E2Net: Resource-Efficient Continual Learning with Elastic Expansion Network
Abstract
Continual Learning methods are designed to learn new tasks without erasing previous knowledge. However, Continual Learning often requires massive computational power and storage capacity for satisfactory performance. In this paper, we propose a resource-efficient continual learning method called the Elastic Expansion Network (E2Net). Leveraging core subnet distillation and precise replay sample selection, E2Net achieves superior average accuracy and diminished forgetting within the same computational and storage constraints, all while minimizing processing time. In E2Net, we propose Representative Network Distillation to identify the representative core subnet by assessing parameter quantity and output similarity with the working network, distilling analogous subnets within the working network to mitigate reliance on rehearsal buffers and facilitating knowledge transfer across previous tasks. To enhance storage resource utilization, we then propose Subnet Constraint Experience Replay to optimize rehearsal efficiency through a sample storage strategy based on the structures of representative networks. Extensive experiments conducted predominantly on cloud environments with diverse datasets and also spanning the edge environment demonstrate that E2Net consistently outperforms state-of-the-art methods. In addition, our method outperforms competitors in terms of both storage and computational requirements.
1 Introduction
Continual Learning (CL) is the process where a machine learning model learns from a changing environment, continuously processing incoming data streams to gain new knowledge while retaining previously acquired knowledge (Arani, Sarfraz, and Zonooz 2022). However, in the context of CL, Deep Neural Networks (DNNs) are susceptible to experiencing Catastrophic Forgetting (CF), a phenomenon where previously acquired knowledge is lost as the network learns new tasks (McCloskey and Cohen 1989). What’s more, efficiently enhancing resource efficiency in CL, crucial for developing genuinely intelligent models, remains a pivotal challenge due to the substantial computing power and storage capacity typically required for satisfactory performance.
Multiple methods have been suggested to tackle the problem of CF in CL. We can broadly classify these methods into regularization-based methods (Li et al. 2022; Li and Hoiem 2016; Yu et al. 2020), which involve utilizing methods like knowledge distillation to penalize alterations in the network weights, architecture-based methods (Golkar, Kagan, and Cho 2019; Rusu et al. 2016; Yan, Xie, and He 2021), which assign isolated parameters that encode the learned knowledge from different tasks, and rehearsal-based methods (Cha, Lee, and Shin 2021; Buzzega et al. 2020; Arani, Sarfraz, and Zonooz 2022), which directly preserve past knowledge by maintaining the data from previous tasks in a rehearsal buffer. Nevertheless, current CL methods primarily prioritize average accuracy, requiring massive computing power and storage capacity.
In existing CL methods, rehearsal-based methods rely on a memory buffer, which can pose significant limitations in terms of performance. (Serrà et al. 2018; Wang et al. 2022). Furthermore, these methods may not be suitable for applications that involve privacy concerns (Shokri and Shmatikov 2015). Regularization-based and architecture-based methods in CL are effective for simple Task-Incremental Learning (Task-IL) but struggle in more challenging Class-Incremental Learning (Class-IL) (Sokar, Mocanu, and Pechenizkiy 2021). Additionally, these methods often depend on expansive models and extensive computations, demanding substantial computational time. Resource-efficient CL requires addressing the challenges of CF while efficiently utilizing limited storage and computing resources to achieve higher average accuracy and lower forgetting. In response to the challenges of CL, several recent methods have been developed to enable efficient memory usage and reduce computational complexity. SNCL (Yan et al. 2022) proposed a Bayesian method for updating sparse networks and NISPA (Gurbuz and Dovrolis 2022) utilized neuroplasticity to perform sparse parameter updates. These methods show that effective results can be achieved in Class-IL for a single task by updating only a small number of parameters, which allows for more flexibility in accommodating future tasks. Furthermore, SupSup (Wortsman et al. 2020) has shown that using a randomly initialized fixed base network and discovering a subnet that can achieve satisfactory results for each task can yield promising results, even when dealing with a large number of tasks. Nonetheless, these methods are marred by compromised accuracy or inapplicability in the Class-IL.
Differing from the aforementioned methods, our method integrates subnet search and knowledge distillation, restricting updated parameters while maintaining the base network’s integrity and avoiding partitioning specific network regions for tasks. In this paper, we propose E2Net, a resource-efficient CL method that can fully utilize storage and computing resources, delivering elevated average accuracy and reduced forgetting within a shorter processing time. E2Net comprises two components: the representative network and the working network. During each training process, the working network undergoes a process known as Representative Network Distillation (RND), where it selects a representative network from a pool of candidate networks for knowledge distillation. By leveraging RND, we can effectively address CF while operating within the constraints of memory and computing resources. To improve the utilization efficiency of storage, we propose Subnet Constraint Experience Replay (SCER), an advanced Experience Replay (ER) (Chaudhry et al. 2019) strategy optimizing rehearsal efficacy through representative-network-based sample storage. We also explore the selection of representative networks, a critical factor in enhancing the working network’s capacity to learn with minimal forgetting and conduct efficient knowledge distillation. In summary, our contributions are as follows:
-
•
We propose E2Net, a novel resource-efficient CL method integrating core subnet search with knowledge distillation. Core subnet search autonomously identifies essential components of the working network with minimal computational complexity. Applied in knowledge distillation, it safeguards key parameters, effectively mitigating catastrophic forgetting without extensive teacher network parameter storage.
-
•
We devised a progressively expanding search space in tandem with RND to facilitate the distillation process. Furthermore, to enhance storage resource utilization, we introduced SCER, optimizing rehearsal efficiency via a sample storage strategy based on representative network structures.
-
•
Experiments conducted in both cloud and edge environments have demonstrated that E2Net outperforms state-of-the-art methods within a short processing time when operating within limited storage resources. Moreover, it can consistently maintain high average accuracy, even on edge devices.
2 Related Work
Regularization-based methods
Regularization-based methods adjust gradient updates to identify and maintain essential task-specific weights, ensuring effective utilization and preservation of key parameters for optimal performance across all tasks. (Yu et al. 2020; Serrà et al. 2018; Li and Hoiem 2016; Chaudhry et al. 2018a; Aljundi et al. 2018). E2Net can also be categorized as a regularization-based CL method, achieving higher average accuracy without the need for intricate regularization parameter storage.
Architecture-based methods
Architecture-based methods allocate distinct parameter sets for each task, isolating task-specific learning to prevent interference and mitigate forgetting. These methods can be classified into two categories: parameter extension methods (Zhao et al. 2022; Yoon et al. 2017; Rusu et al. 2016; Loo, Swaroop, and Turner 2020; Li et al. 2019), which involve growing new branches for each task and freezing the parameters from the previous tasks, and parameter isolation methods (Ebrahimi et al. 2020; Ke, Liu, and Huang 2021; Wang et al. 2020; Serrà et al. 2018; Mallya and Lazebnik 2018), which preserve essential connections while removing specific connections to ensure stable performance on previous tasks. Compared to E2Net, architecture-based methods, entailing model extension, might lack practicality due to their linear increase in computational demands with task count. Additionally, freezing entire layers in these methods may impede further learning (Golkar, Kagan, and Cho 2019).
