Efficient and generalizable nested Fourier-DeepONet for three-dimensional geological carbon sequestration
Abstract
Geological carbon sequestration (GCS) involves injecting CO2 into subsurface geological formations for permanent storage. Numerical simulations could guide decisions in GCS projects by predicting CO2 migration pathways and the pressure distribution in storage formation. However, these simulations are often computationally expensive due to highly coupled physics and large spatial-temporal simulation domains. Surrogate modeling with data-driven machine learning has become a promising alternative to accelerate physics-based simulations. Among these, the Fourier neural operator (FNO) has been applied to three-dimensional synthetic subsurface models. Here, to further improve performance, we have developed a nested Fourier-DeepONet by combining the expressiveness of the FNO with the modularity of a deep operator network (DeepONet). This new framework is twice as efficient as a nested FNO for training and has at least 80% lower GPU memory requirement due to its flexibility to treat temporal coordinates separately. These performance improvements are achieved without compromising prediction accuracy. In addition, the generalization and extrapolation ability of nested Fourier-DeepONet beyond the training range has been thoroughly evaluated. Nested Fourier-DeepONet outperformed the nested FNO for extrapolation in time with more than 50% reduced error. It also exhibited good extrapolation accuracy beyond the training range in terms of reservoir properties, number of wells, and injection rate.
Keywords:
geological carbon sequestration; 3D multiphase flow in porous media; deep neural operator; Fourier-DeepONet; computational cost; extrapolation
1 Introduction
Geological carbon sequestration (GCS) is an essential technology to reduce CO2 emissions at scale. High-fidelity simulations of plume migration pathways and pressure distribution during and after CO2 injection play an important role in decision making in carbon storage projects. The problem can be modeled by solving a multiphase flow of CO2 and water, governed by Darcy’s law, which is expressed by nonlinear partial differential equations (PDEs) [31, 2]. Numerical simulations, such as finite difference, finite element, or finite volume methods, provide insights to guide informed decisions about subsurface scenarios. These simulations allow the prediction of how much CO2 will migrate through sedimentary rocks for effective site selection and injection designs. However, this approach is computationally demanding for performing optimization tasks or decision-making processes, due to not only the multiphysics, multiscale, and multiphase nature of this problem but also the need for high grid resolution [31, 2, 30, 10, 34, 21]. As a result, the trade-off between accuracy and computational cost is inherent in such simulation methods. One technique to address this issue involves subdividing the grid into multiple resolutions, thereby reducing overall computational costs. Local grid refinement (LGR) technique is typically employed to maintain solver accuracy near the CO2 injection location [36]. This method discretizes the region around injection wells with finer grids and gradually coarsens regions further away from them [3, 11, 12, 19]. This approach enables the simulation model to capture the complex physics of CO2 plume migration around the wells with minimal loss of accuracy. However, it is still computationally expensive to use such techniques to model real-world scenarios.
Machine learning (ML) methods have emerged as a potential alternative to traditional numerical approaches due to their capability to learn PDEs and make real-time predictions [5, 40, 8, 45, 29, 33, 35, 17]. Recent advances in ML have shown significant progress in solving subsurface flow problems [34, 36, 45, 29, 33, 35, 37]. ML techniques offer rapid inference, making them particularly useful for tasks such as probabilistic assessment, which require multiple forward simulations. Notably, physics-informed neural networks (PINNs) and their extensions [20, 15, 41, 27] have gained popularity from their ability to make informed predictions in various scientific and engineering applications and already have shown success in many applications [5, 40, 8, 13, 7, 39, 14, 38]. Despite their successes, PINNs struggle with computational cost in real-world scenarios due to the necessity for separate training if DE conditions vary. For example, in GCS, various reservoir conditions and varying injection schemes change the CO2 migration behavior, which makes PINNs inefficient for this application.
Recently, deep neural operators have gained significant attention because of their generalizability in learning the PDE family rather than a single PDE with fixed parameters. They do not require separate training for new conditions [23, 22, 24, 44, 43, 16, 28, 9, 26, 42, 6, 18]. Furthermore, in the field of GCS, a nested Fourier neural operator (FNO) framework has been used to simulate pressure buildup and carbon saturation in three-dimensional (3D) spatial and temporal domains, mirroring real-world scenarios [36]. Nested FNO adopts a similar idea as LGR technique using a separate model per each level of resolution. Despite using this technique, due to the large temporal and 3D spatial domain it still requires a couple of days of training for each level of resolution, and a GPU with large memory (30 GiB). Furthermore, because FNO uses different channels to predict solutions at different times, it performs poorly in predicting unseen times [16].
In our study, we aim to address the challenges arising from computational cost and poor generalizability. We develop a nested Fourier-DeepONet by employing a deep neural operator called Fourier-DeepONet [43, 16], which integrates the cutting-edge FNO [22] with the deep operator network (DeepONet) [23]. Nested Fourier-DeepONet offers significant improvements in GPU memory usage and training time compared to the state-of-the-art nested FNO [36] owing to its design of incorporating separate networks for handling temporal coordinates. This nificantly increases computational efficiency with at least 50% reduction in GPU memory consumption and 50% decrease in training time. Additionally, a nested Fourier-DeepONet demonstrates promising results in extrapolation in terms of sampling parameters that include various injection schemes, subsurface conditions, and temporal coordinates.
The paper is organized as follows. In Section 2, we introduce the problem setup, including the governing equations of multiphase flow and the dataset generated by numerical simulation. In Section 3, after providing a brief overview of DeepONet and FNO, we propose a nested Fourier-DeepONet. In Section 4, we highlight the superior computational efficiency of the nested Fourier-DeepONet compared to the nested FNO and demonstrate its generalization capabilities. We summarize the significance of this work in Section 5.
2 Problem setup
In this work, we investigate carbon migration in varying scenarios of injection schemes and subsurface conditions for GCS. We model 3D GCS as a multiphase flow of CO2 and water in a porous media to predict pressure buildup and gas saturation when injecting CO2 underground over 30 years. To alleviate the computational cost arising from the large spatial and temporal domain, the local refinement technique is employed for data generation, and a nested ML framework is constructed accordingly to make predictions at varying discretizations.
