Enabling OpenMP Task Parallelism on Multi-FPGAs
Abstract
FPGA-based hardware accelerators have received increasing attention mainly due to their ability to accelerate deep pipelined applications, thus resulting in higher computational performance and energy efficiency. Nevertheless, the amount of resources available on even the most powerful FPGA is still not enough to speed up very large modern workloads. To achieve that, FPGAs need to be interconnected in a Multi-FPGA architecture capable of accelerating a single application. However, programming such architecture is a challenging endeavor that still requires additional research. This paper extends the OpenMP task-based computation offloading model to enable a number of FPGAs to work together as a single Multi-FPGA architecture. Experimental results for a set of OpenMP stencil applications running on a Multi-FPGA platform consisting of 6 Xilinx VC709 boards interconnected through fiber-optic links have shown close to linear speedups as the number of FPGAs and IP-cores per FPGA increase.
I Introduction
With the limits imposed by the power density of semiconductor technology, heterogeneous systems became a design alternative that combines CPUs with domain-specific accelerators to improve power-performance efficiency [1]. A modern heterogeneous system typically combines general-purpose CPUs and GPUs to speedup complex scientific applications[2]. However, for many specialized applications that can benefit from pipelined parallelism (e.g. FFT, Networking), FPGA-based hardware accelerators have shown to produce improved power-performance numbers [3, 4, 5, 6]. Moreover, FPGA’s reconfigurability facilitates the adaptation of the accelerator to distinct types of workloads and applications. In order to leverage on this, cloud service companies like Microsoft Azure [7] and Amazon AWS [8] are offering heterogeneous computing nodes with integrated FPGAs.
Given its small external memory bandwidth [9] FPGAs do not perform well for applications that require intense memory accesses. Pipelined FPGA accelerators [10, 11, 12] have been designed to address this problem but such designs are constrained to the boundaries of a single FPGA or are limited by the number of FPGAs that it can handle. By connecting multiple FPGAs, one can design deep pipelines that go beyond the border of one FPGA, thus allowing data to be transferred through optical-links from one FPGA to another without using external memory as temporal storage. Such deep pipeline accelerators can considerably expand the application of FPGAs, thus enabling increasing speedups as more FPGAs are added to the system [13].
Unfortunately, programming such Multi-FPGA architecture is a challenging endeavor that still requires additional research [14, 15]. Synchronizing the accelerators inside the FPGA and seamlessly managing data transfers between them are still significant design challenges that restrict the adoption of such architectures. This paper addresses this problem by extending the LLVM OpenMP task programming model [16] to Multi-FPGA architectures.
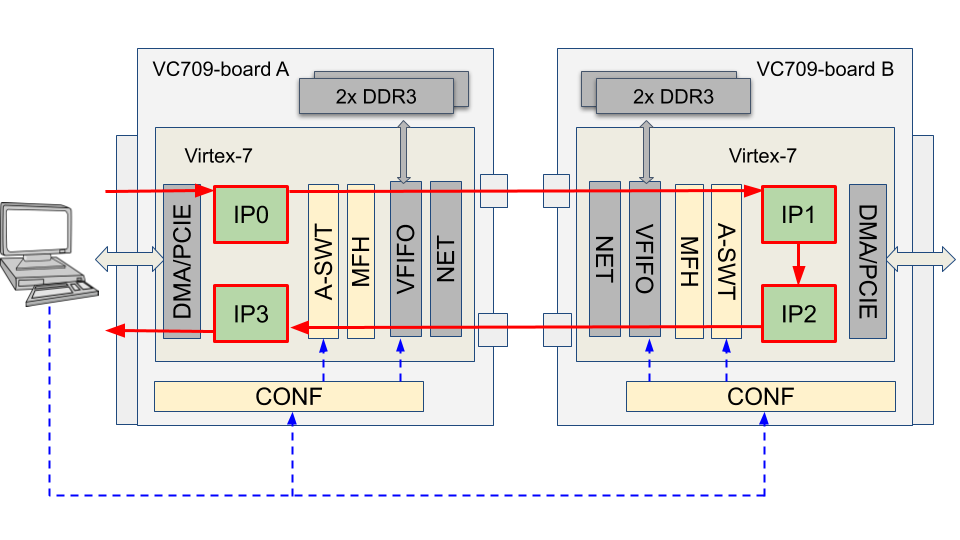
At a higher abstraction level, the programming model proposed in this paper enables the programmer to see the FPGA as a regular OpenMP device and the IP-cores accelerators (IPs) as OpenMP tasks. In the proposed approach, the OpenMP task dependence mechanism transparently coordinates the IPs’ work to run the application. For example, consider the simple problem of processing the elements of a vector V in a pipeline fashion using four IPs (IPO-IP3) programmed in two FPGAs. Each IPi (i = 0-3) performs some specific computation foo(V,i). The Multi-FPGA architecture used in this example is shown Figure 1 and contains two VC709111A similar approach can also be used for modern Alveo FPGAs. FPGA boards interconnected by two fiber-optics links. Each FPGA is programmed with: (a) a module for communication with the PCIE interface (DMA/PCIE); (b) two IPs from the set IP0-IP3; (c) a NET module for communication with the optical fibers; (d) a Virtual FIFO module (VFIFO) for communication with memory; (e) a MAC frame handler (MFH) to pack/unpack data; and (f) a packet switch (A-SWT) module capable of moving data among the IPs, even if they seat on FPGAs from two distinct boards. As shown in the figure, the vector is initially moved from the host memory (left of Figure 1) and then pushed through the IP0-IP3 pipeline, returning the final result into the host memory.
The OpenMP program required to execute this simple application uses just a few code lines (see Listing 3). Its simplicity is possible due to the techniques proposed in this paper, which leverage on the OpenMP task dependence and computation offloading abstraction to hide the complexity needed to move the vector across the four IPs. The proposed techniques extend the OpenMP runtime with an FPGA device plugin which: (a) maps task data to/from the FPGAs; (b) transparently handles the data dependencies between IPs located in distinct FPGAs; and (c) eases the synchronization of IPs’ execution.
The main contributions of this paper are summarized below:
-
•
A new Clang/LLVM plugin that understands FPGA boards as OpenMP devices, and uses OpenMP declare variant directive to specify hardware IPs;
-
•
A mechanism based on the OpenMP task dependence and computation offloading model that enables transparent communication of IPs in a Multi-FPGA architecture;
-
•
A programming model based on OpenMP task parallelism, which makes it simple to move data among FPGAs, CPUs or other acceleration devices (e.g. GPUs), and that allows the programmer to use a single programming model to run its application on a truly heterogeneous architecture.
The rest of the paper is organized as follows. Section II discusses background material and Section III details the software and hardware mechanisms that were designed to enable OpenMP task parallelism on a Multi-FPGA architecture. Section IV shows how this architecture can be used to design a scalable stencil pipeline application. Section V describes the experimental setup and analyzes their results. Section VI discusses related works and finally Section VII concludes the work.
II Background
This section provides background material required for understanding the proposed approach. Section II-A reviews the basic concepts of the OpenMP accelerator programming model, while Section II-B details the Xilinx modules used to assemble the testing platform.
