Equilibrium Inverse Reinforcement Learning
for Ride-hailing Vehicle Network
Abstract.
Ubiquitous mobile computing have enabled ride-hailing services to collect vast amounts of behavioral data of riders and drivers and optimize supply and demand matching in real time. While these mobility service providers have some degree of control over the market by assigning vehicles to requests, they need to deal with the uncertainty arising from self-interested driver behavior since workers are usually free to drive when they are not assigned tasks. If a driver’s behavior can be accurately replicated on the digital twin, more detailed and realistic counterfactual simulations will enable decision making to improve mobility services as well as to validate urban planning.
In this work, we formulate the problem of passenger-vehicle matching in a sparsely connected graph and proposed an algorithm to derive an equilibrium policy in a multi-agent environment. Our framework combines value iteration methods to estimate the optimal policy given expected state visitation and policy propagation to compute multi-agent state visitation frequencies. Furthermore, we developed a method to learn the driver’s reward function transferable to an environment with significantly different dynamics from training data. We evaluated the robustness to changes in spatio-temporal supply-demand distributions and deterioration in data quality using a real-world taxi trajectory dataset; our approach significantly outperforms several baselines in terms of imitation accuracy. The computational time required to obtain an equilibrium policy shared by all vehicles does not depend on the number of agents, and even on the scale of real-world services, it takes only a few seconds on a single CPU.
1. Introduction
With the ubiquitous use of Internet connected mobile devices which collect data and provide computation in real time, mobility services have been seamlessly linking all types of public transportation, from buses, trains, and taxis and shared bicycles, in order to make it more efficient and convenient. One of the key enablers of this revolution lies in the realistic and accurate prediction and simulation of human decision making. For ride-hailing platforms such as Uber and Lyft, where service quality depends heavily on drivers behavior, simulation is also an essential tool for testing route optimization and efficiency of order dispatch. In particular, since it is necessary to address uncertainty arisen from behaviors of uncoordinated self-interested drivers, the use of accurate driver behavior models enables more detailed counterfactual simulations, which will be beneficial for making decisions to improve services.
Imitation of multi-vehicle movement on sparsely connected road graph poses several significant computational challenges. One such challenge is the effective modeling of the graph structures in geographical space. A road network graph is often abstracted and represented as a coarser mesh, since finer-grained data structures tend to be more computationally intensive. However, more sophisticated simulation requires reproduction of road-level driving behavior, which will allow us to analyze vehicle routing to passengers and traffic congestion. In addition, the number of vehicles to be simulated for a ride-hailing service is generally relatively large, ranging from hundreds to thousands. In order to utilize simulation of this scale for actual decision making, the simulation system must be reasonable in terms of execution time and infrastructure cost. Another requirement for practical use is robustness to changes in environmental dynamics and data noise, which is essential when you want to simulate situations that are not in the distribution of training data. To our knowledge, there are no existing literature dealing with these challenges in ride-hailing vehicle network.
In this work, we propose SEIRL (spatial equilibrium inverse reinforcement learning), the first approach to multi-agent behavioral modeling and reward learning in equilibrium on a road network for a ride-hailing service. We focus on a fleet network where each driver is uncooperatively searching for passengers on streets. We propose MDP formulation of passenger-seeking drivers in a road network and a method to compute the optimal policy shared between agents which enables efficient and scalable simulation. We demonstrate that SEIRL is able to recover reward functions that are robust to significant change in the environment seen during training.
This paper makes the following three major contributions:
-
•
Vehicle behavior modeling on the road network: To the best of our knowledge, this is the first study to design multi-agent behavioral modeling in equilibrium on a road network for a ride-hailing service. We have formulated a mathematical model of the ride-hailing matching problem in Markov Decision Processes and proposed an algorithm, Equilibrium Value Iteration, to derive an optimal policy for multiple vehicles in equilibrium, which is efficient in a sense that the policy is shared between agents.
-
•
Spatial Equilibrium Inverse Reinforcement Learning: Within the MaxEnt IRL framework, we integrate SEIRL, an algorithm for learning driver rewards and policies in equilibrium from real multi-vehicle trajectory data. We derive the gradient of MaxEnt IRL when reward changes are accompanied by a change in dynamics and demonstrate that the algorithm is stable under certain conditions.
-
•
Data-driven Evaluation and Counterfactual Simulation: We compared and validated the robustness of SEIRL to changes in dynamics and data noise using real taxi trajectory data in Yokohama City and showed that it obtain significant performance gains over several baselines with unknown dynamics. In addition, we demonstrated the value of counterfactual simulations for supply vehicle optimization given the objective function of the platform.
