ESGNN: Towards Equivariant Scene Graph Neural Network for 3D Scene Understanding
Abstract
Scene graphs have been proven to be useful for various scene understanding tasks due to their compact and explicit nature. However, existing approaches often neglect the importance of maintaining the symmetry-preserving property when generating scene graphs from 3D point clouds. This oversight can diminish the accuracy and robustness of the resulting scene graphs, especially when handling noisy, multi-view 3D data. This work, to the best of our knowledge, is the first to implement an Equivariant Graph Neural Network in semantic scene graph generation from 3D point clouds for scene understanding. Our proposed method, ESGNN, outperforms existing state-of-the-art approaches, demonstrating a significant improvement in scene estimation with faster convergence. ESGNN demands low computational resources and is easy to implement from available frameworks, paving the way for real-time applications such as robotics and computer vision.
Index Terms:
Scene graph, Scene understanding, Point clouds, Equivariant neural network, and Semantic segmentation.I Introduction
Holistic scene understanding serves as a cornerstone for various applications across fields such as robotics and computer vision [1, 2, 3]. Scene graphs, which utilize Graph Neural Network (GNN), offer a lighter alternative to 3D reconstruction while still being capable of capturing semantic information about the scene. As such, scene graphs have recently gained more attention in the robotics and computer vision fields [4]. For scene graph representation, objects are treated as nodes, and the relationships among them are treated as edges.
Recent advancements in scene graph generation have transitioned from solely utilizing 2D image sequences to incorporating 3D features such as depth camera data and point clouds, with the latest approaches, like [5, 6, 7], leveraging both 2D and 3D information for improved representation. However, these methods overlook the symmetry-preserving property of GNNs, which potentially cause scene graphs’ inconsistency, being sensitive to noisy and multi-view data such as 3D point clouds. Hence, this work adopts E(n) Equivariant Graph Neural Network [8]’s Convolution Layers with Feature-wise Attention mechanism [7] to create Equivariant Scene Graph Neural Network (ESGNN). This approach ensures that the resulting scene graph remains unaffected by rotations and translations, thereby enhancing its representation quality. Additionally, ESGNN requires fewer layers and computing resources compared to Scene Graph Fusion (SGFN) [7], while achieving higher accuracy scores with fewer training steps.
In summary, our contributions include:
-
•
We, to the best of our knowledge, are the first to implement Equivariant GNN in generating semantic scene graphs from 3D point clouds for scene understanding.
-
•
Our method, named ESGNN, outperforms state-of-the-art methods, achieving better accuracy scores with fewer training steps.
-
•
We demonstrate that ESGNN is adaptive to different scene graph generation methods. Furthermore, there is significant potential to explore the integration of equivariant GNNs for scene graph representation, with considerable room for future improvement.
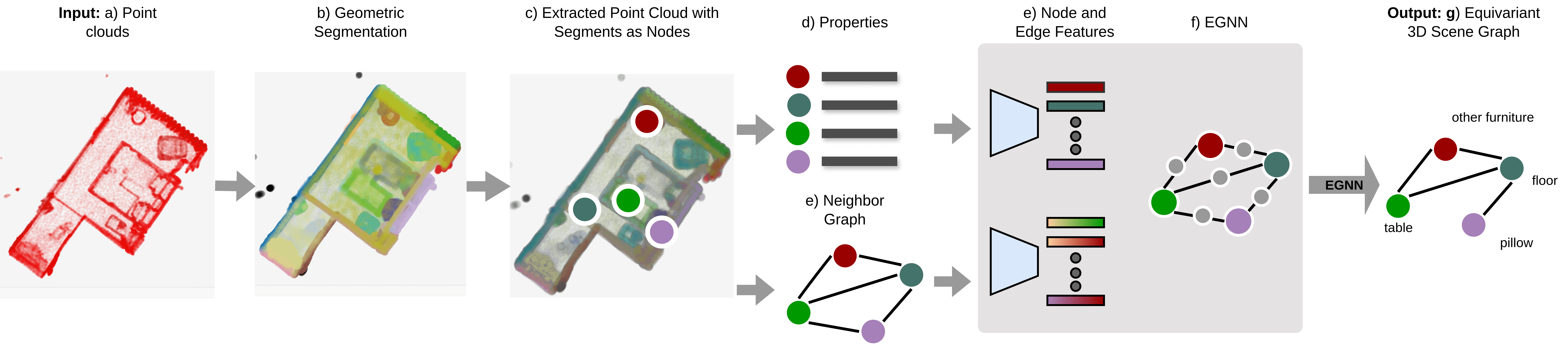
II Overall Framework
Problem Formulation: The Semantic Scene Graph is denoted as , where and represent sets of entity nodes and directed edges, respectively. In this case, each node contains an entity label , a point cloud , an Oriented Bounding Box (OBB) , and a node category . Conversely, each edge , connecting node to where , is characterized by an edge category or semantic relationship denoted by , or can be written in a relation triplet <subject, predicate, object>. Here, , , and represent the sets of all entity labels, node categories, and edge categories, respectively. Given the 3D scene data and that represent the same point cloud of a scene but from different views (rotation and transition), we try to predict the probability distribution of the equivariant scene graph prediction in which the equivariance is preserved:
| (1) |
where is the rotation matrix and is the transition matrix.
