DynamicAvatars: Accurate Dynamic Facial Avatars Reconstruction and Precise Editing with Diffusion Models
Abstract
Generating and editing dynamic 3D head avatars are crucial tasks in virtual reality and film production. However, existing methods often suffer from facial distortions, inaccurate head movements, and limited fine-grained editing capabilities. To address these challenges, we present DynamicAvatars, a dynamic model that generates photorealistic, moving 3D head avatars from video clips and parameters associated with facial positions and expressions. Our approach enables precise editing through a novel prompt-based editing model, which integrates user-provided prompts with guiding parameters derived from large language models[26] (LLMs). To achieve this, we propose a dual-tracking framework based on Gaussian Splatting and introduce a prompt preprocessing module to enhance editing stability. By incorporating a specialized GAN algorithm and connecting it to our control module, which generates precise guiding parameters from LLMs, we successfully address the limitations of existing methods. Additionally, we develop a dynamic editing strategy that selectively utilizes specific training datasets to improve the efficiency and adaptability of the model for dynamic editing tasks.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d56d4299-bf83-496c-becc-d6e586957503/Head_Display.jpg)

1 Introduction
Creating and editing digital avatars of human heads has become a prominent research direction in computer vision, driven by its importance in gaming, film production, and environmental simulation. Efficiently producing and flexibly editing detailed human models is critical for these applications.
Traditional methods utilizing explicit 3D representations, such as point clouds and meshes, often struggle to accurately capture fine geometric details. The inherent complexity of human faces, with their intricate textures, unpredictable poses, and dynamic expressions, further complicates the task of identifying and modeling underlying patterns.
Implicit 3D representation methods have addressed many of these challenges, offering the capability to reconstruct photorealistic human avatars. Neural Radiance Fields [25] (NeRF) have demonstrated remarkable success by introducing novel rendering pipelines and neural-network-based color storage techniques. NeRF-based approaches like [24, 30, 11, 39, 4] have enabled the generation of highly complex scenes and significantly reduced temporal and spatial computation costs. They have also achieved impressive results in reconstructing dynamic scenes and rendering novel views. However, these methods often lack the ability to edit or control facial reconstructions due to limitations in encoding techniques and insufficient use of prior information.
To advance this field, researchers are increasingly turning to 3D Gaussian Splatting [17] (3DGS) as a promising solution. This method excels in real-time performance and offers a structurally simple framework conducive to editing. Prior works, such as 3DGS-DET [5, 8] and other works [40], have demonstrated the feasibility of 3DGS in 3D object detection and urban scene reconstruction, while recent efforts like Rig3dGS [32], Gaussian Editor [7] and etc.[41, 23, 33, 14] focus on digital avatars have addressed some challenges by binding meshes to 3D Gaussian splats and optimizing Gaussian cloning and splitting techniques.
Despite these advancements, current models still face significant challenges in achieving precise and flexible editing. One major limitation lies in editing fine facial features and adornments. Existing text-guided image editing models often exhibit low comprehension when interpreting instructions with precise positional details or highly detailed descriptions. Furthermore, editing in dynamic scenes while maintaining real-time performance remains a persistent obstacle.
Our model can reconstruct dynamic digital human head avatars and supports text-based editing of the reconstructed models, as demonstrated in Figure.1. We achieve successful reconstruction by constraining the relative positions of Gaussian splats and meshes while applying a semantic mask to the splats. During the editing phase, we identify all relevant Gaussian splats contributing to the target editing area using a specifically designed strategy. These splats are then refined using an LLM-based editing process to achieve precise modifications. Our pipeline is illustrated in Figure.2. As shown, our approach is divided into two stages, enabling the modeling and editing of dynamic 3D scenes using Gaussian Splatting. Our contributions are mainly reflected in the following points:
1. We propose a dual-tracking Gaussian method to construct a dynamic Gaussian model from a collection of video clips.
2. We design an LLM-based editing process that leverages a GAN framework to enable precise editing of dynamic scenes based on detailed prompts.
