Edge AI as a Service with Coordinated Deep Neural Networks
Abstract
As artificial intelligence (AI) applications continue to expand in next-generation networks, there is a growing need for deep neural network (DNN) models. Although DNN models deployed at the edge are promising for providing AI as a service with low latency, their cooperation is yet to be explored. In this paper, we consider that DNN service providers share their computing resources as well as their models’ parameters and allow other DNNs to offload their computations without mirroring. We propose a novel algorithm called coordinated DNNs on edge (CoDE) that facilitates coordination among DNN services by establishing new inference paths. CoDE aims to find the optimal path, which is the path with the highest possible reward, by creating multi-task DNNs from individual models. The reward reflects the inference throughput and model accuracy. With CoDE, DNN models can make new paths for inference by using their own or other models’ parameters. We then evaluate the performance of CoDE through numerical experiments. The results demonstrate a increase in the inference throughput while degrading the average accuracy by only . Experiments show that CoDE enhances the inference throughput and, achieves higher precision compared to a state-of-the-art existing method.
Index Terms:
AI as a service, computation offloading, network intelligence, multi-task DNNs, service coordination.I Introduction
Artificial intelligence (AI) is transforming next-generation networks by offering advanced data analytics and intelligent decision-making capabilities. Network operators can expand the capabilities of resource-limited devices by providing AI services, commonly known as AI as a Service (AIaaS). With the rapid growth of deep neural network (DNN) applications in the AI era, delivering DNN models as services has become even more essential. Fig. 1 illustrates a service provider (SP) which is hosting three DNN services in its server. DNNs power everything from video analysis and chatbots to autonomous vehicles, gaming [1], and metaverse [2].
The increasing complexity and computation demands of DNNs lead to a rising need for additional computing resources. Cloud computing platforms with their powerful computing resources [3], edge computing servers located closer to user devices [4, 5, 6], and hybrid cloud-edge environments [7, 8] can provide the high-performance infrastructure required for intensive DNN computation.
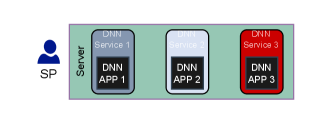
Nevertheless, these computing infrastructures are not capable of meeting the ever-growing users’ demands. Thus, it has become inevitable to enhance the capabilities of the DNN services. To scale up DNN services on both cloud and edge computing architectures, common techniques such as model distribution, horizontal scaling, and replication are used [6],[8, 9]. Existing methods isolate DNN services, requiring dedicated resources and pipelines. This isolation also necessitates a complete training if services want to share a model. However, some SPs might have correlated services that could share models and resources, enhancing capabilities without significant resource increase. In other words, a DNN service, which we call the host service, can use its model parameters and computing resources to perform a part of the task of another DNN service, referred to as the local service, as shown in Fig. 2. This sharing can occur within an SP or across different providers. SPs can create extra inference paths for their DNN services by using other DNN services’ models while introducing only a small number of learning parameters. A path is a sequence of neural network blocks, where the blocks construct the DNN models.

I-A Related Work
Multi-task learning (MTL) is a technique in which a shared model is used to learn multiple tasks simultaneously [10]. MTL leverages task correlations to efficiently share representations and process high-level features among multiple tasks. Neural architecture search methods explore architectural space to optimize MTL model performance, incorporating branches, skip-connections [11], model refinements, or building a model from scratch [12]. Researchers have developed various techniques for constructing MTL models. In [13], a feature fusion technique is used to combine two distinct models to improve the overall performance. BERT models [14] use adapter modules [15] to adapt pre-trained knowledge to new tasks and enable task-specificity without modifying the base models’ parameters. We use this concept to change data representation when passing data to other inference paths.
Another technique to reduce the computational complexity of DNN models and improve their efficiencies is the early exits (EE) method. With this approach, a number of exit branches are added among the model layers. These EE branches make alternative pathways for the DNN services and can reduce the computation for each task with the cost of reduced precision and increased model parameters. Data is routed through the exit branches when the application is time-sensitive or the system is under heavy load [5]. Alongside EE branches, current methods like SPINN [7] employ synergistic approaches to distribute computation among end devices, edge nodes, and cloud services. It requires the sharing of DNN models and increases resource usage for service replication, posing challenges when computing resources are exhausted.
Instead of offloading entire tasks, we can split models across several devices. Each device works on a part of the model and then sends its results to a central unit that combines everything for the final inference. In [16], data is sent across devices with smaller models, halting computation upon acceptable certainty or forwarding outputs to edge nodes. Similarly, in [6], models are distributed across devices, each performing a portion of computation and forwarding results to aggregators.