2. Related Work
Imitation learning, such as behavior cloning (Pomerleau, 1991) and generative adversarial imitation learning (Ho and Ermon, 2016), is a powerful approach to learning policies directly from expert demonstrations to produce a expert-like behavior. They, however, are typically incapable of being applied to general transfer setting. Inferring reward functions from expert demonstrations, which we refer to as inverse reinforcement learning (IRL), is more beneficial for application of counterfactual simulations since the reward function is often considered as the most succinct, robust and transferable representation of a task (Abbeel and Ng, 2004) (Fu et al., 2017). However, IRL is fundamentally ill-defined: in general, many reward functions can make behavior seem rational. To solve the ambiguity, Maximum entropy inverse reinforcement learning (MaxEnt IRL) (Ziebart et al., 2008a) provides a general probabilistic framework by finding the reward function that matches trajectory distribution of the experts. Ziebart et.al has demonstrated an approach to simulate behavior on a road network by learning the routing costs of occupied taxi driving using MaxEntIRL (Ziebart et al., 2008b) in single agent setting.
In multi-agent settings, an agent cannot myopically maximize its reward; it must speculate on how the other agents may act to influence the game’s outcome. Multi-agent systems in which the set of agents behave non-cooperatively according to their own interests are modeled by Markov games. Nash equilibrium (Hu et al., 1998) is stable outcomes in Markov games where each agent acts optimally with respect to the actions of the other agents. However, Nash equilibrium, in the sense that it assumes that real behavior is typically consistently optimal or completely rational, is incompatible with the MaxEnt IRL framework. A recent study extends MaxEnt IRL to Markov games with logistic quantal response equilibrium, proposing model-free IRL solution in multi-agent environment (Yu et al., 2019).
This work relates to multi-agent inverse reinforcement learning (MAIRL), which includes two-player zero-sum games(Lin et al., 2017), two-player general-sum stochastic game(Lin et al., 2019), and cooperative games(Natarajan et al., 2010), in which multiple agent act independently to achieve a common goal. Waugh et.al introduced a technique for predicting and generalizing behavior in competitive and cooperative multi-agent domains, employing the game-theoretic notion of regret and the principle of maximum entropy (Waugh et al., 2013). Although the proposed method, Dual MaxEnt ICE, is performed in computation time that scales polynomially in the number of decision makers, it is still limited to small size games, and not applicable to games of large number of players such as ride-hailing services.
We concern ourselves with Markov potential games, a model settings in which agents compete for a common resource such as networking games in telecommunications (Altman et al., 2006). Transportation network is also a classical game theory problem: each agent seeks to minimize her own individual cost by choosing the best route to reach her destination without taking into account the overall utility. It has been widely studied that selfish routing results in a Nash Equilibrium and often society has to pay a price of anarchy due to lack of coordination (Youn et al., 2008). In contrast, our goal is to develop robust imitation algorithms in ride-hailing services where drivers do not have clear destination and move more stochasticly in search of passengers. Some studies address driver relocation problem for supply and demand matching in continuous geographical state space. Mguni et.al devise a learning method of Nash equilibrium policies that works when the number of agents is extremely large using mean field game framework (Mguni et al., 2018) (Mguni et al., 2019).
Related to our study, there are many works on fleet management for ride-hailing platform and connected taxi cabs. For instance, Xu et.al designed an order dispatch algorithm to optimize resource utilization and user experience in a global and farsighted view (Xu et al., 2018). Li et.al proposed MARL solutions for order dispatching which supports fully distributed execution (Li et al., 2019). Others have proposed vehicle re-balancing methods for autonomous vehicles (Zhang and Pavone, 2016), considering both global service fairness and future costs. Most of these works ignore the complexity of the fine-grained road network and represent the geographical space as a coarser mesh. This reduces the number of states and allows for simple data structures to be used, which dramatically increases processing speed. By treating supply-demand distribution as an image, recent studies have taken advantage of model-free reinforcement learning to fit optimal relocation policy (Oda and Joe-Wong, 2018) (He and Shin, 2019). While these methods have mostly been validated in coarse-grained spaces as small as one kilometer square, they are not applicable to behavioral models in a sparsely connected road graph. Some studies have done to optimize routing on a road network: passenger-seeking route recommendation for taxi drivers (Yuan et al., 2012) (Qu et al., 2014) and multi-agent routing for mapping using a graph neural network based model (Sykora et al., 2020). Although these approaches can generate behavioral sequences that reflect the context of each agent, they require heavy inference processing for each agent. This is not practical for large-scale simulations of mobility services that simulate thousands of agents traveling over a road network with tens of thousands of nodes.
3. Problem Definition
Our goal to imitate passenger-seeking behaviors of multiple taxis in a road network with unknown dynamics. We aim to simulate agents even under significant variation in the environment seen during training. To simplify the problem, we focus on modeling drivers searching for passengers on a street, not drivers waiting for ride-hailing app requests.
