Enhancing Visual Realism: Fine-Tuning InstructPix2Pix for Advanced Image Colorization
Abstract
This paper presents a novel approach to human image colorization by fine-tuning the InstructPix2Pix model, which integrates a language model (GPT-3) with a text-to-image model (Stable Diffusion). Despite the original InstructPix2Pix model’s proficiency in editing images based on textual instructions, it exhibits limitations in the focused domain of colorization. To address this, we fine-tuned the model using the IMDB-WIKI dataset, pairing black-and-white images with a diverse set of colorization prompts generated by ChatGPT. This paper contributes by (1) applying fine-tuning techniques to stable diffusion models specifically for colorization tasks, and (2) employing generative models to create varied conditioning prompts. After finetuning, our model outperforms the original InstructPix2Pix model on multiple metrics quantitatively, and we produce more realistically colored images qualitatively. The code for this project is provided on the GitHub Repository https://github.com/AllenAnZifeng/DeepLearning282.
1 Introduction
Image colorization is the task of adding plausible color information to monochromatic images (Vitoria et al., 2020). Colorization has broad applications, ranging from restoring historical photographs and films to aiding data visualization to enhance the interpretability of medical and satellite imagery. An example of the application of colorization on human faces is shown in Figure 1. The advent of digital technology introduced the concept of automatically colorizing images (Iizuka et al., 2016; Zhang et al., 2016). However, there are many challenges in this field for computers to understand and interpret the context, texture, and shadows in a monochromatic image so that they can apply realistic colors.

Recent developments in machine learning based computer vision techniques enabled more sophisticated and nuanced approaches to colorization. Many works used Convolutional Neural Networks (CNN) to capture the features in an image (Zhang et al., 2016) and used the LAB colorspace for predicting the color of each pixel. Other approaches incorporated both local and global features while training the CNN (Zhang et al., 2016; Iizuka et al., 2016). Generative Adversarial Networks (GAN) also proved to be effective in this field. Among GANs, Isola et al. introduced the Pix2Pix framework, a groundbreaking conditional GAN, to generate high-quality, detailed images (Isola et al., 2018).
We decided to finetune a model for colorization based on InstructPix2Pix, an innovative advancement to the original Pix2Pix model through pairing a language model (GPT-3) with a text-to-image model (Stable Diffusion) (Brooks et al., 2023). It provides a conditional diffusion model such that given an input image and a text instruction, it generates an edited image. The model is trained such that it achieves zero-shot generalization for arbitrary real images and natural human-written instructions. However, the model may have lower performances on a specified transformation, so we decided to finetune the model to complete transformations specifically for colorization.
Our project mainly contributes:
-
•
Using finetuning on stable diffusion models for colorization;
-
•
Using multiple prompts generated by generative models to diversify conditioning;
2 Methods
The original InstructPix2Pix model is designed to edit images based on textual instructions. However, the original model does not perform well when it is only evaluated on the task of colorization. To finetune InstructPix2Pix for colorization, we used the IMDB-WIKI dataset (Rothe et al., 2018) with instructions co-created by ChatGPT. During finetuning, we froze several components unrelated to our task of colorization and focused on finetuning the models related to the image generation.
2.1 Dataset Preparation
We utilized a subset of 766 images from the IMDB-WIKI dataset, which is the largest publicly available dataset of facial images for training (Rothe et al., 2018). We transformed the original colored images into black-and-white images as inputs for the model. The original colored images were used as ground truth to compute loss. Some example images from the dataset are displayed in Figure 1.
Driven in part by the refinement directives articulated in FLAN-V2 (Wei et al., 2021), which underscored the efficacy enhancement associated with the incorporation of Cognitive Tasking (CoT) data, we adopted a methodology that generated 30 synonymous prompts based on the base prompt “colorize the image”. We used GPT-4 to generate these prompts and combined them with our images to construct our dataset.111Our dataset can be found on the link https://huggingface.co/datasets/annyorange/colorized_people-dataset This approach was designed not only to fortify the robustness of testing procedures but also to optimize overall performance. For the validation dataset, we deliberately adhered to employing solely the prompt “colorize the image,” ensuring a consistent basis for meaningful comparisons.
