Ensemble Wrapper Subsampling
for Deep Modulation Classification
Abstract
Subsampling of received wireless signals is important for relaxing hardware requirements as well as the computational cost of signal processing algorithms that rely on the output samples. We propose a subsampling technique to facilitate the use of deep learning for automatic modulation classification in wireless communication systems. Unlike traditional approaches that rely on pre-designed strategies that are solely based on expert knowledge, the proposed data-driven subsampling strategy employs deep neural network architectures to simulate the effect of removing candidate combinations of samples from each training input vector, in a manner inspired by how wrapper feature selection models work. The subsampled data is then processed by another deep learning classifier that recognizes each of the considered 10 modulation types. We show that the proposed subsampling strategy not only introduces drastic reduction in the classifier training time, but can also improve the classification accuracy to higher levels than those reached before for the considered dataset. An important feature herein is exploiting the transferability property of deep neural networks to avoid retraining the wrapper models and obtain superior performance through an ensemble of wrappers over that possible through solely relying on any of them.
I Introduction
Automatic modulation classification plays an important role in modern wireless communications. It finds applications in various commercial and military areas. For example, Software Defined Radios (SDR) use blind recognition of the modulation type to quickly adapt to various communication systems, without requiring control overhead. In military settings, friendly signals should be securely received, while hostile signals need to be efficiently recognized typically without prior information. Under such conditions, advanced real time signal processing and blind modulation recognition techniques are required. Modulation recognition is also important for identifying the source(s) of received wireless signals, which can enable various intelligent decisions for a context-aware autonomous wireless communication system.
A typical modulation classifier consists of two steps: signal preprocessing and classification algorithms. Preprocessing tasks may include noise reduction and estimation of signal parameters such as carrier frequency and signal power. In the second step, three popular categories of modulation recognition algorithms are conventionally selected: Likelihood-Based (LB)[2, 3, 4, 5, 6, 7], Feature-Based (FB)[8, 9, 10, 11, 12, 13] or using an Artificial Neural Network (ANN)[14, 15, 16, 17, 18]. The first compares the likelihood ratio of each possible hypothesis against a threshold, which is derived from the probability density function of the observed wave. Multiple likelihood ratio test (LRT) algorithms have been proposed: Average LRT[19], Generalized LRT[20], Hybrid LRT[7] and quasi-hybrid LRT[2]. For the FB approach, the classification decision is based solely on a subset of selected features. Both LB and FB methods require precise estimates in the first step and have only been derived to distinguish between few modulation types[19, 4, 21, 22]. ANN structures such as Multi-Layer Perceptrons (MLP) have been widely used as modulation type classifiers[14]. Traditional MLP performs well on modulation types such as AM, FM, ASK, and FSK. Recent work has shown that deep neural networks with cutting-edge structures could greatly improve the classification process (see e.g., [23] and [24]), and deliver superior performance to state-of-the-art methods by enabling modulation recognition in presence of a wide variety of modulation types, and with little or no requirements from the preprocessing step.
Deep neural networks have played a significant role in the research domain of video, speech and image processing over the past few years. The recent success of deep learning algorithms is associated with applications that suffer from inaccuracies in existing mathematical models and enjoy the availability of large data sets. Recently, the idea of deep learning has been introduced for modulation classification using a Convolutional Neural Network (CNN) for distinguishing between 10 different modulation types [23]. Simulation results show that a CNN not only demonstrates better accuracy results than current expert-based approaches, but also provides more flexibility in detecting various modulation types. Other deep neural network architectures like the Residual Network (ResNet) [25] were also recently introduced to strengthen feature propagation in deep neural networks by creating shortcut paths between different layers in the network. By adding the bypass connections, an identity mapping is created, allowing the deep network to learn simple functions. A ResNet architecture was shown to be successful for distinguishing between 24 different modulation types in [26]. A Convolutional Long Short-term Deep Neural Network (CLDNN) was recently introduced in [27], by combining the architectures of the CNN and the Long Short-Term Memory (LSTM) into a deep neural network and taking advantage of the complementarity of CNNs, LSTMs, and conventional deep neural network architectures. The LSTM unit is a memory unit of a Recurrent Neural Network (RNN). RNNs are neural networks with memory that are suitable for learning sequence tasks such as speech recognition and handwritten recognition. LSTM optimizes the gradient vanishing problem in RNNs by using a forget gate in its memory cell, which enables the learning of long-term dependencies. The authors in [24] demonstrated the potential of LSTM units for accurately recognizing a wide range of modulation types.
In this work, we first present three different architectures that deliver higher classification accuracy than the CNN introduced in [23] as well as the CLDNN of [24]. We design our own CNN and CLDNN architectures for the modulation recognition task, as well as derive an optimized version of the ResNet architecture of [26] by tuning the number of residual stacks. In contrast to the high SNR classification accuracy acheived by the CNN of [23] using the RadioML2016.10b dataset that was first considered in the same work, our CNN, CLDNN, and ResNet architectures deliver high SNR accuracy values of , , and , respectively. However, we find that the performance of all these architectures, as well as the ones in [23] and [24], suffers degradation, even at high SNR, due to confusions between similar modulation types, in particular those of QAM16 and QAM64 and those of AM-DSB and WBFM. Another major challenge facing machine learning algorithms based on deep neural network architectures is the long training time. For example, for the problem at hand, even the simple CNN architecture in [23] takes approximately 40 minutes to train using three Nvidia Tesla P100 GPU chips. This creates a serious obstacle towards the feasibility of applying such algorithms in real time, where online training is needed to adapt the network architecture to changing environmental conditions. In particular, applying deep learning to autonomous wireless communication systems anticipated in next-generation networks requires significant reduction in training time compared to state-of-the-art methods. In such systems, it is likely that training will be frequently needed to accommodate new environmental conditions. Hence, reducing training time becomes essential for the success of these algorithms. The third major challenge is hardware requirements due to sampling the received signal at high rates, which can be cumbersome in real time, particularly in wideband settings.
