Epidemic changepoint detection
in the presence of nuisance changes
Abstract
Many time series problems feature epidemic changes – segments where a parameter deviates from a background baseline. The number and location of such changes can be estimated in a principled way by existing detection methods, providing that the background level is stable and known. However, practical data often contains nuisance changes in background level, which interfere with standard estimation techniques. Furthermore, such changes often differ from the target segments only in duration, and appear as false alarms in the detection results.
To solve these issues, we propose a two-level detector that models and separates nuisance and signal changes. As part of this method, we developed a new, efficient approach to simultaneously estimate unknown, but fixed, background level and detect epidemic changes. The analytic and computational properties of the proposed methods are established, including consistency and convergence. We demonstrate via simulations that our two-level detector provides accurate estimation of changepoints under a nuisance process, while other state-of-the-art detectors fail. Using real-world genomic and demographic datasets, we demonstrate that our method can identify and localise target events while separating out seasonal variations and experimental artefacts.
Keywords: Change point detection, Epidemic change points, Piecewise stationary time series, Segmentation, Stochastic gradient methods
1 Introduction
The problem of identifying when the probability distribution of a time series changes – changepoint detection – has been studied since the middle of the 20th century. Early developments, such as Shewhart’s control charts (Shewhart, 1930) and Page’s CUSUM test (Page, 1954), stemmed from operations research. However, as automatic sensing systems and continuous data collection became more common, many new use cases for changepoint detection have arisen, such as seismic events (Li et al., 2016), epidemic outbreaks (Texier et al., 2016), physiological signals (Vaisman et al., 2010), market movements (Bracker and Smith, 1999), and network traffic spikes (Hochenbaum et al., 2017). Stimulated by such practical interest, the growth of corresponding statistical theory has been rapid, as reviewed in e.g. Aminikhanghahi and Cook (2016) and Truong et al. (2020).
Different applications pose different statistical challenges. If a single drastic change may be expected, such as when detecting machine failure, the goal is to find a method with minimal time to detection and a controlled false alarm rate (Lau and Tay, 2019). In many other applications the number of changepoints is unknown a priori; the challenge is then to identify the change locations regardless, preferably in a computationally efficient way. Some problems, such as peak detection in sound (Aminikhanghahi and Cook, 2016) or genetic data (Hocking et al., 2017), feature epidemic segments – changepoints followed by a return to the background level – and incorporating this constraint can improve detection or simplify post-processing of ouputs.
However, current detection methods that do incorporate a background level assume it to be stable throughout the dataset (e.g. Fisch et al., 2018; Zhao and Yau, 2019). This is not realistic in several common applications. In genetic analyses such as measurements of protein binding along DNA there may be large regions where the observed background level is shifted due to structural variation in the genome or technical artefacts (Zhang et al., 2008). Similarly, a standard task in sound processing is to detect speech in the presence of dynamic background chatter, so-called babble noise (Pearce et al., 2000). In various datasets from epidemiology or climatology, such as wave height measurements (Killick et al., 2012), seasonal effects are observed as recurring background changes and will interfere with detection of shorter events. Methods that assume a constant background will be inaccurate in these cases, while ignoring the epidemic structure entirely would cost detection power and complicate the interpretation of outputs.
Our goal is to develop a general method for detecting epidemic changepoints in the presence of nuisance changes in the background. Furthermore, we assume that the only available feature for distinguishing the two types of segments is their duration: this would allow analysing the examples above, which share the property that the nuisance process is slower. The most similar research to ours is that of Lau and Tay (2019) for detecting failure of a machine that can be switched on, and thus undergo an irrelevant change in the background level. However, the setting there concerned a single change with specified background and nuisance distributions; in contrast, we are motivated by the case when multiple changes may be present, with only duration distinguishing their types. Detection then requires two novel developments: 1) rapid estimation of local background level, 2) modelling and distinguishing the two types of potentially overlapping segments.
These developments are presented in this paper as follows: after a background section we provide a new algorithm that simultaneously detects epidemic changepoints and estimates the unknown background level (Section 3). The convergence and consistency of this algorithm are proved in the Supplementary Material. While this algorithm is of its own interest, we use it to build a detector that allows local variations in the background, i.e., nuisance changes, in Section 4, again with proven properties. In Section 5 we test various properties of the algorithms with simulations before showing how the proposed nuisance-robust detector can be applied in two problems: detecting histone modifications in human genome, while ignoring structural variations, and detecting the effects of the COVID-19 pandemic in Spanish mortality data, robustly to seasonal effects. Compared to state-of-the-art methods, the proposed detector produced lower false-alarm rates (or more parsimonious models), while retaining accurate detection of true signal peaks.
2 Background
In the general changepoint detection setup, the data consists of a sequence of observations , split by changepoints into segments. Within each segment the observations are drawn from a distribution specific to that segment; these are often assumed to belong to some fixed family , with different values of parameter for each segment. The most common and historically earliest example is the change in mean of a Gaussian (see Truong et al. (2020)), i.e., for each , , for known, fixed . (We assume to keep notation clearer, but multidimensional problems are also common, such as when both the mean and variance of a Gaussian are subject to change.)
While early research focused on optimal hypothesis testing of a single change against no change in a parameter, modern models aim to estimate the position of all changepoints in a given time series, and optionally the vector of segment parameters . A common approach is to use a penalised cost: choose a segment cost function , usually based on negative log-likelihood of the observations given , and a penalty for the number of changepoints . The full cost of (where and ) is then:
| (1) |
Changepoint number and positions are estimated by finding . Such estimation has been shown to be consistent for a range of different data generation models (Fisch et al., 2018; Zheng et al., 2019).
For a discrete problem such as this, computation of the true minimum is not trivial – a naïve brute force approach would require tests. Approaches to reducing this cost fall in two broad classes: 1) simplifying the search algorithm by memoisation and pruning of paths (Jackson et al., 2005; Killick et al., 2012; Rigaill, 2015); 2) using greedy methods to find approximate solutions faster (Fryzlewicz, 2014; Baranowski et al., 2019). In both classes, there are methods that can consistently estimate multiple changepoints in linear time under certain conditions.
The first category is of more relevance here. It is based on the Optimal Partitioning (OP) algorithm (Jackson et al., 2005). Let the data be partitioned into discrete blocks , so . A function that maps each set of blocks to a cost is block-additive if:
| (2) |
If each segment incurs a fixed penalty , then the function defined in (1) is block-additive over segments, and can be defined recursively as:
In OP, this cost is calculated for each , and thus its minimisation requires evaluations of . Furthermore, when the cost function is such that for all :
| (3) |
then at each , it can be quickly determined that some candidate segmentations cannot be “rescued” by further segments, and so they can be pruned from the search space. This approach reduces the complexity to in the best case. It gave rise to the family of algorithms called PELT, Pruned Exact Linear Time (Killick et al., 2012; Zhao and Yau, 2019). Note that OP and PELT do not rely on any probabilistic assumptions and find the exact same minimum as the global exponential-complexity search. Since the introduction of PELT, a number of alternative pruning schemes have been developed (Maidstone et al., 2016).
