthesis: The precondition synthesis uses only buggy code examples. We perform a graph alignment on their PDG representations to know the correspondence between nodes in different examples. The graph alignment is framed as an ILP optimization problem. In our

example, graph alignment determines that the data variables cursor in Figure 1(a) and mProviderCursor in Figure 1(b) correspond to each other. Similarly, the calls moveToFirst correspond. On the other hand, call getString in the first example does not have any corresponding node in the second example. We use this node correspondence map to construct a Unified Annotated PDG (UAPDG) representation that encapsulates information from all buggy examples. Figure 2 partially illustrates this UAPDG . The solid lines in the figure indicate that the corresponding nodes and edges are present in all buggy examples. We project to these solid nodes and edges and obtain , which is shown in Figure 4(a). corresponds to the precondition formula where is described in Figure 4(d). Besides other checks, the precondition asserts that the output of moveToFirst call is ignored, i.e., it is not defined or not used.

Rule Postcondition Synthesis: We now find all non-buggy code examples that satisfy the precondition. We use a satisfiability solver for this. If there are such examples, we synthesize a postcondition from them and strengthen the precondition with so that the overall rule rejects the non-buggy examples. There are no code-after examples in the input that satisfy the precondition, since the value returned by moveToFirst is used in all of these examples. Consequently, we synthesize a vacuous postcondition = False and the overall rule is the same as the precondition we synthesized above.
Rule Refinement: In several cases, the initial set of examples does not capture all code variations. In case of our current rule, the following checks also check the emptiness of the result set:
-
(1)
Cursor.getCount() == 0.
-
(2)
Cursor.isAfterLast() returns True.
These variations are not part of the initial examples. When we run the synthesized rule on code corpus, we encounter examples such as the ones shown in Figure 3(a)-(b) that check the cursor using these code variations. Note these examples are not accompanied by buggy code. We propose rule refinement that uses these additional non-buggy examples to improve the rule. Specifically, we re-synthesize the postcondition by constructing an UAPDG , in a way similar to the UAPDG construction in rule precondition synthesis. However, it turns out that is too general and accepts even the buggy examples. We use this as a forcing function to partition the non-buggy examples and synthesize a conjunctive postcondition for each partition.
Figure 4(a)-(c) illustrate the UAPDGs for the synthesized precondition and the two disjuncts in the postcondition. Figure 4(d) provides the exact rule, expressed as a logical formula. Informally, the synthesized satisfies all code examples that call Cursor.moveToFirst such that they do not check the value returned by this call, nor call Cursor.isAfterLast or Cursor. getCount. When we run this rule again on the code examples, it correctly accepts all the buggy examples and rejects all non-buggy examples, including the additional examples that were used for rule refinement.
3. Program and Rule Representation
In this section, we describe the PDG based representation of code (Section 3.1), the rule syntax (Section 3.2) and introduce Unified Annotated PDGs (UAPDGs) for representing rules (Section 3.3).
3.1. Code Representation
We represent code examples at a method granularity using PDGs (Ferrante et al., 1987). PDG is a labeled graph that captures all data and control dependencies in a program. Nodes in the PDG are classified as data nodes and action nodes. Data nodes are, optionally, labeled with the data types and values for literals, and action nodes are labeled with the operations they correspond to, for e.g., method name for method call nodes, etc. Edges in the PDG correspond to data-flow and control dependencies and are labeled as recv (connects receiver object to a method call node), parai (connects the parameter to the operation), def (connects an action node to the data value it defines), dep (connects an action node to all nodes that are directly control dependent on it) and throw (connects a method call node to a catch node indicating exceptional control flow). See Figure 6 in Appendix B for the PDG of code-after in Figure 1(a).
3.2. Rule Syntax
In this work, we express rules as quantified first-order logic formulas over PDGs (refer to Figure 5 for a detailed syntax of rules). A rule is a formula of the form , where and are a set of quantified variables that range over distinct nodes in a PDG. The precondition evaluates to True on buggy code and the postcondition evaluates to True on correct code, with appropriate instantiations for , . Because of the negation before the postcondition, the entire formula evaluates to True on buggy code and False on correct code. Intuitively, the precondition captures code elements of interest in buggy, and possibly correct, code, and the postcondition captures the same in correct code. The elements appear as existentially quantified variables. This is a rich format that can express a wide range of code quality issues.
Formulas and are quantifier-free sub-rules comprising a conjunction of atomic edge predicates that correspond to edges in the PDG, and atomic node predicates . express various properties at PDG nodes including the node label, data-type, data values for literals, number of parameters for method calls (num-para(x)), declaring class type for static method calls (declaring-type(x)), the set of nodes on which is transitively control dependent (trans-control-dep(x)) and, finally, whether a method call’s output is/is not ignored (output-ignored(x) and its negation)444Predicate output-ignored(x) is True for a method call when it does not return a value or the returned value has no users, and False otherwise..
Note, we exclude disjunctions in preconditions since a rule with a disjunctive precondition can be expressed as multiple rules without a disjunctive precondition, in the rule syntax. Further, a rule with a precondition comprising a negated code pattern (e.g., ) is expressed using a positive pattern in the rule postcondition, and vice-versa. The rule syntax, while mostly captures first-order logic properties over PDGs, includes some higher-order properties, e.g., transitive control dependence.
Checking if a rule satisfies a code example represented as a PDG can be reduced to satisfiability modulo theories (SMT) (Barrett and Tinelli, 2018). Since PDGs are finite graphs, this satisfiability check is decidable. By mapping nodes in the PDG to bounded integers, this check can be reduced to satisfiability in the Presburger arithmetic. Moreover, state-of-the-art SMT solvers such as Z3 (De Moura and Bjørner, 2008) can discharge these checks efficiently.
3.3. Rule Representation
Rules are formulas that accept or reject code examples represented as PDGs. From the rule syntax (Figure 5), a rule is expressed using a precondition and a postcondition. Both the precondition and the postcondition can be expressed as a collection of quantified formulas , where is a conjunctive subrule defined over free variables and bound variables . To represent rules, we need a representation for . We arrive at a representation for , from a PDG representation, in two steps. We first introduce Valuated PDGs (VPDGs; also, sometimes, referred as valuated examples) that are PDGs extended with variables. VPDGs capture a single PDG that is accepted by . We then introduce Unified Annotated PDGs (UAPDGs) that accept sets of VPDGs and represent the quantified formula .
Let Var be a set of variables. A Valuated PDG is a PDG with a subset of its nodes mapped to distinct variables in Var. Informally, a Valuated PDG is a PDG with a valuation for variables.
As mentioned above, a Unified Annotated PDG is defined over a set of free variables and bound variables , and represents an existentially quantified conjunctive formula over PDGs of the form . Note that is a conjunctive subrule that is defined over a set of node predicates ( in Figure 5). These node predicates are expressed using lattices annotating different nodes in a UAPDG (see Section 5 for details). Formally,
Definition 1 (Unified Annotated PDG).
Given a distinct set of free variables and bound variables , a , where is the set of node predicates at expressed using lattices, and and are maps from a disjoint subset of its nodes to distinct variables in and , respectively.
Note that bound variables can be permuted in the map without affecting the semantics of a UAPDG. On the other hand, variables cannot be permuted or renamed in the map , since these variables are free (they are bound to an outer existential quantifier in the rule ). We call nodes in , mapped to variables in , frozen since the variables mapped to these nodes are fixed for a given UAPDG.
For constructing a UAPDG from a set of VPDGs, we need to first identify corresponding nodes in VPDGs and then unify the node predicates at the corresponding nodes. We identify corresponding nodes through graph alignment using ILP (see Section 4.1) and the unification of node predicates is performed by generalization over the lattice. We describe the use of UAPDG representation to synthesize rule preconditions and postconditions in Section 4.
Notation: We use italicized font to denote a single example or a PDG or a Valuated PDG (e.g., C, E, V) and script font to denote sets of examples or a Unified Annotated PDG (e.g., , , , ). Also, we use superscripts, e.g., , to denote the set of free variables over which a UAPDG or VPDG is defined ( denotes UAPDG with no free variables).
Example 2.
Figure 4(b) illustrates a UAPDG defined over free variables and bound variables . The label at each node in the figure visualizes the value of maps , and Lat at that node. In this UAPDG, let be the node with data type "Cursor" and be the node with label "moveToFirst". Then, at node , , and map is undefined. Further, we say that nodes and are frozen in this UAPDG since they are mapped to free variables and respectively.
Translating a UAPDG to an existentially quantified formula over graphs: A UAPDG naturally translates into an existentially quantified conjunctive formula over Valuated PDGs. If is the set of free variables, and is the set of bound variables, the translation of the UAPDG is a formula , where is the conjunction of all satisfying atomic node and edge predicates expressed over and .
Example 3.
Constructing a UAPDG from a Valuated PDG: We can construct a UAPDG from a Valuated PDG or a PDG, which can be seen as a Valuated PDG with an empty node-variable map, in the following manner:
-
•
Inherit the set of nodes and the set of edges from the Valuated PDG.
-
•
Construct the map by iterating over all nodes in the Valuated PDG and computing the lattice values for all node predicates at .
-
•
Initialize with the node-variable map in the Valuated PDG.
-
•
Construct by mapping all nodes outside the domain of to distinct variables in (these nodes are bound locally to an existential quantifier in the formula that captures the UAPDG).
Note that a UAPDG obtained by enhancing a PDG (or Valuated PDG), in the above way, corresponds to a formula that accepts the PDG (or Valuated PDG). Henceforth, in the text, we use UAPDG to refer to both the graph structure obtained by enhancing PDGs or Valuated PDGs and the existentially quantified formulas they corresponds to, interchangeably.
