DUMP: A Dummy-point-based Local Differential Privacy Enhancement Approach under the Shuffle Model
Abstract.
The shuffle model is recently proposed to address the issue of severe utility loss in Local Differential Privacy (LDP) due to distributed data randomization. In the shuffle model, a shuffler is utilized to break the link between the user identity and the message uploaded to the data analyst. Since less noise needs to be introduced to achieve the same privacy guarantee, following this paradigm, the utility of privacy-preserving data collection is improved.
In this paper, we propose DUMP (DUMmy-Point-based), a new framework for privacy-preserving histogram estimation in the shuffle model. In DUMP, dummy messages are introduced on the user side, creating an additional dummy blanket to further improve the utility of the shuffle model. In addition, this new privacy-preserving mechanism also achieves LDP privacy amplification effect to the user uploaded data against a curious shuffler. We instantiate DUMP by proposing two protocols: pureDUMP and mixDUMP, both of which achieving theoretical improvements on accuracy and communication complexity comparing with existing protocols. A comprehensive experimental evaluation is conducted to compare the proposed two designs under DUMP with the existing protocols. Experimental results on both synthetic and real-world datasets confirm our theoretical analysis and show that the proposed protocols achieve better utility than existing protocols under the same privacy guarantee.
PVLDB Reference Format:
PVLDB, 14(1): XXX-XXX, 2020.
doi:XX.XX/XXX.XX
††This work is licensed under the Creative Commons BY-NC-ND 4.0 International License. Visit https://creativecommons.org/licenses/by-nc-nd/4.0/ to view a copy of this license. For any use beyond those covered by this license, obtain permission by emailing [email protected]. Copyright is held by the owner/author(s). Publication rights licensed to the VLDB Endowment.
Proceedings of the VLDB Endowment, Vol. 14, No. 1 ISSN 2150-8097.
doi:XX.XX/XXX.XX
PVLDB Artifact Availability:
The source code, data, and/or other artifacts have been made available at %leave␣empty␣if␣no␣availability␣url␣should␣be␣setURL_TO_YOUR_ARTIFACTS.
1. Introduction
Differential privacy is widely accepted, by both academia and industry (Erlingsson et al., 2014; Team et al., 2017; Ding et al., 2017; Wang et al., 2019), as the standard privacy definition for statistical analysis on databases containing sensitive user information. In the last decades, the community has devoted a number of efforts to designing practical mechanisms achieving better utility while providing reliable privacy guarantee for users, and most of them can be categorized into the central model (Geng et al., 2015; Ghosh et al., 2012) or local model (Kairouz et al., 2014; Holohan et al., 2017). In the central model, the analyst, who collects data from individuals, is responsible to add noise to the aggregated result such that the noisy result will not leak too much information about each individual. In contrast, the local model enables each user to perturb his data before submitting it to an analyst and thus provides a more reliable privacy guarantee even when the analyst is curious. However, mechanisms achieving local differential privacy (LDP) only have limited utility and turn out ill-suited to practice (Bittau et al., 2017). It is known that the estimation error is at least for a wide range of natural problems in the local model ( is the number of users), while an error of just can be achieved in the central model(Duchi et al., 2013).
The above dilemma motivates the study of new approaches that prevent third parties from violating users’ privacy while achieving reasonable utility; the shuffle model, initiated by Bittau et al. (Bittau et al., 2017), is emerging as a promising one. This model introduces an independent third party called shuffler who is responsible for shuffling all (permuted) messages received from users before passing them to the analyst111In practice, various cryptographic tools like nest encryptions (Bittau et al., 2017) can be employed to ensure that the shuffler cannot learn the content of these reports.. Regarding accuracy, for queries that are independent of the sequence, this shuffling will not introduce extra utility loss. Regarding privacy, intuitively, the analyst cannot link each report in a shuffled database to an individual, and thus the privacy against analysts can be amplified. Or, less “noise” shall be added by users to messages for the same privacy, which in turn improves the utility. Though similar (or even better) results could be achieved using heavy cryptographic primitives like homomorphic encryptions and multiparty computation protocols (Lazar et al., 2018; Roy Chowdhury et al., 2020), shuffle-model approaches are more popular in the industry since they are considerably efficient and implementation-friendly! In recent years, several shuffle-model protocols have been presented for various tasks (e.g., frequency estimation (Balcer and Cheu, 2019), data summation (Ghazi et al., 2019b), and range query (Ghazi et al., 2019a)) over either numerical data or categorical data.
We focus on the problem of histogram estimation, the fundamental task over categorical data, in the shuffle model. Many recent works (Wang et al., 2020; Ghazi et al., 2021; Balcer and Cheu, 2019; Balle et al., 2019b; Ghazi et al., 2020b) have aimed to design truly practical mechanisms for this problem, and they indeed have different tradeoffs. In terms of efficiency and implementation-friendliness, the generalized random response (GRR) based mechanisms(Balle et al., 2019b), in which a user just replaces his data by a uniformly random value in the data domain with certain probability , turns out to be optimal: (1) only a single message shall be sent per user, and (2) it directly uses uniform randomness, which is naturally provided by operating systems via standard means. We note the feature (2) is highly desirable in practice: although random variables with many other distributions can be calculated from uniformly random variables, the inexact calculation over finite precision values cannot produce randomness exactly having the specified distribution, and the implemented privacy mechanism may leak significant information of the original data (see (Ilvento, 2020; Mironov, 2012; Balcer and Vadhan, 2018; Gazeau et al., 2016)). More interestingly, Balle et al. (Balle et al., 2019b) proposed the privacy blanket intuition for GRR-based protocols, which gives a thoroughly theoretical explanation on how (and how much) shuffling enhances the privacy, in a conceptually simple manner.
Nonetheless, the estimation error of GRR-based protocols will become unexpectedly large as the domain size grows; the privacy guarantee they can provide is also subjected to the number of users and the data domain size and might not be enough for applications. Subsequent works (Wang et al., 2020; Ghazi et al., 2021; Balcer and Cheu, 2019; Ghazi et al., 2020b) improve the accuracy and achieve errors independent of (under the same privacy guarantee) by letting users randomize their data in rather complex ways (e.g., encoding data using hash functions (Wang et al., 2020) or Hadamard matrix (Ghazi et al., 2021), adding noises from negative binomial distributions (Ghazi et al., 2020b), etc.); some of them (Ghazi et al., 2021; Ghazi et al., 2020b) also enables high privacy guarantee. Yet they indeed sacrifice efficiency and/or implementation-friendliness (detailed comparison will be presented later).
In this work, we present shuffle-model mechanisms for histogram estimation, which are almost as efficient and implementation-friendly as GRR-based protocols (Balle et al., 2019b), enable high privacy guarantee, and have competitive accuracy with (Wang et al., 2020; Ghazi et al., 2021; Balcer and Cheu, 2019; Ghazi et al., 2020b). Moreover, we give an intuition that clearly explains how and how much our mechanisms provide privacy (mimicking the privacy blanket intuition); we believe that such intuition can assist in the design and analysis of future mechanisms.
Our Contributions. We overview our contributions in more detail below.
Dummy blanket & DUMP framework. We introduce the concept of dummy blanket, which enables a very simple method of enhancing user’s privacy (particularly, in the shuffle model) and significantly outperforms the privacy blanket (Balle et al., 2019b) in the accuracy. Recall that privacy blanket provides an insightful view of the GRR mechanism: if each user reports the true value with probability and a uniformly sampled with probability , then, equivalently, there is expected to be uniformly random values among reports. After shuffling, the victim data is mixed with the points, and these points will serve as a “blanket” to hide . Our dummy blanket intuition indeed generalizes the privacy blanket. Specifically, we observe that privacy essentially comes from these uniformly random points and is determined by the number of them, and we do not need to insist that these points are contributed by data randomization. Instead, we allow users to directly add uniformly random points (called dummy points) before reporting to the shuffler. Similar to the case of privacy blanket, these dummy points will also serve as a “blanket” to protect the victim!
