arxiv \excludeversionsubmission
Espresso: Robust Concept Filtering in Text-to-Image Models
Abstract.
Diffusion based text-to-image models are trained on large datasets scraped from the Internet, potentially containing unacceptable concepts (e.g., copyright-infringing or unsafe). We need concept removal techniques (CRTs) which are i) effectivein preventing the generation of images with unacceptable concepts ii) utility-preservingon acceptable concepts, and iii) robustagainst evasion with adversarial prompts. No prior CRT satisfies all these requirements simultaneously. We introduce Espresso, the first robust concept filter based on Contrastive Language-Image Pre-Training (CLIP). We identify unacceptable concepts by using the distance between the embedding of a generated image to the text embeddings of both unacceptable and acceptable concepts. This lets us fine-tune for robustness by separating the text embeddings of unacceptable and acceptable concepts while preserving utility. We present a pipeline to evaluate various CRTs to show that Espresso is more effective and robust than prior CRTs, while retaining utility.
1. Introduction
Diffusion-based text-to-image (T2I) models have demonstrated a remarkable ability to generate high quality images from textual prompts (stable-diffusion; Rombach_2022_CVPR; ramesh2021dalle). They are trained on large datasets of unfiltered content from the Internet (radford2021learning; schuhmann2022laion). Due to their large capacity, T2I models memorize specific concepts, as seen in the generated images (Korn_2023; somepalli2022diffusion; carlini2023extracting). Some of these concepts, may be unacceptable for various reasons, such as copyright infringement (e.g., a movie character or celebrity), or inappropriateness (e.g., “nudity” or “violence”) (gandikota2023erasing; schramowski2022safe; heng2023selective). We need concept removal techniques (CRTs) to minimize unacceptable concepts in generated images.
Ideally, CRTs should be effective in reducing generation of unacceptable concepts while preserving utility on all others, and robust to evasion with adversarial prompts. No existing CRT simultaneously satisfies these requirements (§ 6): i) fine-tuning CRTswhich modify T2I models, trade-off effectiveness for utility (gandikota2023erasing; kumari2023ablating; heng2023selective; schramowski2022safe), and lack robustness (Tsai2023RingABellHR; wen2023hard; pham2023circumventing; yang2023sneakyprompt) ii) filtering CRTs, which detect unacceptable concepts, lack robustness ((rando2022redteaming) and § 6.3). Our goal is to design a CRT that can simultaneously meet all the requirements.
We opt to use a filter as it will not alter the T2I model, thus minimizing impact on utility. We construct our filter using a Contrastive Language-Image Pre-Training (CLIP) model (radford2021learning), an essential component of T2I models. CLIP is pre-trained on a vast dataset encompassing a broad spectrum of concepts (radford2021learning), making it a versatile choice for a filter, unlike specialized classifiers (e.g., (unsafeDiff)). However, a naive CLIP-based filter is susceptible to evasion (rando2022redteaming). {arxiv} Subsequently, prior works have identified the design of a robust filtering-based CRT as an open problem (rando2022redteaming; li2024safegen).
We present a robust content filter, Espresso, by configuring CLIP to identify unacceptable concepts in generated images using the distance of their embeddings to the text embeddings of both unacceptable and acceptable concepts. This allows fine-tuning to improve robustness by increasing the separation between the text embeddings of unacceptable and acceptable concepts, while preserving utility by maintaining the closeness between embeddings of prompts and their images. Our contributions are presenting
-
(1)
Espresso 111We will open-source the code upon publication., the first robust content filter (§ 4), which identifies unacceptable concepts in generated images by measuring the distance of their embeddings to the text embeddings of both unacceptable and acceptable concepts
-
(2)
a complete pipeline for comparative evaluation of CRTs and attacks, (§ 5), and
-
(3)
a comprehensive evaluation of Espresso against seven fine-tuning CRTs, and one filtering CRT, showing that it is more effective and robust while retaining utility (§ 6).
In § 7 and Appendix A, we present the first approach for certifiable robustness of CRTs, exploring theoretical robustness bounds of Espresso against a hypothetically strong adversary. We analyze these bounds to show that Espresso is more robust in practice.
2. Background
2.1. Diffusion based T2I Models
A diffusion based T2I model is a function which generates an image for a given a textual prompt p. It comprises two key components: an encoder () which is used to incorporate the textual prompt in the image generation process, and a diffusion model () which is responsible for the generation of the image.
A popular encoder is CLIP, trained on a large dataset of image-text pairs, to map the embeddings of images and their corresponding text closer together in a joint text-image embedding space (radford2021learning). Given images and their corresponding text prompts , the training data is .
CLIP is trained to maximize the cosine similarity between the embeddings of a prompt and its corresponding image while minimizing the similarity between and any other for a . We denote the cosine similarity as cos(, where is the CLIP image embedding of the image , and is the CLIP text embedding of the prompt . To achieve this, CLIP is trained using a contrastive loss function (yang2023robust; oord2019representation):
where is the temperature parameter to scale predictions (radford2021learning; ModalityGap).
Given access to a pre-trained encoder , the actual images in T2I models are generated by a diffusion model, , parameterized by . During training of , Gaussian noise is added to an initial image for time steps to produce , in a process known as the forward diffusion process. The noise is then iteratively removed to approximate the initial image in the reverse diffusion process. During inference, the reverse diffusion process generates an image from noise. Further, can be conditioned with a textual prompt p to guide the generation of to match the description in p. After generating , is trained by minimizing the following loss function: for each time step , and random Gaussian noise .
Several prominent T2I models (e.g., Stable Diffusion v1.4 (SDv1.4)) improve the efficiency of the diffusion process by computing in the embedding space of a variational autoencoder (VAE), rather than on images (stable-diffusion). For a VAE decoder , VAE encoder , and as the latent representation of in the VAE’s latent space, is trained by minimizing the following objective:
where .
The final image is generated from the approximation, , by passing it through : .
We summarize notations in Table 1.
| Notation | Description |
|---|---|
| T2I | Text-to-Image |
| Text encoder (e.g., CLIP) | |
| CRT | Concept Removal Technique |
| Adversary | |
| Generated image | |
| Generated image with unacceptable concept | |
| Generated image with acceptable concept | |
| CLIP embedding for image | |
| Image generated from adversarial prompt | |
| p | Textual prompt |
| Phrase for acceptable concept | |
| Phrase for unacceptable concept | |
| Textual prompt containing | |
| Textual prompt containing | |
| CLIP embedding for textual prompt p | |
| Adversarially generated textual prompt | |
| Test dataset with acceptable prompts/images | |
| Test dataset with unacceptable prompts/images | |
| Validation dataset with acceptable prompts/images | |
| Validation dataset w/ unacceptable prompts/images | |
| Test dataset with adversarial prompts/images | |
| f | T2I model with CRT where f: |
| F | Function for Espresso classifier |
| Regularization parameter for Espresso fine-tuning | |
| Normalization function | |
| Diffusion model parameterized by | |
| Temperature parameter |
2.2. Concept Removal Techniques
The textual phrase for an acceptable concept is , and for an unacceptable concept is . For a given , is either the opposite (e.g., = violence vs. = peaceful) or a general category of a specific character/object/person (e.g., = R2D2 vs. = robot). We discuss the selection of for a given in § 5.3. An image generated from a T2I model may either contain an unacceptable concept (referred to as ) or an acceptable one (referred to as ). Similarly, a text prompt p may contain a phrase for an acceptable concept () or an unacceptable concept (). An example of an unacceptable prompt containing an unacceptable concept = Captain Marvel, is “Captain Marvel soaring through the sky”. CRTs thwart the generation of by either fine-tuning the T2I model to suppress , or using a classifier as a filter to detect , and serve a replacement image instead.
2.2.1. Fine-tuning CRTs:
We first present six state-of-the-art fine-tuning CRTs:
Concept Ablation (CA) (kumari2023ablating) fine-tunes the T2I model to minimize the KL divergence between the model’s output for and to force the generation of instead of . Formally, they optimize the following objective function:
where , , and is a time-dependent weight, and is the stop-gradient operation.
Forget-Me-Not (FMN) (zhang2023forgetmenot) minimizes the activation maps for by modifying ’s cross-attention layers. Further, fine-tuning , instead of just the cross-attention layers, results in degraded utility.
Selective Amnesia (SA) (heng2023selective) fine-tunes T2I models by adapting continuous learning techniques (elastic weight consolidation and generative replay) for T2I models to forget a concept. They optimize , the probability of generating given and , where are the frozen parameters of the original T2I model:
where is the Fisher information matrix over and , and are probabilities taken over the distributions of and respectively, and is a regularization parameter.
