11email: {rviana,dcampos,mcampos}@soldai.com
Evolutionary optimization of contexts for phonetic correction in speech recognition systems
Resumen
Automatic Speech Recognition (ASR) is an area of growing academic and commercial interest due to the high demand for applications that use it to provide a natural communication method. It is common for general purpose ASR systems to fail in applications that use a domain-specific language. Various strategies have been used to reduce the error, such as providing a context that modifies the language model and post-processing correction methods. This article explores the use of an evolutionary process to generate an optimized context for a specific application domain, as well as different correction techniques based on phonetic distance metrics. The results show the viability of a genetic algorithm as a tool for context optimization, which, added to a post-processing correction based on phonetic representations, can reduce the errors on the recognized speech.
Keywords: Speech recognition, Phonetic distance, Genetic algorithms.
1 Introduction
Automatic speech recognition (ASR) systems are of great relevance in academic and business environments due to the ease of interaction they offer. There has been a growing interest in investigating these systems, which have migrated from probabilistic models to deep neural network systems [5] that have become the standard for professional audio-to-text transformation applications. Deep neural network systems for audio-to-text transformation often use an acoustic model to perform recognition at a first level and are later passed to language models for correction [9]. Commercial services generally operate as a black box, making it difficult for the user to modify language models.
While ASRs generally perform well, they often run into problems when used to recognize specific language domains, so post-processing techniques become relevant [4].
Many of the post-processing and correction tasks of these systems use a context, understood as a set of words, phrases, and expressions related to the particular domain that it is desired to recognize. Some of them have mechanisms to provide a context with which they improve the recognition of certain words and phrases. However, in many cases, it is not enough to significantly improve their performance.
Two particularly interesting topics are the generation of contexts and the phonetic representation for correction. Research has been carried out in this regard; however, there is a lack of experimentation related to the optimal context generation and phonetic representation’s joint operation.
This article presents a method for generating contexts using genetic algorithms to correct the output of the Google speech-to-text processing system. Next, the error correction process’s comparison of different critical strategies is carried out: representation of the sentence to be corrected, candidate selection, and comparison metrics.
The article is structured as follows: Section 2 describes the background to the problem and related work; Section 3 presents the methodology used for the investigation; In section 4, the experimental work carried out is described, the results of which are shown in section 5 and finally in section 6 the conclusions are provided along with some ideas to develop as future work.
2 Background
The error correction algorithms in ASR systems have been approached from different perspectives, including phonetics. Kondrak [11] proposes an algorithm to calculate a metric of phonetic similarity between segments using multivalued articulatory phonetic characteristics. The Kondrak algorithm combines sets of edit operations and local and semi-global alignment models to calculate a set of near-optimal alignments.
Pucher et al. [16] present word confusion matrices using different measures of phonetic distance. The metrics presented are based on the minimum editing distance between phonetic transcriptions and the distances between hidden Markov models. His research shows a correlation between edit distance and word confusion in ASR systems, so these types of corrections become useful for rectifying recognition errors.
In [2] the problem of using the editing distance to compare strings in languages like Korean, where characters represent syllables instead of letters, is highlighted. This is reflected in the fact that substituting one syllable for another provides the same value regardless of the difference between its letters. The traditional solution uses hybrid metrics between characters and syllables; however, the authors argue that this approach does not satisfactorily solve the problem, so they propose an editing distance based on phonemes as a solution.
Droppo and Acero [9] use the phonetic editing distance to incorporate a third element of correction to ASR systems. They incorporate this distance to learn the relative probability of phonetic recognition strings, given an expected pronunciation. This strategy considers the context of the transcripts, changing the probability of correction depending on the words before and after.
Bassil and Semaan [4] employ a post-processing strategy for error correction in ASR systems. The presented method for detecting word errors uses a candidate generation algorithm and a context-sensitive error correction algorithm. The authors report a significant reduction in system errors.
In [7] phonetic correction strategies are used to correct the errors generated by an ASR system. In the cited work, the system’s transcript is transformed into a representation in International Phonetic Alphabet (IPA) format. A sliding window algorithm is used to select candidate phrases for correction according to the words provided, in context and distance to its phonetic representation in IPA format. The authors report an improvement in 30 % of the phrases recognized by the Google service.
An important component for the phonetic correction algorithm is the context used to construct the candidate phrases, so solutions capable of finding optimal configurations among vast search spaces are needed.
Genetic algorithms are stochastic search algorithms based on biological evolution principles and emulate the process through genetic operators applying recombination, mutation, and natural selection in a population [13, 18]. They have been applied to solve complex combinatorial problems, and the results show that they constitute a powerful and efficient strategy when used correctly. [18].