I-B Motivation and Contributions
The mentioned studies showcased the effectiveness of partitioning and aggregation techniques for distributing DNN models. Nevertheless, we still need to investigate how models can collaborate, exchange knowledge, and utilize each other’s computational resources.
In this paper, we propose a coordinated DNN algorithm at the edge, namely CoDE, to enhance the services offered by SPs. CoDE consolidates individual DNN models on a unified platform by knowledge transferring among them [17] and enhances DNN services by employing resources from other DNN services while ensuring the integrity of DNN models.
Our proposed algorithm establishes new computational and inference paths by linking different DNN models. When SPs are under heavy load, they can use the paths to reduce their computation by offloading the tasks. In this way, SPs increase the system capacity and maintain their quality of services (QoS) [18]. In our algorithm, DNN services can bypass their own obstacles using these pathways, as illustrated in Fig. 2b, while coordinating with other SPs.
Sharing the models may compromise the privacy of SPs. To address this concern, our proposed algorithm does not require the SPs to publish their model’s types or parameters. For example, host SPs may indicate support for images or text without revealing task specifics or disclosing model architecture (e.g., CNN, Transformer) without exposing parameters.
Our main contributions are as follows:
-
•
We introduce coordination among DNN models within or across SPs to allow task offloading to other DNN models and provide more service options. We freeze the models’ parameters and split them by a number of blocks. We add learnable links among the models’ layers to create new paths for the tasks. Our algorithm reduces redundant parameters by preventing replication and avoiding EEs.
-
•
We enable the DNN services to either skip their blocks directly by using skip-connections, or use other services’ blocks by using cross-connections. These connections help DNN services decrease their local computation.
-
•
We then propose CoDE that facilitates the coordination of DNN model sharing and SPs’ resource utilization. Our algorithm obtains the optimal paths when maximizing a reward function which reflects the model accuracy and the inference throughput. The algorithm compares the reward with that of the original model so as to either add the new path to the system or discard it.
-
•
We conduct four experiments to assess CoDE’s performance. Results show CoDE can generate paths with a slight decrease in precision with no extra local parameters. In particular, CoDE increases the local service throughput by up to while the average accuracy is reduced by only . Compared to the EE method [4], it achieves superior accuracy with less local computation.
This paper is organized as follows. In Section II, we introduce the system model and the proposed algorithm. In Section III, we explain the experiments and provide the results. Section IV concludes the paper.
II Coordinated DNN on Edge (CoDE)
In this section, we first present the system model and linking blocks. We then propose our coordinated DNNs on edge algorithm which we call as CoDE.
II-A System Model
Each SP offers one or more DNN services, and each DNN service comprises a DNN model. We split pre-trained DNN models into DNN blocks, as shown in Fig. 2a. We maintain model integrity by freezing the parameters of these blocks. It means that these parameters are not getting updated. Each block can make connections with either local front blocks or host blocks with links, as can be seen in Fig. 2b. Links are small neural network modules with learnable parameters. Two types of connections are defined as follow:
-
•
Skip-connection: It connects local blocks to blocks placed ahead in the path with a link, allowing them to skip over the local blocks in the path.
-
•
Cross-connection: It connects two different DNN models with links. These links are established between the host blocks that are included in the generated path. All of the cross-connection links are located on the host server.

SPs design the links’ architecture for their DNNs based on preceding and succeeding block sizes and their architectures. For example, if the SP aims to make skip-connections [11] for one of its DNNs, it can use any links. Otherwise, if it aims to use the host blocks, it just sends data to the host SP, and it takes care of making the new links between the DNN blocks requested by the local SP. A cross-connection allows the local service to offload its computation partially on the host service. On the other hand, a skip-connection can be established on a single service locally to improve efficiency. The batch size of the local and host services are denoted as and , respectively. The local service offloads samples of its batch on the path. To accommodate this offloaded data, the host service reserves space for these samples when a new cross-connection is established, as shown in Fig. 3.
II-B Linking Blocks
The local and host SPs partition their models into and blocks, respectively. Let denote the set of all possible paths while represents a path. Each path is represented by where denotes the local block that connects to the block in the host app with the corresponding link, as shown in Fig. 2b. Similarly, the block in the host app connects to the block in the local app. We ensure that and . Alternatively, skip-connections only involve and since the local server does not communicate with the host. For such cases, we assign , where .