II-A OpenMP Accelerator Model
The OpenMP specification [17] defines a programming model based on code annotations that use minimal modifications of the program to expose potential parallelism. OpenMP has been successfully used to parallelize programs on CPUs and GPUs residing on a single computer node.
Tasks were introduced to OpenMP in version 3.0 [18], to expose a higher degree of parallelism through the non-blocking execution of code fragments annotated with task directives. The annotated code is outlined as tasks that are dispatched to the OpenMP runtime by the control thread. Dependencies between tasks are specified by the depend clause, which the programmer uses to define the set of input variables that the task depends on and the output variables that the task writes to. Whenever the dependencies of a given task are satisfied, the OpenMP runtime dispatches it to a ready queue which feeds a pool of worker threads. The OpenMP runtime manages the task graph, handles data management, creates and synchronizes threads, among other activities.
Listing 1 shows an example of a simple program that uses OpenMP tasks to perform a sequence of increments in the vector V, similarly as discussed in Figure 1. First, the program creates a pool of worker threads. This is done using the #pragma omp parallel directive (line 3). It is with this set of threads that an OpenMP program runs in parallel. Next, the #pragma omp single directive (line 4) is used to select one of the worker threads. This selected thread is called control thread and is responsible for creating the tasks. The #pragma omp task directive (line 6) is used to effectively build N worker tasks, each one encapsulating a call to function foo(V,i) (line 8) that performs some specific operation on the vector V depending on the task (loop) index. Worker threads are created by the OpenMP runtime to run on the cores of the system. In order to assure the execution order of the tasks the depend clause (line 7) is used to specify the input and output dependencies of each task. In the specific case of the example of Listing 1 we have to introduce a deps vector which assures that the foo(V,i) tasks are executed in a pipeline order.
Now assume the user wants to accelerate the above described tasks in a GPU. For this purpose, consider the code in Listing 2 which is the version of Listing 1 using a GPU as an acceleration device. In Listing 2 the target directive (line 6) has a similar role as the task directive from Listing 1, but has for goal to offload the computation to an acceleration device instead of a CPU. The device clause (line 6) receives as an argument an integer which specifies the device that will perform the computation. In the case of Listing 2 this number corresponds to a GPU. Similar to the task directive, the target directive also accepts the depend clause (lines 7). The map clause (line 8) specifies the direction of the transfer operation that the host must execute with the given data. The most common transfer operations are to, from, and tofrom. For example, in line 8 of Listing 2 vector V is annotated with tofrom given that it is first sent from the host memory to the GPU memory, and then received back after processed by function foo. Notice that clause nowait also appears in line 8 of Listing 1. This clause is necessary because, by default, the target directive is blocking. In other words, the nowait clause allows the control thread to create all tasks without waiting for the previous ones to complete. Finally in line 9 of Listing 2 the worker thread foo function is called.
The current LLVM OpenMP implementation of task offloading is not enough to handle devices like Multi-FPGA. This paper proposes an OpenMP plugin implementation for Multi-FPGA devices. Moreover, it extends the LLVM OpenMP runtime to substitute software tasks for target tasks running on hardware IPs of a Multi-FPGA architecture. This is done by implementing the declare variant pragma which is already defined in the OpenMP standard. Also, the depend and the map clauses are used to dynamically create communication paths between the IPs of the various FPGAs in the architecture.
II-B The Hardware Platform
The Xilinx VC709 Connectivity Kit provides a hardware environment for developing and evaluating designs targeting the Virtex-7 FPGA. The VC709 board provides features common to many embedded processing systems, including dual DDR3 memories, an 8-lane PCI Express interface [19], and small SFP connectors for fiber optical (or Ethernet) transceivers. In addition to the board’s physical components, the kit also comes with a Target Reference Design (TRD) featuring a PCI Express IP, a DMA IP, a Network Module, and a Virtual FIFO memory controller interfacing to DDR3 memory. Figure 2 shows the schematic of the main board components and their corresponding components.
This kit was selected to explore the ideas discussed in this paper due to its reduced cost and the fact that the TRD has components ready for inter-FPGAs communication. Each one of the TRD components is explained in more detail below.
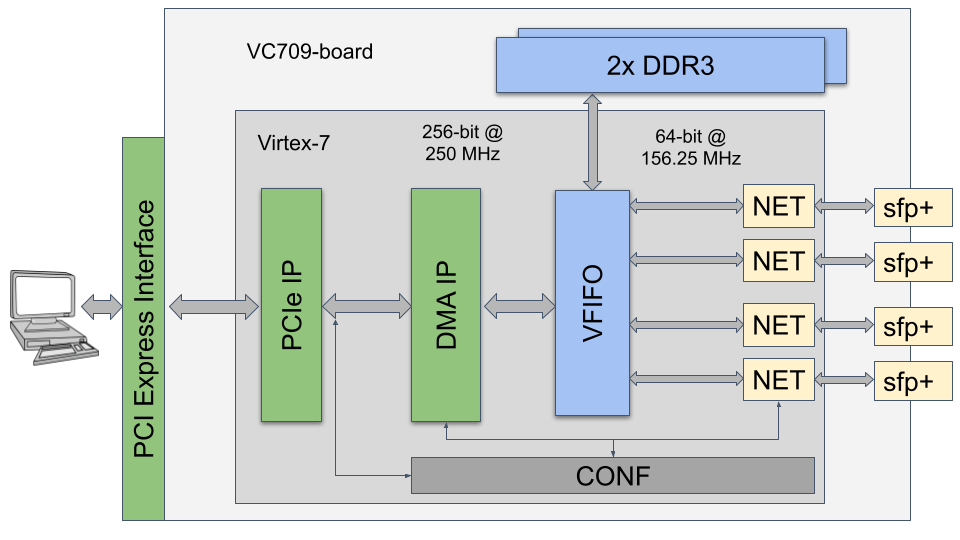
PCIE and DMA. The PCI Express IP (Figure 2) provides a wrapper around the integrated block in the FPGA. The wrapper combines the Virtex-7 XT FPGA Integrated Block for PCIe with transceivers, clocking, and reset logic. It also provides an AXI4-Stream interface to the host.
CONF. The Configuration Registers (Figure 2) are used to read and write control/status information to/from the FPGA components. This information ranges from configuring the network module to reading performance, power, and temperature information. There is also a free address range available that is used to store configuration information to the specific IPs used in this work.
VFIFO. The TRD uses DDR3 space to implement a Virtual FIFO (VFIFO Figure 2). This VFIFO is used to avoid back-pressure to the PCIe/DMA modules.
Network Subsystem. This subsystem is composed of four NET modules (see Figure 2) containing each XGEMAC module and logic required to enable the physical layer of the Multi-FPGA communication network. Each XGEMAC module receives data in the MAC frame format and sends it to the physical layer. Each NET module is connected to an SFP port capable of handling 10Gb/s per channel, resulting in a total of 40Gb/s bandwidth for the board.
III The OpenMP Multi-FPGA Architecture
The approach proposed in this paper has two main goals: (a) to extend the LLVM OpenMP runtime so it can recognize FPGA IPs as OpenMP tasks (i.e.targets) and; (b) to design a hardware mechanism that enables transparent communication of IP data dependencies through the cluster of FPGAs. The following two sections detail how these two goals have been achieved.