Formally, the taxi-passenger matching problem is defined by player Markov games which characterized the following components.
State of the Markov game at time step is denoted by , which includes the geographical location and empty status of individual agent . The agent position represents a road segment, which corresponds to a node in the strongly connected directed graph representing the road connectivity. is a binary variable, where denotes that the agent is vacant and denotes that the agent is occupied.
Action, stands for the edge to the next road that agent follows. The edge connects the road network’s predecessor node to the successor node . We use bold variables without subscript to denote the concatenation of all variables for all agents (e.g., denotes actions of all agents). Executing causes a matching with passengers with probability and state transition subject to the destination distribution of passengers . This ride trip takes a time step of which depends on the road network distance between nodes and , leading to a transition to . On the other hand, if no matching occurs, the agent transitions to , with a move from the beginning of the road to the beginning of the road , which requires a time step of . Here, we use a mathematical model endowed with temporally extended actions which are also known as options and corresponding decision problem for single-agent is known as a semi-Markov decision process (Sutton et al., 1999) (Tang et al., 2019). In a multi-agent setting, since each agent interacts with an environment asynchronously, a state of the environment needs to be determined at every time step. Thus, we assume that an agent remains in the occupied state while carrying a passenger and no actions to take until it arrived the passenger’s destination. Similarly, a vacant agent traveling on a road is not allowed to take any action until it arrived at next node.
Reward of agent is denoted as . Each action takes a moving cost depending on various factors such as driver preferences. If an agent finds a passenger during executing the action, it receives a reward based on the ride trip time. We assume that agents are not cooperative and the reward function is not shared, but identical for all agents.
Policy, specifies the joint probability of taking action in state . We require agents’ actions in each state to be independent. All agents act to maximize the same objective by executing actions through a stochastic policy . The objective of each agent is maximizing its own expected return where is the discount factor and is the initial state of all agents. We further define expected return . To take bounded rationality into consideration, we introduce logistic quantal response equilibrium as a stochastic generalization to Nash equilibrium, where for each state and action, the constraint is given by (Yu et al., 2019) (McKelvey and Palfrey, 1995):
| (1) |
Since the actual reward function is unknown, we consider the problem of inverse reinforcement learning, which estimates the reward function from the driver’s behavioral trajectory. Function approximation is used in order to regress the feature representation of a state-action onto a real valued reward using a mapping . Starting from the initial state distribution , agents generate a trajectory executing joint policy in the environment, denoted as where stands for the index set of the historical trajectories. Inverse reinforcement learning can be interpreted as estimating the parameters of the reward function by solving the following maximum likelihood estimation problem for the expert’s action trajectory in the given data set :
| (2) |
where are the unique stationary distributions for the equilibrium in Equation (1) induced by .
4. Framework
In this section, we describe our proposed approach to the taxi equilibrium policy learning problem. First, we introduce a mathematical model of ride pick-up probability incorporating the effect of traffic flow on a road network. We then introduce a method for estimating the equilibrium policy given the reward function . Finally, we introduce Spatial Equilibrium Inverse Reinforcement Learning (SEIRL), an algorithm for learning the cost function from the trajectories of multiple drivers. Our formulation is intended to model the passenger-seeking behavior on the streets, but it can be applied to the searching behavior for ride-hailing app requests simply by changing pick-up probability.
