Dynamic Metric Embedding into Space
Abstract
We give the first non-trivial decremental dynamic embedding of a weighted, undirected graph into space. Given a weighted graph undergoing a sequence of edge weight increases, the goal of this problem is to maintain a (randomized) mapping from the set of vertices of the graph to the space such that for every pair of vertices and , the expected distance between and in the metric is within a small multiplicative factor, referred to as the distortion, of their distance in . Our main result is a dynamic algorithm with expected distortion and total update time , where is the maximum weight of the edges, is the total number of updates and denote the number of vertices and edges in respectively. This is the first result of its kind, extending the seminal result of Bourgain (Bourgain, 1985) to the growing field of dynamic algorithms. Moreover, we demonstrate that in the fully dynamic regime, where we tolerate edge insertions as well as deletions, no algorithm can explicitly maintain an embedding into space that has a low distortion with high probability. 111 An earlier version of this paper claimed an expceted distortion bound of and a total update time of . The new version obtains the slightly worse bounds of and respectively.
kbmagenta \addauthormsmagenta \addauthorjogreen
1 Introduction
A low distortion embedding between two metric spaces, and , is a mapping such that for every pair of points we have
where is often referred to as the distortion of such an embedding. Low-distortion embeddings have been extensively employed to simplify graph theoretic problems prevalent in the algorithm design literature (Indyk, 2001). This effectiveness stems primarily from the ability to represent any graph using a metric, wherein distances correspond to the shortest paths between two nodes. However, computing numerous graph properties within such a metric is inherently challenging. Thus, by first embedding the graph into an “easy” metric, we can facilitate simplified problem-solving, albeit with an approximation factor determined by the distortion introduced by the embedding. For example, approximation algorithms for the sparsest cut (Linial et al., 1995), bandwidth (Blum et al., 1998) and buy-at-bulk (Awerbuch & Azar, 1997b) graph problems leverage embeddings into low-distortion metric spaces to obtain their near-optimal guarantees.
In the present work, we investigate fundamental embedding problems in the dynamic setting, where the input graph is subject to modification at each iteration by an adversary. Specifically, we address the following question:
Problem 1.
Is it possible to embed any graph , undergoing a dynamic sequence of edge updates, into Euclidean (and more broadly the -metric) space with minimal distortion of the underlying metric’s pairwise distances?
Unsurprisingly, the use of randomization is essential in demonstrating that such a data structure is indeed attainable. Most notably, we build upon the fundamental building blocks of Bourgain, Johnson and Lindenstrauss in further demonstrating the power of randomized decompositions of a graph to efficiently map such an input, undergoing dynamic updates, into Euclidean space for ease of computation with only polylogarithmic expected distortion (see Section 2 for the formal definition) of the original distances between nodes of . These are the first results of their kind in the dynamic input setting.
1.1 Motivation
Metric Embedding. From a mathematical perspective, embeddings of finite metric spaces into normed spaces is a natural extension on the local theory of Banach spaces (J., 2002). The goal of this area of research is to devise mappings, , that preserve pairwise distances up to an additive or multiplicative distortion. In tandem to ensuring this metric is not too heavily distorted, we also seek to ensure that the resulting embedding of a point in the original space has low-dimension (i.e. can be represented by small number of coordinates) to ensure the representation is spacially efficient.
Within this problem framework, the classic question is that of embedding metric spaces into Hilbert space. Considerable literature has investigated embeddings into normed spaces (see the survey (Abraham et al., 2006) for a comprehensive overview of the main results). Most crucially, the cornerstone of the field is the following theorem by Bourgain in 1985:
Theorem 1.1 ((Bourgain, 1985)).
For every -point metric space, there exists an embedding into Euclidean space with distortion .
This landmark result is foundational in the theory of embedding into finite metric spaces. Moreover, it was further shown in (Linial et al., 1995) that Bourgain’s embedding yields an embebdding into any -metric with distorition and dimension – demonstrating a highly efficient and precise algorithm.
We highlight that the above results are of immense value to the field of computer science in the age of big data where the construction of appropriately sized data structures is no longer efficient (or even feasible). For instance, in the field of social media analysis, processing billions of daily tweets to identify trending topics and sentiment analysis would require impractical amounts of storage and computational resources without dimension reduction techniques like topic modeling algorithms (Church, 2017; Subercaze et al., 2015). It is thus essential to reduce these inputs to a more approachable metric space to prevent computational bottle-necking. In this paper, we present the first extension on these seminal tools to the emerging domain of dynamic algorithms. Specifically, we maintain a polylogarithmic (expected) distortion embedding into the -metric through a sequence of updates to the input graph.
Dynamic Algorithm. A dynamic graph algorithm is a data structure that supports edge insertions, edge deletions, and can answer queries on certain properties of the input with respect to the original space’s metrics. While trivially one can run a static algorithm on the graph after each update and rebuild a structure equipped to answer queries, the now large body of work on dynamic algorithms works to devise solutions with considerably faster update and query times. In the present work, we maintain a dynamic data structure that both reduces the dimension of the input for ease of computation and exhibits only a modest expansion of the original metric’s pairwise distances in expectation.
Similar to the fundamental motivation underlying metric embeddings, the emergence of big data has intensified the need for dynamic algorithms capable of efficiently storing representations of massive input graphs, while promptly adapting to any changes that may occur on a variety of machine learning and optimization problems (Bhattacharya et al., 2022; Dütting et al., 2023). As an illustrative example, consider the problem of maintaining connectivity information in a large graph that undergoes edge insertions and deletions – an essential problem in the field of route planning and navigation. In a static scenario, the solution can be trivially achieved by rebuilding the shortest paths between nodes using Djikstra’s algorithm on every source vertex after each update to the graph. However, it is easy to see that for connectivity graphs employed in big data systems, this procedure quickly becomes intractable. Recent advancements in the field of dynamic algorithms have revealed that it is possible to maintain such connectivity information with considerably less overhead in terms of the update time to the data structure without a large loss of accuracy for the paths (Bernstein, 2009; Roditty & Zwick, 2004, 2012). This capacity to adapt data structures to effectively handle diverse queries is rapidly transitioning from being merely helpful to absolutely essential. Building upon this existing body of literature, we present a novel contribution by developing a dynamic embedding structure tailored to capturing the distances between nodes in a graph, specifically within the context of the simplified metric – a highly useful computation in the field of dimension reduction for big data. Importantly, our approach guarantees a polylogarithmic expected distortion, thereby striking a balance between efficiency and accuracy.
