EventRL: Enhancing Event Extraction with Outcome Supervision for Large Language Models
Abstract
In this study, we present EventRL, a reinforcement learning approach developed to enhance event extraction for large language models (LLMs). EventRL utilizes outcome supervision with specific reward functions to tackle prevalent challenges in LLMs, such as instruction following and hallucination, manifested as the mismatch of event structure and the generation of undefined event types. We evaluate EventRL against existing methods like Few-Shot Prompting (FSP) (based on GPT4) and Supervised Fine-Tuning (SFT) across various LLMs, including GPT-4, LLaMa, and CodeLLaMa models. Our findings show that EventRL significantly outperforms these conventional approaches by improving the performance in identifying and structuring events, particularly in handling novel event types. The study emphasizes the critical role of reward function selection and demonstrates the benefits of incorporating code data for better event extraction. While increasing model size leads to higher accuracy, maintaining the ability to generalize is essential to avoid overfitting.
EventRL: Enhancing Event Extraction with Outcome Supervision for Large Language Models
Jun Gao1 Huan Zhao2 Wei Wang3 Changlong Yu4 Ruifeng Xu1 1Harbin Institute of Technology (Shenzhen) [email protected] [email protected] 24Paradigm. Inc. 3Tsinghua University 4HKUST, Hong Kong, China [email protected] [email protected] [email protected]
1 Introduction
Event extraction, a crucial task in natural language processing (NLP), aims at identifying and categorizing events within texts (Chen et al., 2015; Nguyen et al., 2016; Liu et al., 2018; Yang et al., 2019; Lu et al., 2021; Gao et al., 2023a).

Recently, large language models (LLMs) have demonstrated impressive capabilities in language understanding and generation for various tasks (Ouyang et al., 2022; Chen et al., 2021; Achiam et al., 2023; Zhao et al., 2023). However, they also encounter specific challenges, such as instruction following Zhou et al. (2023); Zeng et al. (2023) and the generation of inaccurate or irrelevant content, often referred to as hallucinations Li et al. (2023).
In the context of event extraction tasks, these models encounter similar difficulties, including mismatches in event structure and the generation of undefined event types (Gao et al., 2023a). As illustrated in Figure 1, a mismatch in event structure refers to inaccuracies like incorrectly including an irrelevant argument. For instance, an “Attack” event erroneously includes a non-existent “entity” role. The generation of undefined event types refers to the model’s prediction of event types that are not predefined in the task instruction. For example, in texts related to elections, the model might unpredictably predict a “Vote” event type, which is not defined in the task instruction. These issues can be seen as manifestations of instruction following and hallucination problems within the realm of event extraction. Recent studies (Wang et al., 2023a; Gao et al., 2023b; Sainz et al., 2023) have attempted to address these challenges using Supervised Fine-Tuning (SFT) methods, but the performance has been far from satisfactory. A potential reason for this is that event extraction demands too much recognition for abstract concepts and relations, and it suggests that there is a need to focus more on enhancing the high-level understanding for event comprehension (Huang et al., 2023a).
A major limitation of SFT approaches in event extraction is their inability to accurately recognize errors in event structures, such as incorrect argument inclusion or predicting events not defined in the guidelines. This issue may stem from the reliance on Negative Log Likelihood (NLL) loss, which, while effective for general language modeling, falls short in capturing the intricacies of event extraction. Specifically, when it comes to event extraction, both types of errors—incorrect predictions of event types and incorrect predictions of an event argument’s role—often differ from the correct samples by just a single word in the text. However, in terms of NLL loss, these errors result in only minor differences, failing to reflect their significant impact on event extraction performance. This discrepancy is particularly critical because an error in predicting the event type can lead to a cascade of errors in the extraction of all associated arguments, drastically reducing the accuracy of the entire extraction process. Therefore, while NLL loss might marginally penalize these mistakes, their actual consequences are far more severe.
One potential solution is to integrate feedback on the model’s performance in identifying and structuring events into its training process. This method, known as outcome supervision, draws inspiration from previous works in solving math problems (Uesato et al., 2022; Lightman et al., 2023). By incorporating outcome-based feedback, the model can adjust and refine its strategies for more accurate event identification and structuring, addressing the specific challenges it faces in understanding and extracting events from text. To this end, we introduce EventRL, a novel reinforcement learning framework designed to enhance event extraction by directly responding to the accuracy of the model’s output. EventRL addresses key issues faced by LLMs in event extraction, such as the mismatch in event structures and the generation of undefined event types. It leverages outcome performance as feedback to penalize errors, guiding the model to adjust its strategies for better performance. We explore three event-specific reward functions: Argument-F1, Average-F1, and Product-F1. These functions are designed to improve the model’s comprehension of event structures Moreover, to enhance training stability, we introduce Teacher-Force Threshold and Advantage Clipping strategies, mitigating policy degradation and preventing catastrophic forgetting. Our contributions can be summarized as follows:
-
•
We introduce outcome supervision to LLMs for event extraction, focusing on task outcomes to improve event understanding and extraction. To the best of our knowledge, we are the first to incorporate outcome feedback on event structures into the training process of LLMs for EE.
-
•
We develop EventRL, a novel approach that implements outcome supervision through reinforcement learning with tailored reward functions, to provide a more precise and targeted training method for EE.
-
•
Extensive experiments with LLMs of varying sizes show that EventRL significantly outperforms standard SFT methods. Notably, EventRL shows remarkable improvements in handling unseen events and significantly reduces errors in event structure and type definition, thereby validating the effectiveness of outcome supervision in boosting the capabilities of LLMs in EE.
2 Related Work
Event Extraction
Event Extraction (EE) has evolved from traditional sequence labeling methods to the integration of advanced machine learning models, particularly large language models. The initial approach to EE focused on word-level classification, capturing sentence dependencies (Chen et al., 2015; Nguyen et al., 2016; Liu et al., 2018; Yang et al., 2019; Wadden et al., 2019). A significant shift occurred with the introduction of Machine Reading Comprehension techniques, which transformed EE into a question-answering task, enhancing event extraction (Chen et al., 2020; Du and Cardie, 2020; Li et al., 2020; Zhou et al., 2021; Wei et al., 2021). The subsequent development of sequence-to-structure generation with Transformer-based architectures further streamlined the process by merging event detection and argument extraction (Lu et al., 2021, 2022; Lou et al., 2023). The latest advancement involves LLMs, which, due to their extensive pre-training, demonstrate exceptional generalization capabilities, advancing traditional EE techniques and enabling zero-shot event extraction, marking a notable progression in NLP (Wei et al., 2023; Gao et al., 2023a; Wang et al., 2023a; Sainz et al., 2023; Gao et al., 2023b). In contrast to previous work, our work focuses on utilizing outcome supervision to refine model training of LLMs for event extraction, thereby enhancing performance. Notably, we are the first to incorporate outcome feedback into the LLM training process for EE.
Large Language Models and Outcome Supervision
Large language models has marked a significant advance in the field of NLP. Recent studies have demonstrated the exceptional capability of LLMs, such as ChatGPT and GPT-4, to perform with remarkable performance in event extraction (Gao et al., 2023a; Sainz et al., 2023). These models demonstrate notable performance gain even in zero-shot learning settings, indicating their potential to generalize across different types of event-related information without the need for task-specific training data. Despite the progress, LLMs continue to face challenges related to instruction following (Ouyang et al., 2022) and hallucinations (Huang et al., 2023b; Zhang et al., 2023b; Li et al., 2024). To address these issues, researchers have explored a range of strategies, including Supervised Fine-Tuning (SFT) (Wang et al., 2022; Zhang et al., 2023a; Wang et al., 2023b), Reinforcement Learning from Human Feedback (RLHF) (Stiennon et al., 2020; Ouyang et al., 2022; Kaufmann et al., 2023), and more recently, approaches that combine outcome supervision with reinforcement learning techniques (Uesato et al., 2022; Lightman et al., 2023; Yu et al., 2023) for solving math problems. Building on these seminal works, our work makes the first attempt to introduce outcome supervision for event extraction tasks, which can harness the power of LLMs while directly address their limitations in instruction following and hallucinations, thus significantly improving the efficacy and reliability of event extraction.