| Symbol | Description |
|---|---|
| the number of vehicles | |
| state of the Markov game | |
| state (location on the road network) of agent | |
| action taken by the agent | |
| travel time of action | |
| initial state distribution of state | |
| visitation count of action (or state ) | |
| pick-up probability of action | |
| arrival rate of potential passengers at | |
| dropout rate of potential passengers at | |
| destination distribution of passengers at | |
| ride trip time from to |
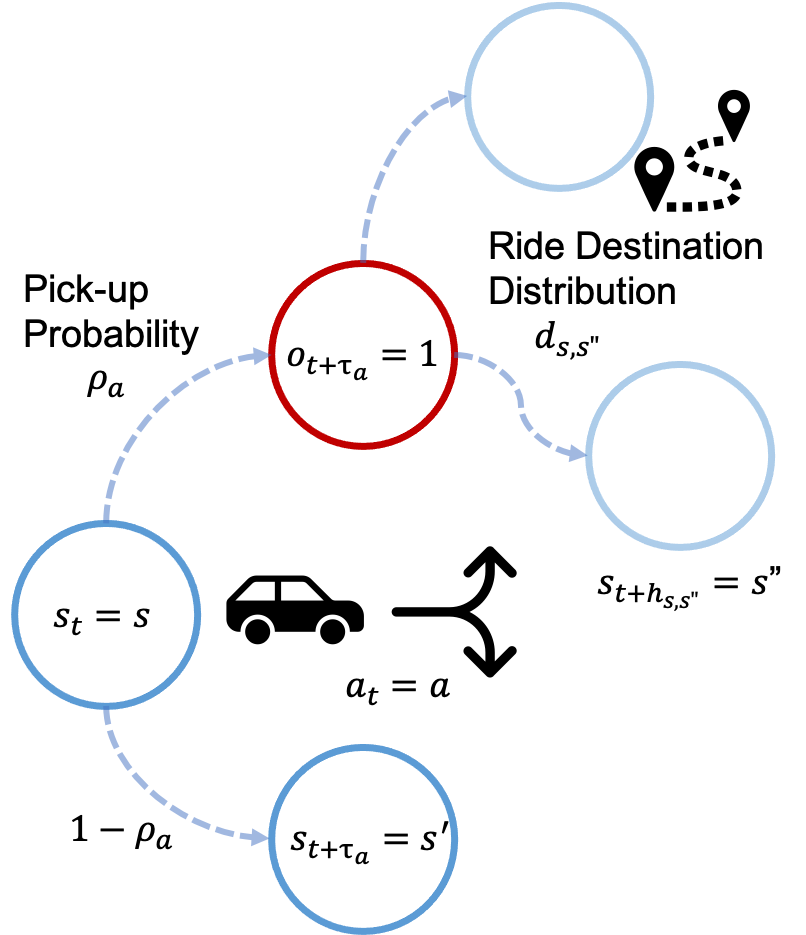

4.1. Pickup Probability Model
While pickups generated on individual road segments are observable, potential passengers who could not catch taxis on streets are not. In order to simulate a driver-passenger matching on a street, we need to estimate potential travel demand for each road segment from observable pickup data. We assume that the probability of the occurrence of a ride for each action should be expressed as a function of the potential demand for the location and the traffic flow rate, or state action visitation count, which is the frequency with which agents perform that action on average. We consider each road as an independent queue model such that a ride will occur if passengers are in the queue when the vehicle passes. Consider a situation where at time , on road , potential passengers occur at a arrival rate and empty vehicles pass at a service rate . There is an upper limit to passenger waiting time which depends on the time and location, and a passenger will disappear at a certain dropout rate . Assuming that the waiting queue length follows a Poisson distribution with an mean of , the number of rides and the probability of ride occurrence are represented as:
| (3) |
where and are unknown parameters we want to estimate and is a given state action visitation count. Given the observational daily draws of vehicle flow and the number of rides , we can estimate and by the maximum likelihood estimation method using the following formula:
| (4) |
Once we got parameters and , we can compute pick-up probability for arbitrary visitation count by equation 3.
4.2. Equilibrium MDP formulation
In general, although the dynamics of the environment, including all vehicle states, are often complex and difficult to model accurately, we can formulate the problem in a tractable way under mild assumptions that we will describe.
Assuming that changes in environmental parameters, such as potential demand, are gradual with respect to the agent’s discount rate , we no longer need to consider changes in environmental parameters over time and can assume that environmental parameters are fixed in the current context to determine the agent’s policies. In this case, since environment is static, each agent acts according to a policy of equilibrium state reached if it has been in the current environment for an infinite amount of time. In other words, estimating policies for different time periods can be treated as different Markov games with different environmental parameters. For example, if we divide the time of day into 30-minute slots, agents act according to an equilibrium policy depending on demand and travel time during the 9:00-9:30 am period, but from 9:30-10:00 am, the environmental parameters change and the equilibrium policy changes accordingly. Thus, we do not include the time of day and season in the state, but call it a context when the transition probability changes, although the state action space is the same.
Since real taxi drivers do not have access to real-time supply-demand distribution, it is natural to expect that they are acting to maximize profitability based on the average supply-demand distribution obtained from their previous experience, not on current states of the environment. Thus, we further assume that, in equilibrium, pickup probability at time on the date can be replaced with expectation over daily draws , i.e., , which is uniquely determined regardless of the current state. As explained in 4.1, the pick-up probability for a given action depends on the demand and the state-action visitation count, meaning that the visitation count of current policy can completely determine the dynamics of the environment.
Given visitation count , each agent policy becomes completely independent on other agents and we can reformulate the multi-agent policy learning problem corresponding to the result of repeatedly applying a stochastic entropy-regularized best response mechanism as the following single-agent forward RL problem:
| (5) |
Suppose we know the reward function . Then, the optimal policy can be computed by iterating following Bellman backups in a single-agent MDP:
| (6) | ||||
where we assume the reward function can be represented as , which is expected pick-up bonus (pick-up probability multiplied by expected fare revenue ) minus linear action cost dependent on features associated with . Since taxi drivers in many countries, including Japan, work on a commission basis, it is natural to think of them as basically acting to minimize idle time and maximize their income. However, many other factors, including familiarity with the area and the level of danger on that road, can be considered as a cost for drivers.
