E-cheating Prevention Measures: Detection of Cheating at Online Examinations Using Deep Learning Approach - A Case Study
Abstract
This study addresses the current issues in online assessments, which are particularly relevant during the Covid-19 pandemic. Our focus is on academic dishonesty associated with online assessments. We investigated the prevalence of potential e-cheating using a case study and propose preventive measures that could be implemented. We have utilised an e-cheating intelligence agent as a mechanism for detecting the practices of online cheating, which is composed of two major modules: the internet protocol (IP) detector and the behaviour detector. The intelligence agent monitors the behaviour of the students and has the ability to prevent and detect any malicious practices. It can be used to assign randomised multiple-choice questions in a course examination and be integrated with online learning programs to monitor the behaviour of the students. The proposed method was tested on various data sets confirming its effectiveness. The results revealed accuracies of 68% for the deep neural network (DNN); 92% for the long-short term memory (LSTM); 95% for the DenseLSTM; and, 86% for the recurrent neural network (RNN).
Index Terms:
Online examination, e-cheating detection, student assessment, intelligence agent, deep learningI Introduction
Online courses have become a feasible option in education. This platform is increasingly recognised in colleges and higher education institutions such as universities, and even implemented in elementary schools – for example, during the Covid-19 pandemic. However, the detached nature of online education raises concerns about the potential risks of academic dishonesty, particularly when students sit for exams at remote locations, in the absence of the disciplinary procedures that are typically employed at examination centres [1, 2, 3]. There is exponential growth in online education, in terms of both student enrolment and the corporate market it entails. However, existing literature indicate a prevalence of online cheating, which involves academic dishonesty by both the faculty and the students [4, 5, 6]. Although online education provides valuable learning opportunities for people who do not have access to traditional quality education due to time or physical constraints, its credibility may be compromised if issues of academic dishonesty are not resolved.
Although online courses have increasingly gained momentum during the Covid-19 pandemic, it should not be established as an accepted mode of education without due diligence in the event of a possible resurgence of the pandemic. For instance, the detached nature of online courses has raised significant concerns as prevalence of e-cheating has been reported [6]. This is because, while traditional sit-down examinations are invigilated, the same cannot be said for the remotely conducted online examinations. Consequently, the credibility of online courses could become questionable.
The present study aims to address the current limitations of cheating at online examinations by proposing artificial intelligence (AI) techniques via the internet protocol (IP) network detector and deep learning-based behaviour detection agent. The research was conducted as a case study, the outcomes of which offer avenues of further improving the intelligent tutoring system. The main contributions of this study are as follows:
-
•
We analysed the limitations of the current online education system, with particular focus on cheating at online examinations.
-
•
We proposed an e-cheating intelligence agent that is based on the relationship model for detecting online cheating using AI techniques. Specifically, we implement an IP detector and a behaviour detector that utilises the long short-term memory (LSTM) network with a densely connected concept, namely DenseLSTM. As AI techniques have evolved rapidly, and has been widely applied in recent years, we utilised state-of-the-art AI techniques for the online exams, which may provide useful insights that contribute to the research area of an intelligent tutoring system.
-
•
We created a new dataset for this study, which is presented in [7]. The records were collected across online exams that were conducted in environments that were highly unregulated (e.g., in the absence of any implemented applications for detecting or preventing e-cheating) during mock, mid-term, and final-term exam periods. The database included training and testing schemes for performance analysis and evaluation.
The paper is organised as follows: Section II analyses the limitations of the existing online education system for preventing online cheating. The proposed framework is presented in Section III and the detailed database information is presented in Section IV. Section V discusses the experimental results, and the conclusions are summarised in the last section.
II Background and Related Works
Students engaging in cheating during examinations is a prevalent phenomenon worldwide, regardless of the country’s stage of development. To this end, early work done by Roger [8], suggested installing the proctoring security program into computers, which enables continuous monitoring of each student’s computer screen on an instructor control view. Similarly, Cluskey et al. [9], proposed an eight-step model for reducing potential cheating by students, which incorporated several criteria that were contributory to the exam, such as the duration of the exam, the time allocated for answering each question, etc. However, this model has limitations given that it required the students to use a special browser in order to access the examination applications, and the consequent necessity for the teacher to change the questions every semester by using the randomised approach [9].
II-A Network Security Methods
The rapid growth of wireless communication technology enables users to remotely access digital resources at any time. Many researchers have focused their work on strengthening the security of online exam protocols to counter the security breaches that could occur in the education sector. Bella et al. [10] proposed a new protocol for online examinations, which bypassed the necessity of involving a trusted third party to maintain discipline. The proposed protocol merged oblivious transfer and visual cryptography that allowed both the students and invigilators to generate aliases. These would only be revealed during the exam, thereby maintaining the anonymity of the students.
