Enabling Multi-threading in Heterogeneous Quantum-Classical Programming Models
Abstract
While quantum computers enable significant performance improvements for certain classes of applications, building a well-defined programming model has been a pressing issue. In this paper, we address some of the key limitations to realizing a generic heterogeneous parallel programming model for quantum-classical heterogeneous platforms. We discuss our experience in enabling user-level multi-threading in QCOR [1] as well as challenges that need to be addressed for programming future quantum-classical systems.
Specifically, we discuss our design and implementation of introducing C++-based parallel constructs to enable 1) parallel execution of a quantum kernel with std::thread and 2) asynchronous execution with std::async. To do so, we provide a detailed overview of the current implementation of the QCOR programming model and runtime, and discuss how we add 1) thread-safety to some of its user-facing API routines, and 2) increase parallelism in QCOR by removing data races that inhibit multi-threading so as to better utilize available computing resources.
We also present preliminary performance results with the Quantum++ [2] back end on a single-node Ryzen9 3900X machine that has 12 physical cores (24 hardware threads) with 128GB of RAM. The results show that running two Bell kernels with 12 threads per kernel in parallel outperforms running the kernels one after the other each with 24 threads (1.63 improvement). In addition, we observe the same trend when running two Shor’s algorthm kernels in parallel (1.22 faster than executing the kernels one after the other). Furthermore, the parallel version is better in terms of strong scalability.
We believe that our design, implementation, and results will open up an opportunity not only for 1) enabling quicker prototyping of parallel-aware quantum-classical algorithms on quantum circuit simulators in the short-term, but also for 2) realizing a generic parallel programming model for quantum-classical heterogeneous platforms in the long-term.
Index Terms:
Quantum-Classical Programming Models, Parallel Programming Models, QCOR, Heterogeneous ComputingI Introduction
Quantum computing is a rapidly evolving field that leverages the laws of quantum mechanics for computation. Since near-term quantum computers are susceptible to significant levels of noise, a hybrid combination of classical computers and quantum computers, namely quantum-classical computers, is explored to mitigate noise while achieving orders-of-magnitude performance improvements for certain classes of applications. Such a hybrid combination can be viewed as one realization of heterogeneous computing where different types of processing elements, including special purpose accelerators, simultaneously and asynchronously work together.
