Enabling Practical Transparent Checkpointing for MPI:
A Topological Sort Approach
Abstract
MPI is the de facto standard for parallel computing on a cluster of computers. Checkpointing is an important component in any strategy for software resilience and for long-running jobs that must be executed by chaining together time-bounded resource allocations. This work solves an old problem: a practical and general algorithm for transparent checkpointing of MPI that is both efficient and compatible with most of the latest network software. Transparent checkpointing is attractive due to its generality and ease of use for most MPI application developers. Earlier efforts at transparent checkpointing for MPI, one decade ago, had two difficult problems: (i) by relying on a specific MPI implementation tied to a specific network technology; and (ii) by failing to demonstrate sufficiently low runtime overhead.
Problem (i) (network dependence) was already solved in 2019 by MANA’s introduction of split processes. Problem (ii) (efficient runtime overhead) is solved in this work. This paper introduces an approach that avoids these limitations, employing a novel topological sort to algorithmically determine a safe future synchronization point. The algorithm is valid for both blocking and non-blocking collective communication in MPI. We demonstrate the efficacy and scalability of our approach through both micro-benchmarks and a set of five real-world MPI applications, notably including the widely used VASP (Vienna Ab Initio Simulation Package), which is responsible for 11% of the workload on the Perlmutter supercomputer at Lawrence Berkley National Laboratory. VASP was previously cited as a special challenge for checkpointing, in part due to its multi-algorithm codes.
1 Introduction
MPI is a de facto standard for multi-node computing in modern HPC sites. Checkpointing of MPI applications has become essential for long-running computations, due to concerns for software resilience, and especially for chaining of resource allocations. Because of reasons of system maintenance (both scheduled and unscheduled), a single resource allocation has a maximum time limit, such as 48 hours.
This work demonstrates a collective clock (CC) algorithm for topological sorting. This represents the first algorithm that can efficiently and transparently checkpoint MPI applications under the newest network architectures. The work relies on the split-process approach originally introduced with the original MANA prototype (MPI-Agnostic, Network-Agnostic checkpointing) [2]. This work demonstrates for the first time a novel algorithm that achieves low runtime overhead, while supporting the newest network interconnects. This is in contrast with MANA, which had a fatal flaw in terms of runtime overhead, when applied to codes making intensive use of MPI collective operations (e.g., MPI_Barrier, MPI_Bcast).
This work showcases the application VASP (Vienna Ab Initio Simulation Package) [3]. On Perlmutter, the #14 supercomputer in the world [4], VASP is responsible for 11% of the CPU cycles [5].
VASP was cited as a future challenge for low-overead transparent checkpointing, in a 2021 study [1, Section IV-B]. As seen in Table II of Section Section IV-B of the study, the VASP workload CaPOH with 4 nodes (128 MPI processes) was shown to incur a runtime overhead of 40% (35 seconds runtime with MANA versus 25 seconds for running VASP natively). That study was run on the Cori supercomputer, a predecessor to the current Perlmutter at NERSC.
The importance of low-overhead transparent checkpointing for VASP is explained by its heavy dependence on FFTs. Efficient FFTs depend heavily on low-latency networks. As VASP runs on more nodes (e.g., above 4 nodes), the workload efficiency degrades, due to a greater fraction of inter-process communication being across the network to a different node. Hence, long-running VASP sessions prefer to run on a small number of nodes, and compensate for the fewer nodes by running for a long time, using chaining of resource allocations through checkpoint-restart. This reliance of VASP on FFRs was confirmed by randomly stopping the computation under GDB, and observing the process stack.
To place transparent checkpointing in perspective, there exist two broad alternatives for checkpointing for MPI:
-
1.
transparent checkpointing; and
-
2.
application-level checkpointing.
The alternative of application-level checkpointing [6, 7, 8, 9, 10] tends to be used on large codes that are memory-bound (that use most of the RAM on a node). In contrast, transparent checkpointing is attractive for the remaining CPU-bound MPI codes, due to its generality and ease-of-use. Unlike the appliction-level case, in transparent checkpointing MPI application, the binary does not have to be modified, re-compiled, or re-linked.
Nevertheless, transparent checkpointing for MPI faced two fundamental obstacles:
-
1.
network dependence: later MPI implementation used newer network interconnects; and
-
2.
runtime overhead: unacceptably high runtime overhead.
Historically, a decade was spent unsuccessfully attempting production-quality, transparent checkpointing in the 2000s and early 2010s [11, 12, 13, 14, 15]. Those activities were primarily targeted toward the dominant network at that time: OFED InfiniBand. Those attempts eventually foundered on the proliferation of newer HPC networks: HDR Mellanox InfiniBand, Cray GNI, Intel Omni-Path, HPE Slingshot-10, and HPE Slingshot-11. In these cases, the earlier approach was abandoned in the face of HPC sites upgrading to newer network interconnects.
After an intervening decade, the first fundamental obstacle (network dependence) was solved by the split process technique, introduced by MANA [2]. The MPI application and the underlying MPI library (and associated network library) were considered as independent programs. They were loaded independently into a single process. The MPI application was compiled with MPI wrapper functions, which were bound at runtime to the MPI library of the second program. At checkpoint time, only the MPI application program was checkpointed. At restart time, the second program (MPI library and network) was loaded, and then at runtime, it determined its own MPI rank in the world communicator, and then loaded the checkpointing image of the MPI application for the given rank.
As discussed in [1], while the transparent checkpointing approach had successfully been brought back to life, there remained the fundamental problem of high runtime overhead. The second problem appeared primarily in MPI codes that intensively called MPI collective operations.
In particular, the high runtime overhead of VASP remained a challenging problem for checkpointing. This heavy reliance of VASP on MPI collective operations is seen in Figure 4 of [1, Section IV-B]: The number of collective MPI operations per second rises drastically, from 4,800 collective operations per second for 128 MPI processes to 7,000 collective operations per second for 256 MPI processes).
This work solves the second fundamental problem, high runtime overhead. The novel collective clock (CC) algorithm uses multiple sequence numbers to track, for each MPI group, how many collective calls have been iterated so far. Incrementing a sequence number for the MPI group of an MPI collective operation does not require network communication, and is inherently low overhead (see the micro-benchmarks in Figures 5 and 6). In the micro-benchmarks and five real-world applications, the typical runtime overhead is from 0% to 5%.
