Enhancing ID and Text Fusion via Alternative Training
in Session-based Recommendation
Abstract.
Session-based recommendation has gained increasing attention in recent years, with its aim to offer tailored suggestions based on users’ historical behaviors within sessions. To advance this field, a variety of methods have been developed, with ID-based approaches typically demonstrating promising performance. However, these methods often face challenges with long-tail items and overlook other rich forms of information, notably valuable textual semantic information. To integrate text information, various methods have been introduced, mostly following a naive fusion framework. Surprisingly, we observe that fusing these two modalities does not consistently outperform the best single modality by following the naive fusion framework. Further investigation reveals an potential imbalance issue in naive fusion, where the ID dominates and text modality is undertrained. This suggests that the unexpected observation may stem from naive fusion’s failure to effectively balance the two modalities, often over-relying on the stronger ID modality. This insight suggests that naive fusion might not be as effective in combining ID and text as previously expected. To address this, we propose a novel alternative training strategy AlterRec. It separates the training of ID and text, thereby avoiding the imbalance issue seen in naive fusion. Additionally, AlterRec designs a novel strategy to facilitate the interaction between the two modalities, enabling them to mutually learn from each other and integrate the text more effectively. Comprehensive experiments demonstrate the effectiveness of AlterRec in session-based recommendation. The implementation is available at https://github.com/Juanhui28/AlterRec.
1. Introduction
In recent years, predicting the next item in user-item interaction sequences, such as clicks or purchases, has gained increasing attention (Wu et al., 2019a; Li et al., 2017; Pang et al., 2022; Hou et al., 2022a). This practice is prevalent across various online platforms, including e-commerce, search engines, and music/video streaming sites. These sequences are created during user-item interactions in sessions. They encode user preferences which are dynamic and evolve over time (Tahmasbi et al., 2021). For instance, a user’s interests may shift from outdoor furniture in spring to indoor tools in autumn. Moreover, in many systems, only the user’s behavior history during an ongoing session is accessible. Therefore, analyzing interactions in active sessions becomes essential for real-time recommendations. This need has spurred the development of session-based recommendations (Wu et al., 2019a; Hou et al., 2022a), which utilizes the sequential patterns in a session to understand and predict the latest user preferences.
In this domain, ID-based methods (Kang and McAuley, 2018; Sun et al., 2019; Wu et al., 2019a) have become the predominant approach, significantly influencing the recommendation paradigm (Yuan et al., 2023; Li et al., 2023). Typically, these methods involve assigning unique ID indexes to users and items, which are then transformed into vector representations. Their popularity stems from their simplicity and effectiveness across various applications (Li et al., 2023). Despite their proven effectiveness, ID-based methods still have limitations. One drawback is their heavy reliance on the ID-based information. They tend to overlook other forms of valuable data, notably rich text information. This exclusion of textual data can result in less informative representations. Such reliance can be problematic in scenarios with limited interactions between users and items. However, most items typically experience sparse interactions, known as long-tail items (Park and Tuzhilin, 2008), which presents a challenge for these methods.
Recognizing these limitations, there has been a shift towards integrating text data for recommendations. The surging volume of text data emphasizes the crucial role of combing text in various domains, such as news recommendation (Li et al., 2022; Wu et al., 2019b) and e-commerce (Jin et al., 2023). These systems aim to accurately identify and match user preferences and interests using the available textual data. They achieve this by processing and encoding various forms of textual content, such as user reviews, product descriptions and titles, and news articles, to provide tailored recommendations. Recent trends indicate an increasing reliance on language models (Kenton and Toutanova, 2019; Brown et al., 2020; Hou et al., 2022b; Wei et al., 2023; Harte et al., 2023) for extracting semantic information from textual data. It is largely due to the exceptional ability of these models to encode textual information effectively. This progress has sparked considerable interests in the research community, particularly in enhancing recommendation systems beyond traditional user-item interaction data (Hou et al., 2022b; Wei et al., 2023; Ren et al., 2023; Yuan et al., 2023; Harte et al., 2023).

The prevailing approach in current literature for combining ID and text information typically employs a naive fusion framework (Hou et al., 2022b; Zhang et al., 2019; Wei et al., 2023), as shown in Figure 1. It involves generating embeddings from ID and text encoders, merging them to form a final embedding, and then using this for loss computation. However, our preliminary study detailed in Section 3.2, reveals that the naive fusion may not be as effective as previously believed in combining ID and text information. 1) Notably, it shows that independent training on just the ID information can yield performance comparable to, or even better than, the naive fusion model. This implies that the naive fusion model may not necessarily enhance, and could potentially reduce the overall performance. This finding aligns with the studies in multi-modal learning (Huang et al., 2022; Wang et al., 2020; Du et al., 2023a), which indicates that the fusion of multiple modalities doesn’t always outperform the best single modality. 2) We further explore one naive fusion implementation as an example to have a deeper understanding of this finding. The exploration suggests a potential imbalance issue: the model heavily relies on the ID component, while the text component appeared undertrained. This imbalance implies that the unexpected finding might be a result of the naive fusion framework’s inability to balance the contributions of the two types of information effectively, thereby hindering optimal overall performance.
The imbalance issue identified in the naive fusion models significantly hinders the accurate integration of textual data. Despite increased efforts to integrate textual content, these methods often fail to effectively capture essential semantic information. It results in a considerable loss of valuable information. This realization shifts our focus towards independent training, which does not exhibit this issue. However, independent training overlooks the potential for ID and text to provide complementary information that could be mutually learning. To address these challenges, we propose a novel Alternative training strategy to combine the ID and text components for session-based Recommendation (AlterRec). This approach separates the training of ID and text and thereby avoiding the imbalance issue. Additionally, it goes beyond simple independent training by enabling implicit interactions between these two modalities, thereby allowing them to inform and learn from each other. More specifically, our model consists of two distinct modules: an ID uni-modal network for encoding ID information, and a text uni-modal network for processing textual data. We design an alternating update strategy, where one module learns from the other by using its generated predictions as training signal. We conduct comprehensive experiments to validate the superior effectiveness of AlterRec over a variety of baselines in real-world datasets.
2. Related Work
2.1. ID-based Methods
These methods convert each user or item into a vector representation using unique ID indices. Traditionally, deep neural networks serve as encoders in this context. For example, GRU4REC (Hidasi et al., 2016) employs a recurrent neural network (RNN) to analyze user-item interaction sequences. More recent advancements have seen the adoption of sophisticated architectures as encoders. For instance, SASRec (Kang and McAuley, 2018) implements a Transformer encoder with self-attention to delineate user preferences within sequences. BERT4Rec (Sun et al., 2019) uses the BERT model, incorporating a cloze objective to model user behaviors. Another approach employs GNNs as encoders (Wu et al., 2019a; Pang et al., 2022). For example, SR-GNN (Wu et al., 2019a) constructs session-specific graphs and introduces a gated GNN to capture complex item transitions. Similarly, HG-GNN (Pang et al., 2022) builds a heterogeneous user-item graph to elucidate user-item transition patterns across multiple sessions. However, these methods overlook additional valuable text information, potentially leading to less informative representations.
