Effective temperature in approximate quantum many-body states
Abstract
In the pursuit of numerically identifying the ground state of quantum many-body systems, approximate quantum wavefunction ansatzes are commonly employed. This study focuses on the spectral decomposition of these approximate quantum many-body states into exact eigenstates of the target Hamiltonian. The energy spectral decomposition could reflect the intricate physics at the interplay between quantum systems and numerical algorithms. Here we examine various parameterized wavefunction ansatzes constructed from neural networks, tensor networks, and quantum circuits, employing differentiable programming to numerically approximate ground states and imaginary-time evolved states. Our findings reveal a consistent exponential decay pattern in the spectral contributions of approximate quantum states across different ansatzes, optimization objectives, and quantum systems, characterized by small decay rates denoted as inverse effective temperatures. The effective temperature is related to ansatz expressiveness and accuracy and shows phase transition behaviors in learning imaginary-time evolved states. The universal picture and unique features suggest the significance and potential of the effective temperature in characterizing approximate quantum states.
Introduction
Understanding the ground state properties of quantum many-body systems is a central challenge in modern physics, with broad implications ranging from fundamental principles of quantum complexity theories to the design of novel materials and quantum technologies [1, 2, 3, 4]. The exponentially large Hilbert space with the system size often precludes analytical solutions and exact numerical methods, necessitating the development of approximate numerical methods. Among these, the use of approximate quantum wavefunction ansatzes has proven to be powerful for its good trade-off between expressivity and complexity.
In this work, we investigate a profound and previously unexplored aspect of approximate quantum states: the effective temperature that characterizes their spectral properties. The concept of temperature arises from statistical mechanics [5]. Here, we apply this concept to quantum many-body pure states, specifically to the approximate states obtained through optimizing different ansatzes. We investigate the effective temperature and its dynamics during variational training, using both energy expectation and fidelity as objectives.
Our work reveals a surprising universality in the effective temperatures of approximate quantum ground states, irrespective of the ansatz structure, objective function, training wellness, or underlying physical system. By decomposing the approximate states into the exact eigenstates of the system Hamiltonian, we observe a spectrum extending to the high-energy end with exponential decay of small decay factors, interpreted as inverse effective temperatures. The effective temperature also shows an intriguing two-stage behavior when approximating pure states of finite “temperature". The universal pattern could play an important role in understanding complex quantum systems or designing new classical and quantum algorithms. The effective temperature offers a new lens to assess the accuracy and reliability of different variational ansatzes and algorithms, potentially guiding the design of more efficient methods.
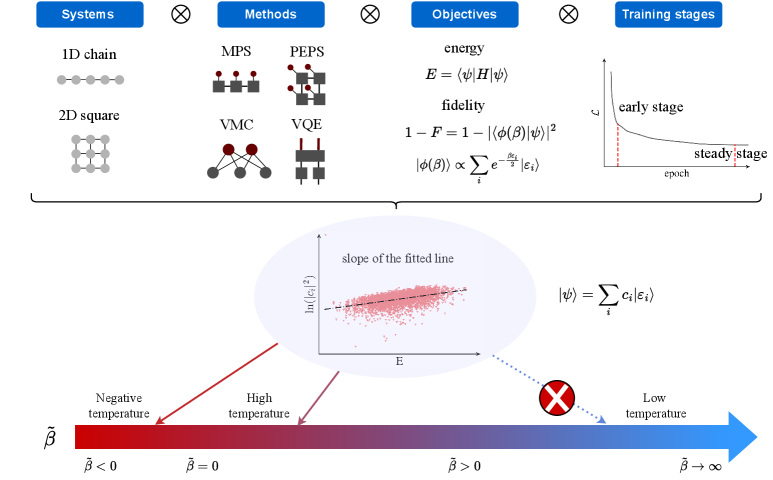
Setups
A wavefunction ansatz comprises a family of parameterized quantum states as with tunable parameters . Such quantum states usually admit a compact and scalable representation on classical computers or quantum computers to circumvent the challenge of the exponentially large Hilbert space for generic quantum many-body systems. The approximate state within the manifold of a given ansatz can be obtained through variational optimization [6] , where is the objective function built on top of the wavefunction. Specifically,
| (1) |
is often utilized to obtain the ground state of the system Hamiltonian . The Hamiltonian has an exact energy spectral decomposition as with being the exact ground state. Additionally, we also frequently utilize the fidelity objective
| (2) |
for numerically approaching ground states. Throughout this work, we perform optimization via gradient descent, namely, the variational parameters are updated in each step according to , where the gradients can be efficiently evaluated using automatic differentiation [7, 8, 9, 10].