A variation on the basic changepoint detection problem is the identification of epidemic changepoints, when a change in regime appears for a finite time and then the process returns to the background level. The concept of a background distribution is introduced, and the segments are defined by pairs of changepoints , outside of which the data is drawn from the background model. The data model then becomes:
| (4) |
An equivalent of the CUSUM test for the epidemic situation was first proposed by Levin and Kline (1985), and a number of methods for multiple changepoint detection in this setting have been proposed (Olshen et al., 2004; Fisch et al., 2018; Zhao and Yau, 2019). These use a cost function that includes a separate term for the background points:
| (5) |
A common choice for the background distribution is some particular “null” case of the segment distribution family, so that and . However, while the value of is known in some settings (such as when presented with two copies of DNA), in other cases it may need to be estimated. Since this parameter is shared across all background points, the cost function is no longer block-additive as in (2), and algorithms such as OP and PELT cannot be directly applied.
One solution is to substitute the unknown parameter with some robust estimate of it, based on the unsegmented series . The success of the resulting changepoint estimation then relies on this estimate being sufficiently close to the true value, and so the non-background data fraction must be small (Fisch et al., 2018). This is unlikely to be true in our motivating case, when nuisance changes in the background level are possible.
Another option is to define
which can be minimised using OP or PELT, and then use gradient descent for the outer minimisation over (Zhao and Yau, 2019). The main drawback of this approach is an increase in computation time proportional to the number of steps needed for the optimisation.
3 Detection of changepoints with unknown background parameter
To estimate the background parameter and changepoints efficiently, while allowing a large proportion of non-background data, we introduce Algorithm 1. The algorithm makes a pass over the data, during which epidemic segments are detected in a standard way, i.e., by minimising penalized cost using OP (steps 3-12). The estimate of parameter is iteratively updated at each time point. We will show that this process converges almost surely to the true for certain models of background and segment levels, or reaches its neighbourhood under more general conditions.
The algorithm then makes a second pass over the data (step 13), repeating the segmentation using the final estimate of . The step is identical to a single application of a known-background changepoint detector, such as the one described in Fisch et al. (2018). Its purpose is to update the changepoint positions that are close to the start of the data and so had been determined using less precise estimates of . This simplifies the theoretical performance analysis, but an attractive option is to use this algorithm in an online manner, without this step. We evaluate the practical consequences of this omission later in Section 5.
By segmenting and estimating the background simultaneously, this algorithm is computationally more efficient than dedicated optimisation over possible values as in Zhao and Yau (2019), while allowing a larger fraction of non-background points than using a robust estimator on unsegmented data, as in Fisch et al. (2018).
We now demonstrate that Algorithm 1 will converge almost surely under certain constraints, and is consistent.
3.1 Convergence
Theorem 1.
Consider the problem of an epidemic change in mean, with data generated as in (4). Assume the distribution and marginal distribution of segment points are symmetric and strongly unimodal, with unknown background mean , and that data points within each segment are iid. Here, is the probability density of parameter corresponding to each data point. Denote by the estimate of obtained by analysing by Algorithm 1. The sequence converges:
-
1.
to almost surely, if .
-
2.
to a neighbourhood almost surely, where as the number of background points between successive segments .
We refer the reader to Appendix A for the proof. It is based on a result by Bottou (1998), who established conditions under which an online minimisation algorithm almost surely converges to the optimum (including stochastic gradient descent as a special case). We show that these conditions are either satisfied directly by the updating process in our algorithm, or longer update cycles can be defined that will satisfy the conditions, in which case the convergence efficiency is determined by .
3.2 Consistency
The changepoint model can be understood as a function over an interval that is sampled to produce observed points. As the sampling density increases, more accurate estimation of the number and locations of changepoints is expected; this property is formalised as consistency of the detector. Fisch et al. (2018) showed that detectors based on minimising penalised cost are consistent in the Gaussian data case, and their result can be adapted to prove consistency of Algorithm 1. We will use the strengthened SIC-type penalty as presented in Fisch et al. (2018), but a similar result can be obtained with .
Additionally, the minimum signal-to-noise ratio at which segments can be detected is formalised as this assumption:
| (6) |
where is a function of the relative strength of the parameter changes and .
Theorem 2.
Let the data be generated from an epidemic changepoint model as in (4), with and Gaussian, and the changing parameter is either its mean or variance (assume the other parameter is known). Further, assume (6) holds for changepoints. Analyse the data by Algorithm 1 with penalty , . The estimated number and position of changepoints will be consistent, i.e. :
| (7) |
for some that do not increase with .
3.3 Pruning
Much of the improvement in performance of change estimation algorithms comes from pruning of the search space. Standard pruning (Killick et al., 2012) can be applied to Algorithm 1. It continues to find optimal solutions in this case, as is shown in Proposition 1.
To implement pruning, the search set for in step 4 would be changed to:
and step 11a would be introduced to update as:
Proposition 1.
Assume a cost function such that (3) applies. If, for some :
then will not be a segment start point in the optimal solution, and can be excluded from consideration for all subsequent .
Proof.
For all , the proof applies as for other pruned algorithms (Killick et al., 2012):
For , segment will exceed the length constraint and thus cannot be part of the final segmentation. ∎
4 Detecting changepoints with a nuisance process
4.1 Problem setup
In this section, we consider the changepoint detection problem when there is an interfering nuisance process. We assume that this process, like the signal, consists of segments, and we index the start and end times as . Data within these segments is generated from a nuisance-only distribution , or from some distribution if a signal occurs at the same time. In total, four states are possible (background, nuisance, signal, or nuisance and signal), so the overall distribution of data points is:
| (8) |
We add two more conditions to ensure identifiability: 1) the nuisance process evolves more slowly than the signal process, so ; 2) signal segments are either entirely contained within a nuisance segment, or entirely out of it:
| (9) |
We adapt the changepoint detection method as follows. Define , a penalty for the number of nuisance segments, and cost functions corresponding to each of the distributions in (8). Then the full cost of a model with true segments and nuisance segments is:
| (10) |
Note that this cost can also be expressed, using as the number of signal segments that overlap a nuisance segment and , as:
Condition (9) ensures that and are independent (no points or are shared between them), so is block-additive over (signal or nuisance) segments and can be minimised by dynamic programming.
4.2 Proposed method
To minimise this cost, we propose the method outlined in Algorithm 2. Its outer loop proceeds over the data to identify segments by the usual OP approach. However, to evaluate the cost , which allows segment and nuisance overlaps, a changepoint detection problem with unknown background level must be solved over . This is achieved by an inner loop using Algorithm 1. If , this method would reduce to a standard detector of epidemic changepoints, with the exception that segments are separated into two types depending on their length; this is very similar to the collective and point anomaly (CAPA) detector in Fisch et al. (2018).
The cost is minimised using Algorithm 1, so by Theorem 2, the number of positions of true segments will be estimated consistently given accurate assignment of the nuisance positions . However, the latter event is subject to a complex set of assumptions on relative signal strength, position, and duration of the segments. Therefore, we do not attempt to describe these in full here, but instead investigate the performance of the method by extensive simulations in Section 5.1.3.