2.2. Text-Integrated Methods
. These methods combine the text information to perform recommendations. For instance, FDSA (Zhang et al., 2019) leverages Word2Vec (Mikolov et al., 2013) for semantic representation and integrate both ID-based and text-based embeddings via the concatenation operation. S³-Rec (Zhou et al., 2020) utilizes an embedding matrix for learning text embeddings, combining textual information through various self-supervised tasks. More recent developments involve the use of language models for text-based embedding due to their advanced text modeling capabilities. UniSRec (Hou et al., 2022b) employs the BERT model for text embedding and combines the ID-based by summing them. LLM2BERT4Rec (Harte et al., 2023) designs to use the text feature extracted by the large language model as the initialization of the item ID embeddings. RLMRec (Ren et al., 2023) and LLMRec (Wei et al., 2023) both use large language models (LLMs) for generating user/item profiles and encoding them into semantic representations. RLMRec aligns ID-based embedding with textual information using contrastive and generative loss, whereas LLMRec integrates the text-based embeddings via summation. Among the methods discussed, the majority follows the naive fusion framework (Zhang et al., 2019; Hou et al., 2022b; Wei et al., 2023), which may not effectively incorporate text information as identified in Section 3.2.



2.3. Multi-modal Learning
The multi-modal learning paradigm, which integrates various data types like text, video, and audio (Liang et al., 2021), aims to enhance overall performance by leveraging the strengths of each modality. However, recent studies have found that fusing multi-modal data does not always outperform best single modality (Peng et al., 2022; Wang et al., 2020; Huang et al., 2022; Du et al., 2023a; Wu et al., 2022; Du et al., 2023b). They study the issue from different angles. For instance, G-Blend (Wang et al., 2020) identifies an overfitting issue and varying convergence rates across modalities, proposing a gradient-blending method for optimal modality integration. OGM-GE (Peng et al., 2022) suggests that a dominant strong modality might lead to imbalanced optimization and introduces an on-the-fly gradient modulation strategy to adjust each modality’s gradient. Huang et al. (2022) theoretically demonstrate a competition between modalities, where the losing modality fails to be adequately utilized.
3. Preliminaries
3.1. Session-based Recommendation
Consider a set of users and items, denoted as and , respectively. Let denote the set of user-item interaction sequences (or sessions). We use to represent one of the sequences, where is the -th item interacted with by the same user in session , and is the total number of interactions. The number of users and items are represented by and , respectively. Each item in is associated with text information, such as product descriptions, titles, or taxonomies, denoted by . Here, each word belongs to a shared vocabulary, and represents the truncated length of the text. Given an item sequence, the objective of session-based recommendation is to predict the next item in the current sequence. Formally, this involves generating a ranking list for all candidate items , where and each is a score indicating the likelihood of item being the next interacted item given a session .
The Naive Fusion Framework. In the realm of session-based recommendation tasks, ID-based and text-based information can be combined to potentially improve the overall performance. The majority of existing methods employ a naive fusion approach combined with a joint training strategy (Hou et al., 2022b; Zhang et al., 2019; Wei et al., 2023). We present the illustration of this framework in Figure 1. Specifically, this approach involves generating two types of embeddings and using ID and text encoders, respectively. These two embeddings can be item-level or session-level. The embeddings are then merged to form a final embedding, denoted as , through methods such as summation or concatenation. This final embedding is used to calculate a relevance score between a given session and the candidate item. This score estimates the likelihood of the item being the next choice in the session. Then the score is used to compute of the loss which optimizes the entire framework. Throughout this paper, the term naive fusion is used to refer to this framework. Notably, existing methods such as UniSRec (Hou et al., 2022b), FDSA (Zhang et al., 2019), and LLMRec (Wei et al., 2023) follow this approach.
3.2. Preliminary Study
In this subsection, motivated by multi-modal learning (Wang et al., 2020; Huang et al., 2022; Peng et al., 2022), we conduct a preliminary study to investigate potential challenges in combining ID and text information for session-based recommendation. This study could motivate more effective integration strategy for these two types of information.
In the naive fusion framework, the ID and text can be treated as two different types of modality that work together to improve the overall performance. However, studies in the multi-modal learning (Wang et al., 2020; Du et al., 2023a; Huang et al., 2022; Peng et al., 2022) reveals a phenomenon: fusing two modalities does not usually outperform the best single modality trained independently. In other words, combining modalities may not enhance, and could potentially reduce, overall performance. Various studies have focused on this phenomenon, offering analysis from different perspectives, such as greedy learning (Wu et al., 2022), modality competition (Huang et al., 2022) and modality laziness (Du et al., 2023b). To effectively merge ID and text information for session-based recommendations, we conduct an investigation to first verify the presence of this phenomenon and then explore its underlying causes. Further details will be provided in the following subsections.
3.2.1. Naive Fusion vs. Independent Training
To examine if the phenomenon mentioned above exists in session-based recommendation, this investigation aims to compare the performance of naive fusion models including our implementation named NFRec, UniSRec (Hou et al., 2022b) and FDSA (Zhang et al., 2019) against their corresponding two single modality models (ID and text) that are trained independently. To ensure a fair comparison, we employ the same ID/text encoder, scoring function, and loss function across both naive fusions and independent training frameworks. These methods have different implementation on the key components. More details are given in Appendix A.
The results on Amazon-French (detailed in Section 5.1.1) are presented in Figure 2 , where “ID only” and “text only” denote the respective ID and text only models that are trained independently. Furthermore, in Figure 2(a), “sum” and “concat” represent our naive fusion implementations using summation and concatenation respectively to combine the two types of information. Due to space limit, we present additional results on another dataset Homedepot in Appendix C, which shows similar phenomenon. We employ two widely used metrics Hits@20 and NDCG@20, where higher scores indicate better performance. We have the following observations:
Observation 1.
Training solely with ID information independently can often achieve performance comparable to, or even better than, naively fusing both ID and text. This indicates the ineffectiveness of naive fusion as a method for combining ID and text.
Observation 2.
The text only model generally results in the worst performance, often exhibiting a substantial performance gap compared to the ID only approach.
The first observation aligns with findings in multi-modal learning studies (Peng et al., 2022; Huang et al., 2022; Wang et al., 2020), indicating a similar phenomenon. This suggests that the integration of ID and text information is not as effective as expected in the session-based recommendation. To gain a more comprehensive understanding of this issue, we will delve into NFRec, which are elaborated upon in the following subsection.


