Enhancing High-Speed Cruising Performance of Autonomous Vehicles through Integrated Deep Reinforcement Learning Framework
Abstract
High-speed cruising scenarios with mixed traffic greatly challenge the road safety of autonomous vehicles (AVs). Unlike existing works that only look at fundamental modules in isolation, this work enhances AV safety in mixed-traffic high-speed cruising scenarios by proposing an integrated framework that synthesizes three fundamental modules, i.e., behavioral decision-making, path-planning, and motion-control modules. Considering that the integrated framework would increase the system complexity, a bootstrapped deep Q-Network (DQN) is employed to enhance the deep exploration of the reinforcement learning method and achieve adaptive decision making of AVs. Moreover, to make AV behavior understandable by surrounding HDVs to prevent unexpected operations caused by misinterpretations, we derive an inverse reinforcement learning (IRL) approach to learn the reward function of skilled drivers for the path planning of lane-changing maneuvers. Such a design enables AVs to achieve a human-like tradeoff between multi-performance requirements. Simulations demonstrate that the proposed integrated framework can guide AVs to take safe actions while guaranteeing high-speed cruising performance.
Index Terms:
Autonomous vehicle, deep reinforcement learning, model predictive control, high-speed cruising.I Introduction
Autonomous vehicles (AVs) have been widely recognized as a promising technology with enormous potential for improving traffic efficiency, road safety, and energy consumption in intelligent transportation systems [1, 2]. Equipped with advanced sensors, such as cameras and LiDARs, AVs demonstrate the capability of perceiving the environment and serving as control actuators for improving traffic flow [3]. However, the penetration rates of AVs can only gradually increase as technological maturity and public acceptance improve, and hence AVs are expected to operate in mixed traffic scenarios together with human-driven vehicles (HDVs). Within this context, the inherent unpredictability of HDVs emphasizes the critical need to investigate the safe control of AVs in mixed-traffic environments. On the one hand, this requires AVs to systematically consider their autonomous driving capabilities and the behavior of surrounding vehicles. On the other hand, it is crucial to make the decisions of AVs understandable by surrounding HDVs to prevent unexpected operations caused by misinterpretations.
Most studies divide the autonomous driving task into three sequentially executed modules, i.e., the behavioral decision-making, path-planning, and motion-control modules, and seek to enhance the safety of AVs by improving each of them in isolation [4, 5, 6]. The behavioral decision-making module, taking into account road rules and traffic conditions, is first executed to help AVs choose between lane keeping and lane changing, based on methods such as finite state machines [7], behavior trees [8], and deep reinforcement learning (DRL) [9, 10, 11]. It is worth noting that DRL-based methods have recently attracted increasing research attention for the behavioral decision-making module, thanks to its ability to make robust decisions efficiently in complex traffic conditions. Then, if lane changing is chosen, the path-planning module is executed to generate a collision-free trajectory, which is typically achieved by formulating an optimization problem [12, 13, 14, 15, 16]. Finally, the motion-control module allows AVs to implement behavioral decisions and maintain precise and stable movement along planned trajectories. Some model-based algorithms, such as linear quadratic regulator [17], sliding mode control [18], and robust H- control [19] are widely used to guarantee autonomous tracking performance. Recently, Model Predictive Control (MPC) [20, 21, 22] has received considerable attention due to its ability to explicitly handle system constraints.
However, the above-mentioned studies enhance AV safety only focusing on individual modules in isolation without considering the coupling between these modules. Intuitively, without accounting for the lower-level modules, the upper-level decisions may not be optimal or even physically feasible [23]. To address this issue, several studies have been conducted to achieve integrated control by combining some of these modules. In [24], a hierarchical reinforcement learning framework is proposed for the integrated control of lane-changing decisions and velocity planning. In [25], an enhanced double DQN algorithm is employed to generate binary actions to choose between lane keeping and lane changing. Reference [26] extends [25] by further introducing a path-planner to provide a safety guarantee in generating lane-changing maneuvers. Nevertheless, to the best of our knowledge, the motion-control module is rarely considered in these integrated frameworks or simply regarded as a kinematic model [24, 25, 26]. Ignoring the motion-control module can render the planned path or behavioral decision infeasible, which is especially possible in high-speed cruising scenarios where the physical constraints of the vehicles are more likely active, making the kinematic models inaccurate and leading to a deterioration in motion-control performance and safety concerns. Therefore, it is crucial to incorporate a motion-control module into the integrated control framework [27].
Moreover, even if safety can be enhanced from a technological perspective, human drivers may not understand the unexpected decisions made by AVs. This lack of understanding could potentially lead to undesirable HDV operations and increase the risk of collisions [28]. Therefore, enhancing the safety of autonomous driving also requires ensuring that HDVs understand the behavior of AVs, typically characterized by their trajectories. One promising solution to improve the interpretability of autonomous driving is to make AV behavior human-like [29, 28]. Current research on achieving human-like behavior in AVs aims to emulate human drivers’ characteristics during navigation, thereby enhancing AVs’ adaptability in complex environments [30]. This pursuit seeks to foster greater compatibility and trust between AVs and HDVs on the road.
The commonly employed approach to achieve human-like capabilities involves the utilization of machine learning models trained on extensive datasets to simulate human behavior. In [31], a model-free DRL framework was proposed to learn obstacle-avoidance behavior from skilled drivers. This framework encompassed a data-driven approach to integrate the expertise of human drivers and a rule-based method to encode fundamental driving rules. Reference [32] proposed heuristic and learning methods for training human-like lane-changing maneuvers based on naturalistic driving data. However, traditional machine learning methods suffer from several drawbacks, including relying solely on trial-and-error exploration and having limited generalization in new driving scenarios. Inverse Reinforcement Learning (IRL) offers advantages, such as the utilization of expert behavior demonstrations to learn task-relevant features and better adaptation to dynamic environments [33]. These advantages enable AVs to better understand and mimic human-like behaviors through demonstrations rather than rely solely on labeled data. Furthermore, unlike the conventional IRL method [34] that focuses on directly learning human driving actions, we learn the reward functions of human drivers’ lane-changing maneuvers in this study to understand the tradeoff between various control objectives. This design helps incorporate the IRL method into the path-planning process to generate a human-like path.
Statement of Contribution. The main contributions of this paper are two-fold. First, we enhance AV safety by proposing an integrated AV control framework in the high-speed cruising scenario that synthesizes the three fundamental modules of autonomous driving, i.e., behavioral decision-making, path-planning, and motion-control modules. Specifically, the behavioral decision-making module leverages Bootstrapped DQN to determine whether to perform lane-keeping or lane-changing, considering the interactions with the path-planning and motion-control modules. The Bootstrapped DQN can effectively enhance the deep exploration ability, which is important with the added complexity brought by the integration with two lower-level modules. Second, we devise an IRL-based approach to learn skilled drivers’ reward function for planning lane-changing paths, which characterizes the human-like tradeoff between various considerations (e.g., vehicle safety, driving comfort, and travel efficiency).
The rest of this paper is organized as follows. Section II introduces the overall framework, while Sections III, IV, and V present the bootstrapped DQN-based decision-making module, the IRL-inspired path-planning module, and the MPC-based motion-control module, respectively. Section VI analyzes the simulation results to highlight the significance of the proposed integrated framework. Section VII concludes the paper.
II Problem Formulation and Overall Framework
II-A Problem Formulation
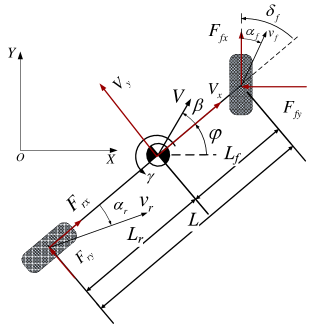
Let us consider a highway scenario where an AV seeks to optimize its high-speed cruising performance. We assume that all surrounding vehicles around this AV are HDVs, which is typical in the early deployment stages of AVs with very low penetration rates. The driving behavior of these surrounding HDVs is characterized by the Intelligent Driver Model (IDM) for car following and the MOBIL model for lane changing, both of which are widely adopted in transportation research [24]. The vehicle dynamics of AVs are modeled using a bicycle model (see Fig. 1) with configuration parameters obtained from a high-fidelity vehicle model in the commercial software Carsim, as detailed in Table I.