Algorithm 2 is stated assuming that a known or estimated value of the parameter , corresponding to the background level without the nuisance variations, is available. In practice, it may be known when there is a technical noise floor or a meaningful baseline that can be expected after removing the nuisance changes. Alternatively, may be estimated by a robust estimator if a sufficient fraction of background points can be assumed; in either case, the (known or estimated) value is substituted to reduce the computational cost. Otherwise, the method can be modified to estimate simultaneously with segmentation, using a principle similar to Algorithm 1.
4.3 Pruning
In the proposed method, the estimation of parameter (the mean of segment ) is sensitive to the segment length, therefore the cost does not necessarily satisfy the additivity condition (3), and so it cannot be guaranteed that PELT-like pruning will be exact. However, we can establish a local pruning scheme that retains the exact optimum with probability as .
Proposition 2.
Assume data is generated from a Gaussian epidemic changepoint model, and that the distance between changepoints is bounded by some function :
At time , the solution space is pruned by removing:
| (11) |
Here . Then , there exist constants , such that when , the true nuisance segment positions are retained with high probability:
The proof is given in Appendix C. The assumed distance bound serves to simplify the detection problem: within each window , at most 1 true changepoint may be present, and the initial part of Algorithm 2 is identical to a standard epidemic changepoint detector. It can be shown that other candidate segmentations in the pruning window are unlikely to have significantly lower cost than the one associated with , and therefore are likely to be retained in pruning.
As this scheme only prunes within windows of size , and setting large may violate the true data generation model, it is less efficient than PELT-type pruning. However, assuming that the overall estimation of nuisance and signal changepoints is consistent, Proposition 2 extends to standard pruning over the full dataset. We show that this holds empirically in Section 5.1.3.
5 Experiments
In this section, we present the results of simulations used to evaluate the performance of the methods, and demonstrations on real-world datasets.
The methods proposed in this paper are implemented in R 3.5.3, and available on GitHub at https://github.com/jjuod/changepoint-detection. The repository also includes the code for recreating the simulations and data analyses presented here.
5.1 Simulations
5.1.1 Algorithm 1 estimates the background parameter consistently
In the first experiment we tested the performance of the algorithm with a fixed background parameter. Three different sets of data were generated and used:
Scenario 1. Gaussian data with one signal segment: data points were drawn as , with a segment of at times , and otherwise (background level).
Scenario 2. Gaussian data with multiple signal segments: data points were drawn as , with:
Scenario 3. Heavy tailed data with one signal segment: data points were drawn from the generalized distribution as , with at times and otherwise (background level).
To evaluate the background level () estimation by Algorithm 1, we generated time series for each of the three scenarios with values of between 30 and 750, with 500 replications for each . Note that the segment positions remain the same for all sample sizes, so the increase in could be interpreted as denser sampling of the time series.
Each time series was analysed using Algorithm 1 to estimate . The maximum segment length was set to and the penalty to . The cost was computed using the Gaussian log-likelihood function with known variance. This means that the cost function was mis-specified in Scenario 3, and so provides a test of the robustness of the algorithm (although the variance was set to , as expected for ).
For comparison, in each replication we also retrieved the median of the entire time series , which is used as the estimate of by Fisch et al. (2018). For scenarios (1) and (2), we also computed the quantiles of as the oracle efficiency limit based on the CLT, with the total number of background points: for (1) and for (2).
Figure 1 shows the results for all three scenarios. It can be seen that Algorithm 1 produced consistent estimates given sufficiently long time series. When the signal-to-noise ratio was large (scenario 1), most of the estimated background values were accurate even at small , and at larger our estimator reached efficiency and accuracy similar to the oracle estimator. Predictably, the median of the non-segmented data produced biased estimates, which nonetheless may be preferrable in some cases, as our estimate showed large variability at low in scenarios 2 and 3. At , our estimator provides the lowest total error in all tested scenarios, even with the mis-specified cost function in scenario 3.

5.1.2 Segment positions estimated by Algorithm 1 are accurate and consistent
The same simulation setup was used to evaluate the consistency of estimated segment number and positions. Data were generated and analysed with Algorithm 1 as in Section 5.1.1, but we also retrieved the changepoint positions that were estimated in step 12. This corresponds to the online usage of the algorithm, in which segmentation close to the start of the data is based on early estimates and may therefore itself be less precise. We extracted the mean number of segments reported by the algorithm and also calculated the true positive rate (TPR) as the fraction of simulations in which the algorithm reported at least 1 changepoint within points of each true changepoint.
The results show that the TPR approaches 1 for all three scenarios (Table 1). As expected, detecting a strong segment was easier than multiple weak ones: segmentation in scenario 1 was accurate even at , while was needed to reach TPR in scenario 2. In scenario 3, the algorithm correctly detected changes at the true segment start and end (TPR ), but the algorithm tended to fit the segment as multiple ones, likely due to the heavy tails of the distribution. Notably, skipping step 13 had very little impact on the performance of the algorithm, suggesting that the faster online version can be safely used.
| (Full algorithm) | (no step 13) | ||||
|---|---|---|---|---|---|
| Scenario | Mean # segm. | TPR | Mean # segm. | TPR | |
| 1 | 30 | 1.112 | 0.932 | 1.138 | 0.924 |
| 90 | 1.040 | 0.998 | 1.056 | 0.998 | |
| 180 | 1.054 | 1.000 | 1.060 | 1.000 | |
| 440 | 1.032 | 1.000 | 1.040 | 1.000 | |
| 750 | 1.028 | 1.000 | 1.034 | 1.000 | |
| 2 | 30 | 0.552 | 0.000 | 0.584 | 0.000 |
| 90 | 1.096 | 0.008 | 1.050 | 0.004 | |
| 180 | 1.762 | 0.086 | 1.720 | 0.080 | |
| 440 | 2.900 | 0.824 | 2.854 | 0.782 | |
| 750 | 3.010 | 0.992 | 3.008 | 0.988 | |
| 3 | 30 | 0.644 | 0.142 | 0.662 | 0.132 |
| 90 | 1.426 | 0.592 | 1.416 | 0.570 | |
| 180 | 1.930 | 0.878 | 1.932 | 0.866 | |
| 440 | 2.798 | 0.998 | 2.798 | 0.996 | |
| 750 | 3.692 | 1.000 | 3.664 | 1.000 | |
5.1.3 Algorithm 2 recovers true signal segments under interference
To evaluate Algorithm 2, we generated time series with both signal and nuisance segments under two different scenarios:
Scenario 1. Gaussian data with a signal segment overlapping a nuisance segment: data points were drawn as , with when , 0 otherwise, and when , 0 otherwise.
Scenario 2. Gaussian data with a nuisance segment and two non-overlapping signal segments: data points were drawn as , with:
Time series were generated for between 30 and 240, in 500 replications at each . Each series was analysed by three methods. Algorithm 2 (proposed) was run with penalties as before. For classical detection of epidemic changes in mean, we used the R package anomaly (Fisch et al., 2018); the implementation allows separating segments of length 1, but we treated them as standard segments and set all penalties to . In both methods, background parameters were set to , and maximum segment length was in scenario 1 and in scenario 2. As an example of a different approach, we included the narrowest-over-threshold detector implemented in R package not, with default parameters. This is a non-epidemic changepoint detector that was shown to outperform most comparable methods (Baranowski et al., 2019). Since it does not include the background-signal distinction, we define signal segments as regions between two successive changepoints where the mean exceeds .
