Efficient Preference-based Reinforcement Learning via Aligned Experience Estimation
Abstract
Preference-based reinforcement learning (PbRL) has shown impressive capabilities in training agents without reward engineering. However, a notable limitation of PbRL is its dependency on substantial human feedback. This dependency stems from the learning loop, which entails accurate reward learning compounded with value/policy learning, necessitating a considerable number of samples. To boost the learning loop, we propose SEER, an efficient PbRL method that integrates label smoothing and policy regularization techniques. Label smoothing reduces overfitting of the reward model by smoothing human preference labels. Additionally, we bootstrap a conservative estimate using well-supported state-action pairs from the current replay memory to mitigate overestimation bias and utilize it for policy learning regularization. Our experimental results across a variety of complex tasks, both in online and offline settings, demonstrate that our approach improves feedback efficiency, outperforming state-of-the-art methods by a large margin. Ablation studies further reveal that SEER achieves a more accurate Q-function compared to prior work.
1 Introduction
Deep Reinforcement Learning (DRL) has recently demonstrated remarkable proficiency in enabling agents to excel in complex behaviors across diverse domains, including robotic control and manipulation [27, 11], game playing [31, 49], and industrial applications [53]. The foundation of success lies in providing a well-designed reward function. However, setting up a suitable reward function has been challenging for many reinforcement learning applications [54, 40]. The quality of the reward function depends heavily on the designer’s understanding of the core logic behind the problem and relevant background knowledge. For example, formulating a reward function for text generation presents a significant challenge due to the inherent difficulty in quantifying text quality on a numerical scale [52, 34]. Despite the substantial efforts of expert engineers in reward engineering, previous research [48, 43] has highlighted various challenges, such as “reward hacking”. In these scenarios, agents focus solely on maximizing their rewards by exploiting misspecification in the reward function, often leading to unintended and potentially problematic behaviors.
Recently, PbRL has gained widespread attention and has fruitful outcomes [23, 35, 28]. Rather than relying on hand-engineered reward functions, humans can provide preference between a pair of agent trajectories, thereby implicitly indicating the desired behaviors or the task’s objectives. Recent research has demonstrated that PbRL can train agents to perform novel behaviors and mitigate the challenges of reward hacking to some extent. However, existing methods still suffer from feedback inefficiency, limiting the applicability of PbRL in practical scenarios. Taking a closer look at PbRL, it involves collecting preference labels, learning a reward model from preferences, optimizing policy with the reward model, and subsequently generating higher-quality trajectories for the next iteration, thereby creating a virtuous circle. Prior research [13, 28] observes that the intrinsic inefficiency of reward learning mechanisms results in an increase in feedback requirements for PbRL. Specifically, insufficient preference label leads to an imprecise reward model. This inaccuracy may cause the Q function to be misled by the erroneous outputs of the reward model, resulting in suboptimal policy, a phenomenon often referred to as confirmation bias [37]. Further, the data coverage in the replay memory is limited to a tiny subset of the whole state-action space. When combined with deep neural networks, the extrapolation of function approximation may erroneously overestimate out-of-distribution state-action pairs to have unrealistic values, and the errors will be back-propagated to previous states [9, 21, 25]. Due to an inaccurate reward model compounded with overestimation bias, the Q function drives a suboptimal policy, which deteriorates the learning cycle and leads to poor performance.
In this work, we present SEER, an efficient framework via aligned estimation from experience for preference-based reinforcement learning. Our approach integrates two complementary techniques: label smoothing and policy regularization. In terms of label smoothing, we smooth human preference labels to mitigate overfitting during reward learning. During RL training, we estimate a conservative using only the transitions in the replay memory, effectively reducing overestimation bias. This estimate is then employed to regularize the policy learning using Kullback-Leibler (KL) divergence. Our empirical evaluations, conducted on a range of complex tasks in both online and offline environments, demonstrate that SEER markedly surpasses baselines. This advantage is particularly obvious when the available human feedback is limited, showcasing SEER’s effectiveness in leveraging limited data to achieve superior performance.
The key contributions of our work are as follows: (1) We propose SEER, a novel feedback-efficient preference-based RL algorithm that combines policy regularization with label smoothing, facilitating efficient and effective learning. (2) Experiments demonstrate that our method outperforms other state-of-the-art PbRL methods and substantially improves feedback efficiency across a variety of complex tasks, both in online and offline settings. (3) We demonstrate that, benefiting from policy regularization and label smoothing, our approach shows a clear advantage over PEBBLE, particularly in scenarios with limited human feedback. We also show that SEER can train an accurate Q function and a better policy.
2 Preliminaries
Preference-based Reinforcement Learning. In the RL paradigm, a finite Markov decision process (MDP) is defined by the tuple . This comprises the state space , action space , transition dynamics, reward function , and discount factor . The transition probability characterizes the stochastic nature of the environment, indicating the probability of transitioning to state upon taking action in state . specifies the reward received for performing action in state . The policy maps the state space to the action space. The objective of the agent is to collect trajectories by interacting with the environment, aiming to maximize the expected return.
In the PbRL framework outlined by Christiano et al. [4], the reward function from reward engineering is replaced by a reward function estimator, , which is learned to align with human preferences. In this context, a segment is defined as a sequence of states and actions, denoted as . A human provides a preference for a pair of segments , where is a distribution over . Following the Bradley-Terry model [2], a preference predictor based on the estimated reward function is formulated as:
| (1) |
where indicates is more consistent with human expert expectations than . The reward model is trained by minimizing the cross-entropy loss between predictions from the preference predictor and actual human preferences:
| (2) |
By optimizing with respect to this loss, segments that align more closely with human receive a higher return.
Twin Delayed DDPG. TD3 [8] introduces several key techniques for improvement. It employs the minimum value between two Q-networks to address the issue of overestimation resulting from function approximation errors. Delayed policy updates and target policy smoothing further refine the training process. TD3 learns two Q-functions, and , by minimizing the mean square Bellman error. Concurrently, it optimizes the policy by maximizing the Q-function values.
For optimizing , it minimizes the temporal difference errors. The target value for the Q networks is defined as:
| (3) |
where , , and denote the target networks for Q and policy networks, respectively. is the discount factor, is clipped exploration noise from and clipped by threshold , with indicating the valid action range. Both Q-functions are trained by regressing to this target:
| (4) |
In updating the policy, the objective is to learn a policy that maximizes . As the Q-function is differentiable with respect to action, gradient ascent can be applied:
| (5) |
where parameters are considered constant.
In our work, we choose DQN [32] and TD3 as the basic RL algorithms for discrete and continuous settings, respectively.

3 Method
In this section, we introduce SEER, a generic framework designed to integrate with any PbRL approach, enhancing feedback efficiency. Figure 1 illustrates the overview of our method. We will detail the three core components of SEER: human label smoothing, conservative estimate and policy regularization. The detailed procedure of our algorithm is outlined in Algorithm 1 (online settings) and 2 (offline settings).
