Efficient Reinforcement Learning of Task Planners for Robotic Palletization through Iterative Action Masking Learning
Abstract
The development of robotic systems for palletization in logistics scenarios is of paramount importance, addressing critical efficiency and precision demands in supply chain management. This paper investigates the application of Reinforcement Learning (RL) in enhancing task planning for such robotic systems. Confronted with the substantial challenge of a vast action space, which is a significant impediment to efficiently apply out-of-the-shelf RL methods, our study introduces a novel method of utilizing supervised learning to iteratively prune and manage the action space effectively. By reducing the complexity of the action space, our approach not only accelerates the learning phase but also ensures the effectiveness and reliability of the task planning in robotic palletization. The experiemental results underscore the efficacy of this method, highlighting its potential in improving the performance of RL applications in complex and high-dimensional environments like logistics palletization.
Index Terms:
Reinforcement Learning, Robotic Palletization, Action Space Masking.I INTRODUCTION
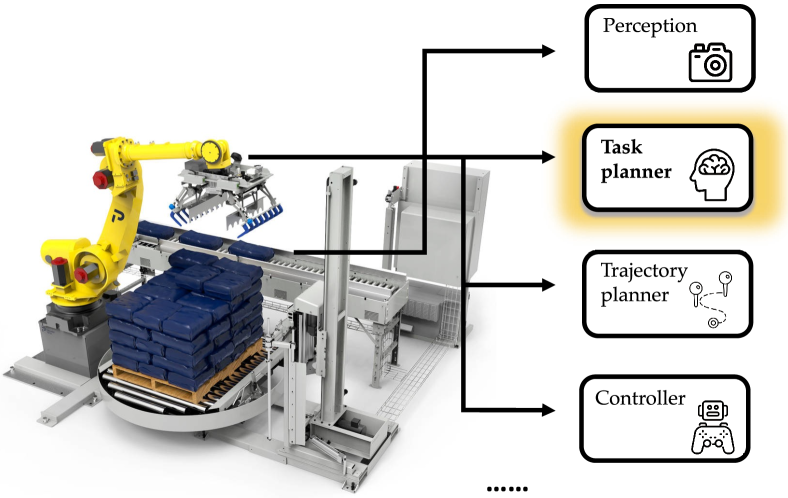
The demand for efficient palletization in warehouses and logistics centers has grown significantly in recent years. This increase is largely driven by the expansion of global trade and the rise of e-commerce, which require rapid and precise handling of goods. Traditional, manual methods of palletization are often unable to meet these demands due to their labor-intensive nature and potential for inconsistency. Consequently, the development of robotic systems for palletization has become crucial. These robotic systems, as illustrated in Fig 1, are complex and composed of various integral components, including perception systems for item identification and localization, task planning modules for decision-making, trajectory planning and control modules for collision-free and precise execution, etc. In this study, our focus is primarily on the task planning module of robotic palletization systems, which functions as determining the optimal picking order from a stream of boxes, deciding how each box should be rotated, and identifying the precise location for placing each box on the pallet, all in an online and dynamic fashion.
The task planning for robotic palletization in most industrial environments can be conceptually framed as a variant of the online 3D Bin Packing Problems (BPP), where the inventory of items is predetermined, yet their sequence of arrival remains unpredictable [1]. Furthermore, in our work we address a more realistic and challenging problem setting that reflects common practice in robotic palletization systems by including a ”buffer” area. This consideration allows the robot to utilize an auxiliary space for storing up to pending items, thereby expanding its operational capabilities beyond merely handling the immediate one. While many research efforts have been made towards addressing online 3D BPP [2, 3, 4, 1], most of the studies rely on hand-coded heuristic methods. In contrast to these approaches, our work aims to statistically learn an optimal and physically feasible palletization task planner. While there are several existing works that use RL to solve online 3D BPP [5, 6, 7], these works are characterized by two primary limitations. Firstly, during policy training, these studies either neglect the aspect of packing stability [5, 6] or assess stability through heuristic-based analyses [7], rendering the policies derived from such methods less viable for deployment in real-world systems where systematic uncertainties are present. Secondly, the problem settings in these works typically overlook the existence of the buffer area, thus potentially limiting their applicability and effectiveness in more complex scenarios.