As before, evaluation metrics were the mean number of segments and the TPR. For the proposed method, we required accurate segment type detection as well, i.e., a true positive is counted when the detector reported a nuisance start/end within of each nuisance changepoint and a signal start/end within of each signal changepoint. In scenario 1, we also extracted the estimate of corresponding to the detected signal segment (or segment closest to if multiple were detected). The average of these over the 500 replications is reported as .
To evaluate the effects of pruning, Algorithm 2 was applied without pruning, or with global pruning as in (11), with at each . Only 5 out of 5000 runs (500 iterations 10 settings) showed any differences between the globally-pruned and non-pruned methods (Supplementary Table S1 in Appendix D), so we only present results obtained with pruning from here on.
We observed that the proposed method (with pruning) successfully detected true signal segments in both scenarios (Figure 2 and Table 2). The number of nuisance detections was accurate in scenario 1, and slightly underestimated in favour of more signal segments in scenario 2, most likely because the simulated nuisance length was close to the cutoff of .

| Scenario | Proposed (S) | Proposed (N) | anomaly | not | |
|---|---|---|---|---|---|
| 1 | 30 | 0.444 | 0.548 | 0.382 | 0.428 |
| 60 | 0.742 | 0.752 | 0.532 | 0.724 | |
| 100 | 0.938 | 0.930 | 0.870 | 0.912 | |
| 160 | 0.984 | 0.972 | 0.982 | 0.994 | |
| 240 | 1.000 | 0.986 | 1.000 | 0.998 | |
| 2 | 30 | 0.700 | 0.110 | 0.934 | 0.152 |
| 60 | 0.924 | 0.238 | 0.962 | 0.872 | |
| 100 | 0.986 | 0.412 | 0.998 | 0.988 | |
| 160 | 0.998 | 0.640 | 1.000 | 1.000 | |
| 240 | 0.998 | 0.764 | 1.000 | 1.000 |
As expected, when nuisance segments are not included in the model (anomaly and not methods), they were identified as multiple changepoints; as a result, the number of segments was over-estimated up to 3-fold. These models are also unable to capture the signal-specific change in mean : anomaly estimated , and not estimated in scenario 1 at . These values correspond to the sum of the signal and nuisance effects. While the estimation is accurate and could be used to recover the value of interest by post-hoc analysis, our proposed method estimated the signal-specific change directly, as in scenario 1 at .
5.2 Real-world Data
5.2.1 ChIP-seq
As an example application of the algorithms proposed in this paper, we demonstrate peak detection in chromatin immunoprecipitation sequencing (ChIP-seq) data. The goal of ChIP-seq is to identify DNA locations where a particular protein of interest binds, by precipitating and sequencing bound DNA. This produces a density of binding events along the genome that then needs to be processed to identify discrete peaks. Typically, some knowledge of the expected peak length is available to the researcher, although with considerable uncertainty (Rashid et al., 2011). Furthermore, the background level may contain local shifts of various sizes, caused by sequencing bias or true structural variation in the genome (Zhang et al., 2008). The method proposed in this paper is designed for such cases, and can potentially provide more accurate and more robust detection.
We used datasets from two ChIP-seq experiments, investigating histone modifications in human immune cells. Broad Institute H3K27ac data was obtained from UCSC Genome Browser, GEO accession GSM733771, as mean read coverage in non-overlapping windows of 25 bp. While ground truth is not available for this experiment, we also retrieved an input control track for the same cell line from UCSC (GEO accession GSM733742). We analysed a window near the centromere of chromosome 1, between 120,100,000 to 120,700,000 bp. This window contains nuisance variation in the background level, as seen in the input control (Figure 3, top). To improve runtime, data was downsampled to approximately 1000 points, each corresponding to mean coverage in a window of 500 bp. All read coordinates in this paper correspond to hg19 genome build.
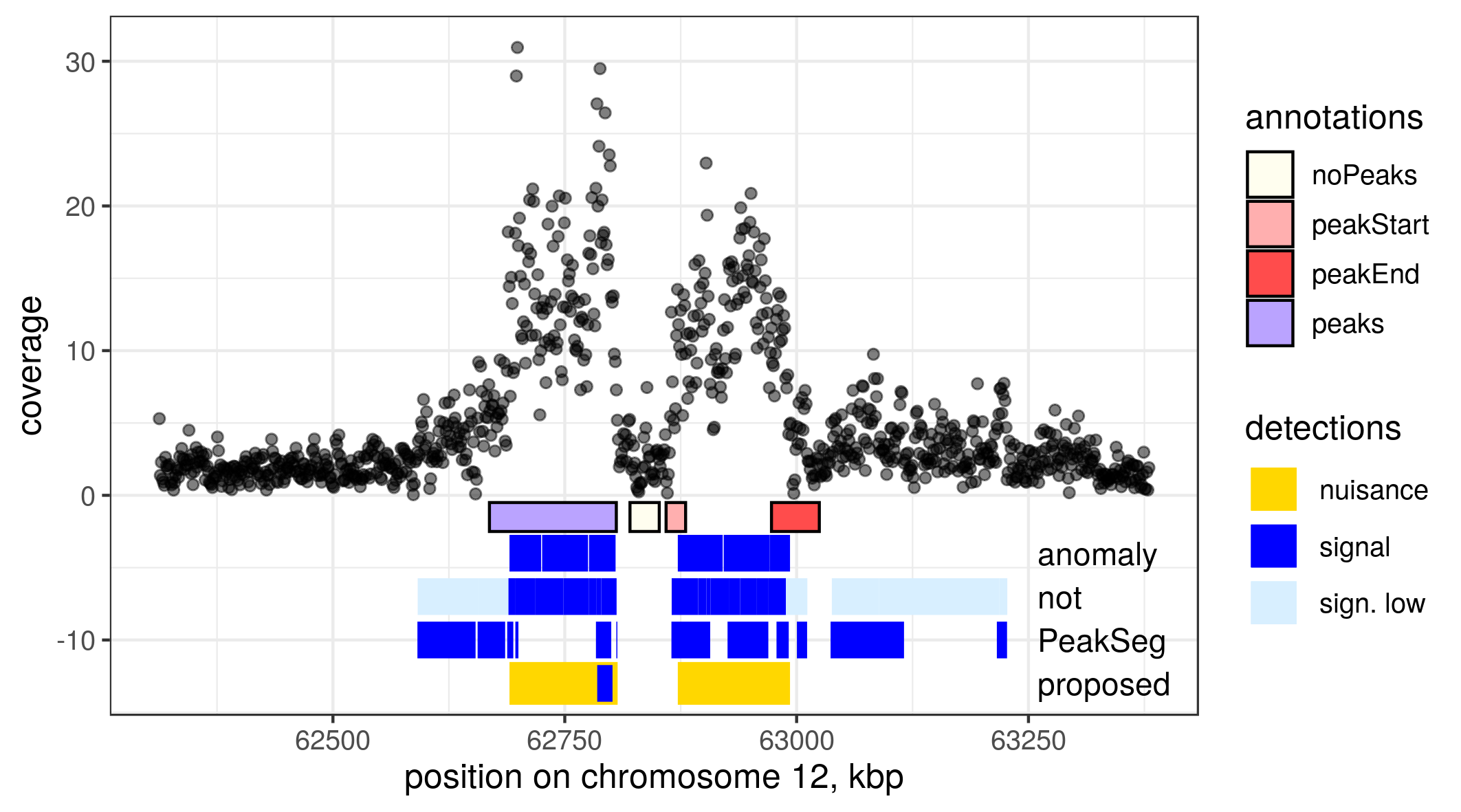
The second dataset was the UCI/McGill dataset, obtained from https://archive.ics.uci.edu/ml/datasets/chipseq. This dataset was previously used for evaluating peak detection algorithms (Hocking et al., 2017, 2018). Mean read coverage at 1 bp resolution is provided, as well as peak annotations based on visual inspection. The annotations are weak labels in the sense that they indicate peak presence or absence in a region, not their exact positions, to acknowledge the uncertainty when labelling visually. From this data, we used the H3K36me3 modification in monocyte sample ID McGill0104, AM annotation. Around the labels in each chromosome, we extracted read coverage for the window between and bp, , , and downsampled to about 1000 points as before. Based on visual inspection of the coverage, we chose a group of labels in chromosome 12, which provides a variety of annotations and a structure that appears to contain both nuisance shifts and signal peaks.
