Dynamic Human Digital Twin Deployment at the Edge for Task Execution: A Two-Timescale Accuracy-Aware Online Optimization
Abstract
Human digital twin (HDT) is an emerging paradigm that bridges physical twins (PTs) with powerful virtual twins (VTs) for assisting complex task executions in human-centric services. In this paper, we study a two-timescale online optimization for building HDT under an end-edge-cloud collaborative framework. As a unique feature of HDT, we consider that PTs’ corresponding VTs are deployed on edge servers, consisting of not only generic models placed by downloading experiential knowledge from the cloud but also customized models updated by collecting personalized data from end devices. To maximize task execution accuracy with stringent energy and delay constraints, and by taking into account HDT’s inherent mobility and status variation uncertainties, we jointly and dynamically optimize VTs’ construction and PTs’ task offloading, along with communication and computation resource allocations. Observing that decision variables are asynchronous with different triggers, we propose a novel two-timescale accuracy-aware online optimization approach (TACO). Specifically, TACO utilizes an improved Lyapunov method to decompose the problem into multiple instant ones, and then leverages piecewise McCormick envelopes and block coordinate descent based algorithms, addressing two timescales alternately. Theoretical analyses and simulations show that the proposed approach can reach asymptotic optimum within a polynomial-time complexity, and demonstrate its superiority over counterparts.
Index Terms:
HDT, end-edge-cloud collaboration, placement and update, accuracy awareness, two-timescale online optimization1 Introduction
Human digital twin (HDT) is defined as a paradigm that can vividly characterize the replication of each individual human in the virtual space while real-time reflecting its actual physical and mental status in the physical space [1], [2]. With the personalized status information maintained in a high-fidelity virtual environment, HDT can be regarded as a “sandbox”, where complex tasks for human-centric services (e.g., activity recognition [3] and vital signal measurement [4]) are able to be repeatedly simulated and tested, guiding the practical implementation. Because of the large potential in assisting complex task execution with human-centric concerns, HDT has been envisioned as a key enabler for Metaverse, Healthcare 5.0, Society 5.0, etc., attracting significant attentions recently [5].
Essentially, the HDT system consists of a number of physical twin (PT) and virtual twin (VT) pairs, where PT stands for the physical entity (i.e., human) and VT represents the corresponding virtual model [6]. Obviously, the successful realization of HDT largely depends on the well construction and management of VT, so as to provide fast-responsive interactions and high-accurate task execution for its paired PT. These requirements prompt the adoption of end-edge-cloud collaborative framework [7], by which HDT can be built and operated at the network edge (while supported by both end devices and the cloud center), guaranteeing pervasive connectivities, customized services and low-delay feedbacks. Although some preliminary efforts have been dedicated on studying similar problems, such as industrial digital twin construction at the edge [8], [9], [10] and service application deployment across edges [11], [12], [13], establishing HDT at the edge for assisting task execution particularly involves some fundamentally different and unique issues that remain unexplored but are of great importance. On one hand, different from position-fixed industrial plants, PTs in the HDT system are highly mobile with unpredictable mobility patterns (including positional and postural variations), leading to potential instability of PT-VT connectivities [1]. Therefore, to guarantee seamless PT-VT interactions, it is necessary to dynamically place the associated VT of each PT on the edge server (ES) that this PT may switch its access to (caused by the random mobility). On the other hand, unlike generalized applications requesting encapsulated services, PTs in the HDT system are extremely personalized and their status may vary frequently by uncertain external factors or physiological state changes, resulting in the potential inconsistency between each PT and its associated VT [14]. Hence, to keep up-to-date high-fidelity VTs, it is necessary to keep the associated VT on the ES updated in a real-time manner (especially for the customized part).
Nevertheless, meeting all aforementioned requirements are very challenging because of the following reasons.
-
1)
To enhance the accuracy of complex task execution assisted by HDT, it is required to construct fine-grained VTs on ESs (by both dynamically place generic models via the cloud and update customized toppings via sensors worn on PTs). However, the data brought by VT constructions can be massive [15], inherently increasing the service delay and energy consumption, and thus the data size of generic model placement and customized model update should be carefully optimized for striking a balance between accuracy and cost. On top of this, considering that the ultimate goal is to assist the task execution, how to timely and efficiently offloading tasks from PTs to ESs (containing associated VTs) should also be jointly considered with VT constructions, because both of them share the same communication and computation resources.
-
2)
Since HDT is time-varying evolutionalized with uncertain PT-VT mobility and status variations, the system optimization has to be conducted online while the statistics of future information (related to human activities) may be hard to obtain, if not impossible [16]. Moreover, the dynamic placement of generic VT models is triggered by PTs’ mobility and access handover among different ESs, which usually happens over a long time period. In contrast, the dynamic update of customized VT models and the complex task offloading are triggered by PTs’ status variations, which may need to be adapted in a much higher frequency. These indicate that such actions for system optimization should be performed asynchronously in different timescales.
To tackle the aforementioned difficulties, in this paper, we propose a novel two-timescale accuracy-aware online optimization approach for building HDT in assisting complex task execution under an end-edge-cloud collaborative framework. Specifically, we consider that each PT’s associated VT (deployed on the ES) consists of a generic model placed by downloading experiential knowledge (e.g., feature parameters and weights) from the cloud center and a customized model updated by uploading personalized data (e.g., behavior characteristics) from sensors worn on the PT. With the objective of maximizing the average accuracy of complex task execution assisted by HDT under stringent energy and delay constraints, and by taking into account the system uncertainties (e.g., random mobility and status variations), we formulate a two-timescale online optimization problem. Particularly, we aim to dynamically optimize i) large-timescale decisions, including the granularity of each PT’s experiential knowledge for placing its generic VT model and the ES access selection of each PT, and ii) small-timescale decisions, including the amount of each PT’s personalized data for updating its customized VT model, task offloading decision (i.e., local computing or edge computing) for each task, and communication and computation resource allocations of each ES. To this end, we develop a novel two-timescale accuracy-aware online optimization approach (TACO) based on the improved Lyapunov optimization. Specifically, the long-term problem is first decomposed into a series of short-term deterministic subproblems with different timescales, and then an alternating algorithm is proposed, integrating piecewise McCormick envelopes (PME) and block coordinate descent (BCD) based methods, for iteratively solving these subproblems. Theoretical analyses show that the proposed approach can produce an asymptotically optimal outcome with a polynomial-time complexity.
The main contributions of this paper are summarized in the following.
-
•
To the best of our knowledge, we are the first to study the HDT deployment at the network edge for assisting human-centric task execution by formulating a two-timescale accuracy-aware online optimization problem, which jointly optimizes VTs’ construction (including dynamic generic model placement and customized model update) and PTs’ task offloading together with the management of PT-ES access selection and corresponding communication and computation resource allocations.
-
•
We propose a novel approach, called TACO, which first decomposes the long-term optimization problem into multiple instant ones. Then, we leverage PME and BCD based algorithms for alternately solving the decoupled subproblems in the large-timescale and small-timescale, respectively.
-
•
We theoretically analyze performance of the proposed TACO approach by rigorously deriving the gap to optimum and the computational complexity in the closed-form. Furthermore, extensive simulations show that the proposed TACO approach can outperform counterparts in terms of improving the HDT-assisted task execution accuracy, and reducing the service response delay and overall system energy consumption.
