Efficient Robust Bayesian Optimization
for Arbitrary Uncertain Inputs
Abstract
Bayesian Optimization (BO) is a sample-efficient optimization algorithm widely employed across various applications. In some challenging BO tasks, input uncertainty arises due to the inevitable randomness in the optimization process, such as machining errors, execution noise, or contextual variability. This uncertainty deviates the input from the intended value before evaluation, resulting in significant performance fluctuations in final result. In this paper, we introduce a novel robust Bayesian Optimization algorithm, AIRBO, which can effectively identify a robust optimum that performs consistently well under arbitrary input uncertainty. Our method directly models the uncertain inputs of arbitrary distributions by empowering the Gaussian Process with the Maximum Mean Discrepancy (MMD) and further accelerates the posterior inference via Nyström approximation. Rigorous theoretical regret bound is established under MMD estimation error and extensive experiments on synthetic functions and real problems demonstrate that our approach can handle various input uncertainties and achieve a state-of-the-art performance.
1 Introduction
Bayesian Optimization (BO) is a powerful sequential decision-making algorithm for high-cost black-box optimization. Owing to its remarkable sample efficiency and capacity to balance exploration and exploitation, BO has been successfully applied in diverse domains, including neural architecture search [32], hyper-parameter tuning [4, 29, 12], and robotic control [18, 5], among others. Nevertheless, in some real-world problems, the stochastic nature of the optimization process, such as machining error during manufacturing, execution noise of control, or variability in contextual factor, inevitably introduces input randomness, rendering the design parameter to deviate to before evaluation. This deviation produces a fluctuation of function value and eventually leads to a performance instability of the outcome. In general, the input randomness is determined by the application scenario and can be of arbitrary distribution, even quite complex ones. Moreover, in some cases, we cannot observe the exact deviated input but a rough estimation for the input uncertainty. This is quite common for robotics and process controls. For example, consider a robot control task shown in Figure 1(a), a drone is sent to a target location to perform a measurement task. However, due to the execution noise caused by the fuzzy control or a sudden wind, the drone ends up at location and gets a noisy measurement . Instead of observing the exact value of , we only have a coarse estimation of the input uncertainty . The goal is to identify a robust location that gives the maximal expected measurement under the process randomness.


To find a robust optimum, it is crucial to account for input uncertainty during the optimization process. Existing works [24, 3, 7, 10] along this direction assume that the exact input value, i.e., in Figure 1(b), is observable and construct a surrogate model using these exact inputs. Different techniques are then employed to identify the robust optimum: [24] utilize the unscented transform to propagate input uncertainty to the acquisition function [24], while [3] integrate over the exact GP model to obtain the posterior with input uncertainty [3]. Meanwhile, [7] designs a robust confidence-bounded acquisition and applies min-max optimization to identify the robust optimum. Similarly, [10] constructs an adversarial surrogate with samples from the exact surrogate. These methods work quite well but are constrained by their dependence on observable input values, which may not always be practical.
An alternative approach involves directly modeling the uncertain inputs. A pioneering work by Moreno et al. [20] assumes Gaussian input distribution and employs a symmetric Kullback-Leibler divergence (SKL) to measure the distance of input variables. Dallaire et al. [13] implement a Gaussian process model with an expected kernel and derive a closed-form solution by restricting the kernel to linear, quadratic, or squared exponential kernels and assuming Gaussian inputs. Nonetheless, the applicability of these methods is limited due to their restrictive Gaussian input distribution assumption and kernel choice. To surmount these limitations, Oliveira et al. propose a robust Gaussian process model that incorporates input distribution by computing an integral kernel. Although this kernel can be applied to various distributions and offers a rigorous regret bound, its posterior inference requires a large sampling and can be time-consuming.
In this work, we propose an Arbitrary Input uncertainty Robust Bayesian Optimization algorithm (AIRBO). This algorithm can directly model the uncertain input of arbitrary distribution and propagate the input uncertainty into the surrogate posterior, which can then be used to guide the search for robust optimum. To achieve this, we employ Gaussian Process (GP) as the surrogate and empower its kernel design with the Maximum Mean Discrepancy (MMD), which allows us to comprehensively compare the uncertain inputs in Reproducing Kernel Hilbert Space (RKHS) and accurately quantify the target function under various input uncertainties(Sec. 3.1). Moreover, to stabilize the MMD estimation and accelerate the posterior inference, we utilize Nyström approximation to reduce the space complexity of MMD estimation from to , where (Sec. 3.2). This can substantially improve the parallelization of posterior inference and a rigorous theoretical regret bound is also established under the approximation error (Sec. 4). Comprehensive evaluations on synthetic functions and real problems in Sec.5 demonstrate that our algorithm can efficiently identify robust optimum under complex input uncertainty and achieve state-of-the-art performance.
2 Problem Formulation
In this section, we first formulize the robust optimization problem under input uncertainty then briefly review the intuition behind Bayesian Optimization and Gaussian Processes.
2.1 Optimization with Input Uncertainty
As illustrated in Figure 1(b), we consider an optimization of expensive black-box function: , where is the design parameter to be tuned. At each iteration , we select a new query point according to the optimization heuristics. However, due to the stochastic nature of the process, such as machining error or execution noise, the query point is perturbed to before the function evaluation. Moreover, we cannot observe the exact value of and only have a vague probability estimation of its value: . After the function evaluation, we get a noisy measurement , where is homogeneous measurement noise sampled from . The goal is to find an optimal design parameter that maximizes the expected function value under input uncertainty:
| (1) |
Depending on the specific problem and randomness source, the input distribution can be arbitrary in general and even become quite complex sometimes. Here we do not place any additional assumption on them, except assuming we can sample from these input distributions, which can be easily done by approximating it with Bayesian methods and learning a parametric probabilistic model [16]. Additionally, we assume the exact values of are inaccessible, which is quite common in some real-world applications, particularly in robotics and process control [25].