3 EventRL
3.1 Overview
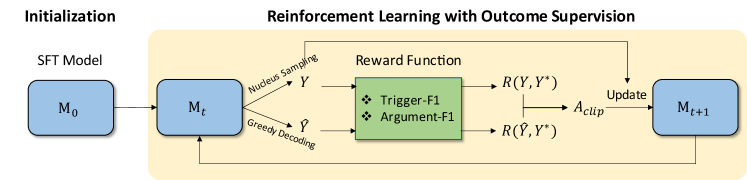
EventRL aims to enhance event extraction through outcome supervision with reinforcement learning for LLMs. As depicted in Figure 2, EventRL begins with an SFT phase to establish a baseline understanding of event extraction. It then progresses to implement outcome supervision, leveraging reward functions based on resulting performance (Trigger-F1 and Argument-F1 scores) to guide the model’s training via reinforcement learning techniques. To ensure stable and effective learning, EventRL incorporates stabilization strategies, including a Teacher-Force Threshold and Advantage Clipping, which are critical for mitigating policy degradation and preventing catastrophic forgetting. The subsequent sections will delve into the detailed implementation of these components.
3.2 Initialization
Input and Output Format
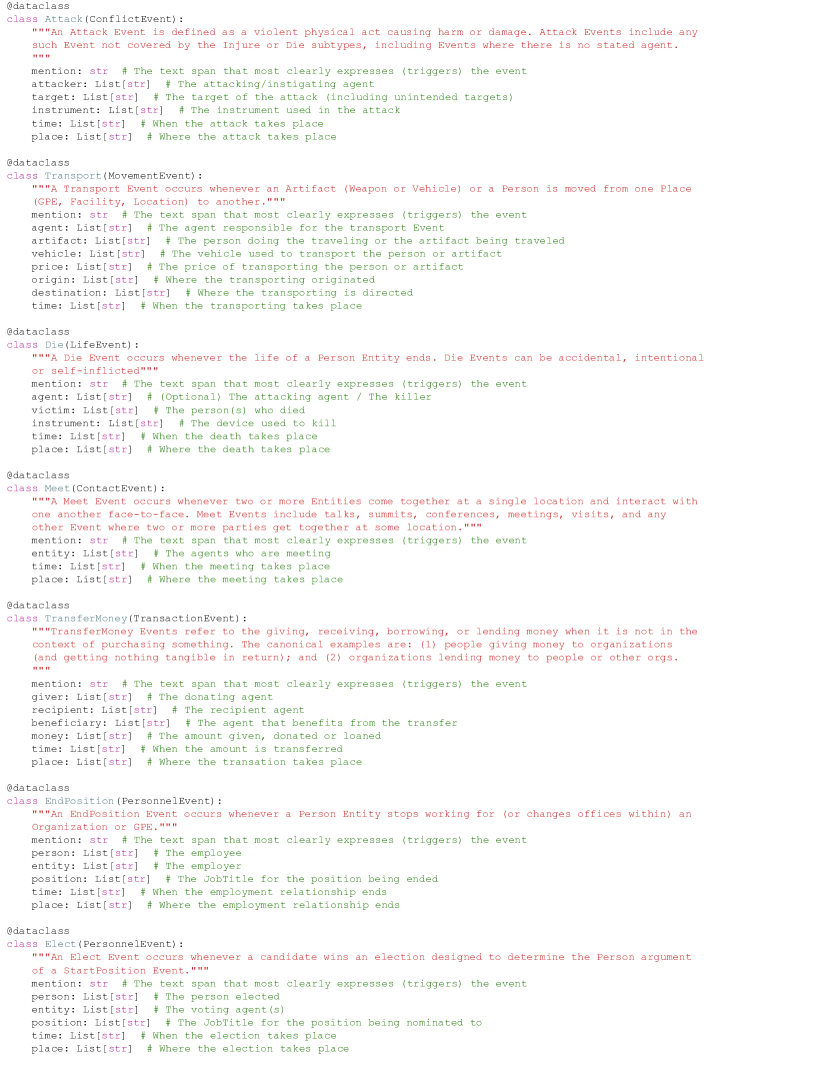
In the Initialization phase of EventRL, we adopt a hybrid input and output format, building upon the work of Sainz et al. (2023). As illustrated in Figure 3, our approach combines structured Python dataclass formats for event definitions with natural language instructions for task descriptions. This allows for precise event representation while maintaining user-friendly instructions. The output is a Python list of dataclass instances, representing the extracted events in a structured and programmatically accessible format. This hybrid format enhances the model’s ability to process and output complex event information accurately, bridging the gap between structured coding and natural language understanding.

Supervised Fine-tuning
The SFT process (Wang et al., 2022; Zhang et al., 2023a; Wang et al., 2023b; Peng et al., 2023) in our approach is an important initial phase that establishes a foundational understanding of the event extraction process in the model. During SFT, the model is trained using a labeled dataset that consists of examples, where each event is explicitly defined with its corresponding triggers and arguments. This dataset provides clear and structured examples of desired event extraction outputs.
3.3 Outcome Supervision with RL
Problem Formulation
To implement outcome supervision, we leverage reinforcement learning (Kaelbling et al., 1996). The RL method treats event extraction as a sequential decision-making process, where the model , guided by its policy , generates predictions , which include event triggers and their arguments, based on inputs .
The model’s parameters are updated to maximize expected rewards, leveraging an advantage-based policy optimization method to guide learning (Sutton and Barto, 2018). The update rule is as follows:
| (1) |
where is the gradient of the log-probability of taking action in state under policy . The advantage function is , where is the reward function and is a baseline reward. This function calculates the difference between the reward for the model’s predictions and a baseline , identifying actions that yield above-average benefits. This approach stabilizes policy gradient estimates by reducing variance (Rennie et al., 2017).
Reward Function
In our EventRL framework, the reward function focuses on two primary aspects: Trigger Extraction and Argument Extraction. These aspects are quantified through Trigger-F1 and Argument-F1 scores, respectively, which serve as the basis for our reward function. The Trigger-F1 score assesses the model’s ability to accurately identify and classify event triggers, while the Argument-F1 score evaluates the precision in identifying and classifying the arguments associated with those triggers. Following previous work (Lu et al., 2021), we adopt the following criteria of the evaluation: A trigger is correct if its event type matches with the ground truth. Similarly, an argument is considered correctly identified if its event type and role match with the ground truth.
In our work, we explore three different reward function designs, shown in the following equation:
| (2) |
The Argument-F1 reward, , focuses on how well the model can identify and classify the arguments of events. Meanwhile, the Average-F1 reward, , gives a balanced look by combining Trigger-F1 and Argument-F1 scores, offering a full view of the effectiveness of the model. Lastly, the Product-F1 reward, , highlights the importance of doing well in both trigger detection and argument extraction by multiplying these scores together, pushing the model to excel in both areas for a better total reward.
In current approaches of instruction tuning, especially in response generation tasks, feedback often comes from model scoring. This can involve predictions from a reward model trained on human preference data (Ouyang et al., 2022) or direct scoring by more advanced models like GPT-4 (Cui et al., 2023). Although, for event extraction tasks, we could train a reward model on positive and negative examples or have GPT-4 score the outputs, the necessity for such methods is reduced. This is because standard evaluation metrics for event extraction already provide a clear reflection of output quality. However, there is still value in the model generating natural language judgements (Xu et al., 2023) to further address and correct training issues. We leave this for future work.
