End-to-End Learning for Simultaneously Generating Decision Map and Multi-Focus Image Fusion Result
Abstract
The general aim of multi-focus image fusion is to gather focused regions of different images to generate a unique all-in-focus fused image. Deep learning based methods become the mainstream of image fusion by virtue of its powerful feature representation ability. However, most of the existing deep learning structures failed to balance fusion quality and end-to-end implementation convenience. End-to-end decoder design often leads to unrealistic result because of its non-linear mapping mechanism. On the other hand, generating an intermediate decision map achieves better quality for the fused image, but relies on the rectification with empirical post-processing parameter choices. In this work, to handle the requirements of both output image quality and comprehensive simplicity of structure implementation, we propose a cascade network to simultaneously generate decision map and fused result with an end-to-end training procedure. It avoids the dependence on empirical post-processing methods in the inference stage. To improve the fusion quality, we introduce a gradient aware loss function to preserve gradient information in output fused image. In addition, we design a decision calibration strategy to decrease the time consumption in the application of multiple images fusion. Extensive experiments are conducted to compare with 19 different state-of-the-art multi-focus image fusion structures with 6 assessment metrics. The results prove that our designed structure can generally ameliorate the output fused image quality, while implementation efficiency increases over 30% for multiple images fusion.
Introduction
The multi-focus image fusion is an important topic in image processing. The limitation of optical lenses naturally presents that only objects within the depth-of-field (DOF) have a focused and clear appearance in a photograph, while other objects are likely to be blurred. Hence it is difficult for objects at varying distances to all be in focus in one camera shot (Li et al. 2017). Many algorithms have been designed to create an all-in-focus image by fusing multiple source images that capture the same scene with different focus points. The fused image can be used for visualization and further processing, such as object recognition and segmentation.
Deep learning based solutions (Yann, Yoshua, and Geoffrey 2015) are accepted to be the prevailing choice for image fusion by virtue of its powerful feature representation ability. Yu Liu introduced a convolution neural network (CNN) to image fusion and proposed a CNN-Fuse fusion method to recognize which part of the image is in-focus with a supervised deep learning structure (Liu et al. 2017). CNN-Fuse reached a better performance compared to traditional fusion algorithms based on the handcrafted features. Boyuan Ma moved further in applying an unsupervised training strategy to fuse images, termed as SESF-Fuse (Ma et al. 2019). It avoided heavy labeling work for images to train the network.
Although deep learning has reached relatively good performance in multi-focus image fusion, the new problems yielded with complex structure design remain unsolved. There are three questions that deserve higher priorities. 1) The balance between fusion quality and end-to-end implementation convenience. Some structures tried to use a decoder to directly output the final fused result (Huang et al. 2020; Zhang et al. 2020a). However, they did not preserve true pixel values in the source image and hardly achieve good performance in fusing evaluation due to the nonlinear mapping mechanism in the decoder. Some other structures generated intermediate decision map (DM) to reconstruct fused result with high quality (Liu et al. 2017; Xu et al. 2020a). But they relied highly on post-processing method (or consistency verification) choices. These methods require empirical parameters to rectify the DM, resulting in limits the generalization of them to different scenes of image fusion. 2) The gradient feature contains rich beneficial information for multi-focus image fusion. However, it was overlooked in many designs. Some deep learning structures used the l2 and SSIM objective functions to optimize the network (Li and Wu 2019; Ram Prabhakar, Sai Srikar, and Venkatesh Babu 2017). These made the gradient feature completely lost during training procedure. 3) The efficiency in multiple images fusion. Currently, most of the multi-focus fusion structures focus on two images based fusion application. With multiple images fusion, the strategy is to go one by one in serial sequence (Ma et al. 2019). However, the time consumption is scarcely acceptable for big volume image fusion.
In order to counterpoise the requirements of fused image quality and training simplicity, we design a gradient aware cascade structure, termed GACN111The code and data are available at https://github.com/Keep-Passion/GACN. It simultaneously generates decision map and fused result with an end-to-end training procedure. The original pixel values in the source are retained to optimize output fused image bypassing empirical post-processing methods. Furthermore, we modify a commonly used gradient based evaluation metric as the training loss function in order to preserve gradient information. For multiple images fusion, we simplify redundant calculations by proposing a calibration module to acquire the activity levels of all images. It helps to significantly decrease the time consumption. We highlight our contributions as follows:
-
•
We propose a network to simultaneously generate decision map and fused result with an end-to-end training procedure.
-
•
We introduce a gradient aware loss function to preserve gradient information and improve output fusion quality.
-
•
We design a decision calibration strategy for multiple images fusion in order to increase implementation efficiency.
-
•
To prove the feasibility and efficiency of the proposed GACN, we conduct extensive experiments to compare with 19 different state-of-the-art (SOTA) multi-focus image fusion structures with 6 assessment metrics. We implement ablation studies additionally to test the impact of different loss function in our structure. The results prove that our designed structure can generally ameliorate the output fused image quality, and increase implementation efficiency over 30% for multiple images fusion.
Related Work
The existing solutions for multi-focus image fusion can be generalized into two orientations: handcrafted feature based and deep learning based algorithms.
Handcrafted Feature Based Fusion Algorithms
Handcrafted feature based fusion algorithms concentrate on the profound image analysis of transform or spatial domains. Transform domain based algorithms adopt decomposed coefficients from a selected transform domain to measure different activity levels in the input source images, such as laplacian pyramid (LP) (Burt and Adelson 1983) and non-subsampled contourlet transform (NSCT) (Zhang and long Guo 2009). Spatial domain based algorithms measure activity levels with gradient features, such as spatial frequency (Li, Kwok, and Wang 2001), multi-scale weighted gradient (MWG) (Zhou, Li, and Wang 2014), and dense SIFT (DSIFT) (Liu, Liu, and Wang 2015).