3.2.2. Exploration of NFRec
In our exploration, we aim to understand how ID and text components perform under NFRec. It will provide insights into why combining these components in a naive fusion framework does not yield the expected improvement. To this end, we take NFRec applying concatenation for fusing ID and text information as one example. The NFRec can be conceptually divided into two segments: the ID component and the text component. Additional details on this division are available in the Appendix B. Test performance and training loss across each epoch on the Amazon-French are presented in Figure 3. For clarity, we label the two components as ”ID in NFRec” and ”text in NFRec” represented by red and green dashed lines, respectively. It is important to note that at epoch 0, all models are in a randomly initialized and untrained state. Additional results on the Homedepot dataset are given in Appendix C.
Figure 3 reveals a significant imbalance issue in NFRec: the performance and loss of the ID component are almost overlapping with those of NFRec. This indicates a heavy reliance on the ID component in NFRec, where the ID dominates the overall performance and loss, and the text component has limited contributions. This suggests that the first observation in Section 3.2.1 may stem from the nature of naive fusion. Specifically, it appears incapable of balancing the modalities to achieve optimal overall performance and tends to overly depend on the stronger ID modality (as noted in the second observation in Section 3.2.1). Supporting this hypothesis is from various studies (Peng et al., 2022; Huang et al., 2022; Wang et al., 2020; Wu et al., 2022) in multi-modal learning which offer empirical and theoretical insights from different angles, such as greedy learning (Wu et al., 2022), modality competition (Huang et al., 2022) and modality laziness (Du et al., 2023b). Further investigation to identify more concrete causes of this phenomenon is designated as one future work.
The analysis above reveals an imbalance issue deriving from naive fusion, suggesting it may not be an effective method for combining ID and text information. To address this, we propose a novel approach involving the alternate training of ID and text information. This method is designed to encourage implicit interactions between the ID and text. The details of this proposed framework are elaborated in the following section.

4. Framework
Having identified the potential imbalance issue with the naive fusion framework in the previous section, we explore to combine ID and text information by training them separately. However, simply training ID and text independently may not fully exploit their potential to provide complementary information. To address these challenges, we introduce AlterRec, a novel alternative training method. Figure 4 provides an overview of AlterRec. The model comprises two key components: the ID and text uni-modal networks, designed to capture ID and semantic information respectively. We employ the predictions from one network as training signals for the other, facilitating interaction and mutual learning through these predictions. AlterRec separates the training of ID and text, effectively avoiding the imbalance issue, as shown in section 5.3. Moreover, it goes beyond independent training by facilitating interaction between ID and text components, enabling them to learn mutually beneficial information from each other and incorporate the text more effectively. Next, we provide further details of these components.
4.1. ID and Text Uni-modal Networks
The ID and text unimodal networks share similar architectures. Each has respective ID/text encoders to generate ID and text embeddings. Based on these embeddings, a scoring function is adopted to calculate the relevance between given session and candidate items. We first introduce two encoders, and then use the ID embedding as an example to illustrate how to define the scoring function.
4.1.1. ID Encoder
The ID encoder in our model is designed to create a unique embedding for each item based on its ID index. This is achieved using an ID embedding matrix , where represents the size of the embedding. Each row, , corresponds to the ID embedding of item . Notably, this matrix is a learnable parameter within the network and updated during the optimization.
4.1.2. Text Encoder
The text encoder in our model is designed to extract textual information from items. Leveraging the advanced language modeling capabilities, we utilize the Sentence-BERT (Reimers and Gurevych, 2019) in this work. For each item , represented by a text sequence , the Sentence-BERT processes the input sentence to generate token embeddings. These embeddings are then aggregated using a pooling layer to form a comprehensive embedding for the entire sentence. And we further use a MLP (Delashmit et al., 2005) to transform the embeddings generated from the Sentence-BERT into a dimensional matrix. Formally:
| (1) |
where and each row corresponds to the text embedding of item . Considering practical constraints, we fix the language model which isn’t updated during the optimization process due to the high training cost.
4.1.3. Scoring Function
In the context of session-based recommendation, our objective is to predict the next item in a sequence of items interacted with by the same user, denoted as . To accomplish this, we generate a prediction score, , for each candidate item . These scores are then used to rank all candidate items, with the top-ranked item predicted as the next item. The process begins with obtaining the session embedding for session . This embedding encodes the user’s interaction behavior within that session. The relevance between the session embedding and each candidate item’s embedding is calculated and used as the score for that item. Next, we introduce two approaches to generate the session embedding, and use the ID embedding as an example since it’s similar for the text embedding.
Session Embedding via Mean Function. To encode the interaction information within session , we can use a mapping function, to operate on the item ID embeddings. A simple yet effective approach is to calculate the mean of the item embeddings within the session. Formally, this is represented as:
| (2) |
Here, denotes the length of the session .
Session Embedding via Transformer. To capture the item-item transition patterns within the same session, we employ the transformer architecture (Vaswani et al., 2017), which utilizes self-attention to weight the relative influence of different items. Formally:
| (3) |
where is the refined embedding after the Transformer. Given the sequential nature of session, we employ a masking matrix in self attention to prevent the model from accessing future information (Zhang et al., 2019). Due to the space limit, more details of the masking matrix is presented in Appendix D. Consequently, the embedding of the last item in the sequence is used as the session embedding, as it encapsulates information from all items in the current session.
| (4) |
where is the -th row of .
Session&Item Relevance. The session embedding can be derived using either or , based on their empirical performance. We determine the relevance between the session and each candidate item using vector multiplication:
| (5) |
Similarly, we can get the score based on the text embedding:
| (6) |
where or .
4.2. Alternative Training
The ID and text data offer different types of information. Our goal is to facilitate their interaction, enabling mutual learning and thereby enhancing overall performance. To this end, we propose an alternative training strategy to use predictions from one uni-modal network to train the other network. These predictions encode information of one modality, allowing one network to learn information from the other. We leverage the predictions from one modality to the other in two aspects. First, we select top-ranked items as augmented positive training samples. These items with top scores are likely very relevant to the current session from the perspective of one modality that could provide more training signals for the other modality especially for items with fewer interactions. Second, we choose other high-scored items as negative samples. These items are ranked higher but not the most relevant ones for one modality and we aim to force the other modality to distinguish them from positive samples. Such negative samples are much harder to be distinguished compared to those from traditional random sampling (Rendle et al., 2012). Thus, we refer to them as hard negative samples in this work. For illustrative purposes, we will use the predictions from the ID uni-modal network to train the text uni-modal network as an example.