Advantage Calculation
To calculate the advantage, we compare the rewards of two distinct strategies for extracting events: greedy decoding and nucleus sampling. When processing a given text, the model generates two outputs: one through greedy decoding () and another via nucleus sampling (). We then assess these outputs by calculating their rewards, for the greedy decoding output and for the nucleus sampling output. The advantage function quantifies the benefit of the nucleus sampling strategy over the greedy decoding by measuring the difference in their rewards:
| (3) |
This comparison highlights the effectiveness of exploratory actions in improving event extraction outcomes compared to the baseline approach.
3.4 Stabilization Strategies in EventRL
To ensure stable training, two key stabilization strategies are implemented: the Teacher-Force Threshold (Bengio et al., 2015) and Advantage Clipping (Schulman et al., 2017).
Teacher-Force Threshold
The Teacher-Force Threshold strategy is employed to mitigate policy degradation, especially in instances where the model’s performance on certain samples is significantly below par. This strategy involves setting a threshold value, denoted as , for the model’s performance score (typically measured using the outcome score from greedy decoding). When the model’s performance on a given sample falls below , the learning process is adjusted to “teacher forcing” mode. In this mode, the model is temporarily guided using the gold events instead of its own generated output , effectively providing a more reliable learning signal.
Advantage Clipping
Advantage Clipping in the EventRL is specifically designed to address the challenge of catastrophic forgetting, a phenomenon where the model’s performance on previously learned tasks deteriorates as it focuses on new ones. This issue often arises when the advantage values for certain samples are too low, leading to negligible updates and causing the model to overlook these samples during training. The strategy involves setting a lower bound for the advantage values, denoted as . This lower bound ensures that every sample, regardless of its initial advantage value, contributes a minimum threshold of influence to the learning process. The advantage clipping process is reformulated to focus solely on the lower bound, as follows: .
| Held-in test | Held-out test | |||||
| Method | Trigger | Argument | AVG | Trigger | Argument | AVG |
| GPT4 + FSP (0-Shot) | 6.04 | 22.08 | 14.06 | 15.42 | 17.69 | 16.56 |
| GPT4 + FSP (1-Shot) | 23.02 | 22.82 | 22.92 | 19.32 | 17.83 | 18.58 |
| GPT4 + FSP (2-Shot) | 24.65 | 23.48 | 24.06 | 24.12 | 18.31 | 21.22 |
| GPT4 + FSP (3-Shot) | 31.58 | 23.53 | 27.55 | 27.07 | 18.61 | 22.84 |
| LLaMa-7B + SFT | 71.33 | 40.74 | 56.03 | 48.51 | 26.18 | 37.35 |
| LLaMa-7B + EventRL (Arg-F1) | 73.06 | 42.34 | 57.70 | 51.15 | 29.32 | 40.23 |
| LLaMa-7B + EventRL (AVG-F1) | 72.34 | 42.29 | 57.32 | 54.59 | 29.81 | 42.20 |
| LLaMa-7B + EventRL (Prod-F1) | 72.03 | 49.41 | 60.72 | 51.71 | 29.97 | 40.84 |
| LLaMa-13B + SFT | 76.23 | 51.16 | 63.69 | 51.61 | 32.46 | 42.04 |
| LLaMa-13B + EventRL (Arg-F1) | 77.61 | 51.93 | 64.77 | 53.07 | 32.83 | 42.95 |
| LLaMa-13B + EventRL (AVG-F1) | 77.26 | 54.55 | 65.90 | 51.53 | 34.93 | 43.23 |
| LLaMa-13B + EventRL (Prod-F1) | 76.23 | 51.66 | 63.94 | 53.79 | 35.03 | 44.41 |
| CodeLLaMa-7B + SFT | 74.31 | 44.16 | 59.23 | 62.21 | 37.26 | 49.74 |
| CodeLLaMa-7B + EventRL (Arg-F1) | 75.35 | 50.84 | 63.09 | 61.64 | 37.93 | 49.78 |
| CodeLLaMa-7B + EventRL (AVG-F1) | 77.14 | 47.06 | 62.10 | 61.62 | 39.01 | 50.32 |
| CodeLLaMa-7B + EventRL (Prod-F1) | 76.60 | 48.39 | 62.49 | 60.34 | 39.69 | 50.01 |
| CodeLLaMa-13B + SFT | 77.70 | 47.21 | 62.46 | 61.40 | 41.98 | 51.69 |
| CodeLLaMa-13B + EventRL (ARG-F1) | 80.88 | 50.51 | 65.69 | 62.56 | 41.39 | 51.97 |
| CodeLLaMa-13B + EventRL (AVG-F1) | 76.98 | 48.18 | 62.58 | 60.86 | 42.37 | 51.62 |
| CodeLLaMa-13B + EventRL (Prod-F1) | 77.03 | 50.78 | 63.91 | 62.57 | 42.14 | 52.35 |
| CodeLLaMa-34B + SFT | 74.65 | 56.69 | 65.67 | 57.98 | 39.52 | 48.75 |
4 Experimental Setup
4.1 Dataset and Data Splitting Strategy
To evaluate our model’s performance comprehensively, we conducted experiments on the ACE05 dataset (Christopher et al., ), known for its diversity in event types. This allows us to test the model’s capability in extracting both familiar (seen) and novel (unseen) event types effectively. The ACE05 dataset, which contains a total of 33 event types, was used to construct our experimental setup. We selected 7 event types for the training set, validation set, and the held-in test set (seen event types). We then chose 19 different event types to form the held-out test set (unseen event types), ensuring a rigorous evaluation of the model’s generalization abilities. To maintain a balanced dataset, we sampled 50 instances for each event type in the training set, 10 for each in the validation set, and 20 for each in both the held-in and held-out test sets. This strategy ensures that the model is trained and evaluated under varied conditions, providing a comprehensive understanding of its performance across different event types. For detailed statistical information, please refer to Appendix A.1.
4.2 Comparison Methods
In our study, we assess the efficacy of EventRL against current methods like Few-Shot Prompting (FSP) and Supervised Fine-Tuning (SFT), applying these methods across various LLMs to evaluate performance in event extraction: (1) Few-Shot Prompting (FSP): Implemented on the specific version of GPT-4 (API version 2023-05-15), provided by the Azure OpenAI Service, this method relies on the model’s intrinsic capabilities by providing a limited set of examples before task execution. (2) Supervised Fine-Tuning (SFT): This approach involves direct training of models on specific datasets, with feedback provided via NLL loss. SFT experiments were primarily conducted on LLaMa variants (LLaMa2-7B and LLaMa2-13B) and CodeLLaMa models (7B, 13B, and 34B versions). (3) EventRL with Proposed Reward Functions: Our proposed EventRL framework was evaluated in three distinct configurations, each utilizing a different reward function designed to optimize the model’s performance in event extraction: EventRL (Arg-F1) utilizes Argument-F1 as feedback, EventRL (Avg-F1) aims to balance Trigger-F1 and Argument-F1, and EventRL (Prod-F1) seeks to maximize the product of Trigger-F1 and Argument-F1. These variants were tested across LLaMa (Touvron et al., 2023) and CodeLLaMa (Roziere et al., 2023) models to investigate their effectiveness in event extraction.
Implementation details of different methods can be found in Appendix A.2.
