Enhanced exemplar autoencoder with cycle consistency loss in any-to-one voice conversion
Abstract
Recent research showed that an autoencoder trained with speech of a single speaker, called exemplar autoencoder (eAE), can be used for any-to-one voice conversion (VC). Compared to large-scale many-to-many models such as AutoVC, the eAE model is easy and fast in training, and may recover more details of the target speaker.
To ensure VC quality, the latent code should represent and only represent content information. However, this is not easy to attain for eAE as it is unaware of any speaker variation in model training. To tackle the problem, we propose a simple yet effective approach based on a cycle consistency loss. Specifically, we train eAEs of multiple speakers with a shared encoder, and meanwhile encourage the speech reconstructed from any speaker-specific decoder to get a consistent latent code as the original speech when cycled back and encoded again. Experiments conducted on the AISHELL-3 corpus showed that this new approach improved the baseline eAE consistently. The source code and examples are available at the project page: http://project.cslt.org/.
Index Terms: cycle consistency loss, voice conversion, auto-encoder
1 Introduction
The purpose of voice conversion (VC) is to transform a speech waveform to make it sound like spoken by another person while preserve the linguistic content. Early studies mainly focused on learning a frame-level one-to-one mapping function, by employing parallel data [1, 2, 3, 4]. This approach is obviously costly, and the application is limited to one-to-one conversion.
Modern voice conversion methods are based on large-scale training with non-parallel data. The basic idea is to learn a disentanglement model that can separate content and speaker information in speech signals, and then perform conversion by picking up content information from the source speaker and speaker information from the target speaker. Most of the approaches are based on the encoder-decoder architecture, where the encoder produces the content code, and the decoder uses them to synthesize the target speech by referring to a new speaker code. Representative models include PPG [5, 6], VAE [7], CVAE [8, 9, 10, 11], VQVAE [12, 13], and AdaIN-VC [14].
In spite of the promising performance, these large-scale models require a big amount of data. Although this is not a serious problem for rich-resource languages, for low-resource language, collecting content/speaker labelled data does impose problems. Moreover, training models with large datasets is not economic in energy consumption. Finally, using a single speaker code to modulate the shared decoder might be insufficient to represent details of the speaker’s trait, for example prosody [11, 15]. The pay-off of the large-scale training, of course, is the ability to perform (nearly) any-to-any conversion. For example, with the AutoVC [10] model trained on more than 100 speakers in VCTK [16], speech of any speaker can be converted to any target speaker, with perhaps just one enrollment utterance.
In some cases, however, the any-to-any capacity is not the most required. For example, I like voice from Albert Einstein, and wish all the lectures being taught in his voice. In this scenario, any-to-one is sufficient and perhaps more suitable: it is easy to train, and may recover more details of the target speaker as the decoder is dedicated to that person. The exemplar autoencoder (eAE) [17] is such a model. It is a vanilla autoencoder (AE) trained with a bunch of utterances (typically tens of minutes) of a particular speaker. The authors argued that if human speech is content-dominated, i.e., content varies more than speaker trait, the eAE model can convert speech of any speaker to the target speaker (speaker for training). However, content-domination is dubious in practice; even if it is held, there is no guarantee that the conversion is of anything perfect or good. A basic reason is that eAE tends to produce information entangled code, as the model does not see any speaker variation when it is trained.