1.2 Our Results
We first explore the decremental setting, where edge weights can only increase dynamically (i.e., nodes move further apart); this is the setting under which our primary algorithmic contributions are effective. For the fully dynamic setting which allows both increases and decreases in edge weights, we show a partial negative result proving that maintaining an embedding into the -metric explicitly that has low distortion with high probability is not feasible. Here explicitly maintaining an embedding means that the entire embedding is updated efficiently, rather just reporting any changes to the data structure (see Section 2 for a more precise definition of these problem regimes).
Theorem 1.2.
There is no fully dynamic algorithm that can explicitly maintain a dynamic embedding into space with high probability.
Though computation is efficient in the target space, we demonstrate that an adversarially selected sequence of updates to the graph can force an update of the embedding for nodes in each step which becomes intractable to maintain. Intuitively, this result is derived from the fact that changing a large number of pairwise distances in the metric is only possible by moving a large number of points, while making a similar change in the input graph can be done easily by, essentially, connecting and disconnecting two components. We expand more formally on this result in Section 3.
The main idea underpinning our primary algorithmic result is a novel combination of the static randomized decomposition of a graph (as utilized by Bourgain) with a decremental clustering algorithm to maintain an embedding into space that exhibits expected distortion and can answer distance queries with polylogarithmic update time. Our algorithmic result is stated formally as follows.
Theorem 1.3.
For every graph with max edge weight and a metric , there is a decremental dynamic algorithm that maintains an embedding, , for the metric induced by the dynamically updated graph into space of dimension that has expected (over the internal randomization of the algorithm) distortion at most and its running time is at most with high probability222Throughout the paper, we say that an event holds with high probability (whp for short), if its probability is at least for some absolute constant ., where denotes the total number of updates. Within this running time, the algorithm explicitly outputs all changes to the embedding and can answer distance queries between pair of vertices in time.
To prove the guarantees of this algorithm, we require an alternative, constructive proof of Bourgain’s lemma. Our algorithm is different from standard approaches to the problem which
can be classified as “Frechet embeddings.” In these embeddings, each coordinates takes the form of where is a specific set. However, these approaches are not suitable for the dynamic setting due to limitations in analyzing their upper bound on for every given and . Specifically, the distances can be maintained only approximately at best, prohibiting us from obtaining an upper bound.
Starting from the static case, we introduce the notion of a (random) -distance preserving cut. There are two main properties of a -distance preserving cut. Ignoring for now the technical parameter of this notation, the parameters and control the following. First, we require that the probability that two vertices are in different sets is at most times the distance between these vertices in . Intuitively, we can expect many close vertices to be on the same side of the cut. On the other hand, for every pair of vertices whose distance in is larger than , we require probability at least that they are on different sides of the cut. The rationale behind the latter property is that such a cut will, with constant probability, properly distribute vertices that are of distance at least in . We then construct such cuts, where the -th cut corresponds to a different choice of the distance steering parameter , i.e. . The final embedding is made by assigning every vertex a vector of coordinates, one coordinate for corresponding to each parameter choice . For every cut we denote its two sides as “left” and “right”. If a vertex is on the left side of the -th cut, we set its -th coordinate to ; if it is on the right side, we set the coordinate to . Using both aforementioned properties of a -distance preserving cut, we show that such an assignment is an embedding with stretch.
To implement this algorithm in the dynamically changing graph , we prove that -distance preserving cuts can be efficiently obtained from a -weak decomposition of , a probabilistic graph partitioning introduced by Bartal (Bartal, 1996). In this decomposition, we partition vertices of into clusters such that the distance (with respect to ) between every pair of vertices in a cluster is at most , but on the other hand, for every edge the probability that this edge connects two different clusters is at most times its weight. To proceed to -distance preserving cuts, we augment this construction by randomly assigning each cluster to one of the two sides of the cut. In the analysis, we manage to show that such simple random assignments guarantee the properties we require from a -distance preserving cut. On the other hand, provided that we are able to dynamically maintain -weak decomposition of , it is simple to update the random assignment after each update. To deal with a -weak decomposition of under dynamic updates, we lean on the result of (Forster et al., 2021) who showed how to maintain such a decomposition under edge deletions. We observe that their framework, with few technical changes, translates to our settings.
We discuss the details of the underlying static tools used to maintain this structure in Section 4 and proceed to augment these procedures to maintain edge weight updates in Section 5. Moreover, we note that the embedding can be used to implement a dynamic distance oracle (all-pairs shortest paths), as for each two vertices in the graph, we can estimate their distances efficiently by calculating the distance between their embeddings. While our distance guarantees only hold in expectation, the update time of a distance oracle based on our algorithm nearly matches the best known bounds for the APSP problem for stretch (Chechik, 2018; Forster et al., 2023), which further shows the tightness of our analysis.
1.3 Related Work
Metric Embedding.
The foundational result for the algorithmic applications of metric embedding is that of Bourgain in 1985 (Bourgain, 1985) which embeds into any metric with logarithmic distortion. When the input metric is already the metric, the result of Johnson and Lindenstrauss (Johnson et al., 1986) shows that its size can be reduced to with distortion for . Recent works have studied lower bounds for the minimum number of dimensions necessary for this compression; e.g., see (Larsen & Nelson, 2017). To the best of our knowledge, these embedding results have no analogous algorithm in the dynamic setting, which we formulate in the present work.
While space is extremely useful for functional approximation and other challenging mathematical problems, there also exists a line of research on the embeddings of an input metric to a tree metric which inherently lends itself to dynamic problems. For embedding into these tree structures, an emphasis is placed on algorithms for probabilistic tree embeddings (PTE) where the host metric is embedded into a distribution of trees. Concretely, given a graph , the objective is to find a distribution over a set of trees such that distances in do not get contracted and the expected distances over the randomly sampled tree distribution do not exceed a multiplicative stretch of (stretch here can be considered interchangeable with the concept of distortion). The preliminary work on such embeddings from Bartal (Bartal, 1996) demonstrated that by a “ball growing” approach, we can embed any graph with stretch with a nearly equivalent lower bound of stretch for any such embedding. This work was later improved to obtain a PTE procedure with optimal stretch (Fakcharoenphol et al., 2003) which has applications in problems for metric labeling (Kleinberg & Tardos, 2002), buy-at-bulk network design (Awerbuch & Azar, 1997a), vehicle routing (Charikar et al., 1998), and many other such contexts (Bartal, 2004; Garg et al., 2000). Our dynamic emebdding procedure combines this ball growing approach with a decremental clustering procedure to efficiently maintain an embedding into the -metric.
Dynamic Embedding.
