Dynamic Adaptation Gains for Nonlinear Systems with Unmatched Uncertainties
Abstract
We present a new direct adaptive control approach for nonlinear systems with unmatched and matched uncertainties. The method relies on adjusting the adaptation gains of individual unmatched parameters whose adaptation transients would otherwise destabilize the closed-loop system. The approach also guarantees the restoration of the adaptation gains to their nominal values and can readily incorporate direct adaptation laws for matched uncertainties. The proposed framework is general as it only requires stabilizability for all possible models.
Index Terms:
Adaptive control, uncertain systems.I Introduction
Adaptive control of systems with unmatched uncertainties, i.e., model perturbations outside the span of the control input matrix, is notoriously difficult because the uncertainties cannot be directly canceled by the control input. This is especially true for nonlinear systems where combining a stable model estimator with a nominal feedback controller does not necessarily yield a stable closed-loop system without imposing limits on the growth rate of the uncertainties, so as to prevent finite escape. The prevailing approach for handling nonlinear systems with unmatched uncertainties has been to construct nominal feedback controllers that are robust to time-varying parameter estimates [1]. More precisely, one seeks to construct an input-to-state stable control Lyapunov function (ISS-clf) [2] which, by construction, ensures the system converges to a region near the desired state despite parameter estimation error and transients. Once an ISS-clf and corresponding controller are known, then any stable model estimator can be employed without concern of instability. From a theoretical standpoint, this framework guarantees stable closed-loop control and estimation despite unmatched uncertainties but requires constructing an ISS-clf – a nontrivial task unless the system takes a particular structure.
The approach discussed above is categorized as indirect adaptive control and entails combining a robust controller with a stable model estimator. Conversely, direct adaptive control uses Lyapunov-like stability arguments to construct a parameter adaptation law that guarantees the state converges to a desired value. This eliminates the robustness requirements inherent to indirect adaptive control which, in some ways, simplifies design. However, since unmatched uncertainties cannot be directly canceled through control, it is necessary to construct a family of Lyapunov functions that depend on the estimates of the unmatched parameters. This model dependency introduces sign-indefinite terms (related to the parameter estimation transients) in the stability proof that require sophisticated direct adaptive control schemes to achieve stable closed-loop control and adaptation. Adaptive control Lyapunov functions (aclf) where proposed to cancel the problematic transient terms by synthesizing a family of clf’s for a modified dynamical system that depends on the family of clf’s [3]. Recently, [4] proposed a method that adjusts the adaptation gain online to cancel the undesirable transient terms and requires no modifications to the standard clf definition or dynamical system of interest.
The main contribution of this work is a new direct adaptive control methodology which generalizes and improves the online adaptation gain adjustment approach from [4], subsequently called dynamic adaptation gains, yielding a superior framework for handling various forms of model uncertainties. The new framework has two distinguishing properties: 1) adaptation gains are individually adjusted online to prevent parameter adaptation transients from destabilizing the system and 2) the adaptation gain is guaranteed to return to its nominal value asymptotically. Conceptually, the adaptation gain is lowered, i.e., adaptation slowed, for parameters whose transients is destabilizing; the adaptation gain then returns to its nominal once the transients subsides. Noteworthy properties are examined, e.g., handling of matched uncertainties, and several forms of the dynamic adaptation gain update law are derived. The approach only relies on stabilizability of the uncertain system so it is a very general framework. Simulation results of a nonlinear system with unmatched and matched uncertainties demonstrates the approach.
Notation: The set of positive and strictly-positive scalars will be denoted as and , respectively. The shorthand notation for a function parameterized by a vector with vector argument will be . The partial derivative of a function will sometimes denoted as where the subscript on is omitted when there is no ambiguity.
II Problem Formulation
This work addresses control of uncertain dynamical systems of the form
| (1) |
with state , control input , nominal dynamics , and control input matrix . The uncertain dynamics are a linear combination of known regression vectors and unknown parameters . We assume that Equation 1 is locally Lipschitz uniformly and that the state is measured. The following assumption is made on the unknown parameters .
Assumption 1.
The unknown parameters belong to a known compact convex set .