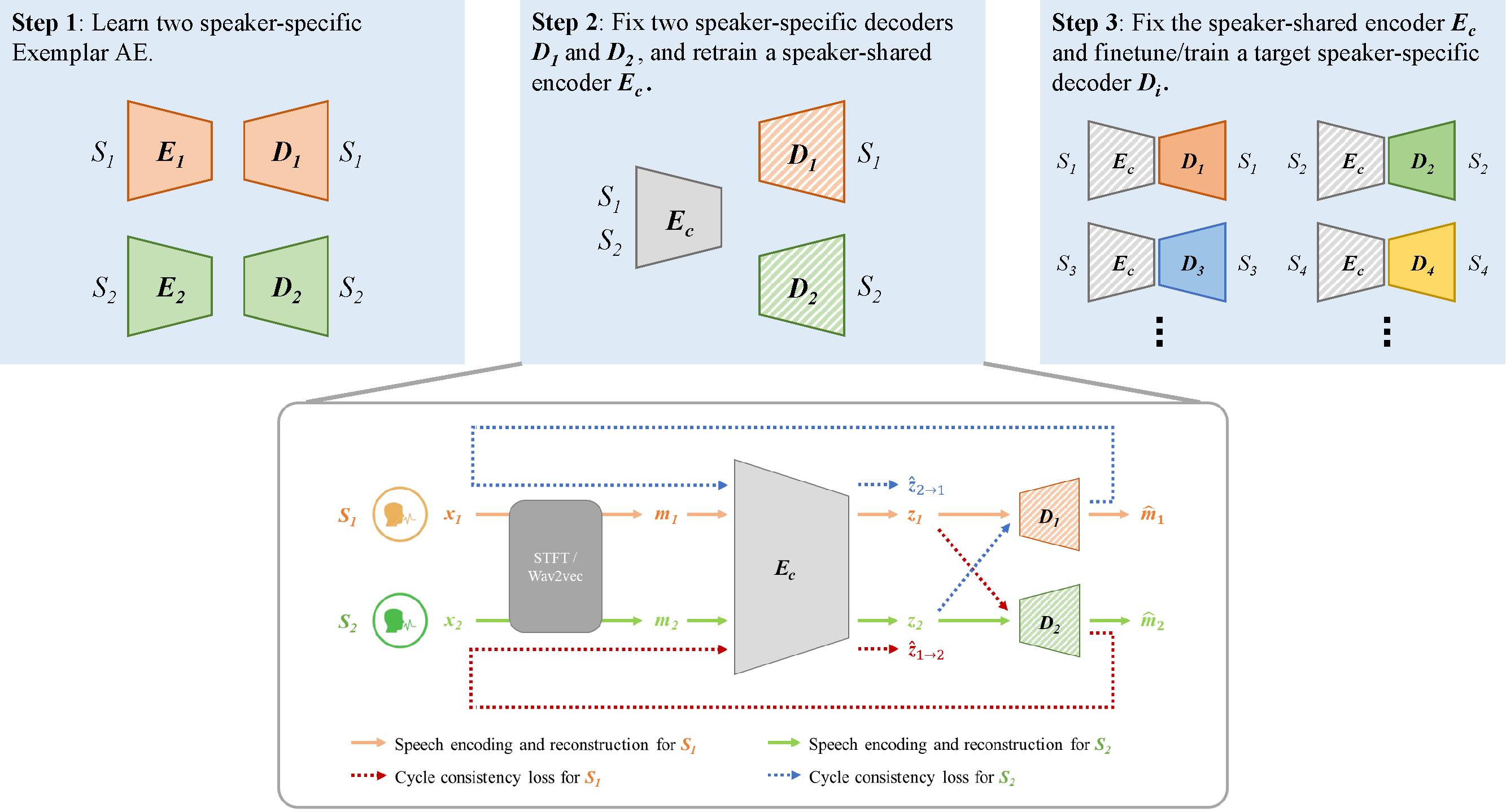
In this paper, we propose to solve the entanglement problem of eAE by a cycle consistency loss. As shown in Fig. 1: Firstly, we train a multi-head eAE with data of multiple speakers, where the encoder is shared while the decoders are speaker-specific (blue and red dash lines). Secondly, we encourage the reconstructed speech close to the original speech in the code space, no matter which decoder is used to perform the reconstruction (yellow arrows). We will show that this simple cycle consistency loss leads to much more disentangled code, even with just two training speakers.

2 Related Works
There are numerous studies in VC. Readers are referred to recent review papers for more technical discussions [18, 19]. Focusing on any-to-one VC, the PPG + synthesizer architecture [5, 6, 20] is a powerful candidate. The shortage is that an ASR system is required, which is impossible for low-resource languages. Using pre-trained models (e.g., Wav2Vec [21, 22] or HuBERT [23]) to substitute ASR systems alleviates the difficulty, however the generated codes are not necessarily speaker-invariant. We will show in the experiments that even with a strong Wav2Vec encoder, the cycle consistency loss still contributes.
