DualVAE: Dual Disentangled Variational AutoEncoder for Recommendation
Abstract
Learning precise representations of users and items to fit observed interaction data is the fundamental task of collaborative filtering. Existing studies usually infer entangled representations to fit such interaction data, neglecting to model the diverse matching relationships between users and items behind their interactions, leading to limited performance and weak interpretability. To address this problem, we propose a Dual Disentangled Variational AutoEncoder (DualVAE) for collaborative recommendation, which combines disentangled representation learning with variational inference to facilitate the generation of implicit interaction data. Specifically, we first implement the disentangling concept by unifying an attention-aware dual disentanglement and disentangled variational autoencoder to infer the disentangled latent representations of users and items. Further, to encourage the correspondence and independence of disentangled representations of users and items, we design a neighborhood-enhanced representation constraint with a customized contrastive mechanism to improve the representation quality. Extensive experiments on three real-world benchmarks show that our proposed model significantly outperforms several recent state-of-the-art baselines. Further empirical experimental results also illustrate the interpretability of the disentangled representations learned by DualVAE.
1 Introduction
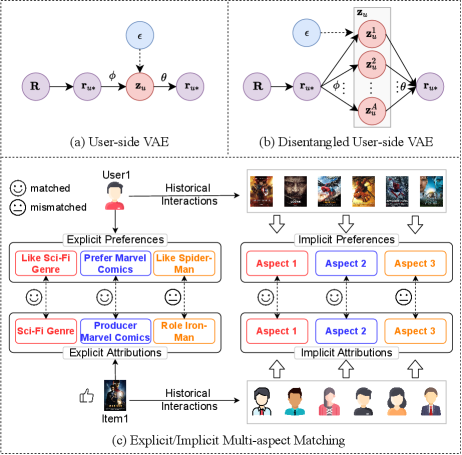
The powerful ability of variational autoencoders (VAEs) [13] to account for uncertainty in the latent space has sparked a surge of interest in integrating variational inference into recommender systems [27, 1, 19]. Traditional VAE-based CF methods [15, 23, 17, 4] generally infer users’ latent variables to reconstruct their interaction vectors, as shown in Figure 1 (a). These methods do not seek to learn deterministic user representations, but rather learn distributions over these representations, making them more suitable for sparse interaction data. However, due to the neglect of the complex entanglement of multiple potential factors behind user decisions, they are insufficient in learning robust and interpretable models.
Recently, disentangled representation learning has received much attention in recommender systems, aiming at improving the representation quality by disentangling latent factors that govern user behaviors [16, 25, 29, 28]. Most existing disentangled VAE-based CF methods [16, 29, 24] are typically designed based only on user-side interaction vectors to infer diverse user preference representations, while items are still entangled in the user vector space. As illustrated in Figure 1 (b), such a user-specific decoupling scheme usually ignores the diverse matching relationships between user preferences and item attributions, which makes the model performance still not satisfactory.
In realistic recommendation scenarios, items generally have multi-aspect attributions. Correspondingly, users have varying degrees of preference for different attributions of items. The preference of a user for an item can be regarded as the agglomeration of affinities between user preferences and item characteristics under different aspects. Take Figure 1 (c) as an example, the movie Item1 has multi-aspect attribution features, including Sci-Fi Genre, Producer Marvel Comics and Role Iron-Man. User1’s explicit preferences are reflected in multiple aspects of items, including Like Sci-Fi Genre, Prefer Marvel Comics producer, and Like Spider-Man. In view of the high matching relationship between User1’s preferences and Item1’s attributions in multiple aspects, there is a high probability that Item1 is recommended to User1. Predictably, coupled user and item representations cannot match such fine-grained correspondence to boost recommendation. Hence, decoupling and inferring multi-aspect features of items and users is necessary to enhance the modeling capability of VAE-based CF models, thereby improving their performance and interpretability. However, disentangled representation learning in such a scenario is non-trivial as it faces the following two challenges:
-
•
Firstly, explicit user preference and item attribute information generally cannot be directly obtained in CF. We can infer implicit multi-aspect representations of users and items by only utilizing the available user-item interaction data, illustrated in Figure 1 (c). However, conventional binary interaction data typically reflect coupled interaction relationships between users and items. How to infer implicit decoupled multi-aspect representations of users and items based on observed binary interaction data becomes the main challenge.