2.2 Bayesian Optimization
In this paper, we focus on finding the robust optimum with BO. Each iteration of BO involves two key steps: I) fitting a surrogate model and II) maximizing an acquisition function.
Gaussian Process Surrogate: To build a sample-efficient surrogate, we choose Gaussian Process (GP) as the surrogate model in this paper. Following [34], GP can be interpreted from a weight-space view: given a set of observations, . Denote all the inputs as and all the output vector as . We first consider a linear surrogate:
| (2) |
where is the model parameters and is the observation noise. This model’s capacity is limited due to its linear form. To obtain a more powerful surrogate, we can extend it by projecting the input into a feature space . By taking a Bayesian treatment and placing a zero mean Gaussian prior on the weight vector: , its predictive distribution can be derived as follows (see Section2.1 of [34] for detailed derivation):
| (3) |
where and is a identity matrix. Note the predictive distribution is also a Gaussian and the feature mappings are always in the form of inner product with respect to . This implies we are comparing inputs in a feature space and enables us to apply kernel trick. Therefore, instead of exactly defining a feature mapping , we can define a kernel: . Substituting it into Eq. 3 gives the vanilla GP posterior:
| (4) |
From this interpretation of GP, we note that its core idea is to project the input to a (possibly infinite) feature space and compare them in the Reproducing Kernel Hilbert Space (RKHS) defined by kernel.
Acquisition Function Optimization: Given the posterior of GP surrogate model, the next step is to decide a query point . The exploitation and exploration balance is achieved by designing an acquisition function . Through numerous acquisition functions exist [28], we follow [25, 7] and adopt the Upper Confidence Bound (UCB) acquisition:
| (5) |
where is a hyper-parameter to control the level of exploration.
3 Proposed Method
To cope with randomness during the optimization process, we aim to build a robust surrogate that can directly accept the uncertain inputs of arbitrary distributions and propagate the input uncertainty into the posterior. Inspired by the weight-space interpretation of GP, we empower GP kernel with MMD to compare the uncertain inputs in RKHS. In this way, the input randomness is considered during the covariance computation and naturally reflected in the resulting posterior , which then can be used to guide the search for a robust optimum(Sec. 3.1). To further accelerate the posterior inference, we employ Nyström approximation to stabilize the MMD estimation and reduce its space complexity (Sec. 3.2).
3.1 Modeling the Uncertain Inputs
Assume are a set of distribution densities over , representing the distributions of the uncertain inputs. We are interested in building a GP surrogate over the probability space , which requires to measure the difference between the uncertain inputs.
To do so, we turn to the Integral Probabilistic Metric (IPM) [23]. The basic idea behind IPM is to define a distance measure between two distributions and as the supremum over a class of functions of the absolute expectation difference:
| (6) |
where is a class of functions that satisfies certain conditions. Different choices of lead to various IPMs. For example, if we restrict the function class to be uniformly bounded in RKHS we can get the MMD [15], while a Lipschitz-continuous realizes the Wasserstein distance [14].
In this work, we choose MMD as the distance measurement for the uncertain inputs because of its intrinsic connection with distance measurement in RKHS. Given a characteristic kernel and associate RKHS , define the mean map such that . The MMD between is defined as:
| (7) |
Without any additional assumption on the input distributions, except we can get samples from respectively, MMD can be empirically estimated as follows [21]:
| (8) |
To integrate MMD into the GP surrogate, we design an MMD-based kernel over as follows:
| (9) |
with a learnable scaling parameter . This is a valid kernel, and universal w.r.t. under mild conditions (see Theorem 2.2, [11]). Also, it is worth to mention that, to compute the GP posterior, we only need to sample points from the input distributions, but do not require their corresponding function values.
With the MMD kernel, our surrogate model places a prior and obtain a dataset . The posterior is Gaussian with mean and variance:
| (10) | ||||
| (11) |
where , and .
3.2 Boosting posterior inference with Nyström Approximation
To derive the posterior distribution of our robust GP surrogate, it requires estimating the MMD between each pair of inputs. Gretton et al. prove the empirical estimator in Eq. 8 approximates MMD in a bounded and asymptotic way [15]. However, the sampling size used for estimation greatly affects the approximation error and insufficient sampling leads to a high estimation variance(ref. Figure 3(a)).
Such an MMD estimation variance causes numerical instability of the covariance matrix and propagates into the posterior distribution and acquisition function, rendering the search for optimal query point a challenging task. Figure 3(b) gives an example of MMD-GP posterior with insufficient samples, which produces a noisy acquisition function and impedes the search of optima. Increasing the sampling size can help alleviate this issue. However, the computation and space complexities of the empirical MMD estimator scale quadratically with the sampling size . This leaves us with a dilemma that insufficient sampling results in a highly-varied posterior while a larger sample size can occupy significant GPU memory and reduce the ability for parallel computation.
To reduce the space and computation complexity while retaining a stable MMD estimation, we resort to the Nyström approximation [33]. This method alleviates the computational cost of kernel matrix by randomly selecting subsamples from the samples() and computes an approximated matrix via . Combining this with the MMD definition gives its Nyström estimator:
| (12) |
where , , are the kernel matrices, represents a m-by-1 vector of ones, defines the sampling size and controls the sub-sampling size. Note that this Nyström estimator reduces the space complexity of posterior inference from to , where and are the numbers of training and testing samples, is the sampling size for MMD estimation while is the sub-sampling size. This can significantly boost the posterior inference of robust GP by allowing more inference to run in parallel on GPU.