We tackle the three aforementioned challenges by introducing a data-driven subsampling stategy that relies on an ensemble of the three deep neural network classifiers presented in this work, as well as the ResNet as a final deep neural network classifier that recognizes the modulation type. Our strategy relies on the learning transferability property of deep neural networks, as we determine the optimal set of samples based on simulations that employ a diverse set of architectures, all of which are suitable for the considered classification task. These simulations are inspired by how wrapper feature selection methods work through model-based evaluations of feature sets. The obtained results demonstrate that not only the proposed data-driven subsampling strategy leads to significant reductions in the required training time, but it also leads to achieving unprecedented classification accuracy values and almost fully resolves the confusions - suffered by traditional methods as well as previous deep learning-based methods - between similar pairs of modulation types like QAM16 and QAM64 as well as AM-DSB and WBFM at higher SNR values (above 2 dB). Using the RadioML2016.10b dataset of [23], the ResNet high SNR classification accuracy increases with subsampling rates as low as , and goes above when subsampling with a rate of or higher. As further illustrated in Section VI, we believe that subsampling led to an increase in classification accuracy in our experiments, due to its effect in reducing overfitting by projecting samples onto a lower dimensional subspace that admits a distinction between different classes through simple decision boundaries.
The rest of this paper is organized as follows. In Section II, we describe the problem. We then provide a detailed description of the proposed approach in Section III, and highlight the obtained results in Section IV. Provided by empirical evidence, we provide a detailed justification for every step of the proposed approach through a benchmarking and ablation study in Section V. Finally, we provide a discussion in Section VI and concluding remarks in Section VII.
II Problem Description
In this work, we consider classification of the modulation type of received wireless signals, using deep neural network classifiers and subsampling techniques. We consider ten widely used modulation schemes: eight digital and two analog modulations. These consist of BPSK, QPSK, 8PSK, QAM16, QAM64, BFSK, CPFSK, and PAM4 for digital modulations, and WBFM, and AM-DSB for analog modulations.
A general expression for the received baseband complex envelope is
| (1) |
where for ,
| (2) |
is the baseband complex envelope of the received signal, and is the instantaneous channel noise at time . In (2), is the received signal amplitude, is the carrier frequency offset, is the time-invariant carrier phase introduced by the propagation delay, is the phase jitter, denotes complex symbols taken from the modulation format, represents the symbol period, is the normalized epoch for time offset between the transmitter and signal receiver, is the composite effect of the residual channel with denoting the channel impulse response and denoting mathematical convolution, and is the transmit pulse shape. We denote by ; the multidimensional vector that includes the deterministic unknown signal or channel parameters for the modulation type. Our goal is to recognize the modulation type from a sampled version of the received signal . This is achieved through a supervised machine learning algorithm that has access to labeled sample vectors. We assume that the data available for training and testing are equi-sized, and so are these available for each of the ten modulation types. We further study this problem under constraints on the allowed sampling rate. Such constraints could reflect a training time limitation, which is analyzed in this work, as well as hardware requirements (e.g., of RF sensors).
Using the RadioML2016.10b dataset that consists of samples taken at around 6 times the Nyquist rate and 8 samples per symbol, a CNN architecture was shown to achieve classification accuracy at dB SNR [23]. As detailed below, we first present three deep neural network architectures that deliver state-of-the-art performance, with classification accuracy values reaching at high SNR. Then, we present a data-driven subsampling strategy that employs the ensemble of the presented architectures and relies on wrapper-based recursive simulations, to deliver accuracy values that exceed at high SNR with sampling rates around the Nyquist rate, and remain above the no subsampling accuracy with sampling rates at or above of the Nyquist rate. To the best of our knowledge, the accuracy values obtained by applying our method with subsampling rates at or above are higher at high SNR than those obtained by applying existing methods in the literature to the same dataset, even with no subsampling, and this superior performance is uniform across the studied SNR range from -20 dB to 18 dB when applying our method with subsampling rates at or above .
III Designing the Ensemble Wrapper Subsampler
The proposed strategy utilizes training data, originally sampled at a high rate, to search for the optimal set of sample indices using an ensemble of deep neural network architectures that were found empirically to be well fit for the considered task. Once the sample indices are determined, we only sample at the corresponding times for training and testing the modulation type classifier. We will show in the sequel that samples chosen by this strategy lead to classification accuracy values that are drastically higher than the state-of-the-art. We begin by introducing three deep classifiers, each achieving high classification results on fully sampled data. Then, we build wrapper models - that we call Subsampler Nets - using each of the three architectures. We then use the ensemble of these models to build a Holistic Subsampler that exploits the diversity in performance delivered by the three models. Finally, we introduce a deterministic variant of -Greedy search that finesses the obtained classification performance, by exploiting the available wrapper-based sample ranking. We present results obtained through the proposed appraoch and justify the need for each of its components in Sections IV and V, respectively.
III-A Deep Neural Network Architectures
Our strategy employs a Convolutional Neural Network (CNN), a Convolutional Long Short-term Deep Neural Network (CLDNN), and a Residual Network (ResNet), whose details we provide below. For all architectures, we use the Adam optimizer and the categorical cross entropy loss function. We also use ReLu activation functions for all layers, except the last dense layer, where we use Softmax activation functions. Robustness and diversity were the key design factors that guided our choice of architectures. The former indicates that each architecture is well fit for the task, even at low sampling rates, which we verified through experimental results, and the latter indicates that the three architectures are independently trained and rely on different mechanisms for capturing task-relevant features. While a CNN relies on a fixed hierarchical representation that first extracts lower-level features through a large number of convolutional kernels, and then captures higher-level semantics through less kernels whose outputs have a wide input receptive field, the ResNet relies on shortcut connections between convolutional layers that are far apart, which provides stable training for deeper layers and allows for dynamically choosing the effective architecture while training (see [28, Chapters -] for more illustration). Also, the ResNet is significantly deeper than the CNN, which makes it likely to reach very different solutions. Further, unlike these two architectures, the CLDNN includes a gated LSTM layer that captures long-term temporal correlations in the convolutional output feature maps.