The rest of this paper is organized as follows. Section 2 reviews the recent related work and highlights the novelties of this paper. Section 3 describes the considered system model and the problem formulation. In Section 4, the two-timescale accuracy-aware online optimization approach, i.e., TACO, is proposed and analyzed theoretically. Simulation results are presented in Section 5, followed by the conclusion in Section 6.
2 Related Work
As one of the key enabler for emerging applications, HDT has recently drawn a lot of research attentions from both academia and industry. For example, Lee et al. in [17] proposed a large-scale HDT construction framework on the cloud server integrated with a synchronization mechanism to reduce system overall data transmission cost. Zhong et al. in [18] introduced a bidirectional long short-term memory based algorithm in designing high-fidelity HDT model with multimodel data on the cloud platform. In [19], Liu et al. developed a cloud HDT based healthcare system by optimizing a patient-data processing workflow to improve the quality of personal health management. However, these papers were mainly restricted to constructing HDT sorely on the cloud server, ignoring the potential of utilizing network edge resources for empowering HDT with the capability of providing pervasive, customized and low-delay services.
While deploying HDT at the network edge has rarely been investigated, some researchers have dedicated in studying the general DT construction at the edge. Dong et al. in [9] proposed a deep learning algorithm for constructing DTs of the mobile edge network, aiming to minimize the normalized energy consumption through the optimization of user associations, resource allocations and offloading probabilities. Zhang et al. in [10] formulated a DT adaptive placement and transfer problem to minimize the DT synchronization delay, which were then solved by the double auction based optimization. Nevertheless, these papers considered that DTs were constructed on fixed locations or placed following pre-known mobility patterns, making them unsuitable for HDT with human-centric features, where PTs are highly mobile with unpredictability. Another stream of related works have been conducted on general mobile service application deployment across edges. For instance, Wang et al. in [11] developed a user-centric learning-driven method for deploying and migrating delay-aware service applications to minimize the total service delay of mobile users. Ouyang et al. [12] formulated a dynamic service deployment problem with the objective of minimizing the user-perceived delay under the uncertain user mobility. However, in these papers, service applications were assumed to have limited and encapsulated types, meaning that they are not customized and do not need to be updated, which largely differ from those of HDT (where on-demand evolution is essential).
To guarantee the long-term performance in online problems, Lyapunov optimization method has been widely recognized as an efficient approach [20], [21], [22], yet most of existing solutions were restricted to problems with decisions in the single timescale only. Recently, some preliminary studies [23], [24] have delved into designing two-timescale Lyapunov methods, by which the original problem was decomposed and further decoupled into subproblems in two different timescales independently and then optimized separately. Besides these, in [16], [25], alternating algorithms were developed in addition to the Lyapunov framework to tackle subproblems in two timescales with coupled relationships but are both convex (or can be easily converted into convex forms). However, these solutions cannot be directly applied in this paper because the considered subproblems (after the decomposition) are not only tightly coupled but also highly non-convex.
In summary, different from all the existing works, this paper proposes a novel two-timescale accuracy-aware online optimization approach to jointly optimize the HDT deployment (i.e., generic placement and customized update of VT model) and task offloading under an end-edge-cloud collaborative framework, where the novelty lies in not only the system model but also the solution.
3 System Model and Problem Formulation
In this section, we first provide a system overview on how HDT is deployed and functioned on ESs. Then, to be more specific, the generic VT model placement in the large-timescale and the customized VT model update together with the task offloading in the small-timescale are described. After that, aiming to enhance the accuracy of complex task execution assisted by HDT, a two-timescale online optimization problem is formulated.
3.1 System Overview
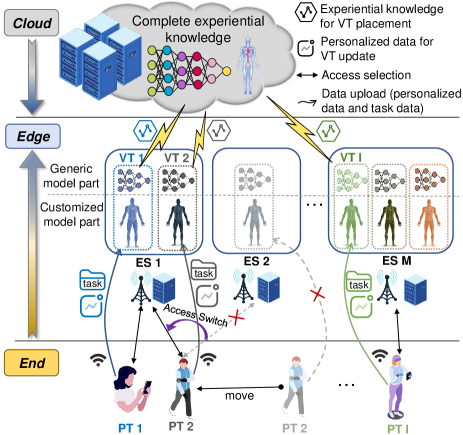
Consider an HDT system building upon an end-edge-cloud collaborative framework, as illustrated in Fig. 1, consisting of a set of end users (regarded as PTs) with cardinality of , multiple geographically distributed ESs denoted as with , and a cloud center (acting as the central controller). PTs (roaming around) generate streams of complex tasks which require the construction of exclusive VT models (forming one-to-one PT-VT pairs) at the edge to assist their task executions. Each VT should be deployed on the ES to which its associated PT may access for offering high-quality and low-delay services. Note that one ES can host multiple VT models for different PTs, and the corresponding communication and computation resources are shared among them. Furthermore, the construction of a high-fidelity VT on the ES consists of two main procedures, i.e., generic model placement and customized model update [26]. For each VT, the generic part of the model is obtained by downloading the experiential knowledge with a selected granularity111Selecting a large (small) granularity of experiential knowledge for generic model placement may increase (decrease) the fidelity of the VT model, while also introducing a large (small) amount of data to be transferred, resulting in high (low) service delay and energy consumption. from the cloud center, and the target ES for its placement is determined following the access selection of the associated PT. By contrast, the customized part of each VT model is updated by uploading the personalized data with an optimized data size222The required size of personalized data for customized model update affects not only the fidelity of the VT model, but also the uplink communication and computation resource allocations among different PT-VT pairs and between their data transmission and task offloading. obtained from sensors worn on the associated PT. After VT establishment, PTs’ tasks can be either transmitted (offloaded) to VTs deployed on the ES or processed locally, depending on the demands of task execution accuracy versus the requirements of service delay and energy consumptions. It is worth noting that although VT models are not able to be built locally, PTs’ tasks can be executed by running offline service applications pre-installed on PTs, which are much less powerful but do not require to be real-time updated.
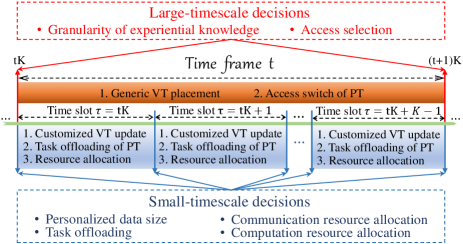
In practice, the dynamic placement of generic VT model and ES access handover of each PT commonly happen in a low frequency (i.e., over a large-timescale)333Particularly, frequently downloading experiential knowledge and switching access points can lead to large configuration costs, including the dramatic increase of delays and energy consumptions [5]., while the update of customized VT models and task offloading together with corresponding communication and computation resource allocations require immediate and frequent adaptation to accommodate the status variation of PT and its task generations [2]. To this end, we define that in the considered online optimization framework, the access selection of each PT and the granularity of experiential knowledge for its generic VT model placement are decided in the large-timescale, while the amount of personalized data for its customized VT model update, task offloading, communication and computation resource allocations are decided in the small-timescale, as shown in Fig. 2. Specifically, the timeline is segmented into coarse-grained time frames, and each frame can be further divided into a combination of fine-grained time slots. Let be the index of the -th time frame, and define as the index of the -th time slot in the -th time frame.
