[table]capposition=top \newfloatcommandcapbtabboxtable[][\FBwidth]
EgoNCE++: Do Egocentric Video-Language Models Really Understand Hand-Object Interactions?
Abstract
Egocentric video-language pretraining is a crucial paradigm to advance the learning of egocentric hand-object interactions (EgoHOI). Despite the great success on existing testbeds, these benchmarks focus more on closed-set visual concepts or limited scenarios. Due to the occurrence of diverse EgoHOIs in the real world, we propose an open-vocabulary benchmark named EgoHOIBench to reveal the diminished performance of current egocentric video-language models (EgoVLM) on fined-grained concepts, indicating that these models still lack a full spectrum of egocentric understanding. We attribute this performance gap to insufficient fine-grained supervision and strong bias towards understanding objects rather than temporal dynamics in current methods. To tackle these issues, we introduce a novel asymmetric contrastive objective for EgoHOI named EgoNCE++. For video-to-text loss, we enhance text supervision through the generation of negative captions by leveraging the in-context learning of large language models to perform HOI-related word substitution. For text-to-video loss, we propose an object-centric positive video sampling strategy that aggregates video representations by the same nouns. Our extensive experiments demonstrate that EgoNCE++ significantly boosts open-vocabulary HOI recognition, multi-instance retrieval, and action recognition tasks across various egocentric models, with improvements of up to +26.55%. Our code is available at https://github.com/xuboshen/EgoNCEpp.

1 Introduction
Humans have long dreamed of embodied agents replacing human labor in various societal roles. One effective strategy to achieve this involves leveraging transferable knowledge from diverse egocentric demonstrations to train these agents to imitate human actions in daily activities. Egocentric videos, captured from first-person views using wearable devices, typically demonstrate how humans interact with nearby objects using their hands. Given its potential application in embodied agents [27, 55, 60] and augmented/virtual reality [12, 29], the understanding of egocentric video, especially hand-object interaction, has seen a surge of interest in recent years. Based on the large-scale dataset Ego4D [11], recent works [21] have proposed pretraining an egocentric video-language model (EgoVLM) to enhance downstream egocentric tasks, such as video-text retrieval [21, 41] and action recognition [40].
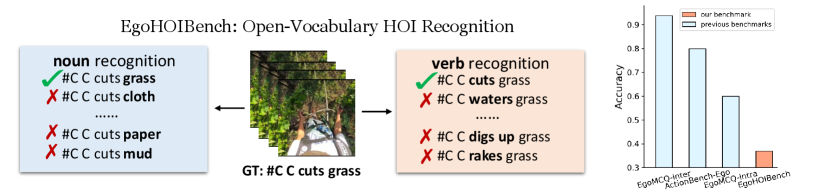
Despite notable advancements in these tasks, we observe that current egocentric hand-object interaction (EgoHOI) benchmarks are either limited to closed-set categories in specific domains [8, 20] or consist of easy open-vocabulary tasks in the open world, which are already well-solved by current EgoVLMs. Therefore, existing benchmarks do not sufficiently evaluate EgoVLMs’ capability to recognize EgoHOIs in real-world applications. This leads us to a question: Do existing EgoVLMs truly understand egocentric hand-object interactions? To address this, we develop EgoHOIBench, a benchmark designed to challenge well-trained EgoVLMs with fine-grained and open-vocabulary EgoHOI understanding trials. Specifically, EgoHOIBench requires models to recognize the correct caption for a given video from a group of caption candidates that differ by only one feasible verb or noun. In Figure 2, we evaluate a state-of-the-art EgoVLM on open-vocabulary benchmarks and observe diminished performance on our EgoHOIBench compared to previous efforts. Despite being trained on extensive EgoHOI data, the EgoVLM still struggles to accurately recognize HOIs in our new benchmark. We attribute their suboptimal performance to two main factors: lack of fine-grained supervision and strong bias towards understanding nouns in HOI.
Specifically, when examining the video-language pretraining that employs video-to-text and text-to-video contrastive losses, it is evident that training batches typically contain numerous easy negative samples (e.g. “cut grass” vs. “pick apple”). While these samples help the model differentiate between coarse-grained HOIs, they fail to provide effective supervision for comprehending finer distinctions in actions such as “pick apple” versus “move apple”, which can be considered as hard negatives for each other. Such hard negatives rarely appear within the same batch. To enhance learning to discern such fine-grained differences, previous works have adopted hard negative mining strategies, which involve sampling data with high feature similarities [31] or selecting visually similar videos recorded in identical environments [59, 21]. However, these heuristic approaches fall short of addressing the intricate challenges posed by EgoHOIBench. Furthermore, since it is much simpler to understand static visual content than to interpret temporal dynamics in a video, EgoVLMs often resort to object recognition as a shortcut for the EgoHOI task. Consequently, these models have developed object-centric feature spaces with a strong bias towards recognizing nouns rather than verbs. Recent studies [26, 3] have explored enhancing VLMs’ verb understanding through hard negative sampling by LLMs. However, these initiatives primarily focus on third-person datasets [52, 46, 6], which overlooks the nuanced challenges in understanding HOI combinations from egocentric views.
To address the aforementioned issues, we introduce EgoNCE++, a new contrastive learning objective that comprises asymmetric video-to-text and text-to-video losses. Specifically, the video-to-text loss enables the model to discern subtle differences in captions for a given video through extensive hard negative supervision, which is achieved by instructing a large language model (LLM) to generate more challenging HOI-related negative captions via in-context learning [5]. Conversely, the text-to-video loss is designed to preserve the well-established object-centric feature space by aggregating video representations whose captions share similar objects. We conduct extensive experimental analyses on various EgoHOI downstream benchmarks and demonstrate that EgoNCE++ can more effectively handle challenges in EgoHOI understanding.
Our contributions can be summarized threefold: (1) We developed EgoHOIBench, a benchmark specifically designed to evaluate models’ capabilities in fine-grained and open-vocabulary EgoHOI comprehension. (2) We propose EgoNCE++, an innovative HOI-aware asymmetric contrastive learning objective for egocentric video-language pretraining. (3) As illustrated in Figure 1, our experimental results demonstrate that EgoNCE++ can be applied to various EgoVLMs, notably improving generalization across six downstream EgoHOI tasks, especially in zero-shot settings.