Closely related to our work is the study of dynamic embeddings into trees. The work of (Forster & Goranci, 2019) initiates the study on the dynamic maintenance of low-stretch such spanning trees, devising an algorithm that yields an average distortion of in expectation with update time per operation. This result was later improved to average distortion and update time bounded by (Chechik & Zhang, 2020).
The restriction of these prior works to the maintenance of spannning trees is an inherently more difficult and limited problem instance. To improve upon the above bounds, (Forster et al., 2021) removes this restriction and designs an embedding procedure that guarantees an expected distortion of in update time, or stretch with update time when embedding into a distribution of trees. This work also devises a decremental clustering procedure that we build upon in the present work to devise our embeddings. We additionally note that the expected distortion objective more closely aligns with our primary result, however our embedding into the -metric is better suited for the class of NP-hard optimization problems whose approximation algorithms rely on the geometry of Euclidean space such as sparsest cut (Arora et al., 2005; Aumann & Rabani, 1998; Chawla et al., 2008), graph decompositions (Arora et al., 2009; Linial et al., 1995), and the bandwidth problem (Dunagan & Vempala, 2001; Feige, 1998; Krauthgamer et al., 2004).
Similar to the present work is the study of dynamic distance oracles as originally studied by (Thorup & Zwick, 2005) in the static setting, and later extended to the decremental setting with a data structure which maintains the distance between any two points from the input metric with stretch, total update time and space (where is any positive integer) (Roditty & Zwick, 2012). This result can be further improved to a distortion of with space for every . (Chechik, 2018) further present a decremental algorithm for the all pairs shortest path (APSP) problem which admits distortion with total update time of and query time . Our embedding which generalizes this notion of distance oracle yields a nearly equivalent update time for expected distortion, further demonstrating the tightness of our analysis.
In the next section, we precisely define the mathematical framework and formalization within which our algorithmic techniques reside.
2 Model and Preliminaries
Let be a weighted, undirected graph on vertices with (at most) edges of positive integer weights in the range from 1 to , where is a fixed parameter known to the algorithm. For an edge , we denote its weight by . For every pair of nodes , let be the length of the shortest weighted path between nodes in , where we define the weight of a path as the sum of the weights of its edges. Throughout, we let denote a power of two that is always larger than the diameter of the graph; note that . We note that is a metric space.
Given a set of vertices , we define the weak diameter of as the maximum distance between the vertices of in the original graph, i.e., For all and , let denote the set of all vertices that are within distance from in the graph , i.e., .
Metric Embedding. The objective of this paper is to construct and maintain an embedding of the metric defined by an input graph to an metric space without distorting the original distances by too much. More formally, given a metric space , an injective mapping is called an embedding, from into . We define the expansion (or stretch) and the contraction of the embedding , respectively, as:
We define the distortion of the embedding as . Note that any embedding satisfies The embeddings in this paper are random functions, and are constructed by randomized algorithms. Given a random embedding , we define its expected distortion as the smallest value for which there exist positive values satisfying such that for all : 333Throughout the paper, we mostly consider . As such, we sometimes use distortion and stretch interchangeably since we are only concerned with the expansion of distances between points.
| (1) |
In this paper, we focus on embeddings into the metric space. In this metric space, the ground set equals , for some positive integer , and for every pair of points , the distance is defined as
where and refer to the -th coordinate of and , respectively.
Dynamic Model. We consider a model where the underlying input graph undergoes a sequence of updates as specified by an oblivious adversary. We assume that the adversary knows the algorithm, but does not have access to the random bits the algorithm uses. We use to denote the corresponding sequence of graphs, where refers to the graph after updates. Throughout, we will use to denote the total number of updates to an input graph. This sequence is fixed by the adversary before the execution of the algorithm, but is revealed to the algorithm gradually, one by one. Our goal is to explicitly maintain an embedding after each update, as formally defined below:
Definition 2.1 (Maintain).
We say that a dynamic algorithm explicitly maintains an embedding of the input graph into a metric space if there exists a sequence of mappings where and outputs the changes in after every update. Formally, after the update , the algorithm should output and for all such that .
We operate in the decremental setting and assume that each update takes the form of an edge weight increase, i.e., for an edge , the value of increases. We note that this is slightly different from the standard definition of the decremental setting which permits the deletion of edges in the input graph. The deletion of an edge can lead the input graph to potentially become disconnected, which means we may have for some time step and . This is problematic, however, because regardless of the value of and , we will always have because the metrics do not allow for infinite distances. This in turn means that we cannot satisfy the bounds for expected distortion (Equation (1)), and as such cannot design a low-distortion embedding. To avoid this issue, we restrict the updates to edge weight increases only, and we note that in practice the removal an edge can be simulated by choosing a large as the dependence of our bounds on will be polylogarithmic. Thus, edge weight increases serve as a necessary stand-in for edge deletions as both will lead to pairwise distances increasing.
In the section that follows, we will show that maintaining a fully dynamic embedding, where edge weights are subject to both increases and decreases, that has low distortion with high probability is unfeasible in the -metric space if the distortion bounds hold. This limitation underpins the rationale for the above decremental problem setting we introduce.
3 Lower Bound for Explicit Maintenance of Fully Dynamic Embeddings
We first present an (oblivious) adversarial construction of edge weight modifications to a graph in the fully dynamic model that cannot be explicitly maintained in the geometry of space without needing to modify the embedding for every node in the original graph. We highlight that this is a high probability result whereas the main algorithmic results we obtain hold in expectation.
Theorem 3.1.
Any fully dynamic algorithm that maintains an embedding into the -metric space which guarantees a distortion of at most with high probability must have an update time at least .
Proof.
Let be a fully dynamic algorithm which guarantees a stretch of at most with high probability. Consider an input graph that consists of two separate complete graphs on vertices, and , comprised of unit edges. Further consider two fixed vertices . If there is a unit edge between these two vertices, then the distance of all elements in and is at most 3 in the graph metric, and therefore in the embedding cannot be more than .
Now, assume an adversary increases the edge weight connecting the vertices and to a value of . In the original graph metric, all pairwise distances between the nodes of and must now be at least . Therefore, the embedded points of one cluster ( or ) must be updated so as to not contract the original metric and maintain the distortion of at most with high probability (see Figure 1 for a depiction of this construction). Therefore, the algorithm must update the embedding for all nodes of one of the complete components of to be at least away from the other with respect to the norm and satisfy the distortion constraints with high probability. Thus, we charge at least to the update time of in the worst case for the maintenance of the embedding. 444Formally, for each pair of vertices in , at least one of them needs to be updated. Since there are pairs and each vertex update resolves the issue for pairs, we need vertex updates. Moreover, we cannot amortize this worst case update occurrence since, in the subsequent iteration, the adversary can change the edge weight back 1 and repeat the cycle – resulting in updates per iteration. ∎

Though this sequence is simplistic, it highlights the inherent limitations of embedding into a complete and locally compact metric like the normed space. We additionally remark that, in the expected distortion setting of our algorithmic result, this lower bound does not persist since a large increase in the expected pairwise distances between nodes does not necessarily imply the embedding for every pair of points has been updated.