This enhancement of MANA is open source. It can currently be found at [16], and will soon replace the current main branch of MANA [17]. The core of the CC algorithm in the new branch can be found in the file seq_num.cpp.
Reducing runtime overhead for transparent checkpointing has become especially important in the most recent generation of very high performance network interconnects. For example, a modern interconnect like HPE Slingshot-11 on the Perlmutter supercomputer enables up to a quarter of a million collective calls per second (see Table 1; OSU micro-benchmark running on four computer nodes). Earlier supercomputer (and therefore earlier MPI codes) used earlier network interconnects such as Ethernet and OFED InfiniBand, and so did not experience such high rates of collective calls. Therefore, since communication efficiency was not under stress, earlier MPI codes tended to prefer the simpler point-to-point communication calls of MPI, and made only limited use of collective communication.
Newer or revised MPI applications are intended to run on newer network interconnects, and therefore tend to require the more efficient CC algorithm for reduced runtime overhead. Table 1 of Section 5 shows the rate of collective communication calls per second across a variety of applications.
1.1 Points of Novelty
This work introduces a new collective-clock algorithm for checkpointing MPI. The central points of novelty are:
-
1.
a novel topoligical sort algorithm for collective communication;
-
2.
the first transparent checkpointing algorithm that supports MPI’s non-blocking collective operations, needed for overlapping computation and communication (Section 4.3); and
-
3.
an implementation of transparent checkpointing for MPI that avoids the high runtime overhead of Garg et al. [2], which had inserted an additional MPI_Barrier in front of each collective operation.
1.2 Organization of Paper
The organization of this work is as follows. Section 2 provides brief background on MPI itself and the split-process architecture that forms the basis for MANA to checkpoint MPI. Section 3 reviews some essential points in the semantics of MPI. Section 4 presents a novel collective-clock (CC) algorithm, which replaces MANA’s original two-phase-commit algorithm. Section 5 provides an experimental evaluation. Section 6 discusses the related work, and Section 7 presents a conclusion.
2 Background
Section 2.1 reviews basic concepts for MPI itself, while Section 2.2 reviews the split process mechanism that is the basis for the MANA architecture. The CC algorithm described here replaces the original two-phase-commit algorithm that was introduced in the original MANA paper [2].
2.1 Review of MPI
Each MPI process has a unique rank as an MPI-specific process id in a given communicator. MPI provides point-to-point operations on the ranks, such as MPI_Send and MPI_Recv. MPI also provides collective operations. Examples include MPI_Barrier, MPI_Bcast, MPI_Alltoall, etc. A collective MPI operation is executed in parallel by a subset of the MPI processes. In this case, each member of the subset of processes for that operation must individually make a corresponding MPI call, to successfully invoke the parallel operation.
The subset of MPI processes participating in an operation is referred to as an MPI group. An MPI_Communicator can be created from an MPI group. Creating a communicator is a parallel operation in which each participating process receives a handle to a common communicator representation, shared by all participating processes. For a single MPI collective operation, all participating processes must call the same MPI collective function with the same MPI communicator.
An initial communicator MPI_COMM_WORLD includes all the MPI processes. Each new group numbers its processes consecutively, beginning with rank 0. MPI_Group_translate_ranks is available to determine the rank of a process within a new group, as compared to a previous group.
Finally, MPI also defines non-blocking variants, such as MPI_Isend, MPI_Irecv, MPI_Ibcast, MPI_Ibarrier and MPI_Ialltoall. The variants have an additional argument, a pointer to an MPI request object. and does not block.
A non-blocking call first initiates the MPI operation. Then non-blocking call immediately sets the request object and returns. MPI may or may not immediately begin executing the operation, depending on the implementation. This enables overlap of communication and computation.
An individual MPI process tests if its part in the operation is locally complete by calling MPI_Test, MPI_Wait, or a related call. The calls to test for completion include both the MPI request and a completion flag argument. The current process has completed its part in the operation if the flag is set to true. The request object is then modified in place to set its value to the pseudo-request MPI_REQUEST_NULL.
2.2 MANA’s Split Process Software Architecture and Checkpointing

The current work adopts MANA’s split process architecture, which is illustrated in Figure 1. The split process architecture was introduced with MANA (MPI-Agnostic Network-Agnostic transparent checkpointing) [2]. Two programs are loaded into a single memory space. The upper half contains the MPI application and a library of wrapper “stub” functions that redirect MPI calls to the lower half. The lower half contains a proxy program that is linked with network and MPI libraries. On restart the upper half is restored and the lower half is replaced by a new one. This design decouples the MPI application from the underlying libraries that “talk” to the hardware.
When MANA takes a checkpoint, it saves only the memory regions associated with the upper half. When MANA restarts, it begins a new “trivial” MPI application with the correct number of MPI processes. Each MPI process becomes the new lower half, and it restores to memory the upper-half checkpoint image file whose world rank is the same as the world rank in the lower half.
Since MANA does not save the lower-half memory, it works independently of the particular network interface, and independently of the MPI implementation (providing that the MPI implementation obeys MPI’s standard API).
Thus, a “safe” state for MANA to checkpoint must obey the following invariant:
Collective Invariant: No checkpoint may take place while an MPI process is inside a collective communication routine in the lower half.
The original MANA paper proposed a two-phase-commit (2PC) algorithm to find a safe state obeying the collective invariant above. The core idea of the earlier two-phase-commit algorithm is to use a wrapper function around each MPI collective call to insert a call to MPI_Barrier (or a call to MPI_Ibarrier followed by a loop of calls to MPI_Test). When it is time to checkpoint, if all processes have entered the barrier, then MANA waits until all processes have completed the collective call. If some processes have not yet entered the barrier, then it is safe to checkpoint because other processes cannot skip the barrier and start the real collective communication. On restart, if one had entered the barrier loop prior to checkpoint, then one calls MPI_Ibarrier again before continuing.
The severest limitation of the old 2PC approach is the high runtime overhead caused by the inserted barrier. The barrier forces all participating processes to synchronize. The synchronization takes extra time and blocks operations that are not required to be synchronized, such as MPI_Bcast. In addition, forced synchronization conflicts with MPI’s non-blocking collective communication model. Thus, non-blocking collective communications were not supported in the original MANA prototype.
3 A Close Look at the MPI Standard
A prerequisite to understand why the CC algorithm is correct requires a precise reading of the MPI standard and its implications. This document primarily cites the MPI-4.0 standard [20].