Information disentanglement has been investigated by multiple authors in VC, mostly by penalizing mutual information (MI) between the content code and the speaker code, including adversarial training [24, 25] and inter-code MI penalty [26]. These MI regularization methods require extra classifier/discriminator, and suffer from unstable training. Moreover, with a very limited number of speakers (2 speakers in our case), computing the MI is not very meaningful.
The idea of cycle consistency loss has been known in CycleGAN [27, 28] and CycleVAE [29, 30]. Our proposal is fundamentally different from these prior work in that our cycle is code-to-code, while the cycle in CycleGAN and CycleVAE is data-to-data. We will show by experiments that this difference is not trivial.
3 Methodology
3.1 Cycle consistency loss for eAE
Before any theoretical discussion for the property and advantage, let’s first describe how the cycle consistency loss is implemented. To make the presentation clear, we use two speeches , from two speakers , to describe the process. The diagram is shown in Fig. 2.
-
•
Step 1. Train two separate speaker-specific eAEs. First transform and to Mel spectrum and via STFT, and train two separate eAEs using and following the process in [17], denoted by {,} and {,} respectively.
-
•
Step 2. Fix the decoders and , and retrain a speaker-shared encoder with cycle consistency loss.
(1) Reinitialize a new encoder , and then forward and to , obtaining the content codes and .
(2) Forward and to and respectively to generate and . The reconstruction loss is computed as follows:
(1) where denotes the -norm. See the yellow and green solid lines in Fig. 2.
(3) Forward and to and respectively (note the code and decoder do not match). The decoding output is then cycled back and fed to the encoder , producing the recycled code and . The cycle consistency loss is computed as follows:
(2) See the red and blue dash lines in Fig. 2.
(3) where is a hyper-parameter to control the ratio of and . In our experiment, we empirically set to 10.
-
•
Step 3. Fix the speaker-shared encoder and finetune existing decoders , or train new decoders , for new target speakers.
During conversion, pass the source speech to , and choose a decoder corresponding to the target speaker to perform decoding, producing reconstructed spectrum . A WaveNet vocoder [31] is then employed to synthesize the converted speech .
3.2 Theoretical analysis
This section presents theoretical analysis for the cycle consistency loss. We start from analyzing why the vanilla eAE tends to fail in practice.
3.2.1 eAE is fragile
We first recite the theoretical augment for eAE presented in [17]. Define and as the speaker factor and content factor respectively, and let denote the speech with content and spoken by speaker , where is the true generating process.
In [17], the authors argued that in the Mel spectrum space, human speech is content-dominated, i.e., speech signals of the same word but spoken by different speakers are more similar than those of different words spoken by the same speaker. Formally speaking:
| (4) |
where denotes distance in Mel spectrum. This assumption is equal to say:
| (5) |
where .
Suppose that the eAE model is trained by speech of , it essentially learns the manifold of . Therefore, for any speech , the eAE function tends to project it to the manifold , which is the RHS of Eq.(5). This leads to the converted version .
The argument above, however, seems over strong. Firstly, although it is generally true that content variation is more significant than speaker variation at the word level, while at the phone level, speaker change could be more drastic. This means that the phone content will be changed by the eAE projection due to speaker variation. Unfortunately, small change on phones may cause serious impact in perception. More qualitative evidences please refer to111http://project.cslt.org/. Moreover, the manifold assumption heavily relies on a tight information bottleneck (IB) on the code, which is not easy to set.
3.2.2 Cycle consistency loss works
The fragility of eAE mentioned above is essentially caused by the content-speaker information entangled in the code; this is in turn caused by the single-speaker training scheme, which makes eAE unaware of any speaker variation. To solve the problem, one may resort to either a pre-trained front such as Wav2Vec [21] or large-scale multi-speaker training as AutoVC [10]. However, with these ‘heavy’ solution, the main advantage of eAE is lost.
