Dynamic Proximal Unrolling Network for Compressive Imaging
Abstract
Compressive imaging aims to recover a latent image from under-sampled measurements, suffering from a serious ill-posed inverse problem. Recently, deep neural networks have been applied to this problem with superior results, owing to the learned advanced image priors. These approaches, however, require training separate models for different imaging modalities and sampling ratios, leading to overfitting to specific settings. In this paper, a dynamic proximal unrolling network (dubbed DPUNet) was proposed, which can handle a variety of measurement matrices via one single model without retraining. Specifically, DPUNet can exploit both the embedded observation model via gradient descent and imposed image priors by learned dynamic proximal operators, achieving joint reconstruction. A key component of DPUNet is a dynamic proximal mapping module, whose parameters can be dynamically adjusted at the inference stage and make it adapt to different imaging settings. Experimental results demonstrate that the proposed DPUNet can effectively handle multiple compressive imaging modalities under varying sampling ratios and noise levels via only one trained model, and outperform the state-of-the-art approaches.
Index Terms:
Dynamic neural networks, deep proximal unrolling, computational imaging, image reconstruction.I Introduction
Compressive imaging depicts a novel imaging paradigm for image acquisition and reconstruction that allows the recovery of an underlying image from far fewer measurements than the Nyquist sampling rate [1, 2, 3, 4], and drives a range of practical applications, such as image or video compressive sensing [2, 5], compressive sensing magnetic resonance imaging (CS-MRI) [6, 7], single-pixel imaging [3, 8], snapshot compressive imaging [9], and compressive phase retrieval (CPR) [10, 11].
Mathematically, given the under-sampled measurements and observation model , the goal of compressive imaging is to find a solution , such that and resides the class of images. Since the sampling ratio, defined as , is typically much less than one, reconstructing a unique solution from limited measurements only is difficult or impossible without proper image priors.
| Ground Truth | Initialization | Reconstruction | |
| BCS ( compression) |

|

|

|
| PSNR | 25.47 dB | 30.13 dB | |
| CS-MRI ( compression) |

|

|

|
| PSNR | 25.86 dB | 33.16 dB | |
| CPR ( compression) |

|

|

|
| PSNR | 9.81 dB | 35.36 dB |
To tackle the fundamental ill-posedness of compressive imaging, traditional methods typically exploit the measurement model knowledge and intrinsic image properties [12, 13, 14, 15, 16, 17, 18], and solve a regularized optimization problem in an iterative scheme [19, 20, 21, 22, 23, 24]. They are effective and flexible to handle a wide variety of measurements based on the well-studied forward model and well-understood behavior but limited in unsatisfactory reconstruction quality and high computational complexity.
In contrast to iterative-based methods, deep-learning-based compressive imaging approaches [25, 26, 27, 28], as an alternative, employ neural networks to directly learn a mapping from measurements to latent quantities entirely based upon data. Once trained, the inference only requires a single forward of the network, without the need for time-consuming optimization and hyper-parameters selection. Nevertheless, the pure deep learning approach cannot offer the flexibility of variational methods in adapting to different imaging modalities and even sampling ratios, largely due to learning a task-specific mapping. Traditionally one would require a separate deep network for each imaging setting even if there is only a tiny change, which limits its practical applications.
Motivated by the observation that many iterative optimization algorithms can be truncated and unfolded into learnable deep neural networks, researchers have explored the hybrid approach (i.e., deep unrolling) that combines the best of both worlds in compressive imaging [29, 30, 31, 32]. Following the unrolling, regularizers or any other free hyper-parameters such as the step size or regularization parameters, can be learned via end-to-end training, rather than being hand-crafted, meanwhile, the physical measurement model can be explicitly exploited. In this way, deep unrolling networks take the merits of interpretability and flexibility of optimization-based methods and fast inference of deep-learning-based approaches, while achieving promising reconstruction performance.
Despite these gains, the existing deep unrolling networks still suffer from severe performance degradation when operating on a measurement matrix significantly different from the training set. An illustrative example of image compressive sensing is shown in Fig. 2, where the model trained on a fixed sampling ratio (“fixed”) produces poor results when testing on unseen sampling ratios during training. While the performance can be improved when training on all sampling ratios jointly (“all”), there is still a large gap between such model and the task-specific model separately trained on each sampling ratio (”optimal”).
Basically, the ill-posedness of compressive imaging and the difficulty of learning to solve the corresponding inverse problem are very distinct under different imaging conditions. Furthermore, learned parameters of a specific unrolling network remain fixed after training, so the inference cannot adapt dynamically to other imaging parameter configurations. To address this issue, in this paper, a novel deep unrolling architecture was proposed, whose key part is a dynamic proximal mapping module. Specifically, this module consists of a convolutional neural network (CNN) that learns/executes proximal operators and several secondary fully connected networks that perform dynamic modification mechanisms to adjust the parameters of CNN given imaging conditions, which can be jointly trained end-to-end. In this way, fully connected networks will dynamically adjust the learned proximal operators at the inference stage and make the unrolling network adapt to different imaging settings.
The effectiveness of the proposed method is verified on three representative compressive imaging applications, i.e., image compressive sensing, CS-MRI, and CPR under various imaging conditions. Furthermore, the applicability of the proposed framework is explored on multiple imaging modalities with different imaging conditions. Experimental results demonstrate that the proposed method can not only effectively tackle varying imaging conditions for a specific compressive imaging task, but also be able to handle multiple imaging modalities via only one single model simultaneously, and outperform the state-of-the-art approaches.
Our main contributions can be summarized as follows:
-
•
We present a dynamic proximal unrolling network (dubbed DPUNet) that can adaptively handle different imaging conditions, and even various compressive imaging modalities via the only one trained model.
-
•
The key part of DPUNet is to develop a dynamic proximal mapping module, which can enable the on-the-fly parameter adjustment at the inference stage and boost the generalizability of deep unrolling networks.
-
•
Experimental results demonstrate DPUNet can outperform the state-of-the-art on image compressive sensing, CS-MRI, and CPR under various imaging conditions without retraining. In addition, we show the extension of DPUNet can simultaneously handle all these imaging tasks via one single trained model, with promising results.
The remainder of this paper is organized as follows. We review related compressive imaging methods in Section II. In Section III, the details of the proposed method including unrolling frameworks and dynamic proximal mapping module are presented. Section IV provides both experimental settings and qualitative results. In Section V, we conclude the paper.

