Ev-Edge: Efficient Execution of Event-based Vision Algorithms on Commodity Edge Platforms
Abstract.
Event cameras have emerged as a promising sensing modality for autonomous navigation systems, owing to their high temporal resolution, high dynamic range and negligible motion blur. To process the asynchronous temporal event streams from such sensors, recent research has shown that a mix of Artificial Neural Networks (ANNs), Spiking Neural Networks (SNNs) as well as hybrid SNN-ANN algorithms are necessary to achieve high accuracies across a range of perception tasks. However, we observe that executing such workloads on commodity edge platforms which feature heterogeneous processing elements such as CPUs, GPUs and neural accelerators results in inferior performance. This is due to the mismatch between the irregular nature of event streams and diverse characteristics of algorithms on the one hand and the underlying hardware platform on the other. We propose Ev-Edge, a framework that contains three key optimizations to boost the performance of event-based vision systems on edge platforms: (1) An Event2Sparse Frame converter directly transforms raw event streams into sparse frames, enabling the use of sparse libraries with minimal encoding overheads (2) A Dynamic Sparse Frame Aggregator merges sparse frames at runtime by trading off the temporal granularity of events and computational demand thereby improving hardware utilization (3) A Network Mapper maps concurrently executing tasks to different processing elements while also selecting layer precision by considering both compute and communication overheads. On several state-of-art networks for a range of autonomous navigation tasks, Ev-Edge achieves 1.28x-2.05x improvements in latency and 1.23x-2.15x in energy over an all-GPU implementation on the NVIDIA Jetson Xavier AGX platform for single-task execution scenarios. Ev-Edge also achieves 1.43x-1.81x latency improvements over round-robin scheduling methods in multi-task execution scenarios.
1. Introduction
Event cameras, also known as Dynamic Vision Sensors (DVS) (et al., 2008), have demonstrated great potential in the field of robotics and autonomous systems such as self-driving cars and unmanned aerial vehicles (UAVs) (et al., 2022d). These bio-inspired low-latency sensors produce asynchronous streams of brightness changes per pixel called events, offering high temporal resolution (millions of events per second), high dynamic range (140 dB) and negligible motion blur (et al., 2022d). In order to effectively process these event data streams, there is a need for suitable algorithms that operate on this sensing modality. Consequently, recent efforts (et al., 2022c, 2023b, f, 2020b) have shown that artificial neural networks (ANNs), spiking neural networks (SNNs) as well as hybrid SNN-ANN algorithms have excelled on a variety of event-based vision tasks such as optical flow estimation, semantic segmentation and depth estimation.

Commodity edge platforms such as NVIDIA Jetson (Platforms, 2021) and Google Coral (et al., 2022e), equipped with heterogeneous processing elements like CPUs, GPUs and specialized neural network accelerators (DLA/TPU/NPU) have gained prominence in running machine learning workloads efficiently. However, we observe that deploying event-based vision systems on these heterogeneous edge platforms leads to suboptimal performance. This is due to the fundamental differences between the sensing modality and the processing requirements of the network on the one hand, and the underlying hardware platform on the other. For example, these networks often convert the raw event streams to image-like event frames. Subsequently, these event frames are processed with fixed-sized matrix multiplication operations regardless of the the number of events generated, resulting in a significant proportion of redundant and wasteful operations, as shown in Figure 1. Although sparse routines could be applied to the event frames, encoding and decoding overheads outweigh the potential benefits. Another crucial factor is the inability of the hardware platform to match the rate at which the vision sensor emits event data. Existing approaches (et al., 2022c, 2020a) either construct event frames by statically counting events or sampling events at a fixed rate without considering the hardware processing capabilities. Finally, in many applications, there is a need to concurrently execute multiple networks in a manner that efficiently shares the resources in the hardware platform.