Overall speaking, we target to optimize the long-term system performance (i.e., the average accuracy of complex task execution assisted by HDT under stringent delay and energy consumption constraints) by determining i) which ES should be selected to access for each PT and what level of granularity of the experiential knowledge should be chosen for placing its generic VT model on the ES in each time frame, and ii) how large the personalized data is required for updating the customized part of each VT model and whether the task of each PT should be processed locally or on the ES (deployed with its associated VT) together with communication and computation resource allocations in each time slot, in an online manner. For convenience, all important notations in this paper are listed in Table I.
| Symbol | Meaning |
|---|---|
| task execution accuracy for PT in time slot | |
| access selection of PT in time frame | |
| total bandwidth resource for accessing ES | |
| bandwidth resource allocation of PT in time slot | |
| total experiential knowledge of PT in time frame | |
| energy consumption of downloading the experiential knowledge of PT in time frame | |
| energy consumption of placing generic VT model in ES in time frame | |
| energy consumption of uploading the personalized data from PT to ES in time slot | |
| energy consumption of updating the customized VT model on the ES in time slot | |
| energy consumption of transmitting task data of PT to ES in time slot | |
| energy consumption of executing PT ’s task | |
| total computation resource of PT ’s local device | |
| total computation resource of ES for all VTs | |
| computation resource allocation of PT in time slot | |
| set of end users (PTs) / corresponding VTs | |
| set of ESs | |
| transmission rate between PT and ES in time slot | |
| total personalized data generated by PT in time slot | |
| delay of downloading the experiential knowledge of PT in time frame | |
| delay of placing generic VT model on ES | |
| delay of uploading the personalized data from PT to ES in time slot | |
| delay of updating customized VT model on the ES | |
| delay of transmitting task data of PT to ES | |
| delay of task execution of PT in time slot | |
| Lyapunov control parameter | |
| experiential knowledge granularity for generic model placement of PT in time frame | |
| personalized data size for customized model update of PT in time slot | |
| task offloading of PT in time slot |
3.2 Generic VT Model Placement
Since PTs are mobile, to construct VT for each of them at the network edge so as to enable seamless PT-VT interactions, the generic VT model should be re-displaced on the ES that its associated PT switches its access to in each time frame . Denote as the access selection decision in the large-timescale indicating whether PT selects to access ES or not in time frame , i.e., if PT connects to ES , and otherwise. Obviously, we should have , meaning that PT cannot access multiple ESs simultaneously [16]. For each PT , its generic VT model is placed on the accessed ES by downloading a certain granularity of experiential knowledge from the cloud center. We define that the full experiential knowledge of each PT for its generic VT model placement has a total size of , and denote as its decision of granularity in time frame . Then, the data size of downloading the experiential knowledge for placing PT ’s VT model in time frame can be represented as . Based on these, the corresponding delay and energy consumption of downloading such experiential knowledge can be respectively expressed as444Note that even for a special case that PT ’s access selection remains unchanged, it is still necessary to periodically replace its generic VT model on the same ES, because the experiential knowledge may experience “data drift” over the time [27].
| (1) |
| (2) |
where and stand for the downlink transmission rate and unit transmission power from the cloud center to each ES, respectively, which are both considered as constants [25], [28].
To exploit this experiential knowledge, each ES has to allocate a proportion of its computation resource for completing the generic VT model placement at the beginning of each time frame. The delay of doing this for PT on ES in time frame can be calculated as
| (3) |
where is the number of CPU cycles required for ES to process a unit of data, is the CPU speed (measured by cycles/s) of ES , and represents the ratio of computation resource allocated to PT for its VT construction at the beginning of time frame (i.e., the first time slot of the frame with ). Referring to the energy model widely used in CMOS circuits[29], the energy consumption of constructing the generic VT model of the associated PT on the ES in each time frame can be calculated as
| (4) |
where is the effective switched capacitance of ES depending on its chip architecture.
3.3 Customized VT Model Update
Since PTs are personalized and their status may vary frequently due to uncertain external or internal factors, to guarantee the timeliness and high-fidelity of VTs on ESs, the customized VT model of each PT should be updated in each time slot . Let be the total amount of personalized data generated by PT , and define as the percentage of personalized data chosen to be uploaded in time slot . Then, the size of personalized data uploaded for updating PT ’s customized VT model in time slot can be expressed as .
Within each time slot , we denote the location of PT as , which is a state information following its random mobility pattern, and let be the fixed location of each ES . The distance between any PT and ES can then be calculated as , and according to Shannon-Hartley formula, the transmission rate from PT to its accessed ES is written as
| (5) |
where is the proportion of communication resource allocated to PT in time slot , is the fading amplitude between PT and ES in time slot (modeled as a circularly symmetric complex Gaussian random variable [30]), is the communication bandwidth of ES , is the spectral density of the channel noise power, is the pre-determined transmission power of PT , and is the path loss exponent [30]. Correspondingly, the delay and energy consumption of PT in uploading the personalized data with size for updating its VT on ES in each time slot can be respectively expressed as
| (6) |
| (7) |
To utilize this personalized data, each ES has to allocate a proportion of its computation resource for completing the customized VT model update in each time slot. The delay of doing this for PT on ES in time slot can be calculated as
| (8) |
where indicates the proportion of computation resource allocated to PT for its VT update in each time slot . Besides, the corresponding energy consumption can be calculated as
| (9) |
3.4 HDT-Assisted Task Execution
Let be the data size of the complex task produced by PT in each time slot , which is allowed to follow a general random distribution. Denote the task offloading decision of PT in time slot as , i.e., if PT offloads the task to its VT on the ES for assistance, and if PT processes it locally. The delay and energy consumption of offloading/transmitting such task from PT to its associated VT deployed on the ES in time slot can be respectively expressed as
| (10) |
| (11) |
Considering the possibility of both edge and local processing, the delay of HDT-assisted task execution of PT in time slot can be calculated as
| (12) | ||||
where is the number of CPU cycles required for PT to locally process a unit of data, and denotes its CPU speed (measured by cycles/s). Besides, the corresponding energy consumption can be calculated as
| (13) | ||||
With the help of HDT at the edge, the accuracy of executing each task from PT in each time slot can be defined as
| (14) |
where represents the task execution accuracy of local processing on PT itself, and stands for the task execution accuracy of edge computing for PT depending on the total size of data used for its VT construction, i.e., , consisting of both experiential knowledge for generic VT model placement in the large-timescale and personalized data for customized VT model update in the small-timescale. Note that is a mapping function that can be obtained via empirical studies or experiments [31].
Similar to [29], [32], we ignore overheads induced by computing outcomes feedback and system control signals. This is because the size of computing outcomes and control signals are much smaller than that of the input data. Technically, these overheads can be seen as small constants [33], which will not affect our analyses.
3.5 Problem Formulation
In summary, the total response delay for all tasks of PT in each time frame can be derived as
| (15) | ||||
and the system overall energy consumption in each time frame can be derived as
| (16) |
To evaluate the core value of building HDT at the network edge, we take the long-term average accuracy of complex task execution assisted by the considered end-edge-cloud collaborative HDT system over all time frames as the performance measurement, which can be expressed as
| (17) |
With the objective of maximizing while ensuring that the response delay for all tasks of each PT and the overall system energy consumption do not exceed certain thresholds, we formulate a two-timescale online optimization problem by jointly optimizing and , denoted in short by a set of large-timescale decision variables , for each PT in any time frame , and , , and , denoted in short by a set of small-timescale decision variables , for each PT in any time slot .