III-A1 CNN


We modify the CNN2 architecture, that was proposed in [23] by having four convolutional layers, and two dense layers, as depicted in Figure 1a. The first parameter below each convolutional layer in the figure represents the number of filters in that layer, while the second and third numbers show the size of each filter. For the two dense layers, we use 128 and 10 neurons in order of their depth in the network.
III-A2 CLDNN
Inspired by [27], we proposed a CLDNN in [1] by adding an LSTM layer into the CNN architecture. The detailed architecture considered for the CLDNN is shown in Figure 1b. The extra LSTM layer is placed between the convolutional layers and the dense layers. In our experiments, an LSTM layer with 50 cells provided the best accuracy.
III-A3 ResNet
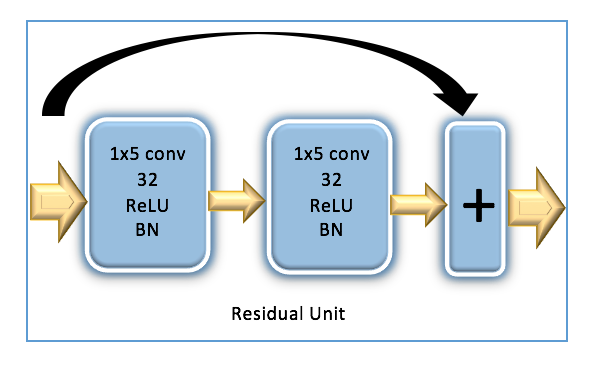
As neural networks grow deeper, their learning performance is challenged by problems like vanishing or exploding gradient and overfitting, and therefore both training and testing accuracy start to degrade after the network reaches a certain depth. The Deep Residual Network (ResNet) architecture that was introduced in the ImageNet and COCO 2015 competitions[25], resolves accuracy degradation issues in deeper neural networks and has been shown to be a robust choice for a wide range of machine learning tasks. Inspired by the ResNet architecture in [26], we designed a similar ResNet but with three residual stacks instead of six, as we found that choice to lead to increased classification accuracy. In our network, three residual stacks are followed by three fully connected layers, where each residual stack consists of one convolutional layer, two residual units, and one max-pooling layer. As seen in [26], for each residual unit, a shortcut connection is created by adding the input of the residual unit with the output of the second convolutional layer of the residual unit. Finally, each convolutional layer in the residual unit uses a filter size of 1x5 and is followed by a batch normalization layer for optimization stability. The overall architecture is observed in Figure 2. As we illustrate below, this architecture delivered the best - or very close to the best - performance among all considered architectures for a wide range of SNR values that only excludes extremely low values.


III-B Subsampler Nets: A Wrapper Feature Selection Approach

The first building block in our ensemble method that employs the architectures provided above, is a supervised wrapper feature selection algorithm that we call the Subsampler Net, which uses a deep neural network to rank the importance of each sample in accordance to the relative drop in classification accuracy that occurs when that sample is removed (set to 0). Similar to other wrapper feature selection methods, a Subsampler Net relies on a classifier to rank sample importance. We will refer to this classifier as the Ranker Model. We use pre-trained models for each of the above three architectures as Ranker Models to construct three separate Subsampler Nets.
Suppose we want to obtain samples from a pool of samples. As shown in Figure 3, the Subsampler Net first starts by setting a sample to (setting both the real and imaginary parts of that sample to ) in a batch of training validation examples and evaluating it using the Ranker Model, which will then provide us with a classification accuracy for that batch. Setting a sample to means that the input neurons to the model for the two features corresponding to that complex sample are dead, which allows us to simulate the removal of that sample from the signal as all the weights from these neurons in the input layer will not contribute to the outcome of the model. This is done times by setting each of the samples to . After evaluating each of the samples, we are left with classification accuracies that correspond to the ability of the model to classify the signal if each of the samples were to be removed. The most important sample, which is the sample whose removal results in the lowest classification accuracy, is then permanently set to for this batch of training examples and added to the final set of samples. Now, we are left with samples and this process is repeated until we are finally left with samples. The Subsampler Net construction is detailed in Algorithm 1.
While attempting this method, we found that normalizing the data by setting the mean of each sample to and the variance to improves performance because when we set an input sample to , we are effectively setting it to the mean, and lower variances now manifest as lower weights in the input layer [29]. We also observed, from experiments that rely on a discrete set of SNR values, that the sample indices chosen for batches of validation examples belonging to the same SNR value were the same in most cases, while they were likely to be distinct from those chosen for batches belonging to different SNR values. Therefore, we divide the available data according to SNR value and obtain a set of sample indices for each SNR.
III-C The Holistic Subsampler: The Best of All Worlds
We next introduce the notion of the Holistic Subsampler, which combines the ability of all three Ranker Models in order to capitalize on their diversity of performance. After the set of samples, that match the required sampling rate, are collected for each of the three Ranker Models, we divide these samples into three tiers.

The Venn diagram in Figure 4 illustrates the division of the tiers. Tier 1 consists of the intersection of all three sets of samples, Tier 2 consists of the samples that belong to two of the three sets of samples, and Tier 3 consists of samples that are selected by only one Subsampler Net. The samples within each of the tiers are sorted according to the sum of the classification accuracy values that occur when that sample is removed using the corresponding Ranker Models. For example, for Tier 2 samples, we sort the samples using the sum of the two obtained classification accuracy values when the sample is removed (set to 0). Akin to the Subsampler Net, the Holistic Subsampler is a recursive algorithm that first selects the best sample, then sets the value of the corresponding sample index to 0 for the whole training set, and calls itself again to find the next best sample. This is done until the desired number of samples is reached. To find the best sample, the top sample - corresponding to the lowest sum of classification accuracy values - is selected from Tier 1. If Tier 1 is empty, then the top sample from Tier 2 is selected. If Tier 1 and Tier 2 are both empty, then the top sample from Tier 3 is selected.