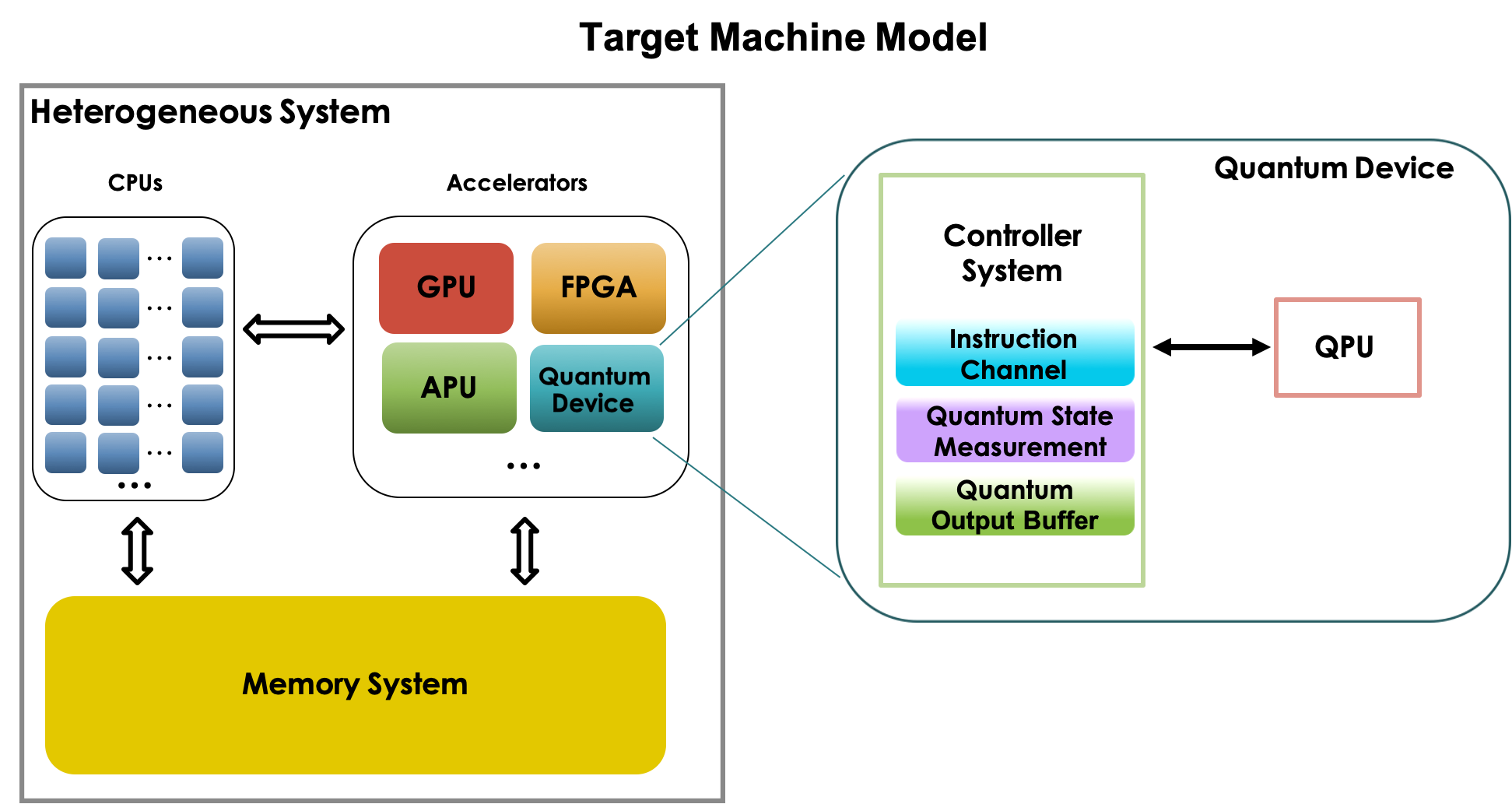
QCOR [1] is a programming system to realize such a heterogeneous quantum-classical model. It is based on the C++-based programming language and a compiler that is built on top of XACC [4] As shown in Figure 1, QCOR’s target machine is a heterogeneous system where multiple CPUs (cores) are connected with quantum devices and other accelerators such as GPUs and FPGAs.
To program quantum devices in QCOR, the user writes a quantum kernel (i.e., a function that will be executed on a quantum device) in quantum computing domain-specific languages (DSLs), such as XACC’s XASM or IBM’s OpenQASM [5]. Similar to other GPU-based heterogeneous programming models such as CUDA [6], SYCL [7], and OpenCL [8], QCOR allows the user to write quantum kernels and CPU control code in the same program. This single-source programming model greatly facilitates quantum-classical programming.
However, one open research question for QCOR and other quantum DSLs is how to provide well-defined, user-level multi-threading support. Specifically, as the machine model in Figure 1 implies, it is possible that multiple CPU cores might simultaneously utilize one or more quantum devices. Currently, there is no user-facing API-level support for multi-threading in quantum-classical programming models like QCOR and DSLs like OpenQASM, although it is typical to internally use multi-threading for accelerating quantum circuit simulations [2, 9, 10, 11].
In this paper, we explore the possibility of enabling user-level multi-threading in QCOR, which enables coarser grain parallelism in quantum-classical programming models. We believe this is an important step towards realizing an end-to-end heterogeneous programming system that can work on general heterogeneous platforms that include quantum computers. This work makes the following key contributions:
-
•
Design and implementation of multi-threading support for a heterogeneous quantum-classical programming model.
-
•
Discussion of scenarios and use cases where user-level multi-threading is beneficial for near-term quantum systems.
-
•
A demonstration which shows that running two quantum kernels in parallel using -threads for each kernel outperforms running the kernel one-by-one using -threads, by factors of 1.22 to 1.63 for the evaluated kernels.
II Motivation
This section highlights our motivation for enabling user-level multi-threading in quantum-classical computing by discussing potential parallelism in quantum-classical programs.
Let us use Shor’s algorithm as a motivating example. In Algorithm 1, Shor is a quantum-classical task that invokes the period-finding quantum kernel (ShorKernel) to estimate exponent . Notice that Shor can be called multiple times until one or more (non-)trivial divisors are found or the entire search space is explored.