In this work, we aim to provide an effective solution to our specific online 3D BPP problem. Due to the combinatorial nature of the action space of the problem, applying RL to solve online 3D BPP suffers from the problem of large action space. This challenge is further exacerbated with the introduction of the ”buffer” area. One commonly used solution to the problem of RL with large action space is through ”invalid action masking” [8, 9, 10], which identifies and masks out the invalid actions and directs the policy to exclusively sample valid actions during the learning phase. Our work adopts a similar approach, pinpointing valid actions as task plans that guarantee the stability of intermediate item stacks on the pallet under gravitational forces throughout the training process. Accurately estimating action masks (i.e., valid actions) for varying states during RL training is crucial, albeit challenging. To address this, we introduce a methodology that learns to estimate action masks through supervised learning (Section III-B). Specifically, leveraging the image-like characteristics of observation and action mask data, we employ a semantic segmentation paradigm [11, 12] to train the action masking model. The training dataset is compiled through an offline data collection phase, utilizing a physics engine to verify the stability of specific placements across various pallet configurations. Moreover, to ameliorate the potential issue of distribution shift inherent in our approach, we propose a DAgger-like framework [13] designed to iteratively refine the action masking model, thereby enhancing the RL policy’s performance (Section III-C).
To assess the efficacy of our proposed methodology, we conducted extensive experiments and compared our results with existing RL-based online 3D BPP solutions. Experimental results indicate that our proposed method outperforms other baselines and is more sampling-efficient. We also demonstrate the effectiveness of our proposed iterative framework through experimental evaluations. Lastly, our learned task planner is deployed in a real-world robotic palletizer to demonstrate the robustness and applicability of our approach in real-world settings.
II RELATED WORK
In this section, we provide a brief review of research on 3D Bin Packing Problems (BPP) under both the offline and online settings.
II-A Offline 3D BPP
The problem of 3D bin packing, a complex variant of the classical bin packing problem, involves efficiently packing objects of various sizes into a finite number of bins or containers with fixed dimensions in three dimensions. The offline version of the problem, where all information about the objects to be packed is known in advance, has been particularly challenging due to its NP-hard nature. Early strategies were heavily reliant on heuristic methods, as initially demonstrated by [14] that extended 2D BPP algorithms to 3D context. This is followed by many research efforts that propose various heuristic and meta-heuristic algorithms to approximate the solutions [15, 16, 17]. More recently, [18, 19] propose to use deep reinforcement learning (DRL) to learn the policy for offline 3D BPP. Our work differs from these works by focusing on online 3D BPP instead of offline version.
II-B Online 3D BPP
In contrast to offline scenarios, online 3D bin packing problems involve making packing decisions without knowledge of future items, presenting unique challenges in achieving optimality and efficiency. Research in this domain has focused on developing adaptive heuristics and algorithms that can handle the sequential nature of item arrivals. Notably, Karabulut et al. [2] proposes deep-bottom-left (DBL) heuristics and Ha et al. [3] extends [2] by employing a strategy that orders empty spaces using the DBL method and positions the current item into the earliest suitable space. [4] introduces a Heightmap-Minimization technique aimed at reducing the volume expansion of items in a package when viewed from the loading perspective. Aside from heuristics-based methods, there are also research attempts utilizing DRL to solve the problem of online 3D BPP [5, 6]. DRL for online 3D BPP typically suffers from the problem of large action space, making the RL algorithms hard to optimize. [5] address this challenge by implementing straightforward heuristics to reduce the action space, yet their demonstrations are confined to scenarios with limited discretization resolution. Conversely, another study by [6] seeks to alleviate this issue by devising a packing configuration tree that employs more intricate heuristics to identify a subset of feasible actions, marking a progression from their prior work. Our research is distinct from these approaches in two critical aspects. Firstly, the scenario we investigate is notably more complex and mirrors real-world conditions more closely. Specifically, we introduce a ”buffer” area, enabling the agent to select any item from a queue of upcoming boxes and rotate it along any axis, thereby significantly expanding the action space. Furthermore, our model accounts for translational and rotational uncertainties that occur when a robot places a box onto the pallet—factors that are overlooked by [6, 5] but are prevalent in actual physical systems. Secondly, from a methodological perspective, our approach diverges from the reliance on varying heuristics to trim the action space. Instead, we introduce a supervised learning-based pipeline to develop an action masking mechanism.
III OUR PROPOSED APPROACH
In this section, we provide detailed description of our proposed method. Initially we specify the problem setting of the online 3D Bin Packing Problem (BPP) addressed in this study, as outlined in Section III-A. Then a comprehensive description of our action masking pipeline, along with its integration into reinforcement learning (RL), is presented in Section III-B. Furthermore, we introduce the iterative adaptation of our proposed algorithm, presented in Section III-C, illustrating the progressive refinement of our approach.