2 Related Work
Egocentric Hand-Object Interaction. Captured by head-mounted cameras, egocentric hand-object interaction (EgoHOI) [11, 7, 53, 30, 58, 24] provides insight into how humans interact with objects from a first-person view. To address this task, Huang et al. [15] and Kazakos et al. [16] focus on recognizing close-set EgoHOIs using additional multimodal cues (e.g., gaze, sound), while Wang et al. [44] adopt a self-supervised approach [13] to exploit visual information. Considering the abundant resources of third-person data, some works [19, 50] aim to transfer view-agnostic knowledge from third-person videos to egocentric viewpoints. However, the unpredictable nature of open-world environments poses new challenges, requiring models to handle a variety of unseen concepts. Recent studies [7, 47] seek to improve the understanding of open-vocabulary EgoHOI, but these efforts are either limited to specific domains like kitchens [8] or laboratories [38], or involving easy EgoHOI recognition that is well-solved by current egocentric models [47, 21] as shown in Figure 2. A promising strategy to address these limitations involves egocentric video-language pretraining [21, 31, 59, 57], which learns generalizable representations by leveraging the Ego4D [11] dataset with over 3,000 hours of footage of daily human interactions. As a pioneering work, EgoVLP [21] uses the EgoNCE loss to treat video-text samples with similar HOIs as positives and visually similar videos as negatives during pretraining. Another method, LaViLa, enhances text supervision by generating diverse positive captions for videos to foster robust contrastive learning through a visual-conditioned GPT-2 [33] and a T5 [34] rephraser. In this work, we assess and address the limitations of these models on our developed EgoHOIBench, with a particular focus on advancing open-vocabulary EgoHOI comprehension.
Hard Negative Mining. Hard negative mining is a pivotal technique [35, 61] used to refine representations within the visual-language metric space during contrastive learning. Traditionally, this process involves pairing positive samples with hard negatives that exhibit high feature similarity in pretraining datasets [31, 4, 18, 51], or selecting hard negative clips recorded in the same environment [21]. Recent innovations have introduced the use of LLMs to generate hard negative captions, aiming to enhance action comprehension [26, 3] in video-VLMs [23], and improve compositional understanding [54] in image-VLMs [32, 17, 42, 56]. For instance, ViA [26] proposes a verb-focused framework that creates negative captions of sentences and verb phrases using an LLM. However, most of these works adapt their methods to third-person datasets [46, 52] such as Kinetics-400 [6], or to close-set recognition tasks [3, 2] like SSv2 [25, 10], which may not fully capture the nuanced challenges of open-world EgoHOIs. In our paper, we demonstrate that employing LLMs to expand hard negative captions during pretraining can significantly enhance fine-grained EgoHOI understanding for EgoVLMs.
3 EgoHOIBench: Open-Vocabulary Egocentric HOI Benchmark
Existing HOI benchmarks in egocentric vision primarily focus on closed-set visual concepts [8, 40] or are limited to simpler open-vocabulary tasks [47], leading to an inadequate capture of complex human activities in the real world. Since the remarkable performance achieved by existing models on these testbeds, as illustrated in Figure 2, the need for a more challenging open-vocabulary benchmark becomes evident. Therefore, we develop EgoHOIBench, which features an expansive vocabulary and includes thousands of verbs and nouns from rich real-life scenarios.
To evaluate the model’s EgoHOI understanding ability, we design each EgoHOI recognition trial as follows: given a video segment , the model is required to distinguish the correct caption from verb-focused hard negative captions , where and only differ in the verb, and similarly, to identify from noun-focused hard negative captions , where is generated by replacing the noun in with alternative nouns. A recognition trial is regarded successful only when the model accurately identifies the correct caption from both verb-focused and noun-focused hard negatives. EgoHOIBench measures the models’ recognition accuracy across all 29K test trials. Details of data construction by leveraging LLM are available in Appendix B.
4 EgoNCE++: HOI-Aware Asymmetric Pretraining Objective
Our goal is to enhance the capability of pretrained EgoVLMs to recognize fine-grained and open-vocabulary EgoHOIs. Firstly, we briefly recap and diagnose the symmetric contrastive learning objectives used by previous EgoVLMs in Section 4.1. We identify that one bottleneck of current objectives is the lack of fine-grained text supervision for videos. Furthermore, EgoVLMs trained with these objectives exhibit a strong bias towards recognizing nouns in HOI understanding. To enhance EgoVLM pretraining by enriched text supervision while maintaining strong noun recognition capabilities, we devise a new contrastive learning objective featuring asymmetric video-to-text and text-to-video losses in Section 4.2. Figure 3 illustrates an overview of our method.

4.1 A Recap of Egocentric Video-Language Pretraining Objectives
Egocentric video-language pretraining (VLP) adheres to the typical VLP paradigm, which utilizes a dual-encoder architecture to perform contrastive learning between video and text modalities. Current EgoVLPs consider two symmetric contrastive learning objectives: InfoNCE [59] and EgoNCE [21, 31]. Both of them employ video-to-text and text-to-video losses in symmetric forms.
InfoNCE [59]. It is a widely used contrastive learning objective, which brings positive samples closer while pushing negative samples further apart through an online cross-entropy loss among video-text pairs. The symmetric InfoNCE loss applied to a batch of (video, caption) samples is formulated as:
| (1) |
where denotes the normalized feature vectors of the -th (video, caption) sample within a batch. and refer to the videos and captions of the batch , respectively. is the temperature parameter.
EgoNCE [21, 31]. It is specifically tailored for egocentric scenarios. As shown in the following video-to-text loss, EgoNCE enhances the learning of subtle differences in scenes by enlarging the batch to include additional video clips with visually similar backgrounds. It also expands positive video-text pairs by including texts that depict similar HOIs occurring in different contexts.
| (2) |
where , and represent the enlarged batch samples. Each corresponds to the (video, caption) pair sourced from the same recording environments as the -th video clip in the original batch. Furthermore, defines the set of captions, each containing at least one verb or noun that matches those in . To save space, we omit displaying the text-to-video loss as it is symmetrically formulated.
Deficiencies of Current Objectives. Although EgoVLMs pretrained with InfoNCE and EgoNCE have acquired substantial knowledge about EgoHOI, they lack fine-grained supervision and exhibit a strong bias towards understanding nouns rather than dynamic visual content. Specifically, InfoNCE tends to sample easy contrastive pairs (e.g., ‘opens a drawer” vs. “picks an egg”), which do not differ significantly by HOI-related words. In contrast, EgoNCE adds more challenging negative samples by enriching its pretraining batches with similar environments. However, EgoNCE treats data with similar HOIs as positives, and the additional samples may appear as positives due to the repeated appearance of the same objects. Therefore, it may inadvertently group similar but distinct HOIs together, such as mistakenly considering “opens a drawer” and “closes a drawer” as a positive pair. As a result, both objectives tend to differentiate between coarse-grained EgoHOIs, not nuanced ones. Moreover, recognizing the objects in frames instead of complex temporal dynamics is a well-known shortcut solution for current models [47]. The strong bias towards nouns diminishes their ability to interpret EgoHOI which requires both verb and noun comprehension. Consequently, both InfoNCE and EgoNCE exhibit considerable limitations in comprehending the EgoHOIs.
