Electromagnetic Property Sensing and Channel Reconstruction Based on Diffusion Schrödinger Bridge in ISAC
Abstract
Integrated sensing and communications (ISAC) has emerged as a transformative paradigm for next-generation wireless systems. In this paper, we present a novel ISAC scheme that leverages the diffusion Schrödinger bridge (DSB) to realize the sensing of electromagnetic (EM) property of a target as well as the reconstruction of the wireless channel. The DSB framework connects EM property sensing and channel reconstruction by establishing a bidirectional process: the forward process transforms the distribution of EM property into the channel distribution, while the reverse process reconstructs the EM property from the channel. To handle the difference in dimensionality between the high-dimensional sensing channel and the lower-dimensional EM property, we generate latent representations using an autoencoder network. The autoencoder compresses the sensing channel into a latent space that retains essential features, which incorporates positional embeddings to process spatial context. The simulation results demonstrate the effectiveness of the proposed DSB framework, which achieves superior reconstruction of the target’s shape, relative permittivity, and conductivity. Moreover, the proposed method can also realize high-fidelity channel reconstruction given the EM property of the target. The dual capability of accurately sensing the EM property and reconstructing the channel across various positions within the sensing area underscores the versatility and potential of the proposed approach for broad application in future ISAC systems.
Index Terms:
Electromagnetic (EM) property sensing, channel reconstruction, integrated sensing and communications (ISAC), diffusion Schrödinger bridge (DSB), generative artificial intelligence (GAI)I Introduction
Integrated sensing and communications (ISAC) has recently garnered considerable attention from both academic and industrial experts, particularly due to its promising implications for the sixth-generation (6G) wireless networks [1, 2]. Unlike the conventional frequency-division sensing and communications (FDSAC) paradigm, which necessitates distinct frequency bands and infrastructure for each operational function, ISAC enables the simultaneous sharing of time, frequency, power, and hardware resources for both communications and sensing functionalities. It is anticipated that ISAC will surpass FDSAC in terms of spectrum efficiency, energy conservation, and hardware demands [3, 4, 5]. Moreover, ISAC has the potential to be integrated with other innovative technologies, such as reconfigurable intelligent surfaces (RISs), to augment the efficacy of sensing and communications systems [6]. Given its myriad advantages, ISAC is expected to play a pivotal role in various emerging applications [7, 8, 9], including digital twins that effectively bridge the physical world with its virtual equivalent in the communications domain [10]. In contrast to image-centric digital twins that prioritize shape and spatial orientation, digital twins designed for communications systems are responsible for the complex reconstruction of communications pathways and the management of channel-specific issues.
Electromagnetic (EM) property sensing represents a groundbreaking advancement in ISAC systems, which leverages the unique property of EM waves to simultaneously sense the environment and enable communications. This novel approach, as discussed in [11], introduces a paradigm shift by using orthogonal frequency division multiplexing (OFDM) signals to acquire the target’s EM property and identify the material of the target. The integration of multiple base stations (BSs) enhances the performance and accuracy of EM property sensing, as explored in [12], where sensing algorithms and pilot are meticulously designed to optimize the sensing process. Additionally, diffusion models have been employed to refine the EM property sensing in ISAC systems, which offers a robust framework to accurately detect and interpret environmental EM characteristics [13].
Meanwhile, wireless channel reconstruction is also a critical aspect of modern wireless systems, which enables accurate signal processing and improved system performance. Recent advancements, such as deep learning and variational Bayesian methods, have significantly enhanced the accuracy and efficiency of channel reconstruction techniques. For instance, deep plug-and-play priors have been proposed to facilitate multitask channel reconstruction in massive multiple-input multiple-output (MIMO) systems, demonstrating notable improvement in handling complex channel conditions [14]. Additionally, variational Bayesian learning has been leveraged to optimize localization and channel reconstruction in RIS-aided systems, offering robust performance in the face of channel uncertainties [15]. In the realm of MIMO systems with doubly selective channels, diagonally reconstructed channel estimation techniques have been developed to mitigate inter-Doppler interference, ensuring more reliable communications [16]. Moreover, near-field MIMO channel reconstruction has shown promise in enhancing the performance of future wireless systems by utilizing limited geometry feedback [17]. Finally, deep learning frameworks have been explored for wireless radiation field reconstruction and channel prediction, pushing the boundaries that can be achieved in wireless systems [18].
In fact, the fields of EM property sensing and channel reconstruction are intrinsically linked through a shared goal of optimizing the performance and reliability of ISAC systems. The close relationship between EM property sensing and channel reconstruction suggests that advances in one area could significantly benefit the other, particularly by enhancing the precision and efficiency of data acquisition and processing. However, no direct attempt has been made to integrate the two fields within a unified framework.
In this paper, we utilize the diffusion Schrödinger bridge (DSB) to realize the sensing of EM property of a target and the reconstruction of the wireless channel in ISAC systems. As a powerful tool recently explored in generative artificial intelligence (GAI), DSB offers a framework for transitioning between probability distributions in a controlled manner [19, 20, 21]. The DSB framework connects EM property sensing and channel reconstruction by establishing a bidirectional process: the forward process transforms the distribution of EM property into the channel distribution, while the reverse process reconstructs the EM property from the channel. To handle the difference in dimensionality between the high-dimensional sensing channel and the lower-dimensional EM property, we use an autoencoder network to generate the latent representations of the channel. The autoencoder compresses the sensing channel into a latent space that retains essential features, which incorporates positional embeddings to process spatial context. The latent is then used within the DSB framework to iteratively generate the EM property. The simulation results demonstrate the effectiveness of the proposed DSB framework, which achieves superior reconstruction of the target’s shape, relative permittivity, and conductivity. Moreover, the proposed method can also realize high-fidelity channel reconstruction given the EM property of the target. The dual capability of accurately sensing the EM property and reconstructing the channel across various positions within the sensing area underscores the versatility and potential of the proposed approach for broad application in future ISAC systems.