3.1 Reward Learning
Revisiting the loss (2) for optimizing the reward model in the framework of PbRL, it is a cross-entropy loss denoting the distance between the true distribution and predicted distribution. But when we assume all segment pairs in the preference dataset hold . In practice, human preference labels tend to exhibit strong polarization, often taking the form of or . Consequently, the loss (2) simplifies to minimizing the negative logarithmic predicted probability of . The preference predictor 1 provided by the Bradley-Terry model [2] is a sigmoid function. Therefore, when we attempt to optimize the reward model such that , we are essentially hoping for the condition to be satisfied. However, this is infeasible and can negatively impact the performance of the reward model. Over-fitting becomes a significant empirical issue, particularly in cases where the action spaces are extremely large, such as with continuous action spaces. Then we smooth the human label according to the following rule:
| (6) |
By applying a smoothing technique to the human preference labels, we aim to achieve a more accurate reward model during the policy learning process.
3.2 Conservative Estimate
By utilizing well-supported state-action pairs from the current replay memory, we bootstrap a conservative estimate . This conservative estimation provides two main advantages: firstly, it enables further exploitation of the information in the replay memory; secondly, it prevents overestimation caused by extrapolation in unseen states and actions. We build the replay memory as a graph for discrete action spaces, which is similar to the method used by Zhu et al. [57], Hong et al. [15]. This allows us to rapidly perform conservative estimations without significant additional computational overhead. For continuous action spaces, we employ a neural network to model .
3.2.1 Discrete Setting
We structure the replay memory as a dynamic and directed graph, which is denoted as . Each vertex in this graph represents a state along with its associated action value estimation , forming the vertex set: . Each directed edge in the graph denotes a transition from state to state through action . These edges also store the estimated reward and the count of transitions , which are crucial for updating the model. The set of graph edges is represented as . To ensure efficient querying, each vertex and edge is assigned a unique key via a hash function, achieving a query time complexity of . Additionally, every vertex contains an action set , which includes the actions executed in state , thus facilitating in-sample updates. Similar to conventional replay memory, this graph stores the most recent experiences, maintaining a fixed memory size.
This graph updating includes two primary components: estimation updating and reward relabeling. Upon observing a transition , we add a new vertex and edge following the previously outlined data structure, initializing and . If an edge for the transition already exists, the visit count is incremented: . For updating the action value estimate , a subset of graph vertices is sampled in reverse order, similar to techniques described in Rotinov [39], Lee et al. [24], to enable rapid and efficient updates. During the update process, the max-operator in the update rule is constrained to operate over instead of the entire action space, preventing visits to out-of-sample actions. Specifically, we update using value iteration, defined by:
| (7) |
where represents the empirical dynamics within the graph. This update rule (Equation 7) ensures that the method never queries values for unseen actions, thereby preventing overestimation. For reward relabeling, we relabel all past experiences using the reward model each time this reward model is updated. This technique maximizes the use of historical transitions and reduces the impact of a non-stationary reward function.
3.2.2 Continuous Setting
For tasks involving continuous actions, using discretization techniques to transform continuous action spaces into discrete ones may be beneficial. For example, RT-2 [3] employs this approach for discretizing actions in robotic applications, and it has also been successfully applied in complex games like DOTA [1] and StarCraft [49].To make our method more comprehensive, we explore methods for estimating in continuous action spaces. To achieve that, we propose an operator analogous to the constrained operator in formula (7) for conservative Q estimation. Drawing from previous work [22, 20, 10], we use the log-sum-exp defined as:
| (8) |
where is a scaling parameter. For any , it follows that . Moreover, , and . Therefore, for any , the operator interpolates between the expectation and the maximum of . And we optimize the by minimizing the Mean-squared-error (MSE) loss, defined as:
| (9) |
where is the transition.
3.3 Policy Learning
In the above section, we develop a strategy for obtaining a conservative estimate . We now propose a policy regularizer tailored for both discrete and continuous settings.
Given that the goal of learning is to derive an optimal policy from the Q network, we use policy regularization to align policy with the current best policy derived from . Specifically, we regularize policy by minimizing the Kullback-Leibler (KL) divergence between and , defined as:
| (10) |
In scenarios with discrete actions, we define as the Boltzmann policy derived from , where . This policy is inherently conservative, considering only the support set for a given state . Similarly, the policy , derived from the network, is expressed as . Total loss is defined as follows:
| (11) |
where is the Q target, is the transition and is the weight factor.
In scenarios with continuous actions, we need a parameterized policy to interact with the environment. For policy learning, is employed to regularize the policy , with the parameters optimized by maximizing the following objective:
| (12) |
where is the weight of the policy regularizer, the partition function normalizes the distribution and the parameters and are considered constants.
3.4 Theoretical Analysis
We conduct a theoretical analysis to show the properties of the conservative estimate, denoted as , in a finite state-action space . To learn , we employ Equation 7 based on the replay buffer. This approach bootstraps only in-distribution actions, yielding a conservative estimate of the action value. In comparison to the function, which bootstraps from the entire action space, reduces extrapolation error from out-of-distribution data. serves as a lower bound for and converges to the global optimum as data coverage expands. The complete proofs of Theorem 3.1 are provided in Appendix C.
Theorem 3.1.
Consider the tabular case with finite state-action space . Let and represent the Q-values learned following the Bellman optimality equation and Equation 7 at time step , respectively. We have and converge to fixed points and , i.e., and . Furthermore, for all , . This equality holds if all state-action pairs are visited.
|
Sokoban |
|||
|
Craftenv |






4 Experiment
In this section, we conduct evaluations across a variety of environments, including puzzle video games from Sokoban [41], robotic construction tasks from CraftEnv [56], locomotion tasks from DeepMind Control Suite (DMControl) [46, 47], robotic manipulation challenges from Meta-world [55], and D4RL [6]. Our aim is to investigate the following key questions: (1) Does SEER demonstrate better feedback efficiency in learning policies across different settings (discrete, continuous) in online environments? (2) Is SEER capable of training more effective policies in offline settings? (3) Can SEER achieve a more accurate Q function estimation? (4) Are the individual components within SEER effective? The answers to questions (1) and (2) are provided in Section 4.2, supported by detailed empirical results. Questions (3) and (4) are explored in Section 4.3 through ablation studies. Additional information about the tasks utilized in our experiments can be found in Appendix D.
4.1 Experimental Settings
Baselines. We compare our algorithm with several state-of-the-art methods, spanning both online, offline PbRL algorithms: Online Methods: (1) PEBBLE [23]: integrates unsupervised pre-training with reward relabeling techniques during policy learning. (2) SURF [35]: employs temporal data augmentation and pseudo labels within a semi-supervised learning framework. (3) MRN [28]: utilizes bi-level optimization methods in reward learning, which is the current state-of-the-art algorithm in online PbRL. Offline Methods: (4) PT [19]: utilizes transformer architecture to derive a non-Markovian reward and preference weighting function for offline PbRL. (5) IPL [13]: directly optimizes the implicit rewards deduced from the learned Q-function, ensuring alignment with expert preferences. Reward-based Methods. Explicit rewards are absent in PbRL settings. We utilize benchmarks that employ ground-truth rewards from the environment, specifically SAC [12] for online scenarios, and IQL [20] and TD3+BC [7] for offline scenarios.
|
DMControl |
|||
|
Meta-world |






Implementation details. In our experiments, we follow the basic settings employed in [23, 35, 28], which include unsupervised exploration techniques and an uncertainty-based trajectory sampling scheme (more details are available in Appendix B.2). Regarding the reward learning setting, all methods utilize an ensemble of three reward models, with their outputs confined to the range of through a hyperbolic tangent function. In line with prior research, we adopt a consistent approach for performance evaluation using a scripted teacher. This teacher supplies preference labels between pairs of trajectory segments based on the environment’s inherent reward function. These preferences faithfully represent the environment’s actual rewards, thus facilitating a quantitative comparison of the algorithms by assessing their true returns. It is important to emphasize that, within the PbRL framework, the agent does not have direct access to these rewards. As for offline settings, we use real-human preference data from Kim et al. [19]. And the number of preference labels required in each task is presented in Appendix B.1.