A literature survey by Ullah et al. [11] discusses the security threats that have been encountered in the past, which are associated with online examinations. They indicated collusion to an be increasingly challenging threat, which typically involves the collaboration of a third party who assists the student by impersonating him or her online. A further study conducted by the same authors [12] revealed the potential mechanisms of security attacks in online cheating. They monitored 31 online participants at an examination, where they assessed the students’ behaviour by employing dynamic profile questions in an online course. The results pointed out that students who cheated by impersonation shared most of the information using a mobile device, and consequently, their response time was significantly different to those who did not cheat.
A recent literature review [13] highlights the significance of advanced technology in enabling the use of techniques such as anomaly detection for addressing the growing concerns of e-cheating. The authors reviewed the current work under five dimensions: network data type, network traffic, intrusion detection, detection methods and open issues. They also emphasised the accurate identification of an individual to be crucial in developing any intrusion detection system that is aimed at restricting their access within the network traffic.
II-B Plagiarism Detection Methods and Tools
Plagiarism detection tools are popular in course evaluations for identifying the unpermitted use of written content by students. For instance, the code plagiarism tool can be used to calculate the similarity between a pair of programs using a token sequence [14] and dependency graph features [15]. Nonetheless, these code plagiarism detection techniques can be circumvented by modifying the code syntax. In order to counter such deceit, Herrera et al. [16] implemented a new language-agnostic methodology, which prevents plagiarism in programming courses without the necessity for code comparison or professor intervention.
A study carried out by Pawelczak [17] examined the achievements and opinions of students over five years regarding the automated evaluation system used in plagiarism detection in programming courses. The data comprised of 228 records, where the analysis was based on tokenizing and averaging several features of the source code. The study revealed a limitation in the method: given that plagiarism detection is dependent on the thresholding value that is used to calculate the level of similarity in the content, thresholding issues in this approach could give rise to false measures of prevention.
II-C Biometrics Methods
It is vital to ensure the presence of an examinee throughout the entire examination. The invigilation of online examinations is difficult, and the absence of a physical invigilator gives rise to a higher possibility of suspicious conduct as well as cheating attempts taking place. Several strategies have been proposed to counter such fraudulent activities during examinations including the monitoring of yaw angle variations, audio presence and active window capture. For instance, Prathish et al. [18] and Narayanan et al. [19] proposed to implement the features of point extraction and yaw angle detection that could assist the instructors in monitoring the students during online examinations. Similarly, Wlodarczyk et al. [20] presented the head pose detection method, which uses the precise localisation of face landmark points that help in identifying the user’s direction of gaze as well as facial recognition.
Hu et al. [21] proposed a novel method of monitoring the students’ behaviour during online assessments, which involved identifying the relevant relationship between the image of a student’s face and his or her corresponding pose. Mahadi et al. [22] suggested that the combination of facial recognition and keystroke dynamics could be the best classifiers for behavioural-based biometric authentication. In similar a study, Ghizlane et al. [23] primarily focused on the identity and access management of students and staff, where they could use a customised model of a smart card-based digital identity control system for accessing academic services, especially online evaluations. This service would help in ensuring that the security of the institute could manage the authorisation of individuals in accessing various types of networks.
Ghizlane et al. [24] also examined the combined use of smart cards and face recognition to authorise and monitor applicants while online exams are conducted in detecting any suspicious behaviour or cheating attempts. They recommended a system that stored a log of photographs taken of each applicant that sits the exam, which could be later checked by administrators. Another study conducted by Garg et al. [25] proposed using the convolutional neural network and the Haar cascade classifier to detect the faces of the exam candidates and to tag these with an associated name that is given at the time of registration, which allows the system to keep track of the applicants’ movements within the timeframe of the exam.
In current online examination settings, biometric authentication is considered to be one of the most popular techniques in verifying the identification of the candidates [26, 27]. In contrast to face-to-face examinations, online assessments do not involve proctors or invigilators, and can be held in different and uncontrolled remote environments. Consequently, establishing authentication goals in online exams are vital in order to verify the identity of the students, as it plays a key role in online security [28, 29]. In a study which focused on enhancing the security of online examinations, Mathapati et al. [30] proposed utilising personal-images as graphical passwords. They suggested using digital pictures that were captured from live video as personalised physical tokens.