II Related Work
Traditionally, the inverse problem of compressive imaging can be attacked by variational optimization methods by minimizing the following cost functional:
| (1) |
by an iterative optimization framework, e.g., the proximal gradient descent (PGD) [19], the alternating direction method of multipliers (ADMM) [23], the iterative shrinkage-thresholding algorithm (ISTA) [21], and the half-quadratic splitting (HQS) [22] algorithm. In the above, indicates the regularization term associated with the prior knowledge of images, which alleviates the ill-posedness of compressive imaging. Many image priors have been designed in the imaging community over the past decades. The well-known examples include structured sparsity [33, 13, 34, 35], group sparse representation (GSR) [16] and nonlocal low-rank [14, 36, 15].
In contrast to handcrafted priors, deep-learning-based compressive imaging approaches have been proposed and demonstrated promising reconstruction results with fast inference speed [26, 37, 27, 28, 38, 39, 40, 41]. A stacked denoising auto-encode (SDA) was first applied to learn statistical dependencies from data, improving signal recovery performance [26]. Fully connected neural networks were proposed for image and video block-based compressive sensing (BCS) reconstruction [27, 38]. Further several CNN-based approaches were developed, which learn the inverse map from compressively sensed measurements to reconstructed images [37, 28, 41]. The basic idea of these works is designing a neural network to directly perform the inverse mapping from observed measurements to desired images by learning network parameters based upon the training dataset :
| (2) |
where is a loss function. However, these network architectures are predefined and fixed for specific problems, which usually cannot adapt to others without retraining. In addition, designing neural networks could be often considered as much an art as a science, without clear theoretical guidelines and domain knowledge [42].
Inspired by the interpretability and flexibility of traditional approaches, an emerging technique called deep unrolling or unfolding has been applied to compressive imaging [29, 30, 31, 32]. By unrolling the iterative optimization framework and introducing learnable parameters , deep unrolling networks can be learned by minimizing the following empirical risk:
| (3) |
where is the given physical measurement model. Preliminary attempts focused on learning fast approximation of specialized iterative solvers attached to well-designed priors. The computation schemes of the resulting networks are concise with the original solvers, but with fixed numbers of iterations and some untied/unshared parameters across layers/iterations. Well-known examples include learned shrinkage-thresholding algorithms (LISTA) [29] and learned approximate message passing (LAMP) algorithms [30]. A similar idea has also been applied to the alternating direction method of multipliers (ADMM) solver for CS-MRI [43], but with the goal to design powerful networks (ADMM-Net) rather than approximating variational methods. In contrast with encoding the sparsity on linear transform domain to network [43], ISTA-Net [32] goes beyond that to nonlinear transform domain sparsity. Moreover, these learned sparsity constraints can be further released into purely data-driven prior to boost the performance [44, 45, 46, 47, 48]. Nevertheless, few works consider the performance degradation of deep unrolling networks under mismatched imaging settings during inference, owing to the constant network parameters. To the best of our knowledge, this paper is the first work that presents a novel dynamic deep unrolling network to solve this issue.
Another approach that can combine the benefits of both deep learning and optimization methods is called plug-and-play (PnP) priors [49]. Its core idea is to plug a denoiser into the iterative optimization such that the image prior is implicitly defined by the denoiser itself. Many deep-learning-based denoisers have been utilized in the PnP framework to resolve compressive imaging problems, without the need for task-specific training [50, 51, 52, 53, 54, 55]. The main strength of PnP over deep unrolling is the generalizability (only one network is required to handle various compressive imaging problems [50]), but its performance often lags behind the deep unrolling network due to the lack of end-to-end training [48]. Meanwhile, it also faces the limitations of high computational complexity and difficulties of tuning parameters [53, 56]. In this work, we propose a dynamic proximal unrolling approach that improves the generalizability of deep unrolling considerably, while still enjoying the joint optimization of parameters via end-to-end learning.

III Method
In this section, we first introduce the iterative proximal optimization algorithm and the corresponding deep unrolling network. Then, we describe the dynamic proximal mapping module – a core component of the proposed dynamic proximal unrolling network. What’s more, we present the applicability of the proposed module to other optimization frameworks. An overview of the proposed network is shown in Fig. 3.
III-A Proximal optimization and deep unrolling
In this paper, we adopt the proximal gradient descent (PGD) algorithm [19] for solving Eq.(1), which provides a general and efficient scheme to split the data-fidelity term and regularization term by alternating between the gradient descent step and proximal mapping step. Starting from the initial point , the whole iterations’ process of PGD can be written as
| (4) | |||
| (5) |
where denotes the iteration index, is the data-fidelity term, denotes the vector differential operator that calculates the gradient of a given function, and is the step-size of the -th iteration. Eq.(4) can be understood as one-step gradient descent for dealing with the data-fidelity term. And denotes the proximal operator for handling the regularization term [20, 21] in Eq.(5).
Given the modular nature of the proximal optimization framework, the overall iterative procedure can be truncated and unrolled into a trainable reconstruction network by replacing all instances of the proximal operator with a trainable deep convolutional neural network (CNN). The CNN is expected to learn/perform the proximal operator in Eq.(5), which can project the corrupted image into the clean image manifold. In this paper, we design a simple yet effective CNN consisting of five convolution (Conv) layers separated by an instance normalization (IN) layer [57] and a rectified linear unit (ReLU). IN was first proposed in style transfer and has shown significant improvement by normalizing feature statistics [57]. To stabilize training [58], an identity skip connection is built between the input and output of the CNN. Mathematically, in the -th iteration, the CNN maps to through
where represents the filters of convolution with a certain kernel and stride size, denotes the convolution operation, and the represents the -th instance normalization operation as
where and are affine parameters learned from data; and are the mean and standard deviation of the input , computed across spatial dimensions independently for each feature channel and each sample.
III-B Dynamic proximal mapping module
Given the training data, the resulting network can be trained end-to-end to learn the proximal mapping. However, the trainable parameters (i.e., ) of the CNN are usually fixed once trained, while different imaging conditions such as varying sampling-ratios or noise-levels all affect the performance of the learned proximal operator. To overcome this limitation, we make a step forward by proposing a dynamic proximal mapping module that can dynamically adjust the parameters of CNN according to different imaging conditions, to perform adaptively proximal operators. To this end, we use a set of secondary fully connected networks, whose inputs are imaging parameters such as the sampling ratio and noise level, and outputs are the parameters () of CNN, shown in Fig. 4. The fully connected networks aim to generate and update the parameters of CNN, i.e., the weights of convolution filters and affine parameters of IN layers. During the training stage, the proximal CNN and fully connected networks can be jointly trained. In the inference stage, given different imaging parameters, fully connected networks will adaptively adjust the learned proximal operator represented by the CNN, thus improving the representation capability.
Specifically, the imaging parameter is an auxiliary input that feeds into fully connected layers with the final layer outputting the convolution filter weights. The output then is reshaped into a 4D tensor of convolution filter weights and convolved with the input image. Based on empirical results in Section IV, we employ a single fully-connected layer to directly learn the weights of convolution filters, which can be written as
| (6) |
where is the imaging parameters related to the imaging settings, represents the weights ( denotes the total number of parameters) of the -th convolution layer in CNN, and are the weight and bias of the corresponding fully-connected layer.
In essence, these fully connected networks introduce a dynamic modulation mechanism for the weights of convolution with imaging parameters. Considering a special case, it is mathematically equivalent to directly learn the weights of convolution without fully-connected layers when the imaging parameters , i.e., . When the imaging parameters are non-zero, the fully connected networks will set up a connection between the CNN weight space and imaging parameters.
For instance normalization layers, we employ two fully-connected layers separated by a ReLU (non-linearity) for the affine parameters of IN, respectively, which can be written as
| (7) |
where represents the parameters or of the -th instance normalization, are the weight and bias of the corresponding two fully-connected layers. Note that continually increasing the fully-connected layers can still improve the performance, but with more learnable parameters and computational complexity (See Section IV).