To ensure equitable comparisons, all methods are trained using the same network architecture and shared hyperparameters, except for method-specific elements. For baseline implementations, we use the publicly available code for PEBBLE 111https://github.com/pokaxpoka/B_Pref, SURF 222https://github.com/alinlab/SURF, MRN 333https://github.com/RyanLiu112/MRN, and IPL 444https://github.com/jhejna/inverse-preference-learning. More comprehensive details about the implementation of our approach and the baselines are provided in Appendix B.
4.2 Results
Discrete Settings. A detailed introduction and visualization of the six puzzle-solving tasks from Sokoban and the three flexible environments from CraftEnv are presented in Appendix D. We select these tasks for our experiments, covering a range of complexities. Figure 2 depicts the learning curves of the average episode return for SEER and baselines on discrete tasks. In each task, SAC utilizes the ground-truth reward, showcasing the best results as the performance upper bound. As observed in Figure 2, SEER quickly achieves remarkable performance early in the training process across various tasks. Interestingly, in several tasks, SEER nearly matches SAC’s benchmark performance with only a limited number of human preference labels, indicating exceptional feedback efficiency. With a limited number of preference labels available, some baselines are significantly influenced by randomness in certain tasks, and their training curves show a downward trend in more challenging tasks. Notably, SEER achieves performance comparable to PEBBLE, but with substantially fewer samples. For example, in the Strip-shaped building task, SEER surpasses PEBBLE’s average performance using only 30% of the total samples. These results suggest that SEER markedly reduces the feedback required to effectively tackle complex tasks, making it a highly efficient approach in PbRL.
| Dataset | IQL (reward) | TD3+BC (reward) | MR | LSTM | PT | IPL | SEER (ours) |
|---|---|---|---|---|---|---|---|
| antmaze-medium-play-v2 | 73.88
4.49 |
0.25
0.43 |
31.13
16.96 |
62.88
5.99 |
70.13
3.76 |
30.19
4.97 |
69.0
14.97 |
| antmaze-medium-diverse-v2 | 68.13
10.15 |
0.25
0.43 |
19.38
9.24 |
20.13
17.12 |
65.25
3.59 |
24.21
5.12 |
67.0
17.44 |
| antmaze-large-play-v2 | 48.75
4.35 |
0.0
0.0 |
24.25
14.03 |
14.13
3.60 |
42.38
9.98 |
12.46
7.2 |
50.67
10.2 |
| antmaze-large-diverse-v2 | 44.38
4.47 |
0.0
0.0 |
5.88
6.94 |
0.00
0.00 |
19.63
3.70 |
0.0
0.0 |
48.0
16.0 |
| antmaze-v2 total | 58.79 | 0.13 | 20.16 | 24.29 | 49.35 | 16.72 | 58.67 |
| hopper-medium-replay-v2 | 83.06
15.80 |
64.42
21.52 |
11.56
30.27 |
57.88
40.63 |
84.54
4.07 |
73.57
6.7 |
85.29
5.11 |
| hopper-medium-expert-v2 | 73.55
41.47 |
101.17
9.07 |
57.75
23.70 |
38.63
35.58 |
68.96
33.86 |
74.52
0.1 |
96.75
4.31 |
| walker2d-medium-replay-v2 | 73.11
8.07 |
85.62
4.01 |
72.07
1.96 |
77.00
3.03 |
71.27
10.30 |
59.92
5.1 |
73.91
1.33 |
| walker2d-medium-expert-v2 | 107.75
2.02 |
110.03
0.36 |
108.32
3.87 |
110.39
0.93 |
110.13
0.21 |
108.51
0.6 |
110.12
0.24 |
| locomotion-v2 total | 84.37 | 90.31 | 62.43 | 70.98 | 83.72 | 79.13 | 91.52 |
| lift-ph | 96.75
1.83 |
- | 84.75
6.23 |
91.50
5.42 |
91.75
5.90 |
97.6
2.9 |
98.0
4.0 |
| lift-mh | 86.75
2.82 |
- | 91.00
4.00 |
90.75
5.75 |
86.75
5.95 |
87.2
5.3 |
93.0
8.94 |
| can-ph | 74.50
6.82 |
- | 68.00
9.13 |
62.00
10.90 |
69.67
5.89 |
74.8
2.4 |
70.0
13.56 |
| can-mh | 56.25
8.78 |
- | 47.50
3.51 |
30.50
8.73 |
50.50
6.48 |
57.6
5.0 |
47.0
9.8 |
| robosuite total | 78.56 | - | 72.81 | 68.69 | 74.66 | 79.3 | 77.0 |
Continuous Settings. We also evaluated SEER’s performance in continuous settings, focusing on three locomotion tasks from DMControl and three robotic simulated manipulation tasks from Meta-world. As depicted in Figure 3, SEER surpasses the baselines in most tasks. Notably, in the Cheetah Run task, SEER achieves 96% of the best performance using only 100 preference labels, showcasing remarkable feedback efficiency. A comparison between the orange (SEER) and green (PEBBLE) curves in the figures clearly indicates that SEER improves upon PEBBLE’s performance. These outcomes, as illustrated in Figure 3, demonstrate that SEER enhances the feedback efficiency of PbRL methods across diverse and complex tasks. It is noteworthy that SEER effectively utilizes the conservative estimate function to regularize policy, resulting in improvements, especially with a limited number of preference labels.
Offline Settings. We benchmark SEER against several offline PbRL algorithms on the D4RL [6] and Robosuite [58] robotics datasets, utilizing real-human preference data from Kim et al. [19]. As before, we aim to avoid using out-of-samples actions. Therefore, we extract the policy using advantage weighted regression [36, 50, 33]. In addition to comparing SEER with two state-of-the-art offline PbRL algorithms, IPL and PT, we also benchmark it against two significant offline RL algorithms. As TD3 is our basic RL algorithm, we include results from TD3 enhanced with Behavior Cloning (TD3+BC) [7]. The comparison also features different reward model architectures: MR (MLP-based), LSTM (LSTM-based), and PT (Transformer-based), corresponding to models proposed in Christiano et al. [4], Early et al. [5], and Kim et al. [19] respectively. Our findings are presented in Table 1. SEER consistently surpasses all baselines in nearly every task. Notably, it exhibits a clear advantage in challenging tasks like antmaze-large. Only our method almost matches the performance of IQL with the task reward and even surpasses IQL in some cases. These results demonstrate the effectiveness of our method across a variety of tasks in offline settings.