2.1 Governing equations
The problem of GCS is governed by mass balance equations for CO2 and water, where the flux of each phase is determined by an extension of Darcy’s law, which describes fluid flow through a porous medium [31] as follows:
| (1) |
| (2) |
Eqs. (1) and (2) represent the law of conservation of mass for the two species within the system: CO2 and water. On the left side of the equations, denotes the porosity of the media, represents the saturation, stands for density, and signifies the mass fraction of each species, with the subscript indicating the phase. Lastly, denotes the injection rate of CO2.
Although molecular diffusion and hydrodynamic dispersion, , are not explicitly simulated, they are implicitly considered as part of numerical diffusion and dispersion resulting from finite difference gradient approximation [36]. The advective mass flux, denoted as , for component , is governed by Darcy’s law for each phase. Here, denotes absolute permeability, stands for fluid pressure, g represents gravitational acceleration, signifies relative permeability, and indicates viscosity. The fluid pressure for the non-wetting phase, , is the sum of the wetting phase pressure, , and the capillary pressure, .
2.2 Nested grid refinement framework
In this work, we aim to predict pressure buildup and gas saturation over a 30-year period based on reservoir conditions (i.e., permeability field, temperature, and initial pressure) and the injection scheme (i.e., injection rate and location) (Fig. 1).

Grid resolution significantly impacts the accuracy of simulations, creating a trade-off between accuracy and computational cost. As discussed in the Introduction, local refinement technique is commonly used to address this challenge. This refinement technique uses increasing grid resolution with decreasing distance from the injection location. In this study, we employ the grid refinement used in Ref. [36]. In total, we have five levels of resolutions where level 0 indicates a global level, and four remaining levels (1–4) represent increased resolution near the well (Fig. 2). A higher level indicates a finer resolution and closer distance to the injection location. The details of the discretization are presented in Table S1 of Wen et al. [36].

As we have five levels of resolutions for predicting pressure buildup and gas saturation, we train one ML model per level (Fig. 1). The output from each level’s model is used as an input for the subsequent level’s model, in conjunction with reservoir conditions and the injection scheme. Among the five resolution levels, only a model at level 0 does not use predictions from a previous level’s, as it is the initial stage of the nested framework. Consequently, this results in a total of five models for predicting pressure buildup. In contrast, there are four models for gas saturation prediction, as no model is trained for gas saturation at level 0.
2.3 Dataset
We utilize an open-source dataset provided by Wen et al. [36], obtained from the full physics numerical simulator ECLIPSE (e300) [1]. The spatial domain of reservoir sampling includes depths ranging from 800 to 4,500 m, with the temperature calculated based on depth and geothermal gradient. For each reservoir, the simulation domain spans a 100-meter depth relative to the top surface, where the upper bound is 800 m. To prevent interactions between different wells, each well is located at least 5,000 m apart, with injection rates ranging from 0.5 to 2.0 MT/y and perforation thicknesses varying from 20 to 100 m. The dataset also considers the variation of the reservoir dip angles from 0 to 2°. Stanford Geostatistical Modeling Software (SGeMS) [32] was used to produce heterogeneous permeability fields. Table S2 from Wen et al. summarizes the parameters used in generating the dataset, encompassing a wide range of inputs that cover potential scenarios for CO2 injection into saline formations [36].
The dataset comprises a total of 3,009 reservoir simulations, each featuring between 1 to 4 wells, resulting in a sum of 7,455 local-level simulations across all wells. 80% of the dataset is used for training, which includes 24 time snapshots, with time intervals exponentially increasing from 1 day to 30 years.
3 Methods
While scientific machine learning has seen numerous attempts to apply deep neural operators to two-dimensional (2D) problems, there has been a lack of efforts to model the 3D spatial domain. Wen et al. [36] initially employed a nested FNO architecture, demonstrating good accuracy for 3D GCS. However, this architecture suffers from high computational costs and discontinuity of the solution in terms of temporal coordinates [36, 16]. In response, we propose a nested Fourier-DeepONet, which offers improved performance compared to FNO in terms of prediction accuracy while significantly reducing computational cost.
3.1 Fourier-DeepONet
We develop a 3D Fourier-DeepONet based on the 2D Fourier-DeepONet proposed in Refs. [43, 16], which is a hybrid architecture combining a deep operator network (DeepONet) [23] and a Fourier neural operator (FNO) [22]. DeepONet extends the theorem proposed by Chen and Chen [4], which asserts that nonlinear operator mappings between input and output functions can be learned from data using neural networks. On the other hand, the FNO parameterizes the integral kernel in Fourier space [22]. FNO computes convolutions in Fourier space rather than physical space to map the input function and the output function discretized on the same equispaced grid.

In Fourier-DeepONet (Fig. 3), we use DeepONet to encode input through a branch net: permeability map, reservoir temperature, initial pressure, and injection rates. At the same time, the trunk net takes the temporal coordinates as input. The outputs of branch net, , and trunk net, , are merged through pointwise multiplication:
where represents the output of the branch-trunk merge operation, serving as the input to the first Fourier layer.
Fourier-DeepONet consists of Fourier layers which are then applied iteratively starting from the transformed input on the same mesh as the outputs (pressure buildup, gas saturation). Each Fourier layer performs the following:
where uses 3D Fast Fourier Transform (FFT) and uses the inverse 3D FFT. And, denotes the th Fourier layer output. is the weight matrix applied in the Fourier space. Another weight matrix is used for a residual connection to compute the output of the (+1)th Fourier layer output, , using as input. Therefore, output of each Fourier layer can be defined as follows:
where is the bias at th Fourier layer and is the nonlinear activation function. Final output of the Fourier layer is then locally transformed back to the output function dimension parametrized by a fully-connected neural network, , as
In this study, 4 Fourier layers are utilized to decode the output.
Fourier-DeepONet is computationally more efficient than FNO because Fourier-DeepONet uses 3D FFT while FNO uses 4D FFT. This reduction occurs because the output of the trunk net undergoes pointwise multiplication with the branch net output, and thus the final output of Fourier-DeepONet does not include the time dimension. Additionally, Fourier-DeepONet can adopt a batch size for both branch and trunk nets, while FNO is incapable of adjusting the batch size for the time coordinates for training. This further reduces the computational cost compared with using a full time batch size.
