EucliDreamer: Fast and High-Quality Texturing for 3D Models with Depth-Conditioned Stable Diffusion
Abstract
We present EucliDreamer [17], a simple and effective method to generate textures for 3D models given text prompts and meshes. The texture is parametrized as an implicit function on the 3D surface, which is optimized with the Score Distillation Sampling (SDS) process [22] and differentiable rendering [16]. To generate high-quality textures, we leverage a depth-conditioned Stable Diffusion [26] model guided by the depth image rendered from the mesh. We test our approach on 3D models in Objaverse [4] and conducted a user study, which shows its superior quality compared to existing texturing methods like Text2Tex. In addition, our method converges 2 times faster than DreamFusion. Through text prompting, textures of diverse art styles can be produced. We hope Euclidreamer proides a viable solution to automate a labor-intensive stage in 3D content creation.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1fd1c05-814f-4c29-a995-f756715144e8/cover.png)
1 Method
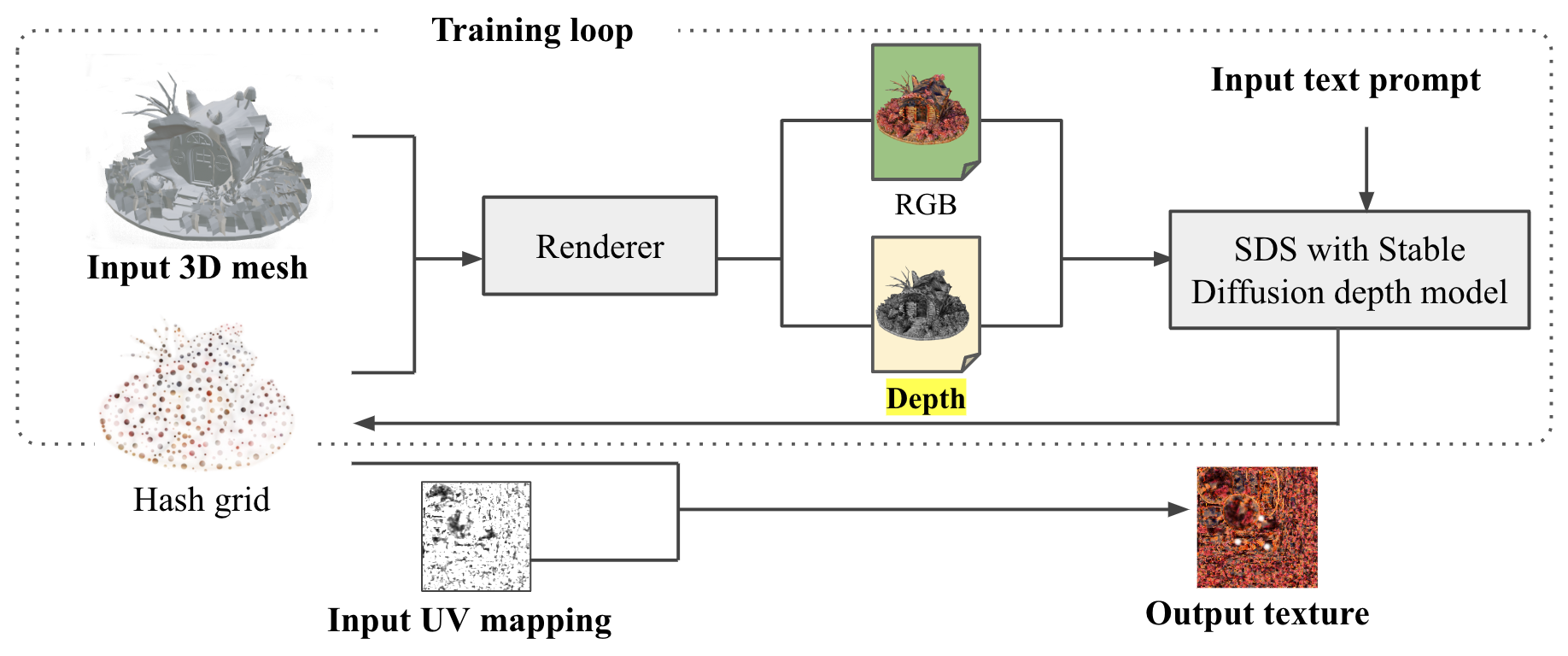
Our method is illustrated in Figure 2. Given a 3D mesh, we represent its texture as an implicit function defined on its surface - an MLP mapping from 2D coordinates on the surface to RGB color values, resembling a NeRF [19]. For compact representation and faster inference, hash grid [21] is adopted in our implementation.
During training, the parameterized texture is optimized to encode a high-quality texture corresponding to a text prompt. Inspired by DreamFusion [22], we acquire supervision signal from a high-capacity text-to-image diffusion model, such as Stable Diffusion. Specifically, the texture is randomly initialized in the beginning. In each training step, 2D images of the textured mesh are produced by a differentiable renderer from random view points, and are iteratively refined via the score distillation sampling (SDS) process by the text-to-image diffusion model. The SDS loss backprops to the MLP through the differentiable renderer.
To improve texture quality and speed-up convergence, we introduce additional depth conditioning for the text-to-image diffusion model, as depth information removes a lot of ambiguities, and helps enhance cross-view consistency. To this end, we leverage a version of Stable Diffusion model that conditions on a depth image 111https://huggingface.co/stabilityai/stable-diffusion-2-depth in addition to text. During training, the depth image is acquired by rendering from the 3D mesh.
When the optimization completes, the texture can be exported by querying each point on the 3D surface. It is then stored as a 2D image and a UV map, suitable for further rendering or editing with ease.
2 Experiment
We use 3D models from Objaverse [4] (a large open-sourced dataset of objects with 800K+ textured models with descriptive captions and tags) to test our approach.
For the main experiments, we run EucliDreamer on a set of 3D meshes from Objaverse. Qualitatively, we compare EucliDreamer visually with other 3D texturing methods, including Text2Tex [3], CLIPMesh [20], and Latent-Paint [18]. Quantitatively, we conduct a user study involving 28 professionals in 3D content creation. They are asked to rank the textures generated by different methods in terms of quality.
Additionally, we demonstrate that EucliDreamer can easily generate diverse art styles for the same object via text prompting. Due to page limit, these results are shown in Figure 8 in supplementary materials.
The hyperparameters of the system is selected to optimize the generation quality. Due to page limit, the detailed study of the effect of these parameters and other implementation details can be found in Supplementary Materials 6. For all experiments, we use concise text prompts to specify the content and style, e.g. ”3D rendering of a [description of the object], realistic, high-quality”.