These types of algorithms have been used to analyze a large number of problems, including knapsack [18], process scheduling problems, the traveling salesperson [13], search for functions for symbolic regression [1], Gaussian kernel functions for sentiment analysis [17], among others.
When using genetic algorithms to solve a problem, possible solutions are expressed as a chain of symbols called a chromosome, where each symbol is a gene. From an initial generation of individuals, the processes of selection, mutation, recombination, and evaluation are iteratively executed, combining the individuals’ genes to produce new variations. Each individual is evaluated according to a function called fitness that describes how well they perform to solve the problem.
3 Methodology
The correction algorithm uses the components of a context (set of words and phrases belonging to the application domain) to detect possible errors in the recognition and correct the transcript of an automatic speech recognition system. It comprises three main elements: phonetic representation, candidate phrase generator for correction, and editing distance metric. As a measure of evaluation of the results, the WER metric (Word Error Rate) was used, which is defined as follows:
| (1) |
where is the number of substitutions, the number of deletions, the number of insertions required to transform the hypothetical phrase into the actual phrase, and the number of words in the actual phrase.
3.1 Phonetic transcription
Phonetic transcription is a system of graphic symbols that represent the sounds of human speech. It is used as a convention to avoid the peculiarities of each written language and to represent those languages without a written tradition [10]. We use as phonetic representations: plain text, IPA, Double Metaphone (DM), and a variant of Double Metaphone with vowels (DMV).
The IPA is a phonetic notation system based on the Latin alphabet, used as a standardized representation of the sounds of the spoken language [6, 19]. Metaphone is a phonetic algorithm that is in charge of indexing words by their pronunciation from the English language [15]. The DM algorithm is an improved version of the Metaphone algorithm, which returns a representation of the letters’ sound in the string when the text is spoken and omits the vowels. The DM has often been used to represent the English language; however, vowel sounds are of importance in Spanish because they serve the Spanish speaker to link words that end in consonant groups [8], so we developed a variant of the DM which adds the vowels that are removed in the original algorithm.
3.2 Candidate Sentence Generation Algorithms
During the phonetic correction process, the search for candidate phrases generates segments of the input string that will be contrasted employing a distance metric with the words and phrases in the context. A candidate phrase is one that is similar to one of the phrases in the context and that may contain an error in the ASR transcript. The experimentation was done utilizing the pivotal window, and the incremental comparison algorithm (based on the phrase’s size in letters or syllables), were used as algorithms for generating candidate phrases.
In [7] the sliding window strategy is presented where a set is generated with a window . The selection of sub phrases is done using a pivot and the set of candidate sentences is generated by the sub phrases { }.
An incremental sub phrase search method was implemented for this article, which is described below:
Let the set of context-specific phrases, and the original transcript divided into words, it is intended to build a set formed by pairs such that is an element of the context capable of substituting the segment for some in .
The algorithm 1 uses a strategy, in which each word in transcript (), the sub phrase to be evaluated is incremented word by word until there are no more elements of the context comparable for their size in letters or syllables according to the threshold. The possible substitutions of for are added to the set as long as their distance is less than . The algorithm’s complexity is where is the number of elements in the context and the size of the transcript in words.
3.3 String Distance Metrics
The edit distance is used to quantify the difference between two text strings in terms of the number of operations required to transform one string into the other. This work experiments with Levenshtein, Damerau-Levenshtein distance metrics, and Optimal Chain Alignment (OSA).
The Levenshtein distance between two character strings is the number of insertions, deletions, and substitutions required to transform one character string into another [12]. The Damerau-Levenshtein distance can be intuitively defined as an extension of the Levenshtein distance by adding the transposition of two adjacent characters [3] as a valid operation. OSA is a restrictive variation of the distance Damerau-Levenshtein, where the transpose operation can only be performed once per character [14], which makes it less computationally expensive.
3.4 Evolutionary context optimization
For the generation of contexts, it was decided to use a genetic algorithm constructed from the sentences’ transcripts to be corrected. Each individual represents a possible context. For the individuals’ construction, all the words were considered individually, and the combinations of 2 words (bigrams) present in the target sentences of the original audios. Individuals were defined by a chromosome where each gene takes the value 1 if the word or bigram is in the context and 0 otherwise.