5 Experimental Results
5.1 Main Results
Overall Performance
Table 1 presents a comprehensive performance comparison of different LLMs, including GPT4, LLaMa, and CodeLLaMa variants, across various training approaches such as SFT (Supervised Fine-Tuning), FSP (Few-Shot Prompting), and our proposed EventRL methods. The table reports Trigger and Argument F1 scores, alongside their averages (denoted as AVG), which are calculated as the mean of the respective Trigger and Argument F1 scores for each method, both for events seen during training (Held-in test) and for novel, unseen event types (Held-out test). Our findings show that EventRL outperforms both SFT and FSP methods in event extraction. Specifically, when comparing the AVG scores, EventRL demonstrates superior overall performance. For example, in the Held-in test, the EventRL (Prod-F1) method using the LLaMa-7B model achieves an AVG score of 60.72, surpassing the SFT method’s 56.03. Similarly, in the Held-out test, EventRL (Prod-F1) with LLaMa-7B reaches an AVG score of 40.84, compared to 37.35 by SFT. This indicates EventRL’s effectiveness in accurately identifying event structures and predicting events.
Moreover, EventRL shows remarkable generalization capabilities, especially in handling unseen event types. Using the LLaMa-13B model, EventRL (Prod-F1) scores an AVG of 44.41 in the Held-out test, outperforming the SFT method’s 42.04. These results highlight EventRL’s robustness and its ability to adapt to new, unseen event types better than the other methods. The success of EventRL can be attributed to its specialized reward functions (Arg-F1, AVG-F1, and Prod-F1), which provide targeted feedback for refining the model’s understanding and extraction of events. This tailored approach ensures that EventRL not only excels in extracting events from texts but also adapts effectively across different model sizes and architectures, including LLaMa and CodeLLaMa variants.
Impact of Different Reward Functions
As shown in Table 1, the choice of reward functions significantly influences the performance of LLMs in event extraction, with AVG-F1 and Prod-F1 rewards demonstrating clear advantages. For the LLaMa-7B model, the Prod-F1 reward function yielded the best AVG Score, reaching 60.72 in Held-in test and 40.84 in Held-out test. This indicates that focusing on the interdependence of trigger and argument performance through the Prod-F1 reward enhances the model’s overall ability to accurately extract events. In the case of the larger LLaMa-13B model, the AVG-F1 reward function achieved an AVG Score of 65.90 in Held-in test, while the Prod-F1 function excelled in Held-out test with an AVG Score of 44.41. This performance trend is also reflected in the CodeLLaMa models, where the Prod-F1 reward again demonstrated its effectiveness, particularly achieving a 52.35 AVG Score in the Held-out test for the CodeLLaMa-13B model. These results underline the importance of carefully selecting reward functions to optimize the event extraction capabilities of LLMs, with Prod-F1 and AVG-F1 rewards proving to be particularly beneficial in fostering a deeper understanding and extraction of events from texts.
5.2 Further Analysis
Ablation Study
Table 2 presents an ablation study focusing on key features of the EventRL approach, particularly looking at the impact of removing Teacher-Forcing and Advantage-Clipping on event extraction performance using the ACE05 dataset. As can be seen, removing Teacher-Forcing led to a significant performance drop, with the Trigger-F1 score decreasing from 73.06 to 65.38 and the Argument F1 score from 42.34 to 27.25 for the Argument-F1. Similarly, excluding Advantage-Clipping resulted in a decline, notably in the Argument-F1 score, from 42.34 to 39.68. These results highlight the critical role of both strategies in ensuring EventRL’s effectiveness and stability for event extraction. More analysis of these two components can be found in Appendix A.3.
| Held-in test | Held-out test | |||
| Method | Trig. | Arg. | Trig. | Arg. |
| SFT | 71.33 | 40.74 | 48.51 | 26.18 |
| EventRL (Arg-F1) | 73.06 | 42.34 | 51.15 | 29.32 |
| w/o Tearcher-Force | 65.38 | 27.25 | 47.34 | 19.28 |
| w/o Advantage-Clip | 67.60 | 39.68 | 46.37 | 24.21 |
| EventRL (Prod-F1) | 72.03 | 49.41 | 51.71 | 29.97 |
| w/o Tearcher-Force | 67.81 | 36.01 | 46.24 | 16.12 |
| w/o Advantage-Clip | 72.20 | 44.60 | 49.11 | 21.24 |
Error Analysis
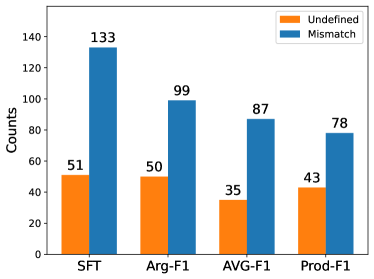
Figure 4 presents a comparative analysis of error types in event extraction when utilizing different training methods on the LLaMa-7B model. The Supervised Fine-Tuning (SFT) method resulted in a notably high occurrence of undefined event type errors, totaling 133, and structural mismatch errors, at 51. In contrast, the EventRL (Arg-F1) reduced “Undefined” errors to 99 and marginally decreased “Mismatch” errors to 50. A more significant improvement is observed with the EventRL (AVG-F1) approach, which cut down “Undefined” errors to 87 and “Mismatch” errors to the lowest count of 35, indicating a superior balance in error mitigation. The EventRL (Prod-F1) also demonstrated improvement, lowering “Undefined” errors to 78 and “Mismatch” errors to 43, although not as effectively as AVG-F1. These numbers highlight the effectiveness of the EventRL training methods in reducing errors in large language model training for event extraction.
Code Data Pretraining Enhances Event Extraction Performance
Table 1 reveals that models enhanced with code data, notably CodeLLaMa, significantly outperform their counterparts without code enhancement, like LLaMa, in event extraction. Specifically, at the 7B scale, CodeLLaMa (SFT) achieved an AVG score of 59.23 in Held-in test and 49.74 in Held-out test, surpassing LLaMa’s 56.03 and 37.35, respectively. This improvement illustrates the positive impact of coding capabilities on the model’s ability to extract events, both seen and unseen. When scaling up to 13B, the gap in performance between CodeLLaMa and LLaMa widens further, especially in the Held-out test, where CodeLLaMa (SFT) scores an AVG of 51.69, compared to LLaMa’s 42.04. Additionally, employing the EventRL method with CodeLLaMa leads to superior outcomes across different reward function setups, demonstrating that code data enhancement not only boosts the model’s understanding of structured information but also enhances its adaptability and accuracy in complex tasks like event extraction.
Analysis on Model Scale
From Table 1, we observe a clear trend that increasing model scale positively impacts event extraction performance. For instance, when comparing the EventRL (Prod-F1) approach, the performance in terms of the AVG score improves significantly as we move from a 7B parameter model to a 13B parameter model, from 60.72 to 65.90 in the Held-in test. This indicates that larger models have enhanced capabilities in processing and understanding complex language structures, which leads to more accurate event extraction. However, scaling the model size further to 34B parameters introduces the risk of overfitting, especially evident in the Held-out test. For example, the CodeLLaMa-34B model, under the SFT approach, shows an AVG score of 65.67 in Held-in test but drops to 48.75 in Held-out test, indicating a decline in the model’s ability to generalize to unseen event types.

Case Study
Figure 5 showcases a comparison between the results of LLaMa-7B + SFT and LLaMa-7B + EventRL (Prod-F1). The input text describes the arrest of six individuals by British anti-terror police in Derbyshire and London. While both methods correctly identified the “ArrestJail” event, the location (“Derbyshire”, “London”), and the action (“arrested”), LLaMa-7B + EventRL (Prod-F1) demonstrated a significant improvement by accurately including “police” as the agent conducting the arrest. Unlike LLaMa-7B + SFT, which missed the agent’s role and the “crime” argument, LLaMa-7B + EventRL (Prod-F1)’s result reflects a comprehensive understanding of the event’s structure, indicating its superior capability in capturing crucial aspects of events. More case studies can be found in Appendix A.3.
