Enhancing LGMD’s Looming Selectivity
for UAV with Spatial-temporal Distributed Presynaptic Connections
Abstract
Collision detection is one of the most challenging tasks for Unmanned Aerial Vehicles (UAVs). This is especially true for small or micro UAVs, due to their limited computational power. In nature, flying insects with compact and simple visual systems demonstrate their remarkable ability to navigate and avoid collision in complex environments. A good example of this is provided by locusts. They can avoid collisions in a dense swarm through the activity of a motion based visual neuron called the Lobula Giant Movement Detector (LGMD). The defining feature of the LGMD neuron is its preference for looming. As a flying insect’s visual neuron, LGMD is considered to be an ideal basis for building UAV’s collision detecting system. However, existing LGMD models cannot distinguish looming clearly from other visual cues such as complex background movements caused by UAV agile flights. To address this issue, we proposed a new model implementing distributed spatial-temporal synaptic interactions, which is inspired by recent findings in locusts’ synaptic morphology. We first introduced the locally distributed excitation to enhance the excitation caused by visual motion with preferred velocities. Then radially extending temporal latency for inhibition is incorporated to compete with the distributed excitation and selectively suppress the non-preferred visual motions. These spatial-temporal competition between excitation and inhibition in our model is therefore tuned to preferred image angular velocity representing looming rather than background movements with these distributed synaptic interactions. Systematic experiments have been conducted to verify the performance of the proposed model for UAV agile flights. The results have demonstrated that this new model enhances the looming selectivity in complex flying scenes considerably, and has potential to be implemented on embedded collision detection systems for small or micro UAVs.
Index Terms:
LGMD, UAV, collision detection, dynamic complex visual scene, presynaptic neural network.I Introduction
Autonomous flying robots or unmanned aerial vehicles (UAVs), especially small and micro aerial vehicles (MAVs), have increasingly displayed considerable potential for serving human society as a result of their flexibility of flight. However, autonomous micro aerial vehicles (MAVs) remain unable to fly automatically and perform tasks safely. One of the reasons is that they have not been equipped with efficient collision detection capabilities. Traditional technologies of collision detection, such as laser [1], ultrasonic [2], and Simultaneous Localization and Mapping(SLAM) [3] are computationally expensive, or greatly rely on objects texture and physical characters such as its ability to absorb and/or reflect light. These impediments make these methods unsuitable for MAVs. On the other hand, vision sensors can capture rich information of the real world and consume less power. However, exploiting the abundant information comes with a cost which, in this case is a demand for an efficient algorithm to extract task-specific features for collision detection.
Nature has demonstrated many successful solutions for dynamic collision detection. For example, locusts can fly with agility in a swarm of millions whilst avoiding collision. Their remarkable collision avoidance relies on a visual motion sensitive neuron: the Lobula Giant Movement Detector (LGMD) [4]. The LGMD neuron has a characteristic preference for looming obstacles (i.e. objects approaching on a directly collision course) other than translating or receding objects, which makes it an ideal model for detecting collisions automatically [5, 6]. Although some of the LGMD inspired models have been successfully embodied on mobile robots for collision detection [7, 8], and we also showed that a LGMD can detect collision in simple flying scenes with a constant flying speed [9]. However, these LGMD models cannot work when it comes to agile flights in complex environments.
Essentially, agile flight is inevitable for flying robots in complex environments, as quick acceleration and ego motions are critical to maintain adequate efficiency. However, it often causes severe background noise to challenge the onboard vision sensor. A conundrum thus exists whereby the quadcopter needs to fly quickly to sustain efficiency, but this results in attitude motion and leads to false positive alarm from motion sensitive models. As an example of this difficulty, Fig. LABEL:Fig:Conundrum present the performance of our previous LGMD model [10] during the flight towards a chair in a collision case. The LGMD model triggers non-negligible false positive alarms during the pitching and accelerating periods. Note these attitude motions in periods (ii) and (iii) of Fig. LABEL:Fig:Conundrum(c) are crucial for achieving efficient agile flights by UAV’s, and the fitting of pan-tilts is not feasible for power limited MAVs. To achieve satisfactory performance in efficient flight, there is a strong demand for improving LGMD model to cope with the characteristics of agile flights and maintain its looming selectivity in these scenes.
A typical LGMD model consists of a few layers, including Photoreceptors, excitation, inhibition, synaptic summation and Feed forward inhibition and a LGMD neuron [4, 12]. The synaptic interactions in these models are simple, for example, the excitation is one-to-one connected from photoreceptor layer to summation layer, the lateral inhibition is spatially distributed but not considering temporal distribution.
Recent researches on locusts’ LGMD neuron indicated that both excitatory [13] and inhibitory [14] synaptic pathways are exquisitely structured and locally distributed to interact with neighbours. The retinotopic mapping seems to play an important role in LGMD’s preference for looming [15], which has been underestimated in previous models. These findings support the assumption that LGMD’s synapses do discriminate spatial-temporal patterns which are embedded across its thousands of synaptic inputs [11].
Inspired by these findings, we propose the distributed presynaptic connection (DPC) structure and incorporate novel morphological strategies, to implement a spatial-temporal filter on image angular velocity to cope with agile flights. The DPC structure involves novel strategies: (1) locally distributed excitation to enhance the excitation caused by visual motion with preferred velocities, and (2) radially distributed temporal latency for inhibition to compete with the distributed excitation and selectively suppress the non-preferred visual motions. We experimentally analysed how the spatial-temporal distributions contribute to LGMD’s looming selectivity and demonstrated the proposed model performs well in agile flights.
In summary, the contributions of this paper are threefold:
-
1.
We proposed a new LGMD model with locally distributed excitation for enhancing image motion with preferred angular velocity (on image) to better cope with agile flights.
-
2.
Temporal distribution is considered and defined in a radially extending manner to compete with the distributed excitation and form the spatial-temporal filter for looming cues.
-
3.
We demonstrated in experiments that the proposed model exhibited distinct preference for looming objects in agile flights and therefore is competent for collision detection for UAVs.
The remainder of this paper is organized as follows. In section II, we review related work on the LGMD models and UAV collision detection. In Section III, our proposed model is formally described with formulations. In Section IV, materials and the experimental setup are described. In Section V, the results of experiments are presented and discussed. Section VI concludes the paper.
II Related Work
In this section, we review the traditional methods used in UAV collision detection. This is followed by a consideration of bio-inspired approaches. Finally, recent relevant biologic researches on LGMD collision detector is introduced.
