Electricity Price Prediction for Energy Storage System Arbitrage: A Decision-focused Approach
Abstract
Electricity price prediction plays a vital role in energy storage system (ESS) management. Current prediction models focus on reducing prediction errors but overlook their impact on downstream decision-making. So this paper proposes a decision-focused electricity price prediction approach for ESS arbitrage to bridge the gap from the downstream optimization model to the prediction model. The decision-focused approach aims at utilizing the downstream arbitrage model for training prediction models. It measures the difference between actual decisions under the predicted price and oracle decisions under the true price, i.e., decision error, by regret, transforms it into the tractable surrogate regret, and then derives the gradients to predicted price for training prediction models. Based on the prediction and decision errors, this paper proposes the hybrid loss and corresponding stochastic gradient descent learning method to learn prediction models for prediction and decision accuracy. The case study verifies that the proposed approach can efficiently bring more economic benefits and reduce decision errors by flattening the time distribution of prediction errors, compared to prediction models for only minimizing prediction errors.
Index Terms:
Electricity price prediction, energy storage systems, decision-focused method, stochastic gradient descent, energy arbitrage.I Introduction
Due to the high penetration of renewables and deregulation of the electricity market, electricity price becomes volatile [1, 2], and hence its accurate prediction is difficult. Electricity price prediction has widespread application in the smart grid, including the energy storage system (ESS) management and scheduling. The predicted price from prediction models is delivered to the downstream ESS scheduling model, making the optimal charging/discharging decisions to maximize its arbitrage benefits [3]. The whole process follows the predict-then-optimize framework [4]. Under this framework, various electricity price prediction methods have been proposed to improve prediction accuracy in recent literature.
Electricity price prediction is a fundamental technique in deregulated electricity markets [8]. Conventional electricity price prediction focuses on the price prediction from the perspectives of prediction horizons and various prediction models [8]. A two-stage electricity price forecast scheme is developed to predict electricity price spike in the first stage and continuous price in the second stage for improving prediction accuracy [9]. Hybrid models are developed to improve prediction accuracy based on wavelet and LSTM networks [10, 11]. Considering energy management and control, the multi-horizon electricity price forecasting models are proposed to improve prediction accuracy and detect the price spikes in [1], revealing its economic value. The holistic approach is developed to recover the energy market structure and predict the nodal market electricity price [14]. Price interval prediction has come forth in recent years. In [15], a Pareto optimal prediction interval construction approach is proposed to predict the electricity price intervals, achieving the interval’s reliability and sharpness. Considering the dynamic price changes from the neighboring regions, the online learning approach provides rolling day-ahead price/interval prediction and 30-min prediction by perceiving the neighboring price fluctuation for improving prediction accuracy [16]. A reinforcement learning-based decision system is proposed to assist the selection of pricing plans for minimizing the end-user payment and consumption payment [17]. The above prediction-based works highlight the prediction accuracy of prediction models but overlook the prediction errors’ direct impact on downstream optimization models.
Due to high electricity price fluctuations, ESS can gain profits by charging at low prices and discharging at high prices [18]. A storage scheduling algorithm is proposed for the joint arbitrage and operating reserve as merchant functions in [19], which can effectively utilize the storage for arbitrage benefits and reserve service. A non-complementary energy storage arbitrage model is developed by replacing the binary variables without jeopardizing practical viability [20]. A bi-level energy storage arbitrage model is constructed by considering the wind power and LMP smooth effect in [21], where the upper layer maximizes the arbitrage revenue and the lower layer simulates the market-clearing. Considering the uncertainty of wind and solar energy, a stochastic energy storage arbitrage model is developed to maximize its profit under the day-ahead and real-time market prices in [22]. An MPC-based ESS control policy is designed in [23] to perform energy arbitrage and local power factor correction, where the electricity price is forecasted by auto-regression. In [24], deep reinforcement learning is developed for real-time ESS charging/discharging control based on the hybrid CNN and LSTM-based price prediction. The operation of the power system requires various ESS application scenarios, including synergies price arbitrage and fast frequency response [25], simultaneous peak shaving and arbitrage [26], and co-optimization of community energy systems [27]. Considering the price prediction uncertainty, the MPC-based multi-objective scheduling is analyzed in [28]. The above optimization-based works formulate the uncertainty of predicted price by sampling or distribution assumptions and seldom consider the optimization models’ reverse impact on upstream prediction models.
The above research indicates the gap between upstream prediction and downstream optimization models. The objective of conventional prediction models is usually to minimize the difference between the predicted price and true price, denoted by prediction error. In contrast, ESS focuses on maximizing arbitrage benefits from electricity price fluctuations. Maximizing benefits can be equivalent to minimizing the difference between the optimal actual decisions under the predicted price and optimal oracle decisions under the true price, denoted by the decision error. The decision error does not necessarily coincide with the prediction error. Recent years have seen increasing work on utilizing prediction considering optimization models. Embedding the differential economic dispatch within the neural network is developed in [5] in the load prediction for the decision quality instead of prediction accuracy. And the embedding framework is further extended to the general economic dispatch in [6, 7]. In [4], the smart “predict, then optimize” (SPO) loss is proposed to learn linear predictor parameters by linear programming to solve the shortest path and portfolio optimization problems.
Inspired by the above works, we propose a decision-focused electricity price prediction approach to take advantage of the downstream ESS arbitrage model’s decision error to train the prediction models. The prediction model target in the proposed approach focuses on minimizing prediction error in the prediction model and decision error in the ESS model. However, the decision error comes from the ESS arbitrage model and cannot apply to training the prediction models directly. To tackle this challenge, we first measure the decision error by regret, transform the regret into tractable surrogate regret, and derive the gradients of surrogate regret to the predicted price for training prediction models. These gradients instruct the prediction models to learn to reduce prediction model decision error. The prediction error is measured by the mean-square-error (MSE) metric. Based on MSE and surrogate regret, we design a hybrid loss function and propose a hybrid stochastic gradient descent (SGD) learning method of updating prediction models’ parameters for prediction and decision accuracy. Finally, we apply the decision-focused learning approach in various prediction models to verify its effectiveness.