Mathematically, such a two-timescale online optimization problem can be formulated as
| (18a) | |||
| (18b) | |||
| (18c) | |||
| (18d) | |||
| (18e) | |||
where constraint (18a) guarantees that one PT can connect to at most one ES in each time frame ; constraints (18b) and (18c) restrict that the communication and computation resource allocation should be less than the total capacities of each ES in any time slot ; constraints (18d) and (18e) are the long-term average task response delay and system overall energy consumption constraints (in which and represent the pre-determined response delay threshold of each PT and the overall system energy consumption threshold, respectively).
Obviously, solving problem directly is very challenging because PTs’ mobilities and status variations, due to human-related characteristics, are highly unpredictable, meaning that it is extremely hard, if not impossible, to obtain system statistics in advance, which necessitates the design of an online optimization algorithm; although Lyapunov optimization [34] is well-known as an effective method to solve such an online problem in general, decision variables in different timescales (i.e., and ) are tightly coupled in not only the objective function but also constraints (18d) and (18e); and all constraints include discrete decision variables (i.e., or ), and constraints (18d) and (18e) are both non-convex. These indicate that is a two-timescale online non-convex mixed integer programming problem, which must be NP-hard.
4 A Two-Timescale Online Optimization Approach (TACO)
In this section, we propose a novel approach, namely TACO, for jointly optimizing VT construction and task offloading in the considered end-edge-cloud collaborative HDT system. Specifically, we first reformulate the two-timescale problem by distributing the task response delay and system overall energy consumption of each time frame into each of its contained time slot . Then, we decompose the problem into multiple short-term deterministic subproblems of different timescales with the help of Lyapunov optimization method but with a two-timescale extension. After that, we introduce an alternating algorithm integrating PME and BCD methods to solve subproblems in the large-timescale and small-timescale, respectively.
4.1 Problem Reformulation
Observed from problem that the delay and energy consumptions caused by the generic VT model placement are on the large-timescale, while those caused by customized VT model update and task execution are on the small-timescale. To facilitate the solution, we evenly distribute the task response delay and system overall energy consumption in each time frame into all time slots within this frame, which yields
| (19) | ||||
| (20) |
Substituting (19) and (4.1) into (18d) and (18e) of problem , we have
| (21a) | |||
| (21b) | |||
Note that the reformulated problem is equivalent to the original problem with exactly the same decision variables remaining in two different timescales, while all long-term constraints have been unified into a single timescale (i.e., in terms of the time slot only) but will not affect the optimization performance.
Obviously, is still a long-term optimization problem, and the major difficulties for solving it are i) how to address the long-term average delay and energy consumption constraints; and ii) how to optimize two-timescale decision variables simultaneously. To this end, in the next subsection, we employ the Lyapunov method [34], and reformulate to accommodate the two-timescale features.
4.2 Problem Decomposition
We first define a delay overflow queue and an energy deficit queue to respectively describe how task response delay of each PT and the overall system energy consumption in time slot may deviate from the long-term budget and . The dynamic evolution of these two queues can be expressed as
| (22) |
| (23) |
After that, we combine the delay overflow queue for all tasks of PTs and energy deficit queue by a vector as , and introduce a quadratic Lyapunov function as [34]:
| (24) |
which quantitatively reflects the congestion of all queues, and should be persistently pushed towards a minimum value to keep queue stabilities. Referring to [35], the conditional Lyapunov drift is given by
| (25) |
where denotes the expectation, and measures the difference of the Lyapunov function between consecutive time slots. Intuitively, by minimizing the Lyapunov drift in (25), we can prevent queue backlogs from the unbounded growth, and thus guarantee that the desired delay and energy consumption constraints can be met.
Accordingly, the Lyapunov drift-plus-penalty function becomes
| (26) |
where a control parameter is introduced, representing the weight of significance on maximizing the HDT-assisted task execution accuracy versus that of strictly satisfying the delay and energy consumption constraints.
Theorem 1
Let , and the drift-plus-penalty is bounded by any possible decisions in any time slot , i.e.,
| (27) | ||||
where
is a positive constant that adjusts the tradeoff between the HDT-assisted task execution accuracy and the satisfaction degree of the delay and energy consumption constraints.
Proof:
Please see Appendix A. ∎
Theorem 1 shows that the drift-plus-penalty is deterministically upper bounded in each time slot . Then, taking the sum over all time slots within time frame for both sides of (27), we have
| (28) |
Then, can be decomposed into multiple subproblems, each of which opportunistically minimize the right-hand-side of (4.2) in one time frame , i.e.,
Note that, in problem , decisions and remain unchanged as those in . This means that, although focuses on the optimization in a single time frame, it still includes two-timescale variables.
4.3 Alternating Algorithm between Two Timescales
4.3.1 Two-Timescale Decoupling and Alternation
To solve problem , we can decouple it into two subproblems (one for the large-timescale, and the other for the small-timescale), and then solve them alternately till the convergence.
Large-timescale Problem: Given the small-timescale decision together with the current backlogs of delay overflow queues of all PTs and the system energy consumption deficit queue , the large-timescale subproblem aims to jointly optimize the granularity of experiential knowledge and access selection at the beginning of each time frame , which can be formulated as
Small-timescale Problem: Given the large-timescale decision , the small-timescale subproblem targets to jointly optimize the personalized data size , bandwidth resource allocation , computation resource allocation and task offloading in each time slot , which can be formulated as
Alternating Process: For (i.e., the beginning of each time frame), we iteratively optimize subproblems and until the objective of converges. Specifically, by fixing small-timescale decisions as (inherited from the last time slot of the previous time frame ), large-timescale subproblem is first solved to optimize . Then, given large-timescale decisions , small-timescale subproblem is solved to update , which is returned back to . For each (i.e., the rest of each time frame), with the optimized large-timescale decisions after the convergence, we repeatedly solve to obtain in each time slot.
4.3.2 Solution for Large-Timescale Decisions
Large-timescale subproblem is non-convex in general, but can be regarded as a bilinear optimization problem (i.e., the problem is linear if we fix one decision variable and optimize the other one within ). This motivates us to design a PME-based algorithm [36], which first constructs convex envelops for bilinear terms, transforming the problem to a piecewise linear form, and then solves it by partitioning and pruning.
Let be an auxiliary variable of bivariate . Then, can be relaxed into a convex optimization problem as
| (29a) | |||
| (29b) | |||
| (29c) | |||
| (29d) | |||
where constraints (29a)-(29d) are the corresponding relaxed ones on bivariate .
Next, to improve the solution quality, we divide and into partitions. Specifically, let be the range of in partition , where and are its lower and upper bounds, respectively. Besides, a new auxiliary variable is introduced, where if the value of belongs to partition , and otherwise. Similarly, the binary variable is first relaxed into a continuous variable and then divided into piecewise areas, where the range of partition is . Based on these, can be converted into a generalized disjunctive programming problem as
| (41) | |||
Then, by applying the convex hull relaxation [37], [38], we can further transform problem into a piecewise linear form as
To this end, we prune and to tighten their relaxed bounds. By traversing each partition of , we first determine the lower bound and upper bound of by solving the following linear programming problem:
| (42) | ||||
Besides, the range of is updated as and after traversing all the partitions of . Then, after pruning all and , we can solve problem in the pruned partition with software-based optimization solvers (e.g., CVX [39]), and obtain its solution . Lastly, we round continuous variables to binary forms for obtaining integer solutions. Note that all constraints are automatically satisfied under because they have been taken into account in the pruning process of (42). The detailed steps of the designed PME-based algorithm for solving the large-timescale problem is presented in Algorithm 1.