Rehearsal-based methods
Rehearsal-based methods employ a rehearsal buffer to store and periodically revisit data from previous tasks, preserving knowledge and combating forgetting. These methods can be further divided into two categories: store examples (Buzzega et al. 2020; Cha, Lee, and Shin 2021; Rebuffi et al. 2017; Chaudhry et al. 2018b, 2021; Aljundi et al. 2019), and generate examples (Shin et al. 2017; Atkinson et al. 2018; Ramapuram, Gregorova, and Kalousis 2020). While rehearsal-based methods have been acknowledged as the current state-of-the-art (Buzzega et al. 2020), there have been criticisms regarding their dependence on a rehearsal buffer (Serrà et al. 2018; Prabhu, Torr, and Dokania 2020; Wang et al. 2022). The effectiveness of these methods can be severely impacted if the buffer size is small. Through efficient resource utilization, EEN significantly reduces reliance on buffers and rehearsal, achieving high average accuracy within a short processing time.
3 Elastic Expansion Network
In this section, we describe E2Net, our proposed resource-efficient CL method. E2Net is illustrated in Figure 1. Our method comprises two critical components: the working network and the representative network. Our method employs a fixed, randomly initialized network as the working network. At each task boundary, we use Candidate Networks Selection (CNS) to select a subset of subnets from the search space (See Sec. 3.2) and designated as the representative network to form the candidate networks (See Sec. 3.3). These candidate networks effectively capture the essence of the working network and can be considered as its core subnet. During the training of a new task, we use RND to facilitate knowledge distillation (See Sec. 3.4), thereby preventing the model from forgetting what it has learned from previous tasks. To improve the storage utilization efficiency of E2Net, we propose the SCER to enhance the model’s ability to mitigate CF (See Sec. 3.5). We first provide an overview of the CL in Sec. 3.1 before introducing the main components of our method E2Net.

3.1 Overview
The CL problem can be defined as learning tasks in a specific order from a dataset that can be divided into tasks, for each task we have a training dataset , where represents the samples of -th task and represents the number of samples for each task. During each task , input samples in and their corresponding ground truth labels are drawn from an i.i.d. distribution.
The objective of CL is to perform sequential training while preserving the performance of previous tasks. This can be achieved by learning an (i.e., the parameter ) that minimizes classification loss across all tasks (Buzzega et al. 2020; Yan et al. 2022), where represents cross-entropy loss:
| (1) |
In line with various CL methods (Wu et al. 2019; Chaudhry et al. 2021), our method incorporates a replay buffer of fixed size , aiding parameter adaptation to new tasks and knowledge retention from prior tasks by storing a limited set of previous samples. During the training process, we optimize the model parameters by leveraging the new data from the current task as well as samples from the replay buffer, following the principles of traditional CL methods based on ER (Chaudhry et al. 2019). The cross-entropy-based classification loss on memory can be formulated as:
| (2) |
3.2 Search Space Formulation
Following the common practice of many CNN models (Cai, Gan, and Han 2019; Lin et al. 2021), we segment the channels in each layer of the CNN model into, on average, groups, where denotes the granularity of search space segmentation. At the boundary of the -th task, we define the size of the search space as , which corresponds to the maximum number of channels in each layer of the representative network. Specifically, this size is times the number of channels in the corresponding layer of the working network. To enable the discovery of potentially superior subnets and maintain a manageable search space, we expand the search space by at the -th task boundary.
In the initial search stages, subnets with fewer parameters and lower performance lead to a reduced pool of representative networks for selection. With each selected representative network incorporating the structural information from the previous candidate networks, the representative network’s size expands as training progresses, leading to more saturated updates. In response to this issue, we apply the cosine annealing algorithm to gradually decrease the value of , which helps to balance the exploration and exploitation of the search space and improve the performance of the final model. For the -th task boundary, where and is the expected number of tasks for CL, the size of the expanded search space (i.e., ) is determined in Eq. (3), where is a constant representing the degree of expansion:
| (3) |
In order to fully leverage the capacity of the working network, when reaching the -th task boundary, the size of the search space should match that of the working network. The value of is thus determined in Eq. (4):
| (4) |
The size of the search space at the -th task boundary (i.e., ) can be calculated using the sum of the expansion sizes of all task boundaries up to the -th task boundary, as shown in Eq. (5).
| (5) |
3.3 Candidate Networks Selection
Candidate Networks Selection (CNS) extracts a subnet from the working network as a core component, termed the representative network, encapsulating essential characteristics and effectively representing overall functionality.
Given a set of architectural configurations for candidate networks, the representative network is defined as a subnet obtained by selecting a subset of layers from the working network based on the architectural configuration . The selection process is represented by the selection scheme , and the parameters of the selected representative network under the architectural configuration are denoted as . The output logits of the network are represented as . To ensure the effective representation of the working network, careful selection of the representative network is essential. We aim to choose a subnet whose output logits closely resemble those of the working network. Moreover, it is crucial to minimize the number of parameters in the representative network, allowing ample room for subsequent search operations. We then can formalize the problem as:
| (6) |
Where represents the number of parameters, and is utilized to control the size of the parameters. To optimize storage efficiency and parameter effectiveness, weight sharing is employed among the representative networks. Meanwhile, the candidate networks retain only a single copy of the working network, from which the representative network is randomly selected.
3.4 Representative Network Distillation
Representative network distillation (RND) aims to transfer the learned information from the representative network to enhance the performance of the working network. During the training stage, the representative network are randomly selected from the candidate networks to carry out knowledge distillation on the working network. We define as the output logits of a subnet obtained by selecting a subset of layers from the working network based on the architectural configuration , where is randomly sampled from the set . Subsequently, we introduce a regularization term to promote the working network’s capacity to preserve and leverage knowledge acquired from previous tasks:
| (7) |
By employing Eq. (7), we preserved the output of the network’s core component from the previous task unchanged. During updates, we activate neurons within the search space and freeze those outside it, concentrating the network’s core within the targeted area. This method enhances the effectiveness of RND in retaining crucial information.
3.5 Subnet Constraint Experience Replay
To address the challenge of effectively storing samples, we introduce the Subnet Constraint Experience Replay (SCER) method. For each sample , SCER computes the parameter size of the current representative network within the working network. A higher proportion suggests increased retention of current sample knowledge, thereby we should reduce the chance of it being added to the buffer space. By selecting samples that contribute significantly to knowledge retention, the method ensures that the retained samples have a higher impact on the overall learning process, leading to more efficient and effective utilization of the buffer space. Drawing from DER (Buzzega et al. 2020), we optimized the classification loss on memory as:
| (8) |
In DER method, a random sample of elements is selected from the input stream. For SCER, we make the assumption that the probability of storing the k-th () sample in the buffer is denoted as , and the probability of retaining the sample in the buffer is denoted as . The calculation of can be performed as follows:
| (9) |
From Eq. (9), we can infer the :
| (10) |
The SCER method may appear similar to the task-stratified sampling strategy, but it is fundamentally different. Our method does not impose restrictions on the sample distribution nor increase computational overhead.111We provide more details about SCER in Appendix A.
