8cm(5cm,21cm) To appear in TIST
Efficient Federated Learning Using Dynamic Update and Adaptive Pruning with Momentum on Shared Server Data
Abstract.
Despite achieving remarkable performance, Federated Learning (FL) encounters two important problems, i.e., low training efficiency and limited computational resources. In this paper, we propose a new FL framework, i.e., FedDUMAP, with three original contributions, to leverage the shared insensitive data on the server in addition to the distributed data in edge devices so as to efficiently train a global model. First, we propose a simple dynamic server update algorithm, which takes advantage of the shared insensitive data on the server while dynamically adjusting the update steps on the server in order to speed up the convergence and improve the accuracy. Second, we propose an adaptive optimization method with the dynamic server update algorithm to exploit the global momentum on the server and each local device for superior accuracy. Third, we develop a layer-adaptive model pruning method to carry out specific pruning operations, which is adapted to the diverse features of each layer so as to attain an excellent trade-off between effectiveness and efficiency. Our proposed FL model, FedDUMAP, combines the three original techniques and has a significantly better performance compared with baseline approaches in terms of efficiency (up to 16.9 times faster), accuracy (up to 20.4% higher), and computational cost (up to 62.6% smaller).
1. Introduction
With a large quantity of data distributed in numerous edge devices, cloud servers may have some shared insensitive data for efficient processing (zhao2018federated, ). Due to data privacy and security concerns, multiple legal restrictions (GDPR, ; CCPA, ) have been put into practice, making it complicated to aggregate the distributed sensitive data within a single high-performance server. As big amounts of training data generally lead to high performance of machine learning models (li2021practical, ), Federated Learning (FL) (mcmahan2017communication, ; liu2022distributed, ; liu2024enhancing, ) becomes a promising approach to collaboratively train a model with considerable distributed data while avoiding raw data transfer.
Traditional FL exploits non-Independent and Identically Distributed (non-IID) data on mobile devices to collaboratively train a global model (mcmahan2017communication, ). Within the training process, the weights or the gradients of the global model are transferred between the devices and the server while the raw data stays in each device. FL typically utilizes a parameter server architecture (liu2022distributed, ; liu2023heterps, ), where a parameter server (server) coordinates the distributed training process. The training process generally consists of multiple rounds, each composed of three stages. First, the server chooses a set of devices and broadcasts the global model to them. Second, each of the chosen devices trains the received model using local data and then sends back the updated model. Third, the server gathers the updated models and aggregates them to form a new global model. This process continues when the predefined condition, e.g., a maximum round number or the convergence of the global model, is not achieved.
Although keeping data within the devices can protect data privacy and security, FL encounters two major challenges, which hinder its application in real-world environments. The first challenge is the limited data within a single edge device, which leads to ineffective local training while potential large amounts of shared insensitive data remain useless on the server. The second challenge is the modest edge devices with limited communication and computation capacity (Li2018Learning, ), which corresponds to inefficient local training on devices. To address the first challenge, we leverage the shared insensitive data on the server and design a new FL framework to improve the accuracy of the global model. To address the second challenge, we propose an adaptive optimization method and an adaptive pruning method within the proposed FL framework to improve model accuracy and reduce training cost.
In addition to the distributed data in edge devices, insensitive data can be transferred to the servers in the cloud to leave space for critical sensitive personal data (Shen2017CloudData, ; yoshida2020hybrid, ), e.g., Amazon Cloud (Amazon, ), Microsoft Azure (Azure, ), and Baidu AI Cloud (Baidu, ). The insensitive data may exist on the server by default before the training process. For instance, the server may have prior learning tasks, either training or inference, which have already collected some data to be re-used for the new task of interest. In addition, some end users may offload some insensitive data to the server with certain incentive mechanism such as for crow-sourcing tasks (wang2016toward, ), or simply to free up some local storage space (ye2023usability, ). Some other recent works are based on the insensitive shared data on the server (yang2022convergence, ; gu2022fedaux, ; lian2022blockchain, ). The shared insensitive data can help improve the efficiency of the FL training process without the restriction of data distribution (see details in Section 3.2). The shared insensitive data can be transferred to the devices for local training in order to improve the accuracy of the global model (zhao2018federated, ; YoonSHY21, ). Although the shared data on the server is not sensitive, they still contain some important personal information. Thus, transferring the shared data to devices may still incur privacy or security problem. In addition, this approach leads to significantly high communication overhead. Furthermore, the existing approaches are inefficient when the shared server data is simply processed as that in edge devices (yoshida2020hybrid, ) or when knowledge transfer is utilized to deal with heterogeneous models (zhang2021parameterized, ; lin2020ensemble, ).
Adaptive optimization methods, such as Stochastic Gradient Descent (SGD) with Momentum (SGDM) (sutskever2013importance, ), Adaptive Moment Estimation (Adam), and Adaptive Gradient (AdaGrad), have gained superb advance in accelerating the training speed and the final accuracy. Most of the existing FL literature adopts the adaptive optimization methods either on the server side (duchi2011adaptive, ; reddi2018adaptive, ; kingma2014adam, ; mills2019communication, ) or on the device side (Yuan2021Federated, ; mills2019communication, ; Liu2020Accelerating, ; gao2021convergence, ; Wang2020SlowMo, ; mills2019communication, ). However, applying the adaptive optimization on either of them often leads to inefficient learning results with inferior accuracy. The adaptive optimization methods can be exploited on both sides, as shown in (jin2022accelerated, ), but the momentum transfer may incur severe communication costs with limited bandwidth between the devices and the server.
Model pruning reduces the size of a model into a slim one while the accuracy remains acceptable. These kinds of methods can be exploited in the training process to improve the efficiency of the training and to significantly reduce the overhead brought by a big model (jiang2023model, ). However, existing pruning approaches incur severe accuracy degradation. The simple application of existing pruning methods in FL does not consider the diverse dimensions and features of each layer (lin2020hrank, ). In addition, as a big model may consist of numerous neurons, simple model pruning strategies cannot choose proper portions of the model to prune and may lead to low training efficiency and inferior accuracy (zhao2018federated, ).
In this work, we introduce a novel efficient FL framework, i.e., FedDUMAP, which enables collaborative training of a global model based on the sensitive device data and insensitive server data with a powerful server and multiple modest devices. We denote the sensitive data as the data that contain personal information and cannot be shared or transferred according to the users. In addition, the insensitive data can contain personal information while it can be transferred to a cloud server. In order to handle the two aforementioned problems, we utilize the shared insensitive data on the server to improve the accuracy of the global model with adaptive optimization with the consideration of the non-IID degrees, which represent the difference between a dataset (either on the server or a device) and the global dataset, i.e., the data on all the devices.
FedDUMAP consists of three modules, i.e., FedDU, FedDUM, and FedAP. FedDU is an FL algorithm, which dynamically updates the global model based on the distributed sensitive device data and the shared insensitive server data. In addition, FedDU dynamically adjusts the global model based on the accuracy and the non-IID degrees of the server data and the device data. Furthermore, we propose a novel adaptive optimization method on top of FedDU, i.e., FedDUM, to improve the accuracy of the model without transferring the momentum from devices to the server or from the server to the devices. We decouple the optimization on the server and the device sides while exploiting the model generated with adaptive optimization from each device to enable the adaptive optimization on the server side. Besides, FedAP removes useless neurons in the global model to reduce the model size so as to reduce the computational overheads and the computation costs on devices without degrading noticeable accuracy. FedAP considers the features of each layer to identify a proper pruning rate, based on the non-IID degrees. Furthermore, FedAP prunes the neurons according to the rank values, which can preserve the performance of the model. To the best of our knowledge, we are among the first to propose exploiting non-IID degrees for dynamic global model updates while utilizing adaptive optimization and adaptive pruning for FL. This manuscript is an extension of a conference version (Zhang2022FedDUAP, ). In this paper, we make four following contributions:
-
(1)
A novel dynamic FL algorithm, i.e., FedDU, which utilizes both shared insensitive server data and distributed sensitive device data to collaboratively train a global model. FedDU dynamically updates the global model with the consideration of the model accuracy, normalized gradients from devices, and the non-IID degrees of both the server data and the device data.
-
(2)
A new adaptive optimization method, i.e., FedDUM, which decouples the optimization between the server side and the device side while exploiting the models generated from devices for the optimization on the server side without additional communication cost.
-
(3)
An original adaptive pruning method, i.e., FedAP, which considers the features of each layer to identify a proper pruning rate based on the non-IID degrees. FedAP prunes the model based on the rank values to preserve the performance of the global model.
-
(4)
Extensive experimentation demonstrates significant advantages of FedDUMAP, including FedDU, FedDUM, and FedAP, in terms of efficiency, accuracy, and computational cost based on three typical models and two real-life datasets.
The rest of this paper is organized as follows. Section 2 explains the related work. Section 3 proposes our framework, i.e., FedDUMAP, including FedDU, FedDUM, and FedAP. Section 4 presents the experimental results using three typical models and two real-life datasets. Finally, Section 5 concludes the paper.