-
•
Secondly, unconstrained inference of decoupled representations of users and items cannot guarantee independence among multi-aspect representations. Meanwhile, the learned aspect-level user preference may deviate from the corresponding aspect-level item representation, resulting in incorrect matching of multi-aspect representations between users and items. Hence, how to maintain independence among representations of different aspects for each user and item so that they do not deviate from the corresponding aspects is another tough challenge.
In this paper, we propose a novel Dual Disentangled Variational AutoEncoder (DualVAE) for collaborative recommendation with implicit feedback, which infers both user-side and item-side disentangled representations. Specifically, to address the first challenge, we transform the traditional VAE paradigm by unifying an attention-aware dual disentanglement module with a disentangled variational inference module and a joint generative module to infer multi-aspect latent representations for users and items. Further, we develop a neighborhood-enhanced representation constraint module to address the second challenge by employing self-supervised contrastive learning with neighborhood-based positive samples and two-level negative samples. Compared to standard VAE, DualVAE can capture multi-aspect uncertainty on both the user-side and the item-side, which helps improve its robustness and performance. Extensive experiments on three real-world benchmarks demonstrate the effectiveness of the proposed DualVAE model. Moreover, we also empirically show that the learned disentangled representations provide good support for explaining user behaviors.
2 Related work
2.1 Latent Representation Learning for CF
To fit dyadic interaction data, much of the literature on collaborative filtering [7] focuses on latent representation learning. Matrix factorization (MF)[14] is a typical CF framework that directly embeds the IDs of users and items into latent feature space. Later, some studies [21, 26, 10, 30] model both users and items by introducing deep neural networks, which can be viewed as a nonlinear extension of MF. For instance, NeuMF [10] treats the recommendation problem with implicit feedback as a binary classification problem and fuses Generalized Matrix Factorization (GMF) with MLP. JCA [30] employs two separate autoencoders to simultaneously learn both user-user and item-item correlations. To further account for uncertainty in latent space, some researchers introduce VAEs [13] into collaborative filtering to improve model robustness [11, 22, 19, 6, 17, 4]. For instance, MultiVAE [15] extends VAEs to capture the latent variables of users with implicit feedback and estimate parameters via Bayesian inference. BiVAE [23] infers the latent representations for users and items through bilateral VAEs. Despite their achievements, the entanglement of latent factors behind user behaviors, is mostly neglected by these methods, leading to weak interpretable results.
2.2 Disentangled Representation Learning for CF
Due to its robust performance and interpretability, disentangled representation learning [2] is gradually being introduced into VAE-based recommender systems. Most of these methods [16, 29, 24] usually decouple users’ diverse preferences based on their collaborative interactions. For example, MacridVAE [16] introduces categorical distributions to disentangle the macro-level and micro-level factors on different items via a variational autoencoder. Zheng et al. [29] propose to structurally disentangle user interest and conformity by training with cause-specific data. Wang et al. [24] utilize structural causal models to generate causal representations that describe the causal relationship between latent factors. Nevertheless, these methods only unilaterally disentangle coarse-grained user preferences, while ignoring the relationship modeling between user preferences and item features in multiple aspects, and hence are not suitable for fitting binary interaction data.
3 Methodology
3.1 Notations and Problem Formulation
We consider an implicit collaborative recommendation that consists of a user set with users and an item set with items. The interaction data is denoted as , where is the observed interaction of user on item . We use to denote ’s interaction vector corresponding to the -th row in , and to denote the -th column in towards item . For traditional VAE-based CF models, the latent variables of per user and item are generally denoted by entangled and , respectively. Considering that an item in general has multi-aspect features, we denote the item latent representation as , where corresponds to ’s representation towards the -th aspect, is the number of aspects, and is the embedding dimension. Similarly, user ’s latent representation is denoted as , where reflects ’s preference under the -th aspect. Our objective in this work is to learn a robust VAE-based CF model to disentangle and infer multi-aspect latent representations of users and items from user-item interactions. After training, we can exploit the learned multi-aspect latent representations to perform top- recommendation.