The cycle consistency loss is a light-weighted solution. We analyze the asymptotic behavior at the optimum point, i.e., when . In this scenario, we have:
| (6) |
This in essence implies that on the reconstructed speech, is independent of . If we further assume that all the decoders can perfectly recover the speech of their corresponding speakers, then the reconstructed speech and original speech are exactly the same. According to Eq.(6), this implies that the code of true speech is independent of . If the number of speakers is abundant and can approximate the entire population, will be truly speaker independent. Surprisingly, we will show in the experiments that by the cycle consistency loss, 2 different-gender speakers are sufficient to train an enhanced eAE that produces fairly independent code .
Note that in the above derivation, we do not impose any constraint on IB. However, IB is still crucial, otherwise could be identical for all . In this case, is independent of but not the speaker, and VC becomes impossible.
4 Experiments
In this section, the proposed enhanced eAE is applied to any-to-one voice conversion task.
4.1 Data
We use speech data from the AISHELL-3 dataset [32] to construct the training and test sets, as shown in Table 1. All the speech signals are formatted with 16kHz sampling rate and 16-bits precision. No overlap in speakers exists between the training and test sets.
| Set | # of Spks | Utters per Spk | Duration per Spk |
|---|---|---|---|
| Train | 4 (2 Female, 2 Male) | 400 | 25 mins |
| Test | 6 (3 Female, 3 Male) | 250 | 15 mins |
4.2 Model
All the eAE models were implemented following [17] with the source code222https://github.com/dunbar12138/Audiovisual-Synthesis.
Preprocessing: The training speech is firstly clipped into segments with 1.6s in length, each being further transformed to a spectrogram by STFT with window size of 800 and hop size of 200. The spectrogram is then transformed to 80128 Mel-spectrogram.
Encoder: The Mel-spectrogram is fed to the encoder which consists of three 1D convolutional layers, each followed by a normalization and ReLU activation. The kernel size of each layer is 5 and the number of channels is 512. The output of the convolutional layers is then fed to two bidirectional LSTM layers with cell dimensions of 32, resulting in a 32-dimensional content code.
Decoder: The content code is passed through the decoder. It is firstly up-sampled to the original time resolution and then input to one 512-channel LSTM layer and three 512-channel 1D convolutional layers with a kernel size of 5. Each layer is accompanied with batch normalization and ReLU activation. Finally, the output is fed into two 1,024-channel LSTM layers and a fully connected layer that produces 80-dim Mel-spectrograms.
Vocoder: We train a WaveNet vocoder [31] to convert Mel-spectrograms to speech signals.
4.3 Metrics
Four metrics are used for quantitative evaluation, including goodness of pronunciation (GOP), character error rate (CER), MOSNet score and speaker classification accuracy (SCA). GOP and MOSNet primarily evaluate the quality of the generation, CER mostly focuses on intelligibility, and SCA is more related to resemblance to the target speaker.
The Kaldi toolkit [33] is used to compute CER and GOP. The pre-trained model in [34] is used to predict the MOSNet score. For SCA test, we train a speaker classification model based on the x-vector structure [35] with 400 background speakers from AISHELL-1 dataset [36] plus the target speakers from the training set. SCA is computed as the accuracy of the converted speech classified to the target speaker.
4.4 Main results
We use two speakers in the training set to train the eAE with and without cycle consistency loss. The 6 speakers in test set (3 males and 3 females) are used to perform two groups of test: same-gender (SG) and cross-gender (CG). Results are reported in Table 2.
Firstly, it can be observed that with the cycle consistency loss, the performance on all the evaluation metrics has been improved consistently and substantially. Secondly, the improvement is more significant in the cross-gender test, leading to performance very similar to that in the same-gender test. This result indicates that the eAE model indeed suffers from large speaker variation, and applying the cycle consistency loss can alleviate the problem to a large extent.
| GOP () | CER(%) () | MOSNet () | SCA(%) () | ||
|---|---|---|---|---|---|
| eAE | SG | 1.489 | 19.29 | 2.712 | 81.85 |
| CG | 1.368 | 21.19 | 2.668 | 80.00 | |
| eAE + Cycle | SG | 1.605 | 14.27 | 2.786 | 85.00 |
| CG | 1.589 | 14.19 | 2.778 | 85.45 |
4.5 Generalization to new target speakers
In this test, we firstly train an eAE with cycle consistency loss as in the previous experiment, and then fix the encoder and train decoders for 6 new speakers selected from AISHELL-3. The same test data in the test set are used to perform test on these new target speakers. For comparison, we also train 6 individual vanilla eAEs for the same 6 speakers. The results are reported in Table 3.
