Department of Computer Science, Technion, Haifa, [email protected] Systems, [email protected] Department of Computer Science, Technion, Haifa, [email protected] \CopyrightG. Sheffi, P. Ramalhete and E. Petrank {CCSXML} <ccs2012> <concept> <concept_id>10011007.10010940.10010941.10010949.10010950</concept_id> <concept_desc>Software and its engineering Memory management</concept_desc> <concept_significance>500</concept_significance> </concept> <concept> <concept_id>10003752.10003753.10003761</concept_id> <concept_desc>Theory of computation Concurrency</concept_desc> <concept_significance>500</concept_significance> </concept> </ccs2012> \ccsdesc[500]Software and its engineering Memory management \ccsdesc[500]Theory of computation Concurrency \EventEditorsJohn Q. Open and Joan R. Access \EventNoEds2 \EventLongTitle42nd Conference on Very Important Topics (CVIT 2016) \EventShortTitleCVIT 2016 \EventAcronymCVIT \EventYear2016 \EventDateDecember 24–27, 2016 \EventLocationLittle Whinging, United Kingdom \EventLogo \SeriesVolume42 \ArticleNo23
EEMARQ: Efficient Lock-Free Range Queries with Memory Reclamation
keywords:
safe memory reclamation, lock-freedom, snapshot, concurrency, range querycategory:
\relatedversionMulti-Version Concurrency Control (MVCC) is a common mechanism for achieving linearizable range queries in database systems and concurrent data-structures. The core idea is to keep previous versions of nodes to serve range queries, while still providing atomic reads and updates. Existing concurrent data-structure implementations, that support linearizable range queries, are either slow, use locks, or rely on blocking reclamation schemes. We present EEMARQ, the first scheme that uses MVCC with lock-free memory reclamation to obtain a fully lock-free data-structure supporting linearizable inserts, deletes, contains, and range queries. Evaluation shows that EEMARQ outperforms existing solutions across most workloads, with lower space overhead and while providing full lock freedom.
1 Introduction
Online Analytical Processing (OLAP) transactions are typically long and may read data from a large subset of the records in a database [52, 57]. As such, analytical workloads pose a significant challenge in the design and implementation of efficient concurrency controls for database management systems (DBMS). Two-Phase Locking (2PL) [64] is sometimes used, but locking each record before it is read implies a high synchronization cost and, moreover, the inability to modify these records over long periods. Another way to deal with OLAP queries is to use Optimistic Concurrency Controls [25], where the records are not locked, but they need to be validated at commit time to guarantee serializability [47]. If during the time that the analytical transaction executes, there is any modification to one of these records, the analytical query will have to abort and restart. Aborting can prevent long read-only queries from ever completing.
DBMS designers typically address these obstacles using Multi-Version Concurrency Control (MVCC). MVCC’s core idea is to keep previous versions of a record, allowing transactions to read data from a fixed point in time. For managing the older versions, each record is associated with its list of older records. Each version record contains a copy of an older version, and its respective time stamp, indicating its commit time. Each update of the record’s values adds a new version record to the top of the version list, and every read of an older version is done by traversing the version list, until the relevant timestamp is reached.
Keeping the version lists relatively short is fundamental for high performance and low memory footprint [11, 37, 19, 34, 35]. However, the version lists should be carefully pruned, as a missing version record can be harmful to an ongoing range query. In the Database setting, the common approach is to garbage collect old versions once the version list lengths exceed a certain threshold [11, 37, 53]. During garbage collection, the entire database is scanned for record instances with versions that are not required for future scanners. However, garbage collecting old versions with update-intensive workloads considerably slows down the entire system. An alternative approach is to use transactions and associate each scan operation with an undo-log [6, 42]. But this requires allocating memory for storing the undo logs and a safe memory reclamation scheme to recycle log entries.
In contrast to the DBMS approach, many concurrent in-memory data-structures implementations do not provide an MVCC mechanism, and simply give up on range queries. Many map-based data-structures provide linearizable [30] insertions, deletions and membership queries of single items. Most data-structures that do provide range queries are blocking. They either use blocking MVCC mechanisms [44, 3, 12], or rely on the garbage collector of managed programming languages [51, 7, 22, 67] which is blocking. It may seem like lock-free data-structures can simply employ a lock-free reclamation scheme with an MVCC mechanism to obtain full lock-freedom, but interestingly this poses a whole new challenge.
Safe manual reclamation (SMR) [59, 61, 56, 66, 41] algorithms rely on retire() invocations by the program, announcing that a certain object has been unlinked from a data-structure. The task of the SMR mechanism is to decide which retired objects can be safely reclaimed, making their memory space available for re-allocation. Most SMR techniques [61, 56, 66, 41] heavily rely on the fact that retired objects are no longer reachable for threads that concurrently traverse the data structure. Typically, objects are retired when deleted from the data-structure. However, when using version lists, if we retire objects when they are deleted from the current version of the data-structure, they would still be reachable by range queries via the version list links. Therefore, it is not safe to recycle old objects with existing memory reclamation schemes. Epoch-based reclamation (EBR) [24, 15] is an exception to the rule because it only requires that an operation does not access nodes that were retired before the operation started. Namely, an existing range query prohibits reclamation of any deleted node, and subsequent range queries do not access these nodes, so they can be deleted safely. Therefore, EBR can be used without making any MVCC-specific adjustments, and indeed EBR is used in many in-memory solutions [65, 3, 44]. However, EBR is not robust [61, 66, 59]. I.e., a slow executing thread may prevent the reclamation of an unbounded number of retired objects, which may affect performance, and theoretically block all new allocations.
One lock-free memory reclamation scheme that can be adopted to provide lock-free support for MVCC is the VBR optimistic memory reclamation scheme [59, 60]. VBR allows a program to access reclaimed space, but it raises a warning when accessed data has been re-allocated. This allows the program to retry the access with refreshed data. The main advantages of VBR are that it is lock-free, it is fast, and it has very low memory footprint. Any retired object can be immediately reclaimed safely. The main drawback111VBR also necessitates type-preservation. However, this does not constitute a problem in our setting, as all allocated memory objects are of the same type. For more details, see Section 3. is that reclaimed memory cannot be returned to the operating system, but must be kept for subsequent node allocations, as program threads may still access reclaimed nodes. Similarly to other schemes, the correctness of VBR depends on the inability of operations to visit previously retired objects. In data structures that do not use multi versions, the deleting thread adequately retires a node after disconnecting it from the data structure. But in the MVCC setting, disconnected nodes remain connected via the version list, foiling correctness of VBR.
In this paper we modify VBR to work correctly in the MVCC setting. It turns out that for the specific case of old nodes in the version list, correctness can be obtained. VBR keeps a slow-ticking epoch clock and it maintains a birth epoch field for each node. Interestingly, this birth epoch can be used to tell whether a retired node in the version list has been re-allocated. As we show in this paper, an invariant of nodes in the version list is that they have non-increasing birth-epoch numbers. Moreover, if one of the nodes in the version list is re-allocated, then this node must foil the invariant. Therefore, when a range query traverses a version list to locate the version to use for its traversal, it can easily detect a node that has been re-allocated and whose data is irrelevant. When a range query detects such re-allocation, it restarts. As shown in the evaluation, restarting happens infrequently with VBR and the obtained performance is the best among existing schemes in the literature. Using the modified VBR in the MVCC setting, a thread can delete a node and retire it after disconnecting it from the data structure (and while it is still reachable via version list pointers).
Recently, two novel papers [65, 44] presented efficient MVCC-based key-value stores. The main new idea is to track and keep a version list of modified fields only and not of entire nodes. For many data-structures, all fields are immutable except for one or two pointer fields. For such data-structures, it is enough to keep a version list of pointers only. The first paper proposed a lock-free mechanism, based on versioned CAS objects (vCAS) [65], and the second proposed a blocking mechanism, based on Bundle objects (Bundles) [44]. While copying one field instead of the entire node reduces the space overhead, the resulting indirection is harmful for performance: to dereference a pointer during a traversal, one must first move to the top node of the version list, and then use its pointer to continue with the traversal. As we show in Section 4, this indirection suffers from high overheads in read-intensive workloads. Bundles ameliorate this overhead by caching the most recent pointer in the node to allow quick access for traversals that do not use older versions. However, range queries still need to dereference twice as many references during a traversal. The vCAS approach presents a more complicated optimization that completely eliminates indirection (which we further discuss in Section 3). However, its applicability depends on assumptions on the original data-structure that many data structures do not satisfy. Therefore, it is unclear how it can be integrated into general state-of-the-art concurrent data-structures. In terms of memory reclamation, both schemes use the EBR technique (that may block in theory, due to allocation heap exhaustion). This means that even vCAS does not provide a lock-free range query mechanism. A subsequent paper on MVCC-specific garbage collectors [8], provides a robust memory reclamation method for collecting the version records, but it does not deal with the actual data-structure nodes.
In this paper we present EEMARQ (End-to-End lock-free MAp with Range Queries), a design for a lock-free in-memory map with MVCC and a robust lock-free memory management scheme. EEMARQ provides linearizable and high-performance inserts, deletes, searches, and range queries.
The design starts by applying vCAS to a linked-list. The linked-list is simple, and so it allows applying vCAS easily. However, the linked-list does not satisfy the optimization assumptions required by [65], and so a (non-trivial) extension is required to fit the linked-list. In the unoptimized variant, there is a version node for each of the updates (insert or delete) and this node is used to route the scans in the adequate timestamp. But this is costly, because traversals end up accessing twice the number of the original nodes. A natural extension is to associate the list nodes with the data that is originally kept in the version nodes. We augment the linked-list construction to allow the optimization of [65] for it. They use a clever mapping from the original version nodes to existing list nodes, that allows moving the data from version nodes to list nodes, and then elide the version nodes. Now traversals need no extra memory accesses to version nodes. This method is explained in Section 3.2.
Second, we extend VBR by adding support for reachable retired nodes on the version list. The extended VBR allows keeping retired reachable version nodes in the data structure (which the original VBR forbids) while maintaining high performance, lock-freedom, and robustness.
Finally, we deal with the inefficiency of a linked-list by adding a fast indexing to the linked-list nodes. A fast index can be obtained from a binary search tree or a skip list. But the advantage we get from separating the linked-list from the indexing mechanism is that we do not have to maintain versions for the index (e.g., for the binary search tree or the skip list), but only for the underlying linked-list. This separation between the design of the versioned linked-list and the non-versioned index, simplifies each of the sub-designs, and also obtains high performance, because operations on the index do not need to maintain versions. Previous work uses this separation idea between the lower level of the skip list or leaves of the tree from the rest for various goals (e.g., [69, 44]).
The combination of all these three ideas, i.e., optimized versioned linked-list, extended VBR, and independent indexing, yields a highly performant data structure design with range queries. Evaluation shows that EEMARQ outperforms both vCAS and Bundles (while providing full lock-freedom). A proof of correctness is provided in the appendix.
2 Related Work
Existing work on linearizable range queries in the shared-memory setting includes many solutions which are not based on MVCC techniques. Some data-structure interfaces originally include a tailor-made range query operation. E.g., there are trees [12, 13, 22, 67], hash tries [55], queues [45, 46, 54], skip lists [5] and graphs [31] with a built-in range query mechanism. Other and more general solutions execute range queries by explicitly taking a snapshot of the whole data-structure, followed by collecting the set of keys in the given range [1, 4]. The Snapcollector [51] forces the cooperation of all executing threads while a certain thread is scanning the data-structure. Despite being lock-free and general, the Snapcollector’s memory and performance overheads are high. The Snapcollector was enhanced to support range queries that do not force a snapshot of the whole data-structure [16]. However, this solution still suffers from major time and space overheads.
Another way to implement range queries is to use transactional memory [23, 32, 49, 50]. Transactions can either be implemented in software or in hardware, allowing range queries to take effect atomically. Although transactions may seem as ideal candidates for long queries, software transactions incur high performance overheads and hardware transactions frequently abort when accessing big memory chunks. Read-log-update (RLU) [39] borrows software transaction techniques and extends read-copy-update (RCU) [40] to support multiple updates. RLU yields relatively simple implementations, but its integration involves re-designing the entire data-structure. In addition, similarly to RCU, it suffers from high overheads in write-extensive workloads.
Arbel-Raviv and Brown exploited the EBR manual reclamation to support range queries [3]. Their technique uses EBR’s global epoch clock for associating data-structure items with their insertion and deletion timestamps. EEMARQ uses a similar technique for associating data-structure modifications with respective timestamps. They also took advantage of EBR’s retire-lists, in order to locate nodes that were deleted during a range query scan. However, while their solution indeed avoids extensive scanning helping when deleting an item from the data-structure (as imposed by the Snapcollector [51]), it may still impose significant performance overheads (as shown in Section 4). EEMARQ minimizes these overheads by keeping a reachable path to deleted nodes (for more details, see Section 3.2).
Multi-Version Concurrency Control
MVCC easily provides isolation between concurrent reads and updates. I.e., range queries can work on a consistent view of the data, while not interfering with update operations. This powerful technique is widely used in commercial systems [21, 19], as well as in research-oriented DBMS [33, 53], in-memory shared environments [65, 44] and transactional memory [23, 32, 36, 49, 50]. MVCC has been investigated in the DBMS setting for the last four decades, both from a theoretical [9, 10, 48, 68, 35] and a practical [42, 19, 37, 53, 33] point of view. A lot of effort has been put in designing MVCC implementations and addressing the unwanted side-effects of long version lists. This issue is crucial both for accelerating version list scans and for reducing the contention between updates and garbage collection. Accelerating DBMS version list scans (independently of the constant need to prone them) has been investigated in [35]. Most DBMS-related work that focuses on this issue, tries to minimize the problem by eagerly collecting unnecessary versions [11, 21, 38, 53, 42, 34, 2].
Safe Memory Reclamation
Most existing in-memory environments that enable linearizable range queries, avoid managing their memory, by relying on automatic (and blocking) garbage collection of old versions [51, 7, 22, 67]. Solutions that do manually manage their allocated memory [65, 44, 3], use EBR for safe reclamation. In EBR, a shared epoch counter is incremented periodically, and upon each operation invocation, the threads announce their observed epoch. The epoch clock can be advanced when no executing thread has an announcement with a previous epoch. During reclamation, only nodes that had been retired at least two epochs ago are reclaimed. EBR is safe for MVCC because a running scan prevents the advance of the epoch clock, and also the reclamation of any node in the data-structure that was not deleted before the scan.
The MVCC-oriented garbage collector from [8] incorporates reference counting (RC) [17, 18, 28], in order to maintain lock-freedom while safely reclaiming old versions. Any object can be immediately reclaimed once its reference count reaches zero, without the need in invoking explicit retire() calls. While RC simplifies reclamation, it incurs high performance overheads and does not guarantee a tight bound on unreclaimed garbage (i.e., it is not robust).