Ramu et al. [31] and Mungai et al. [32] reviewed the importance of keystrokes dynamics in preserving security in online examinations. The proposed architecture used a three-stage authentications process, in which the stages were described as statistical, machine learning and logic comparison. Initially, when an applicant signs into the system, his/her typing style is automatically recorded, for which a template is generated. These templates are subsequently used as a guide to continuously monitor the authenticity of the users, based on several parameters: their dwell time (the time difference between keypress and release); the flight time (the time passed between the key release and keypress of two consecutive keystrokes); and, the typing speed, for better precision and robustness. Ananya and Singh [33] also introduced the keystroke dynamics approach, in which the system does not require any pre-registration and has the capability of keeping track of each student’s typing pattern during the exercise session itself.
II-D Summary
Due to the Covid-19 pandemic, many academic institutes, schools and universities have switched to online teaching, and consequently, online examinations have become a common trend, especially due to its flexibility and usability within different environments [34, 35, 36]. Several studies offer diverse approaches to mitigate cheating at online examinations that largely focus on behaviour analysis, technology innovation, etc. [37, 38, 39]. However, the detection of suspicious behaviour of candidates at online examinations still remains one of the major challenges in fully utilising online education platforms. In this context, we offer a solution for detecting abnormal behaviour of students at online examinations, and thereby for preventing e-cheating, by investigating the use of an AI intelligence agent as a real-time live proctor. The AI intelligence agent was designed utilising network protocol detection and deep learning approaches.
III Methodology
We designed an online examination as a case study, which consisted of multiple-choice questions, in which an e-cheating intelligent agent was used to detect any potential cheating. The e-cheating intelligence agent consists of two main agents: the network IP detection agent (described in Section III-A) and the behaviour detection agent (described in Section III-B). Fig. 1 illustrates the architecture of the proposed system.

III-A Network IP Detection Agent
Emerging security analysis has raised awareness of the challenges of online learning and has captured the rapidly increasing attention of researchers of developing new e-learning assessment methods. The present issues arises from the inadequate understanding of the security dataset that is stored through network protocols and the analyses of data that use semantic association and inference methods [40].
The proposed model is a two-stage process (see Fig. 1). In the first stage, we propose applying an IP detection agent to filter any deceitful activity. For example, the system can monitor the exam candidates’ IP addresses. Most routers allocate dynamic IP addresses, which are numerical labels that are specifically assigned to each device that is connected to a computer network. This would enable the system to issue an alert if a student changed their computer device or their initial location. In the proposed method, there would be several sets of exam questions (such as Set A, B, C, etc.). At the start of an examination, after verification, a student is randomly assigned a set of questions for assessment (e.g., Set A). If any abnormal behaviour is detected, the system changes the questions randomly to another Set (e.g., Set B). Similarly, if an incoming student enters his/her credential to access the online exam platform using an IP address that was previously recorded in the IP list as suspicious, the system will generate a different set of questions to the student. Algorithm 1 summarises the entire process of the IP detection agent.
Input: IP address from a new examinee
Output: Decision
//Initialisation
Let be the list of real-time IP with size
if is not in then
else
end
III-B Behaviour Detection Agent
We devised a behaviour detection agent via a deep learning approach to monitor and analyse the behaviour of all the students. As illustrated in Fig. 1, the agent would alert the instructors and immediately reassign the remaining questions with a new set of questions only in instances where abnormal behaviour is detected in the students during the examinations. The following sub-sections provide a more detailed explanation of the behaviour detection agent.
III-B1 Data pre-processing
Before training the behaviour detection agent, we first transformed each raw data record into a one-hot encoded feature, which defines the behaviour of the student during the examination. For instance, each raw data record contains the results of the 20 multiple-choice questions, the total time (in minutes) taken for answering the examination, and the final score. In this study, we defined the one-hot encoded input feature as: , where . The first 20 elements represent the given answers of the 20 questions as: where the values 1 and 0 reflect whether the answer is correct or incorrect, respectively. The last three elements define the speed of answering the questions, whether fast, normal or slow. The last three elements are defined as the speed of answering questions as fast, normal or slow. Fig. 2 summarises data pre-processing, where the raw data is processed into one-hot encoded features.

Next, we explored how we could label the data record to identify the students’ behaviours. Initially, we labelled the records as one of two major categories of behaviours: ‘normal’ or ‘abnormal’. In defining ‘abnormal’ behaviour, we assessed the speed at which the students have answered in instances where the questions have been answered 90% correctly, according to one-hot encoded features. If the speed was represented as too fast or too slow, they were labelled as ‘abnormal’; in comparison, the rest of the samples were considered as ‘normal’.