Dummy blanket allows us to achieve better accuracy at the cost of slightly increasing communication overhead. To see this, we first show the privacy guarantee is mostly determined by the total number of dummy points. Then, for achieving certain privacy (that needs dummy points), the privacy blanket intuition requires to replace true values, while we just add dummy points. Since original values are preserved, the estimation result of the dummy blanket will be more accurate. Formally, we show the estimation error introduced by dummy blanket is independent of the domain size and always concretely smaller than that of privacy blanket (see Sect.5.1). Regarding communication overhead, note that only the total number of dummy points matters, and thus the amortized communication overhead will be close to a single message when is large. Furthermore, to some extent, the dummy blanket intuition could explain why previous works (Balcer and Cheu, 2019; Wang et al., 2020) improved accuracy: their data randomizers implicitly generate dummy points, though the methodology of adding dummy points and its advantage had never been formally studied.
We incorporate the dummy blanket intuition into the existing shuffle-model framework and present a general DUMP (DUMmy-Point-based) framework for histogram estimation. In DUMP, a user first processes his data using a data randomizer (as he does in the conventional shuffle-model framework), then invokes a dummy-point generator to have a certain amount of dummy points, and finally submits the randomized data together with these dummy points to the shuffler. From the dummy blanket intuition, adding dummy points could enhance privacy without significantly downgrading the accuracy. Note that most existing locally private protection mechanisms (e.g., Randomized Response (Warner, 1965), RAPPOR (Erlingsson et al., 2014), OLH (Wang et al., 2017)) could be formulated as one of the special cases of the data randomizer, and thus the framework admits diverse instantiations which can give different tradeoffs for different purposes.
Instantiations: pureDUMP & mixDUMP. We first instantiate DUMP with an empty data randomizer and obtain the pureDUMP protocol. In pureDUMP, the privacy guarantee is fully provided by dummy points, and thus the analysis of pureDUMP could quantify properties of the dummy blanket. Assume each user adds dummy points and the data domain has size . We prove that (1) pureDUMP satisfies -differential privacy for and ; (2) its expected mean squared error (eMSE) of frequency estimation is . So the eMSE is , surely independent of , and only increases the error in the central model by that is logarithmic in ; the number of messages per user is that will be close to as grows. Moreover, by increasing , can be arbitrarily close to 0 as wishes. Meanwhile, we prove that pureDUMP even satisfies local differential privacy, which is meaningful when the shuffler and the analyst collude.
We then present mixDUMP, which utilizes GRR as the data randomizer in the DUMP framework. mixDUMP leads to a new tradeoff between communication overhead and accuracy. Particularly, since privacy can also be provided by GRR, fewer dummy points are needed. We show that mixDUMP has the smallest communication overhead (compared with all existing multi-messages mechnisms) while its eMSE is still competitive (though slightly larger than that of pureDUMP).
Finally, notice that privacy is determined by the total number of dummy points; when is large, it may not be necessary to ask each user to send even a single dummy point. Therefore we investigate the setting that each user has a certain probability to generate a fixed number of dummy points. Meanwhile, we find that this setting is interesting for the case that not all users are willing to utilize dummy-points-based privacy protection mechanism due to the limited network bandwidth or computation capability of their devices. We formally prove that pureDUMP and mixDUMP can still provide enhanced privacy protection of -differential privacy in this setting. This result allows having smaller communication overhead and better accuracy when is large.
Implementations & Comparisons. We analyze and implement all the existing related protocols (Balle et al., 2019b; Wang et al., 2020; Ghazi et al., 2021; Balcer and Cheu, 2019; Ghazi et al., 2020b) (at least to the best of our knowledge) for comprehensive comparisons. We conduct experiments on both synthetic and real-world datasets; we are the first (also to the best of knowledge) to report (Balcer and Cheu, 2019; Ghazi et al., 2021) on large-size experiments. With the same privacy guarantee, the results show that (1) pureDUMP and mixDUMP have the minimal communication overhead compared with all existing multi-message protocols ((Ghazi et al., 2021; Balcer and Cheu, 2019; Ghazi et al., 2020b)); (2) pureDUMP achieves the best accuracy compared with (Balle et al., 2019b; Wang et al., 2020; Ghazi et al., 2021; Balcer and Cheu, 2019), while the only exception (Ghazi et al., 2020b), achieving near-optimal accuracy, has much higher communication-overhead and has to use randomness from negative-binomial distributions whose implementation is indeed challenging and vulnerable in practice. Details follow.
-
-
Efficiency. The communication overhead of both pureDUMP and mixDUMP decreases with the increase of the numbe of users, while (Ghazi et al., 2021; Balcer and Cheu, 2019) do not have this feature; the expected communication overhead of (Ghazi et al., 2020b) turns out to be concretely larger. In our experiments, for example, over the real-world dataset Ratings (rat, 2017) with and , pureDUMP (and mixDUMP) only require around (and ) expected extra messages per user, while (Ghazi et al., 2021; Balcer and Cheu, 2019) and (Ghazi et al., 2020b) need around , and extra messages respectively. On the other hand, single-message protocols (Balle et al., 2019b; Wang et al., 2020) are less competitive in accuracy and/or subjected to upper-bounds on privacy guarantee (namely, the lower-bounds on ). Particularly, for Ratings, (Balle et al., 2019b) cannot even achieve -privacy with .
- -
-
-
Implementation-friendliness. pureDUMP and mixDUMP are extremely implementation-friendly, as they just generate a fixed amount of uniformly random values with fixed probability and do not involve any cumputation that shall be approximated over finite-precision devices (e.g., base- logarithm ). In contrast, (Ghazi et al., 2020b) uses randomness with the negative binomial distribution s.t. and . 222For , and , . Notice that is not an integer, so we cannot sample from this distribution by naively running independent events that have succesful probability untill seeing failures. We may have to follow the common approach of sampling negative binomial distributions: first sample from a distribution and then sample from a Poisson distribution . Note that sampling from Poisson distributions involves computation, and Mironov (Mironov, 2012) showed that DP meachnisms implementing over double-precision floating-point numbers cannot provide the claimed privacy protection! Other sampling methods for might be possible but to be explored.
2. Background
Central Differential Privacy. The initial setting of differential privacy is defined in central model (Dwork, 2008), in which a trusted analyst collects sensitive data from users, gathers them into a dataset, and works out the statistical results. The statistical results are perturbed by the analyst before being released. Intuitively, differential privacy protects each individual’s privacy by requiring any single element in the dataset has limited impact on the output.
Definition 2.1.
(Central Differential Privacy, CDP). An algorithm satisfies ()-DP,where , if and only if for any neighboring datasets and that differ in one element, and any possible outputs , we have
Here, is called the privacy budget. The smaller means that the outputs of on two adjacent datasets are more similar, and thus the provided privacy guarantee is stronger. is generally interpreted as not satisfying -DP with probability . As usual, we consider the neighboring datasets and having the same number of elements (aka. bounded differential privacy). For simplicity, we assume w.o.l.g. that and differ at the -th element, and we denote them by and .
Local Differential Privacy. The central model assumes the analyst is fully trusted and does not ensure privacy against curious analysts, which is not practical in many scenarios. In constrast, the local model (Kasiviswanathan et al., 2011) allows each user to locally perturb his data using a randomization algorithm before sending it to the untrusted analyst so that the analyst cannot see the raw data. We say satisfies local differential privacy (LDP) if for different data and , the distribution of and that of are close.
Definition 2.2.
(Local Differential Privacy, LDP). An algorithm satisfies -LDP, where , if and only if for any different elements , and any possible outputs , we have
is typically set as , and -LDP can be denoted by -LDP.