6 Conclusion
In this work, we demonstrated that EventRL, a reinforcement learning approach, significantly enhances the performance of LLMs in event extraction. By focusing on outcome supervision and utilizing specialized reward functions, EventRL effectively addresses the challenges of instruction following and hallucination in event extraction, leading to more accurate and reliable event extraction. The method’s success is evident in its superior performance across various model sizes and architectures, particularly in handling novel event types. The importance of selecting appropriate reward functions and the positive impact of code data enhancement on event extraction capabilities have also been highlighted. Furthermore, our findings suggest that while increasing model scale can improve performance, there is a need to balance this with the ability to generalize to avoid overfitting.
Limitations
While EventRL is effective in event extraction for LLMs, it faces certain limitations. Firstly, the success of this method heavily depends on the availability of high-quality, well-balanced datasets and meticulous annotation efforts, which can be challenging and resource-intensive. Secondly, as the data volume increases, the training process becomes more time-consuming, necessitating advanced training frameworks and superior hardware capabilities to manage the computational demands efficiently. Lastly, EventRL is specifically designed to address the intricacies of event extraction tasks and does not inherently enhance the general capabilities of large models across a broader spectrum of NLP tasks. This focus on a niche area, while beneficial for its intended purpose, means that the improvements in event understanding and extraction may not translate to a broader enhancement of the models’ overall performance in diverse linguistic tasks.
References
- Achiam et al. (2023) Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. ArXiv preprint, abs/2303.08774.
- Bengio et al. (2015) Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. 2015. Scheduled sampling for sequence prediction with recurrent neural networks. In Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, December 7-12, 2015, Montreal, Quebec, Canada, pages 1171–1179.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. ArXiv preprint, abs/2107.03374.
- Chen et al. (2015) Yubo Chen, Liheng Xu, Kang Liu, Daojian Zeng, and Jun Zhao. 2015. Event extraction via dynamic multi-pooling convolutional neural networks. In Proc. of ACL, pages 167–176, Beijing, China. Association for Computational Linguistics.
- Chen et al. (2020) Yunmo Chen, Tongfei Chen, Seth Ebner, Aaron Steven White, and Benjamin Van Durme. 2020. Reading the manual: Event extraction as definition comprehension. In Proceedings of the Fourth Workshop on Structured Prediction for NLP, pages 74–83, Online. Association for Computational Linguistics.
- (6) Walker Christopher, Strassel Stephanie, Medero Julie, and Maeda Kazuaki. ACE 2005 Multilingual Training Corpus. https://catalog.ldc.upenn.edu/LDC2006T06.
- Cui et al. (2023) Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Wei Zhu, Yuan Ni, Guotong Xie, Zhiyuan Liu, and Maosong Sun. 2023. Ultrafeedback: Boosting language models with high-quality feedback. ArXiv preprint, abs/2310.01377.
- Du and Cardie (2020) Xinya Du and Claire Cardie. 2020. Event extraction by answering (almost) natural questions. In Proc. of EMNLP, pages 671–683, Online. Association for Computational Linguistics.
- Gao et al. (2023a) Jun Gao, Huan Zhao, Changlong Yu, and Ruifeng Xu. 2023a. Exploring the feasibility of chatgpt for event extraction. ArXiv preprint, abs/2303.03836.
- Gao et al. (2023b) Jun Gao, Huan Zhao, Yice Zhang, Wei Wang, Changlong Yu, and Ruifeng Xu. 2023b. Benchmarking large language models with augmented instructions for fine-grained information extraction. ArXiv preprint, abs/2310.05092.
- Huang et al. (2023a) Kuan-Hao Huang, I Hsu, Tanmay Parekh, Zhiyu Xie, Zixuan Zhang, Premkumar Natarajan, Kai-Wei Chang, Nanyun Peng, Heng Ji, et al. 2023a. A reevaluation of event extraction: Past, present, and future challenges. ArXiv preprint, abs/2311.09562.
- Huang et al. (2023b) Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. 2023b. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ArXiv preprint, abs/2311.05232.
- Kaelbling et al. (1996) Leslie Pack Kaelbling, Michael L Littman, and Andrew W Moore. 1996. Reinforcement learning: A survey. Journal of artificial intelligence research, 4:237–285.
- Kaufmann et al. (2023) Timo Kaufmann, Paul Weng, Viktor Bengs, and Eyke Hüllermeier. 2023. A survey of reinforcement learning from human feedback. ArXiv preprint, abs/2312.14925.
- Li et al. (2020) Fayuan Li, Weihua Peng, Yuguang Chen, Quan Wang, Lu Pan, Yajuan Lyu, and Yong Zhu. 2020. Event extraction as multi-turn question answering. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 829–838, Online. Association for Computational Linguistics.
- Li et al. (2024) Junyi Li, Jie Chen, Ruiyang Ren, Xiaoxue Cheng, Wayne Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. 2024. The dawn after the dark: An empirical study on factuality hallucination in large language models. ArXiv preprint, abs/2401.03205.
- Li et al. (2023) Junyi Li, Xiaoxue Cheng, Wayne Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. 2023. Halueval: A large-scale hallucination evaluation benchmark for large language models. In Proc. of EMNLP, pages 6449–6464.
- Lightman et al. (2023) Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2023. Let’s verify step by step. ArXiv preprint, abs/2305.20050.
- Liu et al. (2018) Xiao Liu, Zhunchen Luo, and Heyan Huang. 2018. Jointly multiple events extraction via attention-based graph information aggregation. In Proc. of EMNLP, pages 1247–1256, Brussels, Belgium. Association for Computational Linguistics.
- Lou et al. (2023) Jie Lou, Yaojie Lu, Dai Dai, Wei Jia, Hongyu Lin, Xianpei Han, Le Sun, and Hua Wu. 2023. Universal information extraction as unified semantic matching. ArXiv preprint, abs/2301.03282.
- Lu et al. (2021) Yaojie Lu, Hongyu Lin, Jin Xu, Xianpei Han, Jialong Tang, Annan Li, Le Sun, Meng Liao, and Shaoyi Chen. 2021. Text2Event: Controllable sequence-to-structure generation for end-to-end event extraction. In Proc. of ACL, pages 2795–2806, Online. Association for Computational Linguistics.
- Lu et al. (2022) Yaojie Lu, Qing Liu, Dai Dai, Xinyan Xiao, Hongyu Lin, Xianpei Han, Le Sun, and Hua Wu. 2022. Unified structure generation for universal information extraction. In Proc. of ACL, pages 5755–5772, Dublin, Ireland. Association for Computational Linguistics.
- Nguyen et al. (2016) Thien Huu Nguyen, Kyunghyun Cho, and Ralph Grishman. 2016. Joint event extraction via recurrent neural networks. In Proc. of NAACL-HLT, pages 300–309, San Diego, California. Association for Computational Linguistics.
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744.
- Peng et al. (2023) Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, and Jianfeng Gao. 2023. Instruction tuning with gpt-4. ArXiv preprint, abs/2304.03277.
- Rennie et al. (2017) Steven J. Rennie, Etienne Marcheret, Youssef Mroueh, Jerret Ross, and Vaibhava Goel. 2017. Self-critical sequence training for image captioning. In 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017, pages 1179–1195. IEEE Computer Society.
- Roziere et al. (2023) Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, et al. 2023. Code llama: Open foundation models for code. ArXiv preprint, abs/2308.12950.
- Sainz et al. (2023) Oscar Sainz, Iker García-Ferrero, Rodrigo Agerri, Oier Lopez de Lacalle, German Rigau, and Eneko Agirre. 2023. Gollie: Annotation guidelines improve zero-shot information-extraction. ArXiv preprint, abs/2310.03668.