4 Static algorithm
We proceed to present our algorithm by first presenting the static partitioning procedure, which is used to initialize our data structure and is subsequently maintained through the sequence of updates specified by the adversary. While our ideas are based on prior work, to our knowledge, this static algorithm is a novel construction that has not appeared before in the literature.
4.1 Distance Preserving Cuts
Our algorithm dynamically maintains an embedding based on a set of cuts in the graph, where each cut is designed to separate vertices with distances above some threshold , while simultaneously preserving distances of the vertices in the graph. We formally define the notion of a distance preserving cut.
Definition 4.1 (Distance preserving cut).
Given a graph , let be a random subset of the vertices. For vertices , let denote the event that are on different sides of the partition , i.e.,
We say that is a -distance preserving cut, or -cut for short, if it has the following three properties:
-
•
for every ,
-
•
for every such that ,
-
•
for every such that .
Following in the algorithmic technique of decomposing the graph into these smaller sets with desirable pairwise distance bounds is a refinement on the ball-growing approach of Bartal (Bartal, 1996) and the padded decomposition at the heart of Bourgain’s embedding results (Bourgain, 1985). Most importantly, this efficient cut set construction allows us to contract edges which are small enough to ignore in the approximation factor and also provide logarithmic distortion bounds on the larger paths – a fact that will be verified in the following analysis.
The main result in this section is the following lemma that guarantees the existence of such cut sets and will be used heavily in our pre-processing graph decomposition at various granularities which in turn leads to the desired distortion bounds promised in Theorem 1.3.
Lemma 4.2.
For every , there exists a -distance preserving cut with and .
We now present the proof of this lemma which uses the randomized decomposition method of Bartal (Bartal, 1996) in conjunction with a novel probabilistic compression procedure. First, we review the definition of an -partition of a graph (as originally defined in Bartal (Bartal, 1996)).
Definition 4.3.
An -partition of is a collection of subsets of vertices such that
-
•
For all , and .
-
•
For all such that , .
-
•
Let denote the subgraph of induced on the vertices of . Such a subgraph is referred to as a “cluster” of the partition and for every , the weak diameter of is bounded above as .
Next, we give the definition of a -weak decomposition - a modificiation on the partition that probabilistically ensures vertices close to each other appear in the same cluster.
Definition 4.4.
Given a graph , let be a (random) partitioning of the vertices. For every , let denote the index such that . We say that is a -weak decomposition of if for every we have
and for every and pair we have .
Following Bartal (Bartal, 1996), we prove that for all there exists a -weak decomposition of that has the additional property that vertices which are closer than are necessarily in the same cluster. Formally,
Theorem 4.5.
Given a graph with parameters , there exists a -weak decomposition with such that for every pair of vertices :
-
•
-
•
If then and are in the same cluster.
Given this randomized decomposition of our graph, we can construct the desired “cut” set that preserves distances by a simple random compression scheme that combines clusters from the above process. Specifically, we take each cluster from Theorem 4.5 and independently assign to one side of the constructed cut, grouping all the clusters into one of two groups. Within these groups we then merge the clusters to obtain our desired cut sets, and . The following lemma verifies that this is a distance preserving cut and the pseudocode is presented in Algorithm 2 for clarity. The proof is deferred to the appendix due to space constraints.
Lemma 4.6.
Given a value , let be the weak decomposition of the graph satisfying the properties of Theorem 4.5, and define the cut as where is a sequence of i.i.d Bernoulli variables with parameter . The cut is a -distance preserving cut with .
4.2 Embedding Procedure
We now proceed to show how to obtain an embedding of the graph using the distance preserving cuts of the previous section. Let be an upper bound on the diameter of the graph . We define our embedding that builds upon Definition 4.1 as follows.
Definition 4.7.
Given a sequence of cuts and parameters , we define the characteristic embedding of as a mapping that sets the -th coordinate of to if and to otherwise, i.e.,
We note the difference our embedding procedure and the existing embedding procedures into space. The standard approach to the problem is to use Frechet embeddings; each coordinate is of the form for some set . These sets are either obtained randomly, or using the partitioning scheme of the Fakcharoenphol-Rao-Talwar (FRT) embedding (Fakcharoenphol et al., 2003). These procedures are not well-suited for the dynamic setting, however because of the analysis of their upper bound on for every pair . Specifically, in order to bound , the approaches rely on
where the inequality follows from the triangle inequality. In the dynamic setting however, (efficiently) maintaining distances can only be done approximately. This means that and would each be within a factor of and which would result in a degradation of our guarantees when maintained dynamically.
We now leverage the key characteristics for a set of distance preserving cuts to demonstrate that the corresponding characteristic embedding preserves the original distances in the -metric with only polylogarithmic distortion.
Theorem 4.8.
Given a graph and a parameter that is a power of satisfying , let be (random) subsets of such that is a -cut with and , and let be the characteristic embedding of these cuts. For every pair of vertices and any :
We note that the constant can be easily removed by multiplying the embedding vectors by . Equipped with this static embedding that only distorts pairwise distances by a polylogarithmic factor, we proceed to adapt the structure to efficiently modify the cut-set decomposition of through a sequence of (adversarially chosen) edge weight increases.
5 Dynamic Algorithm
In this section, we prove Theorem 1.3555Because of the page limit we avoid repeating statements of longer theorems.. We do it by constructing an algorithm that dynamically maintains an embedding of a metric induced by a graph into space of dimension .
Our construction starts by observing a reduction. Informally, in the next theorem we show that in order to maintain dynamically the desired embedding, it is enough to have a dynamic algorithm that for every maintains a -distance preserving cut.
Theorem 5.1.
Assume we are given an algorithm that takes as input the parameter and decrementally maintains a distance preserving cut for a graph undergoing edge weight increases, outputting changes to after each such update, where and . Assume further that the total running time of the algorithm is bounded by whp. Then there is a decremental dynamic algorithm that maintains an embedding of the vertices , where is a power of always satisfying 666For instance, we can set to be the smallest power of larger than ., that has expected (over the internal randomization of the algorithm) distortion at most and running time at most , whp.