Hard Negative Samples. We first generate predictions from the ID uni-modal network for a given session . Then we rank the scores of all candidate items in descending order:
| (7) |
Here, denotes the sequence of ID indices corresponding to the sorted scores.
We select items ranked from to , represented as , as the hard negative samples for training the text uni-modal network. It enables the text uni-modal network to learn from the patterns identified by the ID uni-modal network. These hard negatives play a crucial role in defining the loss function. For a given session with as the target item, we use the cross entropy as the loss function by following most of the related works (Hou et al., 2022b; Wu et al., 2019a; Pang et al., 2022):
| (8) |
where is the Softmax function applied over the target item and the negative samples in .
Similarly, we can use the hard negative sample derived from the text uni-modal network to train the ID uni-modal network. It’s obtained by sorting the scores and identifying the ranking ID index . We define the loss function for the ID uni-modal network as follows:
| (9) |
where the the Softmax function is applied over the target item and the negative samples in .
Positive Sample Augmentation. To train the text uni-modal network, we utilize as additional positive samples which serves as ground-truth target items. Similarly, is used as supplementary positive samples for training the ID uni-modal network. Typically, we set . Accordingly, the loss function in Eq. (8) and (9) is modified as follows:
| (10) |
| (11) |
Here, is a parameter to adjust the importance of the augmented samples. Note that within each network, these augmented samples are paired with the same corresponding hard negative samples as the target item .
Training Algorithm. This algorithm focuses on facilitating the interaction between two networks, and we use the Figure 4(c) as a more straightforward illustration. The training process consists of two stages. 1) Initially, due to the lower quality of the learned embeddings, we don’t employ interaction between two networks. Thus, we apply random negative samples during the first epochs. This involves replacing the hard negatives in Eq. (8) and Eq. (9) with randomly selected negatives with equal number. 2) Subsequently, we shift to training with hard negatives. We start by training the ID uni-modal network using hard negatives derived from the text uni-modal network. After epochs, the training focus shifts to the text uni-modal network, which is trained using hard negatives from the ID uni-modal network. Following another epochs, we resume training the ID uni-modal network and repeat this alternating process. This approach ensures that each network continually learns from the other, thereby potentially improving overall performance. More details of the training process are given in Appendix E.
Upon convergence of both networks, we generate a final relevance score by combining the relevance scores from each network and weighting their contributions. This score is used during the inference stage and is defined as:
| (12) |
Here, is the final score for the candidate item given session , and is a pre-defined parameter.
Homedepot Amazon-Spanish Hits@10 Hits@20 NDCG@10 NDCG@20 Hits@10 Hits@20 NDCG@10 NDCG@20 SASRec 33.58 ± 0.27 40.93 ± 0.14 18.23 ± 0.06 20.09 ± 0.06 70.95 ± 0.32 80.46 ± 0.32 44.88 ± 0.33 47.29 ± 0.34 BERT4Rec 26.06 ± 0.26 31.85 ± 0.45 15.61 ± 0.3 17.08 ± 0.35 64.6 ± 0.13 74.0 ± 0.33 44.6 ± 0.16 46.98 ± 0.18 SRGNN 30.09 ± 0.07 36.0 ± 0.19 15.31 ± 0.13 15.73 ± 0.13 67.02 ± 0.29 76.37 ± 0.12 46.75 ± 0.33 49.12 ± 0.26 HG-GNN 33.17 ± 0.13 40.72 ± 0.20 18.27 ± 0.49 20.19 ± 0.51 N/A N/A N/A N/A CORE 37.04 ± 0.11 44.73 ± 0.06 19.86 ± 0.14 21.81 ± 0.14 71.83 ± 0.15 81.14 ± 0.17 41.05 ± 0.06 43.41 ± 0.08 UnisRec (FHCM) 36.03 ± 0.12 43.67 ± 0.06 20.14 ± 0.79 22.08 ± 0.77 72.15 ± 0.01 81.3 ± 0.02 44.87 ± 0.1 47.2 ± 0.1 UnisRec 34.56 ± 0.23 42.19 ± 0.16 19.01 ± 0.08 20.92 ± 0.08 72.33 ± 0.06 81.42 ± 0.16 45.51 ± 0.05 47.82 ± 0.06 FDSA 32.1 ± 0.34 39.11 ± 0.2 20.44 ± 0.1 22.21 ± 0.06 70.55 ± 0.24 79.84 ± 0.08 49.83 ± 0.15 52.18 ± 0.13 S³-Rec 26.69 ± 0.1 33.04 ± 0.34 16.01 ± 0.14 17.62 ± 0.11 69.61 ± 0.4 78.85 ± 0.62 47.25 ± 0.45 49.6 ± 0.4 LLM2SASRec 34.12 ± 0.29 42.13 ± 0.18 18.69 ± 0.26 20.72 ± 0.22 71.55 ± 0.06 80.68 ± 0.12 48.45 ± 0.15 50.77 ± 0.17 LLM2BERT4Rec 29.51 ± 0.35 37.3 ± 0.33 16.25 ± 0.3 18.22 ± 0.3 66.47 ± 0.2 76.95 ± 0.27 40.29 ± 0.32 42.95 ± 0.35 AlterRec 38.25 ± 0.14 46.31 ± 0.11 20.72 ± 0.06 22.76 ± 0.06 72.41 ± 0.17 81.49 ± 0.09 50.59 ± 0.14 52.9 ± 0.12 AlterRec_aug 38.46 ± 0.1 46.37 ± 0.08 20.74 ± 0.05 22.75 ± 0.03 72.47 ± 0.19 81.45 ± 0.04 50.58 ± 0.02 52.86 ± 0.05 Amazon-French Amazon-Italian Hits@10 Hits@20 NDCG@10 NDCG@20 Hits@10 Hits@20 NDCG@10 NDCG@20 SASRec 69.2 ± 0.15 78.4 ± 0.1 44.89 ± 0.43 47.23 ± 0.44 68.25 ± 0.08 78.37 ± 0.06 43.24 ± 0.18 45.81 ± 0.18 BERT4Rec 63.01 ± 0.11 72.47 ± 0.15 43.84 ± 0.04 46.24 ± 0.07 62.24 ± 0.26 72.38 ± 0.13 42.42 ± 0.15 44.99 ± 0.11 SRGNN 65.61 ± 0.09 74.93 ± 0.09 46.27 ± 0.1 48.64 ± 0.08 65.62 ± 0.26 75.2 ± 0.15 44.85 ± 0.17 47.28 ± 0.15 CORE 69.93 ± 0.02 79.32 ± 0.1 39.4 ± 0.05 41.79 ± 0.07 69.42 ± 0.12 79.4 ± 0.1 39.27 ± 0.05 41.8 ± 0.05 UniSRec (FHCM) 70.35 ± 0.04 79.73 ± 0.13 43.99 ± 0.12 46.37 ± 0.1 69.95 ± 0.06 79.84 ± 0.07 42.97 ± 0.18 45.48 ± 0.2 UniSRec 70.54 ± 0.09 79.74 ± 0.03 44.5 ± 0.06 46.84 ± 0.06 69.99 ± 0.07 79.63 ± 0.03 43.42 ± 0.08 45.87 ± 0.06 FDSA 68.94 ± 0.29 78.16 ± 0.13 48.62 ± 0.11 50.96 ± 0.08 67.88 ± 0.07 77.97 ± 0.11 47.04 ± 0.11 49.6 ± 0.12 S³-Rec 62.82 ± 1.78 72.85 ± 1.01 40.84 ± 2.57 43.39 ± 2.37 60.6 ± 2.92 71.67 ± 2.19 37.88 ± 3.42 40.69 ± 3.22 LLM2SASRec 70.01 ± 0.1 79.15 ± 0.08 48.13 ± 0.08 50.45 ± 0.11 69.2 ± 0.14 79.11 ± 0.06 46.22 ± 0.39 48.73 ± 0.4 LLM2BERT4Rec 65.48 ± 0.02 75.91 ± 0.08 39.8 ± 0.16 42.45 ± 0.15 64.88 ± 0.44 75.9 ± 0.14 31.23 ± 0.26 32.0 ± 0.24 AlterRec 70.61 ± 0.03 79.75 ± 0.07 49.53 ± 0.02 51.86 ± 0.01 69.98 ± 0.01 79.75 ± 0.05 47.87 ± 0.14 50.35 ± 0.14 AlterRec_aug 70.82 ± 0.09 79.84 ± 0.1 49.56 ± 0.06 51.86 ± 0.07 70.13 ± 0.03 79.86 ± 0.11 47.87 ± 0.13 50.34 ± 0.15