4. Rule Synthesis Algorithm
The outline of the rule synthesis algorithm is as follows. We first synthesize the precondition based on violating examples. We then synthesize the postcondition based on conforming examples that satisfy the precondition. If the postcondition is not satisfied by any violating example, the synthesis is complete. If a violating example satisfies a postcondition, we follow a hierarchical partitioning approach: pick a conjunct which is satisfied by the violating example, split the underlying partition based on an entropy-based algorithm and recursively synthesize post-conditions for the new partitions. The final postcondition is the disjunction of postconditions of the leaf partitions.
The overall rule synthesis algorithm is described in Algorithm 1. Inputs to the algorithm is the set of violating and conforming examples . It proceeds in the following steps:
Synthesize precondition from :
This is achieved by method getConjunctiveSubRule().
It first calls method merge to align examples in using ILP (described in detail in Section 4.1 and 4.2). This constructs a UAPDG . Then, it identifies nodes in that have a mapping to some node in each example. This is performed by method project and results in a UAPDG (subscript stands for common). Nodes in are existentially quantified since they correspond to some node in each example in .
This resultant UAPDG is translated to the precondition formula using the translation described in Section 3.3.
Find subset of which satisfy the precondition:
This is accomplished by querying the SMT solver. If a conforming example satisfies the precondition , the solver also returns the model comprising the satisfying node assignments for .
We map these nodes to the corresponding variables in to get the set of VPDGs .
Note that the nodes in the VPDGs mapped to variables in are frozen, since the examples satisfy the precondition through these nodes.
Synthesize postcondition from :
This is achieved by method synthesizePC(). Besides , we also pass to this method violating examples with a node assignment that satisfy the precondition. Initially, all the conforming examples in the input constitute a single partition. For these examples, we use the ILP graph alignment to align unfrozen nodes and synthesize a postcondition (using method getConjunctiveSubRule as before).
If the postcondition is unsatisfiable on all frozen violating examples, we return the synthesized postcondition. Otherwise, it implies that the postcondition synthesized from all examples in the partition is too general to reject violating examples, and we partition the set of conforming examples further. The partitioning algorithm is described in Section 4.3.
Example 1.
Consider postcondition synthesis for the rule described in Section 2.2. Calling getConjunctiveSubrule on all conforming examples satisfying the precondition returns a UAPDG that is same as the synthesized precondition, visualized in Figure 4(a). Violating examples such as code-befores in Figure 1 satisfy . Therefore, confoming examples are partitioned and a separate postcondition is synthesized for each partition (UAPDGs in Figure 4(b-c)).
We next describe the different components of the rule synthesis algorithm in greater detail.
4.1. Maximal Graph Alignment using ILP
Graph alignment amongst the violating examples or conforming examples is one of the key steps in synthesizing the rule precondition or postcondition respectively. Since both the precondition and postcondition formulas are existentially quantified, the synthesis problem is NP-hard (Haussler, 1989). Its hardness stems from different choices available for mapping existential variables to nodes in the example graphs. Alternatively, the synthesis problem can be seen as a search over graph alignments such that aligned nodes in different examples are mapped to the same existential variable. Note that different graph alignments will result in different synthesized formulas. Given multiple graphs, we iteratively align two graphs at a time555This is an instance of a “multi-graph matching” problem. This requires optimization techniques beyond ILP, for e.g., alternating optimization (Yan et al., 2013). We did not explore these solutions since pairwise graph alignment worked well for our application.. We frame the problem of choosing a desirable graph alignment for a pair of example graphs as an ILP optimization problem. Since we want to synthesize formulas that precisely capture the code examples, we choose alignments that maximize the number of aligned nodes and edges.
The ILP objective to maximize graph alignment can also be viewed as minimizing the graph edit distance between code examples. Consequently, our reduction to ILP follows the binary linear programming formulation to compute the exact graph edit distance between two graphs (Lerouge et al., 2017). The node and edge substitutions are considered cost and node/edge additions and deletions are cost operations. We include a detailed reduction to the ILP optimization problem in Appendix C. Below, we describe some constraints on the ILP optimization that are specific to our application:
-
•
We align action nodes only if they have the same label. So, a method call foo in one example cannot align with method bar in another example. However, data nodes that are,optionally, labeled with their types do not have this restriction. This allows us to align data nodes even when their types do not resolve, or when their types are related in the class hierarchy, for e.g., InputStream and FileInputStream.
-
•
Two data nodes align only if they have at least one aligned incoming or outgoing edge. This restricts alignment of data nodes to only occurrences when they are defined or used by aligned action nodes.
-
•
When synthesizing the postcondition, nodes frozen to the same variables in are constrained to be aligned.
When synthesizing rules from code changes, we use the ILP formulation described in this section to perform a fine-grained graph differencing over PDGs in a code change (similar to the GumTree tree differencing algorithm (Falleri et al., 2014)). Graph differencing labels nodes in the PDGs with change tags: unchanged, deleted or added, depending upon whether the node is present in both code-before and code-after, in only code-before, and in only code-after. Now, while aligning the violating code-before’s for synthesizing the precondition, we require that the node alignment respect these change tags, i.e., nodes are aligned only if their change tags are the same. This constraint helps to focus the synthesized precondition formula on the changed code. This constraint is removed when synthesizing the postcondition. This is because even variables frozen in the conforming examples, by design, may not respect these change tags.
4.2. Synthesizing Conjunctive Subrules
In this section, we describe the procedure getConjunctiveSubRule to synthesize a conjunctive subrule from a given set of valuated examples. It has two main steps. First, UAPDGs that correspond to input valuated examples are iteratively merged pairwise to obtain a UAPDG . Second, we project to nodes present in all input examples to obtain UAPDG . Given UAPDGs and , obtained by calling merge followed by a project over-approximates . This property ensures that obtained after merging a set of input valuated examples is saltisfied by all of them. We first describe the merge operation, followed by project.
Let and , be two UAPDGs over the same set of free variables . Let and be the node and edge mappings that are obtained from the graph alignment step. We first extend these mappings to relations and such that , and . Then, returns a UAPDG constructed as follows:
-
•
-
•
We first compute . Since is an edge mapping obtained from the graph alignment step, it follows that . Further, from definition of , it follows that . Once is computed, .
-
•
where the join is applied point-wise to each node predicate at and (we assume that )
-
•
, if
-
•
Nodes not mapped to free variables are mapped to distinct fresh variables– if , then for a distinct variable .
Method project with respect to and projects the merged UAPDG to which has nodes (resp. edges) that map to nodes (resp. edges) in both and , i.e., nodes in are of the form where and edges are of the form where .
Theorem 2.
For any node mapping and edge mapping that is obtained from aligning and , .
The proof outline for the above theorem is presented in Appendix D. Besides, returning the formula for , method getConjunctiveSubrule also returns the set of valuated examples labeled with bound variables used for constructing . This is achieved by projecting to nodes (resp. edges) that map to nodes (resp. edges) in each example. Note, to synthesize conjunctive subrules from a single example (possible in the case of postcondition synthesis), we heuristically include in the subrule all nodes at distance from nodes bound to free variables .
4.3. Partitioning Conforming Examples
In this section, we describe the method generateCandidatePartitions.
This method returns a list of low entropy partitions of the input examples , based on the clustering algorithm in (Li et al., 2004).
Let be the set of nodes in and be the set of nodes in , where and are the UAPDGs obtained after calling merge and then calling project on examples in respectively.
For , let be the set of examples such that maps to a node in
and let . Entropy of a partition with respect to is:
,
, where
,
where .
Nodes in by definition are mapped to nodes in all input examples.
Since code patterns in a rule are often localized, we consider partitions with respect to nodes in that neighbor nodes in . Further, we return the set of all partitions whose entropy is within a margin of the smallest entropy partition.
Each of these partitions is explored in a BFS manner in method synthesizePC.
The process stops at the first partition that synthesizes a postcondition that is unsatisfied by all violating examples.
4.4. Discussion about RhoSynth
Precision and Generalization: RhoSynth prefers precision over recall. For this reason, RhoSynth biases preconditions to more specific formulas using an ILP-based maximal graph alignment, even if it may cause some amount of overfitting. In practice, we minimize overfitting by using diverse examples for synthesizing a rule, for instance, examples that are obtained from code changes that belong to different packages (refer to Appendix A for details). Furthermore, to prevent overfitting, RhoSynth biases postconditions to fewer disjuncts. This is accomplished by partitioning a group of correct examples only when the most-specific conjunctive postcondition synthesized from all correct examples satisfies a violating example. In this case, partitioning the correct examples and synthesizing a postcondition disjunct for each partition becomes necessary. In addition, RhoSynth uses lattices to express all node predicates. This helps generalization when merging groups of conforming and violating examples to synthesize the rule.
Soundness: We next show that RhoSynth is sound, i.e., given a set of violating and conforming examples, if RhoSynth synthesizes a rule then satisfies all violating examples and does not satisfy any conforming example. Formally,
Theorem 3 (Soundness of Rule Synthesis:).
Given a set of violating examples and conforming examples , if the algorithm synthesizeRule successfully returns a rule , then and .
We present a proof outline in Appendix E. It is easy to argue Algorithm 1’s soundness with respect to violating examples. To argue soundness with respect to conforming examples, we rely on the soundness of the merge algorithm (theorem 2). Using Theorem 2, we argue that all valuated conforming examples satisfy the synthesized postcondition. Since the rule negates the synthesized postcondition, none of them satisfy the synthesized rule.
Completeness: RhoSynth does not provide completeness guarantees. This is a design choice made purely based on practical experiments. Incomleteness may arise from incorrect graph alignments or incorrect partitioning of conforming examples when synthesizing rule postconditions. However, in our experiments, we do not encounter cases where either of these lead to rule synthesis failures or imprecise solutions.