3 Results
3.1 Visual Benchmark on Objaverse Models
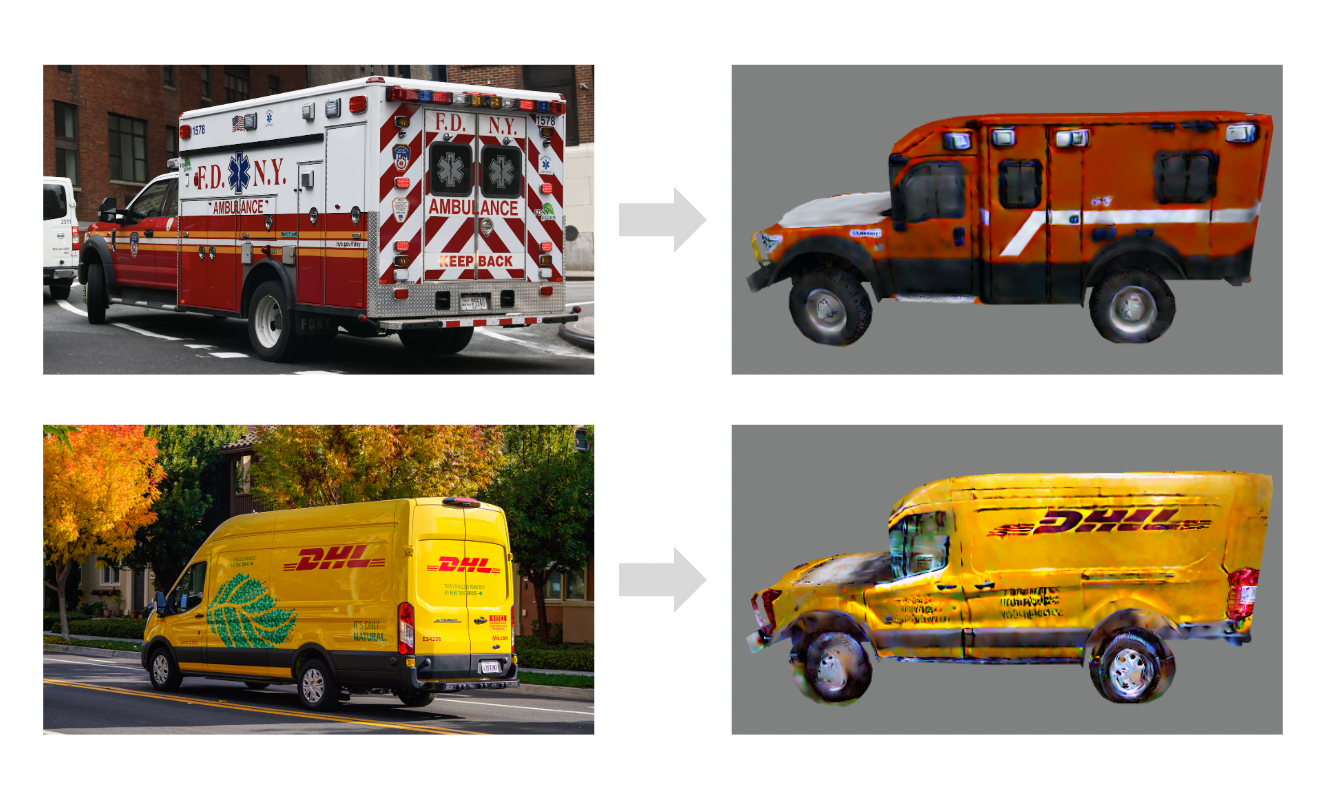
Figure 3 shows some qualitative results. Overall, the generated textures are of superior quality in terms of the realism, the level of detail, cross-view consistency and aesthetics. Notice on the dumpster model, EucliDreamer even accurately captured the specular pattern of the metallic material, a special trait resembling texture baking. For the compass model, not only the coloring is realistic, it also accurately recovers the details such as the characters and the small decorations on the rim.
3.2 User Study on Generation Quality
We invited 28 participants for the user study who are professionals in game industry and 3D content creation, including engineers, researchers and artist. Most of them are experienced with the 3D modeling workflow and downstream applications, thus we expect them to be decent critics of generation quality.
In the study, we present four sets of textured objects: an ambulance, a dumpster, a compass, and a backpack, via online questionnaires. Each set contains four textures generated by CLIPMesh, Latent-Paint, Text2Tex [3], and our method. The participants are asked to rank the results in terms of generation quality, taking into account correctness, fidelity, level of detail and overall aesthetics.
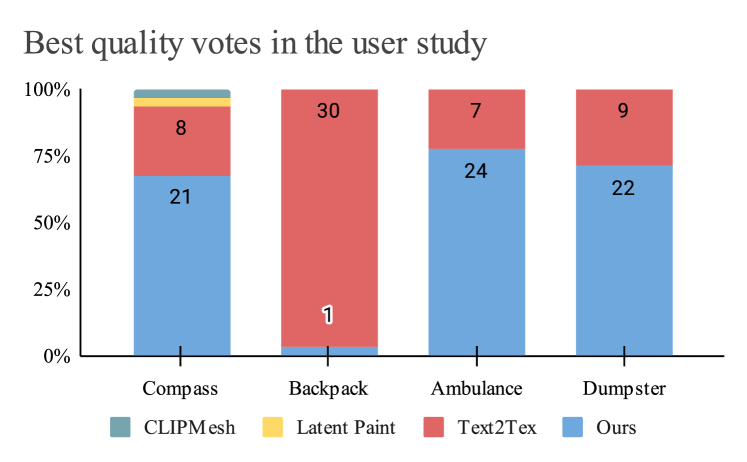
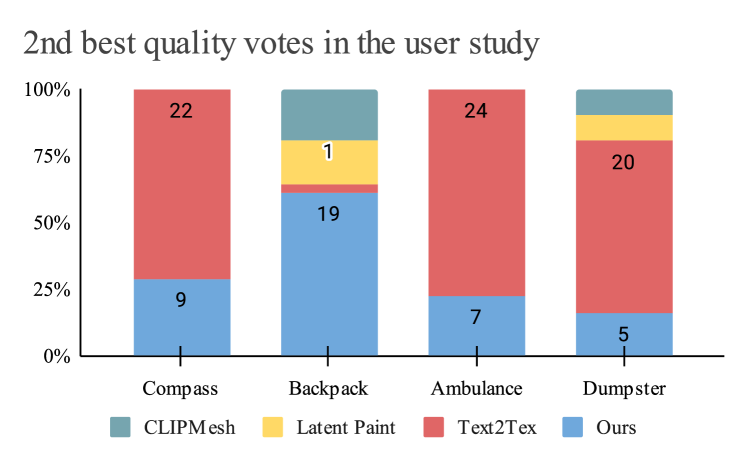
The results are shown in Figure 5 and 5. Most participants selected their top 2 choices from either SOTA Text2Tex [3] or ours. For the ambulance and dumpster objects, the votes are unanimously toward our generated textures. For the compass, about two-thirds voted for ours. The votes for the backpack are diverse for the second-best quality object.