2. Related Work
FL was proposed to train a model using the distributed data within multiple devices while only transferring the model or gradients (mcmahan2017communication, ). Some works ((mcmahan2021advances, ; zhou2022efficient, ; Li2022FedHiSyn, ; liu2024aedfl, ; liu2024fedasmu, ; che2023fast, ; liu2023distributed, ; liu2022multi, ; che2022federated, ; liu2023large, ) and references therein) either focus on the device scheduling or the model aggregation within the server or even with a hierarchical architecture to improve the accuracy of the global model, which only deals with the distributed device data. In order to leave space for sensitive data on devices and with incentive mechanisms (yoshida2020hybrid, ), some insensitive data are transferred to the server or the cloud, which can be directly utilized for training. When all the data are transferred to the server, the server data can be considered as IID data (yoshida2020hybrid, ). However, transferring all the data including the sensitive data incurs severe privacy and security issues with significant communication costs, which is not realistic (jeong2018communication, ). Some existing works utilize the insensitive server with heterogeneous models (he2020group, ), or within one-shot model training (li2021practical, ), based on knowledge transfer methods (dong2022elastic, ; liu2022elastic, ), or label-free data (lin2020ensemble, ; jeong2020federated, ). However, the aforementioned approaches are inefficient (he2020group, ; li2021practical, ) or ineffective (lin2020ensemble, ) without the consideration of the non-IID degrees or big models. Furthermore, while it may lead to significant communication overhead, the transfer of the insensitive server data to devices (zhao2018federated, ; YoonSHY21, ) may incur severe privacy and security issues. The proper devices can be selected for training based on the server data (nagalapatti2021game, ), which can be integrated with our proposed approach.
Without adaptive optimization within the model aggregation process, traditional methods, e.g., FedAvg (mcmahan2017communication, ), may incur the client drift problem, which makes the global model over-fitted to local device data (karimireddy2020scaffold, ). While control parameters (karimireddy2020scaffold, ) can help alleviate the problem, they require the devices to participate all through the training process (karimireddy2020scaffold, ; acar2021federated, ), which may not be feasible in cross-device FL. Adaptive optimization methods, e.g., AdaGrad (duchi2011adaptive, ), Yogi (reddi2018adaptive, ), Adam (kingma2014adam, ; mills2019communication, ) and momentum (rothchild2020fetchsgd, ; mills2021accelerating, ; che2023federated, ; jin2022accelerated, ) can be exploited to address the client drift problem. However, the existing approaches generally consider only one side, i.e., either server side (reddi2021adaptive, ) or device side (Yuan2021Federated, ), which may lead to inferior accuracy. Furthermore, the devices may have heterogeneous non-IID data, which makes the direct application of the momentum method insufficient (Liu2020Accelerating, ). Although adaptive optimization is applied on both the device side and the server side in some recent works (jin2022accelerated, ), the communication of momentum between the server and devices may incur high communication costs.
Model pruning can reduce the size of the model, which corresponds to smaller communication overhead and computation costs compared with the original model within the training process (jiang2023model, ; li2021hermes, ; li2021fedmask, ; deng2022tailorfl, ) and the inference process (yu2021adaptive, ) of FL. However, the shared insensitive server data is seldom utilized. Two types of techniques exist for the pruning process, including filter (structured) pruning and weight (unstructured) pruning. The unstructured pruning set the chosen parameters to 0 while the structure of the original model remains unchanged. Although the accuracy remains almost the same as that of the original one (zhang2021validating, ) while reducing communication overhead (jiang2023model, ), the unstructured pruning cannot reduce computational cost with general-purpose computing resources, e.g., edge devices (lin2020hrank, ). On contrary, structured pruning can modify the model structure by abandoning selected neurons or filters in the original model. As some parts of the original model are removed, the structured pruning leads to significantly smaller computational costs and communication overhead (lin2020hrank, ). However, it is non-trivial to determine the pruning rate, which hinders the application of unstructured pruning in the training process of FL. Sparsification, quantization (konevcny2016federated, ; jia2024efficient, ), or dropout (Bouacida2021FedDropout, ; chen2022fedobd, ) are efficient techniques to reduce the communication overhead as well, which is out of the scope of this paper and can be combined with our proposed approach for better performance.
In this paper, we utilize both the shared insensitive server data and the distributed sensitive device data for FL training. We propose an FL framework, i.e., FedDUMAP, consisting of FedDU, FedDUM, and FedAP. FedDU dynamically adjusts the global model with the shared insensitive server data based on the non-IID degrees and model accuracy. FedDUM considers an adaptive optimization method on both the device and the server sides without additional communication overhead. Furthermore, FedAP prunes the global model with the consideration of the features of each layer and removes the filters based on the rank values to reduce communication and computational costs while achieving high accuracy. The pruning rate is calculated based on the non-IID degrees. FedDUMAP can achieve high accuracy and efficient training at the same time.
3. Method
In this section, we propose our FL framework, i.e., FedDUMAP. We first present the system model. Then, we detail FedDU, which dynamically updates the global model. Afterward, we explain the adaptive momentum-based optimization, i.e., FedDUM, to improve the accuracy of the global model. Finally, we reveal the design of FedAP, which reduces the size of the global model to reduce communication and computational costs.
3.1. System Model
| Notation | Definition |
|---|---|
| ; | The number of edge devices; the number of devices selected for an iteration; the number of selected devices |
| ; ; | The local dataset on Device ; the server data; the index of a device |
| ; | The number of samples on Device ; the number of samples on the server |
| ; | The -th input data sample in Device ; the label of |
| ; | The data sample set; the label set |
| ; ; | The parameters of the global model; the global model in Round ; the aggregated model in Round |
| The distribution of data in Device with 0 representing the server | |
| The probability that a data sample corresponds to Label in Device | |
| ; | The average distribution of two datasets; the distribution of all the device data |
| The distribution of all the data in the selected devices in Round | |
| The non-IID degree of data on Device | |
| ; | The set of all devices and the server; the set of selected devices in Round |
| The local loss function in Device | |
| ; ; | The local epoch; the local batch size; the learning rate |
| ; | The number of iterations performed in the server update; the effective steps for the server update in Round |
| The normalized stochastic gradients on the server in Round | |
| ; | The total number of samples in all the selected devices; the number of samples in the server data |
| The parameters of the -th local iteration of the updated aggregated model in Round | |
| The accuracy of the aggregated model in Round | |
| ; | The initial parameters of the local model in Device ; the parameters of the local model in Device after rounds |
| The Hessian matrix of the loss function on Device | |
| ; | The -th eigenvalue in the Hessian matrix on Device ; the rank of the Hessian matrix on Device |
| ; ; | The expected global pruning rate; the expected pruning rate on Device ; the expected pruning rate of Layer |
| A small value to avoid the division by 0 | |
| ; | The number of parameters in the model; the number of parameters in Layer |
| ; | The rank of the -th filter in Layer ; the number of filters in Layer |
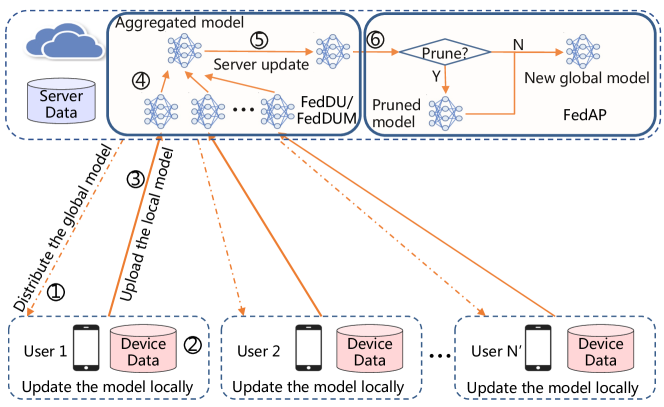
Figure 1 shows the training process of FedDUMAP, where the FL system consists of a server and edge devices. The description of major notations is summarized in Table 1. We consider a powerful server and modest devices. The shared insensitive data is stored on the server, and the distributed sensitive data is dispersed in edge devices. Both the server data and the device data can be utilized to update the model during the FL training process of FL. Let us assume that a dataset , composed of samples, resides on Device . We take as the server data, and as the device data. refers to the -th sample on Device , while represents the corresponding label. We utilize to represent the set of samples and to represent the set of labels. Then, we formulate the objective of the training process as follows:
| (1) |
where represents the loss function on Device with capturing the error of the inference results based on the model with the sample pair and refers to the global model.
With the distributed non-IID data in FL (mcmahan2021advances, ), we utilize the Jensen–Shannon (JS) divergence (fuglede2004jensen, ) to quantize the non-IID degree of a dataset as shown in Formula 2:
| (2) |
where , , , refers to the possibility that a sample is related to Label , and corresponds to the Kullback-Leibler (KL) divergence (kullback1997information, ) as defined in Formula 3:
| (3) |
When the distribution of a dataset differs from that of the global dataset more significantly, the corresponding non-IID degree becomes higher. Although the raw data is not transferred from devices to the server or from the server to the devices in FedDUMAP, we assume that and incur little privacy concern (lai2021oort, ), and can be transferred from devices to the server before the FL training process. When this statistical meta information, i.e., , cannot be shared because of restrictions, we can utilize gradients to calculate the data distribution of the dataset on each device (yang2022improved, ).
The FL training process contains multiple rounds in FedDUMAP, each of which consists of 6 steps. In Step ①, a set of devices ( with referring to the round number) is randomly selected to participate in the training process of Round and the server broadcasts the global model to the device of . Afterward, each device updates the received model with the adaptive momentum-based optimization based on the local data in Step ②. Then, in Step ③, the selected devices upload updated models to the server, and the server aggregates all the received models based on FedAvg (mcmahan2017communication, ) in Step ④. In addition, the server updates (see details of the server update in Section 3.2) aggregated model utilizing the shared insensitive server data and the adaptive momentum-based optimization method (see details in Section 3.3) in Step ⑤. Furthermore, in a predefined round, the server performs model pruning based on the accuracy of the global model and the non-IID degrees (see details in Section 3.4). While Steps ① - ④ resemble those within traditional FL, we propose exploiting the insensitive server data to improve the performance of the global model (in FedDU) with adaptive momentum-based optimization (in FedDUM) on both the server and device sides (Step ⑤) and an adaptive model pruning method (in FedAP) to improve the efficiency of the training process (Step ⑥).
3.2. Server Update
In this section, we explain the design of FedDU, which exploit both the shared insensitive server data and the distributed sensitive device data to adjust the global model. We exploit the non-IID degrees and the model accuracy to determine the weights of aggregated model and those of the normalized gradients based on the server data in FedDU, so as to avoid over-fitting to the server data.
