Evaluating Model-free Reinforcement Learning toward Safety-critical Tasks
Abstract
Safety comes first in many real-world applications involving autonomous agents. Despite a large number of reinforcement learning (RL) methods focusing on safety-critical tasks, there is still a lack of high-quality evaluation of those algorithms that adheres to safety constraints at each decision step under complex and unknown dynamics. In this paper, we revisit prior work in this scope from the perspective of state-wise safe RL and categorize them as projection-based, recovery-based, and optimization-based approaches, respectively. Furthermore, we propose Unrolling Safety Layer (USL), a joint method that combines safety optimization and safety projection. This novel technique explicitly enforces hard constraints via the deep unrolling architecture and enjoys structural advantages in navigating the trade-off between reward improvement and constraint satisfaction. To facilitate further research in this area, we reproduce related algorithms in a unified pipeline and incorporate them into SafeRL-Kit, a toolkit that provides off-the-shelf interfaces and evaluation utilities for safety-critical tasks. We then perform a comparative study of the involved algorithms on six benchmarks ranging from robotic control to autonomous driving. The empirical results provide an insight into their applicability and robustness in learning zero-cost-return policies without task-dependent handcrafting. The project page is available at https://sites.google.com/view/saferlkit.
Introduction
Model-free reinforcement learning (RL) has achieved superhuman performance on many decision-making problems (Mnih et al. 2015; Vinyals et al. 2019). Typically, the agent learns from trial and error and requires minimal prior knowledge of the environment. Such a paradigm features significant advantages in mastering essential skills for complex systems, but concerns about the systematic safety limit the extent of adoption of model-free RL in real-world applications, such as human-robot collaboration (Villani et al. 2018) and autonomous driving (Kiran et al. 2021).
Penalizing unsafe transitions via the reward function is straightforward but sometimes cumbersome to navigate the trade-off between performance and safety. A trivial penalty term may fail to obtain a risk-averse policy, whereas an excessive punishment may make the agent too conservative to explore the environment. Alternatively, incorporating safety into RL via constraints (Altman 1999) is widely adopted since the strength of constraints reflects the human-specified safety requirement, and the agent is desired to optimize its behavior within the constrained policy search space.
In this paper, we explore model-free reinforcement learning methods that adhere to state-wise safety constraints. To better understand how this study is developed, two points deserve further clarification. First, our work is aimed at learning a stationary safe policy under the general model-free settings, instead of refusing any safety violations during the training. The latter is more related to optimal control and relies on the known dynamic model (Cheng et al. 2019) or a carefully designed energy function (Zhao, He, and Liu 2021). Second, we focus on the state-wise constraint at every decision-making step and demonstrate that this type of constraint is more strict and practical toward safety-critical tasks theoretically and empirically. Our contributions in this paper are summarized as follows:
-
1.
We revisit model-free RL following state-wise safety constraints and present SafeRL-Kit, a toolkit that implements prior work in this scope under a unified off-policy framework. Specifically, SafeRL-Kit contains projection-based Safety Layer (Dalal et al. 2018), recovery-based Recovery RL (Thananjeyan et al. 2021), optimization-based Off-policy Lagrangian (Ha et al. 2020), Feasible Actor-Critic (Ma et al. 2021), and the new method proposed in this paper.
-
2.
We propose Unrolling Safety Layer (USL), a novel approach that combines safety projection and safety optimization. USL unrolls gradient-based corrections to the jointly optimized actor-network and thus explicitly enforces the constraints. The proposed method is simple-yet-effective and outperforms state-of-the-art algorithms in learning risk-averse policies.
-
3.
We perform a comparative study based on SafeRL-Kit and evaluate the related algorithms on six different tasks. We further demonstrate their applicability and robustness in safety-critical tasks with the universal binary cost indicator and a constant constraint threshold.
Related Work
Safe RL Algorithms.
Safe RL optimizes policies under episodic or instantaneous constraints. The most common approach to solving the episodic constraint is Lagrangian relaxation (Chow et al. 2017; Tessler at al. 2017; Stooke et al. 2020). Other works (Achiam et al. 2017; Yang et al. 2020) approximate the constrained policy iteration with a quadratic constrained optimization. Recently, first-order methods (Liu, Ding, and Liu 2020; Zhang et al. 2022; Yang et al. 2022a) start to gain attractions as the objective is efficient to optimize and easy to handle multiple constraints. For the instantaneous constraint, Lagrangian relaxation is also a feasible solution (Bohez et al. 2019). Dalal et al. (2018) perform quadratic programming to project actions back to the safe set. Other works model the instantaneous cost as Gaussian Processes and plan in the safety-proven neighboring states (Wachi et al. 2018; Wachi and Sui 2020). In this paper, we formulate safe RL following state-wise safety constraints, which are slightly different from the above genres.
Safe RL Benchmarks.
There have already been some safety-critical benchmarks to evaluate the efficacy of safe RL methods, including traditional MuJoCo tasks (Achiam et al. 2017; Zhang, Vuong, and Ross 2020), navigation in the cluttered environment (Ray, Achiam, and Amodei 2019), safe robotic control task (Yuan et al. 2021) and safe autonomous driving (Li et al. 2021; Herman et al. 2021). However, a comprehensive study on learning a zero-cost-return policy with model-free methods is still absent.