5. Experiment
In this section, we conduct comprehensive experiments to validate the effectiveness of AlterRec. In the following, we will introduce the experimental settings, followed by the results and their analysis.
5.1. Experimental Settings
5.1.1. Datasets
We adopt two real-world session recommendation datasets including textual data. Homedepot: It is a private data from the Home Depot that is derived from user purchase logs on its website111https://www.homedepot.com/. Amazon-M2 (Jin et al., 2023): It’s a multilingual dataset. For the purpose of this study, which does not focus on multilingual data, we extracted unilingual sessions to create individual datasets for three languages: Spanish, French, and Italian. They are denoted as Amazon-Spanish, Amazon-French, and Amazon-Italian, respectively. More details can be found in Appendix F.
5.1.2. Baselines
In our study, we refer to our model without augmentation as AlterRec and to the augmented version as AlterRec_aug. We include a range of baseline methods, encompassing both ID-based approaches and those combining ID and textual data. Our experiment specifically includes the following methods: CORE (Hou et al., 2022a), SASRec (Kang and McAuley, 2018), BERT4Rec (Sun et al., 2019), SR-GNN (Wu et al., 2019a), and HG-GNN (Pang et al., 2022) as ID-based methods. Text-integrated methods include, LLM2BERT4Rec (Harte et al., 2023),UniSRec (Hou et al., 2022b), FDSA (Zhang et al., 2019), and S³-Rec (Zhou et al., 2020). Notably, UniSRec (FHCKM) refers to the UniSRec model pretrained on the FHCKM dataset (Hou et al., 2022b; Ni et al., 2019), as used in the original UniSRec paper, and UniSRec in this work denotes the model pretrained on our datasets, namely Homdepot and three Amazon-M2 datasets. LLM2BERT4Rec incorporates BERT4Rec as one of the backbone models. Additionally, we experiment with another ID-based backbone SASRec as deonted by LLM2SASRec. To ensure a fair comparison, each baseline method employs the same input features as AlterRec, specifically the sentence embeddings generated by Sentence-BERT. An exception is UniSRec (FHCKM), a pretrained model with fixed dimension sizes.
5.1.3. Settings
Empirically, for Homedepot dataset, we use the mean function to generate ID session embedding and Transformer to generate text session embedding. For Amazon-M2, we use Transformer to generate both ID and text session embeddings. To evaluate the model performance, we use two widely adopted metrics Hits@N and NDCG@N, and N is set to be 10 and 20. Higher scores of these metrics indicate better performance. We set the parameters as follows: , , , . Additionally, for the Homedepot dataset, we set , , and for the three Amazon-M2 datasets, , are used. More details are given in Appendix G.
5.2. Performance Comparison
The comparison results are presented in Table 1. Note that HG-GNN (Pang et al., 2022) incorporates both user and item data in its model. However, the Amazon-M2 dataset lacks user information. Consequently, it is not feasible to obtain results for HG-GNN which are denoted as“N/A”. We summarize our observations as follows.
Homedepot Amazon-French Methods Hits@10 Hits@20 Hits@10 Hits@20 AlterRec 38.25 46.31 70.61 79.75 AlterRec_random 37.41 45.41 70.46 79.64 AlterRec_w/o_text 35.64 42.95 68.26 77.23 AlterRec_w/o_ID 30.05 38.73 66.96 76.85
-
•
Alter_aug consistently outperforms other baseline models across a range of datasets, with AlterRec often achieving the second-best performance, hightlighting the effectiveness of our alternative training strategy. Moreover, it demonstrates that integrating augmentation data can further enhance performance. Although UniSRec and FDSA exhibit strong performance in some cases, they do not consistently excel across all metrics. In contrast, AlterRec maintains a balanced and superior performance in both Hits@N and NDCG@N. For instance, AlterRec shows about a 10% improvement over UniSRec based on NDCG@10 and NDCG@20 on Amazon-M2 datasets. Additionally, it achieves approximately 19% and 2% improvements over FDSA based on Hits@10 and Hits@20 on the Homedepot and Amazon-M2 datasets respectively.
-
•
When comparing models that incorporate text data with those solely based on IDs, it’s observed that models including text data typically demonstrate better performance. For example, AlterRec, along with UniSRec and FDSA, generally outperform ID-based models. This indicates that text information could offer complementary information, thereby enhancing overall performance.
5.3. Ablation Study
In this subsection, we evaluate the effectiveness of key components in our model: the hard negative samples and the ID and text uni-modal networks. The results of our ablation study are detailed in Table 2. Our model variants are denoted as follows: ”AlterRec_random” for training with random negative samples, ”AlterRec_w/o_text” for the model excluding the text uni-modal network, and ”AlterRec_w/o_ID” for the model without the ID uni-modal network. Notably, AlterRec_random uses the same number of negative sample with AlterRec. Furthermore, AlterRec_w/o_text and AlterRec_w/o_ID are trained exclusively on a single modality, either ID or text.