An immediate consequence of Assumption 1 is that the parameter estimation error must also belong to a known compact convex set . Each parameter must then have a finite maximum error where for .
III Main Results
III-A Overview
This section presents the main results of this work. We first review the definition of the unmatched control Lyapunov function [4] and its role in the proposed approach. We then derive the first main result followed by several noteworthy extensions, e.g., the scenario where unmatched and matched uncertainties are present in addition to augmenting the adaptation law with model estimation (composite adaptation). We also present the the so-called leakage modification that guarantees the adaptation gains return to their nominal values asymptotically. Conceptually, the proposed approach relies on adjusting the adaptation gain of individual parameter estimates online to prevent destabilization induced by parameter adaptation transients. This is in stark contrast to [4] where a single gain for all parameters was adjusted. Consequently this work can be considered a more general and natural formulation of [4].
III-B Unmatched Control Lyapunov Functions
Similar to [4], the so-called unmatched control Lyapunov function will be used through this letter.
Definition 1 (cf. [4]).
A smooth, positive-definite function is an unmatched control Lyapunov function (uclf) if it is radially unbounded in and for each
where is continuously differentiable, radially unbounded in , and positive-definite.
Remark 1.
Definition 1 can also be stated in terms of a contraction metric [5], see [4, Def. 1] for more details.
Definition 1 is noteworthy because the existence of an uclf is equivalent (see [4, Prop. 1]) to system Equation 1 being stabilizable for all . This is the weakest possible requirement one can impose on Equation 1 and therefore showcases the generality of the approach. Definition 1 involves constructing a clf for each possible model realization, i.e., a family of clf’s, so convergence to the desired equilibrium can be achieved if a suitable adaptation law can be derived. Pragmatically, this can be done analytically, e.g., via backstepping, or numerically via discretization or sum-of-squares programming with the uclf search occurring over the state-parameter space. Definition 1 adopts the certainty equivalence principle philosophy: design a clf (or equivalently a controller) as if the unknown parameters are known and simply replace them with their estimated values online. This intuitive design approach is not generally possible for nonlinear systems with unmatched uncertainties unless additional robustness properties are imposed or the system be modified – both representing a departure from certainty equivalence. The approach developed in this work completely bypasses any additional requirements or system modifications by instead adjusting the adaptation gain online where the so-called adaptation gain update law yields a stable closed-loop system. In other words, the proposed dynamic adaptation gains method expands the use of the certainty equivalence principle to general nonlinear systems with unmatched uncertainties, simplifying the design of stable adaptive controllers.
III-C Dynamic Adaptation Gains
The proposed method involves adjusting the adaptation gain—typically denoted as a scalar or symmetric positive-definite matrix is the literature—to prevent the parameter adaptation transients from destabilization the closed-loop system. It is convenient to express the adaptation gain as a function of a scalar argument that has certain properties. We will make use of the following definition in deriving an adaptation gain update law that achieves closed-loop stability.
Definition 2.
An admissible dynamic adaptation gain is a function with scalar argument such that is the nominal adaptation gain, , and .
Remark 2.
There are several functions at the disposal of the designer when selecting an admissible dynamic adaptation gain. Two examples are or .
With Definitions 1 and 2, we are now ready to state the first main theorem of this work.
Theorem 1.
Consider the uncertain system Equation 1 with being the desired equilibrium point. If an uclf exists, then asymptotically with the adaptation law
| (2a) |
where each is an admissible dynamic adaptation gain whose update law satisfies
| (2b) |
for with .
Proof.
Consider the Lyapunov-like function
| (3) |
where and with finite. Differentiating Equation 3 yields
Since is an uclf then
Noting
then applying Equation 2a yields
If is chosen so Equation 2b is satisfied, then the term in brackets is negative so if . Hence, is non-increasing so and are bounded since is lower-bounded and is bounded by construction. Since is radially unbounded then must also be bounded. By definition, is continuously differentiable so is bounded for bounded , and therefore is uniformly continuous. Since is nonincreasing and bounded from below then exists and is finite so by Barbalat’s lemma . Recalling then we can conclude as as desired. ∎
Remark 3.
Remark 4.
