Eigencurve: Optimal Learning Rate Schedule for SGD on Quadratic Objectives with Skewed Hessian Spectrums
Abstract
Learning rate schedulers have been widely adopted in training deep neural networks. Despite their practical importance, there is a discrepancy between its practice and its theoretical analysis. For instance, it is not known what schedules of SGD achieve best convergence, even for simple problems such as optimizing quadratic objectives. In this paper, we propose Eigencurve, the first family of learning rate schedules that can achieve minimax optimal convergence rates (up to a constant) for SGD on quadratic objectives when the eigenvalue distribution of the underlying Hessian matrix is skewed. The condition is quite common in practice. Experimental results show that Eigencurve can significantly outperform step decay in image classification tasks on CIFAR-10, especially when the number of epochs is small. Moreover, the theory inspires two simple learning rate schedulers for practical applications that can approximate eigencurve. For some problems, the optimal shape of the proposed schedulers resembles that of cosine decay, which sheds light to the success of cosine decay for such situations. For other situations, the proposed schedulers are superior to cosine decay.
1 Introduction
Many machine learning models can be represented as the following optimization problem:
| (1.1) |
such as logistic regression, deep neural networks. To solve the above problem, stochastic gradient descent (SGD) (Robbins & Monro, 1951) has been widely adopted due to its computation efficiency in large-scale learning problems (Bottou & Bousquet, 2008), especially for training deep neural networks.
Given the popularity of SGD in this field, different learning rate schedules have been proposed to further improve its convergence rates. Among them, the most famous and widely used ones are inverse time decay, step decay (Goffin, 1977), and cosine scheduler (Loshchilov & Hutter, 2017). The learning rates generated by the inverse time decay scheduler depends on the current iteration number inversely. Such a scheduling strategy comes from the theory of SGD on strongly convex functions, and is extended to non-convex objectives like neural networks while still achieving good performance. Step decay scheduler keeps the learning rate piecewise constant and decreases it by a factor after a given amount of epochs. It is theoretically proved in Ge et al. (2019) that when the objective is quadratic, step decay scheduler outperforms inverse time decay. Empirical results are also provided in the same work to demonstrate the better convergence property of step decay in training neural networks when compared with inverse time decay. However, even step decay is proved to be near optimal on quadratic objectives, it is not truly optimal. There still exists a gap away from the minimax optimal convergence rate, which turns out to be non-trivial in a wide range of settings and may greatly impact step decay’s empirical performance. Cosine decay scheduler (Loshchilov & Hutter, 2017) generates cosine-like learning rates in the range , with being the maximum iteration. It is a heuristic scheduling strategy which relies on the observation that good performance in practice can be achieved via slowly decreasing the learning rate in the beginning and “refining” the solution in the end with a very small learning rate. Its convergence property on smooth non-convex functions has been shown in Li et al. (2021), but the provided bound is still not tight enough to explain its success in practice.
Except cosine decay scheduler, all aforementioned learning rate schedulers have (or will have) a tight convergence bound on quadratic objectives. In fact, studying their convergence property on quadratic objective functions is quite important for understanding their behaviors in general non-convex problems. Recent studies in Neural Tangent Kernel (NTK) (Arora et al., 2019; Jacot et al., 2020) suggest that when neural networks are sufficiently wide, the gradient descent dynamic of neural networks can be approximated by NTK. In particular, when the loss function is least-square loss, neural network’s inference is equivalent to kernel ridge regression with respect to the NTK in expectation. In other words, for regression tasks, the non-convex objective in neural networks resembles quadratic objectives when the network is wide enough.
The existence of gap in step decay’s convergence upper bound, which will be proven to be tight in a wide range of settings, implies that there is still room for improvement in theory. Meanwhile, the existence of cosine decay scheduler, which has no strong theoretical convergence guarantees but possesses good empirical performance in certain tasks, suggests that its convergence rate may depend on some specific properties of the objective determined by the network and dataset in practice. Hence it is natural to ask what those key properties may be, and whether it is possible to find theoretically-optimal schedulers whose empirical performance are comparable to cosine decay if those properties are available. In this paper, we offer an answer to these questions. We first derive a novel eigenvalue-distribution-based learning rate scheduler called eigencurve for quadratic functions. Combining with eigenvalue distributions of different types of networks, new neural-network-based learning rate schedulers can be generated based on our proposed paradigm, which achieve better convergence properties than step decay in Ge et al. (2019). Specifically, eigencurve closes the gap in step decay and reaches minimax optimal convergence rates if the Hessian spectrum is skewed. We summarize the main contributions of this paper as follows.
-
1.
To the best of our knowledge, this is the first work that incorporates the eigenvalue distribution of objective function’s Hessian matrix into designing learning rate schedulers. Accordingly, based on the eigenvalue distribution of the Hessian, we propose a novel eigenvalue distribution based learning rate scheduler named eigencurve.
-
2.
Theoretically, eigencurve can achieve optimal convergence rate (up to a constant) for SGD on quadratic objectives when the eigenvalue distribution of the Hessian is skewed. Furthermore, even when the Hessian is not skewed, eigencurve can still achieve no worse convergence rate than the step decay schedule in Ge et al. (2019), whose convergence rate are proven to be sub-optimal in a wide range of settings.
-
3.
Empirically, on image classification tasks, eigencurve achieves optimal convergence rate for several models on CIFAR-10 and ImageNet if the loss can be approximated by quadratic objectives. Moreover, it obtains much better performance than step decay on CIFAR-10, especially when the number of epochs is small.
-
4.
Intuitively, our learning rate scheduler sheds light on the theoretical property of cosine decay and provides a perspective of understanding the reason why it can achieve good performance on image classification tasks. The same idea has been used to inspire and discover several simple families of schedules that works in practice.
Problem Setup
For the theoretical analysis and the aim to derive our eigenvalue-dependent learning rate schedulers, we mainly focus on the quadratic function, that is,
| (1.2) |
where denotes the data sample. Hence, the Hessian of is
| (1.3) |
Letting us denote , we can obtain the optima of problem (1.2)
| (1.4) |
Given an initial iterate and the learning rate sequence , the stochastic gradient update is
| (1.5) |
We denote that
| (1.6) |
In this paper, we assume that
| (1.7) |
The reason for this assumption is presented in Appendix G.5.
Related Work
| Scheduler | Convergence rate of SGD in quadratic objectives |
| Constant | Not guaranteed to converge |
| Inverse Time Decay | |
| Step Decay | (Ge et al. (2019); Wu et al. (2021); This work - Theorem 4) |
| Eigencurve | with skewed Hessian spectrums, in worst case (This work - Theorem 1, Corollary 2, 3) |
In convergence analysis, one key property that separates SGD from vanilla gradient descent is that in SGD, noise in gradients dominates. In gradient descent (GD), constant learning rate can achieve linear convergence with for strongly convex objectives, i.e. obtaining in iterations. However, in SGD, cannot even be guaranteed to converge to due to the existence of gradient noise (Bottou et al., 2018). Intuitively, this noise leads to a variance proportional to the learning rate size, so constant learning rate will always introduce a gap when compared with the convergence rate of GD. Fortunately, inverse time decay scheduler solves the problem by decaying the learning rate inversely proportional to the iteration number , which achieves convergence rate for strongly convex objectives, specifically, . However, this is sub-optimal since the minimax optimal rate for SGD is (Ge et al., 2019; Jain et al., 2018). Moreover, in practice, can be very big for large neural networks, which makes inverse time decay scheduler undesirable for those models. This is when step decay (Goffin, 1977) comes to play. Empirically, it is widely adopted in tasks such as image classification and serves as a baseline for a lot of models. Theoretically, it has been proven that step decay can achieve nearly optimal convergence rate for strongly convex least square regression (Ge et al., 2019). A tighter set of instance-dependent bounds in a recent work (Wu et al., 2021), which is carried out independently from ours, also proves its near optimality. Nevertheless, step decay is not always the best choice for image classification tasks. In practice, cosine decay (Loshchilov & Hutter, 2017) can achieve comparable or even better performance, but the reason behind this superior performance is still unknown in theory (Gotmare et al., 2018). All the aforementioned results are summarized in Table 1, along with our results in this paper. It is worth mentioning that the minimax optimal rate can be achieved by iterate averaging methods (Jain et al., 2018; Bach & Moulines, 2013; Défossez & Bach, 2015; Frostig et al., 2015; Jain et al., 2016; Neu & Rosasco, 2018), but it is not a common practice to use them in training deep neural networks, so only the final iterate (Shamir, 2012) behavior of SGD is analyzed in this paper, i.e. the point right after the last iteration.