The shared drivers policy is given by
| (7) |
The visitation count corresponding to traffic flow rate can be obtained by propagating state distributions of agents by executing policy starting from passenger drop-off distribution as initial state distribution. Since we assume that the total number of vehicles is constant and the average total number of empty vehicles can be calculated as by Little’s law, the average drop-off rate, i.e. initial state distribution, is approximated by , where is average ride trip time. Given initial state distribution , the visitation count of policy satisfies
| (8) |
We can compute the policy and visitation count at the equilibrium which holds Equations (6), (7), (8) by iterating Value Iteration and policy propagation, presented in Algorithm 1. First, at the beginning of each iteration, we update the pick-up probability and the initial state distribution according to the previous visitation count, and then we iterate Bellman backups according to Equation 6 to find the optimal policy. Next, we compute the expected visitation count by probabilistically traversing the MDP given the current policy, starting from the initial state distribution. The weighted sum of the previous iteration is used in order to suppress the abrupt changes and to stabilize the algorithm. The process is repeated until mismatch distance ratio between and falls below the threshold, i.e., where is given by Equation 12.
4.3. Equilibrium IRL
Given the expert’s visitation count , our goal is to estimate the parameters of the reward function such that the visitation count in equilibrium is consistent with . Similar to Equation (5), we can simplify multi-agent IRL problem by decomposing likelihood function in Equation (2) into probability of individual agents’ trajectories.
| (9) |
Theorem 1.
Unlike the case of a normal single agent, the transition probability also depends on through and computing the gradient of the second term is not tractable. We further assume and substitute the Taylor expansion of Equation 3:
| (11) | ||||
As can be seen, we have shown that the gradient of the likelihood of multi-agent trajectories can approximate the gradient of MaxEnt IRL, under the assumption , which is satisfied in most cases of ride-hailing services. In addition, as depends on through and computing the gradient is intractable, we drop the pick-up bonus term from reward function . We empirically confirmed that, without pick-up bonus term, reward learning becomes more stable and robust. The entire reward learning process is shown in Algorithm 2, which iterates through the estimation of the equilibrium policy and the visitation count in Algorithm 1 and reward parameter updates with exponentiated gradient descent. In order to prevent abrupt change in weight , we divide gradient by .
5. Experiments
We showcase the effectiveness of the proposed framework for addressing changes in dynamics and data losses in series of simulated experiments using real taxi trajectory data.
5.1. Data Preparation

Width of lines describe visitation count of vacant taxi
For data analytics and performance evaluation, we used taxi trajectories, collected in the city of Yokohama, Kanagawa, Japan during the period between June 2019 and June 2020 sampled at a period of 3-10 seconds. The original raw dataset contains the driver id, trip id, latitude, longitude, and timestamp of the empty vehicle. The first record of each trip id stands for drop off point or market entry point and the last record stands for a pick up point. As a pre-processing, the GPS information was linked to the roads by map-matching, and the routes between the roads were interpolated with the shortest routes to enable aggregation of the data per road, which resulted in low loss ratio. The road network in the region contained 10765 road segments (nodes) and 18649 transitions (edges).
The road travel time was averaged over the time spent on the same road, and any missing data were filled in with the average for each road class.
The behavioral model was evaluated for the period 7:00-22:00 Monday-Thursday. The late night to early morning period was omitted from the evaluation period because there are fewer passengers on streets. For the evaluation, the data set was divided into the following four periods.
-
•
Profile: 12 weeks starting from 2019-04-01
-
•
Train: 12 weeks starting from 2019-07-01
-
•
19Dec: 8 weeks starting from 2019-12-12
-
•
20Apr: 4 weeks starting from 2020-04-01
In each dataset, we treated each 30-minute period as a different context, and in each context we aggregated the number of rides , the number of empty vehicles passing through and the number of vehicles in initial condition on a road-by-road basis. To fit the pick-up probability model in Equation (3), we used daily draws of in Profile dataset.
The number of half-hourly rides in each dataset is shown in Figure 3. While Train dataset was collected in summer 2019, the period of 19Dec is colder holiday season of winter 2019, indicating that 19Dec has a different context than Train dataset at the same hour of day. For 20Apr, the environment is significantly different due to the sharp drop in demand due to COVID-19. By comparing the accuracy in these datasets, we assessed the robustness of the learned policies to the impact of changing dynamics on seasonal variations.