It can be seen that the pre-trained encoder can be effectively adapted to the new speakers, and bring significant performance improvement. This further verifies our conjecture that with the cycle consistency loss, the speaker-shared encoder can produce more disentangled content codes.
| GOP () | CER(%) () | MOSNet () | |
|---|---|---|---|
| eAE | 1.439 | 20.86 | 2.718 |
| eAE + Cycle | 1.539 | 15.23 | 2.760 |
4.6 Ablation study
We perform a couple of ablation studies to understand the behavior of the cycle consistency loss. The same target speaker and test speech as in Section 4.4 is used to perform the study. For simplicity, we only report the results on the cross-gender group, where the cycle consistency loss contributes the best. The overall results are reported in Table 4. For an easy comparison, results of the eAE baseline and eAE + Cycle baseline are reproduced, shown as Model 1 and Model 2 respectively.
| No. | Model | # Spks | GOP | CER(%) | MOSNet | SCA(%) |
|---|---|---|---|---|---|---|
| 1 | eAE | 1 | 1.368 | 21.19 | 2.768 | 80.00 |
| 2 | eAE + Cycle | 2 | 1.589 | 14.19 | 2.778 | 85.45 |
| 3 | eAE + Cycle | 4 | 1.593 | 14.03 | 2.737 | 85.10 |
| 4 | eAE + En-Share | 2 | 1.378 | 21.28 | 2.689 | 80.40 |
| 5 | eAE + Data Cycle | 2 | 1.513 | 18.56 | 2.724 | 82.80 |
| 6 | eAE/W2V | 2 | 1.612 | 11.88 | 2.795 | 89.25 |
| 7 | eAE/W2V + Cycle | 2 | 1.713 | 10.73 | 2.823 | 89.60 |
4.6.1 More training speakers
To test if more training speakers provides additional gains, we use 4 speakers to train an enhanced eAE model. The results are shown as Model 3. By comparing with Model 2, we can see that using two additional speakers does not offer clear advantage, indicating that perhaps 2 speakers are sufficient for the cycle consistency loss to train a reasonable encoder.
4.6.2 Encoder sharing or cycle loss?
One may argue the improvement obtained by the enhanced eAE could be due to the shared encoder, rather than the cycle consistency loss. To response this argument, Model 4 reports the results with encoder sharing only but no cycle loss. Comparing to eAE (Model 1) and advanced eAE (Model 2), we see that only sharing the encoder does not provide much advantage, confirming that cycle consistency loss is the essence of our proposal.
4.6.3 Code cycle and data cycle
The cycle consistency loss presented in the paper follows a code cycle, by . It is also possible to design a data cycle, following the path . This is the way that CycleVAE follows [29, 30]. We implemented the data cycle scheme as Model 5. Comparing to eAE (Model 1) and advanced eAE (Model 2), it can be observed that the data cycle indeed improves eAE, but much less significant than the code cycle.
4.6.4 Work with powerful frontend
Inspired by [22], we use a pre-trained VQW2V model333https://dl.fbaipublicfiles.com/fairseq/wav2vec/wav2vec_small.pt as a more powerful front, to test if the cycle loss still contributes. The results are reported as Model 6 and Model 7. It can be seen that the W2V front provides clear improvement over the Mel spectrum front (Model 6 vs. Model 1 and Model 7 vs. Model 2). Even using a strong front, training with cycle loss still offers additional gains (Model 6 vs Model 7).
5 Conclusion
In this paper, we proposed an enhanced exemplar autoencoder for any-to-one voice conversion. The core design is a cycle consistency loss, which enforces the content code of the reconstructed speech close to the original speech, no matter by whose decoder decodes the speech. We demonstrated theoretically and empirically that the proposed technique can significantly purify the content code, and produce better performance in complex VC tasks, such as cross-gender conversion. In future, we would like to conduct deep investigation on the behavior of the cycle consistency loss, and apply the loss to other VC models.