The ChIP-seq datasets were analysed by the method proposed here (Algorithm 2), an epidemic detector from package anomaly, and the non-epidemic detector not. The length of the signal segments was limited to 50 kbp in anomaly and the proposed method. As an estimate of global mean , the median of the unsegmented data was used, and estimated by the standard deviation of non-segmented data. As before, penalties were set to . Only segments with estimated are shown, as we are a priori interested only in regions of increased binding.
We also used GFPOP, implemented in R package PeakSegDisk (Hocking et al., 2018): this detector has been developed specifically for ChIP-seq data processing, and models a change in Poisson rate parameter. This method does not include a single background level, but enforces alternating up-down constraints. It is intended as a supervised method, with the penalty value chosen based on the best segmentation provided by the training data. Therefore, for the Broad Institute dataset, we repeated the segmentation with , and show the that produces between 2 and 10 segments.
To evaluate the results quantitatively, we calculated the SIC based on each method’s segmentation. We used Gaussian likelihood with parameters matching the detection status (i.e., estimated mean for the points in each segment for points outside segments, and as the standard deviation for all points). The number of parameters was set to : a mean and two endpoints for each of the segments reported, and two for the background parameters.
In the H3K27ac data, all methods detected the three most prominent peaks, but produced different results for smaller peaks and more diffuse change areas (Figure 3, bottom). Both PeakSegDisk and anomaly marked a broad segment in the area around 120,600,000 bp. Based on comparison with the control data, this change is spurious, and it exceeds the 50 kbp bound for target segments. While this bound was provided to the anomaly detector, it does not include an alternative way to model these changes, and therefore still reports one or more shorter segments. In contrast, our method accurately modelled the area as a nuisance segment with two overlapping sharp peaks.
Using not, the data was partitioned into 10 segments. By defining segments with low mean () as background, we could reduce this to 4 signal segments; while this removed the spurious background change, it also discarded the shorter change around 120,200,000 bp, which fits the definition of a signal peak ( kbp) and was retained by the proposed method. This data illustrates that choosing the post-processing required for most approaches is not trivial, and can have a large impact on the results. In contrast, the parameters required for our method have a natural interpretation and may be known a priori or easily estimated, and the outputs are provided in a directly useful form. This data illustrates that choosing the post-processing options is not trivial, and can have a large impact on the results. In contrast, the parameters required for our method have a natural interpretation and may be known a priori or easily estimated, and the outputs are provided in a directly useful form.

In the UCI data, segment detections also generally matched the visually determined labels. However, our method produced the most parsimonious models to explain the changes. Figure 4 shows such an example from chromosome 12, where our method reported two nuisance segments and a single sharp peak around 62,750,000 bp. The nuisance segments correspond to broad regions of mean shift, which were also detected by anomaly and not, but using 6 and 16 segments, respectively. Notably, PeakSeg differed considerably: as this method does not incorporate a single background level, but requires segments to alternate between background and signal, the area around 62,750,000 bp was defined as background, despite having a mean of . In total, 12 segments were reported by this method. This shows that the ability to separate nuisance and signal segments helps produce more parsimonious models, and in this way minimises the downstream efforts such as experimental replication of the peaks.
The visual annotations provided for this region are shown in the first row in Figure 4. Note that they do not distinguish between narrow and broad peaks (single annotations in this sample range up to 690 kb in size). Furthermore, comparison with such labels does not account for finer segmentation, coverage in the peak area, or the number of false alarms outside it. For these reasons we are unable to use the labels in a quantitative way.
Quantitative comparison of the segmentations by SIC also favours our proposed method in both datasets. In the Broad dataset, SICs corresponding to segmentations reported by PeakSeg, not and anomaly were 4447.4, 4532.2, and 4311.6, respectively, while the segmentation produced by our model had an SIC of 4285.8. The smallest criterion values in UCI data were also produced by our method (4664.5), closely followed by anomaly (4664.8), while not segmentation resulted in an SIC of 4705.7 and PeakSeg 6886.7. This suggests that in addition to the practical benefits of separating unwanted segments, the nuisance-signal structure provides a better fit to these datasets than models that allow only one type of segments.
5.2.2 European mortality data
The recent pandemic of coronavirus disease COVID-19 prompted a renewed interest in early outbreak detection and quantification. In particular, analysis of mortality data provided an important resource for guiding the public health responses to it (e.g. Baud et al., 2020; Yuan et al., 2020; Dowd et al., 2020).
We analysed Eurostat data of weekly deaths in Spain over a three year period between 2017 and 2020. Data was retrieved from https://ec.europa.eu Data Explorer. Besides the impact of the pandemic, mortality data contains normal seasonal variations, particularly in older age groups. We use the 60-64 years age group in which these trends are visually clear and thus provide a ground truth.
Data were analysed with the four methods introduced earlier. For the proposed and anomaly methods, we used the median and standard deviation of the first 52 weeks of the dataset as estimates of and , respectively. Penalties in both were set to , as previously. The maximum length of signal segments was set to 10 weeks, to separate seasonal effects. In addition, not was used with default parameters, defining signal as regions where the mean exceeds , and PeakSegDisk with a basic grid search to select the penalty as before.
The results of the four analyses are shown in Figure 5. Three of the methods, anomaly, PeakSeg, and Algorithm 2, detected a sharp peak around the pandemic period. However, anomaly and PeakSeg also marked one winter period as a signal segment, while ignoring the other two. Four segments were created by not, including a broad peak continuing well past the end of the pandemic spike. In contrast, the proposed method marked the pandemic spike sharply, while also labelling all three winter periods as nuisance segments. The resulting detection using our method is again parsimonious and flexible: if only short peaks are of interest, our method reports those with lower false alarm rate than the other methods, but broader segments are also marked accurately and can be retrieved if relevant.