III-A Problem Formulation
The online 3D BPP can be formulated as a Markov decision process (MDP), denoted by , where signifies the state space, denotes the action space, represents the transition probability between states, and encapsulates the real-valued rewards. The objective of RL is to find a policy, , that can maximize the accumulated discounted reward , where represents the discounted factor. In the following, we details the components of the MDP in this study.
State
In the process of palletization, the policy evaluates two primary sources of information: the present configuration of the pallet and the dimensions of the forthcoming boxes. Consequently, we model the state at any given time as , where denotes the current configuration of the pallet, and encapsulates the dimensions of the forthcoming boxes. Following [5], we employ a height map to depict the pallet configuration. This involves discretizing the pallet into an matrix, where each element signifies the discretized height at the corresponding location on the pallet. The variable is conceptualized as a list of 3-dimensional tuples, with each tuple specifying the (length, width, height) of a box. Here, represents the capacity of the ”buffer” area, which is ascertained by the perception system and typically ranges between 3 and 5.
Action
At each timestep, the policy is tasked with executing three sequential decisions: selecting a box from the boxes in the upcoming queue (buffer area), rotating the box to the desired orientation, and positioning the box on the pallet. We restrict our consideration to axis-aligned orientations of the boxes, yielding possible orientations. Furthermore, the front-left-bottom (FLB) corner of the box can be positioned in any grid cell among the cells available on the pallet. Consequently, the action space is of a combinatorial nature, characterized by a dimensionality of , i.e., action . In a typical industrial context, with and (at a 1-inch discretization resolution), this translates to an action space with dimensions. The extensive size of the action space introduces additional complexity to the RL problem, complicating the optimization process [20].
Reward
We conceptualize the accumulated reward as a measure of the space utilization of the current pallet, contingent upon the stability of the items positioned on it. The reward function is formally defined as follows:
| (1) |
Here, serves as an indicator function that validates the physical stability of the boxes on the pallet at state . refers to the cumulative volume of the boxes currently situated on the pallet, while signifies the theoretical maximum volume the pallet can accommodate. Given considerations for safety during transport, it is assumed that the maximum height of the boxes on the pallet should not surpass inches, thus defining . Consequently, we can delineate a dense reward at each timestep as , where denotes the volume of the most recently placed item.
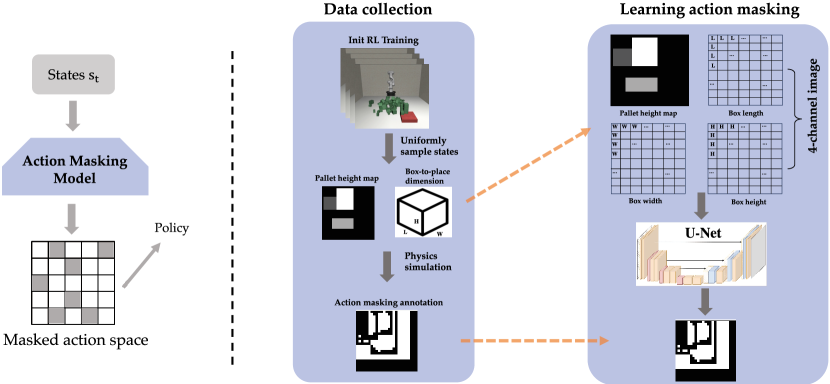
III-B Action Space Masking via Supervised Learning
The principal challenge in applying RL to address the online 3D BPP resides in the expansive dimensionality of the action space, which complicates the optimization of RL algorithms. To counteract this issue, we embrace the strategy of ”invalid action masking” [8, 9, 10], which serves to alleviate the aforementioned challenge. This section elucidates our methodology for developing the action masking model through supervised learning. The fundamental premise behind action space masking is the exclusion of invalid placements that could culminate in unstable pallet configurations. While prior studies have implemented similar strategies to exclude unstable placements and thereby simplify the learning process[7, 5], their approaches to action masking rely predominantly on heuristic algorithms. We posit that heuristic-based action masking exhibits several limitations: (i) The necessity for multiple hyperparameters in most action masking methods poses a challenge in tuning these parameters to accommodate diverse scenarios, such as variations in box sizes and weights. ii) Heuristic methods, particularly those involving the analysis of the center-of-mass (CoM), fail to account for uncertainties inherent in palletization execution, necessitating further elaboration. For instance, consider a heuristic that uses CoM analysis to prevent tipping by restricting box placements that significantly shift the CoM. However, this doesn’t consider real-world uncertainties like slight placement inaccuracies due to robot sensor errors, leading to unexpected CoM shifts and potentially unstable configurations despite heuristic approval. This example underscores the limitations of CoM-based heuristics, highlighting their lack of accommodation for practical uncertainties in robot execution, which questions their reliability in real-world scenarios. In response, our work investigates the feasibility of adopting supervised learning to construct the action masking model. Figure 2 delineates the framework of our proposed methodology for learning action masking. Specifically, the learning process is segmented into the following phases:
Data Collection
The action masking models eliminate unstable placements by learning to infer the stability of sampled box placements during RL training process. Specifically, we aim to identify a set of feasible placements, or action masks , based on the configurations of the pallet and the (rotated) dimensions of the boxes , formulated as . The collection of data samples consisting of pairs along with their corresponding is essential for the learning of the action masking model . However, ensuring that the collected data accurately reflects the RL training distribution poses a significant challenge. To address this, we initially employ a heuristic-based method to develop an initial RL policy , from which we systematically sample and store pairs for subsequent offline data collection.