III-C Dynamic proximal unrolling network
In essence, the structure of the proposed dynamic proximal unrolling network (dubbed DPUNet) is derived from the truncated proximal gradient descent algorithm, combined with a dynamic proximal mapping module.
When given training data, the inputs of the proposed DPUNet are the measurements , corresponding physical forward model and imaging parameters , which are sent to the reconstruction process and fully connected networks, respectively. So the proposed DPUNet can be trained by minimizing the following empirical risk:
| (8) |
where is the operation for generating the dynamic parameters via fully connected layers, and is exploited by the pixel-wise loss.
Given imaging parameters, fully connected networks will update the parameters of CNN to execute the proximal operator at each iteration. Finally, the outputs of the proposed network are reconstructed images, which are used to compute loss with the ground-truth. By back-propagation, the trainable parameters of our network, including the weight and bias of fully connected networks and the gradient step sizes, can be jointly optimized.
Once the model is trained, given the imaging parameters and measurements, the fully connected networks can adaptively generate parameters of CNN and the unrolling network performs the reconstructions. In this way, we can dynamically adjust the learned proximal operator based on the designed fully connected networks at the inference stage, thus enabling the handling of different imaging settings and continuous parameter control.
III-D Other optimization frameworks
A large variety of first-order proximal algorithms have been developed for solving Eq.(1) efficiently [19, 23, 21, 22]. In this paper, we present other two representative proximal optimization frameworks (i.e., HQS and ADMM) to construct dynamic proximal unrolling networks. It has been observed that both of them perform well with the proposed dynamic proximal mapping module.
Unrolled-HQS. HQS tackles Eq.(1) by introducing an auxiliary variable , leading to iteratively solving subproblems for and as
| (9) | ||||
| (10) |
where denotes the iteration index, indicates the penalty parameter.
Assuming that is a linear measurement model, we still adopt the one-step gradient descent and proximal operator to deal with Eq.(9) and Eq.(10), respectively, which can be written as
| (11) | |||
| (12) |
where denotes the transpose of the sampling matrix, denotes the proximal operator, and is step-size at -th iteration.
Once the proximal optimization is determined, the next step is to unroll the iterative process into a dynamic proximal unrolling network by introducing the designed dynamic proximal mapping module. In this way, the free hyper-parameters (i.e., ) of HQS and dynamic proximal mapping module can be jointly learned via end-to-end training.
Unrolled-ADMM. Eq.(1) can also be solved by ADMM, whose iterations can be written as
| (13) | |||
| (14) | |||
| (15) |
where , still indicates the penalty parameter.
Similarly, we use the one-step gradient descent to tackle Eq.(14). Unrolled-ADMM can be derived by unrolling the corresponding iterative optimization and replacing the proximal operator with the designed dynamic proximal mapping module.
Based on empirical results, we demonstrate the proposed dynamic proximal mapping module can be embedded into different proximal optimization frameworks, and boost the generalizability of deep unrolling network. In this paper, we adopt the proximal gradient descent framework as the final choice, owing to its conciseness and effectiveness. More experimental details are presented in Section IV.
IV Experiments
In this section, we mainly focus on three representative compressive imaging modalities: image compressive sensing, compressive sensing magnetic resonance imaging (CS-MRI), and compressive phase retrieval (CPR), and detail experiments to evaluate the proposed method. We first describe the experimental setting including both physical measurement models and implementation details. Then we compare our method against prior art on different tasks under varying imaging conditions and provide an in-depth discussion of the proposed method. Finally, we present an extension of DPUNet to simultaneously handle all these compressive imaging modalities via one single model.
IV-A Experimental Setting
IV-A1 Image CS
Image compressive sensing (CS) is a popular and well-studied linear inverse problem, which enables image or video capturing under a sub-Nyquist sampling rate [2, 59]. Following common practices in previous CS work, we focus on block-based compressive sensing (BCS) tasks to validate the proposed method. Given the sampling ratio, the measurement matrix is a random Gaussian matrix and the measurement is generated by , where is the vectorized version of an image block with a size of . For BCS, we adopt the data-fidelity term , and compute its gradient . Here denotes the transpose of . For initialization, we adopt the linear mapping method, same as ISTA-Net [32]. For a fair comparison, we utilize the same training data pairs in ISTA-Net [32] for training and widely used public dataset Set11 [60] for testing. In order to handle various imaging conditions, we simulate to generate the BCS measurement of each patch with the sampling ratio uniformly sampled from {0.01,0.04,0.1,0.25,0.4,0.5} and add Gaussian noise with the noise level uniformly sampled from [0,50], rather than a specific setting. Then we take as imaging parameters during training because there will always be noise in real CS measurements.
| Sampling Ratio | Noise Level | TVAL3 | D-AMP | NLR-CS | ReconNet | ISTA-Net | ISTA-Net+ | DPUNet |
|---|---|---|---|---|---|---|---|---|
| 26.83 | 30.63 | 26.12 | 25.60 | 30.74 | 31.42 | 31.99 | ||
| 19.08 | 25.92 | 19.84 | 24.39 | 26.36 | 26.87 | 27.20 | ||
| 14.88 | 23.56 | 15.62 | 22.34 | 23.85 | 24.30 | 24.79 | ||
| 26.31 | 29.29 | 25.16 | 25.19 | 28.73 | 30.53 | 31.20 | ||
| 19.33 | 25.08 | 20.05 | 23.78 | 25.42 | 26.21 | 26.59 | ||
| 15.38 | 22.84 | 16.08 | 21.56 | 23.14 | 23.78 | 24.17 | ||
| 25.57 | 27.58 | 24.42 | 24.23 | 27.07 | 29.45 | 30.04 | ||
| 19.47 | 23.93 | 20.51 | 23.12 | 24.46 | 25.28 | 25.70 | ||
| 15.81 | 22.00 | 16.70 | 21.24 | 22.30 | 22.89 | 23.29 | ||
| 21.91 | 20.87 | 21.48 | 21.91 | 23.33 | 24.63 | 25.40 | ||
| 18.83 | 19.68 | 20.23 | 20.92 | 21.30 | 21.85 | 22.26 | ||
| 16.34 | 18.53 | 17.83 | 19.19 | 19.47 | 20.02 | 20.32 | ||
| 11.26 | 5.20 | 11.43 | 17.04 | 17.17 | 17.25 | 17.27 | ||
| 10.90 | 5.19 | 10.93 | 16.44 | 16.47 | 16.46 | 16.58 | ||
| 10.55 | 5.18 | 10.51 | 15.45 | 15.45 | 15.44 | 15.79 |