For an approximate state , we decompose it on the basis of the exact eigenstates of Hamiltonian :
| (3) |
The spectral decomposition coefficients are the central focus of our study. We find that the pairs of roughly follow an exponential decay for the approximate ground state, analogous with Boltzmann distribution,
| (4) |
where we denote the decay factor as the inverse effective temperature for the pure state under investigation.
To gain deeper insights into the spectrum pattern of approximate quantum states, we evaluate additional target states beyond the ground state . This set of states is directly parameterized with an inverse effective temperature as
| (5) |
where is the normalization factor. These states can be understood as imaginary-time evolved states with time from the initial state . Therefore, we call the target states imaginary-time evolved states (ITES). Exact ITES by default admits an exponential decay for spectral decomposition with inverse temperature . We investigate how spectral properties change for approximate ITES which are obtained by optimizing the fidelity objective . This objective reduces to the ground state target in the limit. We find that the approximate ITES spectrum shows an evident two-stage behavior for all ansatzes: from approximate ITES successfully matches for small (high-temperature regime) and shows deviation for large (low-temperature regime). More importantly, the transition point characterizes the lowest effective temperature a given ansatz can reach and implies the intrinsic power of the corresponding ansatz. Notably, the conclusion remains qualitatively the same when the coefficient for each eigenstate in ITES acquires an extra random phase for generality, i.e. .
In this work, we employ various quantum wavefunction ansatzes to demonstrate the universality of our findings, including (1) tensor-network based ansatz including matrix product states (MPS) [11, 12, 13] and projected entangled-pair states (PEPS) [14, 15], (2) neural quantum states (NQS) built on top of neural networks [16, 17], (3) output states from variational quantum circuits [18, 19] such as variational quantum eigensolvers (VQE), [20, 21] and (4) vector state ansatz (VEC) where each wavefunction component is directly modeled as a trainable parameter. We also comment on the relevance of our results to quantum approximate optimization algorithms (QAOA) [22]. We apply these ansatzes to different system Hamiltonians on different lattice geometries and optimize both objectives and . The main findings of this work are summarized in Fig. 1.

Results for approximate ground states
Since producing the exact spectrum requires a full diagonalization of the Hamiltonian, our numerical study is limited to small systems up to size . We use TensorCircuit-NG [*[][.https://github.com/tensorcircuit/tensorcircuit-ng.]Zhang2022] for the numerical simulation of variational training and QuSpin [24] for the exact diagonalization of the Hamiltonian within full Hilbert space or specific charge sectors.
We focus on the two-dimensional XXZ model on a square lattice with spin- degrees of freedom:
| (6) |
where are Pauli matrices on lattice site and denotes the nearest neighbor sites. The phase diagram of this model, as given in Ref. [25], features that separates the spin-flipping phase and the antiferromagnetic phase when . We impose periodic boundary conditions throughout this work. For lattice, we focus on the half-filling charge sector for spectral decomposition while the variational wavefunction ansatzes are still expressed and optimized in the full Hilbert space for simplicity. For lattice, we utilize the full spectral decomposition for most of the ansatzes while restricting to the half-filling sector for VQE states (see SM for details).

Using different ansatzes and variational optimization against or , we obtain different approximate ground states. The typical spectral decomposition patterns of these states are shown in Fig. 2 (a)(b). (See SM for more spectral decomposition results from other variational ansatzes.) We find a robust exponential relation in the spectral decomposition across different ansatzes and training stages. The exponential decay factor extracted from the fitting plays the role of inverse effective temperature. The training dynamics of for different ansatzes and objectives is shown in Fig. 3. We find that the effective temperature is high during training and this is particularly true for optimized approximate ground states where in most cases. Such a small contrasts sharply with imaginary-time evolution based approaches where a large is expected. During variational training, a general trend emerges where first increases and then decreases, implying an upper bound for the possible of a given ansatz. Besides, training dynamics of show similar patterns for both objectives within the same ansatz while for optimizing energy objectives is typically higher due to the unequal penalty on different excited states. Conversely, fidelity objective equally penalizes all excited states and the finite in this case is attributed to the physical prior encoded in the ansatz structures. This understanding is validated by the near-zero for VEC ansatz, which contains the least physical prior in the structure. Furthermore, the trends are more closely aligned within the same family of ansatzes, reflecting its potential power to diagnose intrinsic properties in these ansatzes. The universality and validness of the results are also confirmed with other system sizes, models, and lattice geometries (see SM for details).