5. Implementation Details
PDG representation: We use RhoSynth to synthesize rules for Java. Our implementation uses MUDetect (Sven and Nguyen, 2019) for representing Java source code as PDGs. MUDetect uses a static single assignment format. Further, we transform these PDGs using the following two program transformations to obtain program representations that are more conducive to rule synthesis:
-
(1)
We abstract the label of relational operators such as , etc. to a common label rel_op. This transformation is useful when synthesizing rules from examples that perform a similar check on a data value using different relational operators, for e.g., error < 0 and error == -1. This transformation helps to express rules over such examples using a conjunctive formula over the rel_op label, instead of a disjunction over different relational operators.
-
(2)
If a PDG has multiple calls to the same getter method on the same receiver, we transform it into a PDG that has a single getter call and the value returned by the getter is directly used at other call sites. So, we transform the code snippet foo(url.getPort()); ... if (url.getPort()
== 0) { ... } to the PDG representation of the code snippet v = url.getPort();foo(v);
... if (v == 0) { ... } . Since RhoSynth, typically, does not have access to method declarations of called methods, we use heuristics on the name of the method to identify getter calls.
Lattices: To enable unification of node predicates at corresponding nodes in different PDGs, we lift all the node predicates to lattices in the following manner:
-
(1)
Predicate data-type(x) and declaring-type(x) are lifted to a lattice that captures the longest common prefix and longest common suffix of the string representations of data types. Often, a Java class name shares a common prefix or a suffix with name of its superclass or the interfaces it extends. This lattice is carefully designed to unify such related data types. If nodes and in different examples align to form node where data-type() = “BufferedInputStream” and data-type() = “FileInputStream”, this lattice helps generalize data-type(n) = “*InputStream”.
-
(2)
Predicates label(x), data-value(x), num-para(x), output-ignored(x) are lifted to constant lattices. As an example, if num-para and num-para and and align to form node , then num-para.
-
(3)
Predicate trans-control-dep(x) is lifted to a power-set lattice where set intersection is the join operator. As an example, if trans-control-dep and trans-control-dep and and align to form node , then trans-control-dep.
Solvers: We use the Xpress ILP solver for graph alignment and Z3 (De Moura and Bjørner, 2008) for satisfiability solving. For running a rule on a method, we check if the rule is satisfied by the PDG representation of the method. We have implemented a few algorithmic simplifications that are used to simplify the satisfiability query, for e.g., we can determine that a rule, which asserts existence of a method call foo, will not be satisfied by a method that does not call foo. Due to such simplifications, >99% of the satisfiability queries can be discharged without calling Z3.
6. Evaluation
To understand the effectiveness of RhoSynth, we address the following research questions.
-
RQ1:
How effective is RhoSynth at synthesizing precise rules?
Section 6.2 shows that the precision of rules exceeds 75% in production.
-
RQ2:
Are the synthesized rules “interesting”?
The rules synthesized cover diverse categories and are often discussed on various forums as shown in Section 6.3.
-
RQ3:
What is the effectiveness of iterative rule refinement in improving the precision?
As we show in Section 6.4, rule refinement improves the precision of rules, by as much as 68% in some cases.
-
RQ4:
How does RhoSynth compare against state-of-the-art program synthesis approaches? The baselines used are ProSynth (Raghothaman et al., 2019) and anti-unification based synthesis over ASTs.
The baselines often fail to synthesize rules. (Section 6.5)
-
RQ5:
How does ILP-based graph alignment compare against state-of-the-art code differencing algorithms? We use the GumTree (Falleri et al., 2014) algorithm as a baseline.
Baseline algorithms do not perform well when aligning unpaired code examples for rule synthesis. (Section 6.6)
6.1. Experimental Methodology and Setup
Code Change Examples: We synthesize rules for 31 groups of Java code changes. See Appendix A for a description on the source of the dataset. We provide GitHub links to all the code changes along with the synthesized rules as supplementary material.
Iterative Rule Refinement: We run the synthesized rules on code corpus. We identify rules for iterative refinement based on the detections generated by them. For each rule, we first label detections. If any of these detection is labeled as a false positive (FP), we shortlist the rule for refinement. For such rules, we label up to additional detections. With every false positive, we resynthesize the rule using the original set of code changes and all the FPs encountered till then. We stop when adding the FP does not change the synthesized rule, i.e., rule synthesized after the first FPs is equivalent to the rule synthesized after FPs.
Production Deployment: We have deployed all these rules in an industrial setting, with our internal code review (CR) system. These rules are run on the source code at the time of each code review. Detections generated by these rules on the code diff are provided as code review comments. Code authors can label these comments as part of code review workflow.
Evaluation: We perform two types of evaluation: offline evaluation by software developers on sampled recommendations and ratings and textual feedback obtained from live code reviews from code authors.
In both cases, the users label them as "Useful", "Not Useful" or "Not Sure". In live code review, developers also provide textual feedback. The offline evaluation involves expert developers and does not involve the paper authors.
Metrics: For both the evaluations, we report , computed over all labeled detections.
Experimental Setup: We conducted all our experiments on a Mac OSX laptop with 2.4GHz Intel processor and 16Gb memory. Experiments with ProSynth (Raghothaman et al., 2019) were run in a Docker container with 8Gb memory launched from a Docker image shared by the authors.
6.2. Precision of RhoSynth
In our offline evaluation, detections ( out of ) were labeled "Useful". We have also received feedback from developers on detections generated by these rules during live code reviews. Over a period of months, detections from out of the rules received developer feedback. of these labeled detections ( out of ) were categorized as "Useful" by the developers666Most rules that did not receive developer feedback during live code reviews involved detecting code context with deprecated or legacy APIs. These rules trigger rarely during a code review and are thus more appropriate for a code scanning tool. All these rules were validated during offline evaluation.. Some of the textual feedback from live code reviews are: "Interesting, that is helpful", "Will add this check.", and "we have a separate task to look into the custom polling solution https://XX". A high developer acceptance during code reviews shows that RhoSynth is capable of synthesizing code quality rules which are effective in the real-world.
Table 1 provides more information about these synthesized rules. The synthesis time for these rules range from to , with an average of . Most of these rules are synthesized from few code changes. Rules that only consist of a precondition correspond to a code anti-pattern. rules consist of both a precondition and a postcondition. Of these, rules have a disjunctive postcondition. These disjuncts correspond to different ways of writing code that is correct with respect to the rule. One example of such a rule is check-movetofirst, described in Section 2.2. Another example is executor-graceful-shutdown that intuitively checks if ExecutorService.shutdownNow() call is accompanied by a graceful wait implemented by calling ExecutorService.awaitTermination() or ExecutorService.invokeAll(). Besides the supplementary material, we include visualizations for few synthesized rules in Appendix F.
6.3. Examples of RhoSynth rules
We describe all the rules synthesized by RhoSynth in Table 6.3. A large number of these rules are supported by code documentation or discussions on online forums. They cover a wide range of code quality issues and recommendation categories:
-
•
performance: e.g., use-parcelable, use-guava-hashmap
-
•
concurrency: e.g., conc-hashmap-put, countdown-latch-await
-
•
use of deprecated or legacy APIs: e.g., deprecated-base64, upgrade-enumerator
-
•
bugs: e.g., check-movetofirst, start-activity
-
•
code modernization: e.g., view-binding, layout-inflater
-
•
code simplification: e.g., deseriaize-json-array, use-collectors-joining
-
•
debuggability: e.g., countdownlatch-await, exception-invoke
| S. No. | Rule name | API | Description of the synthesized rules | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 |
|
|
|
|||||||||||||
| 2 |
|
|
|
|||||||||||||
| 3 |
|
|
|
|||||||||||||
| 4 |
|
|
|
|||||||||||||
| 5 |
|
|
|
|||||||||||||
| 6 |
|
|
|
|||||||||||||
| 7 |
|
|
|
|||||||||||||
| 8 |
|
|
|
|||||||||||||
| 9 |
|
|
|
|||||||||||||
| 10 |
|
|
|
|||||||||||||
| 11 |
|
|
|
|||||||||||||
| 12 |
|
|
|
|||||||||||||
| 13 |
|
|
|
|||||||||||||
| 14 |
|
|
|
|||||||||||||
| 15 |
|
|
|
|||||||||||||
| 16 |
|
|
|
|||||||||||||
| 17 |
|
|
|
|||||||||||||
| 18 |
|
|
|
|||||||||||||
| 19 |
|
|
|
|||||||||||||
| 20 |
|
|
|
|||||||||||||
| 21 |
|
|
|