Two key points from the MPI standard will be used frequently in this work.
First, a correct, portable MPI program must assume that MPI collective operations (blocking and non-blocking) are synchronizing. Any program violating this assumption is erroneous.
The reason is that for any given MPI collective operation, a particular MPI library may implement the collective operation as synchronizing. Recall that synchronizing [21, Section 3.2.12] means it acts as a barrier. In a synchronizing call, no process can exit until all processes have entered the call. Hence, portable user programs must assume this more restrictive case. Quoting the standard, “a correct, portable program must invoke collective communications so that deadlock will not occur, whether collective communications are synchronizing or not.” [20, Section 6.14].
Second, once all participating MPI processes have initiated a non-blocking operation, then the operation continues “in background”, and must eventually complete, independently of other actions by any of the MPI processes.
In the words of the standard, “The progress of multiple outstanding non-blocking collective operations is completely independent.” [20, Example 6.36]
4 Collective Clock (CC) Algorithm
The new algorithm is called CC due to its use of a happens-before relation on a vector of “timestamps”. In this sense, it bears a resemblance to the idea of logical clocks [22]. The initial point of departure is that instead of employing logical clocks based on MPI processes, the collective clock is based on logical clocks based on MPI communicators (in fact, on the underlying MPI groups).
The CC algorithm introduces a sequence number for each group of MPI processes. The sequence number is initialized to zero. When a collective operation occurs on a group, the sequence number for that group is incremented locally. When a checkpoint (the analog of a distributed snapshot) is requested, a target (sequence) number is computed for each MPI group, as the maximum of the sequence number of that MPI group that is seen at each MPI process. For the purposes of target numbers, two MPI groups are considered to be the same if they satisfy MPI_SIMILAR, meaning that they contain the same set of MPI processes. If an MPI process has never participated in that group for collective communication, then its sequence number is zero.
At checkpoint time, each MPI process constructs a set of target numbers for each MPI group in which the process participates. The process then continues to execute until, for each MPI group containing that process, the process has reached the target number of that MPI group.
4.1 Definitions
Some formal terms are defined next, and used in the description of the algorithm.
- Global group id (ggid):
-
For the underlying MPI group of a communicator, we assign a global group id (ggid) based on hashing the “world rank” of each participating MPI process according to its rank in MPI_COMM_WORLD. Communicator IDs generated by the MPI library are local resource handles. So we need to compute the ggid to identify communicators globally. By design, similar communicators in the sense of MPI_SIMILAR have the same ggid.
- Sequence number (SEQ[ggid]):
-
The (local) sequence number of a ggid (often denoted SEQ[ggid]) is a local, per-process counter that records the number of calls to (blocking) collective communication routines using that MPI group. If a particular MPI process has never invoked a collective communication using the given MPI group, then the local sequence number for that ggid is zero.
- Target number (TARGET[ggid]):
-
The (global) target number of a ggid (often denoted TARGET[ggid]) is a global value, representing the maximum sequence number of the given ggid across each MPI process.
- Reached a target
-
A target is reached after we execute a blocking collective call whose sequence number is equal to the target number.
- Safe state
-
A safe state of an MPI program in MANA is a state of execution for which it’s safe to checkpoint. Two invariants must hold, to be in a safe state:
Invariant 1: No checkpoint must take place while a rank is inside a collective communication routine. This is the same as the collective invariant from Section 2.2.
Invariant 2: If a collective communication call has started when the checkpoint request arrives, then the checkpoint request must be deferred until all members of the communication can complete the communication. For example, suppose an MPI_Bcast has started, and the sender process has already broadcast its message. Then the checkpoint must be deferred for all receiving processes until they all can complete the communication.
4.2 The CC Algorithm for Blocking Collective calls
This subsection describes the CC algorithm in the context of blocking collective calls. Later the interaction with blocking point-to-point calls will also be discussed.
Unlike the 2PC algorithm of MANA [2], the runtime overhead for CC remains almost zero (see the micro-benchmarks of Section 5), since the only overhead is due to interposing on MPI calls and incrementing a sequence number.
4.2.1 CC algorithm at runtime
MANA provides a wrapper function for each collective communication call. When a communicator is created, if the ggid of the underlying group has not yet been seen, then the sequence number of that ggid is initialized: SEQ[ggid]=0. (See Section 4.1 for the definition of the global group id (ggid).) During normal execution of an MPI application, each time a MANA wrapper function is called on a blocking collective call, the global variable SEQ[ggid] for that communicator is incremented. No network operations are executed, and so the runtime overhead in the CC algorithm remains exceptionally small.
4.2.2 CC algorithm at checkpoint time
At the time of checkpoint, the intuition behind CC is that execution should continue until all MPI processes have reached a safe state. A safe state is defined as a state that satisfies the two safe-state invariants of Section 4.1.
The execution of an MPI computation can be viewed as a directed graph. Each node corresponds to a collective communication call. Each edge of the directed graph is labelled by an MPI process. Each incoming edge of the node corresponds to the MPI process given by the edge label, entering the collective call. Each outgoing edge corresponds to an MPI process exiting the collective call, and the edge label corresponds to that process.
The goal of the CC algorithm is to continue execution until:
-
1.
each node (collective call) that has been visited at checkpoint time by at least one MPI process will have been visited by all participating processes; and
-
2.
no other nodes have been visited.
We define a node to be dependent on a node if there is a directed edge from to . The dependency relation is then extended by transitivity. The extended directed graph is the directed graph that results when for each visited node, all participating processes have reached that node. By transitivity, we define a node to be dependent on a node if there is a path in the extended directed graph from to .
The CC algorithm is a variant of a topological sort. A topological sort dictates the order in which one visits a graph, such that for a node , all nodes that is dependent on are visited before the node is visited. This is a restatement of condition 1, above. In our setting, this is also the problem of finding a safe state for checkpointing.
More formally, we can state the following condition. The process must be allowed to continue to execute if and only if:
CONDITON : the process has visited node , and node is dependent on node , and some other process has already visited node .
The above condition can be viewed as a condition on the sequence numbers that were described earlier. When viewed in this way, Condition A translates to saying the following.
For a given MPI process, the process should be allowed to proceed if and only if:
CONDITON : the process is a member of a group whose global group id () is and .