(Generalized) Randomized Response. Randomized Response (RR) (Warner, 1965) is considered as the first LDP mechanism that supports binary response. It allows each user to provide a false answer with certain probability and thus provides plausible deniability to users. RR mechanism can be extended to support multi-valued domain response, known as Generalized Randomized Response (GRR) (Wang et al., 2017). Denote as the size of the domain . Each user with private value reports the true value with probability and reports a randomly sampled value where with probability . By standard analysis, it is easy to see that, GRR satisfies -LDP when
| (1) |
Shuffle Model. The shuffle model follows the Encode, Shuffle, Analyze (ESA) architecture proposed by Bittau et al. (Bittau et al., 2017). A shuffler is inserted between users and the analyst to break the link between the user identity and the message. Following (Cheu et al., 2019), we describe a shuffle-model protocol by the following three algorithms.
-
-
: . The local randomized encoder takes a single user’s data as input and outputs a set of messages .
-
-
: . The shuffler takes users’ output messages of as input and outputs these messages in a uniformly random order.
-
-
: . The analyst that takes all the output messages of S as input and runs some analysis functions on these messages.
Such a protocol is called a single-message protocol when or a multi-message protocol when .
| Variable | Description |
|---|---|
| Finite and discrete domain {1, 2 , …, k} | |
| Size of domain | |
| Set of users’ input values | |
| Number of users | |
| Set of dummy points | |
| Total number of dummy points | |
| Number of dummy points sent per user | |
| Input value from the user | |
| The value sent from the user | |
| The estimated frequency of elements in | |
| Sample a random binary value under Bernoulli distribution | |
| Uniformly sample a random value from |
3. Histogram Estimation in the shuffle model
3.1. Problem Statement
System Setting. The task is performed in the shuffle model. The system involves an analyst, a shuffler, and users. Specifically, the analyst knows the data domain . We assume the size of is , i.e., . The user has a single data . All users send perturbed data to the shuffler, and the shuffler scrambles the order before transmitting the data to the analyst. For the item in , the analyst estimates frequency (the proportion of users who has a certain value), i.e., . Here if ; otherwise.
Threat Model. Similar to most shuffle-model works, we consider privacy against curious analysts. We concentrate on the standard case, in which the analyst does not collude with shufller. We say a shuffle-model protocol (see Section 2) satisfies -DP against curious analysts, if the algorithm satisfies -DP in the central model (see Definition 2.1). We also study the case that the analyst colludes with the shufller such that he has a direct access to users’ reports. In this case, the differential privacy of against the collusion is equivalent to the local differential privacy of (see Definition 2.2).
Following (Balle et al., 2019b), throughout this paper we consider powerful adversaris who have the same background knowledge, i.e., all other users’ values except one victim’s; thus our mechanisms are also secure against any weaker adversaries. All privacy analyses are under the assumption of bounded differential privacy, thus we do not need to consider the case that some users dropout.
3.2. Existing Related Protocols
There are several existing works on histogram estimation in the shuffle model. To the best of our knowledge, the first protocol is proposed by Balle et al. (Balle et al., 2019b), in which each user randomizes sensitive data with GRR mechanism. Then, other mechanisms are utilized as randomizers to improve the utility of protocols. Ghazi et al. (Ghazi et al., 2021) propose two multi-message protocols: private-coin and public-coin. The private-coin utilizes Hadamard Response as the data randomizer. The public-coin is based on combining the Count Min data structure (Cormode and Muthukrishnan, 2005) with GRR (Wang et al., 2017). The user in the truncation-based protocol proposed by Balcer et al. (Balcer and Cheu, 2019) sends sensitive data with at most (size of data domain) non-repeated data sampled from to the shuffler. However, the truncation-based protocol may suffer from an undesirable communication load, i.e., each user needs to send thousands of messages when there are thousands of candidate values in . The SOLH proposed by Wang et al. (Wang et al., 2020) utilizes Optimal Local Hash (OLH) as the data randomizer to improve the utility when the size of is large. The correlated-noise protocol proposed by Ghazi et al. (Ghazi et al., 2020b) adds noises from negative binomial distributions, which achieves accuracy that is arbitrarily close to that of CDP.
All the above existing protocols seek for more suitable randomizers to improve the utility of the shuffle model. Different from existing works, we try to introduce a new mechanism to provide privacy protection. Our proposed method gets more privacy benefits than existing approaches, which further improves the utility of histogram estimation in the shuffle model.
4. DUMP Framework
4.1. Framework Overview
There are three parties in DUMP framework: user side, shuffler, and analyst. Figure 1 shows the interactions among them.
User Side. There are two types of protection procedures on the user side. One is the data randomizer. Most existing LDP mechanisms could be categorized as one of special cases of the data randomizer such as Randomized Response (RR), Unary Encoding (UE), Optimal Local Hash (OLH), and Hadamard Response (HR). Hence, the output of the data randomizer could be in different forms such as element, vector, or matrix. Besides, the data randomizer directly outputs the user’s sensitive data when no privacy protection is provided by the data randomizer, i.e., . Another is the dummy-point generator, which provides privacy protection by generating dummy points. dummy points are uniformly random sampled from the output space of the data randomizer, where is calculated from the number of users , the domain size , and privacy parameters. The output of mixed with dummy points is then sent to the shuffler.
Shuffler. The operation of shuffler in DUMP is same as the existing shuffle model(Bittau et al., 2017). The shuffler collects all messages from users and removes all implicit metadata (such as IP address, timestamps, and routing paths). Then all messages are randomly shuffled before sending to the analyst.

Analyst. The analyst performs histogram estimation on the set of messages received from the shuffler. It removes the bias caused by dummy points and data randomization to obtain unbiased estimation results.
Under DUMP framework, we design two protocols, pureDUMP and mixDUMP, in Section 5 to show the advantage of dummy points in improving utility. The dummy points provides privacy protection in both two protocols. In addition, the mixDUMP uses GRR as the data randomizer, while no protection is provided by the data randomizer in pureDUMP. We show that the dummy points can improve the accuracy without increasing too much communication overhead under a certain privacy guarantee. Table 2 presents our results alongside existing results, in which all protocols are used for -bins histogram estimation in the shuffle model.
| Protocol | No. Messages per User | No. Bits per Message | Expected Mean Square Error | Condition |
|---|---|---|---|---|
| privacy-amplification(Balle et al., 2019b) | ||||
| SOLH(Wang et al., 2020) | ||||
| truncation-based(Balcer and Cheu, 2019) | 1+ | |||
| private-coin(Ghazi et al., 2021) | 1+ | , | ||
| public-coin(Ghazi et al., 2021) | 1+ | , | ||
| correlated-noise(Ghazi et al., 2020b) | 1+ | |||
| mixDUMP | 1+ | |||
| pureDUMP | 1+ |
4.2. Dummy Blanket
The blanket intuition is first proposed by Balle et al. (Balle et al., 2019b). They decompose the probability distribution of the data randomizer’s output into two distributions to show the privacy enhancement of the shuffle model. One distribution is dependent on the input value and the other is independently random. Consider inputting a dataset into the data randomizer. The output histogram can be decomposed as , where is the histogram formed by independently random data and is the histogram formed by unchanged sensitive data. Suppose that the analyst knows , and remains unchanged. The analyst needs to observe if it tries to break the privacy of from the dataset sent by the shuffler. Although is not randomized, hides like a random blanket.
In this paper, we propose the concept of dummy blanket to take further advantage of the shuffle model. We only consider the uniformly random distributed dummy blanket in this paper. Whether participating in the randomization or not, each user sends uniformly random generated dummy points to the shuffler. The total number of dummy points form a histogram that hides each user’s data like a dummy blanket. In the aforementioned assumptions, the analyst needs to distinguish from . The dummy blanket provides the same privacy guarantee for each user, while the communication overhead is shared by all users. It can bring significant enhancement of utility when there are a large number of users. Moreover, the dummy blanket does not conflict with any randomization mechanism, it can be wrapped outside of the blanket formed by any data randomizer.