We define the inference throughput as the number of predictions a model can make in a given time. The local service has two processing streams: A main stream for its own workload, and a host stream for the offloaded tasks. It allows the service to process its own tasks faster by reducing computation per batch, resulting in an enhanced throughput. We define the total throughput as , which is the sum of the main and host streams throughput as denoted by and , respectively. The block processing time allows SPs to determine the throughput. Also, SPs can simply calculate them with a test batch. We introduce the average accuracy and total throughput for each path as follows:
| (1) |
where and are the accuracy of path and the main path, respectively. We define function for each to represent its reward as below:

| (2) |
where is defined as the accuracy reward function and is the throughput reward function. In order to reward the desired accuracy range , where is set by the local SP, we choose , where is a constant. We also define the throughput reward function that shows the additional throughput path can provide compared to the original throughput . The number of the possible paths is . Searching through the entire space would take a long time since we need to train all the paths. Hence, we employ a mechanism to predict the accuracy values . We use a multi-stage optimization algorithm where, at each stage , we aim to estimate the optimal path, denoted as , using the previously calculated accuracy values of the paths as denoted by set .
We define the distance between and as . By subtracting from , we can identify the blocks that exist in only one of the paths and . We predict the accuracy of path which is shown by with a weighted average of paths in . The predicted value is:
| (3) |
The weighted approach leverages the correlation between paths, as closer paths often lead to similar outcomes. Additionally, we calculate similar to (1). Thus, we formulate the following problem for stage which aims to maximize the reward function:
| (4) | ||||
| subject to | ||||
The above problem is a combinatorial optimization problem. As the number of possible paths increases, the complexity of solving this problem escalates tremendously. The complexity of solving such problem would be in general. Thus, we propose CoDE, as presented in Algorithm 1, to overcome the complexity of this problem. At each stage, the algorithm predicts for all paths with a total throughput higher than . Subsequently, it predicts the path with the highest reward, trains that path, and calculates its actual reward. If the algorithm fails to achieve higher rewards after stages, it terminates the search. The desired path will be generated by linking the blocks of the local and host DNN services. This algorithm handles both cross- and skip-connections. However, by adding a skip-connection, we increase the local service’s parameter count.
By using Algorithm 1, all the links of the cross-connections are positioned on the host DNN services, and the backpropagation process terminates after the entry link. This approach allows services to expand their functionalities without additional parameters on the local device. Generally speaking, it fosters a more flexible network with enhanced capabilities through collaboration among DNN services.
III Experiments
We conduct four experiments to evaluate the performance of our proposed algorithm. Through these experiments, we verify that our approach greatly enhances the overall performance via selective offloading and shortcut routes at the cost of a slightly reduced accuracy, when compared to EE method [4].
III-A Experiment 1: AlexNet - AlexNet
In this experiment, both models are AlexNet [19], with a cross-connection established between them. The objective is to evaluate cross-connection performance for two DNN services with the same architectures but different tasks, depicted in Figs. 5a and 5b. Fig. 4 shows a 6-block architecture, but we add another block at the beginning of the model. The local model is optimized for CIFAR-10, and its accuracy is 86.7%. On the other hand, the host model is optimized separately for ImageNet and Food-101 datasets to assess the performance across different tasks. In addition, to measure the effect of the models, we use random parameters in another task with the same setup. We set the and to 0 and 1, respectively, and conduct the experiments when varying the and , which means that we skip blocks 1 to in the local app. We also vary the number of host blocks from 1 to . All the links are 2D CNN layers. When the actual output size of a block is not equal to the input size of the next block of the path, the transition between the local and the host app or skip-connections, we use a 2D CNN layer.
Fig. 5 shows the accuracy, number of parameters, and the model architectures. The results show a considerable difference between the pre-trained host models and the random model. With and , we reduce million local parameters, and we achieve an accuracy of with Food-101 and with ImageNet. However, the accuracy for the random host model is . It means that if considering the random model as the baseline for the accuracy drop, we can compensate for the accuracy drop with the pre-trained models. Furthermore, if we consider the skip-connection from lout:0 to lin:5 with accuracy of as the baseline, then we can compensate , which is significant.

If we increase the host blocks, we do not necessarily raise the paths’ precision. For example, when is raised from 4 to 5, the accuracy drops from to , contradicting assumptions in EE models. In [4], the author used early exit on VGG-16, which performs more powerfully than AlexNet on CIFAR-10, but its accuracy is dropped from down to , and even EEs add a large number of parameters in the local servers. Our method achieves improvements in both local computation and model accuracy compared to [4].