3.2 Overview
Traditional VAE-based CF models generally define a user-side generative model that generates the observed data from the following distribution,
| (3.1) |
where is a probability distribution over the items learned by a generative model with parameters . Each observed interaction is independently generated from the inferred user latent variable . is the prior of user variable . Different from the one-way generative paradigm, we propose a dual disentangled generative model to generate the observed interaction that encourages multi-aspect disentanglement of both users and items,
| (3.2) |
where the generation of is related to two latent variables . and are the item-aspect and user-aspect probability matrices, in which and are two probability vectors drawn from two aspect distributions and . is the number of aspects. We assume that and , i.e., , , and can be independently generated.
Our proposed DualVAE implements above distributions (, , , , and ) by four modules: 1) Attention-aware dual disentanglement (ADD) module that generates the aspect-aware probability distributions , of users and items. 2) Disentangled variational inference (DVI) module that infers the posterior over disentangled latent variables , of users and items. 3) Joint generation (JG) module that utilizes the inferred user and item latent representations and aspect-aware probability matrices to reconstruct the observed interactions, thereby achieving . 4) Neighborhood-enhanced representation constraint (NRC) module that maintains the correspondence and independence between latent variables by introducing contrastive learning. Next, we will detail the implementation of each module.
3.3 Attention-aware Dual Disentanglement
The ADD module is designed to generate the item-aspect and user-aspect probability vectors, which achieves the aspect assignment of users and items.
item-side aspect disentanglement.
Considering that items usually have different degrees in different aspects, we assign an item-aspect probability matrix over all items in , where is the aspect probability vector of item . To generate the matrix , we assume and adopt the prototype-based attention mechanism to independently infer each aspect-level probability vector . Specifically, we introduce aspect prototypes () shared among items, and obtain the vector from the item-aspect distribution ,
| (3.3) |
where is the -th aspect-level latent representation of item , is a probability that reflects the relation between item and aspect , and is an affinity function (such as cosine) used to calculate the score of item under aspect .
user-side aspect disentanglement.
Similarly, we also define preference prototypes () to calculate user-aspect probability vector from the user-aspect distribution ,
| (3.4) |
where is the -th aspect-level latent representation of user , and is a probability of user on the -th preference.
3.4 Disentangled Variational Inference
The DVI module is designed to infer the multi-aspect latent variables of users and items. In general, latent variables are drawn from prior distributions. We follow the convention to represent the prior over both user and item latent variables via the standard multivariate isotropic Gaussians, i.e., , where is a diagonal matrix. Given the user-item interaction matrix , the goal of variational inference model is to infer the posterior over the latent variables . Proverbially, the true posterior is intractable, and thereby precise inference is infeasible. We therefore exploit Variational Bayes [3] to approximate this posterior distribution by a parameterized function . Obviously, the variational distribution firstly breaks the coupling between and . Considering the statistical independence among users and items, we can set and to achieve the variational inference.
To further obtain disentangled multi-aspect latent representations of users and items, we assume that and . Without loss of generality, we express the variational and as a multivariate normal distribution with a diagonal covariance matrix,
| (3.5) | ||||
where and are the mean and covariance of the disentangled variational distributions, parameterized by two shallow networks and with parameters and ,
| (3.6) | ||||
where and are the -th column of and , respectively, representing the -th aspect probability vectors over all items and users. denotes element-wise product. and are calculated as the aspect-level interaction vectors of user and item , respectively. It is clear to see that , and . Notably, under aspect , the aspect-level probability vectors of items are employed to learn aspect-level latent representations of users, and vice versa. Such operations ensure that the disentangled representations of users and items are in a one-to-one correspondence at the aspect-level. Further, and are sampled by a reparameterization trick [13, 20],
| (3.7) |
where is a noise vector with .
3.5 Joint Generation
Given the user and item latent representations and and the aspect probability matrices and , the JG module is designed to predict the preference of a user towards an item by reconstructing their observed interactions. Specifically, we generate the distribution of user ’s preference towards item by a Poisson distribution [23],
| (3.8) |
where is a differentiable function that utilizes disentangled latent representations of user and item to generate the joint observation ,
| (3.9) | ||||
where is a skip-connection operation to avoid the issue of latent variable collapse [5], is a non-linear function parameterized by , is sigmoid function, and denotes inner product. Notice and and are regarded as aspect-level weights for item and user .