II-A Feature Extraction
In this phase, the framework extracts the feature for scene graph generation, following the three main steps: point cloud reconstruction, geometry segmentation, and point cloud extraction with nodes.
Point Cloud Reconstruction
The proposed framework will take the point cloud data, which can be reconstructed from various techniques such as ORB-SLAM3 or HybVIO [9, 10], as the input. However, for the objective validation purpose of scene graph generation, we use the indoor point cloud dataset 3RScan [11] for ground truth data .
Geometric Segmentation and Point Cloud Extraction with Segments Nodes
Given a point cloud , this geometric segmentation will provide a segment set . Each segment consists of a set of 3D points where each point is defined as a 3D coordinate and a color. Then, the point cloud concerning each entity is fed to the point encoders for node and edge features.
II-B Scene Graph Generation
In this phase, the framework processes the input from feature extraction (Section II-A) to generate the scene graph.
Properties and Neighbor Graph Extraction
From the point cloud, we extract features including the centroid , standard deviation , bounding box size , maximum length , and volume . We create edges between nodes only if their bounding boxes are within 0.5 meters of each other, following [7].
Point Encoders
Node and Edge Classification
Node classes and edge predicates are predicted using two Multi-Layer Perceptron (MLP) classifiers. Our network is trained end-to-end with a joint cross-entropy loss for both objects and predicates , as described in [6].
III Equivariant Scene Graph Generation
For the scene graph generation, we propose the combination of Equivariant Graph Convolution Layers [8] and the Graph Convolution Layers with Feature-wise Attention [7] for network architecture. The overall network architecture is shown in Figure 2, and the details of each layer are presented below.

III-A Graph Initialization
Node features
The node feature includes the invariant features and vector coordinate . consists of the latent feature of the point cloud after going through the PointNet , standard deviation , log of the bounding box size , log of the bounding box volume , and log of the maximum length of bounding box . The coordinate vector of the bounding box is defined by the coordinate of the two furthest corners of the bound box. and are then fed to the MLP for predicting the label of the nodes. Mathematically:
Edge features
For an edge between a source node and a target node where , the edge visual feature is computed as follows:
where , are MLP classifiers that project the properties into a latent space.
III-B Equivariant Scene Graph Neural Network (ESGNN)
Our GNN network, ESGNN, has two main components: ① Feature-wise attention Graph Convolution Layer (FAN-GCL); and ② Equivariant Graph Convolution Layer (EGCL). FAN-GCL, proposed by [7], is used to handle the large input queries of dimensions and targets of dimensions by utilizing multi-head attention. On the other hand, EGCL, proposed by [8], is used to maintain symmetry-preserving equivariance, allowing us to incorporate the bounding box coordinates as node features and update them through the message-passing mechanism.
Message Passing: ESGNN is constructed with 4 message-passing layers, consisting of 2 levels of FAN-GCL followed by the EGCL. Our model architecture is illustrated in Figure 2, and the formula used to update node and edge features () of FAN as well as the EGCL is as follows:
-
•
Update FAN-GCL:
-
•
Update EGCL:
III-C ESGNN With Image Encoder
Similar to segments , we get the region-of-interest (ROI) from multiple corresponding images and feed it through the image encoder [13]. Using the similar EGCL layer ensures the properties of the bounding box coordinate, we also observe better results demonstrated in Section IV-D. The node feature is fed to node classification for object prediction and the edge feature is fed to edge classification for predicate prediction.