The rest of this paper is organized as follows. Section II presents the ISAC system model. Section III describes the DSB model for EM property sensing and channel reconstruction. Section IV proposes the approach to generating the latent in DSB. Section V provides the numerical simulation results, and Section VI draws the conclusion.
Notations: Boldface denotes a vector or a matrix; corresponds to the imaginary unit; , , and represent Hermitian, transpose, and conjugate, respectively; denotes the Kronecker product; and denote the vectorization and unvectorization operation; denotes the nabla operator; denote the identity matrix with compatible dimensions; denotes -norm of the vector ; denotes Frobenius-norm of the matrix ; denotes the element-wise absolute value of complex vectors or matrices; and denote the real and imaginary part of complex vectors or matrices, respectively; denotes the the space of -state path measures on a finite time horizon for any in discrete stochastic processes; the Kullback-Leibler (KL) divergence between distributions and is defined by KLd; the distribution of a real-valued Gaussian random vector with mean and covariance matrix is denoted as ; the distribution of a circularly symmetric complex Gaussian (CSCG) random vector with mean and covariance matrix is denoted as .

II System Model
As illustrated in Fig. 1, consider a multi-antenna mono-static ISAC system for the target’s EM property sensing and the channel reconstruction. The system includes a BS with transmitting antennas and receiving antennas. We suppose that the BS senses only one target at a time. If there are multiple targets, they can be sensed one by one using a time-division approach. Since target positioning has been widely studied in ISAC [22, 23, 24], we assume that the target’s location is accurately known by the BS. We consider two distinct scenarios in this ISAC system. Scenario 1: The BS transmits OFDM pilot signals and utilizes the received echo signals to sense the EM property of the target. Scenario 2: The BS is aware of the EM property of the target and reconstruct the OFDM channels without sending any pilot signals.
II-A Scenario 1
In the channel estimation stage, the BS adopts fully digital precoding structure where the number of radio frequency (RF) chains is equal to the number of transmitting antennas . The central frequency of the signals is denoted by with the corresponding wavelength . The number of subcarriers is denoted by and the frequency spacing between adjacent subcarriers is denoted by . The number of the transmitted symbols in each subcarrier is denoted by . We assume a quasi-static environment where the channels remain unchanged throughout the sensing period.
Since only the signals scattered by the target carry the information of its EM property, we may send the pilot signals towards the target by beamforming properly at the transmitter. Let the subscript represent that the physical quantity is associated with the -th subcarrier. Denote as the overall echo channel from the transmitter to the receiver. Thus, the received signals can be formulated as
| (1) |
where is the pilot symbol on the -th subcarrier; is the CSCG noise at the receiver of the -th subcarrier. Denote as the pilot matrix stacked by time, and denote . Then the overall received pilot signals can be formulated in a compact form
| (2) |
In order to extract the EM property of the target, the BS first needs to estimate by applying the least square (LS) method as
| (3) |
where is the minimum variance unbiased (MVU) estimated sensing channel. We then stack for into a 3rd order tensor as
| (4) |
According to [11, 12, 13], the EM property of the target is implicitly encoded in the received echo signals that are transmitted through the sensing channel. Thus, we can leverage as the prior information to reconstruct the EM property of the target.
II-B Scenario 2
Suppose that the EM property of the target exhibits isotropy [25, 26, 27]. The process of sensing the EM characteristic is essentially about determining the contrast function , which represents the discrepancy in the complex relative permittivity of the target as compared to the surrounding air. Considering the relative permittivity and conductivity of air to be nearly and Siemens per meter (S/m) respectively, the contrast function can be defined as [28, 29]
| (5) |
where denotes the real relative permittivity at point , denotes the conductivity at point , denotes the angular frequency of the EM waves, and is the vacuum permittivity.
Throughout this document, it is presumed that the electric fields exhibit a harmonic time variation characterized by [30]. Let represent the wavelength and represent the wave number within the ambient medium. The total electric field and the incident electric field, which propagate through the medium in the , , and dimensions, are represented by the complex vectors and , respectively. Since the incident electric field is linearly induced by the currents on the transmitting antennas, there is a matrix that linearly maps to , i.e.,
| (6) |
Upon exposure to the incident field , the fields and are governed by the homogeneous wave equation for the incident field and the inhomogeneous wave equation for the total field, respectively [31], i.e.,
| (7) | ||||
| (8) |
Suppose that the BS knows the target is positioned in the region through prior localization. To address the solutions for (7) and (8), the total electric field within can be formulated by the 3D Lippmann-Schwinger equation [31, 32, 33]
| (9) |
where is the dyadic electric field Green’s function that satisfies
| (10) |
Meanwhile, can be formulated as [34]
| (11) |
where is the distance defined as , is the unit vector from to , and is the scalar Green’s function defined as [34].
The echo electric field at the BS’s receiver scattered back from the target can then be formulated as [32, 33]
| (12) |
where denotes the position of the -th receiving antenna. Suppose the receiver can only measure the scalar electric field component in the direction represented by the unit vector . The received echo signals can also be formulated as
| (13) |
where denotes the receiving antenna gain.
Remark 1.
In accordance with (9), (12), and (13), the echo signals that are transmitted through the sensing channel can also be derived through the EM property of the target. As the mapping from to , in (1) depends on the EM property of the target and is actually the composite mapping consisting of (6), (9), (12), and (13). Specifically, (6) maps to ; (9) maps to ; (12) maps to ; (13) maps to .
III DSB for EM Property Sensing and Channel Reconstruction
III-A Point Cloud Representation
We utilize the point cloud representation to concisely and vividly represent the distribution of the target’s EM property. Define the -th normalized 5D point that comprises both the 3D location information and the 2D EM property as
| (14) |
where , , and denote the coordinates of the -th point in each dimension; , , and denote the coordinates of the center of the target; , , and denote the corresponding standard deviations. Here, and represent the dielectric constant and conductivity at the -th point, respectively; and represent their respective central values; and denote their respective standard deviations. Suppose a total of points in (14) constitute the point cloud that represents the target and is defined as .