| TVAL3 | D-AMP | NLR-CS | ReconNet | ISTA-Net | ISTA-Net+ | DPUNet | GroundTruth |
 |
 |
 |
 |
 |
 |
 |
 |
| 22.24 | 21.39 | 23.37 | 22.67 | 23.73 | 24.86 | 25.75 | PSNR |
 |
 |
 |
 |
 |
 |
 |
 |
| 21.38 | 20.96 | 22.58 | 21.79 | 22.27 | 22.66 | 23.20 | PSNR |
IV-A2 CS-MRI
CS-MRI is an advanced technique for fast MRI through reconstruction of MR images from much fewer under-sampled measurements in k-space (i.e., Fourier domain). Following the common practices, we adopt the measurement matrix with the form , where represents the 2-dimensional Fourier transform and is an under-sampling matrix taken as a commonly used pseudo radial sampling mask. We use the same training and testing brain medical images as ISTANet [32]. For initialization, we project the under-sampled Fourier measurements to the image domain via the inverse Fourier transform. For each image, we simulate to generate subsampled measurements in Fourier domain with the sampling ratio uniformly sampled from {0.2,0.3,0.4,0.5} and add Gaussian noise with the noise level uniformly sampled from [0,50].
IV-A3 CPR
Compressive phase retrieval (CPR) is a representative non-linear inverse problem, concerned with the recovery of an underlying image from only the subsampled intensity of its complex transform. Mathematically, the measurements of CPR can be written as with , where the term controls the noise level in this problem [61, 51]. The data-fidelity term adopts the amplitude loss function in [61]. Notice involves complex number operations, we therefore adopt the Wirtinger derivatives [62] to compute its gradient, i.e., , where denotes the Hadamard (element-wise) product and denotes the conjugate transpose of . We test CPR methods under simulated coded Fourier measurements, where the measurement matrix with the form , where represents the 2-dimensional Fourier transform, is diagonal matrices with nonzero elements drawn uniformly from a unit circle in the complex plane [51] and is an matrix made from randomly sampled rows of an identity matrix. Here we initialize with a vector of ones that worked sufficiently well. To train the network, we follow the common practice that uses 160000 overlapping patches (with size ) cropped from 400 images from the BSD dataset [63]. For each patch, we simulate to generate coded Fourier measurements with the sampling ratio uniformly sampled from {0.3,0.4,0.5} and add Poisson shot noise with the noise level uniformly sampled from [0,50].
The inputs of our network are the measurements and corresponding imaging parameters. To keep consistent magnitude of back-propagated gradient, we normalize the maximum value of imaging parameters to one. We train all models using pixel-wise loss and Adam optimizer with PyTorch on one Nvidia GeForce GTX 2080 Ti GPU. The models of BCS are trained in 200 epochs with batch size 64 and learning rate . The model of CS-MRI is trained in 200 epochs with batch size 4 and learning rate . The model of CPR is trained in 20 epochs with batch size 20 and learning rate .
IV-B Performance Comparison
IV-B1 Validations on BCS
To verify the performance of the proposed method, we mainly compare it against three classic CS approaches, namely TVAL3 [64], D-AMP [18], NLR-CS [14], the learning-based approach ReconNet [28] and the representative deep unrolling approach ISTA-Net [32]. Recent works (e.g., SCSNet [41] and OPINE-Net [65]) use data-driven learned sampling matrix to achieve very high performance 111Despite these gains induced by the data-driven sampling matrix, the existing SOTA methods still suffer from the lack of generalization and universality. For example, OPINE-Net is designed for each sampling ratio owing to predefined CNN filters of Sampling Subnet and needs to be separately trained. SCSNet also requires to update the greedy searching strategy for different sampling ratios.. For a fair comparison, in this paper, we only consider the competing methods using a fixed sampling matrix. We use the code made available by the respective authors on their websites. For end-to-end training methods, such as ReconNet and ISTA-Net, we train the corresponding model for each sampling ratio setting. Table I shows all methods’ performance on the Set11 public dataset under various sampling ratios and noise levels. It can be observed that our method outperforms other methods under various sampling ratios via one single trained model. By contrast with ISTA-Net and ReconNet, our method avoids the cumbersome retraining requirement, which is beneficial for real applications. In addition, it is worth mentioning that our method can generalize well to the unseen case during training setting, as . We show the reconstructions of all algorithms under imaging conditions , in Fig. 5. It can be seen that DPUNet produces more accurate and clearer reconstructed images than other competing algorithms.
| Algorithm | Time | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 30 | 50 | 30 | 50 | 30 | 50 | 30 | 50 | CPU/GPU | |||||
| RecPF | 31.41 | 25.06 | 21.33 | 32.47 | 24.76 | 20.61 | 33.05 | 24.37 | 19.96 | 33.46 | 24.00 | 19.41 | 0.39s/- |
| FCSA | 30.71 | 24.11 | 19.19 | 31.31 | 23.07 | 17.93 | 31.28 | 22.28 | 17.21 | 31.29 | 21.78 | 16.77 | 0.64s/- |
| DMRI | 25.77 | 20.23 | 22.06 | 32.15 | 24.66 | 20.69 | 31.80 | 23.71 | 19.64 | 31.35 | 22.92 | 18.80 | 10.28s/- |
| IRCNN | 33.77 | 30.58 | 29.09 | 34.64 | 31.34 | 29.70 | 35.18 | 31.75 | 30.02 | 35.58 | 32.02 | 30.18 | -/12.16s |
| ISTANet | 32.50 | 30.78 | 29.22 | 34.84 | 31.72 | 29.85 | 35.37 | 32.04 | 30.10 | 35.87 | 32.25 | 30.22 | -/0.03s |
| TFPnP | 34.44 | 31.23 | 29.58 | 35.30 | 31.82 | 30.11 | 35.83 | 32.16 | 30.31 | 36.19 | 32.36 | 30.47 | -/0.05s |
| DPUNet | 34.39 | 31.44 | 29.74 | 35.41 | 32.11 | 30.32 | 35.98 | 32.43 | 30.59 | 36.33 | 32.59 | 30.70 | -/0.04s |
| RecPF | FCSA | DMRI | IRCNN | ISTANet | TFPnP | DPUNet | GroundTruth |
 |
 |
 |
 |
 |
 |
 |
 |
| 30.73 | 30.31 | 31.97 | 32.84 | 30.87 | 33.50 | 33.69 | PSNR |
|
 |
|
 |
|
|
|
|
| 23.60 | 23.09 | 22.70 | 27.99 | 28.38 | 28.38 | 28.60 | PSNR |
|
|
|
|
|
|
|
|
| 19.51 | 16.80 | 19.10 | 28.46 | 28.60 | 28.78 | 29.39 | PSNR |
IV-B2 Validations on CS-MRI
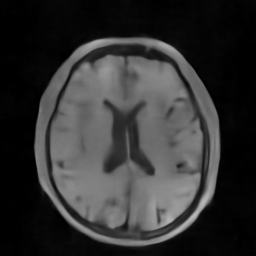