- Schulman et al. (2017) John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal policy optimization algorithms. ArXiv preprint, abs/1707.06347.
- Stiennon et al. (2020) Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F. Christiano. 2020. Learning to summarize with human feedback. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual.
- Sutton and Barto (2018) Richard S Sutton and Andrew G Barto. 2018. Reinforcement learning: An introduction. MIT press.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. ArXiv preprint, abs/2307.09288.
- Uesato et al. (2022) Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. 2022. Solving math word problems with process-and outcome-based feedback. ArXiv preprint, abs/2211.14275.
- Wadden et al. (2019) David Wadden, Ulme Wennberg, Yi Luan, and Hannaneh Hajishirzi. 2019. Entity, relation, and event extraction with contextualized span representations. In Proc. of EMNLP, pages 5784–5789, Hong Kong, China. Association for Computational Linguistics.
- Wang et al. (2023a) Xiao Wang, Weikang Zhou, Can Zu, Han Xia, Tianze Chen, Yuansen Zhang, Rui Zheng, Junjie Ye, Qi Zhang, Tao Gui, et al. 2023a. Instructuie: Multi-task instruction tuning for unified information extraction. ArXiv preprint, abs/2304.08085.
- Wang et al. (2022) Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Atharva Naik, Arjun Ashok, Arut Selvan Dhanasekaran, Anjana Arunkumar, David Stap, Eshaan Pathak, Giannis Karamanolakis, Haizhi Lai, Ishan Purohit, Ishani Mondal, Jacob Anderson, Kirby Kuznia, Krima Doshi, Kuntal Kumar Pal, Maitreya Patel, Mehrad Moradshahi, Mihir Parmar, Mirali Purohit, Neeraj Varshney, Phani Rohitha Kaza, Pulkit Verma, Ravsehaj Singh Puri, Rushang Karia, Savan Doshi, Shailaja Keyur Sampat, Siddhartha Mishra, Sujan Reddy A, Sumanta Patro, Tanay Dixit, and Xudong Shen. 2022. Super-NaturalInstructions: Generalization via declarative instructions on 1600+ NLP tasks. In Proc. of EMNLP, pages 5085–5109, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Wang et al. (2023b) Zhen Wang, Rameswar Panda, Leonid Karlinsky, Rogerio Feris, Huan Sun, and Yoon Kim. 2023b. Multitask prompt tuning enables parameter-efficient transfer learning. ArXiv preprint, abs/2303.02861.
- Wei et al. (2021) Kaiwen Wei, Xian Sun, Zequn Zhang, Jingyuan Zhang, Guo Zhi, and Li Jin. 2021. Trigger is not sufficient: Exploiting frame-aware knowledge for implicit event argument extraction. In Proc. of ACL, pages 4672–4682, Online. Association for Computational Linguistics.
- Wei et al. (2023) Xiang Wei, Xingyu Cui, Ning Cheng, Xiaobin Wang, Xin Zhang, Shen Huang, Pengjun Xie, Jinan Xu, Yufeng Chen, Meishan Zhang, et al. 2023. Zero-shot information extraction via chatting with chatgpt. ArXiv preprint, abs/2302.10205.
- Xu et al. (2023) Weiwen Xu, Deng Cai, Zhisong Zhang, Wai Lam, and Shuming Shi. 2023. Reasons to reject? aligning language models with judgments. ArXiv preprint, abs/2312.14591.
- Yang et al. (2019) Sen Yang, Dawei Feng, Linbo Qiao, Zhigang Kan, and Dongsheng Li. 2019. Exploring pre-trained language models for event extraction and generation. In Proc. of ACL, pages 5284–5294, Florence, Italy. Association for Computational Linguistics.
- Yu et al. (2023) Fei Yu, Anningzhe Gao, and Benyou Wang. 2023. Outcome-supervised verifiers for planning in mathematical reasoning. ArXiv preprint, abs/2311.09724.
- Zeng et al. (2023) Zhiyuan Zeng, Jiatong Yu, Tianyu Gao, Yu Meng, Tanya Goyal, and Danqi Chen. 2023. Evaluating large language models at evaluating instruction following. ArXiv preprint, abs/2310.07641.
- Zhang et al. (2023a) Shengyu Zhang, Linfeng Dong, Xiaoya Li, Sen Zhang, Xiaofei Sun, Shuhe Wang, Jiwei Li, Runyi Hu, Tianwei Zhang, Fei Wu, et al. 2023a. Instruction tuning for large language models: A survey. ArXiv preprint, abs/2308.10792.
- Zhang et al. (2023b) Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, et al. 2023b. Siren’s song in the ai ocean: A survey on hallucination in large language models. corr abs/2309.01219 (2023).
- Zhao et al. (2023) Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. 2023. A survey of large language models. ArXiv preprint, abs/2303.18223.
- Zhou et al. (2023) Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. 2023. Instruction-following evaluation for large language models. ArXiv preprint, abs/2311.07911.
- Zhou et al. (2021) Yang Zhou, Yubo Chen, Jun Zhao, Yin Wu, Jiexin Xu, and Jinlong Li. 2021. What the role is vs. what plays the role: Semi-supervised event argument extraction via dual question answering. In Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, February 2-9, 2021, pages 14638–14646. AAAI Press.
Appendix A Appendix
A.1 Dataset
Dataset Details
| Dataset | Count |
|---|---|
| Train | 285 |
| Dev | 64 |
| Held-in Test | 125 |
| Held-out Test | 380 |
| Event Type | Count |
|---|---|
| Conflict.Attack | 1244 |
| Movement.Transport | 608 |
| Life.Die | 515 |
| Contact.Meet | 254 |
| Personnel.End-Position | 170 |
| Transaction.Transfer-Money | 167 |
| Personnel.Elect | 153 |
| Life.Injure | 121 |
| Contact.Phone-Write | 112 |
| Transaction.Transfer-Ownership | 109 |
| Personnel.Start-Position | 107 |
| Justice.Charge-Indict | 101 |
| Justice.Trial-Hearing | 97 |
| Justice.Sentence | 93 |
| Justice.Arrest-Jail | 79 |
To provide a detailed and comprehensive evaluation of our model, we conducted a series of experiments using the ACE05 dataset, widely recognized for its variety in event types. This diversity enables us to rigorously test the model’s ability to recognize and extract both familiar (seen) and novel (unseen) event types with precision. The ACE05 dataset comprises 33 distinct event types, serving as a robust foundation for our experimental framework.
Our experimental design involved the careful selection of event types for different portions of the dataset: the training set, validation set, and the test sets. Specifically, we chose 7 event types for inclusion in the training and validation sets, as well as the held-in test set. These event types were selected based on their prevalence in the dataset, as indicated by the Table 4. This decision was informed by the observation that the dataset exhibits a significant imbalance in the distribution of event types, with the top 7 event types each having more than 150 samples, while the least represented event type has as few as 2 samples. To ensure a rigorous evaluation of the model’s generalization capabilities, we selected 19 different event types to construct the held-out test set, focusing on unseen event types.
To address the challenge of data imbalance and to maintain a balanced dataset, we adopted a sampling strategy that ensures equitable representation of each event type across different sets. Specifically, we sampled 50 instances for each event type in the training set, 10 for each in the validation set, and 20 for each in both the held-in and held-out test sets. This balanced approach ensures that the model is exposed to and evaluated under a variety of conditions, offering a comprehensive insight into its performance across a wide range of event types. Table 3 shows the statistics of our ACE05 dataset split. We aimed for balance among event types, although some samples might include several events. This method ensures a fair representation across the dataset.
Event Extraction Guidelines
Our work is built upon the foundational work of Sainz et al. (2023), which introduced a Python code-based representation for input and output in information extraction tasks. The essence of this work lies in the integration of event type extraction guidelines into the prompt, enhancing zero-shot generalization capabilities.