When defining the speed of answering questions two factors were considered: the number of questions answered and the level of difficulty of each question. For example, we observed that if the level of difficulty of a question was defined as ‘easy’, most of the students could answer it within 10 to 20 seconds; if it was defined as ‘moderate’ or ‘high’, they required 30 to 40 seconds or 1-2 minutes, respectively. However, the specifics of such labelling criteria are dependent on the subjects or the courses that are evaluated.
III-B2 DenseLSTM
We propose applying a deep learning network, namely DenseLSTM as the behaviour detection agent. The LSTM network was introduced by Hochreiter and Schmidhuber [41], and allows modelling the problem with sequential dependencies data, such as time-series data, natural language processing, behaviour analysis, etc. In our work, we propose to use a densely connected approach with the LSTM network to extract better feature representation for abnormal behaviour prediction.
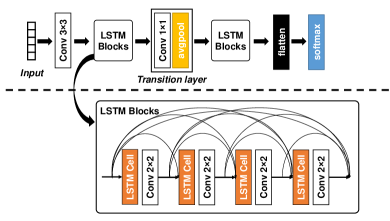
Fig. 3 illustrates the architecture of the DenseLSTM, which consists of a convolutional (conv) layer, two LSTM blocks and a transition layer. The concept of the densely connected network was originally proposed by Huang et al. [42] for image classification. The network introduces direct connections from any layer to all the subsequent layers, which improves the information flow between them by creating a different connectivity pattern. One explanation for this occurrence is the enhanced access each layer has to all the preceding feature maps in its block due to the dense connectivity, and the “collective knowledge” it thereby provides the network.
| Network Layer | Configuration |
|---|---|
| f: 64123; k: 12; stride 2 | |
| 11 ; ; stride 2 | |
| 51216 | |
| 16512 | |
| Y | 1 |
In the LSTM block, the LSTM cell layer decides what information will be discarded from the cell state. As the layer could potentially inadvertently omit useful information, we have implemented the concept of a densely connected network, which keeps the information together instead of deciding “what to forget and which new information should be added.” The features can be accessed from anywhere within the network, and unlike in traditional network architectures, there is no requirement to replicate them from layer to layer. The network used in this study is expected to collect rich information while maintaining a low complexity of features, which can result in achieving a better classification performance.
| ID | Q1 Ans. | Q1 Score | Q2 Ans. | Q2 Score | Q20 Ans. | Q20 Score | Grade | Time | IP | |
|---|---|---|---|---|---|---|---|---|---|---|
| 2000001 | 4 | 2 | 2 | 2 | 4 | 3 | 45 | 15 | 175.116.139.44 | |
| 2000002 | 4 | 2 | 2 | 2 | 4 | 3 | 36 | 20 | 211.214.126.62 | |
| 2000003 | 4 | 2 | 2 | 2 | 1 | 0 | 38 | 20 | 125.186.174.50 | |
| 2000004 | 1 | 0 | 2 | 2 | 2 | 0 | 24 | 18 | 1.236.192.19 | |
| 2000005 | 4 | 2 | 2 | 2 | 2 | 0 | 33 | 17 | 58.236.177.182 | |
| 2000006 | 3 | 0 | 2 | 2 | 2 | 0 | 24 | 14 | 180.71.78.211 | |
| 2000007 | 4 | 2 | 2 | 2 | 4 | 3 | 46 | 25 | 211.243.246.3 | |
| 2000008 | 4 | 2 | 2 | 2 | 4 | 3 | 45 | 24 | 211.243.246.3 | |
| 2000009 | 4 | 2 | 2 | 2 | 1 | 0 | 35 | 26 | 221.147.167.237 | |
| 2000010 | 3 | 0 | 2 | 2 | 1 | 0 | 23 | 14 | 61.74.229.32 |
Let denote the LSTM block with in layers, composed of LSTM cell, layer, rectified linear unit (ReLU) [43] and dropout layers:
| (1) |
where to represent feature outputs and is defined as a concatenation operator. We define as 4 in the first block and as 8 in the second block. A transition layer is implemented in the first block that performs and operations, where is defined as the filter size of the layer that is . Table I tabulates the architecture of the proposed network.
In the training stage, we implement a softmax cross-entropy of logit vector and the respective encoded label:
| (2) |
| (3) |
where , and denote class labels, the number of training samples in Y and the number of classes, respectively.
In summary, we have devised a network using the concept of a densely connected approach to extract better feature representation and to strengthen the feature activation of the network for predicting potential e-cheating.
IV Dataset
We have designed a new dataset, namely, the 7wiseup behaviour dataset, which consists of 94 student records that were acquired from different end-of-term examinations at Pyeongtaek University in South Korea. All records were collected during the Spring semester, 2020.