5. Proposed Protocols
In this section, we present pureDUMP protocol (Section 5.1) and mixDUMP protocol (Section 5.2). For each proposed protocol, we analyze the privacy, accuracy, and efficiency properties.
5.1. pureDUMP: A Pure DUMP protocol
Design of Algorithms. All the privacy guarantee is provided by dummy blanket in pureDUMP. On the user side, instead of randomizing the input data , dummy points are randomly sampled from the domain to hide . Here is determined by privacy parameters when the number of users and the size of data domain are fixed, and the effect of on privacy budget will be discussed later in privacy analysis. Then the shuffler collects all messages from users and randomly shuffles them before sending them to the analyst. From the receiving messages, the analyst can approximate the frequency of each with a debiasing standard step. We omit the description of the shuffling operation as it’s same as in the standard shuffle-based mechanisms. The details of the user-side algorithm and the analyst-side algorithm are given in Algorithm 1 and Algorithm 2, respectively.
Privacy Analysis. Now we analyze the privacy guarantee of pureDUMP. First, we show how much the privacy guarantee on the analyst side is provided by dummy blanket. We focus on the regime where the count of each element in the dummy dataset is much smaller than the total number of dummy points, which captures numerous practical scenarios since the size of data domain is usually large. Therefore, our privacy analysis is based on Lemma 5.1. In fact, the privacy analyses in (Balle et al., 2019b; Wang et al., 2020) are also need to be based on Lemma 5.1, but it is ignored.
Lemma 5.1.
Denote are random variables that follow the binomial distribution, and . For any , and are approximately considered as mutually independent when .
The proof of Lemma 5.1 is in Appendix B.1. Then we show the analysis result of pureDUMP in Theorem 5.2.
Theorem 5.2.
PureDUMP satisfies ()-DP against the analyst for any , , and , where
Proof.
(Sketch) For any two neighboring datasets and , w.l.o.g., we assume they differ in the value, and in , in . Let and be two dummy datasets with dummy points sent by users. What the analyst receives is a mixed dataset that is a mixture of user dataset (or and the dummy dataset (or . We denote (or ). Denote as the number of value in the dummy dataset. To get the same , there should be a dummy point equals to 2 in but equals to 1 in . Thus the numbers of values in other dummy points are in and in . Then we have
As dummy points are all uniformly random sampled from , both and follow binomial distributions, where follows and follows . Denote as and as . Here, and can be considered as mutually independent variables according to Lemma 5.1. Then the probability that pureDUMP does not satisfy -DP is
Let , the can be divided into two cases with overlap that and . According to multiplicative Chernoff bound, we have
Both and are no greater than . We can deduce that always satisfies when and . Substitute into , we can get the upper bound of .
The detailed proof is deferred to Appendix B.2. ∎
Then, we show that when the shuffler colludes with the analyst, each individual user’s data can also be protected in pureDUMP.
Corollary 5.3.
PureDUMP satisfies -LDP against the shuffler for any , , and , where
Proof.
The proof is similar to Theorem 5.2, except that each sensitive data only protected by dummy points generated by its owner. More specifically, LDP protection is provided by dummy blanket composed of dummy points before the shuffling operation. ∎
Accuracy Analysis. We analyze the accuracy of pureDUMP by measuring the Mean Squared Error (MSE) of the estimation results.
| (2) |
where is the true frequency of element in users’ dataset, and is the estimation result of . We first show of pureDUMP is unbiased in Lemma 5.4.
Lemma 5.4.
The estimation result for any in pureDUMP is an unbiased estimation of .
Proof.
∎
Since is an unbiased estimation of , the MSE of in pureDUMP is equal to the variance of according to Equation (2).
| (3) | ||||
Now we calculate the MSE of pureDUMP in Theorem 5.5.
Theorem 5.5.
The MSE of frequency estimation in pureDUMP is
.
Efficiency Analysis. Now we analyze the efficiency of pureDUMP. For an input , the output of each user side consists of messages of length bits. The runtime of the user side is at most . Moreover, is at most when pureDUMP satisfies -DP on the analyst side. The shuffler transmits messages to the analyst with the space of . The runtime of the analyst on input messages is at most and its output has space bits.
According to Theorem 5.5, the expected MSE of estimation in pureDUMP is . Note that the domain size has almost no effect on the estimation error because more dummy points are generated to offset the error caused by the larger domain. When the user side only uses a data randomizer that satisfies -LDP to provide protection, we can deduce from results in (Balle et al., 2019b) that the expected MSE is . By comparison, the estimation error of pureDUMP is always smaller than the method that only using data randomization on the user side, which proves the dummy blanket dominates the randomization in the shuffle model.
5.2. mixDUMP: A DUMP Protocol with GRR
Design of Algorithms. mixDUMP utilizes GRR as the data randomizer to provide privacy guarantee along with dummy points. The details of the algorithm are given in Algorithm 3. Note that GRR mechanism utilized in mixDUMP is a little different from the form in (Wang et al., 2017). To analyze the privacy benefit with the idea of blanket, we use the technique proposed in (Balle et al., 2019b) to decompose GRR into
where is the real data distribution that depends on , and is the uniformly random distribution. With probability , the output is true input, and with probability , the output is random sampled from the data domain. Given the probability of in GRR, it has
where is the privacy budget of LDP.
The procedure of generating dummy points is same as Algorithm 1. Same as before, we omit the description of shuffling operation. The details of the user-side algorithm and the analyst-side algorithm are shown in Algorithm 4 and Algorithm 5, respectively.
Privacy Analysis. We show how much the privacy guarantee is provided by both randomization and dummy blanket to compare with pureDUMP. In particular, we analyze the privacy amplification provided by dummy blanket locally to distinguish the work of adding dummy points on the shuffler side (Wang et al., 2020). We first show the privacy guarantee on the analyst side in Theorem 5.6.
Theorem 5.6.
MixDUMP satisfies ()-DP for any , , , and , where
Proof.
(Sketch) The assumption is same as in Theorem 5.2. We assume the value in and in its neighboring dataset . Denote (or ) as randomized users’ dataset (or ). If the user randomizes its data, then we can easily get
So, we focus on the case that the user does not randomize its data. Denote as the set of users participating in randomization in Algorithm 3, and the size of is . Since the randomized users’ data and dummy points are all follows the uniform distribution, mixDUMP can be regarded as pureDUMP with dummy dataset is introduced. From Theorem 5.2, mixDUMP satisfies -DP, we have
where , . Since follows , according to Chernoff bound, we can get
where . Denote , then we have
The details of this proof is in Appendix B.3. ∎
Then, we analyze the LDP privacy guarantee provided by mixDUMP when the shuffler colludes with the analyst. We show that our design different from (Wang et al., 2020) can obtain privacy benefits from dummy points before shuffling operation, which enables users to be less dependent on trust in the shuffler. When the data randomizer satisfies -LDP, the introduced dummy points can achieve an enhanced LDP with the privacy budget smaller than . The theoretical analysis is shown in Theorem 5.7.
Theorem 5.7.
If the data randomizer satisfies -LDP, after introducing dummy points, -LDP is achieved for any , , where
Proof.
(Sketch) Denote as numbers of values in the user’s reports set where . Denote (or ) as the dummy dataset generated by the user. Let be the true value held by the user. According to the definition of LDP, we compare the probability of shuffler receiving the same set with numbers of k values are when and . We prove the following formula
According to Equation (1) of GRR mechanism, we have
Both and follow binomial distribution, where follows and follows . Based on Lemma 5.1, and are considered as mutually independent variables. Then we have
According to the Chernoff bound, we have
Note that , so . As with the probability larger than , we have
when , it has , where .