We assume that the size of the insensitive server data is significantly bigger than the dataset within a single device. In this case, the straightforward combination of the aggregated model from the devices and the gradients calculated based on the shared insensitive server data leads to inferior accuracy due to objective inconsistency (wang2020tackling, ). Inspired by (wang2020tackling, ), we normalize the gradients generated using the server data to deal with this issue. The model aggregation in FedDU is formulated as Formula 4.
| (4) |
where refers to the weights of the global model in Round , is the weights of the aggregated model from the selected devices in Round as formulated in Formula 5 (mcmahan2017communication, ), corresponds to the size of effective steps for normalized gradients calculated based on the shared insensitive server data as shown in Formula 7, represents the learning rate, refers to the normalized gradients generated based on the server data in Round as formulated in Formula 6.
| (5) |
where refers to the size of the dataset on all the selected devices, corresponds to the gradients generated using the dataset on Device .
| (6) |
where represents the parameters of the global model after aggregating the gradients based on the server data, at th iteration of Round , refers to the gradients calculated using the server data, and corresponds to the number of iterations of Round , is the number of local epochs, is the batch size. Each round corresponds to multiple iterations with a mini-batch of sampled shared insensitive server data.
While has a significant impact on the training process, we dynamically choose an effective step size with the consideration of the model accuracy, the non-IID degrees of both the server data and the device data, with the number of rounds, as formulated in Formula 7.
| (7) |
where represents the model accuracy calculated based on the server data in Round , i.e., defined in Formula 5, corresponds to the size of the shared insensitive server data, is shown in Formula 2, refers to the distribution of the distributed sensitive data in all the chosen devices in Round , is the distribution of the shared insensitive server data, is utilized to ensure the convergence of the global model towards the solution of Formula 1, and corresponds to a hyper-parameter. is calculated using . is small at the beginning of the training. In this stage, the value of should be prominent so as to take advantage of the server data to improve the accuracy of the global model. Then, at a late stage of the training process, should be small to attain the objective defined in Formula 1 while avoiding over-fitting to the shared insensitive server data.
When the distribution of server data resembles that of the overall device data, i.e., is small, or the distribution of the data of the chosen devices differs much from the overall device data, i.e., is significant, we take a significant value of to improve the accuracy of the global model. Furthermore, the data size improves the importance of the dataset, as well. In addition, the weight of the device data is and that of the server data is . Finally, we have as the importance of the server data, which is the second part of Formula 7.
Algorithm 1 explains FedDU. The model is updated using the local dataset on each chosen device (Lines 1 - 3). Afterward, the models are aggregated using Formula 5 (Line 4). Finally, the aggregated model is updated utilizing the shared insensitive server data based on Formula 4 (Line 5).
Let us assume that the expected squared norm of stochastic gradients on the server is bounded, i.e., . Then, in Round , . Afterward, the server update term can be less than . In this case, after sufficient steps, the server update becomes negligible, i.e., , with . Finally, FedDU degrades to FedAvg (mcmahan2017communication, ), the convergence of which is guaranteed with a decaying learning rate (Li2020On, ; Zhou2018On, ).
3.3. Momentum-based Optimization
In order to further improve the accuracy of the global model, we exploit momentum within the server update on the server and within the local iteration on each device. In this section, we propose a simple adaptive momentum approach, i.e., FedDUM, which enables the optimization on both the server and the devices without additional communication cost.
The centralized SGDM can be formulated as:
| (8) |
where is momentum. A simple application of the momentum into the FL environment is to decompose the SGDM to each device while aggregating the momentum as formulated in Formula 9.
| (9) |
In order to extend the optimization into multiple local epochs, we can formulate the process as follows:
| (10) |
where represents the local momentum within Device at global Round and local Iteration , is the local weight for gradients, refers to the gradients with the parameters of the model , and is the local learning rate. Please note that and are local hyper-parameters on each device and are different from those in Formulas 8 and 9, which refer to global parameters on the server. We have the first momentum equal to the global momentum, i.e., , and the first parameters of the model equal to the global parameters, i.e., . However, this simple decomposition may deviate from the momentum of the centralized optimizer and harm the local training (jin2022accelerated, ). In addition, the communication of momentum, i.e., and , may incur significant communication cost. Inspired by (wang2021local, ), we restart the local adaptive optimization and set the momentum buffers to zero at the beginning of local iterations. Furthermore, we calculate the difference between the updated model and the original model as the total gradients as defined in Formula 12. Then, we can utilize Formula 11 below to perform the local iteration in each selected device, which replaces Formula 5 in Algorithm 1 with adaptive momentum:
| (11) |
with and . This operation only requires the parameters of the model transferred from the server to devices without additional communication costs compared with FedAvg. Afterward, we exploit Formula 12 below to calculate the gradients on the server, and utilize Formula 8 to replace Formula 4 in Algorithm 1 with adaptive momentum:
| (12) |
where is the same as that in Formula 4. This only requires the transfer of the parameters of the local updated model, which does not incur additional communication cost compared with FedDU.
FedDUM is shown in Algorithm 2. The local model update is performed according to Formula 11 in parallel in each selected device (Lines 1 - 3). Then, the aggregated gradient is calculated using Formula 12 (Line 4). Afterward, the new global model is updated using the gradients and momentum according to Formula 8 (Line 5).
In order to analyze the adaptive optimization on devices, we have the following assumptions:
Assumption 1.
(Lipschitz Gradient). There exists a constant such that for any and .
Assumption 2.
(Bounded Gradient) for any .
Assumption 3.
(Bounded Momentum) for any .
Then, we can get the following theorem:
Theorem 3.1.
Local momentum deviates from the centralized one at linear rate .
Proof.
From the perspective of dynamics of Ordinary Differential Equations (ODE) (jin2022accelerated, ), we can formulate the difference between the local optimization and the centralized optimization as:
| (13) |
where represents the momentum in centralized optimization, represents the model in centralized optimization, , and . The eigenvalue of Matrix is . Note that and . In addition, for any for some constant . Then, we have:
| (14) |
∎
In the experimentation, we set the local epoch to a small number, e.g., 5, to reduce the deviation between local momentum and centralized optimization.
3.4. Adaptive Pruning
In this section, we present our layer-adaptive pruning method, i.e., FedAP. FedAP considers the diverse features of each layer, the non-IID degrees of both the sensitive shared server data and the distributed sensitive device data, to remove useless filters in the convolutional layers while preserving the accuracy. FedAP can reduce the communication overhead and the computational costs of the training process. Please note that FedAP is performed only once on the server in a predefined round.
Algorithm 3 details FedAP. On the server and each device (Lines 2 - 4), we calculate a proper pruning rate based on the shared sensitive server data or the distributed sensitive device data (Line 3). We denote the initial model on the server or Device . At Round , the updated model is denoted by . Then, the difference between the current model and the original one is . Afterward, we can calculate the Hessian matrix, i.e., . We sort the eigenvalues of in ascending order, i.e., with referring the index of an eigenvalue and referring to the rank of the Hessian matrix. We take as a base function with corresponding to the gradients. We denote the Lipschitz constant of as . Inspired by (zhang2021validating, ), we take the first , which meets the condition of , to reduce accuracy degradation. Then, we can calculate the proper pruning rate by , which is the ratio between the size of pruned eigenvalues and that of all the eigenvalues. As the proper pruning rate significantly differs in diverse devices due to the non-IID distribution, we utilize Formula 15 to generate an aggregated proper pruning rate for the global model (Line 5).
| (15) |
where represents a small value to avoid the division of zero. We take a global threshold value () calculated based on the aggregated proper pruning rate to serve as a baseline value for generating the pruning rate of each layer. is the absolute value of the -th smallest parameter in all the parameters (Lines 6 and 7). Afterward, for each convolutional layer (Line 8), we calculate the proper pruning rate by calculating the ratio between the number of parameters with inferior absolute values than and the number of all the parameters (Lines 9 - 11). Inspired by (lin2020hrank, ), we remove the filters corresponding to the smallest ranks in feature maps (the output of filters) based on the proper pruning rate in the layer (Lines 12 - 15). We take to represent the ranks of feature maps at Layer , where refers to the number of filters in this layer. As the feature maps are almost the same for a given model (lin2020hrank, ), we take the ranks calculated based on the server data and perform the pruning operations on the server because of its powerful computation capacity. We calculate the feature maps in in Line 12 and sort them in Line 13. We keep the filters having the last ranks in the sorted , so as to attain the highest pruning rate (Line 14). In the end, we take the preserved filters in the original model as the layer of the pruned model (Line 15). When there is no available server data, the pruning process can also be performed on the server based on the rank values calculated using the dataset on a device, which are transferred to the server, with the execution of Line 12 being carried out at that device.


4. Experiments
In this section, we demonstrate the experimental results to show the advantages of FedDUMAP by comparing it with state-of-the-art baselines, i.e., FedAvg (mcmahan2017communication, ), FedKT (li2021practical, ), FedDF (lin2020ensemble, ), Data-sharing (zhao2018federated, ), Hybrid-FL (yoshida2020hybrid, ), server-side momentum (reddi2018adaptive, ), device-side momentum (karimireddy2020mime, ), FedDA (jin2022accelerated, ), HRank (lin2020hrank, ), IMC (zhang2021validating, ), and PruneFL (jiang2023model, ).
4.1. Experimental Setup
We evaluate FedDUMAP using an FL system consisting of a parameter server and devices. In each round, we randomly choose devices. We utilize two real-life datasets, i.e., CIFAR-10 and CIFAR-100 (krizhevsky2009learning, ), in the experimentation. We exploit four models, i.e., a simple synthetic CNN network (CNN), ResNet18 (ResNet) (he2016deep, ), VGG11 (VGG) (simonyan2014very, ), and LeNet5 (LeNet) (lecun1998gradient, ). The experimentation of CNN, VGG, and LeNet is carried out on both CIFAR-10 and CIFAR-100, while that of ResNet is performed on CIFAR-100.