|||||||||||||
| 22 |
|
|
|
|||||||||||||
| 23 |
|
|
|
|||||||||||||
| 24 |
|
|
|
|||||||||||||
| 25 |
|
|
|
|||||||||||||
| 26 |
|
|
|
|||||||||||||
| 27 |
|
|
|
|||||||||||||
| 28 |
|
|
|
|||||||||||||
| 29 |
|
|
|
|||||||||||||
| 30 |
|
|
|
|||||||||||||
| 31 |
|
|
|
|||||||||||||
| The synthesized rules along with pointers to supporting blog-posts and code documentation. |
| Rule name |
|
|
|
|
||||||||
| check-file-rename | 6 | - | 4 | - | ||||||||
| check-inputstream-skip | 5 | - | 3 | - | ||||||||
| check-mkdirs | 10 | - | 1 | - | ||||||||
| check-resultset-next | 4 | - | 8 | - | ||||||||
| conc-hashmap-put | 3 | - | 9 | - | ||||||||
| create-list-from-map | 3 | - | 8 | - | ||||||||
| deprecated-base64 | 4 | - | 4 | - | ||||||||
| deprecated-injectview | 16 | - | 6 | - | ||||||||
|
5 | - | 8 | - | ||||||||
| deserialize-json-array | 3 | - | 10 | - | ||||||||
| layout-inflater | 3 | - | 5 | - | ||||||||
| read-parcelable | 7 | - | 6 | - | ||||||||
| replace-long-constructor | 4 | - | 4 | - | ||||||||
| upgrade-http-client | 3 | - | 7 | - | ||||||||
| upgrade-enumerator | 6 | - | 6 | - | ||||||||
| use-collectors-joining | 3 | - | 12 | - | ||||||||
| use-file-read-utility | 3 | - | 15 | - | ||||||||
| use-fs-is-dir | 4 | - | 4 | - | ||||||||
| use-guava-hashmap | 3 | - | 20 | - | ||||||||
| use-parcelable | 3 | - | 4 | - | ||||||||
| use-remove-if | 3 | - | 11 | - | ||||||||
| view-binding | 3 | - | 5 | - | ||||||||
| wrapping-exception | 7 | - | 6 | 8 | ||||||||
| Rules Iteratively Refined | ||||||||||||
| check-actionbar | 3 | 3 | 10 | (14, 14) | ||||||||
|
5 | 2 | 8 | 12 | ||||||||
| check-createnewfile | 3 | 3 | 4 | 6 | ||||||||
| check-movetofirst | 4 | 9 | 2 | (6, 8) | ||||||||
| countdownlatch-await | 11 | 3 | 4 | 9 | ||||||||
| exception-invoke | 4 | 3 | 3 | 6 | ||||||||
|
4 | 4 | 2 | (5, 10) | ||||||||
| start-activity | 5 | 5 | 3 | (5, 6, 11) | ||||||||
| Rule name | # code | Before rule | # new | After rule | ||||
|---|---|---|---|---|---|---|---|---|
| changes | refinement | egs. | refinement | |||||
| PostC | Prec. | PostC | Prec. | |||||
| size | size | |||||||
|
3 | 14 | 32% | 3 | (14, 14) | 100% | ||
|
5 | - | 79% | 2 | 12 | 100% | ||
|
3 | - | 42% | 3 | 6 | 100% | ||
|
4 | - | 40% | 9 | (6, 8) | 100% | ||
|
11 | - | 80% | 3 | 9 | 100% | ||
|
4 | 9 | 76% | 3 | 6 | 100% | ||
|
4 | 9 | 95% | 4 | (5, 10) | 100% | ||
| start-activity | 5 | 9 | 21% | 5 | (5, 6, 11) | 80% | ||
| Macro Avg. | 58% | 97% | ||||||
6.4. Effectiveness of Iterative Rule Refinement
We iteratively refine rules by providing additional non-buggy code examples. These examples correspond to variations in correct code that are not present in the code changes. As can be seen from Table 2, few additional examples are sufficient to refine the rule. All the 8 rules show precision improvements and the (macro) average precision increases from to based on refinement. We use labels from offline evaluation for estimating the precision 777We group all detections by the rule version, and estimate the overall precision based on 10 labels for each group.. In 4 of the 8 rules, the refinement occurs by synthesizing disjunctive postconditions.
| Rule name |
|
|
|||
|---|---|---|---|---|---|
| deprecated-injectview | |||||
|
|||||
| layout-inflater | |||||
| replace-long-constructor | |||||
| use-parcelable | |||||
| view-binding | |||||
| upgrade-enumerator | |||||
| check-actionbar | ✗, TO | ||||
| check-createnewfile | ✗, TO | ||||
| check-file-rename | ✗, TO | ||||
| check-inputstream-skip | ✗, TO | ||||
| check-movetofirst | ✗, TO | ||||
| conc-hashmap-put | ✗, MC | ||||
| create-list-from-map | ✗, MC | ||||
| deprecated-base64 | ✗, MC | ||||
| read-parcelable | ✗, MC | ||||
| upgrade-http-client | ✗, MC | ||||
| use-fs-is-dir | ✗, MC | ||||
| wrapping-exception | ✗, TO | ||||
|
✗, TO | ✗ | |||
| check-mkdirs | ✗, TO | ✗ | |||
| check-resultset-next | ✗, TO | ✗ | |||
| countdownlatch-await | ✗, UnSAT | ✗ | |||
| deserialize-json-array | ✗, MC | ✗ | |||
| exception-invoke | ✗, TO | ✗ | |||
|
✗, TO | ✗ | |||
| start-activity | ✗, TO | ✗ | |||
| use-collectors-joining | ✗, MC | ✗ | |||
| use-file-read-utility | ✗, MC | ✗ | |||
| use-guava-hashmap | ✗, MC | ✗ | |||
| use-remove-if | ✗, MC | ✗ |
6.5. Comparison with baselines
We compare RhoSynth with ProSynth (Raghothaman et al., 2019) and AST anti-unification based approaches, on synthesizing rules without the rule refinement step. Getafix (Bader et al., 2019) and Revisar (Rolim et al., 2018) are representatives for synthesizing AST transformations via anti-unification of tree patterns. A direct comparison against Getafix and Revisar is unfortunately not feasible as the former is not publicly available and the latter does not support Java. Hence, we compare against our own implementation of an anti-unification algorithm over ASTs. The results are described in Table 3. We provide artifacts from these experiment as supplementary material.
ProSynth: ProSynth is a general algorithm to synthesize Datalog programs. It is not particularly tailored to the rule synthesis problem, which is the focus of our work, for two main reasons. First, a datalog program can only express rules that are purely existentially quantified formulas without a postcondition (Ajtai and Gurevich, 1994). ProSynth is thus not able to synthesize rules that have a postcondition. It either times out or returns "Problem unsatisfiable" when synthesizing such rules.
Second, in cases when ProSynth is able to synthesize a rule, the synthesized rule often misses the required code context, i.e., the API of interest or constructs of interest. Synthesizing a rule from few examples is in most cases an underspecified problem. While RhoSynth biases the synthesis of rule preconditions towards larger code context, ProSynth uses a SAT solver based enumeration to synthesize a rule precondition without such an inductive bias. As a result, rules synthesized by ProSynth can miss the required code context as long as they can differentiate between the few positive and negative code examples 888 As an example, the code context for conc-hashmap-put rule must check the result of ConcurrentHashMap.containsKey followed by a call to put, on the same hash map, if containsKey returned False. The rule synthesized by ProSynth just checks for an existence of a containsKey call and misses the remaining code context..
ProSynth times out on 12 rules and returns "Problem unsatisfiable" for 1 rule. On a manual examination of the 18 rules it synthesized, we found that rules do not contain the required code context. These rules would lead to false positives. Hence, we conclude that ProSynth is able to precisely synthesize out of rules.
Anti-unification over ASTs: Given two ASTs, we look at all combination of subtrees rooted at different nodes in the two ASTs. We pick the AST pattern, obtained on anti-unification of these subtrees, that has the largest size and contains the API of interest (column in Table 6.3). We manually examine the AST patterns obtained on anti-unifying code-before and code-after examples. We observe that due to variations in the syntactic structure of code changes, anti-unification misses the required code context in rules. These AST patterns would lead to false positives. This approach is thus able to precisely synthesize at most rules. This experiment shows the limitation of expressing rules over an AST representation.
|
|
|
|
|
|
|
||||||||||||||||||
| check-actionbar | - | 6 | - | - | ||||||||||||||||||||
| 3 | 6 | 18/18 = 100% | 18/18 = 100% | ✓ | ||||||||||||||||||||
| check-await-termination | 2 | 6 | 6/6 = 100% | 4/6 = 66% | ✓ | |||||||||||||||||||
| check-createnewfile | 3 | 4 | 12/12 = 100% | 7/12 = 58% | ✗ | |||||||||||||||||||
| check-movetofirst | 6 | 3 | 45/45 = 100% | 41/45 = 91% | ✗ | |||||||||||||||||||
| 3 | 4 | 12/12 = 100% | 10/12= 83% | ✓ | ||||||||||||||||||||
| countdownlatch-await | 3 | 5 | 15/15 = 100% | 7/15 = 47% | ✗ | |||||||||||||||||||
| exception-invoke | 3 | 3 | 9/9 = 100% | 3/9 = 33% | ✗ | |||||||||||||||||||
| executor-graceful-shutdown | 1 | 2 | - | - | ||||||||||||||||||||
| 3 | 6 | 18/18 = 100% | 9/18 = 50% | ✗ | ||||||||||||||||||||
| start-activity | 3 | 2 | 6/6 = 100% | 6/6 = 100% | ✓ | |||||||||||||||||||
| 1 | 3 | - | - | |||||||||||||||||||||
| - | 5 | - | - |
6.6. ILP-based Graph Alignment vs GumTree
We now compare ILP-based alignment and state-of-the-art code differencing algorithms on aligning unpaired code examples for rule synthesis. GumTree (Falleri et al., 2014) is a popular choice for performing AST differencing. It is effective when aligning code changes in which the two snippets overlap a lot. If the examples are “unpaired” (or have small overlap), GumTree fails in some cases to precisely align them. We consider scenarios covering all iteratively refined rules where a conjunctive postcondition formula is synthesized from a partition of unpaired conforming code examples. In Table 4, we tabulate the number of nodes mappings established by the two alignment algorithms for every pair of code example in the partition. The number of nodes mapped by GumTree range from to in the failed scenarios. ILP maps all the nodes.
When we use node mappings established by the GumTree algorithm to merge these examples, we succeed in synthesizing the desired postcondition in only scenarios. In the remaining scenarios, GumTree fails to map some nodes that form the required context for the rule postcondition, and are hence omitted on subsequent merge operations. These rules would lead to false positives. The ILP-formulation leads to successful synthesis of the specific postcondition in all scenarios.
