Energy-Efficient Designs for SIM-Based Broadcast MIMO Systems
Abstract
Stacked intelligent metasurface (SIM), which consists of multiple layers of intelligent metasurfaces, is emerging as a promising solution for future wireless communication systems. In this timely context, we focus on broadcast multiple-input multiple-output (MIMO) systems and aim to characterize their energy efficiency (EE) performance. To gain a comprehensive understanding of the potential of SIM, we consider both dirty paper coding (DPC) and linear precoding and formulate the corresponding EE maximization problems. For DPC, we employ the broadcast channel (BC)- multiple-access channel (MAC) duality to obtain an equivalent problem, and optimize users’ covariance matrices using the successive convex approximation (SCA) method, which is based on a tight lower bound of the achievable sum-rate, in combination with Dinkelbach’s method. Since optimizing the phase shifts of the SIM meta-elements is an optimization problem of extremely large size, we adopt a conventional projected gradient-based method for its simplicity. A similar approach is derived for the case of linear precoding. Simulation results show that the proposed optimization methods for the considered SIM-based systems can significantly improve the EE, compared to the conventional counterparts. Also, we demonstrate that the number of SIM meta-elements and their distribution across the SIM layers have a significant impact on both the achievable sum-rate and EE performance.
Index Terms:
Optimization, broadcast, EE, MIMO, stacked intelligent metasurface (SIM), multi-user.I Introduction
The framework for the future development of International Mobile Telecommunications (IMT) for 2030 highlights sustainability as a fundamental goal for future communication systems [1]. This means that these systems are expected to be designed with minimal environmental impact, focusing on the efficient use of resources, reducing power consumption, and lowering greenhouse gas emissions. Due to this, the study and development of energy-efficient wireless communications have recently attracted much of attention. At the same time, the global mobile network data traffic is expected to reach 563 exabytes (EBs) by 2029 [2]. To accommodate such a high volume of data traffic, existing network technologies need to evolve, providing additional capabilities. For example, conventional MIMO systems are advancing toward massive MIMO (mMIMO) and ultra-massive MIMO (umMIMO) systems. However, a large number of radio frequency (RF) chains required to support mMIMO transmissions results in substantial power consumption, which leads to an unsustainable and energy inefficient communication model.
A promising technical solution that addresses the growing demand for higher data rates while simultaneously enhancing EE is based on the use of intelligent metasurfaces, specifically reconfigurable intelligent surfaces. RISs are composed of a large number of programmable metamaterial or tiny discrete antenna elements. Each of these elements is capable, using integrated electronic circuits, of dynamically adjusting its electromagnetic (EM) properties (i.e., to form EM fields with controllable amplitudes, phases, polarization) and consequently its EM response to the incoming waves. In this way, RISs can modify the incoming waves in a programmable and controllable manner [3]. This capability allows RISs to simultaneously improve multiple performance metrics, such as spectrum efficiency, EE, coverage. Unfortunately, the multiplicative effect of the path loss of the RIS-assisted links significantly limits the potential EE gains from RIS deployment.
To address the critical issue of RIS, several innovative approaches have been proposed that utilize metamaterial-based antenna technologies instead of conventional antenna arrays in mMIMO transceiver design. These include holographic radio, dynamic metasurface antennas and SIMs. Holographic radio, also known as holographic MIMO (HMIMO), is a hybrid transceiver architecture that achieves high directive gain, spectral efficiency and EE by incorporating a continuous structure of densely packing sub-wavelength metamaterial antenna elements. These element, combined with holographic techniques, are capable of recording and reconstructing the amplitude and the phase of wave fronts [4]. The significantly lower power consumption of HMIMO allows for the deployment of a greater number of antenna elements compared to traditional mMIMO, resulting in higher EE [5]. Similarly, DMAs consist of multiple microstrips, each composed of a multitude of metamaterial radiating elements and connected to a single RF chain [6]. Due to this, DMAs achieve better EE performance than even hybrid analog-to-digital (A/D) architectures, since they do not need additional power to support numerous phase shifters [7]. However, both HMIMOs and DMAs are single layer matasuface structures, which may require a very large number of elements due to practical hardware constraints that limit the number of tunable amplitudes/phases associated with each meta-element.
In contrast, SIMs represent the latest advancement in metamaterial-based antenna technologies. SIMs consist of multiple parallel metasurface layers, each accommodating numerous meta-elements with programmable phase characteristics. These layers are integrated with conventional radio transceivers that employ a small to moderate number of active antennas. The concept of SIMs draws inspiration from the architecture of a deep neural network (DNN), which is a multi-layer neuron structure capable of implementing various functions [8]. Similarly, SIMs can efficiently implement different signal processing tasks, such as transmit precoding and receive combining, directly in the EM domain when properly controlled and programmed. Hence, SIMs have the potential to substantially improve the performance metrics of conventional communication systems, such as the achievable rate and the EE, while requiring minimal additional hardware complexity.
In [9], SIMs were exploited to implement a 2D discrete Fourier transform (DFT) for direction of arrival direction of arrival (DOA) estimation. Moreover, a hybrid channel estimator was proposed in [10], in which the received training symbols were initially processed in the wave domain and subsequently in the digital domain. In [11], the authors jointly optimized the transmit beamforming at the base station (BS) and the SIM phase shifts, to minimize the Cramer-Rao bound (CRB) for target estimation. Using an experimental SIM platform, they evaluated the performance of the proposed algorithms for communication and sensing tasks.