From the perspective of parallel processing, one possibility of parallelizing this algorithm is to run multiple instances of Shor in parallel. Furthermore, since it can require multiple shots to find , it would be also possible to further parallelize the shot loop in Shor (Line 13). Finally, if the ShorKernel is executed on a simulator, there is a massive amount of parallelism as in [2, 9, 10, 11]. Algorithm 2 is a pseudo-parallel version of Algorithm 1. As in the X10 language [12], async represents parallel task creation and execution and foreach represents parallel loop creation and execution.
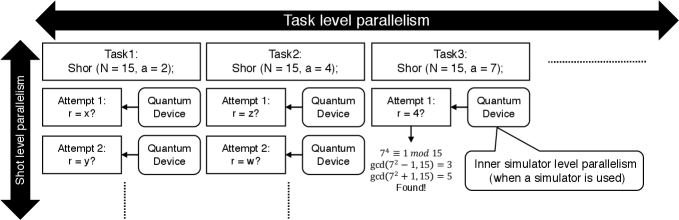
Figure 2 graphically illustrates the potential parallelism in Shor’s algorithm across these three levels. Based on what we discussed for Algorithm 2 and observe in Figure 2, we identify the following multiple levels of parallelism in quantum-classical programs:
Task level parallelism: multiple independent classical tasks that can include quantum kernels are executed in parallel.
Shot level parallelism: multiple independent shots are executed in parallel.
Inner simulator level parallelism: quantum simulators, including state vector and tensor network simulators such as [2, 9, 10, 11], are typically parallelized using OpenMP, CUDA, and the Eigen library to utilize a massive amount of parallelism on CPUs and/or GPUs.
It is worth noting that the actual amount of available parallelism depends not only on algorithms but also on the simulated or physical quantum back ends that are targeted. One example would be when a user executes their program on a current-day single QPU system in which there would be limited parallelism due to the lack of additional physical hardware. However, in most cases, we believe that allowing the user to specify all available parallelism for a quantum-classical task will greatly enhance the performance and expressiveness of quantum-classical programs because there are plenty of computing resources (CPUs, GPUs, and FPGAs) that can accelerate the development of quantum-classical algorithms even on conventional systems.
Thus, we believe that enabling user-level multi-threading in quantum-classical programming models will 1) accelerate the development of a quantum-classical algorithm, and 2) facilitate porting an existing heterogeneous algorithm to a quantum-classical one. It is also worth noting that the goal of this work is not optimizing and fine-tuning quantum-classical parallel programs for a specific target system. Instead, we look to motivate and introduce concrete parallel programming constructs (std::thread and std::async) for quantum-classical programming models.
III QCOR
QCOR is a C++-based high-level quantum-classical programming model. One of the key features of QCOR is that the user can write both quantum and classical kernels and functions in the same code. This feature is not only analogous to existing heterogeneous programming models such as CUDA, OpenCL, and SYCL, but it also also provides a new programming model for heterogeneous quantum-classical computing programs that achieve hybrid quantum-classical workflows. As shown in the machine model in Figure 1, in theory, the user is free to leverage different kinds of processors (e.g., CPUs, GPUs, FPGAs, Quantum Devices) that could all be enabled through a QCOR-style programming model.
1 shows an example of QCOR program that executes the Bell kernel. First, on Line 13, the qalloc API is called to allocate 2-qubits. Then, the kernel written in XASM is invoked on Line 15. Notice that the kernel is defined on Line 3 - 10. After the kernel is invoked, the measurement results can be inspected by printing the content of the quantum register as shown on Line 17. An example output of the QCOR program can be found in 2.
In addition to the simple quantum circuit simulation above, for completeness, we would like to emphasize that QCOR is expressive enough to write a wide variety of quantum-classical algorithms such as the variational quantum eigensolver (VQE) and the Quantum Approximate Optimization Algorithm (QAOA). 3 shows a VQE implementation in QCOR. Note that createObjectiveFunction and createOptimizer are built-in QCOR helper functions that facilitate creating and invoking a classical optimizer with a user-defined objective function with the Deuteron Hamiltonian and the ansatz kernel. More details can be found in [1, 3].
IV Design
IV-A Multi-threading Design Overview
Since QCOR is primarily written in C++, we look to enable user-level multi-threading in QCOR in a way that is acceptable to both QCOR and C++ programmers. For QCOR programmers, our goal is to minimize modifications to the code required for enabling multi-threading. For C++ programmers, our goal is to provide a threading interface that is natural to use. To that end, we leverage C++’s standard threading constructs (std::thread and std::async). However, in terms of general applicability, our discussions should apply to other parallel programming systems for C++, such as OpenMP [13], Kokkos [14], and RAJA [15].