Preliminaries
This study lies in the context of constrained Markov Decision Process (CMDP) (Altman 1999), which extends standard MDP (Sutton and Barto 1998) as a tuple . and denote the state space and the action space, respectively. is the transition probability function to describe the dynamics of the system. is the reward function. is the cost function and reflects the safety violation. is the initial state distribution, and is the discount factor for future reward and cost. A stationary policy maps the given states to probability distributions over action space and the expected discounted return of the policy is where accounts for the stochastic trajectory distribution sampled on . The goal of safe RL is to find the optimal policy:
| (1) |
In a CMDP, the agent is typically constrained by the cost function in two ways. One is the Episodic Constraint. This type of formulation requires the cost-return in the whole trajectory be within a certain threshold, namely , which is suitable for total energy consumption, resource over-utilization, etc. The other is the Instantaneous Constraint. This type of formulation requires the selected actions to enforce the constraint at every decision-making step, namely , which is indispensable in accident and damage avoidance.
Revisit RL toward Safety-critical Tasks
In many safety-critical scenarios, the final policy is assumed to maintain the zero-cost return since any inadmissible behavior could lead to catastrophic failure in the execution. Prior constrained learning paradigms have fatal flaws under this premise. For the episode constraint, with a threshold close to , the agent often either fails to improve policy or receives a cost-return more significant than . The underlying reason is that such a constraint is easy to violate, especially when the time horizon contains thousands of steps. If the algorithm handles the episodic formula directly, it is cumbersome to identify ill actions as well as tweak the policy parameters and the corresponding action sequence. For another, the instantaneous constraint is tighter since it is a sufficient but not necessary condition for the episodic constraint with . Nevertheless, it is problematic to directly enforce at each single decision-making step in complicated dynamics, since some actions have a long-term effect on future visited states and the infeasible states might also be intractable to recover in a single time-step. A more reasonable solution is to prevent the current state from falling into the unsafe set in a certain planning span, which is inspired by model predictive control. Consequently, we define the long-term return for cost as , which is similar to for reward in standard RL by substituting with . Next, we present the formal definitions related to state-wise safe reinforcement learning.
Definition 1 (State-wise safety constraints).
In the whole trajectory, the agent is required to adhere to the following long-term constraint at every visited state
| (2) |
Definition 2 (Optimal state-wise safe policy).
In any feasible state, the optimal action is
| (3) |
Using the cumulative constraint to enhance state-wise safety is not novel (Srinivasan et al. 2020; Ma et al. 2021; Yu et al. 2022). Nevertheless, the choice of is tricky since the relationship between (2) and the desired instantaneous constraint is not straightforward. In this paper, we give a theoretical bound of cost limit as follows.
Proposition 1.
If , any policy satisfying (2) fulfills within the planning span .
Proof.
It is proved by contradiction that if in any step , then . ∎
The above proposition, to some extent, alleviates the concern that decreasing leads to overly conservative policy. For example, if a racing car is able to slow down and avoid the obstacle in 20 steps ahead, setting will not change the optimal sequence for , where . In our experiments, we keep across different safety-critical tasks, which equals the safe planning span of at least 100 steps with a universal binary cost indicator. Empirical results demonstrate that safe RL methods adhering to state-wise safety constraints are robust to this value.
In this paper, we explore model-free RL that adheres to state-wise safety constraints in continuous state-action spaces and unknown dynamics. We classify the most related approaches into the following three categories:
Safety Correction.
This type of methods corrects the initial unsafe decision by projecting it back to the safe set. The projection can be constructed by the control barrier function (Cheng et al. 2019) with known dynamics, implicit safety index (Zhao, He, and Liu 2021) with hand-crafted energy function, or parametric linear model (Dalal et al. 2018) learned from past experiences. However, those approaches are sometimes under-performed regarding cumulative rewards since the correction only guarantees the feasibility but lacks the equivalence with optimality.
Safety Recovery.
This type of methods is especially welcomed in the field of robotics (Thananjeyan et al. 2021; Yang et al. 2022b) and autonomous driving (Chen et al. 2021). The critical idea behind Recovery RL is introducing a dedicated policy that recovers unsafe states, whereas the task policy is trained by the standard RL to achieve the original goal. However, those approaches struggle for a rational recovery policy since it tends to be overly conservative in preventing risky exploration. Furthermore, the decisions between two policies may conflict with each other, which makes the agents stuck near the boundaries of safe regions easily.
Safety Optimization.
This type of methods incorporates safety constraints into the RL objective and yields a constrained sequential optimization task. These approaches employ different optimization objectives to guide the updates of parametric policies, which can be tackled by Lagrangian relaxation (Ha et al. 2020; Ma et al. 2021) or the penalty method (Zhang et al. 2022). Unfortunately, the “soft” loss function in the sample-based learning does not consistently enforce the “hard” constraint in practice and barely leads to zero-cost-return policies even at convergence.
Unrolling Safety Layer: A Novel Approach
Orthogonal to existing algorithms, we propose a novel approach referred to as Unrolling Safety Layer (USL) in this paper, which is inspired by the complementary of safety projection and safety optimization. For projection-based approaches, the correction (even if tractable) only enforces the feasibility but lacks the equivalence to the optimal maximum return. For optimization-based approaches, most of them tend to find the optimal solution to the constrained problem with the help of neural networks. However, the forward computing lacks explicit restrictions on the output actions, and thus the “soft” loss function often fails to fully satisfy “hard” constraints. Recently, Deep Constraint Completion and Correction (DC3) (Donti, Rolnick, and Kolter 2021) shows potential to achieve optimal objective values while preserving feasibility, which is of independent interest to general constrained problems. As illustrated in Figure 1, we employ a similar joint architecture that combines safety optimization (serves as the first stage’s approximate solver) and safety projection (serves as the second stage’s iterative correction). To the best of our knowledge, this is the first study to introduce deep unrolling optimization into safe RL.