In the data collection phase, our goal is to generate the corresponding annotations given the sampled RL states . Specifically, represents the placement stability on every discretized bin of the pallet for a given pallet state and box dimension . To achieve this, we leverage the physics simulation, i.e., MuJoCo [21], to evaluate the stability of every potential placement on the pallet, thereby generating . The dataset thus compiled, denoted as , forms the basis for the subsequent learning stage of the action masking model.
Learning the Action Masking Model
As illustrated in Figure 2, functions as a binary image corresponding in size to , with pixels valued at indicating stable placements and those valued at signifying unstable ones. Leveraging the image-like properties of both the input and the output, we transform the learning challenge into a well-established computer vision task known as semantic segmentation [11, 12, 22]. To this end, we generate three single-channel images mirroring the dimensions of , each channel encoding the length, width, and height of the box, respectively. These images are then combined with to produce a 4-channel image, which serves as the input, with acting as the target output. This input-output pair is subsequently processed by a conventional U-net [22] architecture for training purposes. The resulting neural network, regarded as the trained action masking model , is subsequently integrated into the RL training regimen.
Embedding the Learned Action Masking Model into RL Training
We employ the developed action masking model to trim the action space during RL training, enhancing the efficiency of the learning process. At each timestep, with the pallet configuration and the dimensions of the box to be placed given, the model identifies a viable subset from the total available placements ( placements). The RL policy is then restricted to selecting placements solely from this feasible subset . This strategy effectively narrows the action space, significantly facilitating the RL training. We demonstrate the effectiveness of the action masking model for RL training in Section IV.
III-C Iterative Action Masking for RL Training
While being effective, the learned action masking model can still be inaccurate in certain states, particularly for the out-of-distribution (OOD) states encountered during the RL training process. Such discrepancies arise because during RL training the agent might explore states that diverge significantly from those within the training dataset , leading to a misalignment between the distributions of the training data and the actual scenarios the model faces.
Inspired by DAgger [13], we introduce an iterative enhancement pipeline for refining the learning of the action masking model. This process begins with the application of a heuristic-based method for initial action masking during RL training, yielding the initial policy . Concurrently, we systematically collect state samples during training, assembling dataset via offline collection as detailed in Section III-B. Utilizing , we then train the neural network-based action masking model , as depicted in Section III-B. This model, , is subsequently integrated into a new RL training cycle to derive an enhanced policy . This cycle of training, data collection to form , and model updating to is repeated, each iteration aiming to embed the updated action masking model in the subsequent RL training phase. This iterative process continues until the RL policies cease to show significant improvements, thereby optimally aligning the action masking model with the encountered state distributions. The pseudo code of the proposed method is presented in Algorithm 1.
IV EXPERIMENTAL VALIDATIONS
In this section, we present a thorough quantitative analysis of our proposed approach. Our evaluation is structured to address the following key questions: 1) Does the method outlined in Section III-B successfully learn to identify the feasible subset of placements? 2) Does the integration of the learned action masking model enhance the RL training process, culminating in a superior policy? 3) Does the iterative action masking learning strategy described in Section III-C contribute to further enhancements in the RL agent’s ultimate performance?