Erased Stable Diffusion (ESD) (gandikota2023erasing) fine-tunes the T2I model by modifying the reverse diffusion process to reduce the probability of generating :
where encourages the noise conditioned on to match the unconditioned noise.
Unified Concept Editing (UCE) (gandikota2023unified) fine-tunes the T2I model’s cross-attention layers to minimize the influence of , while keeping the remaining concepts unchanged. Their optimization is:
where , are the parameters of the fine-tuned and original cross-attention layers in , and are the space of pre-defined unacceptable and acceptable concepts, and is a set of concepts for which to preserve utility.
Safe diffusion (SDD) (kim2023towards) fine-tunes the T2I model by encouraging the diffusion model noise conditioned on to match the unconditioned noise, while minimizing the utility drop using the following objective function:
where and .
Moderator (Mod) (wang2024moderator) uses task vectors (ilharco2023editing) to remove the parameters responsible for generating while maintaining the parameters for acceptable concepts. Mod computes the task vector for the unacceptable parameters () and removes them from : where are the new parameters.
2.2.2. Filtering CRTs:
We now describe two filtering CRTs:
Stable Diffusion Filter (SD-Filter) (radford2021learning) is black-box and the design of the filter is not publicly available. However, Rando et. al. (rando2022redteaming) hypothesize that it involves computing the cosine similarity between the embeddings of a generated image, , and a pre-defined set of . If the cosine similarity is greater than some threshold (), then has . Formally, their filter can be described as
where , and denotes normalization. Here indicates and indicates . Note that varies with .
Unsafe Diffusion (UD) (unsafeDiff) is the current state-of-the-art filtering CRT and outperforms SD-Filter (unsafeDiff). UD trains a multi-headed neural network classifier on top of CLIP to identify where each head classifies different : nudity, violence, disturbing, hateful, and political. Their objective is given as where MLP is a multi-layer perceptron, and .
2.3. Evading Concept Removal Techniques
An adversary () may construct adversarial prompts () to evade CRTs and force a T2I model f to generate unacceptable images. We denote a dataset containing adversarial prompts and their corresponding images () as where ideally will contain . By default, we assume is aware of f using a CRT. Otherwise we label as naïve 222Some prior works refer to adversaries that take defenses into account as “adaptive”. In line with standard practice in security research, we assume that adversaries are aware of defenses by default. We use the term “naïve,” for adversaries who are not..
’s objective is to construct which can force a T2I model to output images with while being semantically closer to acceptable prompts so that is incorrectly identified as acceptable while triggering the generation of unacceptable images. The existing attacks construct as an optimization problem using some reference (or the difference between and ) as the ground truth. Different attacks vary in ways to solve this optimization. We present four state-of-the-art attacks below:
PEZ (wen2023hard) constructs by identifying text tokens by minimizing: .
RingBell (Tsai2023RingABellHR) identifies tokens for by first computing the average difference between the embedding vectors of and : from a set of prompts. Then, is computed by minimizing the distance of its text embedding to (, formulated as: where is an initial unacceptable prompt censored by a CRT, and solved using a genetic algorithm.
SneakyPrompt (yang2023sneakyprompt) uses reinforcement learning to construct specifically against filtering CRTs. It searches for tokens to update an initial prompt to form . The reward function is the cosine similarity between and . SneakyPrompt uses as for better effectiveness and faster convergence.
CCE (pham2023circumventing) uses textual-inversion to construct (gal2022textualinversionimage). updates CLIP’s vocabulary to include a new token “<s>” which, when included in , generates ’s desired image. To optimize <s>, we find , an embedding for <s>, corresponding to least mean-squared-error loss , where .
All of these attacks are naïve except for CCE and SneakyPrompt, which account for different fine-tuning CRTs. In § 5.1, we describe how we modify these naïve attacks to account for CRTs.
3. Problem Statement
We describe an adversary model, requirements of an ideal CRT, and limitations of prior works.
Adversary Model. We consider a deployed target T2I model (f) to which a client has blackbox access to send an input (p) and obtain a generated image (). Further, f uses some CRT. The goal of the adversary () is to force f to generate despite the presence of a CRT. We give an advantage to by allowing whitebox access to a local identical copy of f with the CRT for use in designing attacks. This is reasonable as and CLIP are publicly available. For filtering CRTs, we assume that has whitebox access to the filter to use its loss function in designing the attacks.
Requirements An ideal CRT should be: R1 Effectivein minimizing the generation of ; R2 Utility-preserving, maintaining the quality of acceptable images (for fine-tuning CRTs) or not blocking them (for filtering CRTs); and R3 Robustagainst evasion with .
Limitations of Prior Works. We summarize the limitations of prior works which are empirically evaluated later in § 6. Fine-tuning CRTs modify f thereby explicitly creating a trade-off between R1 and R2 (gandikota2023erasing; kumari2023ablating; zhang2023forgetmenot; heng2023selective; heng2023selective; gandikota2023unified; kim2023towards). Further, most of these CRTs do not consider R3 in their design and are susceptible to evasion by with . Filtering CRTs (radford2021learning; unsafeDiff) detect unacceptable concepts either in p (aka prompt filter) or in and block them (a.k.a image filter). Since, they do not modify f, they can maintain R2 without impacting R1. Prior filtering approaches may not be accurate in detecting unacceptable concepts (poor R1) (li2024safegen) and can be easily evaded (poor R3) ((rando2022redteaming) and § 6.3). The state-of-the-art filter, UD, trains specialized classifiers for each concept on large datasets, limiting its generalization to new concepts.
4. Espresso: Robust Filtering CRT
We present Espresso, a robust concept filtering CRT. Espresso uses a classifier F to detect unacceptable concepts in generated images. Following SDv1.4 (stable-diffusion), on detecting an unacceptable concept, Espresso outputs a replacement image (radford2021learning; rando2022redteaming). We identify CLIP as the natural choice for F as it is (a) pre-trained on a large dataset covering a wide range of concepts, and (b) used in many T2I models, and encodes similar information as seen in them. Hence, CLIP is a better choice for a filter than training specialized classifiers for each concept (e.g., (unsafeDiff)).
However, simply using CLIP as F is not sufficient as seen in SDv1.4’s filter () (radford2021learning). Recall from Section 2.2 (Filtering CRTs), thresholds the cosine similarity between the embeddings of and each pre-defined unacceptable concept to identify . Rando et al. (rando2022redteaming) evade by constructing adversarial prompts. Since uses only the cosine similarity to , is free to modify the prompt embeddings in any direction, while constructing . We address this in Espresso by configuring CLIP’s classification objective to allow for fine-tuning to improve robustness.
Configuring CLIP’s Classification Objective. Instead of using the cosine similarity to only as in , we configure the objective function of Espresso to use the cosine similarity to both and . Further, jointly optimizing for two embeddings yields better utility as observed in prior fine-tuning CRTs (kumari2023ablating; Tsai2023RingABellHR; gal2021stylegannada). Given , Espresso checks the cosine similarity of to and . Formally, we define Espresso as
| (1) |
where is the default temperature parameter used in CLIP.
Fine-tuning. The above configuration change lets us use fine-tuning to push acceptable and unacceptable concepts away from each other while maintaining their pairing with their corresponding image embeddings (for utility). Our fine-tuning objectives, inspired by adversarial training, aim to increase the distance between training data and the decision boundary to reduce the impact of adversarial examples (zhang2019theoretically). We use two different fine-tuning variants depending on the group of concepts.
For concepts that have a strong correlation between and the corresponding (for example, where is a broader category that includes ; = R2D2 and = robot), we fine-tune F to increase the difference between and . We minimize:
| (2) |
where denotes normalization. For the case where and are opposites (e.g., = violence and = peaceful), the above objective function might have a low correlation between and the corresponding , leading to poor utility. In this case, we use following objective function:
| (3) |
where , ,
, , , and , and are regularization hyperparameters. We assign equal weight to the loss terms, thus choosing .
The above objective function encourages the CLIP embeddings of and , and and , to be closer together while increasing the distance between and , and and , respectively.
We use prompts ( and ) for fine-tuning in Equations 2 and 3 instead of only concepts ( and ): and already contain and , and provide more context. During fine-tuning, there is a trade-off between R1 and R2 which is inherent to all other fine-tuning CRTs. We subject our fine-tuning to the constraint that achieved the highest effectiveness for the least drop in utility. In Section 6.1, we specify which of the fine-tuning objectives (Equation 2 or 3) are used for which concepts. We show the benefit of fine-tuning in § 6.1.