To optimize our model parameters , and , we proceed with approximate inference and learning by maximizing the evidence lower bound (ELBO) . However, due to the sparsity of observed interactions, directly performing unbiased stochastic optimization on the above objective is inconvenient. We hence exploit the two-way nature of our model and perform alternate optimization in a Gauss-Seidel fashion [23]. Specifically, we split the model parameters into user-related and item-related parts, and then alternately optimize them. Firstly, the user-side objective is updated with fixed item-related parameters,
| (3.10) | ||||
where . The first term is interpreted as reconstruction error, while the second term defines the Kulback-Leibler divergence. Analogously, when keeping user-related parameters fixed, the item-side objective needs to be optimized,
| (3.11) | ||||
where . Note the above objectives and are not conflicting with each other, since maximizing either of them corresponds to the maximization of the overall ELBO.
3.6 Neighborhood-enhanced Representation Constraint
The NRC module is designed to prevent the confusion between latent representations inferred from different aspects and maintain correspondence between aspect-level representations of users and items. Specifically, we first aggregate the interacted neighbors to calculate the aspect-level neighborhood-based representations and of user and item ,
| (3.12) |
where and are the neighbor sets of user and item , respectively. Afterwards, we treat the inferred aspect-level latent representations and neighborhood-based representation of user as positive sample pair. Moreover, we set two kinds of negative samples. Firstly, to constrain the independence among different aspect representations, we set aspect-level negative samples by taking representations of different aspects for the same user as negative samples. Secondly, we use representations from different users under the same aspect as user-level negative samples to guarantee the discrepancy in aspect-level representations among different users. The InfoNCE [8] loss is employed to achieve the contrastive constraint,
| (3.13) |
where is the contrastive loss of each aspect-level representation of user , denotes the cosine similarity measure, is a temperature parameter (generally set to ), and denotes a set of users within a batch. Similarly, the item disentangled representation can be constrained by,
| (3.14) |
where denotes a set of items within a batch. Intuitively, the auxiliary supervision of positive pairs encourages the direction consistency between latent representations of users and items on the same aspect, while the supervision of negative pairs enforces the divergence among different aspects. Note there are also some methods [25] that use distance correlation as a regularizer to achieve representation independence modeling. We do not use such distance correlation, because it can only ensure the independence of the aspects, but cannot guarantee the correspondence between the aspect-level representations of users and items.
Finally, the overall objects for alternately optimization can be set as,
| (3.15) |
where is an adjusted factor to balance the VAE loss and the contrastive loss.
4 Experiment
| Dataset | #Users | #Items | #Feedback | Sparsity |
|---|---|---|---|---|
| ML1M | 6,040 | 3,679 | 1,000,180 | 0.9550 |
| AKindle | 14,356 | 15,885 | 367,477 | 0.9984 |
| Yelp | 31,668 | 38,048 | 1,561,406 | 0.9987 |
| Datasets | ML1M | AKindle | Yelp | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Methods | R@20 | N@20 | R@50 | N@50 | R@20 | N@20 | R@50 | N@50 | R@20 | N@20 | R@50 | N@50 |
| MF [14] | 0.1846 | 0.3122 | 0.3193 | 0.3217 | 0.0453 | 0.0364 | 0.0707 | 0.0398 | 0.0298 | 0.0256 | 0.0589 | 0.0362 |
| NeuMF [10] | 0.2158 | 0.3256 | 0.3569 | 0.3472 | 0.0676 | 0.0459 | 0.1073 | 0.0582 | 0.0547 | 0.0456 | 0.1060 | 0.0622 |
| JCA [30] | 0.2251 | 0.3303 | 0.3814 | 0.3612 | 0.0745 | 0.0464 | 0.1171 | 0.0626 | 0.0550 | 0.0452 | 0.1121 | 0.0663 |
| PoissVAE [15] | 0.2286 | 0.3439 | 0.3790 | 0.3622 | 0.0623 | 0.0392 | 0.1084 | 0.0532 | 0.0556 | 0.0453 | 0.1076 | 0.0648 |
| MultiVAE [15] | 0.2301 | 0.3348 | 0.3819 | 0.3575 | 0.0739 | 0.0459 | 0.1226 | 0.0607 | 0.0563 | 0.0455 | 0.1091 | 0.0653 |
| MacridVAE [16] | 0.2313 | 0.3409 | 0.3865 | 0.3655 | 0.0779 | 0.0475 | 0.1335 | 0.0654 | 0.0601 | 0.0485 | 0.1165 | 0.0681 |
| JoVA [1] | 0.2305 | 0.3409 | 0.3840 | 0.3641 | 0.0754 | 0.0470 | 0.1270 | 0.0631 | 0.0573 | 0.0459 | 0.1122 | 0.0665 |
| BiVAE [23] | 0.2305 | 0.3450 | 0.3853 | 0.3658 | 0.0757 | 0.0477 | 0.1295 | 0.0636 | 0.0575 | 0.0460 | 0.1140 | 0.0670 |
| DualVAE | 0.2365* | 0.3643* | 0.3944* | 0.3816* | 0.0812* | 0.0511* | 0.1378* | 0.0683* | 0.0633* | 0.0514* | 0.1227* | 0.0735* |
| Improvement | 2.27% | 5.59% | 2.04% | 4.32% | 4.24% | 7.13% | 3.21% | 4.37% | 5.32% | 5.98% | 5.32% | 7.93% |