This study aims to devise a controller for the longitudinal (i.e., lane-keeping) and lateral (i.e., lane-changing) movements of the AV in high-speed cruising scenarios. Hence, the AV’s control input is defined by , where and are the longitudinal acceleration and front-wheel steering input, respectively. The AV’s state is defined by , where , and represent the longitudinal velocity, lateral velocity, yaw angle, yaw rate, global longitudinal position, and global lateral position, respectively.
With these notations, the vehicle’s position under the global coordinate system can be modeled as
| (1a) | ||||
| (1b) | ||||
When the vehicle operates with a small steering input, the dynamics of the longitudinal velocity, lateral velocity, and yaw angle can be represented as follows [35].
| (2a) | ||||
| (2b) | ||||
| (2c) | ||||
where represents the vehicle mass, represents the inertia yaw moment of the vehicle, and represent the lateral and longitudinal forces of the front tire, respectively, and represent the lateral and longitudinal forces of the rear tire, respectively, and and represent the distances from the center of gravity (CG) to the front axle and rear axle, respectively. As shown in Fig. 1, the relation between these variables can be described by
| (3) |
where and represent the cornering stiffness of front and rear tires, respectively, and represent the slip angles of front and rear tires, respectively. is the vehicle sideslip angle and calculated by .
| Symbol | Description | Value[units] |
| Vehicle mass | ||
| Inertia yaw moment of the vehicle | ||
| Distance from front axle to CG | ||
| Distance from rear axle to CG | ||
| Cornering stiffness of front tire | ||
| Cornering stiffness of rear tire |
II-B Overall Framework
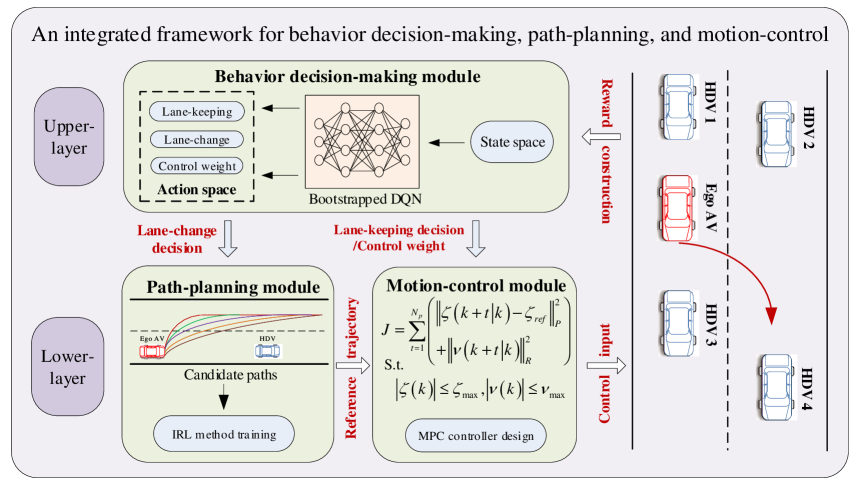
This section presents an integrated framework (see Fig. 2) to systematically combine the decision-making, path-planning, and motion-control modules. The decision-making module chooses between lane-keeping and lane-changing maneuvers, using a DRL agent that takes into account high-speed cruising performance and collision avoidance. If lane keeping is chosen, the DRL agent generates an acceleration/deceleration control signal. If lane changing is chosen, the path-planning module generates an efficient and human-like path that effectively trade off vehicle safety, driving comfort, and travel efficiency, with the corresponding weights learned from experienced drivers using an IRL algorithm. Finally, the motion-control module calculates the control signals with a model predictive controller that tracks the planned path while ensuring the physical feasibility by fully considering the vehicle dynamics constraints and actuator saturation.
Note that, different from existing works that combine only the decision-making module with the path-planning module, we further incorporate the motion-control module into the integrated framework. Such an integration involves two aspects. First, the DRL agent in the behavioral decision-making module generates not only the behavioral decisions but also the control weights that will be used in the motion-control module. Such a treatment systematically aligns the control objectives of the motion-control module with the other two modules. Second, the motion-control module is incorporated into the DRL agent’s training process, thereby ensuring that the trained DRL agent can generate physically feasible actions.
III Bootstrapped DQN-based Behavioral Decision-Making for the Autonomous Vehicle
This section presents a bootstrapped DQN method for the behavioral decision-making module in the integrated framework. Here, we leverage the bootstrapped DQN method to enhance the deep exploration ability to address the added complexity of incorporating the other two modules into the training process.
III-A MDP Formulation
The decision-making process can be described as a Markov Decision Process (MDP), denoted by a tuple , where , , , and are the state space, action space, state transition probability, and reward function, respectively. The details are presented below.
1) State Space. The state space comprises the vehicle states of the ego AV and its relative vehicle states to the HDVs. The state of the MDP at decision step is represented by , where denotes the states (i.e., lateral position, longitudinal position, and velocity) of the ego AV at decision step , and denotes the corresponding states of the surrounding HDV at decision step .
2) Action Space. In a high-speed cruising scenario, the DRL agent in the behavioral decision-making module makes a choice between lane-keeping and lane-changing maneuvers while simultaneously generating the control weights of the motion-control module associated with these driving maneuvers. Therefore, the action for an ego AV comprises lane-keeping and lane-changing decisions, as well as control weights for the motion-control module. Specifically, as illustrated in Table II, the action for an ego AV can be represented as an 8-dimensional vector with being a one-hot vector (i.e., only one element being one and the others being zeros). Here, lane-keeping decisions , , and are binary variables representing the selection of acceleration with a rate of , no acceleration, and deceleration with a rate of , respectively, where the value of is chosen to consider vehicle dynamics and road adhesion limits. The lane-changing decision variable is also a binary variable with indicating the selection of lane-changing maneuvers and the activation of the path-planning module. The weights , , and represent the coefficients of various criteria in the objective function of the motion-planning module, the specific forms of which are defined in Section IV-C.
| Action space | Lane-keeping decision | Lane-changing decision | Control weights | ||
| Acceleration | Moderate | Deceleration | |||
| Value | Path-planning process | ||||
3) Reward. This work incorporates high-speed driving performance and collision avoidance guarantees into the construction of the reward function, defined as follows:
| (5) |
where , , and represent the high-speed incentive, collision penalty, and frequent lane-changing penalty, respectively, with the forms specified as Eq.(6)-Eq.(8), and represent the corresponding coefficients that are chosen as , and , respectively, after experiments.
| (6) | ||||
| (7) | ||||
| (8) |
where Eq.(6) encourages the AV to drive faster, with , , and indicating the ego AV velocity at decision step , minimum velocity, and maximum velocity, respectively. The constraint is ensured in the lower motion-control module via the MPC controller. Eq. (7) employs an artificial potential field (APF) function to penalize the ego AV from being too close to surrounding HDVs to enhance its collision-avoidance ability in high-speed cruising scenarios, where and represent the global lateral and longitudinal positions of ego AV at decision step , while and indicate the global lateral and longitudinal positions of HDV at decision step . The scale factors and normalize the longitudinal and lateral spacing between vehicles. Eq.(8) is a Gaussian-type reward with scale factor implemented to discourage excessive lane-changing maneuvers to reduce the impact on congestion, where is the lateral coordinate of the lane centerline, and normalizes the reward term to be between 0 and 1. During the training process, the scale factors are tuned to minimize collisions. After experiments, , , and are set by -3, -0.5, -0.1, and 2.5, respectively.