Our work, Ev-Edge, addresses these challenges and improves the performance of event-based algorithms on heterogeneous edge platforms by introducing three key optimizations. First, we propose an Event2Sparse Frame converter (E2SF) to convert the raw event streams directly to a sparse frame representation eliminating the need for intermediate event frames. This optimization enables the use of sparse libraries and ensures that the computational overhead is proportional to the number of generated events. Next, we present Dynamic Sparse Frame Aggregator (DSFA), an optimization that improves hardware utilization by dynamically merging sparse frames based on input dynamics and hardware processing capabilities. Finally, we propose Network Mapper (NMP) to allocate concurrently executing tasks to different processing elements while also optimizing layer precision considering both compute and communication overheads.
Across several state-of-the-art ANNs, SNNs and hybrid SNN-ANNs, Ev-Edge achieves 1.28x-2.05x improvements in latency and 1.23x-2.15x in energy over an all-GPU implementation on the NVIDIA Jetson AGX Xavier for single task scenarios. Moreover, Ev-Edge also achieves 1.43x-1.81x latency improvements over round-robin scheduling methods in multi-task execution scenarios with negligible accuracy loss.
2. Background
Event cameras and Input representation. Event cameras are neuromorphic sensors that operate at a high temporal resolution by capturing changes in brightness (log intensity) asynchronously for every pixel in a scene. When the log intensity () at a particular pixel is greater than the threshold () (i.e., ), the camera generates an event. The event data is emitted in Address Event Representation (AER) format as {x,y,t,p}, where x and y corresponds to the pixel location, t represents the timestamp and p is a binary value that indicates whether the polarity of the brightness change is positive or negative.

For processing efficiency and network compatibility, as shown in Figure 2, the asynchronous events are accumulated over a time period to construct event frames. Some works (et al., 2018a) fully accumulate events between two consecutive image frames and encode the total number of events along with the most recent timestamp of intensity change in a pixel. Other works such as (et al., 2020b, a) discretize events between two consecutive image frames into uniformly separated synchronous event frames. During inference, these event frames are either presented to the network as a single input with B channels or sequentially over B/k timesteps, where k denotes the number of concatenated event frames in a timestep. We note that Ev-Edge supports all of the aforementioned input representations.
3. Related Work
In this section, we review prior related research efforts and compare Ev-Edge with them.
Algorithmic Techniques. In order to exploit the spatio-temporal sparsity of events, (et al., 2019) and (et al., 2020c) introduce novel methods for computing event-based convolutions. Our work complements these efforts to provide additional performance gains.
Hardware accelerators. Specialized accelerators such as (et al., 2022b, a) accelerate key computations for processing asynchronous event data. These efforts are orthogonal to our work since we propose algorithmic optimizations to improve the performance of event-based networks on off-the-shelf hardware platforms. Nevertheless, some of our optimizations are also applicable to specialized accelerators.
Mapping frameworks. Several efforts (et al., 2023c, 2022h, 2022g) have formulated mapping of multiple ANNs to a heterogeneous platform as an optimization problem. They consider the cost of compute and communication during the search to determine the final mapping configuration. The Event2Sparse Frame converter and Dynamic Sparse Frame Aggregator components of Ev-Edge are complementary to these frameworks and specifically target the unique challenges of processing temporal event streams. The Network Mapper in Ev-Edge, while similar in objective to these mapping frameworks, also includes a search for layer precision as part of the mapping process.
4. Ev-Edge Framework
Ev-Edge is an optimization framework designed to efficiently execute event-based vision algorithms on heterogeneous edge platforms. Figure 4 presents an overview of the Ev-Edge framework. As an offline step, the pretrained networks are input to the Network Mapper (NMP) which determines the processing element to execute each layer on and the execution order. During inference, the event camera produces raw event streams that are directly converted to sparse frames by the Event2Sparse Frame converter (E2SF). Subsequently, the Dynamic Sparse Frame Aggregator (DSFA) merges these sparse frames while considering both the input dynamics and the hardware processing capabilities to generate merged sparse frames. It is important to note that NMP is an offline process that is executed only once, while E2SF and DEFA optimizations are applied at runtime during inference. The following subsections will delve into a comprehensive description of each of the components.