4.3.3 Solution for Small-Timescale Decisions
Small-timescale subproblem is also non-convex in general, but by relaxing the integer decision (i.e., ), it becomes a block multi-convex problem (i.e., the problem is convex if we solve one block of decision variable while fixing the others). This motivates us to design a BCD-based algorithm by further dividing problem into four subproblems and solving them alternately until the objective function of converges.
Personalized Data Size Determination: Given , and , we have
Bandwidth Resource Allocation: Given , and , we have
Computation Resource Allocation: Given , and , we have
Task Offloading Decision: Given , and , we have
Theorem 2
Problems , , and are all convex.
Proof:
Please see Appendix B. ∎
Thanks to Theorem 2, we can easily solve problems , , and by leveraging existing software-based optimization solvers (e.g. CVX [39]). Note that all these problems have to be solved iteratively, and the iteration terminates whenever the objective of problem can no longer be enhanced. The detailed steps of the designed BCD-based algorithm for solving the small-timescale problem is illustrated in Algorithm 2.
4.4 Analysis of Proposed TACO Approach
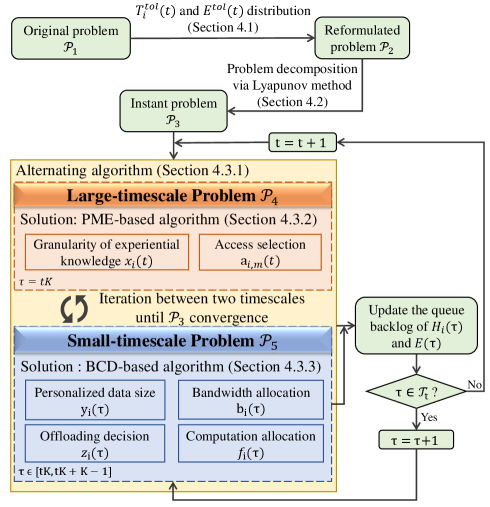
In summary, the proposed two-timescale accuracy-aware online optimization approach (TACO) consists of problem reformulation, decomposition and alternation between two timescales. The flowchart of TACO is shown in Fig. 3.
Theorem 3
The proposed TACO approach can converge with limited alternations and iterations.
Proof:
For problem , the convergence of TACO depends on that of the designed BCD-based algorithm and that of the employed alternating algorithm for problem .
First, to prove the convergence of the BCD-based algorithm, we derive the partial derivatives of the objective function of problem as follows:
| (43) | ||||
| (44) | ||||
| (45) | ||||
| (46) | ||||
Evidently, (43) and (4.4) are constants, and (4.4) and (45) are linear, meaning that all derived partial derivatives are L-lipschitz continuous according to [40], and hence the BCD-based algorithm can converge with limited iterations.
Then, to prove the convergence of the alternating algorithm, we scale the objective function of as
| (47) | ||||
where is the number of alternations. The first inequality holds due to the sub-optimality of by BCD-based algorithm, and the second inequality holds because of the sub-optimality of by PME-based algorithm. This indicates that the objective function of is monotonically decreasing along with the alternating process, and will be lower-bounded by (i.e., by setting two queue backlogs to and all to ) in finite alternations. ∎
Theorem 4
The computational complexity of the proposed TACO approach is , where is the number of PTs, is the number of ESs, is the number of partitions in the PME-based algorithm, is the number of time frames, is the number of iterations in the alternating algorithm between two timescales, and is the number of iterations in the BCD-based algorithm.
Proof:
The complexity of TACO mainly depends on the alternating algorithm integrating PME-based algorithm and BCD-based algorithm.
For the PME-based algorithm, as stated in [41], the computational complexity for obtaining an initial feasible solution is , and that of solving (42) is with the interior point method [42] in the CVX solver. Besides, the linear relaxation and linear programming for solving has an asymptotic computational complexity of [43]. For the BCD-based algorithm, the total computational complexity for solving all subproblems is with the interior point method [42] in CVX solver, and that of the linear relaxation and linear programming solver for solving is .
To sum up, the computational complexity of TACO can be expressed as . ∎
Theorem 5
Given Lyapunov control parameter , the optimality gap between the solution obtained by the proposed TACO approach and the theoretically optimal solution to problem can be expressed as
| (48) |
where stands for the theoretically optimal solution, is the optimality gap of the PME-based algorithm, represents the optimality gap of the BCD-based algorithm, and is defined in (27).
Proof:
First, inequality (4.2) can be intuitively expanded and rewritten as
| (49) | ||||
Then, by summing up (49) over time frames, we have
| (50) | ||||
Afterwards, by moving to the left-hand-side of (50), and then dividing both sides by , inequality (48) can be obtained.
Next, we further analyze the optimality gaps and as follows. For , according to [36], its value is theoretically bounded in the range of . For , by letting and be the solutions given by the BCD-based algorithm and the optimal one, respectively, and taking the subtraction between them, we have
| (51) |
where , , and , which are both constant in each time slot . ∎
5 Simulation Results
In this section, simulations are conducted to evaluate the performance of the proposed TACO approach for jointly optimizing the HDT deployment (i.e., generic placement and customized update of the VT model) and task offloading in an end-edge-cloud collaborative framework. All simulation results are obtained based on real-world datasets (including a human activity dataset [44] and an ES distribution dataset [45]), by taking averages over 1000 runs under various parameter settings.
5.1 Simulation Settings
Consider an HDT system in a square area with ESs and PTs (following a Random-Waypoint (RWP) mobility model under the same settings as those in [46]). According to [31], for the HDT-assisted complex task execution, the average accuracy of edge execution and local execution for any PT ’ s tasks are approximated as (which is a function of the total data size for PT ’s corresponding VT construction at the edge, i.e., ) and , respectively. Table II lists the values of main simulation parameters, while most of them have also been widely employed in the literature [11], [12], [20]. Furthermore, to show the superiority of the proposed TACO approach, the following schemes are simulated as benchmarks. Note that, since the original objectives of these benchmark schemes are different from ours, for the fairness of comparison, we have modified them to adapt to the considered settings and particularly changed their optimization objectives to align with ours.
-
•
LOT [20]: Generic VT model placement from the cloud and PTs’ task offloading are jointly determined by adopting a contract theory-based incentive mechanism. However, this scheme ignores the customized VT update by collecting personalized data from end devices, and it optimizes all decisions synchronously in a single-timescale only.
-
•
CRO [10]: Both generic VT model placement from the cloud and customized VT update from end devices along with PTs’ task offloading are jointly determined by adopting a double auction based optimization, while all decisions are optimized in a single-timescale for simplicity.
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| 500 mW | 5 MHz | ||
| 5 W | 20 GHz | ||
| 4 | 300 cycles/bit | ||
| -174 dBm/Hz | |||
| [6.1, 12.2] Mbits | 50 Mbps | ||
| [73.2, 97.6] Mbits | 10 | ||
| [10, 20] Mbits | 10 | ||
| 1 GHz | 40 |
5.2 Performance Evaluations
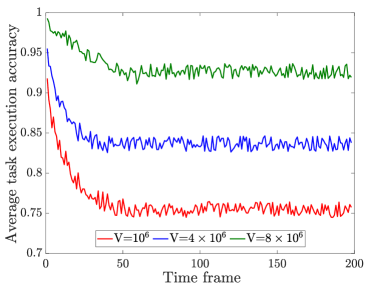
Fig. 4 examines the convergence of the proposed TACO approach in solving problem by showing the average HDT-assisted task execution accuracy under different values of parameter ranging from to . The timeline is divided into time frames, and each frame has time slots. It is shown that, for all three cases, within time frames, the task execution accuracy decreases at the beginning but quickly converges over the time, which verifies the convergence property of TACO in solving problem . Besides, from this figure, it can also be observed that the average task execution accuracy increases with . The reason is that, Lyapunov parameter is introduced to control the weight of significance on maximizing the HDT-assisted task execution accuracy versus that of enforcing the delay and energy consumption constraints, and a larger indicates more emphasis on the task execution accuracy.