II-A Traditional UAV’s Collision Detection
For UAVs, visual collision detection systems can be categorised into two strategic approaches. One is to sense depth and escape when an obstacle is located at a given distance. The other one is to utilize monocular features in the recognition of obstacles or potential risks of collision, without sensing depth.
The first approach requires real-time knowledge about the 3D environment. This can be obtained with the use of a stereo-camera [16], LIDAR [17, 18], optic flow based distance maintenance [19, 20] or SLAM [3]. Such methods are commonly used in UAVs that have sufficient power. However, they cannot discriminate between objects. They simply compute the distance to every object in the whole field of view (FoV), which requires excessive calculation power. Interestingly, in nature only higher species or predators present depth-based detectors, whereas insects tend not to be able to perceive ”depth”, due to limitations resulting from the spacing between their eyes and the lack of overlap in their binocular field. As a consequence, they sacrifice accuracy for a gain in efficiency by making use of basic monocular visual cues which allow them to sense the risk of collision or danger.
The second strategy is to make plenty use of monocular visual features, including but not limited to colour, size, and image motion. For example, one can use a Speeded Up Robust Features (SURF) algorithm to recognise objects by feature points, and avoid the objects in the frontal area [21, 22]. However, recognising the object is not necessary for nor sufficient for detecting potential collisions. It is indirect and therefore neither robust nor efficient. Based on the observation that images of looming objects expand rapidly and in a non-linear way in the run-up-to collision, some researches attempt to detect the expansion of image edges in order to identify approaching obstacles. For example, a SURF algorithm and template matching method have been employed to detect the relative-expansion of a looming object[23]. In addition, a Scale-invariant feature transform (SIFT) algorithm and template matching have been used to detect the relative-expansion [24]. Generally, these traditional recognition methods demand considerable computational power for handling data in complex dynamic scenes.
II-B Bio-inspired Collision Detection
Animals have evolved with efficient sensor systems specialised for their living environments, and many insects are equipped with a designated visual system for flight. For example, optic flow is such an insect (fly)-inspired method for visual motion perception. The field of optic flow can be used for estimating UAV’s ego-motion [25] or collision detection by maintaining the balance of bilateral optic flow [19, 26]. However, it is not effective for detecting head-on collisions. In a complementary approach, optic flow has been combined with the ability to detect expansion. This led to a head-on collision detection system based on divergent optic flow [27, 28].
LGMD is a visual neuron found in the locust’s vision system to provide collision detection. Its characteristic looming selectivity largely arises within its dendritic fan [29]. Because of its compact size and specialised sensitivity to looming objects, computational researches has modelled and applied LGMD network to robots for head-on collision detection [12, 7]. In engineering application, a typical LGMD network can be treated as 3 stages of image process, i.e. (1) motion information extraction and image preprocess, (2) simulated synaptic computation, including local interaction and global summation. This is the key stage of LGMD model that underlies the ability to discriminate looming information. (3) output signal process (to reduce noise and enhance the interested information). A successful hypothesis for modelling the defining feature of LGMD model (stage 2 process) is proposed by Rind [4] in 1996, which point that the LGMD neuron can extract fast moving edges through the ”critical race” 111i.e. Excitation caused by an edge motion must move fast to escape from the impact of laterally distributed inhibition, otherwise, it will lose the race and cannot reach the threshold to activate downstream synapses formed by excitation and lateral inhibition. Based on this hypothesis, it can be deduced that a looming object can be identified by its fast moving edges and the angular size it occupied on the retina. After that, many researches developed this model through image preprocessing or post-processing. For example, Yue and colleagues[12] introduced extra grouping layer to enhance the clustered output and improve the performance. Q Fu [30] proposed on and off pathways in the 1st stage and focused on dark objects in light background; Another paper [31] feed back global intensity to mediate the inhibition weights in order to acquire adaptive sensibility according to different background complexity; Meng [32] introduced additional cells in the 3rd stage to acquire change rate of the converged output so that the model can predict approaching or receding movements. He [33] introduced image moment in preprocessing to enhance the resistance against ambient light change. But these researches mainly contributed to stage 1 or 3, because it is still not exactly known how the synapses corporate to achieve looming information extraction and it is hard to propose new biological plausible model to mimic the synaptic process. Besides, there is another hypothesis about the synapitc interactions claimed that the synapitc interaction can involve multiplication [34], and based on this, Badia [35] modeled the presynaptic layer with (Reichart correlator based EMDs [36]) to detect expanding edges. However, their model requires a unique preprocessing to predict expanded image, which has no evidence supported in biology. Despite this, because it is another related work to model the presynaptic interactions, we will also compare this model in Sec IV-D (Fig. LABEL:Fig:ComplexFlight).
Unfortunately, in agile UAV flights, the complex dynamic image motions generate spurious signals and will challenge the existing LGMD models with false positives. These false positives can hardly be solved by preprocessing or post-processing, demonstrating that the synaptic interactions (in stage 2) of existing models are too simple to discriminate spatial-temporal pattern as we expected.
II-C Emerging Biological Findings about LGMD
Thanks to technology development, recent biology can go further to explore the interneuron connections of the LGMD’s dendrite. Recent biological researches have highlighted the importance of the retinotopic reciprocal connections within the dendritic area. It is also reported that both excitatory and inhibitory presynaptic connections have a degree of overlap [37, 14], which is different from existing LGMD inspired models [8, 30, 6, 10]. Zhu suggested that the distributed excitation increases in response to coherently expanding edges [13]. To conclude, these findings indicate that dendrites receive finely distributed retinotopic projections from the photoreceptors and interact with neighbouring synapses before they converge. The locally distributed interaction is not as simple as previously assumed [4], but potentially forms a filter to discriminate spatial temporal patterns that are mapping across its dendritic fan.
In this paper, we update the model with such a presynaptic layer, which contains locally distributed excitatory and inhibitory reciprocal connections. In the proposed model, the spatial temporal structure of synaptic activity is determined by an overall spatial-temporal distribution in the distributed presynaptic connection (DPC) layer. In experiments, selective response to images with different angular velocity is initiated after the retinotopic mapping in the DPC layer, and before the postsynaptic inhibition (the FFI), demonstrating the DPC process successfully simulated the preference for looming of LGMD neuron. As a result, our model exhibits greatly enhanced robustness in complex scenes. Compared to traditional visual methods, the proposed presynaptic filter is based on linear processing of luminance change, which makes it computationally efficient and endows with the potential to be applied on micro embedded systems.