3.2 Nested Fourier-DeepONet
As discussed in Section 2.2, to predict pressure buildup, we have five levels of grid resolution that result in five different Fourier-DeepONets. For gas saturation prediction, we use four different Fourier-DeepONets for the four resolution levels. We train each Fourier-DeepONet independently at each level for each output and make a nested prediction starting from level 0 up to level 4.
3.2.1 Networks and resolutions
Fourier-DeepONet used for each level is denoted as , where in the subscript denotes the level of resolution in Fig. 1 for pressure buildup prediction. Similarly, for the prediction of gas saturation, we denote the neural operator as and we only train from level 1 to 4. The spatial domains of Fourier-DeepONets at five different levels are (Fig. 2). The entire spatial and temporal domain of each Fourier-DeepONet is , and denotes the temporal domain up to 30 years. The architecture of each Fourier-DeepONet in nested Fourier-DeepONet, including the output shape of each operation for levels 0 to 4, is shown in Tables 3, 4, and 5 in the Appendix A.
3.2.2 Training
For training , we use the reservoir condition and injection scheme as input to the neural operator. For training subsequent levels, we use the true output from the previous level as input in addition to the reservoir condition and injection scheme. Specifically, and use pressure buildup in surrounding each well in the and directions with a width and length of 48 km. For the remaining models, and for = 2–4, the entire ground truth output of the previous level is used for training to predict pressure buildup or gas saturation.
3.2.3 Inference
For a reservoir with wells, the final prediction is combined from network predictions for either pressure buildup or gas saturation prediction. This is because there are four levels of refinement around each injection location, which results in four network predictions per well in addition to the global level prediction. The prediction of pressure buildup at the global level (level 0) around each well will be used as input for the next level (level 1) for pressure buildup and gas saturation per well. Then, each subsequent level , where = 2–4, will be provided with entire outputs from the previous level . When different levels of resolution are combined to construct the entire spatial domain, the subsequent level replaces the overlapping region.
Although we use ground truth output from the previous level as an input for training purposes, it is not possible to obtain ground truth from the previous level in inference scenarios, which necessitates a sequential prediction as described above. Because the nested architecture is designed in such a way that subsequent levels depend on predictions from the previous level, it is susceptible to accumulating errors. To address this, a fine-tuning step is performed to enhance the generalizability.
3.3 Fine-tuning procedure
We adopt a fine-tuning procedure by adding a random perturbation to the network inputs as introduced in Ref. [36]. Specifically for training the subsequent level’s model, we perturb the ground truth output from the previous level by adding the randomly sampled model error. For instance, after the training procedure described in Section 3.2.2, to fine-tune the pressure buildup model at level , the model is further trained using the noised input computed as follows:
corresponds to noised ground truth pressure buildup (). To generate the noise, , we apply the trained model at level to the training dataset and compute the error between the ground truth and the network predictions which results in a set of errors. Then, we randomly sample from the set of errors to obtain the error, . The same procedure can be applied to fine-tuning gas saturation models. We follow Ref. [36] and apply this fine-tuning procedure to , , , and .
3.4 Details of training and evaluation
As Fourier-DeepONet separates temporal coordinates through a trunk network, we have an additional option to select their batch size for training. We observe that GPU memory consumption grows linearly (Fig. 4A) and training time decreases with respect to the time batch size (Fig. 4B) at the global level’s pressure buildup model as an example. In this work, we used a batch size of 6 among the 24-time snapshots, as it significantly reduces GPU memory usage without sacrificing model accuracy (Fig. 4C) and training time efficiency.

For the branch net, we use a batch size of 1, identical to that of Wen et al.’s FNO [36]. We utilized the relative error for training the nested Fourier-DeepONet. The learning rate is set to 0.001, and the Adam optimizer is employed with a decay rate of 0.9 every two epochs. To evaluate error between the model prediction ( and ) and ground truth ( and ), we adopt the same metric as used by Wen et al. [36]:
| (3) |
| (4) |
where if or which is used to prevent overestimation and focus on the error within the plume. Here, denotes the ( = 24) time snapshots over 30 years, given by = {10d, 20d, 30d, 50d, 80d, 110d, 150d, 210d, 280d, 1.0y, 1.3y, 1.7y, 2.2y, 2.8y, 3.6y, 4.6y, 5.9y, 7.5y, 9.4y, 11.9y, 15.0y, 19.0y, 23.9y, 30y}. represents the number of cells in the mesh of . For pressure buildup error, , the absolute difference between the prediction, , and the ground truth, , at each level is normalized by the maximum pressure of the reservoir at each time step, . To evaluate the total error per reservoir, or , we use the following metric:
| (5) |
| (6) |
4 Results
In this section, we highlight the superior computational efficiency of Fourier-DeepONet in terms of both GPU memory consumption and training time. Additionally, we demonstrate the generalization capabilities of the nested Fourier-DeepONet through various experiments, including temporal extrapolation and extrapolation on subsurface conditions and injection schemes. All training experiments were conducted using the NVIDIA A100 80GB GPU. All codes, implemented using the Python library DeepXDE [25], and the dataset will be provided in the following GitHub repository: https://github.com/lu-group/nested-fourier-deeponet-gcs-3d.
4.1 Computational efficiency
As discussed in Section 3.1, the reduced dimension of FFT and flexible batch size for time coordinates result in twice faster training and significant (at least 80%) reduction in GPU memory consumption (Table 1), enabling the training of Fourier-DeepONets even on GPUs with limited memory. Additionally, they lead to a substantial reduction of more than 80% in the number of trainable parameters, both at global and local resolutions, compared to FNO in Ref. [36].
| Model | Level | No. of parameters | GPU memory (GiB) | Training time (hour) |
| FNO [36] | Global | 80.3 M | 33.1 | 37.6 |
| Local 1 | 150.5 M | 18.5 | 41.7 | |
| Local 2–4 | 150.5 M | 25.4 | 61.3 | |
| Fourier-DeepONet | Global | 13.1 M | 4.9 | 14.9 |
| Local 1 | 20.8 M | 3.3 | 20.5 | |
| Local 2–4 | 20.8 M | 5.0 | 28.3 |
4.2 Pressure buildup prediction
In addition to the computational efficiency, nested Fourier-DeepONet demonstrates similar or better accuracy for predicting pressure buildup. We compare the accuracy of Fourier-DeepONets and the state-of-the-art FNOs [36] at all levels in Table 2. As the code for computing the evaluation metrics from Ref. [36] was not public, we implemented our own code for Eqs. (3)–(6). For the accuracy of FNO, we include the accuracy from Ref. [36] and we also report the accuracy from our own FNOs trained using their public code but evaluated using our evaluation metric code.