4 Theoretical Analysis
Assume , and are a set of distribution densities over , representing the distribution of the noisy input. Given a characteristic kernel and associate RKHS , we define the mean map such that .
We consider a more general case. Choosing any suitable functional such that is a positive-definite kernel over , for example the linear kernel and radial kernels using the MMD distance as a metric. Such a kernel is associated with a RKHS containing functions over the space of probability measures .
One important theoretical guarantee to conduct model is that our object function can be approximated by functions in , which relies on the universality of . Let be the class of continuous functions over endowed with the topology of weak convergence and the associated Borel -algebra, and we define such that
which is just our object function, For be radial kernels, it has been shown that is universal w.r.t given that is compact and the mean map is injective [11, 22]. For be linear kernel which is not universal, it has been shown in Lemma 1, [26] that if and only if and further . Thus, in the remain of this chapter, we may simply assume .
Suppose we have an approximation kernel function near to the exact kernel function . The mean and variance are approximated by
| (13) | ||||
| (14) |
where , and .
The maximum information gain corresponding to the kernel is denoted as
Denote as the error function when estimating the kernel . We suppose has an upper bound with high probability:
Assumption 1.
For any , , we may choose an estimated such that the error function can be upper-bounded by with probability at least , that is,
Remark. Note that this assumption is standard in our case: we may assume , where is the feature map corresponding to the . Then when using empirical estimator, the error between and MMD is controlled by with probability at least according to Lemma E.1, [8]. When using the Nyström estimator, the error has a similar form as the empirical one, and under mild conditions, when , we get the error of the order with probability at least . One can check more details in Lemma 1.
Now we restrict our Gaussian process in the subspace . We assume the observation with the noise . The input-induced noise is defined as . Then the total noise is . We can state our main result, which gives a cumulative regret bound under inexact kernel calculations,
Theorem 1.
Let and the corresponding . Suppose the observation noise is -sub-Gaussian, and thus with high probability for some . Assume that both and satisfy the conditions for to be -sub-Gaussian, for a given . Then, under Assumption 1 with and corresponding , setting , running Gaussian Process with acquisition function
| (15) | ||||
we have that the uncertain-inputs cumulative regret satisfies:
| (16) |
with probability at least . Here , and
The assumption that is -sub-Gaussian is standard in fields. The assumption that is -sub-Gaussian can be met when is uniformly bounded or Gaussian, as stated in Proposition 3, [26]. Readers may check the definition of sub-Gaussian in appendix, Definition 1.
To achieve an regret of order , the same order as the exact Improved regret (23), and ensure this with high probability, we need to take , , and this requires a sample size of order for MCMC approximation, or with a same sample size and a subsample size of order for Nyström approximation with some . Note that (16) only offers an upper bound for cumulative regret, in real applications the calculated regret may be much smaller than this bound, as the approximation error can be fairly small even with a few samples when the input noise is relatively weak.
To analysis the exact order of could be difficult, as it is influenced by the specific choice of embedding kernel and input uncertainty distributions . Nevertheless, we can deduce the following result for a wide range of cases, showing that cumulative regret is sub-linear under mild conditions. One can check the proof in appendix B.4.
Theorem 2 (Bounding the Maximum information gain).
Suppose is -th differentiable with bounded derivatives and translation invariant, i.e., . Suppose the input uncertainty is i.i.d., that is, the noised input density satisfies . Then if the space is compact in , the maximum information gain satisfies
Thus, when , the accumulate regret is sub-linear respect to , with sufficiently small .
5 Evaluation
In this section, we first experimentally demonstrate AIRBO’s ability to model uncertain inputs of arbitrary distributions, then validate the Nyström-based inference acceleration for GP posterior, followed by experiments on robust optimization of synthetic functions and real-world benchmark.
5.1 Robust Surrogate
Modeling arbitrary uncertain inputs: We demonstrate MMDGP’s capabilities by employing an RKHS function as the black-box function and randomly selecting 10 samples from its input domain. Various types of input randomness are introduced into the observation and produce training datasets of with different configurations. Figure 2(a) and 2(b) compare the modeling results of a conventional GP and MMDGP under a Gaussian input uncertainty . We observe that the GP model appears to overfit the observed samples without recognizing the input uncertainty, whereas MMDGP properly incorporates the input randomness into its posterior.




To further examine our model’s ability under complex input uncertainty, we design the input distribution to follow a beta distribution with input-dependent variance: . The MMDGP posterior is shown in Figure 2(c). As the input variance changes along , inputs from the left and right around a given location yield different MMD distances, resulting in an asymmetric posterior (e.g., around and ). This suggests that MMDGP can precisely model the multimodality and asymmetry of the input uncertainty.
Moreover, we evaluated MMDGP using a step-changing Chi-squared distribution , where if , and otherwise. This abrupt change in significantly alters the input distribution from a sharply peaked distribution to a flat one with a long tail. Figure 2(d) illustrates that our model can accurately capture this distribution shape variation, as evidenced by the sudden posterior change around . This demonstrates our model can thoroughly quantify the characteristics of complex input uncertainties.