Other reclamation schemes were also considered when designing EEMARQ. NBR [61] was one of the strongest candidates, as it is fast and lock-free (under some hardware assumptions). However, it is not clear whether NBR can be integrated into a skip list implementation (which serves as one of our fast indexes). Pointer–based reclamation methods (e.g., Hazard Pointers [41]) allow threads to protect specific objects (i.e., temporarily prevent their reclamation), by announcing their future access to these objects, or publishing an announcement indicating the protection of a bigger set of objects (e.g., Hazard Eras [56], Interval-Based Reclamation [66], Margin Pointers [62]). Although these schemes are robust (as opposed to EBR), it is unclear how they can be used in MVCC environments. They require that reaching a reclaimed node from a protected one would be impossible (even if the protected node is already retired). I.e., they require an explicit unlinking of old versions before retiring them. Besides the obvious performance overheads, it may affect robustness (as very old versions would not be reclaimed). The garbage collector from [8] uses Hazard Eras for unlinking old versions (to be eventually collected using an RC-based strategy), but it has not been evaluated in practice.
3 The Algorithm
In this Section we present EEMARQ’s design. We start by introducing a new lock-free linearizable linked-list implementation in Section 3.1. The list implementation is based on Harris’s lock-free linked-list [26], and includes the standard insert(), remove() and contains() operations. In Section 3.2 we explain how to add a linearizable and efficient range query operation. We describe the integration of the designated robust SMR algorithm in Section 3.3, and explain how to improve performance by adding an external index in Section 3.4. A full linearizability and lock-freedom proof for our implementation (including the range queries mechanism) appears in Appendix C. Additional correctness proofs for the SMR and fast indexing integration appear in Appendix D and E, respectively.
As discussed in [65], node-associated version lists introduce an extra level of indirection per node access. Methods that use designated version objects for recording updates, suffer from high overheads, especially in read-intensive workloads. For avoiding this level of indirection, we introduce a new variant of Harris’s linked-list. In our new variant, there is no need to store any update-related data in designated version records, since it can be stored directly inside nodes, in a well-defined manner. Associating each node with a single data-structure update (i.e., an insertion or a removal) is challenging. Typically, an insert operation includes a single update, physically inserting a node into the list. A remove operation involves a marking of the target node’s next pointer (serving as its logical deletion, and the operation’s linearization point in many existing implementations) and a following physical removal from the list. In other words, each node may be associated with multiple list updates. Since the target node’s physical deletion is not the linearization point of any operation, there is no need to record this update. However, each node may still be associated with either one or two updates throughout an execution (i.e., its logical insertion and deletion).

In our linked-list implementation, some new node is inserted into the list during every physical update of the list (either a physical insertion or deletion), which obviously yields the desirable association between nodes and data-structure updates (each node is associated with the update that involved its insertion into the list). The node inserted during a physical insertion is simply the inserted node, logically inserted into the list. The node inserted during a physical removal is a designated new node that replaces the deleted node’s successor, and is physically inserted together with the physical removal of the deleted node 222When multiple nodes are physically removed together, it replaces the successor of the last node in the sequence of deleted nodes..
Figure 1 shows an example for inserting a new node during deletion. This list illustration shows the list layout throughout the deletion procedure of two nodes. At the first stage, the list contains five nodes, ordered by their keys (together with the head and tail sentinels). Then, some thread marks node 23 for deletion. At this point, before physically removing it, some other thread marks node 48 for deletion. I.e., both nodes must be physically unlinked together, as successive marked nodes. In order to remove the marked nodes, node 57 is flagged, as it is the successor of the last marked node in the sequence. Node 57 is flagged for making sure that its next pointer does not change. Finally, all three nodes are physically unlinked from the list, together with the physical insertion of a new node, representing the old flagged one. I.e., although all three nodes were physically removed from the list, node 57 was not logically removed, as it was replaced by a new node with the same key. After the physical deletion at stage 5, the three nodes are retired (for more details, see Section 3.3). As opposed to Harris’s implementation, the linearization point of both deletions is this physical removal, which atomically inserts the new representative into the list. Our mapping from modifications to nodes, maps this deletion to the new node, inserted at stage 5 (which represents the deletion of both nodes). In Section 3.2 we explain how this mapping is used for executing range queries.
3.1 The Linked-List Implementation
Our linked-list implementation, together with the list node class, is presented in Algorithm 1. The simple pointer access methods implementation (e.g., mark() in line 21 and getRef() in line 36) appear in Appendix A. In a similar way to Harris’s list, the API includes the insert(), remove() and contains() operations 333The rangeQuery() operation is added in Section 3.2. In addition, lines marked in blue in Algorithm 1 can be ignored at this point. They will also be discussed in Section 3.2. The insert() operation (lines 7-16) receives a key and a value. If there already exists a node with the given key in the list, it returns its value (line 10). Otherwise, is adds a new node with the given key and value to the list, and returns a designated NO_VAL answer (line 16). The remove() operation (lines 17-23) receives a key. If there exists a node with the given key in the list, it removes it and returns its value (line 23). Otherwise, it returns NO_VAL (line 20). The contains() operation (lines 24-27) receives a key. If there exists a node with the given key in the list, it returns its value (line 27). Otherwise, it returns NO_VAL (line 26).
All three API operations use the find() auxiliary method (lines 28-55), which receives a key and returns pointers to two nodes, pred and curr (line 55). As in Harris’s implementation, it is guaranteed that at some point during the method execution, both nodes are consecutive reachable nodes in the list, pred’s key is strictly smaller than the input key, and curr’s key is equal or bigger than the given key. I.e., if curr’s key is strictly bigger than the input key, it is guaranteed that there is no node with the given input key in the list at this point. The method traverses the list, starting from the head sentinel node (line 30), and until it gets to an unmarked and unflagged node with a key which is at least the input key (line 37). Recall that the two output variables are guaranteed to have been reachable, adjacent, unmarked and not flagged at some point during the method execution. Therefore, as long as the current traversed node is either marked or flagged (checked in line 34), the traversal continues, regardless of the current key (lines 34-36). Once the traversal terminates (either in line 35 or 37), if the current two nodes, saved in the pred and curr variables, are adjacent (the condition checked in line 44 does not hold), then the method returns them in line 55. Otherwise, similarly to the original implementation, the method is also in charge of physically removing marked nodes from the list.
As we are going to discuss next, our physical removal procedure, as depicted in Figure 1, is slightly different from the original one [26]. Physical deletions are executed via the trim() auxiliary method (lines 56-71). Although nodes are still marked for deletion in our implementation (line 21), their successful marking does not serve as the removal linearization point. I.e., reachable marked nodes are still considered as list members. The trim() method receives two nodes as its input parameters, pred and victim. victim is the physical removal candidate, and is assumed to already be marked. pred is assumed to be victim’s predecessor in the list, and to be neither marked nor flagged. As depicted in Figure 1, consecutive marked nodes are removed together. Therefore, the method traverses the list, starting from victim, for locating the first node which is not marked (lines 58-59). When such a node is found, the method tries to flag its next pointer, for freezing it until the removal procedure is done. In general, pointers are marked and flagged using their two least significant bits (which are practically redundant when reading node address aligned to a word). Both marked and flagged pointers are immutable, and a pointer cannot be both marked and flagged. Therefore, the flagging trial in line 61 fails if curr’s next pointer is either marked or flagged. If the flagging trial is unsuccessful, and not because some other thread has already flagged curr’s next pointer, the method returns in line 62. Otherwise, a new node is created in order to replace the flagged one (lines 65-67). Note that since this node’s next pointer is flagged (i.e., immutable), it is guaranteed that the new node points to the original one’s current successor. The actual trimming is executed in line 68. If the compare-and-swap (CAS) is successful, then the sequence of marked nodes, together with the single flagged one (at the end of the sequence), are atomically removed from the list, together with the insertion of the new copy of the flagged node (the new copy is neither flagged nor marked).
As the physical removal is necessary for linearizing the removal (as will be further discussed in Section 3.2), a remover must physically remove the deleted node before it returns from a remove() call. The marking of a node in line 21 only determines the remover’s identity and announces its intention to delete the marked node. Therefore, the remover must additionally ensure that the node is indeed unlinked, by calling the find() method in line 22. In Appendix C we formally prove that the list implementation, presented in Algorithm 1, is linearizable and lock-free.
3.2 Adding Range Queries
Given Algorithm 1, adding a linearizable range queries mechanism is relatively straight forward. We use a method which is similar to the vCAS technique [65]. As discussed in Section 1, the vCAS scheme introduces an extra level of indirection for the linked-list per node access. Indeed, we show in Section 4 that the vCAS implementation suffers from high overheads. The original vCAS paper provides a technique for avoiding this level of indirection. The suggested optimization relies on the following (very specific) assumption: a certain node can be the third input parameter to a successful CAS operation only once throughout the entire execution. That successful CAS is considered as the recording of this node, and the property is referred to as recorded-once in [65].
Although the recorded-once property yields a linearizable solution, which reduces memory and time overheads, this assumption does not hold in the presence of physical deletions, as they usually set the deleted node’s predecessor to point to the deleted node’s successor [26], or to another, already reachable node [43, 14], and then, this reachable node is recorded more than once. This makes the suggested technique inapplicable to Harris’s linked-list [26] and most other concurrent data-structures (e.g., [43, 12, 29]). The original vCAS paper implemented a recorded-once binary search tree, based on [20], which we compare against in Section 4. We extend the recorded-once condition and make it fit for the linked-list and other data-structures. We claim that associating each node with the data of a single data-structure update (as provided by our list) is enough for avoiding indirection in this setting. Given such an association, there is no need to store update-related data in designated version records, since it can be stored directly inside nodes, in a well-defined manner.
First, in a similar way to [65, 3, 44], we add a shared clock, for associating each node with a timestamp. The shared clock is read and updated using the getTS() and fetchAddTS() methods, respectively (see Appendix A). The shared clock is incremented whenever a range query is executed (e.g., see line 2 in Algorithm 2), and is read before setting a new node’s timestamp (e.g, see lines 15, 43, 54, 60, 64 and 69 in Algorithm 1). Next, we change the nodes layout (see our node class description in Algorithm 1). On top of the standard fields (i.e., key, value and next pointer), we add two extra fields to each node. The first field is the node’s timestamp (denoted as ts), representing its insertion into the list. Nodes’ ts fields are always initialized with a special value (see lines 11 and 65 in Algorithm 1), to be given an actual timestamp after being inserted into the list. The second field, prior, points to the previous successor of this node’s first predecessor in the list (its predecessor when being inserted into the list). Both fields are set once and then remain immutable. E.g., consider the new node, inserted into the list at stage 5 in Figure 1. Its prior field points to the node whose key is 23, as this is the former successor of the node whose key is 9, which is the first predecessor of the newly inserted node. By its specification, once the prior field is set (see line 13 and 67 in Algorithm 1), it is immutable. These two new fields are not used during the list operations from Algorithm 1, but we do specify their proper initialization, in order to support linearizable range queries. Moreover (and in a similar way to [65, 3]), list inserts and deletes are linearized during the execution of the getTS() method, as follows. Let newNode be the node inserted into the list in line 14, during a successful insert() operation. newNode’s timestamp is set at some point, not later than the CAS in line 15 (it may be updated earlier, by a different thread). The getTS() invocation that precedes the successful update of newNode’s timestamp is the operation’s linearization point. In a similar way, consider a successful remove() operation. The removed node is unlinked from the list during a successful trim() execution. Let newCurr be the node successfully inserted into the list in line 68, during this successful trim() execution. newCurr’s timestamp is set at some point, not later than the CAS in line 69 (it may be updated earlier, by a different thread). The getTS() invocation that precedes the successful update of newCurr’s timestamp is the operation’s linearization point.
Our range queries mechanism is presented in Algorithm 2. The rangeQuery() operation receives three input parameters (see line 1): the lowest and highest keys in the range, and an output array for returning the actual keys and associated values in the range. In addition to filling this array, it also returns its accumulated size in the count variable. The operation starts by fetching and incrementing the global timestamp counter (line 2), which serves as the range query’s linearization point. I.e., the former timestamp is the one associated with the range query. This way, the range query is indeed linearized between its invocation and response, along with guaranteeing that the respective view is immutable during the operation (as new updates will be associated with the new timestamp).
After incrementing the global timestamp counter, the operation uses the find() auxiliary method in order to locate the first node in range (lines 4-12). As opposed to the vCAS mechanism [65], and in a similar way to the Bundles mechanism [44], we observe that until the traversal reaches the target range, there is no need to take timestamps into consideration. This observation is crucial for performance, as there is no need to traverse nodes via the prior fields (which produce longer traversals in practice). In addition, it enables using the fast index (described in Section 3.4) for enhancing the search. During each loop iteration, we first find a node with a key which is smaller than the lowest key in the range (saved as the pred variable in line 5). Then, we optimistically try to find a relatively close node, following prior pointers, until we get to a small enough timestamp (lines 7-8). Since this search may result in a node with a bigger key (e.g., see line 13 in Algorithm 1), the next iteration sends a smaller key as input to the find() execution in line 5. Note that in the worst case scenario, the loop in lines 4-12 stops after the find() execution in line 5 outputs the head sentinel node (as its timestamp is necessarily smaller than ts). Therefore, it never runs infinitely. The purpose of updating in line 12 will be clarified in Section 3.3, as it is related to the VBR mechanism. Note that in any case, this update does not foil correctness, since it is still guaranteed that the range query is linearized between the operation’s invocation and response.
When pred has a key which is smaller than the range lower bound, the operation moves on to the next step (the loop breaks in line 11). At this point, the traversal continues according to the respective timestamp444In Appendix C we prove that a node’s successor at timestamp can be found by starting from its current successor and then following prior references until reaching a node with a timestamp which is not greater than ., until getting to a node with a key which is at least the range lower bound (lines 13-18). Once a node with a big enough key is found, the traversal continues in lines 20-28. At this stage, the count output variable and the output array are updated according to the data accumulated during the range traversal. Finally, the count output variable, indicating the total number of keys in range, is returned in line 29. Note that throughout the traversals in lines 16-17 and lines 26-27, there is no need to update succ’s timestamp (as done in lines 15 and 25), since it serves as a node’s prior and thus, is guaranteed to already have an updated timestamp (see Appendix C).
3.3 Adding A Safe Memory Reclamation Mechanism
Before integrating our list with a manual memory reclamation mechanism, we must first install retire() invocations, for announcing that a node’s memory space is available for re-allocation. Naturally, nodes are retired after unsuccessful insertions, or after they are unlinked from the list. I.e., newNode is retired if the CAS in line 14 is unsuccessful, newCurr is retired if the CAS in line 68 is unsuccessful, and upon a successful trimming in line 68, the unlinked nodes are retired, starting from victim. The last retired node is curr, which is replaced by its new representative in the list, newCurr. Note that we do not handle physical removals of prior links. Handling them is unnecessary, and might cause significant overheads, both to the list operations and to the reclamation procedure. Therefore, retired nodes are still reachable from the list head during retirement: newCurr’s prior field points to victim, making all of the unlinked nodes reachable via this pointer (and their next pointers).
To add a safe memory reclamation mechanism to our list, we use an improved variant of Version Based Reclamation (VBR) [59]. VBR cannot be integrated as is. Similarly to most safe memory reclamation techniques, it assumes that retired objects are not reachable via the data-structure links. This assumption is crucial to the correctness of VBR, as retired objects may be immediately reclaimed. In addition, VBR uses a slow ticking epoch clock, and ensures that the clock ticks at least once between the retirement and future re-allocation of the same node. During execution, the operating threads constantly check that the global epoch clock has not changed. Upon a clock tick, they conservatively treat all data read from shared memory as stale, and move control to an adequate previous point in the code in order to read a fresh value. As long as the clock does not tick, threads may continue executing without worrying about use-after-free issues. The intuition is that if a node is accessed during a certain epoch, then it must have been reachable during this epoch. I.e., even if this node has already been retired, its retirement was during the current epoch, which means that it has not been re-allocated yet (as the clock has not ticked yet).