To distinguish from previous works, the novelties of this paper are demonstrated in three aspects. 1) The proposed approach utilizes prediction and decision errors to train the price prediction model for ESS arbitrage, while Ref. [4, 5, 6, 7] only considers the decision error. 2) Tractable surrogate regret is proposed for training a multi-layer neural network called residual neural network (ResNet) in the context of deep learning, while the predictor of Ref. [4] with similar loss called the SPO loss is a linear model in the context of linear programming. 3) The hybrid loss design and learning method are proposed to improve decision accuracy and increase economic benefits, which are first applied in prediction for ESS arbitrage.
In summary, the contribution of this paper is threefold:
1) To the authors’ best knowledge, this paper first takes advantage of both prediction error and decision error to learn the parameters of prediction models and proposes a decision-focused electricity price prediction approach for ESS arbitrage. Compared with previous prediction methods [9, 10, 11, 12, 13], the proposed decision-focused approach pays attention to the prediction error’s impact on the downstream optimization models, improving the decision accuracy under the predicted price.
2) Tractable surrogate regret is proposed to measure the decision error between the actual decision under the predicted price and the oracle decision under the true price. Its gradients to the predicted price are further derived, which is the key of this paper. Regret of decision under the predicted price is discontinuous and intractable. So this paper relaxes the feasible region of the original problem and derives a tractable upper bound of regret to measure the decision error, denoted by surrogate regret. Surrogate regret gradients to the predicted price are derived and delivered from the downstream optimization model to the upstream prediction model for reducing decision errors.
3) Based on the weighted sum of MSE and surrogate regret, this paper designs a hybrid loss function to measure prediction and decision errors. Then a hybrid SGD learning method for ESS arbitrage is proposed to train prediction models for improving prediction and decision accuracy based on hybrid loss. The case study indicates the proposed decision-focused approach can capture and predict the changing trends of electricity prices more accurately, which leads to the increase of decision accuracy and economic benefits.
The rest of this paper is organized as follows. Section II presents the conventional predict-then-optimize framework. Section III proposes the decision-focused prediction approach and the hybrid stochastic gradient descent method to learn prediction models. Section IV evaluates the effectiveness of the proposed decision-focused approach in the case study. Section V concludes this paper.
II Conventional Predict-then-optimize Framework
This section introduces the predict-then-optimize framework. Fig. 1 presents the day-ahead electricity price prediction and relevant ESS scheduling model, where prediction error is delivered from the upstream prediction model to the downstream ESS model, resulting in decision error.

II-A Upstream Electricity Price Prediction Model
As shown in Fig. 1, day-ahead electricity price prediction is the basis of energy scheduling. This part focuses on the price prediction model formulation, whose general form is as follows:
| (1) |
where is the prediction electricity price, is the input features, and denotes the prediction model. From input feature vector to output predicted price , the whole process is composed of five procedures: i) data pre-processing, ii) feature engineering, iii) model selection, iv) training procedures, v) prediction objective.
II-A1 Data Pre-processing
Data pre-processing transforms raw datasets into the prediction model input features and output datasets, including filling missing values, clearing outliers, and normalizing the datasets.
II-A2 Feature Engineering
Feature engineering selects and formulates the feature vectors from the processed dataset for inputting the prediction model. The electricity price is usually influenced by historical load and price, future load and temperature, and some calendar factors, including weekday/weekend, holiday effects, and day of the year. For more features input, we construct the squares of future load and temperature.
II-A3 Model Selection
Prediction is generally formulated as a regression problem, which maps the input feature vectors into the continuous output prediction values. Various regression models are proposed for electricity price prediction in the smart grid, from conventional linear regression in the statistical domain to burgeoning neural networks in the deep learning domain. These models feature various strengthens and dataset requirements.
In this work, we focus on comparing two kinds of prediction models with different representational capacities: i) the linear regression model [29] in Equation (2); ii) the ResNet model [30] in Equation (3). It should be noted that the model representational capacity refers to the models’ ability to fit variety of functions.
| (2) |
Linear regression model maps the input feature vector to predicted price by and linearly, whose representational capacity is limited.
| (3) | ||||
where refers to the input features and refers to the output of the th layer in the neural network.
While the ResNet model is a group of stacked linear regression and activation function mapping from input to output by a set of , , and , whose representational capacity is large.
As shown in Equations (2) and (3), the parameter number of the linear model is much less than that of the ResNet model due to the multi-layers of the ResNet model, so its representational capacity is much smaller than ResNet models. The two models represent two typical prediction models, i.e., small and high representational prediction models. This paper applies the proposed decision-focused approach in different models to verify its generalization performance in different representational capacity models. In model selection, the ResNet model with high representational capacity is prioritized to capture the high stochasticity of electricity prices under massive training data and fierce price changing; the linear model with high representational capacity is prioritized under limited training data and mild price changing.
II-A4 Training Procedures
Training prediction model for better generalization follows these essential procedures: i) A subset of complete processed data is selected as a testing dataset randomly; ii) the remaining is further split into training and validation set randomly; iii) then we train the prediction model on the training set, evaluate its accuracy on the validation set, and tune model hyperparameters for high accuracy; iv) finally, we test the trained model on the testing set for model evaluation and comparison.
II-A5 Objective of Prediction Models
The objective of prediction models is to minimize the difference between the predicted price and true price , described by MSE in Equation (4).
| (4) |
Then the objective of prediction models is formulated in Equation (5).
| (5) | ||||
| s.t. |
The gradients of MSE to the predicted price can further be derived as:
| (6) | ||||
We note that the variables with the footnote refer to the time elements of the corresponding vector variables.
Based on the above, the training of prediction models usually utilizes the conventional SGD learning method. The model parameters are updated by way of batch updating [31] to improve the calculation efficiency.