Results for approximate imaginary-time evolved states
To better understand the spectrum pattern and the underlying mechanism of effective temperature in approximate ground states, we evaluate approximate ITES whose targets have strictly exponential decay spectrum patterns. For different target s, we identify a two-stage behavior with a putative phase transition or crossover in between. For the high-temperature regime of small , the approximate ITES conforms to the strict exponential decay spectrum pattern with , as shown in Fig. 2 (c). On the contrary, for the low-temperature regime of large , the spectral decomposition follows the exponential decay only for the low-energy part, while a nearly flat spectrum emerges from high-energy contributions. If we attempt to extract a single exponential decay factor in this case, its value is significantly smaller than the exact , as shown in Fig. 2 (d). It is worth noting that the nearly flat spectrum deviation is not due to numerical machine precision, as points of the same magnitude conform to the exponential decay for small but fail to do so for large (see SM for details).

The results of of approximate ITES for different target s are shown in Fig. 4 (a), where the two-stage behavior is evident. For each ansatz, there is a transition point when begins to deviate from and the associated spectrum pattern moves from Fig. 2 (c) to Fig. 2 (d). is a figure of merit as it marks the critical temperature that the ansatz can accurately represent and sets an upper bound on that an ansatz can reach. More importantly, is also correlated with the expressive capacity of the ansatz, as a higher generally implies a better fidelity. In the low temperature limit , the results for approximate ITES are reduced to the results for approximate ground states by optimizing .
We further remark on the fidelity results shown in Fig. 4 (b) with varying methods and s. For low-accuracy ansatzes, the fidelity gets improved with increasing as of larger is closer to the ground state and has smaller entanglement. Such less entangled states can be better suited in ansatzes of limited expressiveness. Conversely, for high-accuracy ansatzes such as tensor network ansatz with large bond dimensions or VEC, the expressive capacity is sufficient for targeting any ITES, and the bottleneck is the optimization difficulty. Since the number of optimization steps is fixed in our simulation, a slower optimization speed results in a worse final fidelity with increasing . In other words, when the target is closer to the ground state manifold, the optimization landscape is harder to navigate (see quantitative analysis for the expressiveness and optimization hardness in the SM).
Discussions and Conclusion
Some hints of the general picture presented in this work are previously reported in QAOA [26, 27] and MPS cases [28], where the optimization of is considered. In the QAOA case, the output states from the QAOA circuits were found to approximate Gibbs distribution with [26], consistent with the findings in this study, which can be regarded as a special limit of the VQE ansatz. In the MPS case, a nearly flat spectrum is identified [28]. Given that the density of states was effectively considered with Gaussian broadening in their work, the spectrum appeared flatter as the exponential decay of small positive was compensated with the high density of states in the middle-energy regime.
The effective temperature has profound implications for understanding numerical methods and many-body systems. One practical implication of such a high-temperature tail in the spectrum is mentioned in Ref. [28], where sampling based energy variance estimation becomes more fragile than expected. The variance is just an example for operator , with expectation . The operator expectation is highly sensitive to small high-energy components when is significantly larger for high-energy inputs. The effective temperature captures finer details than fidelity as demonstrated in Fig. 4: while the fidelity remains the same for larger , the effective temperature continues to vary. This quantity also has strong relevance to the expressive capacity of ansatzes as values differ for different ansatzes, which further confirms that the two-stage behavior in approximating ITES is not a numerical precision issue. Consequently, the metric and the methodology explored in this work serve as a guiding principle to help design better approximate quantum ansatzes and variational algorithms.
The effective temperature metric opens up several intriguing future research directions. We can quantitatively investigate the scaling of effective temperature and its critical value with respect to varying system sizes, Hamiltonian parameters, and ansatz structure parameters, to gain deeper insights into the physics of the system and the intrinsic patterns in numerical methods. It is also interesting to explore whether some approximation methods can be developed to estimate the effective temperature beyond exact diagonalization sizes. The ITES proposed in this work are also of independent academic interest, as they provide a platform to explore the trade-off between expressiveness and optimization hardness, as well as host a putative phase transition at , the nature and universal behavior of which merit future exploration. It is also crucial to validate the general picture of spectrum patterns on more ansatzes including mean-field ansatz, physics-inspired ansatz [29] and advanced hybrid variational ansatzes [30, 31], and more models including integrable systems, many-body localized systems and fermionic systems.
In this work, we have identified a universal pattern in the spectrum of approximate ground states. We define the effective temperature to characterize the exponential decay in the spectrum and investigate the behavior of with different systems, ansatzes, objectives, and training steps. To better understand the underlying mechanism for this metric, we further propose ITES targets and identify the two-stage behaviors in approximating ITES with the figure of merit critical inverse effective temperature . We believe that the universal picture presented here provides a fresh and powerful perspective on benchmarking numerical algorithms and understanding quantum many-body systems.