7. Related Work
Synthesis algorithms for program repair and bug detection: Our work is most closely related to research on synthesis algorithms for automated program repair from code changes (Bader et al., 2019; Rolim et al., 2018, 2017; Miltner et al., 2019; Bavishi et al., 2019; Meng et al., 2013). We can categorize these works based on their techniques. The first category consists of Phoenix (Bavishi et al., 2019) and instantations of the PROSE framework (Polozov and Gulwani, 2015) in Refazer (Rolim et al., 2017) and BluePencil (Miltner et al., 2019). These algorithms search for a program transformation, which explain the set of provided concrete edits, within a DSL. The second category includes Revisar (Rolim et al., 2018), Getafix (Bader et al., 2019) and LASE (Meng et al., 2013) that are based on generalization algorithms over ASTs, using anti-unification or maximum common embedded subtree extraction. Both the above categories of work either rely on an accompanying static analyzer for bug localization or synthesize program transformation patterns that are specific to a given package or domain. Bug localization is harder than repair at a given location (Allamanis et al., 2021). Our approach does not rely on existing static analyzers for bug localization and is able to precisely synthesize new rules. These rules are also applicable to code variations that are present in different packages. Additionally, we observe that correct code may have variations that is not present in code changes. We present an approach to refine rules using additional examples containing such code variations. In comparison, most of the above mentioned prior works rely on paired code changes and none of them support iterative refinement of rules.
DiffCode (Paletov et al., 2018) is an approach to infer rules from code changes geared towards Crypto APIs. Their main focus is on clustering algorithms for code changes. They do not automate the task of synthesizing a rule from a cluster of code changes. Program synthesis has also been recently applied to other code related applications such as API migration (Ni et al., 2021; Gao et al., 2021), synthesis of merge conflict resolutions (Pan et al., 2021), interactive code search (Naik et al., 2021).
Datalog synthesis: There is a rich body of recent work on datalog synthesis (Raghothaman et al., 2019; Si et al., 2018, 2019; Albarghouthi et al., 2017; Mendelson et al., 2021; Thakkar et al., 2021) and its application to code related tasks such as interactive code search (Naik et al., 2021). Datalog programs can express existentially quantified preconditions (Ajtai and Gurevich, 1994) but cannot express rules with a non-vacuous postcondition that introduce quantifier alternation. On the other hand, these algorithms can synthesize recursive predicates that we exclude in our approach. In Section 6, we provide an empirical comparison against ProSynth (Raghothaman et al., 2019) from this category.
Statistical approaches for program synthesis: (Dinella et al., 2020; Tufano et al., 2018) are neural approaches for automatic bug-fix generation. These models are trained on a general bug-fix dataset, not necessarily fixes that correspond to rules, and have a comparatively lower accuracy. TFix (Berabi et al., 2021) improves upon them by fine-tuning the neural models on fixes that correspond to a known set of bug categories or rules. In doing so, it gives up the ability to generate fixes for new rules. (Devlin et al., 2017b; Long and Rinard, 2016) propose a hybrid approach where algorithmic techniques are used to generate candidate fixes and statistical models are used to rank them. (Allamanis et al., 2018; Pradel and Sen, 2018; Vasic et al., 2019; Allamanis et al., 2021) present neural models for detecting bugs caused by issues in variable naming and variable misuse. These approaches cannot be easily tailored to generate new detectors from a given set of labeled code examples.
In the domain of synthesizing String transformations, pioneered by FlashFill (Gulwani, 2011), RobustFill (Devlin et al., 2017a) presents a neural approach for program synthesis as well as program induction. Hybrid approaches such as (Gulwani and Jain, 2017; Kalyan et al., 2018; Verbruggen et al., 2021) complement machine learning based induction with algorithmic techniques and present an interesting direction for exploration in the context of rule synthesis.
Statistical approaches for building bug-detectors include data-mining approaches such as APISan (Yun et al., 2016), PR-Miner (Li and Zhou, 2005) and NAR-miner (Bian et al., 2018). These approaches mine popular programming patterns and flag deviants as bugs. Since these mined patterns are based on frequency, these approaches are not able to distinguish between incorrect code and infrequent code. Recent work on mining code patterns has achieved higher precision in finding bugs when the mined patterns are applied to the same code-base they are extracted from (Ahmadi et al., 2021). Arbitrar (Li et al., 2021) improves upon APISan (Yun et al., 2016) by incorporating user-feedback through active learning algorithms. Both Arbitrar and APISan employ symbolic execution to extract semantic features of a program, as opposed to a lighter-weight static analysis in RhoSynth. Rules based on symbolic execution might be too expensive for a real-time code reviewing application.
Interactive program synthesis: Researchers have recently explored the question-selection problem (Ji et al., 2020) and other user-interaction models (Le et al., 2017; Bavishi et al., 2021; Ferdowsifard et al., 2021) in the context of interactive program synthesis. Rule refinement is also an instance of interactive program synthesis and applying these approaches to the domain of rule synthesis is an interesting research direction.
DSLs for expressing rules in static checkers: Most static checkers, such as SonarQube999https://docs.sonarqube.org/latest/extend/adding-coding-rules/, PMD101010https://pmd.github.io/latest/pmd_userdocs_extending_writing_pmd_rules.html, Semmle and Semgrep, allow users to write their own custom rules. These rules are often written in a DSL such as ProgQuery (Rodriguez-Prieto et al., 2020) or CodeQL. We are not aware of any tool that synthesizes rules in these DSLs automatically from labeled code examples. In fact, a recent survey (Raychev, 2021) identifies automating the rule creation process in static checkers as a largely unexplored area.
Synthesis frameworks: SyGus (Alur et al., 2013) and CEGIS (Solar Lezama, 2008) are two popular synthesis frameworks in domains with logical specifications. Recently, Wang et al. (Wang et al., 2021) have proposed an approach that combines SyGus with decision tree learning for synthesizing specific static analyses that detect side-channel information leaks.
8. Conclusions
In this paper, we present RhoSynth, a new algorithm for synthesizing code-quality rules from labeled code examples. RhoSynth performs rule synthesis on graph representations of code and is based on a novel ILP based graph alignment algorithm. We validate our algorithm by synthesizing more than 30 rules that have been deployed in production. Our experimental results show that the rules synthesized by our approach have high precision (greater than 75% in live code reviews) which make them suitable for real-world applications. In the case of low-precision rules, we show that rule refinement can leverage additional examples to incrementally improve the rules. Interestingly, these synthesized rules are capable of enforcing several documented code-quality recommendations. Through comparisons with recent baselines, we show that current state-of-the-art program synthesis approaches are unable to synthesize most rules.
References
- (1)
- Ahmadi et al. (2021) Mansour Ahmadi, Reza Mirzazade farkhani, Ryan Williams, and Long Lu. 2021. Finding Bugs Using Your Own Code: Detecting Functionally-similar yet Inconsistent Code. In 30th USENIX Security Symposium (USENIX Security 21). USENIX Association. https://www.usenix.org/conference/usenixsecurity21/presentation/ahmadi
- Ajtai and Gurevich (1994) Miklós Ajtai and Yuri Gurevich. 1994. Datalog vs First-Order Logic. J. Comput. Syst. Sci. 49, 3 (1994), 562–588. https://doi.org/10.1016/S0022-0000(05)80071-6
- Albarghouthi et al. (2017) Aws Albarghouthi, Paraschos Koutris, Mayur Naik, and Calvin Smith. 2017. Constraint-Based Synthesis of Datalog Programs. In Principles and Practice of Constraint Programming, J. Christopher Beck (Ed.). Springer International Publishing, Cham, 689–706.
- Allamanis et al. (2018) Miltiadis Allamanis, Marc Brockschmidt, and Mahmoud Khademi. 2018. Learning to Represent Programs with Graphs. In International Conference on Learning Representations. https://openreview.net/forum?id=BJOFETxR-
- Allamanis et al. (2021) Miltiadis Allamanis, Henry Jackson-Flux, and Marc Brockschmidt. 2021. Self-Supervised Bug Detection and Repair. CoRR abs/2105.12787 (2021). arXiv:2105.12787 https://arxiv.org/abs/2105.12787
- Alur et al. (2013) Rajeev Alur, Rastislav Bodik, Garvit Juniwal, Milo M. K. Martin, Mukund Raghothaman, Sanjit A. Seshia, Rishabh Singh, Armando Solar-Lezama, Emina Torlak, and Abhishek Udupa. 2013. Syntax-Guided Synthesis. In Proceedings of the IEEE International Conference on Formal Methods in Computer-Aided Design (FMCAD). 1–17.
- Bader et al. (2019) Johannes Bader, Andrew Scott, Michael Pradel, and Satish Chandra. 2019. Getafix: Learning to Fix Bugs Automatically. Proc. ACM Program. Lang. 3, OOPSLA, Article 159 (Oct. 2019), 27 pages. https://doi.org/10.1145/3360585
- Barrett and Tinelli (2018) Clark Barrett and Cesare Tinelli. 2018. Satisfiability Modulo Theories. Springer International Publishing, Cham, 305–343. https://doi.org/10.1007/978-3-319-10575-8_11
- Bavishi et al. (2021) Rohan Bavishi, Caroline Lemieux, Koushik Sen, and Ion Stoica. 2021. Gauss: Program Synthesis by Reasoning over Graphs. Proc. ACM Program. Lang. 5, OOPSLA, Article 134 (oct 2021), 29 pages. https://doi.org/10.1145/3485511
- Bavishi et al. (2019) Rohan Bavishi, Hiroaki Yoshida, and Mukul R. Prasad. 2019. Phoenix: Automated Data-Driven Synthesis of Repairs for Static Analysis Violations. In Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (Tallinn, Estonia) (ESEC/FSE 2019). Association for Computing Machinery, New York, NY, USA, 613–624. https://doi.org/10.1145/3338906.3338952
- Beck (2002) Kent Beck. 2002. Test Driven Development. By Example (Addison-Wesley Signature). Addison-Wesley Longman, Amsterdam.