In this way, each individual represents a context, which is a potential parameter to the correction algorithm. To evaluate individuals, the correction algorithm was run with the best combination found in the article [7] to each of the 451 sentences. The total WER of each context analyzed was returned as a measure of fitness. A simple genetic algorithm described in the algorithm 2 was used where the function produces individuals randomly. is a function that calculates each individual’s WER, assigns it as a measure of fitness and returns the average WER of the population. The selection was made with a simple tournament strategy. The function performs genetic recombination between the individuals of the population using the random crossing point technique shown in the algorithm 3. Subsequently, the individual-to-individual and gene-to-gene mutation process was carried out according to the mutation probability value, which was reduced every ten generations to reduce the fluctuation and stabilize the error when it approached a minimum.
4 Experiments
The present work experiments were carried out using 451 phrases transcribed by the Google speech recognition system. This same corpus was used in [7], where details of the said corpus’ collection process and format can also be obtained.
4.1 Corrector setting variants
To compare the variants of each element of the algorithm, a total of 72 experiments were carried out with all the combinations of the methods presented in table 1.
| Representation | Phrases Generation | Distance metric | Google STT |
|---|---|---|---|
| Simple text | WIN | Levenshtein | Basic |
| IPA | LET | OSA | Contextual |
| DM | SYL | Damerau-Levenshtein | |
| DMV |
The text of the phrase recognized by the STT system and the context’s phrases were represented differently for processing. For all text representations, it was necessary to carry out a normalization process to remove some punctuation symbols and characters. This normalized version was used directly in the form of simple text or transformed into one of the analyzed phonetic representations: International Phonetic Alphabet (IPA), Double Metaphone (DM), or Double Metaphone with vowels (DMV).
The generation of candidate sentences was experimented with using the pivot window methods (WIN) and the incremental comparison according to the number of characters (LET) or syllables (SYL).
Levenshtein distance and its variants OSA and Damerau-Levenshtein were used as editing distance metrics. Each combination was tested using as input data the 451 transcripts obtained by using the basic Google method and subsequently the transcript resulting from sending the context reported in [7] to the Google service.
For each of the 72 different configurations, different confidence thresholds of the editing metrics were experimented with increments of 0.05 up to a maximum of 0.6. The evaluation of each experimental setup was carried out using the globally accumulated WER metric calculated from the number of edits required to transform the hypothetical transcript into the correct sentence for each example.
4.2 Context optimization
The experimentation described in the previous section was carried out with an empirically generated context according to the a priori knowledge of the domain phrases where transcription errors were observed. In order to optimize the context, a genetic algorithm was run whose parameters were calibrated by conducting experimentation of 30 executions with a reduced version of the problem using a chromosome of size 50, yielding the best results with a population of 50 individuals, 100 generations, 95 % probability of crossover and 5 % probability of mutation.
Once the parameters had been calibrated, the context was optimized using a chromosome size of 355. Each gene represents one of the words or bigrams present in the transcripts of the audios used in the experimentation. The mutation factor was reduced by 20 % every 10 generations. Individuals were evolving for 100 generations.
As a function of fitness, the total WER obtained when executing the correction algorithm for the simple transcription of Google was used using the individual defined by the chromosome as context. The phonetic corrector was run using IPA representation, pivot window selection, Levenshtein distance, and threshold of 0.4, which was the best configuration reported in [7].
Five evolutionary processes of 100 generations were executed where the population was initialized with the 25 best individuals from the previous round and 25 randomly generated to explore different evolutionary variants. The experimentation was done with an Intel i7 processor, 8GB of RAM, and a Debian GNU/Linux operating system. The algorithm was implemented in Python3 and ran five times for a total of 70 hours.
4.3 Error correction with optimized context
In this phase of the experimentation, tests were carried out to measure the effects of context on speech recognition and subsequent correction. The previously generated audio files were sent back to the recognition system in its basic mode and with the genetically generated context. This gave us a direct comparison of the effect of using the optimized context concerning the transcript obtained without sending context; besides, it gave us two baselines on which to apply the correction process to the new transcripts.
To compare the correction process results, the algorithm was applied to the new transcripts produced by both versions of the Google recognizer. The four configuration variants that presented the best results were used in the experimentation described in section 4.1. Taking as input the transcripts obtained by the two modalities of the Google service, two experiments were executed for each one of them. In the first, the experimental context used in [7] was used, which we will denote as , and in the second experiment, the new genetically generated context .