Deep Learning Based Fusion Algorithms
Deep learning based algorithms provide prevalent solutions to image fusion problems. CNN-Fuse (Liu et al. 2017) first used a convolutional network to automatically learn features in each patch of image and decided which patch is the clarity region, which achieved better performance compared to handcrafted feature based algorithms. Afterward, some researchers tried to modify the network to improve the fusion quality or efficiency. Han Tang proposed a pixel-wise fusion CNN to further improve the fusion quality (Tang et al. 2018). Dense-Fuse (Li and Wu 2019), U2Fusion (Xu et al. 2020b), and SESF-Fuse (Ma et al. 2019) fused images in the unsupervised training procedure. IFCNN (Zhang et al. 2020b) presented a general image fusion framework to handle different kinds of image fusion tasks. However, there are still other parts of deep learning based algorithm that need to refine.
The output mode is an important module in network designing. Some algorithms tried to use a decoder to directly output the fused result. Hao Zhang (Zhang et al. 2020a) used only one convolutional layer in decoder to fuse multi-scale features and generate fused result. To improve the reconstructive ability, Hyungjoo Jung (H et al. 2020) used residual block to improve the efficiency of gradient propagation, and some works (Huang et al. 2020; Zhang et al. 2021) used generative adversarial network to automatically ameliorate fusion quality. However, due to nonlinear mapping in the decoder, these structures cannot precisely reconstruct fused result. This leads to relatively unrealistic performance in fusion evaluation. Therefore, some structures resorted to generate an intermediate DM, to decide which pixel should appear in fused result. Some works (Liu et al. 2017; Li et al. 2020) used CNN to directly output DM. SESF-Fuse (Ma et al. 2019) used spatial frequency to calculate gradient in deep features and draw out DM. Han Xu (Xu et al. 2020a) used a binary gradient relation map to further ask decoder to preserve gradient information in DM. Despite the highly fusing quality of these structures, they need some post-processing methods (or consistency verification) with empirical parameters to rectify the DM, such as morphology operations (opening and closing calculation) and small region removal strategy, which limits the generalization of the structure to different scenes of image fusion.
The objective function is a key point in structure optimization. In the field of multi-focus image fusion, the gradient in source images is an important factor to decide which part of the image is clear. However, many deep learning structures only used the l2 norm and SSIM objective function to optimize the network (Li and Wu 2019; Ram Prabhakar, Sai Srikar, and Venkatesh Babu 2017), which did not ask the network to preserve the gradient information in fused image. Hyungjoo Jung (H et al. 2020) proposed structure tensor to preserve the overall contrast of images. Jinxing Li (Li et al. 2020) used an edge-preserving loss function to preserve gradient information, but it only considered gradient intensity and not took orientation information into account. In this work, we try to modify the commonly used classical gradient based evaluation metric as the loss function to directly optimize the network to export clearly fused result.
Most applications of multi-focus fusion are based on multiple images. However, almost multi-focus fusion structures concentrated on two images scene and only used one by one serial fusion strategy for multiple images (Liu et al. 2017; Xu et al. 2020b), which has in-acceptable time consumption. To the best of our knowledge, we are the first work to concentrate on the implementation efficiency in multiple images fusion scene.

Method
In this section, we illustrate the details of the main contributions of this work, such as the network structure, the loss function, and the decision calibration strategy.
Network Structure
The overall fusion network structure is shown in Figure 1. It includes two paths of convolutional operations, feature extraction and decision. First, we use the feature extraction path to collect multi-scale deep features of each source image. Second, we take the spatial frequency (SF) module to calculate activity level of each scale. Third, in the decision path, we concate multi-scale activity levels and feed them into some convolutional operations to draw out the initial DM, which records the probability of each pixel should be in-focused in each source image. Then we apply guided filter (He, Sun, and Tang 2013) to smooth the boundary of DM and acquire final DM. Finally, we cascade the fusion module in our structure and generate the fusion result.
Feature Extraction Path
As shown in Figure 1, the feature extraction path is a siamese architecture (Sergey and Nikos 2015), which uses the same architectures with the same weights. It consists of a cascade of four convolutional layers to extract multi-scale deep features from each source image, and uses densely connection architecture to connect the output of each layer to the other layers, which strengthens feature propagation and reduces the number of parameters (Gao et al. 2017; Xu et al. 2020c). To precisely localize the details of the image, there are no pooling layers in our network.
In addition, we use the squeeze and excitation (SE) module after each convolutional layer, which showed good performance at image recognition and segmentation (Jie, Li, and Gang 2018). It can effectively enhance spatial feature encoding by adaptive recalibrating channel-wise or spatial-feature responses. Same with (Ma et al. 2019), we use channel SE module (CSE) (Guha, Nassir, and Christian 2018) in feature extraction path. CSE uses a global average pooling layer to embed the global spatial information in a vector, which passes through two fully connected layers to acquire a new vector. This encodes the channel-wise dependencies, which can be used to recalibrate the original feature map in the channel direction.
After feature extraction, we calculate multi-scale activity levels using the SF module (Ma et al. 2019). Consider two input images and , and a fused image . Let be the deep features drawn from the convolutional layer of each scale. is one feature vector of pixel in source image with coordinates. We calculate its SF by:
| (1) |
| (2) |
| (3) |
where and are respectively the row and column vector frequencies. is the kernel radius and in our work. The original spatial frequency is block-based, while it is pixel-based in our method. We apply the same padding strategy at the borders of feature maps.
We subtract from to obtain activity level maps for each scale. Then we concate multi-scale activity level maps and feed them into the decision path.
Decision Path
In the decision path, we first use four convolutional layers to generate the initial DM, which records the probability () that each pixel () of the source image is more clear than that of the source image . And the initial DM is optimized by loss function with ground truth DM, as shown in the next section.
In addition, we also use the SE module in the decision path. Specifically, we use spatial squeeze and channel excitation (SSE) (Guha, Nassir, and Christian 2018), to enhance the robustness and representatives of deep features. SSE uses a convolutional layer with one kernel to acquire a projection tensor ( in our work). Each unit of the projection refers to the combined representation for all channels at a spatial location and is used to spatially recalibrate the original feature map.