III-A Extending OpenMP
To explain how the proposed system works, please consider the code fragment shown in Listing 3. The declare variant directive (line 1), which is part of the OpenMP standard, declares a specialized hardware (FPGA IP-core) variation (hw_laplace2d, in line 4) of a C function (do_laplace2d, in line 2), and specifies the context in which that variation should be called. For example, line 3 of Listing 3 states that the variant hw_laplace2d should be selected when the proper vc709 device flag is provided to the compiler at compile time. This compiler flag is matched by the match (device=arch(vc709)) clause and when the call to function do_laplace2d(&V, x, y) (line 16) is to be executed a call to the IP-core hw_laplace2d(int*, int, int) is performed instead.
As shown in line 11 of Listing 3, the main function creates a pipeline of N tasks. Each task receives a vector V containing h*w (height and width) grid elements that are used to calculate a Laplace 2D stencil. As the tasks are created within a target region and the vc709 device flag was provided to the compiler, the hw_laplace2d variant is selected to run each task in line 16. The compiler then uses this name to specify and offload the hardware IP that will run the task. As a result, at each loop iteration, a hardware IP task is created inside the FPGA. Details of the implementation of the Laplace 2D IP and other stencil IPs used in this work are provided in Section IV.
The map clause (line 12) specifies that the data is mapped back and forth to the host at each iteration. However, the implemented mapping algorithm concludes that vector V is sent to the IP from the host memory and its output forwarded to the next IP in the following iteration. The interconnections between these IPs are defined according to the depend clauses (line 13). In the particular example of Listing 3, given that the dependencies between the tasks follow the loop iteration order, a simple pipelined task graph is generated.
A careful comparison of Listing 3 with Listing 2 reveals that in terms of syntax, the proposed approach does not require the user to change anything concerning the OpenMP standard, besides specifying the vc709 flag to the compiler. This gives the programmer a powerful verification flow. He/she can write the software version of do_laplace2d for algorithm verification purpose, and then switch to the hardware (FPGA) version hw_laplace2d by just using the vc709 compiler flag.
To achieve this level of alignment with the OpenMP standard, two extensions were required to the OpenMP runtime implementation: (a) a modification in the task graph construction mechanism and; (b) the design of the VC709 plugin in the libomptarget library. All these changes have been done very carefully to ensure full compatibility with the current implementation of the OpenMP runtime.
Managing the Task Graph. The first modification made to the OpenMP runtime has to do with how it handles the task graph. In the current OpenMP implementation the graph is built and consumed at runtime. Whenever a task has its dependencies satisfied, it is available for a worker thread to execute. After the worker thread finishes, the task output data is sent back to the host memory. This approach satisfies the needs of a single accelerator, but causes unnecessary data movements for an Multi-FPGA architecture as the output data of one (FPGA) task IP may be needed as input to another task IP. To deal with this problem, the OpenMP runtime was changed so that tasks are not immediately dispatched for execution as they are detected by the control thread. In the case of FPGA devices, the runtime waits for the construction of the task graph at the synchronization point at the end of the scope of the OpenMP single clause (line 18 of Listing 3).
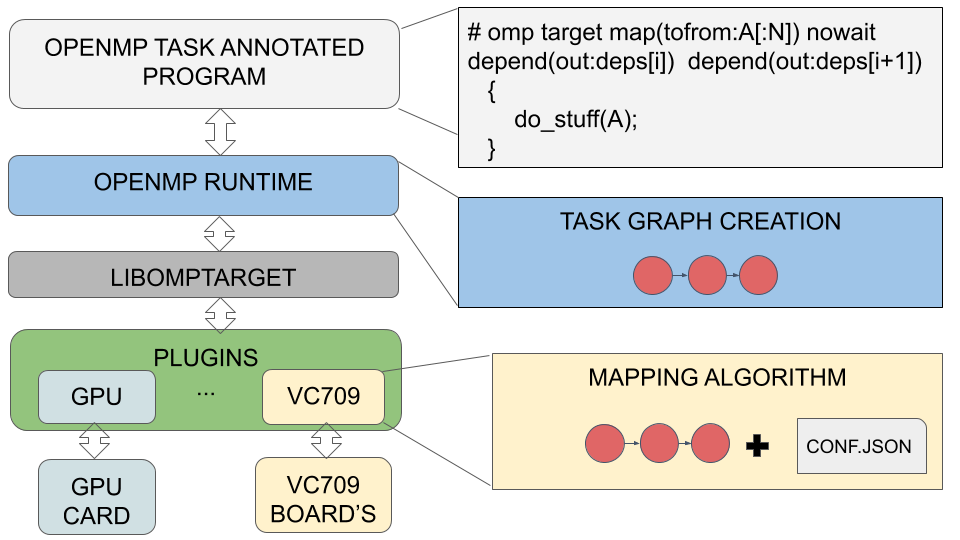
Building the VC709 Plugin. In the OpenMP implementation of the Clang/LLVM compiler [20], kernel/data offloading are performed by a library called libomptarget [21]. This library provides an agnostic offloading mechanism that allows the insertion of a new device to the list of devices that the OpenMP runtime supports and is responsible for managing kernel and data offloading to acceleration devices. Therefore, to allow the compiler to offload to the VC709 board, it was necessary to create a plugin in this library. Figure 3 illustrates where the plugin is located in the software stack.
As shown in Figure 3, the plugin receives the task graph generated by the runtime and maps these tasks to the available IPs in the cluster. The cluster configuration is passed through a conf.json file, which contains: (a) the location of the bitstream files, (b) the number of FPGAs, (c) the IPs available in each FPGA, and (d) the addresses of IPs and FPGAs. As in our experiments, the FPGAs are connected in a ring topology, a round-robin algorithm is used to map tasks to IPs. Each task is mapped in a circular order to the free IP that is closest to the host computer.
III-B Designing the Hardware Platform
Besides the extensions to OpenMP, an entire hardware infrastructure was designed to support OpenMP programming of Multi-FPGA architectures. This infrastructure leverages on the Target Reference Design (TRD) presented in Section II-B, but could also be ported to other modern Alveo FPGAs. To facilitate its understanding, the design is described below using two perspectives: Single-FPGA execution and Multi-FPGA execution.
Single-FPGA Execution. As discussed above, when the acceleration device is an FPGA, OpenMP considers the FPGA IPs as OpenMP tasks which are specified by the name of a predefined variant function.
Consider, for example, the hardware infrastructure in Figure 1, but this time with a single FPGA board and 4 task IPs (IP0-IP3). These IPs are separately designed using a standard FPGA toolchain (e.g. Vivado), which is not addressed in this paper. To connect the IPs into the infrastructure, the designer just needs to ensure that they use the AXI-Stream interface. The infrastructure can be easily changed to accept other interfaces, although for the purpose of this paper AXI-Stream suffices.