4.3 Ablation Studies
Contribution of each technique. To assess the individual contributions of each technique in SEER, we apply human label smoothing and policy regularization. Figure (4a) shows a comparative analysis of SEER’s performance with and without policy regularization on tasks such as Cheetah Run and Quadruped Walk. This visual representation clearly indicates that incorporating policy regularization enables agents to enhance their performance. Figure (4b) displays the impact of varying values on SEER’s performance, underscoring the effectiveness of label smoothing in improving performance. However, we also note that while label smoothing is beneficial, an overly large value can be detrimental. It is observed that in more complex tasks, a smaller is preferable, whereas in less challenging tasks, a larger value tends to yield better results.
Accuracy of value estimation. We assess the accuracy of value estimation in SEER by examining the value estimate trajectory during the learning process on Cheetah Run. Figure (4c) illustrates this by charting the average value estimate across 10000 states and contrasting it with an estimate of the true value. The true value is calculated based on the average discounted return obtained by following the current policy. Notably, a clear overestimation bias is evident in the learning procedure. When constrained by the policy regularizer, SEER shows a significant reduction in overestimation bias, leading to a more accurate Q function. This improvement in Q estimation benefits the learning cycle of PbRL, making it a more effective approach.



5 Related Work
Preference-based Reinforcement Learning. Preference-based RL (PbRL) is a novel way to learn agents from human feedback without reward engineering. Instead, a human provides preferences between the agent’s behaviors, and the agent uses this feedback to perform the task. Christiano et al. [4] formulates a basic framework, and Ibarz et al. [16] utilizes imitation learning as the warm-start strategy to speed up PbRL. To further improve feedback efficiency, PEBBLE [23] replaces PPO [42] with SAC [12] to achieve data efficiency and combines unsupervised pre-training with reward relabeling technique during learning. Building upon this foundation, Park et al. [35] introduces SURF, a semi-supervised reward learning framework that improves reward learning via pseudo-labels and temporal cropping augmentation. MRN [28] incorporates bi-level optimization for improving the quality of the Q function. Besides, some research has various considerations, such as skill extraction [51], intrinsic reward [26], meta-learning [14], and these methods have improved the efficiency to a certain extent. In addition to focusing on PbRL in online settings, a significant portion of research also concentrates on PbRL in offline settings. PT [19] leverages a transformer architecture to learn a non-Markovian reward and preference weighting function. IPL [13] directly optimizes the implicit rewards deduced from the learned Q-function, ensuring alignment with expert preferences. Kang et al. [18] models offline trajectories and preferences in a one-step process without reward learning. When dealing with language models, PbRL naturally facilitates the emergence of reinforcement learning from human feedback (RLHF) [34]. Before that, Stiennon et al. [44], Wu et al. [52] have fine-tuned a summarizing policy following the PbRL paradigm. Our approach is orthogonal to previous approaches, that we use conservative estimate to regularize the neural Q-function to mitigate overestimation and smooth the human label to prevent overfitting of the reward model.
6 Conclusion
In this work, we present SEER, a novel PbRL algorithm that notably enhances feedback efficiency. By integrating policy regularization and label smoothing, SEER not only surpasses previous methods but also significantly improves feedback efficiency across various complex tasks in both online and offline settings. A key strength of our method is its remarkable performance with a limited number of preference labels. Our empirical results and analyses indicate that the enhanced feedback efficiency in SEER primarily arises from two factors: (1) Our approach mitigates overestimation bias, contributing to a more precise Q-function estimation. (2) Label smoothing effectively reduces the reward model’s tendency to overfit. We hope our method can provide inspiration for future work and encourage preference-based reinforcement learning to be better extended to practical applications. SEER’s success in addressing these critical aspects of PbRL demonstrates its potential to influence future research and expand the practical applicability of preference-based reinforcement learning in various domains.
Limitations. First, the preference learning in our algorithm is based on trajectories, which means it cannot accurately discriminate between good and bad actions within one trajectory. Additionally, we do not discuss high-dimensional and multi-modal inputs, such as images and natural language. While these are not the focus of this work, we consider this as an interesting future direction.
References
- Berner et al. [2019] Christopher Berner, Greg Brockman, Brooke Chan, Vicki Cheung, Przemyslaw Debiak, Christy Dennison, David Farhi, Quirin Fischer, Shariq Hashme, Christopher Hesse, Rafal Józefowicz, Scott Gray, Catherine Olsson, Jakub Pachocki, Michael Petrov, Henrique Pondé de Oliveira Pinto, Jonathan Raiman, Tim Salimans, Jeremy Schlatter, Jonas Schneider, Szymon Sidor, Ilya Sutskever, Jie Tang, Filip Wolski, and Susan Zhang. Dota 2 with large scale deep reinforcement learning. CoRR, abs/1912.06680, 2019.
- Bradley and Terry [1952] Ralph Allan Bradley and Milton E. Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39(3/4):324–345, 1952.
- Brohan et al. [2023] Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. arXiv preprint arXiv:2307.15818, 2023.
- Christiano et al. [2017] Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. In Advances in Neural Information Processing Systems (NeurIPS), volume 30, 2017.
- Early et al. [2022] Joseph Early, Tom Bewley, Christine Evers, and Sarvapali Ramchurn. Non-markovian reward modelling from trajectory labels via interpretable multiple instance learning. In Advances in Neural Information Processing Systems (NeurIPS), volume 35, pages 27652–27663, 2022.
- Fu et al. [2020] Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4rl: Datasets for deep data-driven reinforcement learning. arXiv preprint arXiv:2004.07219, 2020.
- Fujimoto and Gu [2021] Scott Fujimoto and Shixiang (Shane) Gu. A minimalist approach to offline reinforcement learning. In Advances in Neural Information Processing Systems (NeurIPS), volume 34, pages 20132–20145, 2021.
- Fujimoto et al. [2018] Scott Fujimoto, Herke van Hoof, and David Meger. Addressing function approximation error in actor-critic methods. In International Conference on Machine Learning (ICML), volume 80, pages 1587–1596, 10–15 Jul 2018.
- Fujimoto et al. [2019] Scott Fujimoto, David Meger, and Doina Precup. Off-policy deep reinforcement learning without exploration. In International Conference on Machine Learning, pages 2052–2062. PMLR, 2019.
- Garg et al. [2023] Divyansh Garg, Joey Hejna, Matthieu Geist, and Stefano Ermon. Extreme q-learning: Maxent RL without entropy. In International Conference on Learning Representations (ICLR), 2023.
- Gu et al. [2017] Shixiang Gu, Ethan Holly, Timothy Lillicrap, and Sergey Levine. Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates. In IEEE International Conference on Robotics and Automation (ICRA), pages 3389–3396, 2017.
- Haarnoja et al. [2018] Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In International Conference on Machine Learning (ICML), volume 80, pages 1861–1870, 2018.
- Hejna and Sadigh [2023] Joey Hejna and Dorsa Sadigh. Inverse preference learning: Preference-based RL without a reward function. 2023.
- Hejna III and Sadigh [2023] Donald Joseph Hejna III and Dorsa Sadigh. Few-shot preference learning for human-in-the-loop RL. In International Conference on Robot Learning (CoRL), pages 2014–2025. PMLR, 2023.
- Hong et al. [2022] Zhang-Wei Hong, Tao Chen, Yen-Chen Lin, Joni Pajarinen, and Pulkit Agrawal. Topological experience replay. In International Conference on Learning Representations (ICLR), 2022.