To smooth the boundary of the fused result, we utilize threshold operation to filter the initial DM () and obtain the boundary region. And then we use guided filter (He, Sun, and Tang 2013) to obtain the smooth DM. Finally, we use the boundary region as threshold region to combine the smooth DM and the initial DM to form the final DM. That is the boundary of the final DM is the smooth DM and the center of the final DM is the initial DM. Note that we only use a threshold operation to generate boundary region and do not hinder the backpropagation of network, which means that our structure can be trained by an end-to-end training procedure. In addition, we do not use non-differentiable post-processing methods with empirical parameters, such as morphology operation and small region removal strategy. Then, we cascade a fusion module using the final DM and source images to generate the fused result. As shown in Eq 4, each pixel of fused image () can be obtained by:
| (4) |
where the probability () in DM also means the fusion ratio of each pixel in the source images.
Finally, we use gradient aware loss function to optimize the network to preserve gradient information in fusion result.
In general, the network can simultaneously generate DM and fusion result with end-to-end training procedure.
Loss Function
We define a gradient aware loss function to optimize the network to simultaneously output DM and clear fusion result. The final loss function is defined in Eq 5.
| (5) |
where is a weight to balance the importance between two losses, and in this work.


is a classical loss function in semantic segmentation (Fausto, Nassir, and Seyedahmad 2016), which is defined in Eq 6.
| (6) |
where the sums run over the pixels, of the predicted binary segmentation map and the ground truth map . Adding 1 is to mitigate the gradient vanishing issue.
In addition, we propose to use to optimize the network to export the final clear fused result. In the field of multi-focus image fusion, it is commonly speculated that only objects within the DOF have a sharp appearance in a photograph, while others are likely to be blurred (Liu et al. 2017). However, lots of previous works did not consider preserving gradient information in network training. In this work, we focus on a classical gradient based fusion evaluation metric, or (Xydeas and Petrovic 2000), and make it differentiable as loss function in an end-to-end training procedure. By using this optimization, we lead the network to preserve gradient information in the final fused result.
is an evaluation metric that measures the amount of edge information transferred from input images to the fused image (Xydeas and Petrovic 2000). Consider two input images and , and a fused image . A sobel edge operator is applied to yield the edge strength and orientation of each pixel . Thus, for an input image :
| (7) |
| (8) |
where and are the respective convoluted results with the horizontal and vertical sobel templates.
The relative strength and orientation value between input image A and fused image F are defined as:
| (9) |
| (10) |
Unfortunately, the Heaviside function in Eq 9 and absolute function in Eq 10 are not differentiable and thus cannot be included in training stage. Therefore, we propose to use the sigmoid function as a smooth approximation to the Heaviside function which is defined as:
| (11) |
where controls the steepness of the curve and closeness to the original Heaviside function, larger means closer approximation ( in our work). Then, Eq 9 can be rewritten as Eq 12.
| (12) |
| (13) |
Note that in pytorch implementation (Adam et al. 2019), the gradient of absolute function is 0 when input of that equals 0, which is differentiable. Thus it can use Eq 10 rather than Eq 13 in pytorch. The detailed analysis can be found in the experiment section.
The edge strength and orientation preservation values, respectively, can be derived as:
| (14) |
| (15) |
where the constants , , and , , determine the shapes of the respective sigmoid functions (same with Eq 11) used to form the edge strength and orientation preservation value. Normally, , , , , . The edge information preservation value is then defined as:
| (16) |
The final assessment is obtained from the weighted average of the edge information preservation values:
| (17) |
where and . is a constant, and usually sets = 1.
In total, we modify a gradient based classical fusion evaluation metric () as a loss function to optimize the network to export clearly fused result.
We further show an experiment to visualize the comparison of and , as shown in Figure 2. It is shown that the fusion model trained with have less noise in the decision map compared to the model without it, which means can act as a post-processing method to improve the fusion quality because it can preserve gradient information in the image.
| Methods | Time(s) | ||||||
|---|---|---|---|---|---|---|---|
| GACN | 0.7169 | 0.97769 | 0.8411 | 0.7948 | 0.897806 | 0.4058 | 0.16 |
| MFF-GAN (2021) | 0.5623 | 0.88652 | 0.8210 | 0.6437 | 0.884512 | 0.3699 | 0.33 |
| FusionDN (2020) | 0.5216 | 0.82352 | 0.8209 | 0.6106 | 0.878785 | 0.3050 | 0.49 |
| U2Fusion (2020) | 0.5590 | 0.86993 | 0.8210 | 0.6388 | 0.882694 | 0.3118 | 0.75 |
| IFCNN (2020) | 0.6486 | 0.93751 | 0.8265 | 0.7158 | 0.891569 | 0.3757 | 0.06 |
| PMGI (2020) | 0.4803 | 0.80668 | 0.8209 | 0.5805 | 0.880374 | 0.3527 | 0.21 |
| SESF-Fuse (2019) | 0.7150 | 0.97761 | 0.8397 | 0.7965 | 0.897133 | 0.3953 | 0.30 |
| Dense-Fuse (2019) | 0.5329 | 0.83965 | 0.8239 | 0.6109 | 0.886998 | 0.4046 | 0.38 |
| CNN-Fuse (2017) | 0.7153 | 0.97706 | 0.8396 | 0.7676 | 0.897800 | 0.4079 | 188.16 |
| DSIFT (2015) | 0.5419 | 0.84643 | 0.8255 | 0.6306 | 0.889215 | 0.3900 | 49.28 |
| MWG (2014) | 0.7041 | 0.97720 | 0.8376 | 0.7878 | 0.898504 | 0.3965 | 24.99 |
| Focus-Stack (2013) | 0.5098 | 0.78907 | 0.8276 | 0.6628 | 0.868776 | 0.2332 | 0.19 |
| SR (2010) | 0.6792 | 0.95132 | 0.8326 | 0.7523 | 0.896763 | 0.3924 | 698.44 |
| NSCT (2009) | 0.6721 | 0.94886 | 0.8272 | 0.7326 | 0.896647 | 0.4037 | 19.99 |
| CVT (2007) | 0.6373 | 0.93765 | 0.8252 | 0.7111 | 0.895890 | 0.4055 | 14.76 |
| DTCWT (2007) | 0.6688 | 0.95190 | 0.8267 | 0.7304 | 0.896893 | 0.4031 | 12.21 |
| SF (2001) | 0.5202 | 0.82904 | 0.8239 | 0.6173 | 0.889395 | 0.4145 | 2.25 |
| DWT (1995) | 0.6444 | 0.91346 | 0.8326 | 0.6997 | 0.890219 | 0.3293 | 11.51 |
| RP (1989) | 0.6652 | 0.94001 | 0.8280 | 0.7330 | 0.892010 | 0.3574 | 11.34 |
| LP (1983) | 0.6834 | 0.95369 | 0.8286 | 0.7509 | 0.897242 | 0.3911 | 11.58 |
Decision calibration for multiple images fusion
Most applications of multi-focus fusion are based on multiple images. However, currently almost multi-focus fusion structures concentrated on two images scene and only used one by one serial fusion strategy for multiple images fusion. As shown at the top of Figure 3, one-by-one serial strategy needs to run times feature extraction paths and times decision paths, where is the number of the source images. In this work, we propose a decision calibration strategy, which shown at the bottom of Figure 3. It only needs to run times feature extraction paths and times decision paths by using the calibration module, which can generally decrease time consumption.