5. Experimental Setup
We describe the attack baselines against CRTs (§ 5.1), metrics (§ 5.2), and present a pipeline for evaluating CRTs (§ 5.3). We use SDv1.4 (stable-diffusion) and its default configuration as f following prior work (gandikota2023erasing; kumari2023ablating; zhang2023forgetmenot; heng2023selective; gandikota2023unified; kim2023towards). We compare Espresso with the seven fine-tuning and one filtering CRTs from § 2.2 (we leave out SD-Filter as UD outperforms it).
5.1. Revisiting Attack Baselines
We modify existing naïve attacks: RingBell, and PEZ, to account for CRTs (indicated with “+”). All CRTs use some variant of the following optimization: detach from p such that the generated image is far from and closer to some . On the other hand, attacks against T2I models design such that is closer to and far from . Hence, to design an effective attack which accounts for such CRTs, in addition to the attacks’ original objectives, we minimize the loss between and while increasing the loss between and . We modify the attacks using the following loss:
| (4) |
where {RingBell, PEZ } when CRT {CA, FMN, SA, ESD, UCE, SDD, UD, Espresso }, and is the attack’s original objective. We assign equal weight to all loss terms and use Recall from § 2.3 that CCE already accounts for different fine-tuning CRTs. For filtering CRTs (UD and Espresso), we modify CCE using Equation 4 and call it CCE +. Finally, typographic attack (noever2021typographicattck) against CLIP superimposes text characters onto an (unrelated) image to fool CLIP by forcing it to focus on the text instead of the image. We turn this into an attack against CRTs by superimposing at the bottom of . Using the resulting adversarial images, we use PEZ + to find their corresponding . We call this attack Typo +.

5.2. Metrics
We now describe the metrics to evaluate each of the requirements. We use a reference CLIP (SDv1.4), separate from f with the CRTs, following prior work (kumari2023ablating; gandikota2023erasing; gandikota2023unified; kim2023towards).
R1 (Effectiveness).
-
•
For fine-tuning CRTs, we use CLIP accuracy (hessel-etal-2021-clipscore; kumari2023ablating) which is the cosine similarity between the embeddings of the generated image with the embeddings of and from the reference CLIP. This gives the likelihood of predicting . Hence, CLIP accuracy should be low (ideally zero) for effective concept removal. Formally, it is:
where and are embeddings from the reference CLIP. For Espresso, if is detected, a replacement image is generated. Here, we calculate the CLIP accuracy on the final set of images after filtering. Since the metrics compare with the reference CLIP, we use the same default replacement image as in the SD v1.4.
-
•
For filtering CRTs, we use false negative rates (FNR) (unsafeDiff; rando2022redteaming) which is the fraction of images with which are not blocked. It should be low (ideally zero).
R2 (Utility).
-
•
For fine-tuning CRTs, we use normalized CLIP score which is the ratio of cosine similarity between and from f, to that from a reference CLIP as a baseline. Here, the baseline from a reference CLIP is assumed to have the maximum achievable CLIP score. Formally, we can write normalized CLIP score as . It should be high (ideally one) for high utility. This metric is different from standard CLIP scores from prior work (hessel-etal-2021-clipscore; kumari2023ablating; kim2023towards; gandikota2023unified) which only measures the cosine similarity between and . We did this to scale the CLIP score between zero and one while comparing f to the reference CLIP.
-
•
For filtering CRTs, we use False Positive Rates (FPR) (unsafeDiff; rando2022redteaming) which is the fraction of images without which are blocked. It should be low (ideally zero).
5.3. Pipeline for Evaluating CRTs
We now describe Figure 1 which includes identifying acceptable concepts (step 1), generation of datasets (step 2), training filters or fine-tuning T2I models with CRTs (step 3), validating acceptable concepts (step 4), and evaluating different CRTs (step 5).
Concept Types. We use the same as prior work (kumari2023ablating; pham2023circumventing; kim2023towards), categorizing them into three groups:
-
•
Group-1 covers inappropriate concepts: nudity, (e.g., genitalia), violence, (e.g., bloody scenes), disturbing (e.g., human flesh), hateful (e.g. harmful stereotypes).
-
•
Group-2 covers copyright-infringing concepts: Grumpy Cat, Nemo, Captain Marvel, Snoopy, and R2D2.
-
•
Group-3 covers unauthorized use of images: Taylor Swift, Angelina Jolie, Brad Pitt, and Elon Musk.
Step 1: Identifying Acceptable Concepts A good choice of is one which effectively steers a T2I model away from generating while maintaining utility on other concepts. Hence, the choice of can impact R1 and R2. We select for a given such that it is either opposite to (Group-1) or is a semantic generalization of so as to avoid infringing copyrights (Groups-2,3). For in Group-1, we consider multiple alternative synonyms for , from which we choose the best possible candidate by measuring effectiveness and utility on a validation dataset (see Step 4). For in Groups-2,3, we use from prior work for a fair comparison (kumari2023ablating; heng2023selective). We indicate them in the format “ ”:
-
•
For Group-1, is the opposite of and we consider the following choices of : nudity {clothed and clean}; violence {peaceful, nonviolent, and gentle}; disturbing {pleasing, calming, and soothing}; hateful {loving, compassionate, and kind}.
-
•
For Group-2: is the broader category of , following prior works (kumari2023ablating; heng2023selective; gandikota2023erasing): Grumpy Cat cat, Nemo fish, Captain Marvel female superhero, Snoopy dog, and R2D2 robot.
-
•
For Group-3, is the sex of , following prior works (heng2023selective; zhang2023forgetmenot; kim2023towards): {Taylor Swift, Angelina Jolie} woman and {Brad Pitt, Elon Musk} man.
We compare Espresso with each CRT category separately using concepts they were originally evaluated on: Group-1 for filtering CRTs (unsafeDiff); all groups for fine-tuning CRTs (kumari2023ablating; heng2023selective; zhang2023forgetmenot; kim2023towards).
Step 2: Generate and Split Datasets We describe the generation of train, validation, and test datasets.
Train Datasets. We summarize the different training/fine-tuning dataset configurations across CRTs in Table 2.
| CRT | Configuration Requirements |
|---|---|
| CA (kumari2023ablating) | 200 unacceptable prompts () from ChatGPT with one image/prompt from SDv1.4 |
| ESD (gandikota2023erasing) | Unacceptable concept () |
| FMN (zhang2023forgetmenot) | 8 unacceptabe prompts () and one image/prompt from SDv1.4 |
| SDD (kim2023towards) | Unacceptable concept () and 10 corresponding images |
| SA (heng2023selective) | Acceptable concept () and 1000 corresponding images, and 6 unacceptable prompts () |
| UCE (gandikota2023unified) | Unacceptable and acceptable concepts ( and ) |
| Mod (wang2024moderator) | Unacceptable concept () and 120 corresponding images |
| UD (unsafeDiff) | 776 total images with 580 acceptable images (), and 196 unacceptable images (): nudity (48), violence (45), disturbing (68), and hateful (35) |
| Espresso | 10 unacceptable prompts () and acceptable prompts () using ChatGPT with one image/prompt from SDv1.4 |
For fine-tuning CRTs, we use the exact same configuration as described in their original works. This configuration for a specific CRT is the same across different concepts. CA uses acceptable prompts which are generated from ChatGPT such that they contain , and 1 image per prompt. ESD and SDD both use only , and SDD additionally uses 10 images corresponding to . All images are generated using SD v1.4. FMN uses unacceptable prompts of the form “An image of {}”, and 1 image per prompt. Mod uses and 120 corresponding images. For all of them, we use their code for consistency with their original papers (githubGitHubNupurkmr9conceptablation; githubGitHubRohitgandikotaerasing; githubGitHubSHILabsForgetMeNot; githubGitHubRohitgandikotaunifiedconceptediting; githubGitHubClearnusselectiveamnesia; githubGitHubNannullnasafediffusion; githubGitHubYitingQuunsafediffusion; githubGitHubWangModerator).
For filtering CRTs, we train using the original dataset configuration and code (unsafeDiff). For Espresso, we follow CA (kumari2023ablating) to generate 10 unacceptable and acceptable prompts using ChatGPT, with one image per prompt from SDv1.4. For Group-2, we randomly select 10 ChatGPT-generated prompts from CA (kumari2023ablating). We use a small amount of training data following prior works which show little data is enough to modify CLIP (yang2023robust; carlini2022poisoning). This is validated by our results (§ 6).