We also assess the effect of the link size on the path performance by reducing CNN filter numbers using two CNN layers. The first layer decreases input layers to either 25 or 5, as shown in Fig. 6, and then the next CNN layer extends it to the next block’s input size. In these cases, if we set , links shrink by almost and times, respectively. By setting the layer’s filter size to 25, the accuracy decreases from to , and if we set it to 5, then the accuracy would be . As a result, SPs can adjust their performance, not just by changing the number of blocks but also with the link size.
To investigate the host models’ effect on the accuracy, we then remove the host blocks and just use the relevant links to measure the effect of the links in the performance alone. The accuracy is significantly reduced to because most of the links are just bottleneck CNN layers, which cannot effectively extract the input’s features.

III-B Experiment 2: AlexNet - Skip-connection
In this experiment with an AlexNet model, skip-connections are established between its blocks. Additionally, we investigate how the number of link parameters affects path performance. In this experiment, links are either one CNN layer in normal mode or two CNN layers with one MaxPool layer in reduced mode. In the normal mode, links are generated in order to convert the output size of the blocks, but in the reduced mode, we use two CNN layers to reduce the number of filters.
When we set to 0 for skip-connections, the accuracy notably decreases. It means that the links cannot be learned properly. On the other hand, when we set to 1, the performance rises, and as the gap between and increases, the accuracy drops more.
Fig. 7a shows that if we reduce the link size by 5 times, it decreases the accuracy slightly. For example, when we set and , the accuracy would be and for the normal and reduced mode, respectively. Both modes have comparatively fewer parameters than the skipped parameters. Fig. 7b shows the number of the link’s parameters and the skipped parameters of the main model. All in all, skip-connection performs less effectively in parameter reduction compared to cross-connection. With and , inference time is , faster than the main model’s inference time of ms.
III-C Experiment 3: AlexNet - MobileNet
In this experiment, we use MobileNet [20] as the host DNN service. Fig. 6 shows that we can compensate for the performance degradation with a host model, even with a different architecture. The host model is optimized for ImageNet 111PyTorch pre-trained model, as shown in Fig. 7c. In this experiment, , , and are set to 0, 5, and 1, respectively, and is varied from 2 to 5. Here, the accuracy increases monotonically with the rise of , which did not happen in Experiment 1. In this scenario, again the number of the added-host parameters, which is the summation of the link’s and the added host’s parameters, is lower than the skipped-local parameters, as shown in Fig. 7d.
By using MobileNet for ImageNet, we can revive the accuracy up to , which is sufficiently high to serve as a coordinated model. This means, we reduce local computation by just by reduction in the overall accuracy.

III-D Experiment 4: Selecting paths
We now explore the impact of accuracy and computation time on path selection. We use two P100 GPUs on the same machine, where the stream’s delay is negligible. In order to calculate the throughput of each path, we use the computation time of each block. We also consider that the host architecture is AlexNet, and use the proposed algorithm and the reward function to find a path. For this test, we set , , , , , and .
In this experiment, exhibits the best overall performance, as can be seen in Fig. 8, with average accuracy and . In simpler terms, this means that SP1 can generate a path with a increase in throughput and only a decrease in the total accuracy. As a result, it is highly efficient for SP1 to generate a path with a host model optimized for ImageNet.
IV Conclusion
In this paper, we studied AIaaS and introduced cooperation among different SPs as well as their DNN models. SPs can use other SPs’ resources to offload their computations without replicating their DNN models on them. The local and host SPs do not necessarily need to have the same DNN models and architectures. We first formulated an optimization problem to find the paths that result in the highest amount of reward. To solve this problem, we then proposed a task-offloading approach called CoDE that facilitates collaboration among the SPs and their DNN models. We further conducted four different experiments to investigate the performance of CoDE. The results show that CoDE can significantly increase the inference throughput compared to the EE methods while degrading the accuracy by a small amount. In future, we will investigate how we can manage the traffic flow dynamically through the paths based on request characteristics, such as time sensitivity and inference deadline.
References
- [1] N. Anantrasirichai and D. Bull, “Artificial intelligence in the creative industries: A review,” Artificial Intelligence Review, vol. 55, no. 1, pp. 589–656, Jul. 2021.
- [2] T. Huynh‐The, Q.-V. Pham, X. Pham, T. Nguyen, Z. Han, and D.-S. Kim, “Artificial intelligence for the metaverse: A survey,” Engineering Applications of Artificial Intelligence, vol. 117, p. 105581, Jan. 2023.