Regardless of whether the models are fine-tuned or not, nested Fourier-DeepONet showcases superior performances across all levels compared with nested FNO we trained. Because errors in Table 2 accumulate at each subsequent level, to demonstrate the accuracy of each individual network, we present the test errors using ground truth input in Table 6 in Appendix B. For individual networks, Fourier-DeepONet has better accuracy for almost all levels except level 3 for the prediction of pressure buildup.
| Nested Fourier-DeepONet | Nested FNO | Nested FNO [36] | |||||
| Without fine-tuning | With fine-tuning | Without fine-tuning | With fine-tuning | Without fine-tuning | With fine-tuning | ||
| Pressure | 0.668% | 0.565% | 0.833% | 0.625% | – | 0.47% | |
| 0.020% | 0.020% | 0.025% | 0.025% | 0.02% | 0.02% | ||
| 0.174% | 0.173% | 0.222% | 0.233% | 0.24% | 0.16% | ||
| 0.329% | 0.318% | 0.400% | 0.374% | 0.41% | 0.30% | ||
| 0.557% | 0.550% | 0.654% | 0.576% | 0.68% | 0.51% | ||
| 1.433% | 1.110% | 1.801% | 1.205% | 1.88% | 0.82% | ||
| Saturation | 1.518% | 1.461% | 1.663% | 1.622% | – | 1.79% | |
| 1.331% | 1.290% | 1.650% | 1.419% | 1.55% | 1.39% | ||
| 1.675% | 1.569% | 1.936% | 1.802% | 1.93% | 1.91% | ||
| 1.649% | 1.583% | 1.888% | 1.737% | 2.00% | 1.77% | ||
| 1.439% | 1.380% | 1.563% | 1.545% | 1.95% | 1.82% | ||
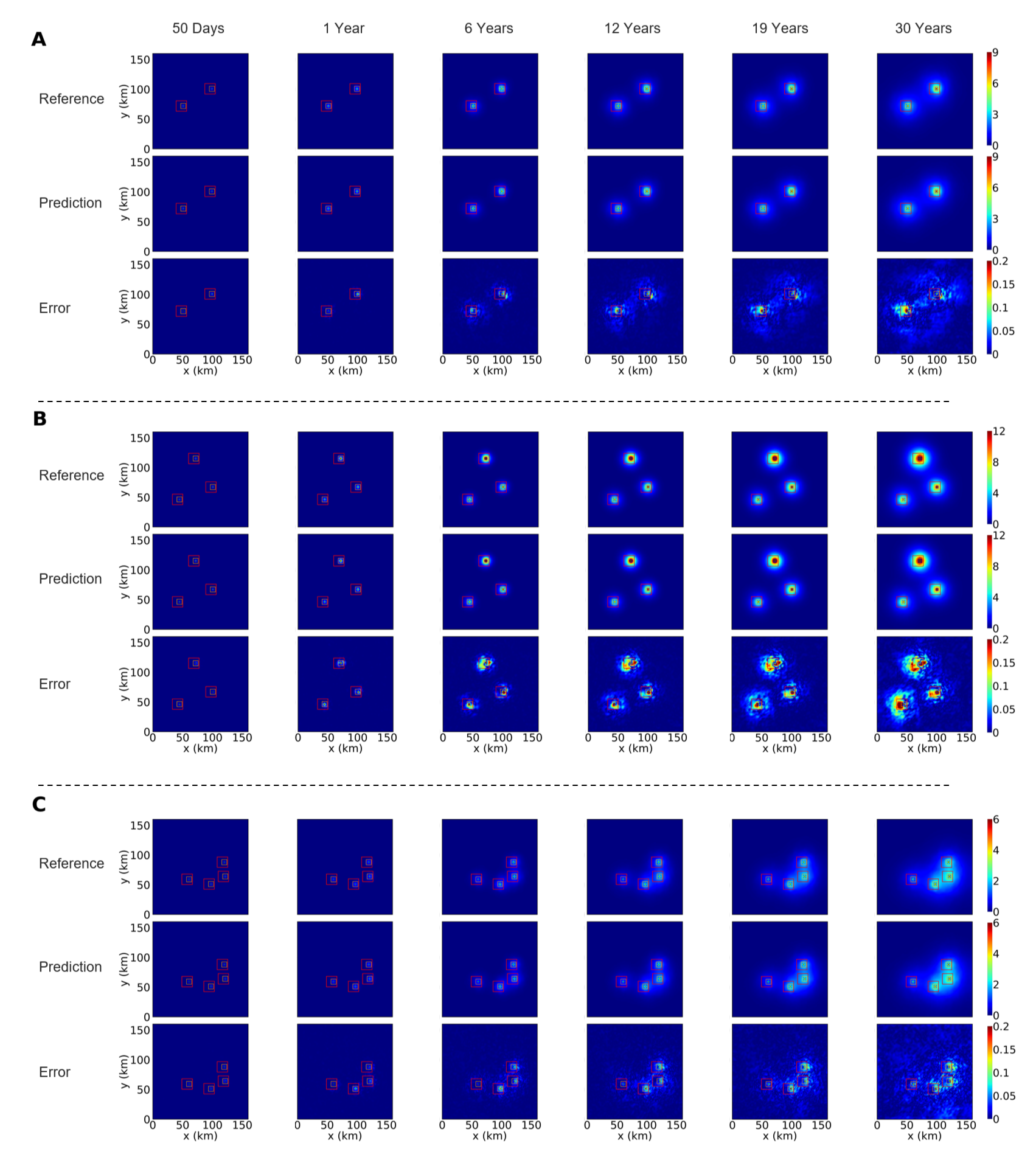
We show pressure buildup predictions and errors (-view at the top layer) of three randomly selected reservoirs with 2–4 wells at 6 different time snapshots, = {50d, 1.0y, 7.5y, 19.0y, 23.9y, and 30y} in Fig. 5. At early times where there is no significant pressure gradient, the error is the lowest. The error increases with time as the injection of CO2 results in the buildup of pressure. For the pressure buildup of the first example (Fig. 5A), both cross-sectional -view at the top layer and -view around the injection point (level 1–4) are shown in Fig. 6A. By employing locally refined models, the errors are significantly reduced through predictions at refined resolutions.