CNN consists of three convolution layers, a fully connected layer, and a final softmax output layer. The first layer contains 32 channels, while the second and third layers have 64 channels. The first and the second layers are followed by max pooling. The fully connected layer contains units and exploits ReLu activation. CNN contains 122570 parameters in total. The mini-batch size is set to for the local model update, and the selected device executes local epochs. The local learning rate is with a decay rate of . is set to 1. The experimentation is carried out using 33 Tesla V100 GPUs to simulate an FL environment composed of a parameter server and 100 devices. We carry out the pruning process in Round 30 in all the experimentation with adaptive pruning. In addition, we exploit the Savitzky–Golay filter (press1990savitzky, ) to smooth the accuracy in figures.
The CIFAR-10 dataset contains 60000 images (50000 for training and 10000 for testing), each corresponding to one of ten categories. We take 40000 images in the training dataset as device data and randomly select * 40000 images from the remaining 10000 images as server data, with . represents the ratio between the size of the shared insensitive server and that of the distributed sensitive device data. For the non-IID setting, we sort the device data according to the label and then divide these data evenly into fractions. Each device is randomly assigned fractions, and most devices contain the data with 2 labels. We utilize the same method to handle the CIFAR-100 dataset.
| Method | (CNN) | (VGG) \bigstrut | |||||||
| 5 | 10 | 20 | 5 | 10 | 20 | \bigstrut | |||
| 0.626 | 0.666 \bigstrut | ||||||||
| 1% | 0.638 | 0.670 \bigstrut | |||||||
| 0.628 | 0.638 | 0.631 | 0.577 | 0.668 | 0.672 | 0.668 | 0.627 \bigstrut | ||
| 5% | 0.663 | 0.700 \bigstrut | |||||||
| 0.636 | 0.639 | 0.648 | 0.436 | 0.674 | 0.684 | 0.690 | 0.651 \bigstrut | ||
| 10% | 0.675 | 0.723 \bigstrut | |||||||
| 0.640 | 0.643 | 0.658 | 0.429 | 0.682 | 0.689 | 0.707 | 0.664 \bigstrut | ||



4.2. Evaluation with non-IID Data
We first conduct comparison of FedDU with FedAvg, FedKT, FedDF, Data-sharing, and Hybrid-FL in terms of model accuracy. Then, we compare FedDUM with server-side momentum, device-side momentum, and FedDA. Afterward, we show the advantages of the adaptive pruning method, i.e., FedAP, with the comparison of FedAvg, IMC, HRank, and PruneFL, in terms of model efficiency. Last but not least, we demonstrate that FedDUMAP, which consists of both FedDUM and FedAP, significantly outperforms the eight state-of-the-art baselines in terms of accuracy, efficiency and computational cost. Finally, we present our ablation study.
| Method | CNN | VGG \bigstrut | |||
| Accuracy | Accuracy \bigstrut | ||||
| \bigstrut | |||||
| FedAvg | 0.626 | 0.666 \bigstrut | |||
| FedDU | 1% | 0.638 | 0.637 | 0.670 | 0.677 \bigstrut |
| 5% | 0.663 | 0.660 | 0.700 | 0.697 \bigstrut | |
| 10% | 0.675 | 0.668 | 0.723 | 0.711 \bigstrut | |






4.2.1. Evaluation on FedDU
In this part, we compare FedDU with five baseline methods, i.e., FedAvg, FedKT, FedDF, Data-sharing, and Hybrid-FL. Afterward, we analyze the effect of , the effect of , the effect of , and the effect of the non-IID degree of server data. Data-sharing transfers the shared server data to devices in order to combine the local data and the server data, which may have a smaller non-IID degree compared with the original local data, so as to improve the accuracy of the updated model on the device. Hybrid-FL takes the shared server data of significant size as an ordinary dataset on a device and utilizes the FedAvg algorithm to perform the training process.
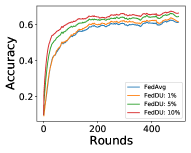
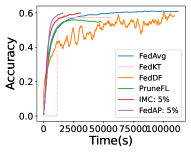
In order to take advantage of the server data, we have significant effective steps at the beginning, which leads to a quick increase of accuracy. Then, at the end of the training, we reduce the effective steps and focus on the device data to achieve high accuracy. Figure 2 shows that FedDU corresponds to excellent efficiency and high accuracy compared with baseline methods with CIFAR-10. In addition, with more server data, FedDU can achieve better performance in terms of accuracy (up to 5.3% higher) for both CNN and VGG. As shown in Figures 3 and 4, FedDU leads to a higher accuracy compared with FedAvg (up to 5.7%), FedKT (up to 22.6%), FedDF (up to 5.0%), Data-sharing (up to 11.7%), and Hybrid-FL (up to 19.5%) for both CNN and ResNet when and . In contrast, Data-sharing has slightly higher accuracy (up to 1.2%) compared with FedDU for VGG, as the more complex model can be better trained with augmented data. Compared with FedDU, Data-sharing needs to transfer the server data to devices, which may incur privacy issues and corresponds to high communication overhead. In addition, Data-sharing leads to a much longer training time to achieve the accuracy of 0.6 (for CNN, up to 15.7 times slower) and 0.4 (for LeNet, up to 28.9 times slower) than FedDU on CNN.
| Method | (CNN) | (VGG) \bigstrut | |||||
|---|---|---|---|---|---|---|---|
| 1.5 | 1 | 0.5 | 1.5 | 1 | 0.5\bigstrut | ||
| FedAvg | 0.626 | 0.666 \bigstrut | |||||
| FedDU | 1% | 0.636 | 0.638 | 0.634 | 0.673 | 0.670 | 0.672 \bigstrut |
| 5% | 0.651 | 0.663 | 0.647 | 0.685 | 0.700 | 0.690 \bigstrut | |
| 10% | 0.669 | 0.675 | 0.668 | 0.724 | 0.723 | 0.715 \bigstrut | |


| Method | (CNN) | (VGG) \bigstrut | |||||
|---|---|---|---|---|---|---|---|
| \bigstrut | |||||||
| FedAvg | 0.626 | 0.666 \bigstrut | |||||
| FedDU | 1% | 0.635 | 0.638 | 0.625 | 0.671 | 0.670 | 0.662 \bigstrut |
| 5% | 0.659 | 0.663 | 0.659 | 0.704 | 0.700 | 0.700 \bigstrut | |
| 10% | 0.645 | 0.675 | 0.667 | 0.696 | 0.723 | 0.718 \bigstrut | |
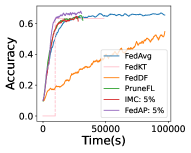
We have similar results on CIFAR-100 as that of CIFAR-10. As shown in Figure 5, FedDU corresponds to a higher accuracy compared with Data-sharing (up to 14.0%), FedKT (up to 16.0%), FedDF (up to 17.0%), Hybrid-FL (up to 20.4%) and FedAvg (up to 2.0%) with CNN, VGG, LeNet and ResNet, when and . In addition, Data-sharing suffers from a much longer training time to achieve the accuracy of 0.2 (up to 25.2 times slower) than FedDU.
Effect of : First, we fix the number of effective steps, and we denote this setting FedDU-Static (FedDU-S). We carry out the experiments with diverse values, i.e., , , and . As shown in Table 2, when the effective number of steps is small, i.e., or , the corresponding accuracy is higher than FedAvg with a small margin, e.g., up to 1.7% for CNN and 2.3% for VGG. However, when the number of effective steps is huge, e.g., , the accuracy becomes the lowest. This is expected as the global model is updated too much towards the central data, which degrades the final performance. We find that dynamical adjustment of , i.e., FedDU, can significantly improve the accuracy (up to 1.7% higher accuracy compared with the static method).
| Methods | Accuracy | Time(0.6) | MFLOPs \bigstrut |
|---|---|---|---|
| FedAvg | 0.666 | 15953 | 153.4 \bigstrut |
| IMC | 0.645 | 11992 | 153.4 \bigstrut |
| PruneFL | 0.652 | 11896 | 153.4 \bigstrut |
| FedAP | 0.670 | 7980 | 56.1 \bigstrut |



Effect of : We can choose a synthetic function of between and . As shown in Table 3, we empirically find that the performance corresponding to is similar to that corresponding to in terms of accuracy, while is slightly better (0.32% on average). Thus, we choose in FedDU.
Effect of : In order to choose an appropriate value of , we empirically analyze the performance corresponding to diverse values of , i.e., 1.5, 1, 0.5. As shown in Table 4, we find that the performance of has the highest accuracy on average. Then, we choose in FedDU.
Influence of the Non-IID Degree of Server Data: The non-IID degree of server data can have a significant influence on the training process. When the non-IID degree is small, the distribution of the server data is similar to that of the global distribution of all the device data, which is beneficial to the training process. Otherwise, the server data is of less help. In order to analyze the influence of the non-IID degree of the server data, we carry out the experiment with diverse non-IID degrees, e.g., , and . As shown in Figure 6, when the non-IID degree is smaller, the training is more efficient and it takes much shorter time to achieve a target accuracy (up to 6.6 times faster to achieve the accuracy of 0.6). However, as shown in Table 5, the accuracy is not directly related to the non-IID degrees.
| Methods | Accuracy | Time(0.49) | MFLOPs \bigstrut |
|---|---|---|---|
| FedAvg | 0.523 | 502 | 0.7 \bigstrut |
| IMC | 0.513 | 583 | 0.7 \bigstrut |
| PruneFL | 0.515 | 529 | 0.7 \bigstrut |
| FedAP | 0.522 | 483 | 0.6 \bigstrut |



4.2.2. Evaluation on FedDUM
In this section, we compare FedDUM with two adapted adaptive optimization methods, i.e., server-side momentum (FedDU-SM) (reddi2018adaptive, ) and device-side momentum (FedDU-DM) (karimireddy2020mime, ), as well as FedDA (FedDU-DA) (jin2022accelerated, ). For a fair comparison, each optimization method is combined with FedDU to utilize the server data in order to improve the accuracy.