According to the proposed programming model, FPGA IPs can execute tasks that have dependencies between each other. In order to implement such dependencies an AXI4-Stream Interconnet (AXIS-IC) module [22] was inserted to the infrastructure (Figure 1). This enables the IPs to communicate directly to each other, based on the OpenMP dependencies programmed between them, thus avoiding unnecessary communication through the host memory.
The AXI4-Stream Interconnect is an IP core that enables the connection of heterogeneous master/slave AMBA® AXI4-Stream protocol compliant endpoint IP. The AXI4-Stream Interconnect routes data from one or more AXI4-Stream master channels to one or more AXI4-Stream slave channels. The VC709 plugin uses the CONF register (Figure 1) bank to program the source and destination ports of each IP according to their specified task dependencies.
Multi-FPGA Cluster Execution. A Multi-FPGA architecture is composed of one or more cluster nodes containing at least one FPGA board each. To enable such architecture, routing capability needs to be added to each FPGA so that IPs from two different boards or nodes communicate through the optical links.
To enable that, a MAC Frame Handler module (MFH) was designed and inserted into the hardware infrastructure, as shown in Figure 1. This module is required because the Network Subsystem that routes packages through the optical fibers that connects the boards receives data in the form of MAC Frames, which contain four fields: (a) destination, (b) source, (c) type/length and (d) payload. Therefore, to use the optical fibers, a module that can assemble and disassemble MAC frames is required.
The MFH module is responsible for inserting and removing the source and destination MAC addresses and type/lengh fields whenever the IPs need to send/receive data through the Network Subsystem. MAC addresses are extracted from the dependencies in the task graph while the type/lengh fields are extracted from the map clause. The VC709 plugin uses this information to set up the CONF registers, which in turn configure the MFH module.
| Kernel | Computations | |||
|---|---|---|---|---|
| 1 |
|
|||
| 2 |
|
|||
| 3 |
|
|||
| 4 |
|
|||
| 5 |
|
With all of these components in place, the proposed OpenMP runtime can to distribute tasks IPs across a cluster of FPGAs and map the dependency graph so that FPGA IPs communicate directly.
IV An Stencil Multi-FPGA Pipeline
Stencil computation is a method where a matrix (i.e. grid) is updated iteratively according to a fixed computation pattern [23]. Stencil computations are used in this paper to show off the potential of the proposed OpenMP-based Multi-FPGA programming model. In this paper, stencil IPs are used to process multiple portions and iterations of a grid in parallel on different FPGAs. There are basically two types of parallelism that can be exploited when implementing stencil computation in hardware: cell-parallelism and iteration-parallelism [13].
As detailed below, these two types of parallelism leverage on a pipeline architecture to improve performance and are thus good candidates to take advantage of the Multi-FPGA programming model described herein. Five different types of stencil IPs have been implemented for evaluation. The IPs were adapted from [13] and their computations are listed in Table I in the following order: (1) Laplace eq. 2-D, (2) Diffusion 2-D, (3) Jacobi 9-pt. 2-D, (4) Laplace eq. 3-D e (5) Diffusion 3-D. The formula in the computations column is used to calculate an element , where t represents the iteration and the indices i, j and k represent the axes of the grid. The values are constants passed to the IPs.
Cell-Parallelism. Figure 4(a) shows an example of cell-parallelism on a stencil computation, where at iteration 2 is computed using the data from its neighboring cells in the yellow area at iteration 1. This can be repeated for other cells at iteration 2, like which is computed in parallel to .
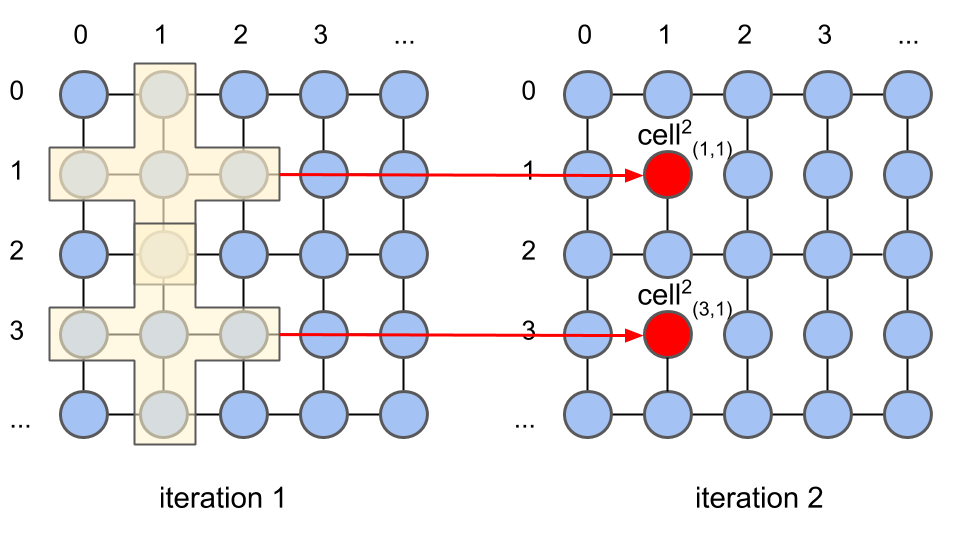
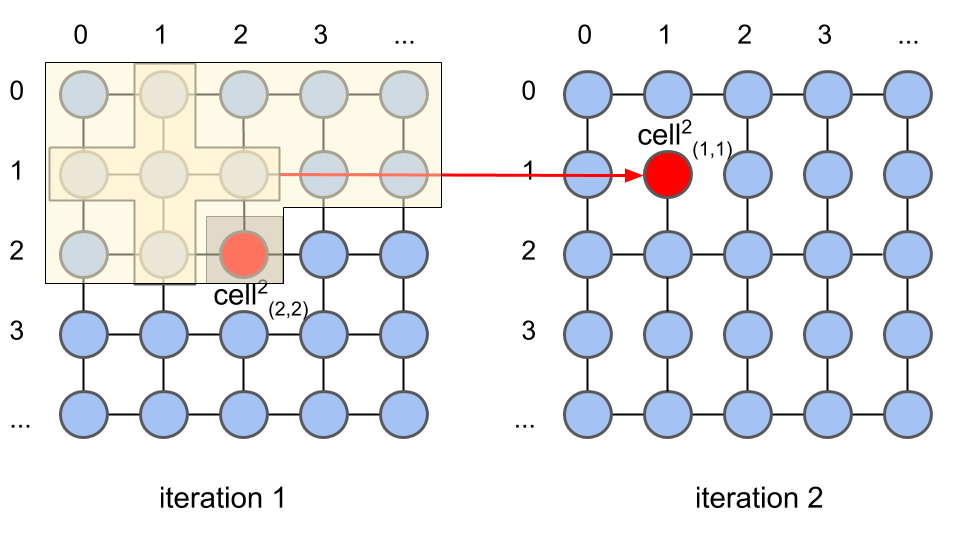
Iteration-Parallelism. This occurs when elements of different iterations are calculated in parallel. Figure 4(b) shows two consecutive iterations (1 and 2) where this happens. As shown in Figure 4(b) at iteration 2 is computed using the data from its neighboring cells in the yellow area at iteration 1. The method also computes other cells in parallel at iteration 2, like .