As in the ChIP-seq data, comparing the results by SIC identifies our method as optimal for this dataset. The values corresponding to PeakSeg, not and anomaly models were 1629.3, 1648.2, and 1626.3 respectively, while Algorithm 2 produced a segmentation with SIC 1568.2. Note that the SIC penalizes both signal and nuisance segments, so in this case our model still appears optimal despite having more parameters.

6 Discussion
In this paper, we have presented a pair of algorithms for improving detection of epidemic changepoints. Similarly to stochastic gradient descent, the iterative updating of the background estimate in Algorithm 1 leads to fast convergence while allowing large fraction of non-background points. This is utilised in Algorithm 2 to analyse nuisance-signal overlaps.
The computational complexity of both algorithms presented here is in the best case, which is similar to state-of-the-art pruned algorithms (Killick et al., 2012; Hocking et al., 2018). However, note that this is stated in the number of required evaluations of . It is usually implicitly assumed that this function can be evaluated and minimised over recursively, so that the total number of operations may also be linear. This would not be achievable with methods that estimate the background level strictly offline, such as aPELT-profile (Zhao and Yau, 2019). Therefore, development of Algorithm 1 was essential to create the overlap detector.
One of major practical benefits of the proposed model is the ability to separate non-target segments. We anticipate that this will greatly improve downstream processing, effectively reducing the false alarm rate or the manual load if the detections are reviewed. Despite that, it is difficult to evaluate this benefit at present: while there are recent datasets with annotations specifically for testing changepoint detection (Hocking et al., 2017; van den Burg and Williams, 2020), they are based on labelling all visually apparent changes. In future work, we expect to provide further application-specific comparisons that would measure the impact of separating and neutralising the nuisance process.
7 Acknowledgements
This work was supported by the Royal Society of New Zealand Marsden Fund and Te Pūnaha Matatini, a New Zealand Centre of Research Excellence.
References
- Aminikhanghahi and Cook (2016) Aminikhanghahi, S. and Cook, D. J. (2016) A survey of methods for time series change point detection. Knowledge and Information Systems, 51, 339–367.
- Baranowski et al. (2019) Baranowski, R., Chen, Y. and Fryzlewicz, P. (2019) Narrowest-over-threshold detection of multiple change points and change-point-like features. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 81, 649–672.
- Baud et al. (2020) Baud, D., Qi, X., Nielsen-Saines, K., Musso, D., Pomar, L. and Favre, G. (2020) Real estimates of mortality following COVID-19 infection. The Lancet Infectious Diseases, 20, 773.
- Bottou (1998) Bottou, L. (1998) Online algorithms and stochastic approximations. In Online Learning and Neural Networks (ed. D. Saad). Cambridge, UK: Cambridge University Press. Revised, oct 2012.
- Bracker and Smith (1999) Bracker, K. and Smith, K. L. (1999) Detecting and modeling changing volatility in the copper futures market. Journal of Futures Markets, 19, 79–100.
- van den Burg and Williams (2020) van den Burg, G. J. J. and Williams, C. K. I. (2020) An evaluation of change point detection algorithms. Preprint arXiv:2003.06222.
- Dowd et al. (2020) Dowd, J. B., Andriano, L., Brazel, D. M., Rotondi, V., Block, P., Ding, X., Liu, Y. and Mills, M. C. (2020) Demographic science aids in understanding the spread and fatality rates of COVID-19. Proceedings of the National Academy of Sciences, 117, 9696–9698.
- Fisch et al. (2018) Fisch, A. T. M., Eckley, I. A. and Fearnhead, P. (2018) A linear time method for the detection of point and collective anomalies. Preprint arXiv:1806.01947.
- Fryzlewicz (2014) Fryzlewicz, P. (2014) Wild binary segmentation for multiple change-point detection. The Annals of Statistics, 42, 2243–2281.
- Harvey et al. (2019) Harvey, N. J. A., Liaw, C., Plan, Y. and Randhawa, S. (2019) Tight analyses for non-smooth stochastic gradient descent. In Proceedings of the Thirty-Second Conference on Learning Theory (eds. A. Beygelzimer and D. Hsu), vol. 99 of Proceedings of Machine Learning Research, 1579–1613. Phoenix, USA: PMLR.
- Hochenbaum et al. (2017) Hochenbaum, J., Vallis, O. S. and Kejariwal, A. (2017) Automatic anomaly detection in the cloud via statistical learning. Preprint arXiv:1704.07706.
- Hocking et al. (2017) Hocking, T. D., Goerner-Potvin, P., Morin, A., Shao, X., Pastinen, T. and Bourque, G. (2017) Optimizing ChIP-seq peak detectors using visual labels and supervised machine learning. Bioinformatics, 33, 491–499.
- Hocking et al. (2018) Hocking, T. D., Rigaill, G., Fearnhead, P. and Bourque, G. (2018) Generalized functional pruning optimal partitioning (gfpop) for constrained changepoint detection in genomic data. Preprint arXiv:1810.00117.
- Jackson et al. (2005) Jackson, B., Scargle, J., Barnes, D., Arabhi, S., Alt, A., Gioumousis, P., Gwin, E., San, P., Tan, L. and Tsai, T. T. (2005) An algorithm for optimal partitioning of data on an interval. IEEE Signal Processing Letters, 12, 105–108.
- Killick et al. (2012) Killick, R., Fearnhead, P. and Eckley, I. A. (2012) Optimal detection of changepoints with a linear computational cost. Journal of the American Statistical Association, 107, 1590–1598.
- Lau and Tay (2019) Lau, T. S. and Tay, W. P. (2019) Quickest change detection in the presence of a nuisance change. IEEE Transactions on Signal Processing, 67, 5281–5296.
- Levin and Kline (1985) Levin, B. and Kline, J. (1985) The cusum test of homogeneity with an application in spontaneous abortion epidemiology. Statistics in Medicine, 4, 469–488.
- Li et al. (2016) Li, S., Cao, Y., Leamon, C., Xie, Y., Shi, L. and Song, W. (2016) Online seismic event picking via sequential change-point detection. In 2016 54th Annual Allerton Conference on Communication, Control, and Computing (Allerton). IEEE.
- Maidstone et al. (2016) Maidstone, R., Hocking, T., Rigaill, G. and Fearnhead, P. (2016) On optimal multiple changepoint algorithms for large data. Statistics and Computing, 27, 519–533.
- Olshen et al. (2004) Olshen, A. B., Venkatraman, E. S., Lucito, R. and Wigler, M. (2004) Circular binary segmentation for the analysis of array-based DNA copy number data. Biostatistics, 5, 557–572.
- Page (1954) Page, E. S. (1954) Continuous inspection schemes. Biometrika, 41, 100.
- Pearce et al. (2000) Pearce, D., Hirsch, H.-g. and Ericsson Eurolab Deutschland Gmbh (2000) The aurora experimental framework for the performance evaluation of speech recognition systems under noisy conditions. In ISCA ITRW ASR2000, 29–32.
- Purkayastha (1998) Purkayastha, S. (1998) Simple proofs of two results on convolutions of unimodal distributions. Statistics & Probability Letters, 39, 97–100.