5.2. Implementation Details
For reward features, we use map attributes including travel time, road class and type of turn, in addition to the statistical features extracted from the Profile dataset, such as how frequent the road was traversed. Additionally, to incorporate unobservable fixed effects of certain actions, we include unique features associated with each actions. This allows the cost of each action to vary independently. Also, L2 regularization is added to the gradient for preventing overfitting. Training iteration is 100 and learning rate is 1.0, multiplied by 0.98 for each iteration to stabilize training. We partitioned time by 3 hours and learned different cost weights for each time zone: 7:00-10:00, 10:00-13:00, 13:00-16:00, 16:00-19:00, 19:00-22:00.
5.3. Evaluation Methods
We compare our apporach with the following baselines.
Opt: We let cost to be travel time and obtain the policy by Value Iteration when initial visitaion count belief is the one in the training dataset.
SE-Opt We let cost to be travel time and obtained equilibrium policy by Algorithm 1.
Tr-Expert Expert policy is calculated from the statistics of the training dataset period .
The Mismatch Distance Ratio (MDR) was used as an accuracy measure of the proximity of the obtained policies to the expert policies, which is given by
| (12) |
where is the length of the road.
The evaluation of SEIRL was performed as follows. First, we estimate the parameters of the cost function to fit the expert visitation count of Train dataset. When evaluating 19Dec or 20Apr dataset, using the environment parameters of each context (every 30 minutes between 7:00 and 22:00) and the learned cost function associated with the context, Algorithm 1 is used to estimate the equilibrium policy. We then calculate the equilibrium visitation count by repeating the policy propagation and compare it with by MDR.
6. Results and Discussion
| Normal | Disabled | Defect5% | Defect10% | |||||
| 19Dec | 20Apr | 19Dec | 20Apr | 19Dec | 20Apr | 19Dec | 20Apr | |
| policy | ||||||||
| Opt | 2.867 | 2.381 | 2.780 | 2.321 | 2.867 | 2.381 | 2.867 | 2.381 |
| SE-Opt | 0.943 | 1.076 | 0.923 | 1.078 | 0.943 | 1.076 | 0.943 | 1.076 |
| SEIRL | 0.223 | 0.328 | 0.291 | 0.391 | 0.363 | 0.485 | 0.411 | 0.543 |
| Tr-Expert | 0.230 | 0.349 | 0.726 | 0.813 | 0.437 | 0.553 | 0.542 | 0.642 |
| Expert | 0.099 | 0.123 | 0.128 | 0.160 | 0.099 | 0.123 | 0.099 | 0.123 |
Using the reward function learned from Train dataset, we evaluated imitation performance of each policy for test datasets (19Dec and 20Apr). The MDR for each policy is shown in the Normal column of Table 2. SEIRL scored the best for both environments, with an error of about 33% during COVID-19 pandemic. There is a large gap between SE-Opt and SEIRL, which can be interpreted as drivers minimizing a more complex reward function rather than simply taking the shortest possible route to potential customers. The fact that SE-Opt is significantly better than Opt indicate that computing the policy in equilibrium has a significant impact on improving imitation accuracy.
Figure 4 visualizes examples of the estimated state value during morning and evening. The clear difference in two geospatial distributions shows that drivers use significantly different policies depending on the context.


The computation time required to update the policy is polynomial to the network size, but not dependent on the number of agents. Depending on the hardware environment, with the problem size of Yokohama city, the policy can be updated in a few seconds even on a single CPU, which is sufficient for real-time computing applications.
6.1. Disabled Area
In order to evaluate the impact of a larger change in dynamics, we next conducted an experiment in which demand in Nishi-ku region (the pink area in Figure 2) is artificially eliminated. Since the spatial distribution of potential demand changes significantly, the actual policy is expected to be very different from the policy in the training enviroment. The ground truth visitation count was created by removing trips that occurred in Nishi-ku region over the same period for the datasets. The result is shown in the Disabled column in Table 2, where SEIRL is the best, significantly ahead of Tr-Expert. These results demonstrate that SEIRL has a high generalization performance.
6.2. Data Loss
Furthermore, since real-life vehicle logs may be missing for various reasons, we evaluated the impact of missing data. The dataset used so far composed of trajectories interpolated by connecting GPS data with the shortest path in order to eliminate the influence of data noise. For actual applications, it is desirable to have good generalization performance even when training on a missing dataset. Therefore, we randomly sampled the nodes (states) of the road network and created the defected training dataset and features with all the data of those states missing, and performed the same evaluation. No specific changes were made to the evaluation dataset. The experiments were conducted for two conditions with a missing percentage of 5% and 10%, and the SEIRL had the lowest MDR in both conditions. In addition, the ratio of MDR deterioration to Normal at 19Dec/20Apr in the 5% deficiency condition was 1.89/1.59 for Tr-Expert compared to 1.63/1.48 for SEIRL. In the 10% deficiency condition, the accuracy deterioration was 2.35/1.84 for Tr-Expert and 1.84/1.65 for SEIRL, which demonstrates that SEIRL is more robust to missing data. Half-hourly MDRs at 5% loss are shown in Figure 5. We confirmed that SEIRL outperformed Tr-Expert at almost all time points.