4.2 An Asymmetric Egocentric Pretraining Objective
To overcome the limitations of InfoNCE and EgoNCE, we propose an asymmetric objective named EgoNCE++. The term “asymmetric” signifies that we craft the video-to-text and text-to-video losses to meet different needs — specifically addressing the issue of inadequate fine-grained supervision and leveraging the strong ability of noun recognition. EgoNCE++ enhances the fine-grained text supervision in the video-to-text loss by utilizing an LLM for hard negative generation, while it maintains the capability to recognize nouns through the text-to-video loss that aggregates video representations with similar nouns.
4.2.1 V2T: HOI-Aware Negative Generation by LLM
We devise the video-to-text loss by integrating a greater number of hard negative samples that are essential for improving EgoHOI recognition. These samples are generated using the comprehensive world knowledge and advanced reasoning capabilities of LLMs, which provide viable alternatives for HOI-related terms. Unlike random sampling of verbs and nouns from a large vocabulary, LLMs ensure that the generated sentences are not only fluent and diverse but also closely aligned with real-world contexts. For instance, an LLM might suggest “C waters grass” as an alternative to “C cuts grass”, avoiding nonsensical outputs like “C drinks grass” that might arise from random sampling.
Note that the LLM may not follow the instructions and thus produces hallucinations or generates synonyms of the original HOIs. To address this, we utilize in-context learning [5] to guide the LLM with specific task examples. Additionally, we employ the Ego4D dictionary to filter out possible synonyms, ensuring that the generated captions maintain their distinctiveness. Each ground truth video caption is then paired with LLM-generated, HOI-aware negative captions, which include verb negatives where only the verb is altered or noun negatives where only the HOI-related noun changes. After generating negative captions with plausible semantics for videos, we implement the following supervision loss to enhance EgoHOI understanding from the video-to-text perspective:
| (3) |
where and denote the verb negatives and noun negatives, respectively.
4.2.2 T2V: Object-Centric Positive Video Sampling
Although the text-to-video process does not directly impact EgoHOI recognition, the text features produced by the frozen text encoder effectively act as anchors to guide the optimization of video features. Specifically, we aim to preserve the capability to recognize coarse-grained nouns by aggregating video representations that depict similar objects and separating those that differ in nouns. To this end, we devise an object-centric text-to-video loss, where denotes the videos that feature similar nouns in their captions:
| (4) |
4.2.3 Training Strategy
To refine the video representation of EgoVLMs for better generalization, we freeze the text encoder while fine-tuning the visual encoder using LoRA [14]. We train the dual encoders with both negative caption mining for videos via an LLM and object-centric positive video sampling for texts. Our final pretraining objective comprises the sum of text-to-video and video-to-text losses.
| (5) |
5 Experiments
5.1 Experimental Settings
To ensure the robustness of our approach, we evaluate a variety of well-known EgoVLMs including EgoVLP [21], EgoVLPv2 [31] and LaViLa [59]. Details of these models can be found in our Appendix C.1. In this paper, we continue to pretrain these models instead of training them from scratch due to computational resource constraints.
Pretraining Dataset and Details. Our pretraining video clips are sourced from EgoClip-3.8M [21], ensuring no overlap with the clips used in EgoHOIBench. The dataset is curated to focus on EgoHOIs and excludes any video that primarily captures activities of other persons, resulting in a dataset of 2.5 million entries. The videos in our dataset are typically about 1 second long, with captions that include verbs and nouns relevant to hand-object interactions. During pretraining, we sample 4 frames from each video. We employ LoRA tuning with both rank and alpha set to 16. The models continue to be pretrained by 10 epochs in 12 hours using 8 A800 GPUs, with a total batch size of 576. We utilize LLaMA3-8B [1] to generate hard negative captions for the videos.
Downstream Benchmark and Evaluation Setups. We evaluate the model on three types of tasks across six benchmarks under a zero-shot setting, where the pretrained model is directly evaluated on downstream tasks without additional fine-tuning: (1) Open-vocabulary EgoHOI recognition on EgoHOIBench, EK-100-OV [7] and ActionBench [47]. EK-100-OV assesses unseen categories in kitchen scenarios, while EgoHOIBench and ActionBench focus on open-world HOI recognition. Unlike the challenging task in our EgoHOIBench, ActionBench only contains a binary classification of semantically reversed sentences. (2) Multi-instance retrieval on Epic-Kitchens-100 [8], a kitchen-oriented retrieval task where multiple video clips may correspond to the same narration. (3) Action recognition on CharadesEgo [40] and EGTEA [20]. CharadesEgo involves 157 indoor activity classes, presenting out-of-domain challenges when compared to Ego4D or Epic-Kitchens as it utilizes different wearable devices, while EGTEA focuses on classifying 106 cooking activities.
| EgoHOIBench | Epic-Kitchens-100-MIR | CharadesEgo | |||||||||||
| METHOD | verb (%) | noun (%) | action (%) | mAP (%) | nDCG (%) | mAP | |||||||
| V T | T V | Avg. | V T | T V | Avg. | ||||||||
| EgoVLP [21] | 40.27 | 68.60 | 30.16 | 25.2 | 19.2 | 22.2 | 28.1 | 25.4 | 26.7 | 19.3 | |||
| EgoVLP++ | 56.11 | 69.05 | 41.63 | 25.6 | 19.7 | 22.7 | 28.6 | 25.7 | 27.1 | 19.7 | |||
| (+15.84) | (+0.45) | (+11.45) | (+0.4) | (+0.5) | (+0.5) | (+0.5) | (+0.3) | (+0.4) | (+0.4) | ||||
| EgoVLPv2 [31] | 36.10 | 63.40 | 26.40 | 26.9 | 19.9 | 23.4 | 28.8 | 26.8 | 27.8 | 17.2 | |||
| EgoVLPv2++ | 44.41 | 64.10 | 32.40 | 28.0 | 19.9 | 23.9 | 29.8 | 26.8 | 28.3 | 17.5 | |||
| (+8.31) | (+0.70) | (+6.0) | (+1.1) | (+0.0) | (+0.5) | (+1.0) | (+0.0) | (+0.5) | (+0.3) | ||||
| LaViLa [59] | 46.61 | 74.33 | 36.85 | 35.1 | 26.6 | 30.8 | 33.7 | 30.4 | 32.0 | 20.6 | |||
| LaViLa++ | 80.63 | 75.30 | 63.17 | 35.8 | 27.5 | 31.7 | 33.9 | 30.7 | 32.3 | 20.9 | |||
| (+34.02) | (+0.97) | (+26.32) | (+0.7) | (+0.9) | (+0.9) | (+0.2) | (+0.3) | (+0.3) | (+0.3) | ||||
5.2 Main Results
Open-Vocabulary EgoHOI Recognition. For this task, models must comprehend targets expressed in free-form language and accurately discriminate between answers given video inputs. As shown in Table 1, all EgoVLMs pretrained using EgoNCE++ demonstrate significant improvements on EgoHOIBench, demonstrating the versatility of our method across EgoVLMs with varying architectures, training strategies, and losses. The notable improvements primarily arise from enhanced verb understanding, e.g. a +34.02% increase in verb accuracy leading to a +26.32% improvement in action accuracy for LaViLa++. In contrast, noun classification has been effectively achieved using previous pretraining objectives, resulting in only minor improvements [47]. Importantly, the pretraining of LaViLa utilizes 56 million captions, while our approach reduces the data volume by 55%, indicating that enriching negative supervision could be more crucial for efficient HOI learning than merely increasing the volume of data. Surprisingly, EgoNCE++ achieves more than double the improvement on LaViLa (+26.32%) than on EgoVLP (+11.45%) and EgoVLPv2 (+6.0%). We consider that the degree of improvement is significantly dependent on the quality of the learned features produced by the frozen text encoder, which act as supervisory signals for EgoNCE++. As the quality of text supervision improves, the visual encoder is tuned to generate more advanced visual representations. Consequently, the notable difference in improvement suggests that the InfoNCE loss adopted by LaViLa may provide superior text features, being more effective than the EgoNCE objective. More results on the other two benchmarks are presented in Section C.3.