A general path loss model for an SIM-assisted wireless communication system was developed in [12], based on which, an algorithm aimed at maximizing the received power was derived. In [13], the authors studied the achievable sum-rate maximization problem for a downlink channel between a SIM-assisted BS and multiple single-antenna users. The achievable rate optimization for a downlink multi-user SIM-assisted system using statistical channel state information (CSI) was proposed in [14]. Utilizing statistical CSI, the ergodic sum-rate was optimized for a satellite communication system in [15]. In [16], a joint optimization of the SIM phase shifts and transmit power allocation for maximizing the sum-rate in a SIM-assisted multi-user multiple-input single-output (MISO) communication system was implemented, employing a deep reinforcement learning (DRL) approach. In [17], the authors optimized the achievable rate in an uplink SIM-based cell-free MIMO architecture with distributed signal processing. In this setup, each access point (AP) performs local detection of user information, and a central processing unit (CPU) subsequently combines these local estimates to recover the final user information.
The integration of SIMs with transmitters and receivers into a so-called SIM-based HMIMO system, which performs signal precoding and combining in the wave domain, was proposed in [18]. The introduced channel fitting approach enables the SIM-based HMIMO system to achieve significant channel capacity gains compared to mMIMO and RIS-assisted counterparts. Furthermore, the optimization of achievable rates for the SIM-based HMIMO system was studied in [19]. An approach for the mutual information maximization in a SIM-based HMIMO system with discrete signaling was presented in [20], using the cutoff rate as an alternative metric. This study demonstrates that incorporating even a small-scale digital precoder into the system can substantially increase the mutual information performance.
Despite the extensive research summarized in the aforementioned papers, the EE analysis of SIM-assisted MIMO systems remains unexplored. Motivated by this gap, we aim to maximize the EE for a SIM-aided broadcast system with DPC and linear precoding. To find the maximum achievable EE in the case of DPC, we formulate a joint optimization problem of the covariance matrix of the transmitted signal and the phase shifts of the SIM meta-elements. For linear precoding, which is more practical, we consider a joint optimization problem of the transmit signal precoding and the phase shifts of the SIM meta-elements. In both cases, the BS has a limited total power budget and the SIM meta-elements are subject to the unit modulus constraint. The main contributions of this paper are summarized as follows:
-
•
For DPC, we exploit the well-known Gaussian MIMO BC-MAC duality, reformulating the original EEmax problem as a function of the users’ covariance matrices in the MAC and the phase shifts of the SIM meta-elements. In the context of the adopted AO framework, we present an efficient solution for optimizing the users’ covariance matrices. This solution is based on a tight and concave lower bound of the achievable sum-rate, which is derived using the SCA method. By applying Dinkelbach’s method, we then obtain the optimal users’ covariance matrices by closed-form expressions. Our complexity analysis demonstrates that our proposed method has significantly lower complexity compared to an existing solution. For the optimization of the phase shifts of the SIM meta-elements, we employ a conventional projected gradient-based method, updating all SIM layers in parallel. This approach is viable considering the large size of this problem. In this context, we derive closed-form expressions for the complex-valued gradients involved.
-
•
For linear precoding, we leverage an interesting recent result for the sum-rate maximization that allows for reformulating the considered EEmax problem as an equivalent one, but with a greatly reduced dimension. After this important step, we again invoke the SCA method to derive a quadratic lower bound of the achievable sum-rate and approximate the EEmax problem as a concave fractional program. Next, we apply Dinkebach’s method to solve the resulting problem, where optimal users’ precoders are found by closed-form expressions. Similar to the DPC-based scheme, the phase shifts of the SIM meta-elements in this setting are optimized in parallel using a conventional projected gradient-based method.
-
•
We present efficient implementations of the proposed algorithms, analyze their computational complexities in terms of the number of complex multiplications, and mathematically prove their convergence.
-
•
We show through simulation results that the proposed algorithms can substantially increase the EE in SIM-aided broadcast communication systems, with greater improvements observed in the case of DPC. Moreover, we demonstrate that using the aforementioned precoding schemes is crucial to mitigate the impact of multi-user inference, especially in systems with a large number of users. We also provide several valuable insights into the design and performance of SIM-based holographic MIMO systems. First, we show that the EE is highly dependent on the number and distribution of SIM meta-elements across the SIM layers. Second, we find that the EE for a SIM-aided system with a low number of meta-elements can even be lower than the EE for a conventional MIMO system without SIM integration. Third, in SIM-aided broadcast systems without digital precoding, optimal EE transmission involves activating only a subset of the available transmit antennas, where each antenna in this subset transmits an independent data stream. Lastly, we demonstrate that at least 3 bits per meta-element are required to ensure that the reduction in EE caused by quantization errors remains within acceptable limits.
Notation: Bold lower and upper case letters represent vectors and matrices, respectively. denotes the space of complex matrices. and denote the transpose and Hermitian transpose of , respectively. is the determinant of and denotes the trace of . is the binary logarithm, is the natural logarithm, denotes the pseudo-inverse and denotes the complex conjugate. denotes the Frobenius norm of which reduces to the Euclidean norm if is a vector. is the vector comprised of the diagonal elements of . The notation means that is positive semidefinite (definite). represents an identity matrix whose size depends from the context. and denote the real and imaginary part of , respectively. For a vector , denotes a diagonal matrix with the elements of on the diagonal. ) denotes a circularly symmetric complex Gaussian random variable with mean and variance . denotes the modulus of the complex number , and || denotes the determinant of . Finally, we denote by the complex gradient of with respect to (w.r.t.) , i.e., .