- Berabi et al. (2021) Berkay Berabi, Jingxuan He, Veselin Raychev, and Martin Vechev. 2021. TFix: Learning to Fix Coding Errors with a Text-to-Text Transformer. In Proceedings of the 38th International Conference on Machine Learning, ICML 2021 (Proceedings of Machine Learning Research).
- Bian et al. (2018) Pan Bian, Bin Liang, Wenchang Shi, Jianjun Huang, and Yan Cai. 2018. NAR-Miner: Discovering Negative Association Rules from Code for Bug Detection. In Proceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (Lake Buena Vista, FL, USA) (ESEC/FSE 2018). Association for Computing Machinery, New York, NY, USA, 411–422. https://doi.org/10.1145/3236024.3236032
- De Moura and Bjørner (2008) Leonardo De Moura and Nikolaj Bjørner. 2008. Z3: An Efficient SMT Solver. In Proceedings of the Theory and Practice of Software, 14th International Conference on Tools and Algorithms for the Construction and Analysis of Systems (Budapest, Hungary) (TACAS’08/ETAPS’08). Springer-Verlag, Berlin, Heidelberg, 337–340.
- Devlin et al. (2017a) Jacob Devlin, Jonathan Uesato, Surya Bhupatiraju, Rishabh Singh, Abdel-rahman Mohamed, and Pushmeet Kohli. 2017a. RobustFill: Neural Program Learning under Noisy I/O. CoRR abs/1703.07469 (2017). arXiv:1703.07469 http://arxiv.org/abs/1703.07469
- Devlin et al. (2017b) Jacob Devlin, Jonathan Uesato, Rishabh Singh, and Pushmeet Kohli. 2017b. Semantic Code Repair using Neuro-Symbolic Transformation Networks. CoRR abs/1710.11054 (2017). http://arxiv.org/abs/1710.11054
- Dinella et al. (2020) Elizabeth Dinella, Hanjun Dai, Ziyang Li, Mayur Naik, Le Song, and Ke Wang. 2020. Hoppity: Learning Graph Transformations to Detect and Fix Bugs in Programs. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net. https://openreview.net/forum?id=SJeqs6EFvB
- Falleri et al. (2014) Jean-Rémy Falleri, Floréal Morandat, Xavier Blanc, Matias Martinez, and Martin Monperrus. 2014. Fine-Grained and Accurate Source Code Differencing. In Proceedings of the 29th ACM/IEEE International Conference on Automated Software Engineering (Vasteras, Sweden) (ASE ’14). Association for Computing Machinery, New York, NY, USA, 313–324. https://doi.org/10.1145/2642937.2642982
- Ferdowsifard et al. (2021) Kasra Ferdowsifard, Shraddha Barke, Hila Peleg, Sorin Lerner, and Nadia Polikarpova. 2021. LooPy: Interactive Program Synthesis with Control Structures. Proc. ACM Program. Lang. 5, OOPSLA, Article 153 (oct 2021), 29 pages. https://doi.org/10.1145/3485530
- Ferrante et al. (1987) Jeanne Ferrante, Karl J. Ottenstein, and Joe D. Warren. 1987. The Program Dependence Graph and Its Use in Optimization. ACM Trans. Program. Lang. Syst. 9, 3 (July 1987), 319–349. https://doi.org/10.1145/24039.24041
- Gao et al. (2021) Xiang Gao, Arjun Radhakrishna, Gustavo Soares, Ridwan Shariffdeen, Sumit Gulwani, and Abhik Roychoudhury. 2021. APIfix: Output-Oriented Program Synthesis for Combating Breaking Changes in Libraries. Proc. ACM Program. Lang. 5, OOPSLA, Article 161 (oct 2021), 27 pages. https://doi.org/10.1145/3485538
- Gulwani (2011) Sumit Gulwani. 2011. Automating String Processing in Spreadsheets Using Input-Output Examples. SIGPLAN Not. 46, 1 (Jan. 2011), 317–330. https://doi.org/10.1145/1925844.1926423
- Gulwani and Jain (2017) Sumit Gulwani and Prateek Jain. 2017. Programming by Examples: PL Meets ML. In Programming Languages and Systems - 15th Asian Symposium, APLAS 2017, Suzhou, China, November 27-29, 2017, Proceedings (Lecture Notes in Computer Science, Vol. 10695), Bor-Yuh Evan Chang (Ed.). Springer, 3–20. https://doi.org/10.1007/978-3-319-71237-6_1
- Haussler (1989) David Haussler. 1989. Learning Conjunctive Concepts in Structural Domains. Mach. Learn. 4 (1989), 7–40. https://doi.org/10.1007/BF00114802
- Ji et al. (2020) Ruyi Ji, Jingjing Liang, Yingfei Xiong, Lu Zhang, and Zhenjiang Hu. 2020. Question selection for interactive program synthesis. In Proceedings of the 41st ACM SIGPLAN International Conference on Programming Language Design and Implementation, PLDI 2020, London, UK, June 15-20, 2020, Alastair F. Donaldson and Emina Torlak (Eds.). ACM, 1143–1158. https://doi.org/10.1145/3385412.3386025
- Kalyan et al. (2018) Ashwin Kalyan, Abhishek Mohta, Oleksandr Polozov, Dhruv Batra, Prateek Jain, and Sumit Gulwani. 2018. Neural-Guided Deductive Search for Real-Time Program Synthesis from Examples. In 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenReview.net. https://openreview.net/forum?id=rywDjg-RW
- Kreutzer et al. (2016) Patrick Kreutzer, Georg Dotzler, Matthias Ring, Bjoern M. Eskofier, and Michael Philippsen. 2016. Automatic Clustering of Code Changes. In Proceedings of the 13th International Conference on Mining Software Repositories (Austin, Texas) (MSR ’16). Association for Computing Machinery, New York, NY, USA, 61–72. https://doi.org/10.1145/2901739.2901749
- Le et al. (2017) Vu Le, Daniel Perelman, Oleksandr Polozov, Mohammad Raza, Abhishek Udupa, and Sumit Gulwani. 2017. Interactive Program Synthesis. CoRR abs/1703.03539 (2017). arXiv:1703.03539 http://arxiv.org/abs/1703.03539
- Lerouge et al. (2017) Julien Lerouge, Zeina Abu-Aisheh, Romain Raveaux, Pierre Héroux, and Sébastien Adam. 2017. New binary linear programming formulation to compute the graph edit distance. Pattern Recognition 72 (Dec. 2017), 254 – 265. https://doi.org/10.1016/j.patcog.2017.07.029
- Li et al. (2004) Tao Li, Sheng Ma, and Mitsunori Ogihara. 2004. Entropy-based criterion in categorical clustering. In Machine Learning, Proceedings of the Twenty-first International Conference (ICML 2004), Banff, Alberta, Canada, July 4-8, 2004 (ACM International Conference Proceeding Series, Vol. 69), Carla E. Brodley (Ed.). ACM. https://doi.org/10.1145/1015330.1015404
- Li et al. (2021) Ziyang Li, Aravind Machiry, Binghong Chen, Mayur Naik, Ke Wang, and Le Song. 2021. ARBITRAR: User-Guided API Misuse Detection. In 2021 IEEE Symposium on Security and Privacy (SP). 1400–1415. https://doi.org/10.1109/SP40001.2021.00090
- Li and Zhou (2005) Zhenmin Li and Yuanyuan Zhou. 2005. PR-Miner: Automatically Extracting Implicit Programming Rules and Detecting Violations in Large Software Code. In Proceedings of the 10th European Software Engineering Conference Held Jointly with 13th ACM SIGSOFT International Symposium on Foundations of Software Engineering (Lisbon, Portugal) (ESEC/FSE-13). Association for Computing Machinery, New York, NY, USA, 306–315. https://doi.org/10.1145/1081706.1081755
- Long and Rinard (2016) Fan Long and Martin Rinard. 2016. Automatic Patch Generation by Learning Correct Code. SIGPLAN Not. 51, 1 (jan 2016), 298–312. https://doi.org/10.1145/2914770.2837617
- Mendelson et al. (2021) Jonathan Mendelson, Aaditya Naik, Mukund Raghothaman, and Mayur Naik. 2021. GENSYNTH: Synthesizing Datalog Programs without Language Bias. In Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, February 2-9, 2021. AAAI Press, 6444–6453. https://ojs.aaai.org/index.php/AAAI/article/view/16799
- Meng et al. (2013) Na Meng, Miryung Kim, and Kathryn S. McKinley. 2013. LASE: Locating and Applying Systematic Edits by Learning from Examples. In Proceedings of the 2013 International Conference on Software Engineering (San Francisco, CA, USA) (ICSE ’13). IEEE Press, 502–511.