Equation 2b is expressed as an update to to make the dynamic adaptation gain interpretation more obvious. For implementation, one should rewrite Equation 2b as a bound on via the chain rule. Note in invertible by Definition 2.
Before deriving various implementable forms of the dynamic adaptation gain update law, it is instructive to analyze its general behavior. For the case where a parameter’s adaptation transients is destabilizing, i.e., for some , we see from Equation 2b that so the adaptation gain decreases to prevent destabilization. In other words, the adaptation rate is slowed for parameters whose adaptation transients could cause instability. Note that there is no concern of the adaptation gain becoming negative since must be an admissible dynamic adaptation gain so, by definition, is lower-bounded by a positive constant. With that said, could become a large negative number which does not affect the proof of Theorem 1 but can have practical implications; this will be discussed in more detail below. Now considering the case where a parameter’s adaptation transients is stabilizing, i.e., for some , we see from Equation 2b that is simply upper-bounded by a positive quantity. Consequently, one can set and still obtain a stable closed-loop system since the transients term is negative thereby leading to the desired stability inequality in the proof of Theorem 1. Another choice would be to let (without exceeding the inequality Equation 2b) until , i.e., the nominal adaptation gain value, at which point one sets . This leads us to one implementable form of the adaptation gain update law.
Corollary 1.
The adaptation gain update law given by
for satisfies condition Equation 2b in Theorem 1 so asymptotically as desired.
The component-wise nature of the adaptation gain update law presented in Corollary 1 systematically checks the adaptation transients of each parameter and adjusts the adaptation gain accordingly to preserve stability. Algorithmically, the update law cycles through each parameter and updates the adaptation gain on the parameters whose transients are problematic. Treating parameters individually rather than as a whole (as in [4], see the Appendix) allows for targeted adjustments to problematic parameters which yields less myopic behavior of the controller and better closed-loop performance. Note this behavior is quite different than that in [8] where the gain was only increased to achieve stability.
Remark 5.
Corollary 1 for can be rewritten as
where and . This form shows that the adaptation gain update is unaffected if an uclf is scaled by a uniformly positive function . This could have implications for safety-critical adaptive control if were akin to a barrier function. If were also to be upper-bounded then a similar relationship can be obtained for the . The gradient term above is similar to the score function in diffusion-based generative modeling [9], where a probability density known only within a scaling factor (the partition function) which disappears in .
III-D Leakage Modification: Bounding
The proof of Theorem 1 requires the individual adaptation gains be lower-bounded. This is accomplished through appropriate selection of each to meet the conditions of Definition 2. It is desirable to ensure the scalar argument remains bounded through means beyond simple parameter tuning to prevent numerical instability cause by becoming too large. Having the adaptation gains return to their nominal value automatically after the adaptation transients has subsided is also ideal. We propose to replace the pure integrator dynamics with nonlinear first-order dynamics, i.e., a leakage modification, to achieve these desirable properties. The modified adaptation gain update law takes the form
| (4) |
where with the -th component, if and otherwise, and . Note corresponds to the transients being destabilizing, so the input of Equation 4 is zero if the transients is stabilizing or has subsided. The following lemma establishes important properties of Equation 4.
Lemma 1.
The output of the dynamic adaptation gain update law Equation 4 remains bounded if the exogenous signal is bounded. Furthermore, the output tends to zero if .
The proof can be found in the Appendix. We now show Equation 4 when combined with Equation 2a yields a stable closed-loop system.
Theorem 2.
Consider the uncertain system Equation 1 with being the desired equilibrium point. If an uclf exists, then asymptotically with the adaptation law Equation 2a and dynamic adaptation gain update law Equation 4. Furthermore, and in turn asymptotically for each .
Proof.
Consider the Lyapunov-like function
where and are defined as before and is sufficiently large [10, 11] but finite to ensure the integral is finite. Differentiating and applying Definitions 1, 2a and 4,
where the second inequality holds by choice of . Also by choice of , Equation 4 is only driven by an input that is either negative or zero, so for all since . Hence, the term in brackets must be negative which yields so is nonincreasing and in turn and are bounded. Using the same arguments as in Theorem 1 and noting is still lower-bounded, as via Barbalat’s lemma. Since by construction, then each as . Hence, by Lemma 1, and in turn for ∎
III-E Matched and Unmatched Uncertainties
A particularly useful property of the dynamic adaptation gains method is the ability to treat matched and unmatched uncertainties separately. This is in stark contrast to the approach taken in [4] where all adaptation gains were adjusted to cancel adaptation transients. The separability inherent to the current method is indicative of the more natural formalism of treating adaptation transients on an individual basis rather than as a whole. The following theorem solidifies this point.