II System Model and Problem Formulation
II-A System Model
We consider a multi-user broadcast system in which a BS with transmit antennas communicates with users, where each user has receive antennas. The BS is also equipped with a SIM, which consists of metasurface layers with meta-elements per layer. In general, SIMs are controlled by external field programmable gate array (FPGA) devices, which adjust the phase shifts of individual meta-elements, thereby implementing signal beamforming directly in the EM wave domain.111By considering both SIM (i.e., wave-based precoding) and digital precoding, our system model is general enough to include the wave-based only precoding as a special case.
The phase shifts of the meta-elements in the -th SIM layer are presented by the diagonal matrix , where and is the phase shift introduced by the -th element of the -th layer. Signal propagation between two consecutive layers, and , of the SIM is modeled by the matrix for . More precisely, signal propagation between the -th meta-element of the -th and the -th meta-element of -th layer of the SIM is presented by the -th element of , which is calculated according to the Rayleigh-Sommerfeld diffraction theory as [21, Eq. (1)]
| (1) |
where is the area of each meta-element, is the distance between the meta-elements of these two layers of the SIM, is the angle between the propagation direction and normal direction of the -th layer, and is the wavelength. Signal propagation between the transmit antenna array and the first layer of the SIM is presented by the matrix , whose elements can be calculated as in (1). Finally, the EM response of the transmit SIM can be written as
| (2) |
For the considered system, the end-to-end channel matrix between the BS and the -th user receive antenna array is given by
| (3) |
where denotes the channel matrix between the final layer of the SIM and user . We assume that is perfectly known to the BS in an effort to investigate its full theoretical potential.
II-B Dirty Paper Coding (DPC)
In a multi-user broadcast system, the received signal at user is given by
| (4) |
where is the channel matrix for user , is the transmitted signal intended for user , and for are the transmitted signals intended for the other users, which act as interference for the detection of . The noise vector consists of independent and identically distributed (i.i.d.) elements that are distributed according to , where is the noise variance. DPC is capable of eliminating the interference term , which is caused by users . Therefore, the achievable rate of user is given by
| (5) |
where, by slight abuse of notation, stands for (i.e., is normalized by the square root of the noise power), is the input covariance matrix of user and . These covariance matrices are constrained by the total power budget as
| (6) |
where is the available transmit power budget.
II-C Multi-user MIMO with Linear Precoding
Although DPC is a capacity achieving scheme, it has high complexity due to its nonlinear processing nature. On the other hand, linear precoding is much simpler to implement in practice. For linear precoding, the transmitted signal is expressed as
| (7) |
where is the signal intended for user and is the corresponding linear precoder. Thus, the received signal at user is given by
| (8) |
By treating the multiuser interference as Gausian noise, the achievable rate of user is given by
| (9) |
where and the precoding matrices have to satisfy the total power constraint:
| (10) |
II-D Problem Formulation
In this paper, our goal is to maximize the EE of the considered communication system, which is defined as the ratio of the sum-rate and the total power consumption. To this end, we model the total power consumption as
| (11) |
where is the data-dependent transmit signal power, is the circuit power per RF chain, is the basic power consumed at the BS, and is the power consumption of the switching circuits (e.g., PIN diode, varactor diodes) of every SIM meta-element.222In this model, we assume that the control and driving circuits of the SIM are integrated in the BS, and the power consumption of these circuits is already included in the BS power consumption, . Note that for the DPC-based scheme and for the linear precoding scheme. Since BSs have the largest power consumption in mobile networks, the users’ consumed power is not taken into account in the considered EE optimization.
For the DPC-based scheme, the EE maximization (EEmax) problem is stated as
| | (12a) | |||
| (12b) | ||||
| (12c) | ||||
where is the system bandwidth. Similarly, the EEmax problem with linear precoding is written as
| | (13a) | |||
| (13b) | ||||
| (13c) | ||||
Since is constant, we will drop it when solving (12) and (13), but it is included in simulation results in Section VII. In the following sections, we present our proposed methods for solving the above two EEmax problems.
III Proposed Solution to DPC-based SIM
To solve (12), we present an iterative optimization algorithm which optimizes the covariance matrices and the SIM phase shifts in an alternating manner, which is a prevailing method in existing studies for SIM. In particular, for fixed phase shifts, we propose a novel method which can optimize the covariance matrices in parallel, using a closed-form expression. Our proposed method is derived by applying Dinkelbach’s method to maximize a quadratic lower bound of the objective, iteratively. The phase shifts of the meta-elements of the SIM layers are optimized by a gradient-based optimization method, which is a natural choice, considering the extremely large size of the SIM.
III-A Covariance Matrix Optimization
We remark that the objective function in (12a) is neither convex nor concave with respect to the optimization variables. To deal with this, we exploit the well-know duality between BCs and MACs, introduced in [22], which states that the achievable sum-rate of the MIMO BC equals the achievable sum-rate of the dual MIMO MAC. Accordingly, (12) is equivalent to the EEmax problem in the dual MAC, which is expressed as
| | (14a) | |||
| (14b) | ||||
| (14c) | ||||
where is the dual MAC of user . Also, , where is the input covariance matrix of user in the dual MAC. Note that the equality constraint in (14b) is treated element-wise. The key idea to develop efficient solutions to (12a) is first to drop the power constraint (12c), which results in
| (15) |
To appreciate the novelty of our proposed method, we briefly describe the block-coordinate method proposed in [23], which optimizes each sequentially, while other variables are fixed. More precisely, let denote the current iterate. Then the next iterate is obtained as
| (16) |
where , , and . Next, to solve (16), the authors of [23] applied Dinkelbach’s method, which leads to the following problem
| (17) |
where is a non-negative parameter. For a given , the above problem can be solved in closed-form [23]. However, such a method requires to find the inverse of which has a complexity of in general, and compute the singular value decomposition (SVD) of which has a complexity of . Thus, the overall complexity of the method presented in [23] is very high.