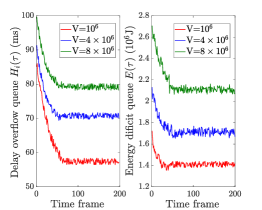
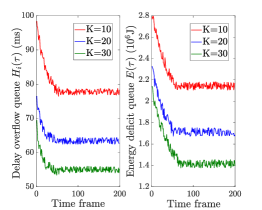
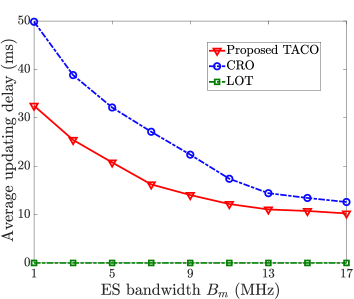
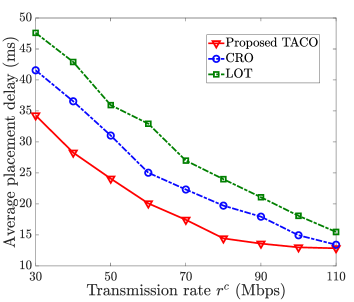
Fig. 5 demonstrates the stability of the proposed TACO approach by showing the performance of delay overflow queue backlog and energy consumption deficit queue backlog brought by the Lyapunov decomposition by varying and . From this figure, we can see that two queue backlogs decrease and quickly stabilize over the time, because TACO focuses on controlling system costs (i.e., service response delay and system energy consumption) to minimize the objective function of , thereby shrinking two queue backlogs, and can eventually achieve a well balance between the task execution accuracy and system costs, leading to a stable outcome. Besides, in Fig. 5(a), it is intuitive that both queue backlogs stabilize on higher values with the increase of as more emphasis is on maximizing the task execution accuracy, resulting in the growth of delay and energy consumption. Meanwhile, Fig. 5(b) shows that both queue backlogs stabilize on lower values with the raise of . This is because a larger value of means that generic VT models are placed with a lower frequency, and hence greatly reduces the generic VT model placement delay (i.e., ) and energy consumption (i.e., ).
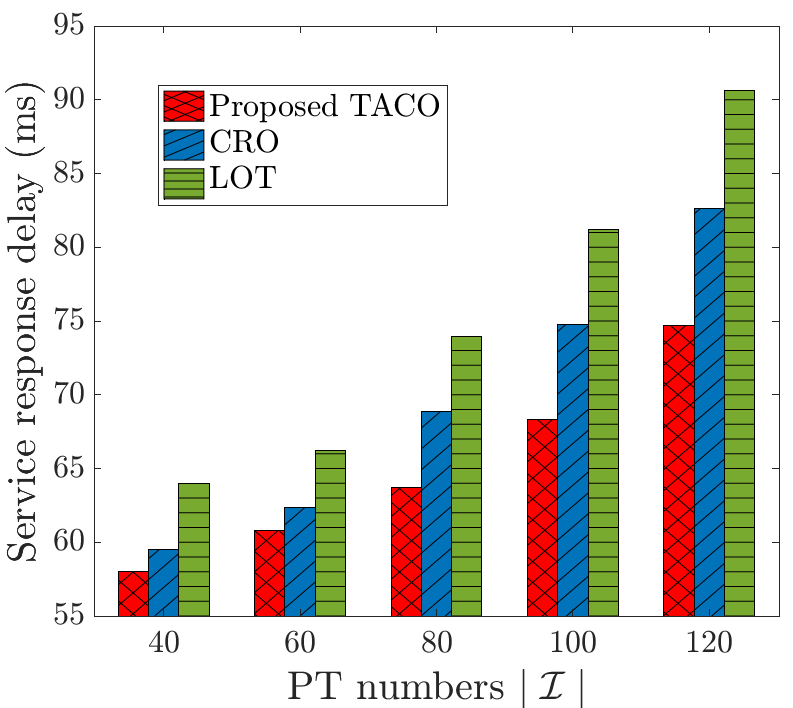
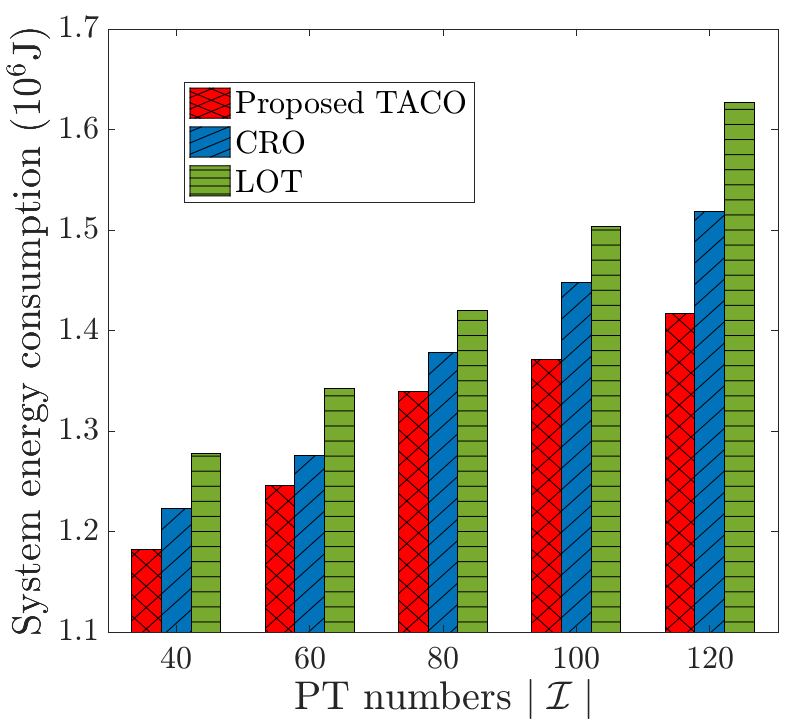
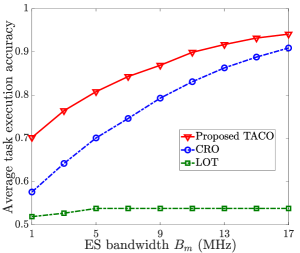
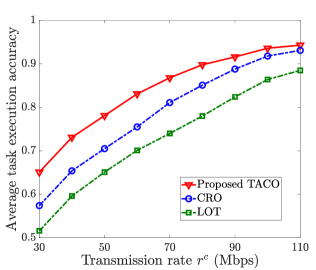
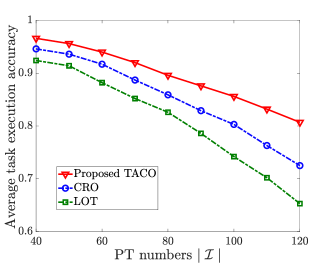
Fig. 6 illustrates the average updating delay of customized VT models (i.e., ) with different ES bandwidth under LOT, CRO and the proposed TACO approach. Since LOT ignores customized VT model update, meaning that personalized data of PTs does not need to be uploaded and processed, the average updating delay maintains as zero regardless of the ES’s bandwidth . In contrast, the average updating delay decreases with the increase of for both CRO and the proposed TACO approach due to the reduction in uploading delay , as more uplink bandwidth resource is provided. Besides, we can also see that TACO outperforms CRO because, with the help of generic VT model placement, TACO needs to upload much less personalized data than that of CRO.