4.3 Gas saturation prediction
For gas saturation network models, the accuracy of nested Fourier-DeepONet and nested FNO is also shown in Table 2. As mentioned in Section 3.4, we do not train the gas saturation model at the global level. As we were able to achieve better accuracy at the global level () and level 1 () for individual prediction (Table 6), the cumulative error arising from earlier levels resulted in lower accuracy with Fourier-DeepONets for both fine-tuned models and those without tuning. This highlights the importance of achieving robust accuracy at earlier levels when using a nested framework.
As shown in Fig. 6B, the CO2 plume footprint is contained within the domain of level 1 even at 30 years of CO2 injection. The error tends to be the largest at the boundary of the footprint in addition to the injection location.
4.4 Generalization and extrapolation capability of nested Fourier-DeepONet
To further investigate the generalizability of nested Fourier-DeepONet on unseen datasets, we conducted experiments to assess its performance under different extrapolation scenarios in terms of reservoir conditions (Sections 4.4.1 and 4.4.2), injection schemes (Section 4.4.3), and temporal coordinates (Section 4.4.4). For temporal extrapolation, we train models based on the first 21 time snapshots out of 24 while using all training samples.

4.4.1 Number of wells
Our dataset contains reservoirs with 1–4 injection wells. Here, we investigate the extrapolation capabilities of Fourier-DeepONet on the number of wells. Specifically, reservoirs containing 1–3 wells (1806 samples) were used to train Fourier-DeepONet at level 0, . Then, we evaluate their prediction accuracy on reservoirs containing 4 wells for pressure buildup prediction, which we refer to as extrapolation. We did not separately train local level (1–4) models for this scenario because the local level models are not subject to the number of wells.
We observe comparable errors for predictions on reservoirs with 1–3 wells (i.e. interpolation) between the baseline model and the model trained with 1–3 wells (Fig. 7A). The baseline model refers to the nested Fourier-DeepONet without fine-tuning in Table 2, which has been trained on the entire dataset. For reservoirs with 4 wells, the third quartile of error in predicting pressure buildup using the extrapolation model is below 2%. This result suggests that the nested Fourier-DeepONet demonstrates strong generalization capabilities across different well configurations.
4.4.2 Permeability field
We assess the extrapolation capability of Fourier-DeepONet on the permeability field by dividing the dataset into five clusters based on the average value of the 3D permeability field in the reservoirs. In the dataset, the permeability fields are well clustered into five groups when projected into a 2D space of mean and variance values (Fig. 7B). The cutoff values separating the clusters, from Group 1 to Group 5, are 1.02, 1.1, 1.25, and 1.377 ln mD, as shown in different colors in Fig. 7B. For this experiment, we select samples from the first four groups for training, which represent 55% (1637 samples) of the original training dataset .
For both pressure buildup and gas saturation prediction, the errors between the baseline model and the extrapolation model are comparable in the interpolation regime (Group 1 to Group 4). Despite the observed error increase in the extrapolation regime (Group 5), the median error for pressure buildup prediction remains below 2%, and the error for gas saturation prediction stays below 5% (Fig. 7B). Because samples with high permeability field mean have larger variances, and having a highly permeable field leads to easier migration of CO2 through the media, it can become more difficult for the model to make accurate predictions under such subsurface conditions. This implies that it is more efficient to allocate computing resources to obtaining datasets of permeability fields of a high magnitude. This analysis offers further insight into the data generation process, indicating that training the models with a broader range of permeability fields, particularly at higher permeabilities, would enhance overall accuracy with minimal tradeoffs regarding lower prediction errors at a lower permeability regime.
4.4.3 Injection rate
Next, we conduct an extrapolation study based on injection rates. We differentiate the samples by their maximum injection rate for pressure buildup models, but we look at each injection rate to differentiate the samples for gas saturation models. Samples with multiple wells inherently have a higher probability of having a larger maximum injection rate, so we use less number of samples for training pressure buildup models (1155 for and 2425 for ) than gas saturation models (4325 for ). The pressure buildup extrapolation models are trained with samples with maximum injection rates up to 1.6 MT/year at the global level and the corresponding samples are selected for training at local levels. On the other hand, we only consider the injection rate for each well for training gas saturation models.
As shown in Fig. 7C, we observe a moderate increase in error when predicting pressure buildup for maximum injection rates above 1.6 MT/yr per reservoir. This increase is not only due to extrapolation errors but also the reduced number of training samples ( 40% of the total samples) available at injection rates below 1.6 MT/yr. Notably, the error increase observed when using a model trained on injection rates up to 1.6 MT/yr for predicting samples in the 1.4–1.6 MT/yr range (interpolation regime) is comparable to that seen in the extrapolation regime relative to a baseline model. This suggests that the contribution of extrapolation errors may be minimal, as a similar error increase is observed within the interpolation regime. Similarly, the error in gas saturation predictions increases to a similar extent for samples with injection rates between 1.4 and 1.6 MT/yr and those above 1.6 MT/yr. This trend indicates that the extrapolation error in the gas saturation model trained on injection rates below 1.6 MT/yr is also likely to be small.
4.4.4 Extrapolation in time
The final experiment involves a temporal extrapolation. Instead of training a model with a reduced number of reservoir samples as in Sections 4.4.1 to 4.4.3, we train models with a limited number of time snapshots (21 out of 24) up to 15 years to assess their generalization capabilities up to 30 years. We train both a nested Fourier-DeepONet and a nested FNO to demonstrate the superior performance of a nested Fourier-DeepONet in temporal extrapolation.