The implementation of the point cloud approach presents a more efficient and uncomplicated alternative for discerning the EM property. Point clouds intrinsically facilitate the distinction between the background medium and the target, thereby eliminating the necessity to analyze the known background medium and significantly reducing the computational burden. Additionally, the representation of data through point clouds permits a clear and prompt visualization of the 3D target, which thereby enhances the intuitive interpretation of the inversion outcomes.
III-B DSB Linking EM Property and Sensing Channel
Let denote the distribution of the EM property and denote the distribution of the latent extracted from the sensing channel. The latent shares the same dimensions as and is denoted as . To estimate the EM property from the sensing channel or to reconstruct the sensing channel from the EM property, we need to link and using DSB. Specifically, DSB establishes the link through a bidirectional process: the forward process gradually transforms into , while the reverse process maps back to . Both processes can be represented via Markov chains.
Denote as the set of that are sequentially generated from to over a sequence of intermediate states. The forward transition is constructed to progressively guide the distribution from to approximate . The joint probability density of is
| (15) |
Similarly, the reverse process can be formulated as a Markovian sequence, with the reverse joint density being
| (16) |
where the conditional probability represents the probability of transitioning from state at time to state at time . We can decompose the conditional probability using Bayesian theorem as
| (17) |
where is the conditional probability of the forward process, is the marginal distribution of state , and is the marginal distribution of state .
However, directly computing the conditional probability using (17) is generally quite challenging due to the complexity of the involved distributions and the recursive nature of the computation. In practice, score-based generative models (SGMs) adopt a more tractable approach to handle the forward process, and thus could simplify the forward process by modeling it as the gradual addition of Gaussian noise to the states over time. The forward process can be represented as
| (18) |
where is the noise level parameter at time step , and is the forward drift term that governs the deterministic part of the state evolution.
For a sufficiently large number of time steps , the distribution of the state at the final time step will converge to , which serves as the starting point for the reverse-time generative process.
The forward process (15) and the reverse process (16) can also be described in a continuous-time framework using stochastic differential equations (SDEs). Specifically, the forward process can be modeled by an SDE as
| (19) |
where , is the drift term function, represents the diffusion coefficient, and denotes the standard Brownian motion. The reverse process, on the other hand, involves solving the time-reversed version of the SDE in (19), and is given by
| (20) |
III-C Iterative Proportional Fitting
The DSB is an extension of the Schrödinger bridge (SB) problem, which incorporates diffusion model to model uncertainty and variability in dynamic systems. In the context of SB problem, we aim to find an optimal distribution that minimizes the KL divergence from a reference path measure . The optimization problem is defined as
| (21) |
where the marginal distributions and correspond to the distributions at the start and end points of the process, respectively. Typically, the reference measure path is generated using the same form of the forward SDE as in (19).
After determining the optimal solution , we can sample by first generating and then iteratively applying the backward transition . Alternatively, we can sample by initially drawing and subsequently applying the forward transition . The SB formulation enables the bidirectional transitions without relying on closed-form expression of and .
Although the SB problem does not have a closed-form solution, it can be tackled using iterative proportional fitting (IPF), which iteratively solves the following optimization problems:
| (22) | |||
| (23) |
where the superscript denotes the number of iterations, and the initialization is set as . However, implementing IPF in real-world scenarios can be computationally prohibitive, as it requires the calculation and optimization of joint densities.
DSB can be viewed as an approximate method for IPF, which simplifies the optimization of the joint density by decomposing it into a sequence of conditional density optimization tasks. Specifically, the distribution is split into the forward and backward conditional distributions and , respectively:
| (24) | |||
| (25) |
It can be shown that optimizing conditional distributions and in (24) and (25) leads to the optimization of the joint distribution in (22) and (23) [21]. We assume that the conditional distributions and are Gaussian distributions, following the assumption commonly used in SGMs and allowing DSB to analytically handle the time reversal process. Consequently, we employ two separate neural networks to model the forward and backward dynamics.
The forward process, which governs the transition of the state from one time step to the next, is mathematically expressed as
| (26) |
where denotes the conditional probability distribution of the state given the state at the previous time step. In the multivariate Gaussian distribution , represents the diffusion coefficient that controls the spread of the distribution, and represents the drift term that accounts for the deterministic part of the state transition in the forward process. For brevity, we define the forward estimation as
| (27) |
Conversely, the backward process, which describes the reverse-time evolution of (26), is given by
| (28) |
where represents the conditional probability distribution of the state given the state at the subsequent time step. Similar to the forward process, the backward process is modeled as a multivariate Gaussian distribution . The term in (28) is the drift term specific to the backward process, which plays an analogous role to in the forward process and can be computed according to (26) as
| (29) |
For brevity, we define the backward estimation as
| (30) |
According to (26) and (27), we can compute the probability density function at time step as
| (31) |
where the integral normalization factor comes from .
Taking the logarithm of and applying the gradient with respect to , we obtain
| (32) |
where we employ the Bayesian rule and then use (26) as
| (33) |
Substituting (32) into (29) and utilizing (27), we obtain
| (34) |
Now, considering the Bayesian update step and substituting (34) into (30), we can derive the backward estimation as
| (35) |
where the expectation is taken over the joint distribution .

To minimize the difference between and the variable on the right-hand-side of (35), we define the loss function as
| (36) |
Similarly, the loss function for the mapping function can be given by
| (37) |
The loss functions (36) and (37) are derived under the assumption that the distribution accurately models the underlying dynamics of the system and that the error introduced by approximating and is minimized in the Frobenius norm sense. The schematic diagram of DSB pipeline with forward and backward processes is shown in Fig. 2, where the latent refers to the compressed features extracted from the sensing channel.
In practical applications, the DSB methodology employs two neural networks to approximate the forward estimation (27) and the backward estimation (30). Let and represent the trainable parameters of two neural networks and in the -th iteration. Specifically, the neural network is used to approximate the backward estimation , and the neural network is used to approximate the forward estimation . The iterative optimization of and is crucial for the DSB methodology.