3.6 The Overall Loss
In summary, the total training objective for E2Net can be expressed by:
| (11) |
the cross entropy loss focuses on learning the current data; provides a distillation technique on the working network to aid in the preservation of knowledge from previous tasks.; helps to replay the knowledge of the past samples.
We provide a detailed description of the overall training procedure of E2Net in Alg. 1 Upon the arrival of new data, our method involves the following steps. Firstly, we extract a representative network and a specific architectural configuration, denoted as , from the candidate network’s architectural configurations . Subsequently, we select a subnet from the working network based on the architectural configuration and optimize the model by minimizing the overall loss, denoted as . This optimization process is performed using gradient descent, which modifies the model and updates the parameters within the search space. Lastly, we use the sampling method in SCER to update the buffer.
| Method | S-CIFAR-10 | S-Tiny-ImageNet | ||||||
| Class-IL | Task-IL | Class-IL | Task-IL | |||||
| JOINT | 92.200.15 | 98.310.12 | 59.990.19 | 82.040.10 | ||||
| SGD | 19.620.05 | 61.023.33 | 7.920.26 | 18.310.68 | ||||
| Buffer Size | 200 | 500 | 200 | 500 | 200 | 500 | 200 | 500 |
| GEM (Lopez-Paz and Ranzato 2017) | 25.540.76 | 26.201.26 | 90.440.94 | 92.160.69 | - | - | - | - |
| iCaRL (Rebuffi et al. 2017) | 49.023.20 | 47.553.95 | 88.992.13 | 88.222.62 | 7.530.79 | 9.381.53 | 28.191.47 | 31.553.27 |
| ER (Riemer et al. 2018) | 44.791.86 | 57.740.27 | 91.190.94 | 93.610.27 | 8.490.16 | 9.990.29 | 38.172.00 | 48.640.46 |
| A-GEM (Chaudhry et al. 2018b) | 20.040.34 | 22.670.57 | 83.881.49 | 89.481.45 | 8.070.08 | 8.060.04 | 22.770.03 | 25.330.49 |
| GSS (Aljundi et al. 2019) | 39.075.59 | 49.734.78 | 88.802.89 | 91.021.57 | - | - | - | - |
| DER (Buzzega et al. 2020) | 61.931.79 | 70.511.67 | 91.400.92 | 93.400.39 | 11.870.78 | 17.751.14 | 40.220.67 | 51.780.88 |
| DER++ (Buzzega et al. 2020) | 64.881.17 | 72.701.36 | 91.920.60 | 93.880.50 | 10.961.17 | 19.381.41 | 40.871.16 | 51.910.68 |
| HAL (Chaudhry et al. 2021) | 32.362.70 | 41.794.46 | 82.513.20 | 84.542.36 | - | - | - | - |
| (Cha, Lee, and Shin 2021) | 65.571.37 | 74.260.77 | 93.430.78 | 95.90.26 | 13.880.4 | 20.120.42 | 42.370.74 | 53.040.69 |
| SNCL (Yan et al. 2022) | 66.161.48 | 76.351.21 | 92.910.81 | 94.020.43 | 12.850.69 | 20.270.76 | 43.011.67 | 52.850.67 |
| ER-ACE (Yu et al. 2022) | 66.560.81 | 72.861.02 | - | - | 17.050.22 | 23.560.85 | - | - |
| E2Net (Ours) | 70.161.23 | 75.680.53 | 93.940.30 | 94.970.29 | 17.681.06 | 24.010.36 | 47.681.23 | 55.100.31 |
4 Experiments
We provide the experimental settings, including the details of datasets, evaluation metrics, implementation, etc., in Appendix B.
4.1 Dataset and Hardware
We conduct experiments on a variety of commonly used public datasets in the field of CL, including Split CIFAR-10 (S-CIFAR-10) (Buzzega et al. 2020), Split CIFAR-100 (S-CIFAR-100) (Chaudhry et al. 2018b), and Split Tiny ImageNet (S-Tiny-ImageNet) (Chaudhry et al. 2019). We conduct comprehensive experiments utilizing the NVIDIA GTX 2080Ti GPU paired with the Intel Xeon Gold 5217 CPU, as well as the NVIDIA Pascal GPU within the NVIDIA Jetson TX2, boasting 8 GB LPDDR4 Main Memory and 32 GB eMMC Flash memory.
4.2 Experimental Setup
Evaluation protocol.
Following previous studies (Delange et al. 2021; Buzzega et al. 2020), we employed the Split CIFAR-10, Split CIFAR-100, and Split Tiny ImageNet datasets to validate the effectiveness of our method in both the Task-IL and Class-IL settings. We utilize average accuracy (ACC) and average forgetting measure (F) as the performance metric for each method222We present the Forgetting results of several experiments in Appendix E.1..
Baselines.
We compared E2Net with several representative baseline methods, including three regularization-based methods: oEWC (Schwarz et al. 2018), SI (Zenke, Poole, and Ganguli 2017) and LwF (Li and Hoiem 2016) and eleven rehearsal-based methods: ER (Riemer et al. 2018), GEM (Lopez-Paz and Ranzato 2017), A-GEM (Chaudhry et al. 2018b), iCaRL (Rebuffi et al. 2017), GSS (Aljundi et al. 2019), HAL (Chaudhry et al. 2021), DER (Buzzega et al. 2020), DER++ (Buzzega et al. 2020), (Cha, Lee, and Shin 2021), SNCL (Yan et al. 2022), ER-ACE (Yu et al. 2022)333We use the method proposed in the paper to improve ER-ACE (Caccia et al. 2021).. In our evaluation, we incorporated two non-continual learning baselines: SGD (lower bound) and JOINT (upper bound). To ensure robustness, all experiments were repeated 10 times with different initialization, and the results were averaged across the runs.
4.3 Experimental Results
Class-IL and Task-IL settings with low buffer size
Table 1 presents the average accuracy of all tasks after training, providing a comprehensive comparison of the proposed method with other existing methods. The results demonstrate that the proposed method achieves superior performance across different experimental settings. Notably, when considering a small buffer size, our method exhibits remarkable superiority over all other existing methods. In Class-IL, E2Net achieves 70.16% and 17.68% accuracies on S-CIFAR-10 and S-Tiny-ImageNet datasets with 200 buffer sizes, outperforming the second-best methods by 3.5% and 0.6%, respectively.