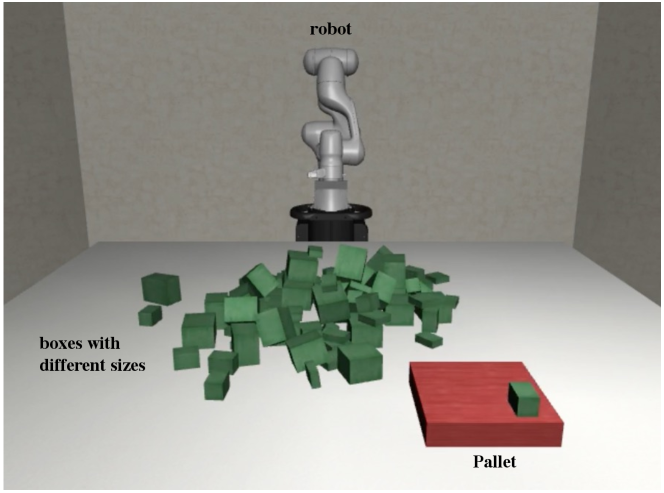
IV-A Experimental Setup
To explore the task planning challenges associated with the palletization problem, we developed a simulated palletization task in MuJoCo [21], reflecting a realistic logistic scenario, as depicted in Figure 3. This simulation environment features 80 boxes of 5 distinct sizes, with dimensions (in inches) of , , , , . The pallet is specified to have dimensions of inches, with a stipulation that the maximum height of stacked boxes cannot exceed 25 inches. For our experiments, we applied a discretization resolution of 1 inch to both the boxes and the pallet.
At each planning step, the task planner receives the current pallet configuration, represented as a height map, and the dimensions of forthcoming boxes in the buffer, then generates a task plan. This plan involves selecting one of the boxes, orienting it as desired, and placing it on the pallet, in accordance with the methodology described in Section III-A. To expedite the learning process, the actual ’pick-rotate-place’ actions by the robot are bypassed; instead, the chosen box is immediately positioned at the planner’s determined goal pose. To account for uncertainties inherent in physical execution, each box placement is subjected to random translational noise on the xy plane and rotational noise around the z-axis , measured in inches and degrees, respectively. The sequence in which the 80 boxes are presented to the policy is randomized and unknown at the start of each RL training episode, and the weights of the boxes are also randomized to further enhance the simulation’s fidelity to real-world variability.
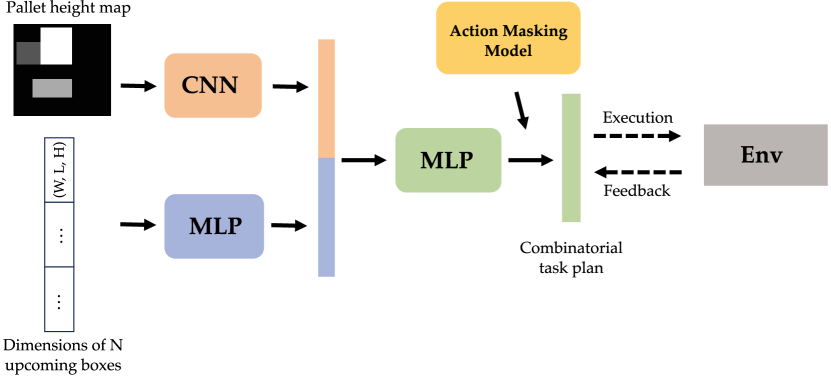
IV-B Implementation Details and Baselines
Our objective is to validate the efficacy of the learned action masking model within the RL training framework. To this end, we implemented two baseline methodologies, NoMask and HeuristicsMask, for comparison against our proposed LearnedMask method, detailed in Section III-B. The implementation specifics are outlined as follows:
NoMask
In the NoMask approach, action masking is not applied during the RL training process. Although this method can be utilized with various RL algorithms, we have chosen to implement PPO [23] for all experiments conducted in this study. During the training, the policy receives as input the discretized pallet height map alongside the dimensions of forthcoming boxes, subsequently generating a combinatorial task plan. To process this information, a Convolutional Neural Network (CNN) is used to encode the 2D height map into a vector, while a Multi-Layer Perceptron (MLP) encodes the dimensions of the incoming boxes. These vectors are then concatenated and supplied to the policy as input. The architecture of the policy is depicted in Figure 4 for further clarification.
HeuristicsMask
The HeuristicsMask configuration is similar to NoMask, with the distinction of incorporating a heuristics-based action masking strategy during RL training. Specifically, we employ the heuristic criteria outlined in Zhao et al. [5] to determine the feasible subset at each timestep. According to these criteria, a placement location is deemed feasible if it satisfies any of the following conditions: 1) more than of the base area of the box to be placed, along with all four of its bottom corners, receive support from the boxes already on the pallet; 2) more than of the base area and at least three of the four bottom corners are supported; or 3) more than of the base area is supported.