Overall, the study indicates a high acceptance of the textures generated by our model.
3.3 Convergence Speed
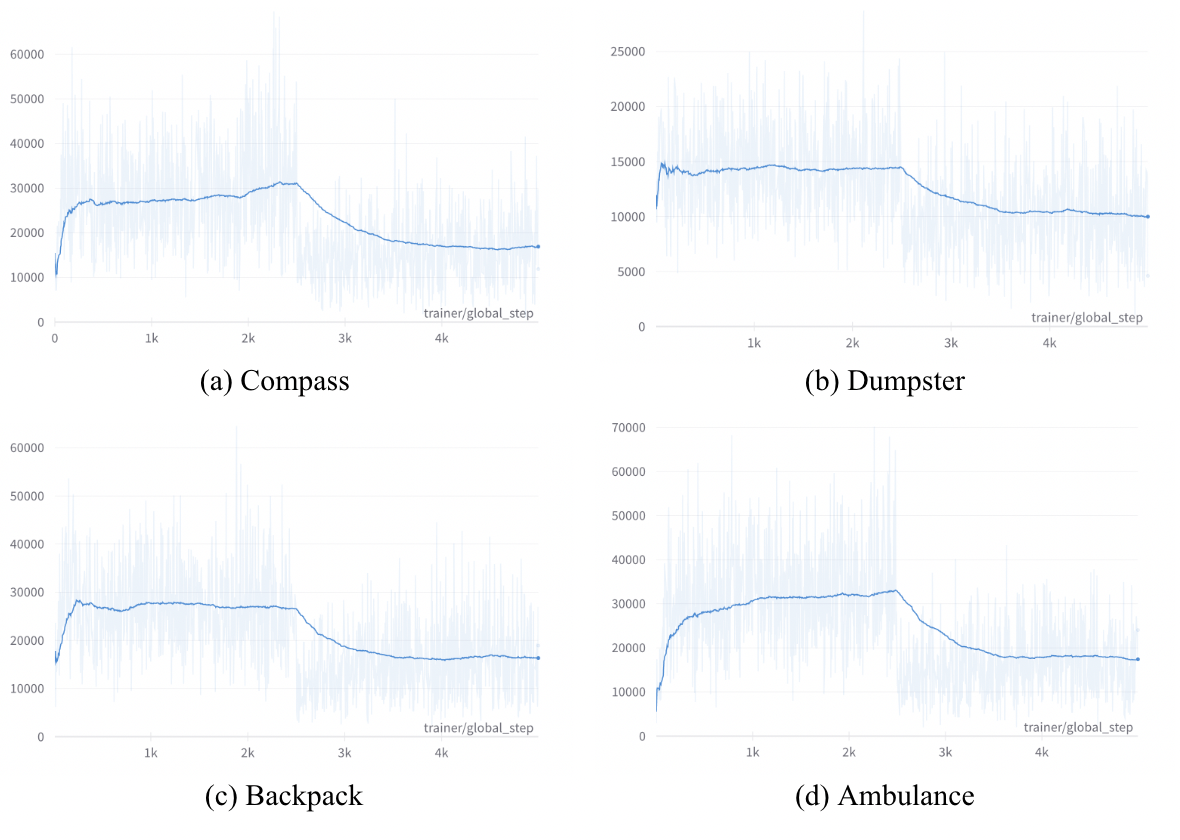
Figure 6 shows the SDS loss throughout the training steps. In general, it takes EucliDreamer around 4300 steps to converge the loss. Note that for all 4 objects being tested, most progress is already made before 2500 steps. In contrast, under identical experimental conditions and using the same set of hyperparameters, DreamFusion [22] requires over 10,000 steps to converge. Thus, the runtime of EucliDreamer is about half of that of DreamFusion. This comparison highlights the superior convergence speed and computational efficiency of our method.
3.4 Importance of Depth Conditioning
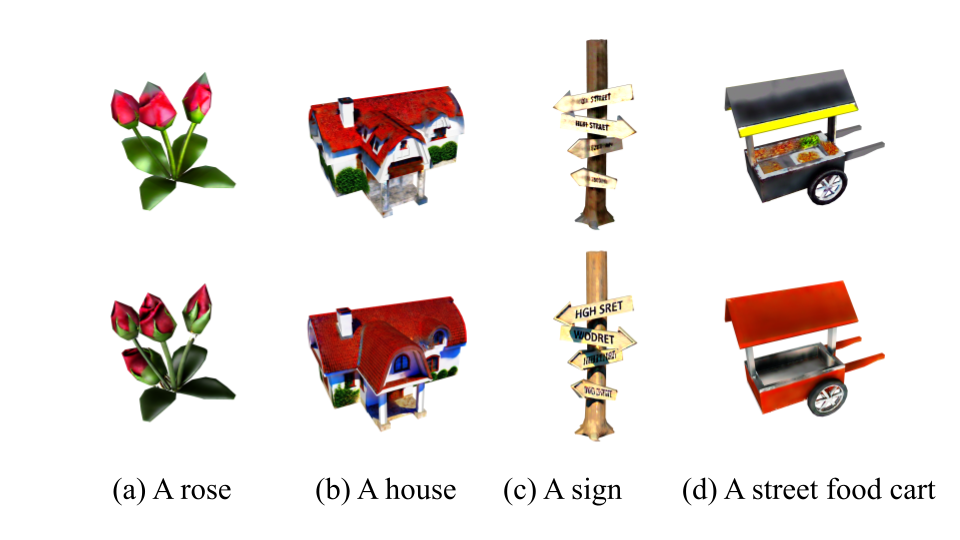
Figure 7 compares the texturing results on 4 models with and without depth-conditioning. We observe that depth-conditioning is especially helpful for ensuring correctness. For instance, without depth information, windows can show up on the roof of the house, and food texture can incorrectly appear on the wall of the food cart container. In addition, depth-conditioning seems to improve the detail quality and texture sharpness. This might due to that it removes a lot of ambiguities and prevents many modes from mixing together.