Our list implementation poses a new challenge in this context. Suppose that the current epoch is , and that a certain node, , is currently in the list (i.e., it has not been unlinked using the trim() method yet). In addition, suppose that ’s prior field points to another node, , that has been retired during an earlier epoch. Then may be reclaimed and re-allocated during . A traversing thread may access ’s prior field during , without getting any indication to the fact that the referenced node is a stale value. Another problem, which does not affect correctness, but may cause frequent thread starvations, is that the global epoch clock is likely to tick during a long range query. In the original VBR scheme, a clock tick forces the executing thread to start its traversal from scratch, even if it has not encountered any reclaimed node in practice.
In order to overcome the above problems, we made some small adjustments to the original VBR scheme. First, we kept the global epoch clock of VBR and the timestamp clock of the range queries separated. We separated the two, as VBR works best with a (very) slow ticking clock. Read-intensive workloads (in which range queries dominate the execution) incur high overheads when combining the two clocks. The separation of the two independent clocks helps overcome the potential aborts. The second step was to modify the nodes’ layout (The VBR-integrated node layout appears in Appendix D). Recall that the VBR scheme adds a birth epoch to every node, along with a version per mutable field. Non-pointer mutable fields are associated with the node’s birth epoch, and pointers are associated with a version which is the maximum between the birth epoch of the node and the birth epoch of its successor. Our list nodes have two mutable fields, their timestamp (changes only once), and their next pointer. The prior pointers are immutable. Accordingly, we associated the node’s timestamp with its VBR-integrated birth epoch, serving as its version (there was no need to add an extra version), and added a designated next pointer version. Writes to the mutable fields are handled exactly as in the original VBR scheme. Accordingly, upon allocation, a node’s timestamp is initialized to , along with the current VBR epoch as its associated birth epoch. When the timestamp is updated (see line 15, 43, 54, 60, 64 and 69 in Algorithm 1, or lines 15 and 25 in Algorithm 2), the birth epoch (also serving as the timestamp’s version) does not change, as the two fields are accessed together, via a wide-compare-and-swap (WCAS) instruction. Similarly, next pointers are associated with the maximum between the two respective birth epochs, and are also updated using WCAS.
Reads are handled in a different manner from the original VBR, as the problems we mentioned above must be treated with special care. The original VBR repeatedly reads the global epoch in order to make sure that it has not changed. In our extended VBR variant, it is read once. After reading the global epoch, and as long as the executing thread does not encounter a birth epoch or a version which is bigger then this epoch, it may continue executing its code. The motivation behind this behavior is that even if a certain node in the system has meanwhile been reclaimed, this node does not pose a problem as long as the current thread does not encounter it. Therefore, traversing threads follow three guidelines: (1) a node’s birth epoch is read again after each read of another field, (2) after dereferencing a next pointer, the reader additionally makes sure that the successor’s birth epoch is not greater than the pointer’s version, and (3) after dereferencing a prior pointer (which is not associated with a version), the reader additionally makes sure that the successor’s birth epoch is not greater than the predecessor’s birth epoch. If any of these conditions does not hold, then the reader needs to proceed according to the original VBR’s protocol. In Appendix D we prove that these three guidelines are sufficient for maintaining correctness. Upon an epoch change, the original VBR enforces a rollback to a predefined checkpoint in the code. Accordingly, we install code checkpoints. Whenever a check that our guidelines impose fails, the executing thread rolls-back to the respective checkpoint. Checkpoints are installed in the beginning of each API operation (i.e., insert(), remove(), contains() and rangeQuery()). Another checkpoint is installed after a successful marking in line 21 of Algorithm 1, as the identity of the marking thread affects linearizability (and therefore, a rollback to the beginning of the operation would foil linearizability). Note that a successful insertion in line 14 does not force a checkpoint (although it affects linearizability, by setting the inserter identity), as it is not followed by any reads of potentially reclaimed memory.
Another issue that needs to be dealt with is the guarantee that life-cycles of nodes, allocated from the same memory address, do not overlap. The original VBR scheme does so by associating each node with a retire epoch. A node’s retire epoch is set upon retirement. During re-allocation, if the current global epoch is equal to the node’s retire epoch, then the global epoch is incremented before re-allocation. We chose to optimize over the original VBR, discarding the retire epoch field, as it adds an extra field per allocated node. Instead, each retire list is associated with the epoch, recorded once it is full (right before it is returned to the global pool of nodes). Upon pulling such a list from the global pool, if its associated epoch is equal to the current one, then the global epoch is incremented.
Finally, consider the following scenario. Suppose that a thread is running a range query, the current epoch is and the current global timestamp is . Next, suppose that another thread, , reclaims a node that has been retired during , and that is relevant for ’s range query. Starting from this point, whenever accesses the newly allocated node, it rolls back and starts its traversal from scratch (as the new node has a birth epoch which is greater then its predecessor through the prior pointer, foiling guideline 3). As long as ’s variable does not change, will infinitely get to the new allocated node and then roll-back to the beginning. We reduce the probability of such scenarios in practice, by updating the variable in line 12 of Algorithm 2. We further ensure that that the current global timestamp is up-to-date by incrementing it upon each re-allocation, if necessary.
3.4 Adding A Fast Index
Our linked-list implementation encapsulates the key-value pairs and enables the timestamps mechanism. However, when key ranges are large, the linked-list does not perform as good as other concurrent data-structures. It forces a linear traversal per operation, as opposed to skip lists [24, 29] and binary search trees [43, 14]. We observe that the index links in such data-structures (e.g., the links connecting the upper levels in a skip list or the inner levels in a tree) are only required for fast access. The actual data exists only in the lowest level of the skip list (or the leaves of an external tree). Therefore, we allow a simple integration of an external index, enabling fast access instead of long traversals. The index should provide an insert(key, node) operation, receiving a key and a node pointer as its associated value. It additionally should provide a remove(key) operation. Finally, instead of providing a contains(key) operation, it should provide a findPred(key) operation, receiving a key and returning a pointer to the node associated with some key which is smaller than the given one.
The findPred(key) can be naively implemented by calling the data-structure search method (there usually exists such method. E.g., [26, 43, 29]) with a smaller key as input. I.e., it is possible to search for key minus 2 or minus 10. Obviously, this does not guarantee that a suitable node will indeed be returned. However, if the selected smaller key is not small enough, it is possible to start a new trial and search for a smaller key. Our experiments showed that limiting the number of such trials per search to a small constant (e.g., 5 in our experiments) is negligible in terms of performance, and is usually enough for locating a relevant node. In addition, the index is used only for fast access, so correctness is not affected even if all trials fail. Specifically, the findPred(key) operation can be easily implemented for a skip list, using its built-in search auxiliary method [24, 29] (as it returns a predecessor with a smaller key). Examples for using a skip list as a fast index have already been introduced for linearizable data-structures [58] and in the transactional memory setting [63]. The findPred(key) operation can also be implemented for some binary search trees, by traversing the left child, instead of the right child, at some point during the search path. We applied this method when implementing our tree index, based on Natarajan and Mittal’s BST [43].
We update the fast index as follows: New Nodes are inserted into the index after being inserted into the list (i.e., right before the insert() operation returns in line 16 of Algorithm 1). Nodes are removed from the index after being removed from the list, and right before being retired (see Section 3.3). Note that the curr node, replaced by newCurr via the CAS in line 68, should be removed from the index, followed by an insertion of newCurr. In our implemented index, we have implemented an update() operation instead. This operation receives as input a node reference, and uses it to replace a node with the same key in the index555The implemented update() operation also takes the node’s birth epoch into account, and does not replace a node with a reclaimed node or with a node with a smaller birth epoch. In case the external index does not provide an update() operation, this also may be executed via the standard remove() operation, followed by a respective insert() operation. The index is read only during the find() auxiliary method. Instead of starting each list traversal from the head sentinel node (see line 30 in Algorithm 1), the traversing thread tries to shorten the traversal by accessing the fast index. I.e., instead of executing the code in lines 30-31 of Algorithm 1, each thread executes the code from Algorithm 3. It starts by initializing the searched key to the input key (received as input in line 28 of Algorithm 1). Then, after finding the alleged predecessor, using the findPred() operation (line 4), if its birth epoch is bigger than the last recorded one, the executing thread rolls-back to its last recorded checkpoint (see Section 3.3). Otherwise, if pred’s key is not smaller than the given input key, or its timestamp is not initialized yet (this is a possible scenario, as we show in Appendix E), the thread starts another trial, with the same key. Otherwise, if pred is either marked or flagged (line 11), the thread starts another trial, with a smaller key. Otherwise, it is guaranteed that pred and predNext hold a valid node and its (unmarked and unflagged) next pointer, respectively, and the thread may start its list traversal from line 32 of Algorithm 1. Note that the code presented in Algorithm 3 always terminates, as in the worst case scenario, the loop breaks after a predefined number of attempts. A full correctness proof appears in Appendix E.
4 Evaluation
For evaluating throughput of EEMARQ, we implemented the linked-list presented in Section 3666For avoiding unnecessary accesses to the global timestamps clock, the field updates from Algoritm 1 and Algorithm 2 were executed only after the field was read, and only if it was still equal to ., including the extended VBR variant, as described in Section 3.3. In addition, we implemented the lock-free skip list from [24] and the lock-free BST from [43]. Both the skip list and the tree were used on top of the linked list, and served as fast indexes, as described in Section 3.4. Deleted nodes from both indexes were manually reclaimed, using the original VBR scheme, according to the integration guidelines from [59] (without the adjustments described in Section 3.3). Each data-structure had its own objects pool (as VBR forces type preservation). Retire lists had 64 entries. Since VBR allows the immediate reclamation of retired nodes, retire lists were reclaimed as a whole every time they contained 64 nodes. I.e., at most 8192 (64 retired nodes X 128 threads) objects were over-provisioned per data-structure at any given moment.






0%U-90%C-10%RQ

50%U-40%C-10%RQ

90%U-0%C-10%RQ

We compared EEMARQ against four competitors, all using epoch-based reclamation. EBR-RQ is the lock-free epoch-based range queries technique by Arbel-Raviv and Brown [3], vCAS is the lock-free technique by Wei et al. [65], Bundles is the lock-based bundled references technique by Nelson et al. [44], and Unsafe uses a naive non-linearizable scan of the nodes in the range without synchronizing with concurrent updates (used as our baseline). We did not compare EEMARQ against RLU [39], as its mechanism is not linearizable, and it was also shown to be slower than our competitors [44]. For EBR-RQ and Bundles, we used the implementation provided by the authors. The Unsafe code was provided by the EBR-RQ authors. The vCAS authors provided a vCAS-based lock-free BST, including their optimization for avoiding indirection (see Section 3.2 for more details). Since there does not exist any respective skip list implementation, we implemented a vCAS-based skip list according to the guidelines from [65]. The vCAS-based skip list was not optimized, as the optimization technique, suggested in [65], does not fit to this data-structure. For our competitors’ memory reclamation, we used the original implementations, provided by [3, 65, 44], without any code or object pools usage changes. In particular, memory was not returned to the operating system. I.e., all implementations used pre-allocated object pools [61, 59] for reclaiming memory.
Setup
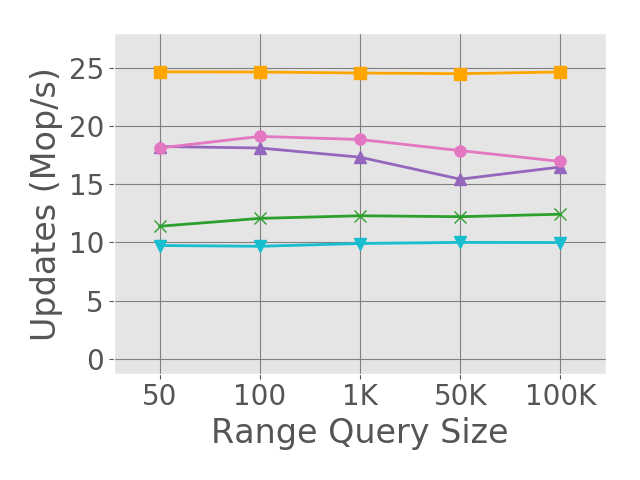
We conducted our experiments on a machine running Linux (Ubuntu 20.04.4), equipped with 2 Intel Xeon Gold 6338 2.0GHz processors. Each processor had 32 cores, each capable of running 2 hyper-threads to a total of 128 threads overall. The machine used 256GB RAM, an L1 data cache of 3MB and an L1 instruction cache of 2MB, an L2 unified cache of 80MB, and an L3 unified cache of 96MB. The code was written in C++ and compiled using the GCC compiler version 9.4.0 with -std=c++11 -O3 -mcx16. Each test was a fixed-time micro benchmark in which threads randomly call the insert(), remove(), contains() and rangeQuery() operations according to different workload profiles. We ran the experiments with a range of 1M keys. Each execution started by pre-filling the data-structure to half of its range size, and lasted 10 seconds (longer experiments showed similar results). Each experiment was executed 10 times, and the average throughput across all executions is reported. Figure 2 shows the skip list and tree scalability under various workloads. The updates (half insert() and half remove()), contains() and rangeQuery() percentiles appear under each graph. Figures 2(a)-2(c) and 2(e)-2(g) show the skip list and tree scalability as a function of the number of executing threads, under a variety of workloads. All queries have a fixed range of 1K keys (following [65]). Figures 2(d) and 2(h) show the effect of varying range query size on the skip list and tree performance. In these experiments, 64 threads perform 25% insert(), 25% remove() and 50% contains(), and 64 threads perform range queries only. In Appendix B we present the respective range queries and updates throughput for Figures 2(d) and 2(h), along with additional results for other workloads.
Discussion
The EEMARQ skip list surpasses the next best algorithm, EBR-RQ, by up to 65% in the lookup-heavy workload (Figure 2(a)), by up to 50% in the mixed workload (Figure 2(b)), and by up to 70% in the update-heavy workload (Figure 2(c)). The EEMARQ tree surpasses its next best algorithm, vCAS, by up to 75% in the lookup-heavy workload (Figure 2(e)), by up to 65% in the mixed workload (Figure 2(f)), and by up to 70% in the update-heavy workload (Figure 2(g)).
The results show that avoiding indirection is crucial to performance. In particular, EEMARQ outperforms its competitors in the lookup-heavy workloads (Figures 2(a) and 2(e)), in which memory is never reclaimed. I.e., its range query mechanism, which completely avoids traversing separate version nodes, has a significant advantage under such workloads. It can also be seen when examining EEMARQ’s competitors. While the vCAS-based tree (which avoids indirection) is EEMARQ’s next best competitor, the vCAS-based skip list (that involves the traversal of designated version nodes) is the weakest among the skip list implementations. In addition, the Bundles technique, which employs such a level of indirection when range queries are executed, also performs worse than most competitors, under most workloads.