Class-IL and Task-IL settings without buffer


The results, as illustrated in Figure 2, present the average accuracy across all tasks following training. In contrast to the conventional practice of preserving certain weights unchanged, our method intelligently adapts and updates crucial weights based on the evolving learning process. This adaptive method allows our method to continually optimize performance, resulting in superior outcomes across diverse experimental scenarios. In Class-IL, our method surpasses the suboptimal method in average accuracy on S-CIFAR-10 and S-Tiny-ImageNet datasets by 8.8% and 6.5%, respectively.
Dataset for 20-task setting

Notably, S-CIFAR-10 and S-Tiny ImageNet datasets comprise a modest number of tasks, 5 and 10 respectively. While this setup offers favorable conditions for assessing E2Net’s performance, it’s essential to acknowledge that with a limited task count, the overall average accuracy could be influenced by higher accuracy in the final two tasks, potentially raising questions about E2Net credibility. To address this concern and ensure a more rigorous evaluation, we conducted comparative analyses between our method and other method on the S-CIFAR-100 dataset, which encompasses 20 tasks. This dataset with a larger number of tasks serves as a more demanding and fair testing ground. Figure 3 presents the performance evaluation of our method on the challenging S-CIFAR-100 dataset. Across all buffer size configurations, our method consistently outperforms other existing methods. Our E2Net achieves an 4.2% improvement over the sub-optimal method DER++ on S-CIFAR-100 dataset with 500 buffer sizes, which is quite notable.
4.4 Ablation Study
Table 2 shows the ablation studies for each component in E2Net on S-CIFAR-10 datasets. To assess the influence of the replay buffer, we conducted an experimental evaluation by removing the replay buffer component from the E2Net model (E2Net w/o BUF). E2Net w/o CNS means that we always select the largest subnet in the search space as the representative network. From the results, we have the following observations: (1) The results of E2Net w/o CNS indicate that it is essential to select the appropriate representative network for knowledge distillation. (2) SCER has been proven to be positive in efficiently selecting saved samples, improving storage utilization and achieving higher average accuracy under limited buffer size. (3) E2Net attained superior average accuracy by comprehensively deploying all components, thus corroborating the efficacy of its components.444We provide more extensive ablation studies about each component in Appendix 7.
| Method | S-CIFAR-10 | |||
| Class-IL | Task-IL | |||
| E2Net w/o BUF | 28.37 | 71.85 | ||
| Buffer Size | 200 | 500 | 200 | 500 |
| E2Net w/o CNS | 69.23 | 75.02 | 94.74 | 95.48 |
| E2Net w/o RND | 64.88 | 72.70 | 91.92 | 93.88 |
| E2Net w/o SCER | 68.97 | 73.94 | 93.47 | 94.42 |
| E2Net | 70.16 | 75.68 | 93.94 | 94.97 |

4.5 Quantitative Study
In this section, we present a comprehensive analysis of our method E2Net by conducting a comparative study against DER++ and ER-ACE. Through this comparison, we assess the advantages and feasibility of our method.
Rehearsal Frequency
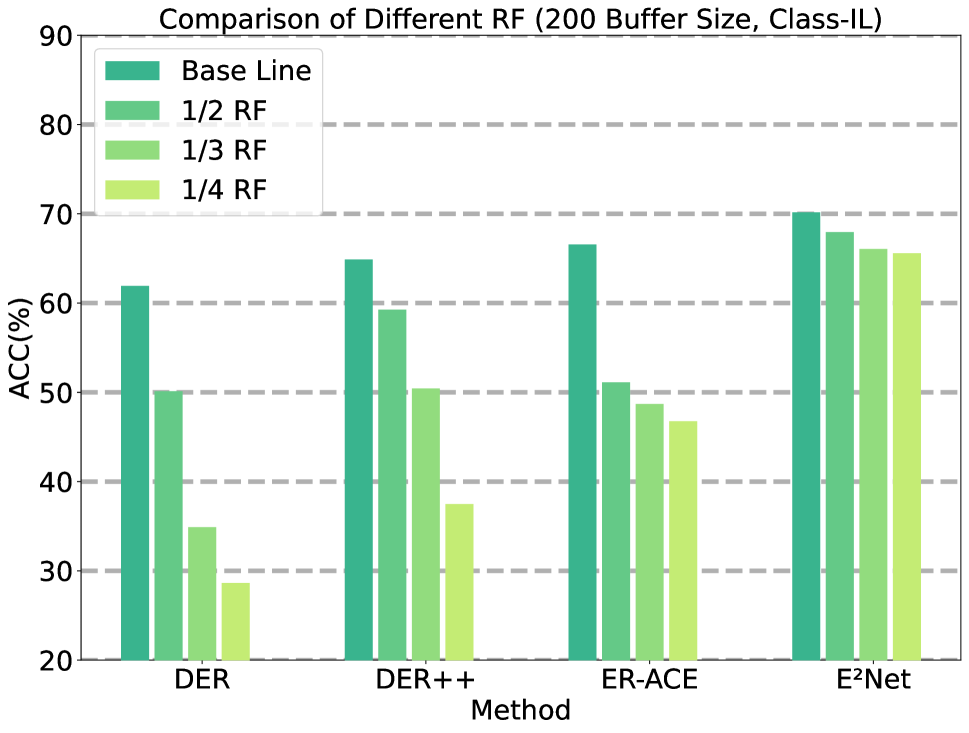
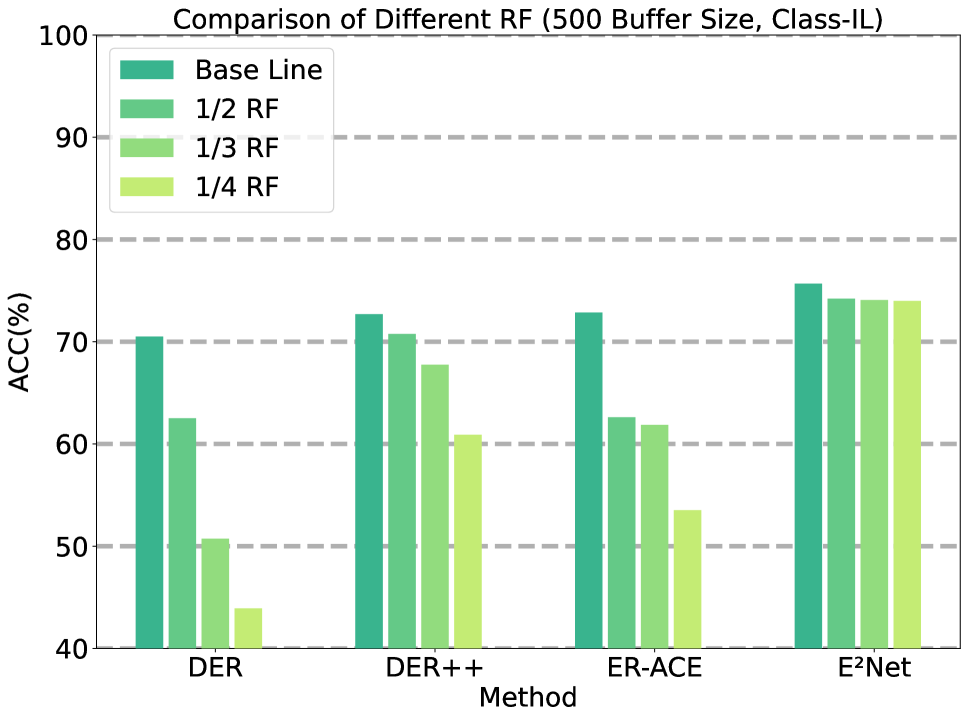
To mitigate heightened computational complexity in rehearsal methods and enhance computing resource efficiency, we opted to decrease the Rehearsal Frequency (RF) during our experimentation. Figure 4 (a) and (b) showcase the achieved accuracy of different methods across various RF on S-CIFAR-10 dataset. Compared to other methods, E2Net exhibits a considerably smaller impact when RF are reduced. Notably, at a buffer size of 500 and 200, our method demonstrated a mere 1.68% and 4.58% decrease in accuracy when the RF was reduced to one-fourth of its original value. This indicates the robustness and effectiveness of our method in handling reduced RF while minimizing the impact on overall accuracy.555We offer additional experimental results concerning rehearsal frequency in the Appendix E.3.