In this paper, we propose a more efficient method based on the fact that a stationary solution to (15) is also globally optimal since (15) is a concave-convex program. This motivates us to adopt the SCA framework, which is normally used to find a stationary solution for nonconvex programs. To proceed, since , we can write where . Thus, (15) is equivalent to the following unconstrained optimization problem:
| (18) |
where . It is easy to see that can be equivalently rewritten as
| (19) | |||
| (20) | |||
| (21) |
In fact, the -th term in the sum above is the capacity of user in the dual MAC, using successive interference cancellation [22]. As shown shortly, the above reformulation of allows for approximating by a “proper bound” to obtain a subproblem that admits a closed-form solution. In this regard, we recall the following inequality [24]:
| (22) |
where . We remark that the above inequality holds for arbitrary , , and , whose sizes are compatible and the equality occurs when and . In light of the SCA framework, we denote by the value of after iterations. Now let
and
Then (22) implies
| (23) |
where
Regarding the complexity of the above approximation, the following remark is in order.
Remark 1.
Since , it may appear that the complexity of constructing the above bound is due to the computation of . However, we emphasize that this is not the case. Specifically, by invoking the matrix-inversion lemma we can write
| (24) | ||||
| (25) | ||||
| (26) | ||||
| (27) |
for . The above equation indeed suggests a recursive method to compute efficiently. Suppose the inverse of is known. Then, we only need to compute the inverse of the matrix , which has complexity of , to obtain . Thus, starting from , we can gradually compute for . In this way, we remark that is also obtained easily.
Now, using the above lower bound of , we consider the following approximate problem
| (28) |
It is important to note that the above problem is a concave-convex fractional program since is concave. Thus, Dinkelbach’s method can be applied to find the optimal solution, which leads to the following parameterized problem
| (29) | |||
| (30) | |||
| (31) |
where is a given parameter. It is important to note that the above optimization problem can be solved independently for each , which admits the following closed-form solution
| (32) |
Let be the optimal solution to (15). Obviously, if , then is also optimal to (12a). On the other hand, if , it is straightforward to see that the optimal solution to (12a) is obtained by solving the sum-rate maximization problem with the sum power constraint, which is defined as:
| | (33a) | |||
| (33b) | ||||
An efficient method for solving the above problem was proposed in [25], which we omit the details for the sake of brevity. Let be the optimal solution to (33). Then it is easy to see that the optimal covariance matrices for (14) are given by
| (34) |
A summary of the described covariance matrix optimization method is presented in Algorithm 1.
III-B SIM Phase Shift Optimization
Since the power consumption does not depend on the channel matrix, the phase shift optimization can improve the EE by increasing the sum-rate of the considered system. Therefore, for fixed , the SIM phase shift optimization problem is formulated as
| (35a) | ||||
| (35b) | ||||
Considering the large size of the SIM, we adopt a gradient-based method to optimize the phase shifts, which consists of the following iterations:
| (36) |
where is the appropriate step size. The gradient of w.r.t. the phase shifts of the SIM is determined by the gradients of w.r.t. the phase shifts of the constituent SIM layers as
The gradient w.r.t. each is provided in Theorem 1.
Theorem 1.
The gradient of w.r.t. is given by
| (37) |
where
| (38a) | ||||
| (38b) | ||||
where .
Proof:
Since all the elements of have the unit amplitude, the projection is defined by
| (43) |
Finally, the the EE optimization algorithm for a SIM-aided broadcast system with DPC precoding is outlined in Algorithm 2.
IV Proposed Solution to Linear Precoding
In this section, we propose an optimization method for the EEmax problem with linear precoding. Similarly as in the previous section, the precoding matrices are found by closed-form expressions, which are derived by implementing Dinkelbach’s method, while the optimal phase shifts for the SIM meta-elements are optimized by a gradient-based method.
IV-A Precoding Matrix Optimization
The precoding matrix optimization, for fixed , in (13) in fact reduces to the EEmax problem in conventional MIMO systems. It can be observed that the complexity of the direct optimization of is proportional to , which can cause a significant complexity burden for systems even with moderate , and thus such a direct optimization method is not practically appealing.
To overcome this issue, we consider an equivalent formulation of (13), introduced in [26], that has a smaller dimension and thus requires a lower computational complexity. Denoting , (13) can be equivalently written as
| | (44a) | |||
| (44b) | ||||
where
| (45) |
are new optimization variables, and is the -th sub-matrix of . The equivalence between (13) and (44) is a result of [26, Prop. 2], and the optimal solutions of the two problems are related as . We remark that, comparing the size of and , the equivalent formulation in (44) can significantly reduce the number of optimization variables for systems with large (i.e., ). In the sequel, similar to the development of Algorithm 1, we first drop (44b) and derive a solution for the unconstrained case. The solution for the constrained case follows immediately.
Upon close inspection, we can observe that the denominator of (44) is a quadratic convex function, while the numerator of (44) is neither convex nor concave function. As a result, finding the solution of (44) is not a trivial task. To find an efficient method for solving (44), we again exploit the inequality, given in (22), to obtain a lower bound of the achievable rate in (45). Utilizing the identity to reformulate (45), the lower bound of the achievable rate of user can be expressed as
| (46) |
where , , , and . Consequently, the resulting approximate problem of (44) is given by
| (47) |
which is a concave-convex optimization problem.
Next, we apply Dinkelbach’s method to solve (47), leading to the following optimization problem
| (48) |
where
| (49) |
and is a given parameter.