5 Results
Fig. 1 (a) shows the variation in the average WER obtained in the experiments grouped by the representation mode with different distance thresholds. The horizontal lines correspond to the WER obtained with the transcription of the basic STT (33.7 %) and the contextual STT (31.1 %). The effect of reducing the WER is observed when transforming the plain text into IPA, especially around the value 0.4 for the threshold, where a minimum average WER of 27.8 % is reached. On the other hand, the representation in DM produced similar results to the other methods for small values of the threshold, however around 0.3, its corrective capacity decreases consistently. The DMV version sustains its performance on par with plain text up to a threshold of 0.4.


In Fig. 1 (b), the average WER obtained by the different experimental configurations grouped by the candidate phrase generation algorithm is observed. The graph shows a better performance of the incremental comparison variants, either by size in letters or syllables, compared to the pivot window. The minimum average WER (29.4 %) is reached with a threshold of 0.4 for the LET method. The SYL version shows very similar results; however, the computational cost of processing is higher.
The best results were obtained with the IPA representation configuration and the LET candidate selection method. The WER obtained from the basic transcript decreased from 33.7 % to 28.1 %, and for the contextual transcript, it decreased from 31.1 % to 27.3 %. This configuration presented a global reduction in the relative WER of 19.3 %. Concerning the three distance metrics evaluated, the difference in the results was practically nil.
The results obtained from the experimentation with the genetic algorithms for the optimization of the context using the experimental configuration described in the section 4.2, indicate that an average error was obtained in the fifth execution of the experiment of 26.5 % , which started with an average error of 31.2 % and decreased to an average of 24.9 % in generation 100.
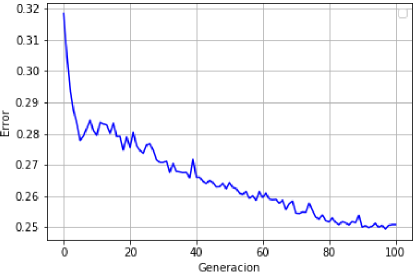
In Fig. 2 the average errors of the 100 generations in the fifth run of the experiment are shown. The best context found with this strategy contained 64 unigrams and 117 bigrams with a total WER of 24.7 %.




In the final phase of the experimentation described in section 4.3, two baselines are obtained to execute the correction process. The WER obtained when comparing the actual sentences spoken with the basic transcription was 32.0 %, while incorporating the genetically generated context, the WER was considerably reduced to 23.2 %. This result allows us to see the impact that an optimized context has on the language model used by Google by reducing the relative WER by 27.3 %.
Fig. 3 shows the correction algorithm results using the IPA representation with the context . Starting from the basic STT, the minimum WER is obtained with a threshold of 0.4 and the LET selection process. With this configuration, the total WER is reduced from 32.0 % to 26.6 %, representing a reduction of 16.9 % in the WER relative. When starting the correction process from the transcription of the contextual STT, the WER decreased from 23.2 % to 21.0 %, reaching a 9.5 % improvement in the relative WER.
Similarly, Fig. 4 shows results using the genetically generated context as input to the correction algorithm. Using this context, a reduction of the minimum WER when using the WIN candidate generation procedure is observed. However, it does not seem to generate good results with the LET method. The absolute minimum WER for the basic STT is 25.3 %, thus reducing the relative WER of 21.0 %. Starting from the contextual STT, a minimum of 20.1 % is reached, representing a reduction of 13.6 % in relative WER.




6 Conclusions and future work
From the results obtained in the experimentation, the phonetic correction algorithm’s usefulness is shown to reduce errors in the transcription of Google, both in its basic and contextual versions. It is observed that the best configuration for the algorithm is obtained using IPA as phonetic representation and incremental selection by letters, managing to reduce the relative WER by 19.0 %.
Similarly, we can mention that genetic algorithms are an efficient alternative for generating contexts since they managed to reduce the WER of Google basic transcription from 32.0 % to 23.2 %. The context was shown to have a crucial value in the performance of the algorithm.
The best results were obtained from the combination of the phonetic correction with the evolutionary optimization of the context, achieving a reduction of the absolute WER of 11.9 % by decreasing it from 32.0 % to 20.1 %, representing an improvement in relative WER of 37.2 %.
The fact that both the phonetic correction algorithm and the evolutionary context optimization are independent of the system used for the transcription and application domain means that the strategy presented can be extended to different ASR systems and application domains.
The algorithms presented throughout this article can take advantage of a priori knowledge of the application domain to mitigate the cold start problem. The above is because if the initial transcripts are not available, a context generated with human knowledge of the domain can be used, as in [7], which can be complemented with genetic algorithms as information is collected about interactions with actual users of the system.