We now show how to maintain a distance preserving cut dynamically, which in turn leads to a dynamic embedding algorithm via Theorem 5.1 and completes the proof of the main result, Theorem 1.3. We start by observing that a -weak decomposition of can be dynamically maintained. We here highlight that the authors of (Forster et al., 2021), building upon the approach of (Chechik & Zhang, 2020), have already proved that a -weak decomposition of can be dynamically maintained under edge deletions (Corollary 3.8). The proof of our observation involves adapting their techniques to the slightly modified definition of dynamic changes we invoke here to handle the continuous nature of space.
Lemma 5.2.
For every and , where is a given constant controlling the success probability, there is a decremental algorithm to maintain a probabilistic weak -decomposition of a weighted, undirected graph undergoing increases of edge weights that with high probability has total update time , where is the total number of updates to the input graph, and (within this running time) is able to report all nodes and incident edges of every cluster that is formed. Over the course of the algorithm, each change to the partitioning of the nodes into clusters happens by splitting an existing cluster into two or several clusters and each node changes its cluster at most times.
Equipped with this tool, we can present the main contribution of this section - the maintenance of a -distance preserving cut under dynamic edge weights increases.
Lemma 5.3.
For every , there is a decremental dynamic algorithm that maintains a -distance preserving cut a of weighted, undirected graph where and . Its total update time is with high probability, where is the total number of updates to the input graph, and, within this running time, explicitly reports all changes to the maintained cut.
6 Conclusion
We here present the first dynamic embedding into space which is equipped to handle edge weight increases – a non-trivial extension of the seminal Bourgain and JL embedding results (Bourgain, 1985; Johnson et al., 1986). Most notably, our embeddings produce only a polylogarithmic distortion of the base metric and exhibit an update time on par with the best known results for the APSP and other embedding based problems. Our embedding procedure additionally reports any modifications within polylogarithmic time and is naturally well suited to the class of NP-hard optimization problems which rely on Euclidean geometry for approximations to the optimal solution. To supplement our algorithmic result, we further present a lower bound for the fully dynamic setting where edge weights can be increased or decreased. In particular, we show that no algorithm can achieve a low distortion with high probability without inheriting an update time of which makes the procedure inefficient in practice.
Impact Statement
This paper presents work whose goal is to advance the field of Machine Learning. There are many potential societal consequences of our work, none which we feel must be specifically highlighted here.
Acknowledgements
We thank the anonymous reviewers for their valuable feedback. This work is Partially supported by DARPA QuICC, ONR MURI 2024 award on Algorithms, Learning, and Game Theory, Army-Research Laboratory (ARL) grant W911NF2410052, NSF AF:Small grants 2218678, 2114269, 2347322 Max Springer was supported by the National Science Foundation Graduate Research Fellowship Program under Grant No. DGE 1840340. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.
References
- Abraham et al. (2006) Abraham, I., Bartal, Y., and Neimany, O. Advances in metric embedding theory. In Proceedings of the thirty-eighth annual ACM symposium on Theory of computing, pp. 271–286, 2006.
- Arora et al. (2005) Arora, S., Lee, J. R., and Naor, A. Euclidean distortion and the sparsest cut. In Proceedings of the thirty-seventh annual ACM symposium on Theory of computing, pp. 553–562, 2005.
- Arora et al. (2009) Arora, S., Rao, S., and Vazirani, U. Expander flows, geometric embeddings and graph partitioning. Journal of the ACM (JACM), 56(2):1–37, 2009.
- Aumann & Rabani (1998) Aumann, Y. and Rabani, Y. An o (log k) approximate min-cut max-flow theorem and approximation algorithm. SIAM Journal on Computing, 27(1):291–301, 1998.
- Awerbuch & Azar (1997a) Awerbuch, B. and Azar, Y. Buy-at-bulk network design. In Proceedings 38th Annual Symposium on Foundations of Computer Science, pp. 542–547, 1997a. doi: 10.1109/SFCS.1997.646143.
- Awerbuch & Azar (1997b) Awerbuch, B. and Azar, Y. Buy-at-bulk network design. In Proceedings 38th Annual Symposium on Foundations of Computer Science, pp. 542–547. IEEE, 1997b.
- Bartal (1996) Bartal, Y. Probabilistic approximation of metric spaces and its algorithmic applications. In Proceedings of 37th Conference on Foundations of Computer Science, pp. 184–193. IEEE, 1996.
- Bartal (2004) Bartal, Y. Graph decomposition lemmas and their role in metric embedding methods. In Albers, S. and Radzik, T. (eds.), Algorithms – ESA 2004, pp. 89–97, Berlin, Heidelberg, 2004. Springer Berlin Heidelberg. ISBN 978-3-540-30140-0.
- Bernstein (2009) Bernstein, A. Fully dynamic (2+ ) approximate all-pairs shortest paths with fast query and close to linear update time. In 2009 50th Annual IEEE Symposium on Foundations of Computer Science, pp. 693–702. IEEE, 2009.
- Bhattacharya et al. (2022) Bhattacharya, S., Lattanzi, S., and Parotsidis, N. Efficient and stable fully dynamic facility location. Advances in neural information processing systems, 35:23358–23370, 2022.
- Blum et al. (1998) Blum, A., Konjevod, G., Ravi, R., and Vempala, S. Semi-definite relaxations for minimum bandwidth and other vertex-ordering problems. In Proceedings of the thirtieth annual ACM symposium on Theory of computing, pp. 100–105, 1998.
- Bourgain (1985) Bourgain, J. On lipschitz embedding of finite metric spaces in hilbert space. Israel Journal of Mathematics, 52:46–52, 1985.
- Charikar et al. (1998) Charikar, M., Chekuri, C., Goel, A., and Guha, S. Rounding via trees: Deterministic approximation algorithms for group steiner trees and k-median. Conference Proceedings of the Annual ACM Symposium on Theory of Computing, pp. 114–123, 1998. ISSN 0734-9025. Proceedings of the 1998 30th Annual ACM Symposium on Theory of Computing ; Conference date: 23-05-1998 Through 26-05-1998.
- Chawla et al. (2008) Chawla, S., Gupta, A., and Räcke, H. Embeddings of negative-type metrics and an improved approximation to generalized sparsest cut. ACM Transactions on Algorithms (TALG), 4(2):1–18, 2008.
- Chechik (2018) Chechik, S. Near-optimal approximate decremental all pairs shortest paths. In 2018 IEEE 59th Annual Symposium on Foundations of Computer Science (FOCS), pp. 170–181. IEEE, 2018.