Training Time
Minimizing overall processing time is crucial when dealing with data streams to ensure that training keeps pace with the rate at which data becomes available to the stream. To assess the performance of E2Net, as well as other rehearsal methods, we measure the wall-clock time upon completion of the final task. Figure 4 (c) illustrates the overall processing time measured on the S-CIFAR-10 dataset. The results demonstrate that our method achieves comparable processing time to DER++ and ER-ACE while achieving higher accuracy. By reducing rehearsal frequency, our method can achieve the shortest processing time and achieve higher computational efficiency.
Edge device Results
| Method | S-CIFAR-10 | |
| Class-IL | Task-IL | |
| DER | 61.02 | 90.86 |
| DER++ | 64.53 | 91.54 |
| E2Net w/ 1/4 RF | 66.17 | 92.40 |
| E2Net | 70.25 | 93.80 |
To demonstrate the practical potential of our method, we conducted evaluations on real edge devices. Table 3 presents the average accuracy of various methods on the Nvidia Jetson TX2. It is evident that our method achieves the highest accuracy, and there is no significant decline in accuracy on the edge device, showcasing the promising practical applicability of our method.
5 Conclusion
To optimize resource utilization efficiency and attain elevated accuracy within a shorter processing time, we propose Elastic Expansion Network, a resource-efficient CL method. E2Net selects the representative network from the search space at each task boundary to form candidate networks. These candidate networks effectively capture the essence of the working network and can be considered as its core components. During the training process of new tasks, we employ the Representative Network Distillation to facilitate knowledge transfer, effectively addressing the issue of forgetting previous task knowledge. To optimize rehearsal efficiency, we introduce the Subnet Constraint Experience Replay method to store and replay samples from data streams based on representative network’s sizes, thereby enhancing the performance of E2Net. Comprehensive experimentation across diverse benchmark datasets and environments substantiates E2Net’s effectiveness in mitigating forgetting. As a main limitation, E2Net makes a assumption about task boundaries. This encourages further research for future real-world applications. If fortunate enough to be accepted, we will release all the source code.
References
- Aljundi et al. (2018) Aljundi, R.; Babiloni, F.; Elhoseiny, M.; Rohrbach, M.; and Tuytelaars, T. 2018. Memory Aware Synapses: Learning What (Not) to Forget. In Ferrari, V.; Hebert, M.; Sminchisescu, C.; and Weiss, Y., eds., Computer Vision – ECCV 2018, volume 11207, 144–161. Cham: Springer International Publishing. ISBN 9783030012182 9783030012199.
- Aljundi et al. (2019) Aljundi, R.; Lin, M.; Goujaud, B.; and Bengio, Y. 2019. Gradient Based Sample Selection for Online Continual Learning. In Neural Information Processing Systems.
- Arani, Sarfraz, and Zonooz (2022) Arani, E.; Sarfraz, F.; and Zonooz, B. 2022. Learning Fast, Learning Slow: A General Continual Learning Method Based on Complementary Learning System. ArXiv.
- Atkinson et al. (2018) Atkinson, C.; McCane, B.; Szymanski, L.; and Robins, A. 2018. Pseudo-Recursal: Solving the Catastrophic Forgetting Problem in Deep Neural Networks. ArXiv.
- Buzzega et al. (2020) Buzzega, P.; Boschini, M.; Porrello, A.; Abati, D.; and Calderara, S. 2020. Dark Experience for General Continual Learning: A Strong, Simple Baseline. ArXiv.
- Caccia et al. (2021) Caccia, L.; Aljundi, R.; Tuytelaars, T.; Pineau, J.; and Belilovsky, E. 2021. Reducing representation drift in online continual learning. arXiv preprint arXiv:2104.05025, 1(3).
- Cai, Gan, and Han (2019) Cai, H.; Gan, C.; and Han, S. 2019. Once for All: Train One Network and Specialize It for Efficient Deployment. ArXiv.
- Cha, Lee, and Shin (2021) Cha, H.; Lee, J.; and Shin, J. 2021. Co2L: Contrastive Continual Learning. 2021 IEEE/CVF International Conference on Computer Vision (ICCV), 9496–9505.
- Chaudhry et al. (2018a) Chaudhry, A.; Dokania, P. K.; Ajanthan, T.; and Torr, P. H. S. 2018a. Riemannian Walk for Incremental Learning: Understanding Forgetting and Intransigence. In Ferrari, V.; Hebert, M.; Sminchisescu, C.; and Weiss, Y., eds., Computer Vision – ECCV 2018, volume 11215, 556–572. Cham: Springer International Publishing. ISBN 9783030012519 9783030012526.
- Chaudhry et al. (2021) Chaudhry, A.; Gordo, A.; Dokania, P.; Torr, P.; and Lopez-Paz, D. 2021. Using Hindsight to Anchor Past Knowledge in Continual Learning. Proceedings of the AAAI Conference on Artificial Intelligence, 35(8): 6993–7001.
- Chaudhry et al. (2018b) Chaudhry, A.; Ranzato, M.; Rohrbach, M.; and Elhoseiny, M. 2018b. Efficient Lifelong Learning with A-GEM. ArXiv.
- Chaudhry et al. (2019) Chaudhry, A.; Rohrbach, M.; Elhoseiny, M.; Ajanthan, T.; Dokania, P.; Torr, P. H. S.; and Ranzato, M. 2019. Continual Learning with Tiny Episodic Memories. ArXiv.
- Delange et al. (2021) Delange, M.; Aljundi, R.; Masana, M.; Parisot, S.; Jia, X.; Leonardis, A.; Slabaugh, G.; and Tuytelaars, T. 2021. A Continual Learning Survey: Defying Forgetting in Classification Tasks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1–1.