III Model Description
This section formulates the proposed distributed presynaptic connection based LGMD model (named ‘D-LGMD’). Considering the neural process is continuous, the whole model is re-formed in continuous integral format, but the contribution of this paper is focused on stage (2) process of LGMD. Besides, in order to retain the looming selectivity during complex background motion, some modification has been made to the threshold process in III-D.
III-A Mechanism and schematic

As determined from geometric analysis, the image of an ideal looming object shows a sharp nonlinear expansion as the object nears the collision point. The angular size and angular velocity of the image both increase non-linearly [39] as shown in Fig. 2 . The non-linear angular velocity symptom of a looming object is very unlikely to be produced by other sources of visual stimuli, such as receding or translating objects. Therefore, we aims to form a spatial-temporal filter in DPC layer to discriminate angular velocities of images on the retina. Following the idea of “critical race” by Rind [4], The DPC layer boosts signals derived from fast expanding edges of looming objects and eliminates interfering stimuli caused by other visual sources. Different from previous models [12, 10, 30], the proposed DPC layer can achieve accurate image angular velocity preference through a combination of locally distributed excitation and the spatial-temporal race against inhibition.


A schematic of the proposed D-LGMD model is presented in Fig. 3. The D-LGMD model is comprised of 3 stages of image processing: 1 motion information extraction (photoreceptors), 2 synaptic local interaction and global summation, 3 output feed back or forward and feature enhancement. The photoreceptors extract image motion, and divides into excitatory and inhibitory pathways. Then the synapses interact with neighbours through the morphologic mapping in DPC layer. after that, inhibition and excitation sum up and will be threshold after grouping and decay (GD). Additionally, the feed forward inhibition (FFI) component, as a side pathway of postsynaptic inhibition [40] mediates the threshold to regulate output MP within a dynamic range. This function is termed FFI mediated grouping and decay (FFI-GD).
Finally, a single output terminal, of which the membrane potential (MP) reflects the threat level of collision in the whole FoV, instructs downstream motion systems to avoid collisions. The morphology of the proposed D-LGMD is shown in the neural model in Fig. 4. In summary, there are 3 main differences compared to previous LGMD models:
-
1.
Excitatory and inhibitory synaptic pathways are both locally distributed and interact with neighbours. They compete in space but also boost coherently expanding edges if they win the competition.
-
2.
The inhibitory latency is radially distributed and increases as the transmission distance extends. This pattern of latency boosts the competition between excitatory and inhibitory synaptic afferents.
-
3.
In the side pathway, FFI no longer switches off the output MP. It mediates the decay threshold after grouping. This new mechanism keeps the output MP in a dynamic range and enables the detector to remain sensitive to looming stimuli in a rapidly changing FoV (as occurs during attitude motion).

III-B Photo-receptor layer
The first layer of the proposed model is a photo receptor layer (P layer). To behave as a motion sensitive visual model, the input layer monitors changes in the absolute luminance hitting each pixel:
| (1) |
where is the unit impulse function, denotes the change in luminance of pixel at time , and refers to the luminance at time . The P layer responds to all image motion equally and does not discriminate between backgrounds or foregrounds, translational, receding or looming movements.
III-C DPC layer
Below the P layer, image changes of the whole FoV are extracted, and only the information on moving edges is input to the subsequent DPC layer. The proposed DPC layer defines the second stage of D-LGMD process, which is the key stage that forms the looming selectivity. This layer enhances stimuli from images of looming or high speed objects and inhibits those from objects involved in lateral translation or from the background. Fig. 3 (b) illustrates the DPC process in pixel manner. Note both the excitation and inhibition are locally distributed. In relation to the current body of research, concerning the LGMD neuron in locusts, the characteristic of the DPC layer are consistent with the following principles:
-
1.
Both excitatory and inhibitory pathways are locally interconnected [14].
- 2.
-
3.
The time race between excitation and inhibition is essential for the preference to image angular velocity. [4].
We have therefore constructed the DPC layer with 2 distributions for excitatory and inhibitory pathways. Furthermore, the time race between excitation and inhibition is integrated in distribution functions as follows:
| (2) | |||
| (3) |
where and are excitation and inhibition at each pixel, respectively. , are the distribution functions of excitation and inhibition, respectively. In relation to principle 3), contains distributions not only in the spatial domain but also in the temporal domain. In agreement with the principle 2), a Gaussian kernel is chosen to describe the two distributions in the spatial domain.
| (4) |
In eq. (4), , are standard differences of excitation and inhibition distribution (Note in application, another parameter will be involved to limit the size of the kernels222In application, can be smaller as long as it is plenty to possess the characters of the spatial-temporal mappings adequately). is the temporal mapping function of inhibitory pathways; The latency is distance-determined, and increases as transmission distance extends.
| (5) |
In eq. (5), are time constants. An example of the temporal latency distribution is shown in Fig. 5 (note when , ). Time latency is necessary to form the spatial-temporal race between excitation and inhibition, which has been well explained previously [4]. In this research, we further put forth that the radially extending temporal distribution sharpens the output curve because it produces a gradient in temporal domain for inhibition. It thus selectively enhances the barrier against visual cues that are comparatively slow. Fig. LABEL:Fig:Neural_shematic_T elucidates this mechanism by comparing the inhibitory impact under constant latency (Fig. LABEL:Fig:Neural_shematic_T (a)) and radially distributed latency (Fig. LABEL:Fig:Neural_shematic_T (b)). In Fig. LABEL:Fig:Neural_shematic_T (a), both stimulus A (the slow one) and stimulus B (the rapid one) at only receive an ”isolated inhibition” (indicated by blue arrows) from the previous time stage . In contrast, with distributed latency in Fig. LABEL:Fig:Neural_shematic_T (b), stimulus A receives ”replicate inhibition” (indicated by red arrows) from both the previous stage and the before-previous stage , while stimulus B completely escapes from the inhibitory range. Therefore, the radially extending latency distribution allows the rapid/preferred stimuli to stand out in the model (more discussion about the advantage of radially distributed latency is given in Fig. 12).
Subsequently, the distributed interconnections, excitation and inhibition, are integrated by a linear summation (note that inhibition has the opposite sign against excitation):
| (6) |
In eq. (6), is the presynaptic sum corresponding to each pixel at time , and is the inhibition strength coefficient. Since additionally, synapses stimuli are not suppressed to give negative values, a Rectified Linear Unit (ReLU) is introduced:
| (7) |
Where .