4.1. Event2Sparse Frame Converter (E2SF)


Several state-of-the-art event-based networks convert asynchronous raw event streams to a synchronous dense event frame representation of the data. As shown in Figure 3, the average number of actual events per event frame can vary widely (0.15%-28.57%) across different networks that estimate optical flow (et al., 2020a, 2022c, 2023a) on the MVSEC (et al., 2018b) dataset, indicating that most event frames are extremely sparse. This results in a high number of wasteful computations as well as increased memory requirements. While the dense event frames can be converted to sparse tensors and processed with sparse linear algebra libraries, the associated encoding and decoding overheads are prohibitive. Instead, we propose an Event2Sparse Frame converter (E2SF) that converts the raw event stream from the camera directly to a sparse frame representation, enabling faster processing of the generated events on commodity edge platforms.
Event cameras such as the Dynamic and Active Vision Sensor (DAVIS) (et al., 2008) output synchronized grayscale frames along with the asynchronous event data. We refer to the timestamps of a pair of consecutive grayscale frames as Tstart and Tend. First, E2SF maps the event timestamps to discretized event bins based on Equation 1. The number of event bins (nB) determines the temporal resolution of the data, which refers to how precisely information is captured in a scene.
| (1) |
The duration of time interval assigned to each event bin, biS is determined and used to scale each timestamp to its respective event bin index . Once the events are assigned to their respective event bins, we accumulate the positive and negative polarities separately for same pixel locations within each event bin. Finally, we iterate over the pixels in each accumulated event bin and store the row indices, column indices and their corresponding polarities as separate channels, similar to the sparse Coordinate (COO) format. Therefore, each event bin is converted to a two-channel sparse frame (positive and negative polarity), like (et al., 2020a). Converting the event data to sparse frame representations enables the use of sparse libraries (et al., 2018c) for improved performance during inference.
4.2. Dynamic Sparse Frame Aggregator (DSFA)

After E2SF transforms the raw events from the camera to synchronous sparse frames, the network processes these frames on the hardware platform to generate task predictions. However, we make a key observation that there still exists a large variance in the number of events generated over time (temporal density) by the vision sensor (Figure 5). Previous approaches (et al., 2020a, 2022c) construct event frames statically either by counting the number of events that have occurred, or at fixed time intervals. However, they do not consider the hardware processing time while generating event frames, resulting in a backlog of event frames during periods of high activity that significantly increases overall latency. To address this challenge, DSFA merges the sparse frames at runtime by adapting to both the varying temporal event densities and the hardware processing capabilities, thereby improving latency with minimal accuracy loss.

Figure 6 outlines the DSFA procedure in detail. DFSA consists of two stages in order to generate merged sparse frames. We populate the event buffer first with sparse frames and propose a novel aggregation method to combine them. Subsequently, we dispatch the merged sparse frames to an inference queue which is later combined to form a batched input representation.