Nested Fourier-DeepONet, trained up to 15 years, exhibits a similar error in the interpolation regime as the baseline model, but only slightly higher errors in the extrapolation regime (Fig. 7D). The rise in error using a nested Fourier-DeepONet is relatively moderate, especially compared to FNO. This is because the use of a trunk net from Fourier-DeepONet allows the solution to be continuous over time, rather than using a separate channel for each time step like FNO. For example, nested Fourier-DeepONet that has been trained up to 15 years extrapolated on 30 years with less than 1% error increase for pressure buildup prediction compared with a baseline model, which is a significant improvement over FNO. Although we observe a moderate error increase in gas saturation prediction (Fig. 7E), Fourier-DeepONet still exhibits roughly a 10% decrease in error compared to FNO. This experiment enables us to assess the model’s performance in the temporal extrapolation regime.
5 Conclusions
In this work, we have developed a nested Fourier-DeepONet framework for simulating a 3D GCS over 30 year period. We also have demonstrated its superior performance over nested FNO not only in accuracy but also in computational efficiency. Fourier-DeepONet is faster in training compared to FNO, thanks to the reduced number of trainable parameters and lower consumption of GPU memory achieved by selecting a smaller time batch size.
Previous 2D GCS experiments by Jiang et al. [16] in temporal interpolation have shown better performance compared to FNO, as the trunk net guarantees continuous prediction with respect to time. Building upon this, our extrapolation experiments have further revealed that the nested Fourier-DeepONet exhibits good extrapolation capability across various scenarios (i.e., number of wells, permeability field, injection rate, time coordinates). This extrapolation analysis provides valuable insight into the maximization of model performance from a limited dataset.
Currently, there are still some limitations to the application of deep neural operators to real-world problems. First, since the current method relies solely on data, the size of the dataset significantly influences the predictive capability of the neural operators. Although deep neural operators demonstrate good generalizability, subsurface conditions can vary widely between sites. To address this challenge, one common approach is to incorporate physics-informed loss functions during neural network training. Another limitation of the current nested framework is the need to train a model for each level, which can be time-consuming. Future advancements could involve developing architectures capable of handling non-equispaced meshes with varying grid points and resolutions. For example, a deep neural operator should be able to train and predict in reservoirs with varying well configurations, involving different numbers of cells.
Acknowledgments
This work was supported by ExxonMobil Technology and Engineering Company and U.S. Department of Energy Office of Advanced Scientific Computing Research under Grants No. DE-SC0025592 and No. DE-SC0025593. We thank Gege Wen et al. for making the dataset public and Alex GK Lee for providing valuable feedback.
Disclosure statement
No potential conflict of interest was reported by the authors.
Author contributions statement
Jonathan E. Lee: Writing – review & editing, Writing – original draft, Visualization, Validation, Software, Methodology, Investigation, Formal analysis, Data curation. Min Zhu: Writing – review & editing, Writing – original draft, Visualization, Validation, Software, Methodology, Investigation, Formal analysis, Data curation. Ziqiao Xi: Visualization, Investigation. Kun Wang: Writing – review & editing, Supervision, Funding acquisition. Yanhua O. Yuan: Writing – review & editing, Supervision, Funding acquisition. Lu Lu: Writing – review & editing, Writing – original draft, Supervision, Resources, Project administration, Methodology, Funding acquisition, Formal analysis, Conceptualization.
Data availability statement
Training data and the code supporting the findings of this study will be available in GitHub at https://github.com/lu-group/nested-fourier-deeponet-gcs-3d. These data were derived from the following resources available in the public domain: Ref. [36].
Appendix A Fourier-DeepONet architecture
The network architectures of Fourier-DeepONets for all levels mentioned in Section 3.2 are shown in Tables 3, 4, and 5.
| Operation | Output shape | ||
| Branch net | Padding(8), Linear | (C, 116, 116, 21, 32) | |
| Trunk net | Linear | (T, 32) | |
| Merge operation | Point-wise multiplication | (C T, 116, 116, 21, 32) | |
| Merge net | Fourier 1 | Fourier3d/Conv1d/Add/GELU | (C T, 116, 116, 21, 32) |
| Fourier 2 | Fourier3d/Conv1d/Add/GELU | (C T, 116, 116, 21, 32) | |
| Fourier 3 | Fourier3d/Conv1d/Add/GELU | (C T, 116, 116, 21, 32) | |
| Fourier 4 | Fourier3d/Conv1d/Add/GELU | (C T, 116, 116, 21, 32) | |
| De-padding | De-padding(8) | (C T, 100, 100, 5, 32) | |
| Projection 1 | Linear | (C T, 100, 100, 5, 128) | |
| Projection 2 | Linear | (C T, 100, 100, 5, 1) | |
| Reshape | - | (C, T, 100, 100, 5) |
| Operation | Output shape | ||
| Branch net | Padding(8), Linear | (C, 56, 56, 41, 36) | |
| Trunk net | Linear | (T, 36) | |
| Merge operation | Point-wise multiplication | (C T, 56, 56, 41, 36) | |
| Merge net | Fourier 1 | Fourier3d/Conv1d/Add/GELU | (C T, 56, 56, 41, 36) |
| Fourier 2 | Fourier3d/Conv1d/Add/GELU | (C T, 56, 56, 41, 36) | |
| Fourier 3 | Fourier3d/Conv1d/Add/GELU | (C T, 56, 56, 41, 36) | |
| Fourier 4 | Fourier3d/Conv1d/Add/GELU | (C T, 56, 56, 41, 36) | |
| De-padding | De-padding(8) | (C T, 40, 40, 25, 36) | |
| Projection 1 | Linear | (C T, 40, 40, 25, 144) | |
| Projection 2 | Linear | (C T, 40, 40, 25, 1) | |
| Reshape | - | (C, T, 40, 40, 25) |
| Operation | Output shape | ||
| Branch net | Padding(8), Linear | (C, 56, 56, 66, 36) | |
| Trunk net | Linear | (T, 28) | |
| Merge operation | Point-wise multiplication | (C T, 56, 56, 66, 36) | |
| Merge net | Fourier 1 | Fourier3d/Conv1d/Add/GELU | (C T, 56, 56, 66, 36) |
| Fourier 2 | Fourier3d/Conv1d/Add/GELU | (C T, 56, 56, 66, 36) | |
| Fourier 3 | Fourier3d/Conv1d/Add/GELU | (C T, 56, 56, 66, 36) | |
| Fourier 4 | Fourier3d/Conv1d/Add/GELU | (C T, 56, 56, 66, 36) | |
| De-padding | De-padding(8) | (C T, 40, 40, 50, 36) | |
| Projection 1 | Linear | (C T, 40, 40, 50, 144) | |
| Projection 2 | Linear | (C T, 40, 40, 50, 1) | |
| Reshape | - | (C, T, 40, 40, 50) |
Appendix B Prediction accuracy for individual networks
Table 6 shows the test accuracy of the nested Fourier-DeepONet and nested FNO models, where ground truth outputs from the previous level are used for and , with = 1–4. Although this approach is not feasible in practice, it allows us to assess how well the model was trained at each individual level. Table 2 corresponds to the “sequential” prediction accuracy, while Table 6 represents the “separate” prediction accuracy, as presented in Table 7 of Ref. [36].