4.1 Experimental Setup
4.1.1 Datasets and Metrics.
The experimental study of DualVAE is conducted on three publicly available benchmark datasets from different platforms: MovieLens-1M (ML1M for short), Amazon Kindle Store (AKindle for short) and Yelp. The first dataset is a MovieLens111https://grouplens.org/datasets/movielens dataset, where each user has at least 20 interactions, the second dataset is collected from Amazon222http://jmcauley.ucsd.edu/data/amazon [18], and the third dataset is from the 2018 Yelp challenge333https://www.yelp.com/dataset.. For the last two datasets, we use a 10-core setting to ensure their data quality. For all datasets, we treat observed user-item interactions as positive feedback. Table 1 summarizes the statistics of the three evaluation datasets. The performance of all models on the testing set is evaluated by two commonly used metrics: Recall (R@N) and Normalized Discounted Cumulative Gain (N@N) [9]. We truncate the ranked list by setting at . The learned recommendation model can get a ranked top-N list from all items to evaluate the two metrics.
4.1.2 Baselines.
We compare DualVAE versus the following two groups of competitive methods: 1) Latent factor model-based CF methods, including MF [14], NeuMF [10] and JCA [30]; 2) VAE-based CF methods, including PoissVAE and MultiVAE [15], MacridVAE [16], JoVA [1], and BiVAE [23]. Note for a fair comparison, PoissVAE, BiVAE and DualVAE all use Poisson likelihood by default in their generative models. For all the baselines, we use the implementations and parameter settings reported in their original papers.
4.1.3 Parameter Settings.
Our model is implemented in Pytorch444https://github.com/georgeguo-cn/DualVAE. For all datasets, we randomly select 80% user interactions for training and the remaining for testing. From the testing set, we randomly select interactions as validation set to tune hyperparameters. For a fair comparison, the total embedding size is fixed to and the mini-batch Adam [12] is employed to update model parameters with a fixed batch size of for all models. The learning rate is searched from . We search the coefficient from and search the aspect number from . We perform the grid search of hyperparameters to obtain the optimal set on different datasets. In addition, all experiments in this paper are performed in the same experimental environment with Intel(R) Xeon(R) Silver 4210R CPU @ 2.40GHz and GeForce RTX 3090.
4.2 Performance Comparison
Table 2 presents the overall performance comparison, from which we have the following key observations:
-
•
DualVAE consistently outperforms all the other baselines on all datasets and metrics. In particular, DualVAE’s improvement over the best baseline is statistically significant in all cases, demonstrating that disentangling multi-aspect features of users and items indeed can help improve performance. Moreover, as the sparsity of datasets increases, the improvement of DualVAE becomes more significant, indicating that capturing multi-aspect uncertainty of user and item feature spaces can further alleviate the data sparsity problem and improve model robustness.
-
•
Dual VAE-based methods outperform user-specific VAE-based methods on all datasets. Specifically, the performance of BiVAE is higher than that of PoissVAE and MultiVAE, while DualVAE achieves better performance than MacridVAE. The results indicate that inferring latent representations of both users and items can better adapt to the two-way nature of interaction data, thereby promoting accuracy.