IV-A Collection Setup
In order to create our database, we utilised an e-class learning management system (LMS), which is adopted by the university. The exam module is crucial for the LMS system, which can be used to set up quizzes and exam questions. The module allows the lecturers to fill out forms that outline vital information such as the exam name, time allocations (opening time, closing time and length of the exam), grades, whether shuffling of questions is allowed, etc. They can add questions from the question bank, using various in-built options for quiz/test settings including the type of examination questions – whether multiple-choice, true/false and short answers, and also allocate marks for each question. The system further enables the staff to add resources including images or links, and to provide general feedback. Once the exam is completed and submitted, the system automatically assigns marks for the questions based on the answers that were pre-determined by the staff. Finally, the system generates a CSV file compiling a list of all the submissions and the candidates’ records including their names, IDs, the answers for each question, the scores for each question, the grades, the total time taken for completion (in minutes), and the IP addresses. Table II shows several records of our dataset.
IV-B Training and Benchmarking Protocols
For training and benchmarking protocols, 94 records each were obtained from mock-exams, and the mid- and final-term exams, respectively. Notably, the records that were used for the training and benchmarking protocols did not overlap. When designing the protocol to develop or train our model, we divided the data set from mock-exams for training and cross-validations at a ratio of 80:20. In addition, due to the imbalanced nature of the dataset, we have applied a data augmentation approach that generated an additional 60 samples representing cases of abnormal behaviour. In the benchmarking scheme, the task was to determine the behaviour of the examinees based on their manner of answering questions.
V Experiments
We conducted several experiments to evaluate the relative performance between our network and other benchmark networks. All the configurations used for the networks are described in Section V-A and the experimental results are presented in Section V-B.
V-A Experimental Setup
V-A1 Configuration of DenseLSTM
The proposed network was implemented using TensorFlow [44]. For the configuration, we applied a learning rate of and the AdamOptimizer [45], where the weight decay and momentum were set to and 0.9, respectively. In the experiments, the batch size was set to 32 and the training was carried out across 250 epochs. The training was conducted using our database according to the protocols set out in Section IV-B; it was performed by the NVidia RTX 2080 Ti GPU.


V-A2 Configuration of Benchmark Networks
We selected several deep networks to evaluate the performance of the behaviour study: the Deep Neural Network (DNN) [46], the LSTM [47] and the Recurrent Neural Network (RNN) [48]. These approaches have been successfully applied in behaviour studies previously [49] and [50]. When conducting the experiments, we tried our best to implement and fine-tune the LSTM and RNN from scratch following the recommendations of [47] and [48], respectively. The training was also conducted using our database and following the protocols in Section IV-B. All the training processes were performed using the NVidia RTX 2080 Ti GPU.
V-B Experimental Results
In order to evaluate the performance of our network in a real-life scenario and in a more objective manner, we used the mid-term and final-term examinations data and compared our experimental results with the results obtained from other benchmark approaches. As shown in Table III, of the different approaches tested, the highest accuracy, of 95.32%, was achieved by our system for overall performance, followed by the second-best, the LSTM system, which reached an accuracy of 91.89%. Our model outperformed the existing benchmark models by 3.5% in accuracy demonstrating its superiority to the other benchmark approaches.
In identifying the source of the improvements in our system, we observed that the accuracy of our network was higher than 92% in analysing the behaviour of students during online exams for both mid-term and final-term examinations, with values of 97.77% and 92.86%, respectively (as shown in Table III). The LSTM system, which was the second-best, demonstrated comparable accuracy scores of 94.49% for the mid-term and 89.29% for the final-term examinations. In contrast, the performance of the DNN approach was low with an accuracy score of 82.74% for the mid-term examination, and only 52.68% accuracy for the final-term examination. In addition, our investigations of the DNN system revealed error rates of 2.23% and 7.14% for mid-term and final-term examinations, respectively, which was associated with false prevention that occurred as a result of several students being extremely slow to select their answers.