Implementing the Karush-Kuhn-Tucker (KKT) first-order optimality condition to (48) by taking the gradient of this expression w.r.t. and setting it to 0, we obtain
| (50) |
To solve for we differentiate two cases. If is row-rank matrix, e.g. (i.e., ), then is invertible, and thus (50) results in
| (51) |
If is column-rank matrix (i.e., ), we rewrite (50) as
| (52) |
and finally obtain
| (53) |
If the obtained solution from (51) or (53) satisfy the power constraint (44b) then it also the general case solution. Otherwise, the optimal is the solution of the achievable rate optimization problem
| | (54a) | |||
| (54b) | ||||
which can be solved by [26, Algorithm 1]. The described optimization algorithm is summarized in Algorithm 3.
IV-B SIM Phase Shift Optimization
For fixed , the SIM phase shift optimization problem is formulated as
| (55a) | ||||
| (55b) | ||||
where the achievable rate for user is expressed as
| (56) |
Since we again apply the projected gradient method for the phase shift optimization, the rate expression in (9) is used, instead of (45). The obvious reason is that it is easier to find the gradient of the objective w.r.t using (9) than using (9).
The optimization of the phase shifts of the BS SIM follows the same steps as in the case of DPC in subsection III-B. Specifically, the phase shifts are iteratively updated as
| (57) |
where is the appropriate step size. Also, the gradient is given by , where is expressed in the following theorem.
Theorem 2.
The gradients of w.r.t. the l-th layer of the SIM at the BS is given by
| (58) |
where , , , and .
Proof:
See Appendix A. ∎
The outline of the proposed algorithm is given in Algorithm 4.
V Computational Complexity
In this section, the computational complexity for SIM-aided broadcast systems with DPC and linear precoding are obtained by counting the required number of complex multiplications. In the following complexity analysis, for ease of exposition, we assume that which is the typical case for a SIM-based broadcast communication system.
V-A DPC Precoding
The optimization of the covariance matrices is performed by Algorithm 1. The complexity of obtaining from can be neglected. In addition, the complexity of calculating all , , and is as explained previously. Furthermore, multiplications is needed to calculate all in (32). The complexity of calculating the objective function is . Let be the number of inner loops (i.e., lines 3 to 7 in Algorithm 1). Then the complexity of lines 1 to 11 in Algorithm 1 is .
For optimizing the SIM phase shifts, we need multiplications for the computation of . The complexity of the matrix inversion and its multiplication with the previous sum is . As all the matrix product are precomputed in advance and the fact that we need only the diagonal elements in (37), the additional complexity is . Hence, the complexity of the gradient calculation is . After obtaining , the complexity of calculating and is . In addition, multiplications is needed for calculating . The complexity of optimizing the SIM phase shifts is given by , where is the number of line search loops.
Therefore, the overall computational complexity for one iteration of the DPC algorithm is given by
| (59) |
V-B Linear Precoding
The optimization of the precoding matrices is specified by Algorithm 3. The calculation of requires multiplications. Computing the initial from requires multiplications. Furthermore, the complexity of calculating all , and is . Next, we need to determine the optimal according to (51) if , or otherwise according to (53). The calculation of the optimal according to (51) requires multiplications and according to (53) , which can be written as
| (60) |
The complexity for calculating and can be neglected. If the number of inner loops (i.e., lines 3 to 8 in Algorithm 3) is , then the complexity of Algorithm 3 is given by .
To optimize the phase shifts of the SIM, we need multiplications to obtain and all matrices. The complexity of calculating and is and the same is also true for . Multiplying these terms with has the complexity of . Utilizing the fact that all the matrix product are precomputed and that we need only the diagonal elements in (58), the additional complexity is . Hence, the complexity of the gradient calculation is . After obtaining , the complexity of calculating and is . To obtain all terms we need multiplications. Any additional complexity for computing can be neglected. Hence, the complexity of optimizing the SIM phase shifts is given by , where is the number of line search loops.
Therefore, the overall computational complexity for one iteration of the linear precoding algorithm is given by
| (61) |
VI Convergence
Let us now prove the convergence of Algorithm 2. First, for a given , Algorithm 2 achieves monotonic convergence, which can be shown as follows. From (23), it holds that
| (62) | |||
| (63) | |||
| (64) | |||
| (65) |
where (a) is a due to (23), (b) is due to the fact that is the optimal solution to (28) and that the optimal objective is no less than the objective of a feasible point, and (c) is true because it is easy to check that , i.e. the equality in (23) occurs when . Regarding (b) above, note again that since (28) is a concave-convex fractional program, Dinkelbach’s method is guaranteed to converge to an optimal solution to (28). Consequently, the sequence increases monotonically to an optimal solution to (18), and thus, Algorithm 2 is able to compute an optimal solution to (14). Next, for given covariance matrices, the SIM phase shift is optimized by a standard projected gradient method, for which the convergence is guaranteed. Also, the projected gradient method always yields an improved solution. In other words, Algorithm 2 generates a non-decreasing objective sequence. Since the feasible sets for the convariance matrices and phase shifts are continuous, the objective sequence produced by Algorithm 2 is guaranteed to converge.
Since Algorithm 4 uses a similar method for the optimization of the precoding matrices, as Algorithm 2 for the optimization of the covariance matrices, we can prove, following the same derivation steps, that for a given Algorithm 4 is guaranteed to provide an optimal solution to (28). In addition, a gradient-based optimization of the SIM phase shifts always increase the objective function. Moreover, the feasible sets for the precoding matrices and phase shifts are continuous, which ensures the convergence of the objective sequence in Algorithm 4.