Paper organization: Section 2 describes the motivation of our eigencurve scheduler. Section 3 presents the exact form and convergence rate of the proposed eigencurve scheduler, along with the lower bound of step decay. Section 4 shows the experimental results. Section 5 discusses the discovery and limitation of eigencurve and Section 6 gives our conclusion.
2 Motivation
In this section, we will give the main motivation and intuition of our eigencurve learning rate scheduler. We first give the scheduling strategy to achieve the optimal convergence rate in the case that the Hessian is diagonal. Then, we show that the inverse time learning rate is sub-optimal in most cases. Comparing these two scheduling methods brings up the reason why we should design eigenvalue distribution dependent learning rate scheduler.
Letting be a diagonal matrix and reformulating Eqn. (1.5), we have
It follows,
| (2.1) | ||||
Since is diagonal, we can set step size scheduling for each dimension separately. Letting us choose step size coordinately with the step size being optimal for the -th coordinate, then we have the following proposition.
Proposition 1.
Assume that is diagonal matrix with eigenvalues and Eqn. (1.7) holds. If we set step size , it holds that
| (2.2) |
The leading equality here is proved in Appendix G.1, with the followed inequality proved in Appendix E. From Eqn. (2.2), we can observe that choosing proper step sizes coordinately can achieve the optimal convergence rate (Ge et al., 2019; Jain et al., 2018). Instead, if the widely used inverse time scheduler is chosen, we can show that only a sub-optimal convergence rate can be obtained, especially when ’s vary from each other.
Proposition 2.
If we set the inverse time step size , then we have
| (2.3) | ||||
Remark 1.
Eqn. (2.2) shows that if one can choose step size coordinate-wise with step size , then SGD can achieve a convergence rate
| (2.4) |
which matches the lower bound (Ge et al., 2019; Jain et al., 2018). In contrast, replacing and in Proposition 2, we can obtain that the convergence rate of SGD being
| (2.5) |
Since it holds that , the convergence rate in Eqn. (2.4) is better than the one in Eqn. (2.5), especially when the eigenvalues of the Hessian ( matrix) decay rapidly. In fact, the upper bound in Eqn. (2.5) is tight for the inverse time decay scheduling, as proven in Ge et al. (2019).
Main Intuition
The diagonal case provides an important intuition for designing eigenvalue dependent learning rate scheduling. In fact, for general non-diagonal , letting be the spectral decomposition of the Hessian and setting , then the Hessian becomes a diagonal matrix from perspective of updating , with the variance of the stochastic gradient being unchanged since is a unitary matrix. This is also the core idea of Newton’s method and many second-order methods (Huang et al., 2020). However, given our focus in this paper being learning rate schedulers only, we move the relevant discussion of their relationship to Appendix H.
Proposition 1 and 2 imply that a good learning rate scheduler should decrease the error of each coordinate. The inverse time decay scheduler is only optimal for the coordinate related to the smallest eigenvalue. That’s the reason why it is sub-optimal overall. Thus, we should reduce the learning rate gradually such that we can run a optimal learning rate associated to to sufficiently drop the error of -th coordinate. Furthermore, given the total iteration and the eigenvalue distribution of the Hessian, we should allocate the running time for each optimal learning rate associated to .
3 Eigenvalue Dependent Step Scheduling

Just as discussed in Section 2, to obtain better convergence rate for SGD, we should consider Hessian’s eigenvalue distribution and schedule the learning rate based on the distribution. In this section, we propose a novel learning rate scheduler for this task, which can be regarded as piecewise inverse time decay (see Figure 1). The method is very simple, we group eigenvalues according to their value and denote to be the number of eigenvalues lie in the range , that is,
| (3.1) |
Then, there are at most such ranges. By the inverse time decay theory, the optimal learning rate associated to eigenvalues in the range should be
| (3.2) |
Our scheduling strategy is to run the optimal learning rate for eigenvalues in each for a period to sufficiently decrease the error associated to eigenvalues in .
To make the step size sequence monotonely decreasing, we define the step sizes as
| (3.3) |
where
| (3.4) |
To make the total error, that is the sum of error associated with , to be small, we should allocate according to ’s. Intuitively, a large portion of eigenvalues lying in the range should allocate a large portion of iterations. Specifically, we propose to allocate as follows:
| (3.5) |
In the rest of this section, we will show that the step size scheduling according to Eqn. (3.3) and (3.5) can achieve better convergence rate than the one in Ge et al. (2019) when is non-uniformly distributed. In fact, a better allocation can be calculated using numerical optimization.
3.1 Theoretical Analysis
Lemma 1.
Since the bias term is a high order term, the variance term in Eqn. (3.6) dominates the error for . For simplicity, instead of using numerical methods to find the optimal , we propose to use defined in Eqn. (3.5). The value of is linear to square root of the number of eigenvalues lying in the range . Using such , eigencurve has the following convergence property.
Theorem 1.
Please refer to Appendix D, F and G for the full proof of Lemma 1 and Theorem 1. The variance term in above theorem shows that when ’s vary largely from each other, then the variance can be close to which matches the lower bound (Ge et al., 2019). For example, letting , and , we can obtain that

We can observe that if the variance of ’s is large, the variance term in Theorem 1 can be close to . More generally, as rigorously stated in Corollary 2, eigencurve achieves minimax optimal convergence rate if the Hessian spectrum satisfies an extra assumption of “power law”: the density of eigenvalue is exponentially decaying with increasing value of in log scale, i.e. . This assumption comes from the observation of estimated Hessian spectrums in practice (see Figure 2), which will be further illustrated in Section 4.1.
Corollary 2.
Given the same setting as in Theorem 1, when Hessian ’s eigenvalue distribution satisfies “power law”, i.e.
| (3.7) |
for some , where , there exists a constant which only depends on , such that the final iterate satisfies
Please refer to Appendix G.3 for the proof. As for the worst-case guarantee, it is easy to check that only when ’s are equal to each other, that is, , the variance term reaches its maximum.
Corollary 3.
Remark 2.
When ’s vary from each other, our eigenvalue dependent learning rate scheduler can achieve faster convergence rate than eigenvalue independent scheduler such as step decay which suffers from an extra term (Ge et al., 2019). Only when ’s are equal to each other, Corollary 3 shows that the bound of variance matches to lower bound up to which is same to the one in Proposition 3 of Ge et al. (2019).
Furthermore, we show that this gap between step decay and eigencurve certainly exists for problem instances of skewed Hessian spectrums. For simplicity, we only discuss the case where is diagonal.
Theorem 4.
The proof is provided in Appendix G.4. Removing this extra term may not seem to be a big deal in theory, but experimental results suggest the opposite.