With the intention of refining our system further, we focused on characterising its sensitivity and specificity by applying the parameters, Receiver Operating Characteristics (ROC) and Area Under the ROC curve (AUC). This enables summarising the trade-off between the true and false positive rates of a model by using different probability thresholds. As shown in Fig. 4, our network (DenseLSTM) achieved the highest AUC values of 0.9972 and 0.9760, for the mid-term and final-term examinations, respectively. The LSTM and RNN systems also demonstrated a similar performance for the mid-term examination by achieving AUC values of 0.9870 and 0.9810, respectively. However, the AUC values achieved by both these approaches for the final-term examinations were lower than 0.94. These comparisons demonstrate that our network has outperformed most of the other benchmark networks for classifying normal and abnormal behaviours of students at online examinations with low sensitivity and high specificity.
| Networks | Mid-term (%) | Final-term (%) | Overall (%) |
|---|---|---|---|
| DNN | 82.74 | 52.68 | 67.71 |
| LSTM | 94.49 | 89.29 | 91.89 |
| RNN | 87.20 | 85.02 | 86.11 |
| DenseLSTM | 97.77 | 92.86 | 95.32 |
V-C Discussion
Our experimental analysis and results demonstrate that the proposed approach can successfully address the challenges pertaining to cheating at online examinations, and in preventing such abnormal behaviour of students. The proposed intelligence agent framework utilises the IP detector and the DenseLSTM network, which enable monitoring the students through network protocols and behaviour analysis to identify any potential plagiarism.
As the examinations were evaluated over two terms, our results have shown a consistently high accuracy. The results confirm the performance of the proposed network to be superior in detecting abnormal behaviour at online examinations due to its ability to better maintain “collective knowledge” from the extracted features within the subsequent layers, instead of “forgetting” the information. This supports our assumption that DenseLSTM performs better than other neural networks.
VI Conclusion
Online learning is a new and exciting opportunity for students and education institutions, which is gaining momentum. In today’s environment, e-learning presents unique opportunities, but also unique challenges. The primary area of concern in online assessments is academic dishonesty in the form of cheating, which students attempt to achieve employing numerous avenues. Therefore, it is the responsibility of the education institutions to implement more effective measures to detect academically dishonest behaviour. This paper discusses the concerns around online cheating and offers plausible mechanisms of monitoring and curtailing such incidences using AI technology.
We have demonstrated the effectiveness of the proposed e-cheating intelligent agent, which successfully incorporates IP detector and behaviour detector protocols. The agent has been tested on four deep learning algorithms: the DNN, DenseLSTM, LSTM and RNN, using two exam datasets (mid-term and final-term exams). The highest overall accuracy of 95.32% was achieved by the DenseLSTM. The average accuracy rate is 90%, which is sufficient to alert the lecturers to review the exam result of concern. We intend to continue developing web-based e-cheating monitoring systems in the future. Such systems would potentially provide a user-friendly interface for tasks such as uploading exam results, choosing algorithms and other features. The system will be tested among lecturers of various subjects, where they would be able to set specific features that they wish to monitor and for detecting abnormal behaviour of students. The existing agent will be improved based on their feedback.
References
- [1] M. A. Sarrayrih and M. Ilyas, “Challenges of online exam, performances and problems for online university exam,” International Journal of Computer Science, vol. 10, no. 1, pp. 439–443, 2013.
- [2] K. Jalali and F. Noorbehbahani, “An automatic method for cheating detection in online exams by processing the student’s webcam images,” in Proc. 3rd Conference on Electrical and Computer Engineering Technology (E-Tech 2017), Tehran, Iran, 2017, pp. 1–6.
- [3] Z. Raud and V. Vodovozov, “Advancements and restrictions of e-assessment in view of remote learning in engineering,” in Proc. 2019 IEEE 60th International Scientific Conference on Power and Electrical Engineering of Riga Technical University (RTUCON), Riga, Latvia, 2019, pp. 1–6.
- [4] N. C. Rowe, “Cheating in online student assessment: Beyond plagiarism,” On-Line Journal of Distance Learning Administration, pp. 1–8, 2004.
- [5] J. Moten Jr., A. Fitterer, E. Brazier, J. Leonard, and A. Brown, “Examining online college cyber cheating methods and prevention measures,” The Electronic Journal of e-Learning, vol. 11, no. 2, pp. 139–146, 2013.
- [6] C. Y. Chuang, S. D. Craig, and J. Femiani, “Detecting probable cheating during online assessments based on time delay and head pose,” Higher Education Research & Development, vol. 36, no. 6, pp. 1123–1137, 2017.
- [7] 7wiseup behaviour dataset. [Online]. Available: http://7wiseup.com/research/e-cheating/data/
- [8] C. F. Roger, “Faculty perceptions about e-cheating during online testing,” Journal of Computing Sciences in Colleges, vol. 22, no. 2, pp. 206–212, 2006.
- [9] G. R. Cluskey, C. R. Ehlen, and M. H. Raiborn, “Thwarting online exam cheating without proctor supervision,” Journal of Academic and Business Ethics, vol. 4, no. 1, pp. 1–7, 2011.