We mainly compare DPUNet with six competing approaches for CS-MRI, including three classic algorithms RecPF [24], FCSA [66] and D-MRI [67], the deep unrolling network ISTANet [32], the state-of-the-art plug-and-play (PnP) approaches IRCNN [54] and TFPnP [53]. We train separate models of ISTANet for each sampling ratio setting in 200 epochs, and retrain TFPnP to adapt to the size of our MR images (i.e., pixels). Table II shows the quantitative performance comparisons on 50 brain medical images under different imaging conditions. It can be seen that DPUNet significantly outperforms other competing algorithms under various imaging conditions with only one trained model. The fact that one single DPUNet model performed so well on almost all sampling ratios, particularly in comparison to the ISTA-Net models, which were trained separately per sampling ratio, again demonstrates that DPUNet generalizes across measurement matrices. What’s more, compared with the plug-and-play approach IRCNN and TFPnP, DPUNet shows higher reconstruction performance owing to end-to-end training. In Fig. 6, we show the reconstructions of three brain MR images and corresponding PSNRs under different sampling ratios () and noise levels () with seven algorithms. It can be observed that DPUNet can reconstruct more details and sharper edges, especially in case of severe noise.
IV-B3 Validations on CPR
We mainly compare DPUNet with two state-of-the-art approaches (BM3D-prGAMP [55] and prDeep [51]) for CPR. We use their respective authors’ implementations and adopt the twelve images used in [51] to quantitatively evaluate different CPR methods. The results of performance comparisons for CPR are summarized in Table III. It can be seen that DPUNet can handle these imaging settings with state-of-the-art results via one single trained network. The visual comparison can be found in Fig. 7. It can be found that our method can still effectively recover desired images, and produce clearer results than other competing methods.
| prGAMP | prDeep | DPUNet | ||
|---|---|---|---|---|
| 31.56 | 30.64 | 33.14 | ||
| 27.46 | 27.69 | 28.63 | ||
| 31.26 | 30.10 | 32.32 | ||
| 26.77 | 27.46 | 28.31 | ||
| 29.05 | 30.00 | 30.96 | ||
| 26.47 | 26.99 | 27.75 |
| prGAMP | prDeep | DPUNet |
 |
 |
 |
| 25.65 | 24.69 | 25.97 |
 |
 |
 |
| 25.41 | 26.86 | 27.56 |
 |
 |
 |
| 35.08 | 34.41 | 36.60 |
IV-C Discussion
IV-C1 Effects of different dynamic architectures
To give some insights of the proposed dynamic proximal mapping module, we conduct an ablation study on different dynamic network architectures, including (1) PUNet: the basic proximal unrolling network without fully connected layers; (2) PUNet + DConv1: PUNet with dynamic convolution via one fully connected layer; (3) PUNet + DConv2: PUNet with dynamic convolution via two fully connected layers; (4) PUNet + DIn1: PUNet with dynamic instance normalization via one fully connected layer; (5) PUNet + DIn2: PUNet with dynamic instance normalization via two fully connected layers; (6) PUNet + DIn3: PUNet with dynamic instance normalization via three fully connected layers; (7) PUNet + DConv1In1: PUNet with dynamic convolution and instance normalization via one fully connected layer; (8) PUNet + DConv2In1: PUNet with dynamic convolution via two fully connected layers and instance normalization via one fully connected layer; (9) PUNet + DConv2In2: PUNet with dynamic convolution and instance normalization via two fully connected layers; (10) DPUNet: PUNet with dynamic convolution via one fully connected layer and dynamic instance normalization via two fully connected layers. All models are trained and tested for image CS tasks on the same experimental setting with noise-free.
To compare the performance, we show PSNRs (dB) of BCS reconstructions () on Set11 with different structures and the number of model parameters (Million), provided in Table IV. It can be seen that the performance of PUNet could be significantly improved by using dynamic convolution or dynamic instance normalization with two fully connected layers, especially by using them together. Considered by the complexity of the model, our final choice (i.e., DPUNet) achieves performance near to the top with a reasonable number of parameters.
| Architectures | CS Ratios | Params | ||
|---|---|---|---|---|
| 10% | 25% | 40% | ||
| PUNet | 26.57 | 31.80 | 34.85 | 1.12 |
| PUNet + DConv1 | 26.87 | 32.47 | 35.50 | 2.24 |
| PUNet + DConv2 | 27.05 | 32.73 | 36.05 | 72.65 |
| PUNet + DIn1 | 26.87 | 32.39 | 35.70 | 1.13 |
| PUNet + DIn2 | 27.15 | 32.74 | 36.12 | 1.46 |
| PUNet + DIn3 | 27.25 | 32.85 | 36.23 | 1.79 |
| PUNet + DConv1In1 | 26.49 | 32.04 | 34.84 | 2.25 |
| PUNet + DConv2In1 | 26.76 | 32.51 | 35.92 | 72.66 |
| PUNet + DConv2In2 | 27.33 | 32.99 | 36.42 | 72.98 |
| DPUNet | 27.31 | 32.99 | 36.48 | 2.58 |
IV-C2 Effects of different optimization frameworks
To provide the insight into the choice of optimization framework, we compare the performance of the proposed three unrolling frameworks on image CS tasks, including their unrolled networks and corresponding dynamic versions. In Table V, it can be seen that the proposed dynamic proximal mapping module can consistently boost the performance of unrolling network derived from PGD, HQS, and ADMM, with average performance gain 1.45dB, 1.60dB, and 1.45dB, respectively. Meanwhile, DPUNet-PGD achieves the highest performance under various sampling ratios compared against other networks, chosen as the final choice.
| Extensions | Sampling Ratios | |||
|---|---|---|---|---|
| 10% | 25% | 40% | 50% | |
| PUNet-PGD | 26.57 | 31.80 | 34.85 | 36.12 |
| DPUNet-PGD | 27.31 | 32.99 | 36.48 | 38.35 |
| PUNet-HQS | 26.05 | 31.18 | 34.16 | 35.55 |
| DPUNet-HQS | 26.74 | 32.49 | 36.08 | 38.04 |
| PUNet-ADMM | 26.16 | 31.30 | 34.33 | 35.80 |
| DPUNet-ADMM | 26.80 | 32.51 | 36.05 | 38.02 |
IV-C3 Generalizability of DPUNet
To further investigate the generalizability of DPUNet, we train and test DPUNet on consistent CS ratios, denoted by DPUNet-optimal. Fig. 8 shows the comparison between the ”DPUNet-optimal”, ”DPUNet”, and ”PUNet” models for image compressive sensing under multiple CS ratios. Note that ”DPUNet-optimal” denotes the (three) models of DPUNet separately trained and tested on each CS ratio, which is expected to get the optimal results. ”DPUNet” and ”PUNet” indicate the single model trained and tested on all CS ratios, and the main difference between them is that ”DPUNet” adopts the proposed dynamic module which ”PUNet” lacks.
It can be observed that a single trained model of DPUNet can achieve very close performance (the average PSNR difference is about 0.24 dB) with the optimal results, while there is a large gap (the average PSNR difference is about 2.18 dB) between ”PUNet” model and the optimal model. Overall, we demonstrate that the proposed dynamic proximal mapping module can significantly boost the generalizability of deep unrolling networks, avoiding time-consuming and storage-consuming retraining.