II-B Downstream Price-based ESS Arbitrage Model
ESS usually works at charging state when electricity price is low and at discharging state when electricity price is high for arbitrage from market. The operation of ESS usually follows the electricity price signals to maximize its benefits as:
| (7) |
where its objective is to maximize the net energy benefits by optimizing its operating power (MW) time interval under market day-ahead electricity price ($/MWh), denoted by . And we note that the variables with the footnote refer to the time elements of the corresponding vector variables. The feasible region of decision variable is subject to a set of operation and technical constraints as follows:
| (8) |
Equation (8) illustrates the operating power of ESS is composed of charging and discharging parts; denotes the charging of ESS from grid, and denotes the discharging of ESS to grid.
| (9) | ||||
where (kWh) refers to the stored energy in the ESS. Equation (9) ensures in the ESS at time t lies in an allowable range, and , refer to the minimum, maximum capacity of the battery system.
| (10) | ||||
Equation (10) prevents the simultaneous charging and discharging of ESS by utilizing the big-M method; M is a large positive number. and are binary indicators of discharging and charging state, where means in the state and means the opposite. and are the maximum values of charging and discharging power. So the whole ESS arbitrage model is formulated as a mixed-integer linear program. We note that ignoring binary variables may lead to the suboptimality of the energy arbitrage model according to Ref. [20].
Under the predict-then-optimize framework, the relationship between prediction and optimization is uni-direct, where the upstream prediction model delivers its price to the downstream optimization model explicitly. Simultaneously, the prediction error is also delivered to the downstream implicitly, which leads to the decision error.
III Methodology
This paper takes advantage of the downstream decision error to improve the prediction model to fill the gap from the optimization model to the prediction model. The prediction model should consider the prediction error and decision error in the training process. This section presents the general decision-focused framework, measures the decision error by regret, formulates the tractable form of regret by surrogate regret, and finally proposes the hybrid SGD method learning for training prediction models.
III-A The Proposed Decision-focused Approach
Fig. 2 introduces the overall decision-focused electricity price prediction approach for ESS arbitrage. As shown on the left side of Fig. 2, the conventional prediction-focused prediction process is based on the MSE between the predicted price and the true price. The right and bottom of Fig. 2 present our main contributions. The decision-focused approach measures the difference between the optimal actual decision under the predicted price and the optimal oracle decision under the true price by regret and then turns it into tractable surrogate regret. Integrating MSE and tractable regret formulates the hybrid loss function, and then a hybrid SGD learning method is proposed to train prediction models.

III-B Regret of Decisions
In this paper, regret describes the difference between the benefit of decisions under predicted values and that under actual values [33], which measures the performance of online learning algorithms, e.g., multi-armed bandits, reinforcement learning, Thompson sampling.
III-B1 Regret Loss of ESS Decisions
In the proposed electricity price prediction for ESS, we measure the difference between optimal actual decisions under the predicted price and optimal oracle decisions under the true price in Definition 1. Low regret loss means asymptotically optimal oracle decisions.
Definition 1 (Regret of ESS decisions).
The regret of ESS decisions is defined as the gap between the benefit under the optimal actual decisions and that under the optimal oracle decisions:
| (11) |
where , denote the optimal oracle decisions under true price and the optimal actual decisions under the predicted price.
III-B2 Discussion
As a typical MILP model, the ESS arbitrage model’s feasible region is a collection of polyhedrons. So its optimal decision probably lies in the extreme point of one polyhedron. Taking two-dimension polyhedrons as an example, Fig. 3 shows that two different predicted electricity prices with the same predicted errors lead to different decision errors and corresponding different regrets. The decision under is the same as under , marked by blue star, while different from under , marked by red star. So the prediction error is not equivalent to decision error under this scenario.

The above example illustrates that the regret of prediction focuses on the impact of prediction errors on decisions. Prediction models should consider regret in learning their parameters, but the gradients of regret to predicted price are hard to calculate directly.
III-C Tractable Transformation of Regret
Regret is discontinuous and non-tractable with respect to predicted price . Based on Ref. [4], we formulate the tractable regret loss function , denoted by surrogate regret.
Firstly, we derive the equivalence of regret definition in Equation (12).
| (12) | ||||
where and denote the optimal benefit under the predicted price and that under the true price respectively.
Relaxing by the optimal decision under will result in an upper bound of Equation (12). This is satisfied for all , and then we derive Equation (13).
| (13) |
is actually a decreasing function of . According to the definition of , a sub-gradient of is given by . is the optimal decision under , so its benefit is less than , i.e., . is less than 0, and hence is a monotone decreasing function. And the of Equation (13) can be replaced by , according to the monotone converge theorem [34]. As is getting larger, the term of tends to be negligible and the optimal of inner maximization problem tends to be , which recovers Equation (12). So the minimum upper bound of regret is established.
| (14) | ||||
When combined with previous prediction model formulation (1), the minimization of prediction models’ regret can be further extended in Equation (15).
| (15a) | ||||
| (15b) | ||||
| (15c) | ||||
| (15d) | ||||
The first equality (15a) of above derives from the fact for any , which is proved in (16). The second equality (15b) derives from the intuition that as all tends to be , so they tend to be the same and can be replaced by a single variable . The first inequality (15c) derives from setting as 2 to get an estimate of upper bound in particular. And the second inequality (15d) relaxes optimal value of under by a feasible decision value .
| (16) |
Definition 2 (Surrogate regret loss of ESS decision).
Given the predicted price and true price , the surrogate regret loss of ESS decision can be defined as:
| (17) | ||||
Remark 1 (Properties of surrogate regret loss).
Given predicted price and true price, proposed surrogate regret loss holds the following properties:
1. ;
2. is a convex function of predicted electricity prices .
Lemma 1 (Gradients of the surrogate regret to predicted prices).
Based on the surrogate regret definition, the gradient of regret to predicted price can be derived as:
| (18) |
| Left side | |||
III-D Hybrid SGD Learning Method for ESS Arbitrage
MSE and surrogate regret focus on the prediction errors and decision errors individually, which view prediction mismatches from the perspectives of the prediction model and the ESS model. So this paper designs a hybrid loss function and proposes a hybrid stochastic gradient descent (SGD) learning method for training prediction model based on the hybrid loss function (19) and its derivatives (20). Fig. 4 presents the scheme of the hybrid SGD learning method.

Definition 3 (Hybrid loss function).
The hybrid loss can be defined as the weighted sum of MSE and surrogate regret to capture decision and prediction errors.
| (19) | ||||
where is a weighted coefficient on MSE, which implies the emphasis extent of minimizing prediction errors.