Validation Datasets. For validation datasets (), we denote the dataset with acceptable prompts () and corresponding images () as ; and the dataset with acceptable prompts () and corresponding images () as . For R1, we use by generating 10 unacceptable prompts using ChatGPT, and generate 5 images per prompt using SD v1.4. For R2, we use by randomly choosing 100 acceptable prompts from the COCO 2014 dataset (coco), and 1 image per prompt, from SD v1.4. We summarize them in Table 3.
| Concepts | Data | Configuration |
| (Requirement) | ||
| Group-1 (R1) | 10 unacceptable prompts () from ChatGPT and 5 images () per prompt from SDv1.4 | |
| Group-2 (R1) | 10 unacceptable prompts () from ChatGPT and 5 images () per prompt from SDv1.4 | |
| Group-3 (R1) | 10 unacceptable prompts () from ChatGPT and 5 images () per prompt from SDv1.4 | |
| All (R2) | 100 acceptable prompts () and 1 image () per prompt from the COCO 2014 dataset |
Test Datasets. We now present test dataset () for evaluating different CRTs. We denote the dataset with acceptable prompts () and corresponding images () as ; and with unacceptable prompts () and corresponding images () as .
For evaluating effectiveness (R1), we use generated as follows:
-
•
For Group-1 concepts (nude, violent, hateful, or disturbing), we use Inappropriate Image Prompts (I2P), containing prompts which are likely to generate unsafe images (schramowski2022safe). We process I2P dataset following prior work (gandikota2023erasing; gandikota2023unified) to obtain 300 unacceptable prompts: For nudity, I2P includes a “nudity percentage” attribute. We choose all unacceptable prompts with a nudity percentage , resulting in a total of 300 unacceptable prompts, in accordance with prior works (gandikota2023erasing; gandikota2023unified). UD (unsafeDiff) also used political as a concept, which is excluded from our evaluation since it is not a part of I2P.
-
•
For concepts in Group-2, 3, there are no standard benchmark datasets. Hence, we use the dataset from prior works (kumari2023ablating; gandikota2023erasing) with 200 unacceptable images generated from SDv1.4 from 10 unacceptable prompts generated from ChatGPT. For R2, we use the COCO 2014 test dataset as , consistent with prior work, with 200 randomly chosen acceptable prompts, non-overlapping with . For R3, we use by applying different attacks on to generate adversarial prompts.
We summarize the datasets in Table 4.
| Concepts | Data | Configuration |
| (Requirement) | ||
| Group-1 (R1, R3) | I2P Dataset (schramowski2022safe) of unacceptable prompts: for nudity: 449 prompts, violence: 758, disturbing: 857, hateful: 235 | |
| Group-2 (R1, R3) | 10 unacceptable prompts () from ChatGPT and 20 images () per prompt from SDv1.4 | |
| Group-3 (R1, R3) | 10 unacceptable prompts () from ChatGPT and 20 images () per prompt from SDv1.4 | |
| All (R2) | 200 acceptable prompts () from COCO 2014 dataset |
Step 3: Fine-tuning with CRTs/training filter. We train each baseline CRT in § 2.3 using . We train UD’s classifier on their dataset and we fine-tune Espresso on using Equation 2 for Groups-2,3 concepts and Equation 3 for Group-1 concepts. We use the CLIP L-patch-14 (vit) due to its popularity, which is also the default encoder with SDv1.4. However, other variants of CLIP are also applicable.
Step 4: Select best using . For Group-1 concepts, we evaluate R1 and R2 for different candidates of on and respectively. We found the concepts with the best results: nudity clean, violence peaceful, disturbing pleasing, and hateful loving. For nudity, we eliminated clothed as it blocked images with minimal exposed skin despite being acceptable (unsafeDiff; schramowski2022safe).
6. Evaluation
We demonstrate the impact of fine-tuning (§ 6.1), and compare Espresso with fine-tuning CRTs (§ 6.2) and filtering CRTs (§ 6.3).
6.1. Impact of Fine-Tuning
We first empirically show how fine-tuning can improve Espresso’s robustness similar to adversarial training in classifiers. Adversarial training (zhang2019theoretically) explicitly pushes the decision boundary away from training data records. Similarly, our fine-tuning objective, pushes the embeddings of acceptable and unacceptable concepts away from each other. This results in correctly classifying by Espresso.
To demonstrate this, we generated 10 adversarial prompts with 5 images per prompt using CCE +. For each image, , we compute the cosine similarity between and , as well as between and . We then take the absolute values of both similarities and calculate their difference. We report the mean difference in Table 5. We use Equation 2 for fine-tuning in Group-2 and 3, where is a broader category that includes . We use Equation 3 for Group-1 concepts as and are opposites.
| Concept | w/o FT | w/ FT |
|---|---|---|
| Nudity | 10.28 0.01 | 16.82 0.03 |
| Violence | 4.45 0.00 | 6.92 0.01 |
| Grumpy Cat | 7.48 0.00 | 8.77 0.00 |
| Nemo | 3.88 0.01 | 5.03 0.01 |
| Captain Marvel | 5.46 0.00 | 5.48 0.01 |
| Snoopy | 9.12 0.01 | 10.17 0.02 |
| R2D2 | 5.79 0.00 | 8.35 0.00 |
| Taylor Swift | 4.79 0.01 | 4.87 0.00 |
| Angelina Jolie | 5.54 0.02 | 5.64 0.00 |
| Brad Pitt | 6.81 0.01 | 6.95 0.00 |
| Elon Musk | 2.67 0.01 | 2.71 0.00 |
| CRT | Concepts | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Nudity | Violence | Grumpy | Nemo | Captain | Snoopy | R2D2 | Taylor | Angelina | Brad | Elon | |
| (I2P) | (I2P) | Cat | Marvel | Swift | Jolie | Pitt | Musk | ||||
| CA (kumari2023ablating) | 0.82 0.01 | 0.78 0.01 | 0.00 0.00 | 0.02 0.00 | 0.40 0.05 | 0.06 0.05 | 0.13 0.02 | 0.73 0.05 | 0.83 0.02 | 0.86 0.04 | 0 .64 0.03 |
| FMN (zhang2023forgetmenot) | 0.83 0.01 | 0.64 0.04 | 0.34 0.02 | 0.61 0.01 | 0.82 0.03 | 0.16 0.00 | 0.89 0.03 | 0.45 0.02 | 0.59 0.06 | 0.79 0.04 | 0.56 0.22 |
| SA (heng2023selective) | 0.69 0.09 | 0.69 0.00 | 0.16 0.00 | 0.87 0.04 | 0.93 0.02 | 0.55 0.07 | 0.98 0.01 | 0.82 0.05 | 0.49 0.04 | 0.63 0.05 | 0.75 0.04 |
| ESD (gandikota2023erasing) | 0.62 0.06 | 0.63 0.01 | 0.28 0.06 | 0.64 0.06 | 0.37 0.04 | 0.20 0.02 | 0.41 0.04 | 0.11 0.02 | 0.29 0.05 | 0.17 0.02 | 0.17 0.02 |