Initially, we allocate an event buffer of size EBufsize to store the generated sparse frames(Evf_k). The event buffer is then partitioned into merge buckets of capacity MBsize, each designated to contain a specific subset of sparse frames. These sparse frames are merged depending on the CMode parameter. Based on the task, DSFA supports three merging modes (cMode); cAdd, which adds the pixels across frames, cAverage, that averages the pixels across frames, and cBatch, which concatenates the sparse frames. For instance, in high-speed scenarios, it is recommended to use cBatch mode to capture the scene accurately. Every merge bucket (MB) tracks the current capacity, time of earliest spike frame (Time(Evf_1)) and merged bucket density (MBmerged). Furthermore, each merge bucket has a status flag that indicates whether it can accept new event frames (AVL) or is at maximum occupancy (FULL). When a sparse frame Evf_k is generated, we use a greedy approach to place it in the earliest available bucket, subject to two conditions (i) The time delay between the current Evf_k and the earliest entry in the merge bucket is within the maximum delay threshold, MtTh (ii) The percentage change in the spatial density of the current event frame and MBmerged is less than the maximum density threshold, MdTh. We note that both MtTh and MdTh needs to be tuned for each task individually. If Evf_k fails to meet either of these conditions, the status of the current bucket is changed to FULL, and the sparse frame is placed in the next merge bucket. However, when cMode is set to cBatch, every generated Evf_k is placed in a new merge bucket. If the event buffer occupancy is greater than EBufsize, we combine each merge bucket according to the specified CMode. The resulting merge buckets are forwarded to their respective inference queues as the latest sparse frames, where the earliest sparse frames in each queue is discarded. The merge buckets are concatenated to form a merged sparse frame representation. This helps in improving the hardware utilization and efficiency of inference execution due to batching of the sparse frames. If the hardware platform becomes available before the event buffer reaches full capacity, we dispatch the available merge buckets to maximize hardware utilization. It is also important to choose an optimal MBsize to achieve the best tradeoff between accuracy and performance. For instance, a smaller MBsize captures temporal information better thereby representing the scene more accurately while a larger MBsize consolidates the events to fewer sparse frames leading to improved performance.
4.3. Network Mapper (NMP)
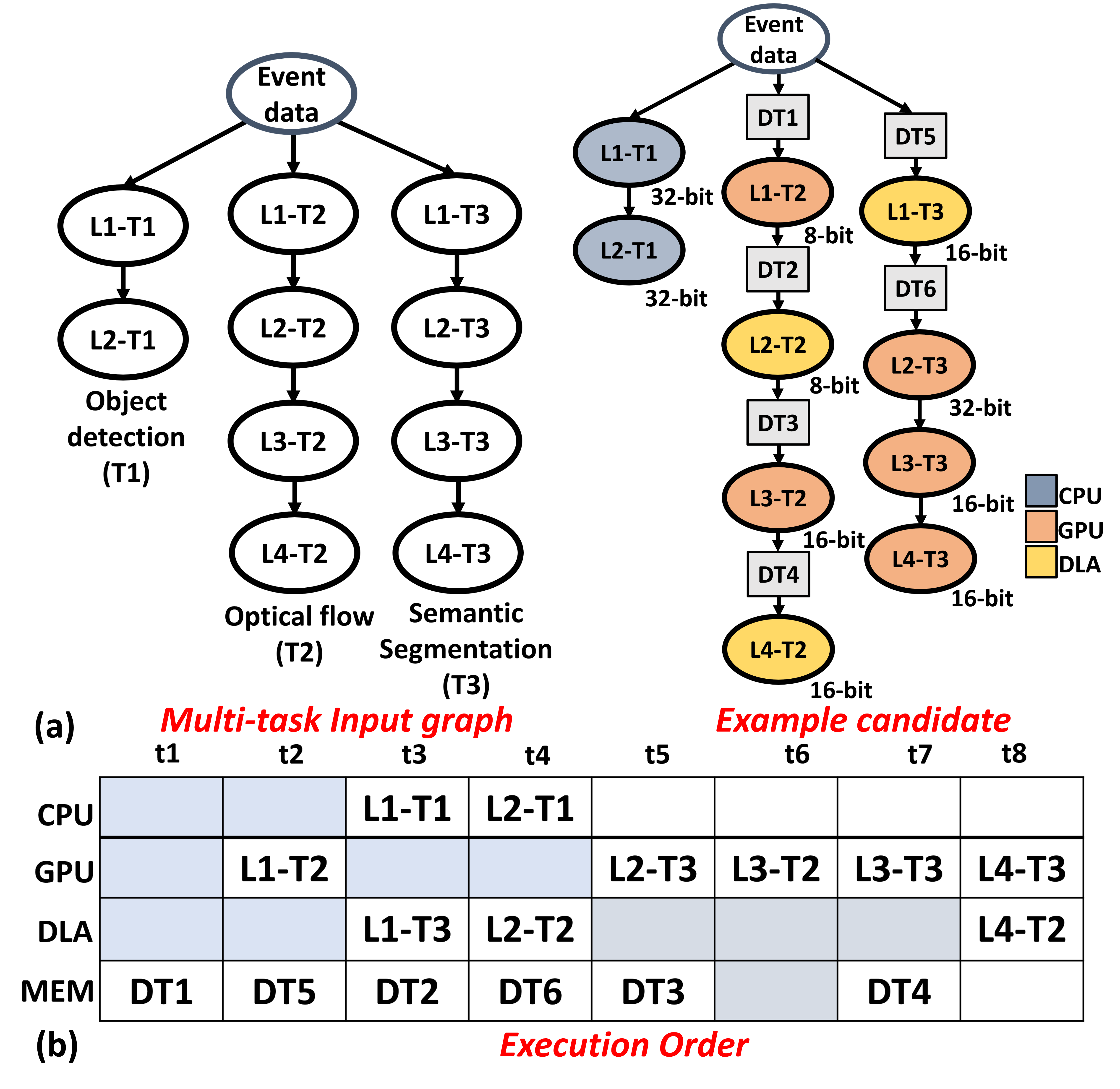