IV Experiments
IV-A Dataset and Metrics
Dataset
We use the 3DSSG - a dataset for scene graph generation built upon 3RScan[11] which is a large-scale, real-world dataset that features 1482 3D reconstructions/snapshots of 478 naturally changing indoor environments - adapting the setting from [7] 111https://github.com/ShunChengWu/3DSSG. The 3RScan dataset [11] is processed with ScanNet [14] for geometric segmentation. The scene graph ground truths in 3DSSG are divided into 2 versions: l20, which includes 20 objects and 8 predicates, and l160, which includes 160 objects and 26 predicates. We mainly use the test set of the l20 version for our experiment.
Metrics
Given the dataset is unbalanced [6] and the objective of scene graphs is to capture the semantic meaning of the surrounding world the most, we use the recall of node and edge as our evaluation metrics. In the training phase, we calculate the recall as the true positive overall positive prediction. For more detailed analysis, we also adopt the metric R@x [6, 7, 5], which takes x most confident predictions and marks it as correct if at least one of these predictions is correct. We apply the recall metrics for the predicate (edge classification), object (node classification), and relationship (triplet <subject, predicate, object>).
IV-B Results
Overall, ESGNN is shown to converge more quickly in the early training epochs and achieve competitive performance throughout further epochs. Table I compares the results between our proposed model - ESGNN with existing models 3DSSG [6] and SGFN [7] on the 3DSSG-l20 dataset with geometric segmentation setting. Ours obtains high results in both relationship, object, and predicate classification. Especially, ESGNN outperforms the existing methods in relationship prediction and obtains significantly higher R@1 in predicate compared to SGFN. ESGNN also works well with unseen data, with competitive results compared to SGFN, shown in Table II.
| Method | Relationship | Object | Predicate | Recall | ||||
|---|---|---|---|---|---|---|---|---|
| R@1 | R@3 | R@1 | R@3 | R@1 | R@2 | Obj. | Rel. | |
| 3DSSG | 32.65 | 50.56 | 55.74 | 83.89 | 98.29 | 55.74 | ||
| SGFN | 37.82 | 48.74 | 62.82 | 81.41 | 98.22 | 63.98 | 94.24 | |
| ESGNN | 86.65 | 94.62 | 94.62 | |||||
| Method | New Relationship | New Object | New Predicate | |||
|---|---|---|---|---|---|---|
| R@1 | R@3 | R@1 | R@3 | R@1 | R@2 | |
| 3DSSG | 39.74 | 49.79 | 55.89 | 84.42 | 83.29 | |
| SGFN | 55.30 | 64.50 | 68.71 | |||
| ESGNN (Ours) | 46.85 | 87.52 | 66.90 | 82.88 | ||
Figure 4 reports the recalls for nodes (objects) and edges (relationships) during training between ESGNN and SGFN on both train and validation sets. The recall slope of ESGNN in the first 10 epochs (5000 steps) is significantly higher than that of SGFN. This indicates that ESGNN has faster convergence and higher initial recall.
ESGNN consistently outperforms the pioneering works overall, or is more data-efficient than SGFN, as it does not need to generalize over rotations and translations of the data, while still harnessing the flexibility of GNNs in larger datasets.
IV-C Ablation Study
In this Section, we report the results of ESGNN with different architectures and settings that we tried, shown in Table III. ① is the SGFN, run as the baseline model for comparison. ② is the ESGNN with a single FAN layer and an EGCL layer. This is our best performer and is used for experiments in Section IV-B. ③ is ESGNN with 2 FAN layers and 2 layers EGCL. ④ is similar to ①. The only difference is that we concatenate coordinate embedding to the output edge embedding after message passing. We expect this modification to improve the performance of edge prediction. ⑤ is similar to ④ with 2 layers of FAN GConv and 2 layers of EGCL.
| Method | Relationship | Object | Predicate | |||
|---|---|---|---|---|---|---|
| R@1 | R@3 | R@1 | R@3 | R@1 | R@2 | |
| ① SGFN | 37.82 | 48.74 | 62.82 | 81.41 | 98.22 | |
| ② ESGNN_1 | 86.70 | 94.34 | ||||
| ③ ESGNN_2 | 35.63 | 44.63 | 57.55 | 84.41 | 93.93 | 97.94 |
| ④ ESGNN_1X | 34.96 | 42.59 | 57.55 | 86.18 | 92.68 | 98.08 |
| ⑤ ESGNN_2X | 37.94 | 50.58 | 59.97 | 85.23 | 98.01 | |
Figure 4 reports the edge and node recalls comparison during training. Models ③ and ⑤ perform well on the train set but poorly on the validation and test sets, potentially suffering overfitting as they contain more layers. Models ④ and ⑤ result in higher edge recalls in several initial epochs, but experience a decline in recall in the later epochs.