The DSB methodology proceeds by alternately training the backward network and the forward network across multiple iterations indexed by . Specifically, during the -th epoch, we train the backward network , while during the -th epoch, we train the forward network . The alternating optimization of and is designed to minimize (24) and (25), which ensures that the forward and backward processes are accurately modeled. Moreover, both and are composed of the same concatsquash layers as in [13].
The convergence of IPF has been rigorously proven in the literature, as demonstrated in [21]. The proof underpins the theoretical soundness of the DSB approach, which confirms that the method will, under appropriate conditions, converge to a solution that satisfies the desired characteristics of DSB.
III-D DSB Training Scheme
III-D1 Initial Forward Model
As highlighted in the previous subsection, DSB and SGM are inherently aligned in their training objectives. Specifically, both methodologies aim to model and approximate the target data distribution through a series of learned transformations that progressively refine an initial noise distribution into a more structured and complex distribution that resembles the data. Given the shared objective of DSB and SGM, it is natural to establish the reference distribution in DSB to mirror the noise schedule employed by SGM. By doing so, the training process in the first epoch of DSB becomes theoretically equivalent to the standard training procedure of SGM.
Therefore, rather than initiating the training process of DSB from scratch, we leverage a pre-trained SGM as the starting forward model to train the first backward model. The pre-trained SGM provides a strong foundation from which DSB can iteratively enhance the quality of generated data through multiple rounds of forward and backward training. Each subsequent epoch in DSB builds upon the results of the previous one, progressively refining the model’s ability to capture the complexities of the target distribution. Consequently, DSB develops a new generative model that surpasses the initial SGM in its capacity to accurately model the target data distribution.
The training process for the first forward epoch in DSB, which corresponds to the second epoch in the overall training procedure, is specifically designed to train a neural network to transform the data distribution into the prior distribution . The purpose of the transformation is to ensure that the intermediate states generated during the forward process adhere to the KL divergence constraint, which is imposed by the trajectories learned in the first backward epoch, as outlined in (24) and (25).
We employ flow matching (FM) models [35] to train the initial forward model in DSB. FM models work by ensuring that the flow of the generated data matches the flow of the real data, which effectively captures the underlying dependencies and relationships within the system [36]. By aligning the trajectories of data points, FM models provide a robust framework to model complex systems, which leads to precise and reliable generation [37]. The entire procedure to train the FM model as the initial forward model within the DSB framework is summarized in Algorithm 1.

III-D2 Loss Function Simplification
In standard DSB, the loss functions for both the forward and backward models have relatively high computational complexity, as detailed in (36) and (37), which renders its physical interpretation challenging. To reduce the complexity, the training loss associated with DSB can be simplified as
| (38) | ||||
| (39) |
The rationale of such simplification will be stated as follows. Since generally the drift term changes mildly and is in close proximity to according to [21], we can assume . Thus, we have
| (40) |
According to (36) and (40), there is . Besides, can also be proved analogously. With the simplified loss functions (38) and (39), the overall procedure to train DSB is summarized in Algorithm 2. Once the training of DSB is completed, the sampling of DSB can be conducted using (26) and (28).
IV Latent Generation
Throughout the DSB process, the dimension of the variables keeps unchanged, which indicates that the dimensions of and should be the same. However, in MIMO systems with multiple subcarriers, the dimension of the sensing channel is typically much higher than the dimension of the point cloud that represents the EM property of the target. Thus, we need to compress the sensing channel into a latent to keep the dimension of the prior equal to the dimension of the 5D point cloud.
In order to generate the latent with the estimated sensing channel, we adopt an autoencoder network with positional embedding information, as shown in Fig. 3. The encoding phase is employed in Scenario 1, while the decoding phase is employed in Scenario 2. The autoencoder is designed to capture the relevant features of the sensing channel while considering the position of the target through positional embedding.
In Scenario 1, the goal is to compress the estimated sensing channel into a latent representation that captures the essential features needed for EM property sensing. First, the estimated sensing channel is passed through the channel transferring module, in which the positional information of the target is embedded into a high-dimensional 3rd tensor using sinusoidal functions inspired by [38]. The positional embedding tensor provides additional context that is crucial for accurate encoding, particularly because the channel features might vary significantly with the target’s position. The positional embedding tensor is then integrated with the channel and is processed by a neural network. The resulting combined data is then compressed by the downscaling module, which reduces the data size and retains only the most relevant features. The output of the downscaling module is a latent that shares the same dimensions with the 5D point cloud , i.e., . The latent is a compressed representation of the target’s features, which will be used in DSB to reconstruct the EM property of the target.
In the autoencoder’s encoding process, both the channel transferring module and the downscaling module mainly consist of convolutional layers. Assume that the dimension of the positional embedding tensor is . The channel transferring module first splits the real and the imaginary parts of the channel and then concatenates them with the positional embedding tensor into the dimension of . Next, the downscaling module reduces the spatial dimensions of the data through striding and pooling, which compresses the input into a more compact form. The dual role of feature extraction and dimensionality reduction is essential to create an efficient latent representation that retains critical information while minimizing the redundancy. The last layer of the downscaling module is a fully connected layer that transforms the flattened input into a vector whose length is to align with the dimension of the 5D point cloud.
In Scenario 2, the objective is to reconstruct the channel from the latent representation produced by DSB, where we incorporate the same positional information as the encoder to ensure the consistency in the reconstruction. The latent representation is first passed through the upscaling module, which reverses the compression applied in the encoding phase and expands the latent to with the same size as that of the sensing channel . Similar to the encoding phase, the same positional embedding tensor is combined with the upscaled data , which ensures that the positional information is also considered in the decoding phase. The combined data is then processed by the reverse channel transferring module, which reverts the transformations applied during the encoding phase and aims to reconstruct the sensing channel as accurately as possible.
In the autoencoder’s decoding process, the upscaling module reverses the encoding process by taking the flattened latent representation as input and using a fully connected layer followed by a series of transposed convolutional layers. The reverse channel transferring module concatenates and the positional embedding tensor and then employs a series of convolutional layers to transform the dimension of the data to . The final output is the reconstructed channel with stacked real and imaginary parts.