Then we derive the hybrid gradients of combining regret and MSE to predicted price as:
| (20) | ||||
The gradients of the hybrid loss function can be calculated explicitly by (20). To improve the calculation efficiency, the gradients of MSE are calculated implicitly by the automatic differentiation algorithm [35] from the Autograd tool [36] in Pytorch. Autograd is a reverse automatic differentiation system for calculating derivatives, which is the core of Pytorch [36]. It records a graph of all the operations performed on a gradient-enabled tensor and creates an acyclic graph called the dynamic computational graph. Gradients are computed by tracing the graph from the root to the leaf and multiplying each gradient through the chain rule.
The automatic differentiation algorithm of Autograd features high calculation efficiency due to its core logic in C++ [35], which can calculate the MSE gradient implicitly in a more efficient way than the explicit calculation by Equation (20). In contrast, the gradients of surrogate regret are calculated explicitly by solving the MILP problem in (18).
To tackle these two distinct ways of calculating gradients, the prediction model training process under hybrid gradients is divided into three steps: 1) calculate the weighted MSE loss of predicted price, back-propagate the MSE loss to the parameters, and retain the gradients for later parameters gradients updating; 2) calculate the gradients of surrogate regret based on Equation (18), feed the gradients to the predicted price, and back-propagate the gradients to the same parameters of the prediction model; 3) update the prediction model parameters based on accumulated gradients. The hybrid gradients updating is achieved by twice back-propagating and only once updating.
Based on the above derivation and discussion, this paper proposes the hybrid SGD learning method for ESS arbitrage to achieve the prediction and decision accuracy in Algorithm 1. We note that the proposed SGD learning method can apply to simple linear prediction models and complex deep learning models.
IV Case Study
This paper utilizes six-year hourly actual electricity price, related temperature, and load datasets from the Pennsylvania-New Jersey-Maryland (PJM) interconnection [37] to verify the effectiveness of the proposed decision-focused approach. All the proposed models and methods are implemented by python equipped with Pytorch package [36] for prediction models, with Cvxpy package [38] for optimization models. The experiment computer is a MacBook Pro laptop with RAM 16 GB, CPU Intel Core I7 (2.6GHz).
This section firstly pre-processes the raw electricity-related data to construct the prediction dataset, then extracts the input-output vectors, trains different day-ahead prediction models, and evaluates various models with different loss functions by multiple metrics.
IV-A Datasets and Models
IV-A1 Data Preparing
We construct the input features from three aspects in Table I: i) the past day information: the hourly load, temperature, and temperature square in the past day; ii) the prediction day information: the prediction temperature and its square in the prediction day; iii) calendar effects: the indicators of weekday, holiday, and day of the year.
Then all the input features are standardized to formulate the final feature vectors based on the mean and standard variance.
As the electricity price fluctuates a lot, we set the output of the prediction model as the log of electricity price, which assumes electricity price follows log-normal distribution [5]. After feature engineering, the 20% of the pre-processed datasets are split randomly into the test set for model evaluation; the 20% of the rest are further split randomly into the validation set for training early stop; the final rest is the training set for learning the parameters of the model.
IV-A2 Models Initializing
Fig. 5 visualizes the whole structure of the prediction process, whose key lies in the design of the ResNet model, which maps constructed input features to output log of price. As shown in Fig. 5, the ResNet model is composed of full connected (FC) layers and residual connected (RC) layers. The parameters of FC layers are initialized randomly, and whereas the parameters of RC layers are initialized by the least square method .

For the ESS arbitrage model, we normalize the energy capacity into 1 MWh. The charging/discharging power depends on the daily depths of charging/discharging, where the depths refer to the ratios of maximum charging/discharging power (MW) to energy capacity (MWh). So the unit of regret in our case is $/MWh.
IV-A3 Hyperparameter Setting
The hyperparameter setting includes the ResNet model and ESS model hyperparameters in Table I.
| ResNet model | ESS arbitrage model | ||
|---|---|---|---|
| Hyper-parameters | Values | Hyper-parameters | Values |
| Optimizer | Adam | / | 0.2 / 0.95 |
| Learning rate | 1e-6 | Depth of charging | 0.5 |
| Hidden layers | [50, 50] | Depth of discharging | 0.5 |
| Batch size | 100 | 0.90 | |
| Dropout | 0.2 | 0.92 | |
| 25 | 1 hour | ||
| Training epochs | 50 |
IV-B Performance of the Decision-focused Prediction Model
IV-B1 Training Process
Fig. 6 visualizes MSE and regret changing in training the decision-focused ResNet prediction model. As training epochs increase, the MSE of three split datasets increase firstly and then decrease at around the 23rd epoch in Fig. 6 (a). In contrast, the regrets of three split datasets decrease shapely at first and then flatten at around 45th epoch in Fig. 6 (b).
The different loss changing curves of MSE and regret show that predicted price features low MSE but high regret under initialized parameters of ResNet. This phenomenon implies that MSE is not consistent with regret. The mere consideration of MSE loss function in training prediction models is not comprehensive.


IV-B2 Models’ Comparison
To verify the effectiveness of the proposed approach, we compare the proposed decision-focused prediction (DFP) model (considering hybrid loss) with the MSE-based model (only considering MSE), multi-layer perceptron (MLP), and random forest (RF) model. The measuring metrics of prediction models’ performance in test set mainly have two components: prediction accuracy metrics, i.e., root-mean-square-error (RMSE), mean-absolute-percentage-error (MAPE) and decision accuracy metrics, i.e., regret and benefits of ESS arbitrage. We note that benefits refer to arbitrage profits from price fluctuation under different prediction models. The affinity propagation algorithm [40] is utilized to acquire the typical week electricity price and visualize changing trends of true prices and predicted prices in Fig. 7, where the oracle (true price) is the benchmark for comparison. As shown in the highlighted area of Fig. 7, the proposed DFP method can predict the changing trend of oracle price more accurately than MLP and RF models, which is the key of accurate decision. We note that the solid blue line with the “oracle” label refers to the true price, which is the benchmark to evaluate the prediction performance.