IV-C4 Robustness on imaging parameters mismatch
In practical applications, while the sampling ratio can be accurately measured, the noise level or signal-to-noise ratio (SNR) is often estimated by related methods [68, 69, 70] since the ground truth is unknown. Thereby, DPUNet should be robust to mismatched imaging parameters, mainly under noisy conditions. To analyze the robustness of DPUNet for the mismatched imaging parameters, we use a range of parameter values of the noise-level as the input at the inference stage, and show average reconstruction results (PSNRs) on Set11 test set from noisy BCS measurements (sampling ratio , noise level ). Fig. 9 illuminates that DPUNet is robust to the inaccuracy of imaging parameters – reaching similar reconstruction results under a range of mismatched imaging parameters. The visual comparisons can see Fig. 10, which also shows visually similar results of reconstructed images.

| * | ||
 |
 |
 |
| 24.81 | 25.11 | 25.11 |
| GroundTruth | ||
 |
 |
 |
| 25.00 | 25.01 | PSNR |
IV-C5 Hyper-parameters analysis
We conduct a hyper-parameters analysis and train different models of our method, then present experimental results. Specifically, we focus on two hyper-parameters of our DPUNet, i.e., unrolling iterations and training epochs. First, we unroll different numbers of proximal optimization iterations and train corresponding models. The performance of different models on image compressive sensing tasks is presented in Table VI. It can be seen that unrolling ten iterations is sufficient for our DPUNet to get promising results. Furthermore, We provide the performance of trained models on different epochs on the image compressive sensing task in Fig. 11. It can be observed that our model trained by 200 epochs can achieve satisfactory performance.
| Model | CS Ratio (on Set11) | ||||
|---|---|---|---|---|---|
| 4% | 10% | 25% | 40% | 50% | |
| DPUNet-5 | 21.56 | 26.09 | 31.08 | 35.00 | 36.88 |
| DPUNet-10 | 22.09 | 27.04 | 32.73 | 36.22 | 38.07 |
| DPUNet-15 | 22.14 | 27.08 | 32.76 | 36.23 | 38.13 |