The details of this proof is in Appendix B.5. ∎
Figure 2 shows the theoretical result of Theorem 5.7. We set , , and show the privacy budget with varying numbers of dummy points on three different sizes of the data domain. We can observe that dummy points significantly reduce the upper bound of the privacy budget of LDP protection, which enables enhanced privacy protection is provided when the shuffler colludes with the analyst.

Accuracy Analysis. We still use MSE as metrics to analyze the accuracy of mixDUMP. Same as before, we first show is unbiased in mixDUMP in Lemma 5.8.
Lemma 5.8.
The estimation result for any in mixDUMP is an unbiased estimation of .
The proof of Lemma 5.8 is deferred to Appendix B.4. Then the MSE of frequency estimation equals to the variance of in mixDUMP. Next, we show the MSE of mixDUMP in Theorem 5.9.
Theorem 5.9.
The MSE of frequency estimation in mixDUMP is
where is the privacy budget of GRR in mixDUMP.
Proof.
Efficiency Analysis. Next, we show the efficiency analysis of mixDUMP. For an input , the output of the user side is messages of length bits. Since we amplify twice in the process of proving the upper bound of the privacy budget in mixDUMP, the advantage of mixDUMP compared to pureDUMP in the number of messages is weakened. When mixDUMP satisfies -DP, is at most . The upper bound of can be approximated as when is close to .
The shuffler transmits dummy points to the analyst with the space of bits. The analyst outputs bits estimated from messages with expected MSE is . Note that is the probability that each user randomizes its data. As , we can amplify . Then, the estimation error can be approximated as .
5.3. Analysis for Practical Implementations
We propose two protocols for privacy-preserving histogram estimation in Subsection 5.1 and Subsection 5.2. Under the assumption that each user sends dummy points, we analyze the performance of the proposed protocols theoretically. In practical implementations, some users might be limited by network bandwidth or computation capability (e.g., running on mobile devices or sensors), and some users may even refuse to send additional dummy points. Taking these conditions into account, we also analyze the privacy and accuracy of the proposed protocols under a more realistic assumption.
The weak assumption of flexible DUMP protocols assumes that each user sends dummy points with the probability of . More specifically, each user uniformly samples random dummy points from with the probability of , and only sends one message with the probability of . In practical implementations, can be obtained by investigating users’ desires or referring to the past experience of collectors. In the following part, we first try to answer how much the weak assumption affects the privacy of protocols in DUMP framework. We prove the following lemma.
Lemma 5.10.
For any DUMP protocols that satisfy -DP for any and , the flexible DUMP protocols satisfy -DP.
Proof.
According to Lemma 5.10, we can get Theorem 5.11 and Theorem 5.12. We show that if each user sends dummy points with the probability of , it can increase the privacy budget and the failure probability of DUMP protocols. Because under this weak assumption, there is a possibility that no user sends dummy points, and it may cause the protocols to fail to satisfy DP.
Theorem 5.11.
The flexible pureDUMP satisfies -DP for any , where , and .
Theorem 5.12.
The flexible mixDUMP satisfies -DP for any , where , and .
Next, we analyze the impact of weak assumptions on the accuracy of the DUMP protocols. Same as before, we first show that the estimation results of flexible pureDUMP and mixDUMP are unbiased in Lemma 5.13 and Lemma 5.14. Both the estimation functions and proofs are deferred to Appendix B.6 and Appendix B.7.
Lemma 5.13.
The estimation result for any in flexible pureDUMP is an unbiased estimation of .
Lemma 5.14.
The estimation result for any in flexible mixDUMP is an unbiased estimation of .
As the weak assumption reduces the strength of privacy protection, the fewer dummy points reduce the MSE of the estimation results. We show the accuracy of the flexible DUMP protocols in Theorem 5.15 and Theorem 5.16, and proofs are deferred to Appendix B.8 and Appendix B.9.
Theorem 5.15.
The MSE of frequency estimation in flexible pureDUMP is
Theorem 5.16.
The MSE of frequency estimation in flexible mixDUMP is
where is the privacy budget of GRR in mixDUMP.
6. Evaluation
6.1. Setup
We design experiments to evaluate the performance of the proposed protocols (pureDUMP and mixDUMP) and compare them with the existing protocols (truncation-based (Balcer and Cheu, 2019), private-coin(Ghazi et al., 2021), public-coin (Ghazi et al., 2021), SOLH (Wang et al., 2020), correlated-noise (Ghazi et al., 2020b)). Note that although the source codes of these existing protocols except SOLH are not formally released, we still implemented them with our best effort and included them for comparison purposes.
In experiments, we measure (1) the accuracy of the proposed protocols, i.e., how much accuracy they improve over existing shuffle protocols; (2) the communication overhead of the proposed protocols, i.e., how many messages does each user needs to send; and how do they compare with existing shuffle protocols. (3) how key parameters would affect the accuracy of the proposed protocols, i.e., the number of users and the size of domain ; Towards these goals, we conduct experiments over both synthetic and real-world datasets. The synthetic datasets allow us to adjust the key parameters of the datasets to observe the impact on the utility of protocols. And the real-world datasets would show the utility of the proposed protocols in a more practical setting.


Environment. All protocols are implemented in Python 3.7 with pyhton-xxhash 1.4.4 and numpy 1.18.1 libraries. All experiments are conducted on servers running Ubuntu 18.04.4 LTS 2.50GHz with 4*32GB memory.
Synthetic Datasets. We generate six synthetic datasets with different sizes of the data domain and the number of users . In the first three datasets, we fix and generate different datasets with , , and , respectively. In the rest of datasets, we fix and generate different datasets with , , and , respectively. All datasets are following a uniform distribution. We observe that the distribution of datasets has little effect on the performance of protocols, so we only show the experimental results on uniform distribution.
Real-World Datasets. We conduct experiments on following two real-world datasets.
-
•
IPUMS (ipu, 2017): We sample of the US Census data from the Los Angeles and Long Beach area for the year 1970. The dataset contains 70,187 users and 61 attributes. We select the birthplace attribute for evaluation, which includes 900 different values.
-
•
Ratings (rat, 2017): This dataset contains 20 million ratings of the movies have been rated by 138,000 users. We sample 494,352 records containing 2,000 different movies.


Protocols for Comparison. We compare pureDUMP and mixDUMP with following protocols.
-
•
private-coin (Ghazi et al., 2021): A multi-message protocol for histogram frequency estimation in the shuffle model. It utilizes the Hadamard response as the data randomizer.
- •
-
•
SOLH (Wang et al., 2020): A single-message protocol for histogram frequency estimation in the shuffle model. It utilizes the hashing-based mechanism OLH as the data randomizer.
-
•
truncation-based (Balcer and Cheu, 2019): A multi-message protocol for histogram frequency estimation in the shuffle model. The protocol can provide privacy protection with .
-
•
correlated-noise (Ghazi et al., 2020b): A multi-message protocol for histogram frequency estimation in the shuffle model. It adds noises from negative binomial distribution to users’ data.
-
•
privacy-amplification (Balle et al., 2019b): A privacy amplification result in the shuffle model. It has amplification effect only when within .
Accuracy Metrics. In our experiments, we use mean squared error (MSE) as the accuracy metrics. For each value in , we compute the real frequency on the sensitive dataset and estimate frequency on the noise dataset. Then we calculate their squared difference for different values.
All MSE results in experiments are averaged with 50 repeats.
For the private-coin and correlated-noise, we calculate the expected mean squared error. As comparisons are required to match messages with Hadamard codewords on the analyst side of private-coin, which leads to excessive computational overhead, i.e., 1,450 hours for dataset with k=512 and n =70,000. In the correlated-noise, we didn’t find a way to sample the negative binomial distribution where is non-integer. We hope in the further we can further improve this implementation.