Theorem 3.
Assume system Equation 1 can be rewritten as
| (5) |
where are the matched parameters with known regression vectors . Let denote the desired equilibrium point. If an uclf exists with corresponding control law , then asymptotically with the controller and adaptation laws
| (6) | ||||
where is a constant symmetric positive-definite matrix and each is an admissible dynamic adaptation gain.
Proof.
Consider the new Lyapunov-like function
where and are defined as before. Differentiating along Equation 5 and substituting yields
Substituting in Eqs. 6 and 2b yields so is nonincreasing. Similar to Theorem 1, we can conclude that as . ∎
III-F Composite Adaptation
Parameter adaptation transients can be markedly improved by combining direct and indirect adaptation schemes to form a composite adaptation law [12]. The following proposition shows composite adaptation with dynamic adaptation gains also yields a stable closed-loop system.
Proposition 1.
Assume a signal for some matrix is available via measurement or computation. If an uclf exists, then asymptotically with the composite adaptation law
where and each is an admissible dynamic adaptation gain whose update law satisfies Equation 2b.
Proof.
Using the Lyapunov-like function from Theorem 1 and applying the composite adaptation law with Equation 2b yields so is nonincreasing. Similar to Theorem 1, we can conclude that as . ∎
IV Simulation Experiments
The developed method was tested on the system
| (7) |
with state , unknown parameters where are unmatched, and being the origin. The system is not feedback linearizable and is not in strict feedback form. The true model parameters are with the set of allowable variations ; the projection operator from [6] was used to bound each parameter. The dynamic adaptation gains took the form and for . Similar to [4], the Riemannian energy of a geodesic connecting and was chosen to be the uclf.
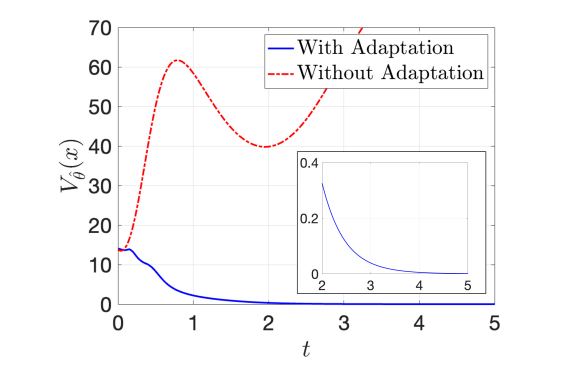
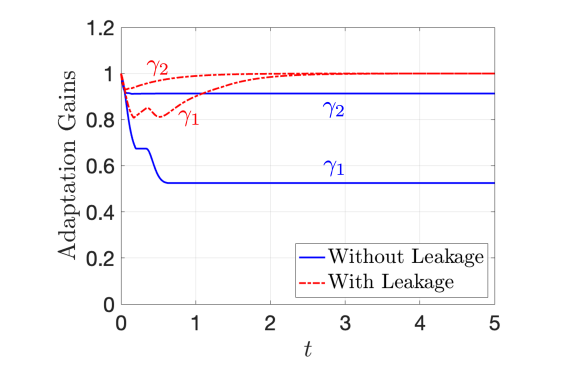
Figure 1(a) shows the uclf—an indicator of tracking performance—with and without adaptation. The proposed method (Corollary 1) successfully stabilizes the origin as predicted by Theorem 1. This is in stark contrast to the no adaptation case where only bounded error can be acheived. The uclf with leakage modification (omitted for clarity) exhibits nearly identical behavior as the uclf with the update law from Corollary 1 which confirms the result stated in Theorem 2. Figure 1(b) shows the individual adaptation gains with and without the leakage modification. The nominal case (blue) sees a reduction in the adaptations gains by 47% and 9%, respectively, indicating the adaptation transients of would have a large destabilizing effect if not compensated for. The leakage modification (red, ) ensures the adaptation gains return to their nominal values as predicted by Theorem 2.