VII Simulation Results
In this section, we evaluate the EE of the considered systems using proposed algorithms by means of Monte Carlo simulations. First, we compare the EE of the proposed algorithms and three benchmark schemes. The first benchmark scheme, referred to as LIN w/o SIM, is based on linear precoding without the presence of a SIM. In that case, the total power consumption is The second benchmark scheme, referred to as LIN w/o prec., does not employ digital precoding; instead data streams are fed directly to transmit antennas, while the phase shifts of the SIM meta-elements are optimized as described in Algorithm 4. The achievable rate for a single user in this scheme can be calculated using (9) and the identity , which ensures that the power constraint (10) is satisfied. The last benchmark scheme, termed LIN w/o prec. red. RF, also does not include a SIM, but differs from the previous one by utilizing a reduced number of transmit antennas and, consequently, a reduced number of RF chains. More precisely, this scheme uses active transmit antennas (i.e., RF chains), each transmitting an independent data stream. The remaining transmit antennas (i.e., RF chains) are inactive, resulting in a total power consumption of
The channel matrix between the BS and user is modeled according to the spatially-correlated channel model as , where denotes the channel between the last SIM layer and the receiver, and follows a complex Gaussian distribution . The free space path loss between the transmitter and the receiver, , is given by , where is the free space path loss at the reference distance , is the path loss exponent, and is the distance between the BS and user . Moreover, is the spatial correlation matrix of the SIM, with its elements defined according to [18, Eq. (14), (15)].
In the following simulation setup, the parameters are set as follows: (i.e., ), , , , , , , and . Unless otherwise specified, the number of meta-elements per SIM layer, , is 100. The BS antennas are placed in a planner array parallel to the -plane and the position of its midpoint is . The inter antenna separation of the BS antennas is in both dimensions. The BS SIM layers are also placed parallel to the -plane, with the midpoint of the -th layer located at . Moreover, the meta-elements in each SIM layer are uniformly placed in a square formation, where each meta-element has dimensions . It is assumed that all users’ ULAs are parallel to the -axis and the midpoint of the -th user’s ULA is positioned at . The users’ coordinates are randomly selected such that is drawn from a uniform distribution between 1.6 m and 2 m with a resolution of 1 cm, is drawn from a uniform distribution between m and 20 m with a resolution of 0.5 m, and is drawn from a uniform distribution between 80 m and 120 m with a resolution of 0.5 m. The circuit power per RF chain is and the basic power consumption at the BS is [7, 27]. The power consumption of each SIM meta-element is [28, 29]. For the DPC method, we use and for linear precoding . Regarding the gradient-based optimization methods, the initial step size value is 1000, and . All results are averaged over 200 independent channel realizations.


The convergence of the proposed algorithms for different number of SIM layers is shown in Fig. 1. In general, we can see that the number of iterations required for the algorithms to converge increases with the number of SIM layers (i.e., meta-elements). A similar, but much more pronounced, effect was previously observed in [20], where the authors optimized the SIM phase shifts on a layer-by-layer basis. Moreover, the EE does not change monotonically with . For DPC, the EE at convergence is almost the same for and , which is visibly larger in the case of linear precoding. This can be attributed to the saturation of the achievable sum-rate as the number of SIM layers increases [19, Fig. 4], coupled with the fact that power consumption scales linearly with the number of meta-elements.
In Fig. 2, we present the EE evaluated for different number meta-elements per SIM layer. Specifically, the numbers of meta-elements considered per SIM layer are 25, 49, 100 and 196. The EE of both the proposed schemes and the benchmark schemes without precoding (i.e., LIN w/o prec. and LIN w/o prec. red. RF) increases with the number of meta-elements per SIM layer. The increase rates of the corresponding EE gradually reduces with . The reason is that for these schemes, the transmitter operates full power, and thus the EE increases in line with the achieved sum-rate, which follows a logarithm function. Among the benchmark schemes without precoding, the LIN w/o prec. red. RF scheme achieves significantly higher EE. This is partly due to lower power consumption, as some of its RF chains are inactive. Additionally, in the LIN w/o prec. scheme, each antenna simultaneously transmits data for all users, while in the LIN w/o prec. red. RF scheme, each active antenna transmits an independent data stream, which better suppresses the multi-user interference. Since the LIN w/o SIM scheme does not incorporate a SIM, its EE is independent of the number of SIM meta-elements. For a small number of meta-elements per SIM layer, this benchmark scheme has the largest EE, while for a higher number of meta-elements the EE of other schemes becomes larger. Finally, we observe that the scheme with DPC achieves a slightly higher EE than the linear precoding scheme, and that this EE difference increases with the number of SIM meta-elements.

In Fig. 3, we present the EE and the achievable sum-rate of the considered system versus the number of SIM layers, while maintaining a constant total of meta-elements. As observed, the EE and the achievable sum-rate of the proposed schemes do not change monotonically with the number of SIM layers, . Both the EE and the achievable sum-rate increase when changes from 1 to 2, which is likely due to the enhanced beamforming capabilities offered by multi-layer structures. However, with increases further, both of performance metrics significantly decrease, potentially reaching levels comparable to those of the LIN w/o SIM scheme, a benchmark scheme that does not utilize a SIM. This effect can be explained by the following reasoning:as the number of meta-elements per SIM layer decreases, the beamforming gain of each individual layer also reduces. Additionally, the signal propagation between adjacent SIM layers can be viewed as a form of path loss, which increases with the number of SIM layers. These two facts contribute to the observed reduction in both EE and achievable sum-rate when the number of SIM layers is greater than two. A similar trend is observed in the benchmark schemes without precoding (i.e., LIN w/o prec. and LIN w/o prec. red. RF), where the EE and the achievable sum-rate also decrease as increases. Among these two scheme, the LIN w/o prec. red. RF scheme achieves much better system performance.