6.2. Experiments with Synthetic Datasets
Overall Results. The influence of domain size on the MSE of pureDUMP and mixDUMP is shown in Figure 3, where the domain size has almost no influence on the MSE of pureDUMP. The influence of number of users on the MSE of pureDUMP and mixDUMP is shown in Figure 4, where the MSE of pureDUMP and mixDUMP is in inverse proportion to the number of users. Meanwhile, the small gap between the theoretical and empirical results validates the correctness of our theoretical error analysis.
Figure 5 and Figure 7 show MSE comparisons of all protocols on two different synthetic datasets. The proposed protocols, pureDUMP and mixDUMP, support any in the range of with higher accuracy. Meanwhile, the numbers of messages sent by each user in all protocols except shuffle-based and SOLH (always one message) are depicted in Figure 6 and Figure 8. The proposed protocols, pureDUMP and mixDUMP, support any in the range of with the best accuracy compared with other protocols, while the only exception correlated-noise, achieving near-optimal accuracy, but has much higher communication overhead 333Since the coefficient is ignored, the declared asymptotic upper bound is smaller than eMSE.. Meanwhile, we observe that the numbers of messages sent by each user in pureDUMP and mixDUMP are always the smallest in all protocols. Although the MSE of truncation-based is performing similar to pureDUMP and mixDUMP, the communication overhead of private-shuffle is at least one order of magnitude higher than pureDUMP and mixDUMP. Since sufficient privacy guarantee can be provided by privacy amplification when hundreds of thousands of users are involved, we set of mixDUMP equals to 8 throughout the experiment to adapt large in the range of .

Influence of Domain Size. We compare the MSE of pureDUMP on three synthetic datasets with different sizes of data domain in Figure 3a. The result shows that the size of the data domain has little influence on the accuracy of pureDUMP. Because according to our theoretical result in Subsection 5.1, the MSE of pureDUMP can be approximately simplified to when is large. Figure 3b shows that the MSE of mixDUMP is proportional to the domain size because the large size of the data domain increases the error introduced by the data randomizer in mixDUMP.
Influence of Users Number. Figure 4a and Figure 4b show the influence of the number of users on the MSE of pureDUMP and mixDUMP, respectively. We can observe that the MSE in inverse proportion to the number of users . The MSE decreases by two orders of magnitude when the number of users increases by an order of magnitude, which is consistent with our efficiency analysis in Subsection 5.1 and Subsection 5.2.


Accuracy Comparisons of Existing Protocols. We choose two synthetic datasets that enable as many protocols as possible can provide privacy protection with within the range of , and MSE values of some out of the valid range of protocols are omitted. The comparison results is shown in Figure 5. We can observe that pureDUMP and mixDUMP always enjoy privacy amplification and have smaller MSE than the other ones except correlated-noise. Meanwhile, we can also observe that pureDUMP has higher accuracy than mixDUMP. It means that dummy points can introduce less error than the data randomizer when providing the same strength of privacy protection. Besides, the privacy-amplification has no privacy amplification on some small values, which causes poor MSE results. Moreover, we can also observe that the lines of public-coin always slightly increase at the beginning. Because the noise obeys binomial distribution, i.e., , where decreases with the increase of , the variance increases before drops to .
Communication Comparisons of Existing Protocols. The communication overhead is compared by computing the number of messages sent by each user in protocols. Since the number of messages sent by each user in private-coin and public-coin is always larger than the other protocols and only these two protocols has length of message larger than for datasets with (see Table 2), comparing the number of messages does not affect the fairness of the results. Moreover, as the number of messages sent by each user in privacy-amplification and SOLH is always , we omit them in our comparisons. We also omit the values which are out of the valid range of the protocol. The comparison results are shown in Figure 6. We can observe that each user always sends fewer messages than others in pureDUMP and mixDUMP, and the mixDUMP requires the least number of messages per user because the data randomizer provides partial privacy protection so that fewer dummy points need to be generated. Note that the number of messages that each user sends in DUMP protocols is less than when a large is required. It means that fewer than dummy points are needed to satisfy a large when there is a sufficient number of users. According to the theoretical results of flexible DUMP protocols in Subsection 5.3, we provide their parameter settings for different on these two synthetic datasets in Appendix A. We can also observe that the number of messages sent by each user increases as increases in truncation-based protocol. Because each user sends additional with probability of where . Hence the probability closes to 1 when increases and a larger number of 1s are sent by each user.
6.3. Experiments with Real-World Datasets
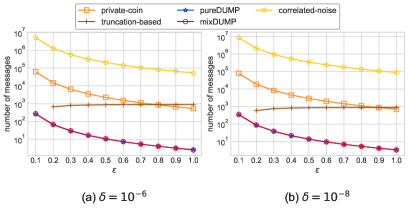
We also conduct experiments on two real-world datasets: IPUMS and Ratings. The MSE comparisons of protocols are shown in Figure 9 and Figure 11, and their corresponding communication overhead are shown in Figure 10 and Figure 12. The privacy-amplification has no privacy amplification on both IPUMS and Ratings datasets, so it’s not involved in the comparison. Besides, public-coin is also not involved in the comparison because most of are not in the valid range of public-coin on both datasets. We can observe that the pureDUMP and mixDUMP still achieve higher accuracy among all protocols except the correlated-noise under the large domain size in real-world datasets. Over the Ratings dataset with and , pureDUMP (and mixDUMP) only require around (and ) expected extra messages per user, whiletruncation-based, private-coin, and correlated-noise need around , and extra messages respectively. On the other hand, single-message protocols privacy-amplification and SOLH are less competitive in accuracy and/or subjected to upper-bounds on privacy guarantee (namely, the lower-bounds on ).
7. Related Works
Anonymous Data Collection. Many works focus on anonymizing users’ messages. Some mechanisms are based on the cryptographic idea, including (Syverson et al., 2004; Lazar et al., 2018; Tyagi et al., 2017; Van Den Hooff et al., 2015). Recently, Chowdhury et al. (Roy Chowdhury et al., 2020) propose a system Crypt that achieves the accuracy guarantee of CDP with no trusted data collector required like LDP. In this approach, users encrypt their messages with homomorphic encryption and then they send messages to an auxiliary server to aggregate and add random noise. After that, the encrypted aggregated result is sent to the analyst, and the analyst decrypts to get the noisy result that satisfies CDP. Other mechanisms are based on the shuffling idea. This idea is originally proposed by Bittau et al. (Bittau et al., 2017). They design Encode, Shuffle, Analyze (ESA) architecture. The ESA architecture eliminates the link between the message and the user identity by introducing a shuffler between users and the analyst. A lot of following works analyze the privacy benefits that come from the shuffle model (Erlingsson et al., 2019; Cheu et al., 2019; Balle et al., 2019b; Feldman et al., 2020). Among them, Feldman et al. (Feldman et al., 2020) provide the tightest upper bound that can be reduced to .
Protocols in the shuffle model. Recent shuffle-related works seek to design more accurate communication-efficient protocols. The studies focus on frequency estimation in the shuffle model are shown in Section 3.2. We show some other related works as a supplement. Some studies focus on binary data summation. Cheu et al. (Cheu et al., 2019) design a single-message protocol for binary summation. Each user only sends one-bit message to the analyst and has expected error at most . Ghazi et al. (Ghazi et al., 2020a) design a multi-message protocol for binary summation where each user sends one-bit messages to the analyst and has expected error at most . Balcer et al. (Balcer and Cheu, 2019) propose a two-message protocol for binary summation with expected error at most . There are also a lot of studies on real data summation and many excellent protocols are proposed (Cheu et al., 2019; Balle et al., 2019b; Ghazi et al., 2019b; Balle et al., 2019a; Ghazi et al., 2020c).