- Chechik & Zhang (2020) Chechik, S. and Zhang, T. Dynamic low-stretch spanning trees in subpolynomial time. In Proceedings of the Fourteenth Annual ACM-SIAM Symposium on Discrete Algorithms, pp. 463–475. SIAM, 2020.
- Church (2017) Church, K. W. Word2vec. Natural Language Engineering, 23(1):155–162, 2017.
- Dunagan & Vempala (2001) Dunagan, J. and Vempala, S. On euclidean embeddings and bandwidth minimization. In International Workshop on Randomization and Approximation Techniques in Computer Science, pp. 229–240. Springer, 2001.
- Dütting et al. (2023) Dütting, P., Fusco, F., Lattanzi, S., Norouzi-Fard, A., and Zadimoghaddam, M. Fully dynamic submodular maximization over matroids. In International Conference on Machine Learning, pp. 8821–8835. PMLR, 2023.
- Fakcharoenphol et al. (2003) Fakcharoenphol, J., Rao, S., and Talwar, K. A tight bound on approximating arbitrary metrics by tree metrics. In Proceedings of the Thirty-Fifth Annual ACM Symposium on Theory of Computing, STOC ’03, pp. 448–455, New York, NY, USA, 2003. Association for Computing Machinery. ISBN 1581136749. doi: 10.1145/780542.780608. URL https://doi.org/10.1145/780542.780608.
- Feige (1998) Feige, U. Approximating the bandwidth via volume respecting embeddings. In Proceedings of the thirtieth annual ACM symposium on Theory of computing, pp. 90–99, 1998.
- Forster & Goranci (2019) Forster, S. and Goranci, G. Dynamic low-stretch trees via dynamic low-diameter decompositions. In Proceedings of the 51st Annual ACM SIGACT Symposium on Theory of Computing, pp. 377–388, 2019.
- Forster et al. (2021) Forster, S., Goranci, G., and Henzinger, M. Dynamic maintenance of low-stretch probabilistic tree embeddings with applications. In Proceedings of the 2021 ACM-SIAM Symposium on Discrete Algorithms (SODA), pp. 1226–1245. SIAM, 2021.
- Forster et al. (2023) Forster, S., Goranci, G., Nazari, Y., and Skarlatos, A. Bootstrapping dynamic distance oracles. arXiv preprint arXiv:2303.06102, 2023.
- Garg et al. (2000) Garg, N., Konjevod, G., and Ravi, R. A polylogarithmic approximation algorithm for the group steiner tree problem. Journal of Algorithms, 37(1):66–84, 2000. ISSN 0196-6774. doi: https://doi.org/10.1006/jagm.2000.1096. URL https://www.sciencedirect.com/science/article/pii/S0196677400910964.
- Henzinger et al. (2018) Henzinger, M., Krinninger, S., and Nanongkai, D. Decremental single-source shortest paths on undirected graphs in near-linear total update time. Journal of the ACM (JACM), 65(6):1–40, 2018.
- Indyk (2001) Indyk, P. Algorithmic applications of low-distortion embeddings. In Proc. 42nd IEEE Symposium on Foundations of Computer Science, pp. 1, 2001.
- J. (2002) J., M. Lectures on discrete geometry. Graduate Texts in Mathematics, 2002. ISSN 0072-5285. doi: 10.1007/978-1-4613-0039-7. URL https://cir.nii.ac.jp/crid/1361981469479209856.
- Johnson et al. (1986) Johnson, W. B., Lindenstrauss, J., and Schechtman, G. Extensions of lipschitz maps into banach spaces. Israel Journal of Mathematics, 54(2):129–138, 1986. doi: 10.1007/BF02764938. URL https://doi.org/10.1007/BF02764938.
- Kleinberg & Tardos (2002) Kleinberg, J. and Tardos, E. Approximation algorithms for classification problems with pairwise relationships: Metric labeling and markov random fields. J. ACM, 49(5):616–639, sep 2002. ISSN 0004-5411. doi: 10.1145/585265.585268. URL https://doi.org/10.1145/585265.585268.
- Krauthgamer et al. (2004) Krauthgamer, R., Lee, J. R., Mendel, M., and Naor, A. Measured descent: A new embedding method for finite metrics. In 45th Annual IEEE Symposium on Foundations of Computer Science, pp. 434–443. IEEE, 2004.
- Larsen & Nelson (2017) Larsen, K. G. and Nelson, J. Optimality of the johnson-lindenstrauss lemma. In 2017 IEEE 58th Annual Symposium on Foundations of Computer Science (FOCS), pp. 633–638. IEEE, 2017.
- Leskovec & Krevl (2014) Leskovec, J. and Krevl, A. SNAP Datasets: Stanford large network dataset collection. http://snap.stanford.edu/data, June 2014.
- Linial et al. (1995) Linial, N., London, E., and Rabinovich, Y. The geometry of graphs and some of its algorithmic applications. Combinatorica, 15:215–245, 1995.
- Roditty & Zwick (2004) Roditty, L. and Zwick, U. On dynamic shortest paths problems. In Algorithms–ESA 2004: 12th Annual European Symposium, Bergen, Norway, September 14-17, 2004. Proceedings 12, pp. 580–591. Springer, 2004.
- Roditty & Zwick (2012) Roditty, L. and Zwick, U. Dynamic approximate all-pairs shortest paths in undirected graphs. SIAM Journal on Computing, 41(3):670–683, 2012.
- Subercaze et al. (2015) Subercaze, J., Gravier, C., and Laforest, F. On metric embedding for boosting semantic similarity computations. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), pp. 8–14, 2015.
- Thorup & Zwick (2005) Thorup, M. and Zwick, U. Approximate distance oracles. Journal of the ACM (JACM), 52(1):1–24, 2005.
Appendix A Empirical validation
We tested the theoretical algorithm guarantees on three different graphs.
Data sets preparation. As the backbone for each graph, we used the social network of LastFM users from Asia available in the Stanford Network Analysis Project dataset (SNAP) (Leskovec & Krevl, 2014). To adhere to our dynamic setting, we randomly chose a subset of 150, 300, and 600 connected nodes to form three different bases of the dynamically changing network. We added random weights from a uniform distribution to these graphs. We augmented each graph by respectively 10000, 5000, and 1000 changes to the topology (queries). Each change increases the weight of a randomly and uniformly chosen edge of the graph by a number chosen from a uniform distribution whose range increases as the process progresses.
Evaluation. We implemented the cut-preserving embedding from Theorem 1.3 and computed the distances between every pair of nodes in the graph after each query. We compared the average of these distances with the average distances computed by an exact algorithm that in an offline fashion computes the shortest distances after each query. Visualized results are presenting in Figure 2.