The EE of the considered schemes for different number of users, , is shown in Fig. 4. For a small , the LIN w/o prec. red. RF scheme provides the best EE, primarily due to the low number of RF chains used in this scheme. However, as increases, the number of RF chains used by this scheme becomes comparable to the total number of RF chains in other schemes. In addition, the lack of capability of adjusting the amplitude of the transmitted signal prevents this scheme from effectively suppressing the multi-user interference [25]. As a result, the EE of this scheme reduces as increases. For the same reason, the EE of the LIN w/o prec. scheme also decreases with an increasing number of users. On the other hand, the EE of the proposed schemes and the LIN w/o SIM scheme increase with , because of the presence of digital precoders that can reduce or even eliminate the multi-user interference, allowing them to exploit the multiuser diversity. Comparing the EE of the proposed schemes with that of the benchmark schemes, we can see that using a SIM in combination with digital precoding almost always provides the best EE, except in cases where is very small.
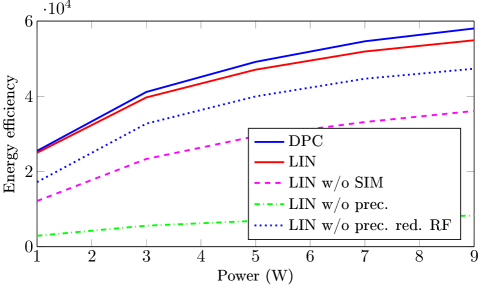
Next, we study how the EE varies with the maximum transmit power, as shown in Fig. 5. The EE curves for all schemes exhibit an approximately logarithmic shape due to the logarithmic increase in the achievable rate. As expected, the proposed schemes achieve higher EE compared to benchmark schemes. Among all the benchmark schemes, the LIN w/o prec. red. RF scheme obtains the largest EE because of a smaller number of RF chains used. The difference between the EE of the proposed scheme with linear precoding scheme and that of any other benchmark scheme generally increases with transmit power, although these differences are almost stabilized at higher transmit power levels. Additionally, the DPC-based scheme consistently shows a noticeable improvement in EE over all other schemes, which can be attributed to the superior interference suppression capabilities of DPC.
In order to better understand the impact of realistic imperfections, we present the EE of the proposed schemes for the case of discrete SIM phase shifts in Fig. 6. The EE generally deteriorates as the number of quantization bits decreases. This effect is more evident for SIMs with a larger number of layers, since they contain more meta-elements and thus can cause a larger EE reduction. As a rule of thumb, at least 3 bits per meta-element are required for SIMs with a small (e.g., 2 or 4) to ensure that the EE reduction caused by quantization errors remains within acceptable limits. For SIMs with a larger , the minimum number of bits per meta-element is expected to be higher.

The per-iteration computational complexity of the proposed optimization schemes are shown in Table I. The relevant iteration counts for Dinkelbach’s method and , and the number of the line search steps, and , are averaged over the number of iterations required for each optimization scheme to reach 95 % of the EE at the 1000-th iteration. It can be observed that the number of iterations of Dinkelbach’s method remains almost unchanged as varies for both schemes, and the same holds true for the number of line search steps. Moreover, the computational complexity of the proposed optimization scheme for DPC-based systems is higher than that of the scheme with linear precoding when is 4 and 8. However, when increases to 12, the DPC-based scheme exhibits significantly lower complexity compared to the linear precoding scheme. This substantial increase in the complexity of the linear precoding scheme is due to the fact that the complexity of the precoding matrix optimization, , is proportional to when .
| DPC | Linear precoding | |||||
|---|---|---|---|---|---|---|
| 4 | 55 | 1 | 4367616 | 51 | 1 | 4129024 |
| 8 | 55 | 1 | 4480256 | 50 | 1 | 4409600 |
| 12 | 55 | 1 | 4592896 | 51 | 1 | 9947392 |
VIII Conclusion
In this paper, we studied the EE maximization in a SIM-aided broadcast system with DPC and linear precoding at the BS. For DPC, we exploited the well-known BC-MAC duality and optimize the users’ covariance matrices by employing a SCA-based technique, which establishes a tight lower bound of the achievable sum-rate, and applying Dinkelbach’s method. A similar approach was used to optimize the precoders in the case of linear precoding. The phase shifts of the SIM meta-elements for DPC and linear precoding were optimized using a conventional projected gradient-based method due to its simplicity. Also, we conducted a computation complexity analysis of the proposed optimization algorithms and proved their convergence. Numerical results showed that implementing these proposed optimization algorithms can significantly improve the EE for SIM-aided broadcast systems. Moreover, we demonstrated that the EE depends on the number of SIM meta-elements and their distribution across the SIM layers. We also found that in SIM-aided broadcast systems without precoding, optimal energy efficient transmission strategies typically involve a subset of active transmit antennas.
Appendix A Proof of Theorem 2
Differentiating in (56) w.r.t. yields
| (66) |
where
| (67) | ||||
| (68) |
Substituting (40) into the previous expressions, we obtain
| (69) | ||||
| (70) |
where
| (71) | ||||
| (72) |
After a few simple mathematical steps, we get
| (73) |
From this gradient expression for the achievable rate of user , we can easily obtain the appropriate gradients for all other users. After summation of all these gradient expressions, we obtain (58). This completes the proof.
References
- [1] “Framework and overall objectives of the future development of imt for 2030 and beyond,” International Telecommunication Union (ITU) Recommendation (ITU-R), 2023.