8. Conclusions
In this paper, a novel framework called DUMP is proposed for privacy-preserving histogram estimation in the shuffle model. Two types of protection mechanisms, data randomization and dummy-point generator, are contained on the user side of DUMP. The analysis results show that the dummy points can get more privacy benefits from shuffling operation. To further explore the advantages of dummy points, two protocols: pureDUMP and mixDUMP are proposed. The proposed protocols achieve better trade-offs between privacy guarantee, statistics accuracy, and communication overhead than existing protocols. Besides, the proposed protocols are also analyzed under a more realistic assumption for practical application, we prove that the privacy and utility of the proposed protocols still hold. Finally, we perform experiments to compare different protocols and demonstrate the advantage of the proposed protocols on both synthetic and real-world datasets. For future work, we will study different distributions of dummy points and apply DUMP to more statistical types such as real number summation, range query, and quantile query.
References
- (1)
- ipu (2017) 2017. IPUMS Census Dataset. https://data.world/uci/ipums-census-database/.
- rat (2017) 2017. Movie rating dataset. https://www.kaggle.com/ashukr/movie-rating-data/.
- Balcer and Cheu (2019) Victor Balcer and Albert Cheu. 2019. Separating local & shuffled differential privacy via histograms. arXiv preprint arXiv:1911.06879 (2019).
- Balcer and Vadhan (2018) Victor Balcer and Salil P. Vadhan. 2018. Differential Privacy on Finite Computers. In ITCS (LIPIcs), Vol. 94. Schloss Dagstuhl - Leibniz-Zentrum für Informatik, 43:1–43:21.
- Balle et al. (2019a) Borja Balle, James Bell, Adria Gascon, and Kobbi Nissim. 2019a. Differentially private summation with multi-message shuffling. arXiv preprint arXiv:1906.09116 (2019).
- Balle et al. (2019b) Borja Balle, James Bell, Adria Gascón, and Kobbi Nissim. 2019b. The privacy blanket of the shuffle model. In Annual International Cryptology Conference. Springer, 638–667.
- Bittau et al. (2017) Andrea Bittau, Úlfar Erlingsson, Petros Maniatis, Ilya Mironov, Ananth Raghunathan, David Lie, Mitch Rudominer, Ushasree Kode, Julien Tinnes, and Bernhard Seefeld. 2017. Prochlo: Strong privacy for analytics in the crowd. In Proceedings of the 26th Symposium on Operating Systems Principles. 441–459.
- Cheu et al. (2019) Albert Cheu, Adam Smith, Jonathan Ullman, David Zeber, and Maxim Zhilyaev. 2019. Distributed differential privacy via shuffling. In Annual International Conference on the Theory and Applications of Cryptographic Techniques. Springer, 375–403.
- Cormode and Muthukrishnan (2005) Graham Cormode and Shan Muthukrishnan. 2005. An improved data stream summary: the count-min sketch and its applications. Journal of Algorithms 55, 1 (2005), 58–75.
- Ding et al. (2017) Bolin Ding, Janardhan Kulkarni, and Sergey Yekhanin. 2017. Collecting telemetry data privately. In Advances in Neural Information Processing Systems. 3571–3580.
- Duchi et al. (2013) John C Duchi, Michael I Jordan, and Martin J Wainwright. 2013. Local privacy and statistical minimax rates. In 2013 IEEE 54th Annual Symposium on Foundations of Computer Science. IEEE, 429–438.
- Dwork (2008) Cynthia Dwork. 2008. Differential privacy: A survey of results. In International conference on theory and applications of models of computation. Springer, 1–19.
- Erlingsson et al. (2019) Úlfar Erlingsson, Vitaly Feldman, Ilya Mironov, Ananth Raghunathan, Kunal Talwar, and Abhradeep Thakurta. 2019. Amplification by shuffling: From local to central differential privacy via anonymity. In Proceedings of the Thirtieth Annual ACM-SIAM Symposium on Discrete Algorithms. SIAM, 2468–2479.
- Erlingsson et al. (2014) Úlfar Erlingsson, Vasyl Pihur, and Aleksandra Korolova. 2014. Rappor: Randomized aggregatable privacy-preserving ordinal response. In Proceedings of the 2014 ACM SIGSAC conference on computer and communications security. 1054–1067.
- Feldman et al. (2020) Vitaly Feldman, Audra McMillan, and Kunal Talwar. 2020. Hiding among the clones: A simple and nearly optimal analysis of privacy amplification by shuffling. arXiv preprint arXiv:2012.12803 (2020).
- Gazeau et al. (2016) Ivan Gazeau, Dale Miller, and Catuscia Palamidessi. 2016. Preserving differential privacy under finite-precision semantics. Theor. Comput. Sci. 655 (2016), 92–108.
- Geng et al. (2015) Quan Geng, Peter Kairouz, Sewoong Oh, and Pramod Viswanath. 2015. The staircase mechanism in differential privacy. IEEE Journal of Selected Topics in Signal Processing 9, 7 (2015), 1176–1184.
- Ghazi et al. (2020a) Badih Ghazi, Noah Golowich, Ravi Kumar, Pasin Manurangsi, Rasmus Pagh, and Ameya Velingker. 2020a. Pure differentially private summation from anonymous messages. arXiv preprint arXiv:2002.01919 (2020).
- Ghazi et al. (2019a) Badih Ghazi, Noah Golowich, Ravi Kumar, Rasmus Pagh, and Ameya Velingker. 2019a. Private Heavy Hitters and Range Queries in the Shuffled Model. arXiv preprint arXiv:1908.11358 (2019).
- Ghazi et al. (2021) Badih Ghazi, Noah Golowich, Ravi Kumar, Rasmus Pagh, and Ameya Velingker. 2021. On the Power of Multiple Anonymous Messages: Frequency Estimation and Selection in the Shuffle Model of Differential Privacy. In Annual International Conference on the Theory and Applications of Cryptographic Techniques. Springer, 463–488.
- Ghazi et al. (2020b) Badih Ghazi, Ravi Kumar, Pasin Manurangsi, and Rasmus Pagh. 2020b. Private counting from anonymous messages: Near-optimal accuracy with vanishing communication overhead. In International Conference on Machine Learning. PMLR, 3505–3514.
- Ghazi et al. (2020c) Badih Ghazi, Pasin Manurangsi, Rasmus Pagh, and Ameya Velingker. 2020c. Private aggregation from fewer anonymous messages. In Annual International Conference on the Theory and Applications of Cryptographic Techniques. Springer, 798–827.
- Ghazi et al. (2019b) Badih Ghazi, Rasmus Pagh, and Ameya Velingker. 2019b. Scalable and differentially private distributed aggregation in the shuffled model. arXiv preprint arXiv:1906.08320 (2019).
- Ghosh et al. (2012) Arpita Ghosh, Tim Roughgarden, and Mukund Sundararajan. 2012. Universally utility-maximizing privacy mechanisms. SIAM J. Comput. 41, 6 (2012), 1673–1693.
- Holohan et al. (2017) Naoise Holohan, Douglas J Leith, and Oliver Mason. 2017. Optimal differentially private mechanisms for randomised response. IEEE Transactions on Information Forensics and Security 12, 11 (2017), 2726–2735.
- Ilvento (2020) Christina Ilvento. 2020. Implementing the Exponential Mechanism with Base-2 Differential Privacy. In CCS. ACM, 717–742.
- Kairouz et al. (2014) Peter Kairouz, Sewoong Oh, and Pramod Viswanath. 2014. Extremal mechanisms for local differential privacy. Advances in neural information processing systems 27 (2014), 2879–2887.
- Kasiviswanathan et al. (2011) Shiva Prasad Kasiviswanathan, Homin K Lee, Kobbi Nissim, Sofya Raskhodnikova, and Adam Smith. 2011. What can we learn privately? SIAM J. Comput. 40, 3 (2011), 793–826.
- Lazar et al. (2018) David Lazar, Yossi Gilad, and Nickolai Zeldovich. 2018. Karaoke: Distributed private messaging immune to passive traffic analysis. In USENIX Symposium on Operating Systems Design and Implementation. 711–725.