The interpretation is that if there’s a node in which , then there will be a future node in which . Hence, the last visited node, , of this process is dependent on a future node in the extended directed graph.
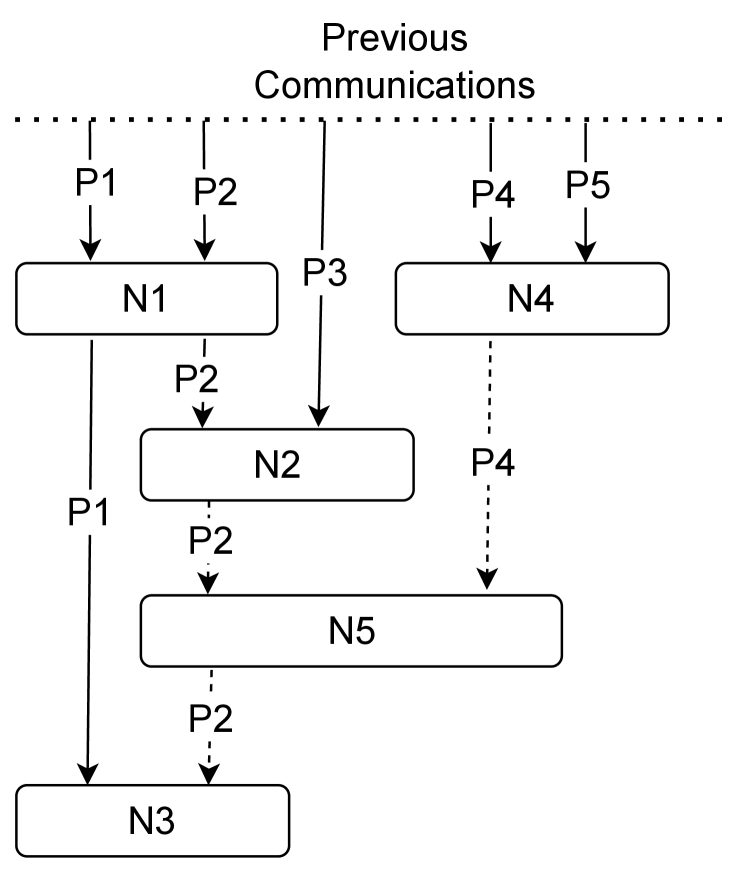
Figure 2 shows two examples of the CC algorithm at checkpoint time as directed graphs. Figure 2(a) shows a simple case. At the time of checkpoint, process 2 () has visited . is dependent on , and has already been visited by another process . According to Condition A, should continue executing until also visits to reach the safe state for checkpointing.
Figure 2(b) shows a more complex case. Similar to the previous example 2(a), should continue executing to visit . In the process, needs to visit a new node , because is also dependent on . On the other hand, is dependent on another node . By applying Condition A again, should continue executing to visit . Then, is able to exit and visit .

4.2.3 The CC pseudo-code (blocking collective calls)
It remains to show pseudo-code for the MPI function wrappers used to implement the CC algorithm. In Algorithm 1, each MPI process exchanges sequence numbers () and computes the targets () by calculating the global maximum sequence number for each .
Algorithm 2 is the implementation of Condition above. Each MPI process executes until it has reached its target for all . While executing, an MPI process may increment for some , such that . In that case, is updated, and the line highlighted by SEND in boldface then sends the new target to all members of the group. The helper function, Wait_for_new_targets() (Algorithm 3) is called at the beginning and end of the wrapper function (Algorithm 2), in order to receive and update any newly incremented targets.
4.2.4 CC at checkpoint time: An example
Figure 3(a) shows an example of target numbers. The groups {1,2}, {2,3}, {3,4,5} and {5,6} (denoting ranks as determined in MPI_COMM_WORLD) have local targets 5, 7, 2, and 3, respectively. Each individual process may have multiple targets. For example, rank 3 has a target of 2 for the group {3,4,5}, and a target of 7 for the group {2,3}. Process 3 has reached the target for the group {3,4,5}, but not yet the target for the group {2,3}. In this case, process 3, 4 and 5 are allowed to continue executing until they finish targets 7, 2, and 3, respectively.
Figure 3(b) shows a more complex case. All processes have reached their targets, except for process 3. Process 3 previously had a target of 7 for the group {2,3}. But process 3 encountered and just executed a new operation on group {3,4,5}. Process 3 increments its local sequence number, for this group, and determines that the local sequence number 3 is larger than the previous shared target of 2 for that group. (SEQ[ggid])>TARGET[ggid] for this group.)


Since the CC algorithm requires at all times that max(SEQ[ggid])==TARGET[ggid] (for the maximum overall MPI processes), the complete CC algorithm adds a new step. The newly incremented SEQ[ggid] must be shared with all other participating processes.
So, process 3 sends a message to processes 4 and 5, with the new local sequence number, 3, for the group. Note that process 3 can locally discover the peer processes for the group {3,4,5} using the local MPI call, MPI_Group_translate_ranks.
Note that since process 5 has a new target for the group {3,4,5}, it will eventually execute the operation on group {5,6} again, and send messages updating the target of that group to 4. This will force process 5 to start executing again.
4.2.5 Blocking collective calls and point-to-point calls
We recall again that blocking collective calls are assumed to be synchronizing (see Section 3), and that “an MPI collective procedure is synchronizing if it will only return once all processes in the associated group or groups of MPI processes have called the appropriate matching MPI procedure.” [20, Section 2.4.2]. Hence, a matched send-receive pair may not “cross” a blocking collective operation, as summarized in Figure 4.

4.3 The CC algorithm extended to non-blocking calls
There are two issues to discuss:
-
1.
How are SEQ[ggid] and TARGET[ggid] set when a collective operation may be non-blocking?
-
2.
What should be done when a “safe” point is reached, but no processes have tested the operation for completion?
4.3.1 How are SEQ[ggid] and TARGET[ggid] set when a collective operation may be non-blocking?
The pseudo-code of Section 4.2.3 updates SEQ[ggid] and TARGET[ggid] at the time of a blocking collective communication call. However, in the non-blocking case, this call is now split between a call that initiates a non-blocking collective communication call (e.g., MPI_Ibcast) and a call that completes the non-blocking collective call (e.g., MPI_Wait or MPI_Test).