2.2 Finetuning Approaches
The InstructPix2Pix architecture is comprised of several key components: the Variational Auto-Encoder (VAE) model (AutoencoderKL) for encoding and decoding images to and from latent representations, the text-encoder from CLIP for encoding the textual instructions, and a conditional U-Net for denoising the encoded image latents (Brooks et al., 2023). The VAE and CLIP focused on encoding the image and instruction into latent space, which is more general and not directly related to our task of colorization. Therefore, we froze these two models in the InstructPix2Pix pipeline and only finetuned the U-Net, which was in charge of denoising the noisy latents into the desired distribution of colored images. Figure 2 shows the architecture of InstructPix2Pix and which models within the pipeline we froze or finetuned.

When finetuning our model, we employed two distinct loss functions to optimize performance: training loss and validation loss. The training loss is the traditional loss for stable diffusion between the predicted and actual noise. The validation loss is calculated based on a pixel-wise Mean Squared Error (MSE) between the generated images and the original ground truth images, specifically within the LAB color domain. This approach ensures that the colorization process faithfully reproduces accurate and realistic colors by closely mirroring the true color values of the original images.
During this process, we adjusted various hyperparameters, namely the learning rate, batch size, and prompt size. The results of varying these hyperparameters are shown in Section 3.2.

3 Results
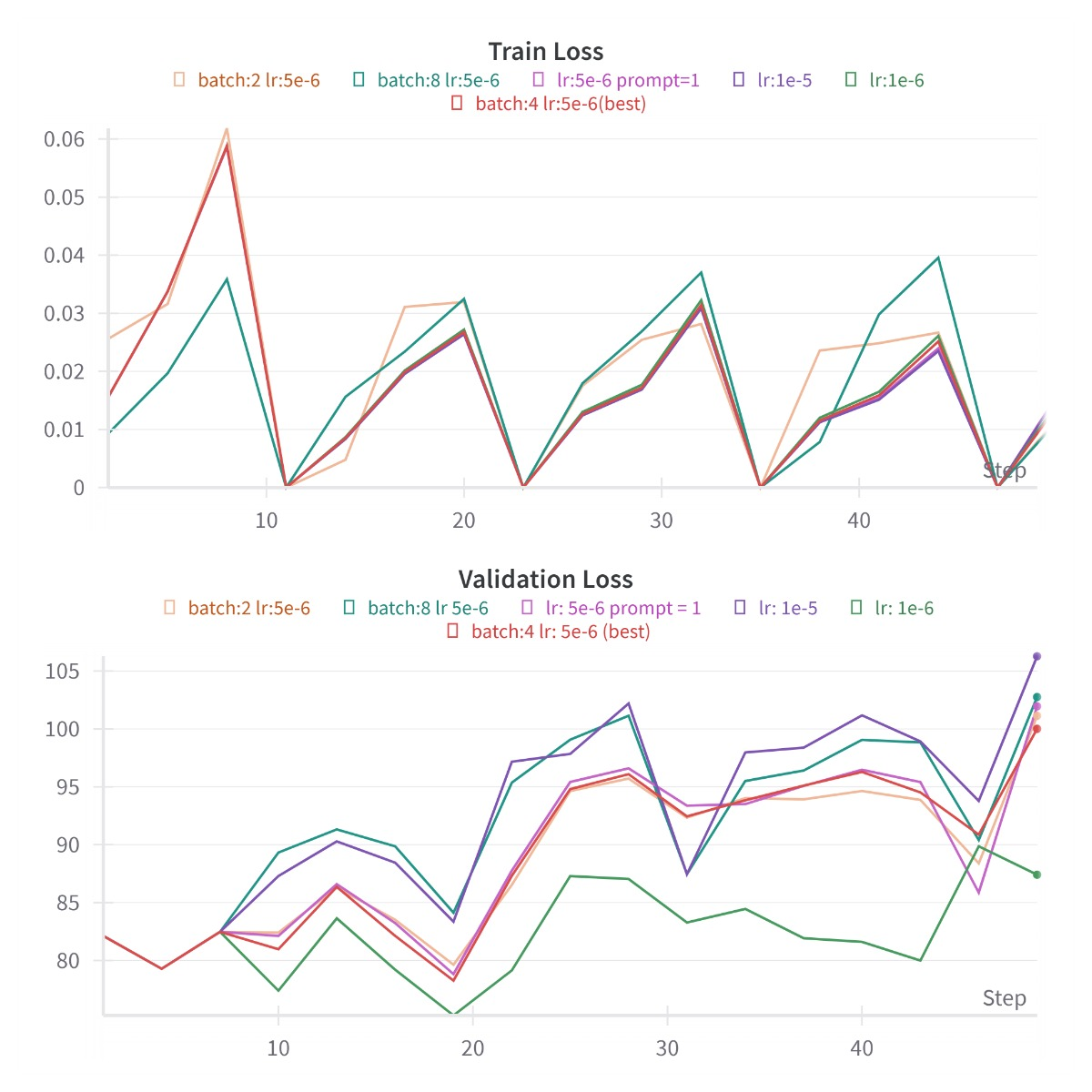
We conducted fine-tuning for 50 updates, and Figure 3 offers a visual comparison between our best fine-tuned model and the original InstructPix2Pix model. Figure 4 displays the training and validation losses for various learning rates, batch sizes, and prompt sizes.