- Mironov (2012) Ilya Mironov. 2012. On significance of the least significant bits for differential privacy. In CCS. ACM, 650–661.
- Roy Chowdhury et al. (2020) Amrita Roy Chowdhury, Chenghong Wang, Xi He, Ashwin Machanavajjhala, and Somesh Jha. 2020. Crypt: Crypto-Assisted Differential Privacy on Untrusted Servers. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data. 603–619.
- Syverson et al. (2004) Paul Syverson, Roger Dingledine, and Nick Mathewson. 2004. Tor: The secondgeneration onion router. In USENIX Security Symposium. 303–320.
- Team et al. (2017) ADP Team et al. 2017. Learning with privacy at scale. Apple Mach. Learn. J 1, 9 (2017).
- Tyagi et al. (2017) Nirvan Tyagi, Yossi Gilad, Derek Leung, Matei Zaharia, and Nickolai Zeldovich. 2017. Stadium: A distributed metadata-private messaging system. In Proceedings of the 26th Symposium on Operating Systems Principles. 423–440.
- Van Den Hooff et al. (2015) Jelle Van Den Hooff, David Lazar, Matei Zaharia, and Nickolai Zeldovich. 2015. Vuvuzela: Scalable private messaging resistant to traffic analysis. In Proceedings of the 25th Symposium on Operating Systems Principles. 137–152.
- Wang et al. (2017) Tianhao Wang, Jeremiah Blocki, Ninghui Li, and Somesh Jha. 2017. Locally differentially private protocols for frequency estimation. In USENIX Security Symposium. 729–745.
- Wang et al. (2020) Tianhao Wang, Bolin Ding, Min Xu, Zhicong Huang, Cheng Hong, Jingren Zhou, Ninghui Li, and Somesh Jha. 2020. Improving Utility and Security of the Shuffler based Differential Privacy. Proceedings of the VLDB Endowment 13, 13 (2020).
- Wang et al. (2019) Tianhao Wang, Bolin Ding, Jingren Zhou, Cheng Hong, Zhicong Huang, Ninghui Li, and Somesh Jha. 2019. Answering multi-dimensional analytical queries under local differential privacy. In Proceedings of the 2019 International Conference on Management of Data. 159–176.
- Warner (1965) Stanley L Warner. 1965. Randomized response: A survey technique for eliminating evasive answer bias. J. Amer. Statist. Assoc. 60, 309 (1965), 63–69.
Appendix A Parameter setting in flexible pureDUMP and mixDUMP
Table 3 and Table 4 show the number of dummy points need to be sent by a user in flexible pureDUMP and mixDUMP, respectively. The number of users is , we show results on two different (size of data domain) and (probability of a user sending dummy points).
| 50 | 500 | |||
| 0.4 | 13 | 127 | 127 | 1270 |
| 0.6 | 6 | 57 | 57 | 565 |
| 0.8 | 4 | 32 | 32 | 318 |
| 1.0 | 3 | 21 | 21 | 204 |
| 50 | 500 | |||
| 0.4 | 12 | 118 | 119 | 1190 |
| 0.6 | 5 | 44 | 46 | 451 |
| 0.8 | 2 | 18 | 20 | 192 |
| 1.0 | 1 | 6 | 8 | 72 |
Appendix B Proofs
B.1. Proof of Lemma 5.1
Proof.
Denote as random variables that follow the binomial distribution, where . Let be a constant value , then the conditional probability distribution () can be expressed as
The marginal distribution can be expressed as
Then we calculate the upper bound of the ratio of these two probability distributions.
The lower bound of the ratio of these two probability distributions can be calculated as
Since are assumed to be much smaller than , can be inferred to be a large value. Hence both and are close to . Besides, is also close to since is a value much smaller than . Therefore, both the upper bound and the lower bound of are close to . We have
We can approximately consider that the distributions of and are independent based on the above proof.
∎
B.2. Proof of Theorem 5.2
Proof.
For any two neighboring datasets and , w.l.o.g., we assume they differ in the value, and in , in . Let and be two dummy datasets with dummy points sent by users. What the analyst receives is a mixed dataset that is a mixture of user dataset (or and the dummy dataset (or . We denote (or ). Denote as the number of value in the dummy dataset. To get the same , there should be a dummy point equals to 2 in but equals to 1 in . Thus the numbers of values in other dummy points are in and in . Then we have
As dummy points are all uniformly random sampled from , both and follow binomial distributions, where follows and follows . Denote as and as . Here, and can be considered as mutually independent variables according to Lemma 5.1. Then the probability that pureDUMP does not satisfy -DP is
Let , can be divided into two cases with overlap that or so we have
According to multiplicative Chernoff bound, we have
To ensure that , we need
For , , where . So we can get . For , , so , where . Therefore, we can get . Note that .
In summary, we can get . Because , when , can be held all the time. So . Therefore, we have , is that . ∎
B.3. Proof of Theorem 5.6
Proof.
The assumptions are same to the proof of Theorem 5.2. The value in and in its neighboring dataset . If the user randomizes its data, then we can easily get
So, we focus on the case that the user does not randomize its data. Denote as the set of users participating in randomization in Algorithm 3, and the size of is . Since the randomized users’ data and dummy points are all follows the uniform distribution, mixDUMP can be regarded as pureDUMP with dummy dataset is introduced. From Theorem 5.2, mixDUMP satisfies -DP, we have
where , . Since is the probability that each user randomizes its data, the number of users participating in randomization follows . Define , and . According to Chernoff bound, we can get
Then we have
∎
B.4. Proof of Lemma 5.8
Proof.
is the true frequency of element appears in users’ dataset. And is the estimation of . We prove in mixDUMP is unbiased.
In GRR mechanism, the probability that each value keeps the true value with the probability , and changes to other values in the data domain with the probability of . We give the estimation function of mixDUMP in Algorithm 5. The formula is
where . To simplify the derivation, we replace with , then we have estimation of
∎
B.5. Proof of Theorem 5.7
Proof.
Denote as numbers of values in the user’s reports set where . Denote (or ) as the dummy dataset generated by the user. Let be the true value held by the user. According to the definition of LDP, we compare the probability of shuffler receiving the same set with numbers of k values are when and . We prove the following formula
According to Equation (1) of GRR mechanism, we have
Since dummy points are uniformly random sampled from , both and follow binomial distribution. follows and follows . Based on Lemma 5.1, and are considered as mutually independent variables. We have
According to the Chernoff bound , where and . That is . Note that , so . As we prove that with the probability larger than , then we have
when , it has , where . ∎
B.6. Proof of Lemma 5.13
Proof.
is the true frequency of element appears in users’ dataset. is the estimation of . We prove in flexible pureDUMP is unbiased.
As each user generates dummy points with probability of , and with probability of does not generate any dummy point, the estimation function is
Then we have
∎
B.7. Proof of Lemma 5.14
Proof.
is the true frequency of element appears in users’ dataset. And is the estimation of . We prove of flexible mixDUMP is unbiased.
In GRR mechanism, the probability that each value keeps unchanged with the probability , and changes to other values in the data domain with the probability of . As each user generates dummy points with probability of , and with probability of does not generate any dummy point, the estimation function is
where . To simplify the derivation, we replace with , then we have estimation of
∎
B.8. Proof of Theorem 5.15
Proof.
As each user sends dummy points with the probability of , the distribution of number of any distinct value in dummy points is . Thus, the estimation function of flexible pureDUMP is
Then, we have
B.9. Proof of Theorem 5.16
Proof.
As each user generates dummy points in probability of in flexible mixDUMP, the distribution of number of any distinct value in dummy points is . Thus, the estimation function of flexible mixDUMP is
where . To simplify derivation, we replace with , and with , we have the variance of is
Lemma 5.14 proves that is unbiased in flexible mixDUMP, thus we have the MSE of flexible mixDUMP is
∎