Stage 1: Policy Network as Approximate Solver
We train a parametric neural network in the first stage as the approximate solver to problem (3), which aims to output sub-optimal actions via naive forward computing. Different from Donti et al. (2021) that simply applies regular term to the objective function, we use the exact penalty function (Zhang et al. 2022) as the alternative. The merit is that one can construct an equivalent counterpart for problem (3) with a finite penalty factor as
| (4) |
Proposition 2.
Let denote the Lagrangian function . Assume that the optimal and exist for the dual problem . If , it holds that
Proof.
The exactness of the penalty function can be referred to our previous work (Zhang et al. 2022). ∎
We use a fixed as a hyper-parameter in the practical implementation and find that a large constant ( in our experiments) is empirically effective across different tasks even if the supremum of Lagrange multipliers is intractable to estimate. Moreover, if the actual tends to be positively infinitive for some critically dangerous states, there would be numerical issues for optimization-based approaches. On the contrary, the objective function (4) under those circumstances can be regarded as a penalty method by adding regularization terms and only gives a sub-optimal initial solution for the next stage. Fortunately, the proposed two-stage architecture does not require an optimal solution in the first stage, and the joint training and inference process with post-projection can tackle this problem to some extent.

Stage 2: Gradient-based Projection
The approximate solver in stage 1 may still output infeasible actions for the following reasons: (a) The supremum of Lagrangian multipliers in Proposition 2 is hard to obtain, and we only settle as a fixed, large but sub-optimal hyper-parameter. (b) The inherent issues of safe RL, such as the approximation in the modeling, sample-based learning, distributional shift, etc., make it possible for the end-to-end actor to violate hard constraints in the policy execution.
To address the above issue, the post-posed projection performs gradient steps to rectify the hard constraint from the initial iteration point . is the differentiable operator that takes intermediate action at iteration as input and performs a gradient descent towards the constraint-violation wrapped with ReLU function:
| (5) |
Here is the normalization factor that rescales the gradients on , and therefore the hyper-parameter determines the maximum step size of the action change.
Notably, the iterative executions of do not always converge to global (or even local) optima for the primal constrained optimization problem (3). Nevertheless, such a method is highly effective in practice if the initial iteration point is close to the optimal solution (Panageas, Piliouras, and Wang 2019; Donti, Rolnick, and Kolter 2021). This fact emphasizes the necessity for training a pre-posed policy network via the exact penalty regularization, which provides a non-pathological initialization for USL. By means of minimizing the objective function (4), the output of may be still infeasible sometimes but already close to the optimal action . Thus, the sequence of is expected to converge to when . However, letting is not practical in use, and thus we set an upper limit as the maximum iterations of USL. Note that the value of needs to match the gradient step-size factor . For example, we set and to enable USL to degrade the normalized action from to within maximum iterations.
More algorithmic details are summarized in Appendix A.
SafeRL-Kit: A Systematic Implementation
To facilitate further research in this area, we release SafeRL-Kit222Project page: https://sites.google.com/view/saferlkit, a reproducible and open-source safe RL toolkit as shown in Figure 2. In brief, SafeRL-Kit contains a list of representative algorithms that address safe learning from different perspectives. Potential users can also incorporate domain-specific knowledge into appropriate baselines to build more competent algorithms for their tasks of interest. Furthermore, SafeRL-Kit is implemented in an off-policy training pipeline, which provides unified and efficient interfaces for fair comparisons among different algorithms on different benchmarks.
Safety-critical Benchmarks
SafeRL-Kit includes six safety-critical benchmarks, ranging from basic robotic control to autonomous driving, which are well-explored in recent literature (Yuan et al. 2021; Ray, Achiam, and Amodei 2019; Li et al. 2021). A short description of the benchmarks is presented below:
- (A) SpeedLimit.
-
The four-legged ant runs along the avenue and receives a cost signal when exceeding the velocity limit.
- (B) Stabilization.
-
The cart pole is rewarded for keeping itself upright while being constrained by angular velocity.
- (C) PathTracking.
-
The quadrotor tracks the green circular trajectory and receives a cost signal if it leaves the area allowed to fly bounded within the red rectangular.
- (D) SafetyGym-PG.
-
The mass point moves to the green goal and is required to get rid of blue hazards.
- (E) PandaPush.
-
The robotic arm pushes the green cube to the destination while avoiding collisions with the red cube.
- (F) SafeDriving.
-
The autonomous vehicle learns to reach the navigation land markers as quickly as possible but is not allowed to collide with other vehicles or be out of the road.


More detailed environment descriptions can be referred to Appendix B.1.
Safe Learning Algorithms
SafeRL-Kit includes five safe learning methods addressing safety-critical tasks from different perspectives.
- Safety Layer
-
(Dalal et al. 2018) for safety projection
- Recovery RL
-
(Thananjeyan et al. 2021) for safety recovery
- Off-Policy Lagrangian Method
-
(Ha et al. 2020) for safety optimization
- Feasible Actor Critic (FAC)
-
(Ma et al. 2021) for safety optimization
- Unrolling Safety Layer (USL).
-
A joint approach proposed in this paper combining safety projection and optimization.