Using the above formulations, the DPC layer forms a spatial-temporal filter, of which the input comprises the motion of the image, and the output consists only of coherently edges from dangerous looming objects whose image on the retina moves relatively fast. Under the DPC manipulation, the temporal information of the image, which results from the latency between E and I pathways, cooperates with the spatial distribution and determines the character of preferred angular velocity. Specifically, the coherent excitations will mutually enhance but must move faster to escape from the rejection band otherwise they will be inhibited. Therefore, only rapidly changing profiles of truly dangerous looming objects stand out after information has passed through the ”spatial-temporal filter”, while the stimuli caused by slowly translating objects or backgrounds are dramatically attenuated and are further eliminated by the threshold in the subsequent layer. The spatial-temporal distributions , , and regulate the competition between excitation and inhibition, therefore, they are critical to shape the selectivity for objects with different angular velocities. Importantly, since the DPC layer discriminates on the basis of angular velocity, if an object is close enough, to the extent that it occupies a large area of the retina and laterally translates at an extreme angular speed, it is also labelled as a ”dangerous target”. As a consequence, the model triggers an alarm. This character is consistent with empirical experiments which show locust behaviour towards a sudden translational movement [43].
III-D FFI mediated grouping and decay
The output of the DPC layer is sent to a grouping and decay (GD) layer and to further reduce the noise and smooth the output. The grouping mechanism allows clusters of excitation from the DPC layer to easily pass to its corresponding GD counterpart and provides a greater MP output. This mechanism is implemented by multiplying the summation in the DPC layer with a passing coefficient as in eq. (8):
| (8) |
Where is the excitation that corresponds to each dendritic cell in the G layer and is an integration from its neighbourhood, and is given by:
| (9) |
where is a constant and is the neighbourhood area. is set to be a matrix in this paper. G layer is followed by a threshold to filter out decayed signals:
| (10) |
After that, a decay threshold is involved to reduce interneuron output of inactive afferent. is mediated by the side pathway postsynaptic inhibition, the FFI, and is given by:
| (11) |
is the baseline threshold, is the total number of pixels in a single frame, m is a constant. is calculated by the previous image changes in the whole FoV, based on 12:
| (12) |
The side pathway FFI no longer switches off the output MP but mediates a threshold level for all single synaptic afferent according to the luminance change in the FoV. This new FFI-GD mechanism further suppress the edges caused by background motion and keeps the output MP within a dynamic range. Moreover, it preserves the ability of D-LGMD to work in complex and dynamic scenes.
III-E LGMD cell
Finally, the MP of the LGMD cell is the summation within the G layer derived from the whole FoV:
| (13) |
If the MP exceeds the threshold, a spike-like response is produced:
| (14) |
In application, an impending collision can be confirmed if successive spikes last consecutively for no less than frames:
| (15) |
| Paramter | Description | Value |
| k | Amplifying constant in Eq. (9) | 1 |
| Threshold baseline in Eq. (11) | 0.5 | |
| Constant cofficient in Eq.(11) | 0.4 | |
| LGMD spiking threshold in Eq. (14) | 0.4 | |
| minimum spikes to alarm in Eq. (15) | 2 |
The LGMD detector will generate an ”avoid” command to the quadcopter if the spikes lasts frames. Regular parameters are listed in Table I. These parameters are consistent in all the conducted experiments.
IV Experiment Results and Discussion
The proposed D-LGMD model includes a spatial-temporal filter, which allows discrimination of angular velocity and warns of imminent collision when the output MP exceeds a specified threshold. Systematic experiments were conducted with the aim of assessing the capability of the D-LGMD model when operating in different visual scenes. We conducted both qualitative comparisons with other LGMD models333In the following sections, ”LGMD model” refers to our previous model used in simple UAV flight [10]. Otherwise, if it refers to another LGMD model, it will be claimed additionally. to reflect the success of the proposed synaptic mappings and also quantitative parameter sensitivity experiments to analyse the feature of D-LGMD. Both simulation and real flight FPV video experiments demonstrate that the proposed D-LGMD model has enhanced selectivity to looming. This is particularly the case when the quadcopter performs agile flight in complex visual scenes.
IV-A Experimental Setup
The quadcopter platform used in this study is inherited from our previous research [9], which is program-controlled to achieve: hover, rotate, accelerate and uniform speed flight tasks. In order to assess different algorithms with identical input image sequences, we used a webcam (OSMO Pocket) , which is fixed on the quadcopter, to record real flight FPV videos. The quadcopter platform is shown in Fig. 7. Visual stimuli input to the neural network comprised both simulated objects and real flight FPV videos. The simulations contain rendered scenes created with Unity Engine software, and basic approaching cubes generated in MATLAB. The neural network was running on a laptop with 2.5GHz Intel Core i5 CPU and 8GB memory.

IV-B Characteristics of D-LGMD
To intuitively illustrate the layered network’s signal processing, an example of unity rendered scene is shown in Fig. LABEL:Fig:Example_Antonomy (a). And a timeline of output data from different layers is shown in Fig. LABEL:Fig:Example_Antonomy (b). The input scene contains a single looming ball with a uniform approaching speed and 4 capsules translating from left to right at different speeds. The P layer acquires luminance changes without any selection, so that stimuli of all the capsules and the looming ball are passed to the DPC layer. The DPC layer discriminates between angular velocities and dramatically attenuates stimuli from translating objects, therefore, it polarised the output into extreme high or low intensity. Subsequently, the G layer further filters sparse or decayed signals and amplifies the grouped excitation under the mediation of FFI.

In a second scenario, simulated stimuli were used to provide input data to compare the responses of the LGMD and D-LGMD models. The normalised output MPs resulting from a looming and receding cube is shown in Fig. 9 (a) and 9 (b) respectively. In the case of the looming cube Fig. 9 (a), the MPs from both the LGMD and D-LGMD models increased in a non-linear fashion as the cube approaches. An increasing in MP of the LGMD model is apparent in the early stages, initially gradual, but increasing continuously in the later stages. In contrast, the MP output from the D-LGMD model remained silent for most of the period but showed a sharp and rapid rise from about frame 15. This is because D-LGMD model is sensitive only to the preferred image angular velocity and not to other visual cues. It is therefore more effective at distinguishing between an object that is closing dangerously, and one that is far away. Similarly, the D-LGMD model also demonstrated a greater capability to reject receding objects, as can be seen from Fig. 9 (b). Hence, analogous to working characteristics of the real LGMD neuron of a locust when facing receding objects [5], the MP of D-LGMD model dropped to zero soon after the initial activation. In contrast, the LGMD model does not demonstrate the ability to effectively ignore receding objects. This result indicates the proposed D-LGMD model is robust against receding interfering stimuli.