Methods
We describe the details of different quantum many-body ansatzes employed in this work. Additional hyperparameters in terms of optimization can be found in Supplemental Materials.
Matrix product states. We use MPS with periodic boundary conditions. The amplitude for the ansatz is given as
| (7) |
where or represents the computational basis and are different tensors with shape . is the bond dimension controlling the expressiveness of the MPS ansatz. For , the ansatz can be an exact representation for any wavefunction in principle even with open boundary conditions. The tensor network graphic representation for the ansatz in Eq. (7) is shown in Fig. 5. Note that we don’t explicitly impose the normalization conditions by canonicalization but leave the MPS ansatz unnormalized. The Hamiltonian expectation is evaluated as
| (8) |
where normalization is explicitly accounted for. For 2D systems, we use the natural order from site to to encode the system sites into 1D MPS. Since we need to consider the full spectrum properties in the calculation, the system size accessible is limited to . Therefore, we don’t rely on the density matrix renormalization group optimization algorithm. Instead, we directly obtain the full wavefunction by contracting the MPS according to Eq. (7) and directly evaluate the Hamiltonian expectation by sparse matrix-vector multiplication where the objective can then be differentiated and variational optimized via gradient descent. For variational optimization, each element in is randomly initialized according to the Gaussian distribution of mean and standard deviation . The total number of variational parameters for MPS ansatz is .

Projected entangled-pair states. The tensor network graphic representation of the PEPS ansatz with periodic boundary conditions is shown in Fig. 6. Similarly, the ansatz is unnormalized by default. During optimization, tensors with shape are randomly initialized with each element following Gaussian distribution of mean and standard deviation . Henceforth, the total number of variational parameters for PEPS is . In the numerical calculation, we first contract the entire PEPS tensor network with physical legs open to directly obtain the full unnormalized wavefunction since the system size is small. We can then compute fidelity or Hamiltonian expectation directly and integrate the whole computation graph with automatic differentiation and variational optimization.

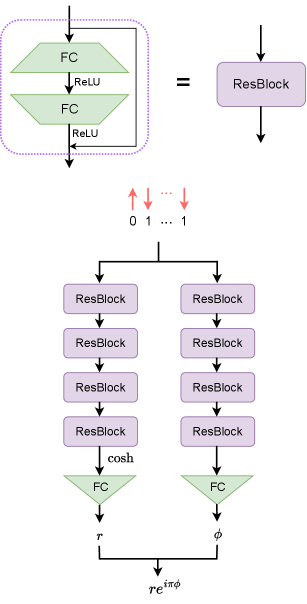
Neural quantum states. For NQS, the probability amplitude is given by the output of neural networks with the input the computational basis, i.e.
| (9) |
where corresponds to the neural network. In this work, we employ a deep neural network with the architecture shown in Fig. 7. Given the small system size, we do not run the variational Monte Carlo method with sampling to optimize the NQS. Instead, similar to the MPS and PEPS cases, we directly evaluate the neural network output on all computational basis inputs to first obtain the (unnormalized) full wavefunction and optimize infidelity or energy based on the wavefunction. The total number of trainable parameters is of order , where is the number of repetitions of the ResBlock and is the width of intermediate fully connected layers. The network width controls the expressiveness of the NQS ansatz.
Variational quantum eigensolver states. In VQE methods, we use the output quantum states from the parameterized quantum circuits (PQC) and the trainable parameters correspond to rotation angles of quantum gates on the PQC. The PQC consists of an initialization block and variational blocks . The initialization block prepares the Bell pair on nearest neighbor qubits so that the initial state is in the sector. Each variation block is given by: , where the total number of circuit parameters is of the order and is the swap gate on qubits and . These parameterized swap gates are applied on the bond between nearest neighbor sites according to the lattice geometry. For 2D square lattice, these two-qubit gates are first applied on all rows following all columns without periodic bonds across the opposite boundaries. For 1D lattice, these two-qubit gates are applied on the system in a ladder fashion with a final periodic bond gate, i.e. the entangling gates apply on the qubit pairs . A schematic of the PQC structure investigated in this work is shown in Fig. 8. The approximate state we use is accordingly. Our numerical simulation for expectation value and fidelity omits quantum noise error and shot sampling error inevitable on real quantum devices. The circuit parameter gradients are obtained via automatic differentiation in our simulation and can be obtained via parameter shift [32] on quantum processors.