Comparing with the other surrogate models: We also compare our model with the other surrogate models under the step-changing Chi-squared input distribution. The results are reported in Figure 7 and they demonstrate our model outperforms obviously under such a complex input uncertainty (see Appendix D.1 for more details)




5.2 Accelerating the Posterior Inference
Estimation variance of MMD: We first examine the variance of MMD estimation by employing two beta distributions and , where is an offset value. Figure 3(a) shows the empirical MMDs computed via Eq. 8 with varying sampling sizes as moves away from . We find that a sampling size of 20 is inadequate, leading to high estimation variance, and increasing the sampling size to 100 stabilizes the estimation.
We further utilize this beta distribution as the input distribution and derive the MMDGP posterior via empirical estimator in Figure 3(b). Note that the MMD instability caused by inadequate sampling subsequently engenders a fluctuating posterior and culminates in a noisy acquisition function, which prevents the acquisition optimizer (e.g., L-BFGS-B in this experiment) from identifying the optima. Although Figure 3(c) shows that this issue can be mitigated by using more samples during empirical MMD estimation, it is crucial to note that a larger sampling size significantly increases GPU memory usage because of its quadratic space complexity of ( and are the sample number of training and testing, is the sampling size for MMD estimation). This limitation severely hinders parallel inference for multiple samples and slows the overall speed of posterior computation.
Table 1 summarizes the inference time of MMDGP posteriors at 512 samples with different sampling sizes. We find that, for beta distribution defined in this experiment, the Nyström MMD estimator with a sampling size of 100 and sub-sampling size of 10 already delivers a comparable result to the empirical estimator with 100 samples (as seen in the acquisition plot of Figure 3(d)). Also, the inference time is reduced from 8.117 to 0.78 seconds by enabling parallel computation for more samples. For the cases that require much more samples for MMD estimation (e.g., the input distribution is quite complex or high-dimensional), this Nyström-based acceleration can have a more pronounced impact.
| Method | Sampling Size | Sub-sampling Size | Inference Time (seconds) | Batch Size (samples) |
|---|---|---|---|---|
| Empirical | 20 | - | 1.143 0.083 | 512 |
| Empirical | 100 | - | 8.117 0.040 | 128 |
| Empirical | 1000 | - | 840.715 2.182 | 1 |
| Nystrom | 100 | 10 | 0.780 0.001 | 512 |
| Nystrom | 1000 | 100 | 21.473 0.984 | 128 |
Effect of Nyström estimator on optimization: To investigate the effect of Nyström estimator on optimization, we also perform an ablation study in Appendix D.2, the results in Figure 8 suggest that Nyström estimator slightly degrades the optimization performance but greatly improves the inference efficiency.
5.3 Robust Optimization
Experiment setup: To experimentally validate AIRBO’s performance, we implement our algorithm 111The code will be available on https://github.com/huawei-noah/HEBO, and more implementation details can be found in Appendix C.1. based on BoTorch [2] and employ a linear combination of multiple rational quadratic kernels [6] to compute the MMD as Eq. 9. We compare our algorithm with several baselines: 1) uGP-UCB [26] is a closely related work that employs an integral kernel to model the various input distributions. It has a quadratic inference complexity of , where and are the sample numbers of the training and testing set, and indicates the sampling size of the integral kernel. 3)GP-UCB is the standard GP with UCB acquisition, which represents a broad range of existing methods that focus on non-robust optimization. 3) SKL-UCB employs symmetric Kullback-Leibler divergence to measure the distance between the uncertain inputs [20]. Its closed-form solution only exists if the input distributions are the Gaussians. 4) ERBF-UCB is the robust GP with the expected Radial Basis Function kernel proposed in [13]. It computes the expected kernel under input distribution using the Gaussian integrals. Assuming the input distributions are sub-Gaussians, this method can efficiently find the robust optimum. Since all the methods use UCB acquisition, we simply distinguish them by their surrogate names in the following tests.
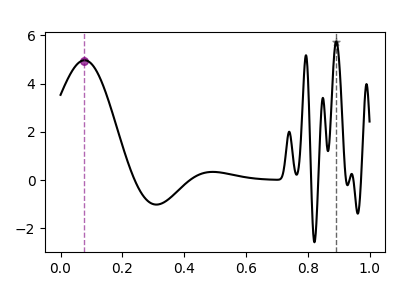



At the end of the optimization, each algorithm needs to decide a final outcome , perceived to be the robust optimum under input uncertainty at step . For a fair comparison, we employ the same outcome policy across all the algorithms: , where is the posterior mean of robust surrogate at and are the observations so far. The optimization performance is measured in terms of robust regret as follows:
| (17) |
where is the global robust optimum and represents the outcome point at step . For each algorithm, we repeat the optimization process 12 times and compare the average robust regret.
1D RKHS function: We begin the optimization evaluation with an RKHS function that is widely used in previous BO works [1, 24, 10]. Figure 4(a) shows its exact global optimum resides at while the robust optimum is around when the inputs follow a Gaussian distribution . According to Figure 4(b), all the robust BO methods work well with Gaussian uncertain inputs and efficiently identify the robust optimum, but the GP-UCB stagnates at a local optimum due to its neglect of input uncertainty. Also, we notice the regret of our method decrease slightly slower than uGP works in this low-dimensional and Gaussian-input case, but later cases with higher dimension and more complex distribution show our method is more stable and efficient.
1D double-peak function: To test with more complex input uncertainty, we design a blackbox function with double peaks and set the input distribution to be a multi-modal distribution . Figure 4(c) shows the blackbox function (black solid line) and the corresponding function expectations estimated numerically via sampling from the input distribution (i.e., the colored lines). Note the true robust optimum is around under the beta distribution, but an erroneous location at may be determined if the input uncertainty is incorrectly presumed to be Gaussian. This explains the results in Figure 4(d): the performance of SKL-UCB and ERBF-UCB are sub-optimal due to their misidentification of inputs as Gaussian variables, while our method accurately quantifies the input uncertainty and outperforms the others.