3.5 Various Art Styles
Our second set of experiments focuses on the diversity of the generated textures. By providing input text prompts of the model content and styles, one can use EucliDreamer to generate 3D textures for a given 3D mesh in certain styles. For example, a prompt of ”a building, damaged, dirty, 3D rendering, high-quality, realistic” will give the building model a rusty and pale feeling, as shown in Figure 8 in Supplementary Materials. Through simply alternating the text prompts, EucliDreamer can provide diverse combinations of color tones, brush strokes, lighting and shadows in the textures, which highlights its flexibility and ”creativity”.
4 Discussion
Through the experiments, we have proved that our method using depth-conditioned Stable Diffusion can generate higher-quality textures in a shorter time. This is as expected, for the following reasons:
In terms of quality, depth information further restricts the probability density on top of the text prompts, eliminating unnatural or physically impossible cases. In some cases, without the depth guidance, the model may generate a texture for a human character with multiple faces, or a tree with leaf textures on where is supposed to be the stem.
In terms of generation time, the time it takes for our method to convergence is shorter for two reasons. First, depth conditioning serves as a constraint that eliminates many possibilities, preventing the ”back and forth” between different modes. Second, we define the implicit function representing the texture such that it sticks to the surface of the object. Both led to a smaller probability space that takes less time to search.
More complex methods exist to address the mode collapse problem and enhance texture quality, e.g. using VSD [32] instead of SDS. However, as shown in our study in Supplementary Materials, for generating textures, using depth conditioning achieves comparable quality while being much simpler.
4.1 Limitations and Future Works
Our method, like many other SDS-based methods, requires that all surfaces of an object to be visible from some angles. Therefore, it may encounter issues with extremely complex structures with holes or obstructions. This might be mitigated by splitting the model into parts.
Also, as our method relies on text-to-image diffusion models that were trained to produce realistic natural images, which may produce ”baked-in” effects into the texture, such as shadows and highlights. This may be undesirable for use cases that requires re-lightable 3D assets. As a future work, a possible solution is to fine-tune a Stable Diffusion variant that produces images with flat lighting style.
4.2 Conclusion
We present a simple and effective solution for automatically generating textures for 3D meshes. High-quality texturing is one of the labor-intensive stages in 3D modeling workflow, which can take an experienced artist many days to complete for a single object. We hope our method can reduce the cost for preparing 3D assets in applications like gaming, animation, virtual reality [33, 15, 9] or even synthetic training data [29, 23, 12] for computer vision models [13, 28, 11, 6], and inspire further research in this direction.
References
- An et al. [2023] Sizhe An, Hongyi Xu, Yichun Shi, Guoxian Song, Umit Ogras, and Linjie Luo. Panohead: Geometry-aware 3d full-head synthesis in 360∘, 2023.
- Armandpour et al. [2023] Mohammadreza Armandpour, Ali Sadeghian, Huangjie Zheng, Amir Sadeghian, and Mingyuan Zhou. Re-imagine the negative prompt algorithm: Transform 2d diffusion into 3d, alleviate janus problem and beyond, 2023.
- Chen et al. [2023] Dave Zhenyu Chen, Yawar Siddiqui, Hsin-Ying Lee, Sergey Tulyakov, and Matthias Nießner. Text2tex: Text-driven texture synthesis via diffusion models, 2023.
- Deitke et al. [2022] Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects, 2022.
- Fuji Tsang et al. [2022] Clement Fuji Tsang, Maria Shugrina, Jean Francois Lafleche, Towaki Takikawa, Jiehan Wang, Charles Loop, Wenzheng Chen, Krishna Murthy Jatavallabhula, Edward Smith, Artem Rozantsev, Or Perel, Tianchang Shen, Jun Gao, Sanja Fidler, Gavriel State, Jason Gorski, Tommy Xiang, Jianing Li, Michael Li, and Rev Lebaredian. Kaolin: A pytorch library for accelerating 3d deep learning research. https://github.com/NVIDIAGameWorks/kaolin, 2022.
- He et al. [2019] Yihui He, Jianing Qian, Jianren Wang, Cindy X Le, Congrui Hetang, Qi Lyu, Wenping Wang, and Tianwei Yue. Depth-wise decomposition for accelerating separable convolutions in efficient convolutional neural networks. arXiv preprint arXiv:1910.09455, 2019.
- Hertz et al. [2023] Amir Hertz, Kfir Aberman, and Daniel Cohen-Or. Delta denoising score, 2023.
- Hetang [2022] Congrui Hetang. Autonomous path generation with path optimization, 2022. US Patent App. 17/349,450.
- Hetang and Wang [2023] Congrui Hetang and Yuping Wang. Novel view synthesis from a single rgbd image for indoor scenes. In 2023 International Conference on Image Processing, Computer Vision and Machine Learning (ICICML), pages 447–450. IEEE, 2023.
- Hetang and Zhang [2023] Congrui Hetang and Ningshan Zhang. Autonomous vehicle driving path label generation for machine learning models, 2023. US Patent App. 17/740,215.
- Hetang et al. [2017] Congrui Hetang, Hongwei Qin, Shaohui Liu, and Junjie Yan. Impression network for video object detection. arXiv preprint arXiv:1712.05896, 2017.
- Hetang et al. [2022] Congrui Hetang, Yi Shen, Youjie Zhou, and Jiyang Gao. Implementing synthetic scenes for autonomous vehicles, 2022. US Patent App. 17/349,489.
- Hetang et al. [2024] Congrui Hetang, Haoru Xue, Cindy Le, Tianwei Yue, Wenping Wang, and Yihui He. Segment anything model for road network graph extraction. arXiv preprint arXiv:2403.16051, 2024.
- Hong et al. [2023] Susung Hong, Donghoon Ahn, and Seungryong Kim. Debiasing scores and prompts of 2d diffusion for robust text-to-3d generation. arXiv preprint arXiv:2303.15413, 2023.
- Joo et al. [2018] Hanbyul Joo, Tomas Simon, and Yaser Sheikh. Total capture: A 3d deformation model for tracking faces, hands, and bodies. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 8320–8329, 2018.
- Laine et al. [2020] Samuli Laine, Janne Hellsten, Tero Karras, Yeongho Seol, Jaakko Lehtinen, and Timo Aila. Modular primitives for high-performance differentiable rendering. ACM Transactions on Graphics (ToG), 39(6):1–14, 2020.