Multi-Instance Retrieval. As shown in Table 1, we observe consistent benefits from EgoNCE++ across all metrics, validating the effectiveness of asymmetric objective in enhancing the model generalization. Here, mAP is a binary metric that regards a retried case with similar HOI as correct and incorrect otherwise, while nDCG is non-binary, which measures the quality of ranked retrieved cases based on their HOI similarity. The results reveal that our approach effectively improves the ranking of candidates while retrieving data with similar HOIs, demonstrating more promising retrieval properties in terms of fine-grained HOI recognition and the diversity of retrieved outcomes.
Action Recognition. This task focuses on human activities in CharadesEgo and kitchen activities in EGTEA. As demonstrated in Table 1, EgoVLMs pretrained using EgoNCE++ exhibit modest improvements over their baselines. The slight enhancements in CharadesEgo stem from the differences between Ego4D and CharadesEgo, where videos are recorded by crowdsourced workers using mobile cameras instead of wearable glasses. More results on EGTEA are available in Section C.3.
| VERB | NOUN | verb (%) | noun (%) | action (%) |
| ✗ | ✗ | 40.70 | 68.86 | 30.51 |
| ✗ | ✓ | 41.47 | 69.06 | 31.29 |
| ✓ | ✗ | 55.16 | 69.03 | 40.81 |
| ✓ | ✓ | 55.29 | 69.03 | 40.88 |
| VERB | NOUN | verb (%) | noun (%) | action (%) |
| ✗ | ✗ | 55.29 | 69.03 | 40.88 |
| ✓ | ✓ | 55.34 | 68.89 | 41.00 |
| ✓ | ✗ | 55.93 | 68.80 | 41.26 |
| ✗ | ✓ | 56.11 | 69.05 | 41.63 |
5.3 Ablation Study
All ablation studies are conducted by continuing to pretrain the EgoVLP model [21].
Type of Negatives in V2T. The impact of verb negatives (“VERB”) or noun negatives (“NOUN”) generated by the LLM is detailed in Table 3. Negative verb samples effectively enhance the model training, improving verb accuracy by +14.89%. In contrast, noun negatives yield a modest impact with an accuracy improvement of +0.17%. This discrepancy could be attributed to the size of the noun vocabulary of about 7k words, which is far larger than the verb vocabulary of about 2k words, making it more challenging to acquire visual knowledge from text supervision with limited data.

Type of Positives in T2V. Table 3 showcases different positive sampling strategies used in T2V loss. The positive sampling aggregates video representations that share similar HOI-related words. Due to the strong bias towards nouns, the results show that only aggregating the nouns brings the largest improvements, while pulling videos with similar verbs slightly damages the recognition of nouns.
| V2T | T2V | verb (%) | noun (%) | action (%) |
| Info | Info | 40.70 | 68.86 | 30.51 |
| ours | Info | 55.29 | 69.03 | 40.88 |
| ours | ours | 56.11 | 69.05 | 41.63 |
| GENERATOR | verb (%) | noun (%) | action (%) |
| rule-based | 43.52 | 68.94 | 32.63 |
| vocab-based | 54.46 | 68.56 | 40.07 |
| LLM-based | 55.29 | 69.03 | 40.89 |

Video-to-Text and Text-to-Video Loss. As shown in Table 5, our video-to-text supervision generated by the LLM (“ours”), clearly enhances the EgoVLM’s ability to distinguish fine-grained details compared to InfoNCE loss (“Info”). Furthermore, optimizing over the text-to-video loss can maintain the strong bias towards nouns, where the EgoHOI recognition also benefits from the aggregation of video representations with similar nouns.
Hard Negative Generator. We compare three hard negative generators: (1) LLM-based, where an LLM performs word substitution tasks through in-context learning; (2) rule-based, where hard negatives are identified by selecting captions with the highest BLEU [28] scores from the pool; (3) vocab-based, where HOI verbs are substituted with arbitrary verbs from the predefined Ego4D vocabulary containing 2,653 verbs. As shown in Table 5, the rule-based approach tends to generate negatives already encountered during contrastive learning, thus offering less fine-grained supervision. However, the vocab-based approach may yield meaningless HOI combinations, acting as easy negatives rather than the more effective hard negatives provided by the LLM, and thus the LLM-based method performs better.
Volume of Used Pretraining Data. Discussion regarding the scale of pretraining data is provided in Figure 4. The results highlight a surge at the point where only 10% of the data (250K) is used, with action accuracy increasing from 30.3% to 39.2%, while using the remaining data only improves by +2.43%.
Number of Negatives. Figure 5 illustrates the trend of HOI recognition accuracy as the number of negative samples increases. There is a clear correlation where using more negatives leads to improved performance. Incorporating hard negative captions for videos not only expands the density of V2T supervision but also broadens the vocabulary associated with the videos.