References
- [1] Y. Stylianou, O. Cappé, and E. Moulines, “Continuous probabilistic transform for voice conversion,” IEEE Transactions on speech and audio processing, vol. 6, no. 2, pp. 131–142, 1998.
- [2] L.-H. Chen, Z.-H. Ling, L.-J. Liu, and L.-R. Dai, “Voice conversion using deep neural networks with layer-wise generative training,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 22, no. 12, pp. 1859–1872, 2014.
- [3] T. Nakashika, T. Takiguchi, and Y. Ariki, “Voice conversion based on speaker-dependent restricted boltzmann machines,” IEICE TRANSACTIONS on Information and Systems, vol. 97, no. 6, pp. 1403–1410, 2014.
- [4] R. Takashima, T. Takiguchi, and Y. Ariki, “Exemplar-based voice conversion using sparse representation in noisy environments,” IEICE Transactions on Fundamentals of Electronics, Communications and Computer Sciences, vol. 96, no. 10, pp. 1946–1953, 2013.
- [5] F.-L. Xie, F. K. Soong, and H. Li, “A kl divergence and dnn-based approach to voice conversion without parallel training sentences.” in Interspeech, 2016, pp. 287–291.
- [6] L. Sun, K. Li, H. Wang, S. Kang, and H. Meng, “Phonetic posteriorgrams for many-to-one voice conversion without parallel data training,” in 2016 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 2016, pp. 1–6.
- [7] M. Luong and V. A. Tran, “Many-to-many voice conversion based feature disentanglement using variational autoencoder,” arXiv preprint arXiv:2107.06642, 2021.
- [8] C.-C. Hsu, H.-T. Hwang, Y.-C. Wu, Y. Tsao, and H.-M. Wang, “Voice conversion from non-parallel corpora using variational auto-encoder,” in 2016 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA). IEEE, 2016, pp. 1–6.
- [9] H. Kameoka, T. Kaneko, K. Tanaka, and N. Hojo, “Acvae-vc: Non-parallel voice conversion with auxiliary classifier variational autoencoder,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 27, no. 9, pp. 1432–1443, 2019.
- [10] K. Qian, Y. Zhang, S. Chang, X. Yang, and M. Hasegawa-Johnson, “Autovc: Zero-shot voice style transfer with only autoencoder loss,” in International Conference on Machine Learning. PMLR, 2019, pp. 5210–5219.
- [11] K. Qian, Y. Zhang, S. Chang, M. Hasegawa-Johnson, and D. Cox, “Unsupervised speech decomposition via triple information bottleneck,” in ICML. PMLR, 2020, pp. 7836–7846.
- [12] A. Van Den Oord, O. Vinyals et al., “Neural discrete representation learning,” Advances in neural information processing systems, vol. 30, 2017.
- [13] D.-Y. Wu, Y.-H. Chen, and H.-Y. Lee, “Vqvc+: One-shot voice conversion by vector quantization and u-net architecture,” arXiv preprint arXiv:2006.04154, 2020.
- [14] J.-c. Chou, C.-c. Yeh, and H.-y. Lee, “One-shot voice conversion by separating speaker and content representations with instance normalization,” arXiv preprint arXiv:1904.05742, 2019.
- [15] K. Qian, Y. Zhang, S. Chang, J. Xiong, C. Gan, D. Cox, and M. Hasegawa-Johnson, “Global rhythm style transfer without text transcriptions,” arXiv preprint arXiv:2106.08519, 2021.
- [16] C. Veaux, J. Yamagishi, K. MacDonald et al., “Cstr vctk corpus: English multi-speaker corpus for cstr voice cloning toolkit,” University of Edinburgh. CSTR, 2017.
- [17] K. Deng, A. Bansal, and D. Ramanan, “Unsupervised any-to-many audiovisual synthesis via exemplar autoencoders.” 2020.
- [18] S. H. Mohammadi and A. Kain, “An overview of voice conversion systems,” Speech Communication, vol. 88, pp. 65–82, 2017.
- [19] B. Sisman, J. Yamagishi, S. King, and H. Li, “An overview of voice conversion and its challenges: From statistical modeling to deep learning,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 132–157, 2020.