Under update-dominated workloads, EEMARQ is faster also thanks to its efficient memory reclamation method. While all other algorithms use EBR as their memory reclamation scheme, EEMARQ enjoys VBR’s inherent locality and fast reclamation process. Moreover, EEMARQ avoids the original VBR’s frequent accesses to the global epoch clock, as described in Section 3.3. Although using VBR forces rollbacks when accessing reclaimed nodes, our fast index mechanism allows a fast retry, which makes the impact of rollbacks small. Indeed, experiments with longer retire lists (i.e., fewer rollbacks) showed similar results. This is clearly shown in Figures 2(d) and 2(h): EEMARQ outperforms its competitors when the query ranges are big (10% of the data-structure range). I.e., possible frequent rollbacks do not prevent EEMARQ from outperforming all other competitors.
5 Conclusion
We presented EEMARQ, a design for a lock-free data-structure that supports linearizable inserts, deletes, contains, and range queries. Our design starts from a linked-list, which is easier to use with MVCC for fast range queries. We add lock-free memory reclamation to obtain full lock-freedom. Finally, we facilitate an easy integration of a fast external index to speed up the execution, while still providing full linearizability and lock-freedom. As the external index does not require version maintenance, it can remain simple and fast. We implemented the design with a skip list and a binary search tree as two possible fast indexes, and evaluated their performance against state-of-the-art solutions. Evaluation shows that EEMARQ outperforms existing solutions across read-intensive and update-intensive workloads, and for varying range query sizes. In addition, EEMARQ’s memory footprint is relatively low, thanks to its tailored reclamation scheme, enabling the immediate reclamation of deleted objects. EEMARQ is the only technique that provides lock-freedom, as other existing methods use blocking memory reclamation schemes.
References
- [1] Yehuda Afek, Hagit Attiya, Danny Dolev, Eli Gafni, Michael Merritt, and Nir Shavit. Atomic snapshots of shared memory. Journal of the ACM (JACM), 40(4):873–890, 1993.
- [2] Panagiotis Antonopoulos, Peter Byrne, Wayne Chen, Cristian Diaconu, Raghavendra Thallam Kodandaramaih, Hanuma Kodavalla, Prashanth Purnananda, Adrian-Leonard Radu, Chaitanya Sreenivas Ravella, and Girish Mittur Venkataramanappa. Constant time recovery in azure sql database. Proceedings of the VLDB Endowment, 12(12):2143–2154, 2019.
- [3] Maya Arbel-Raviv and Trevor Brown. Harnessing epoch-based reclamation for efficient range queries. ACM SIGPLAN Notices, 53(1):14–27, 2018.
- [4] Hagit Attiya, Rachid Guerraoui, and Eric Ruppert. Partial snapshot objects. In Proceedings of the twentieth annual symposium on Parallelism in algorithms and architectures, pages 336–343, 2008.
- [5] Hillel Avni, Nir Shavit, and Adi Suissa. Leaplist: lessons learned in designing tm-supported range queries. In Proceedings of the 2013 ACM symposium on Principles of distributed computing, pages 299–308, 2013.
- [6] Daniel Bartholomew. MariaDB cookbook. Packt Publishing Ltd, 2014.
- [7] Dmitry Basin, Edward Bortnikov, Anastasia Braginsky, Guy Golan-Gueta, Eshcar Hillel, Idit Keidar, and Moshe Sulamy. Kiwi: A key-value map for scalable real-time analytics. In Proceedings of the 22Nd ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, pages 357–369, 2017.
- [8] Naama Ben-David, Guy E Blelloch, Panagiota Fatourou, Eric Ruppert, Yihan Sun, and Yuanhao Wei. Space and time bounded multiversion garbage collection. arXiv preprint arXiv:2108.02775, 2021.
- [9] Philip A Bernstein and Nathan Goodman. Concurrency control algorithms for multiversion database systems. In Proceedings of the first ACM SIGACT-SIGOPS Symposium on Principles of Distributed Computing, pages 209–215, 1982.
- [10] Philip A Bernstein and Nathan Goodman. Multiversion concurrency control—theory and algorithms. ACM Transactions on Database Systems (TODS), 8(4):465–483, 1983.
- [11] Jan Böttcher, Viktor Leis, Thomas Neumann, and Alfons Kemper. Scalable garbage collection for in-memory mvcc systems. Proceedings of the VLDB Endowment, 13(2):128–141, 2019.
- [12] Nathan G Bronson, Jared Casper, Hassan Chafi, and Kunle Olukotun. A practical concurrent binary search tree. ACM Sigplan Notices, 45(5):257–268, 2010.
- [13] Trevor Brown and Hillel Avni. Range queries in non-blocking k-ary search trees. In International Conference On Principles Of Distributed Systems, pages 31–45. Springer, 2012.
- [14] Trevor Brown, Faith Ellen, and Eric Ruppert. A general technique for non-blocking trees. In Proceedings of the 19th ACM SIGPLAN symposium on Principles and practice of parallel programming, pages 329–342, 2014.
- [15] Trevor Alexander Brown. Reclaiming memory for lock-free data structures: There has to be a better way. In Proceedings of the 2015 ACM Symposium on Principles of Distributed Computing, pages 261–270, 2015.
- [16] Bapi Chatterjee. Lock-free linearizable 1-dimensional range queries. In Proceedings of the 18th International Conference on Distributed Computing and Networking, pages 1–10, 2017.
- [17] Andreia Correia, Pedro Ramalhete, and Pascal Felber. Orcgc: automatic lock-free memory reclamation. In Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, pages 205–218, 2021.
- [18] David L Detlefs, Paul A Martin, Mark Moir, and Guy L Steele Jr. Lock-free reference counting. Distributed Computing, 15(4):255–271, 2002.
- [19] Cristian Diaconu, Craig Freedman, Erik Ismert, Per-Ake Larson, Pravin Mittal, Ryan Stonecipher, Nitin Verma, and Mike Zwilling. Hekaton: Sql server’s memory-optimized oltp engine. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, pages 1243–1254, 2013.
- [20] Faith Ellen, Panagiota Fatourou, Eric Ruppert, and Franck van Breugel. Non-blocking binary search trees. In Proceedings of the 29th ACM SIGACT-SIGOPS symposium on Principles of distributed computing, pages 131–140, 2010.
- [21] Franz Färber, Norman May, Wolfgang Lehner, Philipp Große, Ingo Müller, Hannes Rauhe, and Jonathan Dees. The sap hana database–an architecture overview. IEEE Data Eng. Bull., 35(1):28–33, 2012.
- [22] Panagiota Fatourou, Elias Papavasileiou, and Eric Ruppert. Persistent non-blocking binary search trees supporting wait-free range queries. In The 31st ACM Symposium on Parallelism in Algorithms and Architectures, pages 275–286, 2019.
- [23] Sérgio Miguel Fernandes and Joao Cachopo. Lock-free and scalable multi-version software transactional memory. ACM SIGPLAN Notices, 46(8):179–188, 2011.
- [24] Keir Fraser. Practical lock-freedom. Technical report, University of Cambridge, Computer Laboratory, 2004.
- [25] Theo Härder. Observations on optimistic concurrency control schemes. Information Systems, 9(2):111–120, 1984.
- [26] Timothy L Harris. A pragmatic implementation of non-blocking linked-lists. In International Symposium on Distributed Computing, pages 300–314. Springer, 2001.
- [27] Maurice Herlihy. Wait-free synchronization. ACM Transactions on Programming Languages and Systems (TOPLAS), 13(1):124–149, 1991.
- [28] Maurice Herlihy, Victor Luchangco, Paul Martin, and Mark Moir. Nonblocking memory management support for dynamic-sized data structures. ACM Transactions on Computer Systems (TOCS), 23(2):146–196, 2005.
- [29] Maurice Herlihy, Nir Shavit, Victor Luchangco, and Michael Spear. The art of multiprocessor programming. Newnes, 2020.
- [30] Maurice P Herlihy and Jeannette M Wing. Linearizability: A correctness condition for concurrent objects. ACM Transactions on Programming Languages and Systems (TOPLAS), 12(3):463–492, 1990.
- [31] Nikolaos D Kallimanis and Eleni Kanellou. Wait-free concurrent graph objects with dynamic traversals. In 19th International Conference on Principles of Distributed Systems (OPODIS 2015). Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik, 2016.
- [32] Idit Keidar and Dmitri Perelman. Multi-versioning in transactional memory. In Transactional Memory. Foundations, Algorithms, Tools, and Applications, pages 150–165. Springer, 2015.
- [33] Alfons Kemper and Thomas Neumann. Hyper: A hybrid oltp&olap main memory database system based on virtual memory snapshots. In 2011 IEEE 27th International Conference on Data Engineering, pages 195–206. IEEE, 2011.
- [34] Jongbin Kim, Hyunsoo Cho, Kihwang Kim, Jaeseon Yu, Sooyong Kang, and Hyungsoo Jung. Long-lived transactions made less harmful. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, pages 495–510, 2020.
- [35] Jongbin Kim, Kihwang Kim, Hyunsoo Cho, Jaeseon Yu, Sooyong Kang, and Hyungsoo Jung. Rethink the scan in mvcc databases. In Proceedings of the 2021 International Conference on Management of Data, pages 938–950, 2021.
- [36] Priyanka Kumar, Sathya Peri, and K Vidyasankar. A timestamp based multi-version stm algorithm. In International Conference on Distributed Computing and Networking, pages 212–226. Springer, 2014.
- [37] Juchang Lee, Hyungyu Shin, Chang Gyoo Park, Seongyun Ko, Jaeyun Noh, Yongjae Chuh, Wolfgang Stephan, and Wook-Shin Han. Hybrid garbage collection for multi-version concurrency control in sap hana. In Proceedings of the 2016 International Conference on Management of Data, pages 1307–1318, 2016.
- [38] Li Lu and Michael L Scott. Generic multiversion stm. In International Symposium on Distributed Computing, pages 134–148. Springer, 2013.
- [39] Alexander Matveev, Nir Shavit, Pascal Felber, and Patrick Marlier. Read-log-update: a lightweight synchronization mechanism for concurrent programming. In Proceedings of the 25th Symposium on Operating Systems Principles, pages 168–183, 2015.
- [40] Paul E McKenney and John D Slingwine. Read-copy update: Using execution history to solve concurrency problems. In Parallel and Distributed Computing and Systems, volume 509518, 1998.
- [41] Maged M Michael. Hazard pointers: Safe memory reclamation for lock-free objects. IEEE Transactions on Parallel and Distributed Systems, 15(6):491–504, 2004.
- [42] AB MySQL. Mysql, 2001.
- [43] Aravind Natarajan and Neeraj Mittal. Fast concurrent lock-free binary search trees. In Proceedings of the 19th ACM SIGPLAN symposium on Principles and practice of parallel programming, pages 317–328, 2014.
- [44] Jacob Nelson, Ahmed Hassan, and Roberto Palmieri. Bundling linked data structures for linearizable range queries. Technical report, 2022. URL: arXiv:2201.00874.
- [45] Yiannis Nikolakopoulos, Anders Gidenstam, Marina Papatriantafilou, and Philippas Tsigas. A consistency framework for iteration operations in concurrent data structures. In 2015 IEEE International Parallel and Distributed Processing Symposium, pages 239–248. IEEE, 2015.
- [46] Yiannis Nikolakopoulos, Anders Gidenstam, Marina Papatriantafilou, and Philippas Tsigas. Of concurrent data structures and iterations. In Algorithms, Probability, Networks, and Games, pages 358–369. Springer, 2015.
- [47] Christos H Papadimitriou. The serializability of concurrent database updates. Journal of the ACM (JACM), 26(4):631–653, 1979.
- [48] Christos H Papadimitriou and Paris C Kanellakis. On concurrency control by multiple versions. ACM Transactions on Database Systems (TODS), 9(1):89–99, 1984.
- [49] Dmitri Perelman, Anton Byshevsky, Oleg Litmanovich, and Idit Keidar. Smv: Selective multi-versioning stm. In International Symposium on Distributed Computing, pages 125–140. Springer, 2011.
- [50] Dmitri Perelman, Rui Fan, and Idit Keidar. On maintaining multiple versions in stm. In Proceedings of the 29th ACM SIGACT-SIGOPS symposium on Principles of distributed computing, pages 16–25, 2010.
- [51] Erez Petrank and Shahar Timnat. Lock-free data-structure iterators. In International Symposium on Distributed Computing, pages 224–238. Springer, 2013.
- [52] Hasso Plattner. A common database approach for oltp and olap using an in-memory column database. In Proceedings of the 2009 ACM SIGMOD International Conference on Management of data, pages 1–2, 2009.
- [53] Behandelt PostgreSQL. Postgresql. Web resource: http://www. PostgreSQL. org/about, 1996.
- [54] Aleksandar Prokopec. Snapqueue: lock-free queue with constant time snapshots. In Proceedings of the 6th ACM SIGPLAN Symposium on Scala, pages 1–12, 2015.
- [55] Aleksandar Prokopec, Nathan Grasso Bronson, Phil Bagwell, and Martin Odersky. Concurrent tries with efficient non-blocking snapshots. In Proceedings of the 17th ACM SIGPLAN symposium on Principles and Practice of Parallel Programming, pages 151–160, 2012.
- [56] Pedro Ramalhete and Andreia Correia. Brief announcement: Hazard eras-non-blocking memory reclamation. In Proceedings of the 29th ACM Symposium on Parallelism in Algorithms and Architectures, pages 367–369, 2017.
- [57] G Satyanarayana Reddy, Rallabandi Srinivasu, M Poorna Chander Rao, and Srikanth Reddy Rikkula. Data warehousing, data mining, olap and oltp technologies are essential elements to support decision-making process in industries. International Journal on Computer Science and Engineering, 2(9):2865–2873, 2010.
- [58] Gali Sheffi, Guy Golan-Gueta, and Erez Petrank. A scalable linearizable multi-index table. In 2018 IEEE 38th International Conference on Distributed Computing Systems (ICDCS), pages 200–211. IEEE, 2018.
- [59] Gali Sheffi, Maurice Herlihy, and Erez Petrank. VBR: Version Based Reclamation. In Seth Gilbert, editor, 35th International Symposium on Distributed Computing (DISC 2021), volume 209 of Leibniz International Proceedings in Informatics (LIPIcs), pages 35:1–35:18, Dagstuhl, Germany, 2021. Schloss Dagstuhl – Leibniz-Zentrum für Informatik. URL: https://drops.dagstuhl.de/opus/volltexte/2021/14837, doi:10.4230/LIPIcs.DISC.2021.35.
- [60] Gali Sheffi, Maurice Herlihy, and Erez Petrank. Vbr: Version based reclamation. In Proceedings of the 33rd ACM Symposium on Parallelism in Algorithms and Architectures, pages 443–445, 2021.
- [61] Ajay Singh, Trevor Brown, and Ali Mashtizadeh. Nbr: neutralization based reclamation. In Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, pages 175–190, 2021.
- [62] Daniel Solomon and Adam Morrison. Efficiently reclaiming memory in concurrent search data structures while bounding wasted memory. In Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, pages 191–204, 2021.
- [63] Alexander Spiegelman, Guy Golan-Gueta, and Idit Keidar. Transactional data structure libraries. ACM SIGPLAN Notices, 51(6):682–696, 2016.
- [64] Alexander Thomasian and In Kyung Ryu. Performance analysis of two-phase locking. IEEE Transactions on Software Engineering, 17(5):386, 1991.