Training Strategy for Dual Encoder. We further investigate the impact of various training strategies for dual encoders as shown in Table 6. Comparing row 2 and row 3, we observe full tuning outperforms LoRA tuning by +2.76% on EgoHOIBench but underperforms by an average of -0.3% on EK-100-MIR. The results indicate that for full tuning, using additional parameters improves performance but may also lead to decreased generalization ability on out-of-domain benchmarks. Given the importance of generalization in the real world, we opt for LoRA tuning for the visual encoder while keeping the text encoder frozen. When the text encoder is trainable, as shown in rows 4-6, there is a substantial boost in performance on EgoHOIBench, even approaching the results achieved by LaViLa++. However, the lack of generalization to EK-100-MIR suggests severe overfitting to our pretraining dataset.
| EgoHOI-B | EK-100-MIR | ||||
| VIS | TEXT | PARAM | action | mAP | nDCG |
| frozen | frozen | 0M | 30.16 | 22.2 | 26.7 |
| LoRA | frozen | 3.1M | 41.63 | 22.7 | 27.1 |
| full | frozen | 109M | 44.39 | 22.4 | 27.0 |
| frozen | full | 63.5M | 60.18 | 9.6 | 16.8 |
| LoRA | full | 66.7M | 60.01 | 9.8 | 16.9 |
| full | full | 172.5M | 59.82 | 12.5 | 19.2 |
5.4 Visualizations
In Figure 6, we visualize the changes in contrastive similarities from EgoVLP to EgoVLP++ on EgoHOIBench. The values in matrix grid represent the cosine similarity of features between the video in that row and caption in that column. First, the (video, caption) similarities tend to have less variance based on the same nouns than on the same verbs in sentences. For instance, the similarity between video1 and text1 “#c c opens the tap water” is 0.49, whereas its similarity to text2 “#c c operates the tap” is 0.50. These texts share the same noun but different verbs, yet their similarities are nearly identical, leading to potential misclassification. In contrast, the similarity between video1 and text3 “#c c opens the pan” is much lower at -0.01, despite sharing the same verb. After pretraining with EgoNCE++, which offers more text-negative supervision for videos, the diagonal elements, which represent positive video-text pairs, exhibit higher similarities compared to other entries (e.g., video1 is now correctly classified to text1). These results demonstrate that EgoVLP++ achieves better video-text alignments by leveraging EgoNCE++, effectively reducing the excessive focus on nouns over verbs.

6 Conclusion
We construct EgoHOIBench, an open-vocabulary, fine-grained EgoHOI recognition benchmark that highlights the current limitations of EgoVLMs in comprehending hand-object activities. To address these limitations, we propose an asymmetric learning objective called EgoNCE++, which enhances the video-to-text loss using dense hard negatives generated by an LLM, and a text-to-video loss focusing on video-positive sampling. Through extensive experimental analyses of diverse benchmarks, especially our EgoHOIBench, we demonstrate that the proposed EgoNCE++ is effective across different EgoVLMs, regardless of their varying architectures and learning objectives.
References
- [1] Meta AI. Meta llama 3. https://github.com/meta-llama/llama3, 2024.
- [2] Piyush Bagad, Makarand Tapaswi, and Cees GM Snoek. Test of time: Instilling video-language models with a sense of time. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2503–2516, 2023.
- [3] Hritik Bansal, Yonatan Bitton, Idan Szpektor, Kai-Wei Chang, and Aditya Grover. Videocon: Robust video-language alignment via contrast captions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024.
- [4] Hangbo Bao, Wenhui Wang, Li Dong, Qiang Liu, Owais Khan Mohammed, Kriti Aggarwal, Subhojit Som, Songhao Piao, and Furu Wei. VLMo: Unified vision-language pre-training with mixture-of-modality-experts. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022.
- [5] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- [6] João Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4724–4733, 2017.
- [7] Dibyadip Chatterjee, Fadime Sener, Shugao Ma, and Angela Yao. Opening the vocabulary of egocentric actions. Advances in Neural Information Processing Systems, 36, 2024.
- [8] Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Sanja Fidler, Antonino Furnari, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, and Michael Wray. The epic-kitchens dataset: Collection, challenges and baselines. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 43(11):4125–4141, 2021.
- [9] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009.
- [10] Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, et al. The" something something" video database for learning and evaluating visual common sense. In Proceedings of the IEEE international conference on computer vision, pages 5842–5850, 2017.
- [11] Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18995–19012, 2022.
- [12] Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, et al. Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024.
- [13] Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022.
- [14] Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022.
- [15] Yifei Huang, Minjie Cai, Zhenqiang Li, and Yoichi Sato. Predicting gaze in egocentric video by learning task-dependent attention transition. In Proceedings of the European conference on computer vision (ECCV), pages 754–769, 2018.
- [16] Evangelos Kazakos, Jaesung Huh, Arsha Nagrani, Andrew Zisserman, and Dima Damen. With a little help from my temporal context: Multimodal egocentric action recognition. In British Machine Vision Conference (BMVC), 2021.
- [17] Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In International conference on machine learning, pages 12888–12900. PMLR, 2022.
- [18] Junnan Li, Ramprasaath Selvaraju, Akhilesh Gotmare, Shafiq Joty, Caiming Xiong, and Steven Chu Hong Hoi. Align before fuse: Vision and language representation learning with momentum distillation. Advances in neural information processing systems, 34:9694–9705, 2021.
- [19] Yanghao Li, Tushar Nagarajan, Bo Xiong, and Kristen Grauman. Ego-exo: Transferring visual representations from third-person to first-person videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6943–6953, 2021.
- [20] Yin Li, Miao Liu, and James M Rehg. In the eye of beholder: Joint learning of gaze and actions in first person video. In Proceedings of the European conference on computer vision (ECCV), pages 619–635, 2018.
- [21] Kevin Qinghong Lin, Jinpeng Wang, Mattia Soldan, Michael Wray, Rui Yan, Eric Z Xu, Difei Gao, Rong-Cheng Tu, Wenzhe Zhao, Weijie Kong, et al. Egocentric video-language pretraining. Advances in Neural Information Processing Systems, 35:7575–7586, 2022.
- [22] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach. ArXiv, abs/1907.11692, 2019.
- [23] Huaishao Luo, Lei Ji, Ming Zhong, Yang Chen, Wen Lei, Nan Duan, and Tianrui Li. Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning. Neurocomputing, 508:293–304, 2022.
- [24] Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long-form video language understanding. Advances in Neural Information Processing Systems, 36, 2024.
- [25] Joanna Materzynska, Tete Xiao, Roei Herzig, Huijuan Xu, Xiaolong Wang, and Trevor Darrell. Something-else: Compositional action recognition with spatial-temporal interaction networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1049–1059, 2020.
- [26] Liliane Momeni, Mathilde Caron, Arsha Nagrani, Andrew Zisserman, and Cordelia Schmid. Verbs in action: Improving verb understanding in video-language models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15579–15591, 2023.