We designed the proposed DPC structure as a spatial-temporal filter with the purpose of selectively attenuating the signal in reaction to the different angular velocities of the images. Here we can define the ”attenuation” of the DPC layer as the log-transformed function of the summation of DPC pixels and summation of input luminance changes:
| (16) |
Experiments demonstrate that the attenuation is greatly dependent on the angular velocity of the image. For example, Fig. 10 illustrates the changes in attenuation by the D-LGMD model during a looming process. The attenuation of the LGMD model was moderate when reacting to relatively lower angular speeds as shown in the initial stages, and steadily became less intense (i.e. became less negative) as the object moved closer. In contrast, the attenuation by the D-LGMD model was stronger (i.e. more negative) during the initial period and showed a sharper reduction (i.e. became less intense) near the collision point. This means that the D-LGMD model has a much stronger ability to discriminate between the stimuli since the angular velocity of a looming object always increases in a non-linear way.

IV-C Parameter Sensitivity Analysis
The response preference of D-LGMD model is determined by the spatial-temporal distribution. In this subsection, we discussed several parameters which are critical to define this preference. These comprise: the inhibition strength , standard deviations of excitation and inhibition distributions , and time race coefficients . Parameters sets used in later experiments are listed in Table.II for comparison. Please note, parameter set 1-3 present D-LGMD model without radially distributed latency (when , ), and they are compared in Fig. 12a
| Temporal Distribution Parameters | Spatial Distribution Parameters | Other Parameters | ||||||
| sets | a | r | ||||||
| set1 | 0 | 0 | 0 | 0.35 | 1 | 1.5 | 0.5 | 4 |
| set2 | 0 | 0 | 0 | 0.35 | 1.8 | 1.5 | 0.5 | 4 |
| set3 | 0 | 0 | 0 | 0.35 | 2.5 | 1.5 | 0.5 | 4 |
| set4 | -0.1 | 0.5 | 0.7 | 0.35 | 1 | 1.5 | 0.5 | 4 |
| set5 | -0.1 | 0.5 | 0.7 | 0.35 | 1.8 | 1.5 | 0.5 | 4 |
| set6 | -0.1 | 0.5 | 0.7 | 0.35 | 2.5 | 1.5 | 0.5 | 4 |
| set7 | -0.1 | 0.5 | 0.7 | 1 | 5 | 1.5 | 0.5 | 4 |
| set8 | -0.1 | 0.5 | 0.7 | 1 | 5 | 1.5 | 0.5 | 6 |
| set9 | -0.1 | 0.5 | 0.7 | 1.5 | 5 | 1.5 | 0.5 | 6 |
is synaptic distribution calculating radius used to limit the size of the matrix for computing.
| Image Sequence | Backgrounds Complexity | Attitude Motion | Object Texture | Collision Frame |
| Group1 | Cluttered Indoor | Pitch, Accelerating | Pure Colour Chair | 120 |
| Group2 | Cluttered Indoor | Pitch, Accelerating, Decelerating | Gridding Pattern | 140 |
| Group3 | Rotation, Indoor | Yaw | Notebook | 135 |
| Group4 | Simple Indoor | Take off, Pitch | Gridding Pattern | 210 |
| Group5 | Simple Indoor | Take off, Pitch | Carton | 196 |
Fig. 11 shows how changes in and affect the attenuation according to different angular velocities. In general, the D-LGMD model imparts a stronger attenuation (i.e. more negative) for relatively lower speed objects and vice versa. Specifically, increasing enhances the inhibition towards stimuli with higher angular velocities, while increasing reduces the attenuation towards the coherently expanding edges of stimuli with higher angular velocities because they mutually enhance. Thus, tuning the spatial distribution parameters makes it easy to select out preferred angular velocities and to identify image edges of dangerous objects.
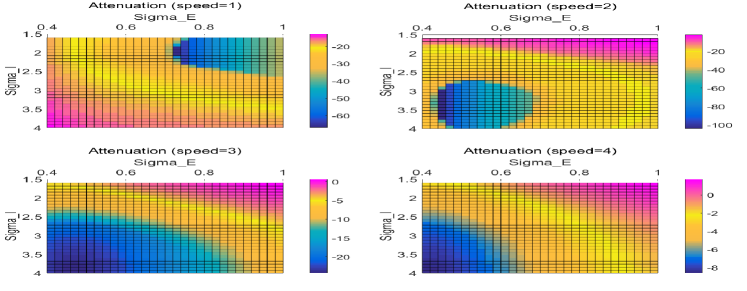
Fig. 12 demonstrated the advantage of radially extending latency, whose morphological mapping is tuned by time race coefficients . The radially distributed latency sharpened the normalised output curve of both MP and normalised MP. Moreover, in the enlarged details of Fig. 12 (a), the parameter sets with weaker response in the beginning climbed over in the looming period. This indicates that as the parameter increases, the performance improves better not only during the looming period (with a stronger output MP) but by showing stronger attenuation when the stimuli is of lower angular velocities. In this case, adjusting for stronger response to stimuli in the looming period does not sacrifice the attenuation towards stimuli that are far away. This occurs because the radially distributed time latency makes it easier for stimuli of higher angular velocities to win the inhibition race as explained previously in Fig. LABEL:Fig:Neural_shematic_T.


IV-D Performance in UAV FPV Videos
Finally, the model was challenged with recorded real flight videos. Various input scenes were tested, including a cluttered indoor environment, taking off, multi-axis attitude motion, self-rotation, acceleration and deceleration. Details of the input sequences are listed in Table III.
In the beginning, the D-LGMD model was challenged by the aforementioned conundrum (the same scene as Fig. LABEL:Fig:Conundrum) during agile flight (input sequences: Group 2). The results are presented in Fig. LABEL:Fig:ComplexFlight. We compared the performance in the same scene of 3 models: our previous LGMD model [10] (dashed blue curve), the EMD based multiplicative LGMD model [35] (dashed green curve), and the proposed D-LGMD model with/without FFI-GD (yellow and purple curves). It is notable that, both dashed curves experienced strong false positives in pitching and accelerating period. While in contrast, the D-LGMD model remains almost silent in these non-collision periods. Instead, as it nears the collision point, the D-LGMD responded a swift activation, and the output MP rises sharply to a high peak. The yellow curve (D-LGMD, without FFI-GD) demonstrates that strong preference for looming emerges after the DPC structure, the performance is satisfactory so that it can even work without post-processing. The purple curve (D-LGMD, with FFI-GD) shows the FFI-GD strategy works well to eliminate small spikes and smooth the curve.