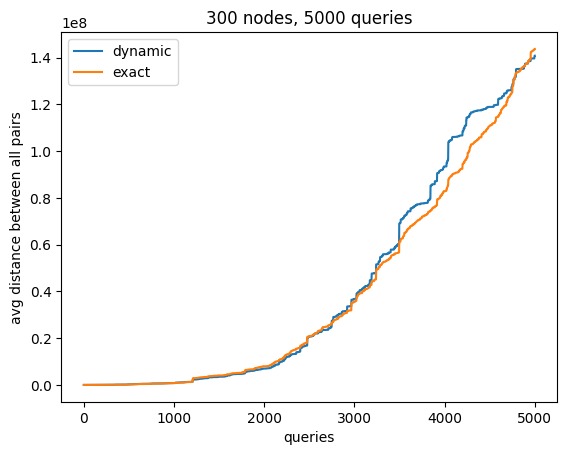

To allow more direct reasoning about the distortion of our embedding, in Figure 3 we provide plots representing, after each query, the ratio of the average distance based on our dynamic embedding to the average distance computed exactly. We would like to note that even though theoretically our embedding is not contractive, this property holds in expectation. In practice, small fluctuations may appear which are particularly visible in the case of a small number of queries.


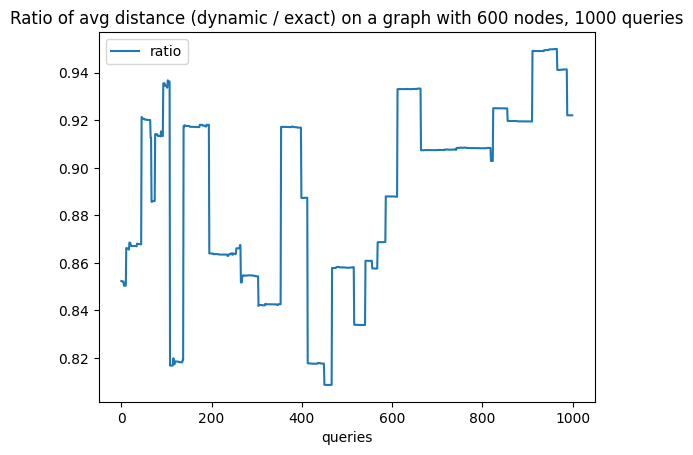
Conclusions. We observed that in these experiments the achieved stretch is within a constant factor of the average over the exact distances which adheres to the theoretical bound of Theorem 1.3 and even surpasses it. This advantage might be a consequence of a couple of things, e.g. the random process involved in the generation, or a few number of testing instances. Nevertheless, we find this results promising. We hope that they can serve as a starting point for further investigation of practicality of dynamic embedding.
Appendix B Omitted Proofs
B.1 Static Algorithm
We briefly provide a sketch of for the proof of Theorem 4.5 below and refer to Bartal (Bartal, 1996) for the full details.
Proof sketch.
We construct the so-called “low diameter randomized decomposition” (LDRD) for the input graph with (parameter ) via the following high-level procedure: first, contract all paths between vertices that are shorter than . Now, starting with the contracted graph we pick an arbitrary vertex, , and select a radius sampled from the geometric distribution with success parameter ; if then we simply replace it with . Note that, with high probability, will not be replaced because of the choice of the parameters. Mark all unmarked vertices contained within the set and define this to be a new cluster of the partition. Repeat this ball-growing process with the next unmarked vertex in and only consider the remaining unmarked vertices to be included in future clusters. This procedure is repeated until all vertices are marked and return the created clusters. Pseudocode for this is provided in Algorithm 1.
To verify the theorem, we proceed to prove each property of a -weak decomposition holds with the additional probabilistic bound. The second property holds by contraction of small edges. Therefore, we need only obtain an upper bound on the probability that the two vertices and are not assigned to the same cluster, ie., . This final point is a standard procedure attributed to (Bartal, 1996) which we overview below.
For some edge , we need to bound the probability that is contained within none of the clusters of the decomposition. Specifically, we need to ensure that after each ball growing procedure (Line 8 of Algorithm 1) is not added to a cluster. We can therefore decompose this value as the probability that exactly one end point of was contained in the last ball grown or neither is contained. Let denote the stage of the ball growing procedure and let denote the event that edge for all . Then we can recursively compute as the probability that exactly one of are contained in , or the probability that neither is as a condition on . The direct computation of these values using the probability density functions for the radius random variable’s distribution and bounding the probability that an endpoint of is contained in Section 3 of (Bartal, 1996) and yields the desired upper bound on the probability that .
∎
Proof of Lemma 4.6.
By the guarantee on the partition given by Theorem 4.5, for every pair of vertices we must have that , and for all such that . Note that if the two nodes are in the same cluster than they must be on the same side of the cut. Therefore, the first two properties of -cuts are proved.
Now, further assume that such that . By construction, for all , have . Therefore, the vertices and cannot be contained in the same cluster. Let and denote the clusters containing and respectively. By construction of the cut set , we have that . Therefore, as claimed. ∎
Proof of Theorem 4.8.
We divide the proof into a few key Claims. For every pair of vertices , define . We first lower bound .
Claim 1.
For every pair of vertices :
Proof.
The first inequality holds for any embedding since is decreasing in ; we therefore focus on the second inequality. We assume that as otherwise the claim is trivially true.
Fix and set to be the maximal integer satisfying . By definition of , we must have . We note that ; we have because and we have because .
Consider the cut . Since , by definition of a distance preserving cut, we have which implies that with probability at least , the -th coordinate and different. This implies the claim by the definition of the characteristic embedding. Formally,
| (Definition of ) | ||||
| (Definition of ) | ||||
| (Assumption on ) | ||||
thus, proving the claim. ∎
We now upper bound .
Claim 2.
For every pair of vertices :
Proof.
As before, first inequality follows from the fact that is decreasing in . We therefore focus on the second inequality. For convenience, we denote . Note that, for every scale , we have
| (2) |
By definition, the norm will merely be a summation on the above over the scales of :
We proceed to bound this summation by bounding individual summands corresponding to manageable scales with the properties of our distance preserving cuts from Section 4.1.
We divide the above sum into three parts depending on the relationship the parameters and :
-
•
Case 1: . For these , we simply bound with .
-
•
Case 2: . In this case, since the cut is distance preserving, we must have .
-
•
Case 3: . Since is distance preserving, we we know that .
We proceed to combine the three cases. We first note that any in Case satisfies which means or equivalently . Therefore,
As for Case 3,
| (3) |
where fore the final inequality we have used the assumption .