In the decision calibration strategy, the first image is used as baseline, and feeds it to the structure with other images. Thus, we can save the parameters of the first image in the feature extraction path and avoid repeating computation. Then it uses final DMs drawn from each decision path to calculate the decision volume (DV), which records the activity levels of all the source images. The calculation process is acting as normalization to draw out relative clarity of each source images, which is shown below:
| (18) |
where , is the index of the source image and is the value of pixel in final DM when fuses the source image and the source image .
Then, we choose the index of maximum in for each pixel as the index of the most clarity pixel in the source images. According to the above indices, we can obtain the entire resulting fusion image.
It is important to notice that the decision calibration strategy can only applied to the DM based network structure without the empirical post-processing methods. Because those empirical post-processing methods, such as morphology operation and small region removal strategy, which used in CNN-Fuse (Liu et al. 2017) and SESF-Fuse (Ma et al. 2019), firstly require to convert the initial DM to the binary DM, which loss the relative clarity information and can not be used in the process of decision volume calculation. Our method, GACN, can draw out the decision map without the empirical post-processing methods, which is more suited to the decision calibration strategy in the application of multiple images fusion.
Experiment
Dataset
Training set
In this paper, we generate multi-focus image data based on MS COCO dataset (Lin et al. 2014). The MS COCO dataset contains annotations for instance segmentation, and our method uses the original image and its segmentation annotation to generate multi-focus image data. That is, we use annotation as threshold region to decide which part of the image should be filtered by gaussian blurring. As shown in Figure 4, the original image ’truck’ and its annotation are obtained by MS COCO. We use gaussian filter to blur the background to form near-focused image and blur the foreground form far-focused image. And we use the defocused spread effect model proposed in (Ma et al. 2020) to further improve the realness of the generated data. Thus we have two inputs of multi-focus images, one ground truth fused result (original image) and one decision map (label) for network training. Because some data in MS COCO dataset contains multiple instances that are not at the same depth-of-field (DOF), so we only select images that contain one instance. Besides, we regard the multi-focus image fusion problem as an image segmentation problem. The imbalance of the foreground and background category often affects the segmentation results, so we further select the image with the foreground size between 20,000 and 170,000 pixels as the training data. Finally, we obtain 5786 images and divide these into training set and validation set according to the ratio of 7:3.

Testing set
Training Procedure
During training, all images were transformed to gray-scale and resized to , then random cropped to . Note that images were gray-scale in the training phase, while images for testing can be gray-scale or color images with RGB channels. For color images that needed to be fused, we transformed the images to gray-scale and calculated a decision map to fuse them. In addition, we used random crop, random blur, random offset, and gaussian noise as data augmentation methods. The initial learning rate was , and this was decreased by a factor of 0.8 at every two epochs. We optimized the objective function by Adam (Kingma and Ba 2015). The batch size and number of epochs were 16 and 50, respectively. Our implementation was derived from the publicly available Pytorch framework (Adam et al. 2019). The network’s training and testing were performed on a station using an NVIDIA Tesla V100 GPU with 32 GB memory.
Evaluation Metrics
We use six classical fusion metrics: (Xydeas and Petrovic 2000), (Yang et al. 2008), (Qiang, Yi, and Jing 2008), (Chen and Blum 2009), and (Haghighat, Aghagolzadeh, and Seyedarabi 2011) to evaluate the quality of fused result. evaluates the amount of edge information transferred from input images to the fused image. calculates the similarity between fused image and the sources(Yang et al. 2008). measures the nonlinear correlation information entropy between the input images and the fused image (Qiang, Yi, and Jing 2008). is a perceptual quality measure for image fusion, which employs the major features in a human visual system model (Chen and Blum 2009). and calculates the mutual information of the edge features and discrete cosine transform feature between the input images and the fused image (Haghighat, Aghagolzadeh, and Seyedarabi 2011). A larger value of any of the above six metrics indicates better fusion performance. For fair comparison, we use appropriate default parameters for these metrics, and all codes are derived from their public resources (Liu 2012; Mohammad and Amirkabiri 2014).
Comparison
To demonstrate the performance of our method, we compare it with recent SOTA fusion methods in objective and subjective assessments.