6.3. Counterfactual Simulation
Finally, as an example of counterfactual simulation using the learned driver behavior model, we demonstrate the optimization of the quantity of supply in a ride-hailing service. The market supply is often determined by the drivers’ decision to enter the market and is not directly controlled. However, it should be possible to adjust the number of drivers entering the market indirectly to some extent by providing some kind of information or incentive to the drivers. The learned driver behavior model can be used to simulate at an arbitrary number of vehicles , thus allowing us to find the optimal amount of supply. Now, suppose that the platform objective is represented by the following:
| (13) |
Here, the first term corresponds to the average revenue on the road , i.e., the number of rides multiplied by the average fare per ride at . The second term represents total cost including fuel and personnel fee, which is assumed to be proportional to driving time. is proportionality constant. is state-action visitation count produced by executing the learned policy in -agents simulation. We varied the number of vehicles per half hour from the current rate of 0.5 to 1.5, and determined the number of vehicles at each time slot with the largest platform objective. The optimized number of vehicles and the objective for are shown in Figure 6. It can be seen that the number of vehicles is lower than the current supply from the end of the morning peak to around 16:00, while it should be increased after 16:00 18:00 and 20:30.







7. Conclusions
This paper proposed the first approach to multi-agent behavioral modeling and reward learning in equilibrium on a road network for a ride-hailing service. We focused on a ride-hailing vehicle network where each driver is uncooperatively searching for passengers on streets. Our proposed MDP formulation enables efficient and scalable simulation by computing the optimal policy in equilibrium shared between agents. We developed a reward learning framework integrated MaxEnt IRL and demonstrated that our method is able to recover policies that are robust to significant variation in dynamics.
Although our proposed method assumes all agents are homogeneous, in reality, driver behavior patterns can vary due to several factors. A possible extension could include learning routing patterns of heterogeneous agents considering multiple garage locations (cab offices). One may also be interested in equilibrium modeling that takes into account the effect of travel time due to congestion such as traffic jams, in addition to matching with passengers.
References
- (1)
- Abbeel and Ng (2004) Pieter Abbeel and Andrew Y Ng. 2004. Apprenticeship learning via inverse reinforcement learning. In Proceedings of the twenty-first international conference on Machine learning. 1.
- Altman et al. (2006) Eitan Altman, Thomas Boulogne, Rachid El-Azouzi, Tania Jiménez, and Laura Wynter. 2006. A survey on networking games in telecommunications. Computers & Operations Research 33, 2 (2006), 286–311.
- Fu et al. (2017) Justin Fu, Katie Luo, and Sergey Levine. 2017. Learning robust rewards with adversarial inverse reinforcement learning. arXiv preprint arXiv:1710.11248 (2017).
- He and Shin (2019) Suining He and Kang G Shin. 2019. Spatio-temporal capsule-based reinforcement learning for mobility-on-demand network coordination. In The World Wide Web Conference. 2806–2813.
- Ho and Ermon (2016) Jonathan Ho and Stefano Ermon. 2016. Generative adversarial imitation learning. In Advances in neural information processing systems. 4565–4573.
- Hu et al. (1998) Junling Hu, Michael P Wellman, et al. 1998. Multiagent reinforcement learning: theoretical framework and an algorithm.. In ICML, Vol. 98. Citeseer, 242–250.
- Li et al. (2019) Minne Li, Zhiwei Qin, Yan Jiao, Yaodong Yang, Jun Wang, Chenxi Wang, Guobin Wu, and Jieping Ye. 2019. Efficient ridesharing order dispatching with mean field multi-agent reinforcement learning. In The World Wide Web Conference. 983–994.
- Lin et al. (2019) Xiaomin Lin, Stephen C Adams, and Peter A Beling. 2019. Multi-agent inverse reinforcement learning for certain general-sum stochastic games. Journal of Artificial Intelligence Research 66 (2019), 473–502.
- Lin et al. (2017) Xiaomin Lin, Peter A Beling, and Randy Cogill. 2017. Multiagent inverse reinforcement learning for two-person zero-sum games. IEEE Transactions on Games 10, 1 (2017), 56–68.
- McKelvey and Palfrey (1995) Richard D McKelvey and Thomas R Palfrey. 1995. Quantal response equilibria for normal form games. Games and economic behavior 10, 1 (1995), 6–38.
- Mguni et al. (2018) David Mguni, Joel Jennings, and Enrique Munoz de Cote. 2018. Decentralised learning in systems with many, many strategic agents. arXiv preprint arXiv:1803.05028 (2018).