- Ebrahimi et al. (2020) Ebrahimi, S.; Meier, F.; Calandra, R.; Darrell, T.; and Rohrbach, M. 2020. Adversarial Continual Learning. In Vedaldi, A.; Bischof, H.; Brox, T.; and Frahm, J.-M., eds., Computer Vision – ECCV 2020, volume 12356, 386–402. Cham: Springer International Publishing. ISBN 9783030586201 9783030586218.
- Golkar, Kagan, and Cho (2019) Golkar, S.; Kagan, M.; and Cho, K. 2019. Continual Learning via Neural Pruning. ArXiv.
- Gurbuz and Dovrolis (2022) Gurbuz, M. B.; and Dovrolis, C. 2022. NISPA: Neuro-Inspired Stability-Plasticity Adaptation for Continual Learning in Sparse Networks.
- He et al. (2016) He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep Residual Learning for Image Recognition. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770–778.
- Ke, Liu, and Huang (2021) Ke, Z.; Liu, B.; and Huang, X. 2021. Continual Learning of a Mixed Sequence of Similar and Dissimilar Tasks. ArXiv.
- Kirkpatrick et al. (2017) Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A. A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; Hassabis, D.; Clopath, C.; Kumaran, D.; and Hadsell, R. 2017. Overcoming Catastrophic Forgetting in Neural Networks. Proceedings of the National Academy of Sciences, 114(13): 3521–3526.
- Krizhevsky (2009) Krizhevsky, A. 2009. Learning Multiple Layers of Features from Tiny Images.
- Le and Yang (2015) Le, Y.; and Yang, X. S. 2015. Tiny ImageNet Visual Recognition Challenge.
- Li et al. (2022) Li, J.; Ji, Z.; Wang, G.; Wang, Q.; and Gao, F. 2022. Learning from Students: Online Contrastive Distillation Network for General Continual Learning. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, 3215–3221. Vienna, Austria: International Joint Conferences on Artificial Intelligence Organization. ISBN 978-1-956792-00-3.
- Li et al. (2019) Li, X.; Zhou, Y.; Wu, T.; Socher, R.; and Xiong, C. 2019. Learn to Grow: A Continual Structure Learning Framework for Overcoming Catastrophic Forgetting. In International Conference on Machine Learning.
- Li and Hoiem (2016) Li, Z.; and Hoiem, D. 2016. Learning Without Forgetting. In Leibe, B.; Matas, J.; Sebe, N.; and Welling, M., eds., Computer Vision – ECCV 2016, volume 9908, 614–629. Cham: Springer International Publishing. ISBN 9783319464923 9783319464930.
- Lin et al. (2021) Lin, J.; Chen, W.-M.; Cai, H.; Gan, C.; and Han, S. 2021. MCUNetV2: Memory-Efficient Patch-based Inference for Tiny Deep Learning. ArXiv.
- Loo, Swaroop, and Turner (2020) Loo, N.; Swaroop, S.; and Turner, R. E. 2020. Generalized Variational Continual Learning. ArXiv.
- Lopez-Paz and Ranzato (2017) Lopez-Paz, D.; and Ranzato, M. 2017. Gradient Episodic Memory for Continual Learning. In NIPS.
- Mallya and Lazebnik (2018) Mallya, A.; and Lazebnik, S. 2018. PackNet: Adding Multiple Tasks to a Single Network by Iterative Pruning. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 7765–7773. Salt Lake City, UT: IEEE. ISBN 9781538664209.
- McCloskey and Cohen (1989) McCloskey, M.; and Cohen, N. J. 1989. Catastrophic Interference in Connectionist Networks: The Sequential Learning Problem. In Psychology of Learning and Motivation, volume 24, 109–165. Elsevier. ISBN 9780125433242.
- Prabhu, Torr, and Dokania (2020) Prabhu, A.; Torr, P. H. S.; and Dokania, P. K. 2020. GDumb: A Simple Approach That Questions Our Progress in Continual Learning. In Vedaldi, A.; Bischof, H.; Brox, T.; and Frahm, J.-M., eds., Computer Vision – ECCV 2020, volume 12347, 524–540. Cham: Springer International Publishing. ISBN 978-3-030-58535-8 978-3-030-58536-5.
- Ramapuram, Gregorova, and Kalousis (2020) Ramapuram, J.; Gregorova, M.; and Kalousis, A. 2020. Lifelong generative modeling. Neurocomputing, 404: 381–400.
- Rebuffi et al. (2017) Rebuffi, S.-A.; Kolesnikov, A.; Sperl, G.; and Lampert, C. H. 2017. iCaRL: Incremental Classifier and Representation Learning. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 5533–5542. Honolulu, HI: IEEE. ISBN 9781538604571.
- Riemer et al. (2018) Riemer, M.; Cases, I.; Ajemian, R.; Liu, M.; Rish, I.; Tu, Y.; and Tesauro, G. 2018. Learning to Learn without Forgetting By Maximizing Transfer and Minimizing Interference. ArXiv.
- Rusu et al. (2016) Rusu, A. A.; Rabinowitz, N. C.; Desjardins, G.; Soyer, H.; Kirkpatrick, J.; Kavukcuoglu, K.; Pascanu, R.; and Hadsell, R. 2016. Progressive Neural Networks. ArXiv.
- Schwarz et al. (2018) Schwarz, J.; Czarnecki, W. M.; Luketina, J.; Grabska-Barwinska, A.; Teh, Y.; Pascanu, R.; and Hadsell, R. 2018. Progress & Compress: A Scalable Framework for Continual Learning. In International Conference on Machine Learning.
- Serrà et al. (2018) Serrà, J.; Surís, D.; Miron, M.; and Karatzoglou, A. 2018. Overcoming Catastrophic Forgetting with Hard Attention to the Task. In International Conference on Machine Learning.
- Shin et al. (2017) Shin, H.; Lee, J. K.; Kim, J.; and Kim, J. 2017. Continual Learning with Deep Generative Replay. In NIPS.
- Shokri and Shmatikov (2015) Shokri, R.; and Shmatikov, V. 2015. Privacy-Preserving Deep Learning. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, 1310–1321. Denver Colorado USA: ACM. ISBN 9781450338325.
- Sokar, Mocanu, and Pechenizkiy (2021) Sokar, G.; Mocanu, D. C.; and Pechenizkiy, M. 2021. SpaceNet: Make Free Space for Continual Learning. Neurocomputing, 439: 1–11.
- Wang et al. (2020) Wang, Z.; Jian, T.; Chowdhury, K.; Wang, Y.; Dy, J.; and Ioannidis, S. 2020. Learn-Prune-Share for Lifelong Learning. In 2020 IEEE International Conference on Data Mining (ICDM), 641–650. Sorrento, Italy: IEEE. ISBN 9781728183169.