Then we analyze the results of different prediction models in Table II. The proposed DFP model achieves lower decision regret than other methods, though it endures high MSE and MAPE metrics than the MLP and the random forest methods. DFP model is apparently superior to the MSE-based model by 90.91% less regret and 46.8% higher benefits.We note that the benefits of different methods in this paper are actually the average daily benefits in the testing set, which is the mean benefits of the decisions from different models in all the testing days. The average arbitrage benefits under the true price without prediction error are $30.712 for a 500-kWh ESS, and the benefits under different models in the case study are scalable to ESSs with different capacities. Compared with MLP methods, DFP reduces 40.3% regret and further increases $1.72 (about 6.11%) daily benefits per MWh on average; compared with random forest model, DFP reduces 33.56% regret and further increases $0.090 (about 3.2 %) daily benefits per MWh on average.
| Prediction models | RMSE | MAPE | Regret | Benefits($) |
|---|---|---|---|---|
| DFP model | 0.294 | 0.0779 | 0.952 | 29.86 |
| MSE-based model | 0.320 | 0.0780 | 10.470 | 20.33 |
| MLP model | 0.0287 | 0.0412 | 1.595 | 28.14 |
| RL model | 0.0267 | 0.0415 | 1.433 | 28.94 |
Note: the hidden layer of MLP is set as 700; the depth of the random forest method is set as 30.
Taking the 500 kWh Li-ion as an example, the detailed hyperparameters of in the 500 kWh ESS arbitrage model (7)-(10) can be derived with , as 10 kWh, 475 kWh, with as 250 kW, and with as 250 kW according to the second column of Table I. We note the depth of charging/discharging reflects the fraction of the capacity added/removed from the fully charged battery, which is utilized to calculate the / . We further compare the average daily ESS benefits from various prediction models in different months in Fig. 8. The method that the day-ahead electricity price is accurately obtained without prediction error (this is impossible in practice) is taken as the benchmark for comparison, denoted by oracle, whose benefit is the highest due to no prediction error. Fig. 8 presents the benefits from July to September are higher than other months due to the high fluctuation in these summer months. The benefit from DFP is closer to that from the oracle model, higher than the other two models. In April, the benefit from DFP acquires $1.60 higher daily energy arbitrage than MLP and $1.10 higher than RF. In the whole year, the benefit from DFP can increase $87.78 compared to RF.

IV-C Analysis of Decision-focused Approach
This part utilizes the proposed hybrid SGD learning method to train the linear model (2) and ResNet model (3) individually to unfold the impact of hybrid loss in different representational capacity models. In each prediction model, we further analyze the effect of different weight parameters in the hybrid loss for deciding its proper value. The weight parameter reflects the trade-off between the prediction error and decision error, which can be selected based on the plenty of experiments in Table III and IV.
IV-C1 Linear Prediction Model
The proposed hybrid loss is utilized for training the simple linear prediction models (2) with different . For comparison, the surrogate regret loss means takes the value of 0, whereas MSE loss means takes a significant value to ignore the effects of surrogate regret part in the hybrid loss.
IV-C1a Performance evaluation
After 100 times training, we evaluate the trained model by the same metrics in the previous part: RMSE, MAPE, regret, and benefits of ESS.
| Loss function | RMSE | MAPE | Regret | Benefits($) | |
|---|---|---|---|---|---|
| MSE | / | 3.395 | 1.03 | 18.780 | 12.02 |
| Surrogate regret | / | 3.239 | 0.985 | 16.214 | 14.59 |
| Hybrid loss | 0.5 | 3.305 | 1.011 | 14.567 | 16.23 |
| Hybrid loss | 1 | 3.352 | 1.025 | 14.901 | 15.90 |
| Hybrid loss | 25 | 3.229 | 0.988 | 7.018 | 23.79 |
| Hybrid loss | 50 | 2.558 | 0.783 | 3.133 | 27.67 |
| Hybrid loss | 100 | 1.586 | 0.482 | 2.154 | 28.65 |
| Hybrid loss | 200 | 0.648 | 0.19 | 2.425 | 28.38 |
As shown in Table III, with the increase of from 25 to 200, the RMSE and MAPE decrease correspondingly. However, the regret of ESS decreases at first and then increases when is 200. In contrast, MSE and surrogate regret loss models feature high RMSE, MAPE, regret, and low benefits. The proposed hybrid loss can help instruct the small representational capacity prediction models to predict and make decisions more accurately, which leads to high benefits. When is 1, the regret of the linear prediction model has doubled than the regret with as 25, while the RMSE and MAPE increase a little.
IV-C1b Errors in different time intervals
When is 25, the RMSE and MAPE of MSE, surrogate regret, hybrid loss are similar, but hybrid loss achieves lower regret compared to the others.

As shown in Fig. 9, though the whole prediction errors under the above three losses are similar, the daily time distribution of prediction errors under MSE and surrogate regret embodies high variation than that under hybrid loss. The difference of error distributions verifies the effectiveness of hybrid loss for instructing the prediction model to reduce decision error.
IV-C1c Results analysis
The above numerical experiments provide valuable insights into the proposed hybrid loss in small representational capacity models. i) Hybrid loss can take advantage of the gradient information from prediction and decision errors to achieve more accurate prediction and decision. ii) With the increasing weight on MSE, the prediction errors are reducing alone while decision errors go down first and up after. This phenomenon can be interpreted as the hard predictable case, where electricity price is hard to predict accurately due to its uncertainty. In this case, the hybrid loss can help reduce prediction and decision errors.
IV-C2 ResNet Prediction Model
Then we apply the hybrid loss to train the complex ResNet models (3) with different .
IV-C2a Performance evaluation
After 50 times training, we evaluate the trained ResNet model by the same metrics previously. Table IV compares the prediction and decision performance of different loss functions.
| Loss function | RMSE | MAPE | Regret | Benefits($) | |
|---|---|---|---|---|---|
| MSE | / | 0.320 | 0.078 | 10.470 | 20.34 |
| Surrogate regret | / | 0.578 | 0.094 | 0.899 | 29.91 |
| Hybrid loss | 0.5 | 0.427 | 0.0779 | 0.875 | 29.93 |
| Hybrid loss | 1 | 0.658 | 0.142 | 0.924 | 29.88 |
| Hybrid loss | 25 | 0.294 | 0.0779 | 0.952 | 29.86 |
| Hybrid loss | 50 | 0.199 | 0.0466 | 1.343 | 29.46 |
| Hybrid loss | 100 | 0.153 | 0.035 | 1.938 | 28.87 |
| Hybrid loss | 200 | 0.144 | 0.03185 | 3.588 | 27.22 |
Similar to linear models, with the increase of from 25 to 200, ResNet prediction models’ RMSE and MAPE decrease correspondingly but models’ regret increase. This phenomenon means that the hybrid loss improves the models’ prediction accuracy at the cost of reducing decision accuracy. When is 1, the regret of the ResNet prediction model is similar to that with as 25, but the RMSE and MAPE have doubled than those with as 25. In contrast, when is above 100, the regret of the ResNet prediction model is almost 3.7 times the value of that with as 25 but is still 34 % of that under MSE-based loss function (only considering ). Compared to MSE, the proposed hybrid loss can reduce decision and prediction errors with lower RMSE and lower regret even with the large value of , which verifies its superiority and robustness.