- [27] Yao Mu, Qinglong Zhang, Mengkang Hu, Wenhai Wang, Mingyu Ding, Jun Jin, Bin Wang, Jifeng Dai, Yu Qiao, and Ping Luo. Embodiedgpt: Vision-language pre-training via embodied chain of thought. Advances in Neural Information Processing Systems, 36, 2024.
- [28] Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Annual Meeting of the Association for Computational Linguistics, 2002.
- [29] Chiara Plizzari, Gabriele Goletto, Antonino Furnari, Siddhant Bansal, Francesco Ragusa, Giovanni Maria Farinella, Dima Damen, and Tatiana Tommasi. An outlook into the future of egocentric vision. arXiv preprint arXiv:2308.07123, 2023.
- [30] Chiara Plizzari, Toby Perrett, Barbara Caputo, and Dima Damen. What can a cook in italy teach a mechanic in india? action recognition generalisation over scenarios and locations. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 13656–13666, 2023.
- [31] Shraman Pramanick, Yale Song, Sayan Nag, Kevin Qinghong Lin, Hardik Shah, Mike Zheng Shou, Rama Chellappa, and Pengchuan Zhang. Egovlpv2: Egocentric video-language pre-training with fusion in the backbone. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 5285–5297, 2023.
- [32] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- [33] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- [34] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67, 2020.
- [35] Joshua David Robinson, Ching-Yao Chuang, Suvrit Sra, and Stefanie Jegelka. Contrastive learning with hard negative samples. In International Conference on Learning Representations, 2021.
- [36] Fiona Ryan, Hao Jiang, Abhinav Shukla, James M. Rehg, and Vamsi Krishna Ithapu. Egocentric auditory attention localization in conversations. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14663–14674, 2023.
- [37] Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. ArXiv, abs/1910.01108, 2019.
- [38] Fadime Sener, Dibyadip Chatterjee, Daniel Shelepov, Kun He, Dipika Singhania, Robert Wang, and Angela Yao. Assembly101: A large-scale multi-view video dataset for understanding procedural activities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21096–21106, 2022.
- [39] Dandan Shan, Jiaqi Geng, Michelle Shu, and David F Fouhey. Understanding human hands in contact at internet scale. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9869–9878, 2020.
- [40] Gunnar A Sigurdsson, Abhinav Gupta, Cordelia Schmid, Ali Farhadi, and Karteek Alahari. Actor and observer: Joint modeling of first and third-person videos. In proceedings of the IEEE conference on computer vision and pattern recognition, pages 7396–7404, 2018.
- [41] Gunnar A. Sigurdsson, Abhinav Kumar Gupta, Cordelia Schmid, Ali Farhadi, and Alahari Karteek. Actor and observer: Joint modeling of first and third-person videos. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7396–7404, 2018.
- [42] Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela. Flava: A foundational language and vision alignment model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15638–15650, 2022.
- [43] Swathikiran Sudhakaran, Sergio Escalera, and Oswald Lanz. Lsta: Long short-term attention for egocentric action recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9954–9963, 2019.
- [44] Huiyu Wang, Mitesh Kumar Singh, and Lorenzo Torresani. Ego-only: Egocentric action detection without exocentric transferring. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 5250–5261, 2023.
- [45] Xiaohan Wang, Linchao Zhu, Heng Wang, and Yi Yang. Interactive prototype learning for egocentric action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 8168–8177, 2021.
- [46] Xin Wang, Jiawei Wu, Junkun Chen, Lei Li, Yuan-Fang Wang, and William Yang Wang. Vatex: A large-scale, high-quality multilingual dataset for video-and-language research. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4581–4591, 2019.
- [47] Zhenhailong Wang, Ansel Blume, Sha Li, Genglin Liu, Jaemin Cho, Zineng Tang, Mohit Bansal, and Heng Ji. Paxion: Patching action knowledge in video-language foundation models. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- [48] Michael Wray, Diane Larlus, Gabriela Csurka, and Dima Damen. Fine-grained action retrieval through multiple parts-of-speech embeddings. In Proceedings of the IEEE/CVF international conference on computer vision, pages 450–459, 2019.
- [49] Saining Xie, Chen Sun, Jonathan Huang, Zhuowen Tu, and Kevin Murphy. Rethinking spatiotemporal feature learning: Speed-accuracy trade-offs in video classification. In Proceedings of the European conference on computer vision (ECCV), pages 305–321, 2018.
- [50] Boshen Xu, Sipeng Zheng, and Qin Jin. Pov: Prompt-oriented view-agnostic learning for egocentric hand-object interaction in the multi-view world. In Proceedings of the 31st ACM International Conference on Multimedia, pages 2807–2816, 2023.
- [51] Hu Xu, Gargi Ghosh, Po-Yao Huang, Dmytro Okhonko, Armen Aghajanyan, Florian Metze, Luke Zettlemoyer, and Christoph Feichtenhofer. VideoCLIP: Contrastive pre-training for zero-shot video-text understanding. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih, editors, Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6787–6800, Online and Punta Cana, Dominican Republic, November 2021. Association for Computational Linguistics.
- [52] Jun Xu, Tao Mei, Ting Yao, and Yong Rui. Msr-vtt: A large video description dataset for bridging video and language. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5288–5296, 2016.
- [53] Zihui Sherry Xue and Kristen Grauman. Learning fine-grained view-invariant representations from unpaired ego-exo videos via temporal alignment. Advances in Neural Information Processing Systems, 36, 2024.
- [54] Mert Yuksekgonul, Federico Bianchi, Pratyusha Kalluri, Dan Jurafsky, and James Zou. When and why vision-language models behave like bags-of-words, and what to do about it? In International Conference on Learning Representations, 2023.
- [55] Andy Zeng, Maria Attarian, brian ichter, Krzysztof Marcin Choromanski, Adrian Wong, Stefan Welker, Federico Tombari, Aveek Purohit, Michael S Ryoo, Vikas Sindhwani, Johnny Lee, Vincent Vanhoucke, and Pete Florence. Socratic models: Composing zero-shot multimodal reasoning with language. In The Eleventh International Conference on Learning Representations, 2023.
- [56] Yan Zeng, Xinsong Zhang, and Hang Li. Multi-grained vision language pre-training: Aligning texts with visual concepts. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvári, Gang Niu, and Sivan Sabato, editors, International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA, volume 162 of Proceedings of Machine Learning Research, pages 25994–26009. PMLR, 2022.
- [57] Chuhan Zhang, Ankush Gupta, and Andrew Zisserman. Helping hands: An object-aware ego-centric video recognition model. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 13901–13912, 2023.