The results in the Table 2 indicate that employing random negative samples hurts performance. Notably, using random negatives behaves like the independent training, lacking interaction between the two modalities. This finding highlights the effectiveness of AlterRec over independent training. Its superior performance is likely due to the use of hard negative samples, which facilitates the learning between the two uni-modal networks. Furthermore, AlterRec significantly outperforms model variants that rely only on ID information, i.e., AlterRec_w/o_text. For instance, AlterRec achieves improvements of 7.82% and 3.26% in terms of Hits@20 on the Homedepot and Amazon-French datasets, respectively. These results demonstrate AlterRec’s superior ability to integrate text information, highlighting its advantage over naive fusion methods.
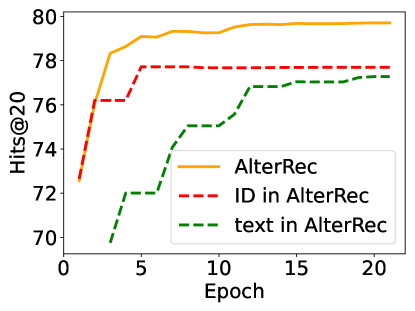
Additionally, we present the performance of AlterRec in Figure 5, including the individual performance of the ID and text components within AlterRec across epochs. These components are denoted as ”ID in AlterRec” and ”text in AlterRec”, respectively. The overall performance of AlterRec is based on the score in Eq. (12). The performance of ”ID in AlterRec” and ”text in AlterRec” are derived from the scores and within . Figure 5 demonstrates that both ID and text components are effectively trained in our model. It showns that the text modality in AlterRec is well-trained, and crucially, AlterRec does not exhibit the imbalance issue commonly associated with naive fusion.




5.4. Performance on Long-tail Items
Textual data offers valuable semantic information that can be used to enhance long-tail items in session-based recommendation. To validate this, we divide the test data into groups based on the popularity of the ground-truth item in the training data. We then compare the performance of various methods in each group against the ID-based method BERT4Rec. The comparative result is presented in Figure 6, where we also show the proportion of each group. This figure reveals that a majority of items have sparse interactions (long-tail items). In most cases, AlterRec outperforms other baselines particularly on long-tail items. For instance, AlterRec achieves the best performance in the [0,30] group on the Homedepot and Amazon-French. It indicates that AlterRec effectively captures textual information, enhancing its performance on long-tail items.
5.5. Parameter Analysis
In this subsection, we analyze the sensitivity of two key hyper-parameters: the parameter which adjusts the contribution of ID and text scores in Eq. (12), and the end index used for selecting hard negative samples as discussed in Section 4.2. We explore how these parameters influence the performance by varying their values across different scales on two datasets, Homedepot and Amazon-French. The results for Hits@20 and NDCG@20 are presented in Figure 7. Regarding , we note a similar trend across both datasets with relatively stable performance. An increase in performance is observed as rises from 0.1 to 0.5, followed by a decrease when is increased from 0.5 to 0.9. This pattern suggests that an value of 0.5 typically yields the best performance, indicating equal contributions from ID and text. For , there is an increasing trend in NDCG@20 on Amazon-French and a decreasing trend in Hits@20 on Homedepot as increases, and the overall performance remains stable. This indicates that the Amazon-French dataset may benefit from relatively more hard negative samples, whereas the Homedepot dataset does not require as many.



6. Conclusion
In this work, we explore an effective method for combining ID and text information in session-based recommendation. We have identified an imbalance issue in the widely-used naive fusion framework, which leads to insufficient integration of text information. To address this, we introduce a novel approach AlterRec employing the alternative training strategy that enables implicit interactions between ID and text, thereby facilitating their mutual learning and enhancing overall performance. Specifically, we develop separate uni-modal networks for ID and text to capture their respective information. By employing hard negative samples and augmented training samples from one network to train the other, we facilitate the exchange of information between the two, leading to improved overall performance. The effectiveness of AlterRec is validated through extensive experiments on various datasets against state-of-the-art baselines, demonstrating its superiority in session recommendation scenarios. In the future, we plan to investigate more advanced models, such as LLaMA, as the text encoders in AlterRec.
References
- (1)
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems 33 (2020), 1877–1901.
- Delashmit et al. (2005) Walter H Delashmit, Michael T Manry, et al. 2005. Recent developments in multilayer perceptron neural networks. In Proceedings of the seventh annual memphis area engineering and science conference, MAESC. 1–15.
- Du et al. (2023a) Chenzhuang Du, Jiaye Teng, Tingle Li, Yichen Liu, Tianyuan Yuan, Yue Wang, Yang Yuan, and Hang Zhao. 2023a. On Uni-Modal Feature Learning in Supervised Multi-Modal Learning. In International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA (Proceedings of Machine Learning Research, Vol. 202), Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett (Eds.). PMLR, 8632–8656.
- Du et al. (2023b) Chenzhuang Du, Jiaye Teng, Tingle Li, Yichen Liu, Tianyuan Yuan, Yue Wang, Yang Yuan, and Hang Zhao. 2023b. On Uni-Modal Feature Learning in Supervised Multi-Modal Learning. arXiv preprint arXiv:2305.01233 (2023).
- Harte et al. (2023) Jesse Harte, Wouter Zorgdrager, Panos Louridas, Asterios Katsifodimos, Dietmar Jannach, and Marios Fragkoulis. 2023. Leveraging Large Language Models for Sequential Recommendation. In Proceedings of the 17th ACM Conference on Recommender Systems. 1096–1102.
- Hidasi et al. (2016) Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk. 2016. Session-based Recommendations with Recurrent Neural Networks. In 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings, Yoshua Bengio and Yann LeCun (Eds.).
- Hou et al. (2022a) Yupeng Hou, Binbin Hu, Zhiqiang Zhang, and Wayne Xin Zhao. 2022a. Core: simple and effective session-based recommendation within consistent representation space. In Proceedings of the 45th international ACM SIGIR conference on research and development in information retrieval. 1796–1801.
- Hou et al. (2022b) Yupeng Hou, Shanlei Mu, Wayne Xin Zhao, Yaliang Li, Bolin Ding, and Ji-Rong Wen. 2022b. Towards universal sequence representation learning for recommender systems. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 585–593.
- Huang et al. (2022) Yu Huang, Junyang Lin, Chang Zhou, Hongxia Yang, and Longbo Huang. 2022. Modality competition: What makes joint training of multi-modal network fail in deep learning?(provably). In International Conference on Machine Learning. PMLR, 9226–9259.