Compared with the single loss design, MSE features low RMSE and MAPE but high regret, while the surrogate regret model features high RMSE and MAPE but low regret. Though hybrid loss models endure a little higher regret than the surrogate regret model, they reduce the RMSE and MAPE of single loss models.
IV-C2b Errors in different time intervals
When takes the value of 25, the RMSE of MSE and hybrid loss models are similar, which are lower than the surrogate regret model. Then we further investigate hourly prediction errors.
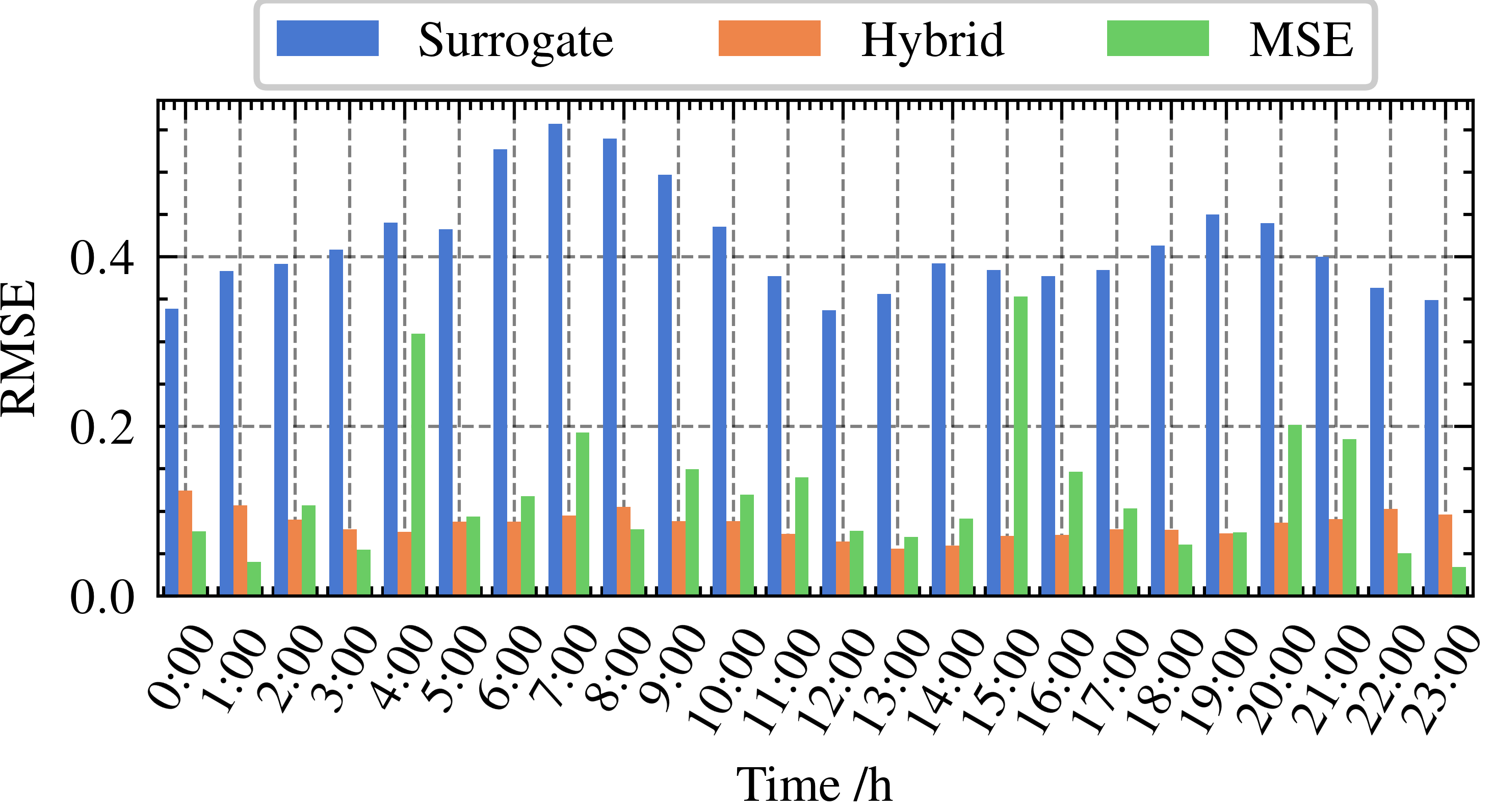
As shown in Fig. 10, though the hourly prediction errors of surrogate regret are higher than those of MSE and hybrid loss, surrogate regret embodies the lowest decision errors. The daily time distribution of prediction errors under MSE embodies significant variation with high prediction errors in the afternoon (12, 13, and 16), leading to wrong ESS decisions. In contrast, the daily time distribution of prediction errors under hybrid loss embodies low variation and time-stable prediction error.
IV-C2c Results analysis
Numerical experiments in the ResNet model help further capture the impacts of hybrid loss in large representational capacity prediction models. i) The model parameter updating directions from prediction and decision errors are inconsistent. ii) The gradients from surrogate regret tend to flatten the time distribution of prediction errors, which leads to more accurate decisions. This can be interpreted as the predictable case, where electricity price shows regularity and can be predicted accurately. In this case, the hybrid loss can help reduce prediction errors at the cost of increasing some decision errors compared to surrogate regret.