Our model operates on a schema defined in Python classes, with docstrings providing guidelines and comments outlining representative annotation candidates. This structured format ensures clarity, facilitates parsing, and aligns with modern Large Language Models’ (LLMs) pretraining on code datasets. The output, beginning after “result =”, comprises a list of class instances, yielding a transparent and easily parsable structure when executed in Python.
A complete example of our event definitions is displayed in Figure 12 within the Held-in Test, showcasing the guidelines used for extracting event types. We have adapted and refined the data processing code, originally available on the GitHub repository 111https://github.com/hitz-zentroa/GoLLIE, to accommodate our specific needs for event extraction.
A.2 Implementation Details
Our implementation of EventRL comprises three pivotal components: Few-Shot Prompting (FSP) with GPT-4, Supervised Fine-Tuning (SFT), and the EventRL framework.
GPT-4 and Few-Shot Prompting (FSP)
For the Few-Shot Prompting experiments, we utilized the GPT-4 API provided by Azure OpenAI Service 222https://learn.microsoft.com/en-us/azure/ai-services/openai/overview, version dated 2023-05-15. Our experiments spanned four settings: 0-shot, 1-shot, 2-shot, and 3-shot. In the 0-shot setup, we did not include any demonstration examples in the instructions. For the 1-shot, 2-shot, and 3-shot setups, we introduced 1, 2, and 3 demonstration examples into the instructions, respectively. We tested across three distinct instruction templates and chose the one that showed the best overall performance for our results’ presentation.
Supervised Fine-Tuning (SFT)
The SFT experiments were conducted on various models: LLaMa-7B/13B and CodeLLaMa-7B/13B/34B. We used the ColossalAI 333https://github.com/hpcaitech/ColossalAI/tree/main framework on two A100 servers. The training setup was as follows: learning rate set to 2e-5, with a minimum learning rate of 2e-6, weight decay at 0.1, micro batch size of 2, global batch size of 64, using bf16 for mixed precision, over 10 training epochs. For the 7B and 13B models, the parallel strategy involved a Tensor Parallel Size of 2 and a Pipeline Parallel Size of 2. The 34B model’s strategy was adjusted to a Tensor Parallel Size of 4 and a Pipeline Parallel Size of 2. We selected the best model checkpoint for final use based on its average Trigger-F1 and Argument-F1 scores on the validation set.
EventRL
Leveraging the SFT groundwork, we proceeded to further train LLaMa-7B/13B and CodeLLaMa-7B/13B models using the EventRL method. The EventRL training was not applied to the 34B model due to computational limits. For the base model selection in EventRL training, we considered the 7B model’s lower overfitting risk and the 13B model’s higher risk, ultimately choosing the best SFT model for the 7B and the checkpoint from the previous epoch of the best SFT model for the 13B. The EventRL was implemented with the Huggingface transformers 444https://github.com/huggingface/transformers framework, setting the training parameters as follows: a learning rate of 5e-6, a global batch size of 32, a micro batch size of 2, spanning 10 training epochs, using bf16 for mixed precision, and applying advantage clipping at 10. We set the teacher forcing threshold at 70 for the 7B model and 30 for the 13B model. The parameters for generating results with the sampling method were a temperature of 0.5 and a top p of 0.95.
A.3 More Analysis on EventRL
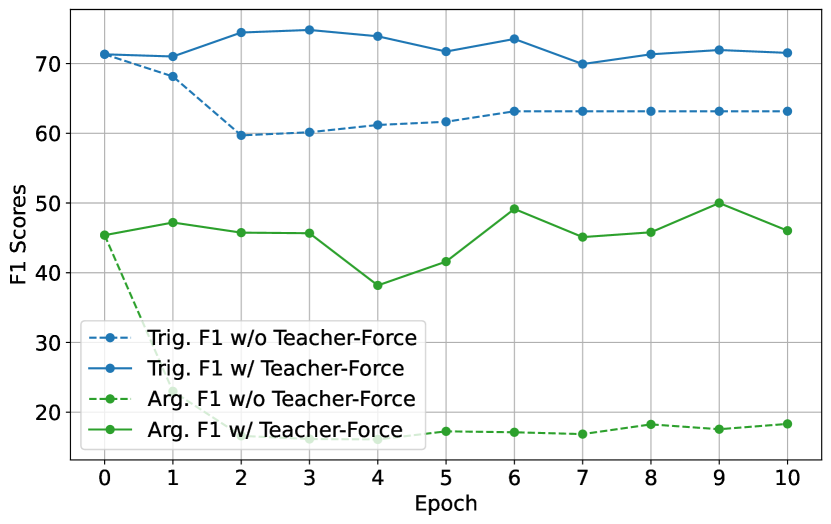
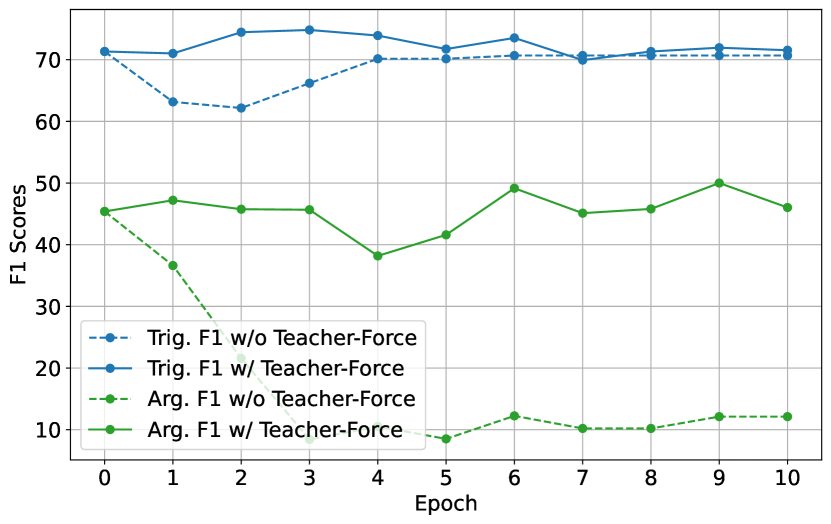
Analysis on Teacher Force Threshold
The Teacher-Force Threshold appears to be a pivotal strategy for stabilizing the training process in EventRL. By examining the Figure 7(a) and Figure 7(b), we can infer that the models with Teacher-Force (denoted by “w/ Teacher-Force” in the legends) maintain or improve performance consistently across epochs, as opposed to models trained without Teacher-Force (denoted by “w/o Teacher-Force”), which exhibit more significant fluctuations and generally lower performance scores.
In Figure 7(a), which shows the EventRL (Arg-F1) model’s performance, the presence of Teacher-Forcing corresponds with higher and more stable Argument F1 scores. The stability is particularly notable in the later epochs, suggesting that Teacher-Forcing aids the model in retaining knowledge over time, likely mitigating the effects of catastrophic forgetting. Similarly, in Figure 7(b) for the EventRL (Prod-F1) method, we see that the use of Teacher-Forcing correlates with more stable Trigger F1 scores. The Trigger F1 performance without Teacher-Force drops noticeably after the first few epochs, while with Teacher-Force, the performance remains relatively stable.