The model was also tested with the same scene but but with a different obstacle with a different shape and pattern, as shown in Fig. 14(input sequences: Group 2). We also evaluated parameter sensitivity during the test (Fig. 14, sets 3,6,7&8). The selected parameter sets were not optimised but chosen as follows:
-
•
Set 3 rarely has excitatory distribution and the temporal latency is constant.
-
•
Set 6 involves distributed latency based on set3.
-
•
Set 7 has wider excitatory and inhibitory distribution kernel but limits the calculating radius, which limits the size of the matrix in the DPC processing in realistic computing, to 4 ( cannot fully reflect the kernel).
-
•
Set 8 involves extending the calculating radius to 6 and makes full use of the convolution kernel.
The results clearly show the different effects of modulating the parameters: Set 3 and 7 exhibit a small response near frame 40 (pitching). This small response is eliminated in set 6 and 8 when adding temporal distribution or increasing the calculating radius respectively. Set 3 and set 6 were largely affected by the decelerating process and led to a decrease in output MP near frame 120. This indicates that these two sets (with smaller , and calculating radius r) may not perform consistently when facing obstacles during a deceleration.
The D-LGMD also worked well when faced with relatively simple backgrounds (Fig. 15 and Fig. 16). The results show that both the LGMD and D-LGMD models are able to detect collision in these simple scenes. However, the results from the LGMD show that several small peaks remain during attitude motion. The attenuation curves provide further interpretation: the D-LGMD model showed stronger discrimination in different periods, strong attenuation is observed after taking off, and the attenuation curve prominently rose up during the looming periods. This demonstrate that, compare to the mussy image motions in taking off period, the model prefers the spatial temporal pattern of real looming object.
Additionally, we challenged the D-LGMD model during self-rotation (yaw motion). Results in Fig. LABEL:fig:rotation indicate the D-LGMD model preserves the ability to discriminate looming cues during rotational flight.








IV-E Computation Complexity
The computational complexity of the proposed DPC layer is mainly determined by the 2D convolutions of the input image sequences with and (equation (2) and (3)), which can be implemented in times for an input image and size kernel. In other words, the computational complexity is mainly determined by the calculating radius and input image size. [calculate a formulation, including the latency with no latency comparison.] The calculating radius should cover a significant area of the kernel for its character to be established. Reducing input image size (provided that the image preserves important features of the looming process) would increase the ability to recognise a looming object because the D-LGMD discriminates between image velocities by pixel interconnections and resizing the input image size also redefines the kernel’s impact area corresponding to the real scene. Therefore, the D-LGMD model can work with extremely low-resolution input because reducing the image size makes the kernel cover a larger area and enhances the barrier to background noise. We systematically analysed the relationship between the ability to recognise (distinguish-ability) to looming, the calculating radius, input image size and computational complexity by 200 trials running on PC. The results are listed in Table IV. The distinguish-ability (DA) is quantified as the average output MP near the peak apex (5 frames before and after) divided by average MP at a false positive point (i.e. Fig. LABEL:Fig:ComplexFlight (f)):
. Theoretically, when , it is impossible to select out looming cues from dynamic backgrounds during agile flight. From experimental experience, if , the model is very competent at filtering out the interfering stimuli and is foreseen to be robust for a range of scenes. As the input size ranging from default to one tenth of the area, the DA initially increased and then decreased. Using parameter set 7 (except r), for all the calculating radii, the best DA results existed when input images were resized to default area ( pixels). The proposed model showed satisfactory DA results even at extremely low resolution ( pixels). An insufficient DA was generated only when computing the default size (1080P) input with , resulting in a . This would mean that the looming object would be distinguishable but not sufficiently prominent.
| Calculating Radius (r) | Image resizing | Distinguish-ability (DA) | O (DPC) | PC Run Time (10 times average) |
| 6 | default | 249.33 | 9.18s | |
| 6 | 0.5 | 9789.28 | 2.75s | |
| 6 | 0.25 | 1.06s | ||
| 6 | 0.1 | 0.75s | ||
| 6 | 0.02 | 1354.10 | 0.60s | |
| 4 | default | 33.44 | 8.71s | |
| 4 | 0.5 | 691.20 | 2.54s | |
| 4 | 0.25 | 4579.40 | 0.98s | |
| 4 | 0.1 | 105.33 | 0.70s | |
| 4 | 0.02 | 184.54 | 0.59s | |
| 3 | default | 9.1 | 8.70s | |
| 3 | 0.5 | 96.75 | 2.53s | |
| 3 | 0.25 | 1227.60 | 0.97s | |
| 3 | 0.1 | 36.13 | 0.67s | |
| 3 | 0.02 | 76.06 | 0.57s | |
| 2 | default | 3.87 | 8.67s | |
| 2 | 0.5 | 11.09 | 2.49s | |
| 2 | 0.25 | 32.29 | 0.95s | |
| 2 | 0.1 | 11.76 | 0.66s | |
| 2 | 0.02 | 18.47 | 0.57s |
Note: DA is defined as the average output MP at peak point divided by average MP at false positive point:
DA . The parameters used are consistent with set 7 in TABLE II (except r).
The input scene is Group1 in Table III.
The PC Run Time covers the whole process of loading 120 frames of input images and running the model.
IV-F Discussion and Future Direction
As shown and discussed in the previous sections, the proposed D-LGMD model have been verified systematically via the experiments both qualitatively and quantitatively. The qualitative results shown in Fig. 8-10 indicate the D-LGMD model is excellent in discriminating image motion caused by looming objects from that of receding or translating ones. The capability of the DPC layer in filtering image motion based on its angular velocity has been explained in Fig.8, and further demonstrated in the supplementary material video 1. The quantitative analysis shown in Fig. 11 and Fig. 12 reflect the characteristic preference on image angular velocity is tunable in our model. More specifically, Fig. 11 also reveals how to tune this model to filter different angular velocity for different scenarios. It is also shown in Fig.12 that a constant temporal latency will lead to less nonlinear selectivity to looming as compared with radially extending latency.