4 Experiments
To demonstrate eigencurve ’s practical value, empirical experiments are conducted on the task of image classification 111Code: https://github.com/opensource12345678/why_cosine_works/tree/main. Two well-known dataset are used: CIFAR-10 (Krizhevsky et al., 2009) and ImageNet (Deng et al., 2009). For full experimental results on more datasets, please refer to Appendix A.
4.1 Hessian Spectrum’s Skewness in Practice
According to estimated222Please refer to Appendix B.2 for details of the estimation and preprocessing procedure. eigenvalue distributions of Hessian on CIFAR-10 and ImageNet, as shown in Figure 3, it can be observed that all of them are highly skewed and share a similar tendency: A large portion of small eigenvalues and a tiny portion of large eigenvalues. This phenomenon has also been observed and explained by other researchers in the past(Sagun et al., 2017; Arjevani & Field, 2020). On top of that, when we plot both eigenvalues and density in log scale, the “power law” arises. Therefore, if the loss surface can be approximated by quadratic objectives, then eigencurve has already achieved optimal convergence rate for those practical settings. The exact values of the extra constant terms are presented in Appendix A.2.





4.2 Image Classification on CIFAR-10 with Eigencurve Scheduling
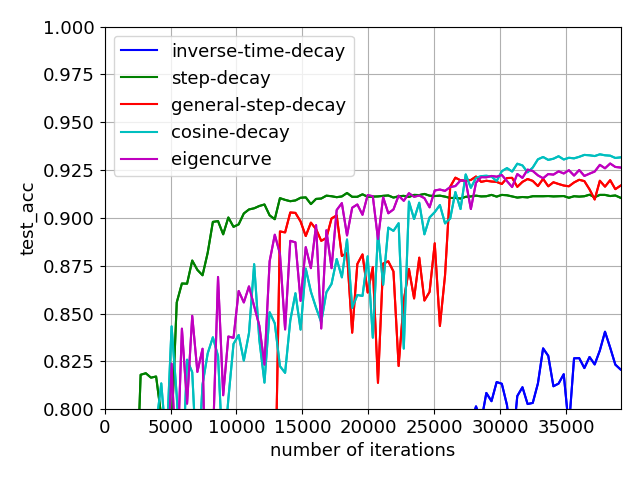
This optimality in theory induces eigencurve ’s superior performance in practice, which is demonstrated in Table 2 and Figure 4. The full set of figures are available in Appendix A.8. All models are trained with stochastic gradient descent (SGD), no momentum, batch size and weight decay . For full details of the experiment setup, please refer to Appendix B.
| #Epoch | Schedule | ResNet-18 | GoogLeNet | VGG16 | |||
| Loss | Acc(%) | Loss | Acc(%) | Loss | Acc(%) | ||
| =10 | Inverse Time Decay | 1.580.02 | 79.451.00 | 2.610.00 | 86.540.94 | 2.260.00 | 84.470.74 |
| Step Decay | 1.820.04 | 73.771.48 | 2.590.02 | 87.040.48 | 2.420.45 | 82.980.27 | |
| General Step Decay | 1.520.02 | 81.990.35 | 1.930.03 | 88.321.32 | 2.140.42 | 86.790.36 | |
| Cosine Decay | 1.420.01 | 84.230.07 | 1.940.00 | 90.560.31 | 2.030.00 | 87.990.13 | |
| Eigencurve | 1.360.01 | 85.620.28 | 1.330.00 | 90.650.15 | 1.870.00 | 88.730.11 | |
| =100 | Inverse Time Decay | 0.730.00 | 90.820.43 | 0.620.02 | 92.050.69 | 1.320.62 | *76.2413.77 |
| Step Decay | 0.260.01 | 91.391.03 | 0.280.00 | 92.830.15 | 0.590.00 | 91.370.20 | |
| General Step Decay | 0.170.00 | 93.970.21 | 0.130.00 | 94.180.18 | 0.200.00 | *92.360.46 | |
| Cosine Decay | 0.170.00 | 94.040.21 | 0.120.00 | 94.620.11 | 0.200.00 | 93.170.05 | |
| Eigencurve | 0.140.00 | 94.050.18 | 0.120.00 | 94.750.15 | 0.180.00 | 92.880.24 | |


4.3 Inspired Practical Schedules with Simple Forms
By simplifying the form of eigencurve and capturing some of its key properties, two simple and practical schedules are proposed: Elastic Step Decay and Cosine-power Decay, whose empirical performance are better than or at least comparable to cosine decay. Due to page limit, we leave all the experimental results in Appendix A.5, A.6, A.7.
| Elastic Step Decay: | (4.1) | |||
| Cosine-power Decay: | (4.2) |
5 Discussion
Cosine Decay and Eigencurve
For ResNet- on CIFAR-10 dataset, eigencurve scheduler presents an extremely similar learning rate curve to cosine decay, especially when the number of training epochs is set to , as shown in Figure 5. This directly links cosine decay to our theory: the empirically superior performance of cosine decay is very likely to stem from the utilization of the “skewness” among Hessian matrix’s eigenvalues. For other situations, especially when the number of iterations is small, as shown in Table 2, eigencurve presents a better performance than cosine decay .



Sensitiveness to Hessian’s Eigenvalue Distributions
One limitation of eigencurve is that it requires a precomputed eigenvalue distribution of objective functions’s Hessian matrix, which can be time-consuming for large models. This issue can be overcome by reusing the estimated eigenvalue distribution from similar settings. Further experiments on CIFAR-10 suggest the effectiveness of this approach. Please refer to Appendix A.3 for more details. This evidence suggests that eigencurve’s performance is not very sensitive to estimated eigenvalue distributions.
Relationship with Numerically Near-optimal Schedulers
In Zhang et al. (2019), a dynamic programming algorithm was proposed to find almost optimal schedulers if the exact loss of the quadratic objective is accessible. While it is certainly the case, eigencurve still possesses several additional advantages over this type of approaches. First, eigencurve can be used to find simple-formed schedulers. Compared with schedulers numerically computed by dynamic programming, eigencurve provides an analytic framework, so it is able to bypass the Hessian spectrum estimation process if some useful assumptions of the Hessian spectrum can be obtained, such as ”power law”. Second, eigencurve has a clear theoretical convergence guarantee. Dynamic programming can find almost optimal schedulers, but the convergence property of the computed scheduler is still unclear. Our work fills this gap.
6 Conclusion
In this paper, a novel learning rate schedule named eigencurve is proposed, which utilizes the “skewness” of objective’s Hessian matrix’s eigenvalue distribution and reaches minimax optimal convergence rates for SGD on quadratic objectives with skewed Hessian spectrums. This condition of skewed Hessian spectrums is observed and indeed satisfied in practical settings of image classification. Theoretically, eigencurve achieves no worse convergence guarantee than step decay for quadratic functions and reaches minimax optimal convergence rate (up to a constant) with skewed Hessian spectrums, e.g. under “power law”. Empirically, experimental results on CIFAR-10 show that eigencurve significantly outperforms step decay, especially when the number of epochs is small. The idea of eigencurve offers a possible explanation for cosine decay’s effectiveness in practice and inspires two practical families of schedules with simple forms.
Acknowledgement
This work is supported by GRF 16201320. Rui Pan acknowledges support from the Hong Kong PhD Fellowship Scheme (HKPFS). The work of Haishan Ye was supported in part by National Natural Science Foundation of China under Grant No. 12101491.
References
- Arjevani & Field (2020) Yossi Arjevani and Michael Field. Analytic characterization of the hessian in shallow relu models: A tale of symmetry, 2020.
- Arora et al. (2019) Sanjeev Arora, Simon S. Du, Wei Hu, Zhiyuan Li, Ruslan Salakhutdinov, and Ruosong Wang. On exact computation with an infinitely wide neural net, 2019.