LearnedMask
LearnedMask (Ours) also shares the same settings as NoMask, except that our proposed learning-based action masking is performed during RL training, as described in Section III-B.
IV-C Experimental Results
In this section, we provide evaluation results under different experimental settings, aiming to address the three questions posed at the outset of Section IV.
IV-C1 Learned Action Masking Model as Accurate Stability Predictor
A fundamental approach to assessing the effectiveness of the learned action masking model involves evaluating the accuracy of its predictions. As outlined in Section III-B, the action masking model functions as an estimator, predicting the stability of specific placements and essentially operates as a semantic segmentation model. Therefore, we employ the standard Intersection-over-Union (IoU) metric to gauge the action masking model’s performance in stability prediction. The performance metrics for both our learned action masking model and the heuristic-based action masking, as introduced in Section IV-B, are reported for comparison. The heuristic-based action masking achieves an IoU of , whereas our learned action masking attains an IoU of , markedly surpassing the heuristic approach. This result demonstrates that the learned action masking model can provide a more accurate action space mask for policy sampling than the heuristic-based method, potentially enhancing RL training outcomes.
IV-C2 RL Policy Performance Improvement with Learned Action Masking
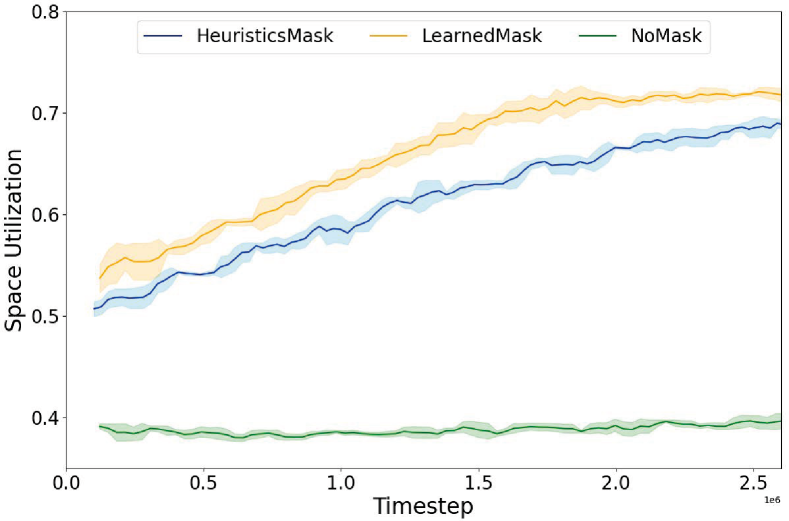
Intuitively, a precisely calibrated action masking model can significantly reduce the exploration space inherent in the original RL problem, thereby simplifying the optimization process. To empirically verify this, we conducted experiments by comparing the policy efficacy of our proposed LearnedMask model against two baselines: NoMask and HeuristicsMask, as elaborated in Section IV-B. We adopted the space utilization as defined in Section III-A as the reward. Figure 5 shows the performance of the three methods under the setting when the buffer size as training proceeds, across random seeds. Observations reveal that both LearnedMask and HeuristicsMask significantly surpass NoMask in performance, thereby affirming the hypothesis that optimization within the original action space of RL is inherently challenging. Action masking thus serves to effectively narrow the problem domain, substantially enhancing policy performance. Moreover, LearnedMask not only converges more rapidly but also achieves superior performance relative to HeuristicsMask, indicative of the premise that a more precise action masking model correlates with improved policy learning.
In a bid to comprehensively assess policy performance across variable configurations, we tabulated the average space utilization metrics for all three methods under varying buffer sizes, specifically, . These results were derived from executing the corresponding policy across 20 iterations and computing the mean reward from these episodes. Notably, during these test episodes, the arriving order of the boxes is random and unknown to the policy, identical to the training phase. The outcomes of this analysis are encapsulated in Table I. As depicted, LearnedPrune consistently outperforms HeuristicsPrune across all experimental conditions, thereby evidencing the robustness of our algorithm. Additionally, an increase in correlates with an enhancement in policy performance, a logical deduction considering the expanded decision-making vista afforded by a larger buffer. Nonetheless, in practical applications, the feasible value of is constrained by various factors, including the limitations of the perception system and physical spatial constraints. Within the context of most industrial palletization scenarios, a buffer size of represents a pragmatic upper limit.