According to the MPI standard, non-blocking collective communication operations are independent from other MPI operations (both blocking and non-blocking) after they are initiated. Therefore, at any point of time between the initiation and completion of a non-blocking collective operation, the operation may or may not be executing in the background. The CC algorithm assumes all initiated nonblocking collective operations immediately start executing in the background. Therefore, it increments the SEQ[ggid] during the initiation phase. This approach guarantees that all possible messages in the network are received before the safe state for checkpointing.
This choice to update during initiation and not later supports a common pattern. A process may initiate multiple non-blocking collective communications at once, and wait for one or all processes to complete using functions like MPI_Waitany and MPI_Waitall. (See [20, Example 6.35].)
4.3.2 What should be done if a “safe” point is reached, but some processes haven’t tested the nonblocking collective operation for completion?
Since the CC algorithm increments the SEQ[ggid] during the initiation of non-blocking communications, it’s possible that some of the communications haven’t finished the communication when all processes reached all targets.
At a safe state, all processes of an incomplete non-blocking communication must have initiated the communication because of the invariant of a safe state. Therefore, the communication will eventually complete if all processes start waiting for completion using functions like MPI_Test and MPI_Wait. The CC algorithm keeps a list of MPI_Request objects for incomplete non-band doelocking communications. When a safe state is reached, the CC algorithm will keep calling MPI_Test on each incomplete MPI_Request until all communication have been completed.
5 Experiments
All experiments were conducted on the Perlmutter Supercomputer at the National Energy Research Scientific Computing Center (NERSC). Perlmutter is the #14 supercomputer on the Top-500 list as of June, 2024 [4]. Perlmutter has 3,072 CPU nodes and 1,792 GPU-accelerated nodes. Each CPU node has two AMD EPYC 7763 processors per node, for a total of 128 physical cores and 512 GB of RAM. The network uses HPE Cray’s Slingshot 11 interconnect. The Cray MPICH version is 8.1.25. Cray mpicc is based on gcc-11.2. The Linux operating system is SUSE Linux Enterprise Server 15 SP4 (Release 15.4), with Linux kernel 5.14.
Experiments are executed both on the older MANA using the 2PC subsystem for collective communication and also replacing this by the CC subsystem of this work. (Note that MANA/2PC does not support non-blocking collective communication calls, and so that experimental comparison is not possible. Because Perlmutter uses a modern network interconnect (Slingshot-11), it is not possible to compare MANA with the older transparent checkpointing packages based on MVAPICH [12] (2006) and Open MPI [13] (2009). Those earlier efforts supported only Ethernet and OFED InfiniBand. And even the underlying BLCR on which they depend was last updated in January, 2013 [23].
The experiments are organized as follows. Section 5.1 presents the OSU Micro-Benchmarks. These micro-benchmarks represent an upper limit of the rate at which an application will make collective communication calls. Those experiments show that at this extreme upper limit, the CC algorithm still performs reasonably, with a typical runtime overhead under 1.3%, as opposed to the 2PC algorithm, whose runtime overhead frequently rises even beyond 100%.
Section 5.2 then discusses the rate of collective communication calls per second across all of the categories of applications analyzed here.
Section 5.3 then analyzes the runtime overhead of five real-world applications. As will be seen, it is at the higher rates of calls per second that 2PC has excessive runtime overhead, and the newer CC algorithm is required.
Finally, in Section 5.4, VASP 6 is analyzed in detail, since it showcases the performance of the CC algorithm for high rates of collective calls per second (2,489 calls per second). VASP 6 is analyzed across a range of one to four computer nodes, as well as showing that checkpoint and restart times remain reasonable.
5.1 Micro-benchmarks
The OSU Micro-Benchmarks 7.0 [24] were used to show the runtime overhead of the new CC algorithm compared to MANA’s original two-phase-commit (2PC) algorithm. Eight micro-benchmarks were chosen for different common patterns of blocking and non-blocking collective communications. Each experiment was repeated 5 times.
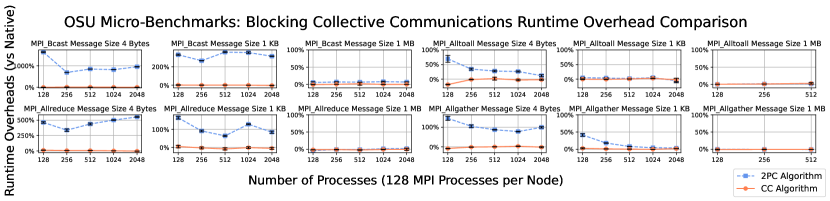

Figure 5 shows the runtime overhead of both MANA’s original two-phase-commit (2PC) and the CC algorithm of this work, with different message sizes (4 Bytes, 1 KB, and 1 MB). We scaled most micro-benchmarks up to 2048 processes over 16 nodes to test the scalability of the CC algorithm. The 2PC algorithm in the original MANA paper does not support non-blocking collective communication. Therefore, overhead is shown only for the CC algorithm, but not for 2PC.
MPI_Alltoall/Ialltoall and MPI_Allgather/Iallgather in the OSU Micro-Benchmarks do not support a message size of 1 MB over 1024 and 2048 processes, due to the default maximum memory limit. Hence, results are shown only up to 512 MPI processes for these cases.
5.1.1 Blocking Collective Communication
The CC algorithm shows lower runtime overhead than 2PC in micro-benchmarks of blocking collective communications. In addition, the CC algorithm’s runtime overhead remains consistently low as the message size or the number of nodes increases, whereas the runtime overhead of the 2PC algorithm varies depending on the message size and number of processes.
The 2PC algorithm inserts barriers that require extra communication and synchronization among processes. The additional communication increases the total latency of collective operations. Depending on the type of collective communication, the additional synchronization may have a different effect on performance. For example, MPI_Bcast becomes slower because senders have to wait for all receivers to receive the message. But for functions like MPI_Alltoall, the effect is minimal because the collective operation naturally requires synchronization among participating processors.
In cases of large message size (1 MB), both algorithms perform identically to the native application. The cost of transferring messages is so large that the extra overhead introduced by each algorithm is insignificant.
5.1.2 Non-blocking Collective Communication
The 2PC algorithm does not support non-blocking collective communications. Therefore, this section discusses runtime overhead for the CC algorithm only.