-
•
Disentanglement-based methods generally achieve better performance than their non-disentanglement counterparts. For instance, MacridVAE outperforms MultiVAE by an average of 3.97% in terms of N@ across all datasets, indicating that disentangling multi-aspect user preferences is beneficial for improving representation quality and performance.
| Datasets | ML1M | AKindle | Yelp | |||
|---|---|---|---|---|---|---|
| Methods | R@20 | N@20 | R@20 | N@20 | R@20 | N@20 |
| w/o ADD | 0.2305 | 0.3450 | 0.0757 | 0.0473 | 0.0575 | 0.0460 |
| w/o ID | 0.2325 | 0.3594 | 0.0801 | 0.0495 | 0.0602 | 0.0489 |
| w/o UD | 0.2316 | 0.3492 | 0.0772 | 0.0483 | 0.0574 | 0.0463 |
| w/o NRC | 0.2321 | 0.3601 | 0.0803 | 0.0501 | 0.0611 | 0.0493 |
| w/o UNS | 0.2354 | 0.3632 | 0.0805 | 0.0503 | 0.0619 | 0.0502 |
| w/o ANS | 0.2353 | 0.3632 | 0.0810 | 0.0509 | 0.0624 | 0.0510 |
| w/o NPS | 0.2345 | 0.3623 | 0.0808 | 0.0508 | 0.0620 | 0.0503 |
| DualVAE | 0.2365 | 0.3643 | 0.0812 | 0.0511 | 0.0633 | 0.0514 |
4.3 Ablation Studies
Table 3 reports the results of ablation studies for various variants of DualVAE. Specifically, w/o ID (w/o UD) denotes that our model only retains user(item)-side aspect disentanglement; w/o UNS and w/o ANS are two variants that do not use user-level and aspect-level negative samples in NRC module, respectively. w/o NPS is a variant that removes neighborhood-based representations and uses inferred aspect-level representations and themselves to construct positive pairs. From Table 3, we can find:
-
•
After removing the ADD module, the performance of DualVAE drops (vs. w/o ADD) by an average of 6.65% and 8.46% respectively on R@ and N@, indicating the effectiveness of attention-aware disentanglement. The performance gap between DualVAE and w/o UD (w/o ID) demonstrates the benefit of shaping the aspect distributions of both users and items in improving performance. Moreover, w/o ID performs better than w/o UD on sparser datasets, which suggests that the user-side disentanglement may bring more performance gains than the item-side to alleviate interaction sparsity.
-
•
The variant w/o NRC removes the NRC module and causes an average performance drop of 2.21% and 2.47% in terms of R@ and N@ respectively, which indicates the necessity of ensuring the correspondence and independence of disentangled representations in promoting performance. The comparison between DualVAE and w/o ANS (w/o UNS) reveals that it is beneficial to maintain the independence of disentangled representations by exploiting two-level negative samples. Moreover, w/o ANS performs slightly better than w/o UNS on AKindle and Yelp, showing that aspect-level differences may be more important than user-level differences in keeping the representation independence. w/o NPS performs worse than DualVAE, which demonstrates the significance of maintaining the correspondence between multi-aspect representations of users and items.



4.4 Hyperparameter Analysis
4.4.1 Impact of Aspect Number .
To investigate the effect of aspect number, we vary in the range and show the performance comparisons in Figure 2 (a). We can observe that the poor performance is achieved when on the datasets Akindle and Yelp, which indicates that one aspect generally is insufficient for fitting interaction data. Overall, the performance first increases with the growth of the number of aspects, and then declines after reaching the optimum (). The results prove that disentangled representation learning is beneficial, but too many aspects may be redundant and will negatively affect performance. The results on ML1M show a similar trend, and the optimal performance is obtained at .
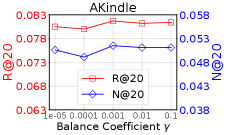
4.4.2 Impact of Balance Coefficient .
The parameter is an adjusted coefficient of contrastive loss. To evaluate the effect of , we search for it from . Figure 2 (b) presents the results in terms of R@ and N@ on the datasets Akindle and Yelp. From the results, we can see that a larger with a stronger independence constraint is desirable for reaching a better performance. In particular, we can set for ML1M and Yelp, and for AKindle to learn a suitable model.


4.5 Interpretability Exploration
4.5.1 Visualization of Aspect Probability.
We first visualize the aspect probability maps of two specific users and in ML1M, as well as their random interactive items, as illustrated in Figure 3. We can see that user pays more attention to the -th aspect, while focuses more on the -rd aspect, which demonstrates that our model indeed can learn personalized user preferences. Furthermore, the aspect probability distributions are similar between users and most of the items they interacted with. In particular, most of ’s interactive items have a higher probability (brighter in the map) in the -th aspect, while and most of its interactive items have a better match in the -rd aspect. This phenomenon suggests that some specific aspects may dominate the interactions between users and items, which provides a good perspective for explaining user behaviors.