- Jin et al. (2023) Wei Jin, Haitao Mao, Zheng Li, Haoming Jiang, Chen Luo, Hongzhi Wen, Haoyu Han, Hanqing Lu, Zhengyang Wang, Ruirui Li, et al. 2023. Amazon-m2: A multilingual multi-locale shopping session dataset for recommendation and text generation. arXiv preprint arXiv:2307.09688 (2023).
- Kang and McAuley (2018) Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recommendation. In 2018 IEEE international conference on data mining (ICDM). IEEE, 197–206.
- Kenton and Toutanova (2019) Jacob Devlin Ming-Wei Chang Kenton and Lee Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of naacL-HLT, Vol. 1. 2.
- Li et al. (2017) Jing Li, Pengjie Ren, Zhumin Chen, Zhaochun Ren, Tao Lian, and Jun Ma. 2017. Neural attentive session-based recommendation. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management. 1419–1428.
- Li et al. (2022) Jian Li, Jieming Zhu, Qiwei Bi, Guohao Cai, Lifeng Shang, Zhenhua Dong, Xin Jiang, and Qun Liu. 2022. MINER: multi-interest matching network for news recommendation. In Findings of the Association for Computational Linguistics: ACL 2022. 343–352.
- Li et al. (2023) Ruyu Li, Wenhao Deng, Yu Cheng, Zheng Yuan, Jiaqi Zhang, and Fajie Yuan. 2023. Exploring the Upper Limits of Text-Based Collaborative Filtering Using Large Language Models: Discoveries and Insights. arXiv preprint arXiv:2305.11700 (2023).
- Liang et al. (2021) Paul Pu Liang, Yiwei Lyu, Xiang Fan, Zetian Wu, Yun Cheng, Jason Wu, Leslie Chen, Peter Wu, Michelle A Lee, Yuke Zhu, et al. 2021. Multibench: Multiscale benchmarks for multimodal representation learning. arXiv preprint arXiv:2107.07502 (2021).
- Mikolov et al. (2013) Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781 (2013).
- Ni et al. (2019) Jianmo Ni, Jiacheng Li, and Julian McAuley. 2019. Justifying recommendations using distantly-labeled reviews and fine-grained aspects. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). 188–197.
- Pang et al. (2022) Yitong Pang, Lingfei Wu, Qi Shen, Yiming Zhang, Zhihua Wei, Fangli Xu, Ethan Chang, Bo Long, and Jian Pei. 2022. Heterogeneous global graph neural networks for personalized session-based recommendation. In Proceedings of the fifteenth ACM international conference on web search and data mining. 775–783.
- Park and Tuzhilin (2008) Yoon-Joo Park and Alexander Tuzhilin. 2008. The long tail of recommender systems and how to leverage it. In Proceedings of the 2008 ACM conference on Recommender systems. 11–18.
- Peng et al. (2022) Xiaokang Peng, Yake Wei, Andong Deng, Dong Wang, and Di Hu. 2022. Balanced multimodal learning via on-the-fly gradient modulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8238–8247.
- Reimers and Gurevych (2019) Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv preprint arXiv:1908.10084 (2019).
- Ren et al. (2023) Xubin Ren, Wei Wei, Lianghao Xia, Lixin Su, Suqi Cheng, Junfeng Wang, Dawei Yin, and Chao Huang. 2023. Representation Learning with Large Language Models for Recommendation. arXiv preprint arXiv:2310.15950 (2023).
- Rendle et al. (2012) Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme. 2012. BPR: Bayesian personalized ranking from implicit feedback. arXiv preprint arXiv:1205.2618 (2012).
- Sun et al. (2019) Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang. 2019. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In Proceedings of the 28th ACM international conference on information and knowledge management. 1441–1450.
- Tahmasbi et al. (2021) Hamidreza Tahmasbi, Mehrdad Jalali, and Hassan Shakeri. 2021. Modeling user preference dynamics with coupled tensor factorization for social media recommendation. Journal of Ambient Intelligence and Humanized Computing 12 (2021), 9693–9712.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems 30 (2017).
- Wang et al. (2020) Weiyao Wang, Du Tran, and Matt Feiszli. 2020. What makes training multi-modal classification networks hard?. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 12695–12705.
- Wei et al. (2023) Wei Wei, Xubin Ren, Jiabin Tang, Qinyong Wang, Lixin Su, Suqi Cheng, Junfeng Wang, Dawei Yin, and Chao Huang. 2023. LLMRec: Large Language Models with Graph Augmentation for Recommendation. arXiv preprint arXiv:2311.00423 (2023).
- Wu et al. (2019b) Chuhan Wu, Fangzhao Wu, Suyu Ge, Tao Qi, Yongfeng Huang, and Xing Xie. 2019b. Neural news recommendation with multi-head self-attention. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). 6389–6394.
- Wu et al. (2022) Nan Wu, Stanislaw Jastrzebski, Kyunghyun Cho, and Krzysztof J Geras. 2022. Characterizing and overcoming the greedy nature of learning in multi-modal deep neural networks. In International Conference on Machine Learning. PMLR, 24043–24055.
- Wu et al. (2019a) Shu Wu, Yuyuan Tang, Yanqiao Zhu, Liang Wang, Xing Xie, and Tieniu Tan. 2019a. Session-based recommendation with graph neural networks. In Proceedings of the AAAI conference on artificial intelligence, Vol. 33. 346–353.
- Yuan et al. (2023) Zheng Yuan, Fajie Yuan, Yu Song, Youhua Li, Junchen Fu, Fei Yang, Yunzhu Pan, and Yongxin Ni. 2023. Where to go next for recommender systems? id-vs. modality-based recommender models revisited. arXiv preprint arXiv:2303.13835 (2023).
- Zhang et al. (2019) Tingting Zhang, Pengpeng Zhao, Yanchi Liu, Victor S Sheng, Jiajie Xu, Deqing Wang, Guanfeng Liu, Xiaofang Zhou, et al. 2019. Feature-level Deeper Self-Attention Network for Sequential Recommendation.. In IJCAI. 4320–4326.
- Zhou et al. (2020) Kun Zhou, Hui Wang, Wayne Xin Zhao, Yutao Zhu, Sirui Wang, Fuzheng Zhang, Zhongyuan Wang, and Ji-Rong Wen. 2020. S3-rec: Self-supervised learning for sequential recommendation with mutual information maximization. In Proceedings of the 29th ACM international conference on information & knowledge management. 1893–1902.





| Dataset | #User | #Item | #Train | #Val | #Test |
| Homedepot | 145,750 | 39,114 | 182,575 | 2,947 | 5,989 |
| Amazon-Spanish | - | 38,888 | 75,098 | 7,900 | 6,237 |
| Amazon-French | - | 40,258 | 96,245 | 10,507 | 8,981 |
| Amazon-Italian | - | 45,559 | 102,923 | 11,102 | 10,158 |
Appendix A Implementation of Naive Fusion
In this section, we give more details of the naive fusion methods in section 3.2.1. We explore three approaches: our own implementation NFRec, UnisRec (Hou et al., 2022b), and FDSA (Zhang et al., 2019), with detains provided in the following.