All the above algorithms in SafeRL-Kit are implemented under the off-policy Actor-Critic architecture. Although these model-free algorithms may inevitably encounter cost signals in the training process, they still enjoy better sample efficiency with fewer unsafe transitions compared with on-policy implementations (Ray, Achiam, and Amodei 2019), and can better leverage human demonstration if needed. The essential updates of backbone networks uniformly follow TD3 (Fujimoto, Hoof, and Meger 2018), and thus we can perform a fair evaluation to see which of them are best suited for safety-critical tasks.
More details of the implemented algorithms can be referred to the Appendix B.2.
Cost Function and Evaluation Metrics
Without loss of generality, we uniformly designate the cost function as a binary indicator (1 for unsafe transitions; 0 for other cases), and our experiments aim to obtain stationary policies that adhere to zero cost signals. It is worth noting that some works define cost more prospectively, for example, using the distance from the car to the road boundary in autonomous driving scenarios (Chen et al. 2021). We omit any task-dependent hand-crafting in our comparative study since they overly rely on domain-specific knowledge and are sometimes intractable on complex tasks. Instead, receiving an instantaneous cost signal is much more straightforward and can be generalized to related tasks.
Considering the properties of safety-critical tasks and the definition of the cost function, we employ the following metrics for the joint evaluation:
- Episodic Return
-
It indicates how well the agent finishes the original task.
- Episodic Cost Rate
-
It indicates how safe the agent is in the test time.
- Total Cost Rate
-
It indicates how safe the agent is in the whole training process.
| Tasks | USL(ours) | Safety Layer | Recovery RL | Lagrangian | FAC | TD3(ref) | |
|---|---|---|---|---|---|---|---|
| (A)Speedlimit | Ep Return | ||||||
| Ep CostRate(%) | |||||||
| Tot CostRate(%) | |||||||
| (B)Stabilization | Ep Return | ||||||
| Ep CostRate(%) | |||||||
| Tot CostRate(%) | |||||||
| (C)Pathtracking | Ep Return | ||||||
| Ep CostRate(%) | |||||||
| Tot CostRate(%) | |||||||
| (D)Safetygym | Ep Return | ||||||
| Ep CostRate(%) | |||||||
| Tot CostRate(%) | |||||||
| (E)Pandapush | Ep Return | ||||||
| Ep CostRate(%) | |||||||
| Tot CostRate(%) | |||||||
| (F)Safedriving | Ep Return | ||||||
| Ep CostRate(%) | |||||||
| Tot CostRate(%) | |||||||
| Tasks | Speedlimit | Pathtracking | ||||
|---|---|---|---|---|---|---|
| USL Models | Ep Return | Ep CostRate(%) | Tot CostRate(%) | Ep Return | Ep CostRate(%) | Tot CostRate(%) |
| Stage 1 + Stage 2 | ||||||
| Stage 1 only | ||||||
| Stage 2 only | ||||||
| Unconstrained | ||||||
| Metrics | USL(ours) | Recovery | Safety Layer | Lagrangian | FAC | TD3(ref) |
|---|---|---|---|---|---|---|
| Normalized Inference Time | 5.0 | 1.2 | 1.6 | 1.0 | 1.0 | 1.0 |
| Average Inference Time (s) | 25E-4 | 6E-4 | 8E-4 | 5E-4 | 5E-4 | 5E-4 |
| Max Control Frequency (Hz) | 400 | 1666 | 1250 | 2000 | 2000 | 2000 |
Experiments
In this section, we empirically evaluate model-free RL toward safety-critical tasks based on SafeRL-Kit and investigate the following research questions.
Q1: How applicable and robust are the algorithms regarding state-wise constraints?
We plot the learning curves of each algorithm on different tasks over five random seeds in Figure 3 and report their mean performance at convergence in Table 1. Detailed hyper-parameters settings are presented in the supplementary material C.1.
TD3 (Fujimoto, Hoof, and Meger 2018) is used as the unconstrained reference for the upper bounds of reward performance and cost signals. On the SpeedLimit task, the safety constraint () is easily violated since the ant is able to move much faster for higher rewards. Thus, we can clearly observe that the TD3 agent achieves over episodic cost rate at convergence while other risk-aware algorithms in SafeRL-kit suppress the explosion of cost rate. On other tasks, the cost signals are more sparse, such as the accidental collisions with obstacles in autonomous driving. Nevertheless, the evaluated algorithms still effectively reduce the likelihood of safety violations.
The empirical results reveal that Safety Layer and Recovery RL are comparatively ineffective in reducing the cost return. For Safety Layer, the main reasons are that the linear approximation to the cost function brings about non-negligible errors, and the single-step correction is myopic for future risks. For Recovery RL, the estimation error of is the major factor affecting its efficacy.
By contrast, Off-policy Lagrangian and FAC have significantly lower cumulative costs. However, Lagrangian-based methods may suffer from the inherent issues due to primal-dual ascents. For one thing, the Lagrangian multiplier tuning causes oscillations in learning curves. For another thing, the performance may heavily depend on the Lagrangian multipliers’ initialization and learning rate. According to the sensitivity analysis, we find that Lagrangian-based methods are susceptible to the learning rate of the Lagrangian multiplier(s) in stochastic primal-dual optimization. First, the oscillating causes non-negligible deviations in the learning curves. Second, the increasing may degrade the performance dramatically. The phenomenon is especially pronounced in FAC, which has a multiplier network to predict the state-dependent . Consequently, we suggest to ensure in practice. We put the sensitivity analysis of these two algorithms in Appendix C.2.