III-D -Greedy Search: The Final Piece of The Puzzle
We note that the Subsampler Net merely selects the best sample at each iteration, without regard to how the selection of a subsequent sample will affect the importance of the currently selected sample to the classification task. We chose to do this in the interest of saving training time of Subsampler Nets in order to render the implementation of the proposed method feasible using low-power communication devices. To tackle this problem, we next propose a variant of the -greedy algorithm [30] in order to explore candidate combinations for subsequent best samples while taking into account dependence relationships between the selected samples.
According to Algorithm 2, we introduce , the exploration factor that determines the number of candidate samples considered for selection at each step. If , then in every step, we explore the best samples according to the ranking provided by the Holistic Subsampler. This is unlike the conventional -greedy algorithm, where represents the probability that the decision taken deviates from the top greedy choice. Our variant of the algorithm explores all of the top routes and is the parameter that determines the number of top routes explored. The Multi-Armed Bandit problem [31], which is one of the most popular applications of the traditional -Greedy Algorithm, is based on a scenario where there is a single top choice and all the other choices are of the same importance before exploration. However, in our case, the choices apart from the top choice have a ranking that reflects their relative importance. Therefore, unlike the Multi-Armed Bandit problem, we do not need to waste time exploring unknown paths, and this is the rationale behind our deviation from the conventional -Greedy Algorithm.

As observed in Figure 5, the -Greedy Search can be represented as a traversal algorithm over an -ary tree whose depth is equal to the desired number of samples , where the subsampling rate is . Each node in the tree corresponds to the selection of a combination of sample indices. The nodes at the same depth are arranged by increasing order of accuracy when removed, which implies that the combination of samples corresponding to the left child of a node has higher priority than that corresponding to the right child of the same node, for the case when . The root node does not represent any sample and is added just for the sake of illustration of how the tree is formed. The leaf nodes are searched from left to right until a classification accuracy that is satisfactory is reached.
We note that setting is equivalent to having an unaltered Holistic Subsampler that greedily chooses the best sample at each iteration, which leads to the leftmost leaf of the tree in Figure 5. This corresponds to node because only a tree with a single branch is formed with the nodes 0, 00, 000, and 0000. Increasing the value of expands the scope of exploration.
III-E Ensemble Wrapper Subsampling
We here finalize the specification of the proposed approach. Given input data with samples per example, we first initialize to and invoke the -Greedy Search. As mentioned earlier, this is the same as invoking the Holistic Subsampler on its own. Next, we proceed to the next SNR value available in the training set. The -Greedy Search is invoked with an value of for this next training set belonging to the next SNR value. If the accuracy is lower than the accuracy for the previous SNR value, then -Greedy Search is invoked again after doubling the value to . The -Greedy Search stops exploring once the accuracy is greater than the accuracy obtained for the previous SNR value. We repeatedly double and invoke -Greedy Search until this stopping criterion is met. The pseudocode for this strategy is given in Algorithm 3.
The function described in Algorithm 3 returns the selected set of sample indices for each SNR value. Note that douling the value of for the -Greedy Search corresponds to searching for combinations of sample indices in a tree that has twice the arity.
IV Experimental Results
In this section, we present an experimental evaluation of the proposed method. First, we specify the dataset used, the programming environment, and hyperparameter settings, then we present the obtained classification accuracy results while highlighting important insights, and finally quantify the reduction in training time for the final classifier with different subsampling rates.

IV-A Dataset
We use the RadioML2016.10b synthetic dataset generated in [23] as the input data. Details about the generation of this dataset can be found in [32]. Figure 6 shows a high-level framework for the data generation process. For digital modulations, the entire Gutenberg works of Shakespeare in ASCII is used, with whitening randomizers applied to ensure equiprobable symbols and bits. For analog modulations, a continuous voice signal consisting of acoustic voice speech with some interludes and off times is used as input. The modulation rate is 8 samples per symbol.

The dataset is split equally among all ten considered modulation types. For the channel model, physical environmental noises like thermal noise and multipath fading were simulated. The models for generating random channel and device imperfections, that determine the parameters in (2), are detailed in [32]111Dataset generation parameters are also available at https://github.com/radioML/dataset. When packaging data, the output stream of each simulation is randomly segmented into vectors as the original dataset with a sample rate of 1M samples per second. Similar to the way that an acoustic signal is windowed in voice recognition tasks, a sliding window extracts 128 samples with a shift of 64 samples, which forms a sample vector in the dataset. 160,000 sample vectors generated using the GNU-radio library developed in [32] are segmented into training and testing datasets. Each example consists of 128 samples, that are represented as a 2128 vector with real and imaginary parts separated. The SNR of the samples is uniformly distributed from -20 dB to 18 dB, with a step size of 2 dB, i.e., the dataset is equally split among all SNR dB values in .
We note from the frequency domain representation of the input waveform depicted in Fig. 7 that the sampling rate of the input waveform is around 6 times the Nyquist rate.
IV-B Implementation Details
We used Keras with TensorFlow as a backend, and a GPU server equipped with three Tesla P100 GPUs with 16 GB memory. For all architectures, we used a batch size of 1024, and a learning rate of 0.001. Only the training set is used by the subsampling algorithm described in Section III with a validation split of 0.25. After selecting the set of sample indices for each of the 20 considered SNR values, we train the ResNet classifier with the corresponding samples, as we found it to deliver the best performance among the three considered architectures222Code is available at: https://github.com/dl4amc/dds.


(b) Accuracy vs SNR for ResNet with Ensemble Wrapper Subsampling.