Our current focus is on enabling coarse-grain parallelism to exploit the full capability of a CPU-QPU system. In one scenario, the user would like a one-to-one relation between a CPU and a QPU to simultaneously perform independent tasks, where is the number of CPU-QPU pairs. Another scenario might be a one-to-many/many-to-one relation between CPU(s) and QPU(s). It is worth noting that the QPU part is not necessarily a hardware QPU device. Since QCOR offers different backends, the QPU part can be a quantum circuit simulation on either a local machine or a cloud service and can also incorporate coarser tasks such as VQE.
IV-B User-Facing API
IV-B1 std::thread
4 shows an example where two threads simultaneously run the Bell kernel using thread. The main function creates two threads (t0 and t1), each of which executes the foo function. In the foo function, it first allocates 2-qubits using qalloc, then invokes the kernel written in XASM in Line 3 - 10, and finally gets the results. This approach enables the user to overlap other work on the main thread with the two threads. Also, the main function can wait on each thread by calling join().
IV-B2 std::async
Another example (5) is asynchronous execution where the main function asynchronously launches the foo() function with async. Similar to the thread example, the user may want to overlap other work with the launched task. However, one interesting difference is that async returns a future object, which helps the user to check the status of the asynchronously launched task and take further action depending on the return value of the task (get()).
IV-C Enabling Thread Safety
Thread safety is usually attributed to a function/routine that can be safely invoked by multiple threads simultaneously. It is very common that thread safety is guaranteed in conventional heterogeneous programming models such as CUDA, OpenCL, and SYCL. For example, the SYCL specification [16] describes this in the following manner: “SYCL guarantees that all the member functions and special member functions of the SYCL classes described are thread safe.”
It is worth noting that enabling thread safety does not necessarily mean improving performance because it essentially prevents multiple threads from simultaneously accessing shared data. In this work, our first priority is to enable thread safety for QCOR’s user-facing API. For portions where parallelization is important, we explore the possibility of increasing parallelism in Section V.
V Implementation
This section discusses how we enable user-level multi-threading in QCOR and XACC.
Since the QCOR and XACC systems include over 200K lines of code written in modern C++, we focus on discussing a few common cases that can possibly inhibit user-level multi-threading. Essentially, these cases are focused on identifying potential sources of data races when multi-threading is added.
V-A Identifying sources of data races
V-A1 Global Variables
Global variables are the most common source of data races because these variables can be accessed simultaneously by multiple threads. The following is a global std::map object that is used to implement qalloc().
// global variable
map<string, shared_ptr<AcceleratorBuffer>>
allocated_buffers{};
Because qalloc() internally invokes map’s insert(), which is not thread-safe, concurrent invocations of qalloc() can be problematic.
V-A2 Services
QCOR depends on different software components provided by QCOR itself and XACC. Typically, xacc::getService<T>(...) is used to obtain a shared pointer to a specific service, namely T in this example. For services that do not derive xacc::Cloneable, the xacc::getService<T>(...) always returns a pointer to the same instance, which can be another source of a data race. The following is an example where a pointer to the qpp accelerator, a software simulator in QCOR/XACC (i.e., Quamtum++[2]), which is used to run the Bell kernel in 4 and 5, is stored into acc.
shared_ptr<Accelerator> acc; // a local variable
acc = xacc::getService<Accelerator>("qpp", ...);
Because Accelerator is not Cloneable, getService<Accelerator>(...) always returns the same qpp instance. This can cause a data collision since multiple threads can simultaneously register their gates to the same accelerator and can thus end up simulating an erroneous circuit.
V-B Implementation Details
In general, we pursue the following two approaches to remove data races that inhibit multi-threading in QCOR and XACC: 1) enabling thread safety and 2) increasing parallelism. The former goal is achieved by adding safety to multi-threaded execution with mutex locks. The latter approach explores the possibility of leveraging multi-threading to accelerate user programs.
V-B1 Enabling thread-safety
For enabling thread-safety, we leverage std::mutex or std::recursive_mutex to enable mutual exclusions. For example, 6 shows qalloc(), which has a non-thread-safe call in Line 5. We first create a mutex object in the global scope, and then the object is used to create a critical section with std::lock_guard.