10D bumped-bowl function: we also extend our evaluation to a 10D bumped-bowl function [27] under a concatenated circular distribution. Figure 9 demonstrates AIRBO scales efficiently to high dimension and outperforms the others under complex input uncertainty(see Appendix D.3).



Robust robot pushing: To evaluate AIRBO in a real-world problem, we employ a robust robot pushing benchmark from [31], in which a ball is placed at the origin point of a 2D space and a robot learns to push it to a predefined target location . This benchmark takes a 3-dimensional input , where are the 2D coordinates of the initial robot location and controls the push duration. We set four targets in separate quadrants, i.e., , and a “twin” target at , and describe the input uncertainty via a two-component Gaussian Mixture Model (defined in Appendix D.4). Following [7, 10], this blackbox benchmark outputs the minimum distance to these 4 targets under squared and linear distances: , where is the Euclidean distance between the ball’s ending location and the -th target. This produces a loss landscape as shown in Figure 5(a). Note that is a more robust target than because of its linear-form distance while pushing the ball to quadrant I is the best choice as the targets, and , match the dual-mode pattern of the input uncertainty. According to Figure 5(b), our method obviously outperforms the others because it efficiently quantifies the multimodal input uncertainty. This can be further evidenced by the push configurations found by different algorithms in Figure 6, in which each dot represents the robot’s initial location and its color represents the push duration. We find that AIRBO successfully recognizes the targets in quadrant I as an optimal choice and frequently pushes from quadrant III to quadrant I. Moreover, the pushes started close to the origin can easily go far away under input variation, so our method learns to push the ball from a corner with a long push duration, which is more robust in this case.
6 Discussion and Conclusion
In this work, we generalize robust Bayesian Optimization to an uncertain input setting. The weight-space interpretation of GP inspires us to empower the GP kernel with MMD and build a robust surrogate for uncertain inputs of arbitrary distributions. We also employ the Nyström approximation to boost the posterior inference and provide theoretical regret bound under approximation error. The experiments on synthetic blackbox function and benchmarks demonstrate our method can handle various input uncertainty and achieve state-of-the-art optimization performance.
There are several interesting directions that worth to explore: though we come to current MMD-based kernel from the weight-space interpretation of GP and the RKHS realization of MMD, our kernel design exhibits a deep connection with existing works on kernel over probability measures [22, 11]. Along this direction, as our theoretic regret analysis in Section 4 does not assume any particular form of kernel and the Nyström acceleration can also be extended to the other kernel computation, it is possible that AIRBO can be further generalized to a more rich family of kernels. Moreover, the MMD used in our kernel is by no means limited to its RKHS realization. In fact, any function class that comes with uniform convergence guarantees and is sufficiently rich can be used, which renders different realizations of MMD. With proper choice of function class , MMD can be expressed as the Kolmogorov metric or other Earth-mover distances [15]. It is also interesting to extend AIRBO with the other IPMs.
7 Acknowledgements
We sincerely thank Yanbin Zhu and Ke Ma for their help on formulating the problem. Also, a heartfelt appreciation goes to Lu Kang for her constant encouragement and support throughout this work.
References
- [1] John-Alexander M Assael, Ziyu Wang, Bobak Shahriari and Nando Freitas “Heteroscedastic treed bayesian optimisation” In arXiv preprint arXiv:1410.7172, 2014
- [2] Maximilian Balandat et al. “BoTorch: A Framework for Efficient Monte-Carlo Bayesian Optimization” In Advances in Neural Information Processing Systems 33, 2020 URL: http://arxiv.org/abs/1910.06403
- [3] Justin J Beland and Prasanth B Nair “Bayesian Optimization Under Uncertainty” In Advances in neural information processing systems, 2017, pp. 5
- [4] James Bergstra, Rémi Bardenet, Yoshua Bengio and Balázs Kégl “Algorithms for hyper-parameter optimization” In Advances in neural information processing systems 24, 2011
- [5] Felix Berkenkamp, Andreas Krause and Angela P Schoellig “Bayesian optimization with safety constraints: safe and automatic parameter tuning in robotics” In Machine Learning Springer, 2021, pp. 1–35
- [6] Mikołaj Bińkowski, Danica J. Sutherland, Michael Arbel and Arthur Gretton “Demystifying MMD GANs” arXiv, 2021 DOI: 10.48550/arXiv.1801.01401
- [7] Ilija Bogunovic, Jonathan Scarlett, Stefanie Jegelka and Volkan Cevher “Adversarially Robust Optimization with Gaussian Processes” In Advances in Neural Information Processing Systems 31 Curran Associates, Inc., 2018
- [8] Antoine Chatalic, Nicolas Schreuder, Alessandro Rudi and Lorenzo Rosasco “Nyström Kernel Mean Embeddings” In International Conference on Machine Learning, 2022
- [9] Sayak Ray Chowdhury and Aditya Gopalan “On Kernelized Multi-armed Bandits” In International Conference on Machine Learning, 2017
- [10] Ryan B. Christianson and Robert B. Gramacy “Robust Expected Improvement for Bayesian Optimization” arXiv, 2023 arXiv:2302.08612