| Held-in test | Held-out test | |||||
|---|---|---|---|---|---|---|
| Method | Trigger | Argument | AVG | Trigger | Argument | AVG |
| GPT4+FSP (0-shot) + Prompt1 | 4.65 | 22.43 | 13.54 | 0.00 | 5.66 | 2.83 |
| GPT4+FSP (0-shot) + Prompt2 | 6.04 | 22.08 | 14.06 | 15.42 | 17.69 | 16.56 |
| GPT4+FSP (0-shot) + Prompt3 | 1.47 | 21.36 | 11.41 | 3.59 | 18.39 | 10.99 |
| GPT4+FSP (1-shot) + Prompt2 + Example1 | 23.02 | 22.82 | 22.92 | 19.32 | 17.83 | 18.58 |
| GPT4+FSP (1-shot) + Prompt2 + Example2 | 8.63 | 24.37 | 16.50 | 8.87 | 19.08 | 13.97 |
| GPT4+FSP (1-shot) + Prompt2 + Example3 | 15.44 | 23.33 | 19.38 | 12.62 | 19.50 | 16.06 |
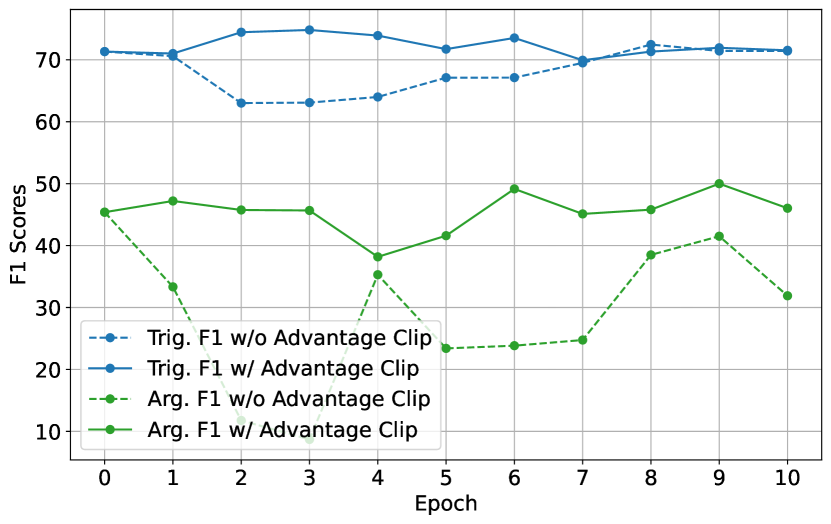
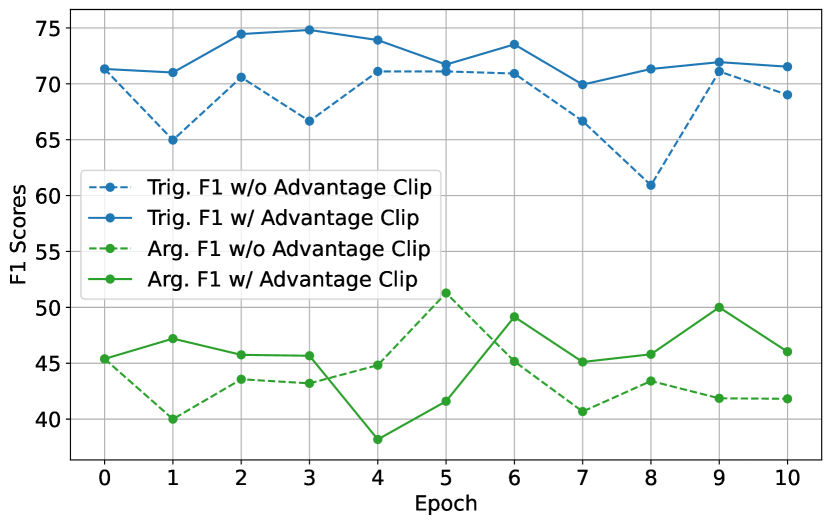
Analysis on Advantage Clipping
For both Argument Extraction (Arg. F1) and Trigger Extraction (Trig. F1), the results suggest that Advantage Clipping contributes to more consistent performance across epochs. Specifically, in Figure 6(a), the use of Advantage Clipping appears to maintain higher F1 scores for Argument Extraction throughout the training epochs, with less variability compared to the setting without Advantage Clipping. The presence of Advantage Clipping seems to prevent drastic drops in performance, which could be indicative of the model retaining previously learned information better, thus mitigating catastrophic forgetting. Similarly, in Figure 6(b), for Trigger Extraction, the application of Advantage Clipping demonstrates a more stable and consistently higher performance curve than without it. The variance is visibly reduced, which suggests that Advantage Clipping allows each sample to influence the learning process enough to be remembered, but not so much that it causes significant performance swings.
The most notable observation is the presence of fewer and less severe dips in performance for both Argument and Trigger F1 scores when Advantage Clipping is applied. This smoothing effect implies that Advantage Clipping indeed sets a floor for learning contributions from each sample, ensuring that all training data is utilized effectively, which is particularly crucial for a model that might otherwise focus too heavily on the most recent or the most rewarding examples.
Case Study
As shown in Figure 8, we analyze two instances where the EventRL (Prod-F1) model outperforms the LLaMa-7B + SFT approach. In the first case, the input text discusses a statement made by Troy Brennan from Harvard Public School of Health regarding lawsuits. The LLaMa-7B + SFT model inaccurately identifies Troy Brennan as a defendant in a lawsuit, reflecting a misunderstanding of the context. In contrast, the LLaMa-7B + EventRL (Prod-F1) model provides a more accurate representation by not assigning specific roles to the entities involved in the “Sue” event. This output aligns better with the input text, which does not explicitly define plaintiffs or defendants but rather discusses the broader issue of lawsuits.
The second input text refers to a situation involving bankruptcy proceedings. The LLaMa-7B + SFT model incorrectly identifies “discharge” as the event mention, which misrepresents the text’s focus. The term "discharge" in the context of bankruptcy refers to the legal process of releasing a debtor from certain obligations, but the key event is the declaration of bankruptcy itself. The LLaMa-7B + EventRL (Prod-F1) model correctly identifies “bankruptcy” as the event mention, providing a more accurate and relevant extraction.
A.4 More Analysis on GPT4+FSP
Analyzing Various Prompts for GPT4+FSP (0-shot)
The performance of GPT-4 with Few-Shot Prompting (0-shot) varies significantly across different prompt templates, illustrating the impact of instructional design on the model’s ability to extract events. Prompt 2 (See Figure 10), which provides a clear and structured task description along with an explicit output format, yields the highest overall performance, especially noticeable in the “Held-out test” section with a notable average score of 16.56. This suggests that the clarity and specificity of the instructions can significantly enhance the model’s understanding and execution of the task. In contrast, Prompts 1 (See Figure 9) and 3 (See Figure 11), despite offering detailed instructions, do not match the effectiveness of Prompt 2, potentially due to differences in how the task and output format are communicated.
Analyzing Different Examples for GPT4+FSP (1-shot)
Introducing examples in the Few-Shot Prompting (1-shot) setup with GPT-4 shows a nuanced effect on performance, underscoring the influence of example selection. The inclusion of Example 1 with Prompt 2 significantly boosts performance across both “Held-in test” and “Held-out test”, achieving an average score of 18.58 in the latter. This improvement indicates that the right example can enhance the model’s understanding of the task, leading to better event extraction outcomes. However, the impact of different examples varies, with Example 2 and Example 3 leading to mixed results.
A.5 Discussion
One key observation from our study is the difference in performance between large and small models. Large models tend to perform better because they have more capacity to understand and process complex information. This means they can better identify the events in texts and figure out the relationships between different parts of the information. However, not everyone can use large models because they need a lot of computing power and resources. This is where our EventRL framework comes into play. EventRL is designed to help smaller models perform better on complex tasks. It does this by focusing on the outcomes of the task and using reinforcement learning to guide the model towards better performance.
With EventRL, even smaller models can improve their ability to extract events from texts. The approach helps these models pay closer attention to the final goal of the task and learn from each attempt. This way, they get better over time at understanding what’s important in the text and how to accurately identify events and their details.