- [3] R. Singh and S. S. Gill, “Edge AI: A survey,” Internet of Things and Cyber-Physical Systems, vol. 3, pp. 71–92, Feb. 2023.
- [4] N. Li, A. Iosifidis, and Q. Zhang, “Graph Reinforcement Learning-based CNN Inference Offloading in Dynamic Edge Computing,” in Proc. of IEEE Globecom, Rio de Janeiro, Brazil, Dec. 2022.
- [5] M. Ebrahimi, A. d. S. Veith, M. Gabel, and E. de Lara, “Combining DNN partitioning and early exit,” in Proc. of International Workshop on Edge Systems, Analytics and Networking, Rennes, France, Apr. 2022.
- [6] L. Zeng, X. Chen, Z. Zhou, L. Yang, and J. Zhang, “Coedge: Cooperative DNN inference with adaptive workload partitioning over heterogeneous edge devices,” IEEE/ACM Transactions on Networking, vol. 29, no. 2, pp. 595–608, Apr. 2020.
- [7] S. Laskaridis, S. I. Venieris, M. Almeida, I. Leontiadis, and N. D. Lane, “SPINN: Synergistic Progressive Inference of Neural Networks over device and cloud,” in Proc. of ACM MobiCom, London, United Kingdom, Apr. 2020.
- [8] A. Banitalebi-Dehkordi, N. Vedula, J. Pei, F. Xia, L. Wang, and Y. Zhang, “Auto-split: A general framework of collaborative edge-cloud AI,” in Proc. of ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, Singapore, Aug. 2021, pp. 2543–2553.
- [9] C. Wu, Q. Peng, Y. Xia, Y. Jin, and Z. Hu, “Towards cost-effective and robust AI microservice deployment in edge computing environments,” Future Gener. Comput. Syst., vol. 141, p. 129–142, Apr. 2023.
- [10] M. Crawshaw, “Multi-task learning with deep neural networks: A survey,” arXiv preprint arXiv:2009.09796, Sep. 2020.
- [11] S. Heo, S. Cho, Y. Kim, and H. Kim, “Real-time object detection system with multi-path neural networks,” in Proc. of IEEE Real-Time and Embedded Technology and Applications Symposium (RTAS), Sydney, Australia, April 2020, pp. 174–187.
- [12] T. Vu, Y. Zhou, C. Wen, Y. Li, and J. Frahm, “Toward Edge-Efficient Dense Predictions with Synergistic Multi-Task Neural Architecture Search,” in Proc. of IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Los Alamitos, CA, Jan. 2023, pp. 1400–1410.
- [13] Y. Gao, H. Bai, Z. Jie, J. Ma, K. Jia, and W. Liu, “MTL-NAS: Task-Agnostic Neural Architecture Search Towards General-Purpose Multi-Task Learning,” in Proc. of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Los Alamitos, CA, Jun. 2020, pp. 11 540–11 549.
- [14] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
- [15] N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. De Laroussilhe, A. Gesmundo, M. Attariyan, and S. Gelly, “Parameter-efficient transfer learning for NLP,” in Proc. of International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 97, Long Beach, CA, Jun. 2019, pp. 2790–2799.
- [16] S. Teerapittayanon, B. McDanel, and H.-T. Kung, “Distributed deep neural networks over the cloud, the edge and end devices,” in Proc. of IEEE International Conference on Distributed Computing Systems (ICDCS), Atlanta, GA, Jun. 2017, pp. 328–339.
- [17] C. Tan, F. Sun, T. Kong, W. Zhang, C. Yang, and C. Liu, “A survey on deep transfer learning,” in Proc. of Artificial Neural Networks and Machine Learning (ICANN), Island of Rhodes, Greece, Oct 2018, pp. 270–279.
- [18] A. Bourechak, O. Zedadra, M. N. Kouahla, A. Guerrieri, H. Seridi, and G. Fortino, “At the Confluence of Artificial Intelligence and Edge Computing in IoT-Based Applications: A Review and New Perspectives,” Sensors, vol. 23, no. 3, p. 1639, Jan. 2023.
- [19] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet Classification with Deep Convolutional Neural Networks,” Advances in Neural Information Processing Systems, vol. 25, p. 1097–1105, 2012.
- [20] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “MobileNets: Efficient convolutional neural networks for mobile vision applications,” arXiv preprint arXiv:1704.04861, Apr. 2017.