Vector states. Since the system size under investigation is small, we can directly build up the so-called vector states ansatz where the wavefunction amplitude of each basis is directly modeled as a trainable parameter. For a spin-1/2 system of size , complex parameters are required, namely, we treat as variational parameters. In our work, the real part and imaginary part of these complex parameters are independently initialized (Gaussian distribution of mean and standard deviation ) and optimized. This is because the Adam optimizer does not work as expected with complex training parameters. This ansatz is expected to encode the least physical prior and be the most unbiased.
Acknowledgments We thank Yi-Fan Jiang, Zi-Xiang Li, and Lei Wang for their valuable discussions. SXZ acknowledges support from a startup grant at CAS-IOP.
References
- Kitaev et al. [2002] A. Kitaev, A. H. Shen, and M. N. Vyalyi, Classical and quantum computation (American Mathematical Soc., Providence, 2002).
- Kempe et al. [2006] J. Kempe, A. Kitaev, and O. Regev, The complexity of the local Hamiltonian problem, SIAM J. Comput. 35, 1070 (2006).
- Zheng et al. [2017] B.-X. Zheng, C.-M. Chung, P. Corboz, G. Ehlers, M.-P. Qin, R. M. Noack, H. Shi, S. R. White, S. Zhang, and G. K.-L. Chan, Stripe order in the underdoped region of the two-dimensional Hubbard model, Science 358, 1155 (2017).
- Lee et al. [2023] S. Lee, J. Lee, H. Zhai, Y. Tong, A. M. Dalzell, A. Kumar, P. Helms, J. Gray, Z.-H. Cui, W. Liu, M. Kastoryano, R. Babbush, J. Preskill, D. R. Reichman, E. T. Campbell, E. F. Valeev, L. Lin, and G. K.-L. Chan, Evaluating the evidence for exponential quantum advantage in ground-state quantum chemistry, Nat. Commun. 14, 1952 (2023).
- Greiner et al. [1995] W. Greiner, L. Neise, and H. Stöcker, Thermodynamics and Statistical Mechanics (Springer New York, New York, NY, 1995).
- Wu et al. [2024] D. Wu, R. Rossi, F. Vicentini, N. Astrakhantsev, F. Becca, X. Cao, J. Carrasquilla, F. Ferrari, A. Georges, M. Hibat-Allah, M. Imada, A. M. Läuchli, G. Mazzola, A. Mezzacapo, A. Millis, J. Robledo Moreno, T. Neupert, Y. Nomura, J. Nys, O. Parcollet, R. Pohle, I. Romero, M. Schmid, J. M. Silvester, S. Sorella, L. F. Tocchio, L. Wang, S. R. White, A. Wietek, Q. Yang, Y. Yang, S. Zhang, and G. Carleo, Variational benchmarks for quantum many-body problems, Science 386, 296 (2024).
- Rumelhart et al. [1986] D. E. Rumelhart, G. E. Hinton, and R. J. Williams, Learning representations by back-propagating errors, Nature 323, 533 (1986).
- Bartholomew-Biggs et al. [2000] M. Bartholomew-Biggs, S. Brown, B. Christianson, and L. Dixon, Automatic differentiation of algorithms, J. Comput. Appl. Math. 124, 171 (2000).
- Liao et al. [2019] H.-J. Liao, J.-G. Liu, L. Wang, and T. Xiang, Differentiable Programming Tensor Networks, Phys. Rev. X 9, 31041 (2019).
- Zhang et al. [2023a] S.-X. Zhang, Z.-Q. Wan, and H. Yao, Automatic differentiable Monte Carlo: Theory and application, Phys. Rev. Res. 5, 033041 (2023a).
- White [1992] S. R. White, Density Matrix Formulation for Quantum Renormalization Groups, Phys. Rev. Lett. 69, 2863 (1992).
- Schollwöck [2011] U. Schollwöck, The density-matrix renormalization group in the age of matrix product states, Ann. Phys. 326, 96 (2011).
- Stoudenmire and White [2012] E. Stoudenmire and S. R. White, Studying Two-Dimensional Systems with the Density Matrix Renormalization Group, Annu. Rev. Condens. Matter Phys. 3, 111 (2012).
- Verstraete and Cirac [2004a] F. Verstraete and J. I. Cirac, Renormalization algorithms for Quantum-Many Body Systems in two and higher dimensions, arXiv:cond-mat/0407066 (2004a).
- Verstraete and Cirac [2004b] F. Verstraete and J. I. Cirac, Valence-bond states for quantum computation, Phys. Rev. A 70, 060302 (2004b).
- Carleo and Troyer [2017] G. Carleo and M. Troyer, Solving the quantum many-body problem with artificial neural networks, Science 355, 602 (2017).
- Deng et al. [2017] D.-L. Deng, X. Li, and S. Das Sarma, Quantum Entanglement in Neural Network States, Phys. Rev. X 7, 021021 (2017).