- Wang et al. (2022) Wang, Z.; Zhang, Z.; Ebrahimi, S.; Sun, R.; Zhang, H.; Lee, C.-Y.; Ren, X.; Su, G.; Perot, V.; Dy, J.; and Pfister, T. 2022. DualPrompt: Complementary Prompting for Rehearsal-free Continual Learning. arXiv.
- Wortsman et al. (2020) Wortsman, M.; Ramanujan, V.; Liu, R.; Kembhavi, A.; Rastegari, M.; Yosinski, J.; and Farhadi, A. 2020. Supermasks in Superposition. ArXiv.
- Wu et al. (2019) Wu, Y.; Chen, Y.; Wang, L.; Ye, Y.; Liu, Z.; Guo, Y.; and Fu, Y. 2019. Large Scale Incremental Learning. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 374–382. Long Beach, CA, USA: IEEE. ISBN 9781728132938.
- Yan et al. (2022) Yan, Q.; Gong, D.; Liu, Y.; Van Den Hengel, A.; and Shi, J. Q. 2022. Learning Bayesian Sparse Networks with Full Experience Replay for Continual Learning. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 109–118. New Orleans, LA, USA: IEEE. ISBN 9781665469463.
- Yan, Xie, and He (2021) Yan, S.; Xie, J.; and He, X. 2021. DER: Dynamically Expandable Representation for Class Incremental Learning. In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 3013–3022. Nashville, TN, USA: IEEE. ISBN 9781665445092.
- Yoon et al. (2017) Yoon, J.; Yang, E.; Lee, J.; and Hwang, S. J. 2017. Lifelong Learning with Dynamically Expandable Networks. ArXiv.
- Yu et al. (2020) Yu, L.; Twardowski, B.; Liu, X.; Herranz, L.; Wang, K.; Cheng, Y.; Jui, S.; and Van De Weijer, J. 2020. Semantic Drift Compensation for Class-Incremental Learning. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 6980–6989. Seattle, WA, USA: IEEE. ISBN 9781728171685.
- Yu et al. (2022) Yu, L. L.; Hu, T.; Hong, L.; Liu, Z.; Weller, A.; and Liu, W. 2022. Continual Learning by Modeling Intra-Class Variation. Trans. Mach. Learn. Res., 2023.
- Zenke, Poole, and Ganguli (2017) Zenke, F.; Poole, B.; and Ganguli, S. 2017. Continual Learning Through Synaptic Intelligence. Proceedings of machine learning research.
- Zhao et al. (2022) Zhao, T.; Wang, Z.; Masoomi, A.; and Dy, J. 2022. Deep Bayesian Unsupervised Lifelong Learning. Neural Networks, 149: 95–106.
Appendix A Subnet Constraint Experience Replay
A.1 Sampling Algorithm
Here, we provide the sampling algorithm for the SCER. This algorithm effectively manages the memory buffer base on the subnet constraints, ensuring that valuable experiences are retained.
A.2 Sample preservation probability in the SCER method
Here we will use mathematical induction to calculate the probability of retaining the sample in the buffer (Eq. (10) in the main paper). For the first samples , we will keep them in the buffer and . For the k-th sample, we keep it with a probability of (which only means it is retained this time). So the probability of being retained in the first samples can be expressed as follows:
Theorem 1.
For any positive integer , the following equation holds:
We will prove this equation using mathematical induction.
Base Step: When , the sum on the left-hand side is , and the right-hand side evaluates to as well. Therefore, the equation holds.
Inductive Hypothesis: Assume that the equation holds for , i.e., .
Inductive Step: We need to show that the equation also holds for . We can expand the sum on the left-hand side as:
Using the inductive hypothesis, is equal to . Thus, we can rewrite the above expression as:
Simplifying, we get:
This proves that the equation holds for .
By the principle of mathematical induction, the equation holds for any positive integer .

Figure 5 illustrates the probability of storing individual samples in a buffer under the SCER method, with the parameters and .
Appendix B Experiment Details
B.1 Datasets
Split CIFAR-10 and Split CIFAR-100 (Krizhevsky 2009) consist of 5 and 20 tasks, each including 2 and 5 classes. Split Tiny ImageNet dataset is constructed by partitioning the original Tiny ImageNet dataset (Le and Yang 2015), which consists of 200 classes, into 10 tasks. Each task contains 20 classes. For Domain Incremental Learning (Domain-IL), previous research (Yan et al. 2022) often relied on Permuted MNIST (Kirkpatrick et al. 2017) and Rotated MNIST datasets (Lopez-Paz and Ranzato 2017). However, these tasks were relatively simple, resulting in the adoption of simplistic base network architectures. Therefore, the number and performance of representative networks searched in the CNS method are greatly limited. As a result, the focus of E2Net was primarily on Task-IL and Class-IL, where the diversity of subnets could be more comprehensively explored.
B.2 Evaluation Metrics
We use the following two metrics to measure the performance of various methods:
| (12) |
| (13) |
We denote the classification accuracy on the -th task after training on the t-th task as . A higher ACC value indicates superior model performance, while a lower F value signifies enhanced anti-forgetting efficacy of the model.
B.3 Implementation Details
For the CIFAR and Tiny ImageNet datasets, we adopted a standard ResNet18 (He et al. 2016) architecture without pretraining as the baseline, following the method taken in (Rebuffi et al. 2017).
In line with (Buzzega et al. 2020), we employ random crops and horizontal flips as data augmentation techniques for both examples from the current task and the replay buffer. It is important to note that data augmentation imposes an implicit constraint on the network.
All models are trained using the Stochastic Gradient Descent (SGD) optimizer and the batch size is fixed at 32. The details of other hyperparameters can be found in Appendix C and Appendix D. In the Split Tiny ImageNet setting, the models are trained for 100 epochs. As for the Split CIFAR-10 and Split CIFAR-100 settings, the models are trained for 50 epochs in each phase. Each batch comprises a combination of half the samples from the new task and half the samples from the buffer. At the end of each batch, the buffer is updated using the proposed SCER. When the rehearsal frequency is set to , the calculation of (Eq. (2) in the main paper) for backpropagation will occur only once every two batches. To ensure the scalability of the search space, we set (Eq. (3) in the main paper).