4.5.2 Interpretability of Disentangled Representations.
We further explore the interpretability of disentangled representations by a case study, as shown in Figure 4. Specifically, we take the AKindle dataset as example, and randomly select two users, and and their interactive items from it to explain their behaviors by analyzing their reviews. Specifically, we present the corresponding user reviews for the interactive items with the highest aspect-level prediction score under two random aspects. For example, interaction has the highest predicted score (thick solid line with color) under the -st aspect (), which implies that the occurrence of this interaction is more related to the matching of user’s preference and item’s characteristic under the -st aspect. From the results, we have the following findings:
-
•
By analyzing different reviews under the same aspect, we can find that the reviews seem to be consistent with some intuitive attribution concepts. Specifically, we can summarize the semantics of the two implicit aspects from the reviews (especially the red words) as: character and author. The results interpret the capability of DualVAE to disentangle multi-aspect preferences from user behaviors.
-
•
A higher prediction score in general corresponds to a higher degree of aspect-level feature matching between users and items. For example, under the -nd aspect, both and really appreciate the author of item , which is a good post-hoc explanation for their purchasing of item . The results further verify the rationality of multi-aspect feature matching between users and items.
5 Conclusion
In this work, we proposed DualVAE, which combines disentangled representation learning with VAE to fit user-item interactions. Specifically, we first designed an attention-aware dual disentanglement module and unified it with a disentangled variational autoencoder to infer multi-aspect latent representations of both users and items for reconstructing the observed interactions. Moreover, we developed a neighborhood-enhanced representation constraint module to ensure the quality of disentangled representations by a contrastive learning with a neighborhood-based positive sample and two-level negative samples. Extensive experiments on three real-world datasets demonstrate the effectiveness of DualVAE. Further empirical studies also explore the interpretability of disentangled representations. For future work, we plan to introduce more content knowledge, such as user reviews, modality information, to establish ground-truth features of users and items for more fine-grained disentangled representations.
6 Acknowledgements
We would like to thank all anonymous reviewers for their valuable comments. The work was partially supported by the National Natural Science Foundation of China under Grant No. 62272176 and the National Key R&D Program of China under Grant No. 2022YFC3802101 and 2023YFB3308301.
References
- [1] B. Askari, J. Szlichta, and A. Salehi-Abari, Variational autoencoders for top-k recommendation with implicit feedback, in Proceedings of SIGIR, 2021, pp. 2061–2065.
- [2] Y. Bengio, A. Courville, and P. Vincent, Representation learning: A review and new perspectives, IEEE Transactions on Pattern Analysis and Machine Intelligence, 35 (2013), pp. 1798–1828.
- [3] D. M. Blei, A. Kucukelbir, and J. D. McAuliffe, Variational inference: A review for statisticians, Journal of the American statistical Association, 112 (2017), pp. 859–877.
- [4] Y. Cho and M. Oh, Stochastic-expert variational autoencoder for collaborative filtering, in Proceedings of WWW, 2022, pp. 2482–2490.
- [5] A. B. Dieng, Y. Kim, A. M. Rush, and D. M. Blei, Avoiding latent variable collapse with generative skip models, in Proceedings of AISTATS, vol. 89, 2019, pp. 2397–2405.
- [6] Z. Gao, T. Shen, Z. Mai, M. R. Bouadjenek, I. Waller, A. Anderson, R. Bodkin, and S. Sanner, Mitigating the filter bubble while maintaining relevance: Targeted diversification with vae-based recommender systems, in Proceedings of SIGIR, 2022, pp. 2524–2531.
- [7] D. Goldberg, D. A. Nichols, B. M. Oki, and D. B. Terry, Using collaborative filtering to weave an information tapestry, Commun. ACM, 35 (1992), pp. 61–70.
- [8] M. Gutmann and A. Hyvärinen, Noise-contrastive estimation: A new estimation principle for unnormalized statistical models, in Proceedings of AISTATS, vol. 9, 2010, pp. 297–304.
- [9] X. He, T. Chen, M. Kan, and X. Chen, Trirank: Review-aware explainable recommendation by modeling aspects, in Proceedings of CIKM, 2015, pp. 1661–1670.