Fig. 7 shows the average placement delay of generic VT models (i.e., ) with different cloud-ES transmission rate under LOT, CRO and the proposed TACO approach. It is obvious that the placement delay decreases logarithmically with the raise of for all schemes. Furthermore, from this figure, we can see that LOT has the worst performance because it ignores customized model update and can only download as much experiential knowledge as possible to improve the average task execution accuracy, resulting in the highest average placement delay. In contrast, both CRO and TACO outperform LOT due to the introduction of customized VT update, alleviating the burden on generic VT model placement. Moreover, the proposed TACO approach achieves the best performance (with the placement delay reduced by and on average compared to CRO and LOT, respectively). This is because TACO builds VTs in two timescales (with large-timescale generic model placement and small-timescale customized model update) which only requires to download experiential knowledge at the beginning of each time frame significantly reducing the total data size in the process of model placement.
Figs. 8 and 9 investigate the service response delay and system energy consumption, achieved by LOT, CRO and the proposed TACO approach with different numbers of PTs . Both figures show that the service response delay and system energy consumption increase exponentially with for all schemes, because a larger implies more demands for VT construction with potentially larger amount of data in competing limited communication and computation resources. Besides, LOT has the worst performances in these two metrics because its task execution accuracy only relies on the experiential knowledge downloaded in VT construction, and thus it has to download much larger amounts of experiential knowledge for guaranteeing a desired task execution accuracy. Meanwhile, CRO and TACO outperform LOT, especially when becomes larger, which reveals the necessity of customized VT model update in addition to generic VT model placement. Moreover, the proposed TACO approach achieves the best performance, and the reason follows the same as that in explaining Fig. 7.
Fig. 10 compares the average task execution accuracy achieved by LOT, CRO and the proposed TACO approach by varying ES’s bandwidth , transmission rate and number of PTs . It is shown that, i) in Fig. 10(a), the average task execution accuracy increases with for all schemes, except for LOT; ii) in Fig. 10(b), the average task execution accuracy increases with for all three schemes; and iii) in Fig. 10(c), the average task execution accuracy decreases with for all three schemes. The main reason is that, when more resource is supplied (i.e., and are large) or total resource demand is less competitive (i.e., is small), more experiential knowledge and personalized data can be transmitted for dynamic VT construction and more tasks can be offloaded for HDT-assisted edge execution, all contributing to the enhancement of task execution accuracy. Furthermore, from this figure, we can see that LOT has the worst performance because it only considers generic VT model placement, and CRO is better than LOT thanks to the joint consideration of both generic VT model placement and customized VT model update. Moreover, TACO achieves the best performance because it further strikes the balance of generic VT model placement and customized VT model update by conducting these two processes asynchronously in two different timescales.
6 Conclusion
In this paper, the optimization of HDT deployment at the network edge has been studied. Particularly, aiming to maximize the accuracy of complex task execution assisted by HDT under various system uncertainties (e.g., random mobility and status variations), a two-timescale online optimization problem is formulated for jointly determining VTs’ construction (including dynamic generic model placement and customized model update) and PTs’ task offloading together with the management of access selection and corresponding communication and computation resource allocations. A novel solution approach, called TACO, is proposed, which decomposes the online problem into a series of deterministic ones and then leverages PME-based and BCD-based algorithms for solving different subproblems in different timescales alternately. Theoretical analyses and simulations show that TACO is superior compared to counterparts in the optimization of HDT deployment at the edge for not only improving the HDT-assisted task execution accuracy, but also reducing the service response delay and overall system energy consumption.
References
- [1] S. D. Okegbile, J. Cai, C. Yi, and D. Niyato, “Human digital twin for personalized healthcare: Vision, architecture and future directions,” IEEE Netw., 2022.
- [2] Y. Lin, L. Chen, A. Ali, C. Nugent, C. Ian, R. Li, D. Gao, H. Wang, Y. Wang, and H. Ning, “Human digital twin: A survey,” arXiv preprint arXiv:2212.05937, 2022.
- [3] P. Thamotharan, S. Srinivasan et al., “Human digital twin for personalized elderly type 2 diabetes management,” J. Clin. Med., vol. 12, no. 6, p. 2094, 2023.
- [4] B. Björnsson, C. Borrebaeck et al., “Digital twins to personalize medicine,” Genome Med., vol. 12, pp. 1–4, 2020.
- [5] J. Chen, C. Yi et al., “Networking architecture and key supporting technologies for human digital twin in personalized healthcare: A comprehensive survey,” IEEE Commun. Surv. Tutor., 2023.
- [6] S. D. Okegbile and J. Cai, “Edge-assisted human-to-virtual twin connectivity scheme for human digital twin frameworks,” in Proc. IEEE VTC, 2022, pp. 1–6.
- [7] J. Ren, D. Zhang, S. He et al., “A survey on end-edge-cloud orchestrated network computing paradigms: Transparent computing, mobile edge computing, fog computing, and cloudlet,” ACM Comput. Surv. (CSUR), vol. 52, no. 6, pp. 1–36, 2019.
- [8] P. Jia, X. Wang, and X. Shen, “Accurate and efficient digital twin construction using concurrent end-to-end synchronization and multi-attribute data resampling,” IEEE Internet Things J., vol. 10, no. 6, pp. 4857–4870, 2022.
- [9] R. Dong, C. She et al., “Deep learning for hybrid 5G services in mobile edge computing systems: Learn from a digital twin,” IEEE Trans. Wirel. Commun., vol. 18, no. 10, pp. 4692–4707, 2019.
- [10] Y. Zhang, H. Zhang, Y. Lu, W. Sun, L. Wei, Y. Zhang, and B. Wang, “Adaptive digital twin placement and transfer in wireless computing power network,” IEEE Internet Things J., pp. 1–1, 2023.
- [11] J. Wang, J. Hu et al., “Online service migration in mobile edge with incomplete system information: A deep recurrent actor-critic learning approach,” IEEE Trans. Mob. Comput., 2022.
- [12] T. Ouyang, Z. Zhou et al., “Follow me at the edge: Mobility-aware dynamic service placement for mobile edge computing,” IEEE J. Sel. Areas Commun., vol. 36, no. 10, pp. 2333–2345, 2018.
- [13] D. Harutyunyan, N. Shahriar et al., “Latency and mobility–aware service function chain placement in 5G networks,” IEEE Trans. Mob. Comput., vol. 21, no. 5, pp. 1697–1709, 2020.
- [14] B. Wang, H. Zhou et al., “Human digital twin in the context of Industry 5.0,” Robot Comput. Integr. Manuf., vol. 85, p. 102626, 2024.
- [15] M. Lauer-Schmaltz, P. Cash et al., “Designing human digital twins for behaviour-changing therapy and rehabilitation: a systematic review,” Proc. Design Soc., vol. 2, pp. 1303–1312, 2022.
- [16] Y. Shi, C. Yi, R. Wang, Q. Wu, B. Chen, and J. Cai, “Service migration or task rerouting: A two-timescale online resource optimization for MEC,” IEEE Trans. Wirel. Commun., 2023.