IV-A IP Implementation
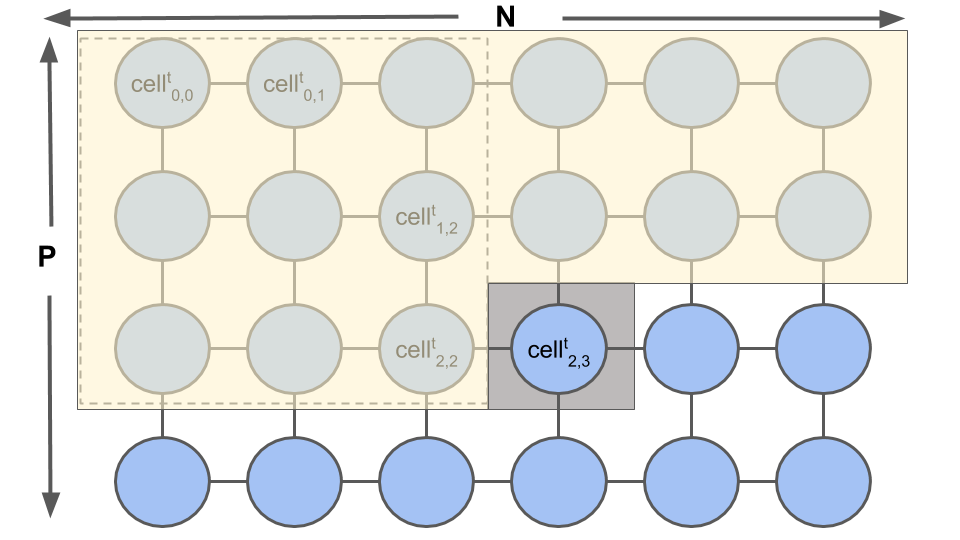
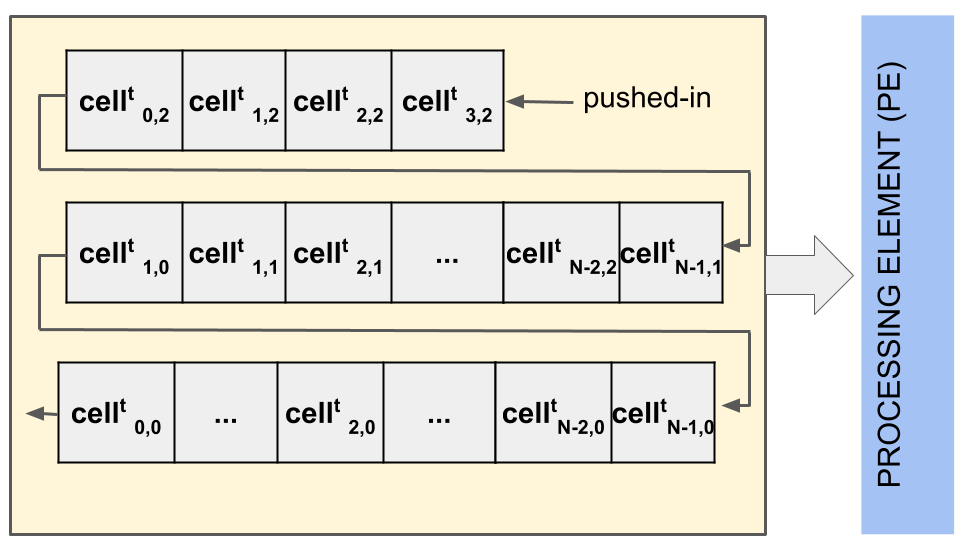
Figure 5 shows an overview of a typical stencil IP implementation using cell and iteration parallelism. Figure 5(a) shows the grid to be computed, and Figure 5(b) the components that implement the stencil, namely: (a) a shift-register that stores the grid data in processing order; and (b) the processing element (PE), which does the actual stencil computation. The cells in Figure 5(a) are computed by the architecture in Figure 5(a) from left-to-right and top-to-bottom one after the other. At each clock cycle, data in the shift-registers are shifted to the left in Figure 5(a), and a new cell value is pushed into the input of the first shift-register (i.e. ). The computation starts after all neighboring data of a cell are available in the shift-register array. In the example of Figure 5, is computed while input data is stored into . In the next clock cycle, the data at at the output of the shift-register is discarded (shifted out), and the data of is pushed into the input of the shift-register. Notice that the data at is no longer required for any computation at this stage.
Each stencil IP has a shift-register and eight processing elements and is thus capable of processing up to eight elements at a time until the end of an iteration. Each IP works with a 256-bit AXI4-Stream interface, as each cell in the matrix is a 32-bit float.
The A-SWT switch in the architecture of Figure 1 can be configured so that the IPs can be reused, thus expanding the system’s capacity to deal with larger grids and iteration counts. By doing so, the stencil pipeline can be scaled in both space and time. Such scaling is required to leverage the processing power of the multiple FPGAs, and to enable the computation of large-size problems that could not be done by a single FPGA due to the lack of resources. Unfortunately, as discussed in the Section V, the size and number of IPs in an FPGA is constrained by the ability of the synthesis tool and designer to make efficient use of the FPGA resources, and this sometimes can become a bottleneck.
V Experimental Results
To evaluate the proposed system, three sets of experiments were performed using the stencil IPs described in Table I. The first set (Section V-A) aimed at evaluating the scalability of the system with respect to the number of FPGAs. For the second set of experiments (Section V-B) the scalability concerning the number of IPs (i.e. number of iterations) was evaluated. Finally, the goal of the third set of experiments was to evaluate FPGA resource utilization. For all experiments, the board used was the Virtex-7 FPGA VC709 Connectivity Kit [24] which contains a Xilinx Virtex-7 XC7VX690T-2FFG1761C FPGA. Compilation of the HDL codes was done using Vivado 2018.3 [25].
Infra-structure issues. The reader must keep in mind that the goal of these experiments was not to show raw performance numbers but to demonstrate the viability and scalability of the proposed programming model. Unfortunately, the infra-structure used in the experiments is not new. They have old Intel Xeon E5410 @2.33GHz CPUs, DDR2 667MHz memories, and archaic PCIe gen1 interfaces, which caused a considerable loss of performance since the FPGA boards use PCIe gen3. Moreover, as detailed in Section V-C, the size of the original TRD kit made it very hard for Vivado to synthesize more IPs per FPGA, thus reducing the number of grid points inside the hardware, and the number of iterations. This harmed the final FPGA utilization and overall performance. However, even under these drawbacks the proposed approach still achieved linear speedups. Therefore, we are confident that after using more modern machines, FPGAs (e.g. U250) and design flow (e.g. Vitis), the resulting performance will be very competitive to that shown in the hand-designed solution of [13], which in some cases surpasses the performance of GTX 980 Ti and P100 GPUs.
| Stencil Name | Grid Size | Iterations | # IPs |
|---|---|---|---|
| Laplace 2D | 4096x512 | 240 | 4 |
| Laplace 3D | 512x64x64 | 240 | 2 |
| Difussion 2D | 4096x512 | 240 | 1 |
| Difussion 3D | 256x32x32 | 240 | 1 |
| Jacobi 9-pt. 2-D | 1024x128 | 240 | 1 |
V-A FPGA Scalability
The FPGA’s scalability experiments were executed with the settings shown in Table II, and varying the number of FPGAs from 1 to 6. The Grid Size column shows the dimensions of the initial grid for each kernel. The more computation a kernel does, the more difficult it was for Vivado to synthesize the design respecting the time constraints. For this reason, the dimensions of the grid at each kernel were adjusted to avoid negative slacks. The Iterations column was set at 240 so that it was possible to execute with all 6 FPGAs. The # IPs column specifies the number of IPs at each FPGA. The number of IPs varies for the same reason as the dimensions of the initial grid. The larger the kernel computation, the smaller the number of IPs Vivado could synthesize within the time constraints. On the other hand, as discussed in Section V-C there is still plenty of hardware to be used before the FPGA runs out of resources, which reinforces the long term potential of the model proposed herein if using a more efficient FPGA design flow like (e.g. U250 and Vitis).