- [11] Andreas Christmann and Ingo Steinwart “Universal Kernels on Non-Standard Input Spaces” In NIPS, 2010 URL: https://api.semanticscholar.org/CorpusID:16968759
- [12] Alexander I Cowen-Rivers et al. “HEBO: pushing the limits of sample-efficient hyper-parameter optimisation” In Journal of Artificial Intelligence Research 74, 2022, pp. 1269–1349
- [13] Patrick Dallaire, Camille Besse and Brahim Chaib-draa “An Approximate Inference with Gaussian Process to Latent Functions from Uncertain Data” In Neurocomputing 74.11, Adaptive Incremental Learning in Neural Networks, 2011, pp. 1945–1955 DOI: 10.1016/j.neucom.2010.09.024
- [14] Arthur Gretton, Dougal Sutherland and Wittawat Jitkrittum “Interpretable comparison of distributions and models” In Advances in Neural Information Processing Systems [Tutorial], 2019
- [15] Arthur Gretton et al. “A kernel two-sample test” In The Journal of Machine Learning Research 13.1 JMLR. org, 2012, pp. 723–773
- [16] Trevor Hastie, Robert Tibshirani, Jerome H Friedman and Jerome H Friedman “The elements of statistical learning: data mining, inference, and prediction” Springer, 2009
- [17] Thomas Kühn “Eigenvalues of integral operators with smooth positive definite kernels” In Archiv der Mathematik 49, 1987, pp. 525–534 URL: https://api.semanticscholar.org/CorpusID:121372638
- [18] Ruben Martinez-Cantin, Nando Freitas, Arnaud Doucet and José A Castellanos “Active policy learning for robot planning and exploration under uncertainty.” In Robotics: Science and systems 3, 2007, pp. 321–328
- [19] Seyedali Mirjalili and Andrew Lewis “Obstacles and difficulties for robust benchmark problems: A novel penalty-based robust optimisation method” In Information Sciences 328 Elsevier, 2016, pp. 485–509
- [20] Pedro Moreno, Purdy Ho and Nuno Vasconcelos “A Kullback-Leibler Divergence Based Kernel for SVM Classification in Multimedia Applications” In Advances in Neural Information Processing Systems 16 MIT Press, 2003
- [21] Krikamol Muandet, Kenji Fukumizu, Bharath Sriperumbudur and Bernhard Schölkopf “Kernel Mean Embedding of Distributions: A Review and Beyond” In Foundations and Trends® in Machine Learning 10.1-2, 2017, pp. 1–141 DOI: 10.1561/2200000060
- [22] Krikamol Muandet, Kenji Fukumizu, Francesco Dinuzzo and Bernhard Schölkopf “Learning from Distributions via Support Measure Machines” In NIPS, 2012
- [23] Alfred Müller “Integral probability metrics and their generating classes of functions” In Advances in applied probability 29.2 Cambridge University Press, 1997, pp. 429–443
- [24] Jose Nogueira, Ruben Martinez-Cantin, Alexandre Bernardino and Lorenzo Jamone “Unscented Bayesian Optimization for Safe Robot Grasping” In 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) Daejeon, South Korea: IEEE, 2016, pp. 1967–1972 DOI: 10.1109/IROS.2016.7759310
- [25] Rafael Oliveira, Lionel Ott and Fabio Ramos “Bayesian Optimisation under Uncertain Inputs” In Proceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics PMLR, 2019, pp. 1177–1184
- [26] Rafael Oliveira, Lionel Ott and Fabio Ramos “Bayesian optimisation under uncertain inputs”, 2019 arXiv:1902.07908
- [27] Nicholas D. Sanders, Richard M. Everson, Jonathan E. Fieldsend and Alma A.. Rahat “Bayesian Search for Robust Optima” arXiv, 2021 arXiv:1904.11416
- [28] Bobak Shahriari et al. “Taking the Human Out of the Loop: A Review of Bayesian Optimization” In Proceedings of the IEEE 104.1, 2016, pp. 148–175 DOI: 10.1109/JPROC.2015.2494218
- [29] Jasper Snoek, Hugo Larochelle and Ryan P Adams “Practical bayesian optimization of machine learning algorithms” In Advances in neural information processing systems 25, 2012
- [30] Niranjan Srinivas, Andreas Krause, Sham M. Kakade and Matthias W. Seeger “Gaussian Process Optimization in the Bandit Setting: No Regret and Experimental Design” In International Conference on Machine Learning, 2009 URL: https://api.semanticscholar.org/CorpusID:59031327
- [31] Zi Wang and Stefanie Jegelka “Max-value entropy search for efficient Bayesian optimization” In International Conference on Machine Learning, 2017, pp. 3627–3635 PMLR
- [32] Colin White, Willie Neiswanger and Yash Savani “Bananas: Bayesian optimization with neural architectures for neural architecture search” In Proceedings of the AAAI Conference on Artificial Intelligence 35.12, 2021, pp. 10293–10301
- [33] Christopher Williams and Matthias Seeger “Using the Nyström Method to Speed Up Kernel Machines” In Advances in Neural Information Processing Systems 13 MIT Press, 2000
- [34] Christopher KI Williams and Carl Edward Rasmussen “Gaussian processes for machine learning” MIT press Cambridge, MA, 2006
Appendix A Nyström Estimator Error Bound
Nyström estimator can easily approximate the kernel mean embedding as well as the MMD distance between two distribution density and . We need first assume the boundedness of the feature map to the kernel :
Assumption 2.
There exists a positive constant such that
The true MMD distance between and is denoted as . The estimated MMD distance when using a Nyström sample size , sub-sample size for respectively, is denoted as . Then the error
and now we have the lemma from Theorem 5.1 in [8]
Lemma 1.
Let Assumption 2 hold. Furthermore, assume that for , the data points are drawn i.i.d. from the distribution and that sub-samples are drawn uniformly with replacement from the dataset Then, for any , it holds with probability at least
provided that, for ,
where and . The notation denotes the effective dimension associated to the distribution .