2 Related Work
2.1 3D Dynamic Head Avatars Editing
Several techniques have been proposed for tasks involving 3D dynamic scenes. Neural Radiance Fields (NeRF) have introduced a groundbreaking perspective in 3D-aware generation through exceptional volumetric rendering. Efficiency improvements have been achieved by optimizing data organization structures and numerical methods. For example, works such as InstantNGP [27] and Mip-NeRF[2] have made significant advancements. However, the implicit information storage approach used by NeRF can be computationally intensive and less efficient compared to explicit methods like voxel grids, point clouds, and Gaussian points.
In our work, we adopt 3D Gaussian Splatting [17] (3DGS) to balance reconstruction quality in 3D head avatar tasks with effective editing capabilities.
A widely adopted approach for modeling dynamic scenes involves encoding color and volume density information into a Multi-Layer Perceptron (MLP) using spatial-temporal coordinates or relative coordinates in a 4D canonical space like [35, 9]. More recent methods like [43, 21], which attach mesh triangles to 3D Gaussians for explicit editing and fine-tuning, have achieved remarkable results in facial scene reconstruction. Building upon these advancements, we introduce a Gaussian tracing method integrated with mesh adjustment to enable flexible and efficient dynamic editing.
2.2 LLM-controlled Image Editing Guidance
Using diffusion models in generating photorealistic images[13] has become a standard approach for image generation like [16, 37, 38]. Foundational works using prompts to guide the diffusion model, such as InstructPix2Pix [3], achieved this by constructing conditional diffusion models and refining prompts with the help of Large Language Models (LLMs) like ChatGPT. Subsequent studies, such as Prompt2Prompt [12], combined structural-aware priors with original text information to enhance control over the generation process.
Recent advancements, such as LLM-grounded Diffusion [19], have highlighted the pivotal role of LLMs in defining prompts and indirectly influencing the quality of generated results. For instance, a self-correcting, LLM-controlled model proposed in SLD [36] improved text-to-image alignment by iteratively refining prompts during the generation process.
Building on this line of research, we aim to explore and optimize the editing process further, ultimately contributing to improved precision and accuracy in fine-grained image editing tasks.
2.3 GAN-based Performance Enhancement
Generative Adversarial Networks [10] (GANs) are widely applied in 3D reconstruction tasks, often in combination with techniques such as Convolutional Neural Networks [28] (CNNs) or implicit functions to enhance generated results. These approaches enable the inference of realistic 3D models from limited visual information, enforce geometric coherence across multiple views, and reduce surface texture and geometry blurring.
In the context of digital avatars, GANs have been employed for generating 3D faces and bodies for some time. StyleGAN [15] is a prominent example, showcasing how GAN-based architectures facilitate expressive face synthesis and demonstrate the potential to generate novel expressions and poses from an initial avatar, while [34] combined GAN with diffusion model which showed positive results. Related works such as EG3D [6] and GenN2N [22] provide practical methods for combining GANs with NeRF to improve synthetic novel-view rendering of facial avatars.
In our research, we observed that the original outputs often suffered from inaccurate colors and texture distortions, particularly around sensitive regions such as the eyes and teeth. To address these issues, we implemented a specialized GAN-based generator module designed to specifically target and correct problematic areas, significantly improving the overall quality and realism of the results.
3 Preliminary
3.1 3D Gaussian Splatting
Gaussian Splatting is based on creating a collection of Gaussian splats, where each splat is characterized by position x and covariance matrix . While the mean of a Gaussian splat is the center point , for each position we have:
| (1) |
Worth to notice that the covariance matrix should be differentiable during optimization process. A matrix decomposition method was introduced to solve this problem as follows:
| (2) |
where R refers to rotation matrix and S refers to scaling matrix.
Each Gaussian Splat can also be described by a set of physical parameters like position vector , scaling vector , rotation quaternion and color . The rendering process involves tracing every 3D points along a ray to determine its contribution to the final color of a specific pixel. This is achieved by accumulating the influence of Gaussian splats intersected by the ray, resulting in the rendering formula:
| (3) |
where represents the color of each 3D point on the trace and is the corresponding density. Note that in an optimized version, we can sort the splats by depth in order to cut off those invisible points.