| Buffer size | |||
|---|---|---|---|
| NoMask | 38.8% | 37.6% | 38.1% |
| HeuristicsMask | 69.4% | 71.9% | 72.7% |
| LearnedMask | 72.1% | 75.1% | 76.2% |
IV-C3 Iterative Policy Improvements with Iterative Action Masking Learning
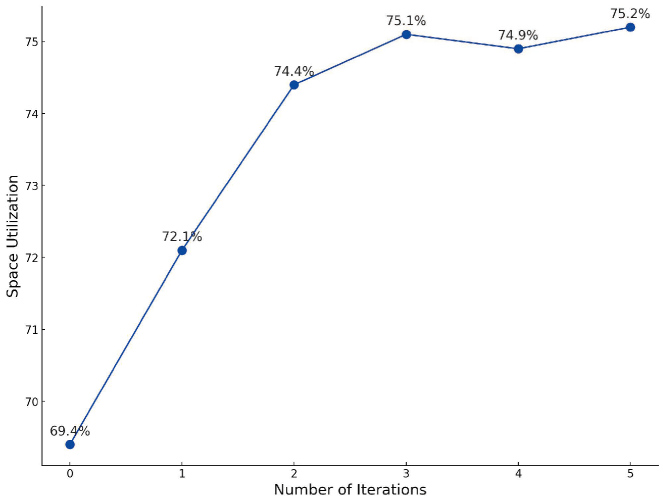
Here we aim to investigate if the iterative action masking learning algorithm in Section III-C can further improve the performance of RL policy over the iterations. Figure 6 delineates the relationship between policy performance and the number of iterations, denoted by . Specifically, denotes the baseline scenario of RL training underpinned by heuristic action masking, represented as HeuristicsMask, while signifies the employment of LearnedMask. Through empirical investigation, we observed a notable enhancement in performance during the initial iterations (), with improvements of and over their immediate predecessors, respectively. However, the policy performance ”saturates” in subsequent iterations (). We hypothesize that this phenomenon is attributed to the substantial mitigation of the initial distribution misalignment issue within the first two iterations (), which directly contributes to the incremental improvements of the derived policies. Consequently, beyond this point, the performance is no longer impeded by the misalignment challenge, rendering additional iterations ineffectual in further elevating the policy’s performance.
IV-D Real-World Deployment
We further tested our RL-based palletization task planner in a real-world physical system. Due to limitations in space and hardware, it was not feasible to implement our algorithm on an industrial-scale robot handling large boxes. Therefore, we utilized a Franka Panda robotic arm as a prototype for our physical system setup, depicted in Figure 7(a). The robot is equipped with a suction-type gripper for box manipulation and an Intel Realsense RGB-D camera mounted in-hand for box detection and localization on the conveyor. Space constraints restrict the camera’s perception to a single box at a time, resulting in an upcoming box count . The boxes, showcased in Figure 7(b), come in 5 different sizes and contain various items to simulate the diversity in weights found in real palletization tasks.
Our methodology involved training the task planner in a simulated environment tailored to the physical system’s specifications regarding pallet and box dimensions. This trained planner was then directly applied to the real-world setup. The robotic system demonstrated proficiency by successfully stacking 35 boxes on the pallet, achieving a space utilization rate of in a single episode. The final pallet configuration, viewed from different angles, is presented in Figure 8. The ability to stack 35 boxes while maintaining compactness and stability showcases the effectiveness and robustness of our learned palletization planner policy. A demo video of the palletization process can be accessed at here.


V CONCLUSION AND FUTURE WORK
This study introduced a novel reinforcement learning-based approach for robotic palletization task planning, emphasizing the significance of iterative action masking learning to manage and prune the action space effectively. Our methodology combines the precision of supervised learning with the adaptive capabilities of reinforcement learning, showcasing substantial improvements in both the efficiency and reliability of task planning for robotic palletization. The experimental validations, both in simulated environments and real-world deployments, have demonstrated the enhanced learning efficiency and operational performance of our proposed method.
A major limitation of our current study is the lack of integration between the task planning phase and the generation of collision-free trajectories for robotic execution. Specifically, our methodology does not account for the ease with which robots can execute the generated plans without encountering physical obstacles. Merging the task planning process with trajectory planning to produce plans that are not only efficient but also physically feasible for robots to execute without collision presents a promising avenue for future research.
References
- [1] F. Wang and K. Hauser, “Robot packing with known items and nondeterministic arrival order,” IEEE Transactions on Automation Science and Engineering, vol. 18, no. 4, pp. 1901–1915, 2020.
- [2] K. Karabulut and M. M. İnceoğlu, “A hybrid genetic algorithm for packing in 3d with deepest bottom left with fill method,” in International Conference on Advances in Information Systems. Springer, 2004, pp. 441–450.