- Bach & Moulines (2013) Francis Bach and Eric Moulines. Non-strongly-convex smooth stochastic approximation with convergence rate o (1/n). arXiv preprint arXiv:1306.2119, 2013.
- Botev et al. (2017) Aleksandar Botev, Hippolyt Ritter, and David Barber. Practical Gauss-Newton optimisation for deep learning. In Doina Precup and Yee Whye Teh (eds.), Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pp. 557–565. PMLR, 06–11 Aug 2017. URL https://proceedings.mlr.press/v70/botev17a.html.
- Bottou & Bousquet (2008) Léon Bottou and Olivier Bousquet. The tradeoffs of large scale learning. In J. Platt, D. Koller, Y. Singer, and S. Roweis (eds.), Advances in Neural Information Processing Systems, volume 20. Curran Associates, Inc., 2008. URL https://proceedings.neurips.cc/paper/2007/file/0d3180d672e08b4c5312dcdafdf6ef36-Paper.pdf.
- Bottou et al. (2018) Léon Bottou, Frank E. Curtis, and Jorge Nocedal. Optimization methods for large-scale machine learning, 2018.
- Byrd et al. (2016) Richard H Byrd, Samantha L Hansen, Jorge Nocedal, and Yoram Singer. A stochastic quasi-newton method for large-scale optimization. SIAM Journal on Optimization, 26(2):1008–1031, 2016.
- Chang & Lin (2011) Chih-Chung Chang and Chih-Jen Lin. Libsvm: a library for support vector machines. ACM transactions on intelligent systems and technology (TIST), 2(3):1–27, 2011.
- Défossez & Bach (2015) Alexandre Défossez and Francis Bach. Averaged least-mean-squares: Bias-variance trade-offs and optimal sampling distributions. In Artificial Intelligence and Statistics, pp. 205–213. PMLR, 2015.
- Deng et al. (2009) Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pp. 248–255. Ieee, 2009.
- Dua & Graff (2017) Dheeru Dua and Casey Graff. UCI machine learning repository, 2017. URL http://archive.ics.uci.edu/ml.
- Erdogdu & Montanari (2015) Murat A Erdogdu and Andrea Montanari. Convergence rates of sub-sampled newton methods. In C. Cortes, N. Lawrence, D. Lee, M. Sugiyama, and R. Garnett (eds.), Advances in Neural Information Processing Systems, volume 28. Curran Associates, Inc., 2015. URL https://proceedings.neurips.cc/paper/2015/file/404dcc91b2aeaa7caa47487d1483e48a-Paper.pdf.
- Frostig et al. (2015) Roy Frostig, Rong Ge, Sham M Kakade, and Aaron Sidford. Competing with the empirical risk minimizer in a single pass. In Conference on learning theory, pp. 728–763. PMLR, 2015.
- Ge et al. (2019) Rong Ge, Sham M Kakade, Rahul Kidambi, and Praneeth Netrapalli. The step decay schedule: A near optimal, geometrically decaying learning rate procedure for least squares. In Advances in Neural Information Processing Systems, pp. 14977–14988, 2019.
- Goffin (1977) Jean-Louis Goffin. On convergence rates of subgradient optimization methods. Mathematical programming, 13(1):329–347, 1977.
- Gotmare et al. (2018) Akhilesh Gotmare, Nitish Shirish Keskar, Caiming Xiong, and Richard Socher. A closer look at deep learning heuristics: Learning rate restarts, warmup and distillation, 2018.
- Goyal et al. (2018) Priya Goyal, Piotr Dollár, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, large minibatch sgd: Training imagenet in 1 hour, 2018.
- Grosse & Martens (2016) Roger Grosse and James Martens. A kronecker-factored approximate fisher matrix for convolution layers. In Maria Florina Balcan and Kilian Q. Weinberger (eds.), Proceedings of The 33rd International Conference on Machine Learning, volume 48 of Proceedings of Machine Learning Research, pp. 573–582, New York, New York, USA, 20–22 Jun 2016. PMLR. URL https://proceedings.mlr.press/v48/grosse16.html.
- Hochreiter & Schmidhuber (1997) Sepp Hochreiter and Jürgen Schmidhuber. Long Short-Term Memory. Neural Computation, 9(8):1735–1780, 11 1997. ISSN 0899-7667. doi: 10.1162/neco.1997.9.8.1735. URL https://doi.org/10.1162/neco.1997.9.8.1735.
- Huang et al. (2020) Xunpeng Huang, Xianfeng Liang, Zhengyang Liu, Lei Li, Yue Yu, and Yitan Li. Span: A stochastic projected approximate newton method. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pp. 1520–1527, 2020.
- Jacot et al. (2020) Arthur Jacot, Franck Gabriel, and Clément Hongler. Neural tangent kernel: Convergence and generalization in neural networks, 2020.
- Jain et al. (2016) Prateek Jain, Sham M Kakade, Rahul Kidambi, Praneeth Netrapalli, and Aaron Sidford. Parallelizing stochastic approximation through mini-batching and tail-averaging. arXiv preprint arXiv:1610.03774, 2016.
- Jain et al. (2018) Prateek Jain, Sham M. Kakade, Rahul Kidambi, Praneeth Netrapalli, and Aaron Sidford. Accelerating stochastic gradient descent for least squares regression, 2018.
- Krizhevsky et al. (2009) Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- Li et al. (2021) Xiaoyu Li, Zhenxun Zhuang, and Francesco Orabona. A second look at exponential and cosine step sizes: Simplicity, adaptivity, and performance, 2021.
- Loshchilov & Hutter (2017) Ilya Loshchilov and Frank Hutter. SGDR: stochastic gradient descent with warm restarts. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings, 2017.
- Marcus et al. (1993) Mitchell P. Marcus, Beatrice Santorini, and Mary Ann Marcinkiewicz. Building a large annotated corpus of English: The Penn Treebank. Computational Linguistics, 19(2):313–330, 1993. URL https://aclanthology.org/J93-2004.
- Neu & Rosasco (2018) Gergely Neu and Lorenzo Rosasco. Iterate averaging as regularization for stochastic gradient descent. In Conference On Learning Theory, pp. 3222–3242. PMLR, 2018.
- Robbins & Monro (1951) Herbert Robbins and Sutton Monro. A stochastic approximation method. The annals of mathematical statistics, pp. 400–407, 1951.
- Sagun et al. (2017) Levent Sagun, Leon Bottou, and Yann LeCun. Eigenvalues of the hessian in deep learning: Singularity and beyond, 2017.
- Schraudolph (2002) Nicol N Schraudolph. Fast curvature matrix-vector products for second-order gradient descent. Neural computation, 14(7):1723–1738, 2002.
- Shamir (2012) Ohad Shamir. Is averaging needed for strongly convex stochastic gradient descent. Open problem presented at COLT, 2012.
- Shamir & Zhang (2012) Ohad Shamir and Tong Zhang. Stochastic gradient descent for non-smooth optimization: Convergence results and optimal averaging schemes, 2012.
- Wu et al. (2021) Jingfeng Wu, Difan Zou, Vladimir Braverman, Quanquan Gu, and Sham M Kakade. Last iterate risk bounds of sgd with decaying stepsize for overparameterized linear regression. arXiv preprint arXiv:2110.06198, 2021.
- Yang et al. (2021) Minghan Yang, Dong Xu, Hongyu Chen, Zaiwen Wen, and Mengyun Chen. Enhance curvature information by structured stochastic quasi-newton methods. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 10654–10663, June 2021.
- Yao et al. (2020) Zhewei Yao, Amir Gholami, Kurt Keutzer, and Michael Mahoney. Pyhessian: Neural networks through the lens of the hessian, 2020.
- Zaremba et al. (2015) Wojciech Zaremba, Ilya Sutskever, and Oriol Vinyals. Recurrent neural network regularization, 2015.