We proceed to bound . Let be the constant such that . In order for to satisfy , we must have which means and which means . It follows that
which is . Plugging this back in Equation (3) we obtain
Combining the two claims, we have the result of Theorem 4.8. ∎
B.2 Dynamic Algorithm
Proof of Theorem 5.1.
The decremental algorithm uses instances of algorithm with the given choice of parameters which allows us to follow the argument provided for the static case in Section 4. Let for . The -th instance of the algorithm maintains a -distance preserving cut . The final embedding is the characteristic embedding of the cuts and parameters . Formally, we set the -th coordinate of to be if and to otherwise.
Upon the arrival of a decremental change, the algorithm inputs this change into every instance of the dynamic decremental algorithm it runs. By assumption on the input algorithm , each run explicitly outputs changes to the structure of the -th cut. Therefore, the main algorithm can adapt to these changes by appropriately changing the coordinates of vertices. Specifically, if a vertex is removed from the -th cut its coordinate changes from to and if it is added the opposite change takes place. Since processing each such change takes constant time, and there are updates in total by assumption on , the total time for the -th instance is . Therefore, by charging the time used for these changes to the total update time of instances of the algorithm , the total running time of the decremental algorithm is at most . As for the distortion, by assumption on algorithm , each run maintains a -distance preserving cut. Thus, the stretch of the maintained embedding follows from applying Theorem 4.8. ∎
Proof sketch of Lemma 5.2.
At a high level, the dynamic algorithm presented in (Forster et al., 2021) for maintaining a weak decomposition undergoing edge deletions relies on the concept of assigning a center to each cluster in the decomposition, an idea initially introduced in (Chechik & Zhang, 2020).
This technique employs a dynamic Single Source Shortest Paths (SSSP) algorithm (specifically, the SSSP algorithm described in (Henzinger et al., 2018)) to monitor the distances from a center to every vertex within the cluster. Whenever an edge is deleted, the change is also updated to the SSSP algorithm. The SSSP algorithm then outputs vertices from the cluster whose distance to the center is greater than a certain threshold, and such that keeping these vertices within the cluster could potentially violate the requirements of a -weak decomposition. To prevent this event, an appearance of such a vertex incurs either a re-centering of the current cluster or splitting the cluster into two or more disjoint new clusters. These operations ensure that eventually the diameter of each cluster satisfies the requirements of the -weak decomposition. Crucially, the authors show that the number of times a cluster is re-centered can be bounded by , for some absolute constant . On the other hand, the splitting procedure is designed in such a way that the size of a cluster that is split from the previous cluster shrinks by at least a factor of . As a result, any vertex can be moved to a new cluster at most times.
Now, the crucial observation that allows us to carry the approach to the case of edge weight increases is the fact that the SSSP algorithm of (Henzinger et al., 2018) also handles edge weight increases while preserving the same complexity bounds. The algorithm then is the same as in (Forster et al., 2021) with the only change that, to monitor distance from a center of a cluster to every other vertex, we use the SSSP version that supports edge weights increases. As for the correctness part, we can carry the analysis from (Forster et al., 2021) with minor changes. In Lemma 3.3, we show that the probability of being an inter-cluster edge is at most , where denotes the weight of edge in the current dynamic graph after updates. This, by the union bound, implies that for every pair of vertices it holds . From the fact that weight updates only increase distances, we observe that Lemmas 3.5 and 3.6 from (Forster et al., 2021) still hold (here, it is also important that updates are independent of the algorithm, which is also true in our model). This observation ultimately gives us that each cluster undergoes a center re-assignment at most times. As a consequence, our derivation of total update time follows from the one in (Forster et al., 2021) with the change that we account time to parse all updates since each edge is present in at most different SSSP instances in their algorithm. ∎
Proof of Lemma 5.3.
Let the graph denote the graph obtained by replacing all edges in with weight with weight . It is easy to see that we can maintain the graph with total update time; we start by preprocessing at the beginning of the algorithm. Next, whenever there is an update to an edge weight, we pass the update along to if the new values of the weight is strictly larger than and ignore it if it is at most . Note that in the latter case the old value is at most as well since we only allow edge-weight increases.
We then use the dynamic decremental algorithm from Lemma 5.2 for the choice of parameters and on the graph . As a consequence of the initialization, a -weak decomposition of the preprocessed is computed. Denote the clusters of this decomposition . We claim that the clusters satisfy the following properties.
-
•
The weak diamater of any in is at most .
-
•
For any , the probability that they are in different clusters is at most .
-
•
Any such that are in the same cluster.
We start with the first property. By definition of a -weak decomposition, if then and are in different clusters. We note however that ; this is because any path connecting and in has at most edges that with replaced weights. Choosing , it follows that for all and in the same cluster. For the second property, we note that the probability that and are in different clusters is at most , and therefore the property follows from . Finally, for the third property, it holds because any two such vertices will have distance in and therefore are always in the same cluster.
After initialization, the algorithm samples uniform and independent values from , one value for each cluster. Next, a cut of is created by grouping vertices from clusters that have been assigned value , denoting this side of the cut . By Lemma 4.6, we have that the cut is a -distance preserving cut. We also note that the cut can be generated with additive overhead to the time complexity of the dynamic decremental algorithm from Lemma 5.2.
Finally, we discuss the algorithm action upon a decremental update of an edge. As mentioned, we maintain by forwarding the update of an edge if necessary depending on whether the new weight is or . The update to is then in turn forwarded to the algorithm that dynamically maintains -weak decomposition of . According to Lemma 5.2, the only changes to the partitioning occur when splitting an existing cluster into two or more new clusters and members of the new clusters need to be explicitly listed. Let be the set of these newly formed clusters. The main algorithm temporarily deletes the vertices belonging to clusters from the dynamic cut it maintains. Then, for each new cluster, it samples independently and uniformly a value from . Again, vertices from clusters that have been sampled are added to those who already had (before the decremental update), while the ones who have just sampled are assigned to the other side of the cut. Since the decremental change is oblivious to the randomness of the algorithm, the random bits assigned to all clusters of the new partitioning obtained from the decremental update are distributed i.i.d. according to a Bernoulli distribution with parameter , and by applying Lemma 4.6 we obtain that the updated cut is also a -distance preserving cut. As for the time complexity, we can observe that the number of changes made to the structure is linearly proportional to the number of vertices changing a cluster after an update. It, therefore, follows that the total update time needed for maintaining the cut is dominated by the time needed to report the changes in the dynamic partitioning, and according to Lemma 5.2, is at most . ∎