NMP efficiently maps the layers of multiple networks to different processing elements on heterogeneous edge platforms while also selecting the optimal layer precision during concurrent execution. The optimization process takes into account the computational and communication overheads and the accuracy degradation due to mixed precision. We represent the multi-task network dependencies as a directed graph, illustrated in Figure 7(a). Each node in the multi-task graph corresponds to a distinct layer of a network, while each edge signifies the data dependencies between the corresponding layers. Within the multi-task input graph, each node can be mapped to a variety of processing elements {, , …, } of the heterogeneous platform. Additionally, each processing element offers a range of precision options. The possible configurations encompassing all feasible mapping schemes and precision choices scales exponentially with the number of layers, i.e., . Hence, relying on naïve ad-hoc methods is impractical. Instead, we formulate the design space exploration as an evolutionary search problem to determine the best mapping and layer precision. We define the objective function in Equation 2 to minimize the latency of tasks {, , …, } such that the accuracy degradation for each task {, , …, } due to mixed precision is within a defined threshold A. Similarly, this procedure can be repeated to optimize for other objectives such as energy as well. We now describe our mapping methodology and latency estimation in more detail in sections 4.3.1 and 4.3.2 .
| (2) |
4.3.1. Mapping methodology
We convert the multi-task input graph to a potential candidate (mapping configuration) by assigning each layer to a processing element and a precision choice supported by the processing element, as shown in Figure 7(a). We also insert data transfer nodes between layers to account for the communication overhead whenever the producer-consumer layers of a task are assigned to different processing elements. We first choose a random initial candidate set of potential solutions. After the initial population is chosen, each candidate is evaluated based on a fitness score. Subsequently, fitter generations of parents are created by crossover and mutation. This procedure is repeated for several iterations to choose the best mapping and precision for the network. Below are the key steps of our evolutionary search algorithm.
Candidate evaluation. The fitness of each candidate is evaluated using the objective function presented in Equation 2. To compute the accuracy of each task, the pretrained network is quantized linearly based on the layer bit-widths specified in the candidate set and evaluated on a validation dataset. It is important to note that accuracy is determined individually for each task. The latency is estimated based on the execution order of the layers on the hardware platform, which is determined by an efficient scheduling algorithm described in section 4.3.2. This process is repeated for all candidates, and their respective fitness scores are stored. Since the search spans multiple iterations, we employ certain optimizations techniques to reduce its complexity. First, we perform inference only on a randomly sampled subset of the validation set. Second, the fitness scores are cached for each new candidate and reused if the same candidate emerges from different parents.