- Zhang et al. (2019) Guodong Zhang, Lala Li, Zachary Nado, James Martens, Sushant Sachdeva, George E. Dahl, Christopher J. Shallue, and Roger Grosse. Which algorithmic choices matter at which batch sizes? insights from a noisy quadratic model, 2019.
Appendix A More Experimental Results
A.1 Ridge Regression
We compare different types of schedulings on ridge regression
This experiment is only an empirical proof of our theory. In fact, the optima of ridge regression has a closed form and can be directly computed with
Thus the optimal training loss can be calculated accordingly. In all experiments, we use the loss gap as our performance metric.
Experiments are conducted on a4a datasets (Chang & Lin, 2011; Dua & Graff, 2017) (https://www.csie.ntu.edu.tw/c̃jlin/libsvmtools/datasets/binary.html#a4a/), which contains samples and features. This dataset is chosen majorly because it has a moderate number of samples and features, which enables us to compute the exact Hessian matrix and its corresponding eigenvalue distribution in acceptable time and space consumption.
In all of our experiments, we set . The model is optimized via SGD without momentum, with batch size 1, initial learning rate , , , , , , , , , , , , and learning rate of last iteration , , , , , , . Here “UNRESTRICTED” denotes the case where is not set, which is useful for eigencurve, who can decide the learning rate curve without setting . Given and , we adjust all schedulers as follows. For inverse time decay and exponential decay , the hyperparameter is computed accordingly based on and . For cosine decay, and is directly used, with no restart adopted. For eigencurve, the learning rate curve is linearly scaled to match the given .
In addition, for eigencurve, we use the eigenvalue distribution of the Hessian matrix, which is directly computed via eigenvalue decomposition, as shown in Figure 6.


All experimental results demonstrate that eigencurve can obtain similar or better training losses when compared with other schedulers, as shown in Table 3.
| Training loss - optimal training loss: | ||
| Schedule | #Epoch = 1 | #Epoch = 5 |
| Constant | 0.0149630.001369 | 0.0047870.000175 |
| Inverse Time Decay | 0.0072840.000190 | 0.0020980.000160 |
| Exponetial Decay | 0.0083510.000360 | 0.0009310.000100 |
| Cosine Decay | 0.0077670.000006 | 0.0011670.000142 |
| Eigencurve | 0.0069770.000197 | 0.0006760.000069 |
| Schedule | #Epoch = 25 | #Epoch = 250 |
| Constant | 0.0013510.000179 | 0.0001220.000009 |
| Inverse Time Decay | 0.0006370.000143 | 0.0000110.000001 |
| Exponetial Decay | 0.0000480.000007 | 0.0000000.000000 |
| Cosine Decay | 0.0000540.000005 | 0.0000000.000000 |
| Eigencurve | 0.0000450.000008 | 0.0000000.000000 |
A.2 Exact Value of the Extra Term on CIFAR-10 Experiments
In Section 4.1, we have already given the qualitative evidence that shows eigencurve ’s optimality for practical settings on CIFAR-10. Here we strengthen this argument by providing the quantitative evidence as well. The exact value of the extra term is presented in Table 4, where we assume CIFAR-10 has batch size , number of epochs and weight decay , while ImageNet has batch size , number of epochs and weight decay .
| Value of the extra term | |||||
| Scheduler | Convergence rate of SGD in quadratic functions | CIFAR-10 + ResNet18 | CIFAR-10 + GoogLeNet | CIFAR-10 + VGG16 | ImageNet + ResNet18 |
| Inverse Time Decay | |||||
| Step Decay | |||||
| Eigencurve | |||||
| Minimax optimal rate | 1 | 1 | 1 | 1 | |
It is worth noticing that the extra term’s value of eigencurve is independent from the number of iterations , since the value only depends on the Hessian spectrum. So basically eigencurve has already achieved the minimax optimal rate (up to a constant) for models and datasets listed in Table 4, if the loss landscape around the optima can be approximated by quadratic functions. For full details of the estimation process, please refer to Appendix B.
A.3 Reusing eigencurve for Different Models on CIFAR-10
For image classification tasks on CIFAR-10, we check the performance of reusing ResNet-18’s eigenvalue distribution for other models. As shown in Table 5, experimental results demonstrate that Hessian’s eigenvalue distribution of Resnet-18 on CIFAR-10 can be applied to GoogLeNet/VGG16 and still achieves good peformance. Here the experiment settings are exactly the same as Section 4.2 in main paper.
| #Epoch | Schedule | GoogLeNet | VGG16 | ||
| Loss | Acc(%) | Loss | Acc(%) | ||
| =10 | Inverse Time Decay | 2.610.00 | 86.540.94 | 2.260.00 | 84.470.74 |
| Step Decay | 2.590.02 | 87.040.48 | 2.420.45 | 82.980.27 | |
| General Step Decay | 1.930.03 | 88.321.32 | 2.140.42 | 86.790.36 | |
| Cosine Decay | 1.940.00 | 90.560.31 | 2.030.00 | 87.990.13 | |
| Eigencurve (transferred) | 1.650.00 | 91.170.20 | 1.890.00 | 88.170.32 | |
| =100 | Inverse Time Decay | 0.620.02 | 92.050.69 | 1.320.62 | *76.2413.77 |
| Step Decay | 0.280.00 | 92.830.15 | 0.590.00 | 91.370.20 | |
| General Step Decay | 0.130.00 | 94.180.18 | 0.200.00 | *92.360.46 | |
| Cosine Decay | 0.120.00 | 94.620.11 | 0.200.00 | 93.170.05 | |
| Eigencurve (transferred) | 0.110.00 | 94.810.19 | 0.200.00 | 93.170.09 | |
A.4 Comparison with Exponential Moving Average on CIFAR-10
Besides learning rate schedules, Exponential Moving Averaging (EMA) method
is another competitive practical method that is commonly adopted in training neural networks with SGD. Thus, it is natural to ask whether eigencurve can beat this method as well. The answer is yes. In Table 6, we present additional experimental results on CIFAR-10 to compare the performance of eigencurve and exponential moving averaging. It can be observed that there is a large performance gap between those two methods.
| Method/Schedule | ResNet-18 | GoogLeNet | VGG16 | |||
| Loss | Acc(%) | Loss | Acc(%) | Loss | Acc(%) | |
| EMA | 0.300.01 | 90.090.82 | 0.330.01 | 93.420.26 | 0.490.00 | 91.870.82 |
| Eigencurve | 0.140.00 | 94.050.18 | 0.120.00 | 94.750.15 | 0.180.00 | 92.880.24 |
A.5 ImageNet Classification with Elastic Step Decay
One key observation in CIFAR-10 experiments is the existence of “power law” shown in Figure 3. Also, notice that in the form of eigencurve , specifically Eqn. (3.5), iteration interval length is proportional to the square root of eigenvalue density in range . Combining those two facts together, it suggests the length of “learning rate interval” should have lengths exponentially decreasing.
Based on this idea, Elastic Step Decay (ESD) is proposed, which has the following form,
Compared to general step decay with adjustable interval lengths, elastic step decay does not require manual adjustment for the length of each interval. Instead, they are all controlled by one hyperparameter , which decides the “shrinking speed” of interval lengths. Experiments on CIFAR-10, CIFAR-100 and ImageNet demonstrate its superiority in practice, as shown in Table 7, Table 8.