Specifically, when the effective dimension satisfies, for some ,
-
•
either for some ,
-
•
or for some .
Then, choosing the subsample size to be
-
•
in the first case
-
•
or in the second case,
we get
Appendix B Proofs of Section 4
B.1 Exact Kernel Uncertainty GP Formulating
Following the same notation in Section 4, now we can construct a Gaussian process modeling over . This model can then be applied to learn from a given set of observations Under zero mean condition, the value of for a given follows a Gaussian posterior distribution with
| (18) | ||||
| (19) |
where , and .
Now we restrict our Gaussian process in the subspace . We assume the observation with the noise . The input-induced noise is defined as . Then the total noise is . To formulate the regret bounds, we introduce the information gain and estimated information gain given any :
| (20) | |||
| (21) |
and the maximum information gain is defined as Here .
We define the sub-Gaussian condition as follows:
Definition 1.
For a given , a real-valued random variable is said to be -sub-Gaussian if:
Now we can state the lemma for bounding the uncertain-inputs regret of exact kernel evaluations, which is originally stated in Theorem 5 in [26].
Lemma 2.
Let and the corresponding . Suppose the observation noise is conditionally -sub-Gaussian. Assume that both and satisfy the conditions for to be -sub-Gaussian, for a given . Then, we have the following results:
-
•
The following holds for all and :
(22) -
•
Running with upper confidence bound (UCB) acquisition function where
and set , the uncertain-inputs cumulative regret satisfies:
(23) with probability at least .
B.2 Error Estimates for Inexact Kernel Approximation
Now let us derivative the inference under the inexact kernel estimations.
Theorem 3.
Proof.
Denote , , and . Now according to the matrix inverse perturbation expansion,
we have
thus
here we use the fact that semi-definite (which means ), , . Combining these results, we have that
holds with a probability at least .
Similarly, we can conduct the same estimation to and , and get holds with a probability at least .
It remains to estimate the error for estimating the information gain. Notice that, with a probability at least ,
here the second equation uses the fact that , and the third and fourth equations use . The last inequality follows from the fact
and is semi-definite. ∎
With the uncertainty bound given by Lemma 3, let us prove that under inexact kernel estimations, the posterior mean is concentrated around the unknown reward function
Theorem 4.
Under the former setting as in Theorem 3, with probability at least , let , taking , the following holds for all :
| (27) | ||||
B.3 Proofs for Theorem 1
Now we can prove our main theorem 1.
Proof of Theorem 1..
Let maximize over . Observing that at each round , by the choice of to maximize the acquisition function , we have
Here we denote The second inequality follows from (27),
and the third inequality follows from the choice of :
Thus we have
From Lemma 4 in [9], we have that
and thus
| (30) |
On the other hand, notice that
| (31) |
we find that the term in (30) can be controlled by in (31), thus we immediately get the result. ∎
B.4 Proofs for Theorem 2
Proof.
Define the square of the MMD distance between as we have
It is not hard to verify that is shift invariant: , and has -th bounded derivatives, thus is shift invariant with -th bounded derivatives. Then take as the Lebesgue measure over , according to Theorem 4, [17], the integral operator is a symmetric compact operator in , and the spectrum of satisfies
Then according to Theorem 5 in [30], we have , which finish the proof. ∎
Appendix C Evaluation Details
C.1 Implementation
In our implementation of AIRBO, we design the kernel used for MMD estimation to be a linear combination of multiple Rational Quadratic kernels as its long tail behavior circumvents the fast decay issue of kernel [6]:
| (32) |
where is a learnable lengthscale and determines the relative weighting of large-scale and small-scale variations.
Depending on the form of input distributions, the sampling and sub-sampling sizes for Nyström MMD estimator are empirically selected via experiments. Moreover, as the input uncertainty is already modeled in the surrogate, we employ a classic UCB-based acquisition as Eq. 5 with and maximize it via an L-BFGS-B optimizer.






Appendix D More Experiments
D.1 Comparing with the Other Models
To compare the modeling performances with the other models, we design the input uncertainty to follow a step-changing Chi-squared distribution: , where if and when . Due to this sudden parameter change, the uncertainty at point is expected to be asymmetric: 1) on its left-hand side, as the Chi-squared distribution becomes quite lean and sharp with a small value of , the distance from to its LHS points, , are relatively large, thus their covariances are small, resulting a fast-growing uncertainty. 2)Meanwhile, when , the suddenly increases to , rendering the input distribution a quite flat one with a long tail. Therefore, the distances between and its RHS points become relatively small, which leads to large covariances and small uncertainties for points in . As a result, we expect to observe an asymmetric posterior uncertainty at .
Several surrogate models are employed in this comparison, including:
-
•
MMDGP-nystrom(160/10) is our method with a sampling size and sub-sampling size . Its complexity is , where and are the sizes of training and test samples (Note: all the models in this experiment use the same training and testing samples for a fair comparison).
-
•
uGP(40) is the surrogate from [25], which employs an integral kernel with sampling size . Due to its complexity, we set the sampling size to ensure a similar complexity as ours.
-
•
uGP(160) is also the surrogate from [25] but uses a much larger sampling size (). Given the same training and testing samples, its complexity is 16 times higher than MMDGP-nystrom(160/10).
-
•
skl is a robust GP surrogate equipped with a symmetric KL-based kernel, which is described in [20].
-
•
ERBF [13] assumes the input uncertainty to be Gaussians and employs a close-form expected RBF kernel.