Objective Assessment
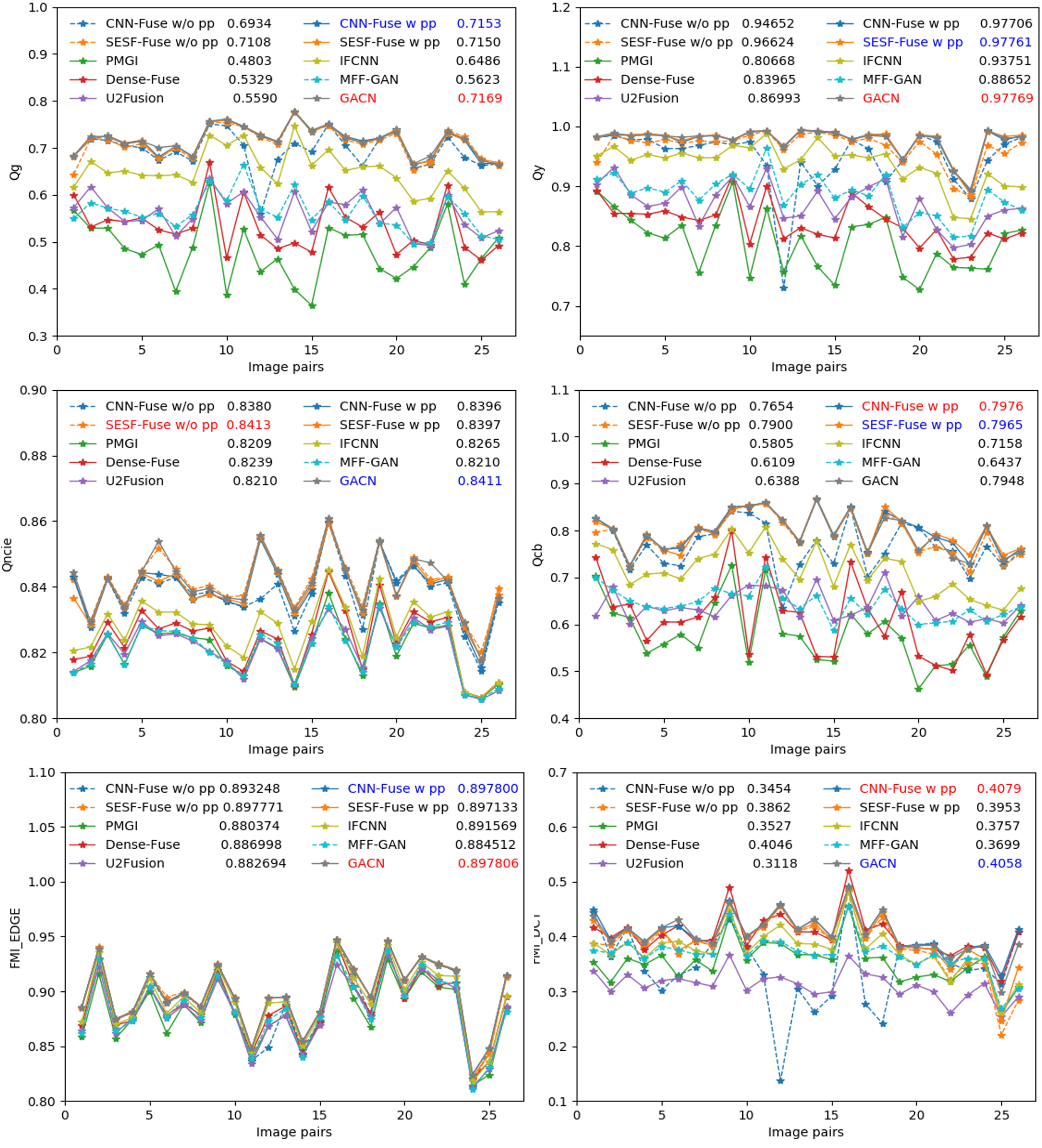
The comparison of our method with existing multi-focus fusion methods are listed in Table 1, such as MFF-GAN (Zhang et al. 2021), FusionDN (Xu et al. 2020c), U2Fusion (Xu et al. 2020b), IFCNN (Zhang et al. 2020b), PMGI (Zhang et al. 2020a), SESF-Fuse (Ma et al. 2019), Dense-Fuse (Li and Wu 2019), CNN-Fuse (Liu et al. 2017), dense SIFT (DSIFT) (Liu, Liu, and Wang 2015), multi-scale weighted gradient (MWG) (Zhou, Li, and Wang 2014), Focus-Stack (Andrew 2013), sparse representation (SR) (Yang and Li 2010), non-subsampled contourlet transform (NSCT) (Zhang and long Guo 2009), curvelet transform (CVT) (Nencini et al. 2007), dual-tree complex wavelet transform (DTCWT) (Lewis et al. 2007), spatial frequency (SF) (Li, Kwok, and Wang 2001), discrete wavelet transform (DWT) (Li, Manjunath, and Mitra 1995), ratio of low-pass pyramid (RP) (Toet 1989), and Laplacian pyramid (LP) (Burt and Adelson 1983). Specifically, we further show detailed comparison of each image pair with nine SOTA deep learning based methods in Figure 5. With two of them are DM based methods (CNN-Fuse and SESF-Fuse), and six of them are decoder based methods (MFF-GAN, FusionDN, U2Fusion, DenseFuse, IFCNN and PMGI). In addition, for CNN-Fuse and SESF-Fuse, we also compare different versions of whether to use post-processing (pp) methods (or consistency verification) with empirical parameters. According to experiment, DM based algorithms generate an intermediate decision map to decide which pixel should appear in the fused result, which can precisely preserve true pixel values of the source image. And decoder based algorithms directly use a decoder to draw out the fused result and cannot preserve true pixel values because of the nonlinear mapping mechanism in the decoder. Therefore, DM based algorithms achieve high performance in objective assessments, while decoder based algorithms show unrealistic performance. In addition, DM based algorithms rely on post-processing methods to rectify DM, so the performance will degrade if we remove it. Our algorithm, GACN can simultaneously generate decision map and fused result with end-to-end training procedure, and gradient information can be preserved by the gradient loss function. Our method, achieves robust promising performance compared to above traditional methods.
In addition, the run times of different fusion methods per image pair on the test set are listed in Table 1. Such methods as GACN, MFF-GAN, FusionDN, U2Fusion, IFCNN, PMGI, SESF-Fuse, CNN-Fuse, and DenseFuse are tested on a GTX 1080Ti GPU, and others on an E5-2620 CPU. GACN achieves an average running time of 0.16 second, which is faster than most of the methods and can be applied to actual application. Although the IFCNN is faster than GACN, it achieves lower fusion quality compared to GACN.