| Domain | Nested Fourier-DeepONet | Nested FNO | Nested FNO [36] | |
| Pressure | 0.069% | 0.080% | - | |
| 0.020% | 0.025% | 0.02% | ||
| 0.039% | 0.061% | 0.10% | ||
| 0.044% | 0.046% | 0.16% | ||
| 0.059% | 0.058% | 0.14% | ||
| 0.128% | 0.148% | 0.45% | ||
| Saturation | 0.486% | 0.461% | - | |
| 1.073% | 1.271% | 1.27% | ||
| 0.733% | 0.667% | 1.00% | ||
| 0.562% | 0.480% | 0.61% | ||
| 0.478% | 0.455% | 0.74% |
References
- [1] Eclipse reservoir simulation software reference manual, 2014.
- [2] Blunt, M. J. Multiphase Flow in Permeable Media: A Pore-Scale Perspective. Cambridge University Press, Oct. 2016.
- [3] Bramble, J. H., Ewing, R. E., Pasciak, J. E., and Schatz, A. H. A preconditioning technique for the efficient solution of problems with local grid refinement. Computer Methods in Applied Mechanics and Engineering 67, 2 (Mar. 1988), 149–159.
- [4] Chen, T., and Chen, H. Universal approximation to nonlinear operators by neural networks with arbitrary activation functions and its application to dynamical systems. IEEE Transactions on Neural Networks 6, 4 (July 1995), 911–917.
- [5] Chen, Y., Lu, L., Karniadakis, G. E., and Dal Negro, L. Physics-informed neural networks for inverse problems in nano-optics and metamaterials. Optics Express 28, 8 (Apr. 2020), 11618.
- [6] Clark Di Leoni, P., Lu, L., Meneveau, C., Karniadakis, G. E., and Zaki, T. A. Neural operator prediction of linear instability waves in high-speed boundary layers. Journal of Computational Physics 474 (Feb. 2023), 111793.
- [7] Daneker, M., Cai, S., Qian, Y., Myzelev, E., Kumbhat, A., Li, H., and Lu, L. Transfer learning on physics-informed neural networks for tracking the hemodynamics in the evolving false lumen of dissected aorta. Nexus 1, 2 (June 2024), 100016.
- [8] Daneker, M., Zhang, Z., Karniadakis, G. E., and Lu, L. Systems Biology: Identifiability Analysis and Parameter Identification via Systems-Biology-Informed Neural Networks. Springer US, 2023, p. 87–105.
- [9] Deng, B., Shin, Y., Lu, L., Zhang, Z., and Karniadakis, G. E. Approximation rates of DeepONets for learning operators arising from advection–diffusion equations. Neural Networks 153 (Sept. 2022), 411–426.
- [10] Doughty, C. Investigation of CO2 plume behavior for a large-scale pilot test of geologic carbon storage in a saline formation. Transport in Porous Media 82, 1 (May 2009), 49–76.
- [11] Eigestad, G. T., Dahle, H. K., Hellevang, B., Riis, F., Johansen, W. T., and Øian, E. Geological modeling and simulation of CO2 injection in the johansen formation. Computational Geosciences 13, 4 (Aug. 2009), 435–450.
- [12] Faigle, B., Helmig, R., Aavatsmark, I., and Flemisch, B. Efficient multiphysics modelling with adaptive grid refinement using a mpfa method. Computational Geosciences 18, 5 (Mar. 2014), 625–636.
- [13] Fan, B., Qiao, E., Jiao, A., Gu, Z., Li, W., and Lu, L. Deep learning for solving and estimating dynamic macro-finance models. Computational Economics (Aug. 2024).
- [14] Hayford, J., Goldman-Wetzler, J., Wang, E., and Lu, L. Speeding up and reducing memory usage for scientific machine learning via mixed precision. Computer Methods in Applied Mechanics and Engineering 428 (Aug. 2024), 117093.
- [15] Jagtap, A. D., and Karniadakis, G. E. Extended physics-informed neural networks (XPINNs): A generalized space-time domain decomposition based deep learning framework for nonlinear partial differential equations. Communications in Computational Physics 28, 5 (2020).
- [16] Jiang, Z., Zhu, M., and Lu, L. Fourier-MIONet: Fourier-enhanced multiple-input neural operators for multiphase modeling of geological carbon sequestration. Reliability Engineering & System Safety 251 (2024), 110392.
- [17] Jiao, A., He, H., Ranade, R., Pathak, J., and Lu, L. One-shot learning for solution operators of partial differential equations. arXiv preprint arXiv:2104.05512 (2021).
- [18] Jin, P., Meng, S., and Lu, L. MIONet: Learning multiple-input operators via tensor product. SIAM Journal on Scientific Computing 44, 6 (Nov. 2022), A3490–A3514.
- [19] Kamashev, A., and Amanbek, Y. Reservoir simulation of CO2 storage using compositional flow model for geological formations in frio field and precaspian basin. Energies 14, 23 (Dec. 2021), 8023.