Crossover. After the parents are chosen, new children are produced by the fittest candidates in the current generation. For every pair of neighboring parents, one of them is chosen as the child for the next generation randomly based on equal likelihood.
Mutation. A specified number of layers in each task is replaced with a random mapping resource and precision choice.
4.3.2. Scheduling methodology and Latency Estimation
Calculating the fitness score for each candidate requires determining the execution order of the layers and estimating latency. This procedure needs to be fast since it needs to be repeated for a large number of candidates across multiple generations.To that end, as shown in Figure 7(b), we establish an execution queue for each device including unified memory in the heterogeneous platform to facilitate parallel execution of certain layers. Based on the data dependencies in the multi-task input graph, we obtain a partial ordering of layers. Subsequently, using this ordering, we serialize nodes within their respective execution queues (obtained from the mapper) that are not already serialized by the data dependencies. As shown in Equation 3, the end time for each node, End_T(node) is determined based on three factors, viz., the completion of all its parent nodes (End_T(ParentN)), the actual execution time of the node (Exec_T(Node)) and completion of all the nodes preceding it in the execution queue (CurDeviceQ_T). Once the end times for all nodes in the graph have been determined, the latency of the candidate is calculated by analyzing the critical path of the graph. The individual execution time for each layer and the communication time between layers are measured on the hardware platform and recorded before the search process begins.
| (3) |
5. Experimental Methodology
In this section, we discuss the experimental setup and benchmarks for evaluating Ev-Edge.
Applications and Datasets. We evaluate Ev-Edge across different tasks and networks summarized in Table 1. We note that optical flow, semantic segmentation and object tracking tasks are validated on different sequences of the Multi Vehicle Stereo Event Camera (MVSEC) dataset (et al., 2018b) while the depth estimation task is validated on the Town 10 sequence of Depth Estimation oN Synthetic Events (DENSE) dataset (et al., 2020b). During multi-task execution, we evaluated our mapping methodology across an all-ANN ( (et al., 2018a), (et al., 2020b)), all-SNN ( (et al., 2022f), (et al., 2023a)) and mixed SNN-ANN configurations ( (et al., 2022c), (et al., 2023b), (et al., 2022f), (et al., 2020b)).
Simulation Setup. Ev-Edge is developed using PyTorch and evaluated on the Jetson Xavier AGX board, a heterogeneous edge platform equipped with a CPU, GPU, and DLA for accelerating deep learning workloads. To profile layer execution times at various precision levels, we use TensorRT (TensorRT, 2021) on both the GPU and DLA. Since there is no explicit method to measure communication times between layers, we approximate the overheads based on the amount of bandwidth and data volume. We utilize the Tegrastats tool to obtain power measurements.
| Network | Task | Type | # Layers |
|---|---|---|---|
| SpikeFlowNet (et al., 2020a) | Optical Flow | SNN-ANN | 12 (4 SNN, 8 ANN) |
| Fusion-FlowNet (et al., 2022c) | Optical Flow | SNN-ANN | 29 (10 SNN, 19 ANN) |
| Adaptive-SpikeNet (et al., 2023a) | Optical Flow | SNN | 8 |
| HALSIE (et al., 2023b) | Semantic Segmentation | SNN-ANN | 16 (3 SNN, 13 ANN) |
| J. Hidalgo-Carrio et. al (et al., 2020b) | Depth Estimation | ANN | 15 |
| DOTIE (et al., 2022f) | Object Tracking | SNN | 1 |
6. Results
This section illustrates the performance improvements obtained by Ev-Edge on state-of-the-art event-based networks.