- Mguni et al. (2019) David Mguni, Joel Jennings, Sergio Valcarcel Macua, Emilio Sison, Sofia Ceppi, and Enrique Munoz de Cote. 2019. Coordinating the crowd: Inducing desirable equilibria in non-cooperative systems. arXiv preprint arXiv:1901.10923 (2019).
- Natarajan et al. (2010) Sriraam Natarajan, Gautam Kunapuli, Kshitij Judah, Prasad Tadepalli, Kristian Kersting, and Jude Shavlik. 2010. Multi-agent inverse reinforcement learning. In 2010 Ninth International Conference on Machine Learning and Applications. IEEE, 395–400.
- Oda and Joe-Wong (2018) Takuma Oda and Carlee Joe-Wong. 2018. MOVI: A model-free approach to dynamic fleet management. In IEEE INFOCOM 2018-IEEE Conference on Computer Communications. IEEE, 2708–2716.
- Pomerleau (1991) Dean A Pomerleau. 1991. Efficient training of artificial neural networks for autonomous navigation. Neural computation 3, 1 (1991), 88–97.
- Qu et al. (2014) Meng Qu, Hengshu Zhu, Junming Liu, Guannan Liu, and Hui Xiong. 2014. A cost-effective recommender system for taxi drivers. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. 45–54.
- Sutton et al. (1999) Richard S Sutton, Doina Precup, and Satinder Singh. 1999. Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning. Artificial intelligence 112, 1-2 (1999), 181–211.
- Sykora et al. (2020) Quinlan Sykora, Mengye Ren, and Raquel Urtasun. 2020. Multi-agent routing value iteration network. arXiv preprint arXiv:2007.05096 (2020).
- Tang et al. (2019) Xiaocheng Tang, Zhiwei Qin, Fan Zhang, Zhaodong Wang, Zhe Xu, Yintai Ma, Hongtu Zhu, and Jieping Ye. 2019. A deep value-network based approach for multi-driver order dispatching. In Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining. 1780–1790.
- Waugh et al. (2013) Kevin Waugh, Brian D Ziebart, and J Andrew Bagnell. 2013. Computational rationalization: The inverse equilibrium problem. arXiv preprint arXiv:1308.3506 (2013).
- Xu et al. (2018) Zhe Xu, Zhixin Li, Qingwen Guan, Dingshui Zhang, Qiang Li, Junxiao Nan, Chunyang Liu, Wei Bian, and Jieping Ye. 2018. Large-scale order dispatch in on-demand ride-hailing platforms: A learning and planning approach. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 905–913.
- Youn et al. (2008) Hyejin Youn, Michael T Gastner, and Hawoong Jeong. 2008. Price of anarchy in transportation networks: efficiency and optimality control. Physical review letters 101, 12 (2008), 128701.
- Yu et al. (2019) Lantao Yu, Jiaming Song, and Stefano Ermon. 2019. Multi-agent adversarial inverse reinforcement learning. arXiv preprint arXiv:1907.13220 (2019).
- Yuan et al. (2012) Nicholas Jing Yuan, Yu Zheng, Liuhang Zhang, and Xing Xie. 2012. T-finder: A recommender system for finding passengers and vacant taxis. IEEE Transactions on knowledge and data engineering 25, 10 (2012), 2390–2403.
- Zhang and Pavone (2016) Rick Zhang and Marco Pavone. 2016. Control of robotic mobility-on-demand systems: a queueing-theoretical perspective. The International Journal of Robotics Research 35, 1-3 (2016), 186–203.
- Ziebart et al. (2008a) Brian D Ziebart, Andrew L Maas, J Andrew Bagnell, and Anind K Dey. 2008a. Maximum entropy inverse reinforcement learning.. In Aaai, Vol. 8. Chicago, IL, USA, 1433–1438.
- Ziebart et al. (2008b) Brian D Ziebart, Andrew L Maas, Anind K Dey, and J Andrew Bagnell. 2008b. Navigate like a cabbie: Probabilistic reasoning from observed context-aware behavior. In Proceedings of the 10th international conference on Ubiquitous computing. 322–331.
Appendix A Appendix
A.1. Maximum Likelihood Estimation for SEIRL
In this section, we include derivation of Equation (10) and (11). From Equation (9), the likelihood function is given by:
| (14) | ||||
Take derivatives of :
| (15) | ||||
where we define
| (16) | ||||
which represent visitation frequencies of state , action and next state in the expert trajectories and a learned policy .
Since we assumed that reward function influences dynamics only through pick-up probability which depends on visitation count , we only consider for transition probability:
| (17) | ||||
In Equation 3, suppose , we can approximate pick-up probability by the Taylor expansion:
| (18) |