As shown in Figure 7, compared with FedAvg and FedDU, FedDUM achieves significantly higher accuracy within the same training time for CNN (up to 6.5% for FedAvg, 1.6% for FedDU), VGG (up to 7.2% for FedAvg, 1.5% for FedDU), and LeNet (up to 4.0% for FedAvg, 1.1% for FedDU) on CIFAR-10. FedDUM leads to a higher accuracy compared with FedDU-SM (up to 4.4%), FedDU-DM (up to 1.6%), and FedDU-DA (up to 6.2%). In addition, FedDU-DA corresponds to a longer total training time (up to 91.8% compared with other methods) because of additional communication cost. Furthermore, FedDUM corresponds to a shorter training time to achieve the target accuracy (up to 1.9 times faster than FedAvg, 44.2% faster than FedDU-SM, 42.9% faster than FedDU-DM and 3.1 times faster than FedDA).


| Method | CNN | VGG \bigstrut | ||||
|---|---|---|---|---|---|---|
| Accuracy | Time(0.3) | MFLOPs | Accuracy | Time(0.3) | MFLOPs \bigstrut | |
| FedAvg | 0.363 | 494 | 4.6 | 0.340 | 12798 | 153.5 \bigstrut |
| IMC | 0.347 | 480 | 4.6 | 0.321 | 8317 | 153.5 \bigstrut |
| PruneFL | 0.355 | 457 | 4.6 | 0.303 | 18817 | 153.5 \bigstrut |
| FedAP | 0.361 | 360 | 2.5 | 0.333 | 7689 | 59.7 \bigstrut |




We have similar results on CIFAR-100. As shown in Figure 8, compared with FedAvg and FedDU, FedDUM achieves significantly higher accuracy for CNN (up to 1.6% for FedAvg), VGG (up to 4.2% for FedAvg, 1.8% for FedDU), and LeNet (up to 1.1% for FedAvg, 0.1% for FedDU), except one case, i.e., slightly lower (0.4%) for CNN compared with FedDU. The advantages of FedDUM become significant compared with FedDU-SM (up to 4.4%), FedDU-DM (up to 1.6%), and FedDU-DA (up to 6.2%), in terms of accuracy. In addition, FedDU-DA corresponds to a longer total training time (up to 91.8% compared with other methods). Furthermore, FedDUM corresponds to a shorter training time to achieve the target accuracy (up to 1.4 times faster than FedAvg, 1.6 times faster than FedDU-SM, 51.8% times faster than FedDU-DM, and 4.0 times faster than FedDA).
4.2.3. Evaluation on FedAP
In this section, we compare FedAP with three baseline methods, i.e., HRank (lin2020hrank, ), IMC (zhang2021validating, ), and PruneFL (jiang2023model, ). We utilize HRank with the shared insensitive server data with multiple pruning rates, e.g., , , , and , within the FL training process. Similarly, we exploit IMC based on the server data in the FL training process. HRank is a structured pruning method, while PruneFL and IMC are unstructured techniques.
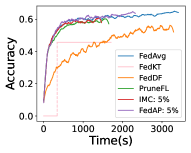
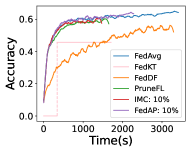
Figure 9 reveals the results based on CNN and VGG with CIFAR10 in terms of training time. FedAP can generate a proper pruning rate (37.8% on average for CNN and 72.0% on average for VGG), with a faster training speed (up to 1.8 times faster) and an excellent accuracy (up to 0.1% accuracy reduction compared with that of FedAvg). However, both the training time and the accuracy decrease at the same time when the pruning rate increases with HRank. FedAP generates adaptive pruning rates for each layer while the accuracy is almost the same as that of FedAvg. Then, we compare FedAP with FedAvg, IMC, and PruneFL. Figure 10 demonstrates that the training speed of FedAP is significantly higher than baselines. In addition, FedAP achieves the highest accuracy while its training time is significantly shorter to achieve the target accuracy of 0.55. As unstructured pruning techniques cannot reduce computational costs with general-purpose hardware, the training time remains unchanged. On the contrary, FedAP corresponds to a much smaller computational cost (up to 55.7% reduction).
| Methods | Accuracy | Time(0.25) | MFLOPs \bigstrut |
|---|---|---|---|
| FedAvg | 0.253 | 897 | 0.7 \bigstrut |
| IMC | 0.257 | 617 | 0.7 \bigstrut |
| PruneFL | 0.255 | 804 | 0.7 \bigstrut |
| FedAP | 0.259 | 546 | 0.6 \bigstrut |



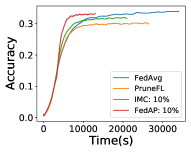


As shown in Figure 11 and Tables 6 and 7, FedAP achieves the highest accuracy and incurs a negligible accuracy reduction (up to 0.1% than FedAvg) while its training time is significantly shorter to achieve the accuracy of 0.6 (up to one time faster than FedAvg, 50.3% faster than IMC, and 49.1% faster than PruneFL).
As shown in Figure 12 and Table 8, with CNN and VGG on CIFAR-100, FedAP achieves the highest accuracy and incurs a negligible accuracy reduction (up to 0.2% and 0.7%) while its training time is significantly shorter to achieve the accuracy of 0.3 (up to 8.2% faster than IMC, 1.4 times faster than PruneFL, and 66.4% faster than FedAvg). As shown in Table 9, similarly with LeNet, FedAP achieves the highest accuracy while its training time is significantly shorter to achieve the accuracy of 0.25 (up to 13.0% faster than IMC, 47.3% faster than PruneFL, and 64.3% faster than FedAvg).
4.2.4. Evaluation on FedDUMAP
In this section, we compare FedDUMAP, consisting of both FedDUM and FedAP, with the baseline approaches. We present the comparison results of CNN, VGG, LeNet with CIRAR-10 and CIFAR-100.
As shown in Table 10, FedDUMAP with CNN achieves higher accuracy compared with FedAvg (5.8%), Data-sharing (5.0%), Hybrid (20.4%), ServerM (1.4%), DeviceM (0.8%), FedDA (2.9%), IMC (7.6%), and PruneFL (7.9%) for CNN. In addition, FedDUMAP has a shorter training time to achieve the target accuracy (up to 2.4 times faster than FedAvg, 16.9 times faster than Data-sharing, 4.3 times faster than IMC, and 5.2 times faster than PruneFL) and a much smaller computational cost (up to 41.3% compared with others).


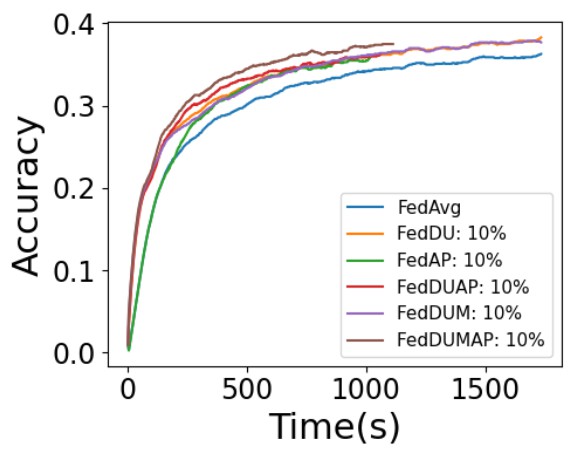

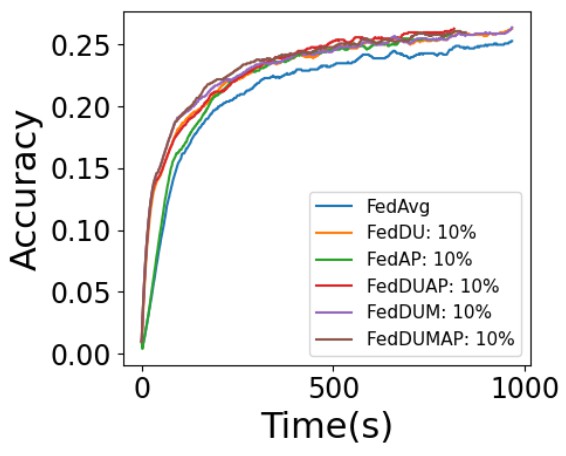
| Method | CNN | VGG | LeNet \bigstrut | ||||||
| Accuracy | Time | MFLOPs | Accuracy | Time | MFLOPs | Accuracy | Time | MFLOPs \bigstrut | |
| FedAvg | 0.626 | 838 | 4.5 | 0.666 | 15953 | 153.3 | 0.523 | 824 | 0.7 \bigstrut |
| D-S | 0.634 | 4447 | 4.5 | 0.735 | 6726 | 153.3 | 0.435 | NaN | 0.7 \bigstrut |
| FedKT | 0.458 | 942 | 4.5 | 0.631 | 11772 | 153.3 | 0.442 | 523 | 0.7 \bigstrut |
| FedDF | 0.634 | 1047 | 4.5 | 0.547 | 12035 | 153.3 | 0.474 | 513 | 0.7 \bigstrut |
| Hybrid-FL | 0.480 | NaN | 4.5 | 0.656 | 14785 | 153.3 | 0.400 | NaN | 0.7 \bigstrut |
| ServerM | 0.670 | 383 | 4.5 | 0.694 | 10797 | 153.3 | 0.528 | 346 | 0.7 \bigstrut |
| DeviceM | 0.676 | 431 | 4.5 | 0.722 | 10700 | 153.3 | 0.560 | 280 | 0.7 \bigstrut |
| FedDA | 0.655 | 582 | 4.5 | 0.695 | 20333 | 153.3 | 0.501 | 1171 | 0.7 \bigstrut |
| IMC | 0.608 | 1316 | 4.5 | 0.645 | 11992 | 153.3 | 0.513 | 733 | 0.7 \bigstrut |
| PruneFL | 0.605 | 1536 | 4.5 | 0.652 | 11896 | 153.3 | 0.515 | 837 | 0.7 \bigstrut |
| FedDUMAP | 0.684 | 248 | 2.7 | 0.728 | 4677 | 57.3 | 0.561 | 249 | 0.6 \bigstrut |
| Method | CNN | VGG | LeNet \bigstrut | ||||||
| Accuracy | Time | MFLOPs | Accuracy | Time | MFLOPs | Accuracy | Time | MFLOPs \bigstrut | |