- [20] Karniadakis, G. E., Kevrekidis, I. G., Lu, L., Perdikaris, P., Wang, S., and Yang, L. Physics-informed machine learning. Nature Reviews Physics 3, 6 (May 2021), 422–440.
- [21] Khebzegga, O., Iranshahr, A., and Tchelepi, H. Continuous relative permeability model for compositional simulation. Transport in Porous Media 134, 1 (July 2020), 139–172.
- [22] Li, Z., Kovachki, N., Azizzadenesheli, K., Liu, B., Bhattacharya, K., Stuart, A., and Anandkumar, A. Fourier neural operator for parametric partial differential equations, 2020.
- [23] Lu, L., Jin, P., Pang, G., Zhang, Z., and Karniadakis, G. E. Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators. Nature Machine Intelligence 3, 3 (Mar. 2021), 218–229.
- [24] Lu, L., Meng, X., Cai, S., Mao, Z., Goswami, S., Zhang, Z., and Karniadakis, G. E. A comprehensive and fair comparison of two neural operators (with practical extensions) based on FAIR data. Computer Methods in Applied Mechanics and Engineering 393 (Apr. 2022), 114778.
- [25] Lu, L., Meng, X., Mao, Z., and Karniadakis, G. E. Deepxde: A deep learning library for solving differential equations. SIAM Review 63, 1 (Jan. 2021), 208–228.
- [26] Lu, L., Pestourie, R., Johnson, S. G., and Romano, G. Multifidelity deep neural operators for efficient learning of partial differential equations with application to fast inverse design of nanoscale heat transport. Physical Review Research 4, 2 (June 2022).
- [27] Lu, L., Pestourie, R., Yao, W., Wang, Z., Verdugo, F., and Johnson, S. G. Physics-informed neural networks with hard constraints for inverse design. SIAM Journal on Scientific Computing 43, 6 (Jan. 2021), B1105–B1132.
- [28] Mao, S., Dong, R., Lu, L., Yi, K. M., Wang, S., and Perdikaris, P. PPDONet: Deep operator networks for fast prediction of steady-state solutions in disk–planet systems. The Astrophysical Journal Letters 950, 2 (June 2023), L12.
- [29] Mo, S., Zhu, Y., Zabaras, N., Shi, X., and Wu, J. Deep convolutional encoder‐decoder networks for uncertainty quantification of dynamic multiphase flow in heterogeneous media. Water Resources Research 55, 1 (Jan. 2019), 703–728.
- [30] Orr, F. M. Theory of gas injection processes. Tie-Line Publications, 2007.
- [31] Pruess, K., and García, J. Multiphase flow dynamics during CO2 disposal into saline aquifers. Environmental Geology 42, 2–3 (Mar. 2002), 282–295.
- [32] Remy, N., Boucher, A., and Wu, J. Applied Geostatistics with SGeMS: A User’s Guide. Cambridge University Press, Jan. 2009.
- [33] Tang, M., Liu, Y., and Durlofsky, L. J. A deep-learning-based surrogate model for data assimilation in dynamic subsurface flow problems. Journal of Computational Physics 413 (July 2020), 109456.
- [34] Wen, G., and Benson, S. M. CO2 plume migration and dissolution in layered reservoirs. International Journal of Greenhouse Gas Control 87 (Aug. 2019), 66–79.
- [35] Wen, G., Hay, C., and Benson, S. M. CCSNet: a deep learning modeling suite for CO2 storage. Advances in Water Resources 155 (2021), 104009.
- [36] Wen, G., Li, Z., Long, Q., Azizzadenesheli, K., Anandkumar, A., and Benson, S. M. Real-time high-resolution CO2 geological storage prediction using nested fourier neural operators. Energy & Environmental Science 16, 4 (2023), 1732–1741.
- [37] Wen, G., Tang, M., and Benson, S. M. Towards a predictor for CO2 plume migration using deep neural networks. International Journal of Greenhouse Gas Control 105 (Feb. 2021), 103223.
- [38] Wu, C., Zhu, M., Tan, Q., Kartha, Y., and Lu, L. A comprehensive study of non-adaptive and residual-based adaptive sampling for physics-informed neural networks. Computer Methods in Applied Mechanics and Engineering 403 (Jan. 2023), 115671.
- [39] Wu, W., Daneker, M., Jolley, M. A., Turner, K. T., and Lu, L. Effective data sampling strategies and boundary condition constraints of physics-informed neural networks for identifying material properties in solid mechanics. Applied Mathematics and Mechanics 44, 7 (July 2023), 1039–1068.
- [40] Yazdani, A., Lu, L., Raissi, M., and Karniadakis, G. E. Systems biology informed deep learning for inferring parameters and hidden dynamics. PLOS Computational Biology 16, 11 (Nov. 2020), e1007575.
- [41] Yu, J., Lu, L., Meng, X., and Karniadakis, G. E. Gradient-enhanced physics-informed neural networks for forward and inverse pde problems. Computer Methods in Applied Mechanics and Engineering 393 (Apr. 2022), 114823.
- [42] Zhang, Z., Moya, C., Lu, L., Lin, G., and Schaeffer, H. D2NO: Efficient handling of heterogeneous input function spaces with distributed deep neural operators. Computer Methods in Applied Mechanics and Engineering 428 (Aug. 2024), 117084.
- [43] Zhu, M., Feng, S., Lin, Y., and Lu, L. Fourier-DeepONet: Fourier-enhanced deep operator networks for full waveform inversion with improved accuracy, generalizability, and robustness. Computer Methods in Applied Mechanics and Engineering 416 (2023), 116300.
- [44] Zhu, M., Zhang, H., Jiao, A., Karniadakis, G. E., and Lu, L. Reliable extrapolation of deep neural operators informed by physics or sparse observations. Computer Methods in Applied Mechanics and Engineering 412 (2023), 116064.
- [45] Zhu, Y., and Zabaras, N. Bayesian deep convolutional encoder–decoder networks for surrogate modeling and uncertainty quantification. Journal of Computational Physics 366 (Aug. 2018), 415–447.