Since the magnitude of the sensing channel varies with the location of the target, we need to normalize the loss function. The training process of the latent generation autoencoder is guided by the normalized mean square error (NMSE) loss function, which measures the difference between the real channel and the reconstructed channel as
| (41) |
By minimizing NMSE of the reconstructed channel , the autoencoder learns to produce accurate latent representations that can faithfully reconstruct the sensing channel.
V Simulation Results and Analysis
Suppose all possible targets can be contained within a cubic region whose size is . We designate the number of scatter points that form the target as . Assume that the BS is positioned at m and needs to sense the target in a 30 m radius sector on the horizontal plane, characterized by . The BS is equipped with a uniform linear array (ULA) with transmitting antennas and a ULA with receiving antennas. The transmitting and the receiving ULAs are both centered at m and are parallel to and directions, respectively, which is analogous to the Mills-Cross configuration [39]. The transmitting and the receiving antennas are set as dipoles polarized along and directions, respectively. The central carrier frequency is set as GHz and the corresponding central wavelength is m. The inter-antenna spacing for both the transmitting and the receiving ULAs is set as m. We assume there are a total of subcarriers whose spacing is set as KHz.
In DSB, we set the number of intermediate time steps as . The diffusion coefficients linearly increase from to and then linearly decrease from to . In order to train DSB, we select 100000 targets from the ShapeNet dataset [40], which are split into training, testing, and validation sets by the ratio 80%, 10%, and 10%, respectively. All the targets in the dataset are uniformly and randomly located in the sector . During the training process, we utilize the Adam optimizer and set the batch size as 128. In order to compute the forward scattering, we convert (9) into a discrete form by the methods of moments (MoM). Then the unknown total electric field is determined with the stabilized biconjugate gradient fast Fourier transform (BCGS-FFT) technique [41].
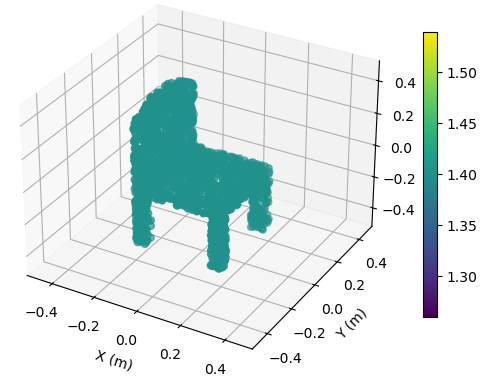
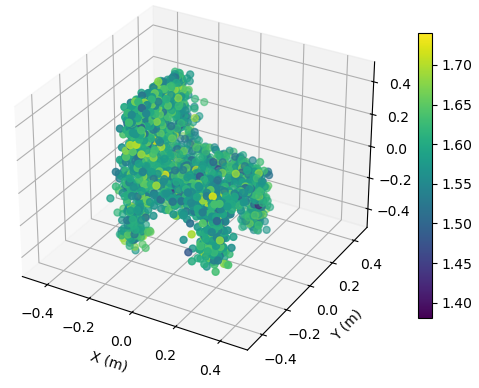
with SNR = 5 dB
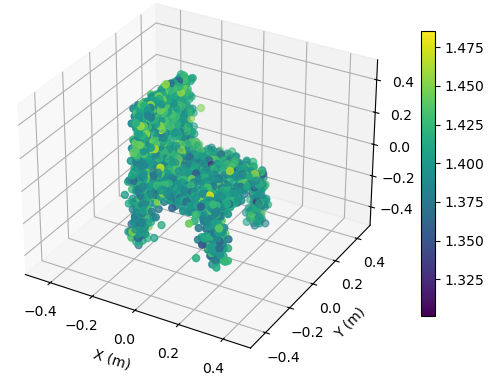
with SNR = 30 dB
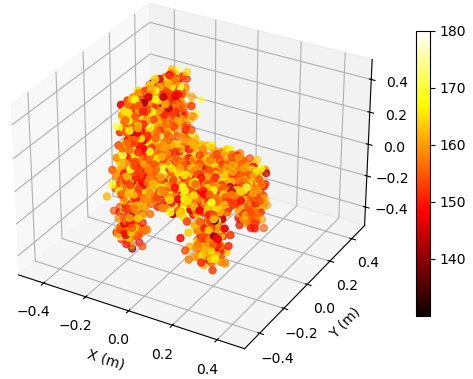
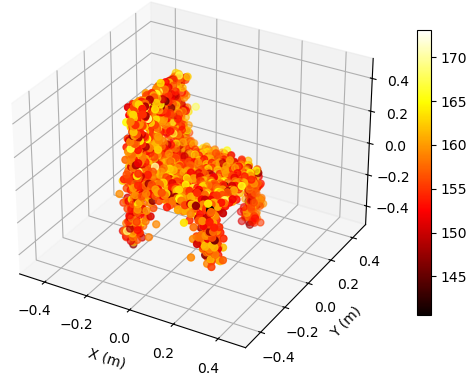
Additionally, we propose the mean Chamfer distance (MCD) between the ground truth and the estimated point clouds as a metric to quantitatively assess the performance of EM property sensing, which is defined as
| (42) |
where denotes the test dataset, denotes the number of samples in the test dataset, and denotes the estimated value of .

V-A Performance of EM Property Sensing
In Scenario 1, a total of pilot symbols are transmitted in each subcarrier to estimate the sensing channel. The signal-to-noise ratio (SNR) at the receiver decides the accuracy of the estimated sensing channel. The estimated channel is then compressed to generate the latent, which is employed to estimate the EM property of the target.