| FedAvg | 0.363 | 494 | 4.6 | 0.340 | 12798 | 153.3 | 0.253 | 897 | 0.7 \bigstrut |
| D-S | 0.243 | NaN | 4.6 | 0.340 | 11842 | 153.3 | 0.159 | NaN | 0.7 \bigstrut |
| FedKT | 0.223 | 484 | 4.5 | 0.313 | 9770 | 153.3 | 0.170 | 718 | 0.7 \bigstrut |
| FedDF | 0.213 | 476 | 4.5 | 0.098 | 11247 | 153.3 | 0.171 | 694 | 0.7 \bigstrut |
| Hybrid-FL | 0.179 | NaN | 4.6 | 0.308 | 22177 | 153.3 | 0.134 | NaN | 0.7 \bigstrut |
| ServerM | 0.342 | 667 | 4.6 | 0.323 | 13775 | 153.3 | 0.256 | 862 | 0.7 \bigstrut |
| DeviceM | 0.386 | 306 | 4.6 | 0.364 | 8011 | 153.3 | 0.264 | 558 | 0.7 \bigstrut |
| FedDA | 0.349 | 777 | 4.6 | 0.319 | 26422 | 153.3 | 0.258 | 891 | 0.7 \bigstrut |
| IMC | 0.347 | 480 | 4.6 | 0.321 | 8317 | 153.3 | 0.257 | 617 | 0.7 \bigstrut |
| PruneFL | 0.355 | 457 | 4.6 | 0.303 | 18817 | 153.3 | 0.255 | 804 | 0.7 \bigstrut |
| FedDUMAP | 0.383 | 202 | 2.8 | 0.396 | 3849 | 61.8 | 0.270 | 393 | 0.6 \bigstrut |
As shown in Table 10, FedDUMAP with VGG achieves a higher accuracy compared with FedAvg (6.2%), IMC (8.3%), PruneFL (7.6%), Hybrid-FL (7.2%), ServerM (3.4%), DeviceM (0.6%), FedDA (3.3%), IMC (8.3%), and PruneFL (7.6%). Although slightly outperforming FedDUMAP (0.7%), Data-sharing incurs severe data security problems. In addition, FedDUMAP corresponds to a shorter training time to achieve the accuracy of 0.6 (up to 2.4 times faster than FedAvg, 43.8% faster than Data-sharing, 2.2 times faster than Hybrid-FL, 1.6 times faster than IMC and 1.5 times faster than PruneFL) and a much smaller computational cost (up to 62.6% reduction for FedAvg, Data-sharing, Hybrid-FL, IMC, and PruneFL).
We obtain similar findings with LeNet. As shown in Table 10, FedDUMAP achieves a higher accuracy compared with FedAvg (3.8%), Data-sharing (12.6%), Hybrid-FL (16.1%), ServerM (3.3%), DeviceM (0.1%), FedDA (6.0%), IMC (4.8%) and PruneFL (4.6%). In addition, FedDUMAP corresponds to a shorter training time to achieve the accuracy of 0.5 (up to 2.3 times faster than FedAvg, 1.9 times than IMC, 2.4 times than PruneFL) and a much smaller computational cost (up to 14.3% reduction for FedAvg, Data-sharing, Hybrid-FL, IMC, and PruneFL).
As shown in Tables 11, with CNN, VGG, and LeNet on CIFAR-100, FedDUMAP achieves a higher accuracy compared with FedAvg (up to 5.6%), Data-sharing (up to 14.0%), Hybrid-FL (up to 20.4%), ServerM (up to 7.3%), DeviceM (up to 3.2%), FedDA (up to 7.7%), IMC (up to 7.5%) and PruneFL (up to 9.3%), except for a single case, i.e., slightly lower than DeviceM (0.3%) for CNN. In addition, FedDUMAP corresponds to a shorter training time to achieve the accuracy of 0.3 (up to 2.3 times faster than FedAvg, 2.1 times faster than Data-sharing, 4.8 times faster than Hybrid-FL, 1.4 times faster than IMC and 3.9 times faster than PruneFL) and a much smaller computational cost (up to 59.7% reduction compared with other methods).
| Method | CNN | VGG | LeNet \bigstrut | ||||||
| Accuracy | Time | MFLOPs | Accuracy | Time | MFLOPs | Accuracy | Time | MFLOPs \bigstrut | |
| FedAvg | 0.626 | 838 | 4.5 | 0.666 | 15953 | 153.3 | 0.523 | 824 | 0.7 \bigstrut |
| FedDU | 0.675 | 284 | 4.5 | 0.723 | 8268 | 153.3 | 0.552 | 284 | 0.7 \bigstrut |
| FedDUM | 0.691 | 311 | 4.5 | 0.738 | 7490 | 153.3 | 0.563 | 284 | 0.7 \bigstrut |
| FedAP | 0.625 | 696 | 3.0 | 0.670 | 7980 | 56.0 | 0.522 | 754 | 0.6 \bigstrut |
| FedDUAP | 0.662 | 278 | 2.8 | 0.714 | 4719 | 58.4 | 0.553 | 267 | 0.6 \bigstrut |
| FedDUMAP | 0.684 | 248 | 2.7 | 0.728 | 4677 | 57.3 | 0.561 | 249 | 0.6 \bigstrut |
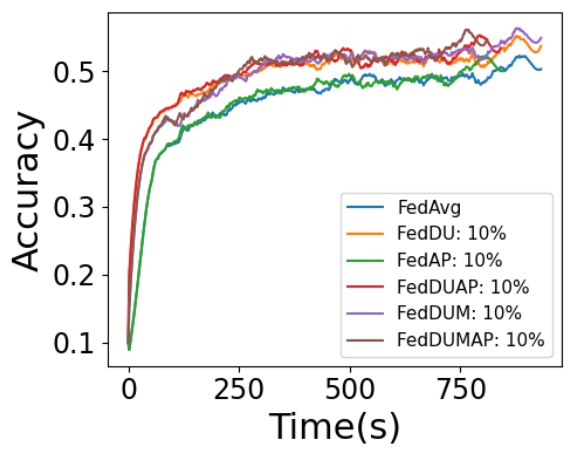
4.2.5. Ablation Study
We conduct the ablation study by measuring the final accuracy, the training time to achieve the accuracy of 0.6 for CNN and VGG, 0.3 for LeNet with CIFAR-10, and the computational cost of FedAvg, FedDU, FedDUM, FedAP, FedDUAP, and FedDUMAP. As shown in Figure 13 and Table 12, the efficiency of FedDUMAP significantly outperforms FedDU, FedDUM, and FedAvg (up to 2.4 times faster), while the accuracy of FedDUMAP is much higher than that of FedDU, FedAP, and FedAvg (up to 6.2%). In addition, the computational cost of FedDUMAP is the smallest for CNN, while it is slightly higher (2.1%) than FedAP for VGG due to the dynamic server update. Although FedDUMAP achieves slightly lower accuracy compared with FedDUM (up to 1.0%), FedDUMAP is much more efficient than FedDU and FedDUM (up to 76.8% faster).
In order to reveal the advantages of FedDUMAP, we also conduct the ablation study with CIFAR-100. We measure the final accuracy, the training time to achieve the accuracy, and the computational cost of diverse methods.
As shown in Figure 14 and Table 13, the efficiency of FedDUMAP significantly outperforms FedDU (up to 2.3 times faster), FedDUM (up to 43.1% faster), and FedAvg (up to 2.3 times faster), while the accuracy of FedDUMAP is much higher than that of FedDU (up to 0.2%), FedAP (up to 6.3%), and FedAvg (up to 5.6%). FedDUMAP corresponds to the shortest training time with CNN, VGG, and LeNet. In addition, the computational cost of FedDUMAP is the smallest for LeNet while it is slightly higher than FedAP for CNN (16.0%) and VGG (3.5%) due to the dynamic server update. Furthermore, FedDUMAP has slightly higher accuracy (up to 1.4% for VGG) compared with that of FedDUM, and the accuracy of FedDUMAP is much higher (up to 5.6% for VGG) than that of FedAvg. In addition, FedDUMAP is much more efficient than FedDUM (up to 43.1% faster for CNN).
| Method | CNN | VGG | LeNet \bigstrut | ||||||
| Accuracy | Time | MFLOPs | Accuracy | Time | MFLOPs | Accuracy | Time | MFLOPs \bigstrut | |
| FedAvg | 0.363 | 494 | 4.6 | 0.340 | 12798 | 153.3 | 0.253 | 897 | 0.7 \bigstrut |
| FedDU | 0.373 | 667 | 4.6 | 0.364 | 6155 | 153.3 | 0.263 | 574 | 0.7 \bigstrut |
| FedDUM | 0.379 | 355 | 4.6 | 0.382 | 5276 | 153.3 | 0.264 | 572 | 0.7 \bigstrut |
| FedAP | 0.361 | 360 | 2.4 | 0.333 | 7689 | 59.6 | 0.259 | 546 | 0.6 \bigstrut |
| FedDUAP | 0.363 | 269 | 2.6 | 0.366 | 3913 | 62.6 | 0.263 | 485 | 0.6 \bigstrut |
| FedDUMAP | 0.383 | 202 | 2.8 | 0.396 | 3849 | 61.8 | 0.270 | 393 | 0.6 \bigstrut |
5. Conclusion
In this paper, we propose a novel FL framework FedDUMAP, which leverages both the shared insensitive server data and the distributed sensitive device data to train the global model. Furthermore, the non-IID degrees of the data is also considered in the FL training process. FedDUMAP consists of a dynamic update FL algorithm, i.e., FedDU, a simple yet efficient adaptive optimization method on top of FedDU, i.e., FedDUM, and an adaptive pruning method, i.e., FedAP. We conduct extensive experimentation to evaluate the performance of FedDUMAP with different models and real-life datasets. According to the experimental results, FedDUMAP significantly outperforms the baseline approaches in terms of accuracy (up to 20.4% higher), efficiency (up to 16.9 times faster), and computational cost (up to 62.6% smaller).