3.2 Precise Edit by LLM

One of the most important parts of editing stage is to ensure the diffusion model could generate an image which is fully correspond to the text-based instructions. To achieve this, many previous works designed an architecture similar to the follows:
1)Define Let represent the input image, where and denote the image height, width, and number of channels, respectively. The user provides a natural language prompt , which is a sequence of tokens:
| (4) |
where is the vocabulary space, and is the number of tokens in the prompt.
The goal is to generate an edited image such that the semantics of are incorporated into , satisfying:
| (5) |
where is a loss function capturing the alignment between and .
2)Encode The input image is passed through an image encoder , producing a latent representation:
| (6) |
where is a feature vector in the latent space of dimension .
The textual prompt is mapped to the same latent space using a text encoder :
| (7) |
3)Align To align image and text features, a joint latent space is defined, where:
| (8) |
Here, is a cross-attention mechanism or a shared embedding model that fuses and . The resulting latent representation captures prompt-specific modifications.
4)Edit The latent code is updated iteratively to incorporate desired edits. For diffusion-based models, this is achieved via a reverse diffusion process:
| (9) |
where represents noise intensity at step , and is sampled from a Gaussian distribution .
5)Decode The output image is further refined through optional denoising or super-resolution processes :
| (10) |
4 Method
4.1 Semantic-based Mesh-Gaussian Tracking

To achieve flexible editing of expressions, textures, and additional accessories on head avatars, it is essential to use a technique that can both reconstruct an accurate head model and facilitate easy editing. Gaussian Avatars proposed using the FLAME[18] mesh to model head avatars, enabling expressive changes. However, this method lacks control over accessories, such as hair, rings, or hats, which are not modeled by FLAME.
As shown in Figure.3, we introduce a novel mesh-Gaussian binding method that differs from Gaussian Avatars [31]. In our approach, we introduce two Gaussian tracking patterns for this stages of the process. The input video is processed with a photometric head tracker to fit the FLAME parameters. Each frame includes multi-view observations, timestep parameters, and known camera parameters. Initially, we track Gaussian splats across each triangle, similar to the method in Gaussian Avatars, to ensure that areas with significant changes can be modeled with high precision. Next, we apply an independent facial composition identifier to generate a semantic mask. This allows us to assign semantic labels to each Gaussian splat when rendered into images, ensuring that the same splats are tracked and manipulated consistently throughout the dynamic scene, maintaining temporal consistency during the editing process. Meanwhile, the rendered results are compared to the real images to train the avatar. In the next stage, we decouple the relationship between the Gaussian splats and the FLAME mesh, enabling the addition and modification of accessories, such as rings and hats.
To enhance rendering quality, we apply adaptive density control operations to adjust the density of the Gaussian splats, selectively densifying and pruning them as needed. We labels the new generated splats and track them to ensure that new Gaussian splats remain connected to the FLAME mesh and semantic masks, preserving the overall structure. Additionally, we optimize the position and scaling of the splats to improve the quality at the same time.
4.2 Dynamic Gaussian Editing
Traditional 3D editing [20] approaches rely on static 2D or 3D masks to restrict changes to specific regions. However, this approach presents challenges, as dynamic updates during training can render static masks inaccurate, limiting their effectiveness. Additionally, static masks in NeRF editing constrain changes to fixed spatial regions, which hampers natural content expansion beyond the mask boundaries.
Recently, semantic segmentation-based masks were introduced by GaussianEditor [7], which partly address this issue by directly assigning semantic labels to individual Gaussian points. This technique increases the accuracy and speed of the editing process compared to previous approaches. However, applying these masks to dynamic scenes directly introduces new challenges in editing stage. For a labeled splat at time , it may not contribute to the color of the corresponding semantic region at time . Conversely, unlabeled splats could still influence the rendering process at later times. This inconsistency can lead to problems such as color mismatches, which modify the appearance of the head avatar, especially when the avatar undergoes significant pose changes over time.