- [10] X. He, L. Liao, H. Zhang, L. Nie, X. Hu, and T. Chua, Neural collaborative filtering, in Proceedings of WWW, 2017, pp. 173–182.
- [11] G. Karamanolakis, K. R. Cherian, A. R. Narayan, J. Yuan, D. Tang, and T. Jebara, Item recommendation with variational autoencoders and heterogeneous priors, in Proceedings of DLRS@RecSys, 2018, pp. 10–14.
- [12] D. P. Kingma and J. Ba, Adam: A method for stochastic optimization, arXiv preprint arXiv:1412.6980, (2014).
- [13] D. P. Kingma and M. Welling, Auto-encoding variational bayes, in Proceedings of ICLR, 2014.
- [14] Y. Koren, R. M. Bell, and C. Volinsky, Matrix factorization techniques for recommender systems, Computer, 42 (2009), pp. 30–37.
- [15] D. Liang, R. G. Krishnan, M. D. Hoffman, and T. Jebara, Variational autoencoders for collaborative filtering, in Proceedings of WWW, 2018, pp. 689–698.
- [16] J. Ma, C. Zhou, P. Cui, H. Yang, and W. Zhu, Learning disentangled representations for recommendation, in Proceedings of NeurIPS, 2019, pp. 5712–5723.
- [17] W. Ma, X. Chen, W. Pan, and Z. Ming, VAE++: variational autoencoder for heterogeneous one-class collaborative filtering, in Proceedings of WSDM, 2022, pp. 666–674.
- [18] J. Ni, J. Li, and J. J. McAuley, Justifying recommendations using distantly-labeled reviews and fine-grained aspects, in Proceedings EMNLP-IJCNLP.
- [19] Z. Ren, Z. Tian, D. Li, P. Ren, L. Yang, X. Xin, H. Liang, M. de Rijke, and Z. Chen, Variational reasoning about user preferences for conversational recommendation, in Proceedings of SIGIR, 2022, pp. 165–175.
- [20] D. J. Rezende, S. Mohamed, and D. Wierstra, Stochastic backpropagation and approximate inference in deep generative models, in Proceedings of ICML, vol. 32, 2014, pp. 1278–1286.
- [21] S. Sedhain, A. K. Menon, S. Sanner, and L. Xie, Autorec: Autoencoders meet collaborative filtering, in Proceedings of WWW, 2015, pp. 111–112.
- [22] I. Shenbin, A. Alekseev, E. Tutubalina, V. Malykh, and S. I. Nikolenko, Recvae: A new variational autoencoder for top-n recommendations with implicit feedback, in Proceedings of WSDM, 2020, pp. 528–536.
- [23] Q. Truong, A. Salah, and H. W. Lauw, Bilateral variational autoencoder for collaborative filtering, in Proceedings of WSDM, 2021, pp. 292–300.
- [24] S. Wang, X. Chen, Q. Z. Sheng, Y. Zhang, and L. Yao, Causal disentangled variational auto-encoder for preference understanding in recommendation, in Proceedings of SIGIR, 2023, pp. 1874–1878.
- [25] X. Wang, H. Jin, A. Zhang, X. He, T. Xu, and T.-S. Chua, Disentangled graph collaborative filtering, in Proceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval, 2020, pp. 1001–1010.
- [26] Y. Wu, C. DuBois, A. X. Zheng, and M. Ester, Collaborative denoising auto-encoders for top-n recommender systems, in Proceedings of WSDM, 2016, pp. 153–162.
- [27] X. Yu, X. Zhang, Y. Cao, and M. Xia, VAEGAN: A collaborative filtering framework based on adversarial variational autoencoders, in Proceedings of IJCAI, 2019, pp. 4206–4212.
- [28] S. Zhao, W. Wei, D. Zou, and X. Mao, Multi-view intent disentangle graph networks for bundle recommendation, in Proceedings of AAAI, 2022, pp. 4379–4387.
- [29] Y. Zheng, C. Gao, X. Li, X. He, Y. Li, and D. Jin, Disentangling user interest and conformity for recommendation with causal embedding, in Proceedings of WWW, 2021, pp. 2980–2991.
- [30] Z. Zhu, J. Wang, and J. Caverlee, Improving top-k recommendation via joint collaborative autoencoders, in Proceedings of WWW, 2019, pp. 3483–3482.