- [65] Yuanhao Wei, Naama Ben-David, Guy E Blelloch, Panagiota Fatourou, Eric Ruppert, and Yihan Sun. Constant-time snapshots with applications to concurrent data structures. In Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, pages 31–46, 2021.
- [66] Haosen Wen, Joseph Izraelevitz, Wentao Cai, H Alan Beadle, and Michael L Scott. Interval-based memory reclamation. ACM SIGPLAN Notices, 53(1):1–13, 2018.
- [67] Kjell Winblad, Konstantinos Sagonas, and Bengt Jonsson. Lock-free contention adapting search trees. ACM Transactions on Parallel Computing (TOPC), 8(2):1–38, 2021.
- [68] Yingjun Wu, Joy Arulraj, Jiexi Lin, Ran Xian, and Andrew Pavlo. An empirical evaluation of in-memory multi-version concurrency control. Proceedings of the VLDB Endowment, 10(7):781–792, 2017.
- [69] Yoav Zuriel, Michal Friedman, Gali Sheffi, Nachshon Cohen, and Erez Petrank. Efficient lock-free durable sets. Proceedings of the ACM on Programming Languages, 3(OOPSLA):1–26, 2019.
Appendix A Auxiliary Methods and Initialization
As described in Section 3.1 and Algorithm 1 and 2, the linked-list represents a map of key-value pairs. Each pair is represented by a node, consisting of five fields: the mutable ts field represents its associated timestamp, the immutable key and value fields represent the pair’s key and value, respectively, the mutable next field holds a pointer to the node’s successor in the list, and the immutable prior field points to the previous successor of its first predecessor in the list.
The list initialization method appears in Algorithm 4. The global timestamps clock is initialized to 2, and the constant, representing an uninitialized timestamp, is set to 1. The list has a single entry point, which is a pointer to the head sentinel node. head’s key is the minimal key in the key range (denoted as ). Its timestamp is set to the initial system timestamp (2 in our implementation) and its next pointer points to the tail sentinel node. tail’s key is the maximal key in the key range (denoted as ), its timestamp is equal to head’s, and its next pointer points to null. Both prior fields point to null, as head has no predecessor, and tail’s predecessor (which is head) has no previous successor. After initialization, the list is considered as empty (the sentinel nodes do not represent map items).
The pseudo code for the global timestamps clock and node pointers access auxiliary methods appears in Algorithm 5. The getTS() method (lines 1-2) is used to atomically read the global timestamps clock (initialized in line 1 of Algorithm 4), and the fetchAddTS() method (lines 3-4) is used to atomically update it.
We use the pointer’s two least significant bits for encapsulating the mark and flag bits (see lines 5-7). The isMarked() (lines 8-10), isFlagged() (lines 11-13), and isMarkedOrFlagged() (lines 14-16) methods receive a pointer and return an answer using the relevant bit mask. The getRef() method (lines 17-18) receives a (potentially marked or flagged) pointer and returns the actual reference, ignoring the mark and flag bits. The mark() (lines 19-23) and flag() (lines 24-28) methods receive a node reference (the input pointer is assumed to be unmarked and unflagged), dereference it, and mark or flag the node’s next pointer (respectively), assuming it is neither marked nor flagged.
Appendix B Additional Graphs
In this Section we present additional results. The experiments setting is described in Section 4. In Figure 3 below we present the respective updates and range queries throughput for Figure 2(d) and 2(h). For convenience, Figure 3(a) is identical to Figure 2(d), and Figure 3(d) is identical to Figure 2(h). Figures 3(b) and 3(e) present the respective range queries throughput, and Figures 3(c) and 3(f) present the respective updates throughput.



The EEMARQ skip list surpasses all competitors, and is comparable to its next best scheme, EBR-RQ (see Figures 3(a)-3(c)). For long range queries, the EEMARQ tree surpasses its competitors (see Figure 3(d)) thanks to its range queries and searches high throughput, as its updates throughput deteriorates when the range queries are long (see Figure 3(f)).






In Figure 4 we isolate the searches (Figure 4(a) and 4(d)), range queries (Figure 4(b) and 4(e)), and updates (Figure 4(c) and 4(f)). For the 100% contains workload (Figure 4(a) and 4(d)), the Bundles data-structures surpass all competitors by small margins. As this workload does not use EEMARQ’s range queries mechanism or VBR’s locality, EEMARQ does not have an advantage when compared against its competitors. For the 100% range queries workload (Figure 4(b) and 4(e)), the EEMARQ data-structures surpass their competitors by high margins, as they impose no indirection, and the executing threads perform no rollbacks (memory is not reclaimed during the execution). For the 100% updates workload (Figure 4(c) and 4(f)), the EEMARQ data-structures are comparable to their best competitors (the EBR-RQ skip list and the EBR-RQ and vCAS trees). It seems that these results are heavily affected by the different skip list and BST implementations, as the Unsafe BST does not surpass the rest of the algorithms for this workload.
In Figure 5 we isolate range queries (as in Figure 4(b) and 4(e)) show the total range queries throughput when the range queries are shorter (100 instead of 1000). The EEMARQ skip list surpasses its competitors by a high margin for short range queries as well (Figure 5(a)), but the EEMARQ tree surpasses its next best competitor (vCAS) by a small margin (Figure 5(b)).


Appendix C Correctness
In this Section we prove that the linked-list implementation, as presented in Algorithms 1 and 2 (without taking reclamation or the fast index integration into account) is linearizable and lock-free. We start by setting preliminaries in Section C.1. We introduce some basic definitions and lemmas in Section C.2, continue with a full linearizability proof in Section C.3, and prove that the implementation is lock-free in Section C.4.
C.1 Preliminaries
We use the basic asynchronous shared memory model from [27]. The system consists of a set of executing threads, communicating through the shared memory. The shared memory is accessed by hardware-provided atomic operations, such as reads, writes, compare-and-swap (CAS) and wide-compare-and-swap (WCAS). The CAS operation receives an address of a memory word, an expected value and a new value. If the address content is equal to the expected value, it replaces it with the new value and returns true. Otherwise, it returns false. The WCAS does the same for two adjacent words in memory. We say that a concurrent implementation is lock-free if, given that the executing threads are run for a sufficiently long time, at least one thread makes progress. In addition, we use the standard correctness condition of linearizability from [30]. Briefly, any operation must take effect at some point (referred to as its linearizability point) between its invocation and response.
A mapping data structure represents a map from a set of unique keys to their respective values. Each key-value pair is represented by a node, consisting typically of immutable key and value, and some other mutable fields (e.g., next pointers). The data-structure has an entry point (e.g., a linked-list head [26] or a tree root [43]). The physical insertion of a node is the act of making it reachable from the entry point, and the physical deletion of a node is its unlinking from the data-structure (making it unreachable from the entry point). Many concurrent data-structure implementations [65, 26, 43] also include a level of logical insertion and deletion between the physical ones. I.e., a reachable node does not necessarily represent a key-value pair which is currently in the map.
C.2 Basic Definitions and Lemmas
Definition C.1.
We say that a node is reachable from a node if there exist nodes such that , , and for every , ’s pointer points to .
Definition C.2.
(reachable nodes) We say that a node is reachable if it is reachable from head.
According to Definition C.2, both head and tail are reachable at initialization. However, while head remains reachable throughout the execution, tail may be removed, and replaced by another node with an key. Only the original node with an key is refereed to as tail.
Note that the reachable path from Definition C.1 may consist of either marked or flagged pointers. Moreover, and as opposed to previous implementations [26, 43, 29], the marking of a node’s next pointer does not serve as its logical deletion from the list.
Before moving on to our linearizability proof, we must first define the term of being logically in the list. This term is presented in Definition C.14, after we define some other basic terms and prove several supporting lemmas.
Definition C.3.
Let be a node. We denote ’s possible states as follows:
-
•
We say that is pending if ’s timestamp is , and there does not exist an execution of the getTS() command in line 15, 43, 54, 60, 64, or 69 of Algorithm 1, or in line 15 or 25 of Algorithm 2, for which (1) the referenced node is , (2) the following CAS execution is successful777Note that the node stops being pending before the CAS is executed.
-
•
We say that is marked if its next pointer is marked.
-
•
We say that is flagged if its next pointer is flagged.
-
•
We say that is active if it is in none of the above states.
Definition C.4.
Definition C.5.
Lemma C.6.
Once a node’s timestamp is not , it is immutable.
Proof C.7.
Lemma C.8.
Marked and flagged next pointers are immutable.
Proof C.9.
Both the mark() and flag() methods, called in line 21 and 61 of Algorithm 1, respectively, change the pointer only if it is neither marked nor flagged (see Figure 5). The two remaining scenarios of pointer updates are in lines 14 and 68 of Algorithm 1. In both cases, the expected and new pointer values are neither marked nor flagged. Therefore, marked and flagged pointer never change.
Lemma C.10.
Let be a node. Then ’s state can only go through the following transitions:
-
•
From being pending to being active.
-
•
From being active to being marked.
-
•
From being active to being flagged.
Proof C.11.
By Lemma C.6, once a node’s timestamp is not , it is immutable. In addition, once the respective getTS() command from Definition C.3 is executed, a node cannot be pending anymore. Therefore, active, marked, and flagged nodes never become pending. In addition, by Lemma C.8, marked and flagged pointers are immutable. In particular, a marked node cannot become active or flagged, and a flagged node cannot become active or marked. It still remains to show that a pending node cannot become marked or flagged. Nodes are marked in line 21 of Algorithm 1, after being returned as the second output parameter from the find() call in line 19. Before this find() call returns, the node’s timestamp is updated in line 54 (if the node is not already active). In a similar way, right before a node is flagged in line 61 of Algorithm 1, its timestamp is updated in line 60, for making sure that it is no longer pending (the update fails if the node is already active).
Lemma C.12.
Let and be two different nodes. Then:
-
1.
If ’s next pointer points to , than is not an infant.
- 2.
-
3.
If was reachable from at a certain point during execution, and is either pending or active, then is still reachable from .
-
4.
If is not an infant, and is either pending or active, then it is reachable.
-
5.
If is not an infant, is ’s successor, and is pending, then is reachable.
-
6.
If was not pending and not reachable at some point, then it is still not reachable.
-
7.
If was ’s successor at a certain point during execution, and either or are pending, then is still ’s successor.
-
8.
If ’s key is smaller than or equal to ’s key, then is not reachable from .
- 9.
-
10.
If is unlinked, then it is not reachable.
-
11.
If is not an infant then there exists a node with a key which is reachable from .
-
12.
If a pointer is assigned into a local variable in Algorithm 1 and is later dereferenced, then it is not null.
Proof C.13.
We are going to prove the lemma by induction on the length of the execution. At the initial stage, head and tail are the only nodes in the list, having and keys (respectively), and head’s next pointer points to tail. By Definition C.4, tail is not an infant, and Invariant 1 holds. Invariants 2, 5, 6, 7, 10 and 12 vacuously hold, and Invariants 3, 4, 8, 9 and 11 hold since tail is head’s successor and both nodes are reachable by Definition C.2. Now, assume that all of the invariants hold at a certain point during the execution, and let be the next execution step, executed by a thread .
-
1.
Assume by contradiction that after executing , there exist two different nodes and , such that ’s next pointer points to , and is an infant. By the induction hypothesis, either is not an infant before executing (and thus, by Definition C.4, it is also not an infant after executing – a contradiction), or ’s next pointer does not point to right before executing . Therefore, has to be a pointer initialization (line 12 or 66 in Algorithm 1) or update (line 14 or 68 in Algorithm 1). In the first two cases, already have a predecessor prior to , and is not an infant by the induction hypothesis – a contradiction. In addition, by Definition C.4, after executing line 14 or 68, is no longer an infant, which also derives a contradiction. Therefore, the invariant holds.
-
2.
We first prove that is still an infant. By Definition C.4, it suffices to assume by contradiction that is not an infant after , and that ’s next step is the execution of line 14 or 68 of Algorithm 1, having as the third input parameter to the respective successful CAS. is either allocated in line 11 or 65, respectively. By Definition C.4, is an infant after allocated. Since is no longer an infant, there exist a former successful CAS execution, either in line 14 or 68, for which is the third input parameter. This implies that was allocated twice – a contradiction.
Now, assume by contradiction that is not pending before either line 14 or 68 of Algorithm 1 is executed, having as the third input parameter to the respective successful CAS. is either allocated in line 11 or 65, respectively. By Definition C.3, is pending after allocated. Since is guaranteed to still be an infant, its timestamp was not updated in line 15 or 69. Therefore, it was either updated in line 43, 54, 60 or 64 of Algorithm 1, or in line 15 or 25 of Algorithm 2. In all cases, already had a predecessor at this point, and by the induction hypothesis (Invariant 1), it is no longer an infant – a contradiction. Therefore, is neither an infant nor pending, and the invariant holds.
-
3.
Assume by contradiction that was reachable from at a certain point during the execution, and that after , is either pending or active, and not reachable from . By the induction hypothesis, is reachable from before . Note that cannot be one of the pointer initializations (in line 12 and 66), as the respective infants did not have any former successors. Therefore, must be a successful CAS execution, either in line 14 or 68 of Algorithm 1.
If is the execution of line 14, then right before , must be reachable from and must be reachable from . Since is still reachable from after executing , is also still reachable from – a contradiction.
Otherwise, if is the execution of line 68, then right before , must be reachable from and must be reachable from . Since is not marked or flagged, by Lemma C.10 it is also guaranteed that it has not been marked or flagged before executing . Therefore, is not among the marked nodes, traversed during the loop in lines 58-59. In addition, it cannot be the flagged node (flagged not later than the execution of line 61). Since marked and flagged pointers are immutable (see Lemma C.8), is reachable from , which is ’s successor, read in line 63. As ’s successor is set to be in line 66, by the induction hypothesis, is reachable from , right before executing . Since does not update ’s next pointer, is also reachable from after executing . Finally, since is ’s successor after executing , is still reachable from – a contradiction.
-
4.
Using Definition C.2 and Invariant 3, it suffices to show that is reachable when it stops being an infant. I.e., when it is the third input parameter to a successful CAS, either in line 14 or 68. In both cases, is not an infant by Invariant 1, and is either active or pending 888Actually, cannot be pending at this point. by Lemma C.8 (as its next pointer is mutable). Therefore, by the induction hypothesis, is reachable. By Definition C.2, is also reachable after executing the respective CAS.
-
5.
Assume by contradiction that after executing , is not an infant, is ’s successor, is pending, and is not reachable. Note that by Invariant 1, is not an infant, and by Invariant 4, it is still reachable after . If is either pending or active, then by Invariant 4, it is reachable – a contradiction. Therefore, must either be marked or flagged. By Lemma C.8, is ’s successor before and thus, by the induction hypothesis, is reachable before . I.e., updates a next pointer.
If is the execution of line 14, then must be reachable from the node referenced by the variable before , and not reachable from it after . By definition C.1, must be reachable from the node referenced by the variable. As the latter is still reachable from the former after the pointer change (via the node referenced by the variable), we get a contradiction.
Otherwise, if is the execution of line 68, then must be reachable from the node referenced by the variable before , and not reachable from it after . I.e., while is not reachable from the variable, must be reachable from it (as remains reachable after the pointer change, and does not change other pointers). The only possible scenario is the one in which is referenced by the variable, as the predecessors of all following nodes remain reachable after this pointer change. Since is no longer pending at this stage (its timestamp is updated no later than the execution of line 64), we get a contradiction.