- Ibarz et al. [2018] Borja Ibarz, Jan Leike, Tobias Pohlen, Geoffrey Irving, Shane Legg, and Dario Amodei. Reward learning from human preferences and demonstrations in atari. In Advances in Neural Information Processing Systems (NeurIPS), volume 31, 2018.
- Jaakkola et al. [1993] Tommi Jaakkola, Michael Jordan, and Satinder Singh. Convergence of stochastic iterative dynamic programming algorithms. Advances in neural information processing systems, 6, 1993.
- Kang et al. [2023] Yachen Kang, Diyuan Shi, Jinxin Liu, Li He, and Donglin Wang. Beyond reward: Offline preference-guided policy optimization. In International Conference on Machine Learning (ICML), volume 202, pages 15753–15768, 23–29 Jul 2023.
- Kim et al. [2023] Changyeon Kim, Jongjin Park, Jinwoo Shin, Honglak Lee, Pieter Abbeel, and Kimin Lee. Preference transformer: Modeling human preferences using transformers for RL. In International Conference on Learning Representations (ICLR), 2023.
- Kostrikov et al. [2022] Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline reinforcement learning with implicit q-learning. In International Conference on Learning Representations (ICLR), 2022.
- Kumar et al. [2019] Aviral Kumar, Justin Fu, Matthew Soh, George Tucker, and Sergey Levine. Stabilizing off-policy q-learning via bootstrapping error reduction. Advances in Neural Information Processing Systems, 32, 2019.
- Kumar et al. [2020] Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative q-learning for offline reinforcement learning. In Advances in Neural Information Processing Systems (NeurIPS), volume 33, pages 1179–1191, 2020.
- Lee et al. [2021] Kimin Lee, Laura M Smith, and Pieter Abbeel. Pebble: Feedback-efficient interactive reinforcement learning via relabeling experience and unsupervised pre-training. In International Conference on Machine Learning (ICML), volume 139, pages 6152–6163, 2021.
- Lee et al. [2019] Su Young Lee, Choi Sungik, and Sae-Young Chung. Sample-efficient deep reinforcement learning via episodic backward update. In Advances in Neural Information Processing Systems (NeurIPS), volume 32, 2019.
- Levine et al. [2020] Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems. arXiv preprint arXiv:2005.01643, 2020.
- Liang et al. [2022] Xinran Liang, Katherine Shu, Kimin Lee, and Pieter Abbeel. Reward uncertainty for exploration in preference-based reinforcement learning. In International Conference on Learning Representations (ICLR), 2022.
- Lillicrap et al. [2016] Timothy P. Lillicrap, Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning. In International Conference on Learning Representations (ICLR), 2016.
- Liu et al. [2022] Runze Liu, Fengshuo Bai, Yali Du, and Yaodong Yang. Meta-reward-net: Implicitly differentiable reward learning for preference-based reinforcement learning. In Advances in Neural Information Processing Systems (NeurIPS), volume 35, pages 22270–22284, 2022.
- Melo [2001] Francisco S Melo. Convergence of q-learning: A simple proof. Institute Of Systems and Robotics, Tech. Rep, pages 1–4, 2001.
- Misra et al. [2003] Neeraj Misra, Harshinder Singh, and Vladimir Hnizdo. Nearest neighbor estimates of entropy. American Journal of Mathematical and Management Sciences, 23(3-4):301–321, 2003.
- Mnih et al. [2013a] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin A. Riedmiller. Playing atari with deep reinforcement learning. CoRR, abs/1312.5602, 2013a.
- Mnih et al. [2013b] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin A. Riedmiller. Playing atari with deep reinforcement learning. CoRR, abs/1312.5602, 2013b.
- Nair et al. [2020] Ashvin Nair, Abhishek Gupta, Murtaza Dalal, and Sergey Levine. Awac: Accelerating online reinforcement learning with offline datasets. arXiv preprint arXiv:2006.09359, 2020.
- Ouyang et al. [2022] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems (NeurIPS), volume 35, pages 27730–27744, 2022.
- Park et al. [2022] Jongjin Park, Younggyo Seo, Jinwoo Shin, Honglak Lee, Pieter Abbeel, and Kimin Lee. SURF: Semi-supervised reward learning with data augmentation for feedback-efficient preference-based reinforcement learning. In International Conference on Learning Representations (ICLR), 2022.
- Peters and Schaal [2007] Jan Peters and Stefan Schaal. Reinforcement learning by reward-weighted regression for operational space control. In International Conference on Machine Learning (ICML), page 745–750, 2007.
- Pham et al. [2021] Hieu Pham, Zihang Dai, Qizhe Xie, and Quoc V. Le. Meta pseudo labels. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11557–11568, 2021.
- Robbins and Monro [1951] Herbert Robbins and Sutton Monro. A stochastic approximation method. The annals of mathematical statistics, pages 400–407, 1951.
- Rotinov [2019] Egor Rotinov. Reverse experience replay. 2019.
- Schenck and Fox [2017] Connor Schenck and Dieter Fox. Visual closed-loop control for pouring liquids. In International Conference on Robotics and Automation (ICRA), pages 2629–2636, 2017.
- Schrader [2018] Max-Philipp B. Schrader. gym-sokoban. https://github.com/mpSchrader/gym-sokoban, 2018.
- Schulman et al. [2017] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. CoRR, abs/1707.06347, 2017.
- Skalse et al. [2022] Joar Skalse, Nikolaus Howe, Dmitrii Krasheninnikov, and David Krueger. Defining and characterizing reward gaming. In Advances in Neural Information Processing Systems (NeurIPS), volume 35, pages 9460–9471, 2022.
- Stiennon et al. [2020] Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize with human feedback. In Advances in Neural Information Processing Systems (NeurIPS), volume 33, pages 3008–3021, 2020.
- Szepesvári [2010] Csaba Szepesvári. Algorithms for reinforcement learning. Synthesis lectures on artificial intelligence and machine learning, 4(1):1–103, 2010.
- Tassa et al. [2018] Yuval Tassa, Yotam Doron, Alistair Muldal, Tom Erez, Yazhe Li, Diego de Las Casas, David Budden, Abbas Abdolmaleki, Josh Merel, Andrew Lefrancq, et al. Deepmind control suite. arXiv preprint arXiv:1801.00690, 2018.
- Tunyasuvunakool et al. [2020] Saran Tunyasuvunakool, Alistair Muldal, Yotam Doron, Siqi Liu, Steven Bohez, Josh Merel, Tom Erez, Timothy Lillicrap, Nicolas Heess, and Yuval Tassa. dm_control: Software and tasks for continuous control. Software Impacts, 6:100022, 2020.
- Victoria et al. [2020] Krakovna Victoria, Mikulik Vladimir, Rahtz Matthew, Everitt Tom, Kumar Ramana, Kenton Zac, Leike Jan, and Legg Shane. Specification gaming: the flip side of ai ingenuity. 2020. URL https://www.deepmind.com/blog/specification-gaming-the-flip-side-of-ai-ingenuity.