Note that for small messages, the runtime overhead for non-blocking communications is higher than for blocking counterparts and less stable. This is because the communication is divided into two phases: initiation and completion. CC has wrappers for the two phases, which contribute to the runtime. Therefore, the constant runtime overhead becomes larger than for the single wrapper of a blocking call. Nevertheless, the runtime overhead quickly decreases as the message size and number of nodes increase.

Figure 6 shows percentages of overlap between communication and computation for non-blocking collective communication, as reported by the OSU Micro-Benchmarks. This overlap can improve the overall performance. The CC algorithm has a comparable amount of overlap compared to the native MPI implementation. Hence, the runtime overhead of CC in real-world programs is expected to be small, as seen in Sections 5.3 and 5.4.
5.2 Rates of Collective Communication Calls per Second
Table 1 shows the rate both of collective and point-to-point communication calls. Each experiment was run across four computer nodes, for a total of 512 processes. The number of collective and point-to-point communication calls per second is computed as the average number of calls per second over all MPI processes. The OSU Micro-Benchmarks in Table 1 is a reference to the number of collective communications calls per second.
| Application | Processes | Input | coll. comm. | point-to-point |
| calls/sec. | calls/sec. | |||
| OSU MicroBench | 512 | MPI_Bcast (msg: 4 bytes) | 255,754.5 | NA |
| VASP 6 | 512 | PdO4 | 2,489.2 | 2,568.9 |
| Poisson Solver | 512 | rel error = 0.01 | 21.3 | NA |
| CoMD | 512 | Cu_u6.eam | 7.8 | 414.2 |
| LAMMPS | 512 | Scaled LJ Liquid | 6.3 | 1,707.5 |
| SW4 | 512 | LOH.1-h50.in | 0.6 | 157.9 |
It is clear that the runtime overhead of an MPI application depends critically on the number of collective communication calls per second. Section 5.3 will analyze the runtime overhead of five real-world applications. The five applications can be categorized according to the rate of collective calls per second. There are three categories: (i) a low rate (less than 10 calls per second: SW4, LAMMPS, CoMD); (ii) a medium rate (tens of calls per second: Poisson Solver); and (iii) a very high rate (hundreds or thousands of calls per second: VASP 6). The OSU Micro-Benchmark (hundreds of thousands of calls per second) is included as an upper limit.
As will be seen in the next subsection, for low rates of collective calls per second, CC and 2PC both have very low runtime overhead. For a medium rate, unfortunately, the 2PC algorithm cannot support Poisson Solver, because this code uses non-blocking collective calls. While CC still performs well, no overhead for 2PC could be exhibited. One of the novelties of the CC algorithm is that it extends to support of non-blocking collective calls, as seen in Section 4.3. For very high rates of calls per second, the CC algorithm widely outperforms the 2PC algorithm. Finally, as was seen in the previous subsection, in the upper limit of the OSU Micro-Benchmarks, CC still performs well, while 2PC can exhibit more than 100% runtime overhead.
5.3 Real-world Applications
We chose five real-world applications to show the CC algorithm’s performance. Figure 7 shows five real-world applications’ runtime performance and standard deviation. All experiments use 512 processes over 4 nodes on Perlmutter. Each test is repeated 5 times.
These applications have different communication patterns. Among the five applications, VASP 6 uses both collective communication and point-to-point communication most intensively (see Table 1). Therefore, of all the real-world applications, VASP 6 places the greatest stress on runtime overhead. Nevertheless, even in this extreme case, CC algorithm achieves a runtime overhead of only 5.2%, while the earlier 2PC algorithm has a runtime overhead of 10.6%.

(NOTE: Poisson uses non-blocking collective calls, supported by the newer CC, but not by 2PC.)
The Poisson Solver [25] uses non-blocking collective communications only. Therefore 2PC is not applicable. The runtime overhead of the CC algorithm is less than 1%.
In contrast, CoMD [26], LAMMPS [27], and SW4 [28] don’t use collective communications frequently enough so that the runtime overhead of both CC and 2PC algotithms are negligible.
The average runtime of SW4 and LAMMPS shown in the graphs indicates both CC and 2PC algorithms run slightly faster than the native applications (less than half a second), but within the standard deviation.
5.4 Scalability of Real-world Application: VASP


We show the CC algorithm’s scalability beyond micro-benchmarks in the case of VASP 6. Figure 8 shows the runtime overhead in each case. The result shows that the CC algorithm scales better than the earlier 2PC algorithm of the original MANA [2], ranging from a runtime overhead of 2% (128 processes) to 5.2% (512 processes).
Both algorithms show a smaller runtime overhead with 256 processes than the result with 128. This is because the 128-process case uses a single node, and the 256-process case uses two nodes. When communicating between two physical nodes, the base cost of communication increases, and so the relative runtime overhead for two nodes is smaller than in the case of a single node.
As discussed in the introduction, VASP depends heavily on efficient FFTs, which requires low-latency networks. When VASP runs on more nodes (e.g., above 4 nodes), the efficiency of many workloads degrade. Therefore, we didn’t test beyond 4 nodes since the performance results will no longer reflect the real-world usage of VASP.
Next, Figure 9 shows that checkpoint and restart times for MANA/CC remain reasonable. This experiment was on a Lustre distributed file system. Each VASP processes uses about 700 MB memory. The checkpoint command is issued at random times, and checkpoint-restart times are averaged over 5 runs. In order to get realistic numbers, checkpoint-restart times are shown over a range from 1 node to 16 nodes. Checkpoint and restart times are very close between the 2PC and CC algorithms. For both 2PC and CC algorithms checkpoint and restart are slower when running on more nodes because there is more data in the memory that needs to be saved and restored.
Each checkpoint image file is 398 MB. The checkpoint image file is smaller than the memory usage because the lower half, which contains the MPI library and network drivers, is not saved in the image.
The time to checkpoint depends strongly on the bandwidth to stable storage. While the current times are based on checkpointing to back-end disk-based Lustre distributed file system, newer architectures are expected to show still better times, based on the use of SSDs for intermediate storage.
6 Related Work
A rich set of library-based packages for checkpointing MPI exists: SCR [6] (2010), FTI [7] (2011), ULFM [8, 29] (2014), and Reinit [9] (2016, a simpler interface inspired by ULFM), and VeloC [10] (2019).