V-B2 Increasing Parallelism
For increasing parallelism, we use a quantum accelerator object (qpu) as a motivating example. In the original implementation, as shown in 7, the qpu object is declared as a global variable and is initialized by calling xacc::getAccelerator(), which internally calls xacc::getService<Accelerator>(). Thus, this example includes the two data race scenarios discussed above in Section V-A.
We remove the data races by i) making Accelerator cloneable to create different instances every time xacc::getAccelerator() is called, and ii) providing a map that maps a current thread ID to the corresponding accelerator object, the latter of which is called QPUManager.
8 shows a brief overview of QPUManager. QPUManager is implemented by using the singleton pattern and contains the setter and getter functions. The setter function takes the return variable of xacc::getAccelerator() and registers the accelerator instance along with a current thread id to the map. Similarly, the getter function returns a qpu instance that corresponds to a current thread.
V-C Current Implementation Status
We have implemented these changes to enable thread-safety for QCOR and have created a pull request against the QCOR [17], QCOR_SPEC [18], and XACC [19] repositories. For increasing multi-threaded parallelism, we have confirmed that the examples (4 and 5) and Shor’s kernel work in a parallel fashion, and we plan to create another pull request to share that functionality.
One small limitation of our implementation is that the user needs to manually call quantum::initialize() API at the beginning of each thread so the runtime can register its thread ID to the QPUManager. In the future, we plan to create a compiler pass that automatically inserts this API call. Alternatively, we could provide qcor::thread and qcor::async wrappers for the original C++ constructs that internally call this initialization function.
VI Preliminary Performance Evaluation
This section presents the results of an empirical evaluation of our extended QCOR programming model and runtime implementation on a single-node platform to demonstrate its performance benefits.
Purposes: The goal of our evaluation is two-fold:
-
1.
to demonstrate that our extended QCOR programming model and runtime system with C++ threading model enables parallel quantum kernel execution.
-
2.
to demonstrate that enabling parallel quantum kernel execution is beneficial in terms of performance.
Platform: We present the performance results on a single-node AMD server, which consists of a 12-core, 24-thread Ryzen9 3900X CPu running at 3.8GHz with 128GB of DRAM.
Quantum Kernels:
We use the following quantum kernels written in XASM:
Experimental variants: For kernel simulations, we use the QppAccelerator backend in QCOR, which uses the Quantum++ library [2].
We compare the following two variants in terms of performance:
-
1.
One-by-One (baseline, conventional): Run the first kernel with -threads and then run the second kernel with -threads.
-
2.
Parallel: Run the two kernels in parallel, each of which uses -threads.
Note that each kernel is executed on multiple physical cores/threads even in the baseline version because Quantum++ uses OpenMP [13]. For both variants, we appropriately set the OMP_NUM_THREADS parameter to specify the number of threads per kernel. However, tuning this parameter for the best performance is beyond the scope of this paper. Instead, our goal is to study scenarios where running multiple quantum kernels simultaneously could lead to performance benefits. Finally, note that shot-level parallelism is not exploited in these versions.
VI-A Impact of Parallel Kernel Execution
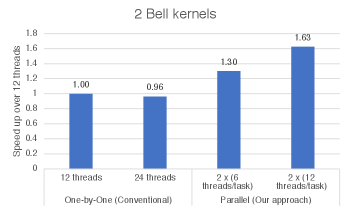
Figure 3 and Figure 4 show relative performance improvements over the baseline execution (one-by-one execution with 12-threads). In one-by-one execution, increasing the number of threads from 12 threads to 24 threads does not improve performance. In contrast, parallel execution of the two kernels enables further performance improvements -i.e., 1.63 for the Bell kernel and 1.22 for Shor’s kernel. Based on an analysis of this kernel using AMD Prof, we observe that increasing the number of threads increases L1 data cache-related performance counter numbers such as L1_DC_MISSES. L1 misses get significantly worse, particularly when increasing the number of threads from 12 to 24, which is why the parallel 12 thread per task version is faster than the original version.
VI-B Strong Scalability Study
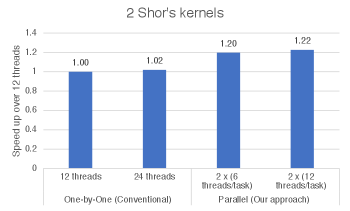
Figure 5 shows strong scalability of two Shor’s kernels with the one-by-one and the parallel approaches. The numbers are relative performance improvements over the single-threaded one-by-one execution. While both approaches show good scalability, the parallel version always outperforms the baseline.