IV-C Classification Accuracy
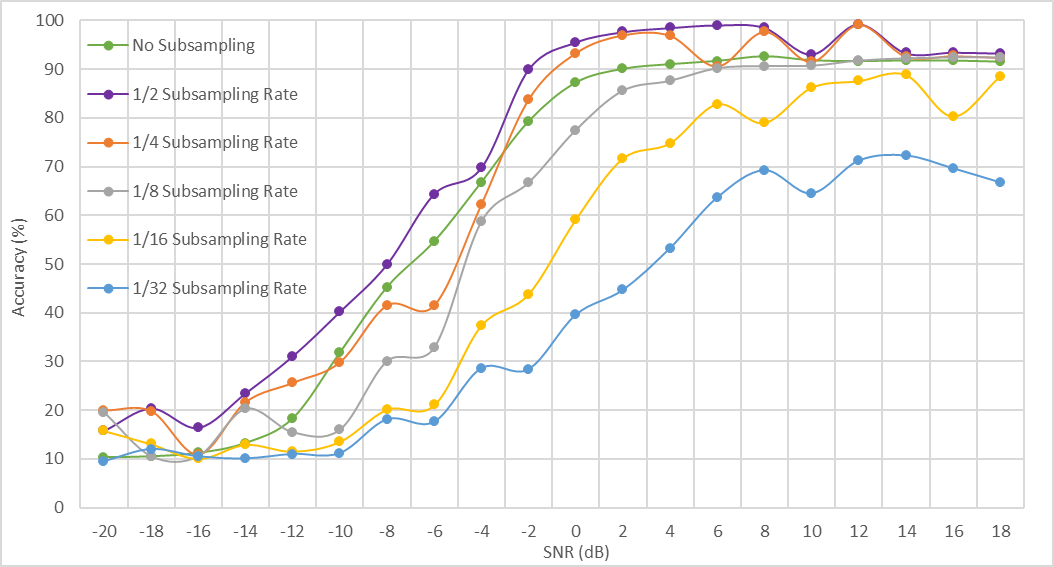
We present the obtained results at different sampling rates in Figure 8. From our results, we note the following.
-
•
Subsampling can lead to higher accuracy: Applying the proposed ensemble wrapper subsampling strategy can result in dramatic improvements in classification accuracy, particularly at low SNR values. The direct cause for this phenomenon at high SNR is resolving confusions between the QAM16/QAM64 and AM-DSB/WBFM pairs, as we illustrate in Section V. To the best of our knowledge, state-of-the-art methods fail at resolving these confusions. We believe that this is because our subsampling strategy reduces overfitting, as we elaborate in Section VI-B.
-
•
Sub-Nyquist Sampling: As noted above, the considered data is originally sampled at around 6 times the Nyquist rate. A subsampling rate of hence corresponds to around of the Nyquist rate, and leads to slightly higher classification accuracy at very high SNR and significantly higher accuracy at very low SNR, than the case with no subsampling. This observation could carry important implications in practice, as the sampling hardware requirements can be dramatically simplified (see [33] for more illustration).
-
•
Minimal Sample Set: Based on the loss in classification accuracy, we can choose the smallest set of samples (smallest value of ) that gives us a classification accuracy higher than a given classification accuracy requirement. For instance, is the smallest number of samples (around Nyquist rate) that can be selected such that the classification accuracy has to be higher than at dB SNR. Similarly, is the smallest number of samples that can be selected given that the classification accuracy has to be higher than at dB SNR.
IV-D Training Time
As a result of subsampling, the training time of the classifier is reduced due to the reduced input dimensions. We show the reduction in training times and high SNR classification accuracy of the ResNet classifier for different subsampling rates in Table I. Note that a subsampling rate as low as , which corresponds to the sub-Nyquist regime with around of the Nyquist rate, and results in approximately of the original training time, still results in a classification accuracy higher than that without subsampling.
| Samples | Time per Epoch | Epochs | Total Training Time | Accuracy ( dB SNR) |
|---|---|---|---|---|
| All | 32.0642s | 37 | 1186.3754s | 91.49% |
| 1/2 | 26.9615s | 33 | 889.7295s | 99.27% |
| 1/4 | 24.2615s | 29 | 703.5835s | 99.13% |
| 1/8 | 21.8361s | 27 | 589.5747s | 97.94% |
| 1/16 | 17.1167s | 26 | 445.0342s | 92.67% |
| 1/32 | 11.6828s | 24 | 280.3827s | 71.14% |
V Benchmarking and Ablation Study
Supported by experimental results, we first provide an analysis of our proposed approach with regard to traditional approaches, and then provide a justification for each of its components. We begin by motivating the need for deep learning via analyzing the performance of a Bayes classifier. Then, we present the results obtained with the considered deep neural network architectures with no subsampling, and highlight the modulation type pairs that are difficult to distinguish even at high SNR. Having motivated the need for subsampling, we then compare the results obtained through our proposed approach with conventional subsampling and feature selection schemes. We finally present an ablation study to demonstrate the performance degradation caused when removing any of the components of the proposed method.
V-A Gaussian Naive Bayes Classifier
We first discuss the performance of a Gaussian naive Bayes classifier, to assess the difficulty of the considered modulation classification task. It will then become clear how deep learning significantly outperforms the naive Bayes classifier. The Gaussian naive Bayes classifier can be described through the conditional probabilities:
| (3) |
where is the likelihood of an observed instance belonging to a certain class , is the observed variance of class , and is the observed mean of class . The predicted output of is the class that maximizes the likelihood function. Instead of trying to classify all ten modulation types, we only used certain pairs to further demonstrate the performance of the Gaussian naive Bayes classifier for simpler tasks.
| Modulation Pairs | Classification Accuracy (All SNR) | Classification Accuracy (18 dB) |
|---|---|---|
| PAM4 vs QAM64 | 68.5% | 82% |
| QAM16 vs QAM64 | 50% | 51% |
| AM-DSB vs BPSK | 70% | 81% |
| AM-DSB vs WBFM | 53% | 53% |
From the results in Table II, we note that even when the Bayes classifier is trained to distinguish pairs that are not challenging at the maximum SNR value, its maximum accuracy is . Further, for challenging pairs, the performance is similar to random guessing even at high SNR.