Experiment results in flying scenarios have been shown in Fig. 13 to Fig.17 which demonstrated that D-LGMD is excellent to cope with agile flights in different scenarios. For example, D-LGMD (with/without FFI-GD) has been compared with other two models, where D-LGMD is robust in the pitching and accelerating periods of an agile flight. The proposed D-LGMD model with different spatial-temporal mapping (set3-8) are compared in Fig.14 - all of them are performed excellently compared with the previous LGMD. It is interesting to note that unexpected output drops (indicated by a red circle) appeared just before collision detected. These drops on the other hands demonstrated that the D-LGMD’s robustness is very much depending on a minimal synaptic distribution calculating radius , which should possess the characters of the spatial-temporal mappings adequately. The attenuation analysis can help to compare filter efficiencies in signal processing. The attenuation analysis on DPC layer shown in Fig. 15 and Fig. 16 further reveals that the proposed D-LGMD can significantly suppress irrelevant input image motions at different agile flying periods, particularly in the taking off, pitching and accelerating periods.
Recent neural physiological studies have discovered new characteristics of LGMD neuon in locusts to be considered in the model. For example, Zhu [13] suggested that the distributed excitation increases in response to coherently expanding edges, FC. Rind [14] reveals the new evidences on lateral inhibition, these all suggest the retinotopic connections from photoreceptoers to the LGMD neuron could be more complex than currently modelled. It is also noticed that ON/OFF seperated LGMD models have also shown their ability in replicating looming detecting capacity [30]. The performance of an ON/OFF channel separated model with the spatial-temporal distributed synaptic mappings is also a research topic to be investigated in the future.
V Conclusion
This paper proposed a computational presynaptic neural network model as a solution for collision detection in agile UAV flight applications. Agile flight of a UAV brings ego-motion of the camera which leads to confusing false positive in visual motion based collision detection algorithms. Our solution is to target the neural filter on nonlinear image angular velocity of the looming objects. This is achieved by integrating a series of locally distributed synaptic mappings into the second stage of LGMD process (in the DPC layer). The proposed DPC structure selectively build the barrier against stimuli from translating and background objects that have relatively lower image angular velocities while the spatial-temporal pattern of looming objects is preferred. Additionally, using an FFI-GD mechanism, the D-LGMD model preserves the ability to detect collision during UAV agile attitude motions including pitching, acceleration, deceleration and self-rotation. Systematic experiments have demonstrated that the proposed model dramatically enhances distinguish-ability of looming objects from agile-flight-derived background noise. Thus, the model is robust in handling complex dynamic visual scenes. Moreover, the proposed model functions well even with extremely small input image sizes ( pixels). In fact, reducing the size of input images did not harm the performance but increased the distinguish-ability towards looming objects. This notable character is likely to deliver a key success factor in energy-limited applications such as in embedded systems and MAVs.
References
- [1] A. Bachrach, R. He, and N. Roy, “Autonomous flight in unknown indoor environments,” International Journal of Micro Air Vehicles, vol. 1, no. 4, pp. 217–228, 2009.
- [2] X. Yu and Y. Zhang, “Sense and avoid technologies with applications to unmanned aircraft systems: Review and prospects,” Progress in Aerospace Sciences, vol. 74, pp. 152–166, 2015.
- [3] B. Steder, G. Grisetti, C. Stachniss, and W. Burgard, “Visual slam for flying vehicles,” IEEE Transactions on Robotics, vol. 24, no. 5, pp. 1088–1093, 2008.
- [4] F. C. Rind and D. Bramwell, “Neural network based on the input organization of an identified neuron signaling impending collision,” Journal of Neurophysiology, vol. 75, no. 3, pp. 967–985, 1996.
- [5] F. C. Rind, “Motion detectors in the locust visual system: From biology to robot sensors,” Microscopy Research & Technique, vol. 56, no. 4, pp. 256–269, 2002.
- [6] Q. Fu, H. Wang, C. Hu, and S. Yue, “towards computational models and applications of insect visual systems for motion perception: A review,” Artificial life, vol. 25, no. 3, pp. 263–311, 2019.
- [7] C. Hu, F. Arvin, and S. Yue, “Development of a bio-inspired vision system for mobile micro-robots,” in Joint IEEE International Conferences on Development and Learning and Epigenetic Robotics. IEEE, 2014, pp. 81–86.
- [8] C. Hu, F. Arvin, C. Xiong, and S. Yue, “A bio-inspired embedded vision system for autonomous micro-robots: the lgmd case,” IEEE Transactions on Cognitive and Developmental Systems, vol. PP, no. 99, pp. 1–1, 2016.
- [9] J. Zhao, X. Ma, Q. Fu, C. Hu, and S. Yue, “An lgmd based competitive collision avoidance strategy for uav,” in IFIP International Conference on Artificial Intelligence Applications and Innovations. Springer, 2019, pp. 80–91.
- [10] J. Zhao, C. Hu, C. Zhang, Z. Wang, and S. Yue, “A bio-inspired collision detector for small quadcopter,” in 2018 International Joint Conference on Neural Networks (IJCNN). IEEE, 2018, pp. 1–7.
- [11] R. B. Dewell and F. Gabbiani, “Biophysics of object segmentation in a collision-detecting neuron,” ELife, vol. 7, p. e34238, 2018.
- [12] S. Yue and F. C. Rind, “Collision detection in complex dynamic scenes using an lgmd-based visual neural network with feature enhancement,” IEEE transactions on neural networks, vol. 17, no. 3, pp. 705–716, 2006.
- [13] Y. Zhu, R. B. Dewell, H. Wang, and F. Gabbiani, “Pre-synaptic muscarinic excitation enhances the discrimination of looming stimuli in a collision-detection neuron,” Cell reports, vol. 23, no. 8, pp. 2365–2378, 2018.
- [14] F. C. Rind, S. Wernitznig, P. Pölt, A. Zankel, D. Gütl, J. Sztarker, and G. Leitinger, “Two identified looming detectors in the locust: ubiquitous lateral connections among their inputs contribute to selective responses to looming objects,” Scientific reports, vol. 6, p. 35525, 2016.
- [15] R. B. Dewell and F. Gabbiani, “Active membrane conductances and morphology of a collision detection neuron broaden its impedance profile and improve discrimination of input synchrony,” Journal of neurophysiology, vol. 122, no. 2, pp. 691–706, 2019.