- Miltner et al. (2019) Anders Miltner, Sumit Gulwani, Vu Le, Alan Leung, Arjun Radhakrishna, Gustavo Soares, Ashish Tiwari, and Abhishek Udupa. 2019. On the Fly Synthesis of Edit Suggestions. Proc. ACM Program. Lang. 3, OOPSLA, Article 143 (Oct. 2019), 29 pages. https://doi.org/10.1145/3360569
- Naik et al. (2021) Aaditya Naik, Jonathan Mendelson, Nathaniel Sands, Yuepeng Wang, Mayur Naik, and Mukund Raghothaman. 2021. Sporq: An Interactive Environment for Exploring Code Using Query-by-Example. In The 34th Annual ACM Symposium on User Interface Software and Technology (Virtual Event, USA) (UIST ’21). Association for Computing Machinery, New York, NY, USA, 84–99. https://doi.org/10.1145/3472749.3474737
- Nguyen et al. (2019) Hoan Anh Nguyen, Tien N. Nguyen, Danny Dig, Son Nguyen, Hieu Tran, and Michael Hilton. 2019. Graph-Based Mining of In-the-Wild, Fine-Grained, Semantic Code Change Patterns. In 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE). 819–830. https://doi.org/10.1109/ICSE.2019.00089
- Ni et al. (2021) Ansong Ni, Daniel Ramos, Aidan Z. H. Yang, Inês Lynce, Vasco M. Manquinho, Ruben Martins, and Claire Le Goues. 2021. SOAR: A Synthesis Approach for Data Science API Refactoring. In 43rd IEEE/ACM International Conference on Software Engineering, ICSE 2021, Madrid, Spain, 22-30 May 2021. IEEE, 112–124. https://doi.org/10.1109/ICSE43902.2021.00023
- Paletov et al. (2018) Rumen Paletov, Petar Tsankov, Veselin Raychev, and Martin Vechev. 2018. Inferring Crypto API Rules from Code Changes. In Proceedings of the 39th ACM SIGPLAN Conference on Programming Language Design and Implementation (Philadelphia, PA, USA) (PLDI 2018). Association for Computing Machinery, New York, NY, USA, 450–464. https://doi.org/10.1145/3192366.3192403
- Pan et al. (2021) Rangeet Pan, Vu Le, Nachiappan Nagappan, Sumit Gulwani, Shuvendu K. Lahiri, and Mike Kaufman. 2021. Can Program Synthesis be Used to Learn Merge Conflict Resolutions? An Empirical Analysis. In 43rd IEEE/ACM International Conference on Software Engineering, ICSE 2021, Madrid, Spain, 22-30 May 2021. IEEE, 785–796. https://doi.org/10.1109/ICSE43902.2021.00077
- Polozov and Gulwani (2015) Oleksandr Polozov and Sumit Gulwani. 2015. FlashMeta: A Framework for Inductive Program Synthesis. In Proceedings of the 2015 ACM SIGPLAN International Conference on Object-Oriented Programming, Systems, Languages, and Applications (Pittsburgh, PA, USA) (OOPSLA 2015). Association for Computing Machinery, New York, NY, USA, 107–126. https://doi.org/10.1145/2814270.2814310
- Pradel and Sen (2018) Michael Pradel and Koushik Sen. 2018. DeepBugs: A Learning Approach to Name-Based Bug Detection. Proc. ACM Program. Lang. 2, OOPSLA, Article 147 (Oct. 2018), 25 pages. https://doi.org/10.1145/3276517
- Raghothaman et al. (2019) Mukund Raghothaman, Jonathan Mendelson, David Zhao, Mayur Naik, and Bernhard Scholz. 2019. Provenance-Guided Synthesis of Datalog Programs. Proc. ACM Program. Lang. 4, POPL, Article 62 (Dec. 2019), 27 pages. https://doi.org/10.1145/3371130
- Raychev (2021) Veselin Raychev. 2021. Learning to Find Bugs and Code Quality Problems - What Worked and What not?. In 2021 International Conference on Code Quality (ICCQ). 1–5. https://doi.org/10.1109/ICCQ51190.2021.9392977
- Rodriguez-Prieto et al. (2020) Oscar Rodriguez-Prieto, Alan Mycroft, and Francisco Ortin. 2020. An Efficient and Scalable Platform for Java Source Code Analysis Using Overlaid Graph Representations. IEEE Access 8 (2020), 72239–72260. https://doi.org/10.1109/ACCESS.2020.2987631
- Rokach and Maimon (2005) Lior Rokach and Oded Maimon. 2005. Clustering Methods. In The Data Mining and Knowledge Discovery Handbook, Oded Maimon and Lior Rokach (Eds.). Springer, 321–352. http://dblp.uni-trier.de/db/books/collections/datamining2005.html#RokachM05a
- Rolim et al. (2017) Reudismam Rolim, Gustavo Soares, Loris D’Antoni, Oleksandr Polozov, Sumit Gulwani, Rohit Gheyi, Ryo Suzuki, and Björn Hartmann. 2017. Learning syntactic program transformations from examples. In Proceedings of the 39th International Conference on Software Engineering, ICSE 2017, Buenos Aires, Argentina, May 20-28, 2017, Sebastián Uchitel, Alessandro Orso, and Martin P. Robillard (Eds.). IEEE / ACM, 404–415. https://doi.org/10.1109/ICSE.2017.44
- Rolim et al. (2018) Reudismam Rolim, Gustavo Soares, Rohit Gheyi, and Loris D’Antoni. 2018. Learning Quick Fixes from Code Repositories. CoRR abs/1803.03806 (2018). arXiv:1803.03806 http://arxiv.org/abs/1803.03806
- Ryzhkov (2011) Evgeniy Ryzhkov. 2011. How to add a new diagnostic rule into PVS-Studio? Days from developers’ life. https://pvs-studio.com/en/blog/posts/0110/
- Schrijver (1986) Alexander Schrijver. 1986. Theory of Linear and Integer Programming. John Wiley & Sons, Inc., USA.
- Si et al. (2018) Xujie Si, Woosuk Lee, Richard Zhang, Aws Albarghouthi, Paraschos Koutris, and Mayur Naik. 2018. Syntax-Guided Synthesis of Datalog Programs. In Proceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (Lake Buena Vista, FL, USA) (ESEC/FSE 2018). Association for Computing Machinery, New York, NY, USA, 515–527. https://doi.org/10.1145/3236024.3236034
- Si et al. (2019) Xujie Si, Mukund Raghothaman, Kihong Heo, and Mayur Naik. 2019. Synthesizing Datalog Programs using Numerical Relaxation. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI 2019, Macao, China, August 10-16, 2019, Sarit Kraus (Ed.). ijcai.org, 6117–6124. https://doi.org/10.24963/ijcai.2019/847
- Sobreira et al. (2018) Victor Sobreira, Thomas Durieux, Fernanda Madeiral, Martin Monperrus, and Marcelo de Almeida Maia. 2018. Dissection of a bug dataset: Anatomy of 395 patches from Defects4J. In 2018 IEEE 25th International Conference on Software Analysis, Evolution and Reengineering (SANER). 130–140. https://doi.org/10.1109/SANER.2018.8330203
- Solar Lezama (2008) Armando Solar Lezama. 2008. Program Synthesis By Sketching. Ph. D. Dissertation. EECS Department, University of California, Berkeley. http://www2.eecs.berkeley.edu/Pubs/TechRpts/2008/EECS-2008-177.html
- Sven and Nguyen (2019) Amann Sven and Hoan Anh Nguyen. 2019. MUDetect : An API-Misuse Detector. https://github.com/stg-tud/MUDetect.
- Thakkar et al. (2021) Aalok Thakkar, Aaditya Naik, Nathaniel Sands, Rajeev Alur, Mayur Naik, and Mukund Raghothaman. 2021. Example-Guided Synthesis of Relational Queries. Association for Computing Machinery, New York, NY, USA, 1110–1125. https://doi.org/10.1145/3453483.3454098
- Tufano et al. (2018) Michele Tufano, Cody Watson, Gabriele Bavota, Massimiliano Di Penta, Martin White, and Denys Poshyvanyk. 2018. An Empirical Investigation into Learning Bug-Fixing Patches in the Wild via Neural Machine Translation. In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering (Montpellier, France) (ASE 2018). Association for Computing Machinery, New York, NY, USA, 832–837. https://doi.org/10.1145/3238147.3240732
- Vasic et al. (2019) Marko Vasic, Aditya Kanade, Petros Maniatis, David Bieber, and Rishabh singh. 2019. Neural Program Repair by Jointly Learning to Localize and Repair. In International Conference on Learning Representations. https://openreview.net/forum?id=ByloJ20qtm
- Verbruggen et al. (2021) Gust Verbruggen, Vu Le, and Sumit Gulwani. 2021. Semantic Programming by Example with Pre-Trained Models. Proc. ACM Program. Lang. 5, OOPSLA, Article 100 (oct 2021), 25 pages. https://doi.org/10.1145/3485477
- Wang et al. (2021) Jingbo Wang, Chungha Sung, Mukund Raghothaman, and Chao Wang. 2021. Data-Driven Synthesis of Provably Sound Side Channel Analyses. In 2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE). 810–822. https://doi.org/10.1109/ICSE43902.2021.00079
- Yan et al. (2013) Junchi Yan, Yu Tian, Hongyuan Zha, Xiaokang Yang, Ya Zhang, and Stephen M. Chu. 2013. Joint Optimization for Consistent Multiple Graph Matching. In 2013 IEEE International Conference on Computer Vision. 1649–1656. https://doi.org/10.1109/ICCV.2013.207
- Yun et al. (2016) Insu Yun, Changwoo Min, Xujie Si, Yeongjin Jang, Taesoo Kim, and Mayur Naik. 2016. APISAN: Sanitizing API Usages through Semantic Cross-Checking. In Proceedings of the 25th USENIX Conference on Security Symposium (Austin, TX, USA) (SEC’16). USENIX Association, USA, 363–378.
Appendix A Input examples to RhoSynth
We obtain code changes from Java GitHub packages that were selected based on their license, i.e., Apache or MIT-license, and star rating111111A list of these GitHub packages is included in the supplementary material.. These code changes are extracted using CPatMiner (Nguyen et al., 2019). The corpus consists of code changes. We cluster PDG representation of these code changes in two phases – (1) we map each code change to a set of APIs that are added, deleted or replaced in the change; (2) for each API, we cluster the mapped code changes using a bottom-up hierarchical clustering algorithm (Rokach and Maimon, 2005) (a code change is featurized using a fixed set of predicate features over its PDG representation and Jaccard distance is used to compute similarity between code changes). The clustering algorithm is tuned to output clusters that have a high homogeneity score. This ensures that all code-changes within the same cluster correspond to the same rule.