V-B Deep Learning with no Subsampling


We present in Figure 9 the classification accuracy of the considered architectures using the considered dataset with no subsampling. We note that - similar to previous work on deep learning for modulation classification - most of the misclassifications at high SNR are due to confusions between the AM-DSB/WBFM and the QAM16/QAM64 pairs, which is evident from the ResNet 18 dB confusion matrix depicted in Figure 9a. We observe by comparing to Figure 8 how the proposed data-driven subsampling method leads deep neural network classifiers to clear this confusion. We believe that this is due to overfitting reduction, as further illustrated in Section VI. We further note that we also considered a pure LSTM architecture by fine tuning that of [34] for the task. Even though this architecture delivered good performance with no subsamlping as shown in Figure 9b, we chose not to use it in our proposed method as it suffered drastic performance degradation with subsampling. We believe that this is due to extreme sensitivity of the captured temporal correlations to absence of few samples.
V-C Conventional Subsampling
We provide in Figure 10a a comparison between the proposed approach and four different subsampling techniques; namely: 1) Uniform Subsampling: where a sample is taken every fixed amount of time, 2) Random Subsampling: where the indices of selected samples is determined randomly with equal probabilities, 3) Magnitude Rank Subsampling: where the indices corresponding to samples with top magnitude values in each example are selected, and 4) Principal Component Subsampling (PCS), where first Principal Component Analysis (PCA) is done over the training set, and the indices corresponding to samples with the top PCA coefficient total magnitude values are selected. A more thorough explanation of these methods is available in [35]. We note that the proposed method leads to - uniformly across all SNR values - superior performance than all these methods. The figure demonstrates results slightly below the Nyquist rate, but this observation extends to all considered subsampling rates. In particular, random subsampling delivers better performance that the other three methods at lower rates, which agrees with the intuition in [33], but this performance remains lower than that of the proposed approach.
V-D Conventional Feature Selection


Feature selection algorithms aim at identifying important input vector elements. In the considered setup, a direct application of a feature selection algorithm for input vectors, would treat each of the elements separately. We handle this with a slight modification to tie the real and imaginary parts of each sample, as illustrated below. In Figure 10b, we show a comparison between the proposed method and four popular feature selection algorithms; namely: 1) Laplacian Score [36]: which is an unsupervised filter feature selection algorithm that selects features with the objective of preserving the data manifold structure through a graph representation [37], 2) Fisher Score [38]: which is a supervised filter feature selection algorithm that selects features such that the features of samples within the same modulation type are similar while the features of samples belonging to other modulation types are as distinct as possible [37], 3) Efficient and Robust Feature Selection (RFS) [39]: which is a computationally efficient embedded feature selection method that exploits the noise robustness - through rotational invariance - property of the joint -norm loss function [40, 41], by applying the -norm minimization on both the loss function and its associated regularization function, and 4) Feature Quality Index (FQI) [42]: which is a wrapper feature selection algorithm that utilizes the output sensitivity of the considered model to changes in the input to rank features. FQI can be considered as a simplified version of our Subsampler Net that relies on the Mean Squared Error (MSE) loss instead of the model’s loss and uses only the initial sample ranking that we use to select the first sample. For each of the techniques examined, except FQI where we have sample scores, we add the two scores obtained for the two features belonging to a sample to obtain a sample score before proceeding to rank the samples. We note how the proposed method delivers significantly better performance than all considered methods, and that this holds for all other considered subsampling rates not shown in the figure. Particularly, our method delivers better performance than FQI, which demonstrates the need for re-ranking samples after each iteration in the Subsampler Net described in Section III-B. Also, we note that this re-ranking does not require model retraining, unlike most other wrapper feature selection algorithms, which makes our method computationally feasible in a wide range of settings.
V-E Ablation Study
We observe from Figure 11 how the relative performance of the three considered Subsampler Nets changes with different sampling rates and SNR values. This is the main motivation behind the Holistic Subsampler that benefits from the performance diversity among the three architectures. However, even the Holistic Subsampler, suffers from significant drops in classification accuracy for a wide range of SNR values at sampling rates well below the Nyquist rate. This motivated our -Greedy step of the proposed approach. In particular, the slope of the classification accuracy curve for the Holistic Subsampler becomes negative towards -, , and dB with a subsampling rate and towards -, , and dB with a subsampling rate. To obtain the results shown in Figure 8, our ensemble wrapper data-driven subsampling algorithm, illustrated in Algorithm 3, applied -Greedy Search with for the and dB SNR values with subsampling rate, as well as at dB SNR with subsampling rate. For the - dB SNR value with both and subsampling rates, an had to be used because having was insufficient, and the same held for dB SNR with rate. It is important to note that our -Greedy step has a time complexity of the Order , if the number of explored combinations has the same order as the number of the constructed tree leaves. Fortunately, this step is typically needed only at very low subsampling rates, where the value of is small, and with small values of .



VI Discussion
VI-A Exploiting Transfer Learning
We note how the Holistic Subsampler achieves better results than any individual Subsampler Net, even though the final classifier relies on a single ResNet architecture. Furthermore, even though each of these architectures is trained to classify the data when all the samples are present at the input, when used as Subsampler Nets, one or more of these samples are set to 0. Hence, we use the trained deep neural network classifiers in two ways other than their intended application that they are trained on: 1- They are used to select samples for another classifier, 2- They are used with only a subset of samples present. This is only possible because of the transferability property of these deep neural network architectures. In general, we believe that exploiting transferability has great potential for various wireless communication tasks that rely on processing received signal samples.
VI-B Subsampling leads to higher accuracy
In Section V-B, we saw that all the deep learning architectures suffered from the same drawback of the AM-DSB/WBFM and QAM16/QAM64 misclassification when no subsampling is used. To further analyze why the proposed subsampling method leads to higher classification accuracies with fewer samples, we will be using Principal Component Anaysis (PCA) [43] and t-Distributed Stochastic Neighbor Embedding (t-SNE) [44] to visualize how subsampling allows us to reduce overfitting, particularly for the aforementioned class pairs. We first subsample the training dataset at dB SNR with a rate of . After subsampling, we have samples, corresponding to features. Finally, we implement PCA and t-SNE to obtain a -Dimensional projection of the training dataset for better visualization. We chose to implement both PCA and t-SNE because PCA clarifies the distinction between AM-DSB and WBFM while t-SNE clarifies the distinction between QAM16 and QAM64 after subsampling, as shown in Figure 12333The t-SNE plots were generated with a perplexity value of , a learning rate of , and were run for iterations.. Observing the figure, we believe that the higher accuracy values stem from the subsampling strategy enabling simpler decision boundaries to distinguish, with high fidelity, between the considered class pairs, which improves generalization performance and reduces overfitting.