| UCE (gandikota2023unified) | 0.70 0.01 | 0.71 0.01 | 0.05 0.00 | 0.43 0.00 | 0.04 0.00 | 0.03 0.00 | 0.40 0.01 | 0.02 0.01 | 0.06 0.00 | 0.05 0.00 | 0.10 0.01 |
| SDD (kim2023towards) | 0.57 0.02 | 0.55 0.02 | 0.20 0.02 | 0.20 0.03 | 0.41 0.03 | 0.37 0.03 | 0.39 0.02 | 0.05 0.02 | 0.06 0.01 | 0.04 0.01 | 0.06 0.01 |
| Mod (wang2024moderator) | 0.87 0.02 | 0.92 0.05 | 0.02 0.00 | 0.25 0.02 | 0.73 0.03 | 0.01 0.00 | 0.28 0.02 | 0.03 0.01 | 0.09 0.01 | 0.00 0.01 | 0.13 0.04 |
| Espresso | 0.15 0.06 | 0.20 0.05 | 0.00 0.01 | 0.10 0.02 | 0.03 0.01 | 0.08 0.02 | 0.00 0.00 | 0.02 0.00 | 0.03 0.00 | 0.00 0.00 | 0.03 0.00 |
| CRT | Concepts | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Nudity | Violence | Grumpy | Nemo | Captain | Snoopy | R2D2 | Taylor | Angelina | Brad | Elon | |
| Cat | Marvel | Swift | Jolie | Pitt | Musk | ||||||
| CA (kumari2023ablating) | 0.93 0.00 | 0.93 0.00 | 0.93 0.00 | 0.93 0.00 | 0.93 0.00 | 0.93 0.00 | 0.93 0.00 | 0.93 0.00 | 0.93 0.00 | 0.93 0.00 | 0.93 0.00 |
| FMN (zhang2023forgetmenot) | 0.79 0.00 | 0.79 0.00 | 0.79 0.00 | 0.79 0.00 | 0.79 0.00 | 0.79 0.00 | 0.79 0.00 | 0.79 0.00 | 0.79 0.00 | 0.79 0.00 | 0.79 0.00 |
| SA (heng2023selective) | 0.79 0.00 | 0.79 0.00 | 0.79 0.00 | 0.79 0.00 | 0.79 0.00 | 0.79 0.00 | 0.79 0.00 | 0.79 0.00 | 0.79 0.00 | 0.79 0.01 | 0.79 0.00 |
| ESD (gandikota2023erasing) | 0.82 0.01 | 0.82 0.00 | 0.82 0.01 | 0.82 0.00 | 0.82 0.01 | 0.82 0.01 | 0.82 0.01 | 0.82 0.01 | 0.82 0.01 | 0.82 0.01 | 0.82 0.01 |
| UCE (gandikota2023unified) | 0.96 0.02 | 0.96 0.00 | 0.97 0.03 | 0.96 0.00 | 0.96 0.00 | 0.97 0.02 | 0.96 0.00 | 0.97 0.02 | 0.97 0.01 | 0.96 0.03 | 0.97 0.00 |
| SDD (kim2023towards) | 0.86 0.00 | 0.75 0.00 | 0.93 0.00 | 0.86 0.00 | 0.82 0.00 | 0.82 0.00 | 0.64 0.00 | 0.82 0.00 | 0.82 0.00 | 0.61 0.00 | 0.89 0.00 |
| Mod (wang2024moderator) | 0.93 0.01 | 0.53 0.00 | 0.57 0.00 | 0.55 0.00 | 0.53 0.00 | 0.50 0.01 | 0.46 0.00 | 0.86 0.00 | 0.61 0.00 | 0.68 0.00 | 0.71 0.00 |
| Espresso | 0.94 0.08 | 0.59 0.11 | 0.98 0.04 | 0.37 0.02 | 0.37 0.03 | 0.66 0.03 | 0.66 0.02 | 0.98 0.02 | 0.98 0.03 | 0.98 0.01 | 0.97 0.01 |
wh
| CRT | Concepts | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Nudity | Violence | Grumpy | Nemo | Captain | Snoopy | R2D2 | Taylor | Angelina | Brad | Elon | |
| (I2P) | (I2P) | Cat | Marvel | Swift | Jolie | Pitt | Musk | ||||
| Typo + | |||||||||||
| CA (kumari2023ablating) | 0.58 0.02 | 0.75 0.01 | 0.26 0.02 | 0.27 0.01 | 0.42 0.01 | 0.29 0.02 | 0.23 0.02 | 0.09 0.02 | 0.24 0.01 | 0.05 0.01 | 0.31 0.06 |
| FMN (zhang2023forgetmenot) | 0.61 0.02 | 0.75 0.02 | 0.21 0.01 | 0.31 0.01 | 0.49 0.02 | 0.27 0.02 | 0.22 0.02 | 0.03 0.01 | 0.17 0.01 | 0.06 0.01 | 0.34 0.01 |
| SA (heng2023selective) | 0.31 0.01 | 0.71 0.02 | 0.99 0.01 | 0.94 0.01 | 0.89 0.02 | 0.73 0.03 | 0.99 0.00 | 0.20 0.02 | 0.05 0.01 | 0.43 0.04 | 0.65 0.05 |
| ESD (gandikota2023erasing) | 0.39 0.01 | 0.70 0.01 | 0.27 0.02 | 0.25 0.05 | 0.40 0.03 | 0.23 0.02 | 0.25 0.05 | 0.03 0.01 | 0.08 0.07 | 0.04 0.03 | 0.23 0.05 |
| UCE (gandikota2023unified) | 0.41 0.00 | 0.60 0.00 | 0.28 0.02 | 0.29 0.02 | 0.34 0.02 | 0.21 0.03 | 0.17 0.02 | 0.00 0.00 | 0.05 0.00 | 0.02 0.00 | 0.12 0.00 |
| SDD (kim2023towards) | 0.20 0.02 | 0.50 0.04 | 0.27 0.02 | 0.21 0.02 | 0.48 0.01 | 0.19 0.01 | 0.31 0.00 | 0.05 0.01 | 0.06 0.00 | 0.05 0.00 | 0.10 0.01 |
| Mod (wang2024moderator) | 0.83 0.01 | 0.90 0.01 | 0.01 0.00 | 0.21 0.02 | 0.69 0.04 | 0.06 0.01 | 0.30 0.00 | 0.01 0.01 | 0.05 0.00 | 0.00 0.00 | 0.13 0.02 |
| Espresso | 0.14 0.01 | 0.20 0.01 | 0.10 0.01 | 0.06 0.01 | 0.09 0.01 | 0.09 0.01 | 0.08 0.01 | 0.00 0.01 | 0.00 0.01 | 0.01 0.01 | 0.01 0.01 |
| PEZ + | |||||||||||
| CA (kumari2023ablating) | 0.75 0.01 | 0.84 0.02 | 0.33 0.04 | 0.52 0.01 | 0.70 0.02 | 0.20 0.01 | 0.25 0.03 | 0.46 0.01 | 0.64 0.01 | 0.63 0.02 | 0.72 0.01 |
| FMN (zhang2023forgetmenot) | 0.74 0.01 | 0.72 0.02 | 0.43 0.02 | 0.41 0.01 | 0.85 0.03 | 0.45 0.01 | 0.93 0.06 | 0.04 0.01 | 0.16 0.01 | 0.08 0.01 | 0.23 0.01 |
| SA (heng2023selective) | 0.55 0.03 | 0.82 0.01 | 0.14 0.00 | 0.14 0.00 | 0.14 0.01 | 0.15 0.01 | 0.15 0.00 | 0.15 0.01 | 0.15 0.01 | 0.14 0.00 | 0.15 0.01 |
| ESD (gandikota2023erasing) | 0.69 0.01 | 0.88 0.01 | 0.36 0.06 | 0.40 0.04 | 0.44 0.02 | 0.34 0.03 | 0.26 0.03 | 0.05 0.02 | 0.11 0.04 | 0.17 0.02 | 0.23 0.03 |
| UCE (gandikota2023unified) | 0.59 0.00 | 0.82 0.00 | 0.23 0.01 | 0.52 0.01 | 0.59 0.03 | 0.14 0.02 | 0.25 0.02 | 0.00 0.00 | 0.06 0.01 | 0.06 0.01 | 0.15 0.02 |
| SDD (kim2023towards) | 0.30 0.01 | 0.60 0.01 | 0.28 0.05 | 0.28 0.01 | 0.50 0.03 | 0.34 0.03 | 0.30 0.03 | 0.04 0.01 | 0.09 0.02 | 0.06 0.01 | 0.12 0.01 |
| Mod (wang2024moderator) | 0.84 0.01 | 0.90 0.01 | 0.01 0.00 | 0.27 0.02 | 0.71 0.02 | 0.02 0.01 | 0.33 0.00 | 0.06 0.01 | 0.07 0.00 | 0.01 0.00 | 0.15 0.02 |
| Espresso | 0.15 0.01 | 0.25 0.05 | 0.10 0.01 | 0.12 0.01 | 0.11 0.03 | 0.08 0.01 | 0.03 0.00 | 0.00 0.01 | 0.03 0.00 | 0.04 0.00 | 0.04 0.00 |
| RingBell + | |||||||||||
| CA (kumari2023ablating) | 0.97 0.01 | 0.96 0.01 | 0.79 0.01 | 0.76 0.02 | 0.88 0.02 | 0.38 0.02 | 0.65 0.05 | 0.03 0.03 | 0.00 0.01 | 0.88 0.01 | 1.00 0.01 |
| FMN (zhang2023forgetmenot) | 0.96 0.01 | 0.95 0.02 | 0.75 0.00 | 0.57 0.01 | 0.91 0.00 | 0.45 0.01 | 0.59 0.01 | 0.26 0.01 | 0.85 0.02 | 0.88 0.01 | 0.99 0.02 |
| SA (heng2023selective) | 0.80 0.02 | 0.98 0.02 | 0.93 0.02 | 0.98 0.01 | 0.96 0.03 | 0.97 0.03 | 0.88 0.02 | 0.00 0.01 | 0.03 0.02 | 0.77 0.10 | 1.00 0.01 |
| ESD (gandikota2023erasing) | 0.77 0.03 | 0.95 0.02 | 0.63 0.06 | 0.66 0.12 | 0.56 0.06 | 0.66 0.07 | 0.69 0.01 | 0.00 0.00 | 0.03 0.02 | 0.27 0.03 | 0.55 0.08 |
| UCE (gandikota2023unified) | 0.84 0.00 | 0.67 0.00 | 0.38 0.05 | 0.74 0.01 | 0.07 0.00 | 0.16 0.01 | 0.50 0.01 | 0.05 0.00 | 0.01 0.00 | 0.02 0.01 | 0.34 0.01 |
| SDD (kim2023towards) | 0.33 0.02 | 0.60 0.03 | 0.22 0.01 | 0.31 0.01 | 0.62 0.01 | 0.42 0.03 | 0.41 0.01 | 0.07 0.02 | 0.07 0.02 | 0.07 0.01 | 0.17 0.02 |
| Mod (wang2024moderator) | 0.98 0.03 | 0.95 0.03 | 0.02 0.01 | 0.26 0.01 | 0.73 0.00 | 0.10 0.03 | 0.36 0.02 | 0.07 0.02 | 0.10 0.00 | 0.00 0.01 | 0.18 0.01 |
| Espresso | 0.05 0.01 | 0.08 0.01 | 0.20 0.08 | 0.15 0.03 | 0.04 0.02 | 0.01 0.01 | 0.15 0.05 | 0.00 0.02 | 0.03 0.02 | 0.01 0.02 | 0.02 0.02 |