IV-D ESGNN with Image Encoder
Our model also poses a potential in application on point-image encoders model together such as JointSSG [5]. We implement our GNN architecture similar to JointSSG and name it Joint-ESGNN. Figure 5 shows the performance of our model with image encoders compared to JointSSG and SGFN.
V Conclusion
In this work, we introduced the Equivariant Scene Graph Neural Network (ESGNN), which enhances robustness and accuracy in generating semantic scene graphs from 3D point clouds. Leveraging E(n) Equivariant Graph Neural Network (EGNN), ESGNN maintains symmetry-preserving properties, outperforming state-of-the-art methods with fewer layers and reduced computational resources. Our results demonstrate ESGNN’s superior performance in generating consistent and reliable scene graphs, paving the way for more efficient 3D scene understanding frameworks in autonomous systems. Future work will optimize ESGNN for specific use cases, incorporate additional sensor data, and handle more complex scenarios.
References
- [1] Kibum Kim, Kanghoon Yoon, Yeonjun In, Jinyoung Moon, Donghyun Kim, and Chanyoung Park. Adaptive self-training framework for fine-grained scene graph generation. In The Twelfth International Conference on Learning Representations, 2024.
- [2] Rongjie Li, Songyang Zhang, and Xuming He. Sgtr: End-to-end scene graph generation with transformer. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19464–19474, 2022.
- [3] Sebastian Koch, Pedro Hermosilla, Narunas Vaskevicius, Mirco Colosi, and Timo Ropinski. Sgrec3d: Self-supervised 3d scene graph learning via object-level scene reconstruction. In 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 3392–3402, 2024.
- [4] Xiaojun Chang, Pengzhen Ren, Pengfei Xu, Zhihui Li, Xiaojiang Chen, and Alex Hauptmann. A comprehensive survey of scene graphs: Generation and application. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(1):1–26, 2023.
- [5] Shun-Cheng Wu, Keisuke Tateno, Nassir Navab, and Federico Tombari. Incremental 3d semantic scene graph prediction from rgb sequences. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5064–5074, 2023.
- [6] Johanna Wald, Helisa Dhamo, Nassir Navab, and Federico Tombari. Learning 3D Semantic Scene Graphs from 3D Indoor Reconstructions. In Proceedings IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
- [7] Shun-Cheng Wu, Johanna Wald, Keisuke Tateno, Nassir Navab, and Federico Tombari. Scenegraphfusion: Incremental 3d scene graph prediction from rgb-d sequences. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7515–7525, 2021.
- [8] Víctor Garcia Satorras, Emiel Hoogeboom, and Max Welling. E(n) equivariant graph neural networks, 18–24 Jul 2021.
- [9] Carlos Campos, Richard Elvira, Juan J. Gomez, José M. M. Montiel, and Juan D. Tardós. ORB-SLAM3: An accurate open-source library for visual, visual-inertial and multi-map SLAM. IEEE Transactions on Robotics, 37(6):1874–1890, 2021.
- [10] Otto Seiskari, Pekka Rantalankila, Juho Kannala, Jerry Ylilammi, Esa Rahtu, and Arno Solin. Hybvio: Pushing the limits of real-time visual-inertial odometry. In 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 287–296, 2022.
- [11] Johanna Wald, Armen Avetisyan, Nassir Navab, Federico Tombari, and Matthias Niessner. Rio: 3d object instance re-localization in changing indoor environments. In 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 7657–7666, 2019.
- [12] R. Qi Charles, Hao Su, Mo Kaichun, and Leonidas J. Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 77–85, 2017.
- [13] S. Wu, J. Wald, K. Tateno, N. Navab, and F. Tombari. Scenegraphfusion: Incremental 3d scene graph prediction from rgb-d sequences. In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7511–7521, Los Alamitos, CA, USA, jun 2021. IEEE Computer Society.
- [14] Angela Dai, Angel X. Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Niessner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.