Transparent checkpointing for MPI also has a long history. It was demonstrated in MPICH-V [30]. Soon after, BLCR [11] was created to provide transparent checkpointing for a tree of processes on a single computer node. BLCR was then leveraged to support transparent checkpointing of MPI. The strategy was for an individual MPI implementation to: (a) disconnect the network connection; (b) use BLCR to transparently checkpoint each individual node; and (c) finally to reconnect the network (or connect it for the first time, if restarting from checkpoint images). This was done for InfiniBand by MVAPICH [12], for Open MPI [31, 13], and for DMTCP [14]. Unfortunately, the underlying BLCR software, itself, was last updated only in January, 2013 [23], and with the newer networks, transparent checkpointing is no longer supported.
MANA [2] was then developed in 2019, using both split processes and the two-phase-commit algorithm for collective calls. The current work shows how to replace the two-phase-commit algorithm with more efficient collective clocks. Earlier developments of MANA were concerned with a production-quality version [32, 1, 33].
The CC algorithm can be viewed as a consistent snapshot algorithm for MPI collective operations. Consistent snapshots to support point-to-point operations in the case of distributed algorithms include: the original Chandy-Lamport algorithm [34] and Baldoni et al. [35].
By analogy, the original Chandy-Lamport algorithm [34] can be considered as a consistent snapshot algorithm for MPI point-to-point operations, although it does not apply to collective operations. Indeed, Baldoni et al. [35] used similar ideas to demonstrate a rollback algorithm for transparent checkpointing of a distributed system with local checkpoints. Like Chandy-Lamport, their algorithm only supports point-to-point operations, and do not apply to collective operations. Clocks and logical clocks [36] themselves have a long history. Two good introductions to the subject are [22] and [37].
Collective communication has also been investigated within the domain of distributed systems. Within distributed systems, a central concern is to make the implementation of collective communication fault-tolerant. This is in comparison with MPI applications, where it is assumed that the underlying MPI library is responsible for fault tolerance.
7 Conclusion
The new CC algorithm reduces the runtime overhead for VASP from up to 10% in MANA’s old two-phase-commit (2PC) algorithm to typically 5% or less in the new algorithm. Similarly, the OSU Micro-Benchmark for blocking collective calls shows a drastic improvement in this stress test (with up to 2048 processes): from above 100% runtime overhead with the old 2PC algorithm to nearly 0% with the new collective-clock (CC) algorithm. For non-blocking collective calls, the older 2PC algorithm does not support that case. But the CC algorithm executes at a runtime overhead typically between 0% and 10%, for up to 2048 processes. An atypical worst case occurs for MPI_Ibcast, where CC can show runtime overheads of up to 50%.
Acknowledgment
We wish to thank Zhengji Zhao for her encouragement and helpful insights. We also wish to thank both NERSC at Lawrence Berkeley National Laboratory and MemVerge, Inc. for the use of their facilities. Finally, we wish to thank Kapil Arya for his enhancement of MANA by correctly tagging the memory regions of the upper and lower halves. This enhancement allowed us to remove the MPICH_SMP_SINGLE_COPY_OFF environment variable, thus improving the runtime overhead in all experiments, both for the original MANA code and for the newer algorithm. And we thank Twinkle Jain for valuable discussions.
References
- [1] Y. Xu, Z. Zhao, R. Garg, H. Khetawat, R. Hartman-Baker, and G. Cooperman, “MANA-2.0: A future-proof design for transparent checkpointing of MPI at scale,” in 2021 SC Workshops Supplementary Proc. (SCWS), pp. 68–78, IEEE, 2021.
- [2] R. Garg, G. Price, and G. Cooperman, “MANA for MPI: MPI-agnostic network-agnostic transparent checkpointing,” in Proc. of the 28th International Symposium on High-Performance Parallel and Distributed Computing, pp. 49–60, 2019.
- [3] J. Hafner, “Ab-initio simulations of materials using VASP: Density-functional theory and beyond,” Journal of computational chemistry, vol. 29, no. 13, pp. 2044–2078, 2008.
- [4] “TOP500 list - June 2024,” June 2024.
- [5] J. Li, G. Michelogiannakis, B. Cook, D. Cooray, and Y. Chen, “Analyzing resource utilization in an HPC system: A case study of NERSC’s Perlmutter,” in International Conference on High Performance Computing, pp. 297–316, Springer, 2023.
- [6] A. Moody, G. Bronevetsky, K. Mohror, and B. R. De Supinski, “Design, modeling, and evaluation of a scalable multi-level checkpointing system,” in SC’10: Proceedings of the 2010 ACM/IEEE International Conference for High Performance Computing, Networking, Storage and Analysis, pp. 1–11, IEEE, 2010.
- [7] L. Bautista-Gomez, S. Tsuboi, D. Komatitsch, F. Cappello, N. Maruyama, and S. Matsuoka, “FTI: High performance fault tolerance interface for hybrid systems,” in Proceedings of 2011 international conference for high performance computing, networking, storage and analysis, pp. 1–32, 2011.
- [8] W. Bland, A. Bouteiller, T. Herault, G. Bosilca, and J. Dongarra, “Post-failure recovery of MPI communication capability: Design and rationale,” The International Journal of High Performance Computing Applications, vol. 27, no. 3, pp. 244–254, 2013.
- [9] I. Laguna, D. F. Richards, T. Gamblin, M. Schulz, B. R. de Supinski, K. Mohror, and H. Pritchard, “Evaluating and extending User-Level Fault Tolerance in MPI applications,” The International Journal of High Performance Computing Applications, vol. 30, no. 3, pp. 305–319, 2016.
- [10] B. Nicolae, A. Moody, E. Gonsiorowski, K. Mohror, and F. Cappello, “VeloC: Towards high performance adaptive asynchronous checkpointing at large scale,” in 2019 IEEE International Parallel and Distributed Processing Symposium (IPDPS), pp. 911–920, IEEE, 2019.
- [11] P. H. Hargrove and J. C. Duell, “Berkeley Lab Checkpoint/Restart (BLCR) for Linux clusters,” Journal of Physics: Conference Series, vol. 46, no. 1, p. 067, 2006.
- [12] Q. Gao, W. Yu, W. Huang, and D. K. Panda, “Application-transparent checkpoint/restart for MPI programs over InfiniBand,” in Int. Conf. on Parallel Processing (ICPP’06), pp. 471–478, 2006.
- [13] J. Hursey, T. I. Mattox, and A. Lumsdaine, “Interconnect agnostic checkpoint/restart in Open MPI,” in Proc. of the 18th ACM Int. Symp. on High Performance Distributed Computing, pp. 49–58, 2009.