Appendix C Hyperparameter Selection
| Method | Buffer | Split Tiny ImageNet | Buffer | Split CIFAR-10 |
| SGD | - | lr: | - | lr: |
| oEWC | - | lr: : : | - | lr: : : |
| SI | - | lr: c: : | - | lr: c: : |
| LwF | - | lr: : T: | - | lr: : T: |
| ER | 200 | lr: | 200 | lr: |
| 500 | lr: | 500 | lr: | |
| GEM | 200 | lr: : | ||
| 500 | lr: : | |||
| A-GEM | 200 | lr: | 200 | lr: |
| 500 | lr: | 500 | lr: | |
| iCaRL | 200 | lr: wd: | 200 | lr: wd: |
| 500 | lr: wd: | 500 | lr: wd: | |
| GSS | 200 | lr: : : | ||
| 500 | lr: : : | |||
| HAL | 200 | lr: : : | ||
| : | ||||
| 500 | lr: : : | |||
| : | ||||
| DER | 200 | lr: : | 200 | lr: : |
| 500 | lr: : | 500 | lr: : | |
| DER++ | 200 | lr: : : | 200 | lr: : : |
| 500 | lr: : : | 500 | lr: : : | |
| CL | 200 | lr: : : | 200 | lr: : : |
| : : : | : : : | |||
| 500 | lr: : : | 500 | lr: : : | |
| : : : | : : : | |||
| ER-ACE | 200 | lr: : | 200 | lr: : |
| 500 | lr: : | 500 | lr: : |
| Method | Buffer | Split CIFAR-100 |
| DER | 100 | lr: : |
| 200 | lr: : | |
| 500 | lr: : | |
| DER++ | 100 | lr: : : |
| 200 | lr: : : | |
| 500 | lr: : : | |
| CL | 100 | lr: : : |
| : : | ||
| 200 | lr: : : | |
| : : | ||
| 500 | lr: : : | |
| : : | ||
| ER-ACE | 100 | lr: : |
| 200 | lr: : | |
| 500 | lr: : |
Table 4 presents the selected optimal hyperparameter combinations for each method in the main paper. The hyperparameters include the learning rate (lr), batch size (bs), and minibatch size (mbs) for rehearsal-based methods. Other symbols correspond to specific methods. It should be noted that the batch size and minibatch size are held constant at 32 for all Continual Learning benchmarks.
Appendix D Hyperparameter Sensitivity
| Method | S-CIFAR-10 | |||
| Class-IL | Task-IL | |||
| Buffer Size | 200 | 500 | 200 | 500 |
| 68.16 | 74.92 | 93.41 | 94.74 | |
| 68.53 | 74.46 | 93.33 | 94.41 | |
| 69.44 | 75.04 | 93.64 | 94.54 | |
| 69.33 | 75.68 | 93.65 | 94.81 | |
| 68.97 | 75.66 | 93.66 | 94.97 | |
| 70.04 | 75.10 | 93.94 | 94.90 | |
| 70.06 | 74.95 | 93.71 | 94.93 | |
| 69.22 | 74.90 | 93.84 | 94.79 | |
| 68.18 | 75.16 | 93.60 | 94.59 | |
| 69.35 | 74.97 | 93.71 | 94.78 | |
| 70.16 | 75.66 | 93.75 | 94.95 | |
| 68.93 | 75.46 | 93.60 | 94.88 | |
| 68.85 | 74.93 | 93.71 | 94.83 | |
| 68.90 | 74.85 | 93.88 | 94.39 | |
In Table 5, we report the performance of E2Net against a range of hyperparameters. (Eq. (9) in the main paper) controls the subsequent impact of network size on SCER. A larger value leads to a smaller number of samples retained by the network. (Eq. (11) in the main paper) controls the distillation effect of the network on model training. A larger value reduces the likelihood of the working network forgetting previous tasks, but it also makes learning new tasks more challenging. After conducting experiments, we found that the best results can be achieved when and and E2Net is not sensitive to the choice of hyperparameters.
Appendix E Additional Results
In this section, we present supplementary results for the experiments outlined in Sec. 4.3.
E.1 Forgetting
| Method | S-CIFAR-10 | |||
| Class-IL | Task-IL | |||
| E2Net w/o BUF | 28.37 | 71.85 | ||
| Buffer Size | 200 | 500 | 200 | 500 |
| GEM | 82.611.6 | 74.314.62 | 9.272.07 | 9.120.21 |
| iCaRL | 28.720.49 | 25.711.10 | 2.633.48 | 2.662.47 |
| ER | 61.242.62 | 74.350.07 | 7.080.64 | 3.540.35 |
| A-GEM | 95.730.20 | 94.011.16 | 16.390.86 | 14.264.18 |
| GSS | 75.254.07 | 62.882.67 | 8.561.78 | 7.733.99 |
| DER | 40.760.42 | 26.740.15 | 6.570.20 | 4.560.45 |
| DER++ | 32.592.32 | 22.384.41 | 5.160.21 | 4.661.15 |
| HAL | 69.114.21 | 62.214.34 | 12.260.02 | 5.411.10 |
| ER-ACE | 35.793.19 | 24.512.19 | 6.921.16 | 4.070.08 |
| E2Net (ours) | 23.542.17 | 16.683.42 | 4.191.13 | 1.840.137 |
Table 6 presents the Forgetting of all tasks after training. Our method exhibits the lowest forgetting, demonstrating the effectiveness of E2Net in preserving previous knowledge, rather than solely focusing on improving the accuracy of subsequent tasks.
E.2 Ablation Study
| Method | S-CIFAR-10 | |
| Class-IL | Task-IL | |
| RND w/o Expansion | 20.16 | 71.15 |
| RND w/ Linear | 25.62 | 68.08 |
| RND w/ Cos | 28.37 | 71.85 |






Representative Network Distillation Module
We investigated the influence of different search space expansion methods on RND without a buffer. Table 7 presents the results obtained by enabling all search spaces at any task boundary (RND w/o Expansion), linearly expanding the search space (RND w/ Linear), and cosine expanding the search space (RND w/ Cos). The findings demonstrate that cosine expansion of the search space significantly improves the method’s performance. Allowing all search spaces from the beginning causes the method to quickly saturate, while linear expansion restricts the method’s initial search capabilities. Both scenarios result in a decline in method performance. These experiments provide valuable insights into the significance of the RND and the impact of different search space expansion methods on the overall performance of the method.
Candidate Networks Selection
In the absence of CNS, we default to selecting the largest network in the current search space as the representative network. However, this method does not consider the varying additional parameters required by different tasks. Similar tasks often require fewer additional parameters, indicating a higher degree of similarity between the representative networks. On the other hand, tasks with significant differences require more additional parameters, representing larger representative network differences. By incorporating CNS, the method can automatically identify the similarity between tasks and adjust the selection of representative networks accordingly to improve performance. Without CNS, the expansion of multiple search spaces requires more stringent rationality requirements and necessitates stronger theoretical support.
Subnet Constraint Experience Replay
Figure 6 illustrates the accuracy of the method for each task on the S-CIFAR-100 dataset. By incorporating the SCER module, the E2Net method achieves more balanced learning of previous knowledge, resulting in improved performance.
E.3 Rehearsal Frequency
Figure 7 illustrates the variations in the average accuracy of the method under distinct RF conditions. Remarkably, in both Task-IL and Class-IL, our method demonstrates the slowest decline in accuracy with decreasing RF. This feature grants E2Net an elastic rehearsal frequency design, enabling dynamic selection of the overall processing time and average accuracy. Figure 8 illustrates the correlation between accuracy and the processing time across different methods. Through dynamic processing time and average accuracy adjustment, our method can cater to a broader range of application scenarios.