Subjective Assessment
We show some visualization results of GACN and other SOTA methods, DM based and decoder based methods, respectively. Firstly, we present the decision maps of GACN with some classical DM based methods (CNN-Fuse and SESF-Fuse) in Figure 6. The influence of post processing method is shown in detail. According to the experiment, the SESF-Fuse and CNN-Fuse require post-processing methods with empirical parameters, such as morphology operation and small size removal strategy, to eliminate noise. If we remove these post processing methods, there will be some artifacts that appear on the results, such as blob noisy in the decision map. Besides, the threshold of kernel size in morphology operation and region removal strategy are empirical parameters which hard to adjust. While our method GACN can draw out good decision map without post-processing methods.
Secondly, we demonstrate the fusion results and difference images of GACN with some classical decoder based methods (Dense-Fuse, PMGI, FusionDN, U2Fusion and MFF-GAN) in Figure 7. The red rectangles and their magnified regions (shown in upper right of the figure) denote the detailed fusion results of different methods. It is shown that there is artifact area at the border of near-focused and far-focused regions for the classical decoder based methods. While GACN shows clear result. The difference image is obtained by subtracting the near-focused image from the fusion result, which is normalized to the range of 0 to 1 for visualization. If the near-focused region is completely detected, the difference image will not show any of its information. Decoder based methods cannot precisely recover the true pixel values in fusion result due to the nonlinear mapping mechanism in the decoder. Therefore most of them have clear contour information in the near-focused region on the difference images. Besides, there is some color distortion in the fusion result of PMGI. And the fusion result of DenseFuse is more blurred than other methods. Fortunately, our method, GACN, achieves robust promising fusing performance on all examples.
Ablation Study
We evaluate our method with different settings to verify the contribution of each module.
Loss Function Study
We first conducted an experiment to figure out which metric is more suitable for evaluation of quality of multi-focus image fusion. We introduce Gaussian blurring with different standard deviations to the fusion result of the testing set. As shown in Figure 8, with the increase of standard deviation of Gaussian kernel, the metric degenerates most obviously compared to other metrics. It is shown that the metric can better reflect the clarity of the fusion result, which means that metric is beneficial to be the loss function for model training.

In addition, we compared the performance of the different combinations of mask-based and gradient-based loss functions to verify the contribution of proposed loss functions, shown in Figure 9. The mask based loss functions include (Fausto, Nassir, and Seyedahmad 2016), (Tsung-Yi et al. 2017), and (Saining and Zhuowen 2015). While gradient-based loss functions include , (Li et al. 2020), and (H et al. 2020). denotes balanced cross entropy which is a classical loss function in image segmentation (Saining and Zhuowen 2015), which can eliminate the impact of imbalance pixels in the foreground and background. denotes focal loss (Tsung-Yi et al. 2017), which leads the network to focus on and correctly detect hard examples. Where refers to edge-preserving loss and ST means structure tensor loss. For the last two losses, we conducted an experiment and pick the best performance with to balance the importance with . According to the experiment, we noted that the performance of the combination of and outperforms other loss settings in most the metrics, which means that the above two losses will both lead the network to export promising fusing result. Besides, we find that is better than , and , which means that can precisely recognize the decision map. And is better than , and , which means that can better lead the structure to preserve gradient information in the fused result.


Differentiation Study
We compared the performance of the absolute function and the smooth approximation for angle calculation (Eq. 10) in in Table 2. We found that directly using the absolute function is a little better than the smooth approximation by using pytorch framework, which might be the reason for the gradient vanish in the sigmoid calculation.
| Settings | |||
|---|---|---|---|
| Abs | 0.7169 | 0.9776 | 0.8411 |
| Smooth | 0.7162 | 0.9773 | 0.8410 |
| Settings | |||
| Abs | 0.7948 | 0.8978 | 0.4058 |
| Smooth | 0.7952 | 0.8977 | 0.4048 |
Multiple images fusion with multi-focus
The example of multiple images fusion is shown in Table 3 and Figure 10. The microscopic image ’chip’ (with the size of ) was obtained by a microscope that took pictures with lots of different focus points. Decision calibration for ’chip’ images fusion can actually increase execution efficiency by about 30.65% compared to one-by-one serial strategy (0.7138’s to 0.4905’s for each image by using GACN), which is more feasible for industrial application. And the same increase of efficiency can also be found in CNN-Fuse and SESF-Fuse, which means that the decision calibration can be applied to other networks. Note that for decision calibration, we deleted the post-processing operations of DM in CNN-Fuse and SESF-Fuse for fair comparison.
The visualization of fusion result of GACN is more clear than that of CNN-Fuse and SESF-Fuse whether in decision calibration or serial strategy. In the future work, we try to eliminate the impact of defocused spread effect for multi-focus image fusion.
| Runtime(s) | One by one serial | Decision calibration |
|---|---|---|
| CNN-Fuse | 886.6872 | 687.5352 |
| SESF-Fuse | 1.1880 | 0.5293 |
| GACN | 0.7138 | 0.4905 |
Conclusion
In this work, we propose a network to simultaneously generate decision map and fused result with an end-to-end training procedure. It avoids utilizing empirical post-processing methods in the inference stage. Besides we introduce a gradient aware loss function to lead the network to preserve gradient information. Also we design a decision calibration strategy to fuse multiple images, which can increase implementation efficiency. Extensive experiments are conducted to compare with existing SOTA multi-focus image fusion structures, which shows that our designed structure can generally ameliorate the output fused image quality for multi-focus images, and increase implementation efficiency over 30% for multiple images fusion. We will further improve the fusion performance of multiple images fusion in future work.
Acknowledgments
The authors would like to thank professor Jiayi Ma of Wuhan University for the advice about the visualization of subjective assessment. In addition, we thank Zhuhai Boming Vision Technology Co., Ltd by providing the dataset of multiple images fusion. The computing work is supported by USTB MatCom of Beijing Advanced Innovation Center for Materials Genome Engineering.
References
- Adam et al. (2019) Adam, P.; Sam, G.; Francisco, M.; Adam, L.; James, B.; Gregory, C.; Trevor, K.; Zeming, L.; Natalia, G.; and Luca, A. 2019. Pytorch: An imperative style, high-performance deep learning library. In Advances in neural information processing systems, 8026–8037.