- Cerezo et al. [2021] M. Cerezo, A. Arrasmith, R. Babbush, S. C. Benjamin, S. Endo, K. Fujii, J. R. McClean, K. Mitarai, X. Yuan, L. Cincio, and P. J. Coles, Variational quantum algorithms, Nat. Rev. Phys. 3, 625 (2021).
- Bharti et al. [2022] K. Bharti, A. Cervera-Lierta, T. H. Kyaw, T. Haug, S. Alperin-Lea, A. Anand, M. Degroote, H. Heimonen, J. S. Kottmann, T. Menke, W.-K. Mok, S. Sim, L.-C. Kwek, and A. Aspuru-Guzik, Noisy intermediate-scale quantum algorithms, Rev. Mod. Phys. 94, 015004 (2022).
- Peruzzo et al. [2014] A. Peruzzo, J. McClean, P. Shadbolt, M.-H. Yung, X.-Q. Zhou, P. J. Love, A. Aspuru-Guzik, and J. L. O’Brien, A variational eigenvalue solver on a photonic quantum processor, Nat. Commun. 5, 4213 (2014).
- Tilly et al. [2022] J. Tilly, H. Chen, S. Cao, D. Picozzi, K. Setia, Y. Li, E. Grant, L. Wossnig, I. Rungger, G. H. Booth, and J. Tennyson, The Variational Quantum Eigensolver: A review of methods and best practices, Phys. Rep. 986, 1 (2022).
- Farhi et al. [2014] E. Farhi, J. Goldstone, and S. Gutmann, A Quantum Approximate Optimization Algorithm, arXiv:1411.4028 (2014).
- Zhang et al. [2023b] S.-X. Zhang, J. Allcock, Z.-Q. Wan, S. Liu, J. Sun, H. Yu, X.-H. Yang, J. Qiu, Z. Ye, Y.-Q. Chen, C.-K. Lee, Y.-C. Zheng, S.-K. Jian, H. Yao, C.-Y. Hsieh, and S. Zhang, TensorCircuit: a Quantum Software Framework for the NISQ Era, Quantum 7, 912 (2023b).
- Weinberg and Bukov [2017] P. Weinberg and M. Bukov, QuSpin: a Python package for dynamics and exact diagonalisation of quantum many body systems part I: spin chains, SciPost Phys. 2, 003 (2017).
- Yunoki [2002] S. Yunoki, Numerical study of the spin-flop transition in anisotropic spin-1/2 antiferromagnets, Phys. Rev. B 65, 092402 (2002).
- Díez-Valle et al. [2023] P. Díez-Valle, D. Porras, and J. J. García-Ripoll, Quantum Approximate Optimization Algorithm Pseudo-Boltzmann States, Phys. Rev. Lett. 130, 050601 (2023).
- Lotshaw et al. [2023] P. C. Lotshaw, G. Siopsis, J. Ostrowski, R. Herrman, R. Alam, S. Powers, and T. S. Humble, Approximate Boltzmann distributions in quantum approximate optimization, Phys. Rev. A 108, 042411 (2023).
- Silvester et al. [2024] J. M. Silvester, G. Carleo, and S. R. White, Unusual energy spectra of matrix product states, arXiv:2408.13616 (2024).
- Yokoyama and Shiba [1987] H. Yokoyama and H. Shiba, Variational Monte-Carlo Studies of Hubbard Model. I, J. Phys. Soc. Japan 56, 1490 (1987).
- Zhang et al. [2022] S.-X. Zhang, Z.-Q. Wan, C.-K. Lee, C.-Y. Hsieh, S. Zhang, and H. Yao, Variational Quantum-Neural Hybrid Eigensolver, Phys. Rev. Lett. 128, 120502 (2022).
- Yuan et al. [2021] X. Yuan, J. Sun, J. Liu, Q. Zhao, and Y. Zhou, Quantum Simulation with Hybrid Tensor Networks, Phys. Rev. Lett. 127, 040501 (2021).
- Crooks [2019] G. E. Crooks, Gradients of parameterized quantum gates using the parameter-shift rule and gate decomposition, arXiv:1905.13311 (2019).
Supplemental Material for “Effective Temperature in Approximate Quantum Many-body States”
I Training dynamics for effective temperature toward the ground state
We conduct numerical experiments on different models and find that the dynamics for show a universal pattern. Fig. S1 and Fig. S2 show the training dynamics for the 1D XXZ model with and as objectives, respectively. The system Hamiltonian for the 1D XXZ model with periodic boundary conditions is defined as:
| (S1) |
Similarly, the training dynamics for 2D XXZ models in antiferromagnetic phases is shown in Fig. S3 which complements the results in the main text where the target ground state is in spin-flipping phases. Besides, we also evaluated with different 2D system size , as shown in Fig. S4.