III-B Bootstrapped DQN
The bootstrapped DQN is leveraged as the RL agent in this paper to enhance training efficiency, which provides exponential learning speed by approximating the population distribution using the distribution of bootstrapped samples , where the data set is obtained by sampling uniformly with replacement from the real data set .
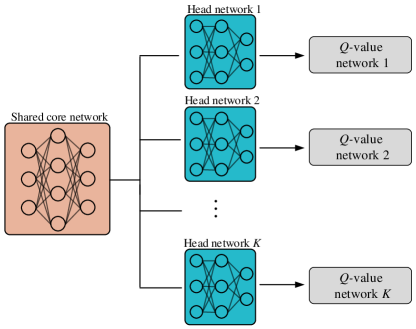
Fig. 3 illustrates the network structure of the bootstrapped DQN that consists of a shared core network and independent branches, each representing a head network. Each head network combined with the core network can be seen as a -value network, denoted by . Note that the training data for each head network only includes the bootstrapped sample with distribution . This allows independent -networks to collaborate and produce improved -value estimation results.
The bootstrapped DQN is implemented by generating a bootstrap mask to acquire a subsample each time after an action is selected. The bootstrap mask at decision step , represented by a binary vector with denoting the number of head networks, indicates which neural network to update with the current transition. Considering the bootstrap mask , the state transition at decision step can be augmented by and stored in the experience buffer. Consequently, the gradient of the -th -value network can be represented as follows.
| (9) |
where
| (10) |
where represents the -th neural network parameters at decision step , represents the approximate target value at decision step , and and refer to the interactive reward with the environment and the discount factor, respectively. represents the action corresponding to the maximum action value of the target network at the state . During the training process, similar to the traditional Q-network [26], we introduce to denote the target network parameter, which satisfies the fixed . It means the target network parameters are updated at a frequency of and remain fixed in between updates. Furthermore, gradient normalization is used to mitigate the impact of back-propagation from each -value network onto the shared core network. The normalized process is represented as follows.
| (11) |
When an RL agent starts the training process and explores potential rewards from the environment, it first follows the basic DQN method. Note that a -value network is randomly chosen at each episode. After completing the training, the optimal policy can output a set of actions. Considering the diversity of the -value network in the Bootstrapped DQN structure, a voting mechanism is introduced to select the optimal action, whereby the action with the highest number of votes across different -value networks will be executed. The pseudo-code for the bootstrapped DQN is shown in Algorithm 1.
IV Path-planning Module Design via IRL Method
After the DRL agent makes a lane-changing decision, the path-planning module is responsible for generating a human-like collision-free trajectory. The path-planning module includes two components: (i) a candidate path generation component that generates a set of possible paths and (ii) a selection component that chooses the optimal trajectory with a reward function learned from skilled human drivers via IRL to characterize human preferences over various control objectives.
IV-A Candidate Paths Generation
To simplify the path-planning process, we employed a widely used polynomial expression [36] to generate candidate paths. The representation of the candidate paths is as follows.
| (12) |
where is the reference lateral position. , , and are the coefficients of the polynomial. In the path-planning process, the constraints, which include both the initial and terminal points of the lane-changing behavior, are designed as follows to determine these coefficients.
| (13) |
where and represent the initial and terminal position of the lane-changing maneuver along the reference path, respectively.
Then by substituting Eq.(13) into Eq.(12), the candidate paths can be further represented as follows.
| (14) |
where and represent the lateral and longitudinal lane-changing distances, respectively. In this work, to facilitate system design, the longitudinal velocity of the AV is treated as constant during the lane-changing maneuver [22], which can be achieved through a Proportional-Integral algorithm in the motion-control module. Let denote the lane-changing duration, and hence the longitudinal distance of the lane-changing maneuver can be expressed as . Note that the mathematical expression for the bounds of is obtained by the constraint (15):
| (15) |
Eq.(15) is derived to ensure the collision avoidance and stability of the AV, where represents the collision-avoidance distance, and and are the available space for the lane-changing maneuver at the current and adjacent lanes, respectively. indicates the minimum safety distance between vehicles, is the maximum allowed deceleration rate, and is the road adhesion coefficient. represents the vehicle sideslip angle at the reference path, which can serve as an indicator to characterize the AV’s stability in vehicle dynamics [21]. Specifically, the reference value of can be calculated as follows.
| (16) |
where
| (17) |
IV-B IRL-Based Optimal Trajectory Selection
To make the behavior of AVs (characterized by their trajectories) understandable by HDVs, this work captures the preference of human drivers over multiple control objectives by introducing an IRL approach to learn skilled drivers’ reward function for planning lane-changing paths. After finishing training, an optimal reference path would be selected to achieve a human-like tradeoff between these control objectives.
1) IRL Reward Construction
In this work, we generate human-like paths by learning the preferences of human drivers over various control objectives, including vehicle safety, driving comfort, and travel efficiency. Such preferences are characterized by a reward function represented as a linear combination of these objectives, whereby the weights are learned via an IRL framework. The training data to the IRL framework involves the paths generated by skilled drivers on a driving simulator, because skilled drivers are more likely able to control the vehicles according to their preferences, while the actions of unskilled drivers may be subject to unexpected errors.
Specifically, AV’s safety is quantified by considering the stability of the vehicle dynamics and the potential collision risk. Driving comfort is indicated by the change rate of the yaw angle, while travel efficiency is represented by the lane-changing duration . A vector of control objectives for a considered candidate path is constructed as follows:
| (18) |
where and represent the control objectives for vehicle stability, collision risk, comfort, and travel efficiency, respectively, with the specific forms given as follows:
| (22) |
where we discretize the lane-changing duration into time instants with equal intervals of 0.1 s, indexed by , and represents the change rate of the yaw angle at the time instant .
The reward function of IRL is then constructed by a linear combination of the feature vector.
| (23) |
where .
2) IRL Training Process
During the training process, we utilize the driving behavior of skilled drivers as expert experience to optimize the feature weight coefficients in Eq.(23). Note that we adopt a maximum entropy method [37] for training the IRL model. The objective of such method is to maximize the likelihood of the driver’s trajectory .
| (24) |
| (25) |
where indicates the total driver’s trajectories collected in the tests. is the candidate path generated by the polynomial expression Eq.(14). and represent the number of candidate paths and feature vector of the driver trajectory, respectively. To guarantee the effectiveness of the training data, the initial state when generating the trajectory is the same as that of driver trajectory .
The objective function of the IRL framework can be written as follows.
| (26) |
The gradient of is computed as:
| (27) | ||||
Eq.(26) could reflect the difference between the driver trajectory and candidate paths. It is employed to iterate and update the feature weight vector using the gradient ascent method Eq.(27). The IRL algorithm flow is presented in Algorithm 2. After completing the training, the feature weight vector is determined. Hence, the AV’s path-planning ability can emulate a skilled driver to effectively balance different control objectives in high-speed cruising scenarios. In the IRL framework, the learning rate and episodes can impact the training effectiveness. By comparing the human-like driving results with different settings, and .
V Motion-control Module Design via MPC Method
In this section, we develop an MPC-based tracking controller to implement the motion control of potential lane-keeping and lane-changing behaviors, in order to accurately track the planned path while respecting constraints on physical dynamics and safety.