V-A1 Performance versus SNR at the Receiver
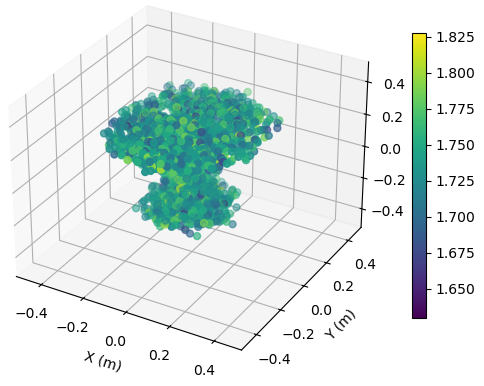
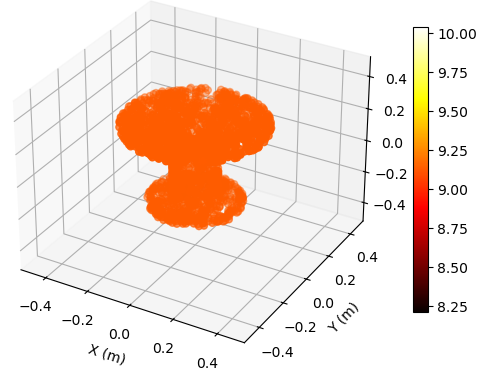
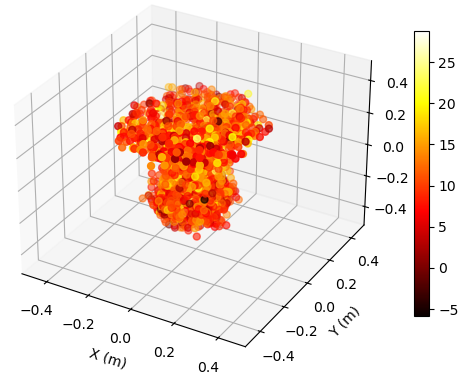
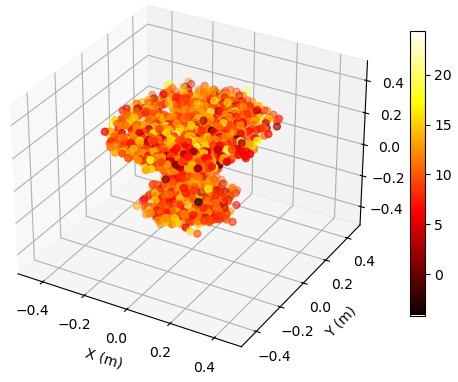
To illustrate the EM property sensing results, we present the reconstructed 5D point cloud of the target in Fig. 4. The center of the target is m, and the target is shown in the coordinate system relative to its center. It is seen from Fig. 4 that, the reconstructed point clouds can reflect the general shape of the target. The values of EM property reconstructed with SNR = 30 dB is much more accurate compared to those reconstructed with SNR = 5 dB. Moreover, a higher SNR value leads to a more precise reconstruction of the target’s shape.
We explore the MCD of the reconstructed 5D point clouds versus SNR in Fig. 5. We set the center of the target as m, m, or m, respectively. It is seen from Fig. 5 that, the MCD decreases with the increase of SNR to an error floor. The MCD is larger when the target is farther from the BS. The phenomenon can be attributed to the fact that when the target is closer to the BS, the sensing channel benefits from a higher number of effective degrees of freedom (EDoF) [42]. As a result, more diverse spatial features of the estimated sensing channel can be extracted, leading to a more accurate reconstruction of the point clouds. Consequently, the error floor of MCD is significantly lower when the target is near the BS, whereas the error increases as the distance between the target and the BS grows, reflecting the reduced EDoF and less diverse spatial feature extraction capability at greater distances.
V-A2 Performance versus Location of the Target
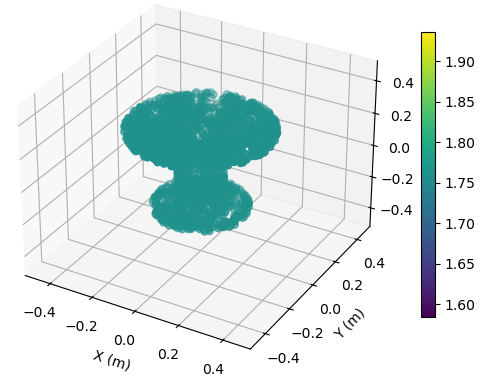
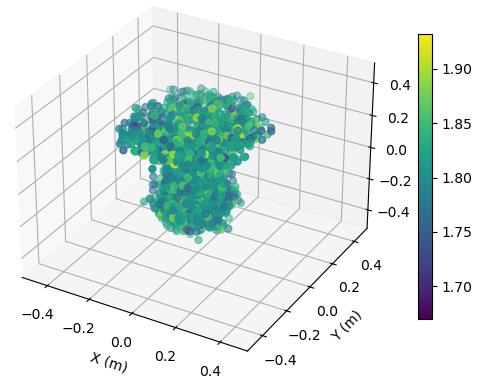
at (25,0,0) m
at (5,0,0) m
at (25,0,0) m
at (5,0,0) m

To illustrate the EM property sensing results, we present the reconstructed point cloud of the target with SNR = 15 dB in Fig. 6. The target is shown in the coordinate system relative to its center. It is seen from Fig. 6 that, the reconstructed 5D point clouds can reflect the general shape of the target. The values of EM property reconstructed with target at m is more accurate compared to those reconstructed with target at m. Moreover, a closer distance results in a more accurate reconstructed shape of the target.
We investigate the MCD of the reconstructed 5D point clouds in relation to the target’s location with an SNR of 30 dB, as illustrated in Fig. 7. The figure reveals that the MCD tends to be lower when the target is positioned closer to the BS. The observation can be explained by the fact that a closer target results in a sensing channel with a greater number of EDoF [42], allowing for the extraction of more diverse spatial features from the estimated sensing channel. Additionally, the MCD shows minimal variation with changes in the angle, indicating that the proposed method is capable of effectively sensing the EM property of the target from any direction within the sector .
V-B Performance of Channel Reconstruction
In Scenario 2, the sensing channel is reconstructed given the EM property and the location of the target. We assume the EM property may not be accurate due to measurement errors.