- Vinyals et al. [2019] Oriol Vinyals, Igor Babuschkin, Wojciech M. Czarnecki, Michaël Mathieu, Andrew Dudzik, Junyoung Chung, David H. Choi, Richard Powell, Timo Ewalds, Petko Georgiev, Junhyuk Oh, Dan Horgan, Manuel Kroiss, Ivo Danihelka, Aja Huang, Laurent Sifre, Trevor Cai, John P. Agapiou, Max Jaderberg, Alexander Sasha Vezhnevets, Rémi Leblond, Tobias Pohlen, Valentin Dalibard, David Budden, Yury Sulsky, James Molloy, Tom Le Paine, Çaglar Gülçehre, Ziyu Wang, Tobias Pfaff, Yuhuai Wu, Roman Ring, Dani Yogatama, Dario Wünsch, Katrina McKinney, Oliver Smith, Tom Schaul, Timothy P. Lillicrap, Koray Kavukcuoglu, Demis Hassabis, Chris Apps, and David Silver. Grandmaster level in starcraft II using multi-agent reinforcement learning. Nature, 575(7782):350–354, 2019.
- Wang et al. [2018] Qing Wang, Jiechao Xiong, Lei Han, peng sun, Han Liu, and Tong Zhang. Exponentially weighted imitation learning for batched historical data. In Advances in Neural Information Processing Systems (NeurIPS), volume 31, 2018.
- Wang et al. [2022] Xiaofei Wang, Kimin Lee, Kourosh Hakhamaneshi, Pieter Abbeel, and Michael Laskin. Skill preferences: Learning to extract and execute robotic skills from human feedback. In Conference on Robot Learning (CoRL), volume 164, pages 1259–1268, 08–11 Nov 2022.
- Wu et al. [2021] Jeff Wu, Long Ouyang, Daniel M. Ziegler, Nisan Stiennon, Ryan Lowe, Jan Leike, and Paul F. Christiano. Recursively summarizing books with human feedback. CoRR, abs/2109.10862, 2021.
- Xu and Yu [2023] Yinda Xu and Lidong Yu. Drl-based trajectory tracking for motion-related modules in autonomous driving. arXiv preprint arXiv:2308.15991, 2023.
- Yahya et al. [2017] Ali Yahya, Adrian Li, Mrinal Kalakrishnan, Yevgen Chebotar, and Sergey Levine. Collective robot reinforcement learning with distributed asynchronous guided policy search. In International Conference on Intelligent Robots and Systems (IROS), pages 79–86, 2017.
- Yu et al. [2020] Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. In Conference on Robot Learning (CoRL), volume 100, pages 1094–1100. PMLR, 2020.
- Zhao et al. [2023] Rui Zhao, Xu Liu, Yizheng Zhang, Minghao Li, Cheng Zhou, Shuai Li, and Lei Han. Craftenv: A flexible collective robotic construction environment for multi-agent reinforcement learning. In International Conference on Autonomous Agents and Multiagent Systems (AAMAS), page 1164–1172, 2023.
- Zhu et al. [2020a] Guangxiang Zhu, Zichuan Lin, Guangwen Yang, and Chongjie Zhang. Episodic reinforcement learning with associative memory. In International Conference on Learning Representations (ICLR), 2020a.
- Zhu et al. [2020b] Yuke Zhu, Josiah Wong, Ajay Mandlekar, and Roberto Martín-Martín. robosuite: A modular simulation framework and benchmark for robot learning. arXiv preprint arXiv:2009.12293, 2020b.
Appendix A The Full Procedure of SEER
The detailed procedures of our proposed method are outlined in Algorithm 1. Our method is based on the established framework of preference-based RL, PEBBLE [23].
In online settings for continuous action spaces, we utilize the constrained operator for conservative estimation . Conversely, in discrete action spaces, a neural network is employed for estimation. In offline settings, our approach initially focuses on training the reward model , followed by policy learning.
Appendix B Experimental Details
In this section, we provide the implementation details, including the basic settings for preference-based RL, the architecture of the neural network, hyper-parameters, and other training details. For each run of experiments, we utilize one NVIDIA Tesla V100 GPU and 8 CPU cores for training.
B.1 Number of Feedback
For the online settings, we use 100 preference pairs in Cheetah Run, Button Press, Window Open; 200 preference pairs in Walker Walk; 300 preference pairs in Push-5×5-1, Push-6x6-1, Push-7×7-1; 1000 preference pairs in Quadruped Walk, Push-5×5-2, Push-6x6-2, Push-7x7-2, Strip-shaped Building, Block-shaped Building, and Simple Two-Story Building tasks; 4000 preference pairs in Sweep Into. And for the offline settings, we use 100 preference pairs in antmaze-medium-play-v2, antmaze-medium-diverse-v2, hopper-medium-expert-v2, walker2d-medium-expert-v2, can-ph, lift-ph; 500 preference pairs in hopper-medium-replay-v2, walker2d-medium-replay-v2, can-mh, lift-mh; 1000 preference pairs in antmaze-large-play-v2, antmaze-large-diverse-v2.
B.2 Basic Settings
In the following section, we provide more details of the unsupervised exploration and the uncertainty-based sampling scheme, both of which are mentioned in Section 4.1. These are pivotal techniques in enhancing the feedback efficiency of algorithms, as referenced in Lee et al. [23]. To ensure a fair comparison, all preference-based RL algorithms in our experiments incorporate both unsupervised exploration and uncertainty-based sampling.
Unsupervised Exploration. The technique of unsupervised exploration in preference-based RL is proposed by Lee et al. [23]. Designing an intrinsic reward based on the entropy of the state efficiently encourages the agent to visit more diverse states and generate more various behaviors. More specifically, it uses a variant of particle-based entropy [30] as the estimation of entropy for the convenience of computation.
Uncertainty-based Sampling. There are some different sampling schemes, including but not limited to uniform sampling, disagreement sampling, and entropy sampling. The latter two sampling schemes are classified as uncertainty-based sampling, which has better performance compared to uniform sampling both intuitively and empirically. In our experiments, all method (online settings) use the disagreement sampling schemes.
| Hyperparameter | Value | Hyperparameter | Value |
|---|---|---|---|
| Number of layers | 3 layers: 1 Conv2d, 2 Linear | Discount | 0.99 |
| Number of kernels of Conv2d | 16 | Batch size | 256 |
| Size of Kernel of Conv2d | 3 | Initial temperature | 0.2 |
| Stride of Conv2d | 1 | (0.9,0.999) | |
| Padding of Conv2d | 0 | Update freq | 4 |
| Hidden units of hidden layer | 128 | Critic target update freq | 8000 |
| Activation Function | ReLU | Critic | 1 |
| Actor optimizer | Adam | Exploration | 1 |
| Critic optimizer | Adam | Learning rate | 1e-4 |
B.3 Architecture and hyperparameters.