V-A Lane-Keeping Motion Control
The lane-keeping motion-control module aims to track the reference acceleration/deceleration signal calculated in the behavioral decision module, while ensuring high-speed cruising of the ego AV. This is achieved via a MPC-based controller with an embedded quadratic programming (QP) problem described as follows. Note that the system state-space equation adopts the vehicle longitudinal dynamics model and can be derived from Eq.(4) [40].
| (28a) | ||||
| (28b) | ||||
| (28c) | ||||
| (28d) | ||||
where the objective function Eq.(28a) minimizes the total costs over a prediction horizon , including (i) the deviation from the maximum speed (the first term) and (ii) the tracking error between the actual acceleration rate and the reference acceleration rate given by the decision-making module (the second term), weighted by constants and . The specific values of and are determined by the DRL agent in the behavioral decision-making module. Constraints (28b) and (28c) impose physical bounds on the acceleration and velocity at each decision step. Constraint (28d) ensures that the spacing between the ego AV and the preceding HDV is lower bounded by the safe spacing. Notice that here we assume that the following HDV will not actively collide with the AV.
V-B Lane-Changing Motion Control
The lane-changing motion-control module devises an MPC-based controller to track the reference path generated by the path-planning module, while ensuring the AV’s lateral stability [38]. The embedded optimization problem of the MPC can be represented as follows. The system state-space equation employs the vehicle lateral dynamics model [22].
| (29a) | ||||
| (29b) | ||||
| (29c) | ||||
| (29d) | ||||
| (29e) | ||||
where , and . The objective function Eq.(29a) includes (i) the deviation from the reference trajectories (the first term) and (ii) the cost of the control inputs (the second term), weighted by positive-definite matrices and . The specific values of and are determined by the behavioral decision-making module, where . is set to guarantee the AV’s heading angle is zero after completing the lane-changing maneuver. Constraint (29b) imposes physical bounds on the front-wheel steering input. Constraints (29c), (29d), and (29e) ensure the AV’s lateral handling stability [38].
VI Simulation
In this section, simulations are conducted to verify the effectiveness of the proposed method using a Simulink/Python joint platform. The vehicle model in Section II and the motion-control module are constructed in Simulink, while the behavioral decision-making and path-planning modules are implemented with Python.
| Parameters | Bootstrapped DQN |
| Learning rate | |
| Reward discount | 0.95 |
| Batch size | 64 |
| Memory capacity | 15000 |
| Target replace | 500 |
| Network layers | 3 |
| Number of neurons |
VI-A Training Process of the Integrated Framework
The integrated framework requires the training of the feature weight vector and the behavioral decision-making policy, which is performed in a sequential manner. First, using collected data of skilled human drivers, the IRL method is trained based on Algorithm 2 to obtain the feature weight vector . Then, Algorithm 1 is employed to train an AV navigating in a high-speed cruising scenario by integrating the behavioral decision-making, path-planning, and motion-control modules. After tuning in the training progress, the hyperparameters of the bootstrapped DQN are given in Table III. Note that during the training process, the initial positions and velocities of HDVs are randomly set. Meanwhile, the Long Short-Term Memory network is employed to obtain the driving behavior of the leading HDVs from the historical data.
Furthermore, to simplify the system design, we set a benchmark for the training of control weights in the motion-control module. For lane-keeping control (Eq.(28a)), to prioritize the optimization objective of tracking the reference acceleration signal, is set as a benchmark. As for the lane-changing control (Eq.(29a)), considering the priority of path-tracking performance, we set . After completing the training, the RL agent in the behavioral decision-making module would output the specific values of control weights.
VI-B Verification of Human-Like Path-Planning
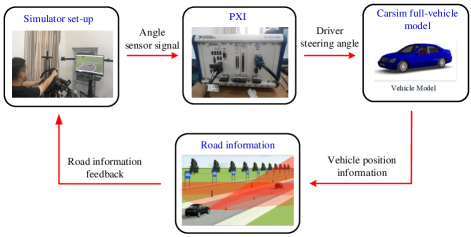
In the path-planning module, we introduce the IRL method to learn skilled drivers’ reward function for planning lane-changing paths. The driving simulator, as depicted in Fig. 5, is employed to collect driver behavior data. More details regarding the driving simulator can be found in [39]. We invite skilled drivers to participate in the tests, who will get familiar with the testing equipment in advance to ensure the accuracy of the test data.
Through these experiments, we construct a dataset comprising 50 drivers’ lane-changing trajectories under different test conditions. This dataset is utilized to update the IRL weight vector . After finishing the training, we employ a set of 10 driver trajectories to evaluate the learning performance. Here, the feature vector in Eq.(18) is calculated to provide a comparison of human-like path-planning performance. The specific indices from IRL’s learning results and driver’s trajectories are presented in Table IV. The average learning errors for different performance indices, including vehicle safety, driving comfort, and travel efficiency, in ten tests are , and , respectively. These results demonstrate the effectiveness of the proposed IRL method in acquiring preferences of human drivers, thereby balancing different control objectives during lane-changing maneuvers.
|
|
|
|
|
||||||||||||
| Test case1 | IRL | 0.000395 | 167.571 | 22.524 | 0.105 | |||||||||||
| Driver | 0.000416 | 163.312 | 30.104 | 0.095 | ||||||||||||
| Test case2 | IRL | 0.000204 | 133.042 | 16.958 | 0.12 | |||||||||||
| Driver | 0.000175 | 141.730 | 19.654 | 0.13 | ||||||||||||
| Test case3 | IRL | 0.000257 | 121.956 | 20.652 | 0.115 | |||||||||||
| Driver | 0.000325 | 134.513 | 18.293 | 0.115 | ||||||||||||
| Test case4 | IRL | 0.000181 | 152.038 | 19.024 | 0.13 | |||||||||||
| Driver | 0.000258 | 160.642 | 21.924 | 0.125 | ||||||||||||
| Test case5 | IRL | 0.000257 | 118.793 | 17.462 | 0.13 | |||||||||||
| Driver | 0.000218 | 115.923 | 18.942 | 0.13 | ||||||||||||
| Test case6 | IRL | 0.000451 | 169.723 | 25.863 | 0.11 | |||||||||||
| Driver | 0.000497 | 181.543 | 28.727 | 0.11 | ||||||||||||
| Test case7 | IRL | 0.000263 | 118.192 | 21.038 | 0.13 | |||||||||||
| Driver | 0.000291 | 123.321 | 19.526 | 0.14 | ||||||||||||
| Test case8 | IRL | 0.000236 | 143.160 | 22.481 | 0.125 | |||||||||||
| Driver | 0.000248 | 138.379 | 21.017 | 0.115 | ||||||||||||
| Test case9 | IRL | 0.000256 | 121.815 | 17.556 | 0.135 | |||||||||||
| Driver | 0.000317 | 113.679 | 20.571 | 0.14 | ||||||||||||
| Test case10 | IRL | 0.000421 | 164.552 | 25.471 | 0.10 | |||||||||||
| Driver | 0.000393 | 179.727 | 23.954 | 0.11 | ||||||||||||
VI-C Verification of the Integrated Framework
1) Overall Performance Analysis
Simulations are conducted to demonstrate the value of the integrated framework in enhancing the overall performance of autonomous driving. Specifically, we compare the resulting performance of the proposed integrated framework with that of a sequential framework that involves separate training and execution of the three fundamental modules, i.e., behavioral decision-making, path-planning, and motion-control. Note that to decouple the training of fundamental modules in the sequential framework, we train the behavioral decision-making module by assuming a simplified path planning procedure with a constant lane-changing execution time (i.e., 2 seconds) and motion control with pre-defined constant control weights.