In summary, the proposed USL is clearly effective for learning constraint-satisfying policies. First, USL achieves higher or competitive returns while adhering to (almost) zero cost return across different tasks. Second, USL features minor standard deviations and oscillations, which demonstrates its robustness. At last, USL generally converges with fewer interactions, which is crucial in sample-expensive risky environments. The underlying reason is that the optimization stage is equivalent to FAC but the state-dependent Lagrangian multipliers are reduced to a single fixed hyper-parameter. Meanwhile, the consistent loss function stabilizes the training process compared with primal-dual optimization. Furthermore, the projection stage explicitly enforces the state-wise constraints intractable in naive forward computing.
Additional experiments for comparing the state-wise constraint, the episodic constraint and reward shaping are placed in the supplementary material C.3.
Q2: How to account for the importance of the two stages in USL?
To better understand the importance of the two stages in our approach, we perform an ablation study as shown in Table 2 and confirm that the two stages must work jointly to achieve the desired performance. An intuitive example is that the solution derived by standard RL may be far away from the desired optimal safe action on tasks such as SpeedLimit. Thus, directly post-optimizing over may not necessarily converge to , and the agent still has a 38% cost rate. Instead, if the initial solution from Stage 1 is close to , it can serve as a valid candidate and the cost rate goes down to 0.63%. Note that, when the unconstrained action is not that far from the safe set, such as on the PathTracking task, both the optimization and projection parts can effectively degrade the cost rate from 24% to less than 1%. However, using only Stage 2 is inferior on episodic return, which is an inherent flaw of the projection-based method.
Q3: How sensitive is USL to its hyper-parameters and how to tune them?
We study the impacts of two pivotal hyper-parameters in USL, namely the penalty factor in the training objective and the maximum iterative number in the post-projection, on the SpeedLimit task. For , Figure 4 shows that final policies are insensitive to its value, and the learning curves are almost identical for sufficiently large values. By contrast, a small value may degenerate the first stage of USL into a “soft” regularization method. In our experiments, we find generally achieves good performance across different tasks. For , Figure 5 shows that USL can enforce the hard constraint within five iterations at most decision-making steps, indicating the possibility of navigating the trade-off between constraint satisfaction and computational efficiency. We set in the sensitivity study and show that the single optimization in Stage 1 can not lead to zero cost return without the aid of the post-posed projection.


Q4: How is the computational efficiency of USL with the additional iterative steps?
The two-stage architecture of USL inevitably brings concerns on computational feasibility in real-world applications. We compare different algorithms on a mainstream computing platform (Intel Core i7-9700K, NVIDIA GeForce RTX 2070). Table 3 shows that USL takes around 4-5 times the inference time of the unconstrained TD3 but still achieves an admissible 400 Hz control frequency. Having said that, we will leave the efforts on improving the time efficiency of USL to accelerate inference speed as future work.
Conclusions
In this paper, we perform a comparative study on model-free reinforcement learning toward safety-critical tasks following state-wise safety constraints. We revisit and evaluate related algorithms from the perspective of safety projection, recovery, and optimization, respectively. Furthermore, we propose Unrolling Safety Layer (USL) and demonstrate its efficacy in improving the episodic return and enhancing the safety-constraint satisfaction with an admissible computational complexity. We also present the open-sourced SafeRL-Kit and invite researchers and practitioners to incorporate domain-specific knowledge into the baselines to build more competent algorithms for their tasks.
Acknowledgments
This work is supported by the National Key R&D Program of China (2022YFB4701400/4701402), the National Natural Science Foundation of China (No. U21B6002, U1813216, 52265002), and the Science and Technology Innovation 2030 – “Brain Science and Brain-like Research” key Project (No. 2021ZD0201405).
References
- Achiam et al. (2017) Achiam, J.; Held, D.; Tamar, A.; and Abbeel, P. 2017. Constrained policy optimization. In International Conference on Machine Learning, 22–31. PMLR.
- Altman (1999) Altman, E. 1999. Constrained Markov decision processes, volume 7. CRC Press.
- Bohez et al. (2019) Bohez, S.; Abdolmaleki, A.; Neunert, M.; Buchli, J.; Heess, N.; and Hadsell, R. 2019. Value constrained model-free continuous control. arXiv preprint arXiv:1902.04623.
- Chen et al. (2021) Chen, B.; Francis, J.; Nyberg, J. O. E.; and Herbert, S. L. 2021. Safe Autonomous Racing via Approximate Reachability on Ego-vision. arXiv preprint arXiv:2110.07699.
- Cheng et al. (2019) Cheng, R.; Orosz, G.; Murray, R. M.; and Burdick, J. W. 2019. End-to-end safe reinforcement learning through barrier functions for safety-critical continuous control tasks. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, 3387–3395.
- Dalal et al. (2018) Dalal, G.; Dvijotham, K.; Vecerik, M.; Hester, T.; Paduraru, C.; and Tassa, Y. 2018. Safe exploration in continuous action spaces. arXiv preprint arXiv:1801.08757.
- Donti, Rolnick, and Kolter (2021) Donti, P. L.; Rolnick, D.; and Kolter, J. Z. 2021. Dc3: A learning method for optimization with hard constraints. arXiv preprint arXiv:2104.12225.
- Fujimoto, Hoof, and Meger (2018) Fujimoto, S.; Hoof, H.; and Meger, D. 2018. Addressing function approximation error in actor-critic methods. In International conference on machine learning, 1587–1596. PMLR.
- Ha et al. (2020) Ha, S.; Xu, P.; Tan, Z.; Levine, S.; and Tan, J. 2020. Learning to walk in the real world with minimal human effort. arXiv preprint arXiv:2002.08550.