We tag each code change with the relative file path, the name and the line number of the method containing the change. We use this triple as a criterion to remove code-change overlap within a cluster. We filtered clusters containing less than 3 examples and having examples from less than 2 repositories or 2 commit ids. The latter ensures that the code changes are not repository-specific. We then choose clusters containing popular APIs belonging to popular frameworks such as Java.util, Android, Apache, Guava, etc. The popularity is determined based on frequency of occurrence in the corpus. This results in 1397 clusters. We pick 300 clusters randomly from this set. The authors manually examined these clusters and select those clusters whose underlying APIs and code constructs find relevant results on a Google search, which is evidence for a general applicability of the code changes in the cluster. For e.g., code-changes for the “use-guava-hashmap” rule involve the HashMap constructor and Maps.newHashMapWithExpectedSize API that have an associated Stack-Overflow post. We spend on average 5 minutes for manually examining each cluster. This examination resulted in 31 clusters which are then input to RhoSynth.
The paper containing the details of clustering is under submission.
Appendix B Example of PDG
Refer to Figure 6 for the PDG of the code-after snippet in Figure 1(a). Oval nodes in the figure indicate data nodes and rectangular nodes indicate action nodes.

Appendix C Maximal Graph Alignment using ILP
In this section, we describe the reduction from maximizing graph alignment to an integer linear program (ILP). Let and , be two UAPDGs over the same set of free variables . Graph alignment on and outputs a node mapping and an edge mapping as follows. The ILP optimization problem is defined over the following set of variables:
-
(1)
are 0-1 variables that are set if
-
(2)
are 0-1 variables that are set if
-
(3)
are 0-1 variables that are set if the corresponding nodes and edges are not mapped by and respectively
The ILP objective function seeks to maximize the number of mapped nodes and edges:
The optimization is subject to the following constraints:
-
(1)
Each node is optionally mapped to a node in : for all .
-
(2)
Each node is optionally mapped to a node in : for all .
-
(3)
Each edge is optionally mapped to an edge in : for all .
-
(4)
Each edge is optionally mapped to an edge in : for all .
-
(5)
Nodes mapped to the same free variables are aligned: if .
-
(6)
Action nodes with different labels are not aligned: if and are action nodes with different labels.
-
(7)
Action nodes with different change tags are not aligned while synthesizing preconditions: if change tag of and are different, where , are both action nodes.
-
(8)
Edges with different labels are not aligned: if and have different labels.
-
(9)
Node and edge mappings satisfy the topological constraints. This means if edges and are mapped then the nodes at their sources and destinations must be mapped: , where and for all and . Similarly, , where and .
-
(10)
If two data nodes align then they must have at least one aligned incoming or outgoing edge:
for data nodes and .
Appendix D Proof of Theorem 2
We first introduce two new lemmas that help us in proving the main theorem.
Lemma 1.
Given a UAPDG . Let be obtained by projecting to a subset of nodes and edges, and , in the following manner:
-
(a)
if .
-
(b)
if .
Then .
Proof.
Let correspond to the formula and correspond to the formula . One can easily argue that . Therefore, any model of will also be a model of . ∎
Lemma 2.
Let and , be two UAPDGs defined over the same set of free variables and bound variables . Let and be node and edge mappings obtained from aligning and such that (a) all nodes in and and all edges in and are mapped through and respectively, and (b) either or . Then .
Proof.
Let . Without loss of generality, let be such that . Let the UAPDGs and correspond to formulas , and respectively. Let be a graph structure with its nodes labeled with and such that is a model for . This implies that .
We want to prove that . With this, we can argue that . We prove by contradiction. Let . Since is a conjunction of various atomic formulas, there is at least one atomic formula that is not satisfied by .
-
-
Let for . Let the node in mapped to and , through or , be and respectively. From the definition of and we deduce that is mapped to and is mapped to , through maps and . Further, given the topological constraints on the alignment maps and one can show that holds in . Since is obtained by conjoining all atomic node and edge predicates that holds in , it implies that . Since, satisfies , it implies that , which is a contradiction.
-
-
Let for . Let the node in mapped to , through or , be . From the definition of and we deduce that is mapped to through maps and . From the construction of , we know that . Since, includes all atomic node predicates that hold over , . Since satisfies , it implies that satisfies and hence the formula , which is a contradiction.
Similarly, we show that . Together, this proves that .
∎
Theorem For any node mapping and edge mapping that is obtained from aligning and , .
Proof.
Let and , be the two UAPDGs, with the same set of free variables . Let the node and edge mappings obtained on aligning and be and respectively. The ILP constraints ensure that respect the maps and , i.e., .
Let and be subsets of and respectively obtained by projecting maps and to . We define sets and by projecting and to in the same way. Let and . From Lemma 1, we know that and . If we can prove that then we can easily show that .
Let us therefore prove that . Without loss of generality, let us assume that bound variables in and are labeled such that . Since,
-
(a)
all nodes in and and all edges in and are mapped through and respectively (from construction of and )
-
(b)
If , then if is mapped to a free variable,it follows from the properties of that . On the other hand, if is mapped to a bound variable, then it follows from our assumption above that .
it follows from Lemma 2 that . From the definition of the project operator, one can easily see that UAPDG . This concludes the proof of the theorem.
∎
Appendix E Proof of Theorem 3
Theorem [Soundness of Rule Synthesis:]
Given a set of violating examples and conforming examples , if the algorithm synthesizeRule successfully returns a return , then and .
Proof.
It is easy to see in the algorithm synthesizeRule (refer to Algorithm 1) that a rule is successfully returned only if , for all .
We now argue that when is successfully returned, , for all . Proving this involves two cases:
(1) When . Since strengthens the precondition, it follows that .
(2) When . Since , to prove that , we need to prove that , or in other words, .
Proof that : Let be a partition in the partition list in method synthesizePC. One can argue that where is the set of valuated conforming examples that satisfy the precondition and is computed at line 2 in algorithm 1. Also note that since , it follows from the definition of that . Without loss of generality, let us assume that (the item in partition). As getConjunctiveRule returns the UAPDG obtained on merging all its input Valuated PDGs, it follows from the soudness of merge algorithm (Theorem 2) that . Consequently, .
∎
Appendix F Synthesized Rule Examples
In this appendix, we list an example code change and visualize the synthesized precondition and postcondition UAPDGs for few code-quality rules described in Table 6.3. Refer to the supplementary material for details about all synthesized rules.
(a) Example code change (b) Precondition of the synthesized rule. (c) A disjunct in the synthesized postcondition: if ‘setSupportActionBar‘ is explicitly called, then the example is conforming. Note this code variation for conforming examples is not present in the code change and included in the rule during rule refinement. (d) A disjunct in the synthesized postcondition: the value returned by ‘getSupportActionBar‘ must be null checked.
(a)
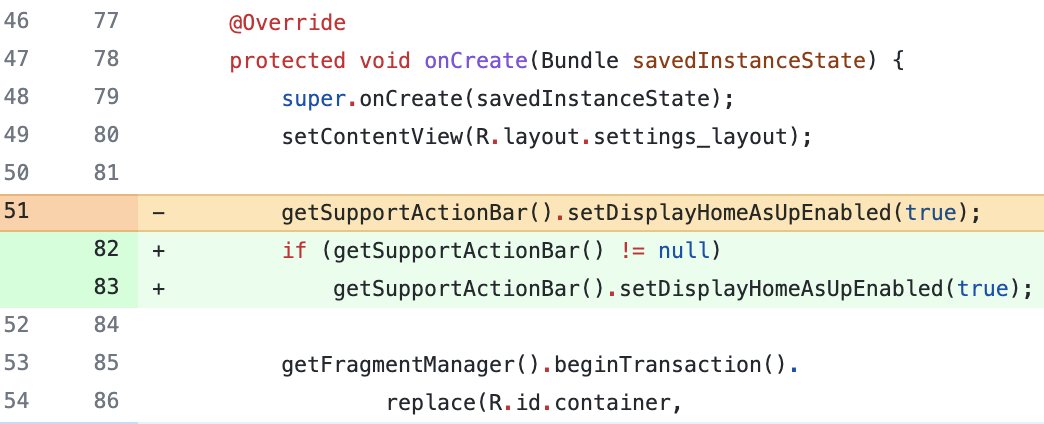
(b)

(c)

(d)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ed15c796-33c9-4eec-84c0-ea9a2c4797d1/postcondition_0_1.png)
URL: https://stackoverflow.com/questions/40795037
(a) Example code change (b) Precondition of the synthesized rule
(a)

(b)
URL: https://developer.android.com/guide/components/intents-common
(a) Example code change (b) Precondition of the synthesized rule (c) A disjunct in the synthesized postcondition: if ‘Intent‘ is created from a class in the same application, then the example is conforming. Note this code variation for conforming examples is not present in the code change and included in the rule during rule refinement. (d) A disjunct in the synthesized postcondition: if a catch block exists to handle an exception thrown by ‘startActivity‘, the code is conforming. This code vairation is also learned from conforming examples during rule refinement. (e) A disjunct in the synthesized postcondition: if ‘Intent.resolveActivity(..)‘ is checked for null, the code is conforming.
(a)

(b)
(c)
(d)
(e)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ed15c796-33c9-4eec-84c0-ea9a2c4797d1/postcondition_0_2.png)
URL: https://github.com/google/gson/blob/master/UserGuide.md#TOC-Serializing-and-Deserializing-Generic-Types
(a) Example code change (b) Precondition of the synthesized rule
(a)

(b)