In this section, we describe the architecture of neural networks in the SAC algorithm, which is used as the baseline method. Then we present the full list of hyperparameters of SAC, PEBBLE, and the proposed SEER. The actor of SAC has three layers; specifically, the first layer is the convolutional layer, composed of 16 kernels with a size of 3. Then we squeeze the output into one dimension as the input for the last two fully connected layers. The two Q networks of SAC have the same architecture as that of the actor: one convolutional layer and two fully connected layers. The detailed parameters of the neural network and hyperparameters during learning are shown in table 2. The hyperparameters of PEBBLE and SEER, which are different from those of SAC, are presented in table 3.
| Hyperparameter | Value | Hyperparameter | Value |
|---|---|---|---|
| Length of segment | 50 | Reward model ensemble size | 3 |
| Learning rate | 0.0003 | Frequency of feedback | 2000 |
| Reward batch size | 128 | Number of train steps | 1e6 |
| Reward update | 200 | Replay buffer capacity | 1e6 |
| Scaling parameter (SEER) | 6 | Graph update batch size (SEER) | 32 |
| Label smooth (SEER) | 0.05 | Regularizer weight (SEER) | 6 |
B.4 Human labels
We incorporate feedback from human subjects experienced in robotic tasks, as outlined in PT [19]555https://github.com/csmile-1006/PreferenceTransformer. Specifically, an informed human instructor evaluates each task by viewing video renderings of trajectory segments. They then determine which of the two segments more effectively facilitates the agent’s goal achievement. Each segment spans 3 seconds, equivalent to 100 time steps. In instances where the human evaluator is unable to discern a preference between segments, they have the option to choose a neutral stance, attributing equal preference to both segments.
Appendix C Proof of Theorem
C.1 Proof of Theorem 3.1
In this section, we analyze the property of in finite state-action space . The proof of has been well-established in previous work [38, 17, 29]. Then the proof of is similar. We first prove the empirical Bellman operator Equation 15 is a -contraction operator under the supremum norm. Then when updating in a sampling manner as Equation 16, it can be considered as a random process. Borrowing an auxiliary result from stochastic approximation, we prove it satisfies the conditions that guarantee convergence. Finally, to prove lower-bounds , we rewrite based on the standard and empirical Bellman operators. When the data covers the whole state-action space, we naturally have .
For proof simplicity, we use denotes policies that interact with the environment and form the current replay memory. We first show existing results for Bellman learning in Equation 14, and then prove Theorem 3.1 in three steps. The Bellman (optimality) operator is defined as:
| (13) |
Previous works have shown the operator is a -contraction with respect to supremum norm:
the supremum norm , is the dimension of vector . Following Banach’s fixed-point theorem, converges to optimal action value if we consecutively apply operator to , .
Further, the update rule in Equation 14, i.e. -learning, is a sampling version that applies the -contraction operator to .
| (14) |
It can be considered as a random process and will converge to , , with some mild conditions [45, 38, 17, 29].
Similarly, we define the empirical Bellman (optimality) operator as:
| (15) |
And the sampling version we used on the graph is:
| (16) |
We split Theorem 3.1 into three lemmas. We first show is a -contraction operator under supremum norm, thus converges to optimal action value , . Then we show the sampling-based update rule in Equation 16 converges to , . Finally, we show lower-bounds , . And when the data covers the whole state-action space, i.e. for all state-action pairs, we naturally have .
Lemma C.1.
The operator defined in Equation 15 is a -contraction operator under supremum norm,
Proof.
We can rewrite as
where the last line follows from . ∎
To show the sampling-based update rule in Equation 16 converges to , we borrow an auxiliary result from stochastic approximation [38, 17].
Theorem C.2.
The random process taking values in and defined as
| (17) |
converges to zero w.p.1 under the following assumptions:
(1) and ;
(2) , with ;
(3) , for .
is a norm. In our proof it is a supremum norm.
Lemma C.3.
Given any initial estimation , the following update rule:
| (18) |
converges w.p.1 to the optimal action-value function if
for all .
Proof.
Based on Theorem C.2, we prove the update rule in Equation 18 converges.
Rewrite Equation 18 as
Subtract from both sides:
Let
| (19) |
and
| (20) |
We get the same random process shown in Theorem C.2 Equation 17. Then, proving is the same as proving converges to zero with probability 1. We only need to show the assumptions in Theorem C.2 are satisfied under the definitions of Equations 19 and 20.
Theorem C.2 (1) is the same as the condition in Lemma C.3. It is easy to achieve, for example, we can choose .
For Theorem C.2 (3), we have
We add and minus a term to make it close to the RHS in Theorem C.2 (3):
Since is bounded, thus is bounded. And clearly the second part can be bounded by with some constant. Thus, we have
for some constant under supremum norm. Thus, by Theorem C.2, converges to zero w.p.1, i.e., converges to w.p.1. ∎
Lemma C.4.
The value estimation obtained by Equation 15 lower-bounds the value estimation obtained by Equation 13:
| (21) |
for all state-action pairs.
Proof.
Following the definition of Equations 13 and 15, we can rewrite as
where the last line follows from . Then we have
Take limit for both sides and since , we have .
When for all state-action pairs, the two contraction operators and are the same. And based on Banach’s fixed-point theorem, there is a unique fixed point. Thus for all state-action pairs., i.e., holds when for all state-action pairs. ∎
Then, we get Theorem 3.1 proved with Lemmas C.1, C.3 and C.4.
Appendix D Environment Specifications
In this section, we delineate the tasks utilized in our experiments. For online settings, discrete tasks include Sokoban [41] and Craftenv [56], while continuous tasks encompass robotic manipulation challenges from Meta-world [55] and locomotion tasks from the DeepMind Control Suite (DMControl) [46, 47]. Regarding offline settings, we incorporate control tasks from the D4RL benchmarks [6].
D.1 Sokoban
Sokoban [41], the Japanese word for ’a warehouse keeper’, is a puzzle video game, which is analogous to the problem of having an agent in a warehouse push some specified boxes from their initial locations to target locations. Target locations have the same number of boxes. The goal of the game is to manipulate the agent to move all boxes to the target locations. Specifically, the game is played on a rectangular grid called a room, and each cell of the room is either a floor or a wall. At each new episode, the environment will be reset, which means the layout of the room is randomly generated, including the floors, the walls, the target locations, the boxes’ initial locations, and the location of the agent. We choose six tasks with different complexities from Push-5×5-1 to Push-7×7-2, which is shown in Figure 5. The numbers in the task name denote respectively the size of the grid and the number of boxes.
State Space. The state space consists of all possible images displayed on the screen. Each image has the same size as the map, and using the way of dividing each pixel of the image by 255 to normalize into [0,1], we preprocess the image to the inputting state.
Action Space. The action space of Sokoban has a total of eight actions, composed of moving and pushing the box in four directions, which are left, right, up, down, push-left, push-right, push-up, push-down in detail.
Reward Setting. The agent gets a punishment with a -0.1 reward after each time step. Successfully pushing a box to the target location, can get a +1 reward, and if all boxes are laid in the right locations, the agent can obtain an extra +10 reward. We set the max episode steps to 120, which means the cumulative reward during one episode ranges from -12 to 10 plus the number of boxes.




D.2 CraftEnv
Craftenv [56], A Flexible Robotic Construction Environment, is a collection of construction tasks. The agent needs to learn to manipulate the elements, including smartcar, blocks, and slopes, to achieve a target structure through efficient and effective policy. Each construction task is a simulation of the corresponding complex real-world task, which is challenging enough for reinforcement learning algorithms. Meanwhile, the CraftEnv is highly malleable, enabling researchers to design their own tasks for specific requirements. The environment is simple to use since it is implemented by Python and can be rendered using PyBullet. We choose three different designs of the building tasks, shown in Figure 6, to evaluate our algorithm in CraftEnv.