V-B1 Performance versus SNR of EM Property

We add Gaussian noise to the 5D point cloud that represents the real EM property of the target, and explore the NMSE of channel reconstruction versus SNR of the EM property. It is seen from Fig. 8 that, as the SNR increases, the NMSE decreases for all target locations. The error floor reaches approximately -34 dB for the target at m, around -27 dB for the target at m, and about -20 dB for the target at m. However, in the low SNR regions, there is an abnormal phenomenon where the NMSE for the target at m is smaller than NMSE for targets at m and m. This behavior suggests that when the target is farther from the BS, the reconstructed channel becomes more dependent on the target’s location and less dependent on its EM property. As a result, the reconstructed channel is less sensitive to the noise affecting the EM property, which leads to higher NMSE values at lower SNR levels compared to the closer targets.
V-B2 Performance versus Location of the Target

We explore the NMSE of channel reconstruction versus location of the target with accurately known EM property in Fig. 9. The NMSE values range from approximately -60 dB near the BS to about -20 dB at the farthest points in the sector. The trend indicates that the NMSE decreases as the distance from the BS increases, yet the variation in angle is not significant. This trend suggests that the channel reconstruction generally becomes more reliable when the target is closer to the BS.
VI Conclusion
This paper introduces a cutting-edge ISAC scheme that utilizes DSB to Bayesian EM property sensing and channel reconstruction within a specific area. The DSB framework facilitates a bidirectional transformation, converting the sensed EM property distribution into a channel distribution and vice versa, while an autoencoder network addresses the dimensionality discrepancy by creating latent representations that maintain crucial spatial features. The latent representations are then used in DSB to progressively generate the EM property of the target. Simulation results highlight the superiority of the DSB framework in reconstructing the target’s shape, relative permittivity, and conductivity. Besides, the proposed method is capable of achieving precise channel reconstruction based on the EM property of the target. The method’s ability to accurately detect the EM property and reconstruct channels at different locations within the sensing region highlights its adaptability and promise for widespread use in the ISAC systems.
References
- [1] Q. Zhang, H. Sun, X. Gao, X. Wang, and Z. Feng, “Time-division ISAC enabled connected automated vehicles cooperation algorithm design and performance evaluation,” IEEE J. Sel. Areas Commun., vol. 40, no. 7, pp. 2206–2218, 2022.
- [2] H. Luo, T. Zhang, C. Zhao, Y. Wang, B. Lin, Y. Jiang, D. Luo, and F. Gao, “Integrated sensing and communications framework for 6G networks,” arXiv preprint arXiv:2405.19925, 2024.
- [3] Z. Ren, Y. Peng, X. Song, Y. Fang, L. Qiu, L. Liu, D. W. K. Ng, and J. Xu, “Fundamental CRB-rate tradeoff in multi-antenna ISAC systems with information multicasting and multi-target sensing,” IEEE Trans. Wireless Commun., Sep. 2023.
- [4] Y. Jiang, F. Gao, Y. Liu, S. Jin, and T. J. Cui, “Near-field computational imaging with RIS generated virtual masks,” IEEE Trans. Antennas Propag., vol. 72, no. 5, pp. 4383–4398, Apr. 2024.
- [5] F. Dong, F. Liu, Y. Cui, W. Wang, K. Han, and Z. Wang, “Sensing as a service in 6G perceptive networks: A unified framework for ISAC resource allocation,” IEEE Trans. Wireless Commun., 2022.
- [6] Y. Jiang, F. Gao, M. Jian, S. Zhang, and W. Zhang, “Reconfigurable intelligent surface for near field communications: Beamforming and sensing,” IEEE Trans. Wireless Commun., vol. 22, no. 5, pp. 3447–3459, 2023.
- [7] Y. Zhong, T. Bi, J. Wang, J. Zeng, Y. Huang, T. Jiang, Q. Wu, and S. Wu, “Empowering the V2X network by integrated sensing and communications: Background, design, advances, and opportunities,” IEEE Network, vol. 36, no. 4, pp. 54–60, 2022.
- [8] T. Ma, Y. Xiao, X. Lei, and M. Xiao, “Integrated sensing and communication for wireless extended reality (XR) with reconfigurable intelligent surface,” IEEE J. Sel. Signal Process., 2023.
- [9] Y. Cui, F. Liu, X. Jing, and J. Mu, “Integrating sensing and communications for ubiquitous IoT: Applications, trends, and challenges,” IEEE Network, vol. 35, no. 5, pp. 158–167, 2021.
- [10] A. Alkhateeb, S. Jiang, and G. Charan, “Real-time digital twins: Vision and research directions for 6G and beyond,” IEEE Commun. Mag., 2023.
- [11] Y. Jiang, F. Gao, and S. Jin, “Electromagnetic property sensing: A new paradigm of integrated sensing and communication,” IEEE Trans. Wireless Commun., May 2024.
- [12] Y. Jiang, F. Gao, S. Jin, and T. J. Cui, “Electromagnetic property sensing in ISAC with multiple base stations: Algorithm, pilot design, and performance analysis,” arXiv preprint arXiv:2405.06364, 2024.
- [13] Y. Jiang, F. Gao, S. Jin, and T. J. Cui, “Electromagnetic property sensing based on diffusion model in ISAC system,” arXiv preprint arXiv:2407.03075, 2024.
- [14] W. Wan, W. Chen, S. Wang, G. Y. Li, and B. Ai, “Deep plug-and-play prior for multitask channel reconstruction in massive MIMO systems,” IEEE Trans. Commun., 2024.
- [15] Y. Li, Y. Luo, X. Wu, Z. Shi, S. Ma, and G. Yang, “Variational bayesian learning based localization and channel reconstruction in RIS-aided systems,” IEEE Trans. Wireless Commun., 2024.
- [16] H. Yin, X. Wei, Y. Tang, and K. Yang, “Diagonally reconstructed channel estimation for mimo-afdm with inter-doppler interference in doubly selective channels,” IEEE Trans. Wireless Commun., 2024.
- [17] S. Eslami, B. Gouda, and A. Tölli, “Near-field MIMO channel reconstruction via limited geometry feedback,” in ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 9256–9260, IEEE, 2024.