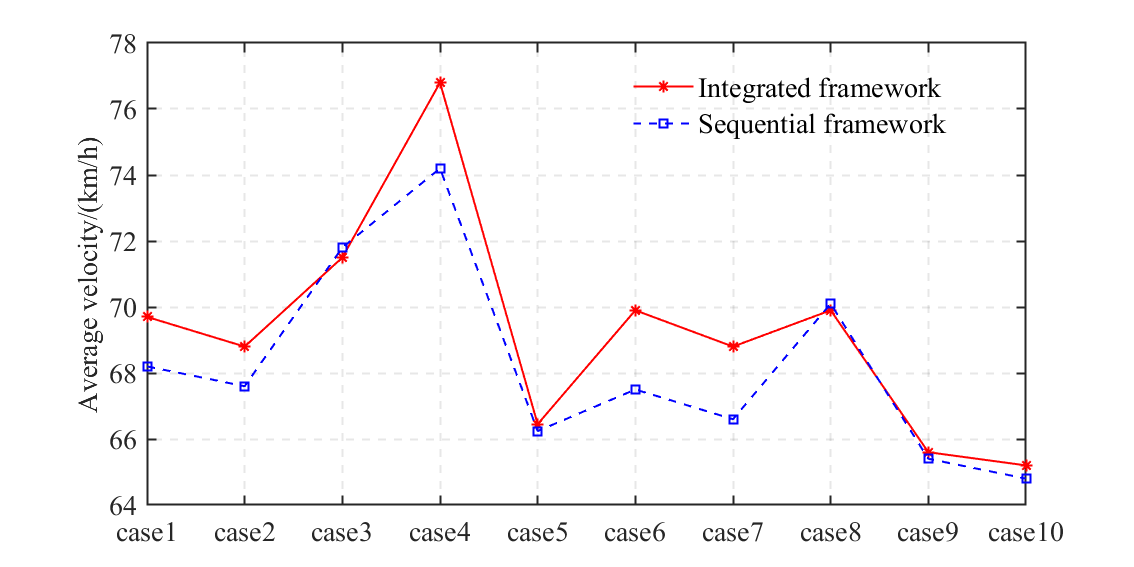
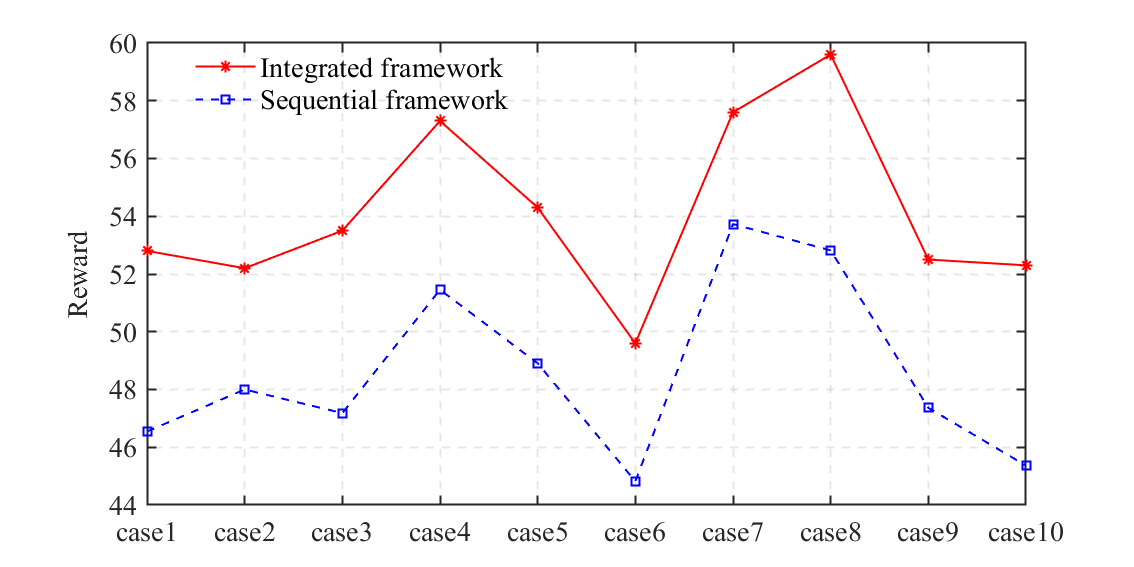
After completing the training for these two frameworks, ten test cases with different initial positions and velocities of HDVs are conducted to verify the control performance. As shown in Figs. 6 and 7, it is clear that the proposed integrated framework outperforms the sequential framework in both the average AV velocity and reward. Overall, the total average velocity and reward with the integrated framework for ten test cases can be improved by and , respectively. Although the average velocity of the AV with the sequential framework is slightly higher than that of the integrated framework in test cases 3 and 8, the integrated framework performs significantly better in ensuring a high reward. This is because the sequential framework cannot make optimal decisions from a global perspective due to the lack of coordination between these fundamental modules. The results demonstrate that the integrated framework can enhance high-speed cruising performance while considering collision avoidance, the interpretability of AVs’ trajectories, and the feasibility of AV motion.
| Description | Math expression |
| AV’s longitudinal tracking | |
| High-speed cruising | |
| Control effort | |
| Description | Math expression |
| Path-tracking accuracy | |
| Stability state | |
| control effort |
2) Value of integrating the motion-control module
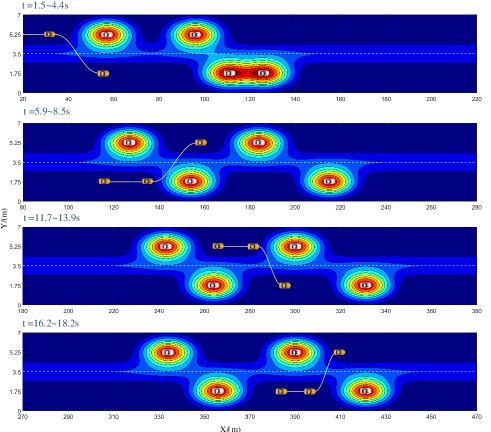
We specifically highlight the value of integrating the motion-control module by dynamically setting up control weights, which has not been considered in the existing literature. To this end, we compare our integrated framework with a semi-integrated framework that only incorporates the path-planning module, while the control weights in the motion-control module are assumed to be pre-defined constants. For both the integrated and semi-integrated frameworks, we simulate a continuous overtaking maneuver scenario, which provides a comprehensive test case to better assess the longitudinal and lateral driving performance of AVs. Specifically, the continuous overtaking maneuver scenario under the integrated framework is shown in Fig. 8.
The value of integrating the motion-control module is illustrated by evaluating the performance indicators summarized in Tables V and VI, respectively, for the longitudinal and lateral control of AVs. The comparison between the integrated framework (i.e., with dynamic weights) and the semi-integrated framework (i.e., with constant weights) is shown in Figs. 9 and 10, whereby it is clear that the ego AV exhibits better high-speed cruising performance and stability. This can be attributed to the DRL agent’s ability to dynamically adjust control weights, thereby ensuring optimal control performance in dynamic driving conditions. From Fig. 10, although the semi-integrated framework with constant control weights consumes slightly less control effort, it performs worse in ensuring path-tracking and stability.
In addition, we assess the stability performance of the ego AV using the phase plane [35]. As depicted in Fig. 11, when introducing the integrated framework with dynamic control weights, the ego AV runs within a smaller region, indicating a more stable state. As the third and fourth lane-changing maneuvers are executed at higher speeds, the stability state of the ego AV deteriorates when using constant control weights in the motion-control module. In contrast, the proposed integrated framework reliably ensures the AV’s stability.