- Le et al. [2023] Cindy Le, Congrui Hetang, Ang Cao, and Yihui He. Euclidreamer: Fast and high-quality texturing for 3d models with stable diffusion depth. arXiv preprint arXiv:2311.15573, 2023.
- Metzer et al. [2022] Gal Metzer, Elad Richardson, Or Patashnik, Raja Giryes, and Daniel Cohen-Or. Latent-nerf for shape-guided generation of 3d shapes and textures, 2022.
- Mildenhall et al. [2020] Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis, 2020.
- Mohammad Khalid et al. [2022] Nasir Mohammad Khalid, Tianhao Xie, Eugene Belilovsky, and Tiberiu Popa. Clip-mesh: Generating textured meshes from text using pretrained image-text models. In SIGGRAPH Asia 2022 Conference Papers. ACM, 2022.
- Müller et al. [2022] Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. Instant neural graphics primitives with a multiresolution hash encoding. ACM Trans. Graph., 41(4):102:1–102:15, 2022.
- Poole et al. [2022] Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion, 2022.
- Qiu et al. [2021] Haibo Qiu, Baosheng Yu, Dihong Gong, Zhifeng Li, Wei Liu, and Dacheng Tao. Synface: Face recognition with synthetic data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10880–10890, 2021.
- Raj et al. [2023] Amit Raj, Srinivas Kaza, Ben Poole, Michael Niemeyer, Nataniel Ruiz, Ben Mildenhall, Shiran Zada, Kfir Aberman, Michael Rubinstein, Jonathan Barron, Yuanzhen Li, and Varun Jampani. Dreambooth3d: Subject-driven text-to-3d generation, 2023.
- Ravi et al. [2020] Nikhila Ravi, Jeremy Reizenstein, David Novotny, Taylor Gordon, Wan-Yen Lo, Justin Johnson, and Georgia Gkioxari. Accelerating 3d deep learning with pytorch3d, 2020.
- Rombach et al. [2022] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, 2022.
- Sella et al. [2023] Etai Sella, Gal Fiebelman, Peter Hedman, and Hadar Averbuch-Elor. Vox-e: Text-guided voxel editing of 3d objects, 2023.
- Song et al. [2018] Guanglu Song, Biao Leng, Yu Liu, Congrui Hetang, and Shaofan Cai. Region-based quality estimation network for large-scale person re-identification. In Proceedings of the AAAI conference on artificial intelligence, 2018.
- Song et al. [2023] Zhihang Song, Zimin He, Xingyu Li, Qiming Ma, Ruibo Ming, Zhiqi Mao, Huaxin Pei, Lihui Peng, Jianming Hu, Danya Yao, et al. Synthetic datasets for autonomous driving: A survey. IEEE Transactions on Intelligent Vehicles, 2023.
- Tangcongrui and Hongwei [2021] HE Tangcongrui and QIN Hongwei. Methods and apparatuses for recognizing video and training, electronic device and medium, 2021. US Patent 10,909,380.
- Thibaux et al. [2023] Romain Thibaux, David Harrison Silver, and Congrui Hetang. Stop location change detection, 2023. US Patent 11,749,000.
- Wang et al. [2023] Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation, 2023.
- Wu et al. [2014] Chenglei Wu, Michael Zollhöfer, Matthias Nießner, Marc Stamminger, Shahram Izadi, and Christian Theobalt. Real-time shading-based refinement for consumer depth cameras. ACM Transactions on Graphics (ToG), 33(6):1–10, 2014.
- Yue et al. [2023] Tianwei Yue, Wenping Wang, Chen Liang, Dachi Chen, Congrui Hetang, and Xuewei Wang. Coreference resolution helps visual dialogs to focus. High-Confidence Computing, page 100184, 2023.
- Zhang et al. [2023a] Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models, 2023a.
- Zhang et al. [2023b] Longxiang Zhang, Wenping Wang, Y Keyi, Jingxian Huang, Qi Lyu, et al. Sliding-bert: Striding towards conversational machine comprehension in long contex. Adv Artif Intell Mach Learn, 2023b.
- Zhou et al. [2023] Zhihao Zhou, Tianwei Yue, Chen Liang, Xiaoyu Bai, Dachi Chen, Congrui Hetang, and Wenping Wang. Unlocking everyday wisdom: Enhancing machine comprehension with script knowledge integration. Applied Sciences, 13(16):9461, 2023.
Supplementary Material
5 Implementation details
To better demonstrate our approach and reproduce our results, we will publish our code on GitHub upon acceptance.
5.1 Parameter selection
For the main experiment, we selected the following parameters that performed the best in 2. The Adam optimizer has a learning rate of 0.01.
| Parameter | Value |
|---|---|
| Batch size | 8 |
| Camera distance | [1.0, 1.5] |
| Elevation range | [10, 80] |
| Sampling step | [0.02, 0.98] |
| Optimizer | Adam |
| Training steps | 5000 |
| Guidance scale | 100 |
The prompt keywords below are added in addition to the original phrase of the object (e.g. “a compass”).