Therefore, if is not an infant, is ’s successor, and is pending, then is reachable.
-
6.
Assume by contradiction that was not pending and not reachable at some point before executing , and that it is reachable after . By the induction hypothesis, it has not been reachable until right before executing . By Definition C.4, a node cannot become an infant after not being an infant. I.e., by Definition C.2, physically inserts into the list. W.l.o.g., assume that for every other node , formerly not reachable (while not being an infant) and then reachable after , is reachable from after . I.e., there are no such nodes that precede after . This means that ’s reachable predecessor after 999By Definition C.2, has a single reachable predecessor was also reachable before , and that updated its next pointer to point to .
For convenience, let us denote this predecessor with . Since is reachable prior to , by Invariant 1 it is not an infant. Consequently, by Invariant 2, cannot be the execution of line 12 or 66. It remains to show that it also cannot be the execution of line 14 or 68.
In both cases, by Invariant 2, ’s successor after is an infant right before , and we get a contradiction. Therefore, a former unreachable (while not being an infant) node never becomes reachable.
-
7.
Assume that was ’s successor at a certain point during the execution, and that either or are pending after . If is ’s successor after , then we are done. Otherwise, by Lemma C.10, either or are pending before , and by the induction hypothesis, is ’s successor right before . Therefore, must change ’s successor, either in line 14 or 68.
If ’s next pointer is updated in line 14, then both and are not pending, as their timestamps were updated no later than the execution of lines 43 and 54 (respectively), during the find() execution, invoked in line 9.
If ’s next pointer is updated in line 68, then is not pending, as its timestamp is updated no later than the execution of line 43, during the calling find() execution. In addition, during this calling find() execution, a pointer to was written into the variable, either in line 31 or 39. Assuming is still pending, by the induction hypothesis, when the condition in line 44 was checked, was still ’s successor. I.e., the variable was updated at least once during the loop in lines 34-36. This means that was either marked or flagged when the condition in line 34 was checked – a contradiction to Lemma C.10. Therefore, if either or are pending after , then is still ’s successor after , and the invariant holds.
-
8.
Assume by contradiction that ’s key is smaller than or equal to ’s key, and that is reachable from . Recall that keys are immutable. Therefore, by the induction hypothesis, was not reachable from before . Then must be a pointer update.
Obviously, cannot be the execution of line 12; The node, returned as output from the find() method, has a key which is at least ’s key (checked either in line 37 or 51). Moreover, since the condition checked in line 10 does not hold for , its key is strictly bigger than ’s key. By the induction hypothesis, all nodes reachable from have bigger keys, so executing line 12 cannot violate the condition.
In a similar way, cannot be the execution of line 66; By the induction hypothesis, ’s key is strictly bigger than ’s key, and thus it is strictly bigger than ’s key. By the induction hypothesis, all nodes reachable from have bigger keys, so executing line 66 cannot violate the condition.
It still remains to show that cannot be the execution of line 14 or 68. First, assume by contradiction that is the execution of line 14. By the induction hypothesis, the invariant holds prior to . Therefore, must be reachable from and must be reachable from . As explained above, the invariant holds for and all of its successive nodes, for any possible path. In addition, by the induction hypothesis, the invariant holds for and all of the nodes preceding it. Since is the node returned from the find() method, its key is strictly smaller than ’s key. Therefore, the violating step cannot be the execution of line 14.
The remaining possible step is the execution of line 68. Again, by the induction hypothesis, must be reachable from and must be reachable from . As explained above, the invariant holds for and all of its successive nodes, for any possible path. In addition, the invariant holds for and all of the nodes preceding it. Since is reachable from , its key is strictly bigger by the induction hypothesis. Consequently, ’s key is also strictly bigger than ’s. Therefore, the violating step cannot be the execution of line 68, and we get a contradiction. Since there are no other possible cases, the invariant holds.
-
9.
If is either pending or active, then by Invariant 4, it is reachable. Otherwise, by the induction hypothesis, it is still reachable before . Assume by contradiction that it is not reachable after , and that either is not the execution of line 68, or was not traversed during the loop in lines 58-59 of the same trim() execution.
If is not the execution of line 68, then it must be a next pointer change. I.e., it must be a successful CAS execution in line 14. If the node, referenced by the variable, is reachable from before , then by Invariant 8, this pointer change does not affect ’s reachability. Otherwise, prior to , must be reachable from the node referenced by the variable. In this case, remains reachable after – a contradiction.
Otherwise, was not traversed during the loop in lines 58-59, but is still the execution of line 68. Let be the node referenced by the variable. If ’s key is not bigger then ’s key, then by Invariant 8, ’s reachability is not affected by this CAS.
By Lemma C.8, all nodes, traversed during the loop in lines 58-59, are immutable after the execution of line 61. Recall that by the induction hypothesis, is still reachable before . Therefore, if ’s key is bigger than ’s key, then it also must be reachable from the node referenced by the variable. I.e., is still reachable after – a contradiction. Any possible case lead to a contradiction and thus, the invariant holds.
-
10.
By Invariant 2, (as defined in Definition C.5) becomes active only after the execution of line 68. At this point, is either marked or flagged, and by Lemma C.10, it is not pending when line 68 is executed. By Invariant 6, it suffices to show that is not reachable after the execution of line 68, during the respective trim() execution from Definition C.5.
Assume by contradiction that is the execution of this update, and that is reachable after . Let be the node referenced by the local variable. By Invariant 8, ’s key is strictly smaller than ’s key, and ’s key is at least ’s key. As ’s timestamp had been updated no later then the execution of line 43, during the calling find() method, is not pending. By Invariant 2, is not an infant. By Definition C.4 and Invariant 2, is pending after executing line 68. Therefore, by Invariant 4 and 5, both and are reachable after executing line 68. By Invariant 8, cannot be reachable at this point – a contradiction. Therefore, if is unlinked, then it is not reachable.
-
11.
Assume by contradiction that after , is not an infant and there does not exist a node with a key which is reachable from . By the induction hypothesis, the invariant holds before . I.e., either is an infant before , or there exists a node with a key which is reachable from .
If is an infant before , then by Definition C.4, must be the execution of line 14 or 68, having referenced by the or variable, respectively. By Invariant 1, ’s successor is not an infant. By the induction hypothesis, a node with a key is reachable from ’s successor, and by Definition C.1, it is also reachable from – a contradiction.
Therefore, there exists a node with a key which is reachable from before . W.l.o.g., assume that is the node with the maximal key, for which there does not exist a reachable node with a key . By Definition C.1, ’s key is smaller than . Let us denote the respective node (with a key ), reachable from before , with . In addition, let us denote ’s successor before , with (By the induction hypothesis, necessarily has a successor before ). By the choice of and Invariant 8, a node with a key is reachable from after . By Definition C.1, updates ’s next pointer. Since is not an infant, by Invariant 2, is the execution of line 14 or 68, having referenced by the variable.
If is the execution of line 14, then is still reachable from – a contradiction. Therefore, is the execution of line 68. Let be the node referenced by the variable. By Invariant 8, does not affect the reachability of any node from . I.e., by the induction hypothesis, a node with a key is reachable from after . As is reachable from after (by Invariant 2 and 7), we get a contradiction to Definition C.1. Therefore, points to NULL. By the induction hypothesis, this means that the last node referenced by the variable, has a key . As the node referenced by the variable has the same key, a node with a key is reachable from after – a contradiction.
Therefore, if is not an infant, there exists a node with a key which is reachable from .
-
12.
By the induction hypothesis, it suffices to show that whenever the , and variables are assigned with a new value (which is later dereferenced), it is not null.
If assigns new values into the and variables in line 9, 19 or 25, then this value is not null by the induction hypothesis.
If assigns a new value into the variable in line 30, then this value is a pointer to , which is obviously not null.
If assigns a new value into the variable in line 36, then by Lemma C.8, this value is the same value for which the condition in line 35 did not hold. I.e., this value is not null.
If assigns a new value into the variable in line 38, then by the induction hypothesis, this value is not null.
If assigns a new value into the variable in line 42 or 50, then since the condition, checked in line 37, does not hold for the node referenced by the variable, and by Invariant 11, the assigned value is not null.
If assigns a new value into the variable in line 59, then the previous node, referenced by the variable, is marked. I.e., it cannot have an key. By Invariant 11, the assigned value is not null.
Finally, if assigns a new value into the variable in line 63, then it is dereferenced iff it is not null.
Before setting linearization points, we still need to define the term of being logically in the list. Next, we are going to prove that (1) an insert() operation logically inserts a new node iff there is no other node with the same key, logically in the list at the operation’s linearization point, (2) a remove() operation either logically removes a node, or does nothing in case there is no node with the input key, which is logically in the list at the operation’s linearization point, (3) a contains() returns true iff there exists a node with the operation’s input key which is logically in the list at its linearization point, and (4) a rangeQuery() operation returns the sequence of all nodes, having keys in the given range, and which are logically in the list during the operation’s linearization point.
Definition C.14.
(logically in the list) We say that a node is logically in the list if it is not pending and not unlinked.
According to Definition C.14, unreachable nodes may still be considered as logically in the list, as long as they are not unlinked (see Definition C.5). Allegedly, this may result in foiling linearizability, as a key may appear twice in the list: an unreachable (but not yet unlinked) node and a newly inserted one might have the same key. However, this scenario is impossible, as we prove in Lemmas C.15, C.17 and C.19 below.
Lemma C.15.
Let and be two nodes, and let and be their keys, respectively. If both nodes are logically in the list, reachable, and is ’s successor, then there does not exist a different node , with a key , which is logically in the list.
Proof C.16.
Assume by contradiction that exists.
By Definition C.1, C.2, and Lemma C.12 (Invariant 8), it is impossible that all three nodes are reachable. Therefore, is not reachable.
By Lemma C.12 (Invariant 9), has already been traversed during the loop in lines 58-59, followed by a successful CAS execution in line 68. Let be the node referenced by and let be the node referenced by at this point. By Lemma C.12 (Invariant 8), ’s key is smaller than ’s key, and ’s key is at least ’s key. Since is still logically in the list, by Definition C.5, is still pending. Therefore, by Lemma C.12 (Invariant 5), is reachable (and consequently, is reachable as well). Now, by Lemma C.12 (Invariant 8), ’s key must be smaller than ’s key, and ’s key must be bigger than ’s key. As all four nodes are reachable, it must hold that is and is . I.e., is pending, and by Definition C.14, is not logically in the list – a contradiction. Therefore, does not exist.
Lemma C.17.
Let and be two nodes, and let and be their keys, respectively. If both nodes are logically in the list, and is ’s successor, then there does not exist a different node , with a key , which is logically in the list.
Proof C.18.
Assume by contradiction that exists. By Lemma C.15, if is reachable, then we are done (as is also reachable, by Definition C.2). Therefore, is not reachable.
By Lemma C.12 (Invariant 9), has already been traversed during the loop in lines 58-59, followed by a successful CAS execution in line 68.
By Lemma C.12 (Invariant 4), is either marked or flagged. Therefore, by Lemma C.8, was also ’s successor right before it stopped being reachable. Assume by contradiction that was logically in the list while was still reachable. Then by Lemma C.15, was not logically in the list when stopped being reachable (as necessarily was ’s successor and reachable at this point). In particular, was pending, and by Definition C.3, it was neither marked nor flagged at this point, which means that it was not traversed during the loop in lines 58-59 (during which was traversed). I.e., cannot be pending, as its timestamp was updated no later than the execution of line 64 – a contradiction. Therefore, started being logically in the list after stopped being reachable. Moreover, by Lemma C.12 (Invariant 4 and 6), became reachable after stopped being reachable.
Going back to ’s traversal in lines 58-59, guaranteed by Definition C.5, let be the node referenced by , let be the node referenced by , and let and be their keys, respectively. By Lemma C.12 (Invariant 8), . Since is still logically in the list, by Definition C.5 and C.14, is pending. By Lemma C.12 (Invariant 4) became reachable after the successful CAS in line 68 was executed. Since was reachable prior to this CAS (by Lemma C.12, Invariant 9), became reachable before .
By Lemma C.12 (Invariant 5), both and are still reachable. As is currently logically in the list, by Lemma C.12 (Invariant 9), it must have been reachable at some point. Since , by Lemma C.12 (Invariant 8), while being reachable, was reachable from . However, , as is currently logically in the list and is still pending. By Lemma C.12 (Invariant 8), . Consequently, . This means that was not traversed during the loop in lines 58-59 (as all traversed nodes must have a key which is not bigger than , by Lemma C.12, Invariant 8). Actually, Since is ’s successor, it must have been referenced by the variable, which means that it was ’s successor when line 68 was executed. By Lemma C.12 (Invariant 7), is still ’s successor. By Definition C.1, is reachable from – a contradiction to Lemma C.12 (Invariant 8). Therefore, does not exist.
Lemma C.19.
Let and be two different nodes with the same key. Then either or is not logically in the list.
Proof C.20.
Assume by contradiction that both and are logically in the list. If either or are reachable, then we get a contradiction to Lemma C.15. Otherwise, if either or have a predecessor which is logically in the list, we get a contradiction to Lemma C.17. Therefore, both are not reachable, and do not have a predecessor which is logically in the list.
By Lemma C.12 (Invariant 9), both nodes have already been traversed during the loop in lines 58-59, followed by a successful CAS execution in line 68. However, they were not traversed during the same trim() invocation, as that would imply they were reachable from each other (a contradiction to Lemma C.12, Invariant 8). W.l.o.g., assume that the CAS, executed in line 68 in the scope of the trim() invocation, associated with , was executed first. Let be the node referenced by and let be the node referenced by at this point. As is still logically in the list, by Definition C.5, is pending. Therefore, by Lemma C.12 (Invariant 5 and 7), both and are still reachable, and is still ’s successor. By Lemma C.12 (Invariant 8), ’s key is smaller than ’s key, and ’s key is at least ’s key.
In a similar way to , by Lemma C.12 (Invariant 9), has already been traversed during the loop in lines 58-59, followed by a successful CAS execution in line 68. Let be the node referenced by and let be the node referenced by at this point. Since is logically in the list, by Definition C.5, is pending. Therefore, by Lemma C.12 (Invariant 5 and 7), both and are reachable, and is ’s successor. By Lemma C.12 (Invariant 8), ’s key is smaller than ’s key, and ’s key is at least ’s key.
By Lemma C.12 (Invariant 9), and are the same node, and and are the same node – a contradiction to the fact that and were traversed during separate trim() invocations.
Therefore, for every two different nodes, and , with the same key, either or is not logically in the list.
C.3 Linearizability
Before handling the list operations, we set a linearization point per find() execution, as the rest of the operations heavily rely on this method. This point is guaranteed by Lemma C.21 below.
Lemma C.21.
Let , be the two nodes returned from a find(key) call. Then:
-
1.
’s key is smaller than the input key.
-
2.
’s key is not smaller than the input key
-
3.
There exists a point during the method execution in which both nodes are reachable and logically in the list and is ’s successor.
-
4.
During the guaranteed point, there does not exist a node , with a key bigger than ’s key and not bigger than ’s key, and which is logically in the list.
Proof C.22.
Let and be the two nodes returned from a find(key) call.
-
1.