- [14] J. Cao, G. Kerr, K. Arya, and G. Cooperman, “Transparent checkpoint-restart over InfiniBand,” in Proc. of the 23rd Int. Symp. on High-Performance Parallel and Distributed Computing (HPDC’14), pp. 13–24, 2014.
- [15] J. Cao, K. Arya, R. Garg, S. Matott, D. K. Panda, H. Subramoni, J. Vienne, and G. Cooperman, “System-level scalable checkpoint-restart for petascale computing,” in 22nd IEEE Int. Conf. on Parallel and Distributed Systems (ICPADS’16), pp. 932–941, IEEE Press, 2016.
- [16] MANA team, “MANA for MPI (github: feature/dynamic_lh branch).” [accessed Aug. 2024].
- [17] MANA team, “MANA for MPI (github).” [accessed Aug. 2024].
- [18] G. E. Blelloch, “Scans as primitive parallel operations,” IEEE Transactions on Computers, vol. 38, no. 11, pp. 1526–1538, 1989.
- [19] F. Cristian, H. Aghili, R. Strong, and D. Dolev, “Atomic broadcast: From simple message diffusion to Byzantine agreement,” Information and Computation, vol. 118, no. 1, pp. 158–179, 1995.
- [20] Message Passing Interface Forum, “MPI: A Message Passing Interface standard: Version 4.0,” June 2021.
- [21] P. V. Bangalore, R. Rabenseifner, D. J. Holmes, J. Jaeger, G. Mercier, C. Blaas-Schenner, and A. Skjellum, “Exposition, clarification, and expansion of MPI semantic terms and conventions: is a nonblocking mpi function permitted to block?,” in Proceedings of the 26th European MPI Users’ Group Meeting, pp. 1–10, 2019.
- [22] R. Baldoni and M. Raynal, “Fundamentals of distributed computing: A practical tour of vector clock systems,” IEEE Distributed Systems Online, vol. 3, no. 02, 2002.
- [23] BLCR team, “Berkeley Lab Checkpoint/Restart for Linux (BLCR) downloads.” [accessed Aug. 2024].
- [24] The Ohio State University’s Network-Based Computing Laboratory, “OSU micro-benchmarks,” 2024. [accessed Aug..-2024].
- [25] T. Hoefler, P. Gottschling, A. Lumsdaine, and W. Rehm, “Optimizing a conjugate gradient solver with non-blocking collective operations,” Parallel Computing, vol. 33, no. 9, pp. 624–633, 2007.
- [26] M. Papa, T. Maruyama, and A. Bonasera, “Constrained molecular dynamics approach to fermionic systems,” Physical Review C, vol. 64, no. 2, p. 024612, 2001.
- [27] A. P. Thompson, H. M. Aktulga, R. Berger, D. S. Bolintineanu, W. M. Brown, P. S. Crozier, P. J. In’t Veld, A. Kohlmeyer, S. G. Moore, T. D. Nguyen, et al., “LAMMPS - a flexible simulation tool for particle-based materials modeling at the atomic, meso, and continuum scales,” Computer Physics Communications, vol. 271, p. 108171, 2022.
- [28] B. Sjögreen and N. A. Petersson, “A fourth order accurate finite difference scheme for the elastic wave equation in second order formulation,” Journal of Scientific Computing, vol. 52, no. 1, pp. 17–48, 2012.
- [29] N. Losada, P. González, M. J. Martín, G. Bosilca, A. Bouteiller, and K. Teranishi, “Fault tolerance of MPI applications in exascale systems: The ULFM solution,” Future Generation Computer Systems, vol. 106, pp. 467–481, 2020.
- [30] A. Bouteiller, T. Herault, G. Krawezik, P. Lemarinier, and F. Cappello, “MPICH-V project: A multiprotocol automatic fault-tolerant MPI,” The International Journal of High Performance Computing Applications, vol. 20, no. 3, pp. 319–333, 2006.
- [31] J. Hursey, J. M. Squyres, T. I. Mattox, and A. Lumsdaine, “The design and implementation of checkpoint/restart process fault tolerance for Open MPI,” in 2007 IEEE International Parallel and Distributed Processing Symposium, pp. 1–8, IEEE, 2007.
- [32] P. S. Chouhan, H. Khetawat, N. Resnik, J. Twinkle, R. Garg, G. Cooperman, R. Hartman-Baker, and Z. Zhao, “Improving scalability and reliability of MPI-agnostic transparent checkpointing for production workloads at NERSC,” in First Int. Symp. on Checkpointing for Supercomputing (SuperCheck21), Feb. 2021. conf. program at: https://supercheck.lbl.gov/resources.
- [33] Y. Xu, L. Belyaev, T. Jain, D. Schafer, A. Skjellum, and G. Cooperman, “Implementation-oblivious transparent checkpoint-restart for MPI,” in Proc. of the SC’23 Workshops of The International Conference on High Performance Computing, Network, Storage, and Analysis, pp. 1738–1747, 2023.
- [34] K. M. Chandy and L. Lamport, “Distributed snapshots: Determining global states of distributed systems,” ACM Transactions on Computer Systems (TOCS), vol. 3, no. 1, pp. 63–75, 1985.
- [35] R. Baldoni, J.-M. Hélary, and M. Raynal, “Rollback-dependency trackability: A minimal characterization and its protocol,” Information and Computation, vol. 165, no. 2, pp. 144–173, 2001.
- [36] L. Lamport, “Time, clocks, and the ordering of events in a distributed system,” Communications of the ACM, vol. 21, pp. 558–565, July 1978.
- [37] M. Raynal, “About logical clocks for distributed systems,” ACM SIGOPS Operating Systems Review, vol. 26, no. 1, pp. 41–48, 1992.
- [38] S. Zhuang, Z. Li, D. Zhuo, S. Wang, E. Liang, R. Nishihara, P. Moritz, and I. Stoica, “Hoplite: Efficient and fault-tolerant collective communication for task-based distributed systems,” in Proceedings of the 2021 ACM SIGCOMM 2021 Conference, pp. 641–656, 2021.
- [39] M. Whitlock, H. Kolla, S. Treichler, P. Pébay, and J. C. Bennett, “Scalable collectives for distributed asynchronous many-task runtimes,” in 2018 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), pp. 436–445, IEEE, 2018.