V Conclusion
We presented a new direct adaptation law that adjusts individual adaptation gains online to achieve stable closed-loop control and learning for nonlinear systems with unmatched uncertainties. A bound on the rate of change of individual adaptation gains that prevents destabilization by the adaptation transients was derived. Noteworthy extensions and modifications were also discussed. The results presented here have important implications in adaptive safety [13] and adaptive optimal control [14]. Future work will explore these implications in addition to deeper investigations into fundmanetal properties of the approach.
Appendix
Proof of Lemma 1.
Consider the time interval where is the supremum of the input to Equation 4 over the time interval of interest [1]. Note the subscript is dropped for clarity. Consider the comparison system where uniformly and is uniformly strictly positive. The comparison system has the virtual dynamics which is contracting in so any two particular solutions converge exponentially to each other [15]. Letting , then is the solution to the virtual dynamics and is bounded. Because is a particular solution of the virtual system and , is bounded. Also, as then so does over some time interval, hence and in turn as desired. ∎
Theorem 4 (cf. [4]).
Consider the uncertain system Equation 1 with being the desired equilibrium. If an uclf exists, then, for any strictly-increasing and uniformly-positive scalar function , asymptotically with the adaptation law
where is a symmetric positive-definite matrix and .
Acknowledgements We thank Miroslav Krstic for stimulating discussions.
References
- [1] M. Krstic, P. V. Kokotovic, and I. Kanellakopoulos, Nonlinear and adaptive control design. John Wiley & Sons, 1995.
- [2] E. D. Sontag and Y. Wang, “On characterizations of the input-to-state stability property,” Systems & Control Letters, vol. 24, no. 5, pp. 351–359, 1995.
- [3] M. Krstić and P. V. Kokotović, “Control lyapunov functions for adaptive nonlinear stabilization,” Systems & Control Letters, vol. 26, no. 1, pp. 17–23, 1995.
- [4] B. T. Lopez and J.-J. E. Slotine, “Universal adaptive control of nonlinear systems,” IEEE Control Systems Letters, vol. 6, pp. 1826–1830, 2021.
- [5] W. Lohmiller and J.-J. E. Slotine, “On contraction analysis for non-linear systems,” Automatica, vol. 34, no. 6, pp. 683–696, 1998.
- [6] J.-J. E. Slotine and W. Li, Applied nonlinear control. Prentice Hall, 1991.
- [7] P. A. Ioannou and J. Sun, Robust adaptive control. Courier Corporation, 2012.
- [8] H. Lei and W. Lin, “Universal adaptive control of nonlinear systems with unknown growth rate by output feedback,” Automatica, vol. 42, no. 10, pp. 1783–1789, 2006.
- [9] Y. Song, J. Sohl-Dickstein, D. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differential equations,” ICLR, 2021.
- [10] R. E. Kalman and J. E. Bertram, “Control system analysis and design via the “second method” of lyapunov: I—continuous-time systems,” Trans. ASME Basic Engineering, Ser. D, vol. 82, pp. 371–400, 1960.
- [11] D. G. Luenberger, Introduction to dynamic systems; theory, models, and applications. John Wiley & Sons, 1979.
- [12] J.-J. E. Slotine and W. Li, “Composite adaptive control of robot manipulators,” Automatica, vol. 25, no. 4, pp. 509–519, 1989.
- [13] B. T. Lopez and J.-J. E. Slotine, “Unmatched control barrier functions: Certainty equivalence adaptive safety,” in 2023 American Control Conference (ACC), pp. 3662–3668, IEEE, 2023.
- [14] B. T. Lopez and J.-J. E. Slotine, “Adaptive variants of optimal feedback policies,” in Learning for Dynamics and Control, PMLR, 2022.
- [15] W. Wang and J.-J. E. Slotine, “On partial contraction analysis for coupled nonlinear oscillators,” Biological Cybernetics, vol. 92, no. 1, pp. 38–53, 2005.