- Andrew (2013) Andrew, C. 2013. Focus Stacking Made Easy with Photoshop. https://github.com/cmcguinness/focusstack.
- Burt and Adelson (1983) Burt, P.; and Adelson, E. 1983. The Laplacian Pyramid as a Compact Image Code. IEEE Transactions on Communications 31(4): 532–540. ISSN 0090-6778. doi:10.1109/TCOM.1983.1095851.
- Chen and Blum (2009) Chen, Y.; and Blum, R. S. 2009. A new automated quality assessment algorithm for image fusion. Image and Vision Computing 27(10): 1421 – 1432. ISSN 0262-8856. doi:https://doi.org/10.1016/j.imavis.2007.12.002.
- Fausto, Nassir, and Seyedahmad (2016) Fausto, M.; Nassir, N.; and Seyedahmad, A. 2016. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In International Conference on 3D Vision, 565–571.
- Gao et al. (2017) Gao, H.; Zhuang, L.; Laurens, V. D. M.; and Q, W. K. 2017. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, 4700–4708.
- Guha, Nassir, and Christian (2018) Guha, R. A.; Nassir, N.; and Christian, W. 2018. Concurrent spatial and channel squeeze and excitation in fully convolutional networks. In International Conference on Medical Image Computing and Computer-Assisted Intervention, 421–429. Springer.
- H et al. (2020) H, J.; Y, K.; H, J.; N, H.; and Sohn. 2020. Unsupervised Deep Image Fusion With Structure Tensor Representations. IEEE Transactions on Image Processing 29: 3845–3858.
- Haghighat, Aghagolzadeh, and Seyedarabi (2011) Haghighat, M. B. A.; Aghagolzadeh, A.; and Seyedarabi, H. 2011. A non-reference image fusion metric based on mutual information of image features. Computers and Electrical Engineering 37(5): 744 – 756. ISSN 0045-7906. doi:https://doi.org/10.1016/j.compeleceng.2011.07.012.
- He, Sun, and Tang (2013) He, K.; Sun, J.; and Tang, X. 2013. Guided Image Filtering. IEEE Transactions on Pattern Analysis and Machine Intelligence 35(6): 1397–1409. ISSN 0162-8828. doi:10.1109/TPAMI.2012.213.
- Huang et al. (2020) Huang, J. H.; Le, Z.; Ma, Y. T.; Mei, X.; and Fan, F. 2020. A generative adversarial network with adaptive constraints for multi-focus image fusion. Neural Computing and Applications 1–11.
- Jie, Li, and Gang (2018) Jie, H.; Li, S.; and Gang, S. 2018. Squeeze-and-Excitation Networks. In The IEEE Conference on Computer Vision and Pattern Recognition, 7132–7141.
- Kingma and Ba (2015) Kingma, D. P.; and Ba, J. 2015. Adam: A Method for Stochastic Optimization. In International Conference on Learning Representations, 1–15.
- Lewis et al. (2007) Lewis, J. J.; O’Callaghan, R. J.; Nikolov, S. G.; Bull, D. R.; and Canagarajah, N. 2007. Pixel- and region-based image fusion with complex wavelets. Information Fusion 8(2): 119 – 130. ISSN 1566-2535. doi:https://doi.org/10.1016/j.inffus.2005.09.006.
- Li, Manjunath, and Mitra (1995) Li, H.; Manjunath, B.; and Mitra, S. 1995. Multisensor Image Fusion Using the Wavelet Transform. Graphical Models and Image Processing 57(3): 235 – 245. ISSN 1077-3169. doi:https://doi.org/10.1006/gmip.1995.1022.
- Li and Wu (2019) Li, H.; and Wu, X. 2019. DenseFuse: A Fusion Approach to Infrared and Visible Images. IEEE Transactions on Image Processing 28: 2614–2623.
- Li et al. (2020) Li, J.; Guo, X.; Lu, G.; Zhang, B.; Xu, Y.; Wu, F.; and Zhang, D. 2020. DRPL: Deep Regression Pair Learning for Multi-Focus Image Fusion. IEEE Transactions on Image Processing 29: 4816–4831.
- Li et al. (2017) Li, S.; Kang, X.; Fang, L.; Hu, J.; and Yin, H. 2017. Pixel-level image fusion: A survey of the state of the art. Information Fusion 33: 100 – 112. ISSN 1566-2535. doi:https://doi.org/10.1016/j.inffus.2016.05.004.
- Li, Kwok, and Wang (2001) Li, S.; Kwok, J. T.; and Wang, Y. 2001. Combination of images with diverse focuses using the spatial frequency. Information Fusion 2(3): 169 – 176. ISSN 1566-2535. doi:https://doi.org/10.1016/S1566-2535(01)00038-0.
- Lin et al. (2014) Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; and Zitnick, C. L. 2014. Microsoft coco: Common objects in context. In European conference on computer vision, 740–755. Springer.
- Liu et al. (2017) Liu, Y.; Chen, X.; Peng, H.; and Wang, Z. 2017. Multi-focus image fusion with a deep convolutional neural network. Information Fusion 36: 191 – 207. ISSN 1566-2535. doi:https://doi.org/10.1016/j.inffus.2016.12.001.
- Liu, Liu, and Wang (2015) Liu, Y.; Liu, S.; and Wang, Z. 2015. Multi-focus image fusion with dense SIFT. Information Fusion 23: 139 – 155. ISSN 1566-2535. doi:https://doi.org/10.1016/j.inffus.2014.05.004.
- Liu (2012) Liu, Z. 2012. Image Fusion Metrics. https://github.com/zhengliu6699/imageFusionMetrics.
- Ma et al. (2019) Ma, B.; Zhu, Y.; Yin, X.; Ban, X.; and Huang, H. 2019. SESF-Fuse: An Unsupervised Deep Model for Multi-Focus Image Fusion. arXiv .