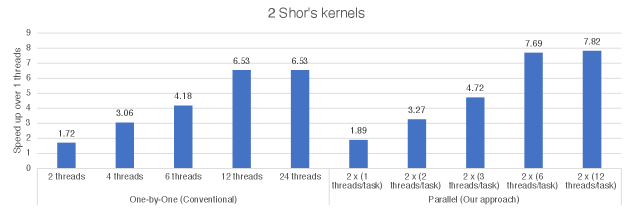
VII Discussion
As shown in Section VI, we demonstrated a scenario where running multiple kernels simultaneously is beneficial. The goal of this section is to summarize difference application scenarios that we believe are good candidates for user-level multi-threading:
Shor’s algorithm: As we discussed in Section II, suppose we factorize using Shor’s algorithm, we can create parallel tasks with a random number s.t. and , each of which invokes Shor’s kernel to estimate and checks if is even and in parallel. Algorithm 2 summarizes the parallel algorithm and Figure 4 shows that running two Shor’s kernels in parallel outperforms one-by-one execution. We anticipate that the performance improvement will be more significant if CPUs with more cores and GPUs are used for simulating Shor’s circuit.
VQE: VQE [21] optimizes a (Hamiltonian ) cost function over a parameterized manifold of quantum states as . For QMA-hard Hamiltonians, dim is large but for many interesting models in physical sciences dim may scale (sub-)polynomially, in which case the optimization problem at hand may still be quite challenging. The pleasantly parallel nature of the optimization process can be utilized with multiple asynchronous quantum kernel instances minimizing over -space.
Asynchronous Quantum JIT Compilation: Shi et al. [22] discusses a scenario where a GPU is used to compile and optimize quantum circuits, which can take several hours. With user-level multi-threading enabled, it is possible to avoid blocking computing resources by asynchronously offloading a compilation task onto a GPU and launching the compiled kernel on a QPU only when it is ready.
Parallel Quantum-Classical Workflow: As generalizations of different parallel execution scenarios discussed above, one can write an entire workflow in which different tasks run on different processing units including CPUs, QPUs, GPUs, and FPGAs.
VIII Related Work
While domain-specific languages (DSLs) for quantum computing significantly facilitate the development of quantum algorithms, many DSLs only focus on the kernel part and do not provide a system-wide programming model. We believe that such a system-wide programming model will become more important in quantum-classical computing because exploiting classical parallelism such as thread-level parallelism can improve end-to-end performance as discussed in Section VI. Here, we briefly discuss existing programming models from the viewpoint of classical parallelism on non-quantum devices.
Qiskit [23] has been one of the most popular programming frameworks for quantum computing. However, it is not appropriate to directly map Qiskit programs to quantum-classical systems unless there is an AOT/JIT-level smart compiler that is aware of the underlying parallel hardware because the Global Interpreter Lock (GIL) may hinder Python-level multi-threaded execution.
Q# is a programming language designed to express hybrid quantum-classical algorithms [24]. Currently, there is no way to express the concept of threads in the Q# language itself [25], nor in the Q# standard library [26]. Additionally, QIR (Quantum Intermediate Representation), a hybrid quantum-classical IR based on LLVM IR that is generated by the Q# compiler front-end, does not explicitly guarantee thread-safety for any runtime functions [27]. Indeed, the reference QIR runtime [28] may exhibit data races if used in multi-threaded code. It is worth noting that QParallel [29] allows the user to explicitly express parallelism in the quantum kernel part, not in the classical part.
Other newer platforms for hybrid quantum-classical computing have been proposed like NVIDIA’s QODA [30], which is designed for the simulation of quantum circuits with GPUs and QPUs. It is unclear what multi-threaded support model QODA uses as it is a proprietary product.
IX Conclusions and Future Work
This paper explores the possibility of enabling user-level multi-threading in QCOR. We made enhancements to QCOR to support C++-based parallel and asynchronous execution of quantum kernels by 1) adding thread safety to QCOR API routines, and 2) increase parallelism by removing data races that inhibit multi-threading.
Our preliminary results with the Bell and Shor’s algorithm kernels show that enabling user-level multi-threading gives us performance improvements over the conventional baseline version in which each kernel is still executed by multiple threads, but is executed one-by-one.
We believe this multi-threading design for heterogeneous quantum-classical programming models will open up an opportunity for rapidly prototyping and developing quantum-classical programs on conventional systems in the short-term. At the same time, we envision that this initial design would be a good starting point for longer-term explorations of heterogeneous programming systems for future quantum-classical systems.