In Figure 4, the training loss, represented by the Mean Squared Error (MSE) loss between the predicted noise and the true noise, exhibits oscillations. This behavior is expected as the model learns to minimize the discrepancy between generated and actual noise. The peaks in the training loss gradually decrease, indicating the model’s convergence to a better fit during fine-tuning.
Conversely, the validation loss, measuring the MSE loss between the predicted colorized image and the original image, shows an increasing trend with the number of training steps. This phenomenon is attributed to the limitation of MSE in perfectly reflecting the absolute quality of colorization. For instance, in colorization tasks, different colors can be valid for the same black-and-white photo under similar lighting conditions. Additionally, the choice of step length during training is a parameter to consider, as evidenced by the different colorization stages in Figure 5.
To further interpret the training process, we captured images at early, middle, and late stages of fine-tuning, as depicted in Figure 5. This visualization underscores the evolution of colorization quality throughout training, providing insights into how the model’s performance improves over time.

3.1 Quantitative Comparison
| Dataset IMDB-WIKI | |||
|---|---|---|---|
| Metric | PSNR ↑ | SSIM ↑ | MAE ↓ |
| InstructPix2pix | 19.7804 | 0.4301 | 22.1093 |
| Fine-Tuned Model | 19.9019 | 0.5348 | 21.3045 |
For a comprehensive assessment, we utilized common image quality metrics: Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM) (Wang et al., 2004), and Mean Absolute Error (MAE). These metrics are widely used in prior studies (Xu et al., 2023; He et al., 2018; Su et al., 2020). PSNR measures fidelity, with higher values indicating improved image quality; SSIM evaluates structural similarity, where higher scores denote more consistent structures, and MAE quantifies the average absolute pixel-wise difference, reflecting overall image similarity. The quantitative results of these metrics on the IMDB-WIKI dataset are illustrated in Table 1. Our approach outperforms the original InstructPix2Pix models in all of the metrics (PSNR, SSIM, and MAE).
3.2 Hyperparameter Tuning
To achieve our best results, we compared several hyperparameters in our model, namely the learning rate, batch size, and the number of generated prompts we used. The comparison of the resultant images is shown in Figure 6. In default, we used learning rate , batch size 4, and 30 generated prompts. We change each hyperparameter separately for each section.

Learning Rate
We set the learning rate to , , . As shown in the second row of Figure 6, the lower learning rate produces an image that is dull and is very close to InstructPix2Pix without much changes, while the higher learning rate produces an image that has very high contrast with vibrant colors. We found the balanced learning rate at with the best results.
Batch Size
We used different batch sizes ranging from 2, 4, and 8. The facial colorization looks better in smaller batch sizes, but larger batch sizes provide some more coloring to the background. However, larger batch sizes update the model more given the same number of training steps, so they might overfit the model and cause the original model to start forgetting.
Number of Prompts
We tested our model using only a single prompt versus 30 generated prompts. In both cases, the prompts used for training are different from the prompt “colorize the image” used in validation. We intended to vary the number of prompts to see if the model will perform worse if it was not well trained on multiple similar prompts and thus fails to generalize to an unseen prompt. However, from Figure 6 there is not much difference between using 1 and 30 prompts. We believe the CLIP text encoder will project similar prompts to similar embeddings, resulting in low differences between the training and validation prompts. One potential approach to improve the prompting mechanism is to introduce soft prompting, thus eliminating the need for hard-coded prompts (Lester et al., 2021).