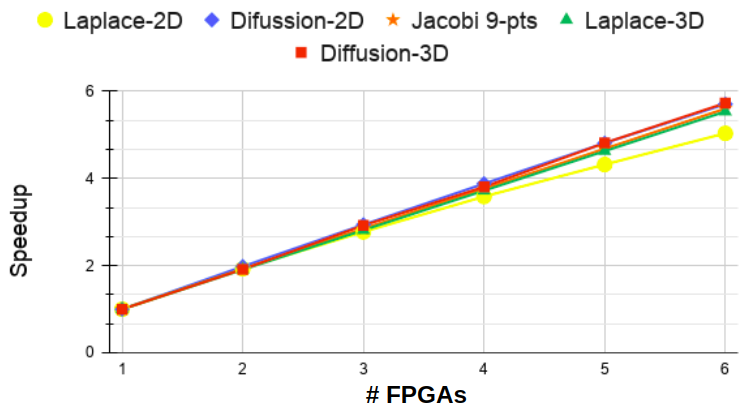
The graph of Figure 6 shows the speedup concerning the execution on a single FPGA, achieved by the various stencil kernels as the number of FPGAs varies on the x-axis. The speedup grows almost linearly with the number of FPGAs for all five kernels. This result shows that it is possible to scale applications using Multi-FPGA architectures by using programming models like the one proposed in this paper to facilitate the design of such systems. The graph of Figure 7 shows, on the y-axis, the number of floating-point operations (GFLOPs) for each kernel as the number of FPGA varies on the x-axis. The Laplace-2D kernel (yellow line) executes more GFLOPs than the other kernels. This is because, although the computation of this kernel is the simplest one, during synthesis, it was possible to insert more IPs (four) per FPGA, which allowed more iteration parallelism as discussed in Section IV. Just below the Laplace-2D is the Laplace-3D (green line), with only 2 IPs per FPGA still managed to sustain a linear performance growth. For the remaining kernels, as they all have only one IP per FPGA, the number of GFLOPs is related to the number of operations executed and the grid’s dimensions. Notice that Diffusion-3D (red line) and Diffusion-2D (blue line) perform less computation than the Jacobi 9-pts (orange line). However, they achieve better GFLOP numbers due to their higher grid dimension, enabling them to take advantage of increased iteration parallelism.
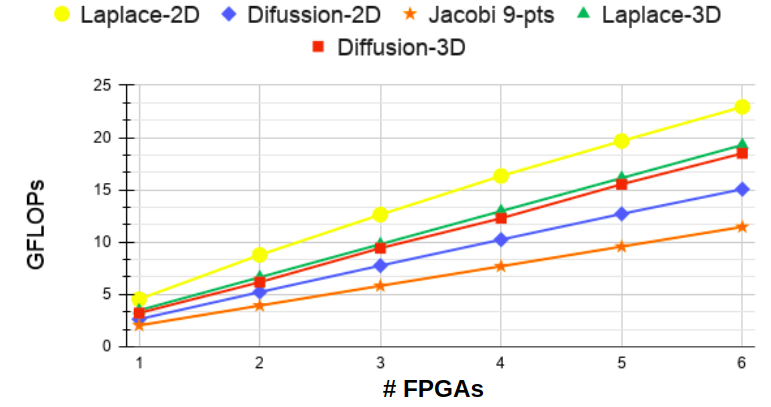
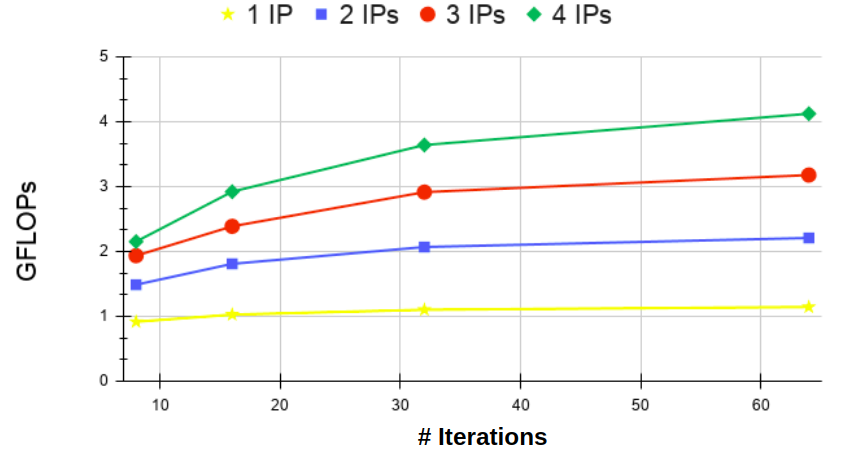
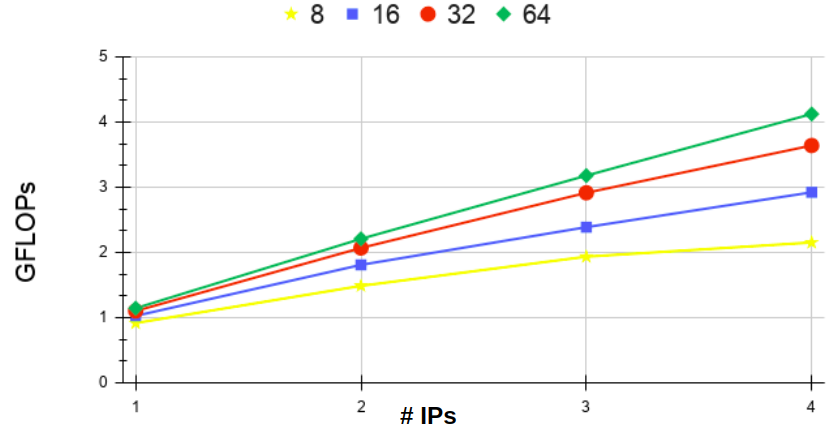
V-B Iteration and IP Scalability
A second experiment was performed to evaluate the IPs’ scalability concerning the number of iterations. The Laplace-2D kernel was used as an example, although similar results have been achieved for the other kernels. The graph in Figure 8 shows, on the y-axis, the number of GFLOPs produced by the system, as the number of iterations varies on the x-axis. The yellow, blue, red, and green lines represent executions with 1, 2, 3, and 4 IPs, respectively. As shown, the execution with a single IP (yellow line) remains practically constant.