-
•
NFRec: It consists of several key components. We give more details of these components. ID and text encoder: We employ the same ID and text encoder as AlterRec which is introduced in section 4.1.1 and section 4.1.2, respectively. Through these two encoders, we obtain the item-level ID embedding and text embeddings . Fusion operation: We fuse the ID and text item embeddings to form a final embedding via summation or concatenation to as mentioned in section 3.2.1. Scoring function: For a given session , we apply the mean function based on the fused item embedding to get the session embedding , and then we use the vector multiplication between session embedding and the candidate item’s fused embedding to get the score . Loss function: We use the cross entropy as the loss function, which follows similar form with Eq. (9).
-
•
UniSRec (Hou et al., 2022b): The model employs the same ID encoder as NFRec, which utilizes a learnable embedding for the ID representation. For text encoder, it leverages a language model enhanced by the proposed adaptor to extract textual information. After pretraining the adaptor using two contrastive loss functions, it merges the ID and text embeddings through summation. UniSRec adopts the same cross-entropy loss function as used in NFRec. We use the official code of UnisRec 222https://github.com/RUCAIBox/UniSRec/tree/master as the implementation.
-
•
FDSA (Zhang et al., 2019): The ID encoder generates ID embeddings using learnable embeddings. The text encoder employs a MLP and an attention mechanism to produce text embeddings. The Transformer is applied to items within a session to create ID and text session embeddings, which are then concatenated to form the final session embedding. Similar with NFRec and UniSRec, FDSA utilizes cross-entropy as the loss function. For the implementation of FDSA, we utilize code from the UniSRec’s repository, which includes the implementation details for FDSA.
Appendix B More Details when exploring NFRec
In this section, we give more details for the exploration conducted in section 3.2.2. We elucidate the process of dividing the NFRec into its ID and text components, and describe how we evaluate the performance and obtain the loss of ”ID in NFRec” and ”text in NFRec.” Details on the implementation of the NFRec are provided in the Appendix A.
For any given item , we derive the ID embedding and text embedding from the corresponding ID and text encoders. These two embeddings are then concatenated to form a final embedding . For a session , the session embedding is obtained by applying the mean function to the final embeddings of the items within session : . This session embedding is represented as a concatenation of two parts derived from the ID and text embeddings, respectively:
| (13) |
The relevance score between a session and an item is then decomposed into two parts:
| (14) |
Thus, the relevance score in NFRec can be decomposed as the summation of the ID and text scores. Accordingly, we evaluate the performance and obtain the loss of “NFRec”, “ID in NFRec” and “text in NFRec” based on , and in Eq. (B), respectively. For the loss function, the cross-entropy is employed.
Appendix C Additional Results in Preliminary Study
Additional results on the Homedepot dataset for investigations in sections 3.2.1 and 3.2.2 are displayed in Figure 8 and Figure 9, respectively. These figures indicate a trend similar to that observed with the Amazon-French dataset. Specifically, Figure 8 reveals that models trained independently on ID data can achieve performance comparable to, or even surpassing, that of naive fusion methods. Furthermore, models relying solely on text information tend to perform the worst. In Figure 9, it is observed that the ID component dominates the performance and loss. These findings are consistent with observations made with the Amazon-French dataset, suggesting that the phenomenon identified in observations 1 and 2 in section 3.2.1, as well as the imbalance issue in NFRec, may be prevalent across various datasets.
Appendix D More Details in Transformer
This section provides additional details on the Transformer in section 4.1.3. We first use positional embeddings to indicate the position of each item in the sequence:
| (15) |
Next, we apply a self-attention layer (Vaswani et al., 2017) to aggregate information from other items. The process is formally defined as:
| (16) |
Here, are the queries, keys, and values respectively, with being three learnable parameters. The factor is used to normalize the values, particularly beneficial when the dimension size is large. Originally, self-attention computes a weighted sum of values. However, considering the sequential nature the interaction data, we employ a masking matrix to prevent the model from accessing future information. In this matrix, if , and , otherwise, with representing element-wise multiplication.
Appendix E Alternative training algorithm
We present the pseudo code of the alternative training algorithm in Algorithm 1. The parameters within the ID and text uni-modal networks are denoted as and , respectively. Initially, as indicated in line 1, both networks are randomly initialized. In the early stages of training, both networks are trained with random negative samples, as indicated in line 2-7. It’s because the embedding learned in the early stage are of lower quality and might not be able to provide useful information. As training progresses, we shift towards employing hard negative samples. At first, the ID unimodal network is trained using predictions from the text unimodal network, as described in lines 9 to 11. After epochs, training shifts to the text unimodal network, utilizing predictions from the ID unimodal network, as indicated in lines 12 to 15. Subsequently, training alternates back to the ID network. This cycle continues until convergence is achieved for both networks. Notably, for AlterRec_aug, we replace the loss function in line 10 and 13 as Eq. (11) and Eq. (10) respectively.
Appendix F Datasets
We provide the data statistics in Table 3. The Homedepot dataset is a sampled dataset of purchase logs from the Homedepot’s website. We include sessions where all items have textual data, i.e., titles, descriptions, and taxonomy. Items in each session is interacted by the same user, who may have engaged in several sessions at distinct timestamps. For the purposes of validation and testing, we select the most recent sessions from different users. Specifically, 10% of these sessions are designated for validation and 20% for testing, with the remainder allocated to training sessions. Typically, the sessions in validation appear after those in the training set, and the sessions for testing appear after those in the validation set. For the three Amazon-M2 datasets, since there is no original validation set, we use about 10% of the training set to create a validation set.
Appendix G Experimental Settings
In our experimental setup, we search the learning rate in and dropout in , and we set hidden dimension as 300, and number of Transformer layer to be 2, for all models. The test results we report are based on the model that achieves the best performance during the validation phase. For text feature extraction in the Homedepot dataset, we utilize Sentence-BERT with the all-MiniLM-L6-v2 model333https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2. In contrast, for the three Amazon-M2 datasets, we employ Sentence-BERT with the distiluse-base-multilingual-cased-v1 model444https://huggingface.co/sentence-transformers/distiluse-base-multilingual-cased-v1, due to its proficiency in handling multiple languages including Spanish, French, and Italian. For each item in the Homedepot dataset, we use title, description, and taxonomy as the textual data. For the Amazon-M2 datasets, we use the title and description as textual data. All baseline methods employ the cross entropy as loss function and are implemented based on the RecBole 555https://recbole.io/index.html.