In future work, we plan to run other quantum-classical tasks, such as VQE, with additional quantum simulation and physical back ends and also use different back ends to demonstrate where user-level multi-threading is most beneficial.
Acknowledgement
We acknowledge DOE ASCR funding under the Quantum Computing Application Teams program, FWP number ERKJ347. We also acknowledge support for this work from NSF planning grant #2016666, “Enabling Quantum Computer Science and Engineering”.
References
- [1] T. M. Mintz, A. J. McCaskey, E. F. Dumitrescu, S. V. Moore, S. Powers, and P. Lougovski, “Qcor: A language extension specification for the heterogeneous quantum-classical model of computation,” J. Emerg. Technol. Comput. Syst., vol. 16, no. 2, mar 2020. [Online]. Available: https://doi.org/10.1145/3380964
- [2] V. Gheorghiu, “Quantum++: A modern c++ quantum computing library,” PLOS ONE, vol. 13, no. 12, pp. 1–27, 12 2018. [Online]. Available: https://doi.org/10.1371/journal.pone.0208073
- [3] Oak Ridge National Laboratory Quantum Computing Institute, “QCOR Specification,” https://github.com/ORNL-QCI/qcor_spec, 2022.
- [4] A. J. McCaskey, D. I. Lyakh, E. F. Dumitrescu, S. S. Powers, and T. S. Humble, “XACC: a system-level software infrastructure for heterogeneous quantum–classical computing,” Quantum Science and Technology, vol. 5, no. 2, p. 024002, feb 2020. [Online]. Available: https://doi.org/10.1088%2F2058-9565%2Fab6bf6
- [5] A. Cross, A. Javadi-Abhari, T. Alexander, N. de Beaudrap, L. S. Bishop, S. Heidel, C. A. Ryan, P. Sivarajah, J. Smolin, J. M. Gambetta, and B. R. Johnson, “OpenQASM 3: A broader and deeper quantum assembly language,” ACM Transactions on Quantum Computing, mar 2022. [Online]. Available: https://doi.org/10.1145%2F3505636
- [6] J. Nickolls, I. Buck, M. Garland, and K. Skadron, “Scalable parallel programming with cuda: Is cuda the parallel programming model that application developers have been waiting for?” Queue, vol. 6, no. 2, p. 40–53, mar 2008. [Online]. Available: https://doi.org/10.1145/1365490.1365500
- [7] Khronos Group, “SYCL Overview,” https://www.khronos.org/sycl/, 2022.
- [8] ——, “OpenCL Overview,” https://www.khronos.org/opencl/, 2022.
- [9] Y. Suzuki, Y. Kawase, Y. Masumura, Y. Hiraga, M. Nakadai, J. Chen, K. M. Nakanishi, K. Mitarai, R. Imai, S. Tamiya, T. Yamamoto, T. Yan, T. Kawakubo, Y. O. Nakagawa, Y. Ibe, Y. Zhang, H. Yamashita, H. Yoshimura, A. Hayashi, and K. Fujii, “Qulacs: a fast and versatile quantum circuit simulator for research purpose,” Quantum, vol. 5, p. 559, Oct. 2021. [Online]. Available: https://doi.org/10.22331/q-2021-10-06-559
- [10] T. Vincent, L. J. O’Riordan, M. Andrenkov, J. Brown, N. Killoran, H. Qi, and I. Dhand, “Jet: Fast quantum circuit simulations with parallel task-based tensor-network contraction,” Quantum, vol. 6, p. 709, May 2022. [Online]. Available: https://doi.org/10.22331/q-2022-05-09-709
- [11] T. Häner, D. S. Steiger, M. Smelyanskiy, and M. Troyer, “High performance emulation of quantum circuits,” in SC ’16: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2016, pp. 866–874.