V Conclusion
This paper proposes a decision-focused electricity price prediction approach for ESS arbitrage by considering the reverse impact of downstream optimization models. Based on the surrogate regret and MSE, a hybrid loss is utilized to measure the combined decision and prediction errors. The hybrid SGD learning method is then proposed for training prediction models, including twice back-propagation and once updating. Based on the PJM dataset, numerical experiments indicate that the proposed approach can predict the price changing trend accurately and improve the decision accuracy efficiently by flattening the daily time distribution of prediction errors. Compared to MSE-based models, the decision-focused approach for electricity prediction can bring more economic benefits and reduce prediction errors.
References
- [1] H. Chitsaz, P. Zamani-Dehkordi, H. Zareipour, and P. P. Parikh, “Electricity price forecasting for operational scheduling of behind-the-Meter storage systems,” IEEE Trans. Smart Grid, vol. 9, no. 6, pp. 6612–6622, Nov. 2018.
- [2] L. Peng, S. Liu, R. Liu, and L. Wang, “Effective long short-term memory with differential evolution algorithm for electricity price prediction,” Energy, vol. 162, pp. 1301–1314, Nov. 2018.
- [3] J. Arteaga and H. Zareipour, “A price-maker/price-taker model for the operation of battery storage systems in electricity markets,” IEEE Trans. Smart Grid, vol. 10, no. 6, pp. 6912–6920, Nov. 2019.
- [4] A. N. Elmachtoub and P. Grigas, “Smart ‘predict, then optimize’,” in Manage. Sci., vol. 68, no. 1, pp.9-26, Mar. 2021.
- [5] P. Donti, B. Amos, and J. Z. Kolter, “Task-based end-to-end model learning in stochastic optimization,” Adv. Neural Inf. Process., 2017, pp. 5484–5494.
- [6] C. Lu, K. Wang, and C. Wu, “Effective end-to-end learning framework for economic dispatch,” ArXiv, 2020, https://arxiv.org/abs/2002.12755.
- [7] J. Han, L. Yan, and Z. Li, “A task-Based day-ahead load forecasting model for stochastic economic dispatch,” IEEE Trans. Power Syst., vol. 36, no. 6, pp. 5294-5304, Nov. 2021.
- [8] R. Weron, “Electricity price forecasting: a review of the state-of-the-art with a look into the future,” Int. J. Forecast., vol. 30, no. 4, pp. 1030–1081, Oct. 2014.
- [9] W. Shi, Y. Wang, Y. Chen, and J. Ma, “An effective Two-Stage Electricity Price forecasting scheme,” Electr. Power Syst. Res., vol. 199, p. 107416, Oct. 2021.
- [10] Z. Chang, Y. Zhang, and W. Chen, “Electricity price prediction based on hybrid model of adam optimized LSTM neural network and wavelet transform,” Energy, vol. 187, p. 115804, Nov. 2019.
- [11] W. Qiao and Z. Yang, “Forecast the electricity price of U.S. using a wavelet transform-based hybrid model,” Energy, vol. 193, p. 116704, Feb. 2020.
- [12] J. P. González, A. M. S. Muñoz San Roque, and E. A. Pérez, “Forecasting functional time series with a new hilbertian ARMAX model: application to electricity price forecasting,” IEEE Trans. Power Syst., vol. 33, no. 1, pp. 545–556, Jan. 2018.
- [13] G. Díaz, J. Coto, and J. Gómez-Aleixandre, “Prediction and explanation of the formation of the Spanish day-ahead electricity price through machine learning regression,” Appl. Energy, vol. 239, pp. 610–625, Apr. 2019.
- [14] A. Radovanovic, T. Nesti, and B. Chen, “A holistic approach to forecasting wholesale energy market prices,” IEEE Trans. Power Syst., vol. 34, no. 6, pp. 4317-4328, Nov. 2019.
- [15] C. Wan, M. Niu, Y. Song, and Z. Xu, “Pareto optimal prediction intervals of electricity price,” IEEE Trans. Power Syst., vol. 32, no. 1, pp. 817-819, Jan. 2017.
- [16] C. Xiao, D. Sutanto, K. M. Muttaqi, M. Zhang, K. Meng, and Z. Y. Dong, “Online sequential extreme learning machine algorithm for better predispatch electricity price forecasting grids,” IEEE Trans. Ind. Appl., vol. 57, no. 2, pp. 1860-1871, Mar.-Apr. 2021.
- [17] T. Lu, X. Chen, M. B. McElroy, C. P. Nielsen, Q. Wu, and Q. Ai, “A reinforcement learning-based decision system for electricity pricing plan selection by smart grid end users,” IEEE Trans. Smart Grid, vol. 12, no. 3, pp. 2176-2187, May 2021.
- [18] S. Comello and S. Reichelstein, “The emergence of cost effective battery storage,” Nat. Commun., vol. 10, no. 1, p. 2038, May 2019.
- [19] H. Khani and H. E. Z. Farag, “Joint arbitrage and operating reserve scheduling of energy storage through optimal adaptive allocation of the state of charge,” IEEE Trans. Sustain. Energy, vol. 10, no. 4, pp. 1705-1717, Oct. 2019.
- [20] Z. Shen, W. Wei, D. Wu, T. Ding, and S. Mei, “Modeling arbitrage of an energy storage unit without binary variables,” CSEE J. Power Energy Syst., vol. 7, no. 1, pp. 156-161, Jan. 2021.
- [21] H. Cui, F. Li, X. Fang, H. Chen, and H. Wang, “Bilevel arbitrage potential evaluation for grid-scale energy storage considering wind power and LMP smoothing effect,” IEEE Trans. Sustain. Energy, vol. 9, no. 2, pp. 707-718, Apr. 2018.
- [22] D. Krishnamurthy, C. Uckun, Z. Zhou, P. R. Thimmapuram, and A. Botterud, “Energy storage arbitrage under day-ahead and real-time price uncertainty,” IEEE Trans. Power Syst., vol. 33, no. 1, pp. 84-93, Jan. 2018.
- [23] M. U. Hashmi, D. Deka, A. Bušić, L. Pereira, and S. Backhaus, “Arbitrage With Power Factor Correction Using Energy Storage,” IEEE Trans. Power Syst., vol. 35, no. 4, pp. 2693–2703, Jul. 2020.