To address this issue, we propose a method, illustrated in Figure.4, that aims to consider all Gaussian splats that contribute to the results across different times and poses. Our approach identifies the shape of the desired editing mask at different times and camera poses. By using the mapping net that generate selected areas across the entire timeline, we can track the Gaussian splats contributing to the target area throughout the dynamic scene. Details of the mapping net can be find in Figure.5.
Next, we edit each image in the selected set to produce an edited image set. Finally, we apply a learning process with a conditional adversarial loss, which helps regulate the Gaussian splats and maintain temporal consistency. This method allows us to edit the entire dynamic model, incorporating the desired changes arbitrarily and efficiently.

4.3 LLM-based Fine Editing
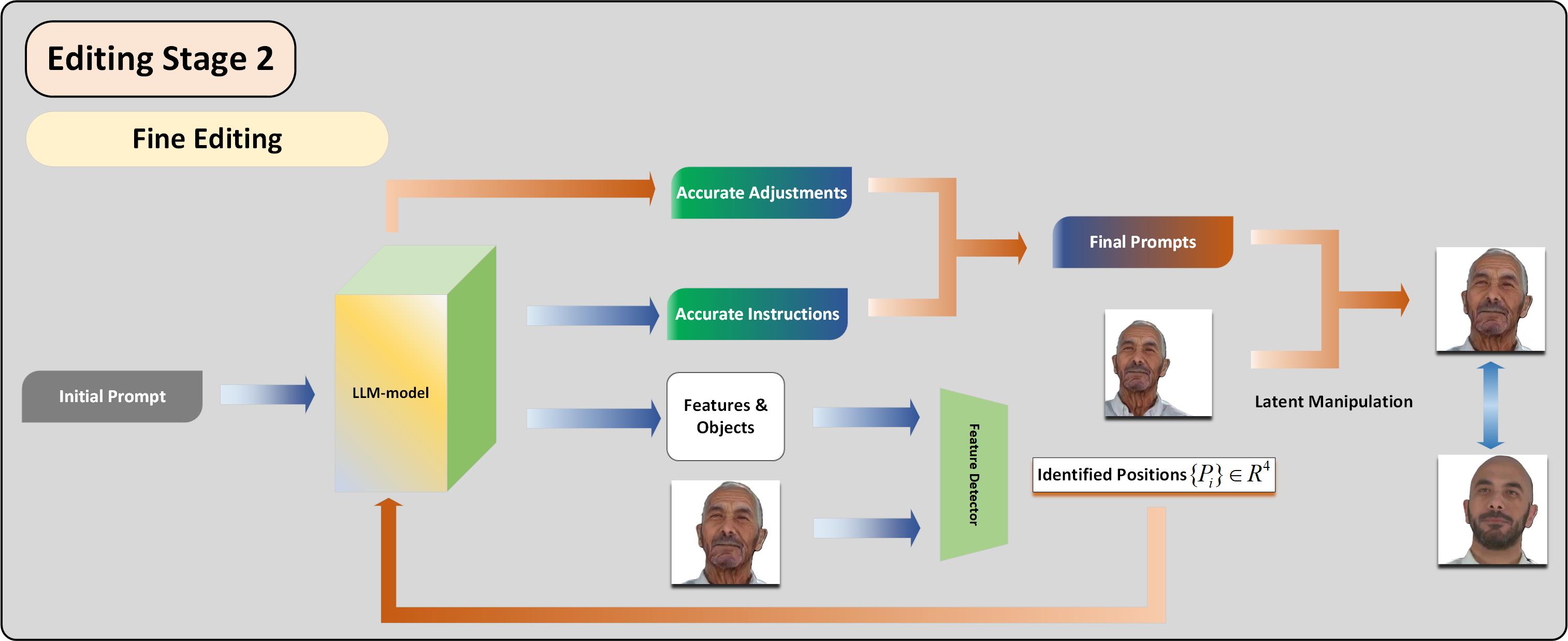
Previous 3D scene editing works based on diffusion model [29] have difficulties in retain the stability of edit and relatively low comprehension ability when facing extreme detailed prompts including described information like directions and relative positions. Works like SLD [36] proposes a LLM-controlled self-correcting model that analyzes the components of prompts and execute instructions in order in latent space. However, this method still lacks the ability of understanding direction and relative position information. Work like [1], bring up a feasible direction to utilize the LLM model to assistant the fine editing of images.