From these training dynamics results toward ground states on different dimensions and different phases, several important features remain consistent as universal patterns for approximate ground states.
-
1.
Optimized approximate ground states admit very small s indicating a nearly flat spectrum across excited states.
-
2.
During training, first increases and then decreases in general, implying an upper bound for the possible of a given ansatz. Moreover, a smaller often indicates a better accuracy at the late stage of training. Besides, initial unless the ansatz has a strong physical prior. For example, in the VQE case, the PQC structure and the initialization render the state very close to the valence bond state at the beginning, resulting in a higher decay factor .
-
3.
For each method, the training dynamics is qualitatively similar for both energy and fidelity objectives though values are typically smaller when optimizing fidelity. The energy objective imposes unequal penalties for different excited state components, i.e. the higher energy the excited state has, the larger penalty it receives. On the contrary, the fidelity objective equally penalizes all excited states which could result in smaller or even negative . Since the fidelity objective shows no preference for different excited states, the finite value in this case can be attributed to the physical prior encoded in the ansatzes. Indeed, for the most unbiased ansatz VEC, is very close to 0 when optimizing . In summary, both the objective structures and the ansatz structures determine the effective temperature of resultant approximate ground states.
-
4.
The same family of ansatzes with different hyperparameters, eg. VMC of different widths or tensor networks with different bond dimensions, usually display similar training dynamics. This observation further supports the conclusion that effective temperature can reflect the intrinsic properties of different numerical methods.
In addition, we also show the error bar given by the exponential fitting in Fig. S5. The uncertainty of the predicted decay factor is relatively small compared to the value, implying that the exponential scaling is a very good description for the spectrum decomposition.





II Training dynamics for the scaling factor toward the ground state
When fitting the exponential decay spectrum, two parameters are required in the form . We focus on the training dynamics for in this section. Parameter is more directly related to the overall approximation accuracy, as the infidelity can be roughly estimated as , where is the density of states for the system. Some typical training dynamics for toward ground state are shown in Fig. S6, S7, and S8. We can observe an evident linear correlation during training between and .



III Training dynamics for effective temperature toward imaginary-time evolved states
We report training dynamics toward ITES in this section, and the limit reduces to the results for approximate ground states. A typical instance of such training dynamics with varying beta is shown in Fig. S9. For optimization targeting high temperature ITES (low ), first increases and then saturates to the target value. Conversely, for low temperature (high ) ITES targets, first increases and then decreases during training and the value of that can be reached is upper bounded by . The distinct training dynamical behaviors are also a reflection of the two-stage behavior. The training dynamics in low temperature regime is consistent with the one in approximating ground states. Via ITES of different temperatures, the results for ground state simulation can be taken as an interpolation from ITES and the maximal reached during training toward ground state is also connected to in ITES training.

IV Spectrum pattern for approximate states from different ansatzes
In this section, we show more scatter plots for pairs from approximate states based on different forms of ansatzes. Fig. S10, S11 and S12 show the spectral decomposition of approximate states generated by MPS, VMC, and PEPS ansatzes, respectively. The approximate ground states in the former two cases are obtained via minimizing infidelity objective while for the latter, energy objective is employed. For ground state targets, the fitted factor continuously varies with the optimization progress. For ITES targets, the spectrum from each type of approximate states exhibits the two-stage behavior with different critical temperatures .
We emphasize that the effective temperature is meaningful and argue against the misconception that the spectral plateau is merely an artifact of numerical precision. Our reasoning is as follows:
-
1.
Many flat spectrum plateaus give in the order , which are numerically significant and much higher than the machine precision floor for double precision (complex128) arithmetic.
-
2.
Many approximate ITES instances exhibit the two-stage behavior such as Fig. S10, demonstrate distinct overlap behaviors for the same energy levels across different target values. For example, points with target overlap strictly follow the exponential decay in approximate high-temperature ITES while the overlap point of the same order fails to do so by forming a plateau for approximate low-temperature ITES. In other words, the plateau formed in the higher energy regime for approximate low-temperature ITES is not due to the naïve interpretation that the magnitudes of overlaps go below the machine precision floor.
-
3.
The critical effective temperature s differ among different ansatzes. This fact further implies that the effective temperature is numerically meaningful. If the underlying mechanism were solely the machine precision floor, would be the same across different methods.