- Herman et al. (2021) Herman, J.; Francis, J.; Ganju, S.; Chen, B.; Koul, A.; Gupta, A.; Skabelkin, A.; Zhukov, I.; Kumskoy, M.; and Nyberg, E. 2021. Learn-to-race: A multimodal control environment for autonomous racing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 9793–9802.
- Kiran et al. (2021) Kiran, B. R.; Sobh, I.; Talpaert, V.; Mannion, P.; Al Sallab, A. A.; Yogamani, S.; and Pérez, P. 2021. Deep reinforcement learning for autonomous driving: A survey. IEEE Transactions on Intelligent Transportation Systems.
- Li et al. (2021) Li, Q.; Peng, Z.; Xue, Z.; Zhang, Q.; and Zhou, B. 2021. Metadrive: Composing diverse driving scenarios for generalizable reinforcement learning. arXiv preprint arXiv:2109.12674.
- Liu, Ding, and Liu (2020) Liu, Y.; Ding, J.; and Liu, X. 2020. Ipo: Interior-point policy optimization under constraints. Proceedings of the AAAI Conference on Artificial Intelligence, 34(04): 4940–4947.
- Luenberger, Ye et al. (1984) Luenberger, D. G.; Ye, Y.; et al. 1984. Linear and nonlinear programming, volume 2. Springer.
- Ma et al. (2021) Ma, H.; Guan, Y.; Li, S. E.; Zhang, X.; Zheng, S.; and Chen, J. 2021. Feasible actor-critic: Constrained reinforcement learning for ensuring statewise safety. arXiv preprint arXiv:2105.10682.
- Mnih et al. (2015) Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A. A.; Veness, J.; Bellemare, M. G.; Graves, A.; Riedmiller, M.; Fidjeland, A. K.; Ostrovski, G.; et al. 2015. Human-level control through deep reinforcement learning. nature, 518(7540): 529–533.
- Panageas, Piliouras, and Wang (2019) Panageas, I.; Piliouras, G.; and Wang, X. 2019. First-order methods almost always avoid saddle points: The case of vanishing step-sizes. Advances in Neural Information Processing Systems, 32.
- Ray, Achiam, and Amodei (2019) Ray, A.; Achiam, J.; and Amodei, D. 2019. Benchmarking safe exploration in deep reinforcement learning. arXiv preprint arXiv:1910.01708, 7: 1.
- Srinivasan et al. (2020) Srinivasan, K.; Eysenbach, B.; Ha, S.; Tan, J.; and Finn, C. 2020. Learning to be safe: Deep rl with a safety critic. arXiv preprint arXiv:2010.14603.
- Sutton and Barto (1998) Sutton, R. S.; and Barto, A. G. 1998. Reinforcement learning: An introduction. MIT press.
- Thananjeyan et al. (2021) Thananjeyan, B.; Balakrishna, A.; Nair, S.; Luo, M.; Srinivasan, K.; Hwang, M.; Gonzalez, J. E.; Ibarz, J.; Finn, C.; and Goldberg, K. 2021. Recovery rl: Safe reinforcement learning with learned recovery zones. IEEE Robotics and Automation Letters, 6(3): 4915–4922.
- Villani et al. (2018) Villani, V.; Pini, F.; Leali, F.; and Secchi, C. 2018. Survey on human–robot collaboration in industrial settings: Safety, intuitive interfaces and applications. Mechatronics, 55: 248–266.
- Vinyals et al. (2019) Vinyals, O.; Babuschkin, I.; Czarnecki, W. M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D. H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. 2019. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature, 575(7782): 350–354.
- Wachi and Sui (2020) Wachi, A.; and Sui, Y. 2020. Safe reinforcement learning in constrained Markov decision processes. In International Conference on Machine Learning, 9797–9806. PMLR.
- Wachi et al. (2018) Wachi, A.; Sui, Y.; Yue, Y.; and Ono, M. 2018. Safe exploration and optimization of constrained mdps using gaussian processes. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32.
- Yang et al. (2022a) Yang, L.; Ji, J.; Dai, J.; Zhang, L.; Zhou, B.; Li, P.; Yang, Y.; and Pan, G. 2022a. Constrained Update Projection Approach to Safe Policy Optimization. In 36th Conference on Neural Information Processing Systems.
- Yang et al. (2020) Yang, T.-Y.; Rosca, J.; Narasimhan, K.; and Ramadge, P. J. 2020. Projection-based constrained policy optimization. arXiv preprint arXiv:2010.03152.
- Yang et al. (2022b) Yang, T.-Y.; Zhang, T.; Luu, L.; Ha, S.; Tan, J.; and Yu, W. 2022b. Safe Reinforcement Learning for Legged Locomotion. arXiv preprint arXiv:2203.02638.
- Yu et al. (2022) Yu, D.; Ma, H.; Li, S.; and Chen, J. 2022. Reachability Constrained Reinforcement Learning. In International Conference on Machine Learning, 25636–25655. PMLR.
- Yuan et al. (2021) Yuan, Z.; Hall, A. W.; Zhou, S.; Brunke, L.; Greeff, M.; Panerati, J.; and Schoellig, A. P. 2021. safe-control-gym: a Unified Benchmark Suite for Safe Learning-based Control and Reinforcement Learning. arXiv preprint arXiv:2109.06325.
- Zhang et al. (2022) Zhang, L.; Shen, L.; Yang, L.; Chen, S.; Wang, X.; Yuan, B.; and Tao, D. 2022. Penalized Proximal Policy Optimization for Safe Reinforcement Learning. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI-22, 3744–3750.