A pointer to was assigned into the variable, either in line 30 or 38. If it was assigned in line 30, then is the head sentinel and its key is obviously smaller than the input key. Otherwise, the condition in line 37, checked right before the assignment, did not hold for . I.e., ’s key must be smaller than the input key.
-
2.
A pointer to was assigned into the variable, either in line 32, 36, 42, or 50. If the last such assignment was in line 32, 36 or 42, then the condition checked in line 37 holds for . Otherwise, the condition checked in line 51 does not hold for . In both cases, ’s key is not smaller than the input key.
-
3.
We are now going to set the guaranteed point, with respect to the last time is assigned into the variable.
If is assigned into the variable for the last time in line 32, then is the head sentinel node, which is not pending and always reachable (by Definition C.2), and thus (By Lemma C.12, Invariant 10), is logically in the list. In addition, is neither marked nor flagged at this point, as the condition checked in line 34 does not hold. If is active when line 31 is executed, then it is reachable by Lemma C.12 (Invariant 4), and by the same lemma (Invariant 10), it is not unlinked. By Definition C.14, it is logically in the list at this point, and we are done. Otherwise, by Lemma C.12 (Invariant 7), it is guaranteed that when becomes active, it is still ’s successor. I.e., it is reachable, thus neither an infant (by Lemma C.12, Invariant 1) nor unlinked (by Lemma C.12, Invariant 10), and by Definition C.14, it is logically in the list. Therefore, if is assigned into the variable for the last time in line 32, then the guaranteed point is the first time is active after the last execution of line 31.
The next scenario is when is assigned into the variable for the last time in line 42. Since the condition from line 40 does not hold, is either pending or active at this point. In addition, since the condition from line 34 does not hold for in the next loop iteration, is also pending or active. Therefore, when ’s successor is read in line 39, by Lemma C.12 (Invariant 4), both nodes are reachable. If both nodes are active at this point, then by Lemma C.12 (Invariant 1 and 10) and Definition C.14, we are done. Otherwise, becomes active no later than the execution of line 43, and becomes active no later than the execution of line 54. By Lemma C.12 (Invariant 7), once the latter becomes active, is still ’s successor. In order to show that both nodes are logically in the list at this point, by Lemma C.12 (Invariant 1 and 10) and Definition C.14, it still remains to show that both nodes are reachable at this point. If is the latter one becoming active, then by Lemma C.12 (Invariant 4) and the fact that is ’s successor, both nodes are reachable at this point. Otherwise, if is the latter one, then by Lemma C.12 (Invariant 5), is still reachable when becomes active. By Definition C.1 and C.2, is reachable at this point as well. By Definition C.14, both nodes are logically in the list at this point. Therefore, if is assigned into the variable for the last time in line 42, then the guaranteed point is the first time both and are not pending after the last execution of line 39.
The last scenario is when is assigned into the variable for the last time in line 50. In this scenario, ’s next pointer is read for the last time in line 47. Since the conditions in lines 48 and 51 do not hold, both and are not marked or flagged. Moreover, is not pending, as its timestamp is updated no later than the execution of line 43. In addition, by Lemma C.12, both are not infants (by Invariant 1) and thus, are reachable (by Invariant 4). By Lemma C.12 (Invariant 5), is still reachable once becomes active. By Definition C.1 and C.2, is reachable at this point as well. By Lemma C.12 (Invariant 1 and 10) and Definition C.14, both nodes are logically in the list at this point. Therefore, if is assigned into the variable for the last time in line 50, then the guaranteed point is the first time is not pending after the last execution of line 47.
Note that cannot be assigned into the variable for the last time in line 36. By Lemma C.12 (Invariant 8), and since the executing thread traverses at least one node during the loop in lines 34-36, ’s key is strictly bigger than the key of the node, referenced be the variable. Therefore, they cannot be equal, and the condition from line 44 holds. I.e., a node pointer is written into the variable, either in line 50, or in the next traversal trial (in case the method restarts before line 50 is executed) – a contradiction to the fact that a pointer to the second output parameter was assigned into the variable for the last time in line 36.
-
4.
Directly holds by Lemma C.15.
Given Lemma C.21, we are now able to set linearization points per list operation.
C.3.1 The insert() Operation
We separate between successful executions (returning NO_VAL in line 16) and unsuccessful executions (returning ’s value in line 10).
Definition C.23.
(Successful inserts - linearization points) Let be the node referenced by the variable when a successful insert() execution returns. Then the operation’s linearization point is set to the step that turns into an active node.
Definition C.24.
We are now going to prove, using Lemmas C.25, C.27, and C.29 below, that Definitions C.23-C.24 above indeed define adequate linearization points. I.e., that each linearization point occurs between the invocation and termination of the operation, and that the operation indeed takes affect at its linearization point.
Lemma C.25.
Proof C.26.
The linearization point guaranteed by Definition C.24 occurs in the scope of the find() execution (by Lemma C.21), and consequently, it occurs between the invocation and response of the unsuccessful insert() execution. The linearization point guaranteed by Definition C.23 occurs after the node’s allocation (done in the scope of the execution), and no later than the execution of line 15 (by Definition C.3). Therefore, it occurs between the invocation and response of the successful insert() execution.
Lemma C.27.
Let be the node referenced by the variable when a successful insert() execution returns, let be its key, and let be the step guaranteed by Definition C.23. Then:
-
1.
Immediately after , is logically in the list.
-
2.
Immediately before , there is no node with a key , which is logically in the list.
Proof C.28.
Recall that becomes active at (and in particular, it is not pending).
- 1.
-
2.
By Lemma C.19, immediately after , there is no node with a key , which is logically in the list. Assume by contradiction that there exists such a node, denoted , immediately before . I.e., by Definition C.14, unlinks . By Definition C.5, was allocated during a trim() execution – a contradiction. Therefore, there is no node with a key , which is logically in the list immediately before .
Lemma C.29.
Let be the input key to an unsuccessful insert() execution. Then at the linearization point, defined by Definition C.24, there exists a node with a key , which is logically in the list.
C.3.2 The remove() Operation
We separate between successful executions (returning ’s value in line 23), and unsuccessful executions (returning NO_VAL in line 20).
Definition C.31.
(Successful removals - linearization points) Let be the node referenced by the variable when a successful remove() execution returns. Then the operation’s linearization point is set to the step that unlinks .
Definition C.32.
We are now going to prove, using Lemmas C.33, C.35, and C.37 below, that Definitions C.31-C.32 above indeed define adequate linearization points. I.e., that each linearization point occurs between the invocation and termination of the operation, and that the operation indeed takes affect at its linearization point.
Lemma C.33.
Proof C.34.
The linearization point guaranteed by Definition C.32 occurs in the scope of the find() execution (by Lemma C.21), and consequently, it occurs between the invocation and response of the unsuccessful remove() execution.
We are now going to show that at the linearization point, guaranteed by Definition C.31, occurs no later then the termination of the find() method, called in line 22. Let , be the two nodes, returned from this find() execution (and not used by the calling remove() operation). By Lemma C.21, ’s key is smaller than ’s key, ’s key is at least ’s key, and there exists a point during the find() execution, in which is ’s successor, and both nodes are reachable and logically in the list.
First, assume by contradiction that is . As is already marked when the find() method is invoked, it is impossible that the find() method returns it (see the conditions in lines 34 and 51) – a contradiction. Therefore, by Lemma C.12 (Invariant 8), is already not reachable at the point, guaranteed by Lemma C.21. By Lemma C.21, is necessarily not logically in the list at this point. Therefore, both linearization points occur between the invocation and response of the remove() execution.
Lemma C.35.
Let be the node, marked during a successful remove() execution, let be its key, and let be the step guaranteed by Definition C.31. Then:
-
1.
is not marked during any other remove() execution.
-
2.
After , is not logically in the list.
-
3.
Immediately before , is logically in the list.
Proof C.36.
Lemma C.37.
Let be the input key to an unsuccessful remove() execution. Then at the linearization point, defined by Definition C.32, there does not exist a node with a key , which is logically in the list.
Proof C.38.
By Lemma C.21, the node referenced by the variable is logically in the list at this point. Since the condition in line 20 holds, by Lemma C.21, its key is bigger than . By Lemma C.21, this node, along with the node referenced by the variable, are logically in the list, and is between their respective keys. By Lemma C.21, there does not exist a node with a key , which is logically in the list at this point.
C.3.3 The contains() Operation
As opposed to the insert() and remove() operations, there is no need to separate between contains() invocations that return NO_VAL in line 26 and an actual value in line 27. Both types of executions are linearized at the same point, as defined in Definition C.39 below.
Definition C.39.
We are now going to prove, using Lemmas C.40 and C.42 below, that Definition C.39 above indeed defines adequate linearization points. I.e., that each linearization point occurs between the invocation and termination of the operation, and that the operation indeed takes affect at its linearization point.
Lemma C.40.
The linearization points, guaranteed by Definition C.39, occur between the invocation and termination of the respective execution.
Proof C.41.
Lemma C.42.
Proof C.43.
Let and be the nodes, referenced by the and variables (respectively) when the operation returns. By Lemma C.21, both and are logically in the list at this point. In addition, ’s key is smaller than and ’s key is at least .
- 1.
- 2.
C.3.4 The rangeQuery() Operation
For proving that the rangeQuery() operation is linearizable, we first need to prove some basic claims. As these claims are irrelevant to the other operations’ linearizability, we are going to prove them below. For convenience, we use the term epoch when relating to the global timestamps clock’s value. In addition, we are going to define the terms of birth epoch and retire epoch in this context101010Note that to this end, we ignore memory reclamation. Therefore, there is no problem with overloading the birth epoch term..
Definition C.44.
(birth epoch and retire epoch) Let be a node. We say that ’s birth epoch is the first epoch in which was logically in the list, and that ’s retire epoch is the first epoch in which stopped being logically in the list.
Lemma C.45.
Suppose that ’s timestamp is , and that . Then is ’s birth epoch.
Proof C.46.
Lemma C.47.
Suppose that is an unlinked node, and let be the node guaranteed by Definition C.5. Then ’s timestamp is ’s retire epoch.
Proof C.48.
Lemma C.49.
Let and be two nodes, and let and be their birth epochs, respectively. Let be the maximum between and . If is ’s successor during an epoch , then has been ’s successor since epoch .
Proof C.50.
By Definition C.4 and Lemma C.12 (Invariants 1 and 2), indeed started to be ’s successor when one of them was pending.
In addition, the other one was not pending:
- 1.
- 2.
- 3.
- 4.
Definition C.51.
(p-predecessor and p-successor) We say that a node is the p-successor of a node , if ’s pointer points to . In this case, we also say that is a p-predecessor of .
Lemma C.52.
Let and be two nodes, let and be their timestamps, and let and be their keys, respectively. If is ’s p-successor, then:
-
1.
.
-
2.
If , then .
-
3.
If , then ’s retire epoch is at least .
-
4.
If and ’s key is smaller than ’s key, then ’s retire epoch is .
-
5.
Let be ’s first predecessor, let be its birth epoch, and let be its key. In addition, let be the maximum between and . Then:
-
(a)
became ’s predecessor no later than epoch .
-
(b)
had been ’s successor until was its successor.
-
(c)
If either is , or both and , then since the global epoch clock showed for the last time, and while was not logically in the list yet, no node with a key between and had been logically in the list.
-
(a)
Proof C.53.
Recall that by Lemma C.6, timestamps are immutable once set. In addition, fields are set upon initialization (either in line 13 or 67), and are immutable as well.
- 1.
- 2.
- 3.
- 4.
-
5.
First, note that both ’s and ’s timestamps are not : as is ’s p-successor, its timestamp is not (as already proven above). In addition, by Definition C.4 and Lemma C.12 (Invariants 1 and 2), ’s timestamp was updated no later than a former execution of line 43.
Second, note that if , then (as both ’s and ’s timestamps were updated during former find() executions).
- (a)
-
(b)
was ’s successor just before . By Lemma C.49, had been ’s successor until was its successor.
-
(c)
Assume that and . By Lemma C.49, was ’s successor when the global epoch clock showed for the last time, and until became reachable.
By Lemma C.12 (Invariants 2 and 4), became reachable either after the execution of line 14 or 68 in Algorithm 1.
If became reachable after the execution of line 14, then both and were logically in the list at this point, and by Lemma C.17, no node with a key between and had been logically in the list since the global epoch clock showed for the last time, and until became reachable. Assume by contradiction that since became reachable, and before it was logically in the list, there had been a logically in the list node, , with a key . By Definition C.14, is not . In addition, by Lemma C.12 (Invariant 8), was not reachable since became reachable, and before it was logically in the list. Since was logically in the list, by Lemma C.12 (Invariant 9), must have been reachable from while still being reachable. I.e, stopped being reachable before became ’s successor, and thus, by Lemma C.15, stooped being logically in the list before became reachable – a contradiction.
Therefore, became reachable after the execution of line 68. By Definition C.5, remained logically in the list until was logically in the list, and . Assume by contradiction that since became reachable, and before it was logically in the list, there had been a logically in the list node, , with a key . By Definition C.14, is not . In addition, by Lemma C.12 (Invariant 8), was not reachable since became reachable, and before it was logically in the list. Since was logically in the list, by Lemma C.12 (Invariant 9), must have been reachable from while still being reachable. I.e, stopped being reachable before became ’s successor, and thus, by Lemma C.15, stooped being logically in the list before became reachable – a contradiction.
Therefore, since the global epoch clock showed for the last time, and until was logically in the list for the first time, no node with a key between and had been logically in the list.
Definition C.54.
(p-reachability) We say that a node is p-reachable from a node if there exist nodes such that , , and for every , is ’s p-successor.
Lemma C.55.
Let be a node, and assume that ’s pointer is initialized. Then 111111The original tail sentinel node, and not just any node with an key is p-reachable from .
Proof C.56.
Recall that ’s prior is never initialized, so the lemma holds for it vacuously. The lemma is proven by Induction on the execution length. For the base case, is p-reachable from itself by Definition C.54. For the induction step, It suffices to show that the lemma holds for ’s (single) p-successor. If ’s p-successor is , then we are done.
Given Lemma C.55, we can now prove that we never dereference a null pointer during the rangeQuery() operation.
Lemma C.57.
A null pointer is never assigned into the , and pointers during a rangeQuery() execution.
Proof C.58.
We are going to prove the lemma by induction on the execution length. The lemma holds vacuously when the operation is invoked. For the induction step:
Corollary C.59.
Null pointers are never dereferenced during the rangeQuery() operation.
Lemma C.60.
Proof C.61.
First, note that ’s timestamp is not , as it is either the sentinel node, returned as the first output parameter, from the find() call in line 5 (i.e., its timestamp was updated no later than the respective execution of line 43), or has a p-predecessor (and therefore, has a non- timestamp, by Lemma C.52).
Now, as the condition, checked in line 7, does not hold for , ’s timestamp is at most . By Lemma C.45, was logically in the list before epoch ended.
If is the sentinel node, then it obviously was logically in the list when epoch ended.
Otherwise, if a pointer to was returned as the first output parameter, from the find() call in line 5 (i.e., the condition in line 7 was checked only once), then by Lemma C.21, was still logically in the list during an epoch which is bigger than (as is always smaller than the current epoch). Therefore, was logically in the list when epoch ended.
Lemma C.62.