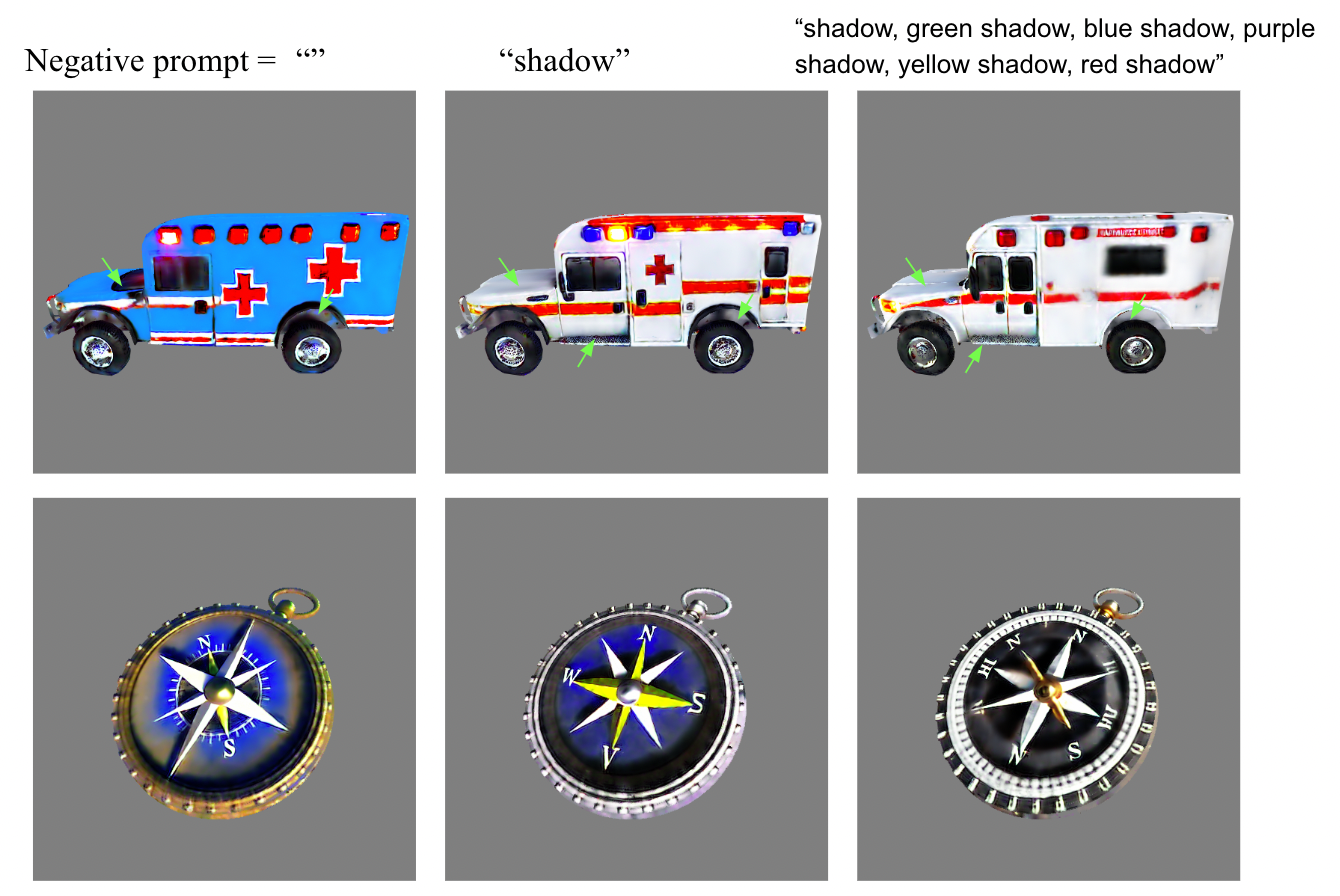
prompt: "animal crossing style, a house, cute, Cartoon, 3D rendering, red tile roof, cobblestone exterior" negative_prompt: "shadow, greenshadow, blue shadow, purple shadow, yellow shadow"
The texture resolution is set to 512*512.
5.2 Infrastructure
ThreeStudio
(https://github.com/threestudio-project/threestudio)
is a unified framework for 3D modeling and texturing from various input formats including text prompts, images, and 3D meshes. It provides a Gradio backend with easy-to-use frontend with input configurations and output demonstration.
We forked the framework and added our approach with depth conditioning. A depth mask is added to encode the depth information.
with torch.no_grad():
depth_mask =
self.pipe.prepare_depth_map(
torch.zeros((batch_size, 3,
self.cfg.resolution,
self.cfg.resolution)),
depth_map,
batch_size=batch_size,
do_classifier_free_guidance=True,
dtype=rgb_BCHW.dtype,
device=rgb_BCHW.device,
)
5.3 Hardware
We used a Nvidia RTX 4090 GPU with 24GB memory. This allows us to run experiments with a batch size up to 8 and dimension 512*512. In theory, a GPU with more memory will allow us to generate textures with higher definition and in better quality.
6 More results from Ablation Studies
Due to the page limit, we show experimental results of elevation range (section 6.3), batch size (section 5.1), guidance scale (section 6.8), negative prompts (section 6.9), and data augmentation (section 6.10) here. The results support our conclusions in the Ablation Studies section 2.
For model understanding and parameter selection, we conduct a series of experiments for EucliDreamer with different settings.

6.1 SDS vs. VSD
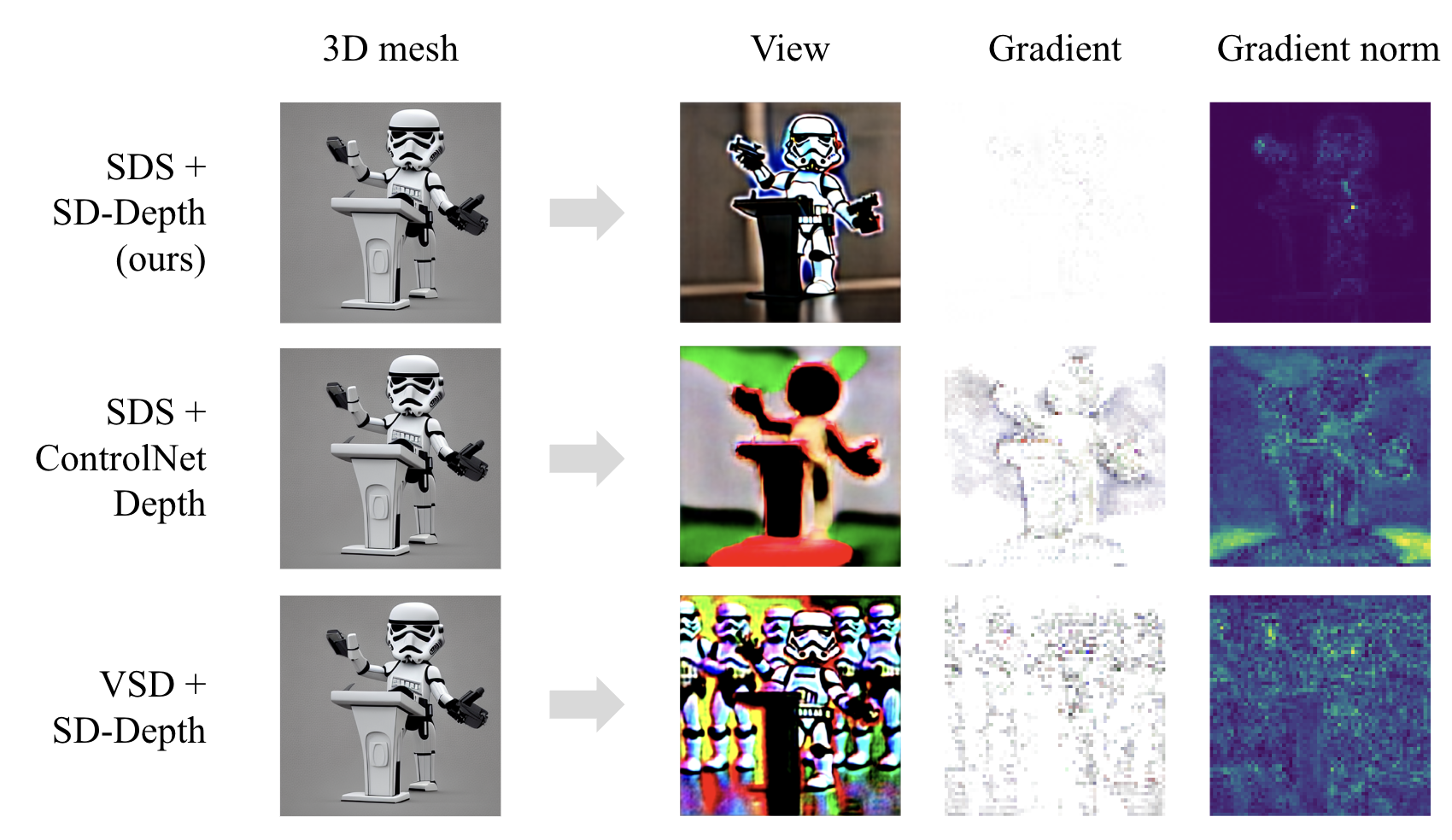
SDS [22] is notoriously known for its lack of diversity and overly smoothed texture. This is because SDS is mean-seeking. Intuitively, a single prompt has multiple plausible generation results. SDS tends to create an average of them (mean seeking). Variational Score Distillation (VSD) is proposed in ProlificDreamer [32] to mitigate this problem by introducing a variational score that encourages diversity. However, in depth-conditioned texturing, there are fewer plausible generation results given a single prompt and depth. This leads to the diversity and details in our approach (mode seeking), even though VSD is not used. Through experiments shown in Figure 9, our approach produces better results without VSD. Thus VSD in ProlificDreamer [32] is not required when Stable Diffusion depth is used.