Single-task execution performance. Figure 8 shows the speedup results of Ev-Edge compared to an all-GPU implementation on the Jetson Xavier AGX hardware platform. We present the improvements achieved by Ev-Edge after each optimization is applied individually as well as the combined improvements. We observe that Ev-Edge consistently outperforms the GPU implementation by 1.23x-2.05x across different levels of optimization. Notably, SNNs (depending on the number of layers) achieve the highest performance improvements, as they have the longest execution times on these platforms as well as high activation sparsity. Also, DSFA does not produce significant benefits in semantic segmentation networks due to the pixel-wise accuracy requirements, limiting the aggressiveness of merging frames. We also report the minimal accuracy degradation due to Ev-Edge in Table 2. In addition to speedup improvements, Ev-Edge also achieves 1.23x-2.15x energy efficiency improvements over an all-GPU implementation.

Multi-task execution performance. Figure 9 shows the latency improvements of NMP for different multi-task network configurations. We compare Ev-Edge to two variations of round-robin scheduling methods. RR-Network is a coarse-grained round-robin allocation policy where each network is assigned to a processing element and the rest of the networks are distributed in a cyclic manner. RR-Layer is a fine-grained round-robin allocation policy where each layer is assigned to a processing element. We notice that NMP provides 1.24x-1.41x improvements over RR-Layer and 1.43x-1.81x over RR-Network. This is because NMP searches from a much larger design space to optimize for both computation and communication overheads. We note that there is minimal accuracy degradation, since we are concurrently optimizing both accuracy and latency similar to single task execution. We also consider another variation of the network mapper, Ev-Edge-NMP-FP which exclusively maps to full precision cores to prevent any accuracy degradation. Ev-Edge-NMP-FP is 1.05x-1.22x slower than Ev-Edge-NMP but still significantly faster than the RR-Network and RR-Layer baselines. Ev-Edge-NMP-FP can be useful for accuracy sensitive applications.

Next we show the fitness score convergence over several generations of evolutionary search in Figure 10(a), indicating that latency and accuracy degradation are minimized simultaneously. We also compare NMP’s evolutionary search technique in Figure 10(b) to random search where the candidates are randomly sampled every generation, for a mixed SNN-ANN network. We observe that Ev-Edge-NMP is 1.42x faster compared to the results of random search.

| Network-Metric | Baseline | Ev-Edge |
|---|---|---|
| SpikeFlowNet (et al., 2020a) (AEE-) | 0.93 | 0.96 |
| Fusion-FlowNet (et al., 2022c) (AEE-) | 0.72 | 0.79 |
| Adaptive-SpikeNet (et al., 2023a) (AEE-) | 1.27 | 1.36 |
| HALSIE (et al., 2023b) (mIOU-) | 66.31 | 64.18 |
| J. Hidalgo-Carrio et al. (et al., 2020b) (Avg Error-) | 0.61 | 0.63 |
| DOTIE (et al., 2020b) (mIOU-) | 0.86 | 0.82 |
7. Conclusion
In this work, we introduced Ev-Edge, a framework to improve the performance of event-based algorithms on heterogeneous edge platforms. Ev-Edge consists of three optimizations that are integrated into the inference pipeline. First, E2SF directly transforms raw event streams to sparse frames without the need to convert to intermediate event frames. Next, DSFA combines the sparse frames at runtime by considering the properties of the event streams as well the hardware efficiency. Finally, NMP determines the best mapping configuration and layer precision for concurrently executing tasks. We demonstrated the efficacy of Ev-Edge across several state of the art SNNs, ANNs and hybrid SNN-ANNs for both single task as well as multi-task scenarios.
Acknowledgements. This work was supported in part by the Micro4AI program from IARPA and the Center for the Co-Design of Cognitive Systems (COCOSYS), a DARPA-sponsored JUMP center, Semiconductor Research Corporation (SRC).
References
- (1)
- et al. (2023a) A. Kosta et al. 2023a. Adaptive-SpikeNet: Event-based Optical Flow Estimation using Spiking Neural Networks with Learnable Neuronal Dynamics. arXiv:2209.11741 [cs.CV]
- et al. (2022a) A. Mauro et al. 2022a. Kraken: A Direct Event/Frame-Based Multi-sensor Fusion SoC for Ultra-Efficient Visual Processing in Nano-UAVs. In 2022 IEEE Hot Chips 34 Symposium. 1–19.