- [58] Lingzhi Zhang, Shenghao Zhou, Simon Stent, and Jianbo Shi. Fine-grained egocentric hand-object segmentation: Dataset, model, and applications. In European Conference on Computer Vision, pages 127–145. Springer, 2022.
- [59] Yue Zhao, Ishan Misra, Philipp Krähenbühl, and Rohit Girdhar. Learning video representations from large language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6586–6597, 2023.
- [60] Sipeng Zheng, Yicheng Feng, Zongqing Lu, et al. Steve-eye: Equipping llm-based embodied agents with visual perception in open worlds. In The Twelfth International Conference on Learning Representations, 2023.
- [61] Mohammadreza Zolfaghari, Yi Zhu, Peter Gehler, and Thomas Brox. Crossclr: Cross-modal contrastive learning for multi-modal video representations. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1450–1459, 2021.
1
Appendix A Discussions
Limitations. Although our EgoNCE++ yields significant improvements across various fine-grained HOI benchmarks for various EgoVLMs, it is not without its limitations. First, there is potential for further enhancement through the use of more advanced language models, and by increasing the number of negative samples. Second, due to computational resource constraints, we do not pretrain our model from scratch. We anticipate that utilizing a more diverse and extensive dataset with EgoNCE++ could lead to even better performance outcomes.
Social Impact. The knowledge of EgoHOI acquired by EgoVLMs can significantly benefit real-world applications such as embodied agents and augmented reality systems. However, the use of egocentric videos raises privacy concerns, as these recordings often capture personal and sensitive information. Such privacy issues could potentially lead to negative impacts if not properly managed.
Appendix B More Details of the EgoHOIBench
B.1 Construction Process
The overall data construction pipeline can be seen in Figure 7. We develop EgoHOIBench based on EgoMCQ [21], which sources a diverse collection of 39,000 video clips from the validation set of the Ego4D dataset. In our curation process, we only keep those EgoHOI clips performed by the camera wearer, excluding clips that record other people’s activities, such as multi-person interactions [36]. To construct the HOI recognition trials as defined in our task definition above, given a video and its ground truth caption, we prompt an LLM to create candidate captions that contain semantically plausible HOIs differing from the ground truth. Specifically, we employ the LLaMA-3-8B [1] model to generate HOI candidates through in-context learning. We show the specific prompts and two exemplary tasks used in this process, and examples of the final cases in Figure 10. To avoid semantic redundancies and ensure the uniqueness of the hard negative candidates, we use the Ego4D dictionary to eliminate possible synonyms from the generated captions. Furthermore, we also select hard negative candidates from the Ego4D captions based on their BLEU scores [28] relative to the ground truth caption, which allows us to choose captions that are structurally similar to the ground truth but differ in semantics from the original pretraining dataset. By doing this, we ensure the trials are challenging in this task. Finally, EgoHOIBench comprises 29,651 video clips, each accompanied by one ground truth caption, 10 verb-focused negative captions, and 10 noun-focused negative captions.

B.2 Vocabulary Statistics
The statistics of the vocabulary information are provided in Figure 8. This dataset features a rich and diverse vocabulary, including approximately 800 verbs and 4,000 nouns. The options generated by LLMs expand the vocabulary by two times more than that of the original correct answers, leading to massive combinations of verbs and nouns.

Appendix C More Experimental Analysis
For fair comparisons, we have re-implemented all experiments in the same environment and under identical settings, without any adjustments to the hyperparameters.
C.1 Implementation Details
As introduced in the main paper, we validate our approach on three EgoVLMs including EgoVLP, its advanced version EgoVLPv2, and LaViLa. EgoVLP is pretrained on the EgoCLIP-3.8M dataset and employs the EgoNCE loss for optimization. EgoVLPv2 enhances the original model by incorporating a cross-attention mechanism between dual encoders and by pretraining on additional proxy tasks. LaViLa, on the other hand, is trained on a vast dataset of 4 million videos, with 56 million captions generated by a visual-conditioned GPT-2 [33] and further refined using a sentence rephraser T5 [34]. This extensive training regimen enables LaViLa to improve the generalization of EgoVLMs.
We provide a summary of existing well-known EgoVLP methods in Table 7. Our proposed EgoNCE++ continues to enhance the capabilities of pretrained EgoVLMs while using significantly fewer parameters. For all models, we employ the AdamW optimizer with parameters (, ) = (0.9, 0.999). The learning rate is managed via a cosine annealing scheduler, initiating at 3e-5 and gradually decreasing to 3e-7. During the training phase, we incorporate standard RandomResizedCrop for data augmentation and use LoRA tuning to continually train our EgoVLM. For EgoVLPv2, we deploy a dual encoder architecture without cross-attention fusion.
| METHOD | Pretrain Data | Objective | Negative Mining | Visual Encoder | Text Encoder | Param |
| EgoVLP | 3.8M | EgoNCE | video sim | ImageNet [9] | DistillBert [37] | 172M |
| EgoVLPv2 | 3.8M | EgoNCE+MLM+VTM | feature sim | ImageNet [9] | Roberta [22] | 364M |
| LaViLa | 4M | InfoNCE | none | CLIP [32] | CLIP [32] | 180M |
| Ours | 2.5M | EgoNCE++ | text sim | EgoVLM | EgoVLM | 3M-43M |
C.2 Benchmark Details
Multi-Instance Retrieval in EK-100-MIR. In this benchmark, we finetune the EgoVLMs using the AdamW optimizer. The learning rate is dynamically adjusted from 3e-3 to 1e-5 using a cosine annealing scheduler that incorporates a linear warmup, starting at 1e-6 for the first epoch. We deploy a total batch size of 128 across 8 GPUs. During both training and inference, 16 frames are sampled from each video.
Action Recognition in EGTEA. For the zero-shot setup, we evaluate mean results across all evaluation splits by conducting a video-text retrieval task between video clips and their corresponding action text labels. We prepend the text labels with the prompt “#C C …” to standardize the input format. For the fine-tuning setup, we leverage the visual encoder and attach an additional linear projection head for the classification purpose. The models are trained and evaluated on the first split of the validation set. We employ the same optimizer, scheduler, batch size, and frame sampling rate as used in EK-100-MIR. At inference time, we perform three spatial crops of size from each frame of the video clip, averaging their predictions to form the final prediction.