IV-D Extension for multiple compressive imaging tasks
Inspired by the same network structure for different compressive imaging modalities, we explore the potential of our method to handle multiple imaging tasks with one single trained model simultaneously. To verify this claim, we present an extension of our method and run a mixed experiment, where we consider three imaging modalities mentioned above under different sampling ratios with varying noise levels. To implement this, we simulate to generate the BCS measurements with the sampling ratio uniformly sampled from {0.01,0.04,0.1,0.25,0.4,0.5} from CS training data-set, CS-MRI measurements with the sampling ratio uniformly sampled from {0.2,0.3,0.4,0.5} from MRI training data-set, and the under-sampling coded diffraction measurements uniformly sampled from {0.3,0.4,0.5} from CPR training data-set, all adding noise with uniformly sampled from [0,50].
Moreover, we add an extra parameter to represent the imaging modality 222For simplicity, we input the parameters for dealing with BCS task, for CS-MRI, and for CPR., and the other parameters are related to the imaging condition (). During training, the BCS, CS-MRI, and CPR training data pairs that include image patches and corresponding measurements are alternately fed to our network, together with imaging parameters {}. The network is trained in 200000 iterations using pixel-wise loss and Adam optimizer with learning rate . It takes about 18 hours to train the model.
The reconstruction results with the extension of our method for all imaging modalities and imaging conditions are provided in Table VII. We can see that our method can not only handle various imaging conditions but also totally different imaging modalities via one single model without retraining. Here we also compare with the results of our baselines, which represent the models of DPUNet trained on a single imaging task (BCS, CS-MRI, or CPR), respectively. It can be seen that the extension of our method still achieves close results to the baselines, despite small performance degradation. It means with the same network structure, our method can handle different imaging tasks via one single trained model without losing much accuracy. We show reconstructed results of a single trained model for multiple imaging modalities with noise level () and different sampling ratios ( for BCS, for CS-MRI, for CPR) in Fig. 1. It can be found that the proposed network is flexible for various imaging conditions and universal for different imaging modalities.
| Task | Ours* | Baselines | ||
|---|---|---|---|---|
| BCS | 29.96 | 30.04 | ||
| 25.57 | 25.70 | |||
| 31.89 | 31.99 | |||
| 27.03 | 27.20 | |||
| CS-MRI | 35.08 | 35.41 | ||
| 31.61 | 32.08 | |||
| 35.97 | 36.33 | |||
| 32.07 | 32.59 | |||
| CPR | 30.56 | 30.96 | ||
| 27.75 | 27.75 | |||
| 32.91 | 33.14 | |||
| 28.38 | 28.63 |
V Conclusion
We have proposed a dynamic proximal unrolling network for a variety of compressive imaging problems under varying imaging conditions. The main contribution of the proposed method is developing a dynamic proximal mapping module, which can dynamically update parameters of the proximal network at the inference stage and make it adapt to different imaging settings and even imaging tasks. As a result, the proposed method can handle a wide range of compressive imaging modalities, including image compressive sensing, CS-MRI, and compressive phase retrieval under varying imaging conditions via one single trained model. Experimental results demonstrate the effectiveness and state-of-the-art performance of the proposed method. Thereby, we envision the proposed network to be applied to embedded mobile devices where storage and computational resources demands become prohibitive, and to handle a variety of imaging tasks via only one trained model.
References
- [1] D. L. Donoho, “Compressed sensing,” IEEE Transactions on information theory, vol. 52, no. 4, pp. 1289–1306, 2006.
- [2] A. Liutkus, D. Martina, S. Popoff, G. Chardon, O. Katz, G. Lerosey, S. Gigan, L. Daudet, and I. Carron, “Imaging with nature: Compressive imaging using a multiply scattering medium,” Scientific reports, vol. 4, no. 1, pp. 1–7, 2014.
- [3] M. F. Duarte, M. A. Davenport, D. Takhar, J. N. Laska, T. Sun, K. F. Kelly, and R. G. Baraniuk, “Single-pixel imaging via compressive sampling,” IEEE signal processing magazine, vol. 25, no. 2, pp. 83–91, 2008.
- [4] R. Kerviche, N. Zhu, and A. Ashok, “Information-optimal scalable compressive imaging system,” in Computational Optical Sensing and Imaging. Optical Society of America, 2014, pp. CM2D–2.
- [5] A. C. Sankaranarayanan, C. Studer, and R. G. Baraniuk, “Cs-muvi: Video compressive sensing for spatial-multiplexing cameras,” in 2012 IEEE International Conference on Computational Photography (ICCP). IEEE, 2012, pp. 1–10.
- [6] M. Lustig, D. Donoho, and J. M. Pauly, “Sparse mri: The application of compressed sensing for rapid mr imaging,” Magnetic Resonance in Medicine: An Official Journal of the International Society for Magnetic Resonance in Medicine, vol. 58, no. 6, pp. 1182–1195, 2007.
- [7] M. Lustig, D. L. Donoho, J. M. Santos, and J. M. Pauly, “Compressed sensing mri,” IEEE signal processing magazine, vol. 25, no. 2, pp. 72–82, 2008.
- [8] F. Rousset, N. Ducros, A. Farina, G. Valentini, C. D’Andrea, and F. Peyrin, “Adaptive basis scan by wavelet prediction for single-pixel imaging,” IEEE Transactions on Computational Imaging, vol. 3, no. 1, pp. 36–46, 2016.
- [9] X. Yuan, D. J. Brady, and A. K. Katsaggelos, “Snapshot compressive imaging: Theory, algorithms, and applications,” IEEE Signal Processing Magazine, vol. 38, no. 2, pp. 65–88, 2021.
- [10] M. L. Moravec, J. K. Romberg, and R. G. Baraniuk, “Compressive phase retrieval,” in Wavelets XII, vol. 6701. International Society for Optics and Photonics, 2007, p. 670120.
- [11] H. Ohlsson, A. Yang, R. Dong, and S. Sastry, “Cprl–an extension of compressive sensing to the phase retrieval problem,” Advances in Neural Information Processing Systems, vol. 25, pp. 1367–1375, 2012.
- [12] S. Ma, W. Yin, Y. Zhang, and A. Chakraborty, “An efficient algorithm for compressed mr imaging using total variation and wavelets,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2008, pp. 1–8.
- [13] H. Y. Liao and G. Sapiro, “Sparse representations for limited data tomography,” in IEEE International Symposium on Biomedical Imaging: From Nano to Macro. IEEE, 2008, pp. 1375–1378.
- [14] W. Dong, G. Shi, X. Li, Y. Ma, and F. Huang, “Compressive sensing via nonlocal low-rank regularization,” IEEE Transactions on Image Processing, vol. 23, no. 8, pp. 3618–3632, 2014.
- [15] X. Qu, Y. Hou, F. Lam, D. Guo, J. Zhong, and Z. Chen, “Magnetic resonance image reconstruction from undersampled measurements using a patch-based nonlocal operator,” Medical Image Analysis, vol. 18, no. 6, pp. 843–856, 2014.
- [16] J. Zhang, D. Zhao, and W. Gao, “Group-based sparse representation for image restoration,” IEEE Transactions on Image Processing, vol. 23, no. 8, pp. 3336–3351, 2014.
- [17] C. Guo and Q. Yang, “A neurodynamic optimization method for recovery of compressive sensed signals with globally converged solution approximating to {} minimization,” IEEE Transactions on Neural Networks and Learning Systems, vol. 26, no. 7, pp. 1363–1374, 2015.
- [18] C. A. Metzler, A. Maleki, and R. G. Baraniuk, “From denoising to compressed sensing,” IEEE Transactions on Information Theory, vol. 62, no. 9, pp. 5117–5144, 2016.
- [19] P. L. Combettes and J.-C. Pesquet, “Proximal splitting methods in signal processing,” in Fixed-point algorithms for inverse problems in science and engineering. Springer, 2011, pp. 185–212.
- [20] M. V. Afonso, J. M. Bioucas-Dias, and M. A. Figueiredo, “Fast image recovery using variable splitting and constrained optimization,” IEEE transactions on image processing, vol. 19, no. 9, pp. 2345–2356, 2010.
- [21] A. Beck and M. Teboulle, “A fast iterative shrinkage-thresholding algorithm for linear inverse problems,” SIAM Journal on Imaging Sciences, vol. 2, no. 1, pp. 183–202, 2009.
- [22] D. Geman and C. Yang, “Nonlinear image recovery with half-quadratic regularization,” IEEE transactions on Image Processing, vol. 4, no. 7, pp. 932–946, 1995.
- [23] S. Boyd, N. Parikh, E. Chu, B. Peleato, J. Eckstein, et al., “Distributed optimization and statistical learning via the alternating direction method of multipliers,” Foundations and Trends® in Machine learning, vol. 3, no. 1, pp. 1–122, 2011.
- [24] J. Yang, Y. Zhang, and W. Yin, “A fast alternating direction method for tvl1-l2 signal reconstruction from partial fourier data,” IEEE Journal of Selected Topics in Signal Processing, vol. 4, no. 2, pp. 288–297, 2010.
- [25] G. Ongie, A. Jalal, C. A. Metzler, R. G. Baraniuk, A. G. Dimakis, and R. Willett, “Deep learning techniques for inverse problems in imaging,” IEEE Journal on Selected Areas in Information Theory, vol. 1, no. 1, pp. 39–56, 2020.