6.2 StableDiffusion depth vs. ControlNet depth
The most straightforward way of depth-conditioned SDS is to use ControlNet [35]. However, empirically we found that the SDS gradient from ControlNet [35] is much noisier than SD-depth. SD-depth concatenates depth with latents. The SDS gradients flow to depth and latents separately, which is less noisy. As shown in Figure 9, we demonstrate better generation results with Stable Diffusion depth than ControlNet depth.
6.3 Elevation range
Elevation range defines camera positions and angles at the view generation step. When it is set between 0-90 degrees, cameras face down and have an overhead view of the object. We find that fixed-angle cameras may have limitations and may miss certain angles, resulting in blurry color chunks at the surface of the object. One way to leverage the parameter is to randomize camera positions so all angles are covered to a fair level.
6.4 Sampling min and max timesteps
The sampling min and max timesteps refer to the percentage range (min and max value) of the random timesteps to add noise and denoise during SDS process. The minimum timestep sets the minimum noise scale. It affects the level of detail of the generated texture. The maximum timestep affects how drastic the texture change on each iteration or how fast it converges. While their values may affect quality and convergence time, no apparent differences were observed between different value pairs of sampling steps. In general, 0 and 1 should be avoided for the parameters.
6.5 Learning Rate
In the context of 3D texture generation, a large learning rate usually leads to faster convergence. A small learning rate creates fine-grained details. We found learning rate of 0.01 with the Adam optimizer is good for 3D texture generation.
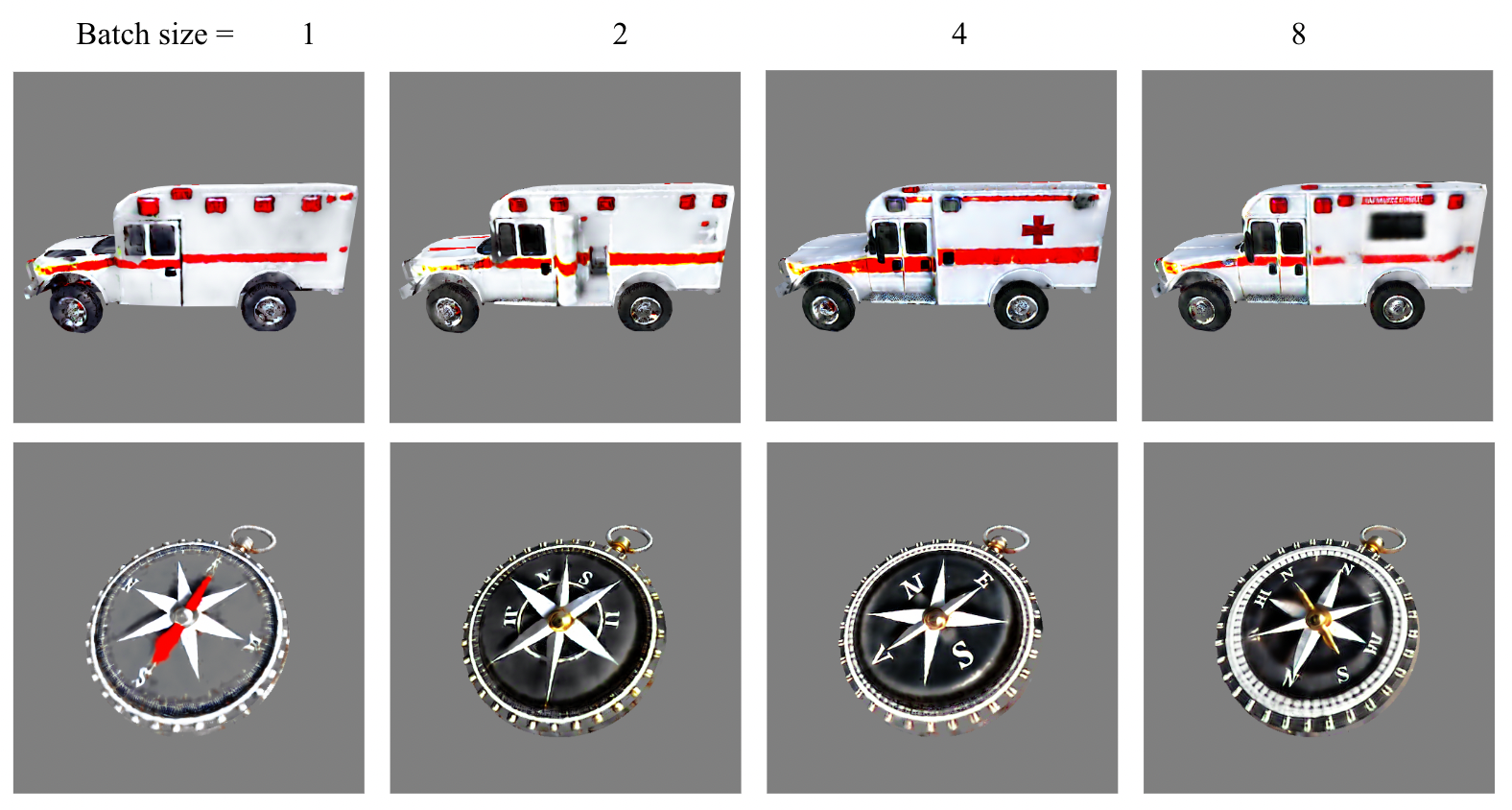
6.6 Batch Size
We set batch sizes to 1, 2, 4, and 8 respectively. Results show that a larger batch size leads to more visual details and reduces excessive light reflections and shadows. More importantly, large batch size increases view consistency. This is because gradients from multiple views are averaged together and the texture is updated once. A batch size of 8 is enough from our observation. A batch size of more than 8 does not lead to a significant reduction in the number of iteration steps.