- [17] D. Lee, J. Cho, and J. Kim, “Meta-human synchronization framework for large-scale digital twin,” in Proc. IEEE MetaCom, 2023, pp. 738–741.
- [18] R. Zhong, B. Hu et al., “Construction of human digital twin model based on multimodal data and its application in locomotion mode identification,” Chin. J. Mech. Eng., vol. 36, no. 1, p. 126, 2023.
- [19] Y. Liu, L. Zhang et al., “A novel cloud-based framework for the elderly healthcare services using digital twin,” IEEE Access, vol. 7, pp. 49 088–49 101, 2019.
- [20] X. Lin, J. Wu, J. Li, W. Yang, and M. Guizani, “Stochastic digital-twin service demand with edge response: An incentive-based congestion control approach,” IEEE Trans. Mob., 2021.
- [21] Y. Ding, K. Li, C. Liu, and K. Li, “A potential game theoretic approach to computation offloading strategy optimization in end-edge-cloud computing,” IEEE Trans. Parallel Distrib. Syst., vol. 33, no. 6, pp. 1503–1519, 2021.
- [22] Y. Shi, C. Yi, B. Chen, C. Yang, K. Zhu, and J. Cai, “Joint online optimization of data sampling rate and preprocessing mode for edge–cloud collaboration-enabled industrial IoT,” IEEE Internet Things J., vol. 9, no. 17, pp. 16 402–16 417, 2022.
- [23] Y. He, Y. Ren et al., “Two-timescale resource allocation for automated networks in IIoT,” IEEE Trans. Wirel. Commun., vol. 21, no. 10, pp. 7881–7896, 2022.
- [24] H. Ma, Z. Zhou, and X. Chen, “Leveraging the power of prediction: Predictive service placement for latency-sensitive mobile edge computing,” IEEE Trans. Wirel. Commun., vol. 19, no. 10, pp. 6454–6468, 2020.
- [25] R. Zhou, X. Wu, H. Tan, and R. Zhang, “Two time-scale joint service caching and task offloading for UAV-assisted mobile edge computing,” in Proc. IEEE INFOCOM, 2022, pp. 1189–1198.
- [26] W. Shengli, “Is human digital twin possible?” Comput. Methods and Programs in Biomed. Update, vol. 1, p. 100014, 2021.
- [27] J. Xie, R. Yang et al., “Dual digital twin: Cloud–edge collaboration with lyapunov-based incremental learning in EV batteries,” Appl. Energy, vol. 355, p. 122237, 2024.
- [28] M. Mohammadi, H. A. Suraweera, and C. Tellambura, “Uplink/downlink rate analysis and impact of power allocation for full-duplex cloud-RANs,” IEEE Trans. Wirel. Commun., vol. 17, no. 9, pp. 5774–5788, 2018.
- [29] C. Yi, J. Cai et al., “A queueing game based management framework for fog computing with strategic computing speed control,” IEEE Trans. Mob., vol. 21, no. 5, pp. 1537–1551, 2020.
- [30] A. Goldsmith, Wireless communications. Cambridge university press, 2005.
- [31] W. Wu, P. Yang et al., “Accuracy-guaranteed collaborative DNN inference in industrial IoT via deep reinforcement learning,” IEEE Trans. Ind. Inform., vol. 17, no. 7, pp. 4988–4998, 2020.
- [32] K.-C. Wu, W.-Y. Liu, and S.-Y. Wu, “Dynamic deployment and cost-sensitive provisioning for elastic mobile cloud services,” IEEE Trans. Mob. Comput., vol. 17, no. 6, pp. 1326–1338, 2017.
- [33] C. Yi, J. Cai et al., “Workload re-allocation for edge computing with server collaboration: A cooperative queueing game approach,” IEEE Trans. Mob. Comput., 2021.
- [34] M. Neely, Stochastic network optimization with application to communication and queueing systems. Springer Nature, 2022.
- [35] L. Georgiadis, M. J. Neely, L. Tassiulas et al., “Resource allocation and cross-layer control in wireless networks,” Found. Trends® Netw., vol. 1, no. 1, pp. 1–144, 2006.
- [36] P. M. Castro, “Tightening piecewise mccormick relaxations for bilinear problems,” Comput. Chem. Eng., vol. 72, pp. 300–311, 2015.
- [37] R. Karuppiah and I. E. Grossmann, “Global optimization for the synthesis of integrated water systems in chemical processes,” Comput. Chem. Eng., vol. 30, no. 4, pp. 650–673, 2006.
- [38] C. A. Meyer and C. A. Floudas, “Global optimization of a combinatorially complex generalized pooling problem,” AIChE J., vol. 52, no. 3, pp. 1027–1037, 2006.
- [39] C. Bliek1ú, P. Bonami, and A. Lodi, “Solving mixed-integer quadratic programming problems with IBM-CPLEX: a progress report,” in Proc. RAMP Symp., 2014, pp. 16–17.
- [40] J. Bolte, S. Sabach, and M. Teboulle, “Proximal alternating linearized minimization for nonconvex and nonsmooth problems,” Math. Program., vol. 146, no. 1-2, pp. 459–494, 2014.
- [41] T. P. Peixoto, “Efficient monte carlo and greedy heuristic for the inference of stochastic block models,” Phys. Rev. E, vol. 89, no. 1, p. 012804, 2014.
- [42] S. P. Boyd and L. Vandenberghe, Convex optimization. Cambridge university press, 2004.
- [43] A. Srinivasan, “Approximation algorithms via randomized rounding: a survey,” Adv. Topics in Math., PWN, pp. 9–71, 1999.
- [44] M. Zhang and A. A. Sawchuk, “USC-HAD: A daily activity dataset for ubiquitous activity recognition using wearable sensors,” in Proc. ACM SAGAware, Pittsburgh, Pennsylvania, USA, September 2012.
- [45] S. Telecom, “The distribution of 3233 base stations,” 2019.
- [46] D. B. Johnson and D. A. Maltz, “Dynamic source routing in ad hoc wireless networks,” Mobile Comput., pp. 153–181, 1996.
Appendix A
By squaring both sides of the delay overflow queue in (22), we have
| (52) | |||
By subtracting from both sides, dividing by 2 and summing up all inequalities for , we have
| (53) | ||||
Similarly, by squaring both sides of the energy deficit queue in (23), we have
| (54) | |||
By subtracting from both sides and dividing by 2, we have
| (55) | ||||
Lastly, by adding to both sides of (LABEL:LyapunovDrift) and taking the expectation of both sides of , inequality (27) can be derived.
Appendix B
For subproblem , the Lagrangian function is given by
| (57) | ||||
By taking the first-order and second-order derivatives of (LABEL:Ptau1), we have
| (58) | ||||
| (59) |
Since , we can conclude that problem is convex.
For subproblem , we denote as the corresponding Lagrangian multiplier, which can be expressed as
| (60) | ||||
Since in (60) decreases monotonically, it is convex when , and thus problem is convex.
For subproblem , we denote as the corresponding Lagrangian multiplier, which can be calculated as
| (61) | ||||
Taking the first-order and second-order derivatives yields
| (62) | ||||
| (63) | ||||
Obviously, when , , and thus problem is convex.
For subproblem , the Lagrangian function is given by
| (64) |
By taking the first-order derivative and second-order derivatives of (B), we have
| (65) | ||||
| (66) |
Since , problem is convex.