-
•
GP utilizes a noisy Gaussian Process model with a learnable output noise level.
According to Figure 7(a), our method, MMDGP-nystrom(160/10), can comprehensively quantify the sudden change of the input uncertainty, evidenced by its abrupt posterior change at . However, Figure 7(b) shows that uGP(40) with the same complexity fails to model the uncertainty correctly. We suspect this is because uGP requires much larger samples to stabilize its estimation of the integral kernel and thus can perform poorly with insufficient sample size, so we further evaluate the uGP(160) with a much larger sampling size in Figure 7(c). It does successfully alleviate the issue but also results in a 16 times higher complexity. Apart from this, Figure 7(d) suggests the noisy GP model with a learnable output noise level is not aware of this uncertainty change at all as it treats the inputs as the exact values instead of random variables. Moreover, Figure 7(e) and 7(f) show that both the skl and ERBF fail in this case, this may be due to their misassumption of Gaussian input uncertainty.
D.2 Ablation Test for Nyström Approximation
In this experiment, we aim to examine the effect of Nyström approximation for optimization. To this end, we choose to optimize an RKHS function (Figure 4(a)) under a beta input distribution: . Several amortized candidates include:
-
•
MMDGP-nystrom is our method with Nystrom approximation, in which the sampling size and sub-sampling size . Its complexity is , where and are the sizes of training and test samples respectively, is the sampling size for MMD estimation, and indicates the sub-sampling size during the Nystrom approximation.
-
•
MMDGP-raw-S does not use the Nystrom approximation but employs an empirical MMD estimator. Due to its complexity, we set the sampling size to ensure a similar complexity as the MMDGP-nystrom.
-
•
MMDGP-raw-L also uses an empirical MMD estimator, but with a larger sampling size ().
-
•
GP utilizes a vanilla GP with a learnable output noise level and optimizes with the upper-confidence-bound acquisition222For a fair comparison, all the methods in this test use a UCB acquisition..
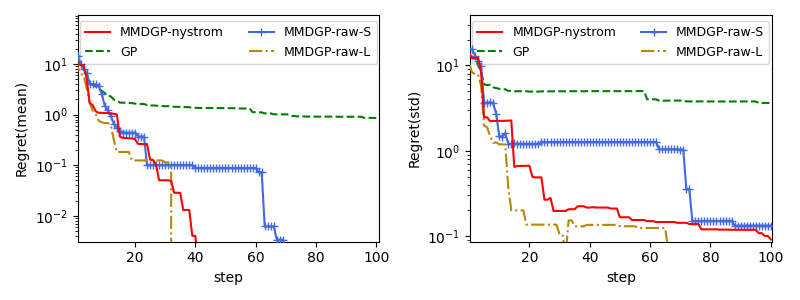
According to Figure 8, we find that 1) with sufficient computation power, the MMDGP-raw-L can obtain the best performance by using a large sample size. 2)However, with limited complexity, the performance MMDGP-raw-S degrades obviously while the MMDGP-nystrom performs much better. This suggests that the Nyström approximation can significantly improve the efficiency with a mild cost of performance degradation. 3) All the MMDGP-based methods are better than the vanilla GP-UCB.
D.3 Optimization on 10D Bumped-Bowl Problem
To further evaluate AIRBO’s optimization performance on the high-dimensional problem, we employ a 10-dimensional bumped bowl function from [27, 19]:
| (33) |
Here, is the i-th dimension of , represents the first 2 dimensions for the variable, and indicates the rest dimensions. The input uncertainty is designed to follow a concatenated distribution of a 2D circular distribution() and a multivariate normal distribution with a zero mean and diagonal covariance of 0.01.
Figure 9 shows the mean and std values of the optimization regrets. We note that 1)when it comes to a high-dimensional problem and complex input distribution, the misassumption of Gaussian input uncertainty renders the skl and ERBF fail to locate the robust optimum and get stuck at local optimums. 2)Our method outperforms the others and can find the robust optimum efficiently and stably, while the uGP with a similar inference cost suffers the instability caused by insufficient sampling and stumbles over iterations, which can be evidenced by its high std values of optimization regret.



D.4 Robust Robot Pushing
This benchmark is based on a Box2D simulator from [31], where our objective is to identify a robust push configuration, enabling a robot to push a ball to predetermined targets under input randomness. In our experiment, we simplify the task by setting the push angle to , ensuring the robot is always facing the ball. Also, we intentionally define the input distribution as a two-component Gaussian Mixture Model as follows:
| (34) |
where the covariance matrix is shared among components and is the weights of mixture components. Meanwhile, as the SKL-UCB and ERBF-UCB surrogates can only accept Gaussian input distributions, we choose to approximate the true input distribution with a Gaussian. As shown in Figure 10, the approximation error is obvious, which explains the performance gap among these algorithms in Figure 5(b).
Apart from the statistics of the found pre-images in Figure 6, we also simulate the robot pushes according to the found configurations and visualize the results in Figure 11. In this figure, each black hollow square represents an instance of the robot’s initial location, the grey arrow indicates the push direction and duration, and the blue circle marks the ball’s ending position after the push. We can find that, as the GP-UCB ignores the input uncertainty, it randomly pushes to these targets and the ball ending positions fluctuate. Also, due to the incorrect assumption of the input distribution, the SKL-UCB and ERBF-UCB fail to control the ball’s ending position under input randomness. On the contrary, AIRBO successfully recognizes the twin targets in quadrant I as an optimal choice and frequently pushes to this area. Moreover, all the ball’s ending positions are well controlled and centralized around the targets under input randomness.