In order to improve the generate quality of results when facing such difficult conditions, we focus on solving misplaced and misunderstand problems related to edit and add accessories based on precise detailed prompts. As Figure.6 shows our method, we propose a framework similar to SLD which can provide a practical way of fine editing. We tend to readjust the structure of prompts based on the LLM and then carefully modify the images generated from the previous stage. This image correction is based on latent space manipulations, and it contains the alignment of multi-view consistency in our method.
4.4 Loss Function and Regularization
The primary loss should focus on the rendered images. Hence we deploy a color loss as follows:
| (11) |
It should be noticed that this loss is used under different value whenever we have the groundtruth image and need to learn the image-level information. In our experiment, we set equals to 0.9 during our modeling stage and 0.7 during editing stage, it has been tested to be effective during ablation study in our work.
The second constraint we need to pay attention is the tracking loss. This one concentrates on dealing with the relative position between the mesh and Gaussian splats, and affiliation between the certain semantic area and Gaussian splats.
| (12) |
To supervise the positions and distributions of the Gaussian splats during the editing stage in order to conserve the basic structure of the model, we need to employ a loss that can punish the misplacement of the splats. Meanwhile, we also need to be aware of optimizing the physical parameters of each Gaussian splat.
| (13) |
where represents Gaussian splat , represents corresponding sub property of like positions, translations and color. For different parameters, we apply the coefficient independently. Finally, we define the adversarial loss in editing stage. The GAN method is used to reduce the color difference between the original one and the objective images.
| (14) |
| (15) |
The overall loss function should be:
| (16) |
| (17) |
In our experiments, we use the Adam algorithm as the optimizer, setting the learning rate to at the beginning of the modeling stage, which gradually decreases to . Each head avatar is trained independently from a scratch model, and we evaluate the fine-tuning ability and the effects of various editing methods on the distinct models constructed.
For each training session, the entire reconstruction process takes approximately 1 hour to complete. Densification and splitting frequencies are determined every 2048 iterations. However, we have not yet investigated the optimal timing for densifying and splitting the Gaussian splats. We believe that future work could involve developing a module capable of detecting Gaussian splat areas and automatically adjusting the densification and splitting processes to optimize performance.
5 Experiments
5.1 Environment Settings
Training: We implement our benchmark using the NeRSemble dataset, where each subject has 16 different camera views around the human head. The model is trained with the same parameter settings and methods as GaussianAvatars, using two RTX 4090 GPUs.
Evaluation: We evaluate our approach based on the following settings:
Reconstruction Evaluation: To demonstrate that our method maintains high reconstruction quality, we compare our results with those of other models. Editing Evaluation: We assess our model’s editing ability from various perspectives, including: 1) Driving the avatar with novel poses and expressions, 2) Modifying the style and identity of the head avatar based on prompts, 3) Adding accessories using prompts that contain detailed position and style information.
We conduct experiments and compare our results with baseline models for both self-reenactment and cross-identity reenactment tasks. For reconstruction and non-prompt-based editing metrics, we use PSNR, SSIM, and LPIPS to evaluate the visual quality of the rendered images. For prompt-based editing, we evaluate edit accuracy using SLM and text-image direction similarity with the InstructPix2Pix metric.







Demonstration of our accessories editing experiments.
5.2 Comparisons for Head Avatar Reconstruction
| Metrics | PSNR | SSIM | LPIPS |
|---|---|---|---|
| GaussianAvatars | 29.3 | 0.865 | 0.113 |
| HeadStudio | 28.4 | 0.771 | 0.159 |
| PointAvatar[42] | 27.1 | 0.689 | 0.147 |
| Ours | 30.1 | 0.907 | 0.094 |
Figure.7 presents qualitative comparisons of novel-view synthesis from various methods. Our approach demonstrates exceptional performance compared to the listed works. Notably, GaussianEditor produces images with noticeable artifacts around the mouth and eye regions, and struggles to generate avatars with novel expressions.