- et al. (2022b) A. Mauro et al. 2022b. SNE: an Energy-Proportional Digital Accelerator for Sparse Event-Based Convolutions. 2022 DATE (2022), 825–830.
- et al. (2018a) A. Zhu et al. 2018a. EV-FlowNet: Self-Supervised Optical Flow Estimation for Event-based Cameras. In Robotics: Science and Systems XIV (RSS2018). Robotics: Science and Systems Foundation. https://doi.org/10.15607/rss.2018.xiv.062
- et al. (2018b) A. Zhu et al. 2018b. The Multivehicle Stereo Event Camera Dataset: An Event Camera Dataset for 3D Perception. IEEE RAL 3, 3 (July 2018), 2032–2039. https://doi.org/10.1109/lra.2018.2800793
- et al. (2018c) B. Graham et al. 2018c. 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks. CVPR (2018).
- et al. (2020a) C. Lee et al. 2020a. Spike-FlowNet: Event-based Optical Flow Estimation with Energy-Efficient Hybrid Neural Networks. arXiv:2003.06696 [cs.NE]
- et al. (2022c) C. Lee et al. 2022c. Fusion-FlowNet: Energy-Efficient Optical Flow Estimation using Sensor Fusion and Deep Fused Spiking-Analog Network Architectures. In ICRA. 6504–6510. https://doi.org/10.1109/ICRA46639.2022.9811821
- et al. (2019) C. Scheerlinck et al. 2019. Asynchronous Spatial Image Convolutions for Event Cameras. IEEE RAL 4, 2 (2019), 816–822.
- et al. (2022d) G. Gallego et al. 2022d. Event-Based Vision: A Survey. IEEE PAMI 44, 1 (Jan. 2022), 154–180. https://doi.org/10.1109/tpami.2020.3008413
- et al. (2020b) J. Hidalgo-Carrio et al. 2020b. Learning Monocular Dense Depth from Events. In 2020 3DV. IEEE, Los Alamitos, CA, USA, 534–542.
- et al. (2022e) K. Seshadri et al. 2022e. An Evaluation of Edge TPU Accelerators for Convolutional Neural Networks. arXiv:2102.10423 [cs.LG]
- et al. (2022f) M. Nagaraj et al. 2022f. DOTIE - Detecting Objects through Temporal Isolation of Events using a Spiking Architecture. arXiv:2210.00975 [cs.CV]
- et al. (2020c) N. Messikommer et al. 2020c. Event-based Asynchronous Sparse Convolutional Networks. ECCV.
- et al. (2008) P. Lichtsteiner et al. 2008. A 128 128 120 dB 15 s Latency Asynchronous Temporal Contrast Vision Sensor. IEEE JSSC 43, 2 (2008), 566–576.
- et al. (2023b) S. Biswas et al. 2023b. HALSIE: Hybrid Approach to Learning Segmentation by Simultaneously Exploiting Image and Event Modalities. arXiv:2211.10754 [cs.CV]
- et al. (2022g) S. Kao et al. 2022g. MAGMA: An Optimization Framework for Mapping Multiple DNNs on Multiple Accelerator Cores. In 2022 HPCA. Los Alamitos, CA, USA, 814–830.
- et al. (2023c) S. Zheng et al. 2023c. Memory and Computation Coordinated Mapping of DNNs onto Complex Heterogeneous SoC. In 2023 DAC. 1–6.
- et al. (2022h) X. Zhang et al. 2022h. H2H: Heterogeneous Model to Heterogeneous System Mapping with Computation and Communication Awareness. In 2022 DAC. 601–606.
- Platforms (2021) NVIDIA Jetson Platforms. 2021. https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/
- TensorRT (2021) NVIDIA TensorRT. 2021. https://developer.nvidia.com/tensorrt