For experiments on CIFAR-10/CIFAR-100, we adopt the same settings as eigencurve , except we only use common step decay with three same-length intervals + decay factor 10.
| #Epoch | Schedule | ResNet-18 | GoogLeNet | VGG16 | |||
| CIFAR-10 | CIFAR-100 | CIFAR-10 | CIFAR-100 | CIFAR-10 | CIFAR-100 | ||
| =10 | Inverse Time Decay | 79.451.00 | 48.731.66 | 86.540.94 | 57.901.27 | 84.470.74 | 50.040.83 |
| Step Decay | 79.670.74 | 54.540.26 | 88.370.13 | 63.050.35 | 85.180.06 | 45.860.31 | |
| Cosine Decay | 84.230.07 | 61.261.11 | 90.560.31 | 69.090.27 | 87.990.13 | 55.420.28 | |
| ESD | 85.380.38 | 64.170.57 | 91.230.33 | 70.460.41 | 88.670.21 | 57.230.39 | |
| =100 | Inverse Time Decay | 90.820.43 | 69.820.37 | 92.050.69 | 73.540.28 | *76.2413.77 | 67.700.49 |
| Step Decay | 93.680.07 | 73.130.12 | 94.130.32 | 76.800.16 | 92.620.15 | 70.020.41 | |
| Cosine Decay | 94.040.21 | 74.650.41 | 94.620.11 | 78.130.54 | 93.170.05 | 72.470.28 | |
| ESD | 94.060.11 | 74.760.33 | 94.650.11 | 78.230.20 | 93.250.12 | 72.500.26 | |
For experiments on ImageNet, we use ResNet-50 trained via SGD without momentum, batch size and weight decay . Since no momentum is used, the initial learning rate is set to instead of . Two step decay baselines are adopted. “Step Decay [30-60]” is the common choice that decays the learning rate 10 folds at the end of epoch and epoch . “Step Decay [30-60-80]” is another popular choice for the ImageNet setting (Goyal et al., 2018), which further decays learning rate 10 folds at epoch . For cosine decay scheduler, the hyperparameter is set to be 0. As for the dataset, we use the common ILSVRC 2012 dataset, which contains 1000 classes, around 1.2M images for training and 50,000 images for validation. For all experiments, we search for ESD, with other hyperparameter search and selection process being the same as eigencurve .
| Schedule | Training loss | Top-1 validation acc(%) | Top-5 validation acc(%) | |
| #Epoch=90 | Step Decay [30-60] | 1.47260.0057 | 75.550.13 | 92.630.08 |
| Step Decay [30-60-80] | 1.47380.0080 | 76.050.33 | 92.830.15 | |
| Cosine Decay | 1.46970.0049 | 76.570.07 | 93.250.05 | |
| ESD () | 1.43170.0027 | 76.790.10 | 93.310.05 |
A.6 Language Modeling with Elastic Step Decay
More experiments on language modeling are conducted to further demonstrate Elastic Step Decay’s superiority over other schedulers.
For all experiments, we follow almost the same setting in Zaremba et al. (2015), where a large regularized LSTM recurrent neural network (Hochreiter & Schmidhuber, 1997) is trained on Penn Treebank (Marcus et al., 1993) for language modeling task. The Penn Treebank dataset has a training set of 929k words, a validation set of 73k words and a test set of 82k words. SGD without momentum is adopted for training, with batch size 20 and 35 unrolling steps in LSTM.
Other details are exactly the same, except for the number of training epochs. In Zaremba et al. (2015), it uses 55 epochs to train the large regularized LSTM, which is changed to 30 epochs in our setting, since we found that the model starts overfitting after 30 epochs. We conducted hyperparameter search for all schedules, as shown in Table 9.
| Scheduler | Form | Hyperparameter choices |
| Inverse Time Decay | , and set , so that | |
| General Step Decay | , if | , , |
| Cosine Decay | , | |
| Elastic Step Decay | , , | |
| Baseline |
Experimental results show that Elastic Step Decay significantly outperforms other schedulers, as shown in Table 10.
| Scheduler | Validation perplexity | Test perplexity |
| Inverse Time Decay | 114.91.1 | 112.71.1 |
| General Step Decay | 82.40.1 | 79.10.2 |
| Baseline (Zaremba et al., 2015) | 82.2 | 78.4 |
| Cosine Decay | 82.40.4 | 78.50.4 |
| Elastic Step Decay | 81.10.2 | 77.40.3 |
A.7 Image Classification on ImageNet with Cosine-power Scheduling
Another key observation in CIFAR-10 experiments is that eigencurve ’s learning rate curve shape changes in a fixed tendency: more “concave” learning rate curves for less training epochs, which inspire the cosine-power schedule in following form.
Results in Table 11 show the schedulings’ performance with , which are denoted as /Cosine/ respectively. Notice that the best scheduler gradually moves from small to larger when the number of epochs increases. For #epoch=270, since the number of epochs is large enough to make model converge, it is reasonable that the accuracy gap between all schedulers is small.
For experiments on ImageNet, we use ResNet-18 trained via SGD without momentum, batch size and weight decay . Since no momentum is used, the initial learning rate is set to instead of . The hyperparameters is set to be 0 for all cosine-power scheduler. As for the dataset, we use the common ILSVRC 2012 dataset, which contains 1000 classes, around 1.2M images for training and 50,000 images for validation.
| #Epoch | Schedule | Training loss | Top-1 validation acc (%) | Top-5 validation acc (%) |
| 1 | 5.40850.0080 | 30.010.21 | 55.260.33 | |
| Cosine | 5.43300.0106 | 26.430.31 | 50.850.43 | |
| 5.49390.0157 | 21.810.21 | 44.530.09 | ||
| 5 | 2.95150.0057 | 57.270.15 | 80.710.12 | |
| Cosine | 2.83890.0061 | 55.670.08 | 79.460.16 | |
| 2.91600.0099 | 52.750.20 | 77.110.08 | ||
| 30 | 2.17390.0046 | 67.560.03 | 87.820.09 | |
| Cosine | 2.04020.0031 | 67.970.10 | 88.120.03 | |
| 2.05250.0032 | 67.410.05 | 87.700.10 | ||
| 90 | 1.9056 | 69.85 | 89.46 | |
| Cosine | 1.7676 | 70.46 | 89.75 | |
| 1.7403 | 70.42 | 89.69 | ||
| 270 | 1.7178 | 71.37 | 90.31 | |
| Cosine | 1.5756 | 71.93 | 90.33 | |
| 1.5250 | 71.69 | 90.37 |


A.8 Full Figures for Eigencurve Experiments in Section 4.2









Appendix B Detailed Experimental Settings for Image Classification on CIFAR-10/CIFAR-100
B.1 Basic Settings
As mentioned in the main paper, all models are trained with stochastic gradient descent (SGD), no momentum, batch size and weight decay . Furthermore, we perform a grid search to choose the best hyperparameters of all schedulers, with a validation set created from samples in the training set, i.e. one-tenth of the training set. The remaining samples are then used for training the model. After obtaining hyperparameters with the best validation accuracy, we train the model again with the full training set and test the trained model on test set, where 5 trials of experiments are conducted. The mean and standard deviation of the test results are reported.
Here the grid search explores hyperparameters and , where denotes the initial learning rate and stands for the learning rate of last iteration. “UNRESTRICTED” denotes the case where is not set, which is useful for eigencurve, who can decide the learning rate curve without setting . Given and , we adjust all schedulers as follows. For inverse time decay, the hyperparameter is computed accordingly based on and . For cosine decay, and is directly used, with no restart adopted. For general step decay, we search the interval number in and decay factor in . For step decay proposed in Ge et al. (2019), the interval number is fixed to be , along with a decay factor . For eigencurve, two major modifications are made to make it more suitable for practical settings:
Here we change to so that it is possible to adjust the initial learning rate of eigencurve. We also change the fixed constant to a general constant , which is aimed at making the learning rate curve smoother. The learning rate curve of eigencurve is then linearly scaled to match the given .