This can be attributed to two key factors: 1) GaussianEditor does not utilize a mesh model for constraints, which limits the regularization of the Gaussian splat distribution. 2)The editing algorithm in GaussianEditor is prompt-based, and such edits lack the necessary information to effectively alter the expressions of head avatars. Additionally, the inherent randomness of the diffusion model makes it challenging to maintain stable control over fine-grained edits, such as expressions.
As shown in Table.1, we present quantitative comparisons between our method and several other prominent approaches.
5.3 Comparisons for Head Avatar Editing
| Metrics | Average | Spacial | Attribute |
|---|---|---|---|
| GaussianEditor | 24.4% | 15.2% | 33.6% |
| GenN2N | 36.4% | 27.4% | 45.4% |
| Ours | 67.5% | 64.9% | 70.1% |
As illustrated in Figure.8 and Figure.9, DynamicAvatars demonstrates outstanding scene editing and the ability to render finely edited images compared to other methods. It is evident that our model effectively interprets the information described in the prompt and generates photorealistic images, thanks to the preprocessing module. Moreover, our model excels in style modification while maintaining accurate expressions and texture colors, owing to the GAN framework that supervises facial image generation.
Table.2 presents the statistics of the quantitative comparisons regarding editing ability. Our approach outperforms other methods in handling complex editing scenarios, such as detailed prompts and mixed style-expression edits.
6 Conclusion
We propose DynamicAvatars, which enhances control and flexibility in editing. The dual tracking of Gaussians enables improved reconstruction and editing quality, while the prompt preprocessing architecture enhances the diffusion model’s ability to generate accurate edited images. Additionally, the incorporation of a GAN method helps reduce color discrepancies, making style edits more natural, particularly in facial regions. Furthermore, our approach integrates various functionalities for manipulating head avatars and optimizes each step to achieve higher quality results. The dynamic Gaussian editing capability allows for more efficient and intuitive editing of dynamic scenes.
References
- Bar-Tal et al. [2023] Omer Bar-Tal, Lior Yariv, Yaron Lipman, and Tali Dekel. Multidiffusion: Fusing diffusion paths for controlled image generation, 2023.
- Barron et al. [2021] Jonathan T. Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, and Pratul P. Srinivasan. Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. ICCV, 2021.
- Brooks et al. [2022] Tim Brooks, Aleksander Holynski, and Alexei A Efros. Instructpix2pix: Learning to follow image editing instructions. arXiv preprint arXiv:2211.09800, 2022.
- Cao et al. [2024a] Junyi Cao, Zhichao Li, Naiyan Wang, and Chao Ma. Lightning NeRF: Efficient hybrid scene representation for autonomous driving. arXiv preprint arXiv:2403.05907, 2024a.
- Cao et al. [2024b] Yang Cao, Yuanliang Ju, and Dan Xu. 3dgs-det: Empower 3d gaussian splatting with boundary guidance and box-focused sampling for 3d object detection, 2024b.
- Chan et al. [2021] Eric R. Chan, Connor Z. Lin, Matthew A. Chan, Koki Nagano, Boxiao Pan, Shalini De Mello, Orazio Gallo, Leonidas Guibas, Jonathan Tremblay, Sameh Khamis, Tero Karras, and Gordon Wetzstein. Efficient geometry-aware 3D generative adversarial networks. In arXiv, 2021.
- Chen et al. [2023] Yiwen Chen, Zilong Chen, Chi Zhang, Feng Wang, Xiaofeng Yang, Yikai Wang, Zhongang Cai, Lei Yang, Huaping Liu, and Guosheng Lin. Gaussianeditor: Swift and controllable 3d editing with gaussian splatting, 2023.
- Chen et al. [2024] Ziyu Chen, Jiawei Yang, Jiahui Huang, Riccardo de Lutio, Janick Martinez Esturo, Boris Ivanovic, Or Litany, Zan Gojcic, Sanja Fidler, Marco Pavone, Li Song, and Yue Wang. Omnire: Omni urban scene reconstruction. arXiv preprint arXiv:2408.16760, 2024.