VI-D Value of the Bootstrapped DQN for Training the Behavioral Decision-Making Module
1) Comparison of Different DRL Strategies
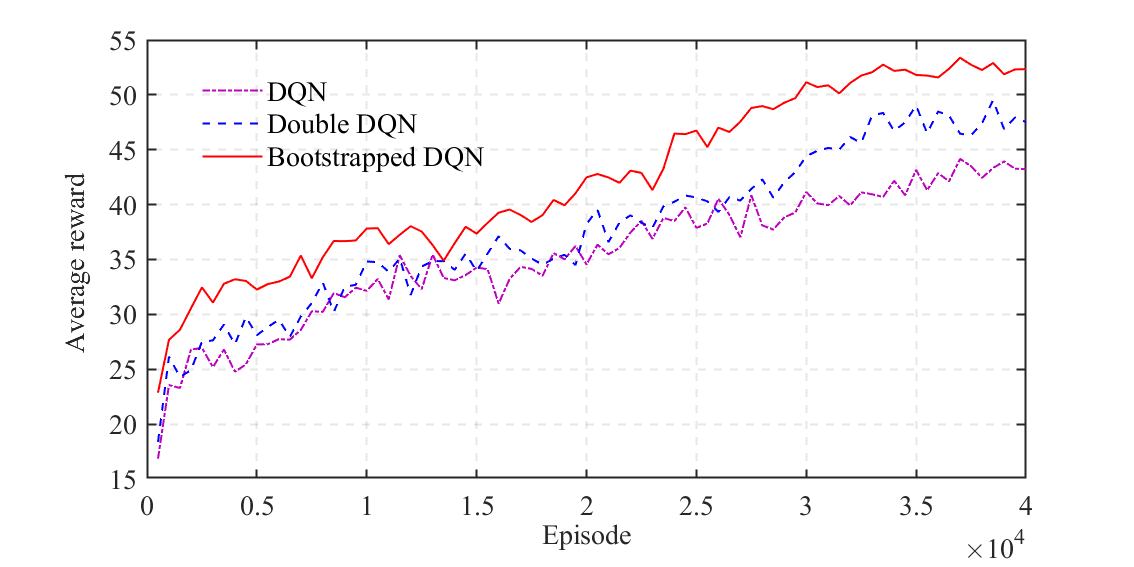
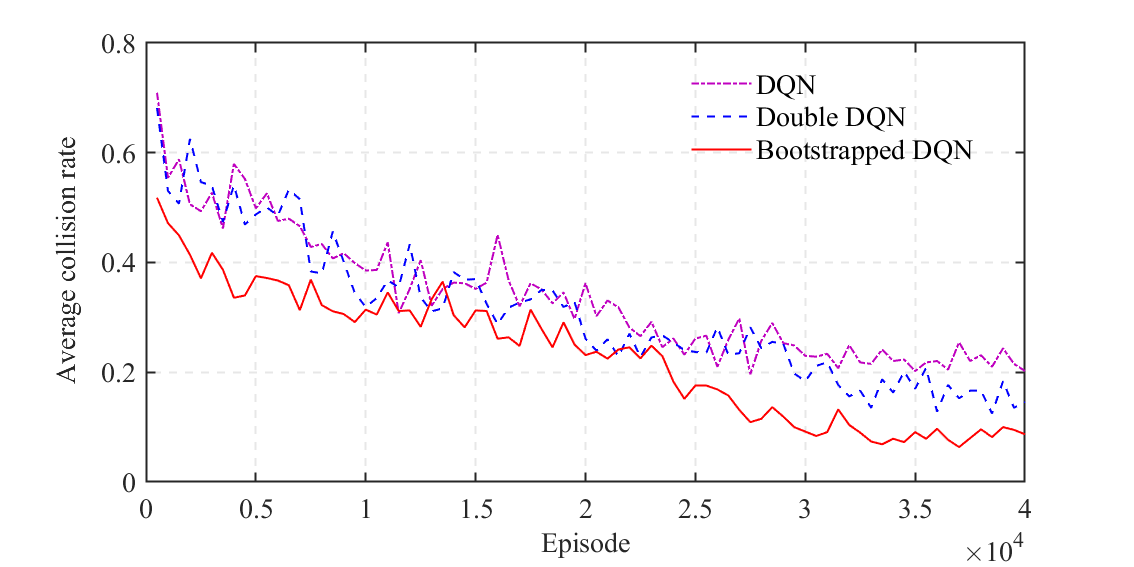
We demonstrate the value of using the Bootstrapped DQN for training the behavioral decision-making module by comparing it with other widely used DRL algorithms, including DQN and double DQN, in the same simulation environment as the proposed framework. As illustrated in Figs. 12 and 13, the bootstrapped DQN outperforms other strategies in both the average reward and the collision rate. Specifically, the bootstrapped DQN exhibits the potential to achieve a maximum reduction of and in the average collision rate compared to the DQN and double DQN, respectively. These results indicate the ability of the bootstrapped DQN to enhance the training of the behavioral decision-making module in the complex integrated framework proposed in this work.
2) Sensitivity Analysis on the Number of Head Networks in the Bootstrapped DQN
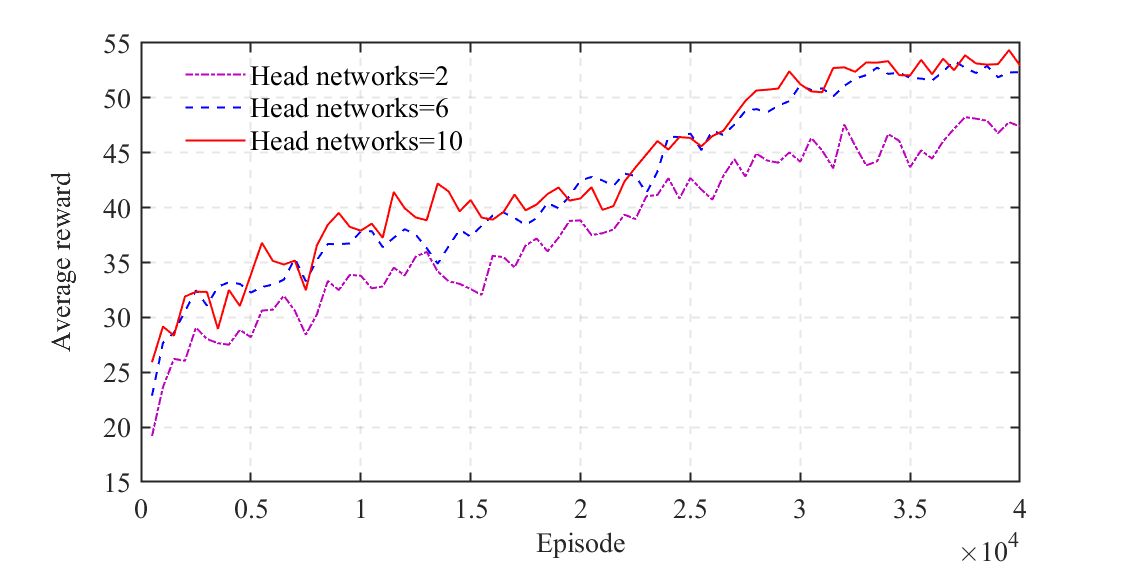
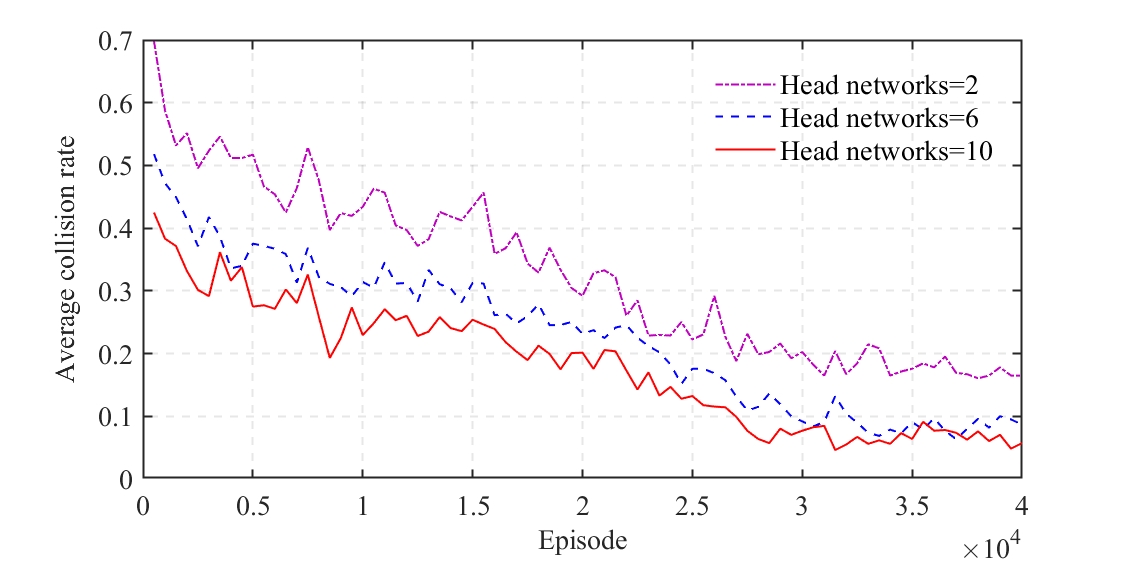
We perform a sensitivity analysis on the number of head networks in the bootstrapped DQN. As shown in Figs. 14 and 15, the bootstrapped DQN results in a higher average reward and a lower collision rate when employing more head networks. This can be attributed to the enhancement of the exploration capability with the increasing number of head networks. However, the marginal benefits of having more head networks diminish when the number of head networks reaches 6. This is because an adequate number of head networks could guarantee the precision of the uncertain Q-value estimation. Since more head networks consume more computing resources, we select the number of head networks as 6 in this work.