References
- (1) Y. Zhao, M. Li, L. Lai, N. Suda, D. Civin, and V. Chandra, “Federated learning with non-iid data,” arXiv preprint arXiv:1806.00582, 2018.
- (2) Official Journal of the European Union, “General data protection regulation,” https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:32016R0679, 2016, online; accessed 12/02/2021.
- (3) “California consumer privacy act home page,” https://www.caprivacy.org/, 2018, online; accessed 14/02/2021.
- (4) Q. Li, B. He, and D. Song, “Practical one-shot federated learning for cross-silo setting,” in Int. Joint Conf. on Artificial Intelligence (IJCAI), 2021.
- (5) B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” in Artificial Intelligence and Statistics (AISTATS), 2017, pp. 1273–1282.
- (6) J. Liu, J. Huang, Y. Zhou, X. Li, S. Ji, H. Xiong, and D. Dou, “From distributed machine learning to federated learning: a survey,” Knowledge and Information Systems, vol. 64, no. 4, pp. 885–917, 2022.
- (7) J. Liu, C. Chen, Y. Li, L. Sun, Y. Song, J. Zhou, B. Jing, and D. Dou, “Enhancing trust and privacy in distributed networks: a comprehensive survey on blockchain-based federated learning,” Knowledge and Information Systems, pp. 1–27, 2024.
- (8) J. Liu, Z. Wu, D. Feng, M. Zhang, X. Wu, X. Yao, D. Yu, Y. Ma, F. Zhao, and D. Dou, “Heterps: Distributed deep learning with reinforcement learning based scheduling in heterogeneous environments,” Future Generation Computer Systems, vol. 148, pp. 106–117, 2023.
- (9) H. Li, K. Ota, and M. Dong, “Learning iot in edge: Deep learning for the internet of things with edge computing,” IEEE Network, vol. 32, no. 1, pp. 96–101, 2018.
- (10) J. Shen, J. Shen, X. Chen, X. Huang, and W. Susilo, “An efficient public auditing protocol with novel dynamic structure for cloud data,” IEEE Transactions on Information Forensics and Security, vol. 12, no. 10, pp. 2402–2415, 2017.
- (11) N. Yoshida, T. Nishio, M. Morikura, K. Yamamoto, and R. Yonetani, “Hybrid-FL for wireless networks: Cooperative learning mechanism using non-iid data,” in IEEE Int. Conf. on Communications (ICC), 2020, pp. 1–7.
- (12) Amazon, “Amazon cloud,” https://aws.amazon.com, 2021, online; accessed 30/12/2021.
- (13) Microsoft Azure, “Microsoft azure,” https://azure.microsoft.com/, 2021, online; accessed 30/12/2021.
- (14) Baidu, “Baidu ai cloud,” https://cloud.baidu.com/, 2021, online; accessed 30/12/2021.
- (15) K. Wang, X. Qi, L. Shu, D.-j. Deng, and J. J. Rodrigues, “Toward trustworthy crowdsourcing in the social internet of things,” IEEE Wireless Communications, vol. 23, no. 5, pp. 30–36, 2016.
- (16) X. Ye, Y. Zhang, X. Xiao, S. Yi, and R. Lan, “Usability enhanced thumbnail-preserving encryption based on data hiding for jpeg images,” IEEE Signal Processing Letters, 2023.
- (17) K. Yang, S. Chen, and C. Shen, “On the convergence of hybrid server-clients collaborative training,” IEEE Journal on Selected Areas in Communications, vol. 41, no. 3, pp. 802–819, 2022.
- (18) H. Gu, B. Guo, J. Wang, W. Sun, J. Liu, S. Liu, and Z. Yu, “Fedaux: an efficient framework for hybrid federated learning,” in ICC 2022-IEEE International Conference on Communications. IEEE, 2022, pp. 195–200.
- (19) Z. Lian, Q. Zeng, W. Wang, T. R. Gadekallu, and C. Su, “Blockchain-based two-stage federated learning with non-iid data in iomt system,” IEEE Transactions on Computational Social Systems, 2022.
- (20) T. Yoon, S. Shin, S. J. Hwang, and E. Yang, “Fedmix: Approximation of mixup under mean augmented federated learning,” in Int. Conf. on Learning Representations (ICLR), 2021.
- (21) J. Zhang, S. Guo, X. Ma, H. Wang, W. Xu, and F. Wu, “Parameterized knowledge transfer for personalized federated learning,” Advances in Neural Information Processing Systems (NeurIPS), vol. 34, 2021.
- (22) T. Lin, L. Kong, S. U. Stich, and M. Jaggi, “Ensemble distillation for robust model fusion in federated learning,” in Advances in Neural Information Processing Systems (NeurIPS), 2020.
- (23) I. Sutskever, J. Martens, G. Dahl, and G. Hinton, “On the importance of initialization and momentum in deep learning,” in Int. Conf. on Machine Learning (ICML), 2013, pp. 1139–1147.
- (24) J. Duchi, E. Hazan, and Y. Singer, “Adaptive subgradient methods for online learning and stochastic optimization.” Journal of machine learning research, vol. 12, no. 7, 2011.
- (25) S. Reddi, M. Zaheer, D. Sachan, S. Kale, and S. Kumar, “Adaptive methods for nonconvex optimization,” in Annual Conf. on Neural Information Processing Systems (NeurIPS), 2018, pp. 1–17.
- (26) D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- (27) J. Mills, J. Hu, and G. Min, “Communication-efficient federated learning for wireless edge intelligence in iot,” IEEE Internet of Things Journal, vol. 7, no. 7, pp. 5986–5994, 2019.
- (28) H. Yuan, M. Zaheer, and S. Reddi, “Federated composite optimization,” in Int. Conf. on Machine Learning (ICML), vol. 139, 2021, pp. 12 253–12 266.
- (29) W. Liu, L. Chen, Y. Chen, and W. Zhang, “Accelerating federated learning via momentum gradient descent,” IEEE Transactions on Parallel and Distributed Systems (TPDS), vol. 31, no. 8, pp. 1754–1766, 2020.
- (30) H. Gao, A. Xu, and H. Huang, “On the convergence of communication-efficient local sgd for federated learning,” in AAAI Conf. on Artificial Intelligence, vol. 35, no. 9, 2021, pp. 7510–7518.
- (31) J. Wang, V. Tantia, N. Ballas, and M. Rabbat, “Slowmo: Improving communication-efficient distributed sgd with slow momentum,” in Int. Conf. on Learning Representations (ICLR), 2020, pp. 1–27.
- (32) J. Jin, J. Ren, Y. Zhou, L. Lyu, J. Liu, and D. Dou, “Accelerated federated learning with decoupled adaptive optimization,” in International Conference on Machine Learning. PMLR, 2022, pp. 10 298–10 322.
- (33) Y. Jiang, S. Wang, V. Valls, B. J. Ko, W.-H. Lee, K. K. Leung, and L. Tassiulas, “Model pruning enables efficient federated learning on edge devices,” IEEE Transactions on Neural Networks and Learning Systems, vol. 34, no. 12, pp. 10 374–10 386, 2023.
- (34) M. Lin, R. Ji, Y. Wang, Y. Zhang, B. Zhang, Y. Tian, and L. Shao, “Hrank: Filter pruning using high-rank feature map,” in IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 1529–1538.
- (35) H. Zhang, J. Liu, J. Jia, Y. Zhou, H. Dai, and D. Dou, “Fedduap: Federated learning with dynamic update and adaptive pruning using shared data on the server,” in Int. Joint Conf. on Artificial Intelligence (IJCAI), 2022, pp. 1–7, to appear.
- (36) P. Kairouz, H. B. McMahan, B. Avent, A. Bellet, and M. B. et al., “Advances and open problems in federated learning,” Foundations and Trends® in Machine Learning, vol. 14, no. 1, 2021.
- (37) C. Zhou, J. Liu, J. Jia, J. Zhou, Y. Zhou, H. Dai, and D. Dou, “Efficient device scheduling with multi-job federated learning,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 9, 2022, pp. 9971–9979.
- (38) G. Li, Y. Hu, M. Zhang, J. Liu, Q. Yin, Y. Peng, and D. Dou, “Fedhisyn: A hierarchical synchronous federated learning framework for resource and data heterogeneity,” in Int. Conf. on Parallel Processing (ICPP), ser. Int. Conf. on Parallel Processing (ICPP), 2022, pp. 1–10, to appear.
- (39) J. Liu, T. Che, Y. Zhou, R. Jin, H. Dai, D. Dou, and P. Valduriez, “Aedfl: efficient asynchronous decentralized federated learning with heterogeneous devices,” in Proceedings of the 2024 SIAM International Conference on Data Mining (SDM). SIAM, 2024, pp. 833–841.