State Space. We assume that the agent can obtain all the information in the map. Therefore, the state consists of all knowledge of smartcar, blocks, folded slopes, unfolded slopes’ body, and unfolded slopes’ foot, including the position and the yaw angle.
Action Space. The available actions of an agent are designed based on real-world smartcar models, including a total of fifteen actions. Besides all eight directions moving actions, i.e. forward, backward, left, right, left-forward, left-backward, right-forward, and right-backward, there are interaction-related actions, designed to simulate the building process in the real world. Specifically, the agent can act lift and drop actions to decide whether or not to carry the surrounding basic element, and can flod or unflod slopes to build the complex buildings. In addition, the actions of rotate-left and rotate-right control the agent to rotate the main body to the left and right, and stop action is just a non-action.
Reward Setting. CraftEnv is a flexible environment as mentioned above. We can specify our own reward function for different construction tasks. For the relatively simple tasks of building with specified shape requirements, we can use discrete reward, where some reward is given when part of the blueprint is built. While, for building tasks with high complexity, various reward patterns should be designed to encourage the agent to build with different intentions.



D.3 Robotic tasks
In our experiments, we utilize robotic manipulation tasks from Meta-world [55] and locomotion tasks from the DeepMind Control Suite (DMControl) [46, 47], which is visualized in Figure 7. Meta-World comprises 50 diverse manipulation tasks with a common structural framework, while DMControl offers a collection of stable, rigorously tested tasks, serving as benchmarks for continuous control learning agents. These tasks are equipped with well-formulated reward functions that facilitate agent learning. For performance evaluation, Meta-world introduces an interpretable success metric for each task, which serves as the standard evaluation criterion across various settings. This metric often hinges on the proximity of task-relevant objects to their final goal positions, quantified as , with representing a nominal distance threshold, such as 5 cm. DMControl, conversely, employs episode returns for evaluation. We adopt fixed-length episodes of 1000 timesteps as a proxy. Given that all reward functions are designed such that is in proximity to goal states, learning curves that measure total returns can maintain consistent y-axis limits of . This uniformity simplifies interpretation and facilitates averaging across tasks.






D.4 D4RL benchmark
AntMaze. AntMaze involves a navigation challenge where a Mujoco Ant robot must locate and reach a specified goal. The data for this task is derived from a pre-trained policy designed to navigate various maze layouts, primarily focusing on two configurations: medium and large. The data are compiled using two distinct strategies: diverse and play. Diverse data sets are produced by the pre-trained policy, which utilizes random start and goal locations, whereas play data sets are generated with specific, intentionally selected goal locations. The task’s reward structure is sparse, awarding points only when the robot is within a predefined proximity to the goal; otherwise, no reward is granted.
Gym-Mujoco Locomotion. In Gym-Mujoco locomotion tasks, the objective is to manage simulated robots (Walker2d, Hopper) to advance forward while minimizing energy expenditure (action norm) to ensure safe behavior. Two data generation methodologies are employed: medium-expert and medium-replay. The emphmedium-expert data sets have an equal mix of expert demonstrations and suboptimal (partially-trained) demonstrations. The emphmedium-replay data sets come from the replay buffer of a partially-trained policy. The robot’s forward velocity, a control penalty, and a survival bonus all contribute to determining the task’s reward.
Robosuite Robotic Manipulation. In Robosuite’s robotic manipulation tasks [58], various 7-DoF simulated hand robots perform distinct tasks. Our experiments utilize environments simulated with Panda by Franka Emika, focusing on two specific tasks: lifting a cube (lift) and relocating a coke can from a table to a designated bin (can). Data collection involves inputs from either a single proficient teleoperator (ph) or six teleoperators with varying skill levels (mh). The task’s reward is sparse, with further details deferred to the original paper.
Appendix E Additional Experiments
E.1 Ablation Study
Impact on Preference Amounts. To evaluate how the quantity of preferences influences the performance of SEER, we carry out an additional experiment to evaluate SEER’s efficacy with varying amounts of human preferences. We consider the number of preferences on Sokoban tasks. The training curves of the average episode return of all methods on tasks are in Figure 8. The results indicate that the performance of the policy gradually improves as the number of preference labels increases. When provided with sufficient preference labels, SEER can approach the performance upper bound. The learning curves depicting the average episode return for all methods across tasks are presented in Figure 8. The results suggest that as the number of preference labels increases, there’s a corresponding improvement in the policy’s performance. As the provision of preference labels increases, SEER is capable of approaching optimal performance for each task.
|
Push-5x5-1 |




Computational Efficiency of SEER. When developing algorithms for improved performance and sample efficiency, it is also important to consider the training time overhead in real-world applications. In discrete settings, vertices are stored in a dictionary using their hashes as keys, enabling state retrieval in time. Moreover, updates are only required at the end of each episode. In continuous settings, SEER allows the actor to update at a lower frequency, thus not significantly increasing computational costs. To quantitatively demonstrate the time overhead of all methods, we summarize the training time (hour) of SEER and baseline methods on Push-7x7-2 and Cheetah Run in the table below. As shown in Table 5, compared to the backbone algorithm PEBBLE, SEER does not significantly increase training time overhead, whereas SURF incurs a noticeable increase in time due to the need to label samples.
| Task/Methods | PEBBLE | SURF | MRN | SEER (ours) |
|---|---|---|---|---|
| Push-7x7-2 | 2.78 | 3.56 (+28.1%) | 3.11 (+11.9%) | 2.84 (+2.2%) |
| Cheetah Run | 3.23 | 3.83 (+18.6%) | 3.42 (+5.9%) | 3.31 (+2.5%) |
Sensitivity Analysis of the Parameter . Policy regularization is an important technique in SEER. In our experiments, we did a parameter search for and chose a robust value in the middle of the search space. The table below displays the performance of SEER on Cheetah Run with various values of . In all our experiments conducted in online settings, we set to 6, as shown in Table 3.
| 0 | 0.1 | 1.0 | 5.0 | 10.0 | |
|---|---|---|---|---|---|
| Cheetah Run | 542.1 | 579.7 | 697.3 | 710.7 | 713.5 |
E.2 Human Experiments
We demonstrate that agents can perform various novel behaviors based on human feedback using SEER, as shown in Figure 9. Specifically, we illustrate a cheetah running solely on its hind legs, guided by 200 preference labels. In offline settings, all tasks utilize feedback provided by a human instructor.

Appendix F Full Experimental results
We present all the results of the discrete tasks.

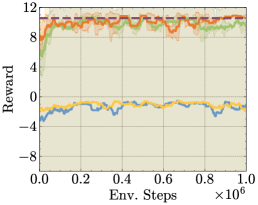


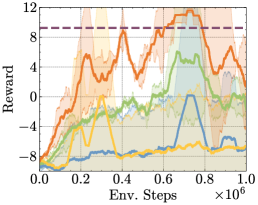

Appendix G Impact Statements
Preference-based reinforcement learning allows us to tackle a wide range of problems and achieve robust AI without the need for reward engineering. However, it also poses potential risks, such as a malicious user manipulating preferences to instill harmful behaviors in the agent. Our method enhances the efficiency of preference-based RL, thereby simplifying the process of teaching both desirable and undesirable behaviors. When developing real-world applications, in addition to performance, safety is also a crucial consideration.