- Zhang, Vuong, and Ross (2020) Zhang, Y.; Vuong, Q.; and Ross, K. W. 2020. First order constrained optimization in policy space. arXiv preprint arXiv:2002.06506.
- Zhao, He, and Liu (2021) Zhao, W.; He, T.; and Liu, C. 2021. Model-free safe control for zero-violation reinforcement learning. In 5th Annual Conference on Robot Learning.
Supplementary Material A: Algorithmic Details
Supplementary Material B: Implementation Details
B.1 Safety-Critical Benchmarks
| Environments | Descriptions |
(a) SpeedLimit
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d79a72c6-404d-486d-9cfa-f9e0c9956546/antrun.png)
|
Refer to Zhang, Vuong, and Ross (2020). The observation space () contains ego-information, including position, linear velocity, quaternion, the angular velocity, the feet contact forces, etc. The action space () denotes the forces applied to each motors. The four-legged ant is rewarded for running along the avenue, which is calculated by the forward distance towards the target . However, it is constrained with its linear velocity . In our experiments, the agent receives cost signal if or the ant is out of the yellow boundary , i.e., . |
(b) Stabilization
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d79a72c6-404d-486d-9cfa-f9e0c9956546/cartpole.png)
|
Refer to Yuan et al. (2021). The cart-pole is rewarded for keeping itself upright, but is constrained with its angular degree and angular velocity . The observation space () contains the horizontal position of the cart , the velocity of the cart , the angle of the pole w.r.t vertical and the angular velocity of the pole . The action space () is the force applied to the center of the mass of the cart. The reward function is an instantaneous signal of +1 if the pole is upright (). The agent receives a +1 cost signal if or . In our experiments, we set . |
|
(c) PathTracking
|
Refer to Yuan et al. (2021). The drone (UAV) is rewarded for tracking a circular trajectory, but the safe area is bounded within a smaller rectangular. The observation space () contains the translation position and velocity of the drone in the plane, as well as the pitch angle and pitch angular velocity . The action space () denotes the thrusts generated by the two motors. The reward function is in a quadratic form w.r.t to the reference and . The agent receives cost signal if it is out of the area allowed to fly. In our experiments, we set and . |
(d) Safetygym-PG
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d79a72c6-404d-486d-9cfa-f9e0c9956546/navi1.png)
|
Refer to Ray, Achiam, and Amodei (2019). The observation space () contains ego information and Lidar information (towards hazards and the goal respectively), etc. The action space () denotes the linear velocity and angular velocity of the point mass. The point mass is rewarded for getting close to the green destination. However, it is the agent receives cost signal if it overlaps with the virtual blue hazards. Due to the original point-goal environment is not designed for zero-cost tasks, we inherit the setting as Zhao, He, and Liu (2021), where the number of hazards is 8 and the radius of them is 0.3m. |
(e) PandaPush
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d79a72c6-404d-486d-9cfa-f9e0c9956546/pandapush1.png)
|
Refer to Zhang et al. (2022). The 7-DoF Franka Emika Panda manipulator is required to push the green cube to the destination marked in yellow and the environment returns a sparse reward (0 for finished and -1 for unfinished). We add a red cube in the optimal path and return a +1 if the green cube collides with the obstacle. The observation () contains ego information, obstacle information and destination information. We adopt position control to move the manipulator end-effector, i.e., the action () is the increments on X-Y-Z axis. |
(f) SafeDrive
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d79a72c6-404d-486d-9cfa-f9e0c9956546/metadrive.png)
|
Refer to Li et al. (2021). Metadrive is a compositional, lightweight and realistic platform for vehicle autonomy. Most importantly, it provides pre-defined environments for safe policy learning in autopilots. Concretely, the observation is encoded by a vector containing ego-state, navigation information and surrounding information detected by the Lidar. We control the speed and steering of the car to hit virtual land markers for rewards (By default, Li et al. (2021) conduct a reward shaping by penalizing collisions and overstepping the road; otherwise it would be too hard to learn), and the cost function is +1 if the vehicle collides with other obstacles or it is out of the road. |
B.2 Safe Learning Algorithms
Safety Projection
This type of method corrects the initial unsafe decision by projecting it back to the safe set. In SafeRL-Kit, the representative model-free method is Safety Layer which is added on the top of the original policy network. Specifically, Safety Layer utilizes a parametric linear model to approximate the single-step cost function with supervised training and solves the quadratic programming as follows
| (A.1) | ||||
to find the ”closest” action to the feasible region. Since there is only one compositional cost signal in our problem, the closed-form solution of problem (A.1) is
| (A.2) |
By the way, the is trained from offline data in Dalal et al. (2018). In SafeRL-Kit, we instead learn the linear model with the policy network synchronously, considering the side-effect of distribution shift. We also employ a warm-up for the safety critic in the training process to avoid inaccurate estimation and wrong corrections.
Safety Recovery
The critical insight behind safety recovery is to introduce an additional policy that recovers potential unsafe states. In SafeRL-Kit, the representative model-free method is Recovery RL (Thananjeyan et al. 2021). We first learn a safe critic to estimate the future probability of constraint violation as
| (A.3) |
This formulation is slightly different from the standard Bellman equation since it assumes the episode terminates when the agent receives a cost signal. We remove the early-stopping condition for agents to better master complex skills but still preserve the original formulation of in (A.3) since it limits the upper bound of the safe critic and eliminates the over-estimation in Q-learning. In the phase of policy execution, the recovery policy takes over the control when the predicted value of the safe critic exceeds the given threshold:
| (A.4) |
It is of the best practice to store and simultaneously in the replay buffer, and utilize them to train and respectively in Recovery RL. This technique ensures that can learn from the new MDP, instead of proposing same unsafe actions continuously. Similar to Safety Layer, Recovery RL also has a warm-up stage where is trained but is not utilized in SafeRL-Kit.