- Rashid et al. (2011) Rashid, N. U., Giresi, P. G., Ibrahim, J. G., Sun, W. and Lieb, J. D. (2011) ZINBA integrates local covariates with DNA-seq data to identify broad and narrow regions of enrichment, even within amplified genomic regions. Genome Biology, 12, R67.
- Rigaill (2015) Rigaill, G. (2015) A pruned dynamic programming algorithm to recover the best segmentations with 1 to change-points. Journal de la Société Française de Statistique, 156, 180–205.
- Shewhart (1930) Shewhart, W. A. (1930) Economic quality control of manufactured product. Bell System Technical Journal, 9, 364–389.
- Texier et al. (2016) Texier, G., Farouh, M., Pellegrin, L., Jackson, M. L., Meynard, J.-B., Deparis, X. and Chaudet, H. (2016) Outbreak definition by change point analysis: a tool for public health decision? BMC Medical Informatics and Decision Making, 16.
- Truong et al. (2020) Truong, C., Oudre, L. and Vayatis, N. (2020) Selective review of offline change point detection methods. Signal Processing, 167, 107299.
- Vaisman et al. (2010) Vaisman, L., Zariffa, J. and Popovic, M. R. (2010) Application of singular spectrum-based change-point analysis to EMG-onset detection. Journal of Electromyography and Kinesiology, 20, 750–760.
- Yuan et al. (2020) Yuan, J., Li, M., Lv, G. and Lu, Z. K. (2020) Monitoring transmissibility and mortality of COVID-19 in europe. International Journal of Infectious Diseases, 95, 311–315.
- Zhang et al. (2008) Zhang, Y., Liu, T., Meyer, C. A., Eeckhoute, J., Johnson, D. S., Bernstein, B. E., Nussbaum, C., Myers, R. M., Brown, M., Li, W. and Liu, X. S. (2008) Model-based analysis of ChIP-seq (MACS). Genome Biology, 9, R137.
- Zhao and Yau (2019) Zhao, Z. and Yau, C. Y. (2019) Alternating pruned dynamic programming for multiple epidemic change-point estimation. Preprint arXiv:1907.06810.
- Zheng et al. (2019) Zheng, C., Eckley, I. A. and Fearnhead, P. (2019) Consistency of a range of penalised cost approaches for detecting multiple changepoints. Preprint arXiv:1911.01716.
- Zidek and van Eeden (2003) Zidek, J. V. and van Eeden, C. (2003) Uncertainty, entropy, variance and the effect of partial information, vol. 42 of Lecture Notes–Monograph Series, 155–167. Institute of Mathematical Statistics.
Appendix A Proof of Theorem 1 (Convergence of Algorithm 1)
Bottou (1998) analyses the case of an online algorithm iteratively minimising some function (where represents the complete data and the parameters). Data points arrive sequentially, and at each iteration an estimate of the location of the minimum is obtained using some update function and learning rate as:
| (12) |
This updating mechanism gives rise to stochastic gradient descent if , but for the following argument this is not required.
To make the link with Algorithm 1 explicit, the update equation applied by this algorithm can be written as:
Then (i.e., the background mean that is to be estimated), and we ask whether the sequence of updates converges . It was shown by Bottou (1998) that this occurs almost surely if the following three conditions are met:
-
1.
“convexity” – a single optimum exists and the expected value of the updates always points towards it:
(13) -
2.
learning rate convergence:
(14) -
3.
bounded variance of the updates:
(15)
Thus, proof of convergence of our algorithm reduces to showing that these requirements are satisfied. We start with the assumption that the global mean of segment points is also , and then relax this requirement.
The following lemma will be needed:
Lemma 1.
Let be a unimodal distribution, symmetric around a point (so that when and when ), such as a Gaussian. Consider a truncated random variable with pdf:
for some . Then .
Proof.
| (16) |
When , is increasing throughout the integration range, and ; the opposite is true for . If , split the integral in (A) as:
The first integral covers the range where is increasing, and thus is positive. Since , for , and by symmetry of around and monotonicity, so the second interval is positive as well. Similarly, for . ∎
A.1 When the global mean of segments matches the background mean
Consider the case that the background points are independent draws from , so that the points within each segment are , with known, and . Let be the value of the background mean estimated by Algorithm 1 after processing data points. In this case .
Proof.
Denote the true class of the next data point by (1 for background points, 0 for signal). Algorithm 1 estimates this as:
Initially, assume for simplicity that the true maximum segment length is 1 (and so only is tested). When , the background estimate is updated as:
(otherwise ). So , and hence the learning rate convergence conditions (14) are satisfied.
Substituting in the costs based on a one-dimensional Gaussian pdf , if:
| (17) |
The distribution of true segment data points is symmetric with mean by assumption (as is easily verified for the Gaussian case). The background point distribution is also automatically symmetric. Thus, the overall distribution of the points used to update the estimate is a truncation of a symmetric unimodal distribution. In the present case, it is a truncated normal with limits , based on (17); more generally it is a truncated variant of the parent distribution with symmetric limits of the form , and parent mean (that the acceptance set is an interval follows from the unimodality of ).
This means that satisfies the requirements for Lemma 1 with , which implies the “convexity” condition (13):
Following a similar approach – conditioning on – and using the law of total variance it can be shown that the variance of is finite, as required for the condition (15), and so .
Remark. So far, we assumed that segment length . If segments occur and are tested in non-overlapping windows of any fixed size , the result is similar: if:
where . This can be expressed as truncation limits for accepted , analogously to (17):
| (18) |
The pdf of is a -fold convolution of . Since , as shown earlier, is symmetric unimodal, so is their convolution, and hence the distribution of , with a mean (Purkayastha, 1998). In the special case when is the normal pdf, this can also be shown directly from Gaussian properties. Then Lemma 1 implies condition (13), and the rest of the proof follows as before.
When all segment positions (overlapping or not) are tested, the background point acceptance rule is:
As demonstrated earlier, . Define three sets of based on which rules they pass: , , , and let and be the probabilities of the corresponding sets. Clearly, . We are interested in the mean of the points accepted as background, i.e. . Assume w.l.o.g. , as the other case is symmetric. We will now show that for sufficiently large , , satisfying (13).
Using the conditional mean formula:
| (19) |
Assume for now . Then, to obtain , we need:
| (20) |
Denote , which is an increasing function of , and consider the growth of both sides of (20) as increases. For the Gaussian or other distributions in the exponential family with mean , truncated to a symmetric region , it is known that (Zidek and van Eeden, 2003). Then (denoting ):
Hence:
where is the pdf of given . Hence, this side grows with as .
To analyse , we first simplify the background acceptance condition. For any , by definition of and additivity of , we have:
where is some distance function, is the mean of points , and is a constant depending only on .
It is also helpful to note that , hence:
| (21) |
This corresponds to the case when all were identified as background.
Using the Gaussian cost, i.e. , and recursive formula for the mean, the acceptance condition for becomes:
| (22) |
By substituting in the value of from (A.1), we obtain the following lower bound for :
Thus, we have the following bound for at any :
| (23) |
Therefore, as increases, grows faster than . This means that , and thus , such that for , and thus , (20) holds.