- [24] J. Cao, D. Harrold, Z. Fan, T. Morstyn, D. Healey, and K. Li, “Deep reinforcement learning-based energy storage arbitrage with accurate lithium-ion battery degradation model,” IEEE Trans. Smart Grid, vol. 11, no. 5, pp. 4513–4521, Sept. 2020.
- [25] E. Pusceddu, B. Zakeri, and G. Castagneto Gissey, “Synergies between energy arbitrage and fast frequency response for battery energy storage systems,” Appl. Energy, vol. 283, p. 116274, Feb. 2021.
- [26] S. F. Schneider, P. Novák, and T. Kober, “Rechargeable batteries for simultaneous demand peak shaving and price arbitrage business,” IEEE Trans. Sustain. Energy, vol. 12, no. 1, pp. 148–157, Jan. 2021.
- [27] T. Terlouw, T. AlSkaif, C. Bauer, and W. van Sark, “Multi-objective optimization of energy arbitrage in community energy storage systems using different battery technologies,” Appl. Energy, vol. 239, pp. 356–372, Apr. 2019.
- [28] U. R. Nair, M. Sandelic, A. Sangwongwanich, T. Dragičević, R. Costa-Castelló and F. Blaabjerg, “An analysis of multi objective energy scheduling in PV-BESS system under prediction uncertainty,” IEEE Trans. Energy Convers., vol. 36, no. 3, pp. 2276-2286, Sept. 2021.
- [29] Y. Wang, D. Chang, S. Qin, Y. Fan, H. Mu and G. Zhang, “Separating multi-source partial discharge signals using linear prediction analysis and isolation forest algorithm,” IEEE Trans. Instrum. Meas., vol. 69, no. 6, pp. 2734-2742, Jun. 2020.
- [30] X. Ren, H. Mosavat-Jahromi, L. Cai and D. Kidston, “Spatio-temporal spectrum load prediction using convolutional neural network and ResNet,” IEEE Trans. Cogn. Commun. Netw., early access.
- [31] I. Goodfellow, Y. Bengio, and A. Courville, Deep learning. MIT Press, MA, 2016.
- [32] J. Mandi, E. Demirovic, P. J. Stuckey, and T. Guns, “Smart predict-and-optimize for hard combinatorial optimization problems,” AAAI-20, vol. 34, no. 02, pp. 1603-1610, Apr. 2020.
- [33] R. S. Sutton and A. G. Barto, Reinforcement learning: an introduction. Cambridge, MA, USA: A Bradford Book, 2018.
- [34] A. Linero-Bas and D. Nieves-Roldán, “A generalization of the monotone convergence theorem,” J. Mach. Learn. Res., vol. 18, no. 4, p. 158, Jun. 2021.
- [35] A. Paszke et al., “Automatic differentiation in PyTorch,” NIPS 2017 Workshop on Autodiff, Long Beach, California, USA, 2017.
- [36] A. Paszke et al., “PyTorch: An imperative style, high-performance deep learning library,” Adv. Neural Inf. Process., 2019, pp. 8024–8035.
- [37] PJM., https://dataminer2.pjm.com/list [Online].
- [38] S. Diamond and S. Boyd, “CVXPY: A Python-embedded modeling language for convex optimization,” J. Mach. Learn. Res., vol. 17, no. 83, pp. 1–5, 2016.
- [39] F. Pedregosa et al.,“Scikit-learn: machine learning in Python,” J. Mach. Learn. Res., vol. 12, pp. 2825–2830, 2011.
- [40] B. J. Frey and D. Dueck, “Clustering by passing messages between data points,” Science, vol. 315, no.5814, pp. 972-976, Feb. 2007.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/2c41b409-fe74-49b0-8b63-e58e1ae968cc/LinweiSang.png) |
Linwei Sang (S’20) received the M.S. degree from the School of Electric Engineering, Southeast University, China in 2021. He is currently pursuing the Ph.D. degree in the Tsinghua-Berkeley Shenzhen Institute, Tsinghua University, Shenzhen, China. His research includes machine learning application in smart grid, the control of the distributed energy, and demand side resource management. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/2c41b409-fe74-49b0-8b63-e58e1ae968cc/YinliangXu.png) |
Yinliang Xu (SM’19) received the B.S. and M.S. degrees in control science and engineering from the Harbin Institute of Technology, Harbin, China, in 2007 and 2009, respectively, and the Ph.D. degree in electrical and computer engineering from New Mexico State University, Las Cruces, NM, USA, in 2013. He is currently an Associate Professor with Tsinghua-Berkeley Shenzhen Institute, Tsinghua Shenzhen International Graduate School, Tsinghua University, Beijing, China. His research interests include distributed control and optimization of power systems, renewable energy integration, and microgrid modeling and control. |
| Huan Long (M’15) received the B.Eng. degree from Huazhong University of Science and Technology, Wuhan, China, in 2013, and the Ph.D. degree from the City University of Hong Kong, Hong Kong, in 2017. She is currently an Associate Professor with the School of Electrical Engineering, Southeast University, Nanjing, China. Her research fields include artificial intelligence applied in modeling, optimizing, monitoring the renewable energy system and power system. |
| Qinran Hu (SM’21) received the B.S. degree from Chien-Shiung Wu College, Southeast University, Nanjing, China, in 2010, and the M.S. and Ph.D. degrees from the University of Tennessee, Knoxville, TN, USA, in 2013 and 2015, respectively, all in electrical engineering. He was a Postdoctoral Fellow with Harvard University, Cambridge, MA, USA, from 2015 to 2018. He joined the School of Electrical Engineering, Southeast University, in October 2018. His research interests include power system optimization, demand aggregation, and virtual power plant. |
| Hongbin Sun (Fellow, IEEE) received his double B.S. degrees from Tsinghua University in 1992, the Ph.D from Dept. of E.E., Tsinghua University in 1996. He is now ChangJiang Scholar Chair professor and the director of energy management and control research center, Tsinghua University. He also serves as the editor of the IEEE TSG, associate editor of IET RPG, and member of the Editorial Board of four international journals and several Chinese journals. His technical areas include electric power system operation and control with specific interests on the Energy Management System, Automatic Voltage Control, and Energy System Integration. |