Safety Optimization
State-wise safe safe RL can be formulated as a constrained sequential optimization problem
| (A.5) |
and can be tackled via the dual problem in the parametric space as follows
| (A.6) |
Off-policy Lagrangian applies stochastic primal-dual optimization (Luenberger, Ye et al. 1984) to update primal and dual variables alternatively, which follows as
| (A.7) |
Notably, the timescale of primal variable updates is required to be faster than the timescale of Lagrange multipliers. Thus, we set in SafeRL-Kit.
The constraint in Off-policy Lagrangian is based on the expectation of the safety critic. Feasible Actor-Critic (FAC) (Ma et al. 2021) introduces state-wise constraints for each ”feasible” initial states and reformulates (A.6) as
| (A.8) |
The distinctiveness of problem (A.8) is there are infinitely many Lagrangian multipliers that are state-dependent. In SafeRL-Kit, we employ a neural network activated by Softplus function to map the given state to its corresponding Lagrangian multiplier . The primal-dual ascents of policy network is similar to (A.7); the updates of multiplier network is given by
| (A.9) |
Besides, we set a different interval schedule (for delay steps) and (for delay steps) in SafeRL-Kit to stabilize the training process inspired by Fujimoto et al. (2018).
Supplementary Material C: Experimental Details
C.1 Hyper-parameter Settings
| Hyper-parameter | Safety Layer | Recovery RL | Lagrangian | FAC | USL(ours) |
|---|---|---|---|---|---|
| Cost Limit | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 |
| Reward Discount | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 |
| Cost Discount | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 |
| Warm-up Ratio | 0.2 | 0.2 | N/A | N/A | N/A |
| Batch Size | 256 | 256 | 256 | 256 | 256 |
| Critic LR | 3E-4 | 3E-4 | 3E-4 | 3E-4 | 3E-4 |
| Actor LR | 3E-4 | 3E-4 | 3E-4 | 3E-4 | 3E-4 |
| Safe Critic LR | 3E-4 | 3E-4 | 3E-4 | 3E-4 | 3E-4 |
| Safe Actor LR | N/A | 3E-4 | N/A | N/A | N/A |
| Multiplier LR | N/A | N/A | 1E-5 | 1E-5 | N/A |
| Multiplier Init | N/A | N/A | 0.0 | N/A | N/A |
| Policy Delay | 2 | 2 | 2 | 2 | 2 |
| Multiplier Delay | N/A | N/A | N/A | 12 | N/A |
| Penalty Factor | N/A | N/A | N/A | N/A | 5 |
| Iterative Step | N/A | N/A | N/A | N/A | 20 |
C.2 Additional Sensitivity Study between Lagrangian, FAC and USL
In this section, we study the sensitivity to hyper-parameters of Lagrangian-based methods and newly proposed USL in Figure 6 and Figure 7, respectively. We found that Lagrangian-based methods are susceptible to the learning rate of the Lagrangian multiplier(s) in stochastic primal-dual optimization. First, the oscillating causes non-negligible deviations in the learning curves. Besides, the increasing may degrade the performance dramatically. The phenomenon is especially pronounced in FAC, which has a multiplier network to predict the state-dependent . Thus, we suggest in practice. As for USL, we find if the penalty factor is too small, the cost return may fail to converge. Nevertheless, if is sufficiently large, the learning curves are robust and almost identical. Thus, we suggest in experiments and a grid search for better performance.










C.3 Additional Comparative Study between State-wise Safe RL, Episodic Safe RL and Reward Shaping
In Section 1: Introduction, we claim that “Penalizing unsafe transitions on the reward function (i.e., ) is straightforward but sometimes cumbersome to navigate the trade-off between performance and safety.” In this section, we empirically demonstrate that by changing punishment intensities of the reward shaping method on the Stabilization task.




In Section 3: Revisit RL toward Safety-critical Tasks, we claim that “In many safety-critical scenarios, the final policy is supposed to maintain the zero-cost return since any inadmissible behavior could lead to catastrophic failure in the execution. Prior constrained learning paradigms have fatal flaws under this premise. For the episode constraint, if we set the threshold close to , the agent either fails to improve policy or receives a cost-return more significant than .” In this section, we empirically demonstrate that episodic safe RL may not work toward safety-critical tasks when we set in the corresponding constraint . We perform a comparative study on the Stabilization task and take CPO, PPO-L, TRPO-L (Ray, Achiam, and Amodei 2019) as episodic baselines. The results show that CPO/PPO-L/TRPO-L fails to improve policy and receives a cost-return more significant than when we set . Instead, the state-wise safe RL method (we take USL as an example) can obtain a reasonable policy while adhering to zero-cost return in the end.



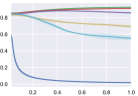
In Section 3: Revisit RL toward Safety-critical Tasks, we claim that “Empirical results demonstrate safe RL methods adhering to state-wise safety constraints are robust to value.” In this section, we empirically demonstrate that change from 0.1 to 1 (namely, change safe planning span from 100 to 1) won’t affect the learning curves too much. However, when we set , it degenerates to the instantaneous safety constraint, and the agent cannot obtain a zero-cost return policy at convergence.