Action Recognition in CharadesEgo. We perform a video-text retrieval task to achieve action recognition by matching video clips with their corresponding action text labels during zero-shot evaluation. During inference, we also sample 16 frames from each video.
| METHOD | HOI DETECTOR | TYPE | OPEN-SET | CLOSE-SET | ||
| top-1 action (%) | top-5 action (%) | top-1 action (%) | top-5 action (%) | |||
| S3D [49] | ✓ | fine-tune | 0 | - | 37.6 | - |
| 2S3D [49] | ✓ | fine-tune | 0.1 | - | 36.7 | - |
| OAP+AOP [7] | ✓ | fine-tune | 11.2 | - | 35.9 | - |
| LaViLa | ✗ | zero-shot | 7.57 | 22.78 | 16.59 | 34.88 |
| LaViLa++ | ✗ | zero-shot | 8.48 | 21.36 | 17.34 | 36.96 |
| (+0.91) | (-1.42) | (+0.75) | (+2.08) | |||
C.3 Main Results
C.3.1 Zero-Shot Setup Evaluation
Open-Vocabulary EgoHOI Recognition on EK-100-OV. The EK-100-OV [7] aims to recognize unseen categories, especially novel objects, at inference time. We evaluate both LaViLa and LaViLa++ on this benchmark in the zero-shot setup, with results illustrated in Table 8. Although our model does not outperform those specifically designed to extract object region features using an HOI detector [39], it demonstrates strong generalization capabilities and competitive results on top-5 actions, with 2,639 candidate actions considered at inference time. When compared to LaViLa, our enhanced model LaViLa++ shows clear improvement across most key metrics (e.g., +0.91% in open-set top-1 action accuracy), highlighting its effectiveness in adapting to open-set conditions.
Open-Vocabulary Action Recognition on ActionBench. The ActionBench [7] is a binary classification task focused on distinguishing the correct sentence answer from its antonyms. In Table 9, we evaluate both LaViLa and LaViLa++ in the zero-shot setup. The results indicate that our LaViLa++ can almost accurately classify the correct semantics of verbs from its antonyms, surpassing the state-of-the-art work proposed in [47] and even approaching the human-level recognition ability.
| MODEL | InternVideo* | Clip-Vip* | Singularity* | Human | LaViLa | LaViLa++ |
| ACTION ACCURACY | 90.1 | 89.3 | 83.8 | 92.0 | 79.89 | 91.18 |
| METHOD | mean-acc | top1-acc |
| LaViLa | 30.92 | 35.08 |
| LaViLa++ | 31.43 | 33.02 |
Action Recognition on EGTEA. As shown in Table 10, we evaluate LaViLa and LaViLa++ on the EGTEA dataset under zero-shot setup. Here, the metric “top1 acc” does not account for the class imbalance whereas the metric “mean acc” eliminates long-tail imbalance. LaViLa++ performs clearly better results on the mean-acc metric, indicating that our model effectively generalizes to the long-tail classes. Given that the EGTEA dataset is confined to cooking activities, which may introduce strong biases that LaViLa++ does not fully capture, it is reasonable that LaViLa++ falls short in the top1-acc metric.
C.3.2 Fine-Tuning Setup Evaluation
In this setup, we further finetune the model on the training and validation splits of the downstream datasets after pretraining.
Multi-Instance Retrieval on EK-100-MIR. As illustrated in Table 11, LaViLa++ outperforms its original version in terms of nDCG but shows a decrease in mAP. These results suggest that while our approach enhances the ranking of candidates, it does not as effectively retrieve data with similar HOIs, underlining a trade-off between fine-grained HOI recognition and the diversity of retrieved outcomes. Despite these, LaViLa++ leverages the robust pretrained knowledge in LaViLa, delivering competitive performance on the EK-100-MIR dataset.
Action Recognition on EGTEA. This benchmark specifically focuses on cooking activities. Notably, LaViLa++ achieves state-of-the-art performance on EGTEA, showcasing its ability to leverage the robust generalization capabilities from LaViLa. The improvement observed on EGTEA demonstrates that our proposed approach is robust even when evaluated on out-of-domain benchmarks.
C.4 Further Analysis
Distance between Positive Similarity and Negative Similarities. In order to examine how a correct video-text pair is distinguished from negative video-text pairs, we define a novel metric PND to measure the distance between the correct option and wrong options:
| (6) |
| EgoVLP | EgoVLP++ | LaViLa | LaViLa++ | |
| VERB | -1.36 | 1.68 | -0.84 | 11.08 |
| NOUN | 8.68 | 9.02 | 14.58 | 14.24 |
where , denote the scale of the dataset and the number of wrong options, respectively. The calculated results on EgoHOIBench are multiplied by 100 and shown in Table 12. As can be seen, our pretrained models improve the discrimination ability, e.g. increasing the PND of verbs from -1.36 to 1.68 and from -0.84 to 11.08 on EgoVLP and LaViLa, respectively. We observe that LaViLa achieves a larger verb improvement than EgoVLP, while LaViLa’s PND of nouns is already at a high value of 14.58, surpassing EgoVLP++’s 9.02 by a large margin. We suggest that LaViLa has learned a well-established feature space that enables nouns to be well recognized compared to EgoVLP. Therefore, even if the PND of nouns decreases slightly, the noun recognition still remains robust.
| LoRA | PARAMS | verb (%) | noun (%) | action (%) |
| 1 | 0.24M | 54.76 | 68.86 | 40.52 |
| 4 | 0.82M | 55.11 | 68.89 | 40.95 |
| 16 | 3.14M | 55.29 | 69.03 | 40.89 |
| 32 | 6.24M | 55.01 | 68.80 | 40.64 |
LoRA Rank. We conduct another study to investigate the impact of rank configurations for LoRA. As detailed in Table 13, our findings reveal that a LoRA rank of 16 enhances generalization capabilities, while even a minimal rank of 1 can significantly improve EgoHOI recognition performance. This trend indicates that relatively small training adjustments can significantly enhance the visual feature space, leading to better performance with minimal computational cost.
Appendix D Qualitative Results
Object-Centric Feature Space. We illustrate the EgoVLMs’ feature space in Figure 9, including LaViLa and EgoVLP. We observe that after egocentric pretraining, the noun-focused features are well clustered, while the verb-focused features tend to be more scattered, proving again that understanding nouns is much easier than verbs.

Negatives Sampled Different Generators. We provide a few examples to show negative samples produced by different generators in Figure 11. It’s important to note that LLM-based captions appear to be more semantically plausible than captions from vocab-based or rule-based generators, which may include words that are never seen in the Ego4D dictionary.
Comparison before/after Using EgoNCE++. As we discussed before, EgoVLP++, EgoVLP++ significantly outperforms EgoVLP after pretraining using EgoNCE++. To visualize this, we provide a few examples to show both improved cases and bad cases in Figure 12 and in Figure 13, respectively. As can be seen in Figure 12, EgoNCE++ helps the model to learn more robust video-text alignments, enabling our refined model to identify fine-grained EgoHOIs. On the other hand, Figure 13 showcases some extreme cases that our model struggles to handle. In these cases, the background tends to be more complex while the differences among actions are subtle to differentiate.