- [26] A. Mousavi, A. B. Patel, and R. G. Baraniuk, “A deep learning approach to structured signal recovery,” in 2015 53rd annual allerton conference on communication, control, and computing (Allerton). IEEE, 2015, pp. 1336–1343.
- [27] M. Iliadis, L. Spinoulas, and A. K. Katsaggelos, “Deep fully-connected networks for video compressive sensing,” Digital Signal Processing, vol. 72, pp. 9–18, 2018.
- [28] K. Kulkarni, S. Lohit, P. Turaga, R. Kerviche, and A. Ashok, “Reconnet: Non-iterative reconstruction of images from compressively sensed measurements,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 449–458.
- [29] K. Gregor and Y. LeCun, “Learning fast approximations of sparse coding,” in Proceedings of the 27th international conference on international conference on machine learning, 2010, pp. 399–406.
- [30] M. Borgerding, P. Schniter, and S. Rangan, “Amp-inspired deep networks for sparse linear inverse problems,” IEEE Transactions on Signal Processing, vol. 65, no. 16, pp. 4293–4308, 2017.
- [31] Y. Yang, J. Sun, H. Li, and Z. Xu, “Deep admm-net for compressive sensing mri,” in Proceedings of the 30th international conference on neural information processing systems, 2016, pp. 10–18.
- [32] J. Zhang and B. Ghanem, “Ista-net: Interpretable optimization-inspired deep network for image compressive sensing,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 1828–1837.
- [33] S. Mun and J. E. Fowler, “Block compressed sensing of images using directional transforms,” in 2009 16th IEEE international conference on image processing (ICIP). IEEE, 2009, pp. 3021–3024.
- [34] S. Ravishankar and Y. Bresler, “Mr image reconstruction from highly undersampled k-space data by dictionary learning,” IEEE Transactions on Medical Imaging, vol. 30, no. 5, pp. 1028–1041, 2010.
- [35] Z. Zha, B. Wen, X. Yuan, J. Zhou, C. Zhu, and A. C. Kot, “A hybrid structural sparsification error model for image restoration,” IEEE Transactions on Neural Networks and Learning Systems, pp. 1–15, 2021.
- [36] J. Mairal, F. R. Bach, J. Ponce, G. Sapiro, and A. Zisserman, “Non-local sparse models for image restoration,” in The IEEE International Conference on Computer Vision (ICCV), vol. 29, 2009, pp. 54–62.
- [37] A. Mousavi and R. G. Baraniuk, “Learning to invert: Signal recovery via deep convolutional networks,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2017, pp. 2272–2276.
- [38] A. Adler, D. Boublil, M. Elad, and M. Zibulevsky, “A deep learning approach to block-based compressed sensing of images,” arXiv preprint arXiv:1606.01519, 2016.
- [39] M. Yamaç, M. Ahishali, S. Kiranyaz, and M. Gabbouj, “Convolutional sparse support estimator network (csen): From energy-efficient support estimation to learning-aided compressive sensing,” IEEE Transactions on Neural Networks and Learning Systems, pp. 1–15, 2021.
- [40] C.-M. Feng, Z. Yang, H. Fu, Y. Xu, J. Yang, and L. Shao, “Donet: Dual-octave network for fast mr image reconstruction,” IEEE Transactions on Neural Networks and Learning Systems, pp. 1–11, 2021.
- [41] W. Shi, F. Jiang, S. Liu, and D. Zhao, “Scalable convolutional neural network for image compressed sensing,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 12 290–12 299.
- [42] J. R. Hershey, J. L. Roux, and F. Weninger, “Deep unfolding: Model-based inspiration of novel deep architectures,” arXiv preprint arXiv:1409.2574, 2014.
- [43] J. Sun, H. Li, Z. Xu, et al., “Deep admm-net for compressive sensing mri,” in Advances in neural information processing systems, 2016, pp. 10–18.
- [44] C. Metzler, A. Mousavi, and R. Baraniuk, “Learned d-amp: Principled neural network based compressive image recovery,” in Advances in Neural Information Processing Systems, 2017, pp. 1772–1783.
- [45] H. K. Aggarwal, M. P. Mani, and M. Jacob, “Modl: Model-based deep learning architecture for inverse problems,” IEEE transactions on medical imaging, vol. 38, no. 2, pp. 394–405, 2018.
- [46] W. Dong, P. Wang, W. Yin, G. Shi, F. Wu, and X. Lu, “Denoising prior driven deep neural network for image restoration,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 41, no. 10, pp. 2305–2318, 2018.
- [47] L. Wang, C. Sun, Y. Fu, M. H. Kim, and H. Huang, “Hyperspectral image reconstruction using a deep spatial-spectral prior,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 8032–8041.
- [48] K. Zhang, L. V. Gool, and R. Timofte, “Deep unfolding network for image super-resolution,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 3217–3226.
- [49] S. V. Venkatakrishnan, C. A. Bouman, and B. Wohlberg, “Plug-and-play priors for model based reconstruction,” in IEEE Global Conference on Signal and Information Processing. IEEE, 2013, pp. 945–948.
- [50] J. Rick Chang, C.-L. Li, B. Poczos, B. Vijaya Kumar, and A. C. Sankaranarayanan, “One network to solve them all–solving linear inverse problems using deep projection models,” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 5888–5897.
- [51] C. A. Metzler, P. Schniter, A. Veeraraghavan, and R. G. Baraniuk, “prdeep: Robust phase retrieval with a flexible deep network,” in international conference on machine learning, 2018, pp. 3498–3507.
- [52] T. Meinhardt, M. Moller, C. Hazirbas, and D. Cremers, “Learning proximal operators: Using denoising networks for regularizing inverse imaging problems,” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 1781–1790.
- [53] K. Wei, A. Aviles-Rivero, J. Liang, Y. Fu, C.-B. Schönlieb, and H. Huang, “Tuning-free plug-and-play proximal algorithm for inverse imaging problems,” in International Conference on Machine Learning. PMLR, 2020, pp. 10 158–10 169.
- [54] K. Zhang, W. Zuo, S. Gu, and L. Zhang, “Learning deep cnn denoiser prior for image restoration,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 3929–3938.
- [55] C. A. Metzler, A. Maleki, and R. G. Baraniuk, “Bm3d-prgamp: Compressive phase retrieval based on bm3d denoising,” in 2016 IEEE International Conference on Image Processing (ICIP). IEEE, 2016, pp. 2504–2508.
- [56] K. Wei, A. Aviles-Rivero, J. Liang, Y. Fu, H. Huang, and C.-B. Schönlieb, “Tfpnp: Tuning-free plug-and-play proximal algorithm with applications to inverse imaging problems,” arXiv preprint arXiv:2012.05703, 2020.
- [57] D. Ulyanov, A. Vedaldi, and V. Lempitsky, “Improved texture networks: Maximizing quality and diversity in feed-forward stylization and texture synthesis,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 6924–6932.
- [58] K. He, X. Zhang, S. Ren, and J. Sun, “Identity mappings in deep residual networks,” in European conference on computer vision. Springer, 2016, pp. 630–645.
- [59] A. C. Sankaranarayanan, L. Xu, C. Studer, Y. Li, K. F. Kelly, and R. G. Baraniuk, “Video compressive sensing for spatial multiplexing cameras using motion-flow models,” SIAM Journal on Imaging Sciences, vol. 8, no. 3, pp. 1489–1518, 2015.
- [60] B. M. Roth S., “Fields of experts,” in IEEE Conference on Computer Vision and Pattern Recognition, 2009, p. 205.
- [61] L. Yeh, J. Dong, J. Zhong, L. Tian, M. Chen, G. Tang, M. Soltanolkotabi, and L. Waller, “Experimental robustness of fourier ptychography phase retrieval algorithms,” Optics Express, vol. 23, no. 26, pp. 33 214–33 240, 2015.
- [62] E. J. Candes, X. Li, and M. Soltanolkotabi, “Phase retrieval via wirtinger flow: Theory and algorithms,” IEEE Transactions on Information Theory, vol. 61, no. 4, pp. 1985–2007, 2015.
- [63] D. Martin, C. Fowlkes, D. Tal, and J. Malik, “A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics,” in Proceedings Eighth IEEE International Conference on Computer Vision. ICCV 2001, vol. 2. IEEE, 2001, pp. 416–423.
- [64] C. Li, W. Yin, H. Jiang, and Y. Zhang, “An efficient augmented lagrangian method with applications to total variation minimization,” Computational Optimization and Applications, vol. 56, no. 3, pp. 507–530, 2013.
- [65] J. Zhang, C. Zhao, and W. Gao, “Optimization-inspired compact deep compressive sensing,” IEEE Journal of Selected Topics in Signal Processing, vol. 14, no. 4, pp. 765–774, 2020.
- [66] J. Huang, S. Zhang, and D. Metaxas, “Efficient mr image reconstruction for compressed mr imaging,” Medical Image Analysis, vol. 15, no. 5, pp. 670–679, 2011.
- [67] E. M. Eksioglu, “Decoupled algorithm for mri reconstruction using nonlocal block matching model: Bm3d-mri,” Journal of Mathematical Imaging and Vision, vol. 56, no. 3, pp. 430–440, 2016.
- [68] D. R. Pauluzzi and N. C. Beaulieu, “A comparison of snr estimation techniques for the awgn channel,” IEEE Transactions on communications, vol. 48, no. 10, pp. 1681–1691, 2000.
- [69] M. Riffe, M. Blaimer, K. Barkauskas, J. Duerk, and M. Griswold, “Snr estimation in fast dynamic imaging using bootstrapped statistics,” in Proc Intl Soc Mag Reson Med, vol. 1879, 2007.
- [70] O. Dietrich, J. G. Raya, S. B. Reeder, M. F. Reiser, and S. O. Schoenberg, “Measurement of signal-to-noise ratios in mr images: influence of multichannel coils, parallel imaging, and reconstruction filters,” Journal of Magnetic Resonance Imaging: An Official Journal of the International Society for Magnetic Resonance in Medicine, vol. 26, no. 2, pp. 375–385, 2007.