- [3] C. T. Ha, T. T. Nguyen, L. T. Bui, and R. Wang, “An online packing heuristic for the three-dimensional container loading problem in dynamic environments and the physical internet,” in Applications of Evolutionary Computation: 20th European Conference, EvoApplications 2017, Amsterdam, The Netherlands, April 19-21, 2017, Proceedings, Part II 20. Springer, 2017, pp. 140–155.
- [4] F. Wang and K. Hauser, “Stable bin packing of non-convex 3d objects with a robot manipulator,” in 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 8698–8704.
- [5] H. Zhao, Q. She, C. Zhu, Y. Yang, and K. Xu, “Online 3d bin packing with constrained deep reinforcement learning,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 1, 2021, pp. 741–749.
- [6] H. Zhao, Y. Yu, and K. Xu, “Learning efficient online 3d bin packing on packing configuration trees,” in International Conference on Learning Representations, 2021.
- [7] H. Zhao, C. Zhu, X. Xu, H. Huang, and K. Xu, “Learning practically feasible policies for online 3d bin packing,” Science China Information Sciences, vol. 65, no. 1, p. 112105, 2022.
- [8] O. Vinyals, T. Ewalds, S. Bartunov, P. Georgiev, A. S. Vezhnevets, M. Yeo, A. Makhzani, H. Küttler, J. Agapiou, J. Schrittwieser et al., “Starcraft ii: A new challenge for reinforcement learning,” arXiv preprint arXiv:1708.04782, 2017.
- [9] C. Berner, G. Brockman, B. Chan, V. Cheung, P. Debiak, C. Dennison, D. Farhi, Q. Fischer, S. Hashme, C. Hesse et al., “Dota 2 with large scale deep reinforcement learning,” arXiv preprint arXiv:1912.06680, 2019.
- [10] D. Ye, Z. Liu, M. Sun, B. Shi, P. Zhao, H. Wu, H. Yu, S. Yang, X. Wu, Q. Guo et al., “Mastering complex control in moba games with deep reinforcement learning,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 04, 2020, pp. 6672–6679.
- [11] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille, “Semantic image segmentation with deep convolutional nets and fully connected crfs,” arXiv preprint arXiv:1412.7062, 2014.
- [12] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 3431–3440.
- [13] S. Ross, G. Gordon, and D. Bagnell, “A reduction of imitation learning and structured prediction to no-regret online learning,” in Proceedings of the fourteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings, 2011, pp. 627–635.
- [14] S. Martello, D. Pisinger, and D. Vigo, “The three-dimensional bin packing problem,” Operations research, vol. 48, no. 2, pp. 256–267, 2000.
- [15] O. Faroe, D. Pisinger, and M. Zachariasen, “Guided local search for the three-dimensional bin-packing problem,” Informs journal on computing, vol. 15, no. 3, pp. 267–283, 2003.
- [16] T. G. Crainic, G. Perboli, and R. Tadei, “Ts2pack: A two-level tabu search for the three-dimensional bin packing problem,” European Journal of Operational Research, vol. 195, no. 3, pp. 744–760, 2009.
- [17] K. Kang, I. Moon, and H. Wang, “A hybrid genetic algorithm with a new packing strategy for the three-dimensional bin packing problem,” Applied Mathematics and Computation, vol. 219, no. 3, pp. 1287–1299, 2012.
- [18] R. Hu, J. Xu, B. Chen, M. Gong, H. Zhang, and H. Huang, “Tap-net: transport-and-pack using reinforcement learning,” ACM Transactions on Graphics (TOG), vol. 39, no. 6, pp. 1–15, 2020.
- [19] J. Zhang, B. Zi, and X. Ge, “Attend2pack: Bin packing through deep reinforcement learning with attention,” arXiv preprint arXiv:2107.04333, 2021.
- [20] G. Dulac-Arnold, R. Evans, H. van Hasselt, P. Sunehag, T. Lillicrap, J. Hunt, T. Mann, T. Weber, T. Degris, and B. Coppin, “Deep reinforcement learning in large discrete action spaces,” arXiv preprint arXiv:1512.07679, 2015.
- [21] E. Todorov, T. Erez, and Y. Tassa, “Mujoco: A physics engine for model-based control,” in 2012 IEEE/RSJ international conference on intelligent robots and systems. IEEE, 2012, pp. 5026–5033.
- [22] O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in International Conference on Medical image computing and computer-assisted intervention. Springer, 2015, pp. 234–241.
- [23] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint arXiv:1707.06347, 2017.