On the other hand, the execution with 4 IPs shows an increase in performance until reaching a plateau. The executions with 2 and 3 IPs also show a gradual performance increase. This experiment reveals that by increasing the number of IPs, it is possible to improve the system’s scalability in terms of iterations.
The graph of Figure 9 shows on the y-axis the number of GFLOPs for the Laplace-2D kernel as the number of IPs increase (x-axis). Each line in the graph is a different number of iterations. The graph reinforces the insight revealed in Figure 8: as more IPs are added to the system, the more significantly the increase in the number of iterations improve performance. This can be confirmed by looking at the distances between the lines in Figure 9, which grow larger as the number of IPs increase. This experiment also supports the case for Multi-FPGA architectures.
| Stencil | Slice LUTs | Block RAM | DSP | |||
| # | % | # | % | # | % | |
| Laplace-2D | 12138 | 7,5% | 8 | 0,7% | 16 | 0,4% |
| Diffusion-2D | 25024 | 15,4% | 8 | 0,7% | 80 | 2,2% |
| Jacobi 9-pt | 45733 | 28,3% | 8 | 0,7% | 144 | 4,0% |
| Laplace 3-D | 21790 | 13,5% | 65 | 6,0% | 17 | 0,5% |
| Difussion-2D | 27615 | 17,1% | 23 | 2,1% | 97 | 2,7% |
V-C Resource Utilization
Regarding resource utilization, the graph in Figure 10 shows the percentage of occupancy of the FPGA main components of the proposed infra-structure (not considering the IPs). Remarkably, the DMA/PCIe component occupies 30.2% of the available LUTs. This large utilization is because the DMA/PCIe was designed to support a board with four communication channels, although the proposed approach just requires one. Components MFH, SWITCH, VFIFO, and Network occupy, respectively, 1.7%, 11.5%, 13.2% , and 6.1% of the available LUTs. BRAMs are used by the DMA/PCIe (5.5%), VFIFO (18.3%), and NET (2.4%). The most significant usage of BRAMs comes from VFIFO, which uses it to multiplex and demultiplex the four channels of the virtual FIFO. DSP is the least used component (1%).
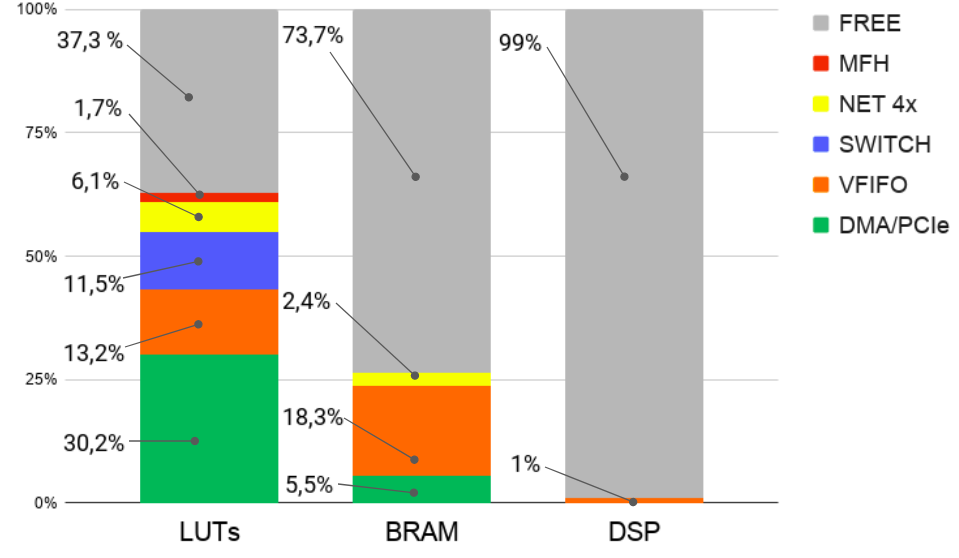
Table III shows the quantity and percentage of the FPGA components used by each IP from the free region (gray area) of Figure 10. The percentage of the available LUTs effectively used by the stencil IPs varies from 7.5% to 28.3%, depending on the complexity of the kernel. As for BRAM, the utilization ranges from 0.7% to 6.0%. This is directly linked to the size of the shift-registers, and is impacted by the size of the grid to be calculated. The number of DSP components used by the IPs varies from 0.4% to 4.0%, and is related to the number of multiplications performed by each kernel. The small utilization of the FPGA resources by the kernels has been previously discussed in the beginning of Section V. Additional work will be done to address these shortcomings.
VI Related Works
This section summarizes the main works found in the literature with proposals for using OpenMP in FPGAs that uses LLVM.
Choi et al [26] uses information provided by pragmas to generate better parallel hardware. The compiler synthesizes one kernel IP per thread in the source program.
Sommer et al [27] uses Vivado HLS to generate hardware for the code regions annotated with OpenMP target directives. Their work fully supports omp target directives (including its map clause). It is also the first work that leverages the LLVM libomptarget library to enable an FPGA synthesis flow.
Ceissler et al [28] describe HardCloud, an OpenMP platform that integrates pre-designed FPGA IPs to an OpenMP program. The authors propose three more clauses to the OpenMP 4.X standard: use, check and module that allow the access of IP’s inputs/outputs directly from OpenMP code.
Knaust et al [29] use Clang [30] to outline omp target regions at the level of the LLVM IR, and feed them into Intel’s OpenCL HLS tool-chain to generate a hardware kernel for the FPGA. Their approach uses Intel’s OpenCL API to allow the communication between host and FPGA.
To the best of our knowledge, and contrary to the previous works, which focused mostly on the synthesis and single FPGA architectures, this paper is the first to enable OpenMP task parallelism to integrate IPs into a Multi-FPGA architecture.
VII Conclusions
This paper proposes to extend the OpenMP task-based computation offloading programming model to enable several FPGAs to work together as a single Multi-FPGA architecture. Experimental results for a set of OpenMP stencil-based applications running on a Multi-FPGA platform consisting of 6 Xilinx VC709 FPGA boards interconnected through fiber-optic links have shown close to linear speedups as the number of FPGAs and IP-cores per FPGA increase.
References
- [1] K. O’Neal and P. Brisk, “Predictive modeling for cpu, gpu, and fpga performance and power consumption: A survey,” in 2018 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), July 2018, pp. 763–768.
- [2] Z. Guo, T. W. Huang, and Y. Lin, “Gpu-accelerated static timing analysis,” in 2020 IEEE/ACM International Conference On Computer Aided Design (ICCAD), 2020, pp. 1–9.
- [3] T. El-Ghazawi, E. El-Araby, M. Huang, K. Gaj, V. Kindratenko, and D. Buell, “The promise of high-performance reconfigurable computing,” Computer, vol. 41, no. 2, pp. 69–76, Feb 2008.