6.7 With vs. without gradient clipping
Intuitively gradient clipping can avoid some abnormal updates and mitigate the Janus problem, shown in Debiased Score Distillation Sampling (D-SDS) [14]. In the context of texture generation, we do not observe Janus problem due to the fact that the mesh is fixed. In our experiments, there’s no noticeable benefit of gradient clipping.
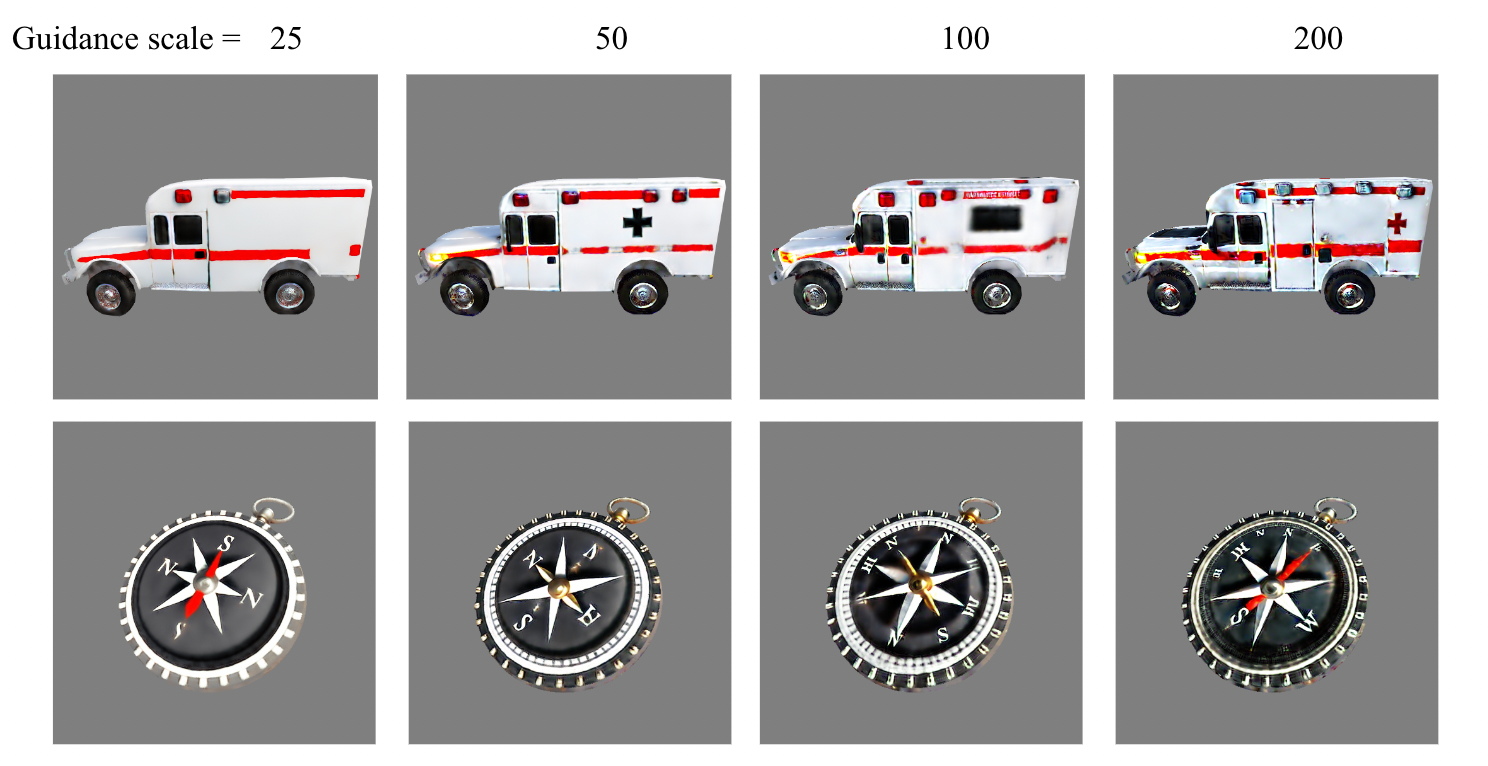
6.8 Guidance scale
The guidance scale specifies how close the texture should be generated based on input text prompts. We find that the guidance scale affects diversity and saturation. Even with the depth conditional diffusion model, a high guidance scale like 100 is still required.
6.9 Negative prompts
Negative prompts in Stable Diffusion can fix some artifacts caused by SDS. Adding negative prompts like ”shadow, green shadow, blue shadow, purple shadow, yellow shadow” will help with excessive shadows.
6.10 Data augmentation
We found that adjusting the camera distance can improve both resolution and generation quality. We experimented with three different ranges of camera distance, shown in Figure 10. The distance range of [1.5, 2.0] produces the optimal outcomes regarding the quality of textures and colors. This can be attributed to its ability to simulate viewpoints most representative of conventional photography, similar to the usual perspectives from which an ambulance is observed.

6.11 Image-to-texture using Dreambooth3D
Dreambooth3D [24] was initially proposed as an extension of DreamFusion [22] to enable image-to-3D shape generation. We partially finetuned Stable Diffusion depth with the user-provided image(s), generated textures with finetuned stable-diffusion-depth from step 1, fine-tuned Stable Diffusion depth again with outputs from step 2, and then generated final results with finetuned stable-diffusion-depth from step 3. Shown in Figure 11, combined with Dreambooth3D [24], our approach generates satisfactory textures given a 3D mesh and a single image as inputs.