VII CONCLUSION
In this study, we present an autonomous driving framework to systematically enhance the safe driving capabilities of AVs in high-speed cruising scenarios by integrating behavioral decision-making, path-planning, and motion-control modules. We further improve the interpretability of AV driving decisions by learning the reward function of skilled drivers for planning lane-changing paths in the path-planning module. Taking into account the complexity of the integrated framework, we introduce a bootstrapped DQN to enhance the deep-exploration ability. The DRL agent would adaptively choose between potential lane-keeping and lane-changing maneuvers, while generating control weights for the MPC-based motion-control module. Our simulation results indicate that the proposed integrated framework can effectively guide AVs to ensure high-speed cruising performance while avoiding collisions. In comparison to the conventional sequential framework, the average reward in test cases can be improved by by the proposed method.
This paper opens several interesting directions for future work. First, we would like to extend our framework to enable cooperative control in connected and autonomous vehicle systems. Second, it would be interesting to improve the generalizability of the proposed framework to various driving scenarios (e.g., mandatory lane changes at highway bottlenecks, adverse weather conditions, etc.).
References
- [1] L. Zhao and A. A. Malikopoulos, “Enhanced mobility with connectivity and automation: A review of shared autonomous vehicle systems,” IEEE Intelligent Transportation Systems Magazine, vol. 14, no. 1, pp. 87–102, 2020.
- [2] D. Phan, A. Bab-Hadiashar, C. Y. Lai, B. Crawford, R. Hoseinnezhad, R. N. Jazar, and H. Khayyam, “Intelligent energy management system for conventional autonomous vehicles,” Energy, vol. 191, p. 116476, 2020.
- [3] J. Van Brummelen, M. O’Brien, D. Gruyer, and H. Najjaran, “Autonomous vehicle perception: The technology of today and tomorrow,” Transportation research part C: emerging technologies, vol. 89, pp. 384–406, 2018.
- [4] Y. Ye, X. Zhang, and J. Sun, “Automated vehicle’s behavior decision making using deep reinforcement learning and high-fidelity simulation environment,” Transportation Research Part C: Emerging Technologies, vol. 107, pp. 155–170, 2019.
- [5] J. Wang, X. Yuan, Z. Liu, W. Tan, X. Zhang, and Y. Wang, “Adaptive dynamic path planning method for autonomous vehicle under various road friction and speeds,” IEEE Transactions on Intelligent Transportation Systems, 2023.
- [6] C. Hu, Y. Chen, and J. Wang, “Fuzzy observer-based transitional path-tracking control for autonomous vehicles,” IEEE Transactions on Intelligent Transportation Systems, vol. 22, no. 5, pp. 3078–3088, 2020.
- [7] Y. Hu, L. Yan, J. Zhan, F. Yan, Z. Yin, F. Peng, and Y. Wu, “Decision-making system based on finite state machine for low-speed autonomous vehicles in the park,” in 2022 IEEE International Conference on Real-time Computing and Robotics (RCAR). IEEE, 2022, pp. 721–726.
- [8] E. Giunchiglia, M. Colledanchise, L. Natale, and A. Tacchella, “Conditional behavior trees: Definition, executability, and applications,” in 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC). IEEE, 2019, pp. 1899–1906.
- [9] M. Zhu, X. Wang, and Y. Wang, “Human-like autonomous car-following model with deep reinforcement learning,” Transportation research part C: emerging technologies, vol. 97, pp. 348–368, 2018.
- [10] E. Balal, R. L. Cheu, and T. Sarkodie-Gyan, “A binary decision model for discretionary lane changing move based on fuzzy inference system,” Transportation Research Part C: Emerging Technologies, vol. 67, pp. 47–61, 2016.
- [11] G. Xiong, Z. Kang, H. Li, W. Song, Y. Jin, and J. Gong, “Decision-making of lane change behavior based on rcs for automated vehicles in the real environment,” in 2018 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2018, pp. 1400–1405.
- [12] B. Li, T. Acarman, Y. Zhang, Y. Ouyang, C. Yaman, Q. Kong, X. Zhong, and X. Peng, “Optimization-based trajectory planning for autonomous parking with irregularly placed obstacles: A lightweight iterative framework,” IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 8, pp. 11 970–11 981, 2021.
- [13] Z. Han, D. Wang, F. Liu, and Z. Zhao, “Multi-agv path planning with double-path constraints by using an improved genetic algorithm,” PloS one, vol. 12, no. 7, p. e0181747, 2017.
- [14] L. Claussmann, M. Revilloud, D. Gruyer, and S. Glaser, “A review of motion planning for highway autonomous driving,” IEEE Transactions on Intelligent Transportation Systems, vol. 21, no. 5, pp. 1826–1848, 2019.
- [15] P. Scheffe, T. M. Henneken, M. Kloock, and B. Alrifaee, “Sequential convex programming methods for real-time optimal trajectory planning in autonomous vehicle racing,” IEEE Transactions on Intelligent Vehicles, vol. 8, no. 1, pp. 661–672, 2022.
- [16] S. A. Fayazi and A. Vahidi, “Mixed-integer linear programming for optimal scheduling of autonomous vehicle intersection crossing,” IEEE Transactions on Intelligent Vehicles, vol. 3, no. 3, pp. 287–299, 2018.
- [17] S. Xu and H. Peng, “Design, analysis, and experiments of preview path tracking control for autonomous vehicles,” IEEE Transactions on Intelligent Transportation Systems, vol. 21, no. 1, pp. 48–58, 2019.
- [18] C.-L. Hwang, C.-C. Yang, and J. Y. Hung, “Path tracking of an autonomous ground vehicle with different payloads by hierarchical improved fuzzy dynamic sliding-mode control,” IEEE Transactions on Fuzzy Systems, vol. 26, no. 2, pp. 899–914, 2017.
- [19] Y. Chen, C. Hu, and J. Wang, “Human-centered trajectory tracking control for autonomous vehicles with driver cut-in behavior prediction,” IEEE Transactions on Vehicular Technology, vol. 68, no. 9, pp. 8461–8471, 2019.
- [20] Z. Wang, J. Zha, and J. Wang, “Autonomous vehicle trajectory following: A flatness model predictive control approach with hardware-in-the-loop verification,” IEEE Transactions on Intelligent Transportation Systems, vol. 22, no. 9, pp. 5613–5623, 2020.
- [21] J. Liang, Y. Lu, G. Yin, Z. Fang, W. Zhuang, Y. Ren, L. Xu, and Y. Li, “A distributed integrated control architecture of afs and dyc based on mas for distributed drive electric vehicles,” IEEE transactions on vehicular technology, vol. 70, no. 6, pp. 5565–5577, 2021.