- [10] G. Bella, R. Giustolisi, G. Lenzini, and P. Y. A. Ryan, “A secure exam protocol without trusted parties,” in Proc. International Conference on ICT Systems Security and Privacy Protection, Hamburg, Germany, 2015, pp. 495–509.
- [11] A. Ullah, H. Xiao, and T. Barker, “A classification of threats to remote online examinations,” in Proc. IEEE 7th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 2016, pp. 1–7.
- [12] A. Ullah, H. Xiao, and T. Barker, “A dynamic profile questions approach to mitigate impersonation in online examinations,” Journal of Grid Computing, vol. 17, no. 2, p. 209–223, 2018.
- [13] G. Fernandes Jr. et al., “A comprehensive survey on network anomaly detection,” Telecommunication Systems, vol. 70, p. 447–489, 2018.
- [14] L. Mariani and D. Micucci, “Audentes: Automatic detection of teNtative plagiarism according to a rEference solution,” ACM Transactions on Computing Education, vol. 12, no. 2, p. 1–26, 2012.
- [15] K. Chen, P. Liu, and Y. Zhang, “Achieving accuracy and scalability simultaneously in detecting application clones on android markets,” in Proc. 36th International Conference on Software Engineering, Hyderabad, India, 2014, p. 175–186.
- [16] G. Herrera, M. Nuñez-del-Prado, J. G. L. Lazo, and H. Alatrista, “Through an agnostic programming languages methodology for plagiarism detection in engineering coding courses,” in Proc. IEEE World Conference on Engineering Education (EDUNINE), Lima, Peru, 2019, pp. 1–6.
- [17] D. Pawelczak, “Benefits and drawbacks of source code plagiarism detection in engineering education,” in Proc. IEEE Global Engineering Education Conference (EDUCON), Tenerife, Spain, 2018, pp. 1048–1056.
- [18] S. Prathish, S. Athi Narayanan, and K. Bijlani, “An intelligent system for online exam monitoring,” in Proc. International Conference on Information Science (ICIS), Kochi, India, 2016, pp. 138–143.
- [19] A. Narayanan, R. M. Kaimal, and K. Bijlani, “Yaw estimation using cylindrical and ellipsoidal face models,” IEEE Transactions on Intelligent Transportation Systems, vol. 15, no. 5, pp. 2308–2320, 2014.
- [20] M. Wlodarczyk, D. Kacperski, P. Krotewicz, and K. Grabowski, “Evaluation of head pose estimation methods for a non-cooperative biometric system,” in Proc. 23rd International Conference Mixed Design of Integrated Circuits and Systems (MIXDES), Lodz, Poland, 2016, pp. 394–398.
- [21] S. Hu, X. Jia, and Y. Fu, “Research on abnormal behavior detection of online examination based on image information,” in Proc. 10th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC), Hangzhou, China, 2018, pp. 88–91.
- [22] N. A. Mahadi et al., “A survey of machine learning techniques for behavioral-based biometric user authentication,” Recent Advances in Cryptography and Network Security, 2018.
- [23] M. Ghizlane, F. H. Reda, and B. Hicham, “A smart card digital identity check model for university services access,” in Proc. the 2nd International Conference on Networking, Information Systems & Security, New York, NY, USA, 2019, pp. 1–4.
- [24] M. Ghizlane, B. Hicham, and F. H. Reda, “A new model of automatic and continuous online exam monitoring,” in Proc. 2019 International Conference on Systems of Collaboration Big Data, Internet of Things Security (SysCoBIoTS), Casablanca, Morocco, 2019, pp. 1–5.
- [25] K. Garg, K. Verma, K. Patidar, N. Tejra, and K. Patidar, “Convolutional neural network based virtual exam controller,” in Proc. 4th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 2020, pp. 895–899.
- [26] A. Fayyoumi and A. Zarrad, “Novel solution based on face recognition to address identity theft and cheating in online examination systems,” Advances in Internet of Things, vol. 4, pp. 5–12, 2014.
- [27] N. A. Karim and Z. Shukur, “Review of user authentication methods in online examination,” Asian Journal of Information Technology, vol. 14, no. 5, pp. 166–175, 2015.
- [28] R. Bawarith, A. Basuhail, A. Fattouh, and S. Gamalel-Din, “E-exam cheating detection system,” International Journal of Advanced Computer Science and Applications, vol. 8, no. 4, pp. 1–6, 2017.
- [29] S. G. A. Hadian and Y. Bandung, “A design of continuous user verification for online exam proctoring on m-learning,” in Proc. 2019 International Conference on Electrical Engineering and Informatics (ICEEI), Bandung, Indonesia, 2019, pp. 284–289.