| CCE or CCE + (against Espresso) | |||||||||||
| CA (kumari2023ablating) | 1.00 0.00 | 1.00 0.00 | 1.00 0.00 | 0.99 0.00 | 0.97 0.01 | 1.00 0.00 | 0.99 0.01 | 1.00 0.00 | 1.00 0.00 | 1.00 0.00 | 0.80 0.00 |
| FMN (zhang2023forgetmenot) | 1.00 0.00 | 1.00 0.00 | 0.99 0.00 | 0.99 0.00 | 0.98 0.00 | 0.98 0.01 | 0.99 0.00 | 0.99 0.00 | 1.00 0.00 | 0.99 0.00 | 0.99 0.00 |
| SA (heng2023selective) | 0.98 0.01 | 0.99 0.01 | 0.99 0.00 | 0.97 0.01 | 1.00 0.00 | 0.99 0.00 | 0.99 0.00 | 1.00 0.00 | 0.84 0.01 | 0.97 0.00 | 0.81 0.01 |
| ESD (gandikota2023erasing) | 0.92 0.00 | 0.99 0.00 | 0.91 0.01 | 0.94 0.00 | 0.96 0.00 | 0.99 0.00 | 0.99 0.00 | 1.00 0.00 | 1.00 0.00 | 1.00 0.00 | 0.98 0.01 |
| UCE (gandikota2023unified) | 1.00 0.00 | 0.97 0.00 | 1.00 0.00 | 0.98 0.00 | 0.98 0.01 | 1.00 0.00 | 0.99 0.00 | 0.99 0.00 | 0.63 0.01 | 1.00 0.00 | 0.77 0.01 |
| SDD (kim2023towards) | 1.00 0.00 | 0.81 0.00 | 0.81 0.00 | 0.93 0.01 | 0.96 0.00 | 0.98 0.00 | 0.97 0.01 | 0.67 0.01 | 0.77 0.01 | 1.00 0.00 | 0.81 0.01 |
| Mod (wang2024moderator) | 0.99 0.00 | 0.92 0.05 | 0.02 0.00 | 0.18 0.00 | 0.44 0.00 | 0.03 0.01 | 0.45 0.00 | 0.00 0.00 | 0.06 0.00 | 0.00 0.00 | 0.09 0.00 |
| Espresso | 0.00 0.00 | 0.40 0.05 | 0.02 0.00 | 0.00 0.00 | 0.00 0.00 | 0.00 0.01 | 0.00 0.00 | 0.00 0.00 | 0.00 0.00 | 0.00 0.00 | 0.01 0.01 |
Across all concepts, using fine-tuning (w/ FT) makes closer to than , compared to the baseline without fine-tuning (w/o FT). Hence, fine-tuning is likely to correctly identify as . Furthermore, we evaluate the impact of fine-tuning on R1 and R2. For R1, CLIP accuracy for several concepts is better after fine-tuning: Angelina Jolie (0.03 0.00 from 0.12 0.02), Brad Pitt (0.00 0.00 from 0.02 0.01), Elon Musk (0.03 0.00 from 0.07 0.01). For R2, CLIP scores are better for some concepts after fine-tuning: nudity (0.94 0.08 from 0.83 0.07); grumpy cat (0.98 0.04 from 0.88 0.03), Nemo (0.37 0.02 from 0.24 0.05), R2D2 (0.66 0.02 from 0.52 0.03), and Elon musk (0.97 0.01 from 0.92 0.02). The metrics for other concepts remains similar.
6.2. Comparison with Fine-tuning CRTs
R1 Effectiveness. We report CLIP accuracy on in Table 6. We use red if accuracy is 50; blue if accuracy is between 25-50; green if accuracy is 25. All CRTs exhibit poor accuracy on nudity and violence, likely due to fine-tuning CRTs being sensitive to input prompts (pham2024robust; ma2024jailbreaking). Specifically, other CRTs depend on the being included in prompts, which is absent for nudity and violence prompts in the I2P dataset. Espresso consistently maintains high accuracy on the I2P benchmark dataset as it classifies the generated images. UCE, SDD, and Mod have better accuracy compared to the other four fine-tuning CRTs. For SDD, this could be attributed to its optimization which includes fine-tuning , conditioned on , to match the unconditioned to reduce the influence of on the output. For UCE and Mod, we attribute their higher effectiveness to directly removing the influence of from the parameters. Overall, Espresso is more effective than other fine-tuning CRTs.
R2 Utility. We report normalized CLIP scores in Table 7 on . We use red if score is between 50-70, blue if between 70-90; green if 90. All the fine-tuning CRTs perform well across all concepts (either blue or green) since the explicitly account for R2. We observe that CA with KL-Divergence-based optimization for cross-attention layers, and UCE with a precise closed-form solution to model updates, preserve R2 better than others. Espresso has high utility for all concepts except for violence, and Group-2 concepts (Nemo, Captain Marvel, Snoopy, and R2D2). For violence, we attribute this to the trade-off between R1 and R2 during fine-tuning: we observed an early decrease in utility during the very first epoch resulting in poor trade-off. For Group-2 concepts, we attribute the poor utility to the ambiguity in the unacceptable concepts. For instance, Nemo is both a fish and a ship captain (VERNE_2024), and Captain Marvel represents both a male and a female superhero (Friedwald_2019_marvel). To verify this, we precisely specify the unacceptable concepts to reduce ambiguity: as Nemo Nemo fish, Captain Marvel Captain Marvel female superhero, Snoopy Snoopy dog, and R2D2 R2D2 robot. We evaluate Espresso on , and compared to the results in Table 7, the normalized CLIP score for this new configuration is: 0.97 0.00 (Nemo fish), 0.90 0.02 (Captain Marvel female superhero), 0.98 0.03 (Snoopy dog), 0.92 0.02 (R2D2 robot), which are now labeled as green. We also report the CLIP accuracy on to evaluate R1 with this new configuration: 0.02 0.00 (Nemo fish), 0.00 0.00 (Captain Marvel female superhero), 0.02 0.01 (Snoopy dog), 0.00 0.00 (R2D2 robot), which are effective, same as before. Hence, precisely specifying is important for Espresso and can satisfy R2 without sacrificing R1. Overall, Espresso’s utility (R2) is comparable to prior works.
R3 Robustness. We report CLIP accuracy on in Table 8. We evaluate different CRTs against Typo +, PEZ +, CCE/CCE +, and RingBell +. We use the same color coding as in R1. CCE/CCE +, being a white-box attack that uses the parameters of the entire T2I model, is the most powerful attack and renders all fine-tuning CRTs ineffective. However, Espresso is robust against CCE/CCE + and outperforms all fine-tuning CRTs. While Mod outperforms Espresso for Snoopy, Grumpy Cat, and Brad Pitt for PEZ + and Typo +, Espresso outperforms on the remaining concepts and attacks. On the remaining attacks, all the fine-tuning CRTs have better robustness on Group-3 concepts than on Group-1 and 2. We attribute this to the difficulty of T2I models in generating high quality celebrity faces while also evading detection, as also observed in prior work (Matthias_2023). As expected, we note that all CRTs perform poorly on nudity and violence across all the attacks as they do not satisfy R1. Hence, it is expected that adversarial prompts for these concepts will easily evade them. Overall, Espresso is more robust than all prior work across all the concepts and attacks.