- [22] J. Ji, A. Khajepour, W. W. Melek, and Y. Huang, “Path planning and tracking for vehicle collision avoidance based on model predictive control with multiconstraints,” IEEE Transactions on Vehicular Technology, vol. 66, no. 2, pp. 952–964, 2016.
- [23] B. Paden, M. Čáp, S. Z. Yong, D. Yershov, and E. Frazzoli, “A survey of motion planning and control techniques for self-driving urban vehicles,” IEEE Transactions on intelligent vehicles, vol. 1, no. 1, pp. 33–55, 2016.
- [24] J. Peng, S. Zhang, Y. Zhou, and Z. Li, “An integrated model for autonomous speed and lane change decision-making based on deep reinforcement learning,” IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 11, pp. 21 848–21 860, 2022.
- [25] K. B. Naveed, Z. Qiao, and J. M. Dolan, “Trajectory planning for autonomous vehicles using hierarchical reinforcement learning,” in 2021 IEEE International Intelligent Transportation Systems Conference (ITSC). IEEE, 2021, pp. 601–606.
- [26] S. Li, C. Wei, and Y. Wang, “Combining decision making and trajectory planning for lane changing using deep reinforcement learning,” IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 9, pp. 16 110–16 136, 2022.
- [27] J. Hawke, R. Shen, C. Gurau, S. Sharma, D. Reda, N. Nikolov, P. Mazur, S. Micklethwaite, N. Griffiths, A. Shah et al., “Urban driving with conditional imitation learning,” in 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 251–257.
- [28] H. Liu, R. Yang, L. Wang, and P. Liu, “Evaluating initial public acceptance of highly and fully autonomous vehicles,” International Journal of Human–Computer Interaction, vol. 35, no. 11, pp. 919–931, 2019.
- [29] P. A. Ruijten, J. M. Terken, and S. N. Chandramouli, “Enhancing trust in autonomous vehicles through intelligent user interfaces that mimic human behavior,” Multimodal Technologies and Interaction, vol. 2, no. 4, p. 62, 2018.
- [30] C. Wei, E. Paschalidis, N. Merat, A. Solernou, F. Hajiseyedjavadi, and R. Romano, “Human-like decision making and motion control for smooth and natural car following,” IEEE Transactions on Intelligent Vehicles, 2021.
- [31] R. Emuna, A. Borowsky, and A. Biess, “Deep reinforcement learning for human-like driving policies in collision avoidance tasks of self-driving cars,” arXiv preprint arXiv:2006.04218, 2020.
- [32] D. Xu, Z. Ding, X. He, H. Zhao, M. Moze, F. Aioun, and F. Guillemard, “Learning from naturalistic driving data for human-like autonomous highway driving,” IEEE Transactions on Intelligent Transportation Systems, vol. 22, no. 12, pp. 7341–7354, 2020.
- [33] M. Naumann, L. Sun, W. Zhan, and M. Tomizuka, “Analyzing the suitability of cost functions for explaining and imitating human driving behavior based on inverse reinforcement learning,” in 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 5481–5487.
- [34] P. M. Kebria, A. Khosravi, S. M. Salaken, and S. Nahavandi, “Deep imitation learning for autonomous vehicles based on convolutional neural networks,” IEEE/CAA Journal of Automatica Sinica, vol. 7, no. 1, pp. 82–95, 2019.
- [35] J. Liang, Y. Li, G. Yin, L. Xu, Y. Lu, J. Feng, T. Shen, and G. Cai, “A mas-based hierarchical architecture for the cooperation control of connected and automated vehicles,” IEEE Transactions on Vehicular Technology, vol. 72, no. 2, pp. 1559–1573, 2022.
- [36] F. Wang, T. Shen, M. Zhao, Y. Ren, Y. Lu, B. Feng, and G. Yin, “Lane-change trajectory planning and control based on stability region for distributed drive electric vehicle,” IEEE Transactions on Vehicular Technology, 2023.
- [37] B. D. Ziebart, A. L. Maas, J. A. Bagnell, A. K. Dey et al., “Maximum entropy inverse reinforcement learning.” in Aaai, vol. 8. Chicago, IL, USA, 2008, pp. 1433–1438.
- [38] K. Zhang, J. Wang, N. Chen, and G. Yin, “A non-cooperative vehicle-to-vehicle trajectory-planning algorithm with consideration of driver’s characteristics,” Proceedings of the Institution of Mechanical Engineers, Part D: Journal of automobile engineering, vol. 233, no. 10, pp. 2405–2420, 2019.
- [39] J. Liang, Y. Lu, J. Feng, G. Yin, W. Zhuang, J. Wu, L. Xu, and F. Wang, “Robust shared control system for aggressive driving based on cooperative modes identification,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2023.
- [40] B. A. H. Vicente, S. S. James, and S. R. Anderson, “Linear system identification versus physical modeling of lateral–longitudinal vehicle dynamics,” IEEE Transactions on Control Systems Technology, vol. 29, no. 3, pp. 1380–1387, 2020.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a9cecf5f-5b43-4d47-8a4c-92ff263d3771/JHL.jpg) |
Jinhao Liang received the B.S. degree from School of Mechanical Engineering, Nanjing University of Science and Technology, Nanjing, China, in 2017, and Ph.D. degree from School of Mechanical Engineering, Southeast University, Nanjing, China, in 2022. Now he is a Research Fellow with Department of Civil and Environmental Engineering, National University of Singapore. His research interests include vehicle dynamics and control, autonomous vehicles, and vehicle safety assistance system. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a9cecf5f-5b43-4d47-8a4c-92ff263d3771/YKD.jpg) |
Kaidi Yang (Member, IEEE) is an Assistant Professor in the Department of Civil and Environmental Engineering at the National University of Singapore. Prior to this, he was a postdoctoral researcher with the Autonomous Systems Lab at Stanford University. He obtained a PhD degree from ETH Zurich and M.Sc. and B.Eng. degrees from Tsinghua University. His main research interest is the operation of future mobility systems enabled by connected and automated vehicles (CAVs) and shared mobility. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a9cecf5f-5b43-4d47-8a4c-92ff263d3771/CPT.jpg) |
Chaopeng Tan received his B.S. and Ph.D. degrees in traffic engineering from Tongji University, Shanghai, China in 2017 and 2022, respectively. He was also a visiting Ph.D. student at the University of Washington (Seattle) from 2019 to 2021. He is currently a Research Fellow with the Department of Civil and Environmental Engineering, National University of Singapore. His main research interests include intelligent transportation systems, traffic modeling and control with connected vehicles, and privacy-preserving traffic control. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a9cecf5f-5b43-4d47-8a4c-92ff263d3771/JXW.png) |
Jinxiang Wang received the B.S. degree in mechanical engineering and automation, and the Ph.D. degree in vehicle engineering from Southeast University, Nanjing, China, in 2002 and 2010, respectively. From 2014 to 2015, he was a Visiting Research Scholar with the Department of Mechanical and Aerospace Engineering, The Ohio State University, Columbus, OH, USA. He is currently an Associate Professor with the School of Mechanical Engineering, Southeast University. His research interests include vehicle dynamics and control, assisted-driving system, and control on autonomous vehicles. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a9cecf5f-5b43-4d47-8a4c-92ff263d3771/GDY.jpg) |
Guodong Yin received the Ph.D. degree in mechanical engineering from Southeast University, Nanjing, China, in 2007. From August 2011 to August 2012, he was a Visiting Scholar with the Department of Mechanical and Aerospace Engineering, The Ohio State University, Columbus, OH, USA. He is currently a Professor with the School of Mechanical Engineering, Southeast University. He was the recipient of the National Science Fund for Distinguished Young Scholars. His research interests include vehicle dynamics and control, automated vehicles, and connected vehicles. |