- Gafni et al. [2020] Guy Gafni, Justus Thies, Michael Zollhöfer, and Matthias Nießner. Dynamic neural radiance fields for monocular 4d facial avatar reconstruction, 2020.
- Goodfellow et al. [2014] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Advances in neural information processing systems, pages 2672–2680, 2014.
- Hedman et al. [2021] Peter Hedman, Pratul P. Srinivasan, Ben Mildenhall, Jonathan T. Barron, and Paul Debevec. Baking neural radiance fields for real-time view synthesis. ICCV, 2021.
- Hertz et al. [2022] Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626, 2022.
- Huang et al. [2024] Yi Huang, Jiancheng Huang, Yifan Liu, Mingfu Yan, Jiaxi Lv, Jianzhuang Liu, Wei Xiong, He Zhang, Shifeng Chen, and Liangliang Cao. Diffusion model-based image editing: A survey, 2024.
- Jiang et al. [2024] Yuheng Jiang, Zhehao Shen, Yu Hong, Chengcheng Guo, Yize Wu, Yingliang Zhang, Jingyi Yu, and Lan Xu. Robust dual gaussian splatting for immersive human-centric volumetric videos, 2024.
- Karras et al. [2019] Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4401–4410, 2019.
- Kawar et al. [2023] Bahjat Kawar, Shiran Zada, Oran Lang, Omer Tov, Huiwen Chang, Tali Dekel, Inbar Mosseri, and Michal Irani. Imagic: Text-based real image editing with diffusion models. In Conference on Computer Vision and Pattern Recognition 2023, 2023.
- Kerbl et al. [2023] Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics, 42(4), 2023.
- Li et al. [2017] Tianye Li, Timo Bolkart, Michael. J. Black, Hao Li, and Javier Romero. Learning a model of facial shape and expression from 4D scans. ACM Transactions on Graphics, (Proc. SIGGRAPH Asia), 36(6):194:1–194:17, 2017.
- Lian et al. [2023] Long Lian, Boyi Li, Adam Yala, and Trevor Darrell. Llm-grounded diffusion: Enhancing prompt understanding of text-to-image diffusion models with large language models. arXiv preprint arXiv:2305.13655, 2023.
- Lin et al. [2021] Kai-En Lin, Lei Xiao, Feng Liu, Guowei Yang, and Ravi Ramamoorthi. Deep 3d mask volume for view synthesis of dynamic scenes. In ICCV, 2021.
- Liu et al. [2024a] Xinqi Liu, Chenming Wu, Jialun Liu, Xing Liu, Chen Zhao, Haocheng Feng, Errui Ding, and Jingdong Wang. Gva: Reconstructing vivid 3d gaussian avatars from monocular videos. Arxiv, 2024a.
- Liu et al. [2024b] Xiangyue Liu, Han Xue, Kunming Luo, Ping Tan, and Li Yi. Genn2n: Generative nerf2nerf translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5105–5114, 2024b.
- Luo et al. [2024] Haimin Luo, Min Ouyang, Zijun Zhao, Suyi Jiang, Longwen Zhang, Qixuan Zhang, Wei Yang, Lan Xu, and Jingyi Yu. Gaussianhair: Hair modeling and rendering with light-aware gaussians. arXiv preprint arXiv:2402.10483, 2024.
- Martin-Brualla et al. [2021] Ricardo Martin-Brualla, Noha Radwan, Mehdi S. M. Sajjadi, Jonathan T. Barron, Alexey Dosovitskiy, and Daniel Duckworth. NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections. In CVPR, 2021.
- Mildenhall et al. [2021] Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: representing scenes as neural radiance fields for view synthesis. Commun. ACM, 65(1):99–106, 2021.
- Minaee et al. [2024] Shervin Minaee, Tomas Mikolov, Narjes Nikzad, Meysam Chenaghlu, Richard Socher, Xavier Amatriain, and Jianfeng Gao. Large language models: A survey, 2024.
- Müller et al. [2022] Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. Instant neural graphics primitives with a multiresolution hash encoding. ACM Trans. Graph., 41(4):102:1–102:15, 2022.