Let be the last node assigned into the variable during a loop iteration in lines 13-18, and let be the node referenced by the variable during this assignment. In addition, let be ’s key, and let be ’s key. Then when epoch ended:
-
1.
Both nodes were logically in the list.
-
2.
There was no node with a key , that was logically in the list when epoch ended.
Proof C.63.
We are going to prove the lemma by induction on the number of loop iterations. For the base case, before the loop started, by Lemma C.60, was logically in the list when epoch ended, and the rest holds vacuously.
For the induction step, first assume that a pointer to was assigned into the variable in line 14. By the induction hypothesis, was logically in the list when epoch ended (either by Lemma C.60, or by the induction hypothesis). In addition, as the condition from line 16 did not hold for , by Lemma C.45, ’s birth epoch is at most . Since is ’s successor during the current epoch, which is obviously bigger than , by Lemma C.49, was also ’s successor when epoch ended. Assume by contradiction that was not logically in the list when epoch ended. Then by Lemma C.12 (Invariant 10), it was also not reachable. By Definition C.1, was not reachable as well at this point. By Definition C.5, became unlinked when became unlinked – a contradiction. Therefore, was also logically in the list when epoch ended. By Lemma C.17, there was no node with a key , that was logically in the list when epoch ended.
Now, assume that a pointer to was assigned into the variable in line 17. Then since the condition in line 16 did not hold for , ’s birth epoch is at most . By the induction hypothesis, was logically in the list when epoch ended. Specifically, ’s birth epoch is at most as well.
Let be the previous node referenced by the variable. Then ’s timestamp is bigger than . By Lemma C.52, had been ’s successor when epoch ended, and there was no node with a key , that was logically in the list when epoch ended.
It still remains to show that was logically in the list when epoch ended. Assume by contradiction that was not logically in the list when epoch ended. Then by Lemma C.12 (Invariant 10), it was also not reachable. By Definition C.1, was not reachable as well at this point. By Lemma C.12 (Invariant 4), it was neither pending nor active – a contradiction to Lemma C.8 (as its next pointer was later updated to point to ). Therefore, was logically in the list when epoch ended.
Lemma C.64.
Proof C.65.
The lemma holds directly from Lemma C.62.
Lemma C.66.
Proof C.67.
W.l.o.g., the lemma holds from Lemma C.62 as well.
Lemma C.68.
Let be the node, referenced by the variable when line 19 is executed. Then among all nodes that are logically in the list when epoch ends, has the minimal key which is at least .
Proof C.69.
Since the condition in line 13 holds for , ’s key is at least . In addition, by Lemma C.64, was logically in the list when epoch ended. If ’s key is , then the lemma holds by Lemma C.19. Otherwise, since ’s key is bigger than , is not the first node referenced by the variable (see line 10). By Lemma C.64, the previous node referenced by the variable was also logically in the list, and also ’s predecessor, when epoch ended. Since the condition in line 13 did not hold for that node, its key is necessarily smaller than . By Lemma C.17, among all nodes that were logically in the list when epoch ended, had the minimal key which was at least .
Lemma C.70.
For every key , written into the output array in line 21, it holds that , and belongs to a node that was logically in the list when ended.
Proof C.71.
Lemma C.72.
Proof C.73.
Assume by contradiction that ’s key and value were not written into the output array in lines 21-22. W.l.o.g., let be the node with the minimal key, whose key and value were not written. By Lemma C.68, cannot be the node referenced by the variable when line 19 is executed. Let be the node with the maximal node in range which is smaller than ’s key. By the choice of , was referenced by the variable during the loop in lines 20-28. As ’s key is smaller than ’s key, and ’s key is in range, let be the next node, referenced by the variable. By the choice of , ’s key is bigger than ’s key. By Lemma C.66, was not logically in the loop when epoch ended – a contradiction.
We can now define a linearization point per rangeQuery() execution.
Definition C.74.
(rangeQuery - linearization points) A rangeQuery() execution is linearized when epoch 121212the final value terminates.
We are now going to prove, using Lemmas C.75 and C.77 below, that Definition C.74 above indeed defines adequate linearization points. I.e., that each linearization point occurs between the invocation and termination of the operation, and that the operation indeed takes affect at its linearization point.
Lemma C.75.
The linearization point, guaranteed by Definition C.74, occurs between the invocation and termination of the respective execution.
Proof C.76.
If is read in line 2, then epoch terminates in this line, which is between the invocation and termination of the respective execution. Otherwise, is the epoch before the current epoch, when line 12 is executed for the last time. As the global epoch was incremented at least once during this execution, epoch necessarily ended between the invocation and termination of the execution.
Lemma C.77.
Let and be the input parameters to a rangeQuery() execution, and let be the set of keys, returned using the output array. Then at the linearization point, defined by Definition C.74, it holds that contains exactly the keys of all of the nodes which are logically in the list, with keys between and .
We conclude with the following theorem:
C.4 Lock-Freedom
We are going to prove that during every possible execution, at least one of the executing threads terminates its operation. To derive a contradiction, we assume the existence of an execution , in which, starting from a certain point, no thread terminates its operation. Let be the last step executed before this point. As the total number of threads is finite and bounded, we assume, w.l.o.g., that no operation is invoked after .
As the CAS execution in line 14 of Algorithm 1 is successfully executed at most once per insert() execution, we can assume that the next pointer of a finite number of nodes are updated in line 14 after . In a similar way, as nodes can only be marked once, during a remove() execution, we can assume that a finite number of nodes become marked after . In addition, by Definition C.5 and Lemma C.12 (Invariant 9 and 10), there is a one-to-one function between the set of flagged nodes to the set of marked nodes. Therefore, we can also assume that a finite number of nodes become flagged after . Finally, by Definition C.5 and Lemma C.12 (Invariant 9 and 10), there is also a one-to-one function between the set of pointer updates in line 68 to the set of marked nodes. Although the number of pointer changes in lines 12, 13, 66, and 67 (in Algorithm 1) may still be unbounded, by Lemma C.12 (Invariant 2), these pointers belong to infant nodes, which are not reachable. Therefore, w.l.o.g., we can assume that all of the list pointers (i.e., pointers that belong to nodes that are reachable from the sentinel node) are immutable after .
Since the list pointers are immutable after , by Lemma C.12 (Invariant 11), the loop in lines 33-42 of Algorithm 1 should always terminates. Then, if the condition in line 44 does not hold, the find() execution terminates, and otherwise, the trim() method is invoked.
Assume by contradiction that the trim() method may indeed be invoked at this stage. During the trim() execution, by Lemma C.12 (Invariant 11), the loop in lines 58-59 must terminate, and the condition in line 61 must hold (as otherwise, the CAS in line 68 must be successful due to the list immutability – a contradiction). This means that the node referenced by the is not flagged, and the executing thread did not flag it. As this node is necessarily not marked (the condition in line 58 did not hold for it), we get a contradiction to the list’s immutability.
Therefore, every find() invocation eventually terminates after . This implies that every contains() invocation eventually terminates after as well.
Moving on to the rangeQuery() operation, by Lemma C.12 (Invariant 11) and Lemma C.55, the loops in lines 7-8, 13-18, and 20-28 must terminate. It still remains to show that the loop in lines 4-12 terminates. The find() invocation in line 5 must terminate. In addition, by Lemma C.21, every new loop iteration searches for a smaller key. At a worst case scenario, the find() invocation in line 5 eventually finds , which obviously has a timestamp which is smaller than , and a key which is smaller than , and the loop terminates. Therefore, every rangeQuery() invocation eventually terminates after as well.
Now, assume an insert() execution after . The find() execution in line 9 must terminate, and the operation must return in line 10. Otherwise, by the list immutability, the CAS in line 14 should be successful – a contradiction to the list immutability.
Finally, assume a remove() execution after . By Lemma C.21 and the list’s immutability, the second output parameter, returned from the find() invocation in line 19, should not be marked or flagged. Therefore, the execution must return in line 20, as otherwise, the marking in line 21 must succeed (which is a contradiction to the list’s immutability).
Since every possible scenario derives a contradiction, we conclude with Theorem C.80.
Appendix D VBR Integration - Correctness
As discussed in Section 3.3, we had to change VBR in order to integrate it correctly into our list implementation. More specifically, let be an executing thread, and assume that currently has a pointer to a node , with a birth epoch 131313As opposed to Appendix C, here we must separate between a node’s timestamp (related to the global timestamps clock) an birth epoch (related to the global epoch clock, used for VBR). (already read by ). In addition, let be the last reclamation epoch has recorded. Then must follow these three guidelines:
-
1.
If ’s next step accesses one of ’s fields (e.g., its timestamp, key, value, next pointer or prior pointer), then it must be followed by a read of ’s birth epoch. If it is bigger than , then must rollback to its previous checkpoint.
-
2.
If ’s next step dereferences ’s next pointer (assuming it is not null), then must additionally check that ’s successor’s birth epoch is not bigger than ’s next pointer version. If it is bigger, then must rollback to its previous checkpoint.
- 3.
Recall that nodes are retired after being unlinked (see Definition C.5 in Appendix C). I.e., a retired node is never reachable, but may still be p-reachable from a reachable node. The original VBR paper [59] rigorously proves that VBR maintains the original implementation’s linearizability and lock freedom guarantee. Given this proof, we are going to prove that, given our list implementation and the new VBR variant, stale values are always ignored. In addition, we prove that the new VBR variant does not foil the original VBR’s lock-freedom. These two guarantees will be proven by showing equivalence between the two reading mechanisms. Note that, as updates and checkpoint installations remain unchanged, we do not need to handle them. For convenience, let us denote the new VBR variant with VBRN, and assume both schemes are integrated into the same lock-free linearizable implementation. Note that a rollback during a VBR-integrated execution does not necessarily imply a rollback during the equivalent VBRN-integrated execution. E.g., a thread may hold a pointer to a node , with a birth epoch which is smaller than the current epoch. If the global epoch changes, a further read of one of ’s fields in the VBR-integrated execution, would result in a rollback. However, since ’s birth epoch is still smaller than the current epoch, this read would not result in a rollback during the equivalent VBRN-integrated execution. On the other hand, a rollback during a VBRN-integrated execution does imply a rollback during the equivalent VBR-integrated execution, as we prove in Lemma D.1:
Lemma D.1.
If a rollback is performed in the VBRN-integrated execution, then a rollback is also performed in the VBR-integrated execution.
Proof D.2.
We prove the lemma with respect to the three VBRN guidelines. Let be an executing thread, and assume that currently has a pointer to a node , with a timestamp and a birth epoch (already read by ). In addition, let be the last reclamation epoch has recorded (obviously, ). Recall that in VBR, the global epoch is re-read upon each (either mutable or immutable) field access, followed by a rollback whenever the global epoch has changed.
Assume that rollbacks due to guideline 1. Then after reading one of ’s fields, it re-reads ’s birth epoch, which is bigger than . By the VBR original invariants, this necessarily implies an epoch change since the last time read ’s birth epoch. Therefore, would read the global epoch and rollback in the VBR-integrated execution as well (if it has not done so already).
Assume that rollbacks due to guideline 2. Then after reading ’s next pointer, re-reads ’s birth epoch, which is still , followed by a read of ’s successor’s birth epoch, which is bigger than . As birth epochs are set according to the current global epoch, this implies that the global epoch has necessarily changed. Therefore, would read the global epoch and rollback in the VBR-integrated execution as well (if it has not done so already).
Assume that rollbacks due to guideline 3. Then after reading ’s prior pointer, re-reads ’s birth epoch, which is still , followed by a read of ’s p-successor’s birth epoch, which is bigger than . As nodes are always allocated after their p-successors already have a birth epoch (see Lemma C.12, Invariant 1 and 2), this implies that the referenced node is not ’s p-successor. I.e., the global epoch has necessarily changed. Therefore, would read the global epoch and rollback in the VBR-integrated execution as well (if it has not done so already).
Lemma D.1 directly implies that VBRN maintains lock-freedom. It still remains to show that stale values are always ignored during VBRN-integrated executions.
Lemma D.3.
During a VBRN-integrated execution, a rollback is performed upon each read of a stale value.
Proof D.4.
Assume by contradiction that at some point, an executing thread reads a stale value and does not perform a following rollback, for the first time during the execution.
If the stale value is a node’s field (i.e., a node’s timestamp, key, value, next pointer or prior pointer), and the node has already been reclaimed since accessed it for the first time, then by Guideline 1, must read the node’s birth epoch. As must have recorded the global epoch before accessing the node for the first time, this node’s birth epoch is necessarily bigger than ’s recorded epoch. I.e., by Guideline 1, must perform a rollback – a contradiction.
Otherwise, if accesses a node for the first time, then it must access it either via a next pointer or a prior pointer of some node .
First, assume that is already reclaimed by the time reads the next pointer. By Guideline 1, and as already explained above, must perform a rollback after reading the pointer. Therefore, we can assume that has not been reclaimed at this point.
Now, assume that is accessed via ’s next pointer, and that is not ’s original successor. Let be ’s successor (i.e., and were allocated from the same address). Since ’s next pointer changes during an epoch which is at least the one recorded by , by Lemma C.8 and Lemma C.12 (Invariant 4), it is still reachable when stops being its successor. I.e., by Definition C.1, is still reachable at this point as well. By Lemma C.12 (Invariant 10), ’s retire epoch is at least the global epoch when reads ’s next pointer. I.e., ’s birth epoch must be bigger than the last epoch, recorded by . By Guideline 2, must perform a rollback – a contradiction.
The remaining possible scenario is that is accessed via ’s prior pointer. Let be ’s p-successor (i.e., and were allocated from the same address). By Lemma C.12, (Invariant 1 and 2), ’s birth epoch is at most ’s birth epoch. Therefore, since and are allocated from the same address, ’s birth epoch is strictly bigger than ’s birth epoch. By Guideline 3, must perform a rollback – a contradiction.
As there are no other types of accesses, and every possible scenario derives a contradiction, threads always rollback after reading stale values.
Appendix E Fast Index Integration - Correctness
After showing how to integrate our list with a safe and lock-free memory reclamation scheme (see Section 3.3 and Appendix D), in this section we prove that adding a fast index (as described in Section 3.4), does not foil lock-freedom or linearizability.
Integrating the code from Figure 3 obviously does not foil lock-freedom, as the loop in lines 3-13 stops after a finite and predefined number of iterations. Therefore, we only need to show that the integration does not foil linearizability.
Lemma E.1.
Proof E.2.
The lemma obviously holds if the condition in line 14 holds, since ’s key is necessarily smaller than the input key, and it is always logically in the list.
Otherwise, a pointer to was returned from the findPred() call in line 4. As the condition in line 9 does not hold for , its key is indeed smaller than .
Assume by contradiction that is not the node, encountered during this findPred() execution. Since the condition in line 8 did not hold for , it is guaranteed that was allocated before this findPred() invocation – a contradiction.
It is still possible that the index is not up to date. I.e., a different node was allocated from ’s address before , and its respective index node has not been removed from the index yet. However, regardless of this scenario, since the conditions in lines 9 and 11 did not hold for , it was an active node (see Definition C.3 in Appendix C) before line 6 was executed for the last time. By Definition C.14, was logically in the list when line 6 was executed for the last time. In addition, since the condition in line 11 did not hold for , by Lemma C.10, it was neither marked nor flagged when line 6 was executed for the last time.