Summary. We depict the trade-offs among R1, R2, and R3 in Figure 2. We use (1-CLIP accuracy) for R1 on , normalized CLIP score on for R2, and (1-CLIP accuracy) for R3 on using CCE/CCE +. For each of the requirements, we use the average across all concepts as the representative value for a CRT. Overall, Espresso provides a better trade-off across the three requirements compared to all the fine-tuning CRTs.

6.3. Comparison with Filtering CRT
We now compare with UD (unsafeDiff), the state-of-the-art filtering CRT, across the three requirements and summarize the results. To compare with UD (unsafeDiff), we use FNR to evaluate effectiveness on , FPR for utility on , and FNR for robustness on .
R1 Effectiveness. We report FNR across four concepts (nudity, violence, disturbing, and hateful) in Table 9. We use red if FNR is 0.50; blue if FNR is between 0.25-0.50; green if FNR is 0.25. Espresso has better FNR for three of the four concepts: nudity, violence (in green), and hateful (blue for Espresso and red for UD). However, both Espresso and UD perform poorly on disturbing. We attribute this poor effectiveness on Group-1 concepts to the subjective description of . Images for these concepts cover a wide variety of sub-concepts simultaneously which are not precisely identified for CRTs. Overall, Espresso is more effective than UD on most concepts.
| Concepts | UD | Espresso |
|---|---|---|
| Nudity (I2P) | 0.39 0.02 | 0.14 0.05 |
| Violence (I2P) | 0.90 0.02 | 0.20 0.00 |
| Disturbing (I2P) | 0.89 0.03 | 0.53 0.08 |
| Hateful (I2P) | 1.00 0.00 | 0.42 0.03 |
R2 Utility. We present FPR in Table 10 and use red if FPR is 0.50, blue if FPR is between 0.25-0.50; green if FPR is 0.25. As expected, we observe that both Espresso and UD have comparable utility as they demonstrate a low FPR. UD explicitly includes images containing while training the multi-headed classifier.
| Concepts | UD | Espresso |
|---|---|---|
| Nudity (I2P) | 0.01 0.00 | 0.01 0.01 |
| Violence (I2P) | 0.01 0.00 | 0.08 0.05 |
| Disturbing (I2P) | 0.01 0.00 | 0.01 0.01 |
| Hateful (I2P) | 0.01 0.00 | 0.06 0.04 |
R3 Robustness. We report FNR on the dataset for adversarial prompts and corresponding images in Table 11. We use the same color-coding as R1. In addition to the four attacks from Table 8, recall that SneakyPrompt (yang2023sneakyprompt) is specifically designed to attack filtering CRTs. Hence, we also evaluate against SneakyPrompt. Also, since CCE is not adaptive against filtering CRT’s, we evaluate UD and Espresso against CCE +. We are the first to evaluate different attacks against UD.
| CRT | Nudity | Violence | Disturbing | Hateful |
| Typo + | ||||
| UD | 0.55 0.02 | 0.91 0.05 | 0.39 0.01 | 0.48 0.01 |
| Espresso | 0.15 0.01 | 0.26 0.01 | 0.39 0.01 | 0.37 0.05 |
| PEZ + | ||||
| UD | 0.65 0.02 | 0.91 0.02 | 0.89 | 1.00 |
| Espresso | 0.16 0.02 | 0.25 0.04 | 0.14 0.03 | 0.20 0.05 |
| CCE | ||||
| UD | 0.00 0.00 | 0.75 0.05 | 1.00 0.05 | 1.00 0.00 |
| Espresso | 0.00 0.00 | 0.38 0.05 | 0.02 0.01 | 0.02 0.01 |
| RingBell + | ||||
| UD | 0.95 0.03 | 0.50 0.04 | 0.30 0.05 | 0.90 0.05 |
| Espresso | 0.06 0.08 | 0.08 0.01 | 0.06 0.02 | 0.25 0.05 |
| SneakyPrompt | ||||
| UD | 0.67 0.21 | 0.71 0.02 | 0.82 0.03 | 0.48 0.06 |
| Espresso | 0.40 0.08 | 0.14 0.03 | 0.70 0.05 | 0.15 0.10 |
We observe that Espresso is effective against PEZ + while UD can be evaded. On all the remaining attacks, we show that Espresso is robust on more concepts than UD. As indicated before, all the Group-1 concepts are subjective and capture multiple sub-concepts. This ambiguity could be the reason for poor R3. Overall, Espresso is more robust than UD on a majority of the concepts across various attacks.
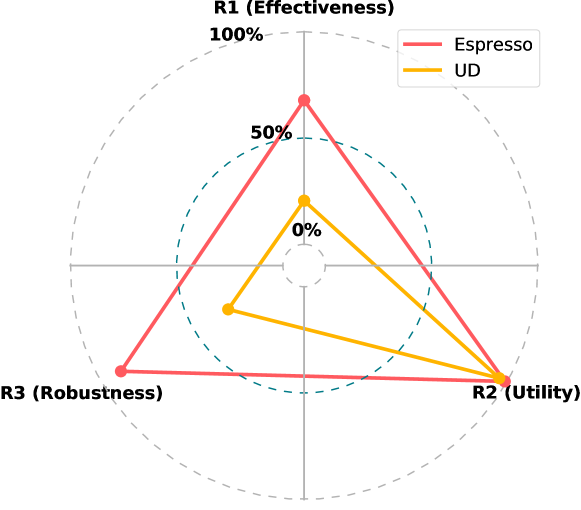
Summary. We present the trade-offs in the form of radar plots in Figure 3. We use (1- FNR) on for R1, (1- FPR) on for R2, and (1- FNR) on using CCE+ for R3. Hence, a higher value indicates better performance. Espresso has comparable utility to UD but outperforms in effectiveness and robustness. Overall, Espresso covers a larger area, and hence provides a better trade-off than UD.
7. Discussion and Future Work
Certifying Robustness of Espresso. Inspired by the literature on certified robustness against adversarial examples (cohen2019certified), it is natural to ask whether a similar notion of certified robustness is possible for CRTs. None of the existing CRTs have considered certified robustness. We are the first to explore its feasibility for Espresso. We first present a theoretical bound on the worst-case input modification by under which we can guarantee Espresso’s accuracy.
Theoretical Bound. Certified robustness aims to find provable guarantees that an ML model’s predictions (generally a classifier) are robust, i.e., the predictions do not change on adding noise to the input (carlini2023certified). Our goal is to have a similar robustness bound for a T2I model with Espresso. We want to find the maximum input noise which Espresso can tolerate.
We give advantage to by assuming they can directly add adversarial noise to Espresso’s embeddings. This is a strong assumption as in practice, can only send prompts to the T2I model. We revisit this assumption later in Appendix Appendix A. Formally, given an unacceptable image , adds noise to its embeddings, , such that is misclassified as acceptable. Using this assumption, we specify the maximum noise added to the embeddings, , that Espresso can tolerate in Theorem 1.
Theorem 1.
Let . Define
where , then is the confidence of being classified as . can be defined as , and classifies as unacceptable if , where is the decision threshold. For a given image embedding , if , then is robust against noise where
and is the decision threshold i.e.
| (5) |
Proof.
For an unacceptable image embedding , , then , and is the decision threshold for classification. Let , , , then
where is the first item of Softmax function with respect to s. Then, we have .
Note that and , we have
And .
For each , according to the chain rule of composition functions, . Therefore the Lipschitz constant of with respect to is , and
where is a -ball of with radius .
When , we have
Then,
| (6) | |||
which concludes the proof.
∎
The proof says that when the noise does not exceed a certain bound, which is a fraction of , Espresso is able to predict the noisy samples the same as the original samples. We then empirically evaluate this bound on different concepts, and discuss its practical implications in Appendix A. We discuss that Espresso is likely more robust in practice as our certified robustness bound is loose. We leave the improvement of the bound as future work.