- O’Shea and Nash [2015] Keiron O’Shea and Ryan Nash. An introduction to convolutional neural networks, 2015.
- Pandey et al. [2023] Karran Pandey, Paul Guerrero, Matheus Gadelha, Yannick Hold-Geoffroy, Karan Singh, and Niloy Mitra. Diffusion handles: Enabling 3d edits for diffusion models by lifting activations to 3d, 2023.
- Pumarola et al. [2020] Albert Pumarola, Enric Corona, Gerard Pons-Moll, and Francesc Moreno-Noguer. D-NeRF: Neural Radiance Fields for Dynamic Scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020.
- Qian et al. [2024] Shenhan Qian, Tobias Kirschstein, Liam Schoneveld, Davide Davoli, Simon Giebenhain, and Matthias Nießner. Gaussianavatars: Photorealistic head avatars with rigged 3d gaussians. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20299–20309, 2024.
- Rivero et al. [2024] Alfredo Rivero, ShahRukh Athar, Zhixin Shu, and Dimitris Samaras. Rig3dgs: Creating controllable portraits from casual monocular videos, 2024.
- Shao et al. [2024] Zhijing Shao, Zhaolong Wang, Zhuang Li, Duotun Wang, Xiangru Lin, Yu Zhang, Mingming Fan, and Zeyu Wang. SplattingAvatar: Realistic Real-Time Human Avatars with Mesh-Embedded Gaussian Splatting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024.
- Wang et al. [2023] Zhendong Wang, Huangjie Zheng, Pengcheng He, Weizhu Chen, and Mingyuan Zhou. Diffusion-gan: Training gans with diffusion, 2023.
- Wu et al. [2024] Guanjun Wu, Taoran Yi, Jiemin Fang, Lingxi Xie, Xiaopeng Zhang, Wei Wei, Wenyu Liu, Qi Tian, and Xinggang Wang. 4d gaussian splatting for real-time dynamic scene rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 20310–20320, 2024.
- Wu et al. [2023] Tsung-Han Wu, Long Lian, Joseph E Gonzalez, Boyi Li, and Trevor Darrell. Self-correcting llm-controlled diffusion models. arXiv preprint arXiv:2311.16090, 2023.
- Yang et al. [2022] Binxin Yang, Shuyang Gu, Bo Zhang, Ting Zhang, Xuejin Chen, Xiaoyan Sun, Dong Chen, and Fang Wen. Paint by example: Exemplar-based image editing with diffusion models. arXiv preprint arXiv:2211.13227, 2022.
- Yang et al. [2023] Binxin Yang, Shuyang Gu, Bo Zhang, Ting Zhang, Xuejin Chen, Xiaoyan Sun, Dong Chen, and Fang Wen. Paint by example: Exemplar-based image editing with diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18381–18391, 2023.
- Yu et al. [2023] Heng Yu, Joel Julin, Zoltan A Milacski, Koichiro Niinuma, and Laszlo A Jeni. Dylin: Making light field networks dynamic. arXiv preprint arXiv:2303.14243, 2023.
- Yu et al. [2024] Zehao Yu, Anpei Chen, Binbin Huang, Torsten Sattler, and Andreas Geiger. Mip-splatting: Alias-free 3d gaussian splatting. Conference on Computer Vision and Pattern Recognition (CVPR), 2024.
- Zhao et al. [2024] Zhongyuan Zhao, Zhenyu Bao, Qing Li, Guoping Qiu, and Kanglin Liu. Psavatar: A point-based shape model for real-time head avatar animation with 3d gaussian splatting, 2024.
- Zheng et al. [2023] Yufeng Zheng, Wang Yifan, Gordon Wetzstein, Michael J. Black, and Otmar Hilliges. Pointavatar: Deformable point-based head avatars from videos, 2023.
- Zhou et al. [2024] Zhenglin Zhou, Fan Ma, Hehe Fan, Zongxin Yang, and Yi Yang. Headstudio: Text to animatable head avatars with 3d gaussian splatting. In ECCV, 2024.