So far we assumed . Clearly, for larger values of , is even smaller and (13) is satisfied.
For the case when , consider the worst case scenario (this is the bound to , and thus to , imposed by ). Similarly to (19), we need:
However, based on (23), , so again such that , and condition (13) holds.
And so overall satisfies condition (13). Since the distribution of accepted still has bounded support imposed by , condition (15) still holds, and the learning rate condition (14) holds as before, implying convergence.
∎
A.2 When the global mean of segments does not match the background mean
Consider now for some , in particular , so that the overall mean of segment points is . Then if , any segment points that were misclassified as background will (on average) push the estimates away from the background mean, in violation of the “convexity” condition (13).
We assume that each segment point is followed by no less than background points. Then, as , . For every finite , such that .
Proof.
Suppose that a misclassification at time is followed by correctly classified background points: , for , for . For the points , almost sure convergence of was established above, i.e. for all , there exists a such that . Therefore, given :
| (24) |
Indexing the segment-background cycles by , denote the first estimate of that segment by , so the set of these estimates are:
The elements of this sequence can be expressed recursively as:
with .
A.3 Martingale Approach
We can also describe the update process over the background points using martingales. The algorithm estimates are random variables ; let be the sequence of -algebras such that for each , is measurable with respect to . Using Lemma 1, and assuming again, within each cycle the estimates comprise a supermartingale over the points , here is the first hitting time of the process realisation to value .
Consider again the problematic case when the global mean does not match the background mean and misclassification pushes the estimate away from the background mean, i.e. . In order for to converge, we need the perturbed estimates to return to a value below in each cycle. At the extremes, we have:
| starting position | |||
Clearly, . However, the number of background points required to satisfy will depend on five factors: the distribution and penalty (since they determine the distribution of update values ), the size of estimated background set at time (as it determines the relevant ), and and .
In practice, is bounded by the available data, so there is a non-zero probability that, over the segment-background cycles indexed by :
In that case, define ; the final estimate of will be bound by . As increases, for any .
Similar reasoning applies when .
Appendix B Proof of Theorem 2 (Consistency)
Proof.
Some general consistency results for changepoint detection by penalised cost methods are given in Fisch et al. (2018). In particular, an equivalent of our Theorem 2 is established for any algorithm that detects changepoints by exactly minimising a cost , where marks robust estimates of background parameters. While the original statement uses the median and interquartile range of for and , the proof only requires that the estimates satisfy certain upper bounds on deviations from the true values. Therefore, we will first show that the online estimates produced by Algorithm 1 are within these bounds, and then follow the rest of the proof from Fisch et al. (2018).
Noting again that Algorithm 1 is effectively a stochastic gradient descent procedure, with each data point seen precisely once, we can use the error bound on estimates produced by such algorithms as provided in Theorem 7.5 of Harvey et al. (2019):
Theorem 3 ((Harvey et al., 2019)).
Let function be 1-strongly convex and 1-Lipschitz. A stochastic gradient algorithm for minimising this function runs for cycles, and at each cycle updates the estimate as in (12) with , . Then:
Using , and assuming without loss of generality that , we can establish an upper bound on the error of background parameters estimated by Algorithm 1 after cycles:
Application of Boole’s inequality leads to:
| (25) |
for some constants and sufficiently large . Since the objective function in our algorithm is the Gaussian log-likelihood (i.e., the updates approximate its gradient), for any given segmentation it is 1-strongly convex. For other functions, overall consistency can still be achieved similarly, but the convergence rate may be slower than .
Having established the bound on estimate errors, we can use Lemma 9 from Fisch et al. (2018) and the proof method reported there.
First, introduce an event based on a combination of bounds limiting the behaviour of Gaussian data , which for any , occurs with probability , with some constant and sufficiently large (Lemmas 1 and 2 in Fisch et al. (2018)). Conditional on this event, the following lemma holds for the epidemic cost defined as in (5):
Lemma 2 ((Fisch et al., 2018)).
Let be the set of true segment positions , and the vector of true segment means. Assume holds, and some are available for which the event in (25) holds. Then, there exist constants and such that when ,
This lemma, together with results established for classical changepoint detection, can be used to show that the cost of any inconsistent solution will exceed the cost based on true segment positions and parameters (Proposition 8 in Fisch et al. (2018)):
Proposition 3 ((Fisch et al., 2018)).
Define to be any set of segments that does not satisfy the consistency event in (7). Let be the parameters estimated by minimising the cost for a given segmentation (i.e. the vector of means and/or variances of for each ). Assume holds. Then there exist constants and such that, when :
See the original publication for a detailed proof of these results.
Finally, for a given set of changepoints, using fitted maximum-likelihood parameters by definition results in minimal cost:
Thus, when Proposition 3 holds, we have:
Appendix C Proof of Proposition 2 (Pruning of Algorithm 2)
Proof.
Denote the true start and end of a nuisance segment as . Consider the case when . Pruning at time will not remove this point (i.e. ) iff:
with such that the right hand side is minimised and .
Denote by the Gaussian cost calculated with MLE estimates of the parameters (i.e. mean and variance of ). Note that since and , the required event to preserve can be stated as
We can establish the probability of this using the following bound (Proposition 4 in Fisch et al. (2018)):
Lemma 3.
Let be piecewise-Gaussian data. Choose any subset , with a true changepoint at , i.e., we have for , and for . Then, for any candidate changepoint and any , there exist constants such that:
is true for all with when .
Now take . Note that there is one and only one changepoint within because of the required distance between changepoints. Applying Lemma 3 to such states that, conditional on an event with probability , the following is true for all :
where we also used the fact that .
Therefore, with the same probability, . Also, because then and is not considered in the pruning scheme, and clearly . The case for follows by symmetry, and obviously no true changepoint can be pruned out if , so the overall probability of retaining a true changepoint remains at . ∎
Appendix D Supplementary Table
| (Full) | (Pruned) | |||||||
|---|---|---|---|---|---|---|---|---|
| Scenario | Run number | Segm. type | Start | End | Segm. type | Start | End | |
| 1 | 30 | 88 | N | 7 | 21 | S | 7 | 11 |
| 30 | 88 | S | 13 | 15 | N | 12 | 21 | |
| 30 | 88 | S | 16 | 20 | S | 16 | 20 | |
| 100 | 84 | N | 21 | 69 | S | 21 | 50 | |
| 100 | 84 | S | 51 | 68 | S | 51 | 69 | |
| 2 | 30 | 378 | N | 10 | 18 | S | 10 | 12 |
| 30 | 378 | S | 13 | 15 | S | 16 | 18 | |
| 30 | 393 | N | 2 | 12 | N | 3 | 12 | |
| 30 | 393 | S | 4 | 7 | S | 4 | 7 | |
| 30 | 393 | S | 16 | 18 | S | 16 | 18 | |
| 30 | 393 | S | 22 | 24 | S | 22 | 24 | |
| 240 | 445 | N | 55 | 95 | N | 55 | 95 | |
| 240 | 445 | S | 121 | 144 | S | 121 | 144 | |
| 240 | 445 | N | 170 | 218 | S | 170 | 192 | |
| 240 | 445 | S | 193 | 214 | S | 215 | 218 | |