- [2] “Mobile data traffic outlook – Ericsson Mobility Report,” 2024, [Accessed 05-07-2024]. [Online]. Available: https://www.ericsson.com/en/reports-and-papers/mobility-report/dataforecasts/mobile-traffic-forecast
- [3] M. Di Renzo et al., “Smart radio environments empowered by reconfigurable intelligent surfaces: How it works, state of research, and the road ahead,” IEEE Journal on Selected Areas in Communications, vol. 38, no. 11, pp. 2450–2525, 2020.
- [4] T. Gong et al., “Holographic MIMO communications: Theoretical foundations, enabling technologies, and future directions,” IEEE Communications Surveys & Tutorials, vol. 26, no. 1, pp. 196–257, 2024.
- [5] A. Zappone et al., “Energy efficiency of holographic transceivers based on RIS,” in GLOBECOM 2022-2022 IEEE Global Communications Conference. IEEE, 2022, pp. 4613–4618.
- [6] N. Shlezinger et al., “Dynamic metasurface antennas for 6G extreme massive MIMO communications,” IEEE Wireless Communications, vol. 28, no. 2, pp. 106–113, 2021.
- [7] L. You et al., “Energy efficiency maximization of massive MIMO communications with dynamic metasurface antennas,” IEEE Transactions on Wireless Communications, vol. 22, no. 1, pp. 393–407, 2022.
- [8] C. Liu et al., “A programmable diffractive deep neural network based on a digital-coding metasurface array,” Nature Electronics, vol. 5, no. 2, pp. 113–122, 2022.
- [9] J. An et al., “Two-dimensional direction-of-arrival estimation using stacked intelligent metasurfaces,” arXiv preprint arXiv:2402.08224, 2024.
- [10] Q.-U.-A. Nadeem et al., “Hybrid digital-wave domain channel estimator for stacked intelligent metasurface enabled multi-user MISO systems,” arXiv preprint arXiv:2309.16204, 2023.
- [11] Z. Wang et al., “Multi-user ISAC through stacked intelligent metasurfaces: New algorithms and experiments,” arXiv preprint arXiv:2405.01104, 2024.
- [12] N. U. Hassan et al., “Efficient beamforming and radiation pattern control using stacked intelligent metasurfaces,” IEEE Open Journal of the Communications Society, vol. 5, pp. 599–611, 2024.
- [13] J. An et al., “Stacked intelligent metasurfaces for multiuser downlink beamforming in the wave domain,” arXiv preprint arXiv:2309.02687, 2023.
- [14] A. Papazafeiropoulos et al., “Achievable rate optimization for large stacked intelligent metasurfaces based on statistical CSI,” IEEE Wireless Communications Letters, 2024, Early Access.
- [15] S. Lin et al., “Stacked intelligent metasurface enabled LEO satellite communications relying on statistical CSI,” IEEE Wireless Communications Letters, vol. 13, no. 5, pp. 1295–1299, 2024.
- [16] H. Liu et al., “DRL-based orchestration of multi-user MISO systems with stacked intelligent metasurfaces,” arXiv preprint arXiv:2402.09006, 2024.
- [17] Q. Li et al., “Stacked intelligent metasurfaces for holographic MIMO aided cell-free networks,” IEEE Transactions on Communications, 2024, Early Access.
- [18] J. An et al., “Stacked intelligent metasurfaces for efficient holographic MIMO communications in 6G,” IEEE Journal on Selected Areas in Communications, vol. 41, no. 8, pp. 2380–2396, 2023.
- [19] A. Papazafeiropoulos et al., “Achievable rate optimization for stacked intelligent metasurface-assisted holographic MIMO communications,” arXiv preprint arXiv:2402.16415, 2024.
- [20] N. S. Perović and L.-N. Tran, “Mutual information optimization for SIM-based holographic MIMO systems,” arXiv preprint arXiv:2403.18307, 2024.
- [21] X. Lin et al., “All-optical machine learning using diffractive deep neural networks,” Science, vol. 361, no. 6406, pp. 1004–1008, 2018.
- [22] S. Vishwanath et al., “Duality, achievable rates, and sum-rate capacity of gaussian MIMO broadcast channels,” IEEE Transactions on Information Theory, vol. 49, no. 10, pp. 2658–2668, 2003.
- [23] J. Xu and L. Qiu, “Energy efficiency optimization for MIMO broadcast channels,” IEEE Transactions on Wireless Communications, vol. 12, no. 2, pp. 690–701, 2013.
- [24] H. H. M. Tam et al., “Successive convex quadratic programming for quality-of-service management in full-duplex MU-MIMO multicell networks,” IEEE Transactions on Communications, vol. 64, no. 6, pp. 2340–2353, 2016.
- [25] N. S. Perović et al., “On the maximum achievable sum-rate of the ris-aided mimo broadcast channel,” IEEE Transactions on Signal Processing, vol. 70, pp. 6316–6331, 2022.
- [26] X. Zhao et al., “Rethinking WMMSE: Can its complexity scale linearly with the number of BS antennas?” IEEE Transactions on Signal Processing, vol. 71, pp. 433–446, 2023.
- [27] S. He et al., “Coordinated beamforming for energy efficient transmission in multicell multiuser systems,” IEEE Transactions on Communications, vol. 61, no. 12, pp. 4961–4971, 2013.
- [28] J. Wang et al., “Reconfigurable intelligent surface: Power consumption modeling and practical measurement validation,” IEEE Transactions on Communications, 2024, Early Access.
- [29] C. Huang et al., “Reconfigurable intelligent surfaces for energy efficiency in wireless communication,” IEEE Transactions on Wireless Communications, vol. 18, no. 8, pp. 4157–4170, 2019.