Notice that the learning rate can be larger than , while the loss still does not explode. There are several explanations for this phenomenon. First, in basic non-smooth analysis of GD and SGD with inverse time decay scheduler, the learning rate can be larger than if the gradient norm is bounded (Shamir & Zhang, 2012). Second, deep learning has a non-convex loss landscape, especially when the parameter is far away from the optima. Hence it is common to use larger learning rate at first. As long as the loss does not explode, it is okay. So we still include large learning rate in our grid search process.
B.2 Settings for Eigencurve
In addition, for our eigencurve scheduler, we use PyHessian (Yao et al., 2020) to generate Hessian matrix’s eigenvalue distribution for all models. The whole process consists of three phases, which are illustrated as follows.
1) Training the model
Almost all CNN models on CIFAR-10 have non-convex objectives, thus the Hessian’s eigenvalue distributions are different for different parameters. Normally, we want the this distribution to reflect the overall tendency of most parts of the training process. According to the phenomenon demonstrated in Appendix E, figure A.11-A.17 of Yao et al. (2020), the eigenvalue distribution of ResNet’s Hessian presents similar tendency after training 30 epochs, which suggests that the Hessian’s eigenvalue distribution can be used after sufficient training.
In all CIFAR-10 experiments, we use the Hessian’s eigenvalue distribution of models after training 180 epochs. Since the goal here is to sufficiently train the model, not to obtain good performance, common baseline settings are adopted for training. For all models used for eigenvalue distribution estimation, we adopt SGD with momentum , batch size , weight decay and initial learning rate . On top of that, we use step decay, which decays the learning rate by a factor of at epoch and . All of them are default settings of the PyHessian code (https://github.com/amirgholami/PyHessian/blob/master/training.py, commit: f4c3f77).
ImageNet adopts a similar setting, with training epochs being 90, SGD with momentum , batch size , weight decay , inital learning rate and step decay schedule decays learning rate by a factor of at epoch and .
2) Estimating Hessian matrix’s eigenvalue distribution for the trained model
After obtaining the checkpoint of a sufficiently trained model, we then run PyHessian to estimate the Hessian’s eigenvalue distribution for that checkpoint. The goal here is to obtain the Hessian’s eigenvalue distribution with sufficient precision. To be more specific, the length of intervals around each estimated eigenvalue. PyHessian estimates the eigenvalue spectral density (ESD) of a model’s Hessian, in other words, the output is a list of eigenvalue intervals, along with the density of each interval, where the whole density adds up to . Precision means the interval length here.
It is natural that the estimation precision is related to the complexity of the PyHessian algorithm, e.g. the better precision it yields, the more time and space it consumes. More specifically, the algorithm has a time complexity of and space complexity , where is the number of model parameters, is the number of samples used for estimating the ESD, is the batch size and is the iteration number of Stochastic Lanczos Quadrature used in PyHessian, which controls the estimation precision (see Algorithm 1 of Yao et al. (2020)).
In our experiments, we use for ResNet-18 and for GoogLeNet/VGG16, which gives an eigenvalue distribution estimation with precision around to . and are both set to due to GPU memory constraint, i.e. we use one mini-batch to estimate the eigenvalue distribution. It turns out that this one-batch estimation is good enough and yields similar results to full dataset settings shown in Yao et al. (2020).
However, space complexity is still a bottleneck here. Due to the large number of and space complexity of PyHessian, the value of cannot be very large. In practice, with a NVIDIA GeForce 2080 Ti GPU, which has around GB memory, the maximum acceptable parameter number is around . This implies that the model has to be compressed. In our experiments, we reduce the number of channels by a factor of for all models. For ResNet-18, . For GoogLeNet, . For VGG16, . Notice that those compressed models are only used for eigenvalue distribution estimation. In experiments of comparing different scheduling, we still use the original model with no compression.
One may refer to https://github.com/opensource12345678/why_cosine_works/tree/main/eigenvalue_distribution for generated eigenvalue distributions.
3) Generating eigencurve scheduler with the estimated eigenvalue distribution
After obtaining the eigenvalue distribution, we do a preprocessing before plug it into our eigencurve scheduler.
First, we notice that there are negative eigenvalues in the final distribution. Theoretically, if the parameter is right at the optimal point, no negative eigenvalues should exist for Hessian matrix. Thus we conjecture that those negative eigenvalues are caused by the fact that the model is closed to optima , but not exactly at that point. Furthermore, the estimation precision loss can be another cause. In fact, most of those negative eigenvalues are small, e.g. of those negative eigenvalues lie in , and can be generally ignored without much loss. In our case, we set them to their absolute values.
Second, for a given weight decay value , we need to take the implicit L2 regularization into account, since it affects the Hessian matrix as well. Therefore, for all eigenvalues after the first step, we add to them.
After preprocessing, we plug the eigenvalue distribution into our eigencurve scheduler and generates the exact form of eigencurve.
For experiments with 100 epochs, we set , so that the learning rate curve is much smoother. For experiments with 10 epochs, we set . In our experiments, serves as a fixed constant, not hyperparameters. So no hyperparameter search is conducted on . One can do that in practice though, if computation resource allows.
B.3 Compute Resource and Implementation Details
All the code for results in main paper can be found in https://github.com/opensource12345678/why_cosine_works/tree/main, which is released under the MIT license.
All experiments on CIFAR-10/CIFAR-100 are conducted on a single NVIDIA GeForce 2080 Ti GPU, where ResNet-18/GoogLeNet/VGG16 takes around 20mins/90mins/40mins to train 100 epochs, respectively. High-precision eigenvalue distribution estimation, e.g. , requires around 1-2 days to complete, but this is no longer necessary given the released results.
The ResNet-18 model is implemented in Tensorflow 2.0. We use tensorflow-gpu 2.3.1 in our code. The GoogLeNet and VGG16 model is implemented in Pytorch, specifically, 1.7.0+cu101.
B.4 License of PyHessian
According to https://github.com/amirgholami/PyHessian/blob/master/LICENSE, PyHessian (Yao et al., 2020) is released under the MIT License.
Appendix C Detailed Experimental Settings for Image Classification on ImageNet
One may refer to https://www.image-net.org/download for specific terms of access for ImageNet. The dataset can be downloaded from https://image-net.org/challenges/LSVRC/2012/2012-downloads.php, with training set being “Training images (Task 1 & 2)” and validation set being “Validation images (all tasks)”. Notice that registration and verification of institute is required for successful download.
ResNet-18 experiments on ImageNet are conducted on two NVIDIA GeForce 2080 Ti GPUs with data parallelism, while ResNet-50 experiments are conducted on 4 GPUs in a similar fashion. Both models take around 2 days to train 90 epochs, about 20mins-30mins per epoch. Those ResNet models on ImageNet are implemented in Pytorch, specifically, 1.7.0+cu101.
Appendix D Important Propositions and Lemmas
Proposition 3.
Letting be a monotonically increasing function in the range , then it holds that
| (D.1) |
If is monotonically decreasing in the range , then it holds that
| (D.2) |
Lemma 2.
Function with and is monotone decreasing in the range and monotone increasing in the range .
Proof.
We can obtain the derivative of as
Thus, it holds that when . This implies that is monotone increasing when . Similarly, we can obtain that is monotone decreasing when . ∎
Lemma 3.
It holds that
| (D.3) |
Proof.
∎
Appendix E Proof of Section 2
Proof of Proposition 1.
By iteratively applying Eqn. (2.1), we can obtain that
Summing up each coordinate, we can obtain the result. ∎
Proof of Proposition 2.
Let us denote . By Eqn. (2.1), we can obtain that
The third inequality is because function is monotone decreasing in the range , and it holds that
The last inequality is because function is monotone increasing in the range , and it holds that
By , , and summing up from to , we can obtain the result. ∎
Appendix F Preliminaries
Lemma 4.