- [30] M. Mathapati, T. S. Kumaran, A. K. Kumar, and S. V. Kumar, “Secure online examination by using graphical own image password schemer,” in Proc. 2017 IEEE International Conference on Smart Technologies and Management for Computing, Communication, Controls, Energy and Materials (ICSTM), Chennai, India, 2017, pp. 160–164.
- [31] T. Ramu and T. Arivoli, “A framework of secure biometric based online exam authentication: An alternative to traditional exam,” International Journal of Scientific and Engineering Research, vol. 4, no. 11, pp. 52–60, 2013.
- [32] P. K. Mungai and R. Huang, “Using keystroke dynamics in a multi-level architecture to protect online examinations from impersonation,” in Proc. 2017 IEEE 2nd International Conference on Big Data Analysis (ICBDA), Chennai, India, 2017, pp. 160–164.
- [33] Ananya and S. Singh, “Keystroke dynamics for continuous authentication,” in Proc. 2018 8th International Conference on Cloud Computing, Data Science Engineering (Confluence), Noida, India, 2018, pp. 205–208.
- [34] M. A. Almaiah, . A. Al-Khasawneh, and A. Althunibat, “Exploring the critical challenges and factors influencing the e-learning system usage during covid-19 pandemic,” Education and Information Technologies, pp. 1–20, 2020.
- [35] M. H. Rajab, A. M. Gazal, and K. Alkattan, “Challenges to online medical education during the covid-19 pandemic,” Cureus, vol. 12, no. 7, pp. 1–11, 2020.
- [36] O. B. Adedoyin and E. Soykan, “Covid-19 pandemic and online learning: the challenges and opportunities,” Interactive Learning Environments, pp. 1–13, 2020.
- [37] N. A. Shukor, Z. Tasir, and H. Van der Meijden, “An examination of online learning effectiveness using data mining,” Procedia - Social and Behavioral Sciences, vol. 172, pp. 555–562, 2020.
- [38] N. Yan and O. T.-S. Au, “Online learning behavior analysis based on machine learning,” Asian Association of Open Universities Journal, vol. 14, no. 2, pp. 97–106, 2019.
- [39] C. S. González-González, A. Infante-Moro, and J. C. Infante-Moro, “Implementation of e-proctoring in online teaching: A study about motivational factors,” Sustainability, vol. 12, p. 3488, 2020.
- [40] Y. Yao, L. Zhang, J. Yi, Y. Peng, W. Hu, and L. Shi, “A framework for big data security analysis and the semantic technology,” in Proc. 2016 6th International Conference on IT Convergence and Security (ICITCS), Prague, Czech Republic, 2016, pp. 1–4.
- [41] S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Computation, vol. 9, no. 8, p. 1735–1780, 1997.
- [42] G. Huang, Z. Liu, G. Pleiss, L. Van Der Maaten, and K. Weinberger, “Convolutional networks with dense connectivity,” IEEE Transactions on Pattern Analysis and Machine Intelligence, p. 1–1, 2019.
- [43] V. Nair and G. E. Hinton, “Rectified linear units improve restricted boltzmann machines,” in Proc. 27th International Conference on Machine Learning (ICML), Haifa, Israel, 2010, pp. 1–8.
- [44] Tensorflow. [Online]. Available: https://tensorflow.org
- [45] D. P. Kingma and J. L. Ba, “Adam: A method for stochastic optimization,” in Proc. International Conference on Machine Learning (ICML), Lille, France, 2015, pp. 1–15.
- [46] N. Kriegeskorte and T. Golan, “Neural network models and deep learning,” Current Biology, vol. 29, no. 7, pp. R231–R236, 2019.
- [47] K. Greff, R. K. Srivastava, J. Koutník, B. R. Steunebrink, and J. Schmidhuber, “LSTM: A search space odyssey,” IEEE Transactions on Neural Networks and Learning Systems, vol. 28, no. 10, pp. 2222–2232, 2019.
- [48] D. Rumelhart, G. Hinton, J. Koutník, and R. Williams, “Learning representations by back-propagating errors,” Nature, vol. 323, p. 533–536, 1986.
- [49] M. Zerkouk and B. Chikhaoui, “Long short term memory based model for abnormal behavior prediction in elderly persons,” in Proc. International Conference on Smart Homes and Health Telematics (ICOST), New York, NY, USA, 2019, pp. 36–45.
- [50] Z. Hao, M. Liu, Z. Wang, and W. Zhan, “Human behavior analysis based on attention mechanism and LSTM neural network,” in Proc. 2019 IEEE 9th International Conference on Electronics Information and Emergency Communication (ICEIEC), Beijing, China, 2019, pp. 346–349.