- [16] S. Hrabar, G. S. Sukhatme, P. Corke, K. Usher, and J. Roberts, “Combined optic-flow and stereo-based navigation of urban canyons for a uav,” in 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2005, pp. 3309–3316.
- [17] C. Richter, W. Vega-Brown, and N. Roy, “Bayesian learning for safe high-speed navigation in unknown environments,” in Robotics Research. Springer, 2018, pp. 325–341.
- [18] C. Richter, A. Bry, and N. Roy, “Polynomial trajectory planning for aggressive quadrotor flight in dense indoor environments,” in Robotics Research. Springer, 2016, pp. 649–666.
- [19] C. Sabo, A. Cope, K. Gurny, E. Vasilaki, and J. Marshall, “Bio-inspired visual navigation for a quadcopter using optic flow,” AIAA Infotech@ Aerospace, vol. 404, 2016.
- [20] J. Keshavan, G. Gremillion, H. Alvarez-Escobar, and J. S. Humbert, “Autonomous vision-based navigation of a quadrotor in corridor-like environments,” International Journal of Micro Air Vehicles, vol. 7, no. 2, pp. 111–123, 2015.
- [21] W. G. Aguilar, V. P. Casaliglla, and J. L. Pólit, “Obstacle avoidance based-visual navigation for micro aerial vehicles,” Electronics, vol. 6, no. 1, p. 10, 2017.
- [22] R. Carloni, V. Lippiello, M. D’auria, M. Fumagalli, A. Y. Mersha, S. Stramigioli, and B. Siciliano, “Robot vision: Obstacle-avoidance techniques for unmanned aerial vehicles,” IEEE Robotics & Automation Magazine, vol. 20, no. 4, pp. 22–31, 2013.
- [23] T. Mori and S. Scherer, “First results in detecting and avoiding frontal obstacles from a monocular camera for micro unmanned aerial vehicles,” in 2013 IEEE International Conference on Robotics and Automation. IEEE, 2013, pp. 1750–1757.
- [24] A. Al-Kaff, F. García, D. Martín, A. De La Escalera, and J. M. Armingol, “Obstacle detection and avoidance system based on monocular camera and size expansion algorithm for uavs,” Sensors, vol. 17, no. 5, p. 1061, 2017.
- [25] A. Briod, J. C. Zufferey, and D. Floreano, “A method for ego-motion estimation in micro-hovering platforms flying in very cluttered environments,” Autonomous Robots, vol. 40, no. 5, pp. 789–803, 2016.
- [26] J. R. Serres and F. Ruffier, “Optic flow-based collision-free strategies: From insects to robots,” Arthropod structure & development, vol. 46, no. 5, pp. 703–717, 2017.
- [27] J. C. Zufferey and D. Floreano, “Fly-inspired visual steering of an ultralight indoor aircraft,” IEEE Transactions on Robotics, vol. 22, no. 1, pp. 137–146, 2006.
- [28] J.-L. Stevens and R. Mahony, “Vision based forward sensitive reactive control for a quadrotor vtol,” in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018, pp. 5232–5238.
- [29] Graham and Lyle, “How not to get caught,” Nature Neuroscience, vol. 5, no. 12, pp. 1256–1257, 2002.
- [30] Q. Fu, C. Hu, J. Peng, F. C. Rind, and S. Yue, “A robust collision perception visual neural network with specific selectivity to darker objects,” IEEE Transactions on Cybernetics, 2019.
- [31] Q. Fu, H. Wang, J. Peng, and S. Yue, “Improved collision perception neuronal system model with adaptive inhibition mechanism and evolutionary learning,” IEEE Access, pp. 1–1, 2020.
- [32] H. Meng, K. Appiah, S. Yue, A. Hunter, M. Hobden, N. Priestley, P. Hobden, and C. Pettit, “A modified model for the lobula giant movement detector and its fpga implementation,” Computer vision and image understanding, vol. 114, no. 11, pp. 1238–1247, 2010.
- [33] L. He, N. Aouf, J. F. Whidborne, and B. Song, “Integrated moment-based lgmd and deep reinforcement learning for uav obstacle avoidance,” in 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 7491–7497.
- [34] F. Gabbiani, G. Laurent, N. Hatsopoulos, and H. G. Krapp, “The many ways of building collision-sensitive neurons,” Trends in neurosciences, vol. 22, no. 10, pp. 437–438, 1999.
- [35] S. Bermudez, i Badia, P. Pyk, and P. F. Verschure, “A fly-locust based neuronal control system applied to an unmanned aerial vehicle: the invertebrate neuronal principles for course stabilization, altitude control and collision avoidance,” International Journal of Robotics Research, vol. 26, no. 7, pp. 759–772, 2007.
- [36] W. Reichardt, “Autocorrelation, a principle for the evaluation of sensory information by the central nervous system,” Sensory communication, pp. 303–317, 1961.
- [37] Y. Zhu and F. Gabbiani, “Fine and distributed subcellular retinotopy of excitatory inputs to the dendritic tree of a collision-detecting neuron,” Journal of neurophysiology, vol. 115, no. 6, pp. 3101–3112, 2016.
- [38] F. Gabbiani, H. G. Krapp, and G. Laurent, “Computation of object approach by a wide-field, motion-sensitive neuron,” Journal of Neuroscience, vol. 19, no. 3, pp. 1122–1141, 1999.
- [39] ——, “Computation of object approach by a wide-field, motion-sensitive neuron,” Journal of Neuroscience, vol. 19, no. 3, pp. 1122–1141, 1999.
- [40] R. D. Santer, R. Stafford, and F. C. Rind, “Retinally-generated saccadic suppression of a locust looming-detector neuron: investigations using a robot locust,” Journal of The Royal Society Interface, vol. 1, no. 1, pp. 61–77, 2004.
- [41] H. Cuntz, A. Borst, and I. Segev, “Optimization principles of dendritic structure,” Theoretical Biology and Medical Modelling, vol. 4, no. 1, p. 21, 2007.
- [42] H. Cuntz, F. Forstner, A. Borst, and M. Häusser, “One rule to grow them all: a general theory of neuronal branching and its practical application,” PLoS computational biology, vol. 6, no. 8, p. e1000877, 2010.
- [43] F. C. Rind and P. J. Simmons, “Orthopteran dcmd neuron: a reevaluation of responses to moving objects. i. selective responses to approaching objects,” Journal of Neurophysiology, vol. 68, no. 5, pp. 1654–1666, 1992.