- [18] H. Lu, C. Vattheuer, B. Mirzasoleiman, and O. Abari, “A deep learning framework for wireless radiation field reconstruction and channel prediction,” arXiv preprint arXiv:2403.03241, 2024.
- [19] Z. Tang, T. Hang, S. Gu, D. Chen, and B. Guo, “Simplified diffusion Schrödinger bridge,” arXiv preprint arXiv:2403.14623, 2024.
- [20] Y. Shi, V. De Bortoli, A. Campbell, and A. Doucet, “Diffusion schrödinger bridge matching,” in Advances in Neural Information Processing Systems (A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, eds.), vol. 36, pp. 62183–62223, Curran Associates, Inc., 2023.
- [21] V. De Bortoli, J. Thornton, J. Heng, and A. Doucet, “Diffusion Schrödinger bridge with applications to score-based generative modeling,” in Advances in Neural Information Processing Systems, vol. 34, pp. 17695–17709, Curran Associates, Inc., 2021.
- [22] R. Liu, M. Jian, D. Chen, X. Lin, Y. Cheng, W. Cheng, and S. Chen, “Integrated sensing and communication based outdoor multi-target detection, tracking, and localization in practical 5g networks,” Intelligent and Converged Networks, vol. 4, no. 3, pp. 261–272, 2023.
- [23] P. Gao, L. Lian, and J. Yu, “Cooperative ISAC with direct localization and rate-splitting multiple access communication: A Pareto optimization framework,” IEEE J. Sel. Areas Commun., vol. 41, no. 5, pp. 1496–1515, 2023.
- [24] Z. Zhang, H. Ren, C. Pan, S. Hong, D. Wang, J. Wang, and X. You, “Target localization and performance trade-offs in cooperative ISAC systems: A scheme based on 5G NR OFDM signals,” arXiv preprint arXiv:2403.02028, 2024.
- [25] L. Li, L. G. Wang, F. L. Teixeira, C. Liu, A. Nehorai, and T. J. Cui, “Deepnis: Deep neural network for nonlinear electromagnetic inverse scattering,” IEEE Trans. Antennas Propag., vol. 67, no. 3, pp. 1819–1825, 2018.
- [26] Y. Chen, H. Zhang, T. J. Cui, F. L. Teixeira, and L. Li, “A mesh-free 3-D deep learning electromagnetic inversion method based on point clouds,” IEEE Trans. Microwave Theory Tech., vol. 71, no. 8, pp. 3530–3539, 2023.
- [27] H. Zhang, Y. Chen, T. J. Cui, F. L. Teixeira, and L. Li, “Probabilistic deep learning solutions to electromagnetic inverse scattering problems using conditional renormalization group flow,” IEEE Trans. Microwave Theory Tech., vol. 70, no. 11, pp. 4955–4965, 2022.
- [28] Z. Liu and Z. Nie, “Subspace-based variational Born iterative method for solving inverse scattering problems,” IEEE Geosci. Remote Sens. Lett., vol. 16, no. 7, pp. 1017–1020, 2019.
- [29] J. Guillemoteau, P. Sailhac, and M. Behaegel, “Fast approximate 2D inversion of airborne tem data: Born approximation and empirical approach,” Geophysics, vol. 77, no. 4, pp. WB89–WB97, 2012.
- [30] C. A. Balanis, Advanced Engineering Electromagnetics. USA: Wiley: Hoboken, NJ, 2 ed., 2012.
- [31] O. J. F. Martin and N. B. Piller, “Electromagnetic scattering in polarizable backgrounds,” Phys. Rev. E, vol. 58, pp. 3909–3915, Sep 1998.
- [32] J. O. Vargas and R. Adriano, “Subspace-based conjugate-gradient method for solving inverse scattering problems,” IEEE Trans. Antennas Propag., vol. 70, no. 12, pp. 12139–12146, 2022.
- [33] F.-F. Wang and Q. H. Liu, “A hybrid Born iterative Bayesian inversion method for electromagnetic imaging of moderate-contrast scatterers with piecewise homogeneities,” IEEE Trans. Antennas Propag., vol. 70, no. 10, pp. 9652–9661, 2022.
- [34] H. F. Arnoldus, “Representation of the near-field, middle-field, and far-field electromagnetic Green’s functions in reciprocal space,” JOSA B, vol. 18, no. 4, pp. 547–555, 2001.
- [35] Y. Lipman, R. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,” in International Conference on Learning Representations, PMLR, 2023.
- [36] A. Tong, N. Malkin, G. Huguet, Y. Zhang, J. Rector-Brooks, K. Fatras, G. Wolf, and Y. Bengio, “Conditional flow matching: Simulation-free dynamic optimal transport,” arXiv preprint arXiv:2302.00482, vol. 2, no. 3, 2023.
- [37] L. Klein, A. Krämer, and F. Noé, “Equivariant flow matching,” Advances in Neural Information Processing Systems, vol. 36, 2024.
- [38] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.
- [39] A. M. Molaei, T. Fromenteze, V. Skouroliakou, T. V. Hoang, R. Kumar, V. Fusco, and O. Yurduseven, “Development of fast fourier-compatible image reconstruction for 3D near-field bistatic microwave imaging with dynamic metasurface antennas,” IEEE Trans. Vehi. Tech., vol. 71, no. 12, pp. 13077–13090, 2022.
- [40] A. X. Chang, T. Funkhouser, L. Guibas, P. Hanrahan, Q. Huang, Z. Li, S. Savarese, M. Savva, S. Song, H. Su, et al., “Shapenet: An information-rich 3D model repository,” arXiv preprint arXiv:1512.03012, 2015.
- [41] X. Millard and Q. H. Liu, “Simulation of near-surface detection of objects in layered media by the BCGS-FFT method,” IEEE Trans. Geosci. Remote Sens., vol. 42, no. 2, pp. 327–334, 2004.
- [42] Y. Jiang and F. Gao, “Electromagnetic channel model for near field MIMO systems in the half space,” IEEE Commun. Lett., vol. 27, no. 2, pp. 706–710, 2023.