VI-C Designing the Ranker Models
The performance of a Subsampler Net heavily depends on the performance of the model used to rank the features. In some cases, however, even the state-of-the-art models do not have high classification accuracy values. In such cases, we believe that better feature selection results can be obtained with a Subsampler Net by training the ranker model for more epochs beyond what is suggested by the Early Stopping algorithm (see e.g., [28, Chapter ]). This is as we found this strategy to be useful in multiple settings and further observed that it can significantly increase the discrepancy in weight magnitudes across the different features. For example, we considered a toy example constructed in TensorFlow Playground with a single-hidden-layer network that distinguishes between two classes based on two features, and the second is more salient as it enables forming a decision boundary that allows for better classification. Each of these features have three weights in the input layer and as expected, the weights connected to Feature quickly manifest, after several epochs, into weights of higher average magnitude than those belonging to Feature as shown in Fig. 13. As the number of training epochs increases - even from to which is way more than needed for this small network - the difference in the average magnitudes of the weights increases. This implies that the ranker will be able to better rank the saliency of features because the accuracy difference will increase when suppressing each of these features.



VI-D Sensitivity to SNR estimate
Even though both the final classifier and the ranker models used in the proposed subsampling method are trained using the whole training set across all considered SNR values, the selected set of sample indices is different for each SNR value, and hence, we expect a real time system employing this method to have an accurate estimate of the SNR value, in order to know the right set of sample indices. We made this choice, as we found it to deliver a significantly superior performance to the extreme alternative, where the same set of sample indices is selected for all SNR values. In future work, we plan to investigate the impact of small errors in such an estimate, by comparing the different sets of selected sample indices for adjacent SNR values. We plan to also benefit from analyzing these sets of sample indices, to better understand the roles of different ranker models at different SNR values.
VII Concluding Remarks
In this work, we considered the problem of recognizing one out of ten modulation types with a constraint on the sampling rate in an erroneous wireless environment that is difficult to model. We first identified three deep neural network architectures that are well fit for the task and deliver state-of-the-art classification accuracy, namely a CNN, CLDNN and ResNet. We then presented a wrapper data-driven subsampling approach that employs all three architectures - as an ensemble - for selecting a set of samples that maximizes the classification accuracy via recursive simulations aided by -Greedy deterministic explorations. Our experimental results, using the RadioML2016.10b dataset of [23], indicate that using the proposed method with a ResNet classifier leads to very high classification accuracy values, that to the best of our knowledge, have not been reached before even at sampling rates well above the Nyquist rate. Further, even in the sub-Nyquist regime, we achieve almost perfect classification (accuracy above 99%) at high SNR. We also noted the drastic reduction in the classifier’s training time as a result of subsampling. We plan to further investigate in future work the potential of employing deep learning for subsampling in wireless communication systems, as we believe that the insights distilled from this work carry practical significance beyond the considered modulation classification task.
References
- [1] X. Liu, D. Yang, and A. El Gamal, “Deep neural network architectures for modulation classification,” in Proc. IEEE Asilomar Conference on Signals, Systems and Computers, 2017.
- [2] J. Sills, “Maximum-likelihood modulation classification for psk/qam,” in Proc. IEEE Military Communications Conference (MILCOM), 1999.
- [3] A. Polydoros and K. Kim, “On the detection and classification of quadrature digital modulations in broad-band noise,” IEEE Transactions on Communications, vol. 38, no. 8, pp. 1199–1211, 1990.
- [4] P. Sapiano and J. Martin, “Maximum likelihood PSK classifier,” in Proc. IEEE Military Communications Conference (MILCOM), 1996.
- [5] B. F. Beidas and C. L. Weber, “Asynchronous classification of MFSK signals using the higher order correlation domain,” IEEE Transactions on communications, vol. 46, no. 4, pp. 480–493, 1998.
- [6] P. Panagiotou, A. Anastasopoulos, and A. Polydoros, “Likelihood ratio tests for modulation classification,” in MILCOM 2000 Proceedings. 21st Century Military Communications. Architectures and Technologies for Information Superiority (Cat. No. 00CH37155), vol. 2. IEEE, 2000, pp. 670–674.
- [7] L. Hong and K. Ho, “Antenna array likelihood modulation classifier for BPSK and QPSK signals,” in Proc. IEEE Military Communications Conference (MILCOM), 2002.
- [8] S.-Z. Hsue and S. S. Soliman, “Automatic modulation recognition of digitally modulated signals,” in Proc. IEEE Military Communications Conference (MILCOM), 1989.
- [9] L. Hong and K. Ho, “Identification of digital modulation types using the wavelet transform,” in Proc. IEEE Military Communications Conference (MILCOM), 1999.
- [10] A. Swami and B. M. Sadler, “Hierarchical digital modulation classification using cumulants,” IEEE Transactions on communications, vol. 48, no. 3, pp. 416–429, 2000.
- [11] G. Hatzichristos and M. P. Fargues, “A hierarchical approach to the classification of digital modulation types in multipath environments,” in Proc. IEEE Asilomar Conference on Signals, Systems, and Computers, 2001.
- [12] S. S. Soliman and S.-Z. Hsue, “Signal classification using statistical moments,” IEEE Transactions on Communications, vol. 40, no. 5, pp. 908–916, 1992.
- [13] L. Lichun, “Comments on signal classification using statistical moments,” IEEE Transactions on Communications, vol. 50, no. 2, p. 195, 2002.
- [14] L. Mingquan, X. Xianci, and L. Lemin, “AR modeling-based features extraction of multiple signals for modulation recognition,” in Proc. IEEE International Conference on Signal Processing, 1998.