4 Conclusion and Future Work
In this paper, we presented an innovative approach to image colorization by fine-tuning the InstructPix2Pix model. Our method focused on selectively freezing components of the InstructPix2Pix model and fine-tuning the U-Net for image latent denoising. The results, both qualitative and quantitative, demonstrate a significant enhancement in the model’s ability to realistically colorize images. From a qualitative perspective, the colorization results of our model stand out in their visual perception. The colors in the images generated by our model strike a harmonious balance – they are neither too dull and close to grayscale nor too sharp and overly vibrant. Quantitatively, our model outperforms the original InstructPix2Pix in Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Mean Absolute Error (MAE). Inspired by FLAN-V2, we employed GPT-4 to generate a diverse array of 30 prompts to ensure diverse prompt conditioning in model training.
The current method has areas that can be improved. A primary concern is the inconsistency in the loss metrics: the training loss is based on noise prediction, whereas the validation loss relies on pixel-wise MSE in the LAB color space. This misalignment could potentially limit the model’s effectiveness in generalizing to real-world colorization tasks. To enhance this, we propose combining these two loss functions by adding learnable weights, allowing for joint optimization during the training phase. This approach would enable the model to not only accurately predict noise but also improve color fidelity as reflected in the LAB MSE. Such a unified training process is likely to result in more consistent improvements, where enhancements in training loss directly translate to better validation performance.
Further exploration into the effects of various hyperparameters on model performance is also essential. While our study experimented with different learning rates, batch sizes, and prompt quantities, a more in-depth investigation could provide deeper insights into optimal settings for these parameters. This could involve extensive experiments with varying prompt structures or the exploration of soft prompting techniques, offering a more nuanced approach to training.
References
- Brooks et al. (2023) Brooks, T., Holynski, A., and Efros, A. A. Instructpix2pix: Learning to follow image editing instructions, 2023.
- He et al. (2018) He, M., Chen, D., Liao, J., Sander, P. V., and Yuan, L. Deep exemplar-based colorization. ACM Transactions on Graphics (TOG), 37(4):1–16, 2018.
- Iizuka et al. (2016) Iizuka, S., Simo-Serra, E., and Ishikawa, H. Let there be color! joint end-to-end learning of global and local image priors for automatic image colorization with simultaneous classification. ACM Trans. Graph., 35(4), jul 2016. ISSN 0730-0301. doi: 10.1145/2897824.2925974. URL https://doi.org/10.1145/2897824.2925974.
- Isola et al. (2018) Isola, P., Zhu, J.-Y., Zhou, T., and Efros, A. A. Image-to-image translation with conditional adversarial networks, 2018.
- Lester et al. (2021) Lester, B., Al-Rfou, R., and Constant, N. The power of scale for parameter-efficient prompt tuning. CoRR, abs/2104.08691, 2021. URL https://arxiv.org/abs/2104.08691.
- Rothe et al. (2018) Rothe, R., Timofte, R., and Gool, L. V. Deep expectation of real and apparent age from a single image without facial landmarks. International Journal of Computer Vision, 126(2-4):144–157, 2018.
- Su et al. (2020) Su, J.-W., Chu, H.-K., and Huang, J.-B. Instance-aware image colorization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7968–7977, 2020.
- Vitoria et al. (2020) Vitoria, P., Raad, L., and Ballester, C. Chromagan: Adversarial picture colorization with semantic class distribution, 2020.
- Wang et al. (2004) Wang, Z., Bovik, A. C., Sheikh, H. R., and Simoncelli, E. P. Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing, 13(4):600–612, 2004.
- Wei et al. (2021) Wei, J., Bosma, M., Zhao, V. Y., Guu, K., Yu, A. W., Lester, B., Du, N., Dai, A. M., and Le, Q. V. Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652, 2021.
- Xu et al. (2023) Xu, R., Tu, Z., Du, Y., Dong, X., Li, J., Meng, Z., Ma, J., Bovik, A., and Yu, H. Pik-fix: Restoring and colorizing old photos. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 1724–1734, 2023.
- Zhang et al. (2016) Zhang, R., Isola, P., and Efros, A. A. Colorful image colorization, 2016.