Let objective function be quadratic. Running SGD for -steps starting from and a learning rate sequence , the final iterate satisfies
| (F.1) | ||||
where .
Proof.
Reformulating Eqn. (1.5), we have
Thus, we can obtain that
| (F.2) |
We can decompose above stochastic process associated with SGD’s update into two simpler processes as follows:
| (F.3) |
which entails that
| (F.4) | ||||
| (F.5) | ||||
| (F.6) |
where the last equality in Eqn. (F.4) and Eqn. (F.5) is because the commutative property holds for .
Thus, we have
where the last equality is because when and are different, it holds that
due to independence between and . ∎
Lemma 5.
Given the assumption that , then the variance term satisfies that
| (F.7) |
where .
Proof.
Denote , then
| (F.8) |
where the second equality is entailed by the fact that are symmetric matrices.
Therefore, we have,
where the third and sixth equality come from the cyclic property of trace, while the first inequality is because of the condition , where
∎
Lemma 6.
Letting be the smallest positive eigenvalue of , then the bias term satisfies that
| (F.9) |
Proof.
Letting be the spectral decomposition of and be -th column of , we can obtain that
Since is the smallest positive eigenvalue of , it holds that
∎
Appendix G Proof of Theorems
Lemma 7.
Let learning rate is defined in Eqn. (3.3). Assuming with , the sequence satisfies that
| (G.1) |
where is defined as
| (G.2) |
Proof.
First, we divide learning rates into two groups: those who are guaranteed to cover a full interval and those who may not.
Furthermore, because is monotonically decreasing with respect to , by Proposition 3, we have
∎
Lemma 8.
Letting sequence be defined in Eqn. (G.2), given , it holds that
| (G.3) | ||||
Proof.
Notice that is a monotonically increasing function, we have,
∎
Lemma 9.
Letting be a positive sequence, given , it holds that
| (G.4) |
Proof.
First, we have
Furthermore, we reformulate the term as follows
| (G.5) | ||||
| (G.6) | ||||
| (G.7) | ||||
| (G.8) |
Combining above results, we can obtain that
∎
Lemma 10.
Letting us denote with defined in Eqn. (3.3), for , it holds that
| (G.9) |
Proof.
If holds for , then it naturally follows that
where the last equality is entailed by the fact that and defined in Eqn. (3.3) is monotonically decreasing. We then prove holds for .
For , we have
| (G.10) | ||||
1) If , then it naturally follows .
2) If , denote , we have , where and . It follows,
Therefore,
where the second inequality is entailed by the fact that .
∎
Lemma 11.
Letting be defined as Lemma 10 and index satisfy , then has the following property
| (G.11) |
Proof.
By the fact that , we have
Setting in above equation, we have
| (G.12) |
Now we bound the variance term. First, we have
where the first inequality is because . Hence, we can obtain
Furthermore, combining with Eqn. (G.1) and the condition , we can obtain
where the last inequality is because of the condition and the definition of .
Therefore, we have
∎
Lemma 12.
Proof.
Lemma 13.
For , the learning rate sequence defined in Eqn. (3.3) satisfies
| (G.15) |
Lemma 14.
Proof.
The target of this lemma is to obtain the explicit form to bound the bias term.
First, by Eqn. (G.1) and the condition , we have
| (G.16) | ||||
For , since for , it follows,
| (G.17) |
G.1 Proof of Lemma 1
See 1
G.2 Proof of Theorem 1
See 1
Proof.
G.3 Proof of Corollary 2
See 2
Proof.
According to Theorem 1,
The key terms here are and . As long as we can bound both terms with a constant , the corollary will be directly proved.
1) If , then there is only one interval with . By setting , this completes the proof.
2) If , then bounding and be done by computing the value of under power law. For all interval except the last interval, we have,
Therefore, we have
| (G.18) |
holds for all interval except the last interval . This last interval may not completely covers due to the boundary truncated by , but we still have
It follows,
Thus,
Here the last inequality for is entailed by and .
By setting , we obtain
∎
G.4 Proof of Theorem 4
See 4
Proof.
The lower bound here is an asymptotic bound. Specifically, we require
| (G.19) |
In Ge et al. (2019), step decay has following learning rate sequence:
| (G.20) |
where . Notice that the index start from instead of . For consistency with our framework, we set , which produces the exact same step decay scheduler while only adding one extra iteration, thus does not affect the overall asymptotic bound.
We first translate the general notations to diagonal cases so that the idea of the proof can be clearer.
Furthermore, according to Lemma 4, where ,
Here the second equality is entailed by the fact that and are diagonal, and the third equality comes from . Thus, by denoting and , we have,
| (G.21) | ||||
To proceed the analysis, we divide all eigenvalues into two groups:
| (G.22) |
where group are those large eigenvalues that the variance term will finally dominate, and group are those small eigenvalues that the bias term will finally dominate. Rigorously speaking,
a) For :
Step decay’s bottleneck in variance term actually occurs at the first interval that satisfies
| (G.23) |
We first show that interval is well-defined for any dimension . Since , it follows from the definition of in Eqn. (G.22),
On the other hand, since we assume in Eqn. (G.19), which implies , it follows
where the second inequality comes from in assumption (1), and the third inequality is entailed by given the definition of in Eqn. (1.6).
As a result, we have
thus
will guaranteed be satisified for some interval . Since interval is the first interval satisifies Eqn. (G.23), we also have
| (G.24) |
Back to our analysis for the lower bound, by focusing on the variance produced by interval only, we have,
Here the first inequality is obtained by focusing variance generated in interval only. The second inequality utilizes . The fourth inequality is entailed by for , where by mathematical induction, we can extend this inequality for more terms as long as . The fifth inequality comes from .
b) For :
Step decay’s bottleneck will occur in the bias term. Since , it follows from the definition of in Eqn.(G.22),
we have
where the first inequality is caused by for and applying mathematical induction for to obtain as long as . The second equality is because . The second inequality comes from . The last inequality follows .
In sum, we have obtained
By combining with Eqn. (G.21), we have
where the first inequality is because both the bias and variance terms are non-negative, given and .
∎
Remark 3.
The requirement and assumption for can be replaced with , since in that case holds for and . In particular, if , this requirement on becomes .
G.5 The Reason of Using Assumption (1.7)
In all of our analysis, we employ assumption (1.7)
which is the same as the one in Appendix C, Theorem 13 of Ge et al. (2019). This key theorem is the major difference between our work and Ge et al. (2019), which directly entails its main theorem by instantiating with specific values in its assumptions.
Appendix H Relationship with (Stochastic) Newton’s Method
Our motivation in Proposition 1 shares a similar idea with (stochastic) Newton’s method on quadratic objectives
where the parameters are also updated coordinately in the “rotated space”, i.e. given and . In particular, when the Hessian is diagonal and , the update formula is exactly the same as the one for Proposition 1.
Despite of this similarity, our method differ from Newton method’s and its practical variants in several aspects. First of all, our method focuses on learning rate schedulers and is a first-order method. This property is especially salient when we consider eigencurve’s derivatives in Section 4.3: only hyperparameter search is needed, just like other common learning rate schedulers. In addition, most second-order methods, e.g. Schraudolph (2002); Erdogdu & Montanari (2015); Grosse & Martens (2016); Byrd et al. (2016); Botev et al. (2017); Huang et al. (2020); Yang et al. (2021), approximates the Hessian matrix or the Hessian inverse and exploits the curvature information, while eigencurve only utilizes the rough estimation of the Hessian spectrum. On top of that, this estimation is only an one-time effect and can be even further removed for similar models. These key differences highlight eigencurve’s advantages over most second-order methods in practice.