- (40) J. Liu, J. Jia, T. Che, C. Huo, J. Ren, Y. Zhou, H. Dai, and D. Dou, “Fedasmu: Efficient asynchronous federated learning with dynamic staleness-aware model update,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 12, 2024, pp. 13 900–13 908.
- (41) T. Che, Y. Zhou, Z. Zhang, L. Lyu, J. Liu, D. Yan, D. Dou, and J. Huan, “Fast federated machine unlearning with nonlinear functional theory,” in International conference on machine learning. PMLR, 2023, pp. 4241–4268.
- (42) J. Liu, X. Zhou, L. Mo, S. Ji, Y. Liao, Z. Li, Q. Gu, and D. Dou, “Distributed and deep vertical federated learning with big data,” Concurrency and Computation: Practice and Experience, vol. 35, no. 21, p. e7697, 2023.
- (43) J. Liu, J. Jia, B. Ma, C. Zhou, J. Zhou, Y. Zhou, H. Dai, and D. Dou, “Multi-job intelligent scheduling with cross-device federated learning,” IEEE Transactions on Parallel and Distributed Systems, vol. 34, no. 2, pp. 535–551, 2022.
- (44) T. Che, Z. Zhang, Y. Zhou, X. Zhao, J. Liu, Z. Jiang, D. Yan, R. Jin, and D. Dou, “Federated fingerprint learning with heterogeneous architectures,” in 2022 IEEE international conference on data mining (ICDM). IEEE, 2022, pp. 31–40.
- (45) J. Liu, D. Dong, X. Wang, A. Qin, X. Li, P. Valduriez, D. Dou, and D. Yu, “Large-scale knowledge distillation with elastic heterogeneous computing resources,” Concurrency and Computation: Practice and Experience, vol. 35, no. 26, p. e7272, 2023.
- (46) E. Jeong, S. Oh, H. Kim, J. Park, M. Bennis, and S.-L. Kim, “Communication-efficient on-device machine learning: Federated distillation and augmentation under non-iid private data,” arXiv preprint arXiv:1811.11479, 2018.
- (47) C. He, M. Annavaram, and S. Avestimehr, “Group Knowledge Transfer: Federated Learning of Large CNNs at the Edge,” Advances in Neural Information Processing Systems (NeurIPS), vol. 33, 2020.
- (48) D. Dong, J. Liu, X. Wang, W. Gong, A. Qin, X. Li, D. Yu, P. Valduriez, and D. Dou, “Elastic deep learning using knowledge distillation with heterogeneous computing resources,” in European Conference on Parallel Processing workshop, ser. European Conference on Parallel Processing workshop, 2022, pp. 116–128.
- (49) J. Liu, D. Dong, X. Wang, W. Gong, A. Qin, X. Li, P. Valduriez, D. Dou, and D. Yu, “Large-scale knowledge distillation with elastic heterogeneous computing resources,” Concurrency and Computation: Practice and Experience, pp. 1–16, 2022, to appear.
- (50) W. Jeong, J. Yoon, E. Yang, and S. J. Hwang, “Federated semi-supervised learning with inter-client consistency & disjoint learning,” in Int. Conf. on Learning Representations (ICLR), 2020.
- (51) L. Nagalapatti and R. Narayanam, “Game of gradients: Mitigating irrelevant clients in federated learning,” AAAI Conf. on Artificial Intelligence, vol. 35, no. 10, pp. 9046–9054, 2021.
- (52) S. P. Karimireddy, S. Kale, M. Mohri, S. Reddi, S. Stich, and A. T. Suresh, “Scaffold: Stochastic controlled averaging for federated learning,” in Int. Conf. on Machine Learning (ICML), 2020, pp. 5132–5143.
- (53) D. A. E. Acar, Y. Zhao, R. Matas, M. Mattina, P. Whatmough, and V. Saligrama, “Federated learning based on dynamic regularization,” in Int. Conf. on Learning Representations (ICLR), 2021, pp. 1–36.
- (54) D. Rothchild, A. Panda, E. Ullah, N. Ivkin, I. Stoica, V. Braverman, J. Gonzalez, and R. Arora, “Fetchsgd: Communication-efficient federated learning with sketching,” in Int. Conf. on Machine Learning (ICML), 2020, pp. 8253–8265.
- (55) J. Mills, J. Hu, G. Min, R. Jin, S. Zheng, and J. Wang, “Accelerating federated learning with a global biased optimiser,” arXiv preprint arXiv:2108.09134, 2021.
- (56) T. Che, J. Liu, Y. Zhou, J. Ren, J. Zhou, V. S. Sheng, H. Dai, and D. Dou, “Federated learning of large language models with parameter-efficient prompt tuning and adaptive optimization,” arXiv preprint arXiv:2310.15080, 2023.
- (57) S. J. Reddi, Z. Charles, M. Zaheer, Z. Garrett, K. Rush, J. Konečný, S. Kumar, and H. B. McMahan, “Adaptive federated optimization,” in Int. Conf. on Learning Representations (ICLR), 2021.
- (58) A. Li, J. Sun, P. Li, Y. Pu, H. Li, and Y. Chen, “Hermes: an efficient federated learning framework for heterogeneous mobile clients,” in Proceedings of the 27th Annual International Conference on Mobile Computing and Networking, 2021, pp. 420–437.
- (59) A. Li, J. Sun, X. Zeng, M. Zhang, H. Li, and Y. Chen, “Fedmask: Joint computation and communication-efficient personalized federated learning via heterogeneous masking,” in Proceedings of the 19th ACM Conference on Embedded Networked Sensor Systems, 2021, pp. 42–55.
- (60) Y. Deng, W. Chen, J. Ren, F. Lyu, Y. Liu, Y. Liu, and Y. Zhang, “Tailorfl: Dual-personalized federated learning under system and data heterogeneity,” in Proceedings of the 20th ACM Conference on Embedded Networked Sensor Systems, 2022, pp. 592–606.
- (61) S. Yu, P. Nguyen, A. Anwar, and A. Jannesari, “Adaptive dynamic pruning for non-iid federated learning,” arXiv preprint arXiv:2106.06921, 2021.
- (62) Z. Zhang, J. Jin, Z. Zhang, Y. Zhou, X. Zhao, J. Ren, J. Liu, L. Wu, R. Jin, and D. Dou, “Validating the lottery ticket hypothesis with inertial manifold theory,” Advances in Neural Information Processing Systems (NeurIPS), vol. 34, 2021.
- (63) J. Konečnỳ, H. B. McMahan, F. X. Yu, P. Richtárik, A. T. Suresh, and D. Bacon, “Federated learning: Strategies for improving communication efficiency,” arXiv preprint arXiv:1610.05492, 2016.
- (64) J. Jia, J. Liu, C. Zhou, H. Tian, M. Dong, and D. Dou, “Efficient asynchronous federated learning with sparsification and quantization,” Concurrency and Computation: Practice and Experience, vol. 36, no. 9, p. e8002, 2024.
- (65) N. Bouacida, J. Hou, H. Zang, and X. Liu, “Adaptive federated dropout: Improving communication efficiency and generalization for federated learning,” in IEEE Conf. on Computer Communications Workshops (INFOCOM WKSHPS), 2021, pp. 1–6.
- (66) Y. Chen, Z. Chen, P. Wu, and H. Yu, “Fedobd: Opportunistic block dropout for efficiently training large-scale neural networks through federated learning,” arXiv preprint arXiv:2208.05174, 2022.
- (67) B. Fuglede and F. Topsoe, “Jensen-shannon divergence and Hilbert space embedding,” in Int. Symposium on Information Theory (ISIT), 2004, p. 31.
- (68) S. Kullback, Information theory and statistics. Courier Corporation, 1997.
- (69) F. Lai, X. Zhu, H. V. Madhyastha, and M. Chowdhury, “Oort: Efficient federated learning via guided participant selection,” in USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2021, pp. 19–35.
- (70) M. Yang, X. Wang, H. Qian, Y. Zhu, H. Zhu, M. Guizani, and V. Chang, “An improved federated learning algorithm for privacy-preserving in cybertwin-driven 6g system,” IEEE Transactions on Industrial Informatics, 2022.
- (71) J. Wang, Q. Liu, H. Liang, G. Joshi, and H. V. Poor, “Tackling the objective inconsistency problem in heterogeneous federated optimization,” Advances in Neural Information Processing Systems (NeurIPS), 2020.
- (72) X. Li, K. Huang, W. Yang, S. Wang, and Z. Zhang, “On the convergence of fedavg on non-IID data,” in Int. Conf. on Learning Representations (ICLR), 2020.
- (73) F. Zhou and G. Cong, “On the convergence properties of a k-step averaging stochastic gradient descent algorithm for nonconvex optimization,” in Int. Joint Conf. on Artificial Intelligence (IJCAI), 7 2018, pp. 3219–3227.
- (74) J. Wang, Z. Xu, Z. Garrett, Z. Charles, L. Liu, and G. Joshi, “Local adaptivity in federated learning: Convergence and consistency,” in The Int. Workshop on Federated Learning for User Privacy and Data Confidentiality in Conjunction with ICML (FL-ICML), 2021.
- (75) S. P. Karimireddy, M. Jaggi, S. Kale, M. Mohri, S. J. Reddi, S. U. Stich, and A. T. Suresh, “Mime: Mimicking centralized stochastic algorithms in federated learning,” arXiv preprint arXiv:2008.03606, 2020.
- (76) A. Krizhevsky, G. Hinton et al., “Learning multiple layers of features from tiny images,” Technical report, University of Toronto, 2009.
- (77) K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778.
- (78) K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” in Int. Conf. on Learning Representations (ICLR), 2015.
- (79) Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998.
- (80) W. H. Press and S. A. Teukolsky, “Savitzky-golay smoothing filters,” Computers in Physics, vol. 4, no. 6, pp. 669–672, 1990.