- Ma et al. (2020) Ma, H.; Liao, Q.; Zhang, J.; Liu, S.; and Xue, J. H. 2020. An -matte boundary defocus model-based cascaded network for multi-focus image fusion. IEEE Transactions on Image Processing 29: 8668–8679.
- Mohammad and Amirkabiri (2014) Mohammad, H.; and Amirkabiri, R. M. 2014. Fast-FMI: non-reference image fusion metric. In 2014 IEEE 8th International Conference on Application of Information and Communication Technologies, 1–3. IEEE.
- Nejati, Samavi, and Shirani (2015) Nejati, M.; Samavi, S.; and Shirani, S. 2015. Multi-focus image fusion using dictionary-based sparse representation. Information Fusion 25: 72 – 84. ISSN 1566-2535. doi:https://doi.org/10.1016/j.inffus.2014.10.004.
- Nencini et al. (2007) Nencini, F.; Garzelli, A.; Baronti, S.; and Alparone, L. 2007. Remote sensing image fusion using the curvelet transform. Information Fusion 8(2): 143 – 156. ISSN 1566-2535. doi:https://doi.org/10.1016/j.inffus.2006.02.001.
- Qiang, Yi, and Jing (2008) Qiang, W.; Yi, S.; and Jing, J. 2008. Performance evaluation of image fusion techniques. Image fusion: algorithms and applications 19: 469–492.
- Ram Prabhakar, Sai Srikar, and Venkatesh Babu (2017) Ram Prabhakar, K.; Sai Srikar, V.; and Venkatesh Babu, R. 2017. DeepFuse: A Deep Unsupervised Approach for Exposure Fusion With Extreme Exposure Image Pairs. In Proceedings of the IEEE international conference on computer vision, 4714–4722.
- Saining and Zhuowen (2015) Saining, X.; and Zhuowen, T. 2015. Holistically-nested edge detection. In Proceedings of the IEEE international conference on computer vision, 1395–1403.
- Savić and Babić (2012) Savić, S.; and Babić, Z. 2012. Multifocus image fusion based on empirical mode decomposition. In 19th IEEE International Conference on Systems, Signals and Image Processing, 91–94.
- Sergey and Nikos (2015) Sergey, Z.; and Nikos, K. 2015. Learning to compare image patches via convolutional neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, 4353–4361.
- Tang et al. (2018) Tang, H.; Xiao, B.; Li, W.; and Wang, G. 2018. Pixel Convolutional Neural Network for Multi-Focus Image Fusion. Information Sciences 125–141. doi:https://doi.org/10.1016/j.ins.2017.12.043.
- Toet (1989) Toet, A. 1989. Image fusion by a ratio of low-pass pyramid. Pattern Recognition Letters 9(4): 245 – 253. ISSN 0167-8655. doi:https://doi.org/10.1016/0167-8655(89)90003-2.
- Tsung-Yi et al. (2017) Tsung-Yi, L.; Priya, G.; Ross, G.; Kaiming, H.; and Piotr, D. 2017. Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision, 2980–2988.
- Xu et al. (2020a) Xu, H.; Fan, F.; Zhang, H.; Le, Z.; and Huang, J. 2020a. A Deep Model for Multi-Focus Image Fusion Based on Gradients and Connected Regions. IEEE Access 8: 26316–26327.
- Xu et al. (2020b) Xu, H.; Ma, J.; Jiang, J.; Guo, X.; and Ling, H. 2020b. U2Fusion: A Unified Unsupervised Image Fusion Network. IEEE Transactions on Pattern Analysis and Machine Intelligence .
- Xu et al. (2020c) Xu, H.; Ma, J.; Le, Z.; Jiang, J.; and Guo, X. 2020c. Fusiondn: A unified densely connected network for image fusion. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, 12484–12491.
- Xydeas and Petrovic (2000) Xydeas, C. S.; and Petrovic, V. 2000. Objective image fusion performance measure. Electronics Letters 36(4): 308–309. ISSN 0013-5194. doi:10.1049/el:20000267.
- Yang and Li (2010) Yang, B.; and Li. 2010. Multifocus Image Fusion and Restoration With Sparse Representation. IEEE Transactions on Instrumentation and Measurement 59(4): 884–892. ISSN 0018-9456. doi:10.1109/TIM.2009.2026612.
- Yang et al. (2008) Yang, C.; Zhang, J. Q.; Wang, X. R.; and Liu, X. 2008. A novel similarity based quality metric for image fusion. Information Fusion 9(2): 156–160.
- Yann, Yoshua, and Geoffrey (2015) Yann, L.; Yoshua, B.; and Geoffrey, H. 2015. Deep learning. Nature 521(7553): 436–444.
- Zhang et al. (2021) Zhang, H.; Le, Z.; Shao, Z.; Xu, H.; and Ma, J. 2021. MFF-GAN: An unsupervised generative adversarial network with adaptive and gradient joint constraints for multi-focus image fusion. Information Fusion 66: 40 – 53. ISSN 1566-2535. doi:https://doi.org/10.1016/j.inffus.2020.08.022.
- Zhang et al. (2020a) Zhang, H.; Xu, H.; Xiao, Y.; Guo, X.; and Ma, J. 2020a. Rethinking the image fusion: A fast unified image fusion network based on proportional maintenance of gradient and intensity. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, 12797–12804.
- Zhang and long Guo (2009) Zhang, Q.; and long Guo, B. 2009. Multifocus image fusion using the nonsubsampled contourlet transform. Signal Processing 89(7): 1334 – 1346. ISSN 0165-1684. doi:https://doi.org/10.1016/j.sigpro.2009.01.012.
- Zhang et al. (2020b) Zhang, Y.; Liu, Y.; Sun, P.; Yan, H.; Zhao, X.; and Zhang, L. 2020b. IFCNN: A general image fusion framework based on convolutional neural network. Information Fusion 54: 99–118.
- Zhou, Li, and Wang (2014) Zhou, Z.; Li, S.; and Wang, B. 2014. Multi-scale weighted gradient-based fusion for multi-focus images. Information Fusion 20: 60 – 72. ISSN 1566-2535. doi:https://doi.org/10.1016/j.inffus.2013.11.005.