- [20] C.-c. Yeh, P.-c. Hsu, J.-c. Chou, H.-y. Lee, and L.-s. Lee, “Rhythm-flexible voice conversion without parallel data using cycle-gan over phoneme posteriorgram sequences,” in 2018 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2018, pp. 274–281.
- [21] J.-h. Lin, Y. Y. Lin, C.-M. Chien, and H.-y. Lee, “S2vc: A framework for any-to-any voice conversion with self-supervised pretrained representations,” arXiv preprint arXiv:2104.02901, 2021.
- [22] W.-C. Huang, Y.-C. Wu, and T. Hayashi, “Any-to-one sequence-to-sequence voice conversion using self-supervised discrete speech representations,” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 5944–5948.
- [23] F. Kreuk, A. Polyak, J. Copet, E. Kharitonov, T.-A. Nguyen, M. Rivière, W.-N. Hsu, A. Mohamed, E. Dupoux, and Y. Adi, “Textless speech emotion conversion using decomposed and discrete representations,” arXiv preprint arXiv:2111.07402, 2021.
- [24] O. Ocal, O. H. Elibol, G. Keskin, C. Stephenson, A. Thomas, and K. Ramchandran, “Adversarially trained autoencoders for parallel-data-free voice conversion,” in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp. 2777–2781.
- [25] J. Wang, J. Li, X. Zhao, Z. Wu, and H. Meng, “Adversarially learning disentangled speech representations for robust multi-factor voice conversion,” arXiv preprint arXiv:2102.00184, 2021.
- [26] D. Wang, L. Deng, Y. T. Yeung, X. Chen, X. Liu, and H. Meng, “Vqmivc: Vector quantization and mutual information-based unsupervised speech representation disentanglement for one-shot voice conversion,” arXiv preprint arXiv:2106.10132, 2021.
- [27] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 2223–2232.
- [28] S. Lee, B. Ko, K. Lee, I.-C. Yoo, and D. Yook, “Many-to-many voice conversion using conditional cycle-consistent adversarial networks,” in ICASSP. IEEE, 2020, pp. 6279–6283.
- [29] P. L. Tobing, Y.-C. Wu, T. Hayashi, K. Kobayashi, and T. Toda, “Non-parallel voice conversion with cyclic variational autoencoder,” arXiv preprint arXiv:1907.10185, 2019.
- [30] K. Matsubara, T. Okamoto, R. Takashima, T. Takiguchi, T. Toda, Y. Shiga, and H. Kawai, “High-intelligibility speech synthesis for dysarthric speakers with lpcnet-based tts and cyclevae-based vc,” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 7058–7062.
- [31] A. v. d. Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalchbrenner, A. Senior, and K. Kavukcuoglu, “Wavenet: A generative model for raw audio,” arXiv preprint arXiv:1609.03499, 2016.
- [32] Y. Shi, H. Bu, X. Xu, S. Zhang, and M. Li, “Aishell-3: A multi-speaker mandarin TTS corpus and the baselines,” arXiv preprint arXiv:2010.11567, 2020.
- [33] D. Povey, A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, P. Motlicek, Y. Qian, P. Schwarz et al., “The Kaldi speech recognition toolkit,” in IEEE workshop on automatic speech recognition and understanding, 2011.
- [34] C.-C. Lo, S.-W. Fu, W.-C. Huang, X. Wang, J. Yamagishi, Y. Tsao, and H.-M. Wang, “Mosnet: Deep learning based objective assessment for voice conversion,” arXiv preprint arXiv:1904.08352, 2019.
- [35] D. Snyder, D. Garcia-Romero, G. Sell, D. Povey, and S. Khudanpur, “X-vectors: Robust dnn embeddings for speaker recognition,” in 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2018, pp. 5329–5333.
- [36] H. Bu, J. Du, X. Na, B. Wu, and H. Zheng, “Aishell-1: An open-source mandarin speech corpus and a speech recognition baseline,” in 2017 20th Conference of the Oriental Chapter of the International Coordinating Committee on Speech Databases and Speech I/O Systems and Assessment (O-COCOSDA). IEEE, 2017, pp. 1–5.