- [4] S. Lee, J. Kim, and J. S. Vetter, “Openacc to fpga: A framework for directive-based high-performance reconfigurable computing,” in 2016 IEEE International Parallel and Distributed Processing Symposium (IPDPS), May 2016, pp. 544–554.
- [5] M. Strickland, “Fpga accelerated hpc and data analytics,” in 2018 International Conference on Field-Programmable Technology (FPT), Dec 2018, pp. 21–21.
- [6] M. Reichenbach, P. Holzinger, K. Häublein, T. Lieske, P. Blinzer, and D. Fey, “Heterogeneous computing utilizing fpgas,” Journal of Signal Processing Systems, vol. 91, no. 7, pp. 745–757, Jul 2019. [Online]. Available: https://doi.org/10.1007/s11265-018-1382-7
- [7] A. M. Caulfield, E. S. Chung, A. Putnam, H. Angepat, J. Fowers, M. Haselman, S. Heil, M. Humphrey, P. Kaur, J. Kim, D. Lo, T. Massengill, K. Ovtcharov, M. Papamichael, L. Woods, S. Lanka, D. Chiou, and D. Burger, “A cloud-scale acceleration architecture,” in 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Oct 2016, pp. 1–13.
- [8] “Amazon EC2 F1 Instances,” https://aws.amazon.com/ec2/instance-types/f1, Nov 2019, [Online; accessed 25. Nov. 2019]. [Online]. Available: https://aws.amazon.com/ec2/instance-types/f1
- [9] J. Cong, Z. Fang, M. Lo, H. Wang, J. Xu, and S. Zhang, “Understanding performance differences of fpgas and gpus: (abtract only),” in Proceedings of the 2018 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, ser. FPGA ’18. New York, NY, USA: ACM, 2018, pp. 288–288. [Online]. Available: http://doi.acm.org/10.1145/3174243.3174970
- [10] W. Jiang, E. H.-M. Sha, X. Zhang, L. Yang, Q. Zhuge, Y. Shi, and J. Hu, “Achieving super-linear speedup across multi-fpga for real-time dnn inference,” ACM Trans. Embed. Comput. Syst., vol. 18, no. 5s, pp. 67:1–67:23, Oct. 2019. [Online]. Available: http://doi.acm.org/10.1145/3358192
- [11] U. Farooq, I. Baig, and B. A. Alzahrani, “An efficient inter-fpga routing exploration environment for multi-fpga systems,” IEEE Access, vol. 6, pp. 56 301–56 310, 2018.
- [12] M. M. Azeem, R. Chotin-Avot, U. Farooq, M. Ravoson, and H. Mehrez, “Multiple fpgas based prototyping and debugging with complete design flow,” in 2016 11th International Design Test Symposium (IDT), Dec 2016, pp. 171–176.
- [13] H. M. Waidyasooriya and M. Hariyama, “Multi-fpga accelerator architecture for stencil computation exploiting spacial and temporal scalability,” IEEE Access, vol. 7, pp. 53 188–53 201, 2019.
- [14] D. M. Kunzman and L. V. Kale, “Programming heterogeneous systems,” in 2011 IEEE International Symposium on Parallel and Distributed Processing Workshops and Phd Forum, May 2011, pp. 2061–2064.
- [15] J. Pu, S. Bell, X. Yang, J. Setter, S. Richardson, J. Ragan-Kelley, and M. Horowitz, “Programming heterogeneous systems from an image processing dsl,” ACM Trans. Archit. Code Optim., vol. 14, no. 3, pp. 26:1–26:25, Aug. 2017. [Online]. Available: http://doi.acm.org/10.1145/3107953
- [16] “OpenMP 4.5 Specifications,” http://www.openmp.org/mp-documents/openmp-4.5.pdf, Accessed on Oct 13, 2019. [Online]. Available: http://www.openmp.org/mp-documents/openmp-4.5.pdf
- [17] B. Chapman, G. Jost, and R. Van Der Pas, Using OpenMP: Portable Shared Memory Parallel Programming. MIT press, 2008, vol. 10.
- [18] “OpenMP 3.0 Specifications,” https://www.openmp.org/wp-content/uploads/spec30.pdf, Accessed on Oct 13, 2019. [Online]. Available: https://www.openmp.org/wp-content/uploads/spec30.pdf
- [19] R. Budruk, D. Anderson, and E. Solari, PCI Express System Architecture. Pearson Education, 2003.
- [20] C. Lattner and V. Adve, “Llvm: A compilation framework for lifelong program analysis & transformation,” in Proceedings of the International Symposium on Code Generation and Optimization: Feedback-directed and Runtime Optimization, ser. CGO ’04. Washington, DC, USA: IEEE Computer Society, 2004, pp. 75–. [Online]. Available: http://dl.acm.org/citation.cfm?id=977395.977673
- [21] C. Bertolli, S. F. Antao, G.-T. Bercea, A. C. Jacob, A. E. Eichenberger, T. Chen, Z. Sura, H. Sung, G. Rokos, D. Appelhans, and K. O’Brien, “Integrating gpu support for openmp offloading directives into clang,” in Proceedings of the Second Workshop on the LLVM Compiler Infrastructure in HPC, ser. LLVM ’15. New York, NY, USA: ACM, 2015, pp. 5:1–5:11. [Online]. Available: http://doi.acm.org/10.1145/2833157.2833161
- [22] “Axi4-stream interconnect v1.1 logicore ip product guide (pg035).” [Online]. Available: https://www.xilinx.com/support/documentation/ip_documentation/axis_interconnect/v1_1/pg035_axis_interconnect.pdf
- [23] G. Roth, J. Mellor-Crummey, K. Kennedy, and R. G. Brickner, “Compiling stencils in high performance fortran,” in Proceedings of the 1997 ACM/IEEE Conference on Supercomputing, ser. SC ’97. New York, NY, USA: Association for Computing Machinery, 1997, p. 1–20. [Online]. Available: https://doi.org/10.1145/509593.509605
- [24] “Xilinx virtex-7 fpga vc709 connectivity kit,” https://www.xilinx.com/products/boards-and-kits/dk-v7-vc709-g.html, (Accessed on 11/11/2020).
- [25] “Vivado design suite user guide: Release notes, installation, and licensing (ug973),” (Accessed on 11/16/2020).
- [26] J. Choi, S. Brown, and J. Anderson, “From software threads to parallel hardware in high-level synthesis for fpgas,” in 2013 International Conference on Field-Programmable Technology (FPT), Dec 2013, pp. 270–277.
- [27] L. Sommer, J. Korinth, and A. Koch, “Openmp device offloading to fpga accelerators,” in 2017 IEEE 28th International Conference on Application-specific Systems, Architectures and Processors (ASAP), July 2017, pp. 201–205.
- [28] C. Ceissler, R. Nepomuceno, M. Pereira, and G. Araujo, “Automatic offloading of cluster accelerators,” in 2018 IEEE 26th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), April 2018, pp. 224–224.
- [29] M. Knaust, F. Mayer, and T. Steinke, “Openmp to fpga offloading prototype using opencl sdk,” in 2019 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), May 2019, pp. 387–390.
- [30] LLVM Project. (2007) Clang: a C language family frontend for LLVM. [Online]. Available: https://clang.llvm.org/