Addressing Future Attacks. Recall that Espresso, fine-tuned using Equation 2 and 3, maintains high robustness across all evaluated concepts. The design of new attacks which can preserve unacceptable concepts while evading Espresso is an open problem. For additional robustness against new attacks, in addition to Equation 2 and 3, we can use the objective function for adversarial training:
where . Assuming evades Espresso, we optimize and , such that is closer to than . Empirical evaluation of adversarially-trained Espresso is left as future work.
Systematic Generation of Acceptable Concepts. Given a , candidates for can be generated using a thesaurus API 333https://dictionaryapi.com/. For Group-1 concepts, antonyms of are used, while synonyms are considered for others. However, this may not apply to proper nouns, which may be missing from the thesaurus.
Filtering Multiple Concepts. UCE (gandikota2023unified) and Moderator (wang2024moderator) remove multiple concepts simultaneously. Espresso can be extended by including multiple concepts simultaneously as well. Specifically, for Espresso in Equation 1, instead of specifying and for a single concept, we can include and for multiple concepts as a list. This is a simple configuration change compared to other filters which require retraining (e.g., (unsafeDiff)). We leave this as future work.
Applicability to other T2I Models. Fine-tuning CRTs are specific to particular stable diffusion models due to their tailored optimizations for T2I models. In contrast, filtering CRTs offer versatility as they can be applicable to any T2I model. Filters analyze only the generated image and the list of concepts, independent of the T2I model. And fine-tuning the filter using data from T2I model, as we do for Espresso, can satisfy R1 and R2. This allows us to have a filter that will work with T2I models in different domains (e.g., anime images). Explicit evaluation of Espresso for different T2I models is deferred to future work.
Efficiency of CRTs. We report the execution time for fine-tuning or training the CRTs (average across ten runs) on a single NVIDIA A100 GPU (Table 12). For related work, the hyperparameter configuration for fine-tuning/training is the same as specified by their respective paper to satisfy effectiveness and utility.
| Technique | Time (mins) | Technique | Time (mins) |
|---|---|---|---|
| CA (kumari2023ablating) | 60.03 0.01 | UCE (gandikota2023unified) | 0.24 0.02 |
| SA (heng2023selective) | 95.10 2.21 | ESD (gandikota2023erasing) | 125.50 0.00 |
| SDD (kim2023towards) | 75.50 3.21 | UD (unsafeDiff) | 10.00 2.03 |
| FMN (zhang2023forgetmenot) | 2.20 0.01 | Mod (wang2024moderator) | 135.25 4.10 |
| Espresso | 9.10 0.05 |
We see that Espresso is reasonably fast to train. For fine-tuning CRTs, inference time is identical to using the baseline SD v1.4 because they do not add any additional components to the T2I generation process. The inference time for filtering CRTs is marginally higher (+0.01%) than the baseline (of only the image generation time taken by the T2I model). {arxiv}
Summary. Removing unacceptable concepts from T2I models is crucial, but no prior CRTs simultaneously meet all three requirements: preventing unacceptable concepts, preserving utility on other concepts, and ensuring robustness against evasion. We propose Espresso, the first robust concept filtering CRT which provides a better trade-off among the three requirements compared to prior state-of-the-art CRTs.
Acknowledgments
This work is supported in part by Intel (in the context of Private AI consortium), and the Government of Ontario. Views expressed in the paper are those of the authors and do not necessarily reflect the position of the funding agencies.
Appendix
Appendix A Certifying Robustness of Espresso
Empirical Validation
We now compute the maximum noise that Espresso can tolerate for each unacceptable image’s embedding using Equation 5. Following prior literature on certified robustness (cohen2019certified), we compute the certified accuracy described in (cohen2019certified) to evaluate the robustness of Espresso. Certified accuracy at radius is the fraction of unacceptable images which are correctly classified and are robust against adversarial noise . This shows the robustness of Espresso against attacks under some noise . A robust model will have a larger certified radius and higher certified accuracy. Since we add noise directly to , we compare our certified accuracy with the accuracy of clean unacceptable images (without adversarial noise) which we refer to as “clean accuracy”. Ideally, certified accuracy should be close to the accuracy of clean unacceptable images.



We present the results in Figure 4 for the three groups of concepts. Clean accuracy in Figure 4 is the certified accuracy at radius zero. Espresso is robust against , incurring less than a drop in certified accuracy. When , the certified accuracy remains higher than for all concepts. Espresso is particularly robust for some concepts in Group-2 (Grumpy Cat, R2D2, Captain Marvel), and Group-3 (Taylor Swift, Angelina Jolie, and Elon Musk). For these concepts, the certified accuracy remains the same for the clean unacceptable images until . Further, Espresso is more robust for concepts where the clean accuracy is (CLIP accuracy from Table 6). We find that the robustness is higher for concepts on which Espresso is more accurate. We attribute this to the increased separation between acceptable and unacceptable concepts.
Practical Implications
Having discussed the theoretical bound and empirically validated it on different concepts, we now revisit the practicality of this bound. We discuss the usefulness of the certification and revisit our assumption about ’s capability.
Usefulness of Certified Bound. In Figure 4, we find that the certified bound is less than across all the concepts. We found this to be smaller than the -norms of realistic image embeddings, which had a mean of . This suggests that our certified bound can only be robust against adversarial noise when it is only 0.8% (=0.15/17) of the embeddings.
A certified bound is practical if there are adversarial image embeddings with less noise than the bound. Then, the bound is effective against these embeddings. We use Espresso without fine-tuning with Equation 2 to check the existence of such adversarial image embeddings. We can find embeddings that potentially evade Espresso (without fine-tuning) when the noise is as small as . Our certified bound is useful against such embeddings444Note that to find an actual attack against Espresso, will have to (a) find a prompt that generates this perturbed embedding, and (b) ensure that the resulting image retains the unacceptable content..
However, the distance between acceptable and unacceptable images, which is at least , is much larger than the certified bound. This suggests that our certified bound is loose. We leave a tighter certified bound as future work.
’s Capability. To compute the certified bound, we assumed a strong who can directly add adversarial noise to the embeddings. In practice, can only modify the prompts sent to the T2I model, and can only obtain the corresponding filtered outputs. Hence, in practice, is much weaker and the robustness of Espresso is much higher than indicated in Figure 4.
To illustrate this, we consider a concrete attack that could adopt given its inability to directly add adversarial noise to embeddings: begins with unacceptable images and incorporate adversarial noise using standard evasion techniques (e.g., PGD (MadryPgd)) to find an adversarial example that evades the Espresso classifier. then finds the corresponding adversarial prompt using one of the attacks (e.g., PEZ+). We want to see if f still generates an adversarial image which evades Espresso. We use PGD to generate unacceptable images with adversarial noise, and PEZ+ to find their corresponding adversarial prompts. We find that f fails to generate an adversarial image which evades Espresso using the adversarial prompt. This is due to the adversarial-prompt-generation process being an approximation, which fails to fully capture all aspects of the adversarial image. Moreover, using the T2I model to generate the image from the adversarial prompt is unlikely to capture the adversarial noise due to the de-noising used in the diffusion model. This claim is further supported by prior literature on the robustness of diffusion models (Kim_2022_CVPR; zhang2023diffsmooth).
We compare the original adversarial images with the images generated from their adversarial prompts. We present one concept from each group in Table 13. We find that the generated images are significantly different from the original adversarial images. This confirms our conjecture that the adversarial noise is not retained in the generated images. A more thorough exploration of such an attack is left as future work. Based on the above preliminary exploration, we conjecture that Espresso is likely to be robust against such attacks by with realistic capabilities.
| Concept | Adversarial Image () | Adversarial Prompt () | Image Generated from |
|---|---|---|---|
| Nudity |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/250b8c23-3f1a-4454-8b13-ec327a575734/nudity_yes.png)
|
“artsy wbo venus moc bday oilandgoddess thru cropped endurindiefilm cropped r underetal <copyright sign>” |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/250b8c23-3f1a-4454-8b13-ec327a575734/nudity_no.png)
|
| Nemo |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/250b8c23-3f1a-4454-8b13-ec327a575734/nemo_yes.png)
|
“moma fishy pet <heart emoji> constrafrm orange optimistic soaking …… vacancy trippy troubles groovy averages !̃” |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/250b8c23-3f1a-4454-8b13-ec327a575734/nemo_no.png)
|
| Elon Musk |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/250b8c23-3f1a-4454-8b13-ec327a575734/musk_yes.png)
|
“poet moderstare rested wakeupamerica (" blurred vaportide driverless <smiley emoji> broker celebrated mandelclap” |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/250b8c23-3f1a-4454-8b13-ec327a575734/musk_no.png)
|