- [15] B. G. Mobasseri, “Digital modulation classification using constellation shape,” in Proc. IEEE International Conference on Signal Processing, 2000.
- [16] L. Mingquan, X. Xianci, and L. Leming, “Cyclic spectral features based modulation recognition,” in Proc. International Conference on Communication Technology (ICCT), 1996.
- [17] E. E. Azzouz and A. K. Nandi, “Modulation recognition using artificial neural networks,” Signal Processing, vol. 56, no. 2, pp. 165–175, 1997.
- [18] K. E. Nolan, L. Doyle, D. O’Mahony, and P. Mackenzie, “Modulation scheme recognition techniques for software radio on a general purpose processor platform,” in Proc. Joint IEI/IEE Symposium on Telecommunication Systems, Dublin, 2001.
- [19] K. Kim and A. Polydoros, “Digital modulation classification: the BPSK versus QPSK case,” in Proc. IEEE Military Communications Conference (MILCOM), 1988.
- [20] N. E. Lay and A. Polydoros, “Per-survivor processing for channel acquisition, data detection and modulation classification,” in Proc. IEEE Asilomar Conference on Signals, Systems, and Computers, 1994.
- [21] C.-S. Park, J.-H. Choi, S.-P. Nah, W. Jang, and D. Y. Kim, “Automatic modulation recognition of digital signals using wavelet features and SVM,” in Proc. International Conference on Advanced Communications Technology, 2008.
- [22] L. De Vito, S. Rapuano, and M. Villanacci, “Prototype of an automatic digital modulation classifier embedded in a real-time spectrum analyzer,” IEEE Transactions on Instrumentation and Measurement, vol. 59, no. 10, pp. 2639–2651, 2010.
- [23] T. O’Shea, J. Corgan, and T. Clancy, “Convolutional radio modulation recognition networks,” in Proc. International conference on engineering applications of neural networks, 2016.
- [24] N. E. West and T. O’Shea, “Deep architectures for modulation recognition,” in International Symposium on Dynamic Spectrum Access Networks (DySPAN), 2017.
- [25] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- [26] T. O’Shea, T. James, T. Roy, and T. Clancy, “Over-the-air deep learning based radio signal classification,” IEEE Journal of Selected Topics in Signal Processing, vol. 12, no. 1, pp. 168–179, 2018.
- [27] T. N. Sainath, O. Vinyals, A. W. Senior, and H. Sak, “Convolutional, long short-term memory, fully connected deep neural networks,” in Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2015.
- [28] I. Goodfellow, Y. Bengio, and A. Courville, Deep learning. MIT Press, 2016.
- [29] S. Ramjee and A. E. Gamal, “Efficient wrapper feature selection using autoencoder and model based elimination,” arXiv:1905.11592, 2019.
- [30] B. C. Stadie, S. Levine, and P. Abbeel, “Incentivizing exploration in reinforcement learning with deep predictive models,” arXiv:1507.00814, 2015.
- [31] S. Bubeck, N. Cesa-Bianchi et al., “Regret analysis of stochastic and nonstochastic multi-armed bandit problems,” Foundations and Trends® in Machine Learning, vol. 5, no. 1, pp. 1–122, 2012.
- [32] T. O’Shea and N. West, “Radio machine learning dataset generation with gnu radio,” in Proc. GNU Radio Conference, 2016.
- [33] Y. C. Eldar, Sampling Theory: Beyond Bandlimited Systems. Cambridge University Press, 2015.
- [34] S. Rajendran, W. Meert, D. Giustiniano, V. Lenders, and S. Pollin, “Deep learning models for wireless signal classification with distributed low-cost spectrum sensors,” IEEE Transactions on Cognitive Communications and Networking, vol. 4, no. 3, pp. 433–445, 2018.
- [35] S. Ramjee, S. Ju, D. Yang, X. Liu, A. E. Gamal, and Y. C. Eldar, “Fast deep learning for automatic modulation classification,” IEEE Machine Learning for Communications Emerging Technologies Initiatives, available at: arXiv:1901.05850, 2019.
- [36] X. He, D. Cai, and P. Niyogi, “Laplacian score for feature selection,” in Advances in neural information processing systems, 2006, pp. 507–514.
- [37] J. Li, K. Cheng, S. Wang, F. Morstatter, R. P. Trevino, J. Tang, and H. Liu, “Feature selection: A data perspective,” ACM Comput. Surv., vol. 50, pp. 94:1–94:45, 2017.
- [38] Q. Gu, Z. Li, and J. Han, “Generalized fisher score for feature selection,” arXiv:1202.3725, 2012.
- [39] F. Nie, H. Huang, X. Cai, and C. H. Ding, “Efficient and robust feature selection via joint -norms minimization,” in Advances in neural information processing systems, 2010, pp. 1813–1821.
- [40] C. Ding, D. Zhou, X. He, and H. Zha, “R 1-pca: rotational invariant l 1-norm principal component analysis for robust subspace factorization,” in Proceedings of the 23rd international conference on Machine learning. ACM, 2006, pp. 281–288.
- [41] J. Li, K. Cheng, S. Wang, F. Morstatter, R. P. Trevino, J. Tang, and H. Liu, “Feature selection,” ACM Computing Surveys, vol. 50, no. 6, p. 1–45, Dec 2017. [Online]. Available: http://dx.doi.org/10.1145/3136625
- [42] K. De Rajat, N. R. Pal, and S. K. Pal, “Feature analysis: Neural network and fuzzy set theoretic approaches,” Pattern Recognition, vol. 30, no. 10, pp. 1579–1590, 1997.
- [43] G. Ivosev, L. Burton, and R. Bonner, “Dimensionality reduction and visualization in principal component analysis,” Analytical chemistry, vol. 80, no. 13, pp. 4933–4944, 2008.
- [44] L. v. d. Maaten and G. Hinton, “Visualizing data using t-sne,” Journal of machine learning research, vol. 9, no. Nov, pp. 2579–2605, 2008.