The spectral decomposition for VQE states is special due to the specific structure and state preparation protocol we used in this work. The corresponding scatter plot at the early and late stages of ground state training is shown in Fig. S13. As we can see, several different branches emerge in the spectral decomposition with more training steps. These branches are labeled by different charge numbers as the system Hamiltonian is symmetric. Therefore, the decay factor by considering spectrum contribution from all charge sectors is larger than the one fitted only in the half-filling sector which is highlighted in orange in the figure. We always present the decay factor extracted from the half-filling sector in VQE cases in this work.
In addition, we also stack the spectral decomposition for a series of ansatzes in one figure to better illustrate the two-stage behavior for approximating ITES, see Fig. S14.


V Other metrics for approximate imaginary-time evolved states
In this section, we report some other metrics for approximate ITES as further evidence for the two-stage behavior. To diagnose the deviation from the exponential decay in the spectrum, we introduce mean squared error inspired by machine learning. Specifically, we construct MSE as , where the target sequence and approximate sequence are spectral decomposition overlap for exact ITES and for approximate ITES, respectively. When MSE begins to deviate from 0 with increasing , the training enters the low-temperature stage where . The results of MSE are shown in Fig. S15.
We also report the squared Pearson coefficients and the uncertainty in Fig. S16 and Fig. S17. Pearson coefficient close to 1 and uncertainty on close to 0 are both strong signals of good exponential fitting and the high-temperature stage. Notably, extracted from different metrics are consistent. It is an interesting future direction to explore whether universal critical behaviors can be identified around with these metrics.



VI Expressiveness and trainability targeting imaginary-time evolved states
In this section, we provide quantitative analysis for the change of required expressive capacity and optimization efforts with varying when approximating ITES. For the numerical simulation in this section, we use MPS ansatz with bond dimension to approximate ITES in 2D XXZ model on lattice with , . The optimization employs Adam optimizer with an exponential decay learning schedule (initial learning rate , and the learning rate halves every step). We calculate the entanglement entropy for ITES of different s, where the subsystem partition contains all sites on the left half. This quantity characterizes the expressive capacity required to accurately approximate the target states as higher entanglement requires larger bond dimensions to capture. We also conduct the optimization toward ITES and record the training steps required to reach a given infidelity threshold . Though the initialization and the optimizer are the same for different ITES, we find that the required number of training steps is much larger for low temperature (high ) targets. In other words, through the lens of ITES, we identify that the optimization becomes more difficult and slow for low temperature ITES near ground state manifold. The expressive capacity and optimization time required for approximating ITES of different temperatures are summarized in Fig. S18. In this figure, we can see the evident change in expressiveness and optimization efforts required.

Based on the above observations, we can explain the different trends of approximation accuracy with varying target . For low-accuracy ansatzes, the bottleneck is at the expressive capacity to accurately capture the target state. Therefore, with larger , the state is closer to the ground state with smaller entanglement entropy, resulting in looser expressiveness requirements and the performance of these low-accuracy ansatzes is improved. On the contrary, for high accuracy ansatzes, the ansatz is powerful enough to represent ITES of any temperature and the bottleneck is in optimization. As larger slows down the optimization, the fidelity obtained via a fixed number of training steps becomes worse. This understanding of the competition between expressiveness and optimization perfectly explains Fig. 4 (b) in the main text.
We also conduct the optimization using a more suitable optimizer L-BFGS (default hyperparameters provided by SciPy with function value and gradient tolerance and max iteration ), which greatly improves the fidelity for high-accuracy ansatzes in low-temperature regime (high ). This fact further supports the claim that the expressive capacity of these high-accuracy ansatzes is sufficient, the fidelity drop is mainly due to optimization hardness and insufficient training steps. The training dynamics for MPS ansatz () toward ITES with both Adam and L-BFGS optimizers are shown in Fig. S19.

VII Hyperparameters for variational optimization
For the optimization hyperparameters of each method, we use the following settings in Table. 1 unless explicitly specified.
| Method | Optimizer | Initial learning rate | Learning schedule |
|---|---|---|---|
| PEPS | Adam | constant | |
| MPS | Adam | exponential decay: halved each 1000 steps | |
| VMC | Adam | exponential decay (halved each 200 steps) at first 800 steps then constant | |
| VQE | Adam | exponential decay: halved each 2000 steps | |
| VEC | Adam | constant |
In terms of the number of training steps, we keep the optimization process until convergence when approximating ground states. When targeting ITES, the total training steps for each method are listed in Table 2.
| Method | The number of training steps |
|---|---|
| PEPS | 600 |
| MPS | 400 |
| VMC | 3500 |
| VQE | 2000 |
| VEC | 600 |