- [12] P. Charles, C. Grothoff, V. Saraswat, C. Donawa, A. Kielstra, K. Ebcioglu, C. von Praun, and V. Sarkar, “X10: An object-oriented approach to non-uniform cluster computing,” vol. 40, no. 10, p. 519–538, oct 2005. [Online]. Available: https://doi.org/10.1145/1103845.1094852
- [13] L. Dagum and R. Menon, “Openmp: An industry-standard api for shared-memory programming,” IEEE Comput. Sci. Eng., vol. 5, no. 1, pp. 46–55, Jan. 1998. [Online]. Available: https://doi.org/10.1109/99.660313
- [14] C. R. Trott, D. Lebrun-Grandié, D. Arndt, J. Ciesko, V. Dang, N. Ellingwood, R. Gayatri, E. Harvey, D. S. Hollman, D. Ibanez, N. Liber, J. Madsen, J. Miles, D. Poliakoff, A. Powell, S. Rajamanickam, M. Simberg, D. Sunderland, B. Turcksin, and J. Wilke, “Kokkos 3: Programming model extensions for the exascale era,” IEEE Transactions on Parallel and Distributed Systems, vol. 33, no. 4, pp. 805–817, 2022.
- [15] D. Beckingsale, R. Hornung, T. Scogland, and A. Vargas, “Performance portable c++ programming with raja,” in Proceedings of the 24th Symposium on Principles and Practice of Parallel Programming, ser. PPoPP ’19. New York, NY, USA: Association for Computing Machinery, 2019, p. 455–456. [Online]. Available: https://doi.org/10.1145/3293883.3302577
- [16] Khronos Group, “SYCL 2020 Specification,” https://registry.khronos.org/SYCL/specs/sycl-2020/html/sycl-2020.html, 2022.
- [17] Hayashi, Akihiro, “Initial Thread-Safe Implementation,” https://github.com/qir-alliance/qcor/pull/157, 2021.
- [18] Young, Jeffrey and Hayashi, Akihiro, “Runtime section, multi-threaded support, reorganization of exec model,” https://github.com/ORNL-QCI/qcor_spec/pull/9, 2021.
- [19] Hayashi, Akihiro, “Initial Thread-Safe Implementation,” https://github.com/eclipse/xacc/pull/455, 2021.
- [20] S. Beauregard, “Circuit for shor’s algorithm using 2n+3 qubits,” Quantum Info. Comput., vol. 3, no. 2, p. 175–185, mar 2003.
- [21] A. Peruzzo, J. McClean, P. Shadbolt, M.-H. Yung, X.-Q. Zhou, P. J. Love, A. Aspuru-Guzik, and J. L. O’Brien, “A variational eigenvalue solver on a photonic quantum processor,” Nature Communications, vol. 5, no. 4213, Jul 2014. [Online]. Available: http://dx.doi.org/10.1038/ncomms5213
- [22] Y. Shi, N. Leung, P. Gokhale, Z. Rossi, D. I. Schuster, H. Hoffmann, and F. T. Chong, “Optimized compilation of aggregated instructions for realistic quantum computers,” in Proceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems, ser. ASPLOS ’19. New York, NY, USA: Association for Computing Machinery, 2019, p. 1031–1044. [Online]. Available: https://doi.org/10.1145/3297858.3304018
- [23] A. tA-v et al., “Qiskit: An open-source framework for quantum computing,” 2021.
- [24] K. Svore, A. Geller, M. Troyer, J. Azariah, C. Granade, B. Heim, V. Kliuchnikov, M. Mykhailova, A. Paz, and M. Roetteler, “Q#: Enabling Scalable Quantum Computing and Development with a High-level DSL,” in Proceedings of the Real World Domain Specific Languages Workshop 2018. New York, NY, USA: Association for Computing Machinery, Feb. 2018, pp. 1–10. [Online]. Available: https://doi.org/10.1145/3183895.3183901
- [25] Microsoft, “Q# Language Specification,” https://github.com/microsoft/qsharp-language/tree/main/Specifications/Language, 2022.
- [26] ——, “Microsoft Quantum Development Kit Libraries,” https://github.com/microsoft/QuantumLibraries/, 2022.
- [27] QIR Alliance, “Quantum Intermediate Representation (QIR) Specification,” https://github.com/qir-alliance/qir-spec/tree/main/specification, 2022.
- [28] Microsoft, “The Native QIR Runtime,” https://github.com/microsoft/qsharp-runtime/tree/main/src/Qir/Runtime, 2022.
- [29] T. Häner, V. Kliuchnikov, M. Roetteler, M. Soeken, and A. Vaschillo, “Qparallel: Explicit parallelism for programming quantum computers,” 2022. [Online]. Available: https://arxiv.org/abs/2210.03680
- [30] NVIDIA, “NVIDIA QODA: The Platform for Hybrid Quantum-Classical Computing,” https://developer.nvidia.com/qoda, 2022.