Among future research lines, it is necessary to validate the results with a corpus of different application domains; in addition, experimentation using weighted editing costs considers phonetic characteristics of Spanish and the original audio such as noise, duration, the energy of the signal, among others. Another line of research is the comparison with deep learning algorithms since the problem of error correction in ASR systems can be considered a translation of erroneous transcripts to correct transcripts, so algorithms Machine translation can be helpful.
Referencias
- [1] Anjum, A., Sun, F., Wang, L., Orchard, J.: A novel continuous representation of genetic programmings using recurrent neural networks for symbolic regression. CoRR abs/1904.03368 (2019), http://arxiv.org/abs/1904.03368
- [2] Bae, B., Kang, S.s., Hwang, B.y.: Edit Distance Calculation by Phonetic Rules and Word-length Normalization 2 Related Works 3 Edit Distance for Korean Words 4 Phoneme-based Edit Distance. Advances in Computer Science (1), 315–319 (2012)
- [3] Bard, G.V.: Spelling-error tolerant, order-independent pass-phrases via the damerau-levenshtein string-edit distance metric. In: Proceedings of the Fifth Australasian Symposium on ACSW Frontiers - Volume 68. pp. 117–124. ACSW ’07, Australian Computer Society, Inc., Darlinghurst, Australia, Australia (2007), http://dl.acm.org/citation.cfm?id=1274531.1274545
- [4] Bassil, Y., Semaan, P.: Asr context-sensitive error correction based on microsoft n-gram dataset. CoRR abs/1203.5262 (2012)
- [5] Becerra, A., de la Rosa, J.I., González, E.: A case study of speech recognition in spanish: From conventional to deep approach. In: 2016 IEEE ANDESCON. pp. 1–4 (Oct 2016). https://doi.org/10.1109/ANDESCON.2016.7836212
- [6] C., M.M.K.: Phonetic notation. The World’s Writing Systems pp. 821–846 (1996)
- [7] Campos Sobrino, D., Campos Soberanis, M.A., Martínez Chin, I., Uc Cetina, V.: Correccion de errores del reconocedor de voz de google usando métricas de distancia fonética. Research in Computing Science (In Press) (04 2018)
- [8] Chela-Flores, B.: Consideraciones teórico-metodológias sobre la adqusición de consonantes posnucleares del inglés. RLA. Revista de lingüística teórica y aplicada 44 (12 2006). https://doi.org/10.4067/S0718-48832006000200002
- [9] Droppo, J., Acero, A.: Context dependent phonetic string edit distance for automatic speech recognition. In: 2010 IEEE International Conference on Acoustics, Speech and Signal Processing. pp. 4358–4361 (March 2010). https://doi.org/10.1109/ICASSP.2010.5495652
- [10] Hualde, J.: The sounds of Spanish. Cambridge University Press (2005)
- [11] Kondrak, G.: Phonetic alignment and similarity. Computers and the Humanities 37(3), 273–291 (Aug 2003). https://doi.org/10.1023/A:1025071200644, https://doi.org/10.1023/A:1025071200644
- [12] Levenshtein, V.I.: Binary codes capable of correcting deletions, insertions and reversals. Soviet Physics Doklady 10(8), 707–710 (feb 1966), doklady Akademii Nauk SSSR, V163 No4 845-848 1965
- [13] Luo, J., Baz, D.E.: A survey on parallel genetic algorithms for shop scheduling problems. CoRR abs/1904.04031 (2019), http://arxiv.org/abs/1904.04031
- [14] Navarro, G.: A guided tour to approximate string matching. ACM Comput. Surv. 33(1), 31–88 (Mar 2001). https://doi.org/10.1145/375360.375365, http://doi.acm.org/10.1145/375360.375365
- [15] Philips, L.: Hanging on the metaphone. Computer Language Magazine 7(12), 39–44 (December 1990), accessible at http://www.cuj.com/documents/s=8038/cuj0006philips/
- [16] Pucher, M., Turk, A., J., A., Fecher, N.: Distance, phonetic and for, measures and recognition, speech and optimization, grammar. 3rd Congress of the Alps Adria Acoustics Association (2007)
- [17] Roman, I., Mendiburu, A., Santana, R., Lozano, J.A.: Sentiment analysis with genetically evolved gaussian kernels. CoRR abs/1904.00977 (2019), http://arxiv.org/abs/1904.00977
- [18] Shah, S.: Genetic algorithm for a class of knapsack problems. CoRR abs/1903.03494 (2019), http://arxiv.org/abs/1903.03494
- [19] Wall, J.: International phonetic alphabet for singers : a manual for English and foreign language diction. Dallas, Tex. : Pst (1989), running title: IPA for singers